한 번에 많은 분포 시각화하기
여러 개의 분포를 동시에 비교해야 하는 상황은 매우 흔합니다. 대표적인 예가 날씨 데이터입니다. 월별 기온 변화를 시각화할 때, 단순히 평균값만 보여주는 게 아니라 각 월 안에 관측된 온도의 분포를 함께 보여주고 싶을 수 있습니다. 이럴 때는 12개월분, 즉 12개의 온도 분포를 한꺼번에 효과적으로 보여줘야 합니다. 분포 시각화: 히스토그램 및 밀도 그림 장이나 분포 시각화: 경험적 누적 분포 함수 및 q-q 그림 장에서 배운 방식들은 분포의 개수가 많아지면 화면이 너무 복잡해져서 사용하기 어렵습니다. 대신 상자 그림, 바이올린 그림, 능선 그림 같은 방식들이 훌륭한 대안이 됩니다.
많은 수의 분포를 다룰 때는 항상 ’반응 변수(response variable)’와 ’그룹화 변수(grouping variable)’라는 개념으로 접근하는 것이 좋습니다. 반응 변수는 우리가 그 분포를 알고 싶어 하는 대상(예: 온도)이고, 그룹화 변수는 데이터를 구분하는 기준(예: 월)입니다. 이 장에서 소개할 기법들은 모두 한 축에는 반응 변수를, 다른 축에는 그룹화 변수를 할당합니다. 먼저 세로축에 반응 변수를 두는 방식부터 시작해서, 가로축에 두는 방식까지 차례로 살펴보겠습니다.
세로축을 기준으로 분포 시각화하기
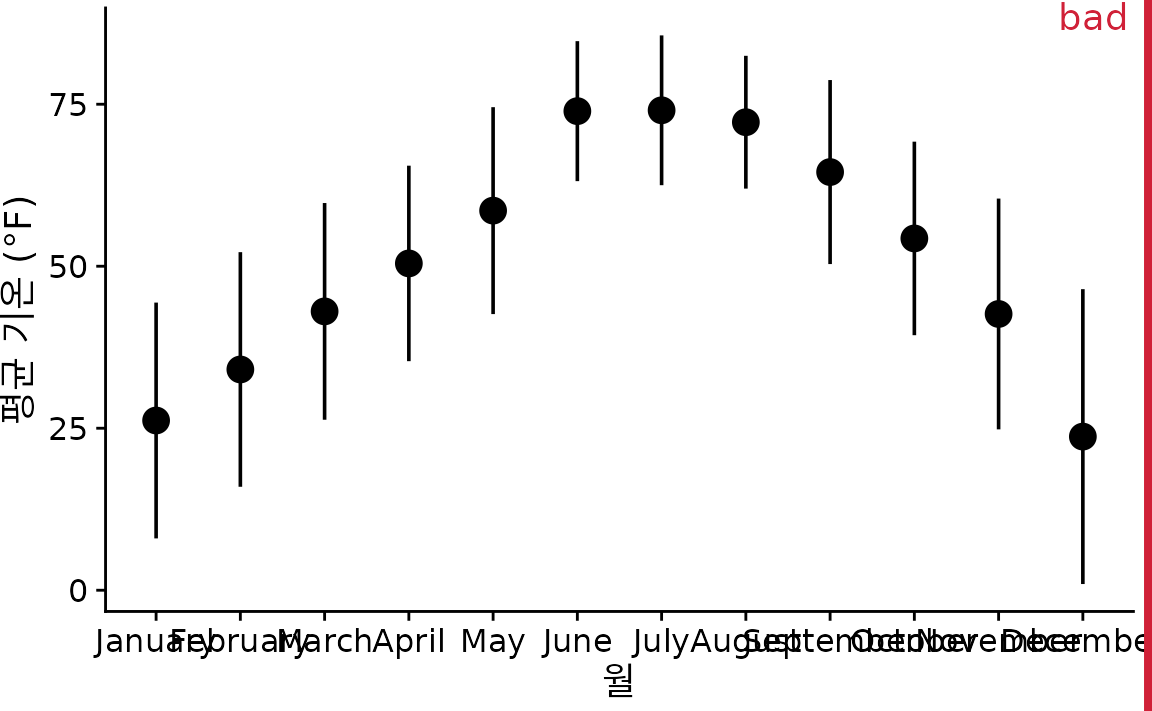
여러 분포를 한눈에 보여주는 가장 단순한 방법은 평균이나 중앙값을 점으로 찍고, 그 주변의 변동 폭을 ’오차 막대(error bar)’로 표시하는 것입니다. 그림 ?fig-lincoln-temp-points-errorbars는 2016년 네브래스카주 링컨의 월별 기온 분포를 이 방식으로 그린 것입니다. 하지만 저는 이 그래프에 “나쁨” 표시를 해두었습니다. 몇 가지 치명적인 문제점이 있기 때문입니다.
첫째, 수많은 데이터를 겨우 점 하나와 막대 두 개로 축약하면서 너무 많은 정보가 사라집니다. 둘째, 그 점이 정확히 무엇(평균인지 중앙값인지)을 뜻하는지 직관적으로 알기 어렵습니다. 셋째, 오차 막대가 무엇을 나타내는지도 불분명합니다. 표준 편차인가요, 표준 오차인가요, 아니면 95% 신뢰 구간인가요? 사실 이에 대해 공식적으로 약속된 표준은 없습니다. 넷째, 데이터가 한쪽으로 치우쳐(skewed) 있는 경우 대칭형 오차 막대는 통계적 사실을 왜곡할 위험이 큽니다. 실제로 기온 데이터는 대개 비대칭적인 특성을 보입니다.
(ref:lincoln-temp-points-errorbars) 2016년 네브래스카주 링컨의 일일 평균 기온. 점은 각 월의 일일 평균 기온을 나타내고, 오차 막대는 매월 온도의 표준 편차의 두 배 범위를 나타냅니다. 이 그래프는 “나쁨”으로 분류되었는데, 오차 막대가 보통 추정치의 불확실성을 보여주는 용도로 쓰이지 데이터 자체의 변동성을 보여주는 데는 적합하지 않기 때문입니다. 데이터 출처: Weather Underground
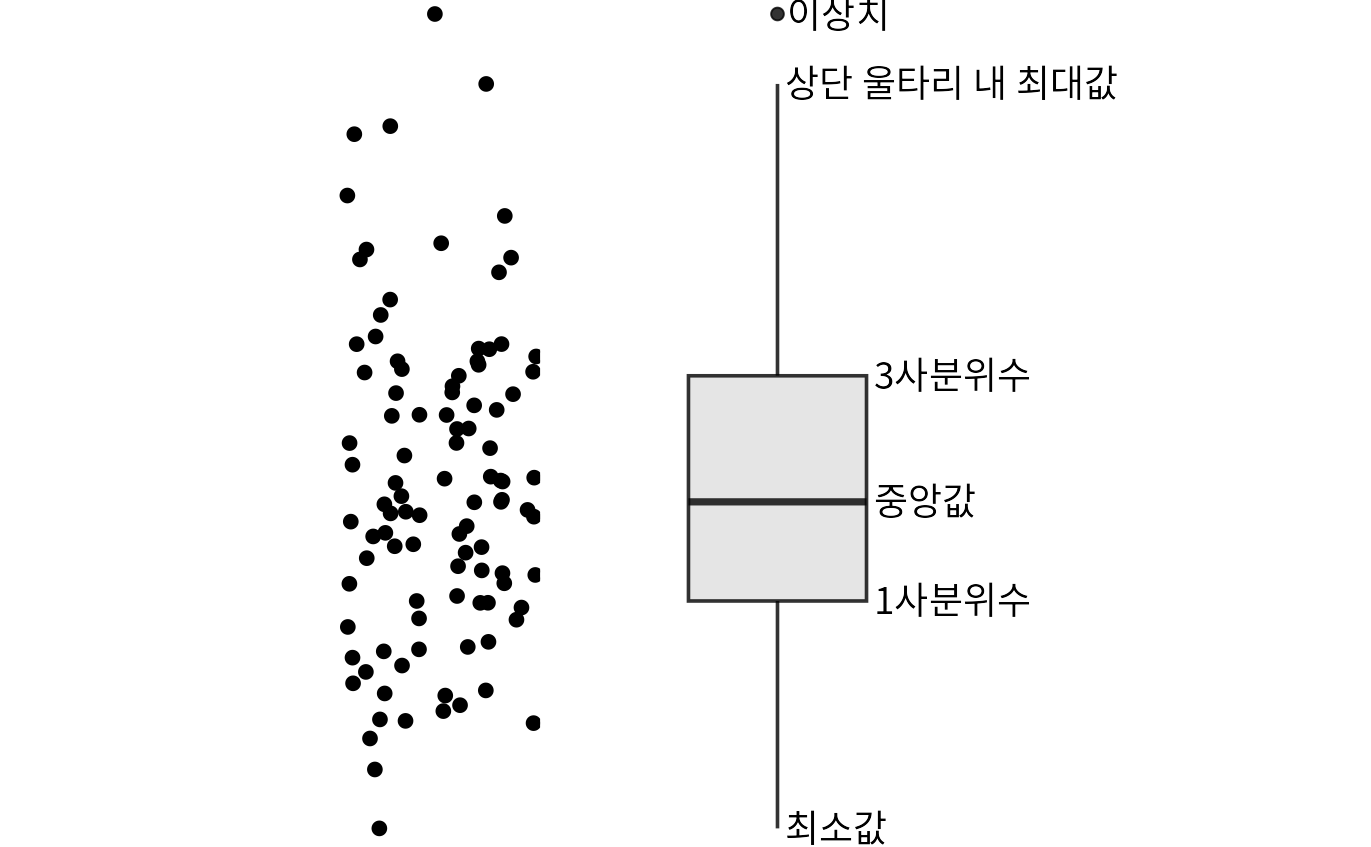
이러한 단점들을 극복하기 위해 가장 널리 쓰이는 시각화 도구가 바로 상자 그림(boxplot)입니다. 상자 그림은 데이터를 사분위수(quartiles)를 기준으로 나누어 정해진 규칙에 따라 시각화합니다(그림 Figure 11.2).
(ref:boxplot-schematic) 상자 그림의 구조. 왼쪽의 점 구름(dot cloud) 데이터를 오른쪽과 같은 상자 그림으로 변환합니다. 상자 중앙의 굵은 선은 중앙값을 뜻하며, 상자의 위아래 끝은 각각 3사분위수와 1사분위수를 나타내어 전체 데이터의 중간 50%가 이 상자 안에 위치함을 보여줍니다. 상자 밖으로 뻗어 나간 선(수염, whiskers)은 데이터의 범위를 나타내는데, 보통 상자 높이의 1.5배 이내에 있는 최댓값과 최솟값까지 뻗습니다. 이 범위를 벗어나는 데이터는 ’이상치(outliers)’로 간주하여 점으로 따로 표시합니다.
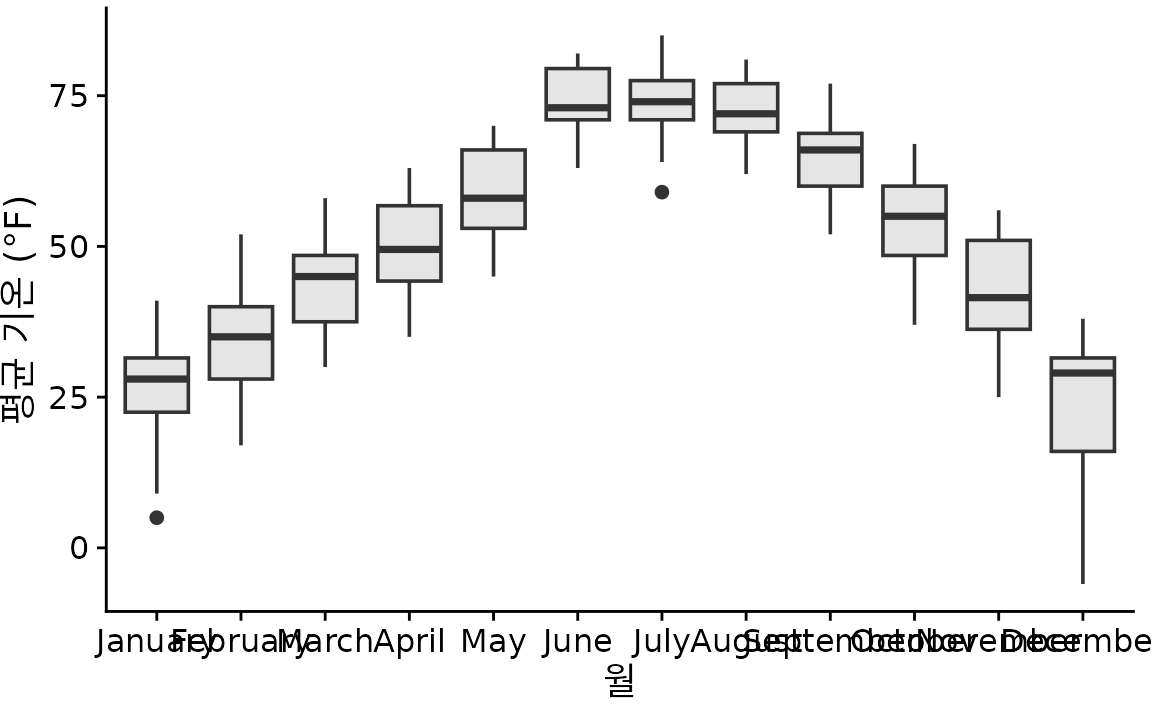
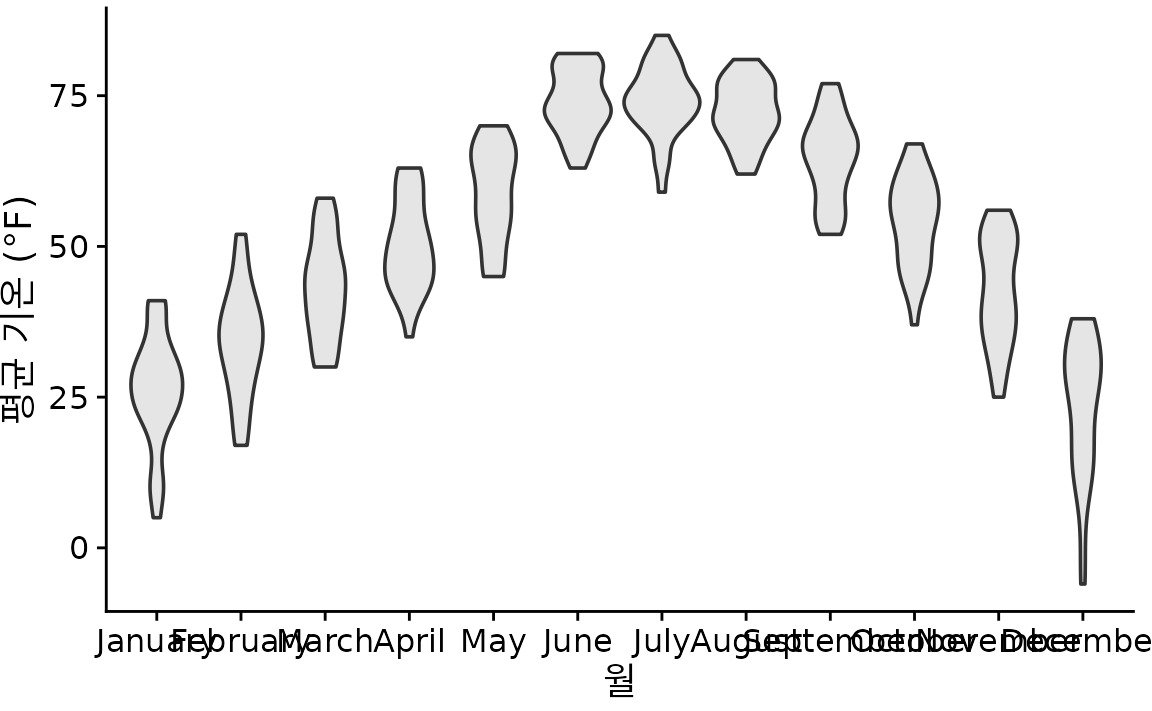
상자 그림은 단순하면서도 정보가 풍부하며, 여러 그룹의 분포를 나란히 비교할 때 매우 효과적입니다. 링컨의 기온 데이터를 상자 그림으로 그리면 그림 ?fig-lincoln-temp-boxplots와 같습니다. 이 그래프를 통해, 예를 들어 12월 기온 분포는 아주 길게 아래쪽으로 꼬리가 늘어져 있고(대부분 춥지만 며칠은 극심한 한파가 옴), 7월 같은 달은 비교적 대칭적인 분포를 보인다는 사실을 알 수 있습니다.
(ref:lincoln-temp-boxplots) 네브래스카 주 링컨의 일일 평균 기온을 상자 그림으로 시각화했습니다.
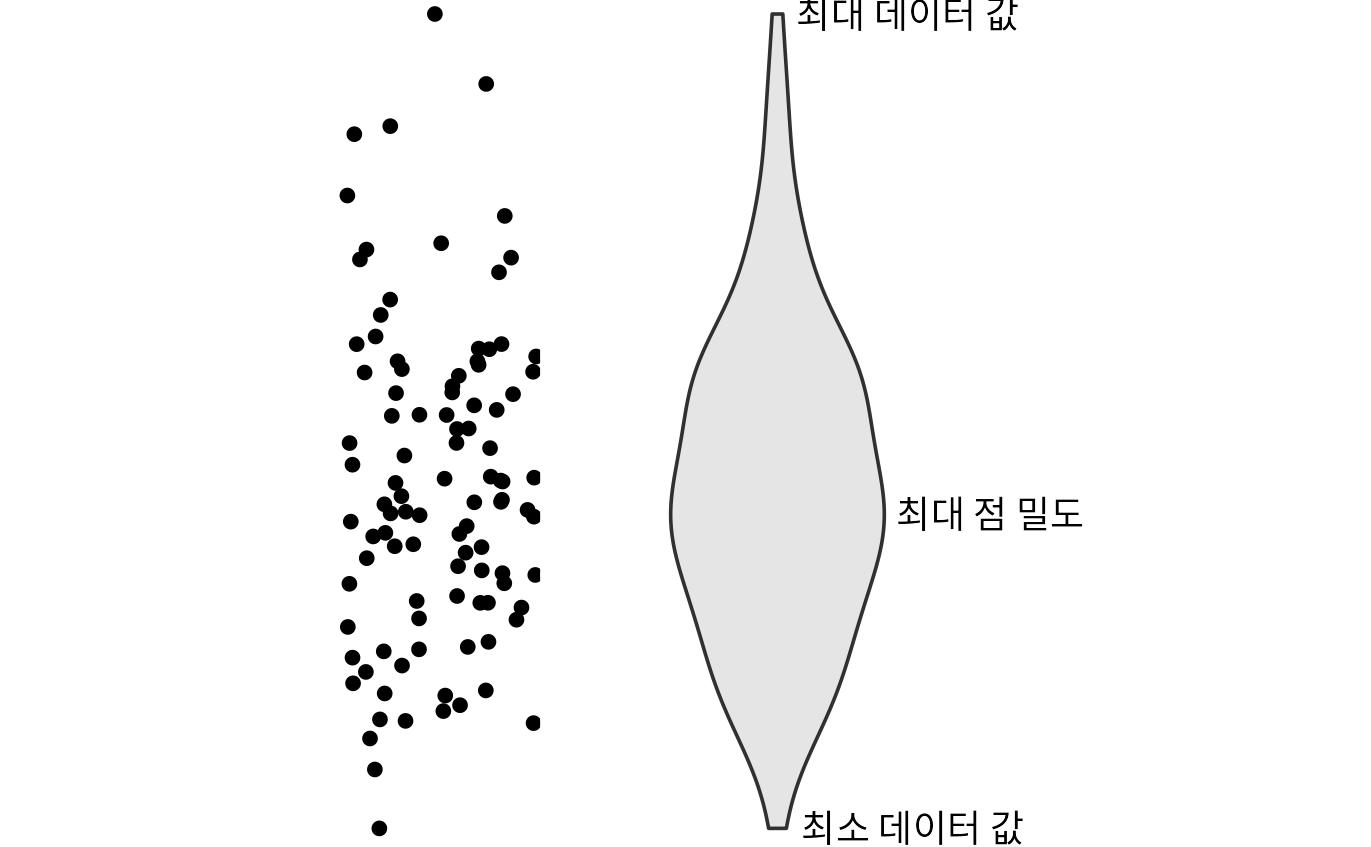
상자 그림은 1970년대 통계학자 존 튜키(John Tukey)가 고안했습니다. 당시엔 그래프를 손으로 직접 그려야 했기 때문에, 간단한 규칙만으로 많은 정보를 담을 수 있는 상자 그림이 큰 인기를 끌었습니다. 하지만 현대의 강력한 컴퓨팅 환경에선 더 정교한 시각화가 가능해졌고, 그 결과 최근에는 상자 그림을 대신해 바이올린 그림(violin plot)이 자주 쓰입니다. 바이올린 그림은 밀도 추정치를 90도 회전한 뒤 대칭으로 이어 붙여 만든 모양입니다(그림 Figure 11.4). 상자 그림의 역할을 그대로 수행하면서도 데이터의 미묘한 흐름을 훨씬 잘 보여줍니다. 특히 상자 그림이 놓치기 쉬운 ‘이봉형(bimodal, 봉우리가 두 개인)’ 데이터의 특성도 바이올린 그림에서는 명확히 드러납니다.
(ref:violin-schematic) 바이올린 그림의 구조. 왼쪽의 점 구름 데이터가 오른쪽 바이올린 그림으로 변환되는 과정을 보여줍니다. 특정 점수(y값)에서 바이올린의 가로 폭은 해당 점수가 나타나는 빈도(밀도)를 의미합니다. 이론적으로 바이올린 그림은 밀도 곡선을 90도 회전한 뒤 대칭으로 이어 붙인 형태입니다. 가장 뚱뚱한 부분은 데이터가 가장 조밀하게 모여 있는 구간입니다.
바이올린을 사용하여 분포를 시각화하기 전에 각 그룹에 점 밀도를 부드러운 선으로 표시할 만큼 충분한 데이터 포인트가 있는지 확인하십시오.
링컨 기온 데이터를 바이올린 그림으로 그려보면(그림 Figure 11.5), 몇몇 달의 기온 분포에서 봉우리가 두 개로 나뉘는 현상을 발견할 수 있습니다. 예를 들어 11월에는 화씨 50도와 35도 근처에서 데이터가 모여 있는 ’이봉성’이 관찰됩니다.
(ref:lincoln-temp-violins) 네브래스카 주 링컨의 일일 평균 기온을 바이올린 그림으로 시각화했습니다.
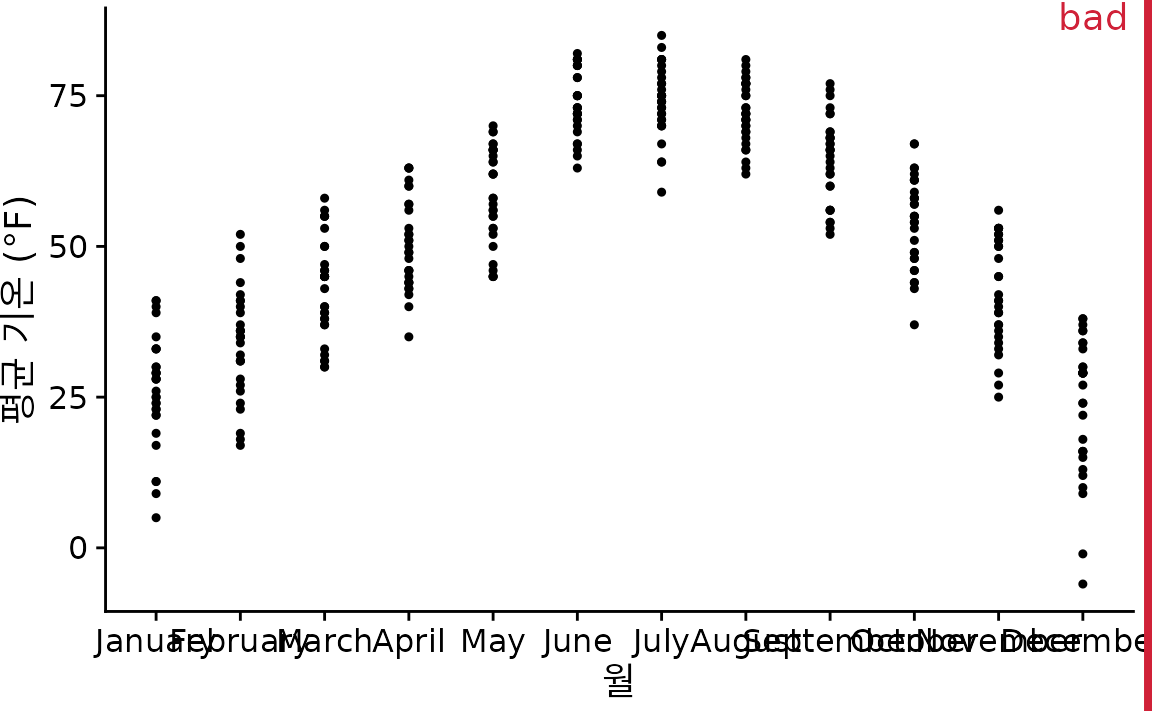
바이올린 그림도 밀도 추정 기반이라서, 데이터가 드문 곳이 마치 꽉 차 있는 것처럼 보이게 만드는 등의 단점이 있습니다. 이를 보완하는 가장 확실한 방법은 개별 데이터 포인트를 점으로 직접 찍어주는 것인데(그림 Figure 11.6), 이를 스트립 차트(strip chart)라고 부릅니다. 다만 데이터가 많으면 점들이 겹쳐서 알아보기 힘들 수 있는데, 이럴 때 점들을 옆으로 살짝 흐트러뜨리는 지터링(jittering) 기법을 사용하면 좋습니다(그림 Figure 11.7).
(ref:lincoln-temp-all-points) 네브래스카주 링컨의 일일 평균 기온을 스트립 차트로 표현했습니다. 각 점은 하루의 기온을 나타냅니다. 점들이 무수히 겹쳐 있어 실제 밀도를 파악하기 어렵기 때문에 “나쁨”으로 분류되었습니다.
(ref:lincoln-temp-jittered) 같은 데이터를 스트립 차트로 그리되, 가로 방향으로 점들을 살짝 흩뜨려(jittering) 밀도를 더 잘 보이게 만들었습니다.

데이터 세트가 너무 희소하여 바이올린 시각화를 정당화할 수 없는 경우 원시 데이터를 개별 점으로 플로팅할 수 있습니다.
한 걸음 더 나아가, 바이올린 그림의 형태와 실제 데이터 점을 결합한 방식도 있습니다. 바로 시나 플롯(Sina plot)입니다. 개별 점을 다 보여주면서도 전체적인 밀도에 비례해 점들을 배치하기 때문에, 분포와 개별 관측값을 동시에 파악하기에 매우 좋습니다(그림 Figure 11.8).
(ref:lincoln-temp-sina) 링컨의 일일 평균 기온을 시나 플롯(개별 점과 바이올린의 조합)으로 나타낸 것입니다. 점들이 분포의 밀도에 비례하여 흩어져 있습니다. ’시나 플롯’이라는 이름은 이 기법을 고안한 코펜하겐 대학교 학생 시나 하디 소히(Sina Hadi Sohi)의 이름을 딴 것입니다.

가로축을 기준으로 분포 시각화하기
데이터의 분포를 가로 방향으로 쌓아 올리듯 배치하는 방법도 있습니다. 이 모습이 마치 웅장한 산맥처럼 보인다고 해서 능선 그림(ridgeline plot)이라고 부릅니다. 능선 그림은 특히 시간에 따른 분포의 변화 추세를 한눈에 보여줄 때 매우 효과적입니다.
가장 표준적인 능선 그림은 밀도 추정 방식을 사용합니다(그림 Figure 11.9). 바이올린 그림과 원리는 비슷하지만, 여러 그룹을 수직으로 나열하기 때문에 분포의 차이가 훨씬 더 직관적으로 다가옵니다. 예를 들어 11월의 이봉성 분포는 바이올린 그림(Figure 11.5)보다 능선 그림(Figure 11.9)에서 훨씬 뚜렷하게 보입니다.
(ref:temp-ridgeline) 2016년 네브래스카주 링컨의 기온을 능선 그림으로 표현했습니다. 매월 온도의 분포를 산맥처럼 쌓아 올린 형태입니다.
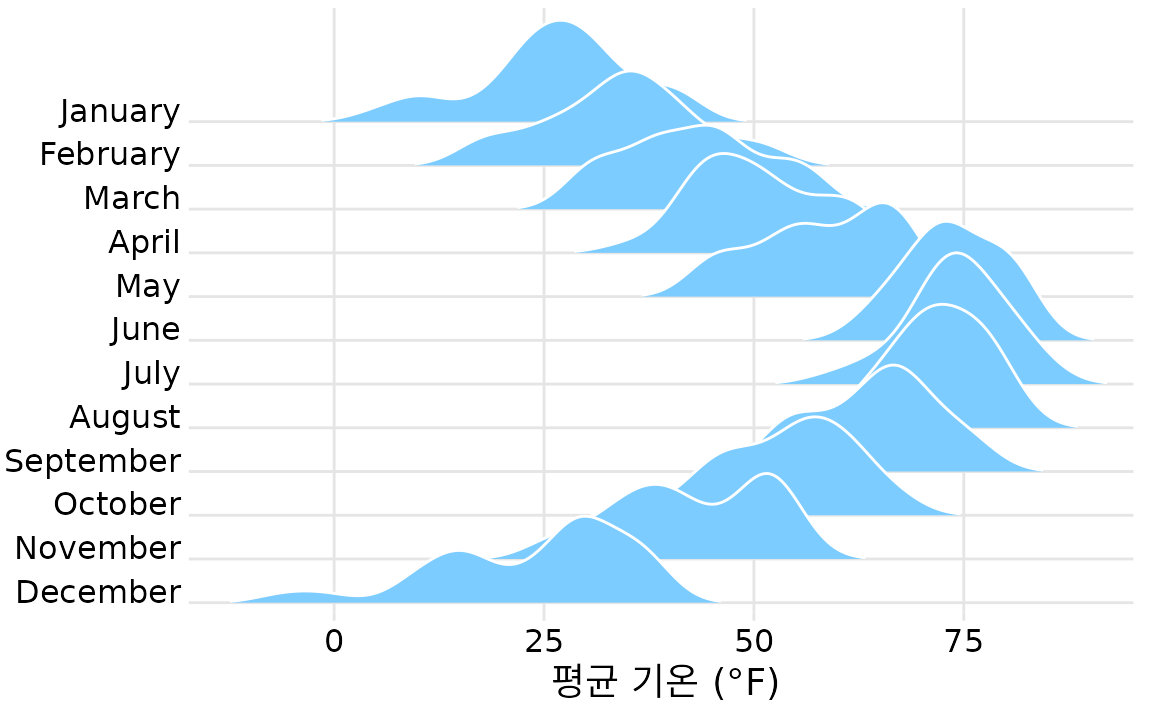
능선 그림에는 밀도 자체를 나타내는 별도의 수치 축이 없는데, 이는 바이올린 그림도 마찬가지입니다. 이 그림들의 목적은 정확한 밀도 수치를 읽어내는 것이 아니라, 여러 그룹 간의 분포 ’모양’과 ’상대적인 높이’를 한눈에 비교하는 데 있기 때문입니다.
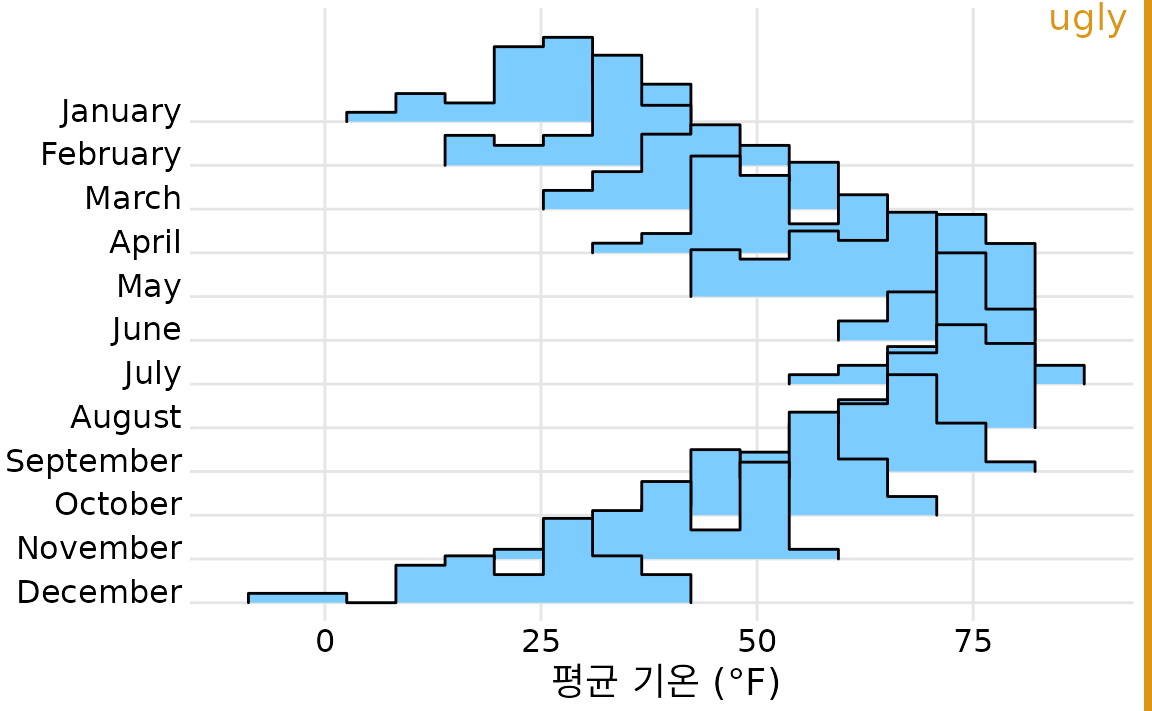
능선 그림에 밀도 곡선 대신 히스토그램을 쓰는 것도 불가능하진 않지만, 추천하지 않습니다. 그림 ?fig-temp-binline을 보면 알 수 있듯, 여러 히스토그램이 어설프게 겹치면서 시각적으로 매우 혼란스럽고 지저분해 보이기 때문입니다.
(ref:temp-binline) 링컨의 기온을 히스토그램 형태의 능선 그림으로 그린 것입니다. 경계선이 겹치고 복잡하여 매우 알아보기 어렵습니다.
능선 그림은 아주 많은 수의 그룹을 비교할 때 진가를 발휘합니다. 그림 ?fig-movies-ridgeline은 약 100년에 걸친 영화 상영 시간의 분포를 보여주는데, 무려 100여 개의 분포가 담겨 있음에도 흐름을 읽기가 매우 쉽습니다. 1920년대엔 영화 길이가 들쑥날쑥했지만, 1960년대부터는 약 90분 정도로 표준화되는 과정을 선명하게 확인할 수 있습니다.
(ref:movies-ridgeline) 시간에 따른 영화 길이의 진화. 1960년대 이후 대부분의 영화는 약 90분 길이입니다. 데이터 출처: 인터넷 영화 데이터베이스, IMDB
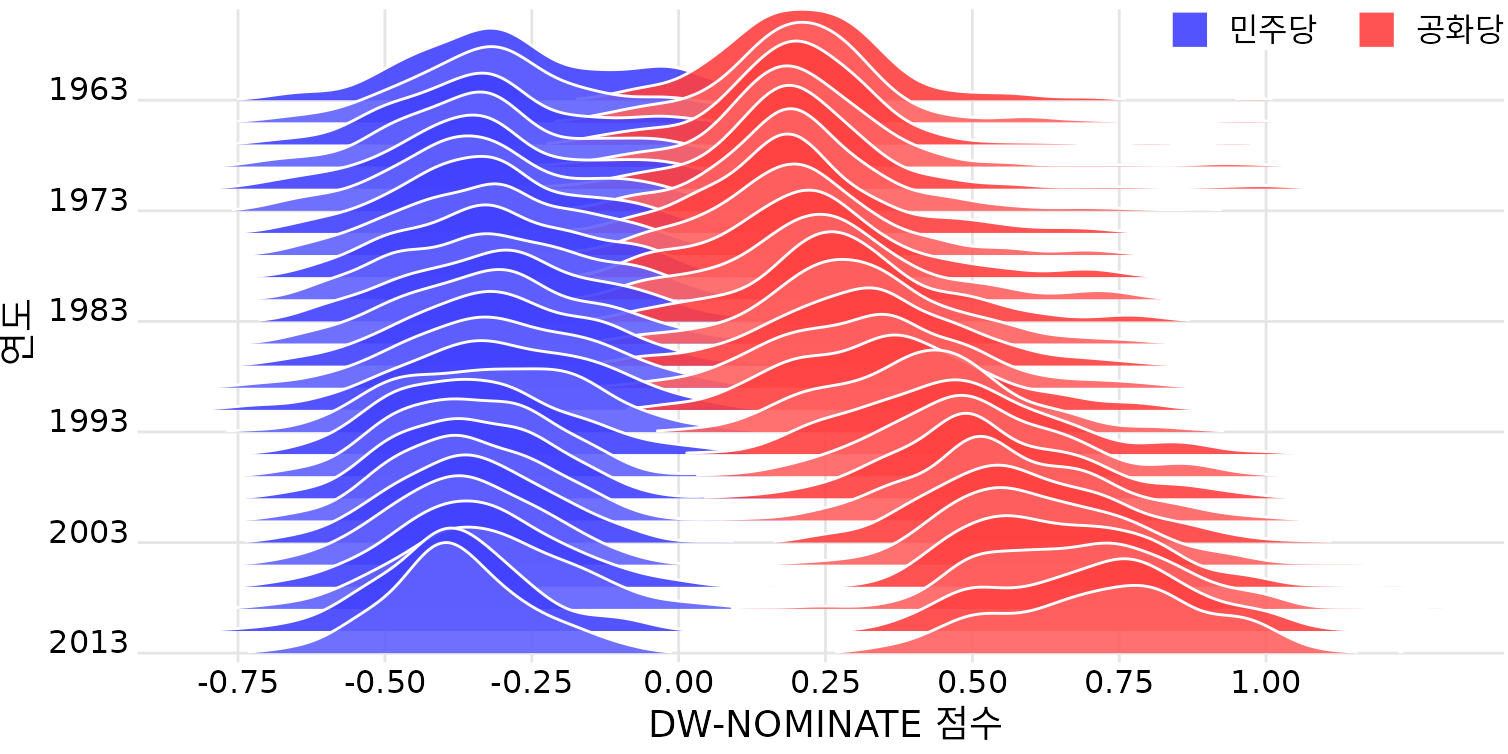
또한 능선 그림은 두 집단의 성향 차이를 시간순으로 분석할 때도 매우 유용합니다. 그림 ?fig-dw-nominate-ridgeline은 미국 하원 의원들의 투표 패턴(보수/진보 성향)을 수십 년간 추적한 것입니다. 민주당과 공화당의 분포를 서로 다른 색으로 칠해 엇갈려 배치함으로써, 시간이 흐를수록 두 당의 정치적 양극화가 얼마나 심해졌는지를 한 폭의 그림으로 완벽하게 보여줍니다.
(ref:dw-nominate-ridgeline) 미국 하원의 투표 패턴이 점점 더 양극화되고 있습니다. DW-NOMINATE 점수는 정당 간 및 시간 경과에 따른 의원들의 투표 패턴을 비교하는 데 자주 사용됩니다. 여기서는 1963년부터 2013년까지 각 의회에 대해 민주당과 공화당에 대해 별도로 점수 분포를 보여줍니다. 각 의회는 첫해로 표시됩니다. 원본 그림 개념: McDonald (2017).
McDonald, Ian. 2017. “DW-NOMINATE Using Ggjoy.” http://rpubs.com/ianrmcdonald/293304.