| 순위 | 제목 | 주말 총수입 | |||
|---|---|---|---|---|---|
| 1 | 스타워즈: 라스트 제다이 | $71,565,498 | |||
| 2 | 쥬만지: 새로운 세계 | $36,169,328 | |||
| 3 | 피치 퍼펙트 3 | $19,928,525 | |||
| 4 | 위대한 쇼맨 | $8,805,843 | |||
| 5 | 페르디난드 | $7,316,746 |
양 시각화하기
시각화의 많은 상황에서 우리는 특정 수치들의 ’크기’에 주목합니다. 예를 들어 여러 자동차 브랜드의 총 판매량, 도시별 인구수, 혹은 종목별 올림픽 선수들의 평균 연령 등을 보여주고 싶을 수 있습니다. 이런 데이터들은 공통적으로 ’범주(자동차 브랜드, 도시, 종목)’와 그에 대응하는 ’수치(판매량, 인구수, 연령)’로 구성됩니다. 저는 이를 수량(amounts) 시각화라고 부릅니다. 핵심은 각 수치가 얼마나 큰지를 효과적으로 전달하는 데 있기 때문입니다. 수량을 보여주는 가장 기본적이면서 표준적인 방법은 막대 그래프이며, 그 외에도 그룹 막대, 누적 막대, 점 그래프, 히트맵 등 다양한 변형이 존재합니다.
막대 그래프
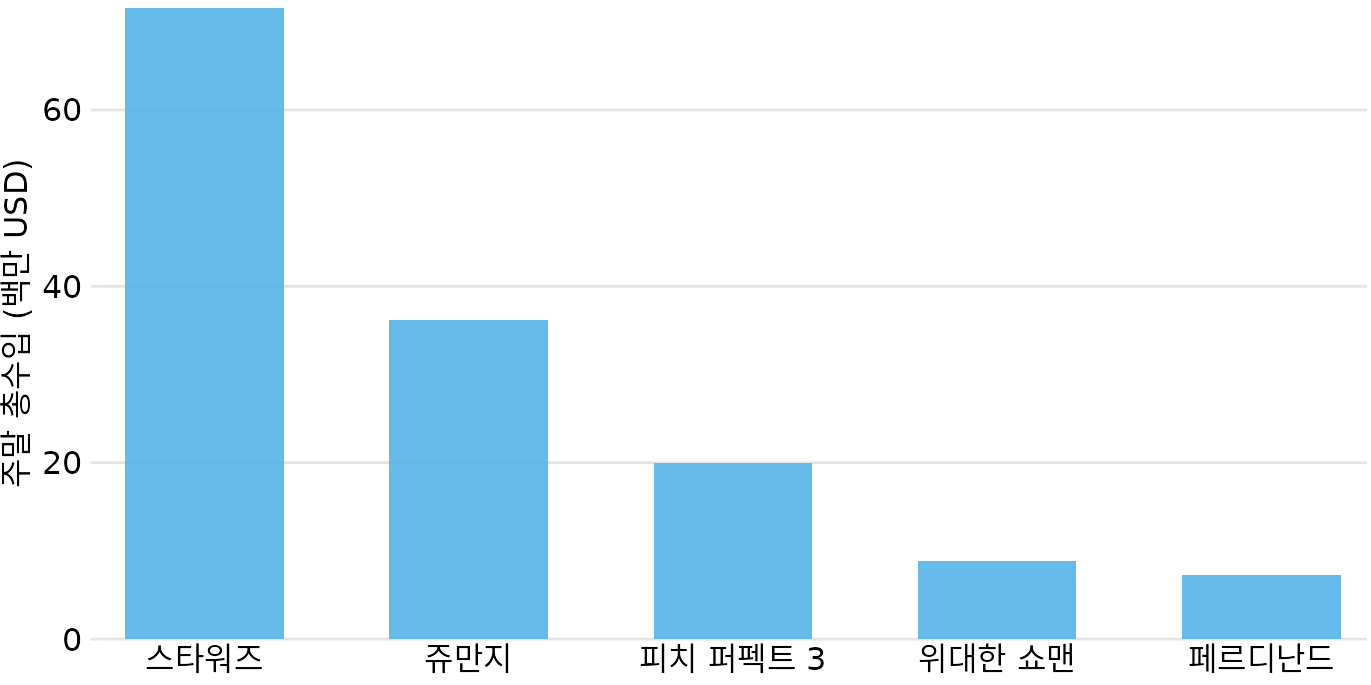
막대 그래프의 기본 개념을 영화 티켓 판매량 예제로 살펴보겠습니다. 표 ?tbl-boxoffice-gross는 2017년 크리스마스 주말 당시 북미 박스오피스 상위 5위권 영화들의 수입을 보여줍니다. “스타워즈: 라스트 제다이”가 압도적인 1위를 차지했으며, 4·5위인 “위대한 쇼맨”이나 “페르디난드”보다 거의 10배 많은 수익을 올렸음을 알 수 있습니다.
이런 데이터는 대개 세로 막대 그래프로 그립니다. 각 영화마다 0에서 시작하여 주말 수입에 해당하는 높이까지 막대를 세우는 방식입니다(그림 Figure 8.1). 이를 막대 그래프(bar graph) 혹은 막대 차트(bar chart)라고 부릅니다.
(ref:boxoffice-vertical) 2017년 12월 22~24일 주말 북미 박스오피스 상위 영화들의 수입을 보여주는 막대 그래프. 데이터 출처: Box Office Mojo (http://www.boxofficemojo.com/).
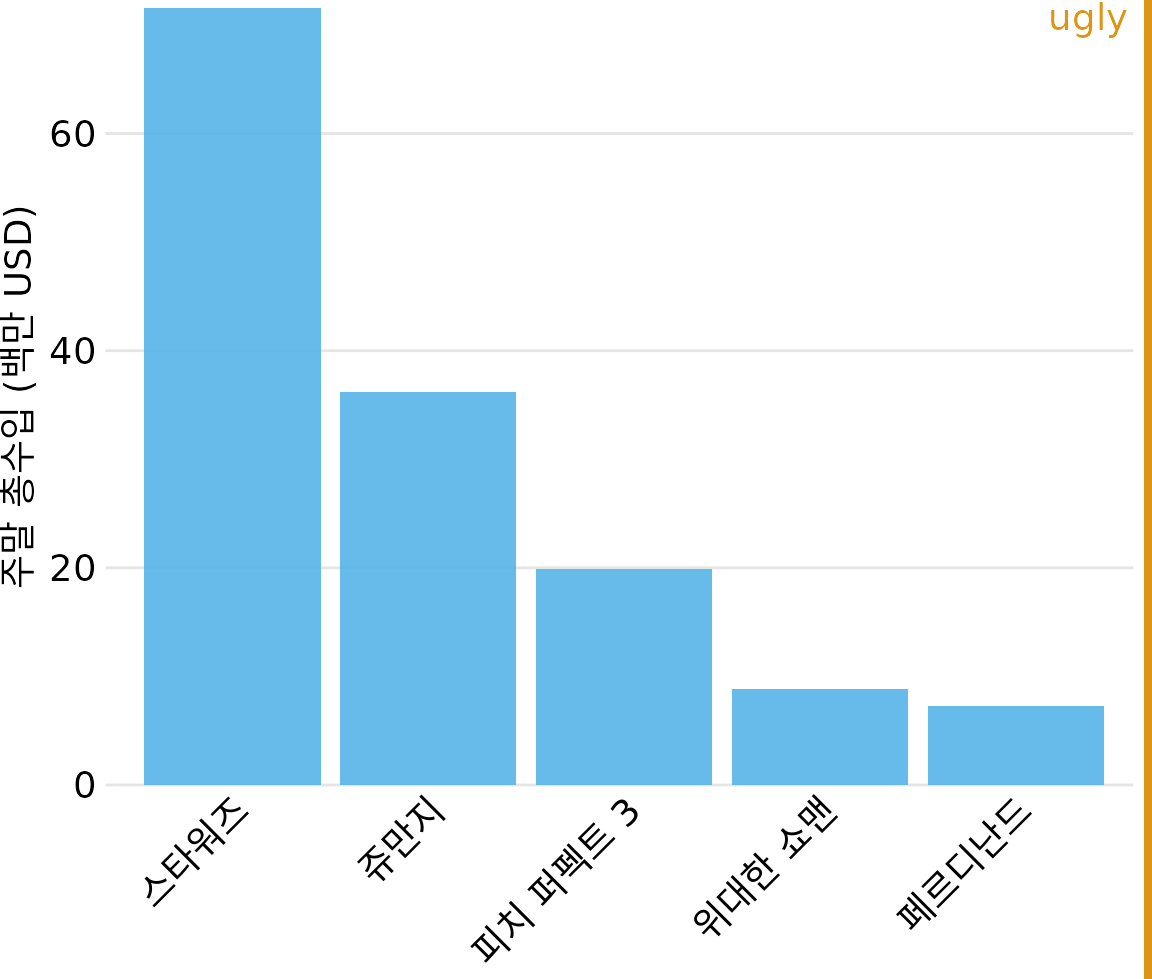
세로 막대 그래프에서 자주 겪는 문제 중 하나는 각 막대의 이름을 나타내는 레이블이 가로 공간을 많이 차지한다는 점입니다. 그림 ?fig-boxoffice-vertical만 해도 영화 제목들을 아래에 다 적기 위해 그래프의 가로 폭을 꽤 넓게 잡아야 했습니다. 공간을 아끼려고 막대를 바짝 붙이고 레이블을 비스듬히 회전시키기도 하지만(그림 Figure 8.2), 저는 이 방식을 추천하지 않습니다. 결과물이 깔끔하지 못하고 읽기도 불편하기 때문입니다. 레이블이 정식 명칭일 경우 회전시켜도 보기 좋지 않은 경우가 많습니다.
(ref:boxoffice-rot-axis-tick-labels) 텍스트 레이블을 회전시킨 막대 그래프 예시. 회전된 텍스트는 가독성이 떨어지며 그래프 하단에 불필요한 공백을 만듭니다. 저는 개인적으로 이런 배치를 권장하지 않습니다. 데이터 출처: Box Office Mojo (http://www.boxofficemojo.com/).
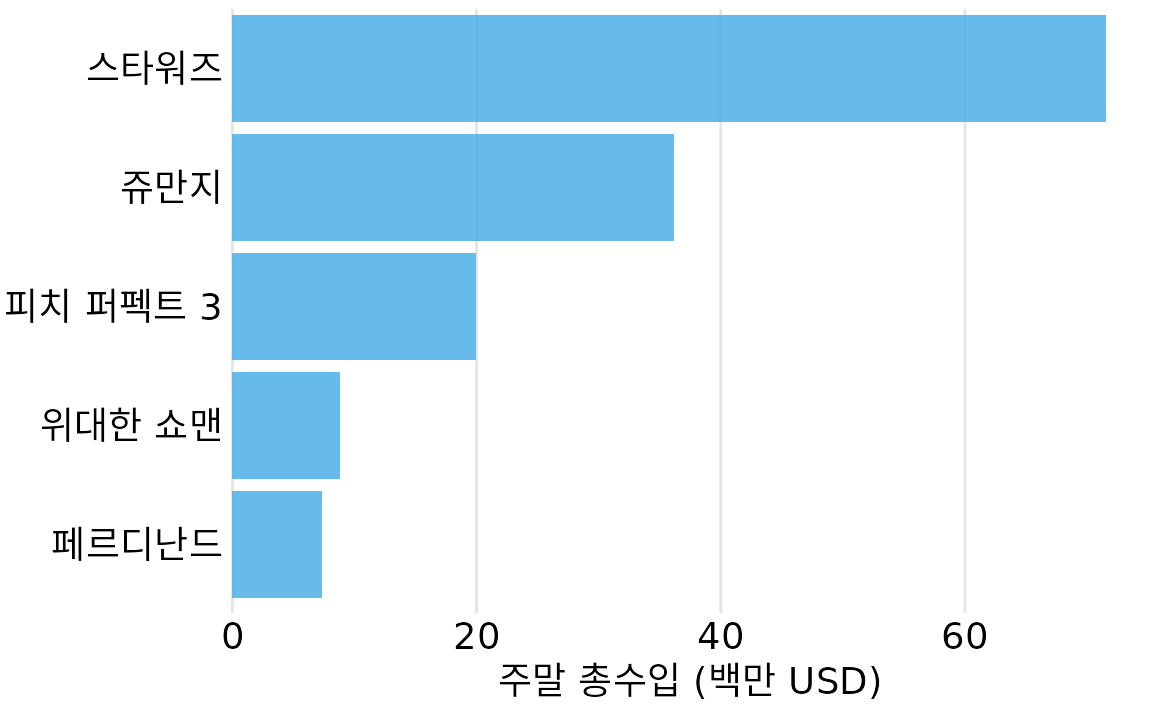
긴 레이블 문제를 해결하는 더 세련된 방법은 x축과 y축을 바꾸어 막대를 가로로 눕히는 것입니다(그림 Figure 8.3). 이렇게 하면 텍스트를 포함한 모든 시각 요소가 수평으로 정렬되어 훨씬 간결하고 가독성이 좋아집니다. 그림 ?fig-boxoffice-rot-axis-tick-labels나 ?fig-boxoffice-vertical과 비교해볼 때 훨씬 눈이 편안함을 알 수 있습니다.
(ref:boxoffice-horizontal) 가로 막대 그래프로 표현한 박스오피스 데이터. 가로형 배치는 긴 텍스트 레이블을 다룰 때 가장 효과적인 방법입니다. 데이터 출처: Box Office Mojo (http://www.boxofficemojo.com/).
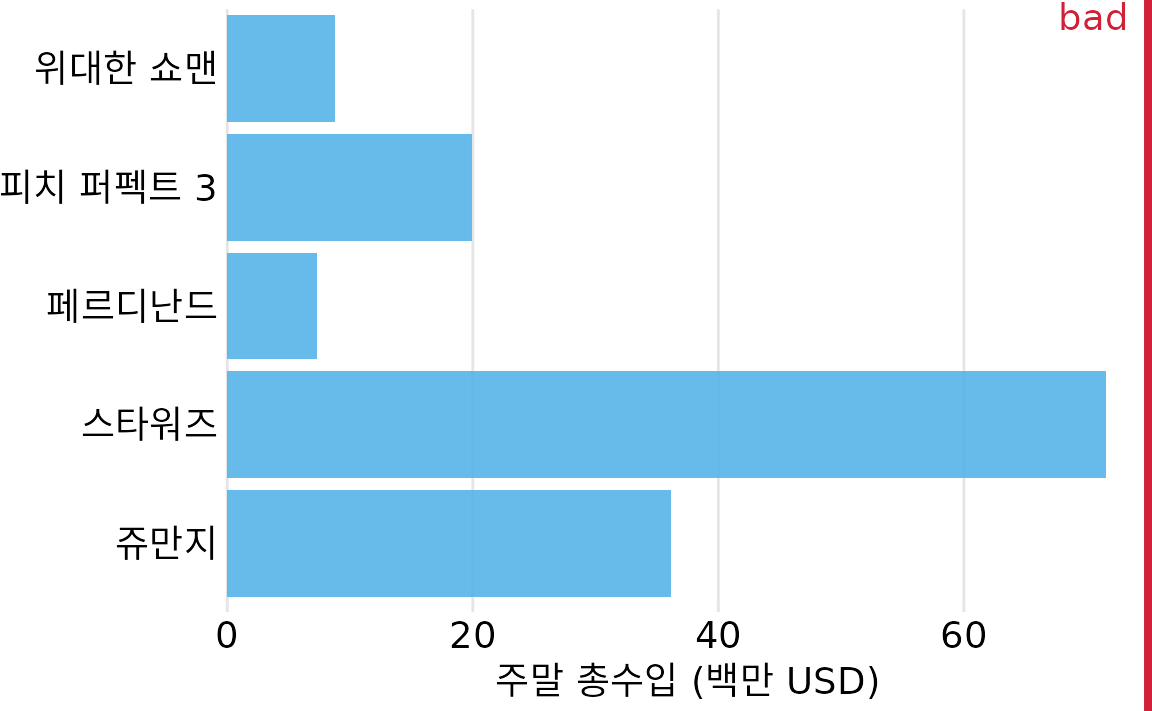
막대 그래프를 그릴 때 놓치기 쉬운 포인트가 바로 ’정렬 순서’입니다. 별다른 고민 없이 막대를 임의의 순서나 알파벳 순으로 두는 경우가 많은데, 이는 좋지 않은 습관입니다(그림 Figure 8.4). 특별한 이유가 없다면 막대는 수치 크기 순으로 정렬하는 것이 훨씬 직관적이며 독자가 정보를 파악하기도 쉽습니다.
(ref:boxoffice-horizontal-bad-order) 부적절한 순서로 정렬된 막대 그래프 예시. 여기서는 영화 제목 글자 수 순서로 정렬했는데, 이는 데이터의 본질과 아무 상관 없는 인위적인 순서일 뿐입니다. 이런 배치는 정보를 파악하는 데 방해가 됩니다. 데이터 출처: Box Office Mojo (http://www.boxofficemojo.com/).
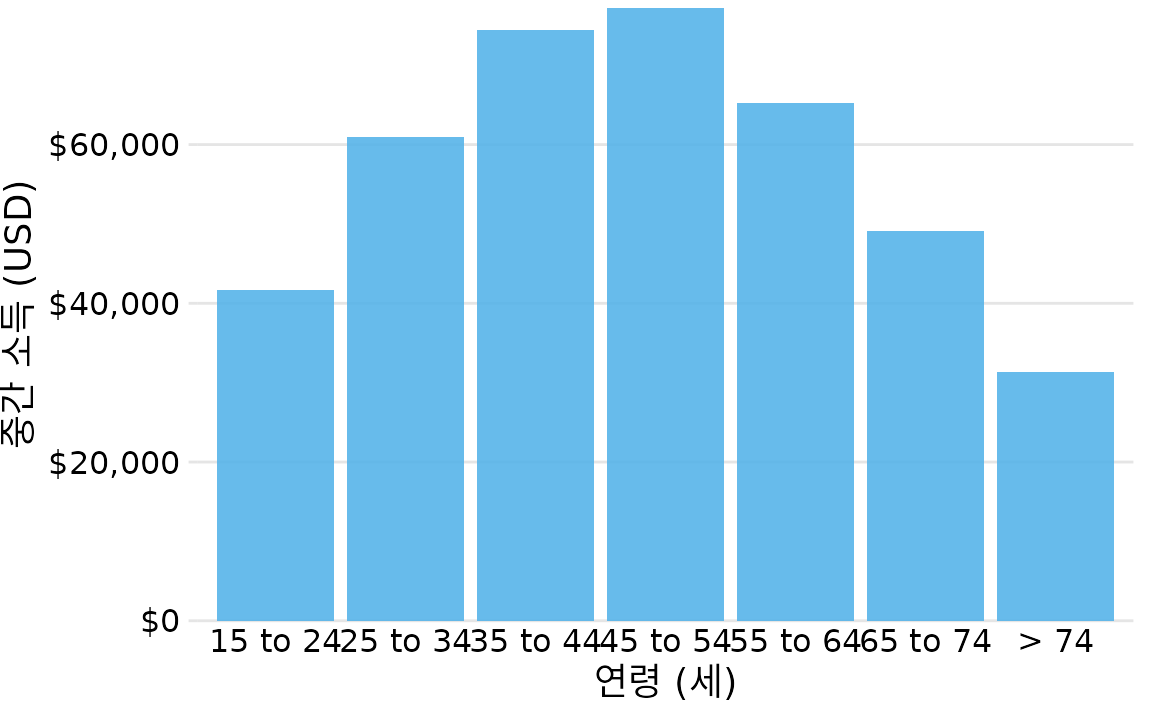
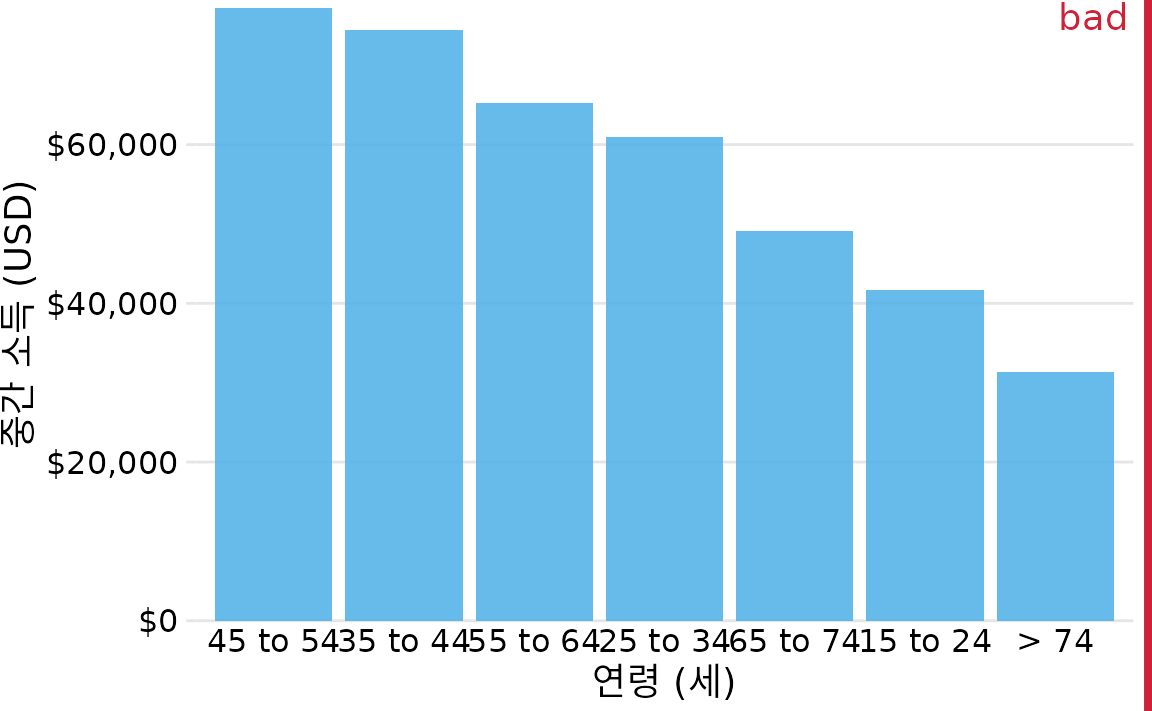
물론 막대가 나타내는 범주 자체에 자연스러운 순서가 있다면 그 순서를 따라야 합니다. 연령대, 성적, 혹은 시간 등 순서형(ordinal) 변수를 다룰 때는 수치가 크더라도 마음대로 순서를 바꿔서는 안 됩니다. 예를 들어 그림 ?fig-income-by-age는 미국의 연령대별 가구 소득 중앙값을 보여주는데, 당연히 연령대가 낮은 쪽에서 높은 쪽으로 정렬되어야 합니다. 단순히 막대 높이순으로 연령대를 섞어버리면(그림 Figure 8.6) 데이터의 맥락을 완전히 놓치게 됩니다.
(ref:income-by-age) 2016년 미국 연령대별 가구 소득 중앙값. 45~54세 연령층에서 소득이 가장 높음을 알 수 있습니다. 데이터 출처: 미국 인구조사국
(ref:income-by-age-sorted) 연령대를 소득 순으로 잘못 정렬한 예시. 시각적으로는 정돈되어 보일지 몰라도, 연령이라는 중요한 흐름을 잃어버렸기 때문에 잘못된 시각화입니다. 데이터 출처: 미국 인구조사국
막대 순서에 주의하십시오. 막대가 순서 없는 범주를 나타내는 경우 데이터 값의 오름차순 또는 내림차순으로 정렬하십시오.
그룹 막대와 누적 막대 그래프
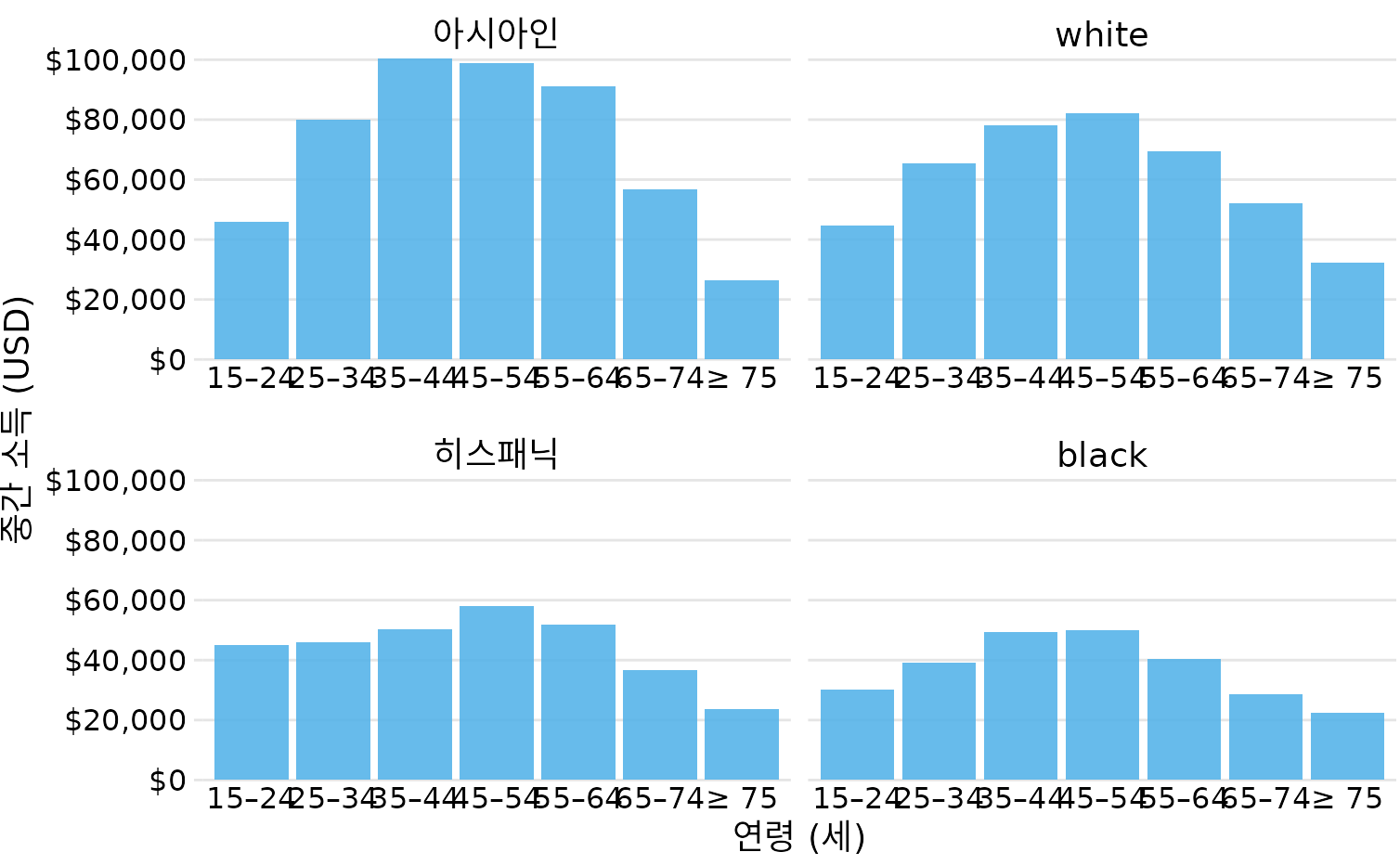
지금까지는 하나의 범주형 변수를 다루는 법을 보았습니다. 하지만 실제로는 두 개의 범주형 변수를 동시에 분석해야 할 때가 많습니다. 예를 들어, 연령대별 소득뿐만 아니라 ‘인종별’ 소득 차이까지 한꺼번에 보고 싶을 수 있죠. 이럴 때 유용한 것이 그룹 막대 그래프(grouped/dodged bar graph)입니다(그림 Figure 8.7). 그룹 막대 그래프는 x축에 첫 번째 범주(연령대)를 두고, 각 연령대 안에서 두 번째 범주(인종)별로 막대들을 나란히 배치합니다.
(ref:income-by-age-race-dodged) 2016년 미국 가구 연령대 및 인종별 소득 중앙값. 연령대를 x축으로 삼고, 각 연령대 내에서 아시아인, 백인, 히스패닉, 흑인의 소득을 나란히 보여줍니다. 데이터 출처: 미국 인구조사국
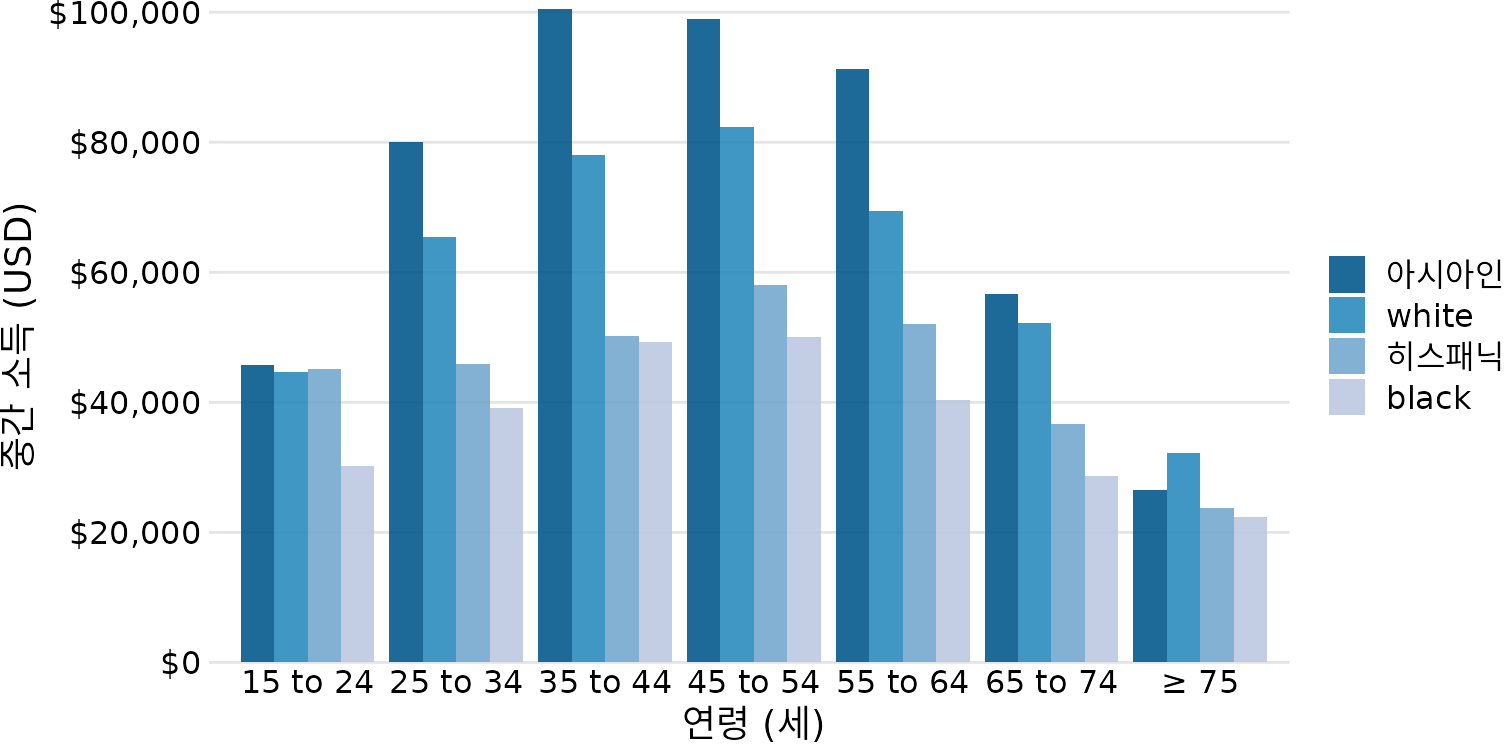
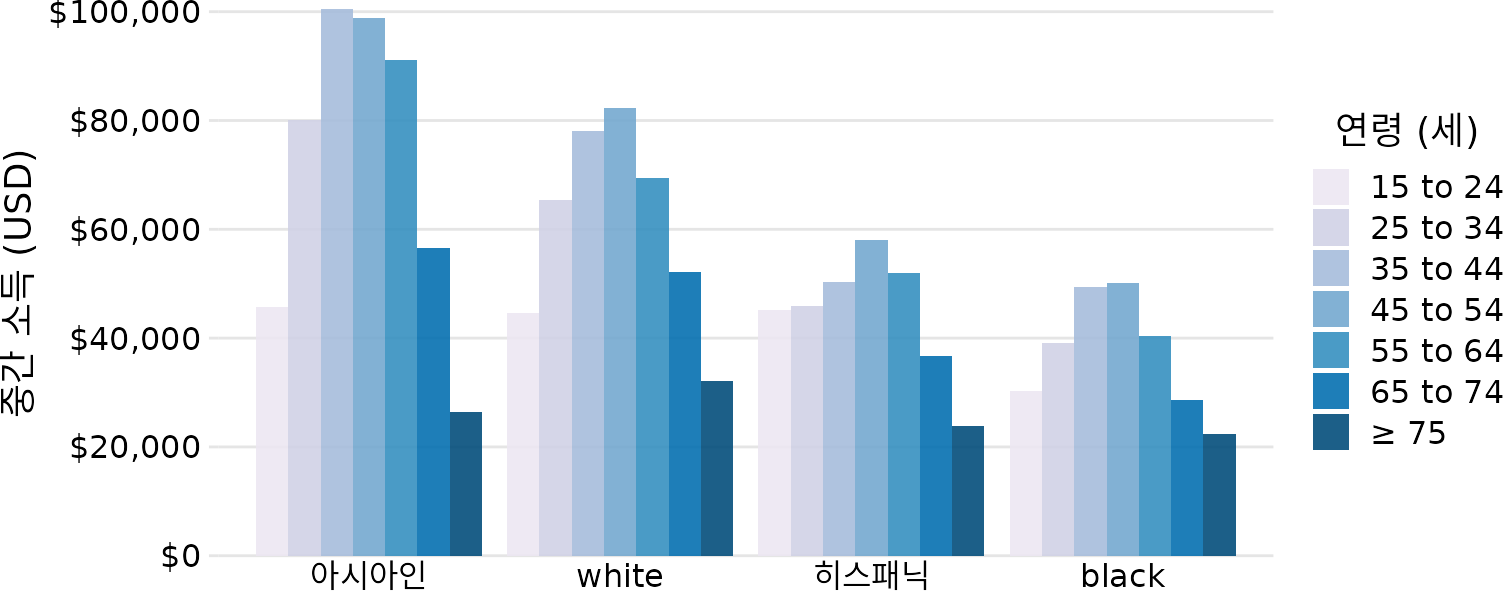
그룹 막대 그래프는 많은 정보를 한꺼번에 보여주지만, 자칫하면 그래프가 너무 복잡해질 수 있습니다. 그림 ?fig-income-by-age-race-dodged만 해도 틀린 정보는 아니지만, 한눈에 읽어내기가 쉽지는 않습니다. 특히 특정 인종 내에서 연령별 변화를 파악하기가 매우 어렵습니다. 이 배치는 특정 연령대 안에서의 인종 간 차이를 강조하고 싶을 때만 적합합니다. 만약 인종별 전반적인 소득 패턴이 더 궁금하다면, 그림 ?fig-income-by-race-age-dodged처럼 인종을 x축으로 삼고 연령대를 그 안의 개별 막대로 두는 것이 더 나을 수 있습니다.
(ref:income-by-race-age-dodged) 인종을 x축으로 설정한 연령대별 소득 데이터. 그림 ?fig-income-by-age-race-dodged와 같은 데이터지만, 인종별 전체적인 흐름을 비교하기에는 이 방식이 더 유리합니다. 데이터 출처: 미국 인구조사국
두 그림 모두 범주 하나는 x축 위치로, 다른 하나는 색상으로 표현합니다. 하지만 색상으로 정보를 인코딩하면 독자가 매번 범례를 대조하며 색상을 머릿속으로 번역해야 하므로 인지적 부담이 큽니다. 이런 부담을 낮추는 가장 좋은 방법은 애초에 색상을 쓰지 않고 면 분할(faceting)을 활용해 여러 개의 그래프를 나란히 배치하는 것입니다(그림 Figure 8.9). 저는 이 방식이 훨씬 명료하고 깔끔한 대안이라고 생각합니다.
(ref:income-by-age-race-faceted) 면 분할을 활용한 연령 및 인종별 소득 시각화. 그룹 막대 하나로 뭉뚱그리는 대신 네 개의 개별 그래프로 나누어 표현했습니다. 색상에 의존하지 않으면서도 각 범주의 정보를 아주 선명하게 전달할 수 있습니다. 데이터 출처: 미국 인구조사국
막대 그래프를 나란히 두는 대신 위로 쌓아 올리는 누적 막대 그래프(stacked bar graph)가 더 좋을 때도 있습니다. 개별 수치들의 합계 자체가 의미 있는 정보일 때 누적 방식이 빛을 발합니다. 앞선 예제의 소득 중앙값은 서로 더한다고 해서 의미 있는 값이 되지 않지만, 영화별 티켓 수입은 합치면 전체 박스오피스 규모가 되므로 누적이 가능합니다. 특히 인원수 데이터에서 남성과 여성을 각각 센 뒤 누적하면, 각 성별의 비중과 동시에 전체 인원수라는 두 마리 토끼를 한 번에 보여줄 수 있습니다.
이 원칙을 1912년 타이타닉호 침몰 사고의 승객 데이터로 설명하겠습니다. 당시 승객들은 1·2·3등석 중 하나에 탑승했으며, 전체적으로 여성을 압도하는 수의 남성들이 타고 있었습니다. 등실별 성별 분포를 시각화하기 위해 각 등실을 축으로 잡고, 남성 막대 위에 여성 막대를 쌓아 올렸습니다(그림 Figure 8.10). 이제 막대 전체의 높이는 각 함실의 총 승객 수를 나타내며, 그 안의 색칠된 비율로 성별 비중을 알 수 있습니다.
(ref:titanic-passengers-by-class-sex) 타이타닉호의 선실 등급 및 성별 승객 분포.
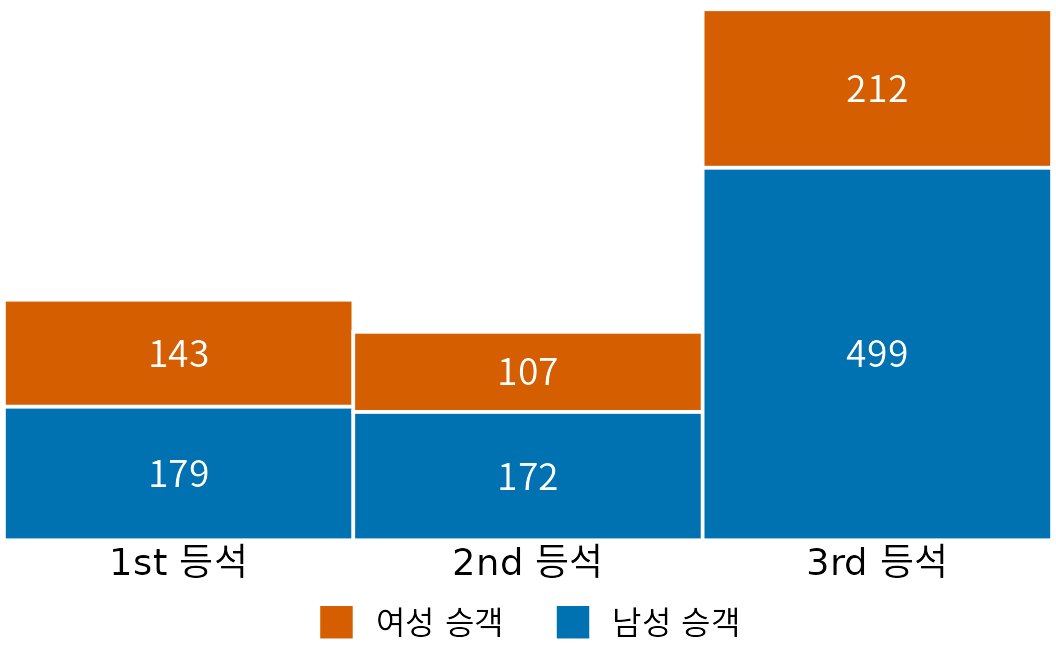
그림 ?fig-titanic-passengers-by-class-sex는 앞서 보여드린 그래프들과 달리 y축 숫자가 없습니다. 대신 각 막대 안에 실제 인원수를 직접 적어 넣었죠. 데이터의 범주가 많지 않을 때는 이렇게 직접 숫자를 적는 것이 시각적 노이즈를 줄이면서 더 정확한 정보를 전달하는 좋은 방법이 될 수 있습니다.
점 그래프와 히트맵
수량을 표현하는 방법이 꼭 막대여야 할 필요는 없습니다. 막대 그래프의 치명적인 제약 중 하나는, 막대의 길이 자체가 수치에 비례해야 하므로 반드시 0에서 축이 시작되어야 한다는 점입니다. 하지만 데이터에 따라서는 이것이 비효율적이거나 데이터의 미세한 차이를 가려버릴 수 있습니다. 이럴 때는 막대 대신 축의 해당 지점에 점을 찍는 점 그래프(dot plot)가 훌륭한 대안이 됩니다.
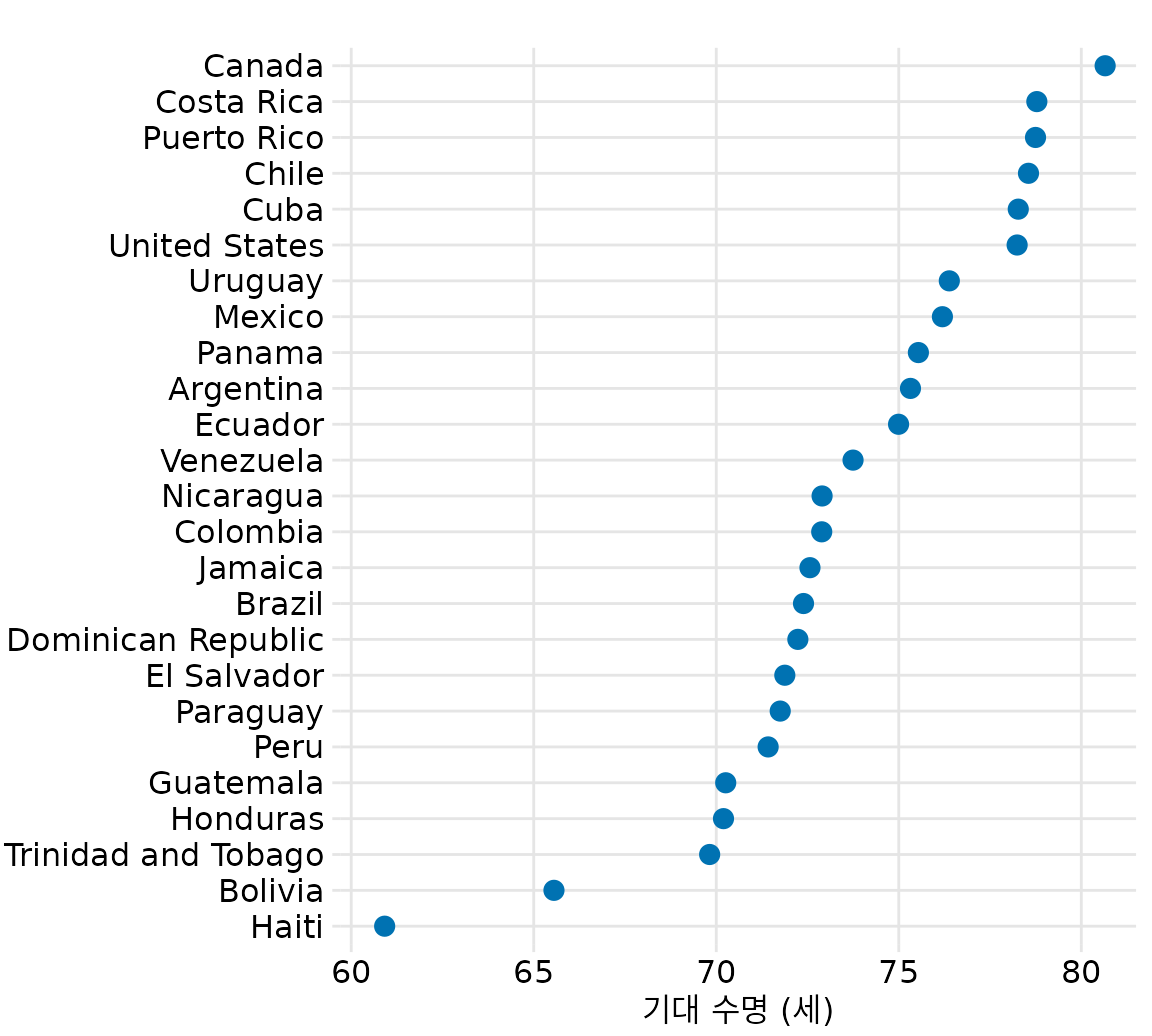
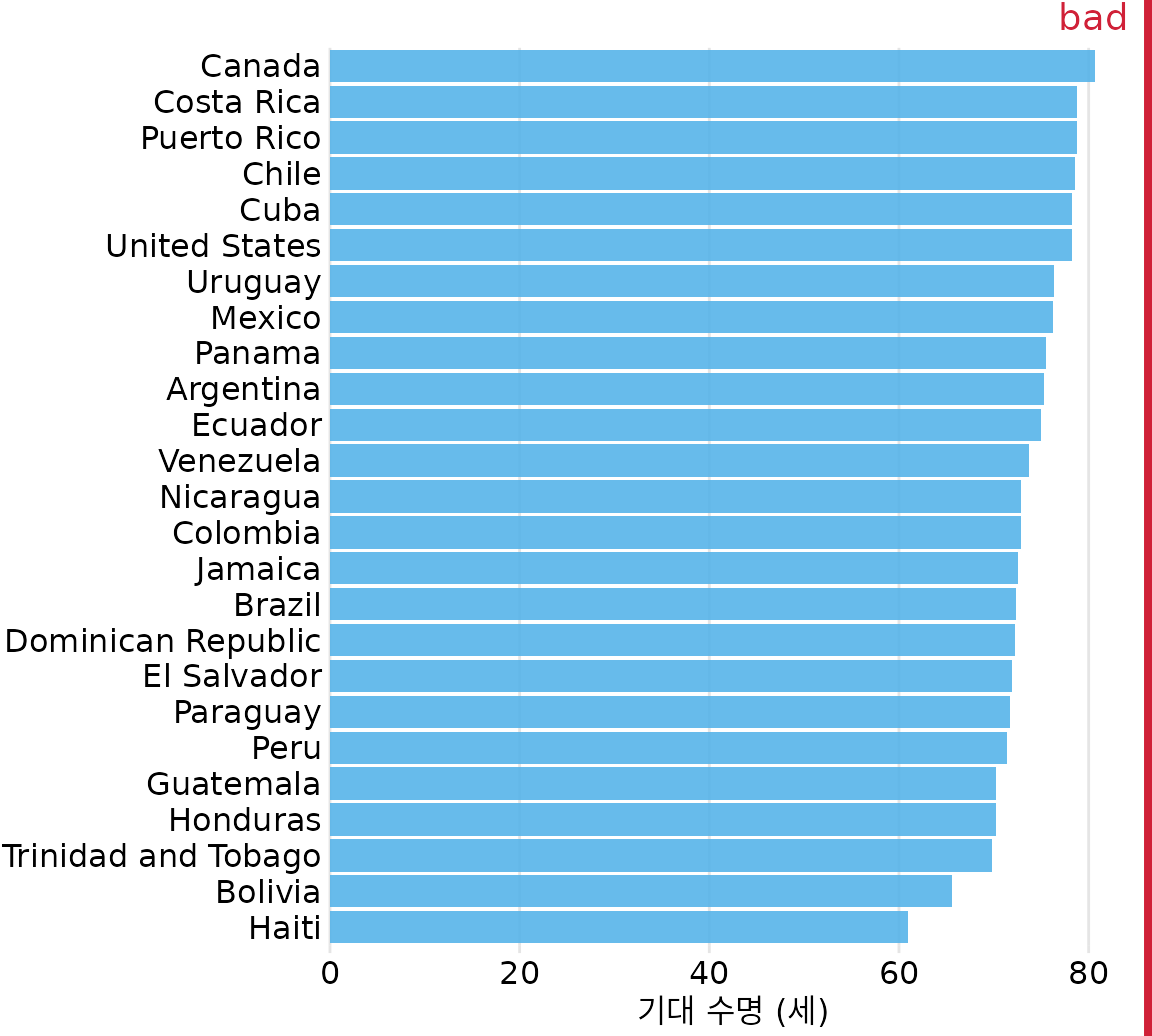
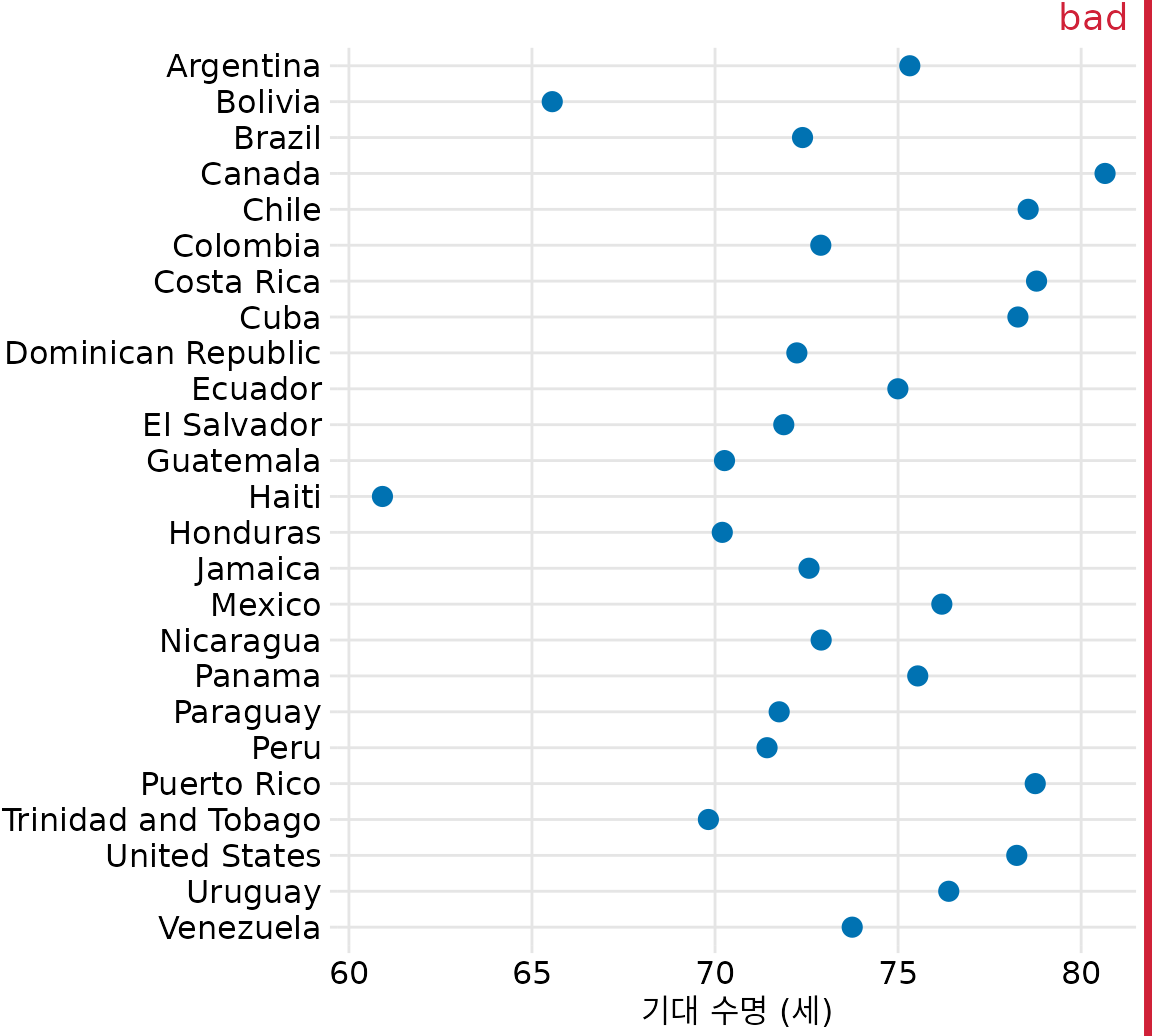
그림 ?fig-Americas-life-expect는 아메리카 대륙 25개국의 기대 수명을 점 그래프로 나타낸 예시입니다. 대부분의 국가가 60세에서 81세 사이에 분포해 있는데, x축의 범위를 이 구간에 맞춤으로써 국가 간의 미묘한 차이를 확연히 드러내고 있습니다. 캐나다가 단연 1위이며 볼리비아와 아이티가 하위권임을 한눈에 알 수 있죠. 만약 이를 막대 그래프로 그렸다면(그림 Figure 8.12) 시선이 막대 중간의 긴 몸통에 머물게 되어, 우리가 정말 알고 싶은 끝부분의 차이를 제대로 포착하지 못했을 것입니다.
(ref:Americas-life-expect) 2007년 아메리카 대륙 국가들의 기대 수명. 데이터 출처: Gapminder
(ref:Americas-life-expect-bars) 같은 데이터를 막대 그래프로 그린 예시. 막대가 너무 길어 정작 중요한 국가 간의 차이는 눈에 잘 들어오지 않습니다. 이처럼 차이가 미세한 데이터에는 막대 그래프가 적절하지 않습니다. 데이터 출처: Gapminder
물론 점 그래프에서도 정렬은 매우 중요합니다. 앞선 예시들은 모두 기대 수명이 높은 것에서 낮은 것으로 정렬되어 있습니다. 만약 이를 국가 이름 순서(알파벳 순)로 그대로 방치했다면, 그림 ?fig-Americas-life-expect-bad처럼 정보도 없고 읽기도 힘든 어지러운 그래프가 되었을 것입니다.
(ref:Americas-life-expect-bad) 알파벳 순서로 무질서하게 배치된 점 그래프. 패턴을 읽어내기가 불가능에 가깝습니다. 정렬되지 않은 시각화가 왜 나쁜지를 보여주는 전형적인 사례입니다. 데이터 출처: Gapminder
지금까지는 막대나 점의 ’위치’를 이용해 수량을 나타냈습니다. 하지만 데이터가 너무 방대해지면 이 방식들은 한계가 드러납니다. 이미 앞서 보았듯 범주가 몇 개만 늘어나도 그래프가 금세 지저분해지죠. 만약 20개 국가의 20년치 데이터를 한꺼번에 보여줘야 한다면 산점도는 최악의 선택이 될 것입니다.
이런 대규모 데이터에는 위치 대신 ’색상’에 수치를 매핑하는 히트맵(heatmap)이 효과적입니다. 그림 ?fig-internet-over-time은 1994년부터 2016년까지 20개국의 인터넷 보급률 변화를 히트맵으로 보여줍니다. 수치를 색상의 강도로 표현하기 때문에 특정 시점의 정확한 숫자 값을 읽는 데는 조금 불리할 수 있지만, 전반적인 거시적 흐름을 파악하는 데는 이보다 더 좋은 방법이 없습니다. 어떤 국가가 인터넷을 먼저 받아들였는지, 어느 시기에 폭발적으로 성장했는지가 한눈에 드러납니다.
(ref:internet-over-time) 국가별 인터넷 보급률의 변천사. 색상은 100명당 사용자 수를 뜻하며, 2016년 보급률 순서대로 정렬했습니다. 데이터 출처: World Bank
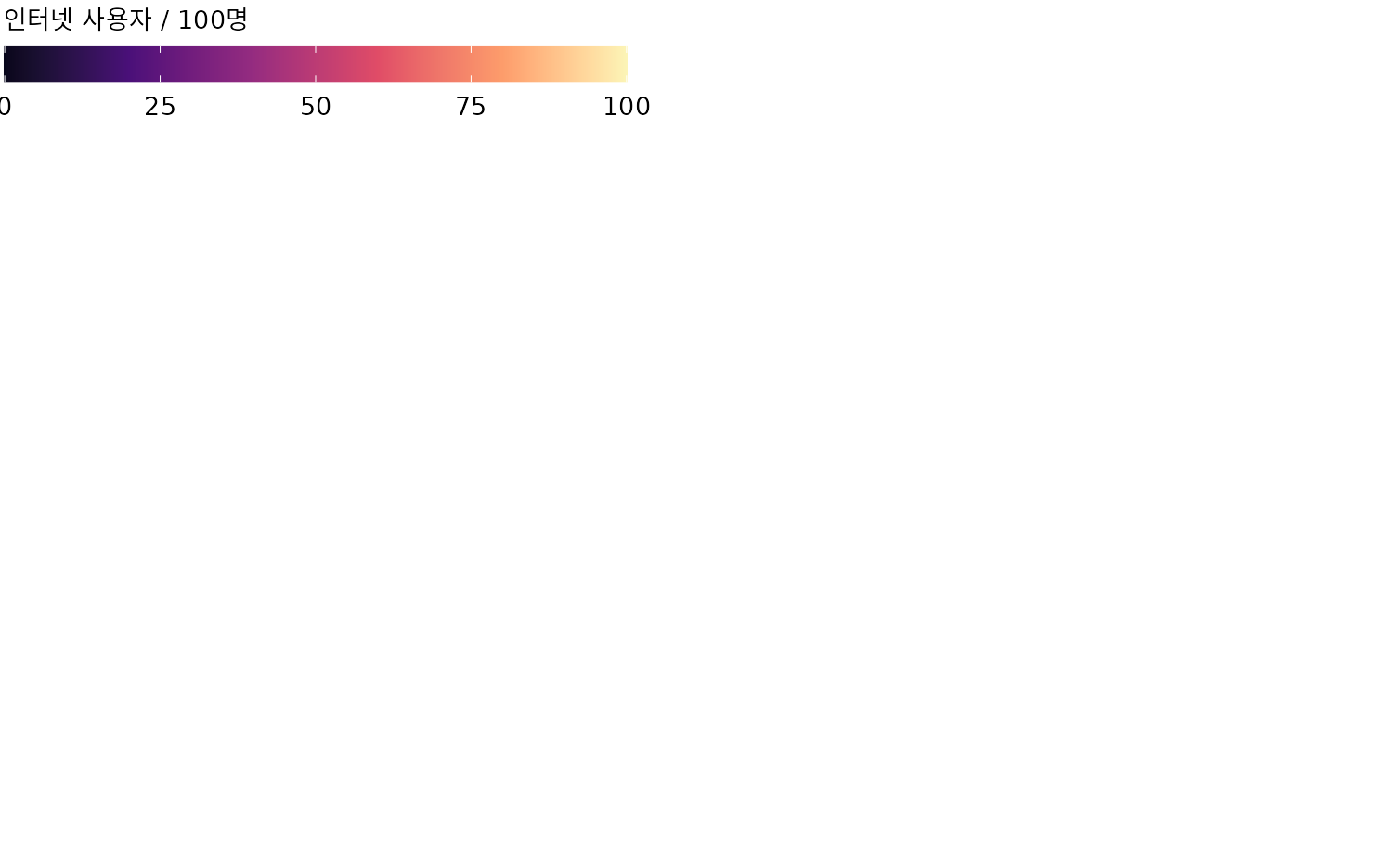
당연히 히트맵에서도 정렬은 결정적인 역할을 합니다. 그림 ?fig-internet-over-time은 ’현재(2016년) 시점’의 보급률을 기준으로 정렬되어 있습니다. 그래서 영국이나 일본 같은 국가들이 미국보다 위에 있죠. 하지만 관심 있는 포인트가 현재가 아니라 ’도입 시기’라면 어떨까요? 그림 ?fig-internet-over-time2처럼 보급률이 20%를 처음 넘긴 해를 기준으로 정렬할 수도 있습니다. 이 그래프에서는 미국이 상위권으로 올라와, 도입은 빨랐으나 최근 성장세가 다른 국가들에 비해 상대적으로 완만해졌음을 시각적으로 바로 확인할 수 있습니다.
(ref:internet-over-time2) 보급률이 처음으로 20%를 넘긴 시점을 기준으로 정렬한 히트맵. 데이터 출처: World Bank
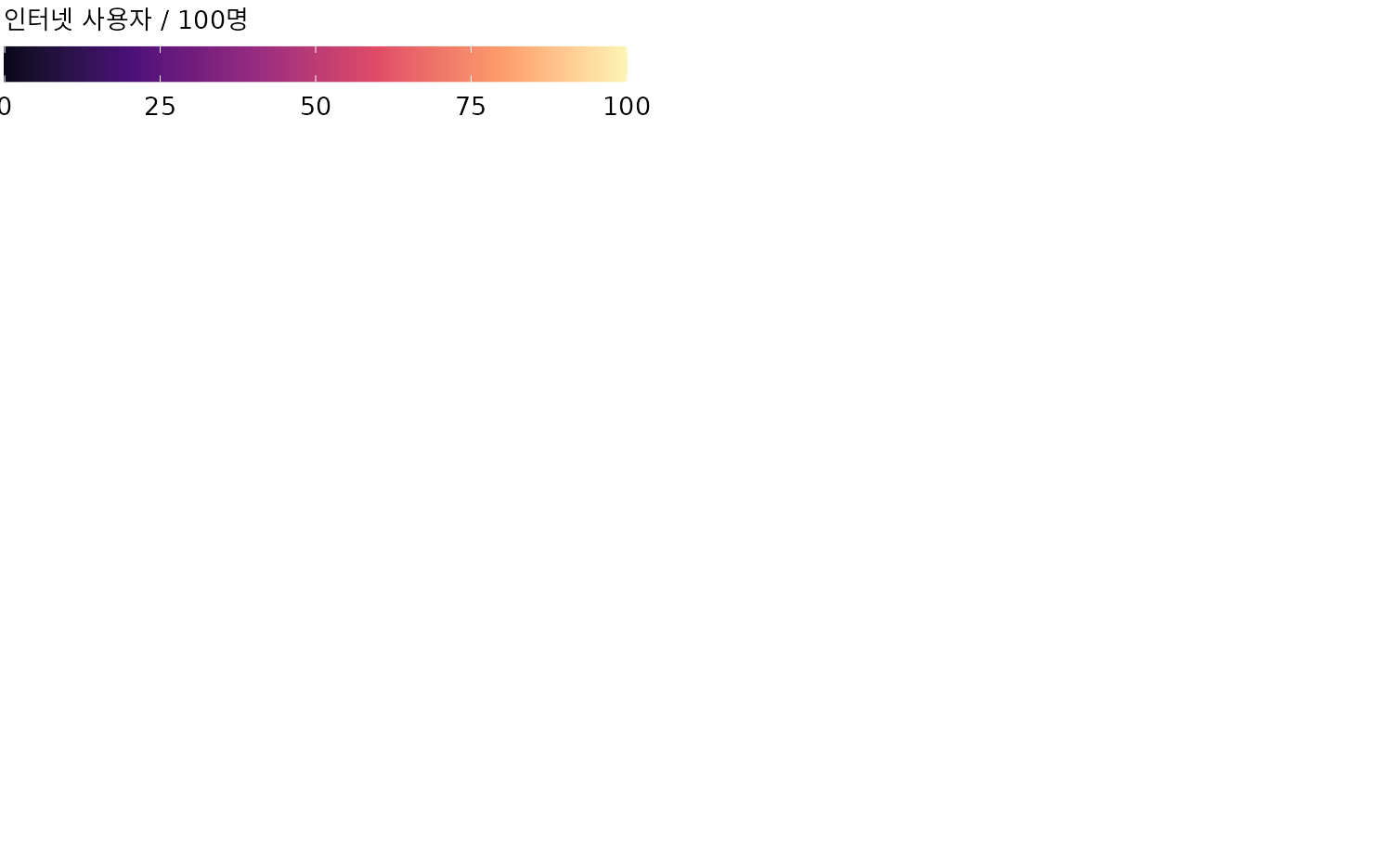
두 그림 모두 완벽하고 올바른 데이터 표현입니다. 차이는 어떤 ’이야기’를 하려느냐에 있습니다. 2016년 현재의 순위가 궁금하다면 그림 ?fig-internet-over-time이 적합하고, 국가별 기술 도입의 역동성을 보여주고 싶다면 그림 ?fig-internet-over-time2가 훨씬 설득력 있는 자료가 될 것입니다.