중복 코딩
챕터 ?sec-color-pitfalls에서는 색상이 항상 우리가 원하는 만큼 효과적으로 정보를 전달할 수 없다는 것을 보았습니다. 식별하고 싶은 항목이 많으면 색상으로 식별하는 것이 작동하지 않을 수 있습니다. 플롯의 색상을 범례의 색상과 일치시키기가 어려울 것입니다(그림 Figure 21.1). 그리고 두세 가지 다른 항목만 구별해야 하는 경우에도 색칠된 항목이 매우 작거나(그림 Figure 21.11) 색각 이상이 있는 사람들에게 색상이 비슷하게 보이는 경우(그림 Figure 21.7 및 Figure 21.8) 색상이 실패할 수 있습니다. 이러한 모든 시나리오의 일반적인 해결책은 주요 정보를 전달하기 위해 전적으로 색상에 의존하지 않고 그림의 시각적 모양을 향상시키기 위해 색상을 사용하는 것입니다. 저는 이 디자인 원칙을 중복 코딩이라고 부르는데, 여러 다른 미적 차원을 사용하여 데이터를 중복적으로 인코딩하도록 유도하기 때문입니다.
중복 코딩을 사용한 범례 디자인
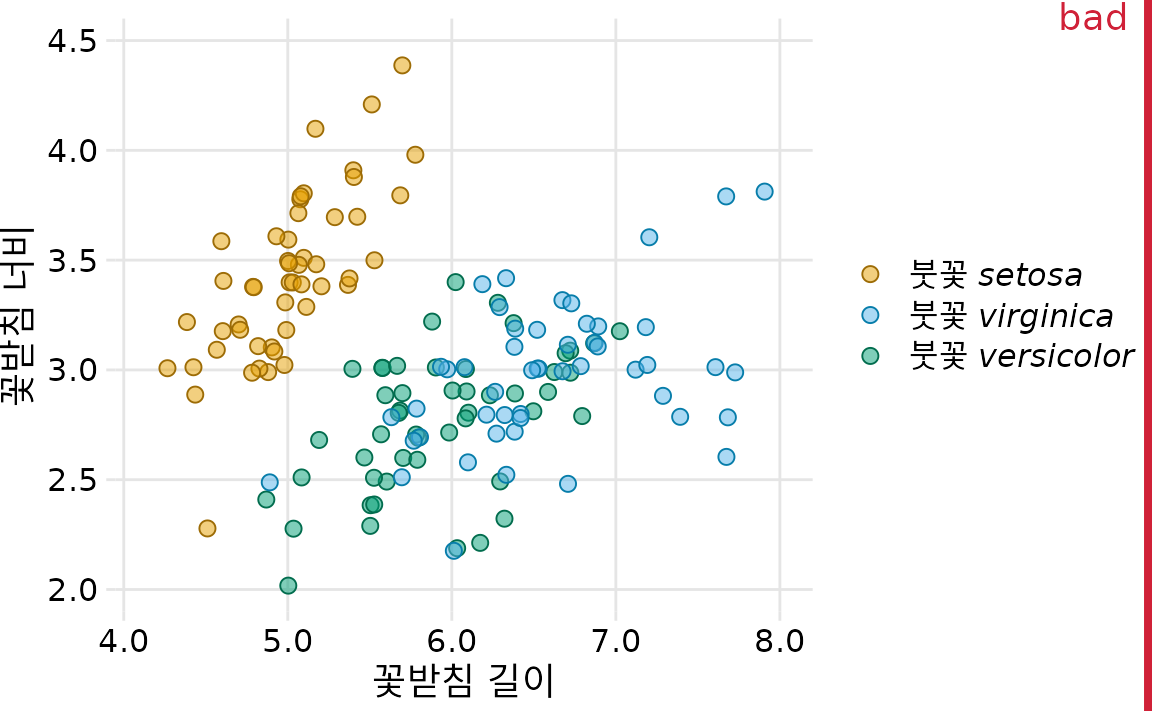
여러 데이터 그룹의 산점도는 종종 여러 그룹을 나타내는 점이 색상만 다른 방식으로 디자인됩니다. 예를 들어 그림 ?fig-iris-scatter-one-shape를 생각해 보십시오. 이 그림은 세 가지 다른 붓꽃 종의 꽃받침 너비 대 꽃받침 길이를 보여줍니다. (꽃받침은 꽃 피는 식물의 꽃 외부 잎입니다.) 여러 종을 나타내는 점은 색상이 다르지만 그 외에는 모든 점이 정확히 동일하게 보입니다. 이 그림에는 세 가지 뚜렷한 점 그룹만 포함되어 있지만 정상적인 색각을 가진 사람들에게도 읽기가 어렵습니다. 문제는 두 종인 Iris virginica와 Iris versicolor의 데이터 포인트가 서로 섞여 있고 해당 두 색상인 녹색과 파란색이 서로 특별히 구별되지 않기 때문에 발생합니다.
(ref:iris-scatter-one-shape) 세 가지 다른 붓꽃 종(Iris setosa, Iris virginica, Iris versicolor)의 꽃받침 너비 대 꽃받침 길이. 각 점은 한 식물 표본의 측정을 나타냅니다. 중복 플로팅을 방지하기 위해 모든 점 위치에 약간의 지터가 적용되었습니다. 녹색의 virginica 점과 파란색의 versicolor 점을 서로 구별하기 어렵기 때문에 그림은 “나쁨”으로 표시되었습니다.
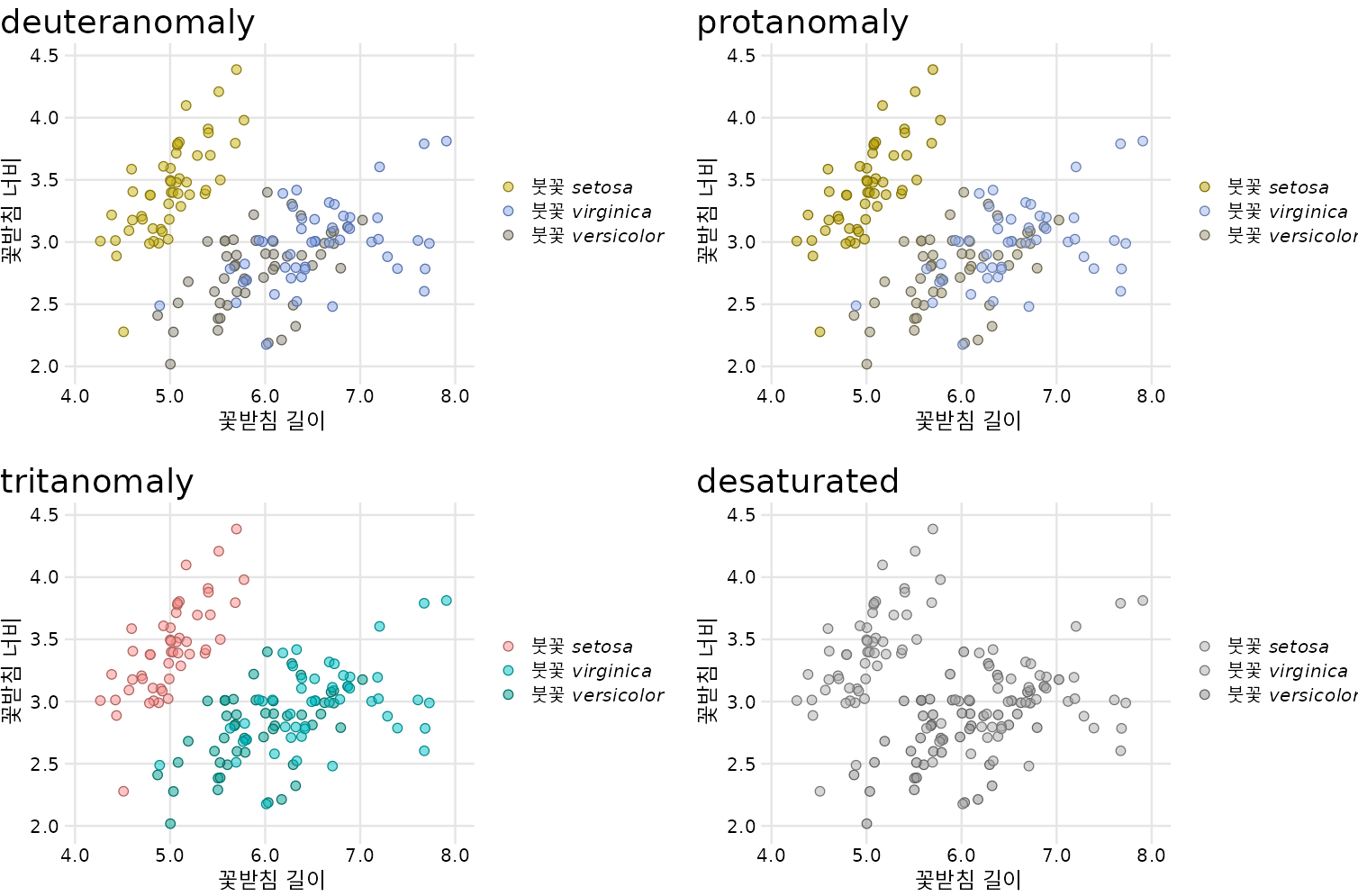
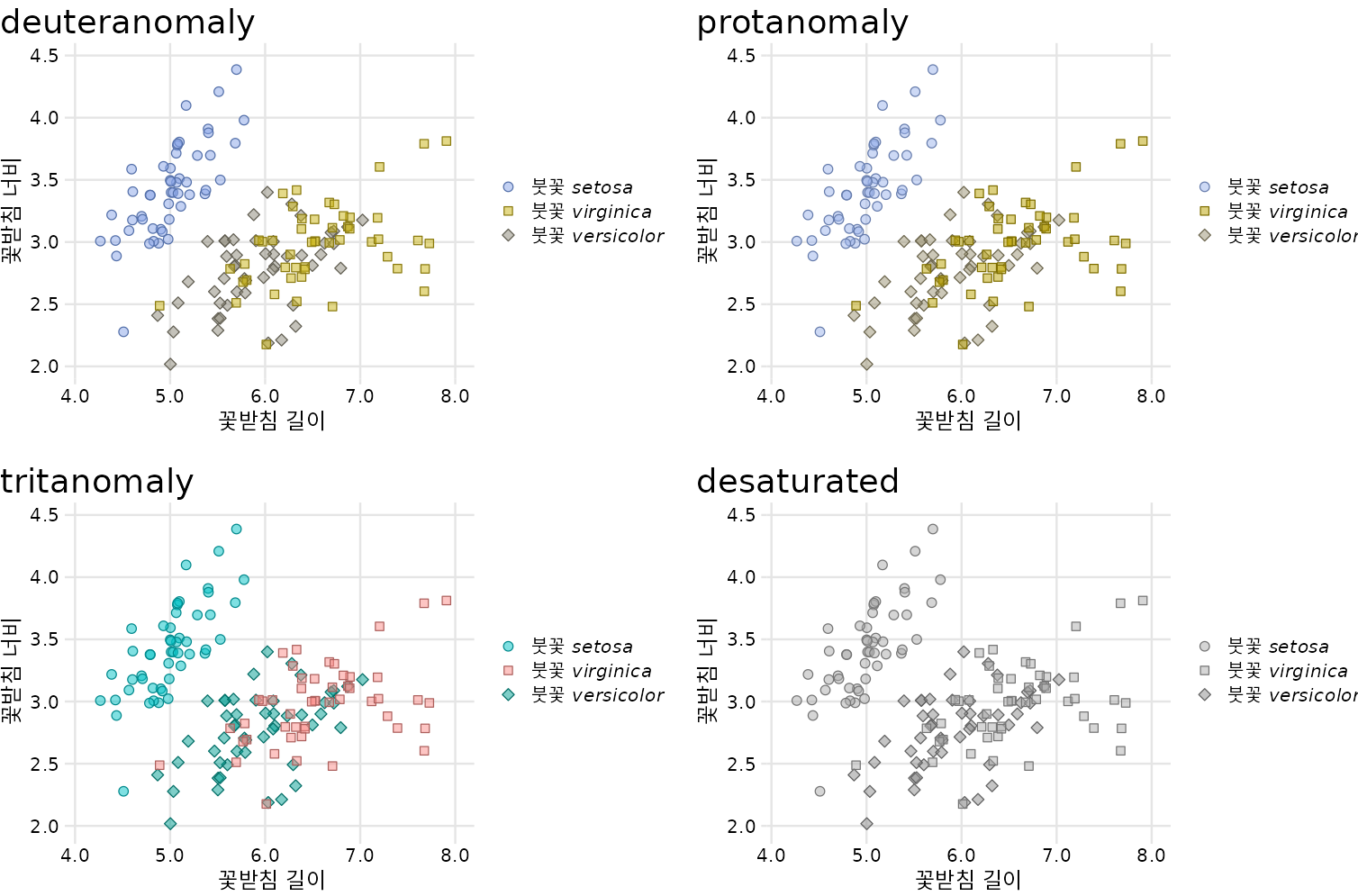
놀랍게도 녹색과 파란색 점은 정상적인 색각을 가진 사람보다 적록 색각 이상(중색약 또는 적색약)이 있는 사람에게 더 뚜렷하게 보입니다(그림 Figure 22.2, 위쪽 행과 그림 Figure 22.1 비교). 반면에 청황색 이상(삼색약)이 있는 사람에게는 파란색과 녹색 점이 매우 유사하게 보입니다(그림 Figure 22.2, 왼쪽 아래). 그리고 그림을 회색조로 인쇄하면(즉, 그림을 채도 감소시키면) 붓꽃 종을 구별할 수 없습니다(그림 Figure 22.2, 오른쪽 아래).
(ref:iris-scatter-one-shape-cvd) 그림 ?fig-iris-scatter-one-shape의 색각 이상 시뮬레이션.
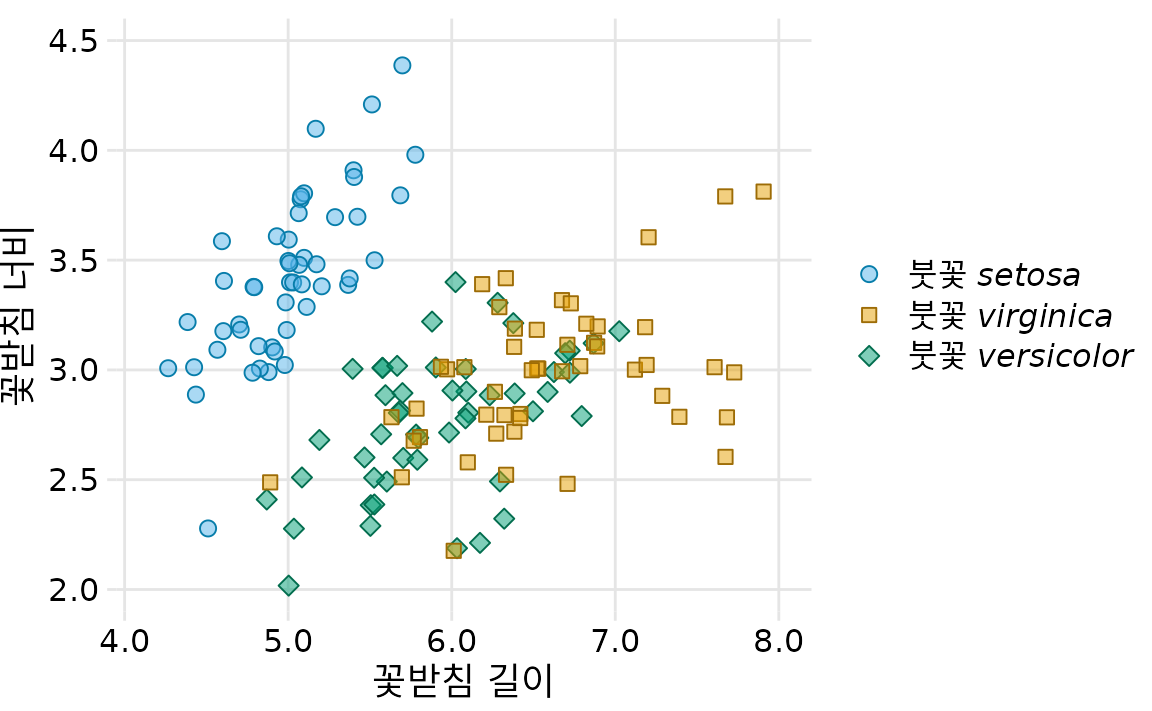
이러한 문제를 완화하기 위해 그림 ?fig-iris-scatter-one-shape에 두 가지 간단한 개선 사항을 적용할 수 있습니다. 첫째, Iris setosa와 Iris versicolor에 사용된 색상을 바꿔 파란색이 더 이상 녹색 바로 옆에 있지 않도록 할 수 있습니다(그림 Figure 22.3). 둘째, 세 가지 다른 기호 모양을 사용하여 모든 점이 다르게 보이도록 할 수 있습니다. 이러한 두 가지 변경 사항을 적용하면 그림의 원본 버전(그림 Figure 22.3)과 색각 이상 및 회색조 버전(그림 Figure 22.4) 모두 읽을 수 있게 됩니다.
(ref:iris-scatter-three-shapes) 세 가지 다른 붓꽃 종의 꽃받침 너비 대 꽃받침 길이. 그림 ?fig-iris-scatter-one-shape와 비교하여 Iris setosa와 Iris versicolor의 색상을 바꾸고 각 붓꽃 종에 고유한 점 모양을 지정했습니다.
(ref:iris-scatter-three-shapes-cvd) 그림 ?fig-iris-scatter-three-shapes의 색각 이상 시뮬레이션. 여러 점 모양을 사용했기 때문에 완전히 채도가 낮은 회색조 버전의 그림도 읽을 수 있습니다.
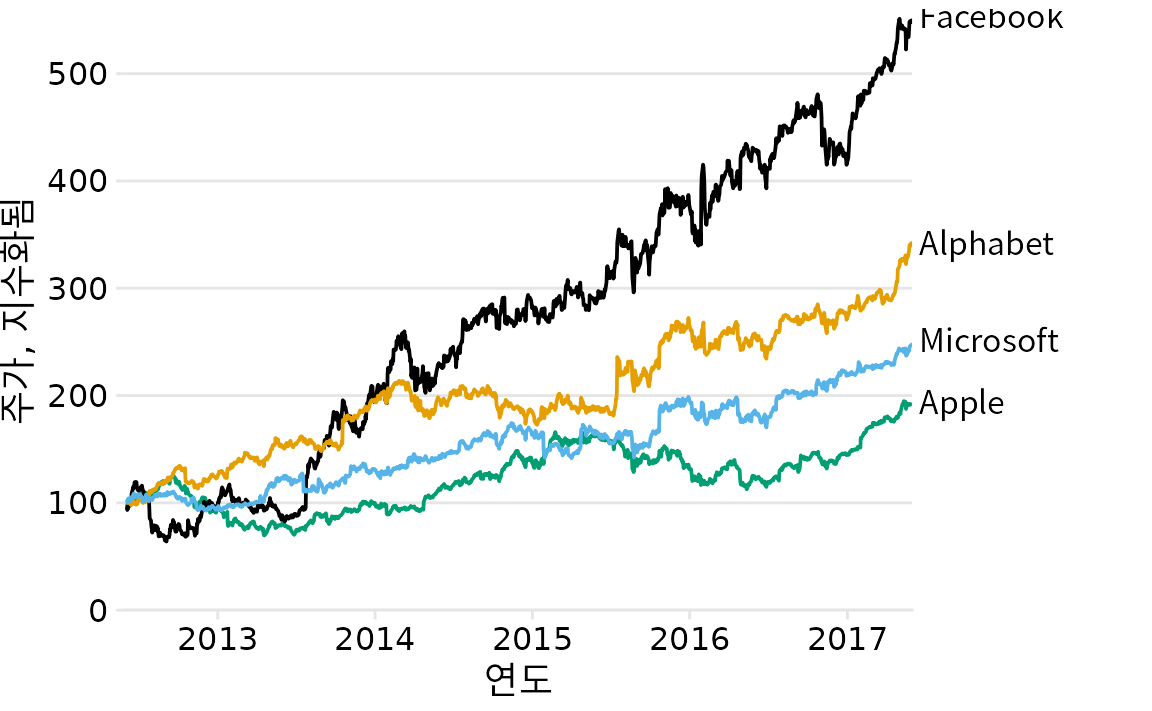
점 모양을 변경하는 것은 산점도에 대한 간단한 전략이지만 다른 유형의 플롯에는 반드시 작동하지 않습니다. 선 플롯에서는 선 유형(실선, 파선, 점선 등, 그림 Figure 1 참조)을 변경할 수 있지만 파선이나 점선을 사용하면 종종 최적이 아닌 결과가 나옵니다. 특히 파선이나 점선은 완벽하게 직선이거나 약간만 구부러지지 않으면 일반적으로 보기 좋지 않으며 두 경우 모두 시각적 노이즈를 만듭니다. 또한 플롯에서 범례로 여러 유형의 파선 또는 점선 패턴을 일치시키는 데 상당한 정신적 노력이 필요한 경우가 많습니다. 그렇다면 그림 ?fig-tech-stocks-bad-legend과 같은 시각화는 어떻게 해야 할까요? 이 그림은 선을 사용하여 네 가지 다른 주요 기술 회사의 시간 경과에 따른 주가 변화를 보여줍니다.
(ref:tech-stocks-bad-legend) 4개 주요 기술 회사의 시간에 따른 주가. 각 회사의 주가는 2012년 6월에 100과 같도록 정규화되었습니다. 이 그림은 범례의 회사 이름을 데이터 곡선과 일치시키는 데 상당한 정신적 에너지가 필요하기 때문에 “나쁨”으로 표시되었습니다. 데이터 출처: Yahoo Finance
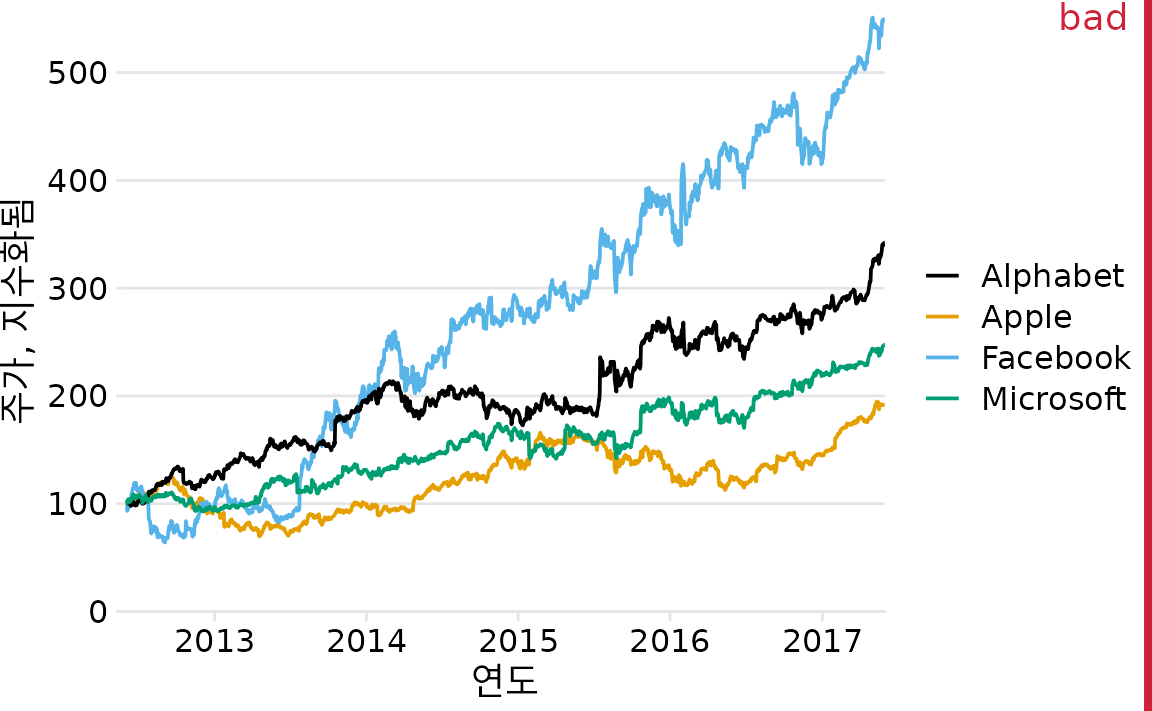
그림에는 네 개 회사의 주가를 나타내는 네 개의 선이 포함되어 있습니다. 선은 색맹 친화적인 색상 척도를 사용하여 색상으로 구분됩니다. 따라서 각 선을 해당 회사와 연관시키는 것은 비교적 간단해야 합니다. 그러나 그렇지 않습니다. 여기서 문제는 데이터 선에 명확한 시각적 순서가 있다는 것입니다. 페이스북을 나타내는 노란색 선은 분명히 가장 높은 선이고 애플을 나타내는 검은색 선은 분명히 가장 낮은 선이며 알파벳과 마이크로소프트는 그 사이에 순서대로 있습니다. 그러나 범례의 네 회사 순서는 알파벳, 애플, 페이스북, 마이크로소프트(알파벳순)입니다. 따라서 인식된 데이터 선의 순서는 범례의 회사 순서와 다르며 데이터 선을 회사 이름과 일치시키는 데 놀라울 정도로 많은 정신적 노력이 필요합니다.
이 문제는 범례를 자동 생성하는 플로팅 소프트웨어에서 흔히 발생합니다. 플로팅 소프트웨어에는 뷰어가 인식할 시각적 순서에 대한 개념이 없습니다. 대신 소프트웨어는 가장 일반적으로 알파벳순과 같이 다른 순서로 범례를 정렬합니다. 범례의 항목을 데이터에서 인식된 순서와 일치하도록 수동으로 다시 정렬하여 이 문제를 해결할 수 있습니다(그림 Figure 22.6). 결과는 범례를 데이터와 훨씬 쉽게 일치시킬 수 있는 그림입니다.
(ref:tech-stocks-good-legend) 4개 주요 기술 회사의 시간에 따른 주가. 각 회사의 주가는 2012년 6월에 100과 같도록 정규화되었습니다. 데이터 출처: Yahoo Finance
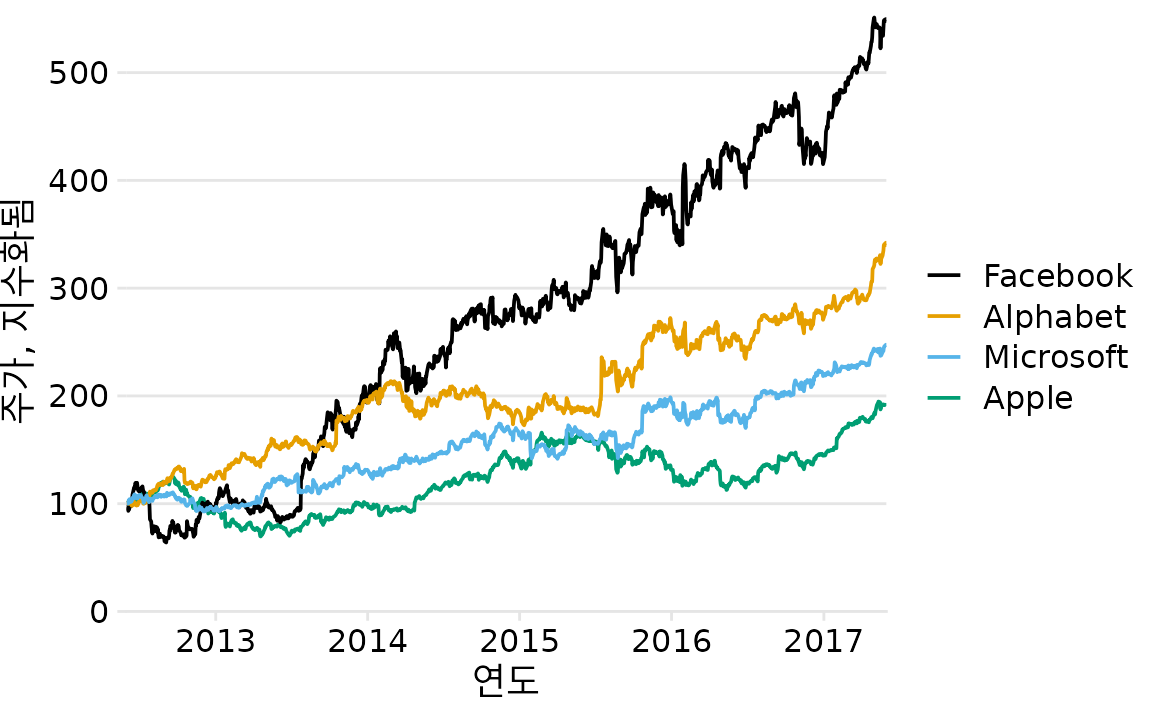
데이터에 명확한 시각적 순서가 있는 경우 범례에서 해당 순서를 일치시키십시오.
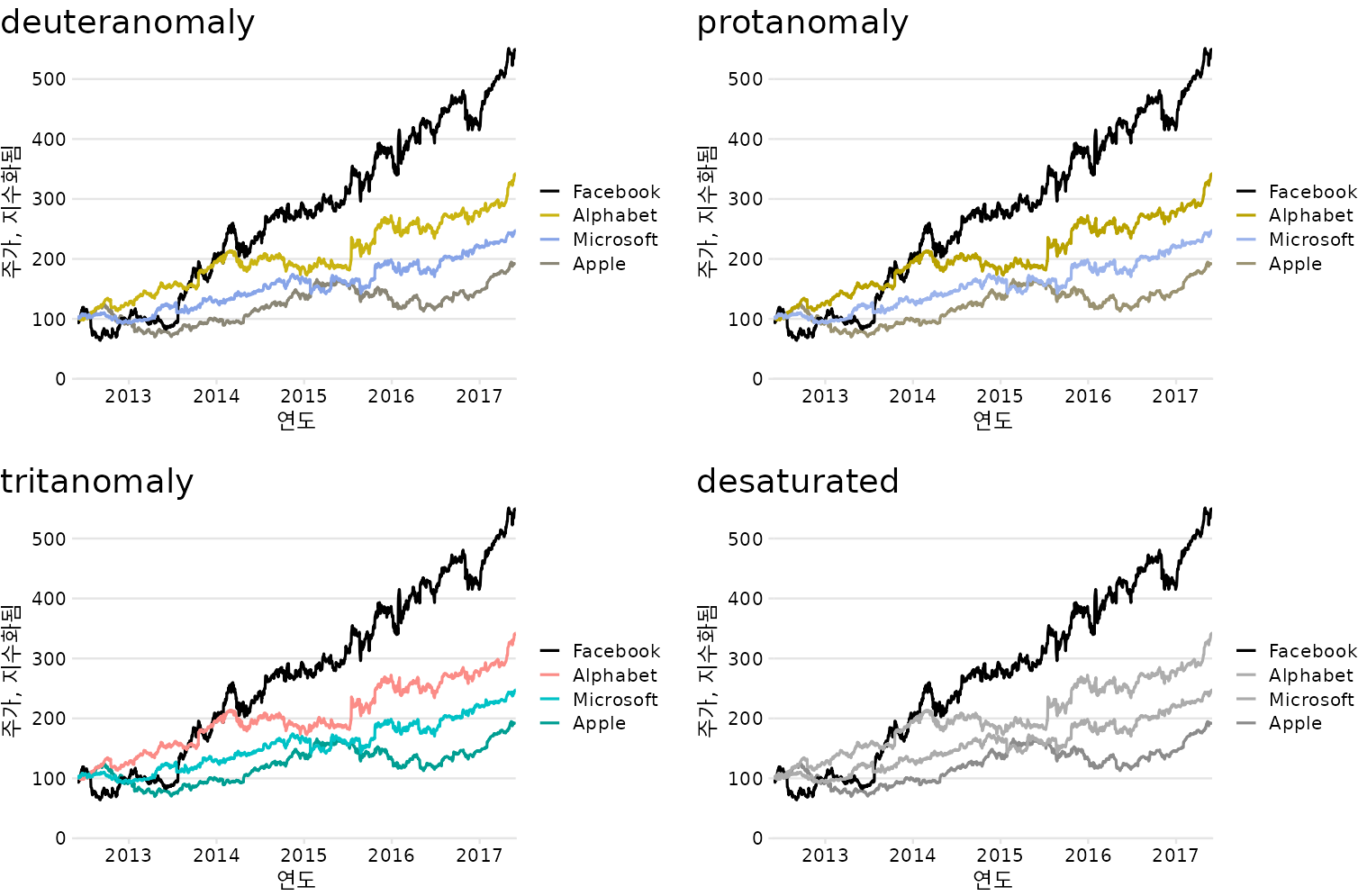
범례 순서를 데이터 순서와 일치시키는 것은 항상 도움이 되지만 색각 이상 시뮬레이션에서는 그 이점이 특히 분명합니다(그림 Figure 22.7). 예를 들어 파란색과 녹색을 구별하기 어려운 삼색약 버전의 그림에서 도움이 됩니다(그림 Figure 22.7, 왼쪽 아래). 회색조 버전에서도 도움이 됩니다(그림 Figure 22.7, 오른쪽 아래). 페이스북과 알파벳의 두 색상이 거의 동일한 회색 값을 갖지만 마이크로소프트와 애플은 더 어두운 색으로 표시되고 아래 두 자리를 차지한다는 것을 알 수 있습니다. 따라서 가장 높은 선은 페이스북에 해당하고 두 번째로 높은 선은 알파벳에 해당한다고 올바르게 가정합니다.
(ref:tech-stocks-good-legend-cvd) 그림 ?fig-tech-stocks-good-legend의 색각 이상 시뮬레이션.
범례 없이 그림 디자인하기
여러 미학적 요소에 데이터를 중복적으로 인코딩하여 범례 가독성을 향상시킬 수 있지만 범례는 항상 독자에게 추가적인 정신적 부담을 줍니다. 범례를 읽을 때 독자는 시각화의 한 부분에서 정보를 가져와 다른 부분으로 옮겨야 합니다. 일반적으로 범례를 완전히 제거하면 독자의 삶을 더 쉽게 만들 수 있습니다. 그러나 범례를 제거한다고 해서 단순히 범례를 제공하지 않고 대신 그림 캡션에 “노란색 점은 Iris versicolor를 나타냅니다.”와 같은 문장을 쓰는 것을 의미하지는 않습니다. 범례를 제거한다는 것은 명시적인 범례가 없더라도 여러 그래픽 요소가 무엇을 나타내는지 즉시 명확하도록 그림을 디자인하는 것을 의미합니다.
우리가 사용할 수 있는 일반적인 전략은 직접 레이블링이라고 하며, 그림의 나머지 부분에 대한 안내 역할을 하는 적절한 텍스트 레이블이나 기타 시각적 요소를 배치하는 것입니다. 이전에 챕터 색상 사용의 일반적인 함정(그림 Figure 21.2)에서 50개 이상의 뚜렷한 색상으로 범례를 그리는 대신 직접 레이블링 개념을 접했습니다. 주가 그림에 직접 레이블링 개념을 적용하려면 각 회사의 이름을 해당 데이터 선의 끝 바로 옆에 배치합니다(그림 Figure 22.8).
(ref:tech-stocks-good-no-legend) 4개 주요 기술 회사의 시간에 따른 주가. 각 회사의 주가는 2012년 6월에 100과 같도록 정규화되었습니다. 데이터 출처: Yahoo Finance
가능하면 범례가 필요 없도록 그림을 디자인하십시오.
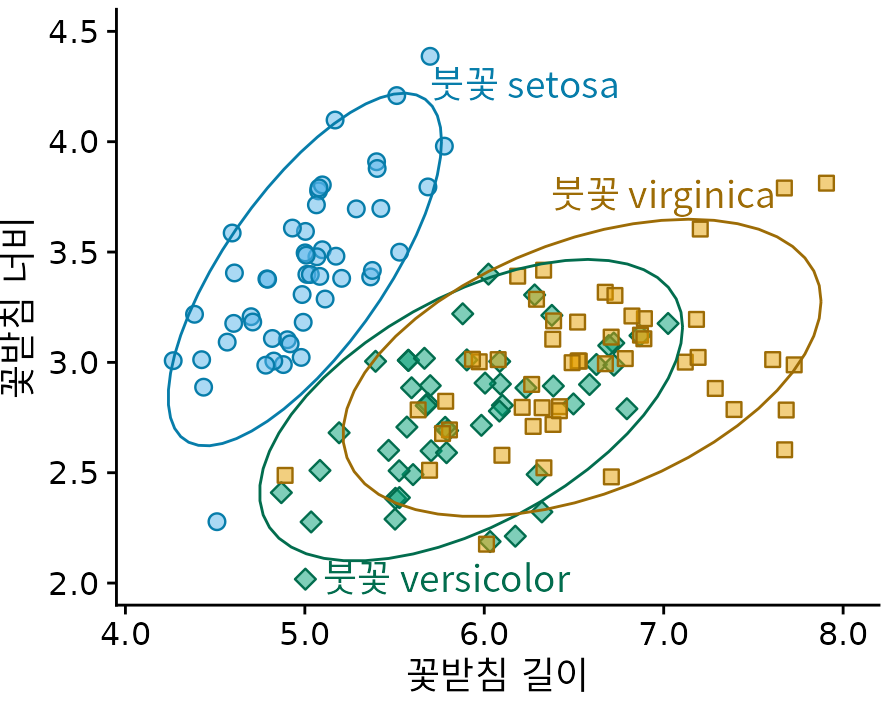
이 장의 시작 부분에 있는 붓꽃 데이터(그림 Figure 22.3)에도 직접 레이블링 개념을 적용할 수 있습니다. 세 그룹으로 나뉘는 많은 점의 산점도이므로 개별 점이 아닌 그룹에 직접 레이블을 지정해야 합니다. 한 가지 해결책은 점의 대부분을 둘러싸는 타원을 그리고 타원에 레이블을 지정하는 것입니다(그림 Figure 22.9).
(ref:iris-scatter-with-ellipses) 세 가지 다른 붓꽃 종의 꽃받침 너비 대 꽃받침 길이. 그림이 너무 복잡해져서 이 그림에서 배경 격자를 제거했습니다.
밀도 그림의 경우에도 마찬가지로 색상으로 구분된 범례를 제공하는 대신 곡선에 직접 레이블을 지정할 수 있습니다(그림 Figure 22.10). 그림 ?fig-iris-scatter-with-ellipses와 Figure 22.10 모두에서 데이터와 동일한 색상으로 텍스트 레이블을 색칠했습니다. 색칠된 레이블은 직접 레이블링 효과를 크게 향상시킬 수 있지만 매우 형편없는 결과가 나올 수도 있습니다. 텍스트 레이블이 너무 밝은 색상으로 인쇄되면 레이블을 읽기 어렵습니다. 그리고 텍스트는 매우 얇은 선으로 구성되므로 색칠된 텍스트는 종종 동일한 색상의 인접한 채워진 영역보다 더 밝게 보입니다. 저는 일반적으로 각 색상의 두 가지 다른 음영, 즉 채워진 영역에는 밝은 음영을 사용하고 선, 윤곽선 및 텍스트에는 어두운 음영을 사용하여 이러한 문제를 해결합니다. 그림 Figure 22.9 또는 ?fig-iris-densities-direct-label을 자세히 살펴보면 각 데이터 포인트 또는 음영 처리된 영역이 밝은 색상으로 채워지고 동일한 색조의 더 어두운 색상으로 윤곽선이 그려져 있음을 알 수 있습니다. 그리고 텍스트 레이블은 동일한 더 어두운 색상으로 그려집니다.
(ref:iris-densities-direct-label) 세 가지 다른 붓꽃 종의 꽃받침 길이 밀도 추정치. 각 밀도 추정치는 해당 종 이름으로 직접 레이블이 지정됩니다.
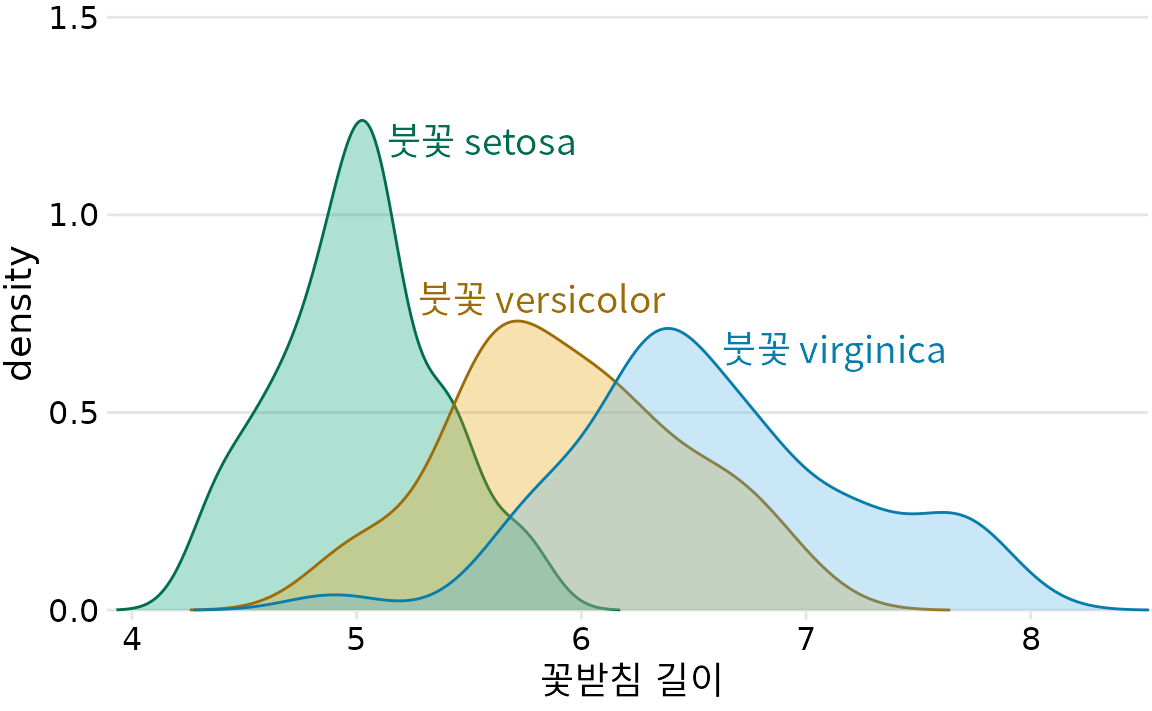
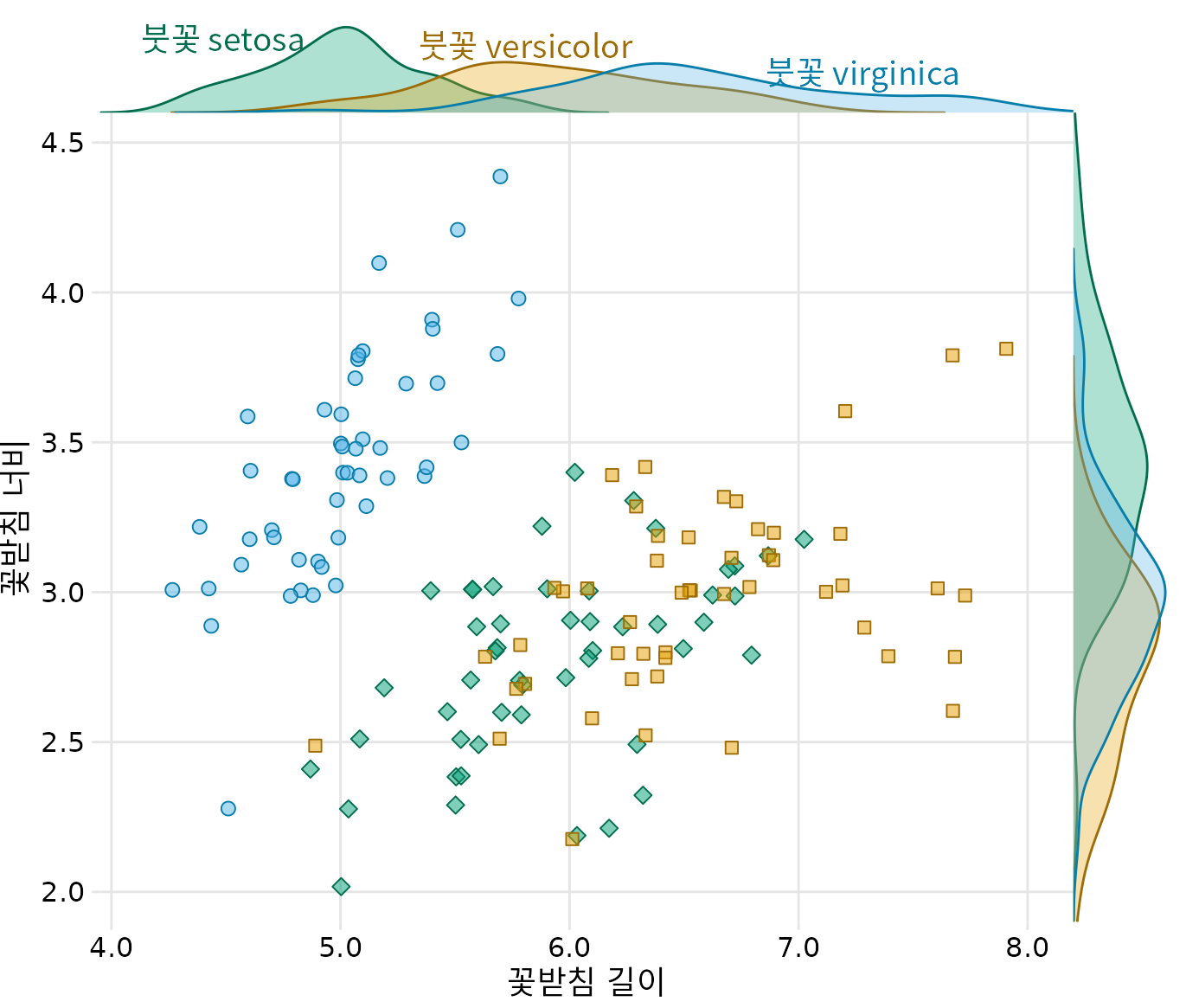
그림 ?fig-iris-densities-direct-label과 같은 밀도 그림을 범례 대체물로 사용하여 산점도의 여백에 밀도 그림을 배치할 수도 있습니다(그림 Figure 22.11). 이렇게 하면 중앙 산점도 대신 여백 밀도 그림에 직접 레이블을 지정할 수 있으므로 직접 레이블이 지정된 타원이 있는 그림 ?fig-iris-scatter-with-ellipses보다 다소 덜 복잡한 그림이 됩니다.
(ref:iris-scatter-dens) 세 가지 다른 붓꽃 종의 꽃받침 너비 대 꽃받침 길이, 각 종에 대한 각 변수의 주변 밀도 추정치 포함.
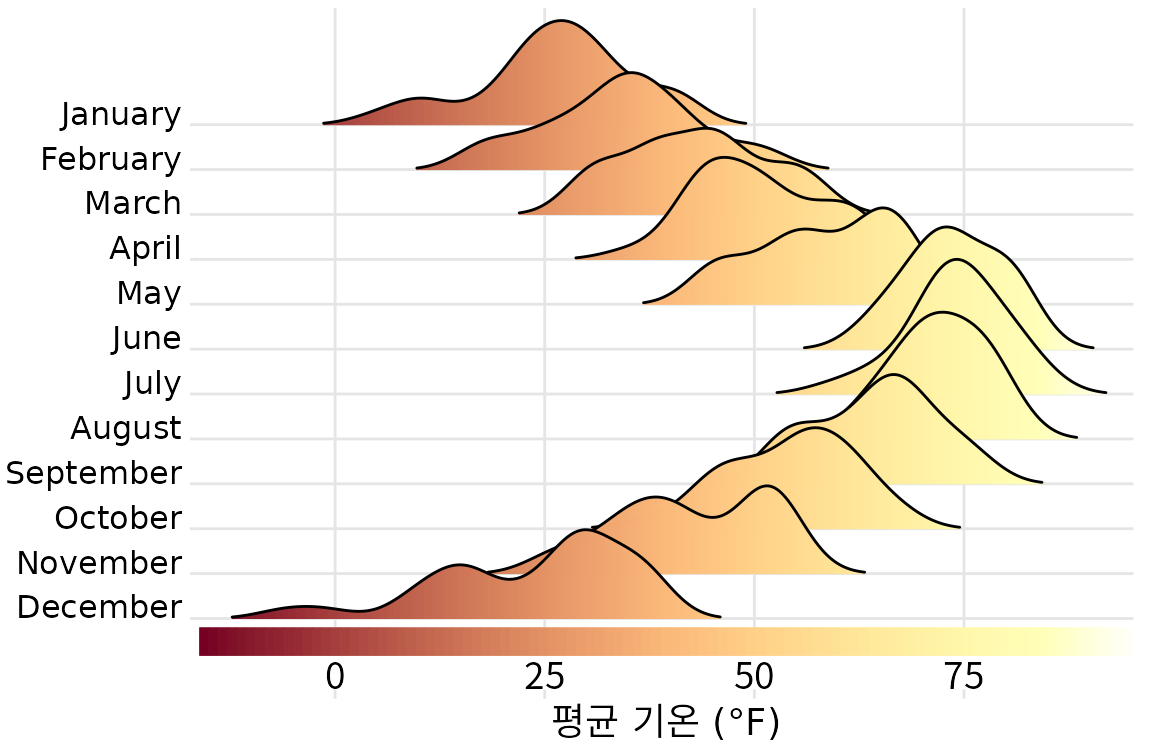
그리고 마지막으로 단일 변수를 여러 미학적 요소에 인코딩할 때 일반적으로 여러 미학적 요소에 대해 여러 개의 개별 범례를 원하지 않습니다. 대신 모든 매핑을 한 번에 전달하는 단일 범례와 유사한 시각적 요소만 있어야 합니다. 동일한 변수를 주 축을 따른 위치와 색상에 매핑하는 경우 참조 색상 막대가 동일한 축을 따라 실행되고 통합되어야 함을 의미합니다. 그림 ?fig-temp-ridgeline-colorbar는 온도를 x 축을 따른 위치와 색상 모두에 매핑하고 따라서 색상 범례를 x 축에 통합한 경우를 보여줍니다.
(ref:temp-ridgeline-colorbar) 2016년 네브래스카 주 링컨의 기온. 이 그림은 그림 ?fig-temp-ridgeline의 변형입니다. 이제 온도는 x 축을 따른 위치와 색상으로 모두 표시되며 x 축을 따른 색상 막대는 온도를 색상으로 변환하는 척도를 시각화합니다.