중첩된 점 처리하기
크거나 매우 큰 데이터 세트를 시각화하려는 경우 단순한 x–y 산점도가 잘 작동하지 않는 문제를 종종 경험합니다. 많은 점이 서로 겹쳐 부분적으로 또는 완전히 겹치기 때문입니다. 그리고 데이터 값이 낮은 정밀도로 기록되거나 반올림되어 여러 관찰값이 정확히 동일한 숫자 값을 갖는 경우 작은 데이터 세트에서도 유사한 문제가 발생할 수 있습니다. 이러한 상황을 설명하는 데 일반적으로 사용되는 기술 용어는 “중복 플로팅”, 즉 많은 점을 서로 겹쳐서 플로팅하는 것입니다. 여기서는 이러한 문제에 직면했을 때 취할 수 있는 몇 가지 전략을 설명합니다.
부분 투명도 및 지터링
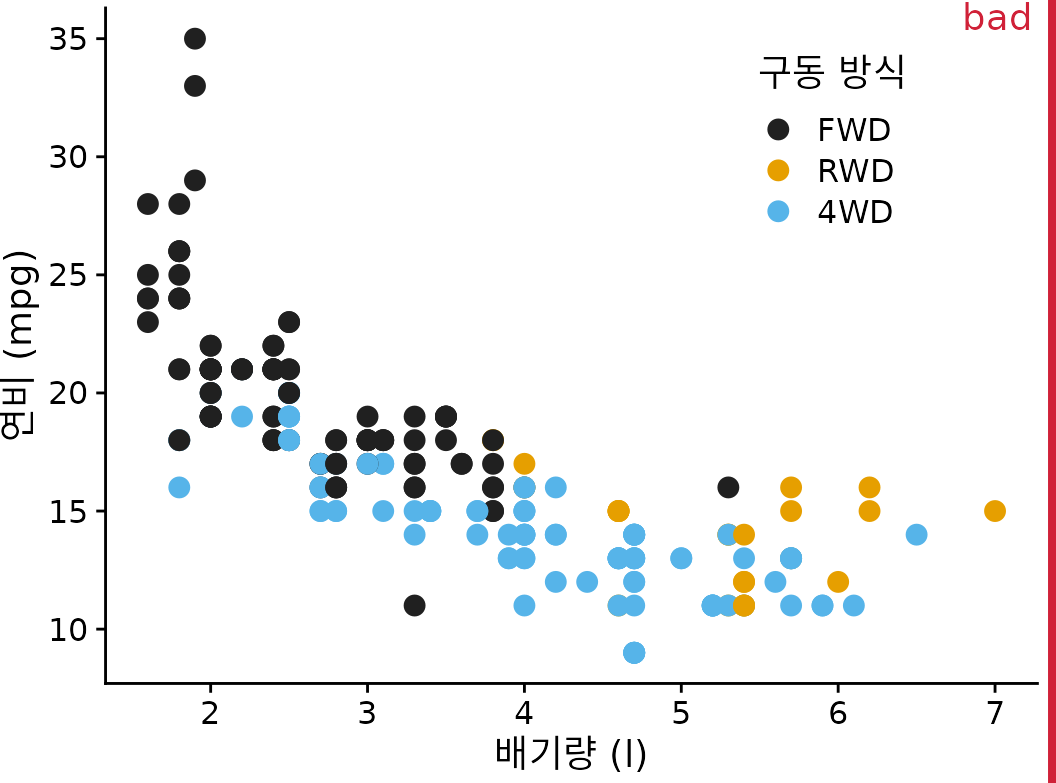
먼저 데이터 포인트 수는 적당하지만 반올림이 광범위한 시나리오를 고려해 보겠습니다. 저희 데이터 세트에는 1999년에서 2008년 사이에 출시된 234개 인기 자동차 모델의 도시 주행 연비와 엔진 배기량이 포함되어 있습니다(그림 Figure 20.1). 이 데이터 세트에서 연비는 갤런당 마일(mpg)로 측정되며 가장 가까운 정수 값으로 반올림됩니다. 엔진 배기량은 리터 단위로 측정되며 가장 가까운 데시리터로 반올림됩니다. 이러한 반올림으로 인해 많은 자동차 모델이 정확히 동일한 값을 갖습니다. 예를 들어 총 21대의 자동차가 2.0리터 엔진 배기량을 가지며 그룹으로서 19, 20, 21 또는 22mpg의 네 가지 다른 연비 값만 갖습니다. 따라서 그림 ?fig-mpg-cty-displ-solid에서 이러한 21대의 자동차는 네 개의 개별 점으로만 표시되므로 2.0리터 엔진이 실제보다 훨씬 덜 인기 있는 것처럼 보입니다. 또한 데이터 세트에는 2.0리터 엔진을 장착한 두 대의 4륜 구동 자동차가 포함되어 있으며 검은색 점으로 표시됩니다. 그러나 이러한 검은색 점은 노란색 점으로 완전히 가려져 2.0리터 엔진을 장착한 4륜 구동 자동차가 없는 것처럼 보입니다.
(ref:mpg-cty-displ-solid) 1999년에서 2008년 사이에 출시된 인기 자동차의 도시 연비 대 엔진 배기량. 각 점은 하나의 자동차를 나타냅니다. 점 색상은 구동 방식(전륜 구동(FWD), 후륜 구동(RWD) 또는 4륜 구동(4WD))을 나타냅니다. 많은 점이 다른 점 위에 그려져 가려지기 때문에 그림은 “나쁨”으로 표시되었습니다.
이 문제를 완화하는 한 가지 방법은 부분 투명도를 사용하는 것입니다. 개별 점을 부분적으로 투명하게 만들면 중복된 점이 더 어두운 점으로 나타나므로 점의 음영이 해당 위치의 점 밀도를 반영합니다(그림 Figure 20.2).
(ref:mpg-cty-displ-transp) 도시 연비 대 엔진 배기량. 점이 부분적으로 투명해졌기 때문에 다른 점 위에 있는 점은 이제 더 어두운 음영으로 식별할 수 있습니다.
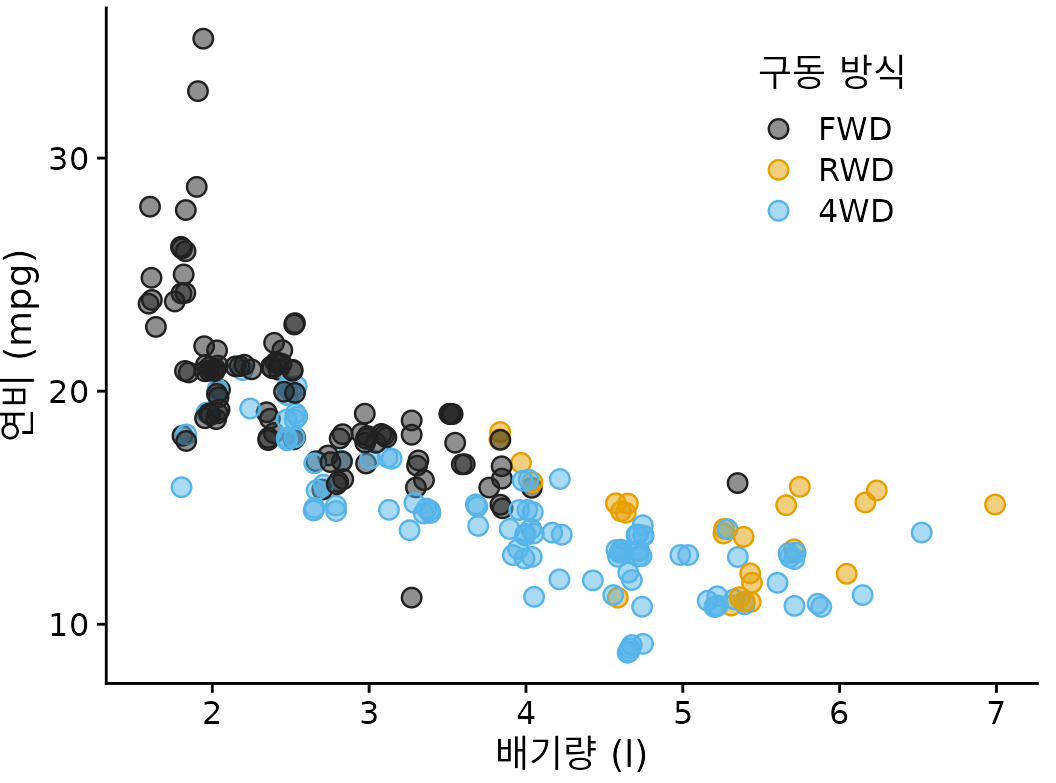
그러나 점을 부분적으로 투명하게 만드는 것만으로는 중복 플로팅 문제를 해결하기에 항상 충분하지 않습니다. 예를 들어 그림 ?fig-mpg-cty-displ-transp에서 일부 점이 다른 점보다 더 어두운 음영을 갖는 것을 볼 수 있지만 각 위치에 몇 개의 점이 겹쳐 그려졌는지 추정하기는 어렵습니다. 또한 음영의 차이는 명확하게 보이지만 자명하지는 않습니다. 이 그림을 처음 보는 독자는 일부 점이 다른 점보다 더 어두운 이유를 궁금해하며 해당 점이 실제로는 서로 겹쳐 쌓인 여러 점이라는 것을 깨닫지 못할 것입니다. 이러한 상황에서 도움이 되는 간단한 트릭은 점에 약간의 지터를 적용하는 것입니다. 즉, 각 점을 x 또는 y 방향 또는 둘 다에서 임의로 약간 이동시키는 것입니다. 지터를 사용하면 어두운 영역이 서로 겹쳐 그려진 점에서 발생한다는 것이 즉시 명확해집니다(그림 Figure 20.3). 또한 이제 처음으로 2.0리터 엔진을 장착한 4륜 구동 자동차를 나타내는 검은색 점이 명확하게 보입니다.
(ref:mpg-cty-displ-jitter) 도시 연비 대 엔진 배기량. 각 점에 약간의 지터를 추가하면 플롯의 메시지를 크게 왜곡하지 않고 중복된 점을 더 명확하게 볼 수 있습니다.
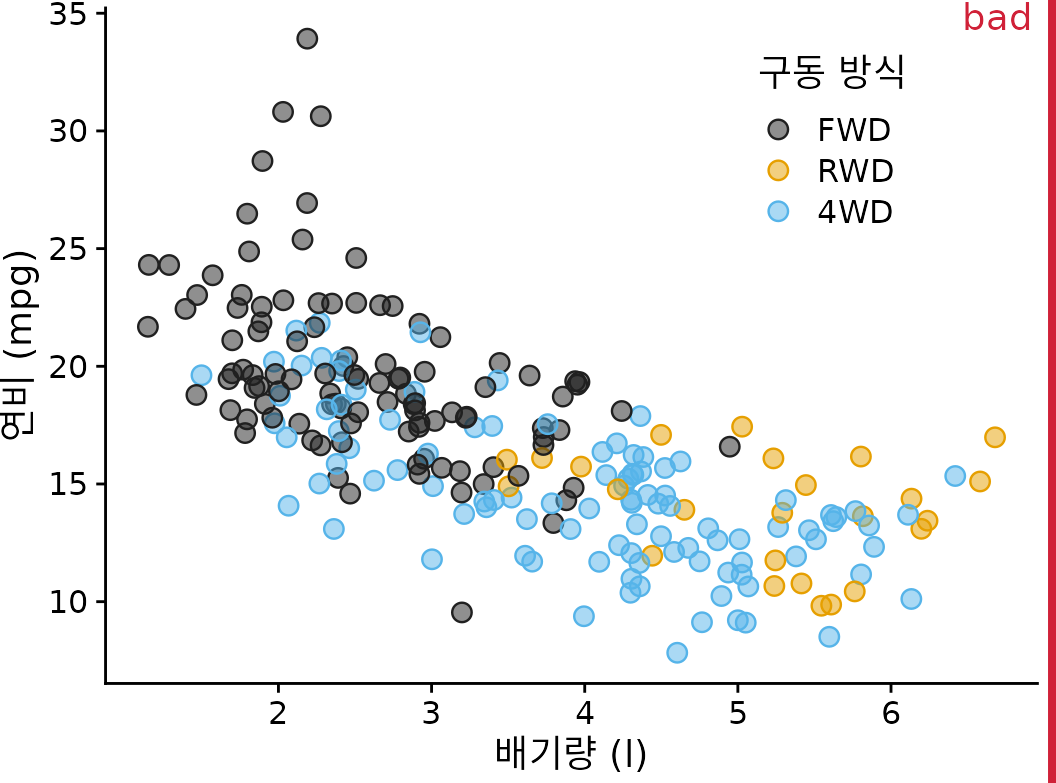
지터링의 한 가지 단점은 데이터를 변경하므로 신중하게 수행해야 한다는 것입니다. 너무 많이 지터링하면 기본 데이터 세트를 대표하지 않는 위치에 점을 배치하게 됩니다. 결과는 데이터의 오해의 소지가 있는 시각화입니다. 예를 들어 그림 ?fig-mpg-cty-displ-jitter-extreme를 참조하십시오.
(ref:mpg-cty-displ-jitter-extreme) 도시 연비 대 엔진 배기량. 점에 너무 많은 지터를 추가하여 기본 데이터 세트를 정확하게 반영하지 않는 시각화를 만들었습니다.
2D 히스토그램
개별 점의 수가 매우 많아지면 부분 투명도(지터링 유무에 관계없이)만으로는 중복 플로팅 문제를 해결하기에 충분하지 않습니다. 일반적으로 발생하는 현상은 점 밀도가 높은 영역은 균일한 어두운 색상의 얼룩으로 나타나는 반면 점 밀도가 낮은 영역에서는 개별 점이 거의 보이지 않는다는 것입니다(그림 Figure 20.5). 그리고 개별 점의 투명도 수준을 변경하면 이러한 문제 중 하나를 완화하면서 다른 문제를 악화시킬 뿐입니다. 어떤 투명도 설정도 동시에 두 가지 문제를 모두 해결할 수는 없습니다.
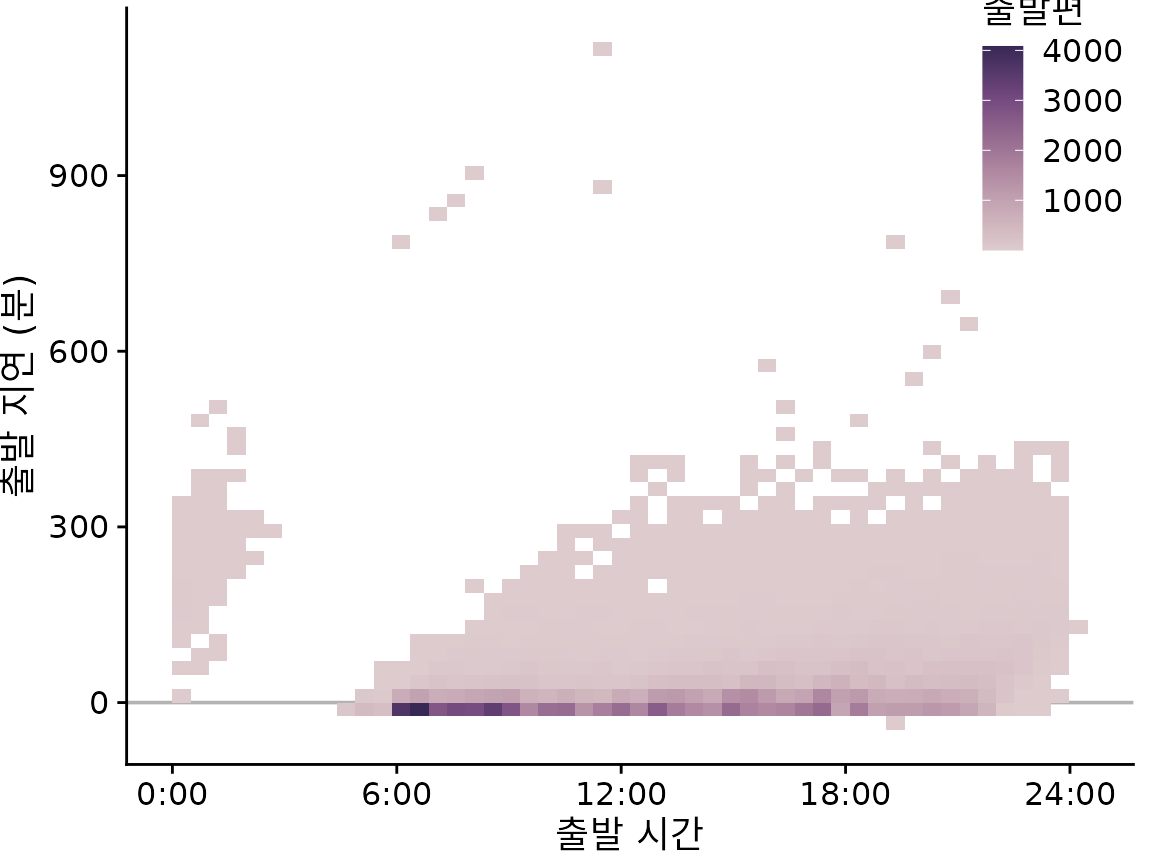
(ref:nycflights-points) 2013년 뉴어크 공항(EWR)에서 출발하는 모든 항공편의 출발 시간 대비 분 단위 출발 지연. 각 점은 하나의 출발을 나타냅니다.
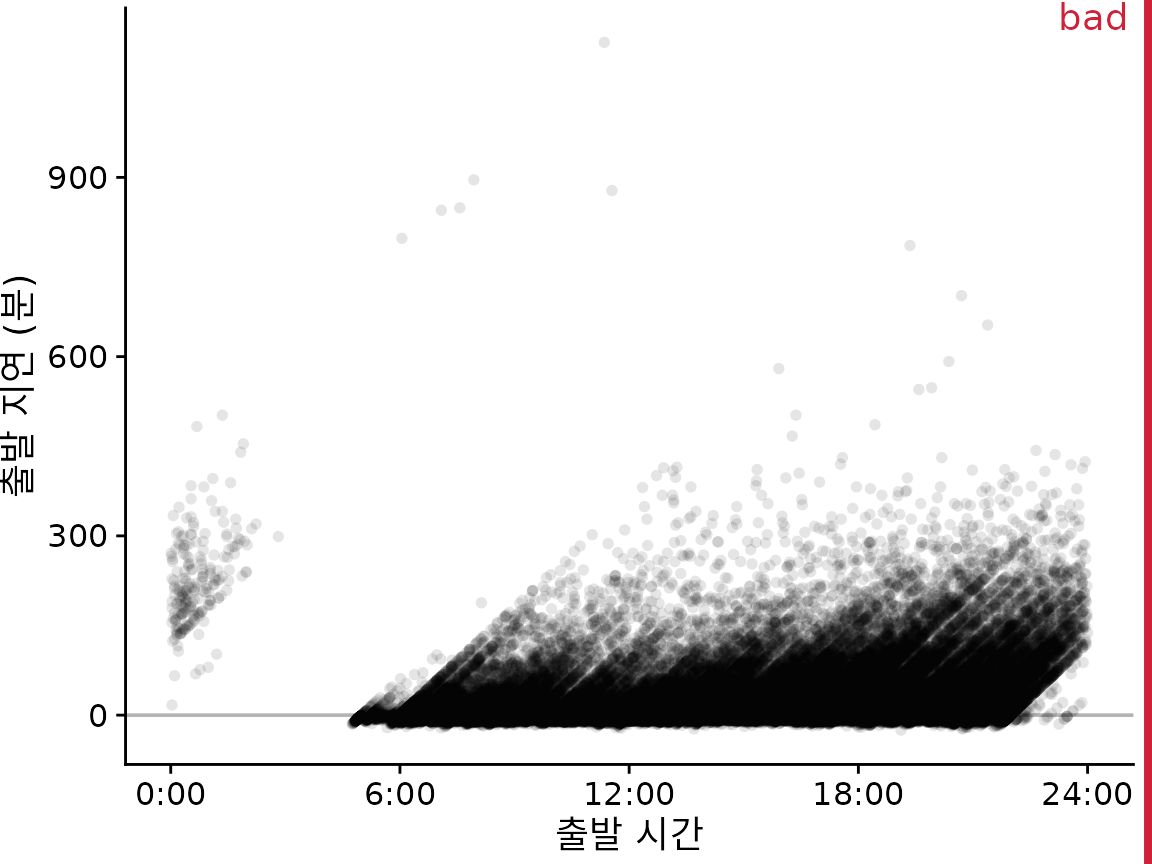
그림 ?fig-nycflights-points는 100,000건 이상의 개별 항공편에 대한 출발 지연을 보여주며 각 점은 하나의 항공편 출발을 나타냅니다. 개별 점을 상당히 투명하게 만들었음에도 불구하고 대부분은 0분에서 300분 사이의 출발 지연 사이에 검은색 띠를 형성합니다. 이 띠는 대부분의 항공편이 거의 정시에 출발하는지 아니면 상당한 지연(예: 50분 이상)으로 출발하는지를 모호하게 만듭니다. 동시에 가장 지연된 항공편(400분 이상 지연)은 점의 투명도 때문에 거의 보이지 않습니다.
이러한 경우 개별 점을 플로팅하는 대신 2D 히스토그램을 만들 수 있습니다. 2D 히스토그램은 개념적으로 챕터 ?sec-histograms-density-plots에서 논의된 1D 히스토그램과 유사하지만 이제 데이터를 2차원으로 구간화합니다. 전체 x–y 평면을 작은 사각형으로 세분화하고 각 사각형에 몇 개의 관찰값이 들어가는지 계산한 다음 해당 개수로 사각형을 색칠합니다. 그림 ?fig-nycflights-2d-bins는 출발 지연 데이터에 대한 이 접근 방식의 결과를 보여줍니다. 이 시각화는 항공편 출발 데이터의 몇 가지 중요한 특징을 명확하게 강조합니다. 첫째, 낮 시간(오전 6시부터 오후 9시경까지)의 대부분의 출발은 실제로 지연 없이 또는 심지어 일찍(음의 지연) 출발합니다. 그러나 적당한 수의 출발에는 상당한 지연이 있습니다. 또한 하루 중 비행기가 늦게 출발할수록 지연이 더 커질 수 있습니다. 중요하게도 출발 시간은 예정된 출발 시간이 아니라 실제 출발 시간입니다. 따라서 이 그림은 일찍 출발하도록 예정된 비행기가 절대 지연되지 않는다는 것을 반드시 알려주지는 않습니다. 그러나 비행기가 일찍 출발하면 지연이 거의 없거나 매우 드문 경우 약 900분 지연된다는 것을 알려줍니다.
(ref:nycflights-2d-bins) 출발 시간 대비 분 단위 출발 지연. 각 색칠된 사각형은 해당 시간에 해당 출발 지연으로 출발하는 모든 항공편을 나타냅니다. 색칠은 해당 사각형으로 표시되는 항공편 수를 나타냅니다.
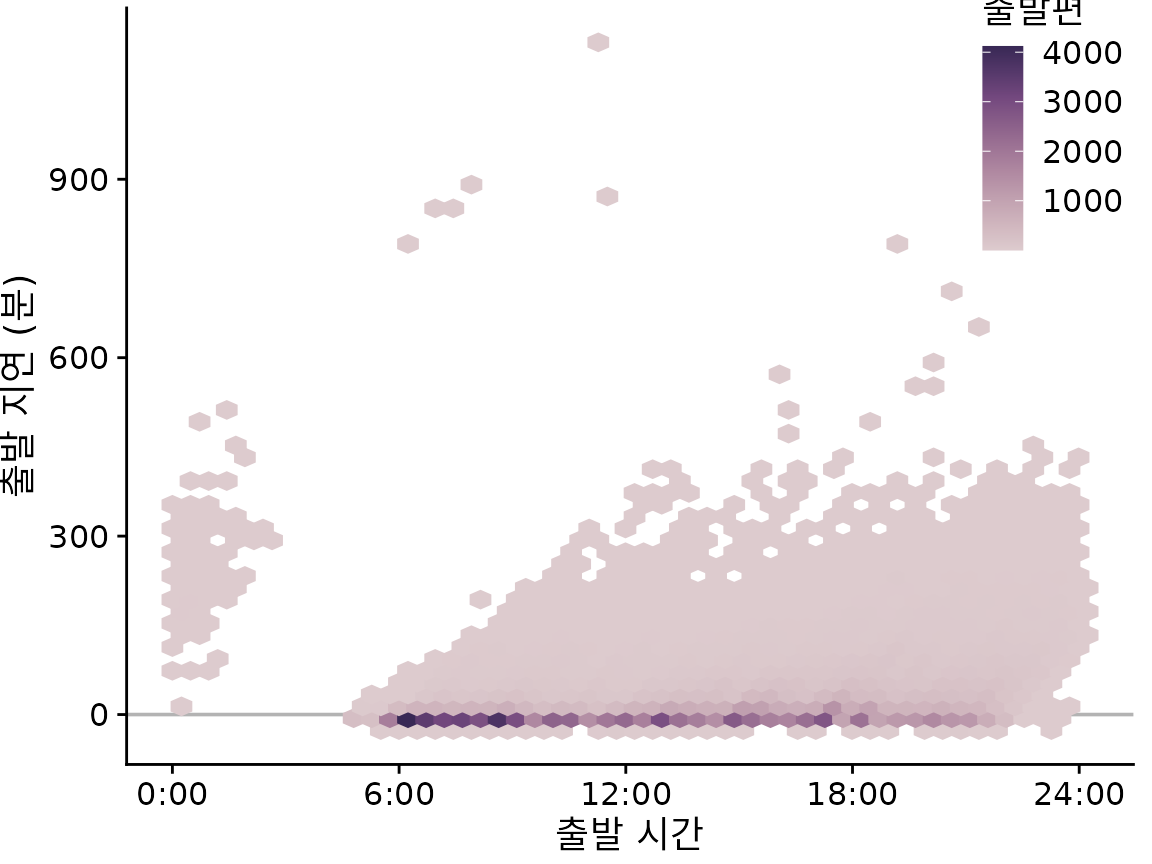
데이터 포인트를 사각형으로 구간화하는 대신 육각형으로 구간화할 수도 있습니다. Carr et al. (1987) 이 처음 제안한 이 접근 방식은 육각형의 점이 동일 면적 정사각형의 점보다 평균적으로 육각형 중심에 더 가깝다는 장점이 있습니다. 따라서 색칠된 육각형은 색칠된 사각형보다 데이터를 약간 더 정확하게 나타냅니다. 그림 ?fig-nycflights-hex-bins는 직사각형 구간화 대신 육각형 구간화를 사용한 항공편 출발 데이터를 보여줍니다.
(ref:nycflights-hex-bins) 출발 시간 대비 분 단위 출발 지연. 각 색칠된 육각형은 해당 시간에 해당 출발 지연으로 출발하는 모든 항공편을 나타냅니다. 색칠은 해당 육각형으로 표시되는 항공편 수를 나타냅니다.
등고선
데이터 포인트를 사각형이나 육각형으로 구간화하는 대신 플롯 영역 전체의 점 밀도를 추정하고 등고선으로 여러 점 밀도 영역을 나타낼 수도 있습니다. 이 기법은 점 밀도가 x 및 y 차원 모두에서 천천히 변할 때 잘 작동합니다.
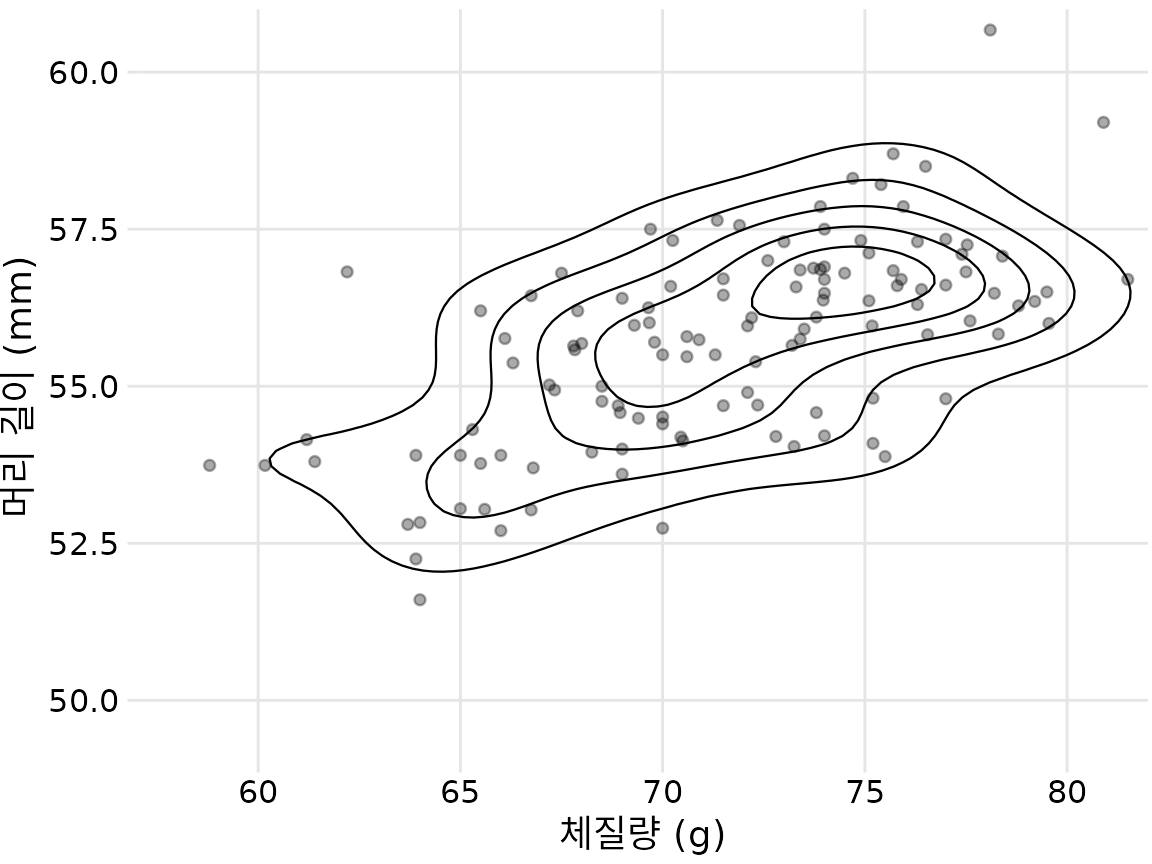
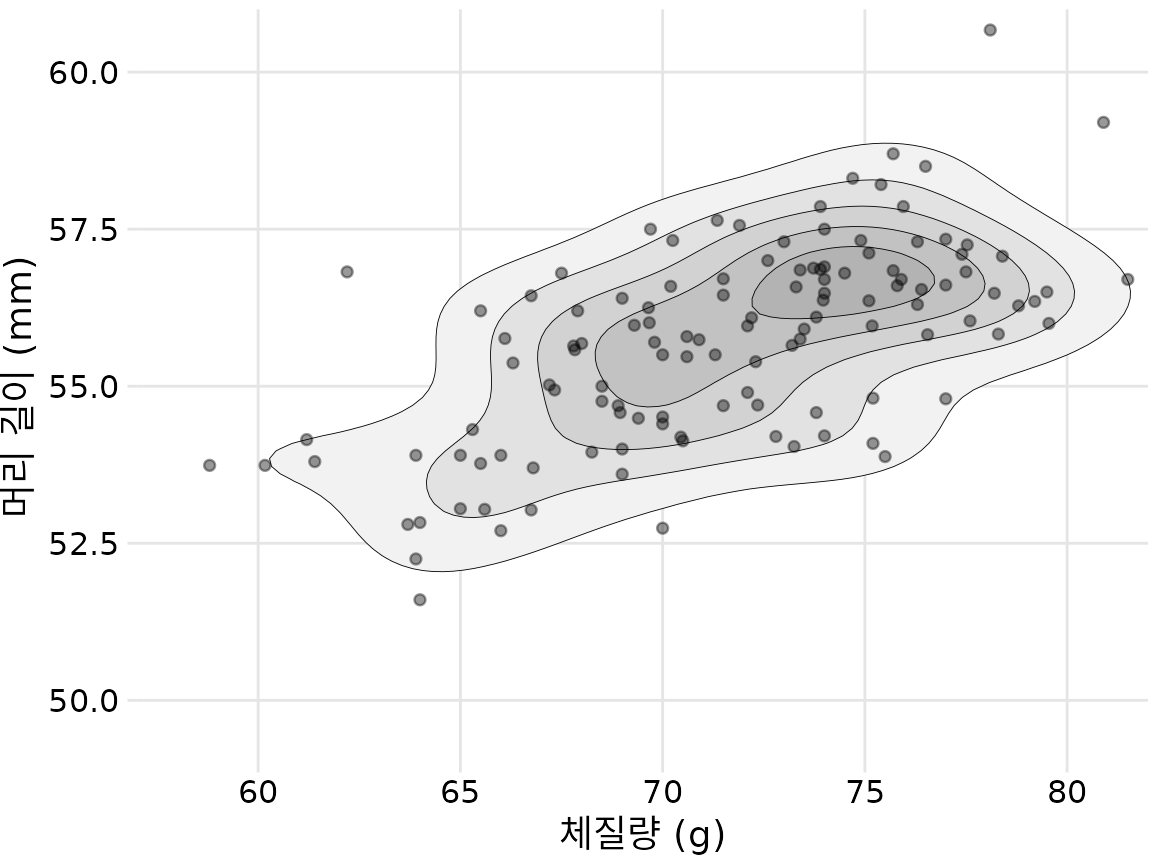
이 접근 방식의 예로 챕터 ?sec-visualizing-associations의 파랑어치 데이터 세트로 돌아가 보겠습니다. 그림 ?fig-blue-jays-scatter은 123마리 파랑어치의 머리 길이와 체질량 간의 관계를 보여주었으며 점들 사이에 약간의 중복이 있었습니다. 점을 더 작고 부분적으로 투명하게 만들고 유사한 점 밀도 영역을 나타내는 등고선 위에 플로팅하여 점 분포를 더 명확하게 강조 표시할 수 있습니다(그림 Figure 20.8). 등고선으로 둘러싸인 영역을 음영 처리하고 더 높은 점 밀도를 나타내는 영역에 더 어두운 색상을 사용하여 점 밀도 변화에 대한 인식을 더욱 향상시킬 수 있습니다(그림 Figure 20.9).
(ref:blue-jays-contour) 그림 ?fig-blue-jays-scatter에서와 같이 123마리 파랑어치의 머리 길이 대 체질량. 각 점은 하나의 새에 해당하며 선은 유사한 점 밀도 영역을 나타냅니다. 점 밀도는 플롯 중앙, 체질량 75g 및 머리 길이 55mm와 57.5mm 사이에서 증가합니다. 데이터 출처: 키스 타빈, 오벌린 대학
(ref:blue-jays-contour-filled) 123마리 파랑어치의 머리 길이 대 체질량. 이 그림은 그림 ?fig-blue-jays-scatter와 거의 동일하지만 이제 등고선으로 둘러싸인 영역이 점점 더 어두운 회색 음영으로 음영 처리됩니다. 이 음영은 점 구름 중앙으로 갈수록 점 밀도가 증가한다는 더 강한 시각적 인상을 만듭니다. 데이터 출처: 키스 타빈, 오벌린 대학
챕터 ?sec-visualizing-associations에서는 수컷과 암컷 새에 대해 머리 길이와 체질량 간의 관계도 살펴보았습니다(그림 Figure 14.2). 수컷과 암컷 새에 대해 별도로 색칠된 등고선을 그려 등고선으로도 동일한 작업을 수행할 수 있습니다(그림 Figure 20.10).
(ref:blue-jays-contour-by-sex) 123마리 파랑어치의 머리 길이 대 체질량. 그림 ?fig-blue-jays-scatter-sex에서와 같이 등고선을 그릴 때 색상으로 새의 성별을 나타낼 수도 있습니다. 이 그림은 수컷과 암컷 새의 점 분포가 어떻게 다른지 강조합니다. 특히 수컷 새는 플롯 영역의 한 영역에 더 밀집되어 있는 반면 암컷 새는 더 널리 퍼져 있습니다. 데이터 출처: 키스 타빈, 오벌린 대학
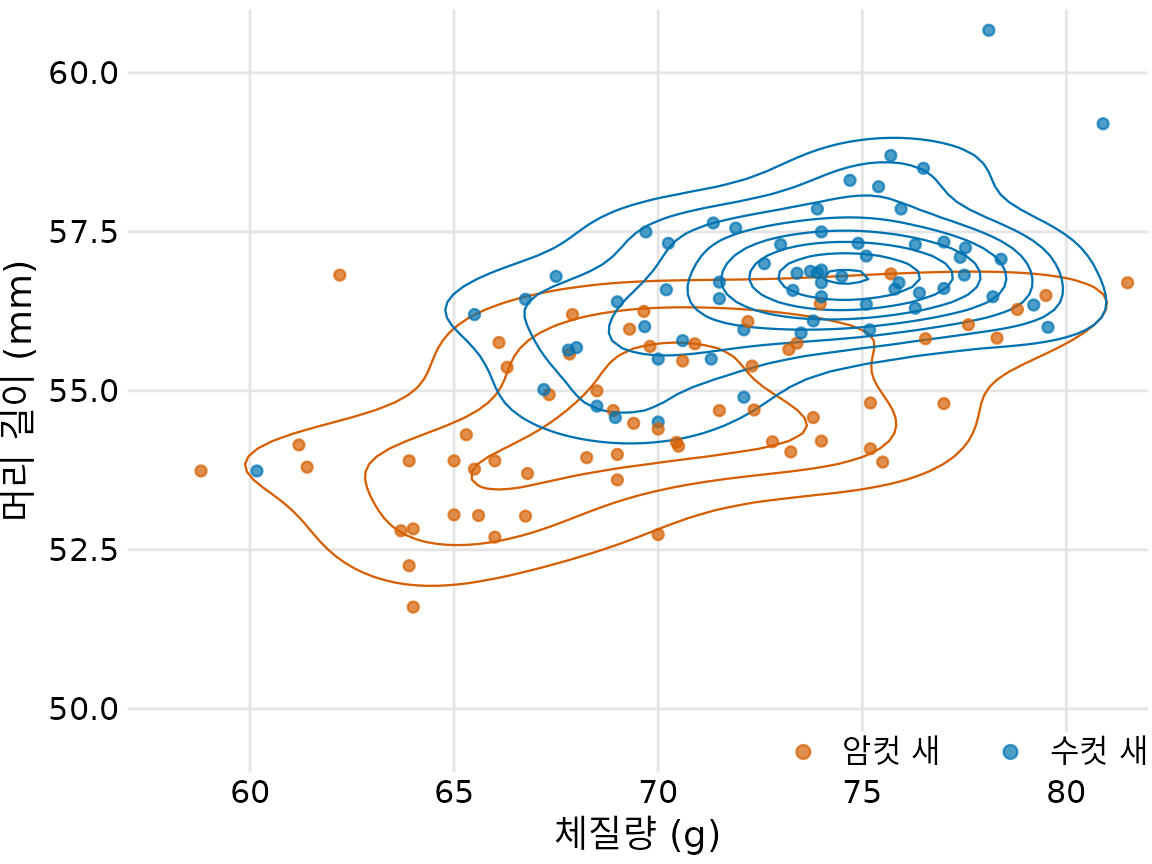
여러 색상으로 여러 등고선 집합을 그리는 것은 한 번에 여러 점 구름의 분포를 보여주는 강력한 전략이 될 수 있습니다. 그러나 이 기법은 신중하게 사용해야 합니다. 뚜렷한 색상을 가진 그룹 수가 적고(2~3개) 그룹이 명확하게 분리된 경우에만 작동합니다. 그렇지 않으면 서로 교차하는 여러 색상의 선이 뒤엉켜 특정 패턴을 전혀 보여주지 못할 수 있습니다.
이 잠재적인 문제를 설명하기 위해 53,940개 다이아몬드에 대한 정보(가격, 무게(캐럿), 컷 포함)가 포함된 다이아몬드 데이터 세트를 사용합니다. 그림 ?fig-diamonds-points는 이 데이터 세트를 산점도로 보여줍니다. 중복 플로팅에 명확한 문제가 있음을 알 수 있습니다. 서로 겹쳐 있는 여러 색상의 점이 너무 많아서 다이아몬드가 가격-캐럿 스펙트럼에서 어디에 있는지에 대한 전반적인 개요 외에는 아무것도 식별할 수 없습니다.
(ref:diamonds-points) 53,940개 개별 다이아몬드의 캐럿 값 대비 가격. 각 다이아몬드의 컷은 색상으로 표시됩니다. 광범위한 중복 플로팅으로 인해 여러 다이아몬드 컷 간의 패턴을 식별할 수 없으므로 플롯은 “나쁨”으로 표시됩니다. 데이터 출처: 해들리 위컴, ggplot2
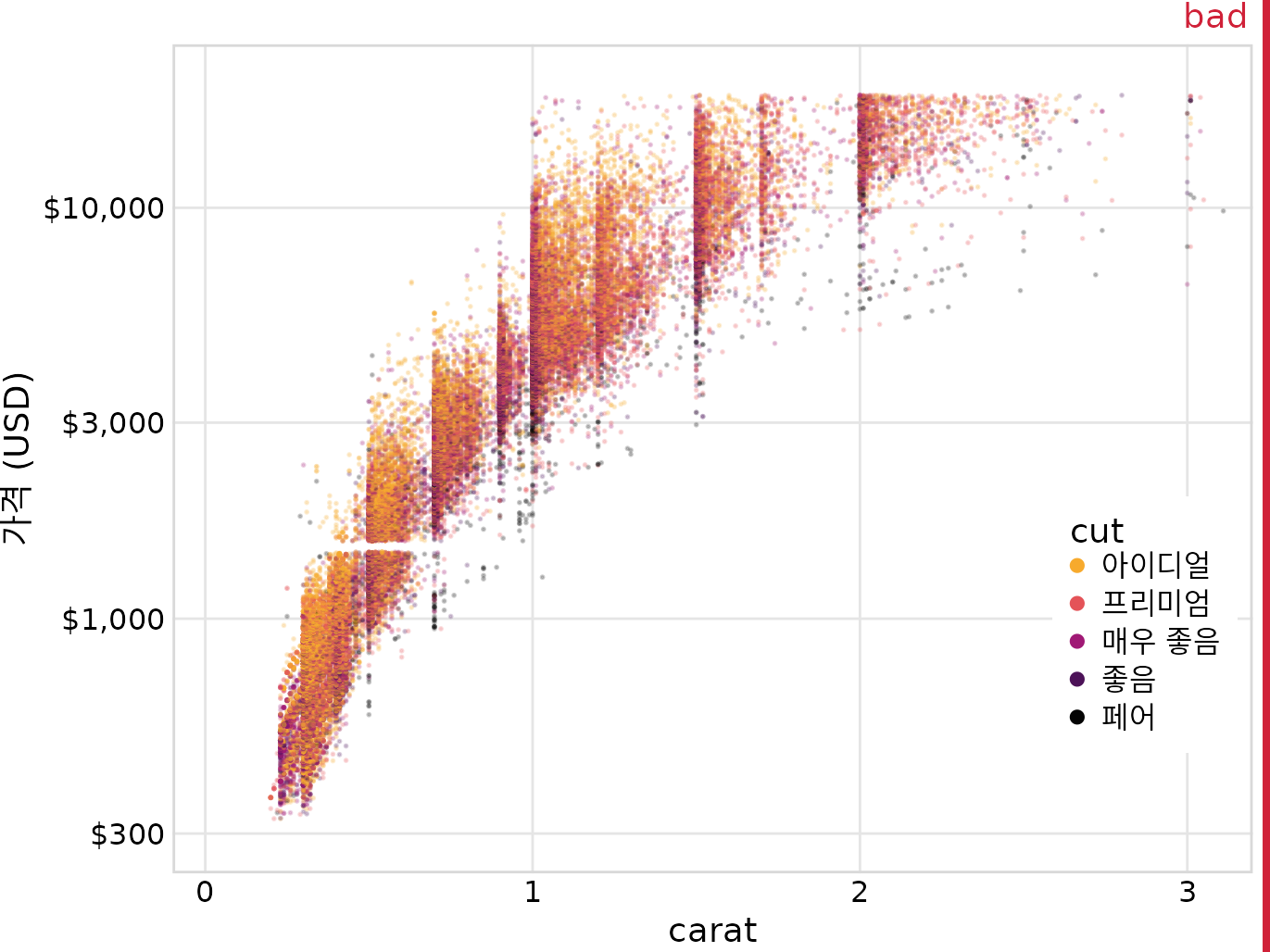
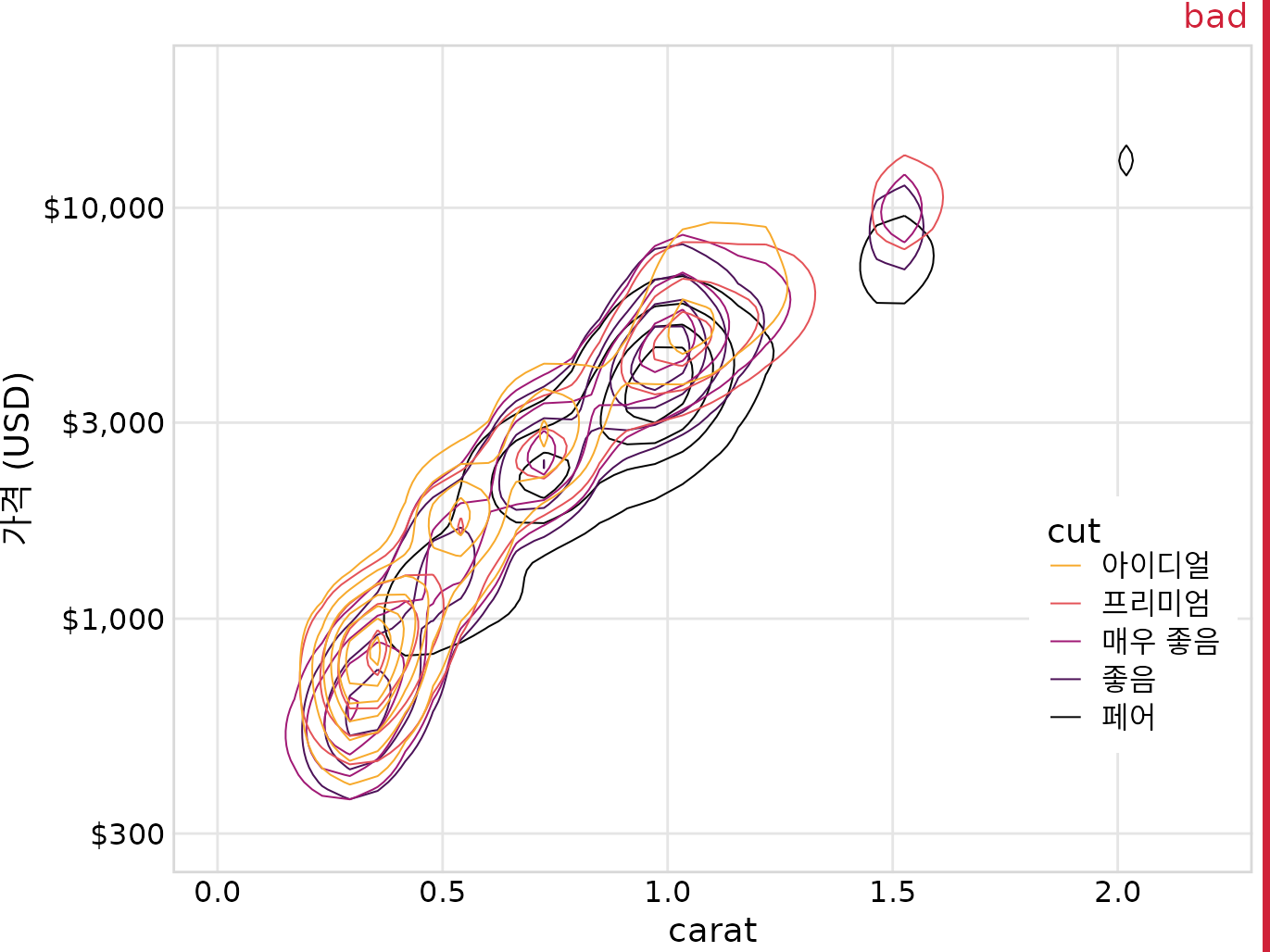
그림 ?fig-blue-jays-contour-by-sex에서와 같이 여러 컷 품질에 대해 색칠된 등고선을 그리려고 할 수 있습니다. 그러나 다이아몬드 데이터 세트에는 5가지 뚜렷한 색상이 있으며 그룹이 심하게 겹칩니다. 따라서 등고선 그림(그림 Figure 20.12)은 원래 산점도(그림 Figure 20.11)보다 훨씬 낫지 않습니다.
(ref:diamonds-contour-colors) 다이아몬드의 캐럿 값 대비 가격. 그림 ?fig-diamonds-points와 같지만 이제 개별 점이 등고선으로 대체되었습니다. 결과 플롯은 등고선이 모두 서로 겹쳐 있기 때문에 여전히 “나쁨”으로 표시됩니다. 개별 컷에 대한 점 분포나 전체 점 분포를 식별할 수 없습니다. 데이터 출처: 해들리 위컴, ggplot2
여기서 도움이 되는 것은 각 컷 품질에 대한 등고선을 자체 플롯 패널에 그리는 것입니다(그림 Figure 20.13). 모든 것을 하나의 패널에 그리는 목적은 그룹 간의 시각적 비교를 가능하게 하는 것일 수 있지만 그림 ?fig-diamonds-contour-colors는 너무 복잡하여 비교가 불가능합니다. 대신 그림 ?fig-diamonds-contour-facets에서는 배경 격자를 통해 등고선이 격자선에 대해 정확히 어디에 있는지 주의하여 컷 품질 간의 비교를 할 수 있습니다. (각 패널에 등고선 대신 부분적으로 투명한 개별 점을 플로팅하여 유사한 효과를 얻을 수 있었을 것입니다.)
(ref:diamonds-contour-facets) 다이아몬드의 캐럿 값 대비 가격. 여기서 그림 ?fig-diamonds-contour-colors의 밀도 등고선을 가져와 각 컷에 대해 개별적으로 그렸습니다. 이제 더 나은 컷(매우 좋음, 프리미엄, 아이디얼)이 더 나쁜 컷(페어, 좋음)보다 캐럿 값이 낮은 경향이 있지만 캐럿당 가격은 더 높다는 것을 알 수 있습니다. 데이터 출처: 해들리 위컴, ggplot2
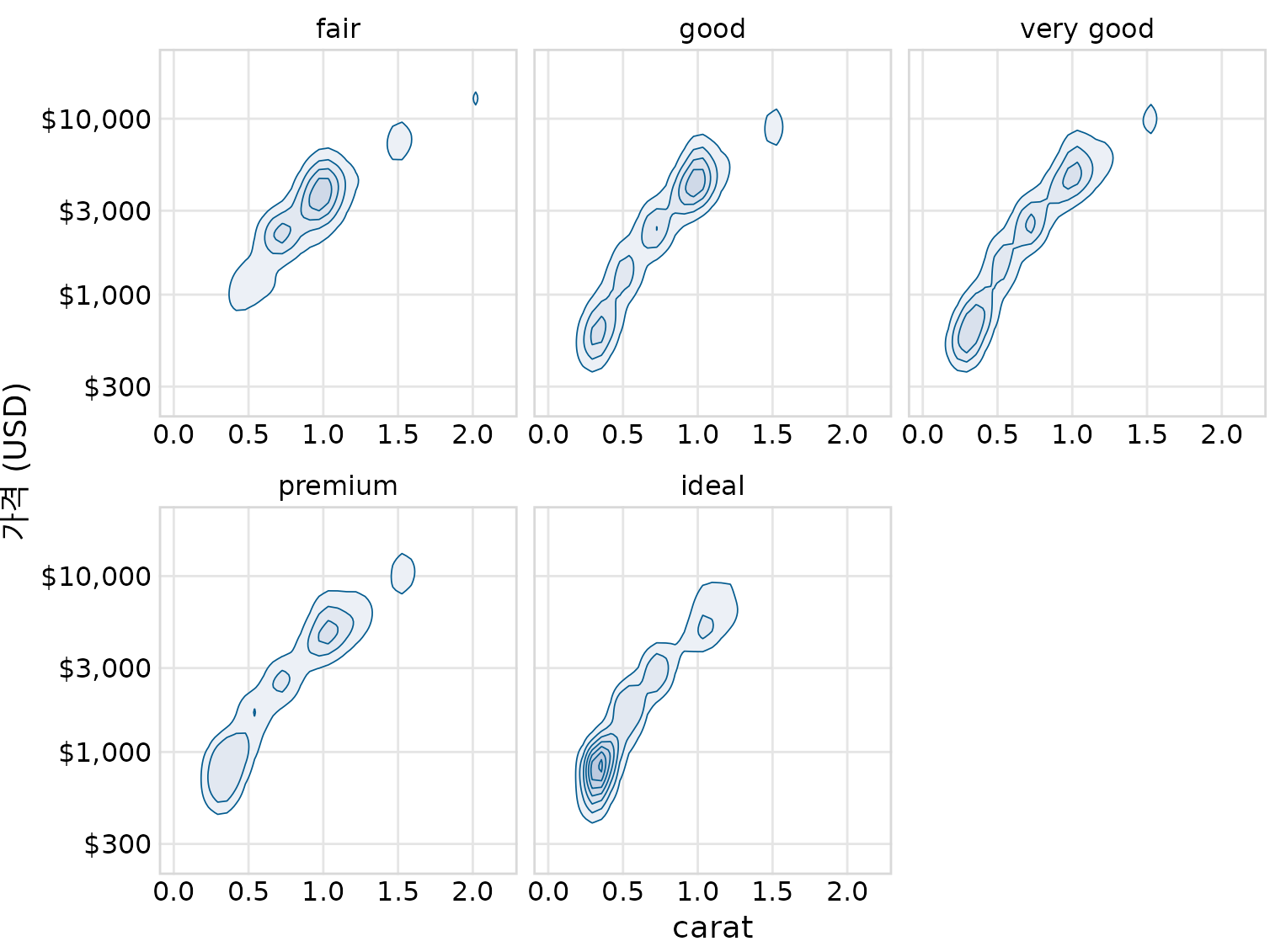
두 가지 주요 추세를 파악할 수 있습니다. 첫째, 더 나은 컷(매우 좋음, 프리미엄, 아이디얼)은 더 나쁜 컷(페어, 좋음)보다 캐럿 값이 낮은 경향이 있습니다. 캐럿은 다이아몬드 무게의 단위입니다(1캐럿 = 0.2그램). 더 나은 컷은 더 많은 재료를 제거해야 하므로 (평균적으로) 더 가벼운 다이아몬드를 만드는 경향이 있습니다. 둘째, 동일한 캐럿 값에서 더 나은 컷은 더 높은 가격을 받는 경향이 있습니다. 이 패턴을 보려면 예를 들어 0.5캐럿의 가격 분포를 살펴보십시오. 분포는 더 나은 컷에 대해 위쪽으로 이동하며 특히 아이디얼 컷 다이아몬드의 경우 페어 또는 좋음 컷 다이아몬드보다 상당히 높습니다.
Carr, D. B., R. J. Littlefield, W. L. Nicholson, and J. S. Littlefield. 1987. “Scatterplot Matrix Techniques for Large N.” J. Am. Stat. Assoc. 82: 424–36.