|
|
|
분포 시각화: 히스토그램 및 밀도 그림
데이터 세트에서 특정 변수가 어떻게 분포되어 있는지 파악해야 하는 상황은 매우 흔합니다. 구체적인 예를 들기 위해 양 시각화하기 장에서 보았던 타이타닉호 승객 데이터를 다시 살펴보겠습니다. 타이타닉호에는 약 1,300명의 승객이 탑승했는데(승무원 제외), 그중 756명의 연령 정보가 알려져 있습니다. 우리는 어린이, 청년, 중년, 노인 등 각 연령대별로 승객이 얼마나 많았는지 알고 싶을 것입니다. 이렇듯 집단 내에서 여러 값의 상대적인 비중을 나타내는 것을 연령 분포(age distribution)라고 합니다.
단일 분포 시각화
모든 승객을 비슷한 연령대별로 그룹을 묶은 뒤, 각 그룹의 인원수를 세어보면 연령 분포를 파악할 수 있습니다. 이 과정을 거치면 표 ?tbl-titanic-ages와 같은 결과가 나옵니다.
이 표를 시각화하기 위해 각 연령 구간의 너비를 가로로, 해당 구간의 인원수를 높이로 하는 막대들을 그릴 수 있습니다(그림 Figure 9.1). 이런 형태의 그래프를 히스토그램(histogram)이라고 부릅니다. (올바른 히스토그램이 되려면 모든 막대의 너비가 일정해야 합니다.)
(ref:titanic-ages-hist1) 타이타닉호 승객 연령 히스토그램.
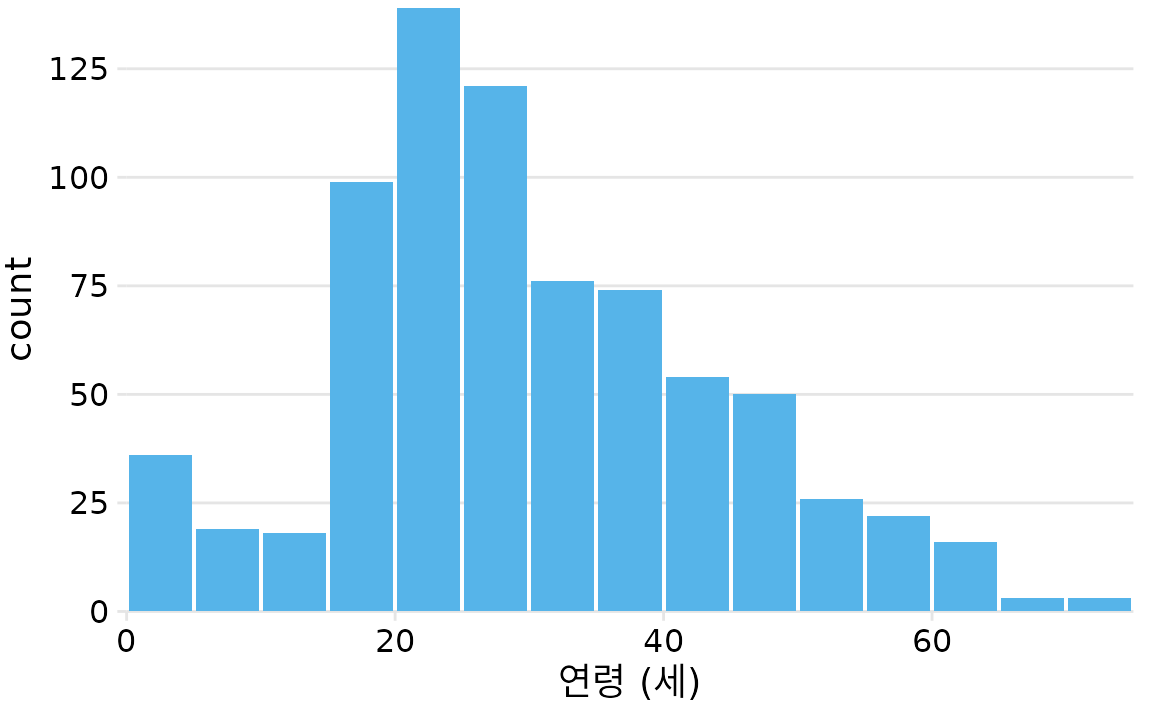
히스토그램은 데이터를 특정 구간으로 나누어 만들기 때문에, 구간의 너비를 어떻게 설정하느냐에 따라 모양이 크게 달라집니다. 대부분의 시각화 도구는 자동으로 구간 너비를 정해주지만, 이것이 항상 최선의 선택은 아닙니다. 따라서 데이터의 실제 흐름을 정확히 파악하려면 반드시 여러 가지 구간 너비를 시도해봐야 합니다. 구간 너비가 너무 좁으면 그래프가 지나치게 굴곡지고 복잡해져서 전체적인 경향을 읽기 어렵습니다. 반대로 너무 넓으면 10세 전후의 하락세 같은 세밀한 특징들이 뭉개져 버릴 수 있습니다.
타이타닉 승객의 연령 분포를 예로 들면, 구간 너비가 1년이면 너무 세밀하고 15년이면 너무 뭉뚱그려집니다. 3~5년 정도가 데이터의 특성을 보여주기에 적당함을 알 수 있습니다(그림 Figure 9.2).
(ref:titanic-ages-hist-grid) 히스토그램은 선택한 구간 너비에 따라 달라집니다. 여기서 동일한 타이타닉호 승객 연령 분포가 네 가지 다른 구간 너비로 표시됩니다. (a) 1년; (b) 3년; (c) 5년; (d) 15년.
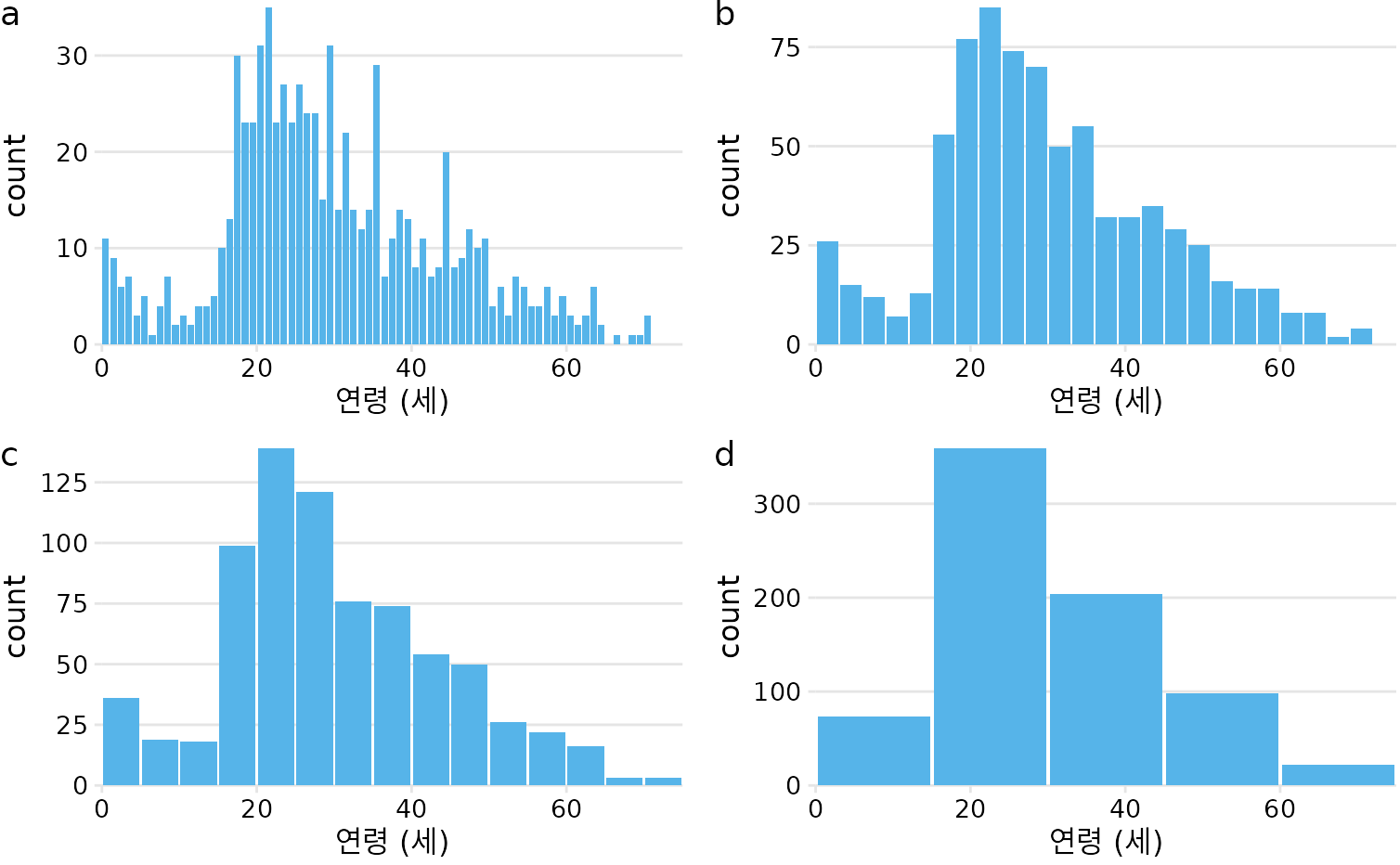
히스토그램을 만들 때는 항상 여러 구간 너비를 탐색하십시오.
히스토그램은 18세기부터 널리 쓰여온 방식입니다. 손으로 그리기도 쉽고 직관적이기 때문이죠. 하지만 최근에는 컴퓨팅 성능이 좋아지면서 밀도 그림(density plot)이 그 자리를 대신하는 경우가 많아졌습니다. 밀도 그림은 데이터의 확률 분포를 부드러운 곡선으로 나타냅니다(그림 Figure 9.3). 이 곡선을 그리는 가장 대표적인 방법은 커널 밀도 추정(Kernel Density Estimation, KDE)입니다. 각 데이터 포인트 위치에 작은 곡선(커널)을 놓고, 모든 곡선을 합산하여 전체적인 밀도를 계산하는 방식입니다. 이때 곡선의 너비를 결정하는 파라미터를 대역폭(bandwidth)이라고 하며, 가장 흔히 쓰이는 커널 모양은 종 모양의 가우시안(Gaussian) 커널입니다.
(ref:titanic-ages-dens1) 타이타닉호 승객 연령 분포의 커널 밀도 추정치. 곡선의 높이는 곡선 아래 면적이 1이 되도록 조정됩니다. 밀도 추정은 가우시안 커널과 대역폭 2를 사용하여 수행되었습니다.
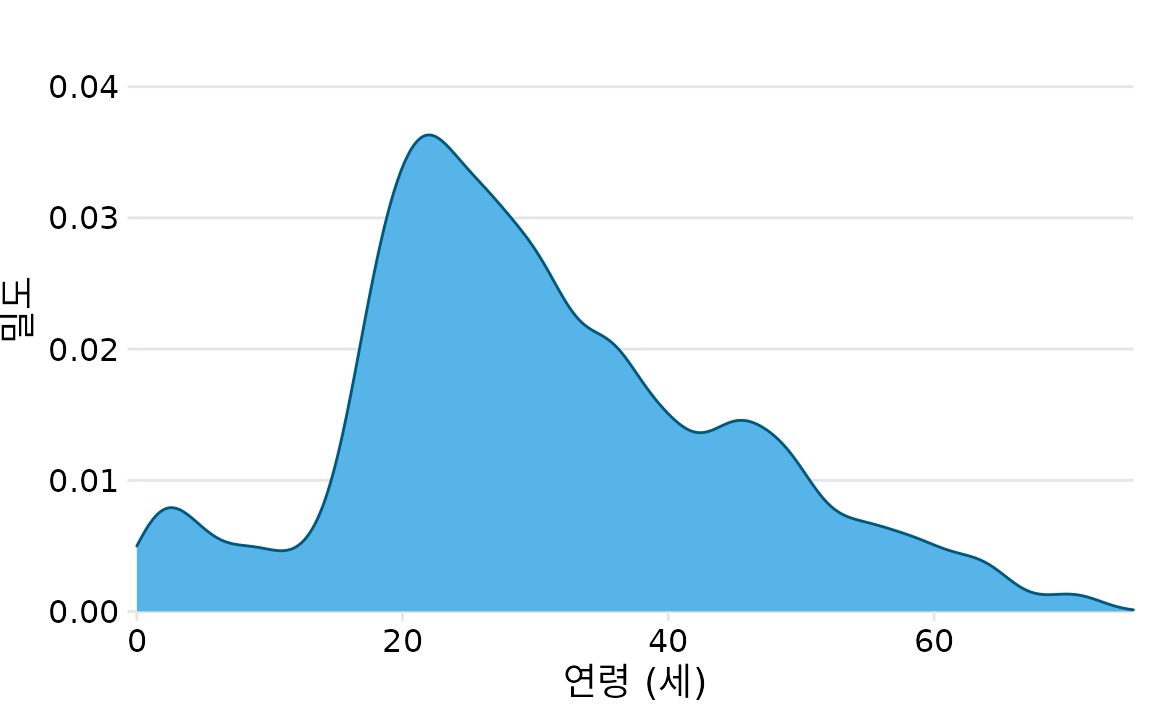
히스토그램의 구간 너비처럼, 밀도 그림에서도 대역폭과 커널의 선택이 결과물의 모양을 결정합니다(그림 Figure 9.4). 대역폭이 너무 좁으면 곡선이 너무 들쭉날쭉해져서 큰 흐름을 보기 어렵고, 너무 넓으면 중요한 세부 정보가 사라집니다. 커널의 종류도 영향을 주는데, 가우시안 커널은 매끄러운 곡선을 만드는 반면 직사각형(rectangular) 커널은 계단 모양의 각진 선을 만듭니다(그림 Figure 9.4 (d)). 데이터가 많을수록 커널의 종류는 크게 중요하지 않게 됩니다. 밀도 그림은 데이터가 많을 때는 매우 신뢰할 만한 도구이지만, 데이터 포인트가 몇 개 없을 때는 오히려 데이터의 실제 모습을 왜곡할 위험이 있습니다.
(ref:titanic-ages-dens-grid) 커널 밀도 추정치는 선택한 커널과 대역폭에 따라 달라집니다. 여기서 동일한 타이타닉호 승객 연령 분포가 이러한 매개변수의 네 가지 다른 조합에 대해 표시됩니다. (a) 가우시안 커널, 대역폭 = 0.5; (b) 가우시안 커널, 대역폭 = 2; (c) 가우시안 커널, 대역폭 = 5; (d) 직사각형 커널, 대역폭 = 2.
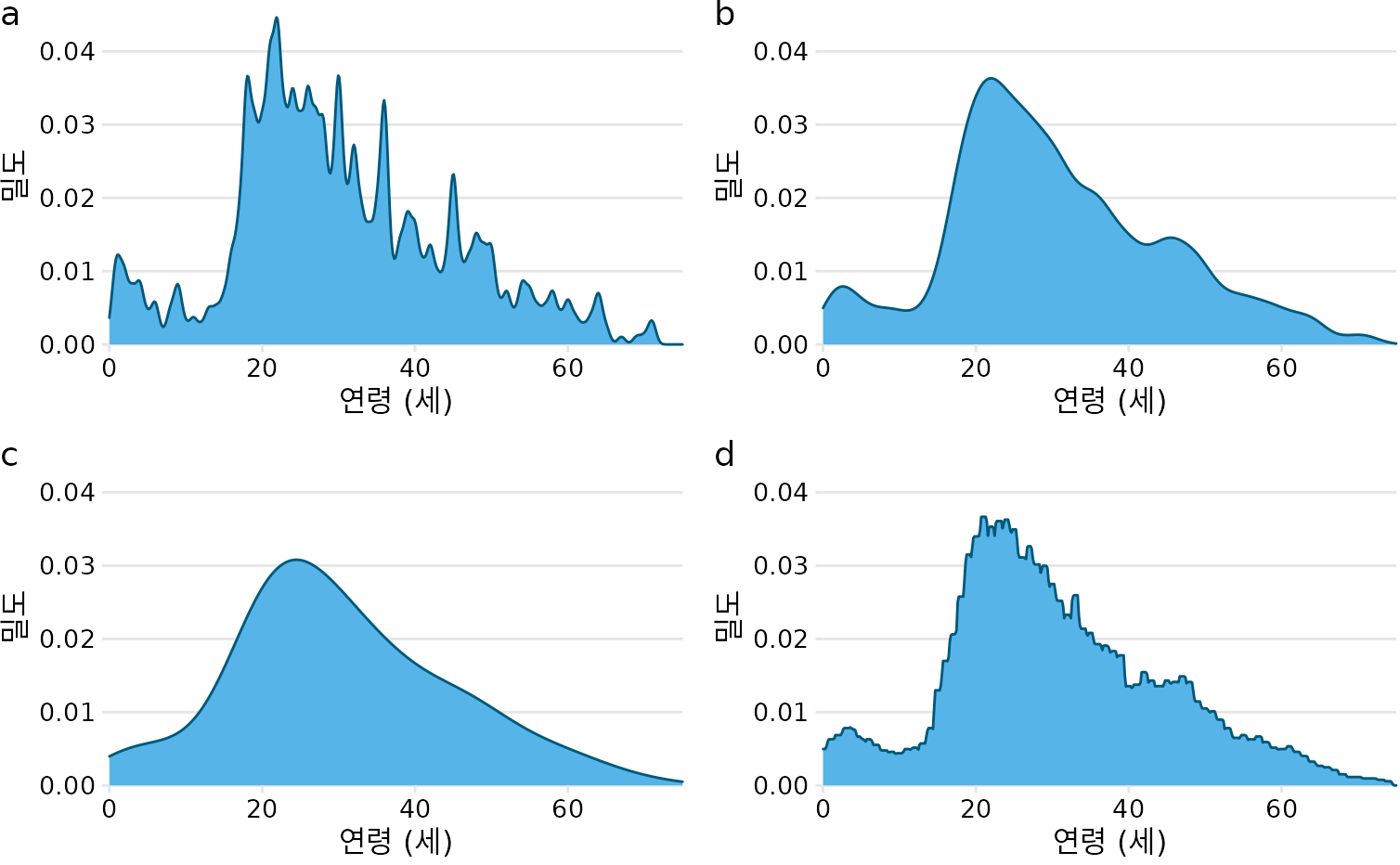
밀도 곡선은 대개 곡선 아래의 전체 면적이 1이 되도록 그려집니다. 이 때문에 y축의 수치가 다소 생소하게 느껴질 수 있습니다. 예를 들어 연령이 0세에서 75세까지라면 평균 높이는 약 0.013(1/75) 정도가 됩니다. 그림 ?fig-titanic-ages-dens-grid를 보면 y축 값이 0에서 0.04 사이에 분포하며 평균적으로 0.01 근처임을 확인할 수 있습니다.
커널 밀도 추정을 사용할 때 주의할 점이 하나 있습니다. 데이터가 전혀 없는 영역임에도 불구하고, 분포의 꼬리 부분이 늘어나면서 마치 데이터가 존재하는 것처럼 보일 수 있다는 것입니다. 자칫하면 현실적으로 불가능한 결과물을 낼 수 있는데, 예를 들어 아무 조치를 취하지 않으면 ‘음수(-)’ 연령대의 승객이 있는 것처럼 그려질 수 있습니다(그림 Figure 9.5).
(ref:titanic-ages-dens-negative) 커널 밀도 추정은 분포의 꼬리를 데이터가 없고 데이터가 존재할 가능성조차 없는 영역으로 확장할 수 있습니다. 여기서 밀도 추정은 음의 연령 범위로 확장되도록 허용되었습니다. 이것은 분명히 무의미하며 피해야 합니다.
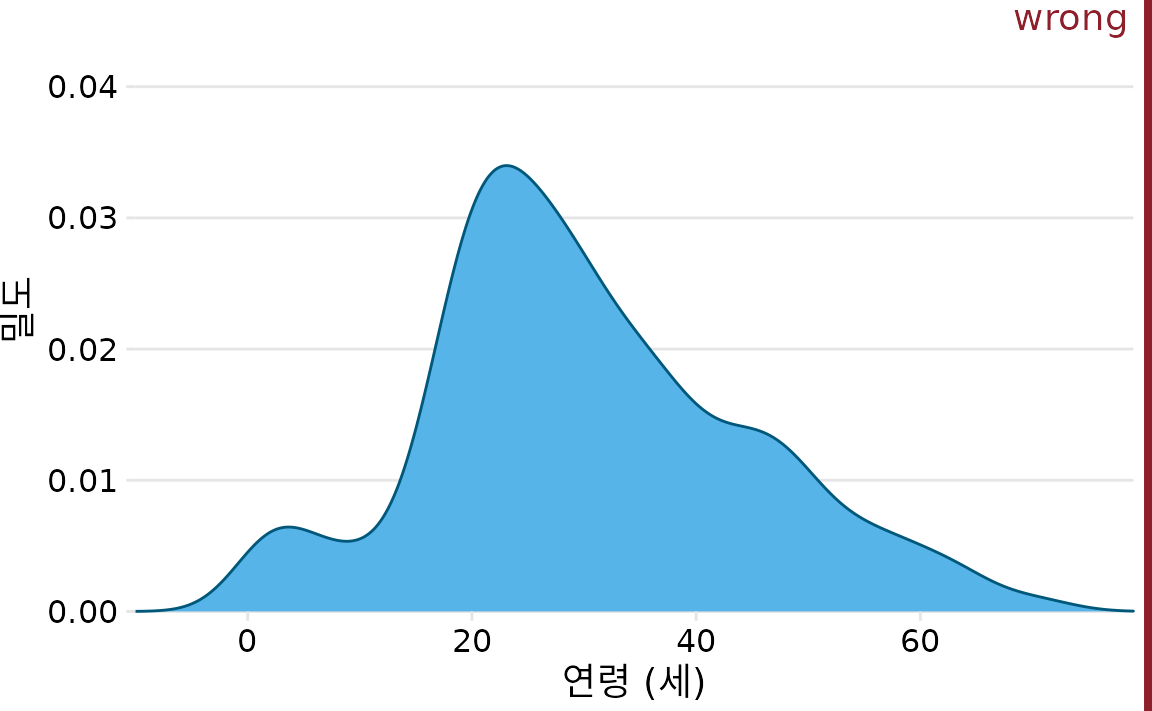
밀도 추정치가 무의미한 데이터 값의 존재를 예측하지 않는지 항상 확인하십시오.
그렇다면 분포를 시각화할 때 히스토그램과 밀도 그림 중 무엇을 써야 할까요? 이 주제는 전문가들 사이에서도 의견이 분분합니다. 밀도 그림이 임의적이고 왜곡의 여지가 있다며 싫어하는 사람도 있고, 히스토그램 역시 구간 설정에 따라 얼마든지 오해를 불러일으킬 수 있다고 지적하는 사람도 있습니다. 제 생각에 이는 결국 취향과 목적의 문제입니다. 때로는 데이터의 특정 성질을 보여주기에 더 적합한 방식이 있을 수 있죠. 누적 분포 함수나 Q-Q 플롯(Chapter 분포 시각화: 경험적 누적 분포 함수 및 q-q 그림) 같은 대안도 존재합니다. 다만, 여러 개의 분포를 한 번에 비교할 때는 밀도 그림이 히스토그램보다 확실한 강점이 있습니다.
여러 분포를 동시에 시각화하기
하나의 그래프에 여러 분포를 동시에 보여줘야 할 때가 많습니다. 예를 들어 타이타닉 승객의 연령 분포가 남성과 여성 사이에 어떤 차이가 있는지 알고 싶다고 해봅시다. 흔히 쓰이는 방법은 남성 막대 위에 여성 막대를 쌓아 올리는 누적 히스토그램(stacked histogram)입니다(그림 Figure 9.6).
(ref:titanic-age-stacked-hist) 성별별로 계층화된 타이타닉호 승객 연령 히스토그램. 이 그림은 누적 히스토그램이 중첩 히스토그램과 쉽게 혼동될 수 있기 때문에 “나쁨”으로 표시되었습니다(그림 Figure 9.7 참조). 또한 여성 승객을 나타내는 막대의 높이를 서로 쉽게 비교할 수 없습니다.
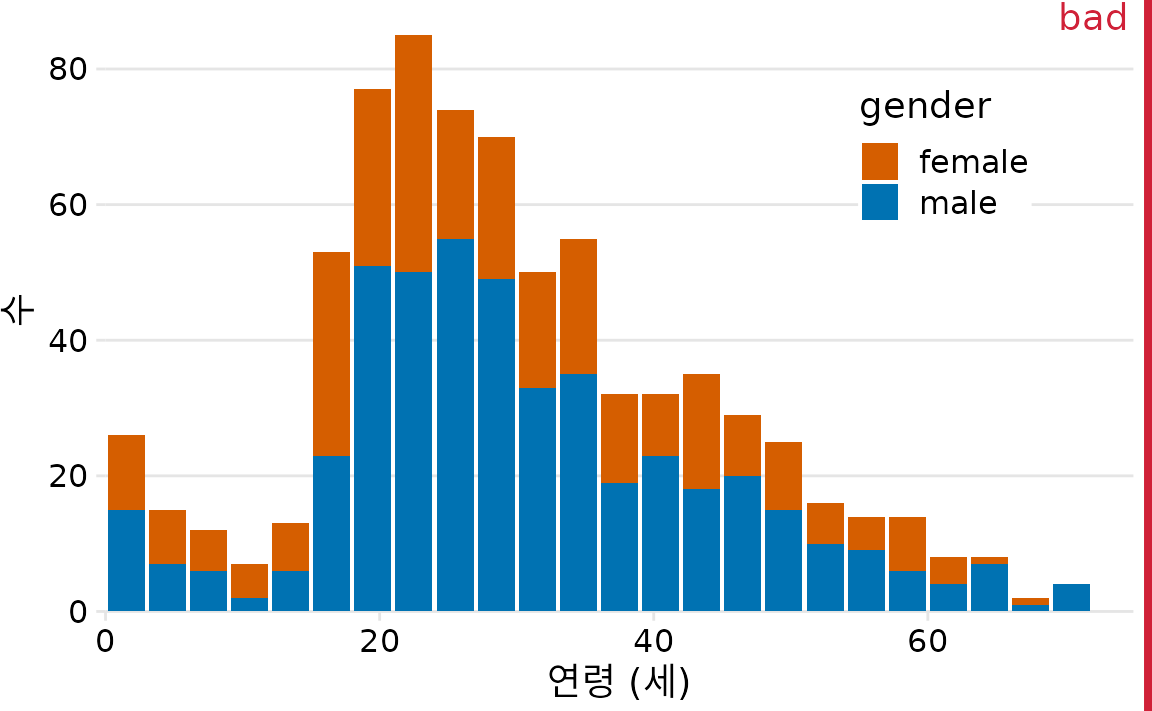
저는 이런 방식의 시각화를 권장하지 않습니다. 두 가지 치명적인 문제가 있기 때문입니다. 첫째, 막대가 정확히 어디서 시작하는지 알기 어렵습니다. 18~20세 여성 인원수가 색깔이 변하는 지점부터인지, 아니면 0부터인지 헷갈리게 됩니다(정답은 전자입니다). 둘째, 여성 승객의 인원수를 서로 비교하기가 불가능에 가깝습니다. 막대들의 시작 높이가 제각각이기 때문입니다. 예를 들어 남성이 여성보다 평균 연령이 높다는 사실이 이 그래프에서는 전혀 드러나지 않습니다.
대안으로 모든 막대를 0에서 시작하게 하고 투명도를 조절해 겹쳐 그리는 방식(overlapping histogram)을 생각해볼 수 있습니다(그림 Figure 9.7).
(ref:titanic-age-overlapping-hist) 남성 및 여성 타이타닉호 승객의 연령 분포, 두 개의 중첩된 히스토그램으로 표시. 이 그림은 모든 파란색 막대가 0에서 시작한다는 명확한 시각적 표시가 없기 때문에 “나쁨”으로 표시되었습니다.
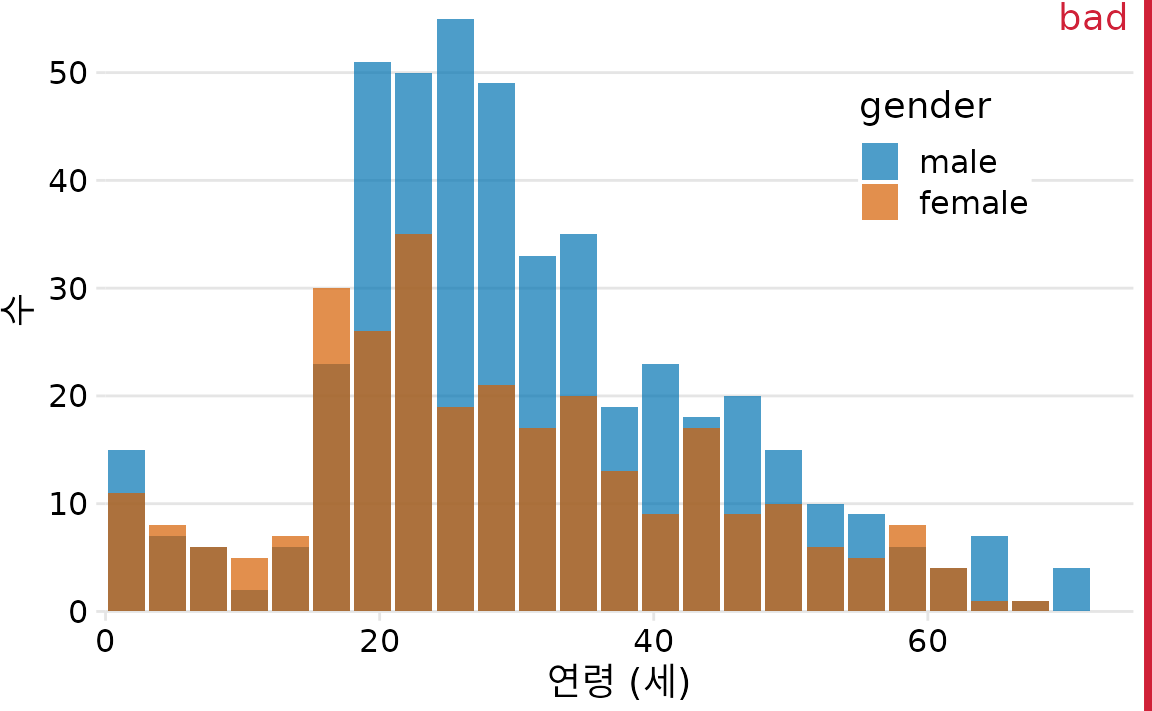
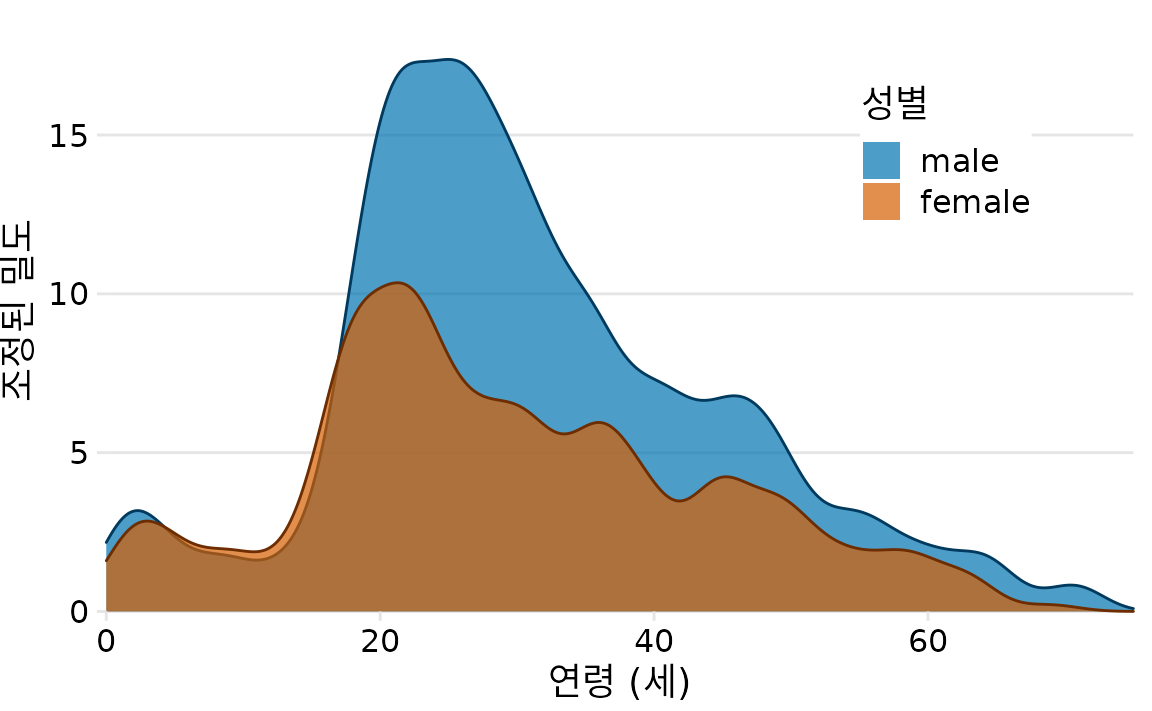
반면 중첩 밀도 그림(overlapping density plot)은 연속적인 선 덕분에 분포를 구분하기가 훨씬 수월합니다. 다만, 이 데이터처럼 두 분포가 겹치는 구간이 많을 때는 여전히 조금 지저분해 보일 수 있습니다(그림 Figure 9.8).
(ref:titanic-age-overlapping-dens) 남성 및 여성 타이타닉호 승객 연령의 밀도 추정치. 남성 승객이 여성 승객보다 많았음을 강조하기 위해 각 곡선 아래 면적이 알려진 연령의 남성 및 여성 승객 총 수(각각 468명 및 288명)에 해당하도록 밀도 곡선의 크기를 조정했습니다.
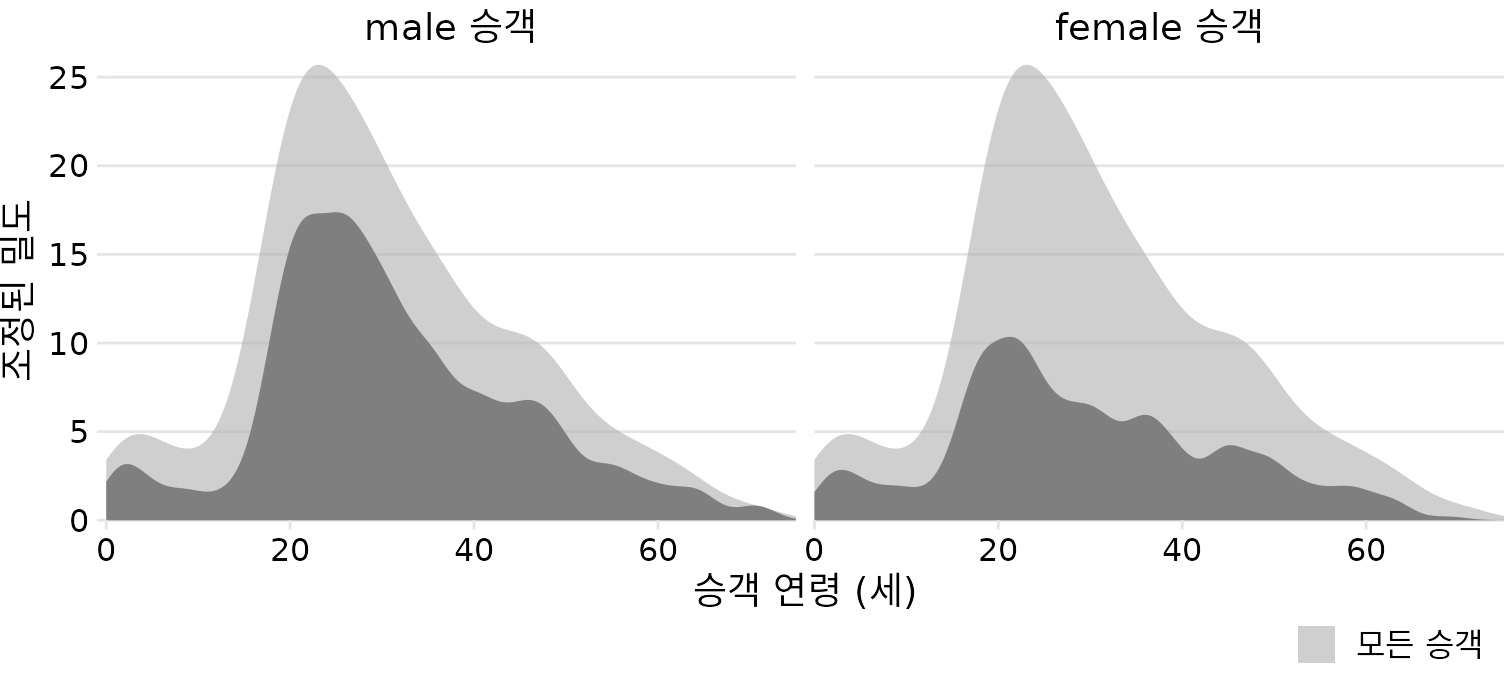
이런 경우 가장 좋은 해결책은 남녀 분포를 따로 떼어내어 전체 분포에 대한 비율로 보여주는 것입니다(그림 Figure 9.9). 이 시각화를 통하면 20~50세 구간에서 여성이 남성보다 확연히 적었다는 사실을 직관적으로 이해할 수 있습니다.
(ref:titanic-age-fractional-dens) 남성 및 여성 타이타닉호 승객의 연령 분포, 승객 총계의 비율로 표시. 색칠된 영역은 각각 남성 및 여성 승객 연령의 밀도 추정치를 나타내고 회색 영역은 전체 승객 연령 분포를 나타냅니다.
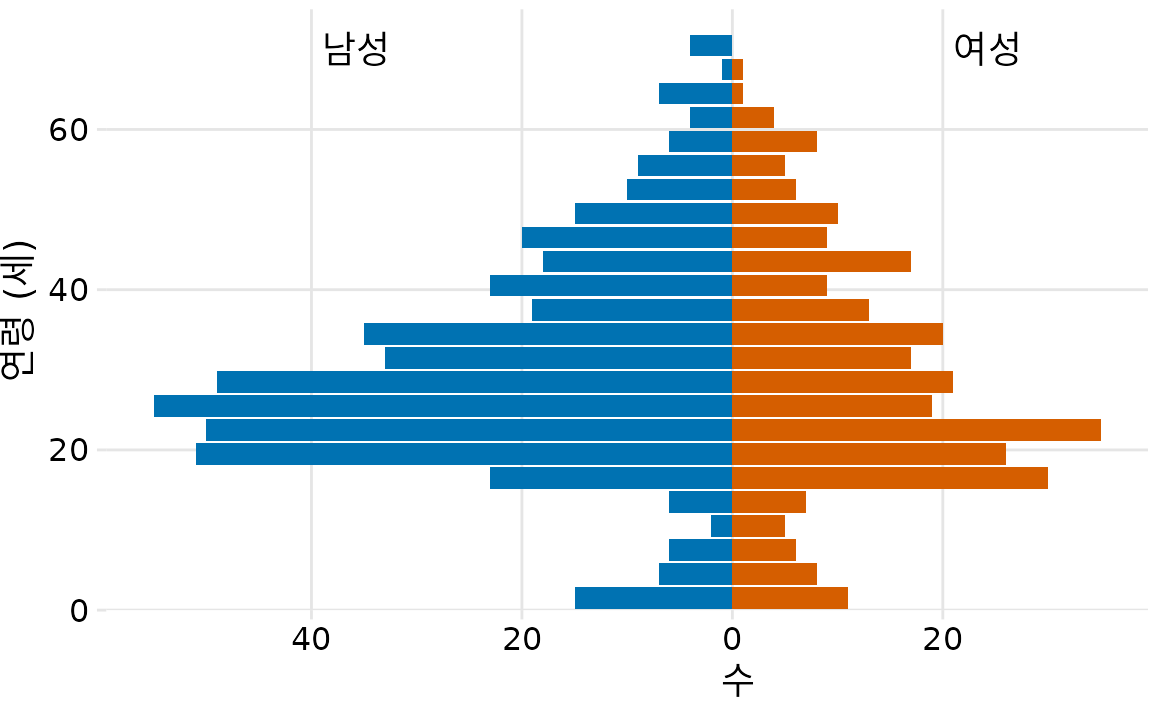
마지막으로 딱 두 개의 분포만 비교할 때는 히스토그램을 90도 회전시켜 서로 반대 방향을 보게 만드는 연령 피라미드(age pyramid) 형식이 매우 유용합니다(그림 Figure 9.10).
(ref:titanic-age-pyramid) 연령 피라미드로 시각화된 남성 및 여성 타이타닉호 승객의 연령 분포.
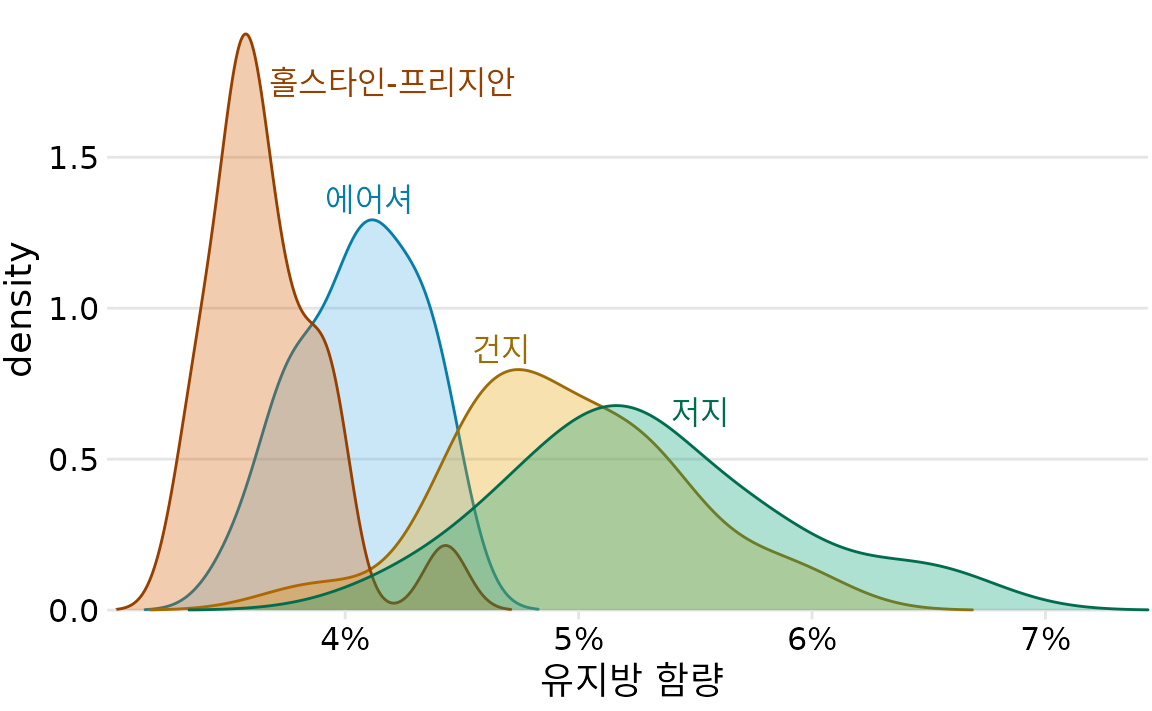
다만 이 방식은 비교 대상이 셋 이상이 되면 사용할 수 없습니다. 분포가 많을 때는 히스토그램보다는 밀도 그림이 훨씬 효과적입니다. 예를 들어 네 종류의 소 품종별 우유 유지방 비율을 비교할 때는 밀도 그림이 가장 적합한 선택입니다(그림 Figure 9.11).
(ref:butterfat-densitites) 네 가지 소 품종 우유의 유지방 비율 밀도 추정치. 데이터 출처: 캐나다 순종 젖소 생산 능력 기록
한 번에 여러 분포를 시각화하려면 히스토그램보다 커널 밀도 그림이 일반적으로 더 잘 작동합니다.