추세 시각화하기
산점도(둘 이상의 정량적 변수 간의 연관성 시각화 장)나 시계열(시계열 및 시간 흐름에 따른 데이터 시각화 장) 그래프를 만들 때, 때로는 개별 데이터 포인트 하나하나보다 데이터가 보여주는 전체적인 추세(trend)에 더 관심이 갈 때가 있습니다. 실제 관측값 위에(혹은 대신에) 직선이나 곡선으로 추세선을 그려주면, 독자가 데이터의 핵심 특징을 한눈에 파악하는 데 큰 도움이 됩니다. 추세를 파악하는 방법은 크게 두 가지입니다. 이동 평균처럼 데이터를 부드럽게 만드는 평활화(smoothing) 기법을 쓰거나, 특정 함수 형태를 데이터에 맞추는 적합(fitting) 기법을 사용하는 것입니다. 추세를 파악하고 나면, 거기서 벗어난 특이값을 찾거나 데이터를 추세, 주기성, 노이즈 등으로 분리하여 더 깊이 있게 분석할 수도 있습니다.
평활화
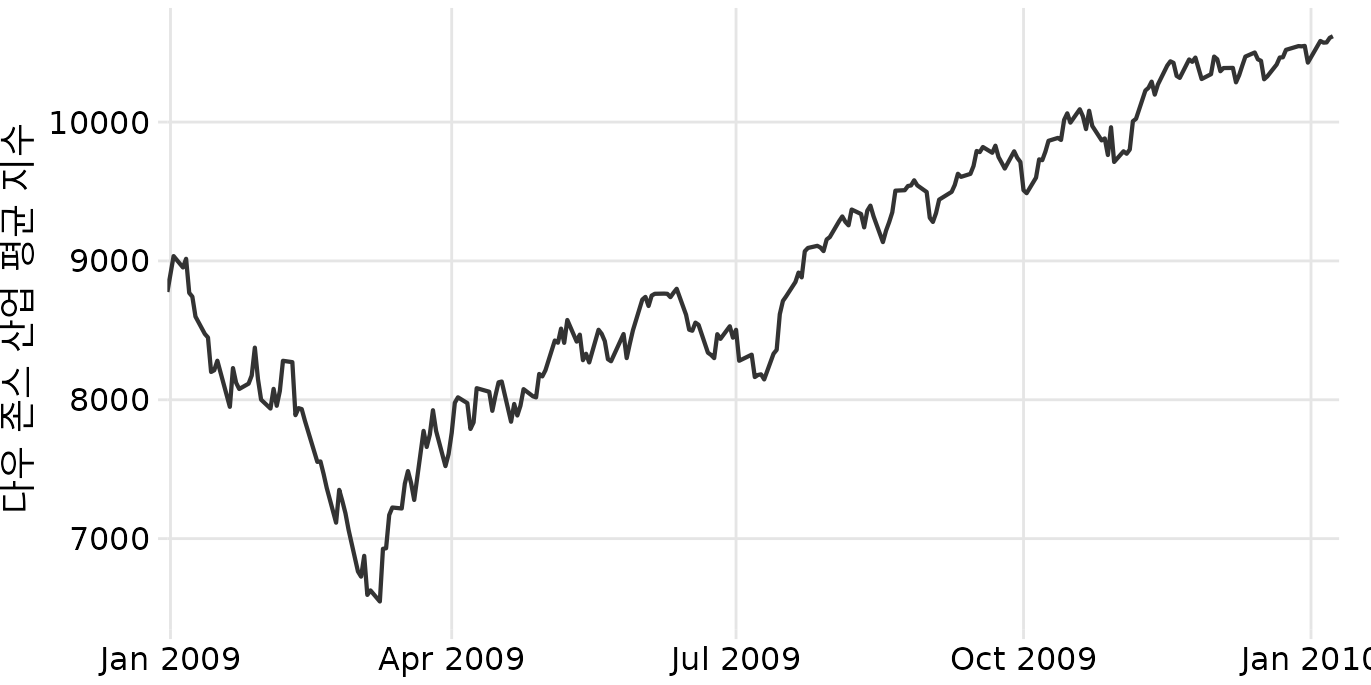
미국 30개 대형 상장 기업의 주가를 나타내는 주가 지수인 다우 존스 산업 평균 지수(줄여서 다우 존스)의 시계열을 생각해 보겠습니다. 특히 2008년 금융 위기 직후인 2009년을 살펴보겠습니다(그림 Figure 16.1). 금융 위기의 끝자락인 2009년 첫 3개월 동안 시장은 2400포인트 이상(~27%) 하락했습니다. 그런 다음 나머지 기간 동안 천천히 회복되었습니다. 덜 중요한 단기 변동을 덜 강조하면서 이러한 장기 추세를 어떻게 시각화할 수 있을까요?
(ref:dow-jones) 2009년 다우 존스 산업 평균 지수의 일일 종가. (데이터 출처: Yahoo! Finance)
통계적으로 말하면, 우리는 주식 시장 데이터에서 무의미한 미세 변동(노이즈)을 걸러내고 주요 패턴만 남기는 평활화 작업을 하려는 것입니다. 금융 분석가들은 주로 이동 평균(moving average)을 사용합니다. 예를 들어 ’20일 이동 평균’은 최근 20일간의 가격을 평균 내어 하나의 점을 찍고, 다음 날이 되면 기간을 하루 옮겨 다시 평균을 내는 식으로 연결한 선입니다.
이동 평균을 그릴 때는 해당 기간의 평균값을 어느 시점에 표시할지가 중요합니다. 금융계에서는 보통 기간의 ’마지막 날’을 기준으로 삼는데, 이렇게 하면 추세선이 실제 데이터보다 뒤처지는 지연(lag) 현상이 발생합니다(그림 Figure 16.2 (a)). 평균 기간이 길수록 이 지연은 더 심해집니다. 반면 통계학자들은 대게 기간의 ’가운데 날’을 기준으로 잡으며, 이 방식은 추세선이 원본 데이터와 잘 겹쳐 보여 훨씬 자연스럽습니다(그림 Figure 16.2 (b)).
(ref:dow-jones-moving-ave) 2009년 다우 존스 산업 평균 지수의 이동 평균 비교. (a) 이동 창의 끝에 평균을 표시하여 실제 데이터보다 뒤처지는(lag) 모습. (b) 이동 창의 중앙에 표시하여 데이터와 잘 일치하는 모습.
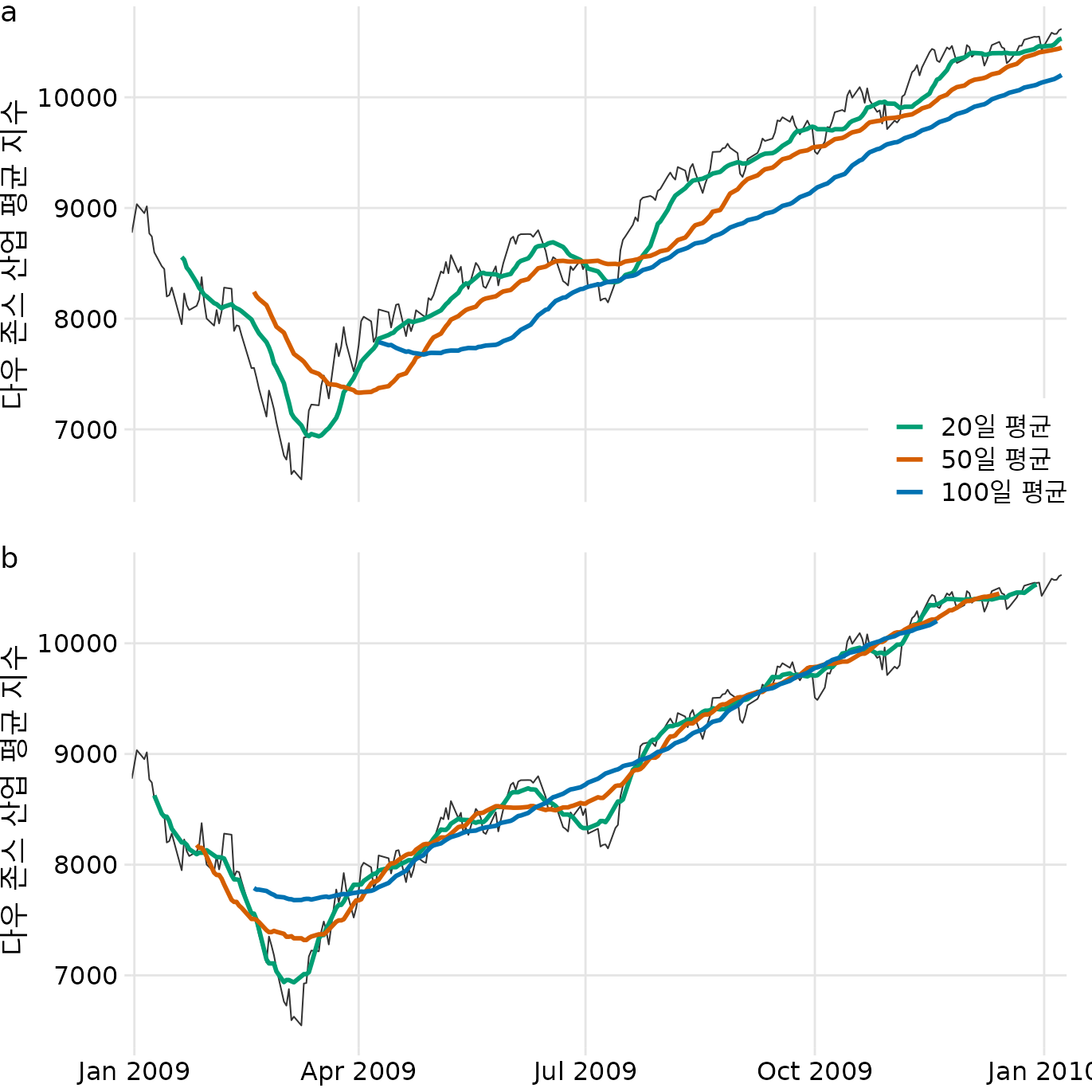
평활화된 시계열을 지연 유무에 관계없이 플로팅하든 관계없이 평균을 계산하는 시간 창의 길이가 평활화된 곡선에 남아 있는 변동의 규모를 설정한다는 것을 알 수 있습니다. 20일 이동 평균은 작고 단기적인 스파이크만 제거하고 그 외에는 일일 데이터를 밀접하게 따릅니다. 반면에 100일 이동 평균은 몇 주에 걸쳐 발생하는 상당히 큰 하락이나 급등도 제거합니다. 예를 들어 2009년 1분기에 7000포인트 아래로 급락한 것은 100일 이동 평균에서는 보이지 않으며 8000포인트 아래로 거의 내려가지 않는 완만한 곡선으로 대체됩니다(그림 Figure 16.2). 마찬가지로 2009년 7월경의 하락은 100일 이동 평균에서는 완전히 보이지 않습니다.
이동 평균은 가장 단순한 평활화 방법이지만 몇 가지 눈에 띄는 한계가 있습니다. 우선, 평균을 낼 앞뒤 데이터가 부족한 시계열의 시작과 끝부분이 잘려 나갑니다(그림 Figure 16.2). 평활화를 많이 할수록(평균 기간이 길수록) 잘리는 구간도 길어집니다. 또한, 이동 평균은 완전히 매끄럽지 않고 자잘한 굴곡(wiggle)이 남을 수 있습니다. 이는 평균 계산 범위(창) 안으로 특정 튀는 데이터가 들어오거나 나갈 때 평균값이 툭툭 변하기 때문입니다.
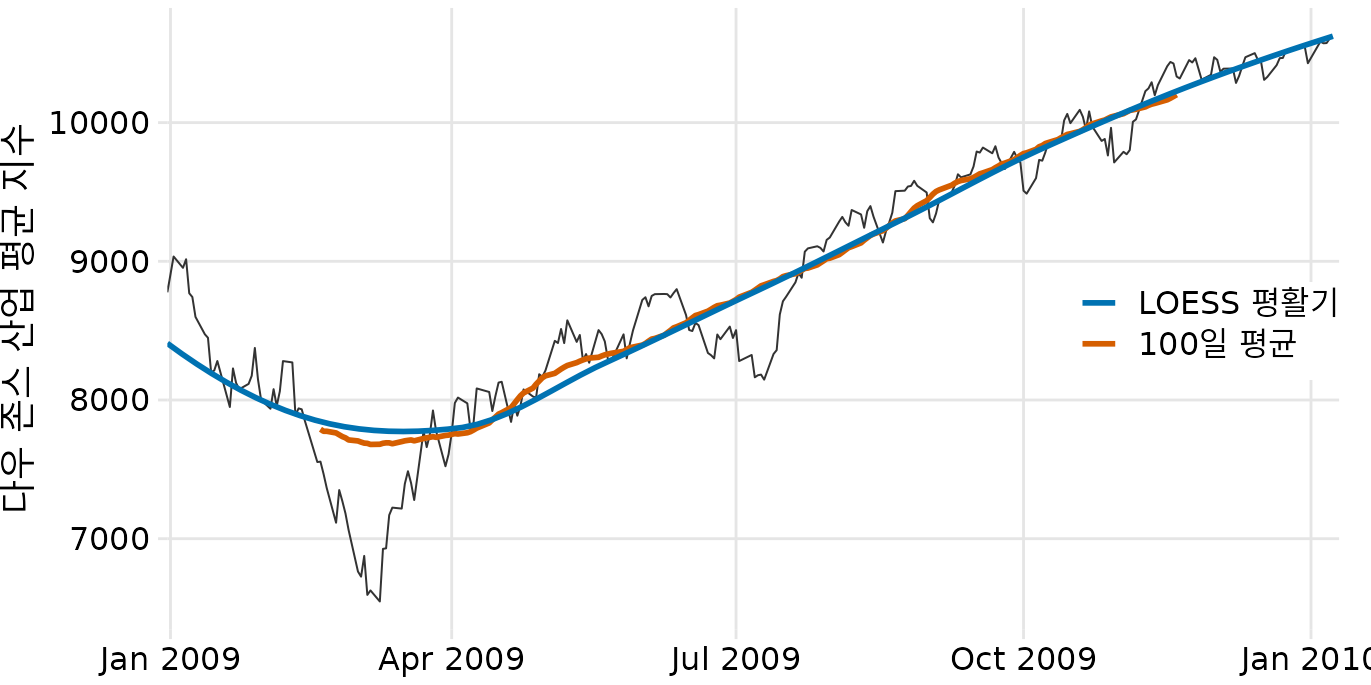
이런 단점을 보완하기 위해 통계학자들은 더 정교한 기법들을 개발했습니다. 대표적인 것이 LOESS(로에스, 국소 추정 산점도 평활화)입니다. LOESS는 데이터의 일부분에 다항식을 적합시키되, 중심부에 가까운 점에 더 큰 가중치를 주는 방식을 씁니다. 덕분에 단순 이동 평균보다 훨씬 부드럽고 자연스러운 추세선을 그릴 수 있습니다(그림 Figure 16.3).
(ref:dow-jones-loess) LOESS 평활화와 100일 이동 평균의 비교. LOESS 곡선이 훨씬 더 부드러우며 데이터 전체 범위에 걸쳐 추세를 잘 보여줍니다.
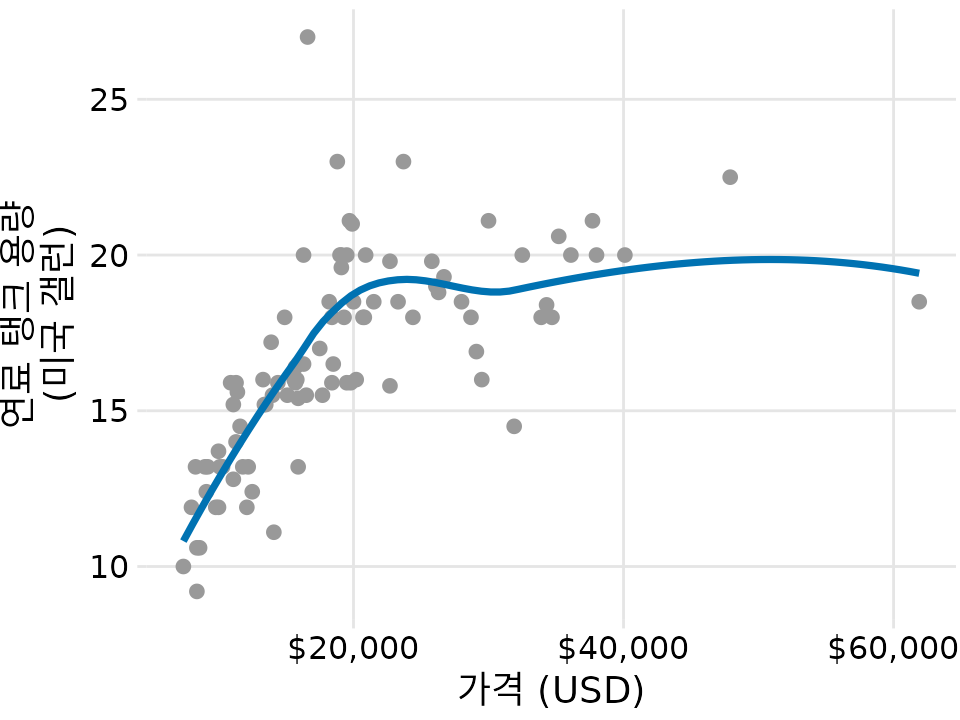
특히 LOESS는 시계열뿐 아니라 일반적인 산점도에도 널리 쓰입니다. 그림 ?fig-tank-capacity-loess는 자동차 가격과 연료 탱크 용량의 관계를 LOESS로 보여줍니다. 이를 통해 가격이 약 2만 달러까지는 탱크 용량이 정비례해서 늘어나다가, 그 이후로는 가격이 더 올라도 용량이 더는 커지지 않는다는 흥미로운 추세를 한눈에 파악할 수 있습니다.
(ref:tank-capacity-loess) 1993년 모델 연도에 출시된 93개 자동차의 연료 탱크 용량 대 가격. 각 점은 하나의 자동차에 해당합니다. 실선은 데이터의 LOESS 평활화를 나타냅니다. 연료 탱크 용량은 약 20,000달러까지 가격에 따라 거의 선형적으로 증가한 다음 수평을 이룹니다. 데이터 출처: 로빈 H. 록, 세인트로렌스 대학교
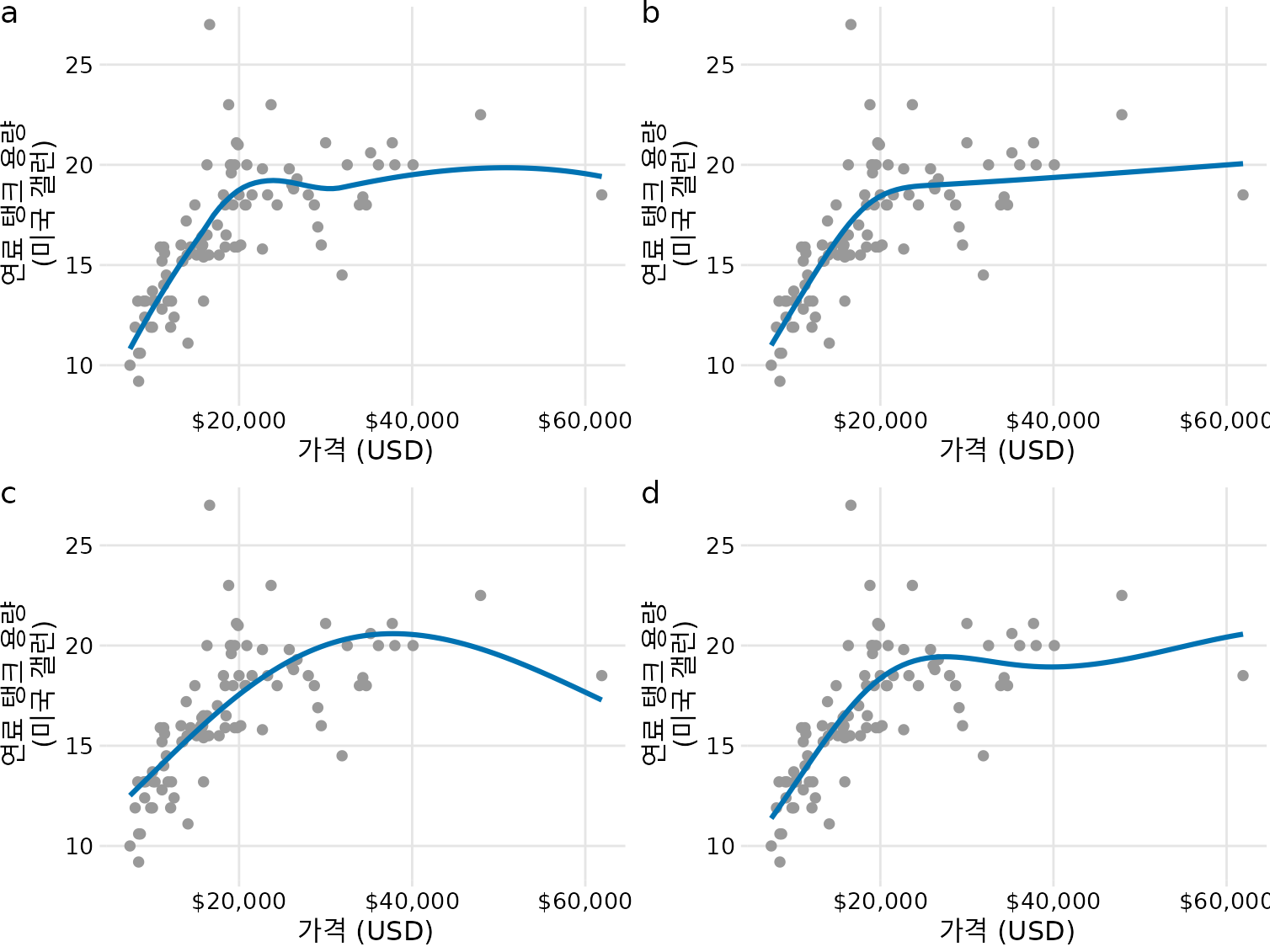
LOESS가 사람 눈에 보기 좋지만 데이터가 많으면 계산이 느리다는 단점이 있습니다. 대안으로 스플라인(spline) 모델을 쓰기도 합니다. 스플라인은 여러 개의 다항식 조각을 매끄럽게 이어 붙인 함수입니다. 스플라인을 쓸 때는 매듭(knots)이라는 개념이 중요한데, 매듭을 어떻게 잡느냐에 따라 추세선의 모양이 확 달라질 수 있습니다(그림 Figure 16.5).
(ref:tank-capacity-smoothers) 평활화 모델에 따른 차이. (a) LOESS, (b) 3차 회귀 스플라인, (c) 얇은 판 회귀 스플라인, (d) 가우시안 프로세스 스플라인. 모델 선택에 따라 특히 데이터의 경계 부분에서 큰 차이가 발생할 수 있습니다.
대부분의 데이터 시각화 소프트웨어는 LOESS와 같은 국소 회귀 유형이나 스플라인 유형으로 구현된 평활화 기능을 제공합니다. 평활화 방법은 이러한 모든 유형의 평활기의 상위 집합인 GAM(일반화 가법 모델)이라고 할 수 있습니다. 평활화 기능의 출력은 적합된 특정 GAM 모델에 크게 의존한다는 점에 유의해야 합니다. 여러 다른 선택 사항을 시도하지 않으면 보이는 결과가 통계 소프트웨어에서 만든 특정 기본 선택 사항에 어느 정도 의존하는지 결코 깨닫지 못할 수 있습니다.
평활화 함수의 결과를 해석할 때는 주의하십시오. 동일한 데이터 세트를 여러 가지 다른 방식으로 평활화할 수 있습니다.
정해진 함수로 추세 보여주기
일반적인 평활화 기법은 데이터에 따라 예측 불가능하게 움직이기도 하고, 그 수치 자체가 가지는 의미를 해석하기 어려울 때가 있습니다. 만약 데이터의 특성을 잘 설명할 수 있는 수학적 함수(모델)를 알고 있다면, 그 함수를 데이터에 적합(fitting)시키는 것이 훨씬 강력한 분석 도구가 됩니다.
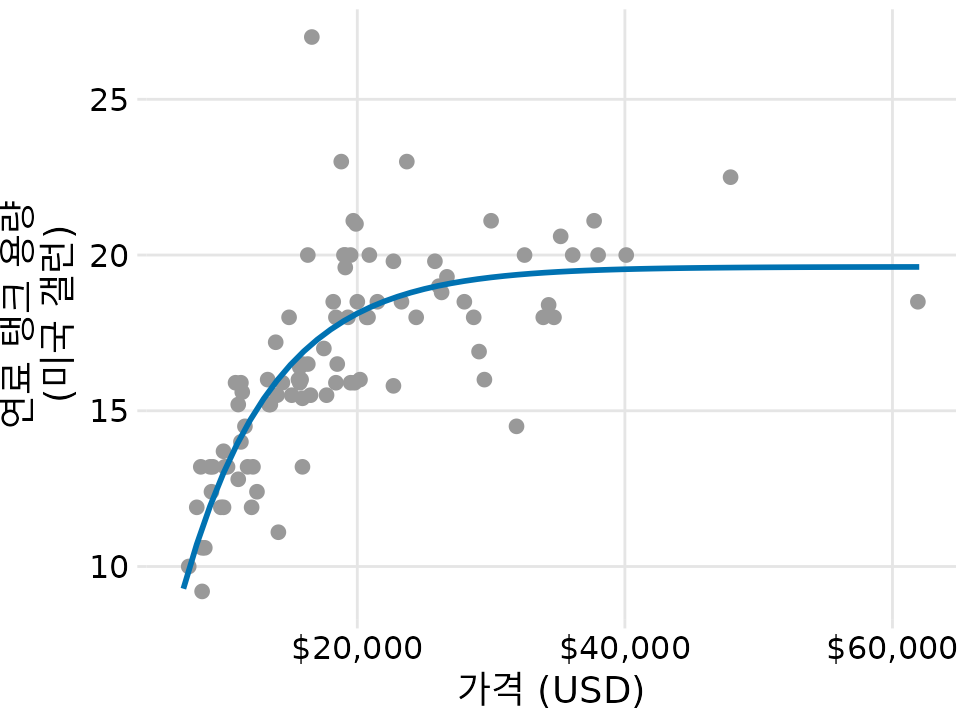
가령 자동차 연료 탱크 데이터의 경우, 일정 수준에서 수평이 되는 ‘포화’ 특성을 가진 함수를 써볼 수 있습니다(그림 Figure 16.6). 이렇게 하면 데이터가 보여주는 물리적 현상을 더 정확하게 반영하는 추세선을 얻을 수 있습니다.
(ref:tank-capacity-model) 특정 분석 모델(지수 포화 함수)을 적합시킨 모습. 공식 \(y = A - B \exp(-mx)\)를 사용해 데이터의 물리적 특성을 더 잘 반영했습니다.
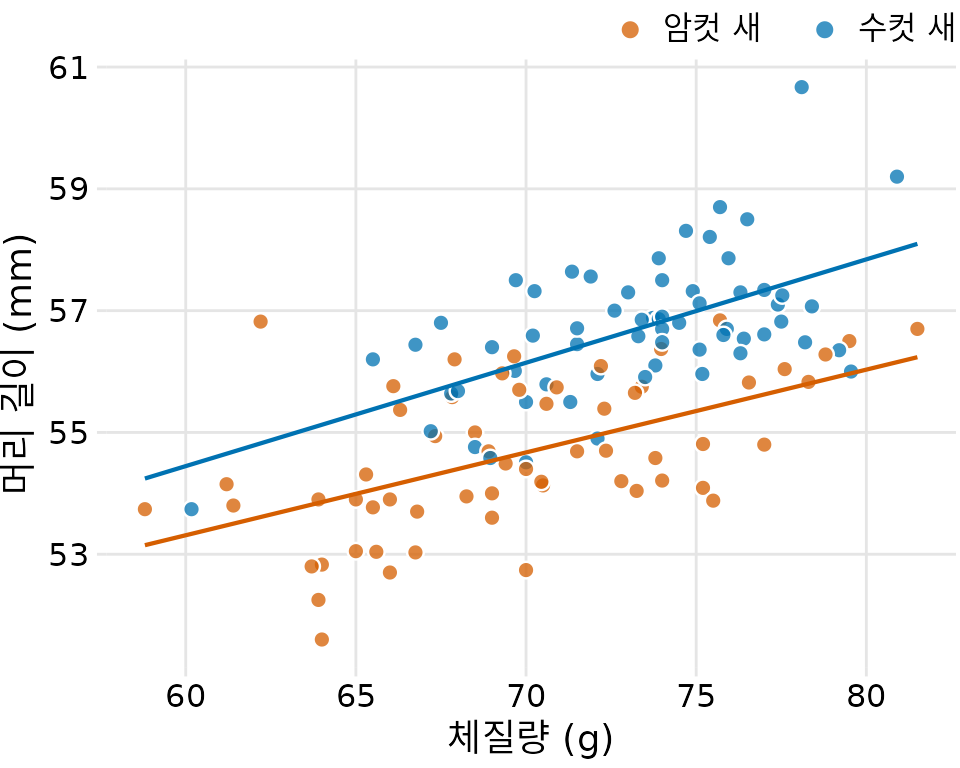
가장 널리 쓰이는 함수는 역시 단순한 직선(\(y = A + mx\))입니다. 세상의 많은 관계는 놀라울 정도로 선형적입니다. 앞에서 본 파랑어치의 체질량과 머리 길이 관계가 좋은 예입니다. 산점도 위에 직선을 하나만 그어줘도 독자는 “아, 몸무게가 늘면 머리도 커지는구나”라는 추세를 훨씬 명확하게 받아들입니다(그림 Figure 16.7).
(ref:blue-jays-scatter-line) 파랑어치의 체질량과 머리 길이 관계에 선형 추세선을 추가한 모습. 직선을 통해 변수 간의 양의 상관관계를 더 쉽게 인지할 수 있습니다.
데이터가 비선형 관계를 보이는 경우, 어떤 함수를 써야 할지 고민될 수 있습니다. 이럴 때는 선형 관계가 나타나도록 축을 변환해보는 것이 좋은 전략입니다. 예를 들어 bioRxiv 프리프린트 제출 데이터(시계열 및 시간 흐름에 따른 데이터 시각화 장 참조)는 매달 일정한 비율로 성장하는 ‘지수 성장’ 형태를 띱니다. 지수 함수 \(y = A\exp(mx)\)를 이 데이터에 적합시켜보면 그림 ?fig-biorxiv-expfit처럼 아주 잘 어울리는 것을 볼 수 있습니다.
(ref:biorxiv-expfit) bioRxiv에 제출된 월별 논문 수와 지수 함수 적합(점선). (데이터 출처: Jordan Anaya, http://www.prepubmed.org/)
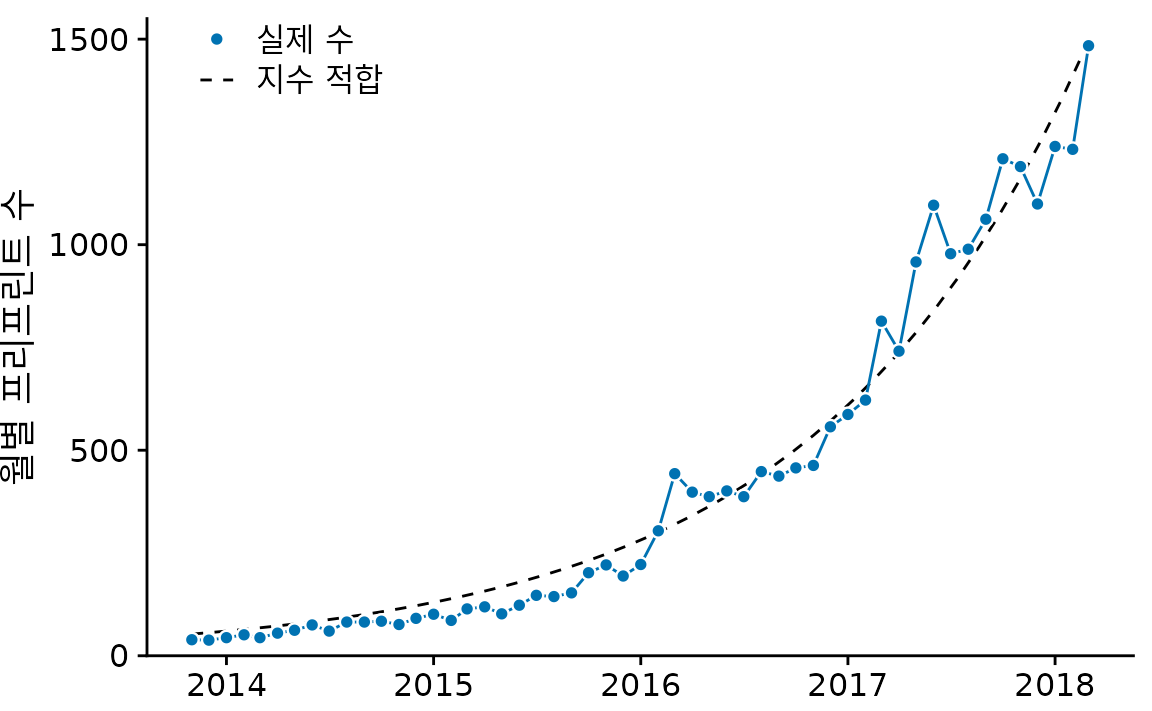
원래 곡선이 지수 함수 \(y = A\exp(mx)\)이면 y 값의 로그 변환은 선형 관계 \(\log(y) = \log(A) + mx\)로 바뀝니다. 따라서 로그 변환된 y 값(또는 동등하게 로그 y 축)으로 데이터를 플로팅하고 선형 관계를 찾는 것은 데이터 세트가 지수적 성장을 보이는지 확인하는 좋은 방법입니다. bioRxiv 제출 건수의 경우 로그 y 축을 사용할 때 실제로 선형 관계를 얻습니다(그림 Figure 16.9).
(ref:biorxiv-logscale) 로그 눈금으로 본 bioRxiv 제출 건수. 로그 축에서 직선에 가깝게 나타나는 것은 데이터가 지수적으로 성장하고 있음을 의미합니다.
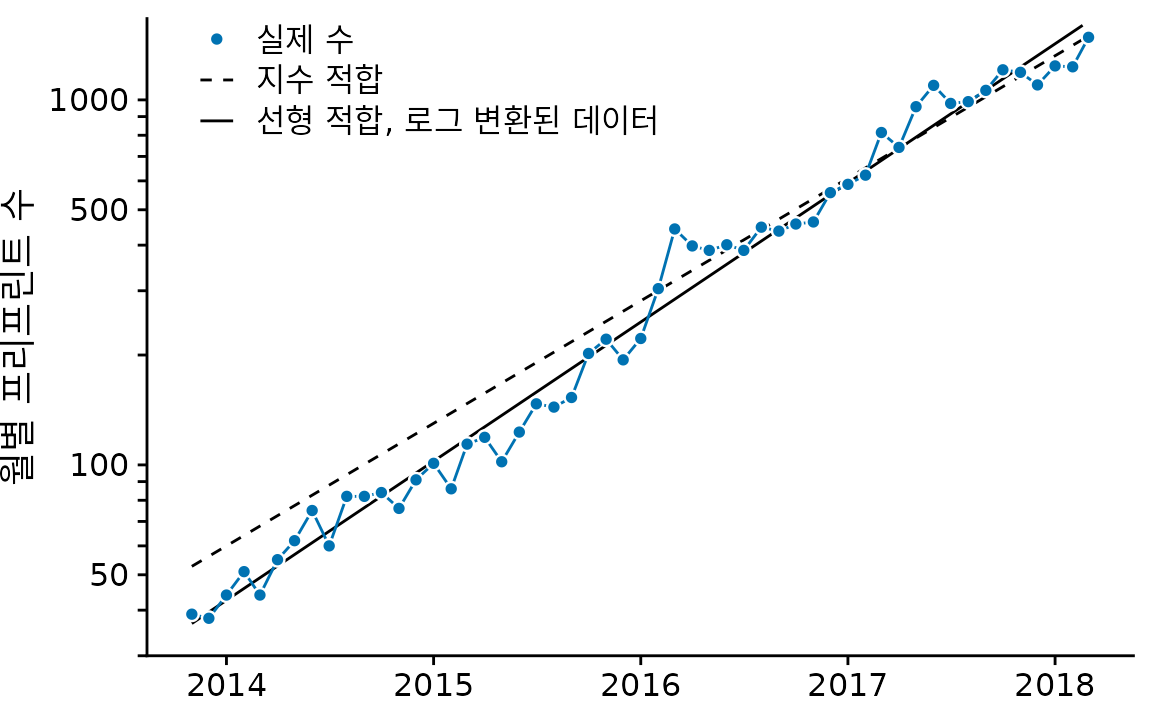
그림 ?fig-biorxiv-logscale에서 실제 제출 건수 외에도 그림 ?fig-biorxiv-expfit의 지수 적합과 로그 변환된 데이터에 대한 선형 적합도 보여줍니다. 이 두 적합은 비슷하지만 동일하지는 않습니다. 특히 점선 기울기가 약간 벗어난 것처럼 보입니다. 선은 시계열의 절반 동안 개별 데이터 포인트 위에 체계적으로 위치합니다. 이것은 지수 적합의 일반적인 문제입니다. 데이터 포인트에서 적합된 곡선까지의 제곱 편차는 가장 작은 데이터 값보다 가장 큰 데이터 값에 대해 훨씬 크므로 가장 작은 데이터 값의 편차는 적합이 최소화하는 전체 제곱합에 거의 기여하지 않습니다. 결과적으로 적합된 선은 가장 작은 데이터 값을 체계적으로 초과하거나 미달합니다. 이러한 이유로 저는 일반적으로 지수 적합을 피하고 대신 로그 변환된 데이터에 대한 선형 적합을 사용하도록 권장합니다.
변환되지 않은 데이터에 비선형 곡선을 적합시키는 것보다 변환된 데이터에 직선을 적합시키는 것이 일반적으로 더 좋습니다.
그림 ?fig-biorxiv-logscale과 같은 플롯은 y 축이 로그이고 x 축이 선형이므로 일반적으로 로그-선형이라고 합니다. 우리가 접할 수 있는 다른 플롯에는 y 축과 x 축이 모두 로그형인 로그-로그 또는 y가 선형이고 x가 로그형인 선형-로그가 있습니다. 로그-로그 플롯에서는 \(y \sim x^\alpha\) 형태의 멱법칙이 직선으로 나타나고(예는 그림 Figure 10.7 참조) 선형-로그 플롯에서는 \(y \sim \log(x)\) 형태의 로그 관계가 직선으로 나타납니다. 다른 함수 형태는 더 특수한 좌표 변환으로 선형 관계로 바꿀 수 있지만 이러한 세 가지(로그-선형, 로그-로그, 선형-로그)는 광범위한 실제 응용 분야를 다룹니다.
추세 제거 및 시계열 분해
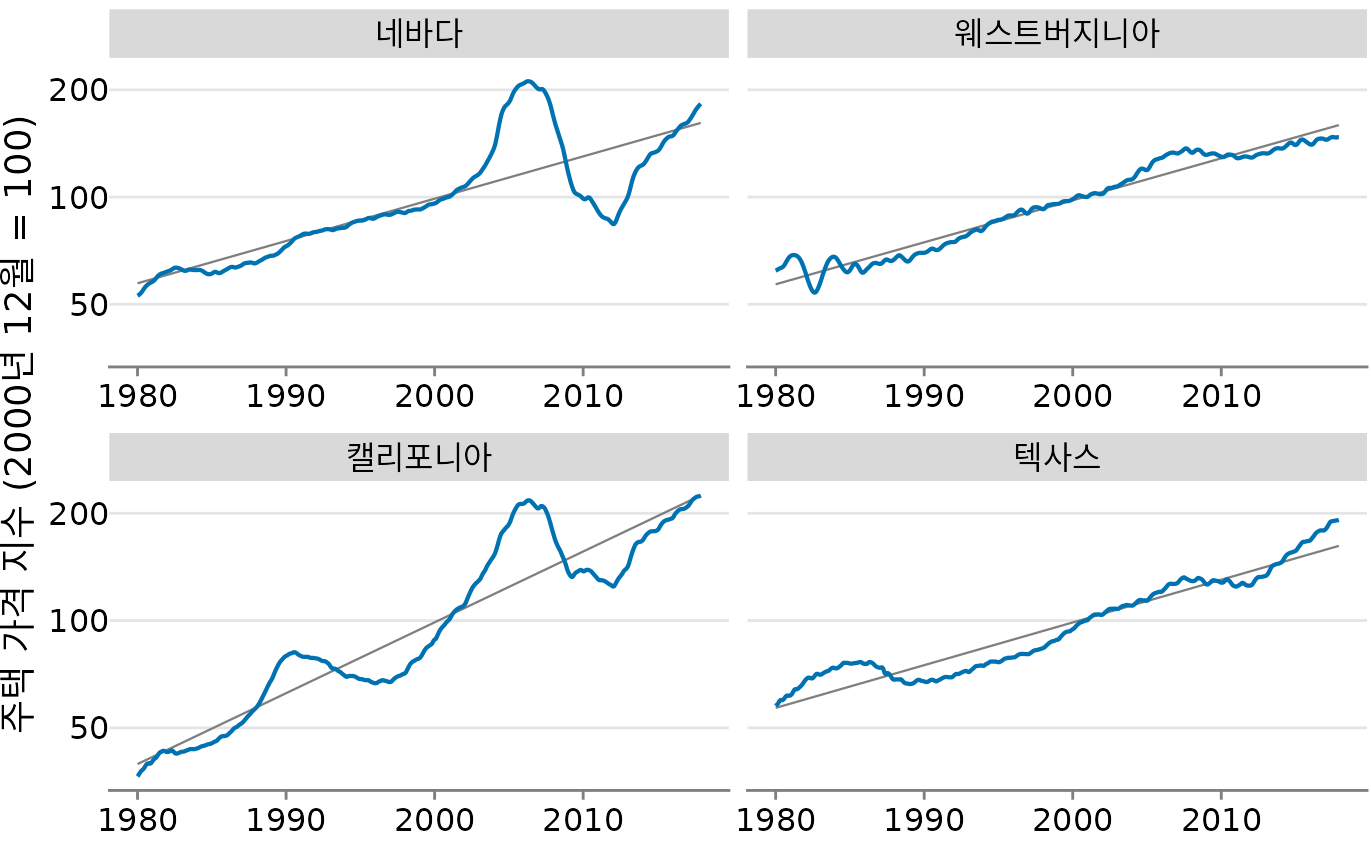
뚜렷한 장기 추세가 있는 모든 시계열의 경우, 그 추세를 걷어내야 비로소 보이는 것들이 있습니다. 이를 추세 제거(detrending)라고 합니다. 미국의 주택 가격 지수를 예로 들어보겠습니다. 주택 가격은 장기적으로 완만하게 오르는 경향이 있지만, 중간중간 ’거품’이 끼어 급등락하곤 합니다. 그림 ?fig-hpi-trends는 장기 추세(직선)와 실제 가격 변화를 보여줍니다.
장기간에 걸쳐 주택 가격은 인플레이션과 거의 일치하는 일관된 연간 성장을 보이는 경향이 있습니다. 그러나 이러한 추세 위에 주택 거품이 겹쳐 심각한 호황과 불황 주기를 야기합니다. 그림 ?fig-hpi-trends는 4개 미국 주의 실제 주택 가격 지수와 장기 추세를 보여줍니다. 1980년에서 2017년 사이에 캘리포니아는 1990년과 2000년대 중반에 두 번의 거품을 겪었음을 알 수 있습니다. 같은 기간 동안 네바다는 2000년대 중반에 한 번의 거품만 경험했으며 텍사스와 웨스트버지니아의 주택 가격은 전체 기간 동안 장기 추세를 밀접하게 따랐습니다. 주택 가격은 백분율 증분, 즉 지수적으로 증가하는 경향이 있으므로 그림 ?fig-hpi-trends에서 로그 y 축을 선택했습니다. 직선은 캘리포니아의 경우 연간 4.7%의 가격 상승을 나타내고 네바다, 텍사스, 웨스트버지니아의 경우 각각 연간 2.8%의 가격 상승을 나타냅니다.
(ref:hpi-trends) 미국 4개 주의 주택 가격 지수(파란색)와 장기 추세(회색 직선). y축이 로그 눈금이므로 직선은 일정한 비율의 성장을 의미합니다. (데이터 출처: 프레디 맥)
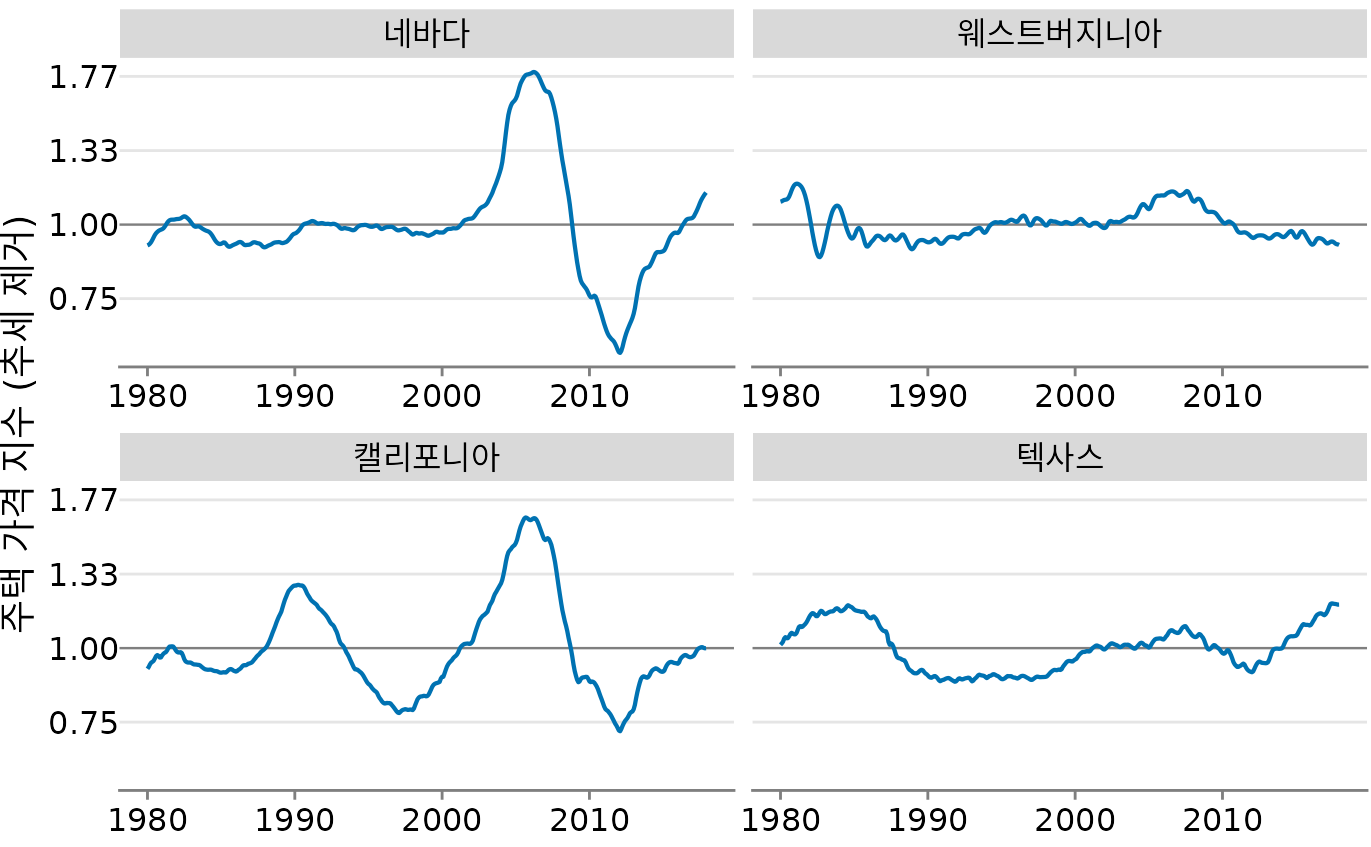
각 시점의 실제 가격 지수를 해당 장기 추세 값으로 나누어 주택 가격 추세를 제거합니다. 시각적으로 이 나눗셈은 그림 ?fig-hpi-trends에서 회색 선을 파란색 선에서 빼는 것처럼 보입니다. 변환되지 않은 값의 나눗셈은 로그 변환된 값의 뺄셈과 동일하기 때문입니다. 결과적인 추세 제거 주택 가격은 주택 거품을 더 명확하게 보여줍니다(그림 Figure 16.11). 추세 제거는 시계열의 예상치 못한 움직임을 강조하기 때문입니다. 예를 들어 원래 시계열에서 1990년부터 약 1998년까지 캘리포니아의 주택 가격 하락은 완만해 보입니다(그림 Figure 16.10). 그러나 같은 기간 동안 장기 추세를 기준으로 가격이 상승할 것으로 예상했습니다. 예상 상승에 비해 가격 하락은 상당했으며 가장 낮은 지점에서 25%에 달했습니다(그림 Figure 16.11).
(ref:hpi-detrended) 추세를 제거한 주택 가격 지수. 장기 추세에서 벗어난 ’거품’의 규모를 훨씬 명확하게 확인할 수 있습니다.
더 나아가 시계열을 여러 성분으로 쪼개는 분해(decomposition) 작업을 할 수도 있습니다. 보통 시계열은 장기 추세, 주기적 변동(계절성), 그리고 무작위 노이즈(나머지)의 합으로 이루어집니다. 날씨나 대기 성분 데이터가 대표적인 예입니다.
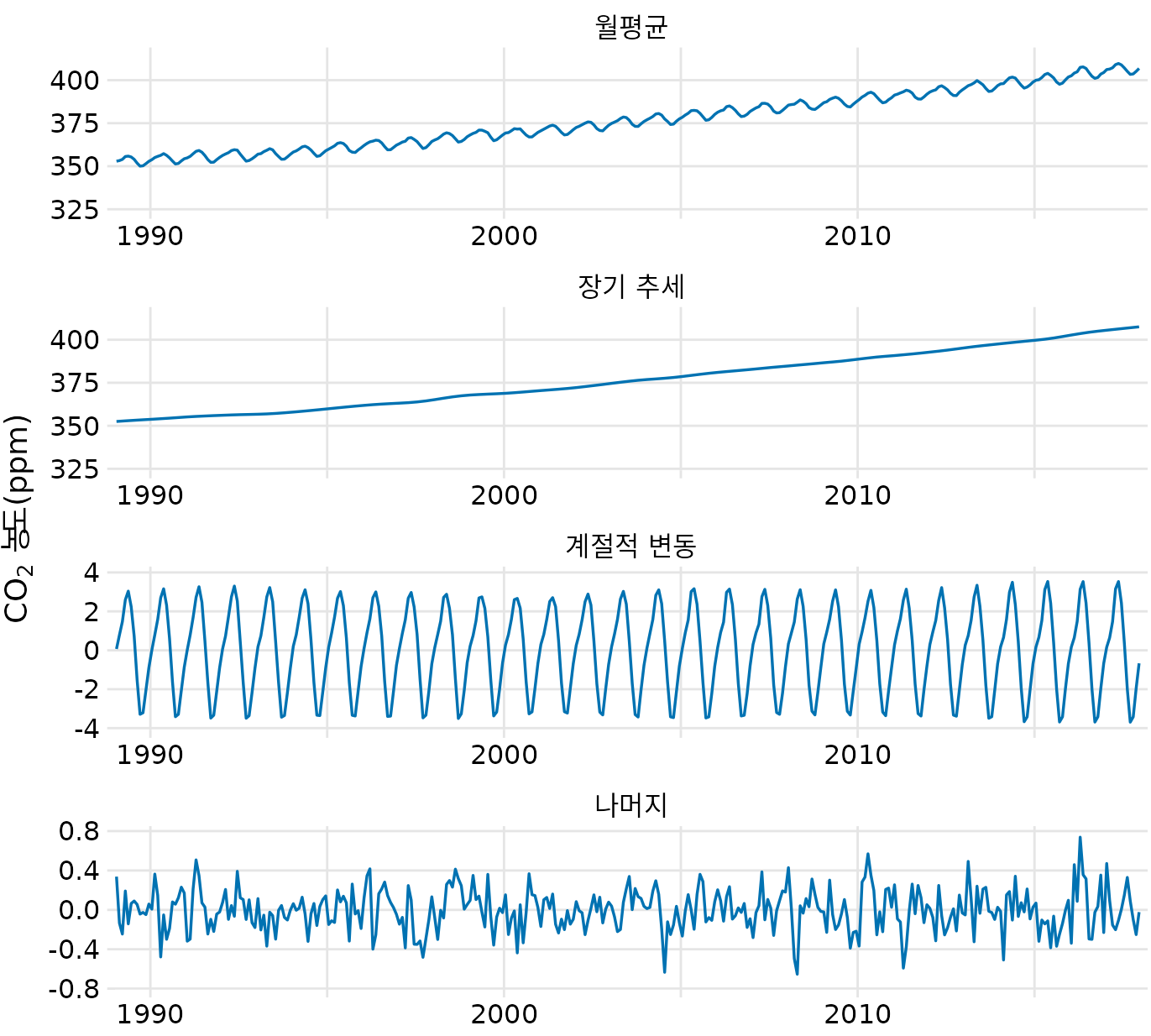
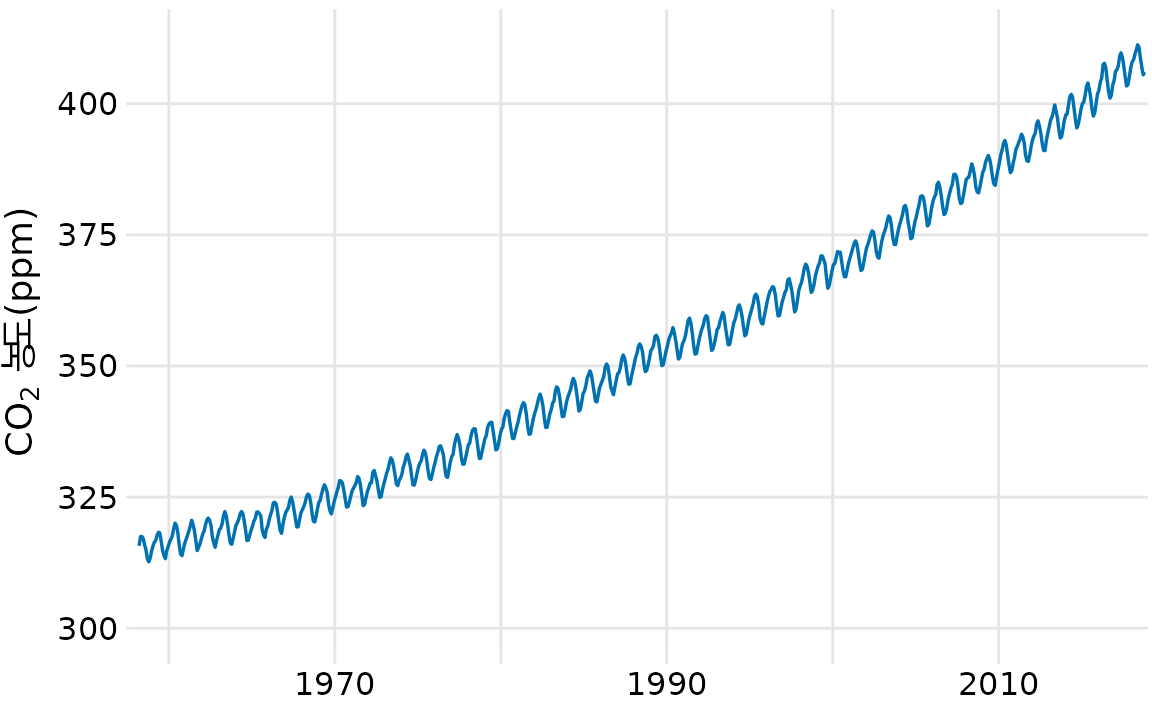
대기 중 이산화탄소가 늘어나는 ‘킬링 곡선’을 분해해보면(그림 Figure 16.12, Figure 16.13), 꾸준히 상승하는 장기 추세와 북반구 식물의 성장 주기에 따른 계절적 변동이 아주 뚜렷하게 갈려 나옵니다. 이렇게 데이터를 분해하면, 전체적인 온난화 추세뿐 아니라 지구가 내쉬고 들이마시는 ’숨결’ 같은 미세한 주기성까지도 명확하게 시각화할 수 있습니다.
(ref:keeling-curve) 킬링 곡선: 시간 경과에 따른 대기 중 CO2 농도 변화. (데이터 출처: NOAA/ESRL, 스크립스 해양 연구소)
(ref:keeling-curve-decomposition) 킬링 곡선의 시계열 분해. 월평균 데이터를 장기 추세, 계절적 변동, 그리고 나머지(노이즈) 성분으로 나누어 보여줍니다.