시계열 및 시간 흐름에 따른 데이터 시각화
이전 장들에서는 두 정량적 변수 사이의 관계를 보여주는 산점도를 다루었습니다. 만약 두 변수 중 하나가 ’시간’이라면 어떨까요? 시간은 데이터에 특별한 질서를 부여합니다. 데이터 포인트마다 고유한 순서가 생기기 때문입니다. 우리는 시간 순서대로 데이터를 배열하고, 각 포인트의 이전과 이후가 무엇인지 정의할 수 있습니다. 이러한 시간적 순서를 강조하고 싶을 때 가장 즐겨 쓰는 방식이 선 그래프(line graph)입니다. 하지만 선 그래프는 꼭 시간에만 국한되지 않습니다. 데이터에 어떤 종류의 순서가 존재한다면 언제든 사용할 수 있습니다. 예를 들어 실험 조건(용량 등)을 단계적으로 바꿀 때 나타나는 반응을 시너지 있게 표현할 수 있습니다. 이 장에서는 하나의 시계열부터 여러 변수가 얽힌 복잡한 시계열까지, 효과적으로 시각화하는 방법을 살펴보겠습니다.
단일 시계열
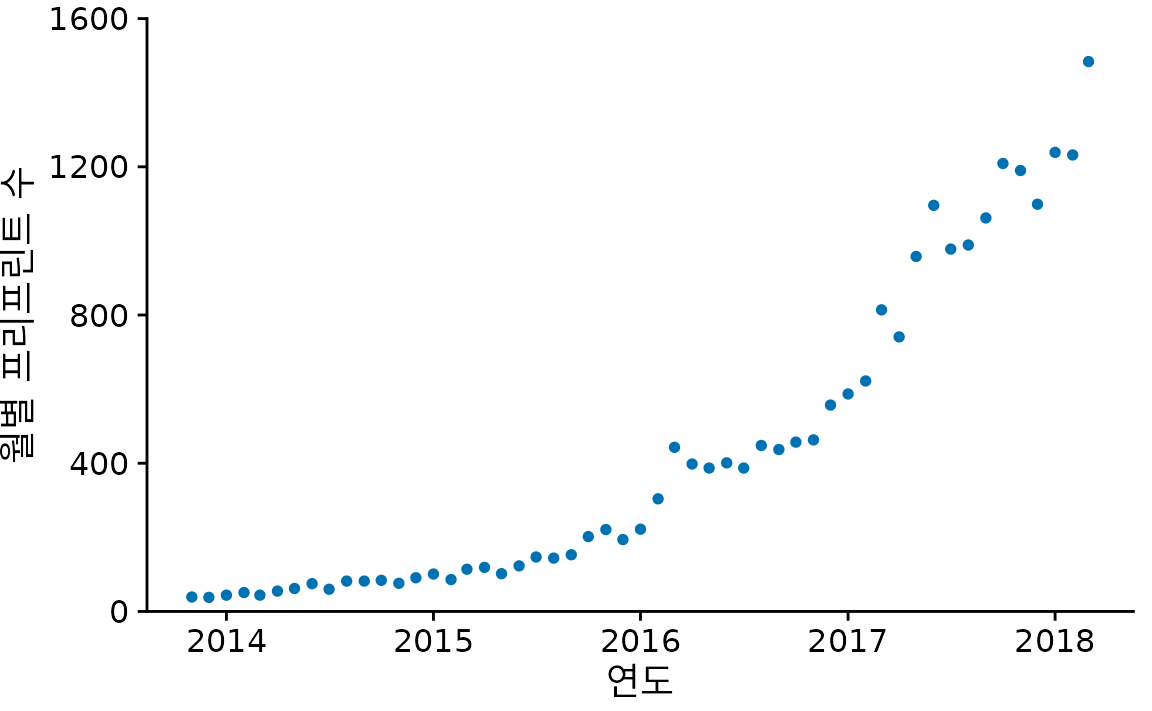
먼저 생물학 분야의 프리프린트(preprint) 제출 현황을 예로 들어보겠습니다. 프리프린트는 정식 논문 심사를 거쳐 저널에 실리기 전, 연구자들이 온라인에 미리 공개하는 논문을 말합니다. 2013년 11월에 설립된 bioRxiv는 생물학 분야의 대표적인 프리프린트 서버로, 설립 이후 제출 건수가 크게 늘었습니다. 각 월의 실제 제출 건수를 찍어보면 그림 ?fig-biorxiv-dots와 같은 산점도가 됩니다.
(ref:biorxiv-dots) 2014년 11월 설립부터 2018년 4월까지 bioRxiv에 제출된 월별 논문 수. 각 점은 한 달의 제출 건수를 나타냅니다. (데이터 출처: Jordan Anaya, http://www.prepubmed.org/)
하지만 그림 ?fig-biorxiv-dots는 일반적인 산점도(둘 이상의 정량적 변수 간의 연관성 시각화 장 참조)와는 느낌이 다릅니다. x축을 따라 점들이 일정한 간격으로 놓여 있고, 각 점에는 앞뒤 순서가 명확하기 때문입니다. 이렇게 인접한 점들을 선으로 연결하여 데이터의 흐름을 강조한 것이 바로 선 그래프입니다(그림 Figure 15.2).
(ref:biorxiv-dots-line) 점과 선을 함께 사용한 bioRxiv 제출 건수 그래프. 선은 데이터 사이의 순서를 강조하며 독자의 시선을 안내하는 역할을 합니다.
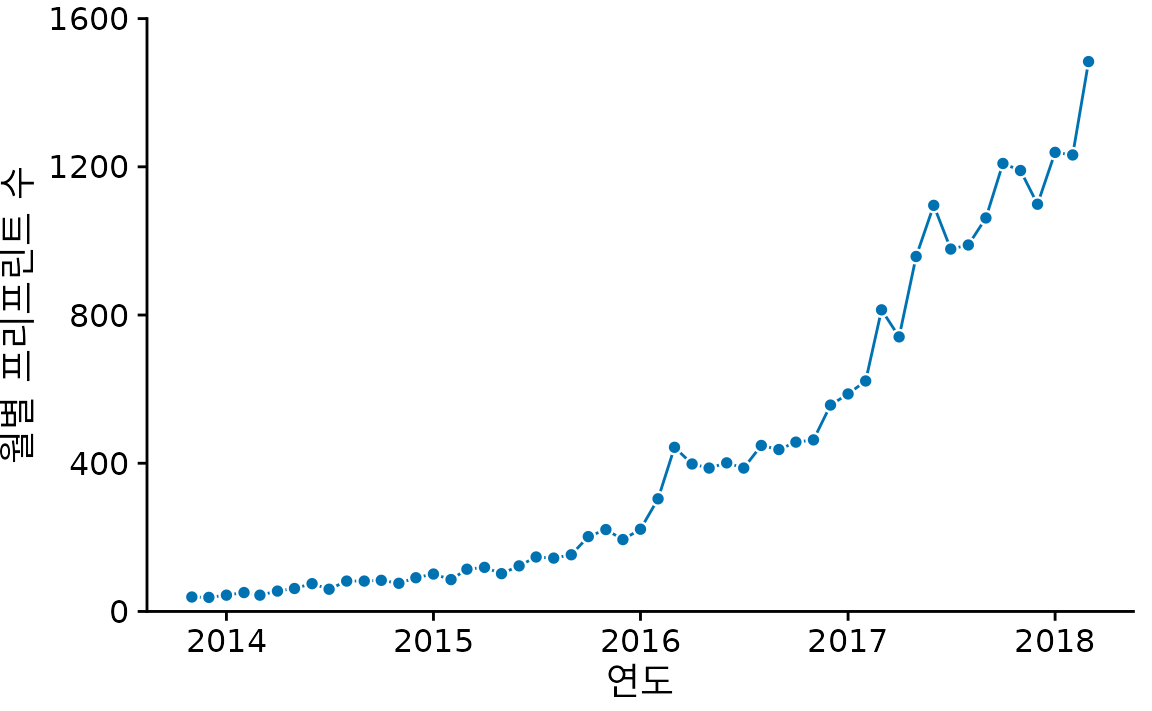
엄격하게 따지면 점과 점 사이의 선은 실제 관측값이 아닙니다. 관측하지 않은 중간 시간대의 데이터를 ‘그럴듯하게’ 이은 것에 불과하기 때문에, 선을 긋는 것이 적절치 않다고 생각할 수도 있습니다. 하지만 점들이 너무 띄엄띄엄 있거나 불규칙할 때, 선은 우리 눈이 데이터의 흐름을 쫓도록 돕는 훌륭한 길잡이가 됩니다. 이럴 때는 캡션에 “선은 흐름을 파악하기 위한 가이드라인입니다” 같은 설명을 덧붙이는 것도 좋은 방법입니다.
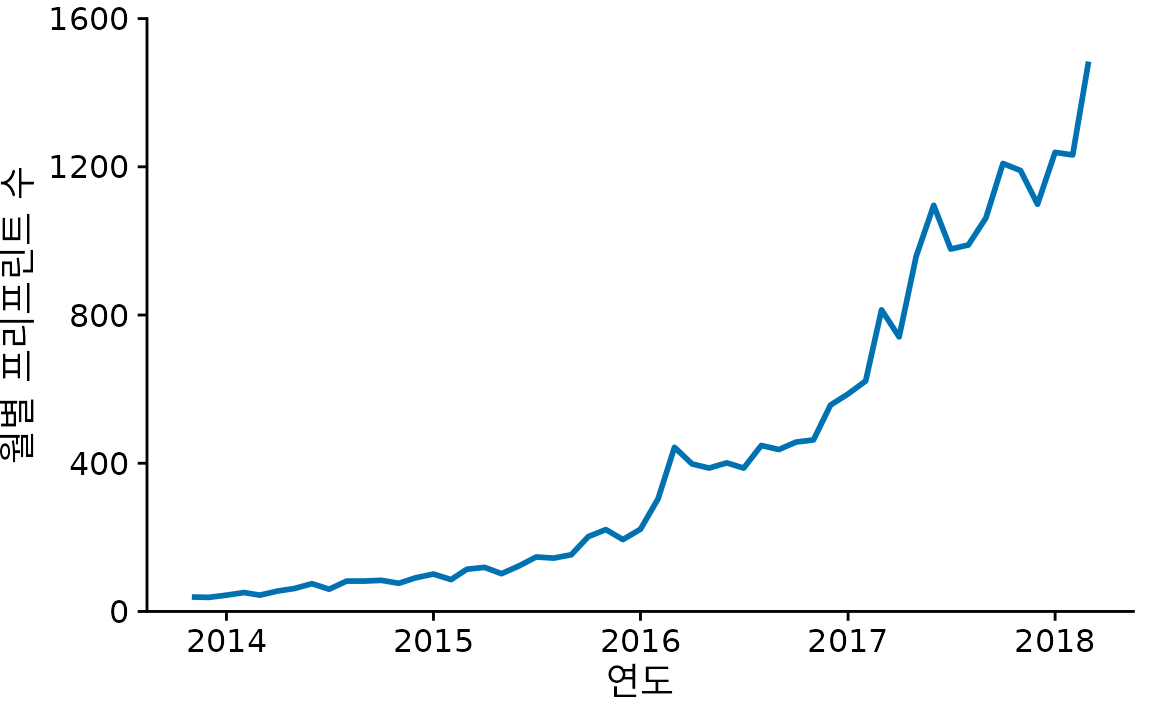
사실 시계열 데이터에서는 선만 남기고 점을 아예 없애는 것이 매우 흔한 관행입니다(그림 Figure 15.3). 점을 빼면 개별 데이터 하나하나보다는 전반적인 ’추세’에 시선이 더 집중됩니다. 그래프가 훨씬 깔끔해 보이기도 하죠. 데이터가 촘촘할수록 개별 점의 중요도는 낮아지므로, bioRxiv 데이터처럼 시계열이 긴 경우에는 선만 그리는 것이 더 나을 수 있습니다.
(ref:biorxiv-line) 점을 생략하고 선으로만 표현한 그래프. 개별 관측값보다는 시간 흐름에 따른 전반적인 추세를 강조하고 싶을 때 적합합니다.
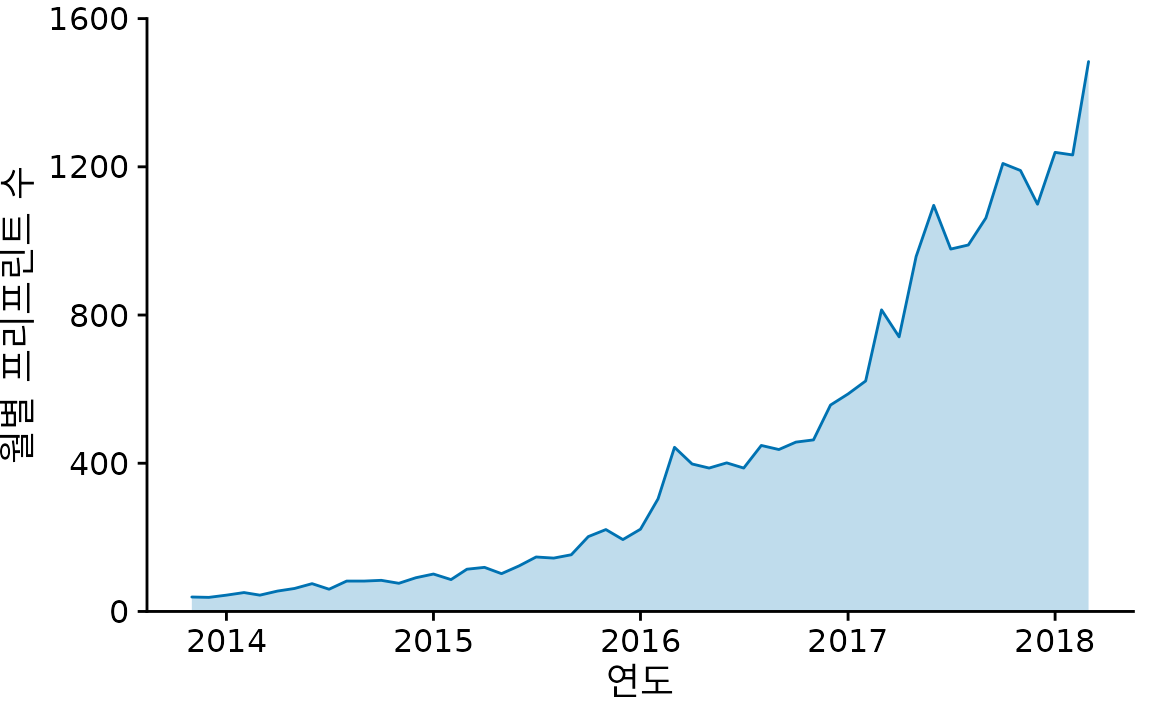
선 아래쪽을 색으로 채워 넣는 방법도 있습니다(그림 Figure 15.4). 이렇게 하면 데이터가 차지하는 ’면적’이 도드라져 전반적인 규모 변화가 훨씬 실감 나게 느껴집니다. 다만, 이 방식은 y축이 반드시 0부터 시작해야 하며, 데이터값이 모두 양수여야 왜곡이 없습니다.
(ref:biorxiv-line-area) 선 아래쪽을 색으로 채운 그래프. 면적을 통해 데이터의 규모와 전반적인 추세를 더욱 효과적으로 전달할 수 있습니다.
다중 시계열과 용량-반응 곡선
여러 개의 시계열을 한 번에 보여줘야 할 때는 더 세심한 주의가 필요합니다. 정보가 겹쳐서 읽기 힘들어질 수 있기 때문입니다. 예를 들어 세 개의 프리프린트 서버 데이터를 산점도로만 그리면(그림 Figure 15.5), 점들이 서로 뒤섞여서 어느 것이 어느 서버의 데이터인지 구분하기가 매우 어렵습니다. 이럴 때 점들을 선으로 이어주면 각각의 흐름을 쫓아가기가 훨씬 수월해집니다(그림 Figure 15.6).
(ref:bio-preprints-dots) 세 개의 프리프린트 서버 제출 건수를 점으로만 표시한 모습. 데이터가 서로 겹쳐 인지하기 어렵기 때문에 “나쁨” 사례로 꼽힙니다.
(ref:bio-preprints-lines) 점들을 선으로 연결하여 세 서버의 추세를 구분하기 쉽게 만든 모습.
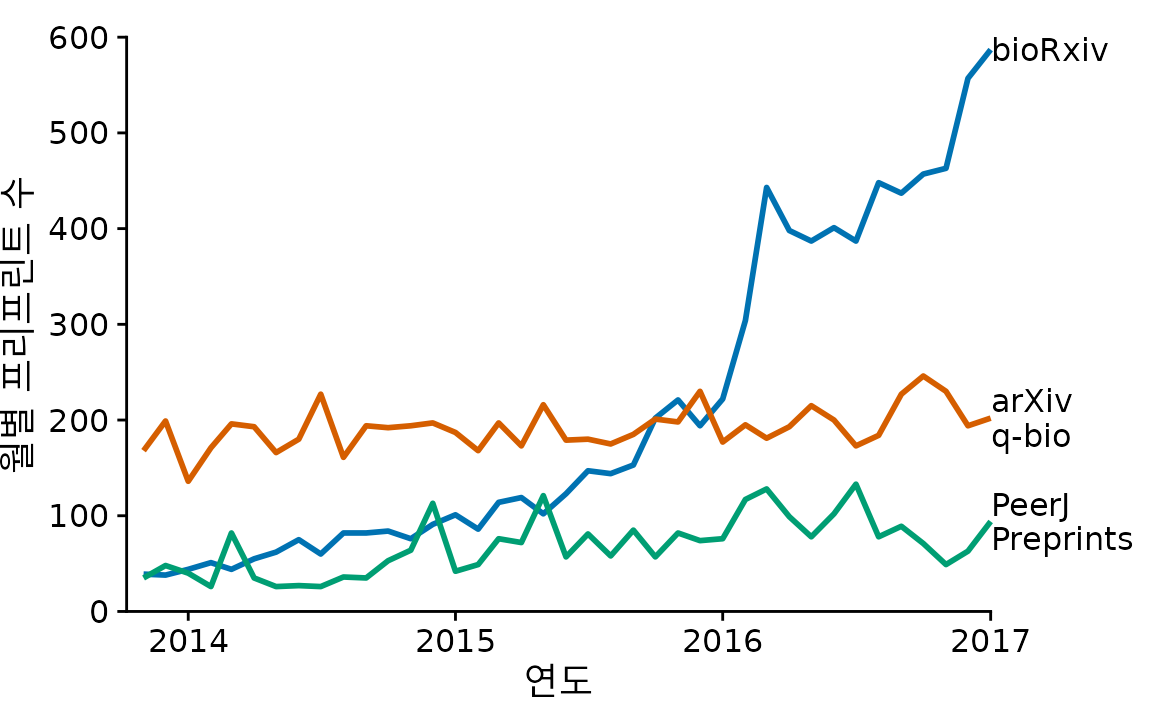
그림 ?fig-bio-preprints-lines도 나쁘지 않지만, 별도의 범례(legend)는 독자에게 “이 색은 뭐였지?” 하고 눈을 돌리게 만드는 불편함을 줍니다. 선 끝에 직접 레이블을 달아주면(그림 Figure 15.7) 굳이 범례를 찾아볼 필요가 없습니다. 점까지 아예 제거해서 선의 흐름만 남기면, 복잡한 데이터라도 아주 선명하고 읽기 편한 그래프가 됩니다.
(ref:bio-preprints-direct-label) 선에 직접 레이블을 달아 범례를 확인하는 수고를 덜어준 최종 그래프. 점을 제거해 시각적인 복잡도도 줄였습니다.
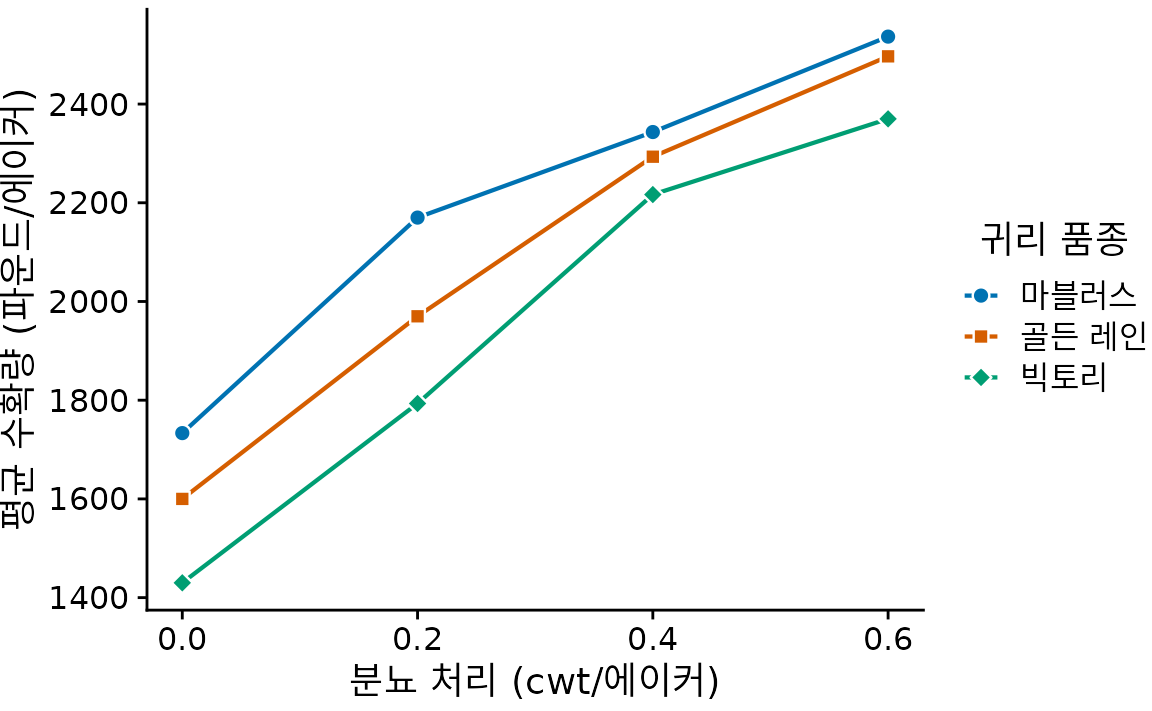
선 그래프는 ’시간’에만 국한되지 않습니다. x축에 놓인 변수에 따라 자연스러운 순서가 있다면 언제든 쓸 수 있습니다. 대표적인 사례가 약물이나 비료의 양을 늘릴 때 성능이 어떻게 변하는지 보여주는 용량-반응 곡선(dose-response curve)입니다. 그림 ?fig-oats-yield는 비료 투입량에 따른 귀리 수확량의 변화를 보여주는데, 세 품종 모두 비슷한 반응 곡선을 그리면서도 기초 체질(비료가 없을 때의 기본 수확량)에는 차이가 있음을 잘 보여줍니다.
(ref:oats-yield) 비료(분뇨) 투입량에 따른 귀리 품종별 수확량 변화 곡선. 질소 공급이 늘어남에 따라 품종에 관계없이 수확량이 전반적으로 증가하는 양상을 보입니다.
두 가지 반응 변수의 시계열
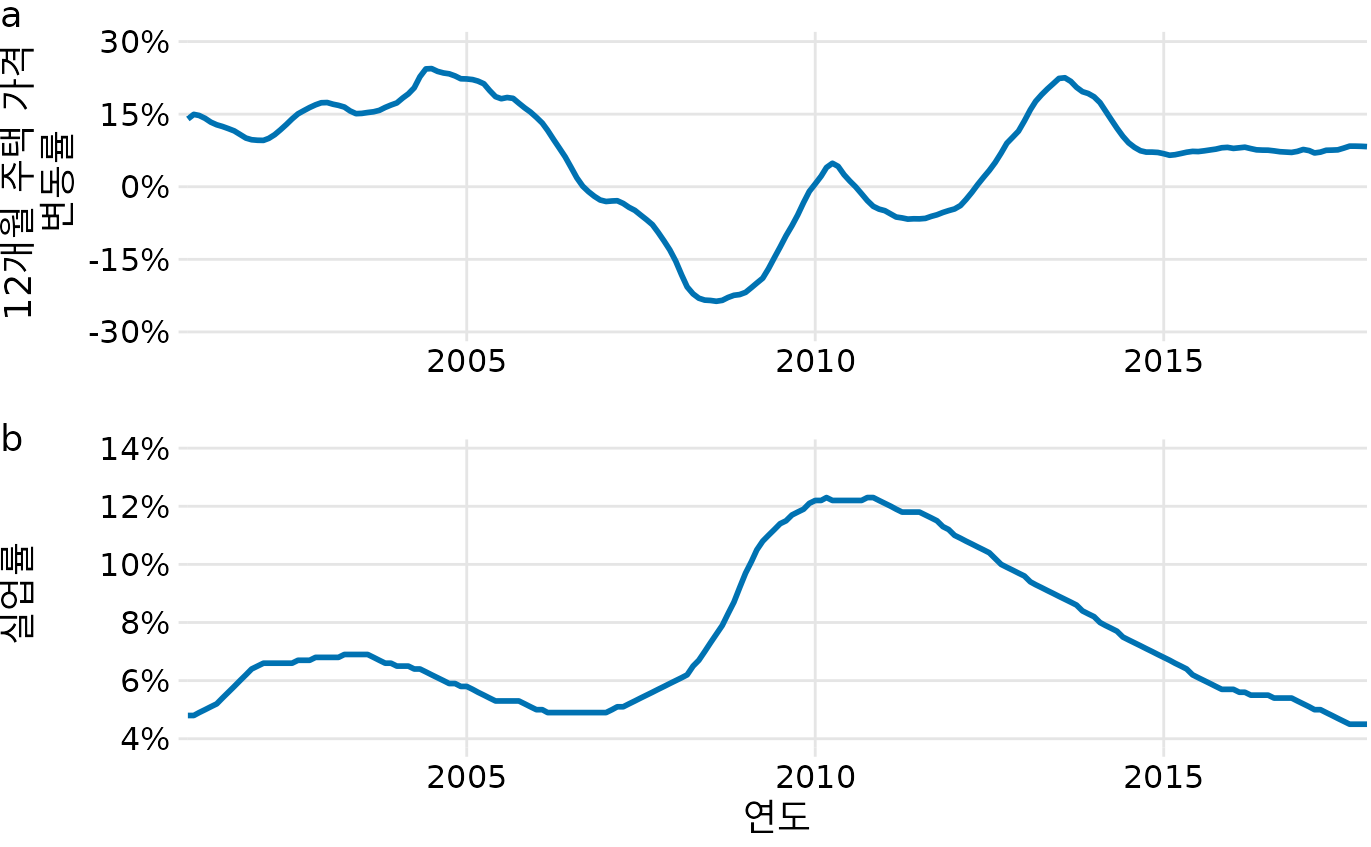
지금까지는 하나의 결과값(제출 건수, 수확량 등)이 시간이 지남에 따라 어떻게 변하는지만 보았습니다. 하지만 두 개의 서로 다른 결과값이 동시에 변할 때도 많습니다. 거시경제 데이터가 대표적인데, 가령 ‘주택 가격’과 ’실업률’ 사이의 관계가 그렇습니다. 보통 실업률이 낮으면 경제가 활발해 주택 가격이 오르고, 실업률이 높으면 그 반대가 될 것으로 예상할 수 있습니다.
이 데이터를 두 개의 그래프를 위아래로 쌓아서 그릴 수도 있습니다(그림 Figure 15.9). 각각의 변화는 잘 보이지만, 두 변수를 서로 정밀하게 비교하기는 번거롭습니다. 실업률이 오를 때 집값이 내리는 시점을 찾으려면 위아래 그래프를 번갈아 보며 눈을 바쁘게 움직여야 하기 때문입니다.
(ref:house-price-unemploy) 2001년부터 2017년까지 시간의 흐름에 따른 (a) 주택 가격 변동률과 (b) 실업률의 변화.
이럴 때는 x축에 실업률을, y축에 주택 가격 변동률을 두고 시간이 흐름에 따라 점들이 이동하는 경로를 그려보는 것이 좋습니다(그림 Figure 15.10). 이를 연결된 산점도(connected scatterplot)라고 부릅니다. 물리학이나 공학에서는 시스템의 상태 변화를 나타내는 위상 초상화(phase portrait)라고도 합니다. 이미 ?sec-coordinate-systems-axes 장에서 휴스턴과 샌디에이고의 기온 변화를 이런 방식으로 비교해본 적이 있습니다.
(ref:house-price-path) 주택 가격 변동률과 실업률의 관계를 보여주는 연결된 산점도. 색이 어두울수록 최근 데이터를 나타냅니다. 두 변수가 서로 반대 방향으로 움직이면서 시계 반대 방향의 소용돌이 패턴을 형성합니다.
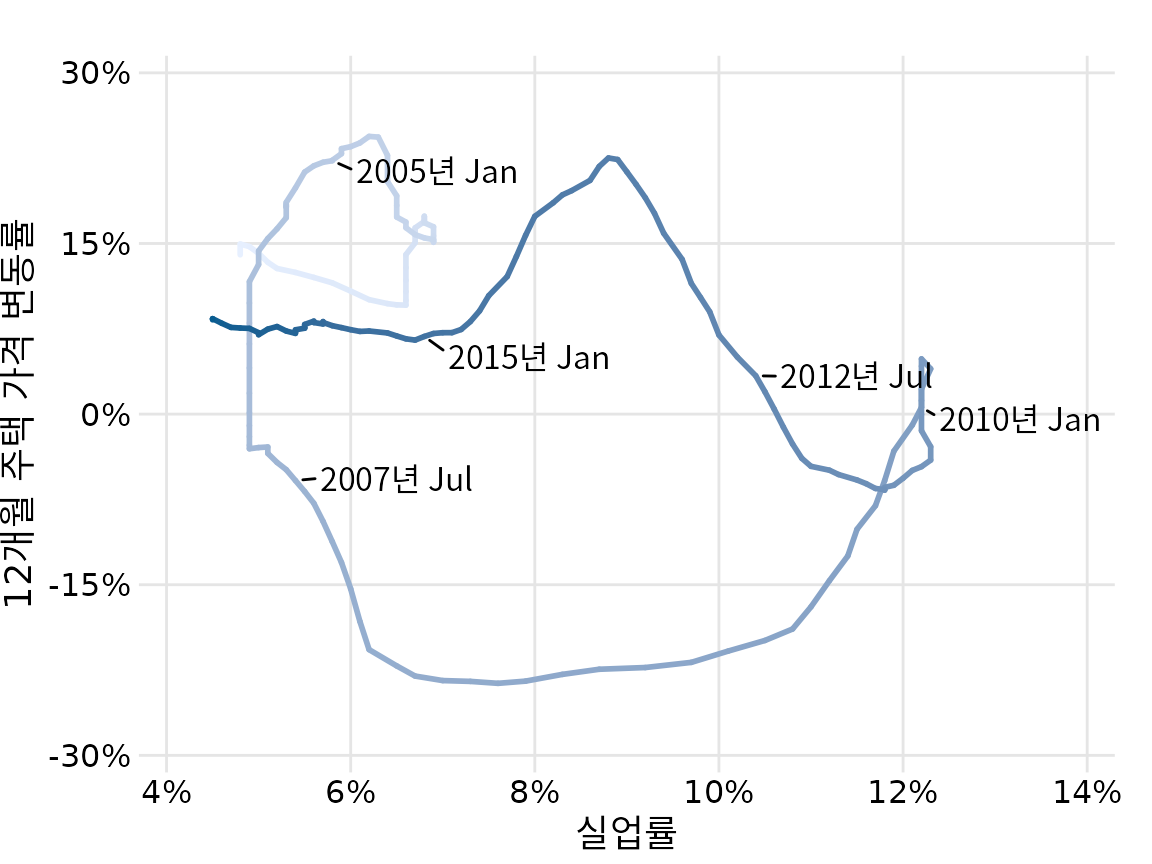
연결된 산점도에서 선이 왼쪽 아래에서 오른쪽 위로 향하면 두 변수가 함께 늘어나는 비례 관계를 뜻하고, 왼쪽 위에서 오른쪽 아래로 향하면 서로 반대로 움직이는 반비례 관계임을 나타냅니다. 만약 선이 뱅글뱅글 돌아 원이나 나선 모양을 그린다면, 두 변수가 주기적으로 순환하는 관계임을 암시합니다. 그림 ?fig-house-price-path에서도 집값과 실업률이 궤적을 그리며 회전하는 독특한 패턴을 확인할 수 있습니다.
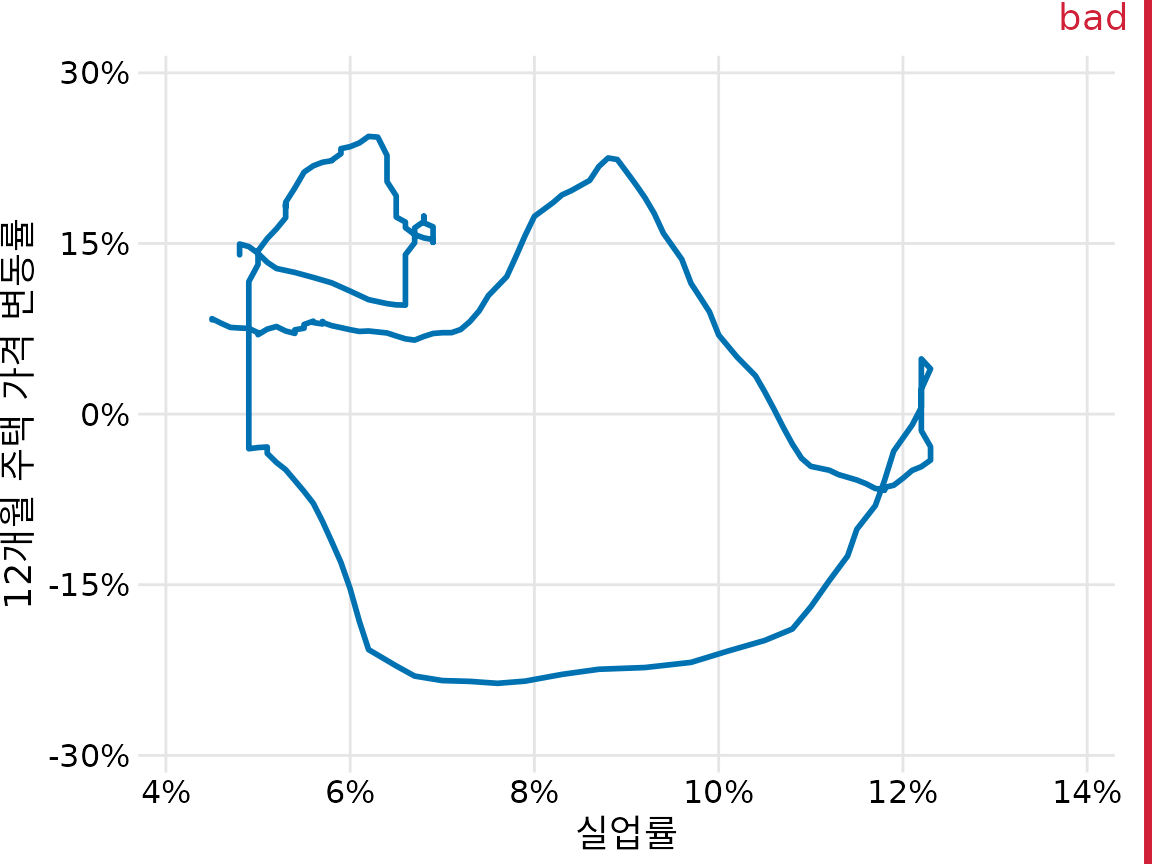
연결된 산점도를 그릴 때는 데이터의 흐름(방향)을 표시하는 것이 매우 중요합니다. 이런 힌트가 없으면 그저 의미 없이 엉킨 실타래처럼 보이기 쉽습니다(그림 Figure 15.11). 여기서는 색이 점점 어두워지는 효과(Figure 15.10)를 주어 시간의 흐름을 나타냈습니다.
(ref:house-price-path-bad) 시간 흐름이나 방향 정보가 빠진 연결된 산점도. 데이터의 선후 관계를 알 수 없어 패턴을 해석하기 어렵기 때문에 “나쁨”으로 표시되었습니다.
선 그래프와 연결된 산점도 중 어느 것이 나을까요? 선 그래프가 이해하기는 쉽지만, 데이터에 숨겨진 복잡한 순환 패턴을 찾아내는 데는 연결된 산점도가 훨씬 뛰어납니다. 실제로 위하래로 나뉜 선 그래프(Figure 15.9)만 봐서는 집값과 실업률의 관계를 파악하기 힘들지만, 연결된 산점도(Figure 15.10)에서는 소용돌이치는 궤적이 아주 명확하게 드러납니다. 비록 처음 접하는 사람에게는 낯설고 혼란스러울 수 있지만, 독자를 데이터의 흥미로운 이야기 속으로 끌어들이는 강력한 도구가 될 수 있습니다.
연결된 산점도는 한 번에 두 개의 변수만 표시할 수 있지만 더 높은 차원의 데이터 세트를 시각화하는 데에도 사용할 수 있습니다. 요령은 먼저 차원 축소를 적용하는 것입니다(챕터 둘 이상의 정량적 변수 간의 연관성 시각화 참조). 그런 다음 차원 축소된 공간에 연결된 산점도를 그릴 수 있습니다. 이 접근 방식의 예로 세인트루이스 연방 준비 은행에서 제공하는 100개 이상의 거시경제 지표에 대한 월별 관찰 데이터베이스를 시각화합니다. 모든 지표에 대해 주성분 분석(PCA)을 수행한 다음 PC 2 대 PC 1(그림 Figure 15.12 (a)) 및 PC 3(그림 Figure 15.12 (b))의 연결된 산점도를 그립니다.
(ref:fred-md-PCA) 주성분 공간에서 연결된 산점도로 고차원 시계열 시각화. 경로는 1990년 1월부터 2017년 12월까지 100개 이상의 거시경제 지표의 공동 움직임을 나타냅니다. 경기 침체 및 회복 시기는 색상으로 표시되며 세 번의 경기 침체 종료 지점(1991년 3월, 2001년 11월, 2009년 6월)도 레이블로 표시됩니다. (a) PC 2 대 PC 1. (b) PC 2 대 PC 3. 데이터 출처: M. W. McCracken, 세인트루이스 연준
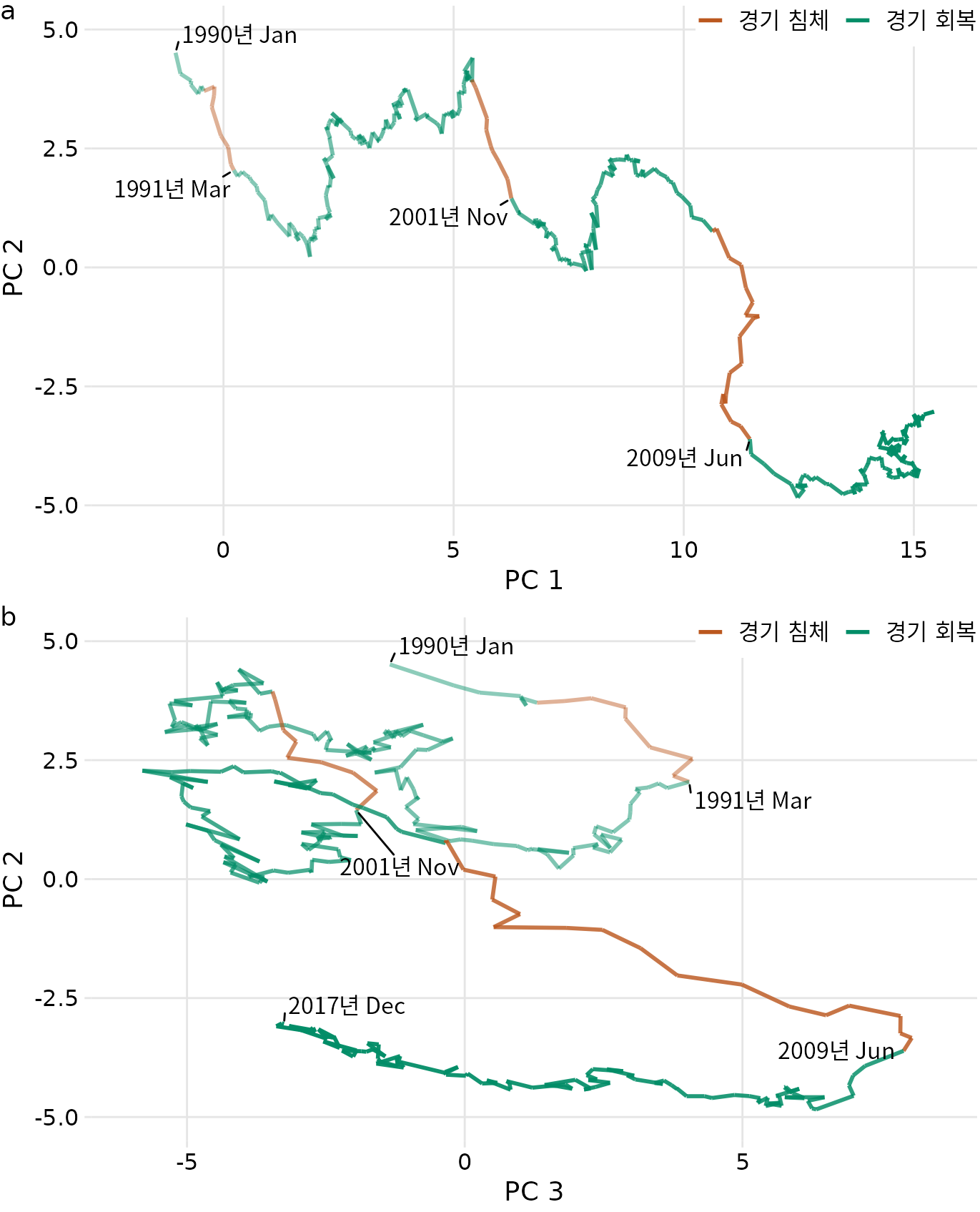
특히 그림 Figure 15.12 (a)는 왼쪽에서 오른쪽으로 시간이 흐르는 일반적인 선 그림처럼 보입니다. 이 패턴은 PCA의 일반적인 특징으로 인해 발생합니다. 첫 번째 구성 요소는 종종 시스템의 전체 크기를 측정합니다. 여기서 PC 1은 대략 경제의 전체 크기를 측정하며 시간이 지남에 따라 거의 감소하지 않습니다.
경기 침체 및 회복 시기를 색상으로 구분하여 연결된 산점도를 색칠하면 경기 침체는 PC 2의 하락과 관련이 있는 반면 회복은 PC 1 또는 PC 2의 명확한 특징과 관련이 없음을 알 수 있습니다(그림 Figure 15.12 (a)). 그러나 회복은 PC 3의 하락과 관련이 있는 것으로 보입니다(그림 Figure 15.12 (b)). 또한 PC 2 대 PC 3 플롯에서는 선이 시계 방향 나선 모양을 따르는 것을 볼 수 있습니다. 이 패턴은 경기 침체가 회복을 따르고 그 반대의 경우도 마찬가지인 경제의 주기적인 특성을 강조합니다.