분포 시각화: 경험적 누적 분포 함수 및 q-q 그림
분포 시각화: 히스토그램 및 밀도 그림 장에서는 히스토그램이나 밀도 그림으로 분포를 시각화하는 방법을 살펴보았습니다. 이 방식들은 매우 직관적이고 시각적으로도 아름답습니다. 하지만 앞서 논의했듯이, 두 방식 모두 사용자가 설정하는 파라미터(히스토그램의 구간 너비, 밀도 그림의 대역폭)에 따라 그래프의 모양이 크게 달라진다는 한계가 있습니다. 따라서 이들은 데이터 자체를 있는 그대로 보여주는 시각화라기보다, 데이터에 대한 하나의 ’해석’으로 보는 것이 더 적절합니다.
히스토그램이나 밀도 그림 대신 모든 데이터 포인트를 점으로 일일이 찍어 보여줄 수도 있습니다. 하지만 데이터 세트가 커지면 이 방식은 한계가 명확하며, 개별 포인트보다는 전체적인 분포 특성을 한눈에 보여주는 집계 방식이 필요하게 됩니다. 이를 위해 통계학자들은 경험적 누적 분포 함수(Empirical Cumulative Distribution Function, ECDF)와 분위수-분위수(Quantile-Quantile, Q-Q) 그림을 고안했습니다. 이 시각화 방식들은 사용자의 주관적인 파라미터 설정이 필요 없으며, 모든 데이터를 빠짐없이 보여준다는 장점이 있습니다. 다만 히스토그램이나 밀도 그림에 비해 직관적으로 이해하기가 조금 어렵고, 전문적인 연구 기여물 외에는 자주 쓰이지 않는 편입니다. 그럼에도 불구하고 데이터 시각화의 깊이를 더하고 싶은 이들이라면 꼭 익혀두어야 할 훌륭한 기법입니다.
ECDF를 설명하기 위해, 제가 대학에서 학생들을 가르칠 때 자주 접하는 가상의 예시인 ‘학생 시험 성적’ 데이터를 활용해 보겠습니다. 50명의 학생이 0점에서 100점 사이의 점수를 받을 수 있는 시험을 쳤다고 가정해 봅시다. 학점 기준을 정하기 위해 이 성적 분포를 가장 효과적으로 보여주는 방법은 무엇일까요?
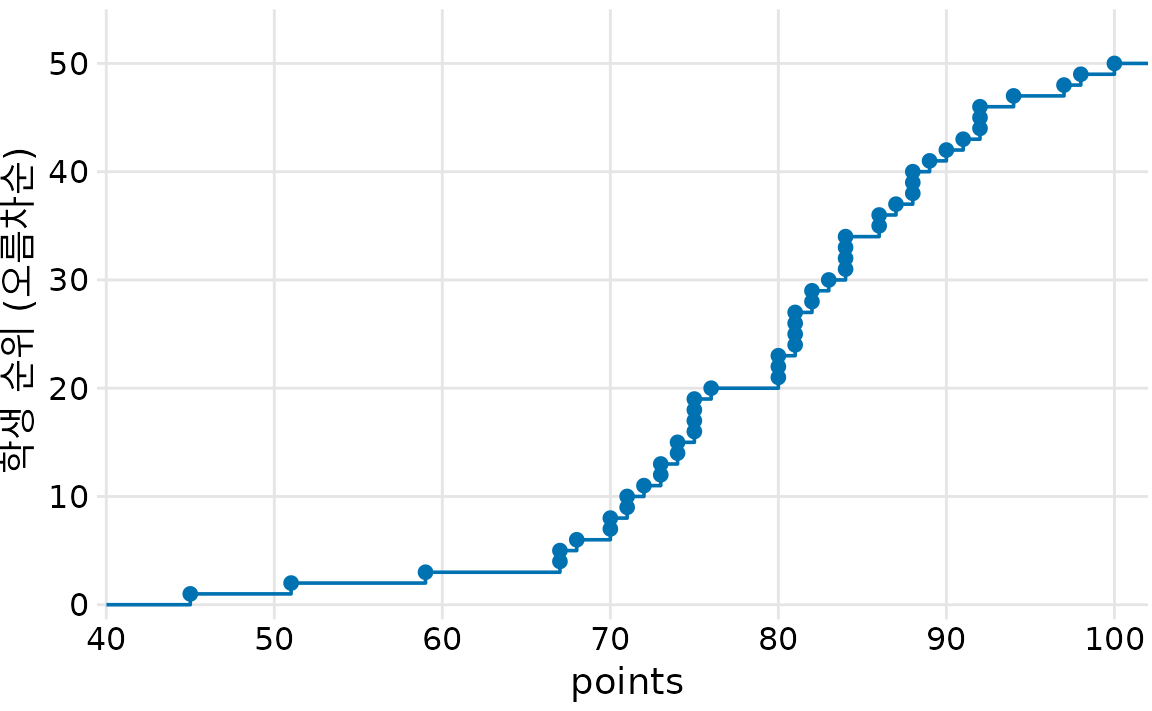
가장 낮은 점수부터 한 명씩 학생들의 순위를 매겨본다고 합시다. 특정 점수 이하를 받은 학생의 총 인원수를 해당 점수와 짝지어 그래프로 그리면, 0점에서 시작해 100점에서 인원수 50명으로 끝나는 오름차순 그래프가 됩니다. 이것이 바로 경험적 누적 분포 함수(ECDF) 혹은 간단히 누적 분포입니다. 그래프의 각 점은 한 명의 학생을 나타내며, 선은 각 점수대별로 해당 점수 이하를 받은 학생들의 최대 순위를 연결한 것입니다(그림 Figure 10.1).
(ref:student-grades) 50명의 가상 수업 학생 성적의 경험적 누적 분포 함수.
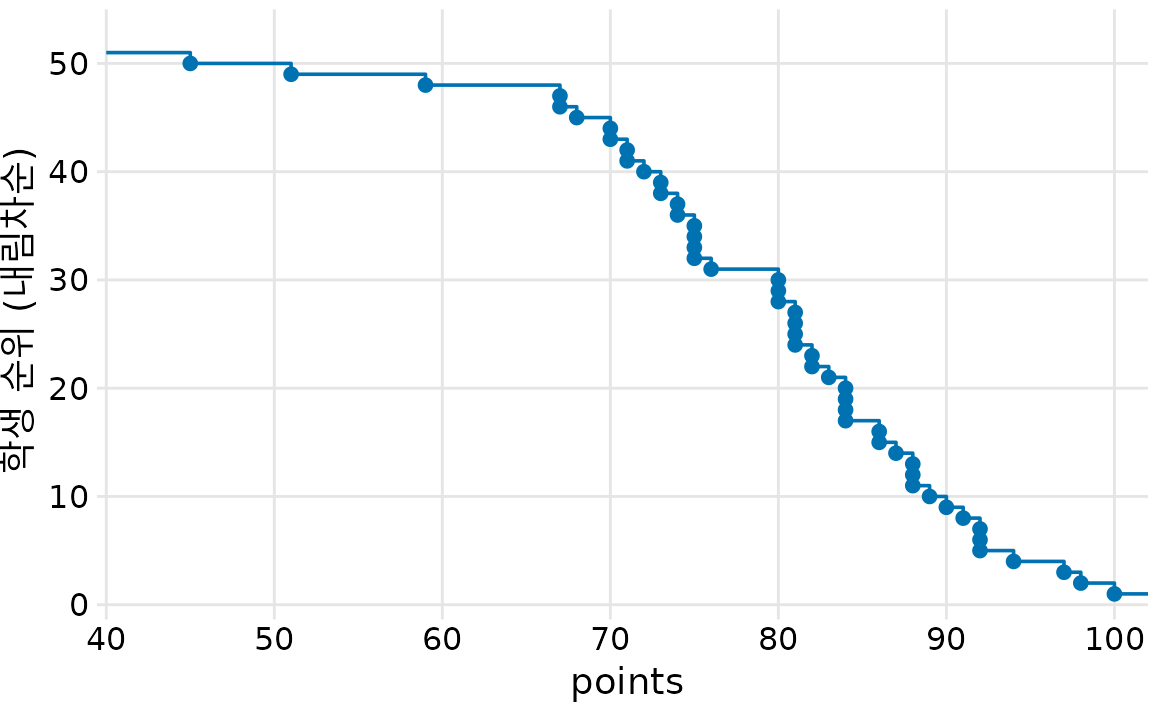
반대로 학생들의 점수를 높은 순(내림차순)으로 나열하면 어떨까요? 이 경우 그래프의 모양은 이전과 대칭을 이루게 됩니다. 이 역시 ECDF의 한 형태이며, 선은 특정 점수 이상을 받은 학생들의 최소 순위를 나타내게 됩니다(그림 Figure 10.2).
(ref:student-grades-desc) 내림차순 ecdf로 표시된 학생 성적 분포.
일반적으로는 오름차순 누적 분포 함수가 훨씬 더 많이 쓰이지만, 내림차순 함수도 중요한 용도가 있습니다. 특히 데이터의 분포가 한쪽으로 심하게 치우쳐 있을 때 유용하게 사용됩니다(매우 치우친 분포 절 참조).
실제 사용 시에는 개별 데이터 포인트를 일일이 표시하기보다는, y축을 전체 인원수로 나누어 ’누적 빈도(0%~100%)’로 정규화한 부드러운 선으로 그리는 것이 일반적입니다(그림 Figure 10.3).
(ref:student-grades-normalized) 학생 성적의 Ecdf. 학생 순위는 총 학생 수로 정규화되어 플로팅된 y 값이 해당 점수 이하를 받은 학급 학생의 비율에 해당합니다.
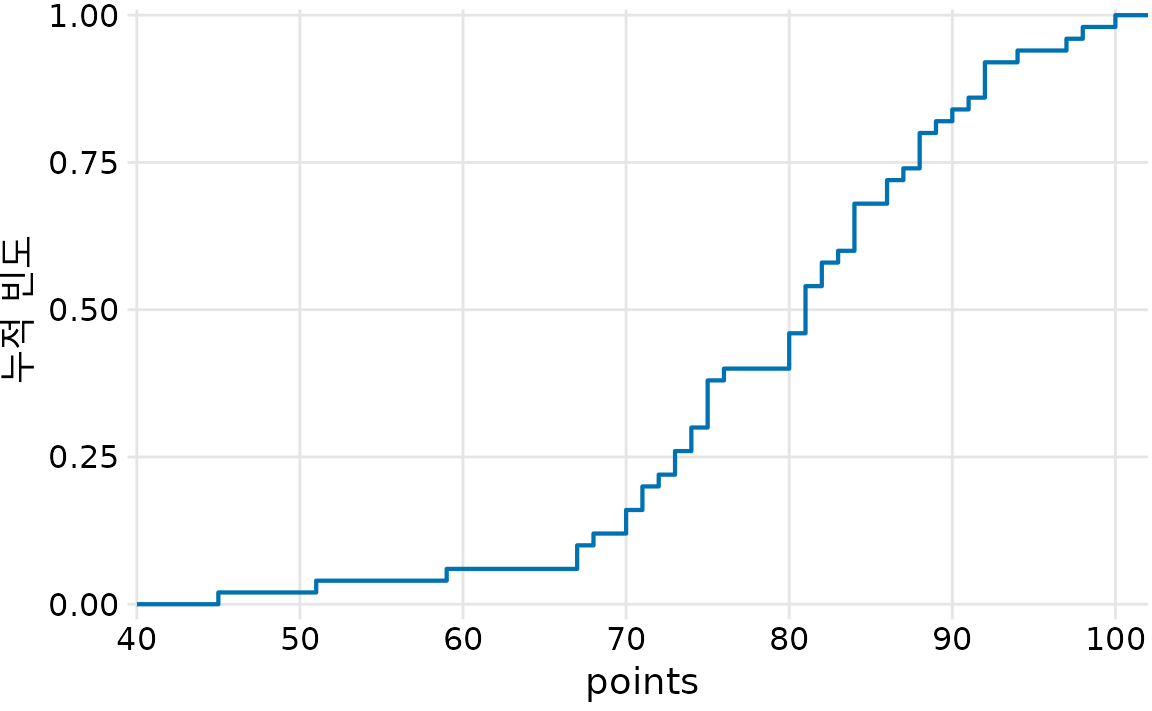
이 그래프에서는 성적 분포의 핵심 정보를 바로 읽어낼 수 있습니다. 예를 들어 하위 25%의 점수는 75점 미만이며, 중간값(누적 빈도 0.5)은 81점임을 알 수 있습니다. 또한 상위 20%는 90점 이상을 받았다는 사실도 명확히 드러납니다.
저는 ECDF가 학생들의 불만을 최소화하는 학점 경계선을 찾는 데 매우 유용하다고 생각합니다. 예를 들어 이 예시의 80점 근처를 보면 수평선이 길게 이어지다가 80점에서 가파르게 솟아오릅니다. 이는 80점을 받은 학생은 3명이나 되는데, 그 바로 아래 점수인 79점이나 78점을 받은 학생은 없고 76점까지 내려가야 다음 학생이 있다는 뜻입니다. 이럴 때 B학점의 기준을 80점으로 잡으면, 80점을 받은 학생 3명은 간신히 B를 받아 만족할 것이고 76점을 받은 학생은 점수 차이가 크므로 이의를 제기하기 힘듭니다. 만약 기준을 81점으로 잡았다면 80점을 받은 학생 3명이 모두 제 연구실을 찾아와 점수 조정을 해달라고 부탁했겠죠.
매우 치우친 분포
많은 실제 데이터 세트는 오른쪽으로 아주 길게 꼬리가 늘어진, 심하게 치우친(skewed) 분포를 보입니다. 도시별 인구수, SNS 친구 수, 책에 등장하는 단어 빈도, 학술 논문 피인용 횟수, 개인 순자산 등이 대표적인 사례입니다(Clauset, Shalizi, and Newman 2009). 이런 데이터들은 평균값은 작더라도 아주 드물게 엄청나게 큰 값이 존재하는 특징이 있습니다. 특히 멱법칙(power-law) 분포를 따르는 경우가 많은데, 예를 들어 순자산이 100만 달러인 사람보다 50만 달러인 사람이 4배 더 많고, 200만 달러인 사람은 1/4 수준으로 줄어드는 식입니다. 이 관계는 기준액이 1만 달러든 1억 달러든 동일하게 유지되곤 합니다. 그래서 이를 ‘규모에 상관없는’ 혹은 규모 없는(scale-free) 분포라고도 부릅니다.
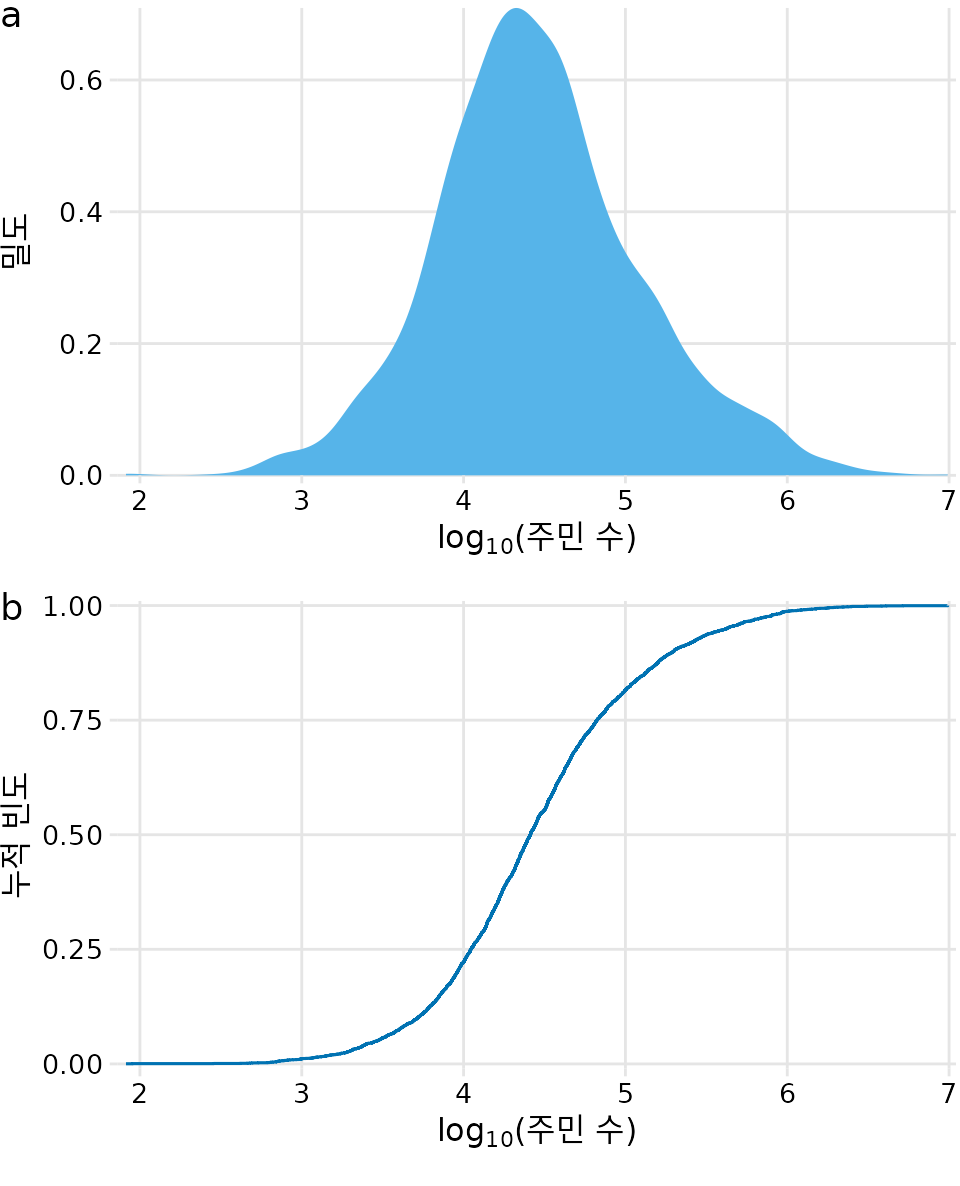
2010년 미국 인구 조사 데이터를 바탕으로 각 카운티(County)별 거주자 수를 살펴보겠습니다. 인구 분포가 매우 불균형한데, 대부분의 카운티는 주민 수가 적지만(중앙값 약 2만 5천 명), 로스앤젤레스 카운티처럼 인구가 1,000만 명에 육박하는 곳도 있습니다. 이런 데이터를 일반적인 밀도 그림이나 ECDF 그대로 그리면, 데이터의 특징을 전혀 읽어낼 수 없는 쓸모없는 그래프가 됩니다(그림 Figure 10.4).
(ref:county-populations) 2010년 미국 인구 조사에 따른 미국 카운티의 주민 수 분포. (a) 밀도 그림. (b) 경험적 누적 분포 함수.
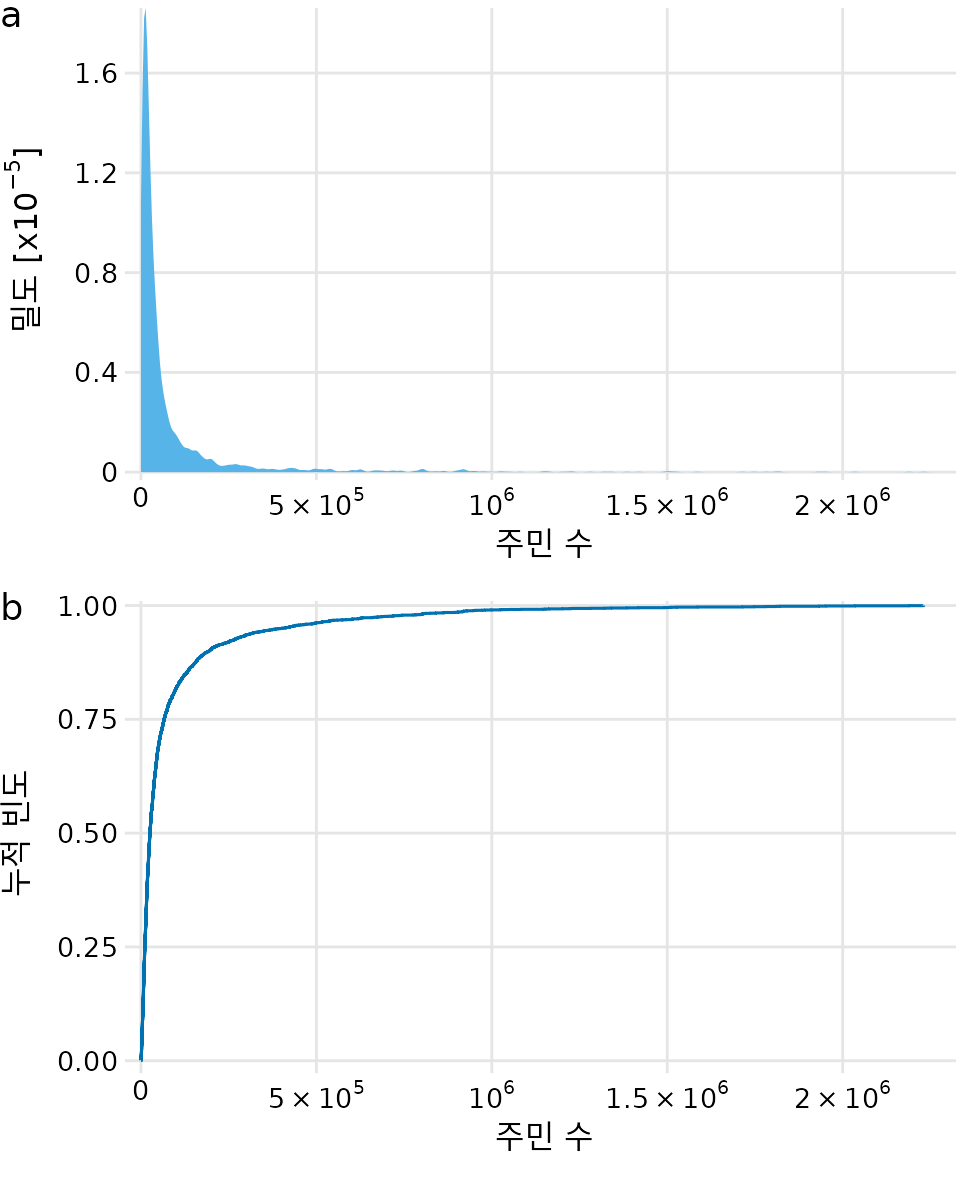
밀도 그림(그림 Figure 10.4 (a))은 0 근처에서만 뾰족하게 솟아올라 나머지 부분의 변화를 볼 수 없고, ECDF(그림 Figure 10.4 (b)) 역시 0 근처에서 급격히 직선으로 올라가 버립니다. 이럴 때는 데이터를 로그 변환(log transformation)한 뒤 시각화하는 것이 좋은 방법입니다. 실제로 카운티 인구 분포는 완벽에 가까운 로그 정규(log-normal) 분포를 따릅니다. 로그를 취해 그린 밀도 그림은 아름다운 종 모양을, ECDF는 매끄러운 S자 모양을 보여줍니다(그림 Figure 10.5).
(ref:county-populations-log) 미국 카운티 주민 수의 로그 분포. (a) 밀도 그림. (b) 경험적 누적 분포 함수.
마지막으로 이 분포가 진정한 멱법칙을 따르는지 확인하려면 x축과 y축 모두에 로그를 적용한 내림차순 ECDF를 그려보면 됩니다. 이 그래프에서 멱법칙은 직선으로 나타나는데, 카운티 인구의 경우 오른쪽 끝부분이 거의 직선에 가깝긴 하지만 완벽하지는 않음을 알 수 있습니다(그림 Figure 10.6).
(ref:county-populations-tail-log-log) 해당 주민 수 이상의 카운티 상대 빈도 대 카운티 주민 수.
진정한 멱법칙의 사례로 소설 ’모비 딕’에 등장하는 단어들의 빈도 분포를 보겠습니다. x, y축 모두 로그를 취해 내림차순 ECDF로 그리면 경이로울 정도로 매끈한 직선을 확인할 수 있습니다(그림 Figure 10.7).
(ref:word-counts-tail-log-log) 소설 모비 딕의 단어 수 분포. 소설에서 해당 횟수 이상으로 나오는 단어의 상대 빈도 대 단어가 사용된 횟수가 표시됩니다.
분위수-분위수 그림
분위수-분위수(Q-Q) 그림은 실제 데이터가 특정 이론적 분포(대개 정규 분포)를 잘 따르고 있는지 확인하고 싶을 때 매우 유용한 도구입니다. ECDF와 마찬가지로 데이터를 순위순으로 나열하는 것이 기본이지만, 축의 기준이 다릅니다. Q-Q 그림은 데이터의 각 순위별 이론적인 예상값이 어디여야 하는지를 계산하여 이를 실제 관찰값과 직접 비교합니다. 예를 들어 평균이 10이고 표준편차가 3인 정규 분포라면, 상위 50%는 10에 있어야 하고, 84%는 13에, 하위 2.3%는 4에 있어야 합니다. 이런 식으로 모든 데이터 포인트를 ’이론적 값’과 ’실제 관찰값’으로 대응시켜 산점도를 그립니다.
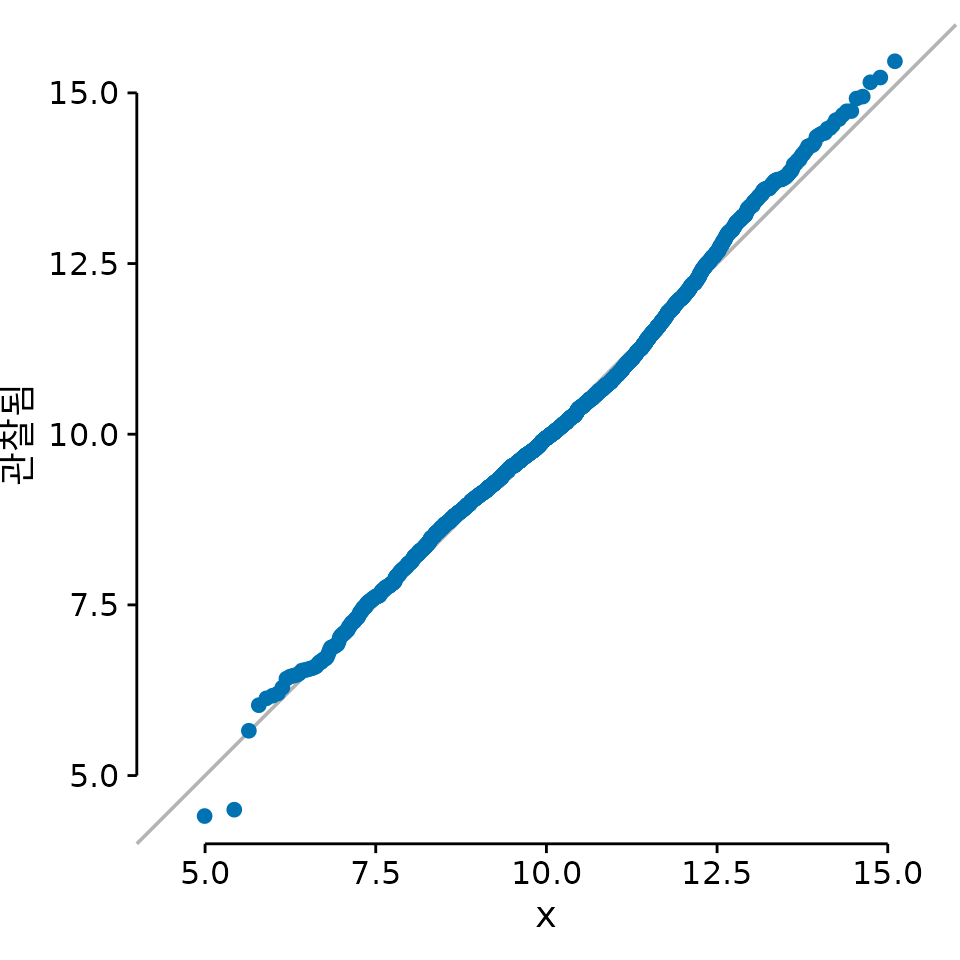
이 장의 시작 부분에 있는 학생 성적 분포에 대해 이 절차를 수행하면 그림 ?fig-student-grades-qq를 얻을 수 있습니다.
(ref:student-grades-qq) 학생 성적의 q-q 그림.
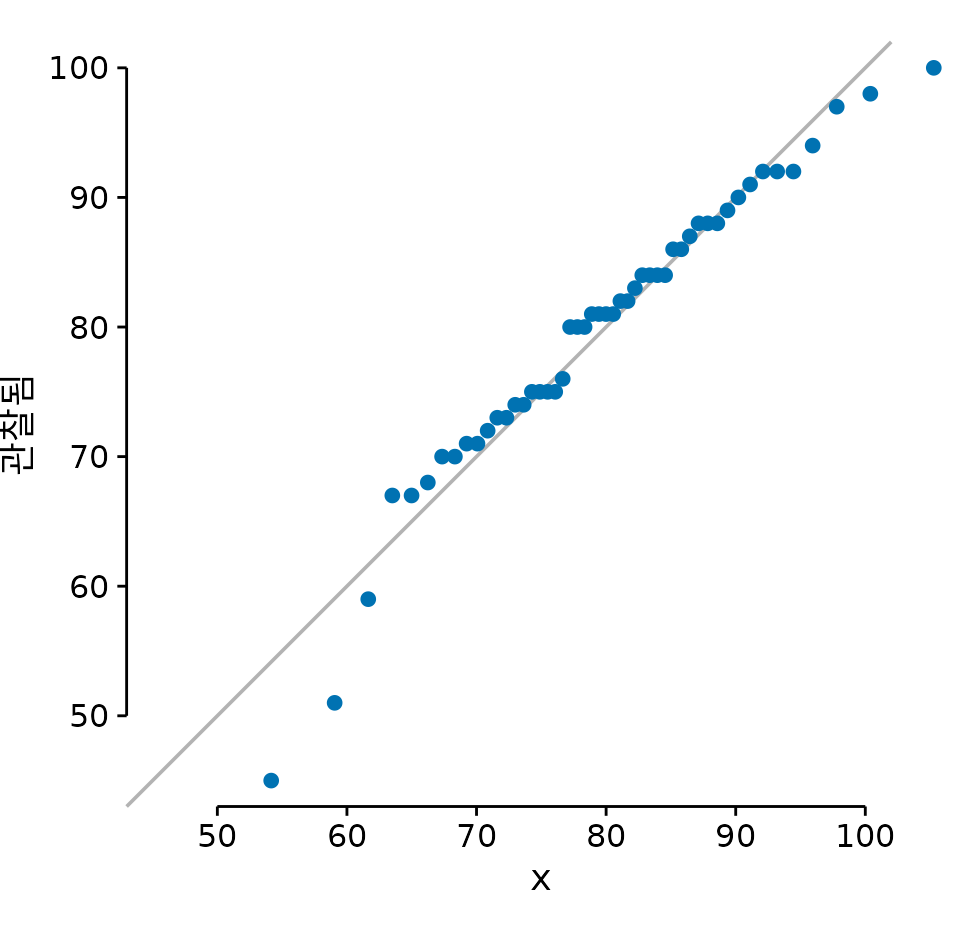
여기서 대각선 실선은 회귀선이 아니라 ’관찰값 = 이론값’인 x=y 선입니다. 점들이 이 선 위에 가지런히 놓여 있다면 데이터가 해당 분포(여기서는 정규 분포)를 잘 따르고 있다는 강력한 증거가 됩니다. 그림 ?fig-student-grades-qq를 보면 학생 성적은 정규 분포를 대체로 잘 따르지만, 양쪽 끝부분에서 약간의 이탈이 보입니다. 특히 상위권에서 점수가 선 아래로 처지는 이유는 시험 만점이 100점으로 정해져 있기 때문입니다. 아무리 뛰어난 학생이라도 100점이라는 한계선에 부딪히게 되는 것이죠.
또한 Q-Q 그림은 앞서 설명한 미국 카운티 인구 분포가 로그 정규 분포를 따른다는 가설을 검증하는 데도 쓰입니다. 로그 변환된 값들이 정규 분포를 따른다면 Q-Q 그림의 점들은 x=y 선 위에 정확히 일치해야 합니다. 그림 ?fig-county-populations-qq를 보면 점들과 선이 거의 완벽하게 일치함을 알 수 있는데, 이는 카운티 간 인구 분포가 실제로 전형적인 로그 정규 분포임을 말해줍니다.
(ref:county-populations-qq) 미국 카운티 주민 수의 로그에 대한 q-q 그림.
Clauset, A., C. R. Shalizi, and M. E. J. Newman. 2009. “Power-Law Distributions in Empirical Data.” SIAM Review 51: 661–703.