이야기 전달과 요점 제시
대부분의 데이터 시각화는 커뮤니케이션을 목적으로 수행됩니다. 데이터 세트에 대한 통찰력이 있고 잠재적인 청중이 있으며 청중에게 통찰력을 전달하고 싶습니다. 통찰력을 성공적으로 전달하려면 청중에게 명확하고 흥미로운 이야기를 제시해야 합니다. 이야기에 대한 필요성은 과학자와 엔지니어에게는 충격적으로 보일 수 있으며, 그들은 이를 꾸며내거나, 왜곡하거나, 결과를 과장하는 것과 동일시할 수 있습니다. 그러나 이러한 관점은 추론과 기억에서 이야기가 하는 중요한 역할을 간과합니다. 우리는 좋은 이야기를 들으면 흥분하고 이야기가 나쁘거나 없을 때는 지루해합니다. 더욱이 모든 커뮤니케이션은 청중의 마음에 이야기를 만듭니다. 우리가 명확한 이야기를 직접 제공하지 않으면 청중이 이야기를 만들어낼 것입니다. 최상의 시나리오에서는 그들이 만들어낸 이야기가 제시된 자료에 대한 우리 자신의 견해와 상당히 가깝습니다. 그러나 훨씬 더 나쁠 수도 있고 종종 그렇습니다. 만들어낸 이야기는 “이것은 지루하다”, “저자가 틀렸다”, 또는 “저자는 무능하다”일 수 있습니다.
이야기를 전달하는 목표는 사실과 논리적 추론을 사용하여 청중의 흥미를 유발하고 흥분시키는 것이어야 합니다. 이론 물리학자 스티븐 호킹에 대한 이야기를 들려드리겠습니다. 그는 21세에 운동 뉴런 질환 진단을 받았고(박사 과정 1년차) 2년밖에 살지 못할 것이라는 진단을 받았습니다. 호킹은 이러한 곤경을 받아들이지 않고 과학에 모든 에너지를 쏟기 시작했습니다. 호킹은 결국 76세까지 살았고 당대 가장 영향력 있는 물리학자 중 한 명이 되었으며 심각한 장애를 앓으면서도 모든 중요한 연구를 수행했습니다. 저는 이것이 설득력 있는 이야기라고 주장합니다. 또한 전적으로 사실에 기반한 사실입니다.
이야기란 무엇인가?
시각화를 이야기로 전환하는 전략을 논의하기 전에 이야기가 실제로 무엇인지 이해해야 합니다. 이야기는 사실이든 허구이든 특정 순서로 제시되어 청중에게 감정적인 반응을 불러일으키는 관찰, 사실 또는 사건의 집합입니다. 감정적인 반응은 이야기 시작 부분의 긴장감 고조와 이야기 끝부분의 어떤 유형의 해결을 통해 만들어집니다. 긴장에서 해결로의 흐름을 스토리 아크라고도 하며 모든 좋은 이야기에는 명확하고 식별 가능한 아크가 있습니다.
숙련된 작가들은 인간의 사고 방식과 공명하는 표준적인 스토리텔링 패턴이 있다는 것을 알고 있습니다. 예를 들어 시작-도전-행동-해결 형식으로 이야기를 전달할 수 있습니다. 사실 이것은 제가 이전 하위 섹션에서 호킹 이야기에 사용한 형식입니다. 저는 주제인 물리학자 스티븐 호킹을 소개하며 이야기를 시작했습니다. 다음으로 21세에 운동 뉴런 질환 진단이라는 도전을 제시했습니다. 그런 다음 그의 과학에 대한 맹렬한 헌신이라는 행동이 이어졌습니다. 마지막으로 호킹이 길고 성공적인 삶을 살았고 결국 당대 가장 영향력 있는 물리학자 중 한 명이 되었다는 해결책을 제시했습니다. 다른 이야기 형식도 일반적으로 사용됩니다. 신문 기사는 종종 리드-전개-해결 형식 또는 더 짧게는 리드-전개 형식을 따르며, 여기서 리드는 요점을 미리 제시하고 후속 자료는 자세한 내용을 제공합니다. 이 형식으로 호킹 이야기를 전달하고 싶다면 “블랙홀과 우주론에 대한 우리의 이해를 혁신한 영향력 있는 물리학자 스티븐 호킹은 의사의 예후보다 53년 더 살았고 심각한 장애를 앓으면서도 가장 영향력 있는 연구를 모두 수행했습니다.”와 같은 문장으로 시작할 수 있습니다. 이것이 리드입니다. 전개에서는 호킹의 삶, 질병, 과학에 대한 헌신에 대한 더 심층적인 설명을 이어갈 수 있습니다. 또 다른 형식은 행동-배경-전개-절정-결말이며, 시작-도전-행동-해결보다 약간 더 빠르게 이야기를 전개하지만 리드-전개만큼 빠르지는 않습니다. 이 형식에서는 “심각한 장애와 조기 사망의 가능성에 직면한 젊은 스티븐 호킹은 아직 할 수 있는 동안 자신의 흔적을 남기기로 결심하고 모든 노력을 과학에 쏟기로 결정했습니다.”와 같은 문장으로 시작할 수 있습니다. 이 형식의 목적은 청중을 끌어들이고 초기에 감정적인 연결을 만드는 것이지만 최종 해결책을 즉시 알려주지는 않습니다.
이 장의 목표는 이러한 표준적인 스토리텔링 형식을 더 자세히 설명하는 것이 아닙니다. 이 자료를 다루는 훌륭한 자료가 있습니다. 과학자와 분석가에게는 특히 Schimel (2011) 을 추천합니다. 대신 데이터 시각화를 스토리 아크에 어떻게 가져올 수 있는지 논의하고 싶습니다. 가장 중요한 것은 단일 (정적) 시각화가 전체 이야기를 거의 전달하지 못한다는 것을 깨달아야 한다는 것입니다. 시각화는 시작, 도전, 행동 또는 해결을 설명할 수 있지만 이러한 모든 이야기 부분을 한 번에 전달할 가능성은 낮습니다. 완전한 이야기를 전달하려면 일반적으로 여러 개의 시각화가 필요합니다. 예를 들어 프레젠테이션을 할 때 먼저 배경이나 동기 부여 자료를 보여준 다음 도전을 만드는 그림을 보여주고 결국 해결책을 제공하는 다른 그림을 보여줄 수 있습니다. 마찬가지로 연구 논문에서는 설득력 있는 스토리 아크를 함께 만드는 일련의 그림을 제시할 수 있습니다. 그러나 전체 스토리 아크를 단일 그림으로 압축하는 것도 가능합니다. 이러한 그림에는 도전과 해결이 동시에 포함되어야 하며 리드로 시작하는 스토리 아크와 유사합니다.
그림을 이야기에 통합하는 구체적인 예를 제공하기 위해 이제 두 개의 그림을 기반으로 이야기를 들려드리겠습니다. 첫 번째 그림은 도전을 만들고 두 번째 그림은 해결책 역할을 합니다. 제 이야기의 맥락은 생물 과학 분야의 프리프린트 성장입니다(챕터 시계열 및 시간 흐름에 따른 데이터 시각화 참조). 프리프린트는 과학자들이 공식적인 동료 검토 및 공식 출판 전에 동료들과 공유하는 초고 형태의 원고입니다. 과학자들은 과학 원고가 존재했던 한 원고 초안을 공유해 왔습니다. 그러나 1990년대 초 인터넷의 출현과 함께 물리학자들은 원고 초안을 중앙 저장소에 저장하고 배포하는 것이 훨씬 더 효율적이라는 것을 깨달았습니다. 그들은 과학자들이 원고 초안을 업로드, 다운로드 및 검색할 수 있는 웹 서버인 프리프린트 서버를 발명했습니다.
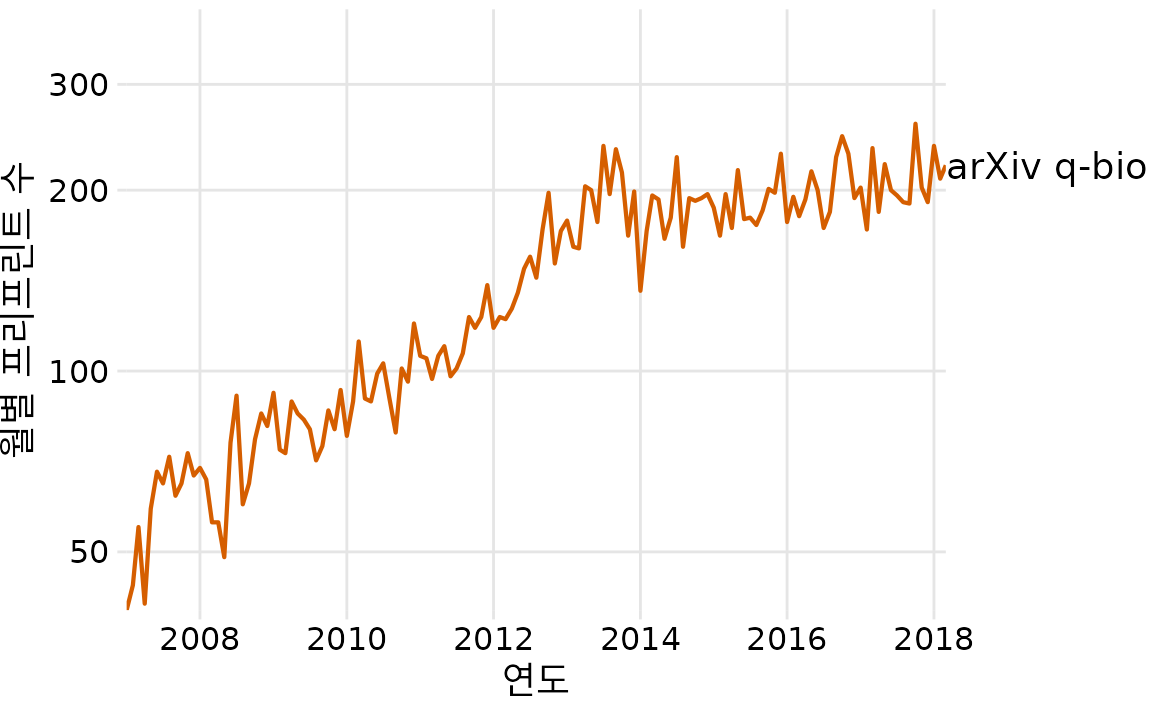
물리학자들이 개발하여 오늘날에도 사용하고 있는 프리프린트 서버는 arXiv.org입니다. 설립 직후 arXiv.org는 수학, 천문학, 컴퓨터 과학, 통계학, 정량 금융, 정량 생물학을 포함한 관련 정량 분야로 확장되어 인기를 얻기 시작했습니다. 여기서 저는 arXiv.org의 정량 생물학(q-bio) 섹션에 대한 프리프린트 제출에 관심이 있습니다. 월별 제출 건수는 2007년부터 2013년 말까지 기하급수적으로 증가했지만 그 후 갑자기 성장이 멈췄습니다(그림 Figure 31.1). 2013년 말에 정량 생물학의 프리프린트 제출 환경을 급격하게 변화시킨 무언가가 있었음에 틀림없습니다. 이러한 제출 성장률의 급격한 변화를 일으킨 원인은 무엇일까요?
(ref:q-bio-monthly-growth) 프리프린트 서버 arXiv.org의 정량 생물학(q-bio) 섹션에 대한 월별 제출 건수 증가. 2014년경 성장률에 급격한 변화가 나타납니다. 2014년까지는 성장이 빨랐지만 2014년부터 2018년까지는 거의 성장이 없었습니다. y 축은 로그 눈금이므로 y의 선형 증가는 프리프린트 제출 건수의 기하급수적인 성장에 해당합니다. 데이터 출처: Jordan Anaya, http://www.prepubmed.org/
2013년 말이 생물학에서 프리프린트가 본격적으로 시작된 시점이며 아이러니하게도 이것이 q-bio 아카이브의 성장을 둔화시켰다고 주장합니다. 2013년 11월, 생물학 전용 프리프린트 서버인 bioRxiv가 콜드 스프링 하버 연구소(CSHL) 출판사에서 시작되었습니다. CSHL 출판사는 생물학자들 사이에서 매우 존경받는 출판사입니다. CSHL 출판사의 지원은 생물학자들 사이에서 일반적으로 프리프린트, 특히 bioRxiv의 수용에 큰 도움이 되었습니다. arXiv.org에 대해 상당히 의심스러워했을 동일한 생물학자들은 bioRxiv에 대해 훨씬 더 편안함을 느꼈습니다. 그 결과 bioRxiv는 생물학자들 사이에서 빠르게 수용되었으며 arXiv가 결코 달성하지 못했던 수준에 도달했습니다. 실제로 출시 직후 bioRxiv는 월별 제출 건수가 급격하고 기하급수적으로 증가하기 시작했으며 q-bio 제출 건수의 둔화는 bioRxiv의 이러한 기하급수적인 성장 시작과 정확히 일치합니다(그림 Figure 31.2). 그렇지 않았다면 q-bio에 프리프린트를 제출했을 많은 정량 생물학자들이 대신 bioRxiv에 제출하기로 결정한 것으로 보입니다.
(ref:q-bio-bioRxiv-monthly-growth) q-bio로의 제출 증가세 둔화는 bioRxiv 서버 도입과 동시에 발생했습니다. 일반 목적 프리프린트 서버 arxiv.org의 q-bio 섹션과 전용 생물학 프리프린트 서버 bioRxiv로의 월별 제출 증가세가 표시됩니다. bioRxiv 서버는 2013년 11월에 가동되었으며 그 이후로 제출률이 기하급수적으로 증가했습니다. 그렇지 않았다면 q-bio에 프리프린트를 제출했을 많은 과학자들이 대신 bioRxiv에 제출하기로 결정한 것으로 보입니다. 데이터 출처: Jordan Anaya, http://www.prepubmed.org/
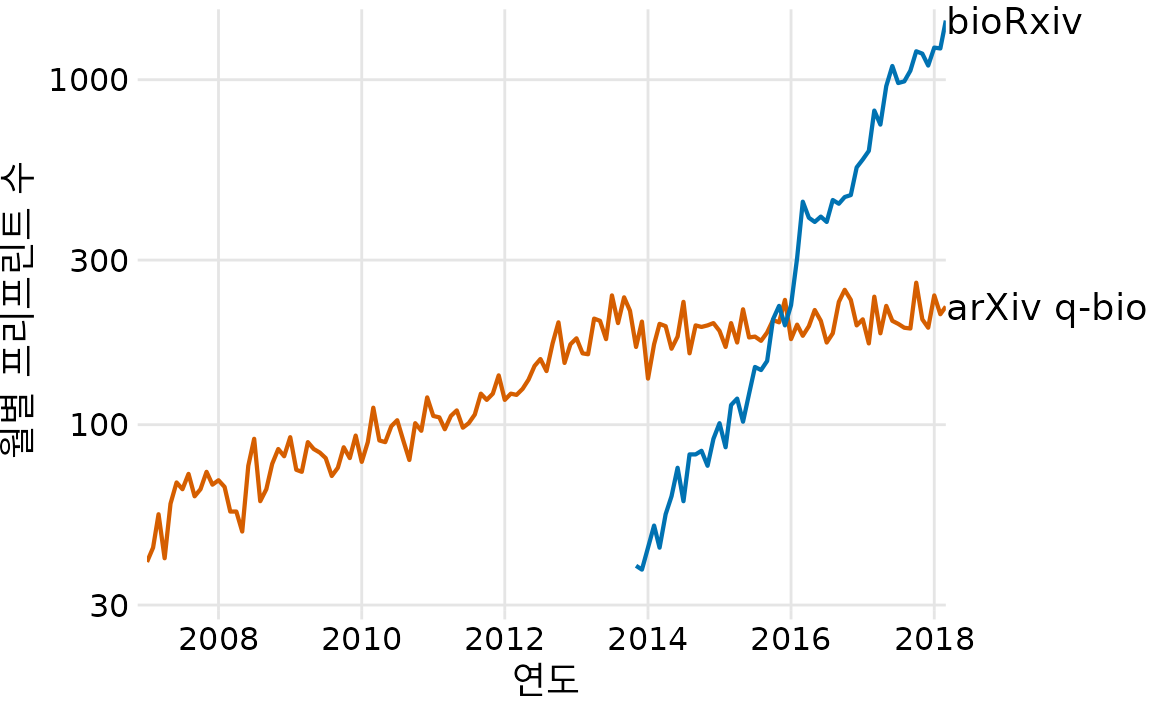
이것이 생물학의 프리프린트에 대한 제 이야기입니다. 첫 번째 그림(그림 Figure 31.1)이 두 번째 그림(그림 Figure 31.2)에 완전히 포함되어 있음에도 불구하고 의도적으로 두 개의 그림으로 이야기를 전달했습니다. 저는 이 이야기가 두 부분으로 나뉘었을 때 가장 강력한 영향을 미친다고 생각하며 이것이 제가 강연에서 발표하는 방식입니다. 그러나 그림 ?fig-q-bio-bioRxiv-monthly-growth만으로도 전체 이야기를 전달할 수 있으며 단일 그림 버전은 소셜 미디어 게시물과 같이 청중의 주의 집중 시간이 짧을 것으로 예상되는 매체에 더 적합할 수 있습니다.
장군들을 위한 그림 만들기
이 장의 나머지 부분에서는 청중이 이야기에 연결되고 전체 스토리 아크 내내 참여하도록 돕는 개별 그림 및 그림 세트를 만드는 전략에 대해 설명합니다. 첫째, 가장 중요한 것은 청중이 실제로 이해할 수 있는 그림을 보여주어야 한다는 것입니다. 이 책 전체에서 제공한 모든 권장 사항을 따르더라도 혼란스러운 그림을 준비할 수 있습니다. 이런 일이 발생하면 두 가지 일반적인 오해의 희생자가 되었을 수 있습니다. 첫째, 청중이 그림을 보고 즉시 전달하려는 요점을 추론할 수 있다는 것입니다. 둘째, 청중이 복잡한 시각화를 신속하게 처리하고 표시된 주요 추세와 관계를 이해할 수 있다는 것입니다. 이러한 가정은 모두 사실이 아닙니다. 독자가 시각화의 의미를 이해하고 우리가 보는 것과 동일한 데이터 패턴을 볼 수 있도록 최선을 다해야 합니다. 이것은 일반적으로 적을수록 좋다는 것을 의미합니다. 가능한 한 그림을 단순화하십시오. 이야기와 관련이 없는 모든 특징을 제거하십시오. 중요한 점만 남겨야 합니다. 저는 이 개념을 “장군들을 위한 그림 만들기”라고 부릅니다.
몇 년 동안 저는 미 육군이 자금을 지원하는 대규모 연구 프로젝트를 담당했습니다. 연례 진행 보고서에서 프로그램 관리자들은 저에게 많은 그림을 포함하지 말라고 지시했습니다. 그리고 제가 포함한 모든 그림은 우리 프로젝트가 어떻게 성공하고 있는지 매우 명확하게 보여주어야 했습니다. 프로그램 관리자들은 장군이 각 그림을 보고 우리가 하는 일이 이전 기능보다 어떻게 개선되거나 초과하는지 즉시 알 수 있어야 한다고 말했습니다. 그러나 이 프로젝트에 참여한 동료들이 연례 진행 보고서를 위해 저에게 보낸 그림 중 많은 그림이 이 기준을 충족하지 못했습니다. 그림은 일반적으로 지나치게 복잡하거나 혼란스러운 기술 용어로 레이블이 지정되거나 명확한 요점이 전혀 없었습니다. 대부분의 과학자들은 장군들을 위한 그림을 만들도록 훈련받지 않았습니다.
청중이 복잡한 시각적 디스플레이를 신속하게 처리할 수 있다고 가정하지 마십시오.
어떤 사람들은 이 이야기를 듣고 장군들이 그다지 똑똑하지 않거나 과학에 별로 관심이 없다고 결론을 내릴 수 있습니다. 저는 그것이 정확히 잘못된 교훈이라고 생각합니다. 장군들은 단순히 매우 바쁩니다. 암호 같은 그림을 해독하는 데 30분을 할애할 수 없습니다. 그들이 기초 연구를 위해 과학자들에게 수백만 달러의 납세자 기금을 제공할 때 그들이 대가로 기대할 수 있는 최소한의 것은 가치 있고 흥미로운 무언가가 성취되었다는 몇 가지 명확한 증거입니다. 이 이야기는 또한 특히 군사 자금 지원에 관한 것으로 오해해서는 안 됩니다. 장군들은 시각화를 통해 도달하고자 하는 모든 사람에 대한 은유입니다. 논문이나 연구 제안서의 과학 심사관, 신문 편집자, 또는 근무하는 회사의 상사나 상사의 상사일 수 있습니다. 이야기가 전달되기를 원한다면 이러한 모든 장군들에게 적합한 그림을 만들어야 합니다.
장군들을 위한 그림을 만드는 데 방해가 되는 첫 번째 것은 아이러니하게도 현대 시각화 소프트웨어를 사용하여 정교한 데이터 시각화를 쉽게 만들 수 있다는 점입니다. 거의 무한한 시각화 능력으로 인해 더 많은 데이터 차원을 계속 추가하고 싶은 유혹이 생깁니다. 그리고 실제로 저는 데이터 시각화 세계에서 가능한 가장 복잡하고 다면적인 시각화를 만드는 추세를 봅니다. 이러한 시각화는 매우 인상적으로 보일 수 있지만 명확한 이야기를 전달할 가능성은 낮습니다. 2013년 뉴욕시 지역에서 출발하는 모든 항공편의 도착 지연을 보여주는 그림 ?fig-arrival-delay-vs-distance를 생각해 보십시오. 이 그림을 처리하는 데 시간이 좀 걸릴 것이라고 생각합니다.
(ref:arrival-delay-vs-distance) 뉴욕시로부터의 거리 대 평균 도착 지연. 각 점은 하나의 목적지를 나타내며 각 점의 크기는 2013년 뉴욕시 3개 주요 공항(뉴어크, JFK 또는 라과디아) 중 하나에서 해당 목적지까지의 항공편 수를 나타냅니다. 음의 지연은 항공편이 일찍 도착했음을 의미합니다. 실선은 도착 지연과 거리 간의 평균 추세를 나타냅니다. 델타 항공은 이동 거리에 관계없이 다른 항공사보다 도착 지연이 지속적으로 낮습니다. 아메리칸 항공은 단거리의 경우 평균적으로 지연이 가장 낮지만 장거리의 경우 지연이 가장 높습니다. 이 그림은 지나치게 복잡하기 때문에 “나쁨”으로 표시되었습니다. 대부분의 독자는 혼란스러워하며 그림이 무엇을 보여주는지 직관적으로 파악하지 못할 것입니다. 데이터 출처: 미국 교통부, 교통 통계국.
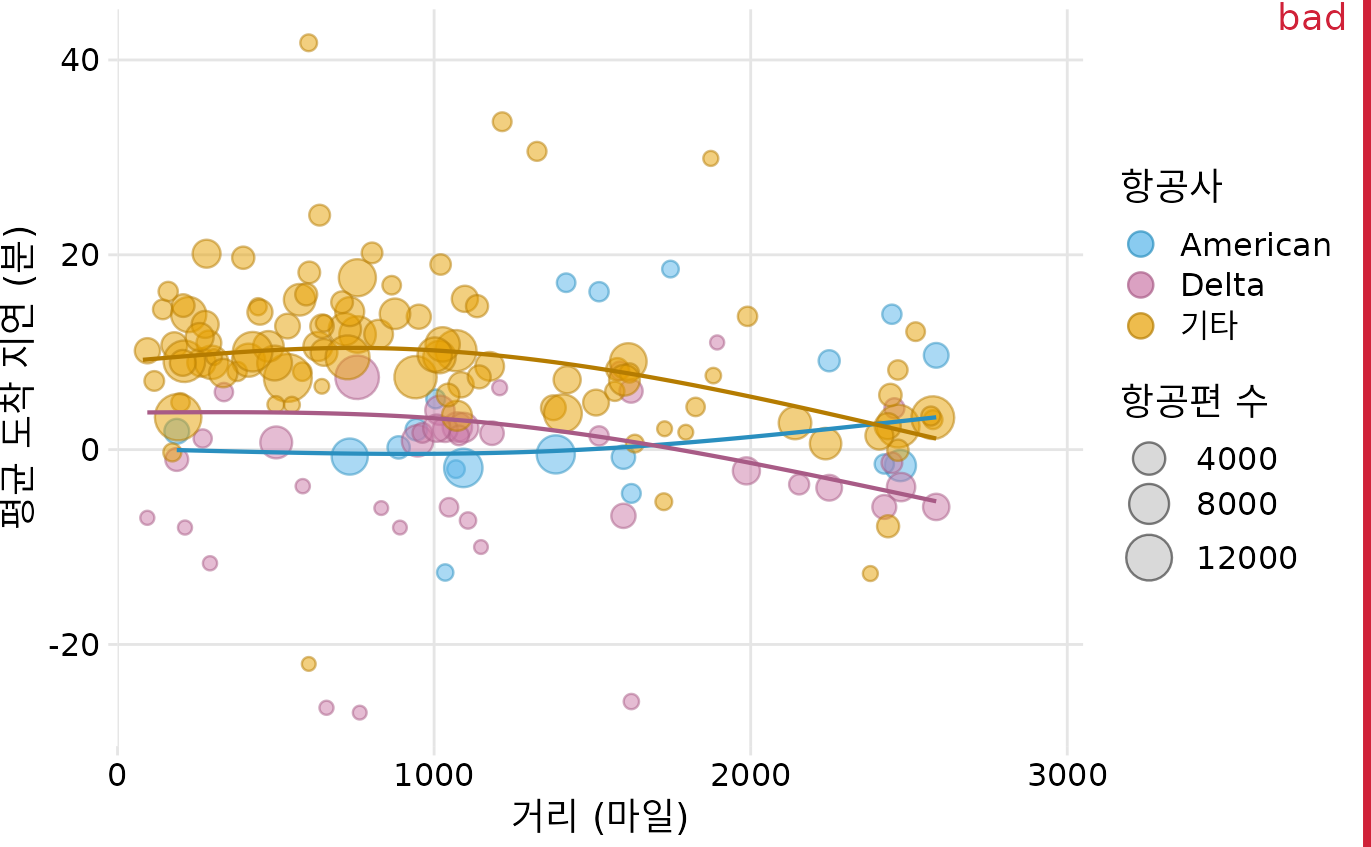
그림 ?fig-arrival-delay-vs-distance의 가장 중요한 특징은 아메리칸 항공과 델타 항공의 도착 지연이 가장 짧다는 것이라고 생각합니다. 이 통찰력은 간단한 막대 그래프로 훨씬 더 잘 전달됩니다(그림 Figure 31.4). 따라서 그림 ?fig-mean-arrival-delay-nyc은 항공사의 도착 지연에 대한 이야기라면 보여주어야 할 올바른 그림입니다. 비록 그 그래프를 만드는 것이 데이터 시각화 기술에 도전이 되지 않더라도 말입니다. 그리고 이러한 항공사가 뉴욕시에서 많이 운항하지 않기 때문에 지연이 적은지 궁금하다면 아메리칸 항공과 델타 항공이 모두 뉴욕시 지역의 주요 항공사임을 강조하는 두 번째 막대 그래프를 제시할 수 있습니다(그림 Figure 31.5). 이 두 막대 그래프는 모두 그림 ?fig-arrival-delay-vs-distance에 표시된 거리 변수를 버립니다. 괜찮습니다. 이야기와 관련이 없는 데이터 차원을 시각화할 필요는 없습니다. 비록 우리가 그것들을 가지고 있고 그것들을 보여주는 그림을 만들 수 있더라도 말입니다. 복잡하고 혼란스러운 것보다 단순하고 명확한 것이 더 좋습니다.
(ref:mean-arrival-delay-nyc) 2013년 뉴욕시 지역 출발 항공편의 항공사별 평균 도착 지연. 아메리칸 항공과 델타 항공은 뉴욕시 지역 출발 모든 항공사 중 평균 도착 지연이 가장 낮습니다. 데이터 출처: 미국 교통부, 교통 통계국.
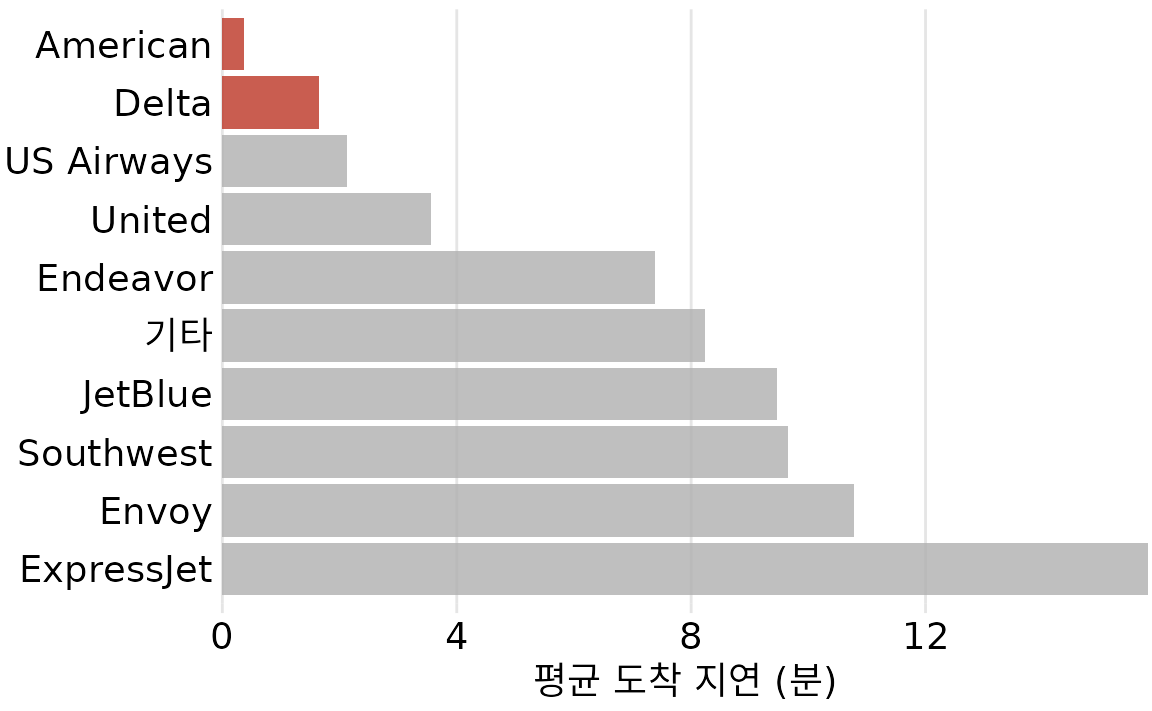
(ref:number-of-flights-nyc) 2013년 뉴욕시 지역 출발 항공편 수, 항공사별. 델타 항공과 아메리칸 항공은 뉴욕시 지역 출발 항공편 수 기준으로 각각 4위와 5위 항공사입니다. 데이터 출처: 미국 교통부, 교통 통계국.
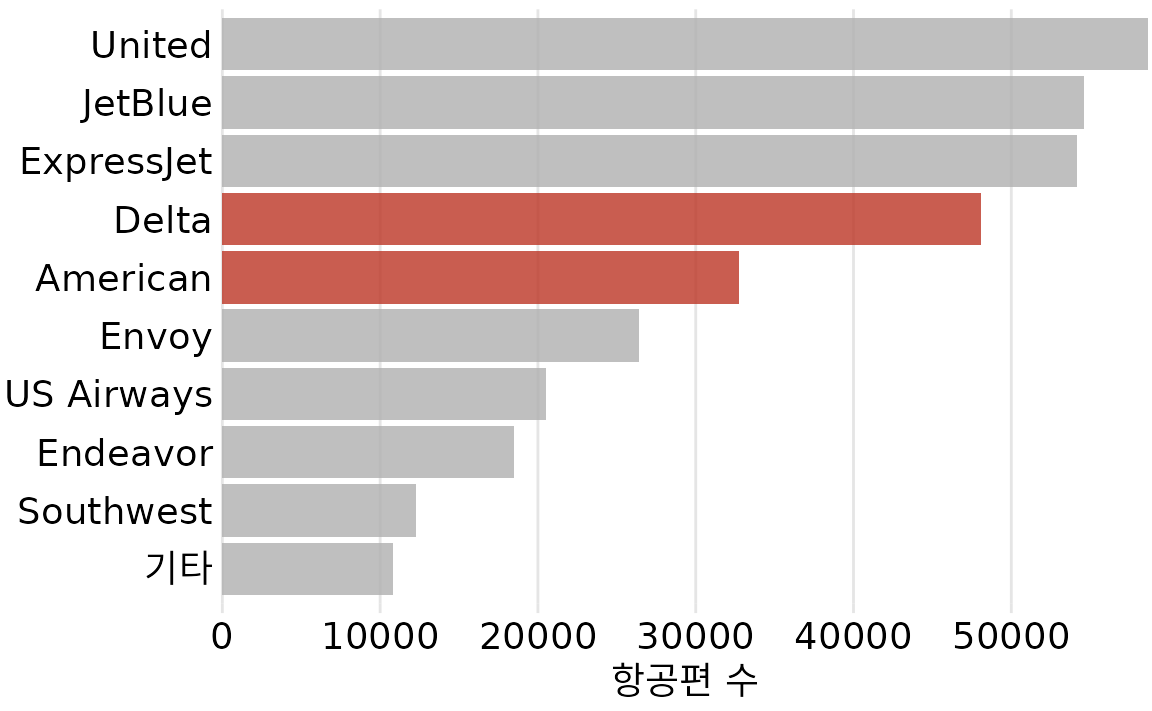
한 번에 너무 많은 데이터를 보여주려고 하면 아무것도 보여주지 못할 수 있습니다.
복잡한 그림으로 점진적으로 나아가기
그러나 때로는 한 번에 많은 양의 정보를 포함하는 더 복잡한 그림을 보여주고 싶을 때가 있습니다. 이러한 경우 최종 그림을 완전한 복잡성으로 보여주기 전에 단순화된 버전의 그림을 먼저 보여주면 독자가 더 쉽게 이해할 수 있습니다. 동일한 접근 방식은 프레젠테이션에도 매우 권장됩니다. 매우 복잡한 그림으로 바로 넘어가지 마십시오. 먼저 쉽게 이해할 수 있는 하위 집합을 보여주십시오.
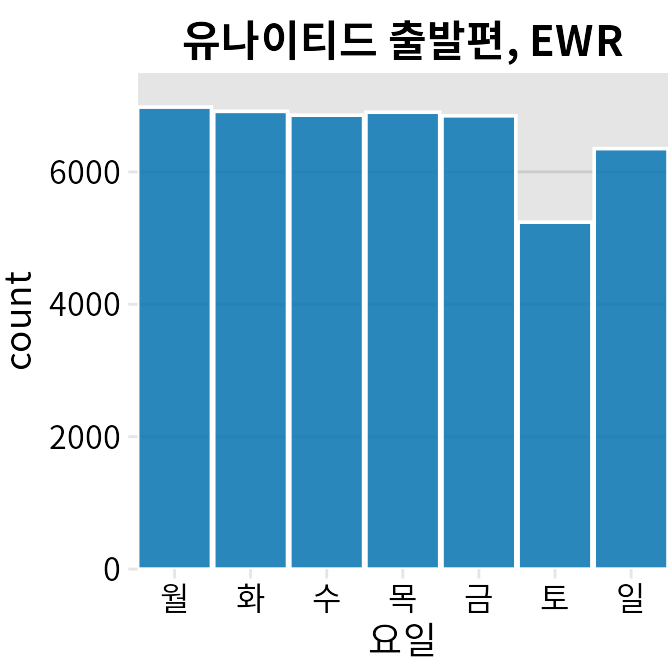
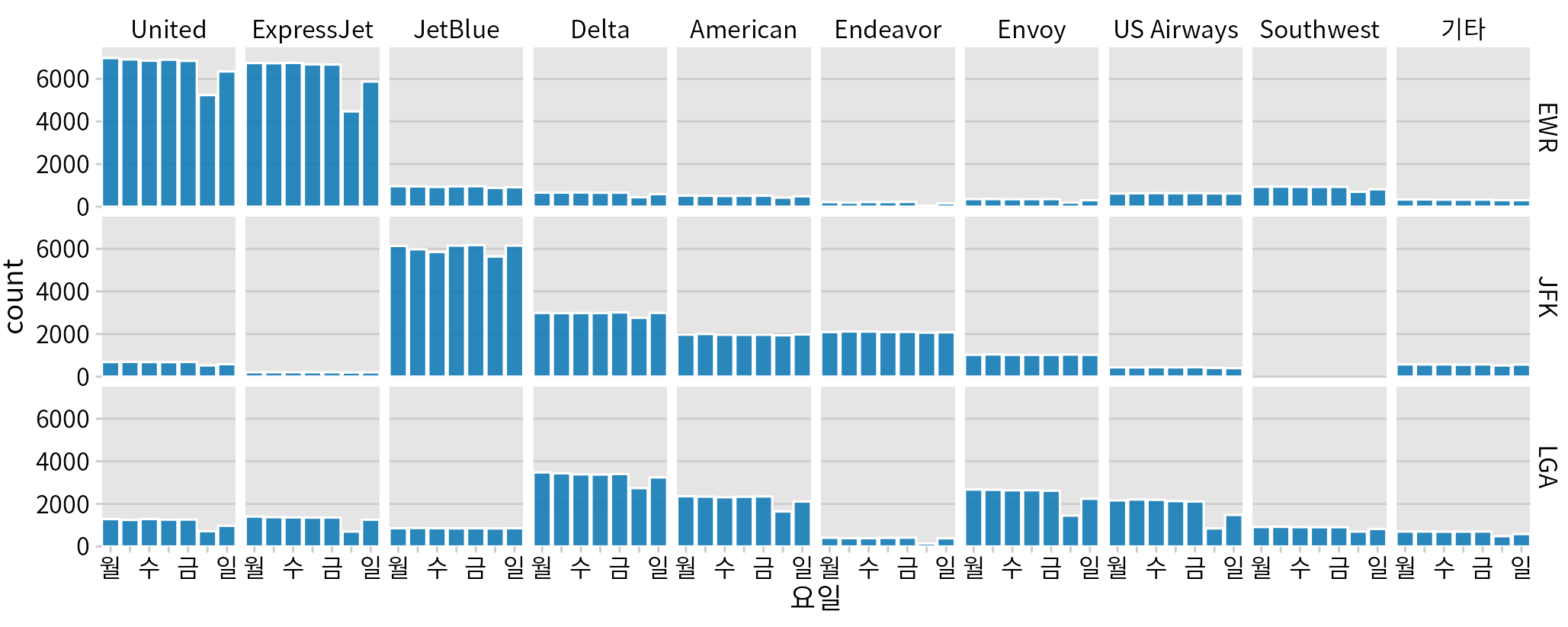
이 권장 사항은 최종 그림이 유사한 구조의 하위 플롯 격자를 보여주는 작은 다중 플롯(챕터 다중 패널 그림)인 경우 특히 관련이 있습니다. 청중이 먼저 단일 하위 플롯을 본 경우 전체 격자를 훨씬 쉽게 이해할 수 있습니다. 예를 들어 그림 ?fig-united-departures-weekdays는 2013년 뉴어크 공항(EWR)에서 출발하는 유나이티드 항공편의 총 수를 요일별로 분류하여 보여줍니다. 이 그림을 보고 이해한 후에는 10개 항공사와 3개 공항에 대한 동일한 정보를 한 번에 보는 것이 훨씬 처리하기 쉽습니다(그림 Figure 31.7).
(ref:united-departures-weekdays) 2013년 뉴어크 공항(EWR)에서 출발하는 유나이티드 항공편, 요일별. 대부분의 요일은 거의 동일한 수의 출발편을 보이지만 주말에는 출발편이 더 적습니다. 데이터 출처: 미국 교통부, 교통 통계국.
(ref:all-departures-weekdays) 2013년 뉴욕시 지역 공항 출발편, 항공사, 공항, 요일별 분류. 유나이티드 항공과 익스프레스젯이 뉴어크 공항(EWR) 출발편의 대부분을 차지하고, 젯블루, 델타, 아메리칸, 엔데버가 JFK 출발편의 대부분을 차지하며, 델타, 아메리칸, 엔보이, US 에어웨이스가 라과디아(LGA) 출발편의 대부분을 차지합니다. 모든 항공사는 아니지만 대부분의 항공사는 주중보다 주말에 출발편이 적습니다. 데이터 출처: 미국 교통부, 교통 통계국.
기억에 남는 그림 만들기
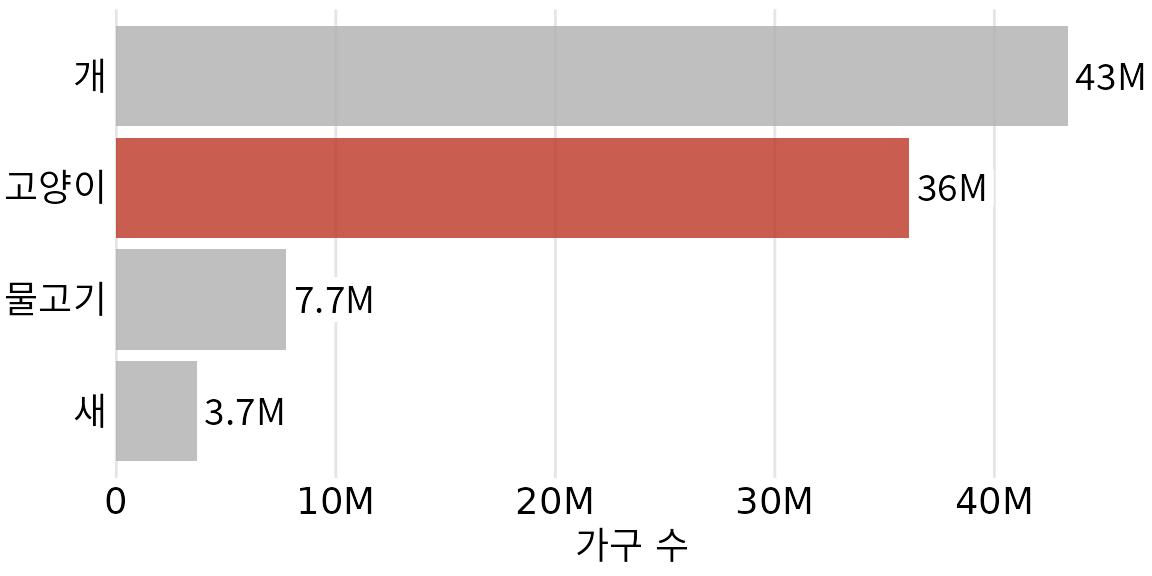
간단한 막대 그래프와 같은 단순하고 깔끔한 그림은 주의를 산만하게 하는 것을 피하고 읽기 쉬우며 청중이 전달하려는 가장 중요한 요점에 집중할 수 있도록 하는 장점이 있습니다. 그러나 단순함에는 단점이 따를 수 있습니다. 그림이 일반적으로 보일 수 있습니다. 눈에 띄고 기억에 남게 만드는 특징이 없습니다. 10개의 막대 그래프를 빠르게 연속해서 보여주면 구분하기 어렵고 나중에 무엇을 보여주었는지 기억하기 어려울 것입니다. 예를 들어 그림 ?fig-petownership-bar을 잠깐 보면 이 장의 앞부분에서 논의한 그림 ?fig-number-of-flights-nyc과의 시각적 유사성을 알 수 있습니다. 그러나 두 그림은 막대 차트라는 점 외에는 공통점이 없습니다. 그림 ?fig-number-of-flights-nyc는 항공사별 뉴욕시 지역 출발 항공편 수를 보여주는 반면 그림 ?fig-petownership-bar는 미국 가정에서 가장 인기 있는 애완동물을 보여줍니다. 어떤 그림도 그림이 다루는 주제를 직관적으로 인식하는 데 도움이 되는 요소가 없으므로 어떤 그림도 특별히 기억에 남지 않습니다.
(ref:petownership-bar) 가장 인기 있는 애완동물(개, 고양이, 물고기 또는 새) 중 하나 이상을 키우는 가구 수. 이 막대 그래프는 완벽하게 명확하지만 반드시 특별히 기억에 남지는 않습니다. “고양이” 열은 그림 ?fig-number-of-flights-nyc과의 시각적 유사성을 만들기 위해서만 강조 표시되었습니다. 데이터 출처: 2012년 미국 애완동물 소유 및 인구 통계 자료집, 미국 수의학 협회
인간 인식에 대한 연구에 따르면 시각적으로 더 복잡하고 독특한 그림이 더 기억에 남습니다(Bateman et al. 2010; Borgo et al. 2012). 그러나 시각적 독특함과 복잡성은 기억력에만 영향을 미치는 것이 아니라 정보에 대한 빠른 개요를 얻는 능력이나 값의 작은 차이를 구별하는 것을 어렵게 만들 수 있습니다. 극단적인 경우 그림은 매우 기억에 남지만 완전히 혼란스러울 수 있습니다. 이러한 그림은 멋진 예술 작품으로 잘 작동하더라도 좋은 데이터 시각화는 아닙니다. 다른 극단적인 경우 그림은 매우 명확하지만 잊혀지고 지루할 수 있으며 이러한 그림은 우리가 바라는 만큼의 영향을 미치지 못할 수도 있습니다. 일반적으로 우리는 두 극단 사이의 균형을 이루고 그림을 기억에 남고 명확하게 만들고 싶습니다. (그러나 의도된 청중도 중요합니다. 그림이 기술적인 과학 출판물을 위한 것이라면 일반적으로 널리 읽히는 신문이나 블로그를 위한 그림보다 기억력에 덜 신경을 쓸 것입니다.)
데이터의 특징을 반영하는 시각적 요소(예: 데이터 세트가 다루는 사물이나 물체의 그림 또는 픽토그램)를 추가하여 그림을 더 기억에 남게 만들 수 있습니다. 일반적으로 사용되는 한 가지 접근 방식은 각 이미지 사본이 표시된 변수의 정의된 양에 해당하도록 반복된 이미지 형태로 데이터 값 자체를 표시하는 것입니다. 예를 들어 그림 ?fig-petownership-bar의 막대를 개, 고양이, 물고기, 새의 반복된 이미지로 바꿀 수 있으며 각 완전한 동물은 500만 가구에 해당하도록 축척을 조정합니다(그림 Figure 31.9). 따라서 시각적으로 그림 ?fig-petownership-isotype은 여전히 막대 그래프로 기능하지만 이제 그림을 더 기억에 남게 만드는 약간의 시각적 복잡성을 추가했으며 데이터가 의미하는 바를 직접 반영하는 이미지를 사용하여 데이터도 표시했습니다. 그림을 잠깐만 보더라도 물고기나 새보다 개와 고양이가 훨씬 더 많았다는 것을 기억할 수 있을 것입니다. 중요하게도 이러한 시각화에서는 이미지를 사용하여 데이터를 나타내는 것이지 단순히 시각화를 장식하거나 축에 주석을 다는 데 이미지를 사용하는 것이 아닙니다. 심리 실험에서 후자의 선택은 도움이 되기보다는 주의를 산만하게 하는 경향이 있습니다(Haroz, Kosara, and Franconeri 2015).
(ref:petownership-isotype) 가장 인기 있는 애완동물 중 하나 이상을 키우는 가구 수, 아이소타이프 그래프로 표시. 각 완전한 동물은 해당 종류의 애완동물을 키우는 500만 가구를 나타냅니다. 데이터 출처: 2012년 미국 애완동물 소유 및 인구 통계 자료집, 미국 수의학 협회
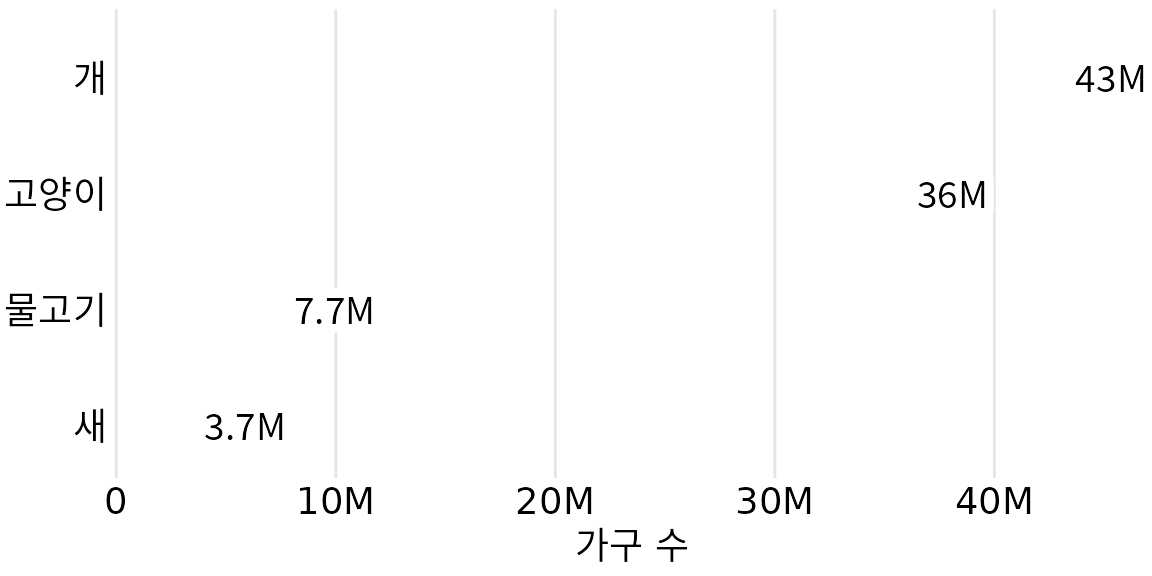
그림 ?fig-petownership-isotype과 같은 시각화는 종종 아이소타이프 플롯이라고 합니다. 아이소타이프라는 단어는 국제 타이포그래피 그림 교육 시스템(International System Of TYpographic Picture Education)의 약자로 도입되었으며 엄밀히 말하면 물체, 동물, 식물 또는 사람을 나타내는 로고와 유사한 단순화된 픽토그램을 의미합니다(Haroz, Kosara, and Franconeri 2015). 그러나 값의 크기를 나타내기 위해 동일한 이미지의 반복된 사본을 사용하는 모든 유형의 시각화에 적용하기 위해 아이소타이프 플롯이라는 용어를 더 광범위하게 사용하는 것이 합리적이라고 생각합니다. 결국 접두사 “iso”는 “동일한”을 의미하고 “type”은 특정 종류, 등급 또는 그룹을 의미할 수 있습니다.
일관성을 유지하되 반복하지 마십시오
챕터 ?sec-compound-figures에서 복합 그림에 대해 논의할 때 더 큰 그림의 여러 부분에 대해 일관된 시각적 언어를 사용하는 것이 중요하다고 언급했습니다. 그림 전체에서도 마찬가지입니다. 더 큰 이야기의 일부인 세 개의 그림을 만드는 경우 해당 그림이 함께 속하는 것처럼 보이도록 디자인해야 합니다. 그러나 일관된 시각적 언어를 사용한다고 해서 모든 것이 정확히 동일하게 보여야 한다는 의미는 아닙니다. 오히려 그 반대입니다. 여러 분석을 설명하는 그림이 시각적으로 구별되어 청중이 한 분석이 끝나고 다른 분석이 시작되는 위치를 쉽게 인식할 수 있도록 하는 것이 중요합니다. 이는 포괄적인 이야기의 여러 부분에 대해 여러 시각화 접근 방식을 사용하여 가장 잘 달성할 수 있습니다. 이미 막대 그래프를 사용했다면 다음에는 산점도, 상자 그림 또는 선 그래프를 사용하십시오. 그렇지 않으면 여러 분석이 청중의 마음속에서 흐릿해지고 이야기의 한 부분과 다른 부분을 구별하기 어려워집니다. 예를 들어 챕터 ?sec-compound-figures의 그림 ?fig-athletes-composite-good을 막대 그래프만 사용하도록 다시 디자인하면 결과가 눈에 띄게 덜 뚜렷하고 더 혼란스러워집니다(그림 Figure 31.10).
(ref:athletes-composite-repetitive) 남성 및 여성 운동선수의 생리학 및 신체 구성. 오차 막대는 평균의 표준 오차를 나타냅니다. 이 그림은 지나치게 반복적입니다. 그림 ?fig-athletes-composite-good과 동일한 데이터를 보여주고 일관된 시각적 언어를 사용하지만 모든 하위 그림은 동일한 유형의 시각화(막대 그래프)를 사용합니다. 이로 인해 독자가 (a), (b), (c) 부분이 완전히 다른 결과를 보여준다는 것을 처리하기 어렵습니다. 데이터 출처: Telford and Cunningham (1991)
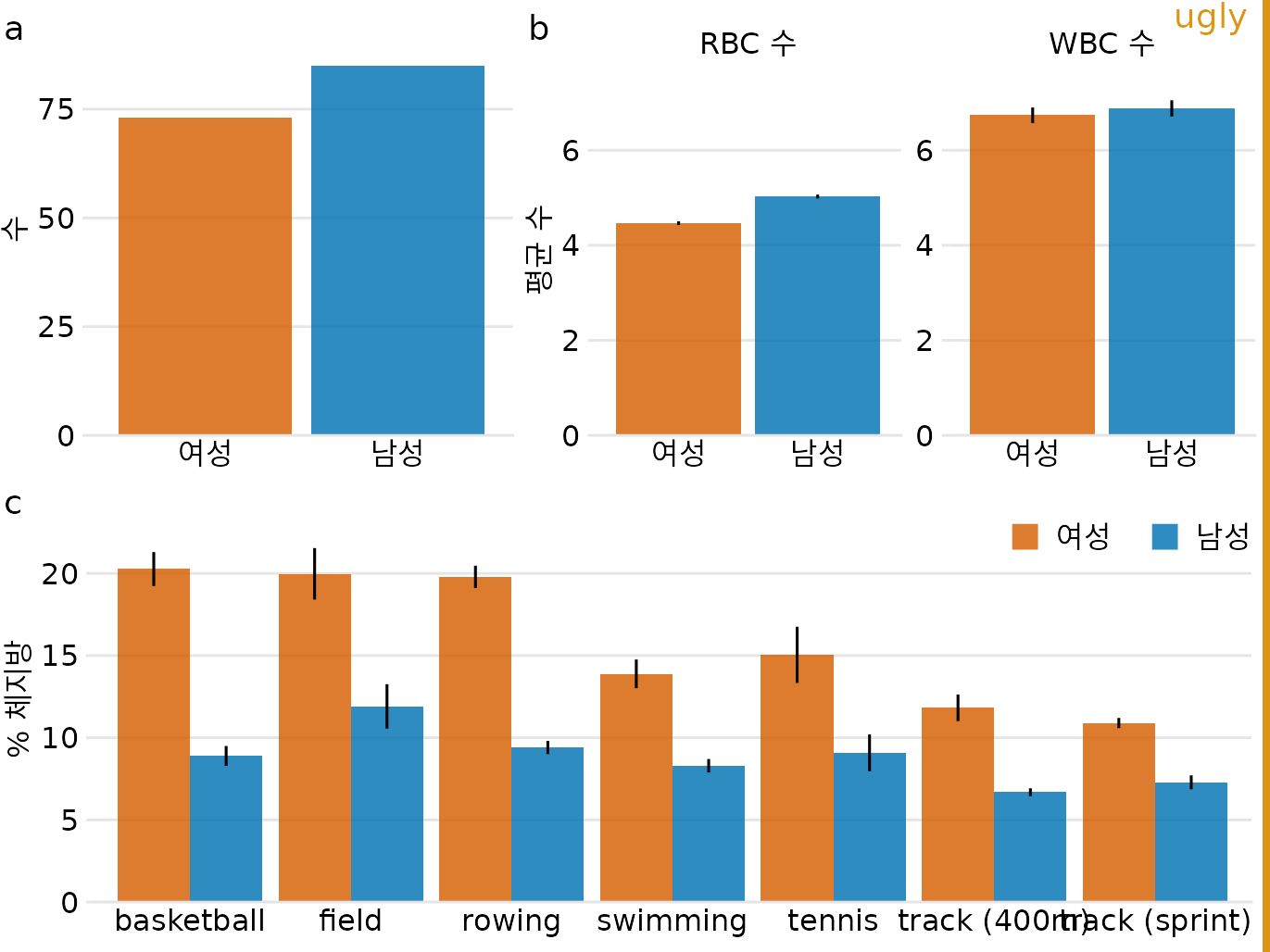
프레젠테이션이나 보고서를 준비할 때는 각기 다른 분석에 대해 다른 유형의 시각화를 사용하는 것을 목표로 하십시오.
반복적인 그림 세트는 종종 각 부분이 동일한 유형의 원시 데이터를 기반으로 하는 다중 부분 이야기의 결과입니다. 이러한 시나리오에서는 각 부분에 대해 동일한 유형의 시각화를 사용하고 싶은 유혹이 들 수 있습니다. 그러나 전체적으로 이러한 그림은 청중의 주의를 끌지 못합니다. 예를 들어 페이스북 주식에 대한 이야기를 두 부분으로 나누어 생각해 보겠습니다. (i) 페이스북 주가는 2012년부터 2017년까지 급격히 상승했습니다. (ii) 주가 상승은 다른 대형 기술 회사의 주가 상승을 앞질렀습니다. 그림 ?fig-tech-stocks-repetitive에 표시된 것처럼 시간 경과에 따른 주가를 보여주는 두 개의 그림으로 이러한 두 가지 진술을 시각화하고 싶을 수 있습니다. 그러나 그림 Figure 31.11 (a)는 명확한 목적을 수행하며 그대로 유지해야 하지만 그림 Figure 31.11 (b)는 동시에 반복적이며 요점을 모호하게 만듭니다. 우리는 알파벳, 애플, 마이크로소프트의 주가의 정확한 시간적 진화에 특별히 관심이 있는 것이 아니라 페이스북의 주가보다 덜 성장했다는 점을 강조하고 싶을 뿐입니다.
(ref:tech-stocks-repetitive) 5년 간격 동안의 페이스북 주가 성장 및 다른 기술주와의 비교. (a) 페이스북 주가는 2012년 중반 주당 약 25달러에서 2017년 중반 주당 150달러로 상승했습니다. (b) 다른 대형 기술 회사의 주가는 같은 기간 동안 비슷하게 상승하지 않았습니다. 가격은 2012년 6월 1일에 100으로 지수화되어 쉽게 비교할 수 있습니다. 이 그림은 (a)와 (b) 부분이 반복적이므로 “못생김”으로 표시되었습니다. 데이터 출처: Yahoo Finance
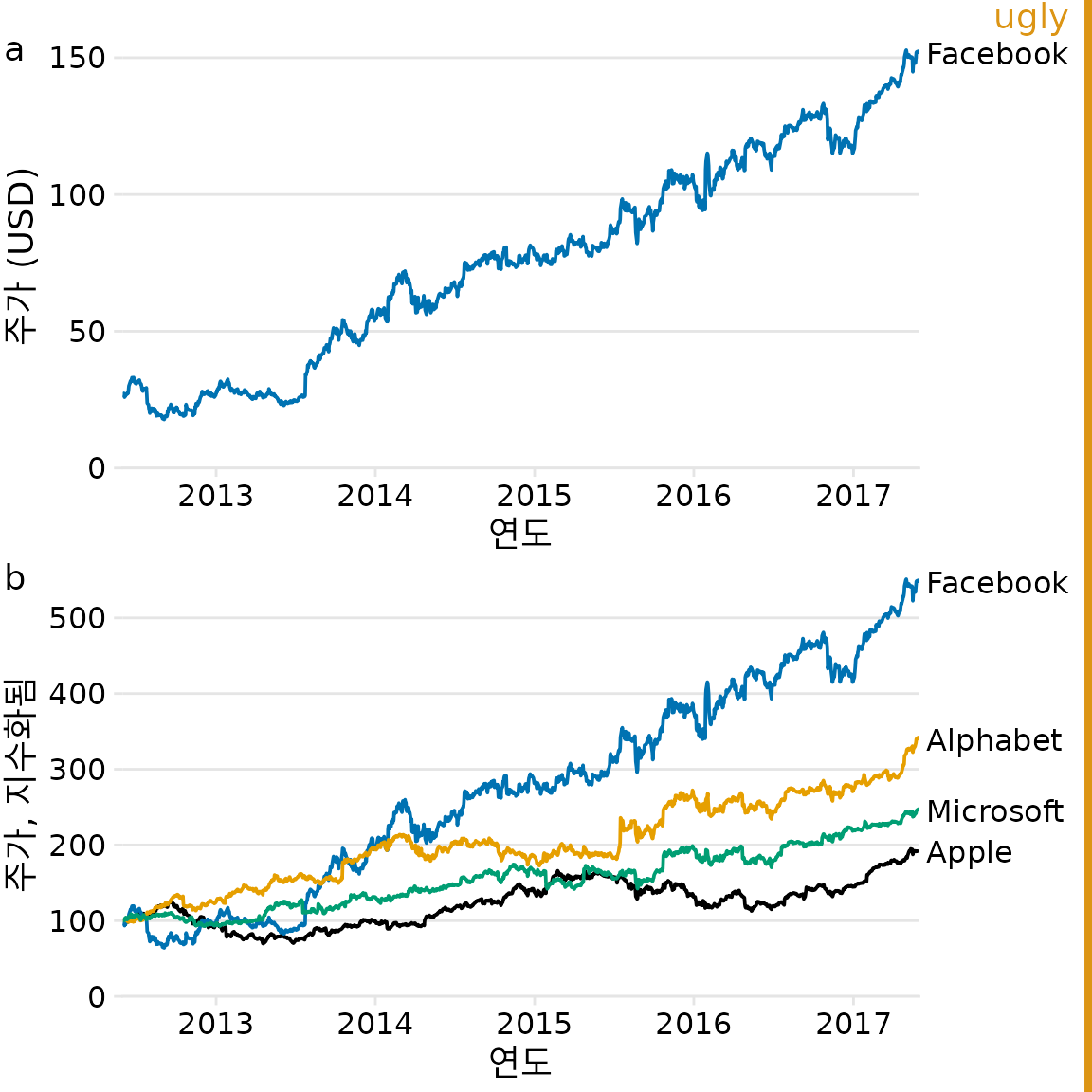
- 부분은 그대로 두고 (b) 부분을 백분율 증가를 보여주는 막대 그래프로 바꾸는 것이 좋습니다(그림 Figure 31.12). 이제 각기 독특하고 명확한 요점을 제시하고 조합하여 잘 작동하는 두 개의 개별 그림이 생겼습니다. (a) 부분은 독자가 원시 기본 데이터에 익숙해지도록 하고 (b) 부분은 관련 없는 정보를 제거하면서 효과의 크기를 강조합니다.
(ref:tech-stocks-diverse) 5년 간격 동안의 페이스북 주가 성장 및 다른 기술주와의 비교. (a) 페이스북 주가는 2012년 중반 주당 약 25달러에서 2017년 중반 주당 150달러로 거의 450% 상승했습니다. (b) 다른 대형 기술 회사의 주가는 같은 기간 동안 비슷하게 상승하지 않았습니다. 가격 상승률은 90%에서 240% 사이였습니다. 데이터 출처: Yahoo Finance
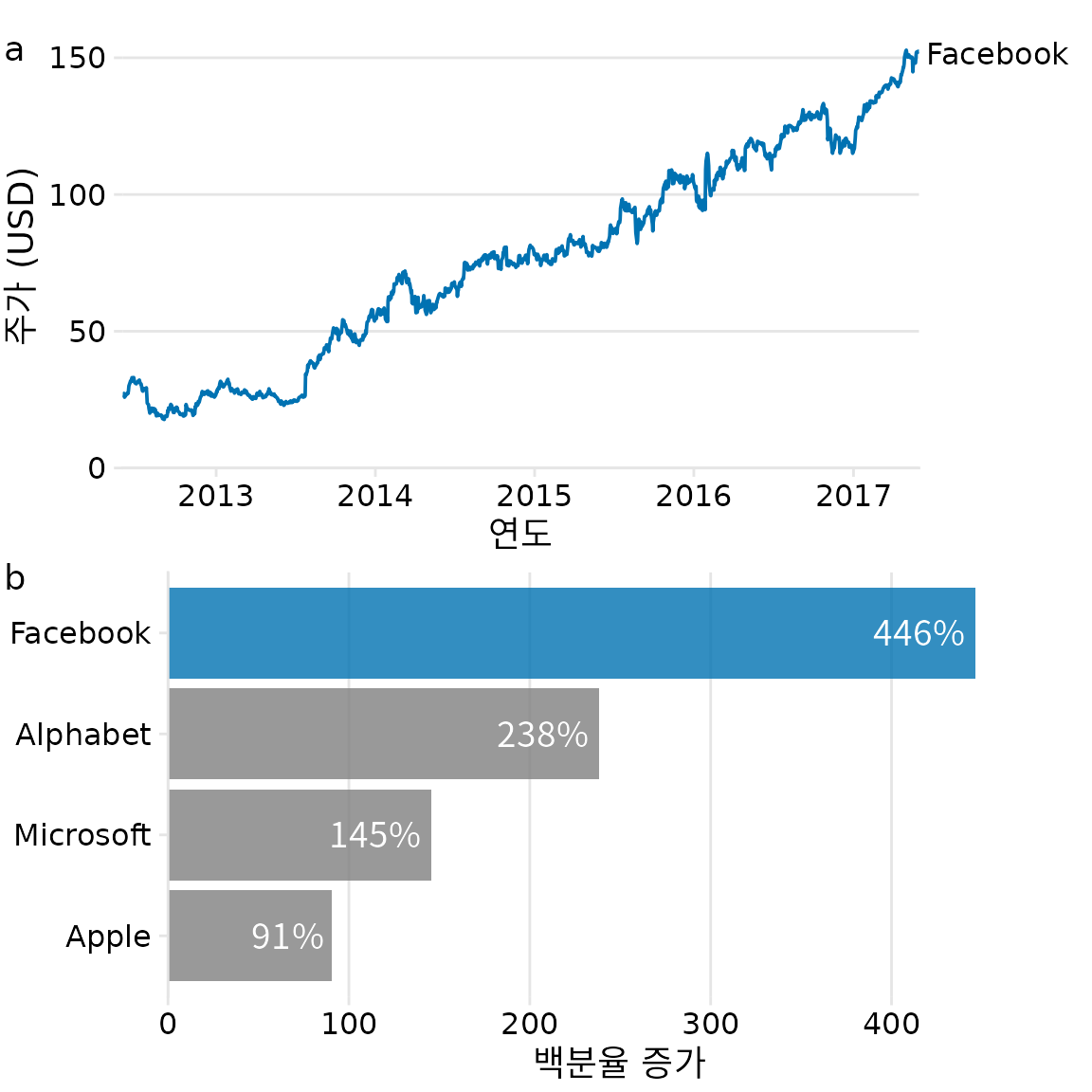
그림 ?fig-tech-stocks-diverse은 이야기를 전달하기 위해 그림 세트를 준비할 때 따르는 일반적인 원칙을 강조합니다. 가능한 한 원시 데이터를 보여주는 그림으로 시작하고 후속 그림에서는 점점 더 파생된 양을 보여줍니다. 파생된 양(예: 백분율 증가, 평균, 적합된 모델의 계수 등)은 크고 복잡한 데이터 세트의 주요 추세를 요약하는 데 유용합니다. 그러나 파생되었기 때문에 덜 직관적이며 원시 데이터를 보여주기 전에 파생된 양을 보여주면 청중이 따라가기 어려울 것입니다. 반대로 원시 데이터를 보여줌으로써 모든 추세를 보여주려고 하면 너무 많은 그림이 필요하거나 반복적이게 됩니다.
이야기를 전달하는 데 몇 개의 그림을 사용해야 할까요? 답은 출판 매체에 따라 다릅니다. 짧은 블로그 게시물이나 트윗의 경우 그림 하나를 만드십시오. 과학 논문의 경우 3~6개의 그림을 권장합니다. 과학 논문에 6개보다 훨씬 많은 그림이 있는 경우 일부는 부록이나 보충 자료 섹션으로 옮겨야 합니다. 수집한 모든 증거를 문서화하는 것은 좋지만 지나치게 많은 수의 대부분 유사하게 보이는 그림을 제시하여 청중을 지치게 해서는 안 됩니다. 다른 맥락에서는 더 많은 수의 그림이 적절할 수 있습니다. 그러나 이러한 맥락에서는 일반적으로 여러 이야기를 전달하거나 하위 플롯이 있는 포괄적인 이야기를 전달하게 됩니다. 예를 들어 한 시간짜리 과학 프레젠테이션을 요청받으면 일반적으로 세 가지 개별 이야기를 전달하는 것을 목표로 합니다. 마찬가지로 책이나 논문에는 하나 이상의 이야기가 포함되며 실제로는 장이나 섹션당 하나의 이야기가 포함될 수 있습니다. 이러한 시나리오에서는 각 개별 스토리라인이나 하위 플롯을 3~6개 이하의 그림으로 제시해야 합니다. 이 책에서는 장 내 섹션 수준에서 이 원칙을 따르고 있음을 알 수 있습니다. 각 섹션은 거의 독립적이며 일반적으로 6개 이하의 그림을 보여줍니다.
Bateman, S., R. Mandryk, C. Gutwin, A. Genest, D. McDine, and C. Brooks. 2010. “Useful Junk? The Effects of Visual Embellishment on Comprehension and Memorability of Charts.” ACM Conference on Human Factors in Computing Systems, 2573–82. https://doi.org/10.1145/1753326.1753716.
Borgo, R., A. Abdul-Rahman, F. Mohamed, P. W. Grant, I. Reppa, and L. Floridi. 2012. “An Empirical Study on Using Visual Embellishments in Visualization.” IEEE Transactions on Visualization and Computer Graphics 18: 2759–68. https://doi.org/10.1109/TVCG.2012.197.
Haroz, S., R. Kosara, and S. L. Franconeri. 2015. “ISOTYPE Visualization: Working Memory, Performance, and Engagement with Pictographs.” ACM Conference on Human Factors in Computing Systems, 1191–1200. https://doi.org/10.1145/2702123.2702275.
Schimel, J. 2011. Writing Science: How to Write Papers That Get Cited and Proposals That Get Funded. Oxford University Press.
Telford, R. D., and R. B. Cunningham. 1991. “Sex, Sport, and Body-Size Dependency of Hematology in Highly Trained Athletes.” Medicine and Science in Sports and Exercise 23: 788–94.