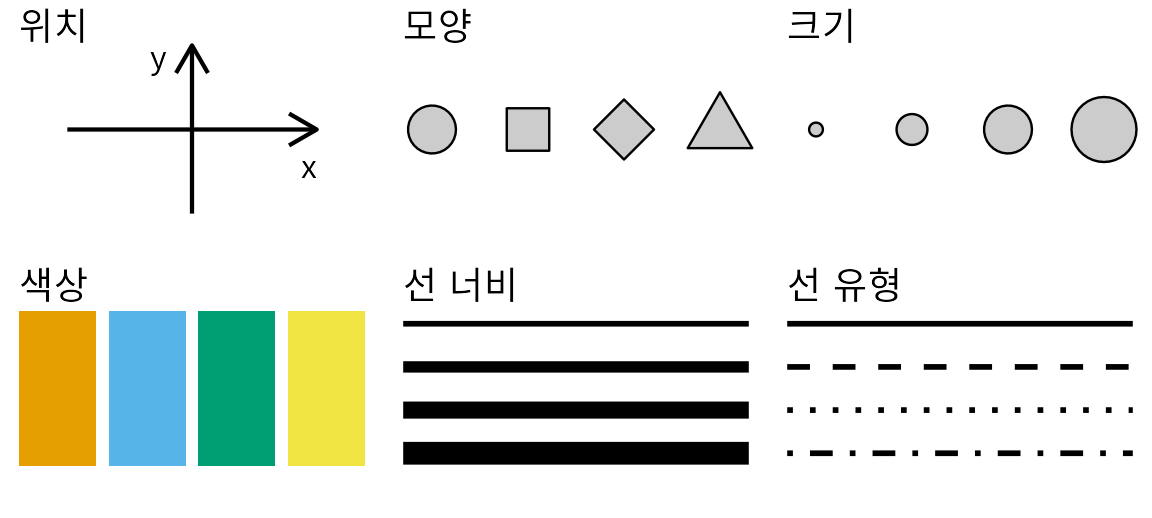
데이터를 시각화할 때, 우리는 데이터 값을 체계적이고 논리적인 규칙에 따라 변환하여 최종 결과물을 구성하는 시각적 요소로 만듭니다. 데이터 시각화에는 수많은 유형이 있고, 언뜻 보기에는 산점도, 파이 차트, 히트맵 사이에 공통점이 별로 없어 보일 수도 있습니다. 하지만 이 모든 시각화 방식은 데이터 값이 종이 위의 잉크 자국이나 화면 위의 색상 픽셀로 변환되는 과정을 포착하는 공통된 언어로 설명할 수 있습니다. 여기서 핵심은 모든 데이터 시각화가 데이터 값을 결과물의 정량화 가능한 특징으로 연결한다는 것입니다. 이러한 특징을 미학적 요소(aesthetics)라고 부릅니다.
미학적 요소는 주어진 그래픽 요소의 모든 측면을 설명합니다. 그림 ?fig-common-aesthetics에 몇 가지 예시가 나와 있습니다. 모든 그래픽 요소에서 가장 기본이 되는 구성 요소는 역시 요소가 놓이는 위치(position)입니다. 일반적인 2차원 그래픽에서는 x와 y 좌표로 위치를 나타내지만, 다른 좌표계나 1차원 또는 3차원 시각화도 가능합니다. 다음으로 모든 그래픽 요소에는 모양(shape), 크기(size), 색상(color)이 있습니다. 흑백 그림을 만들더라도 배경이 흰색이면 요소는 검은색으로, 배경이 검은색이면 흰색으로 나타나야 하므로 색상의 개념이 필요합니다. 마지막으로 선을 사용해 데이터를 시각화할 때는 선의 너비나 점선 패턴(선 유형)이 달라질 수 있습니다. 그림 ?fig-common-aesthetics에 표시된 것 외에도 데이터 시각화에서 마주하는 미학적 요소는 훨씬 더 다양합니다. 예를 들어 텍스트를 표시할 때는 글꼴 종류, 스타일, 크기를 지정해야 하며, 그래픽 요소들이 겹칠 때는 투명도 등을 설정해야 할 수도 있습니다.
(ref:common-aesthetics) 데이터 시각화에서 흔히 쓰이는 미학적 요소: 위치, 모양, 크기, 색상, 선 너비, 선 유형. 이 중 일부는 연속형 데이터와 이산형 데이터를 모두 표현할 수 있지만(위치, 크기, 선 너비, 색상), 다른 요소들은 대개 이산형 데이터만 표현할 수 있습니다(모양, 선 유형).
미학적 요소는 크게 두 그룹으로 나뉩니다. 연속적인 데이터를 표현할 수 있는 요소와 그렇지 않은 요소입니다. 연속적인 데이터 값은 그 사이에 미세한 중간값이 무수히 존재하는 데이터를 말합니다. 예를 들어 시간은 연속적인 값입니다. 50초와 51초라는 두 시간 사이에는 50.5초, 50.51초, 50.50001초 등 무수히 많은 중간값이 존재하기 때문입니다. 반면 방 안의 사람 수는 이산적인 값입니다. 사람은 5명 혹은 6명일 수 있지만, 5.5명일 수는 없습니다. 그림 ?fig-common-aesthetics의 예시에서 위치, 크기, 색상, 선 너비는 연속적인 데이터를 나타낼 수 있지만, 모양과 선 유형은 대개 이산적인 데이터만을 표현하는 데 쓰입니다.
다음으로 시각화하려는 데이터의 유형을 살펴보겠습니다. 흔히 데이터를 단순히 숫자로 생각하기 쉽지만, 숫자 값은 우리가 마주하는 여러 데이터 유형 중 단 두 가지에 불과합니다. 연속형 및 이산형 숫자 외에도 데이터는 범주형, 날짜나 시간 형식, 또는 텍스트 형식으로 존재할 수 있습니다(표 ?tbl-basic-data-types). 숫자로 이루어진 데이터를 정량적(quantitative) 데이터라고 하며, 범주로 나뉘는 데이터를 정성적(qualitative) 데이터라고 합니다. 정성적 데이터를 담는 변수를 요인(factor)이라 부르고, 그 안의 각 범주를 수준(level)이라고 합니다. 요인의 수준은 대개 순서가 없지만(표 ?tbl-basic-data-types의 ‘개, 고양이, 물고기’ 예시), 수준 사이에 고유한 순서가 존재하는 경우 이를 정렬할 수도 있습니다(표 ?tbl-basic-data-types의 ‘좋음, 보통, 나쁨’ 예시).
| 변수 유형 예시 | 적절한 척도 | 설명 | |
|---|---|---|---|
| 정량적/수치적 1.3, 5.7, 연속적 1.5x | 83, 연속적 10-2 | 임의의 수치 값 유리 | . 정수, 수 또는 실수일 수 있습니다. |
| 정량적/수치적 1, 2, 3, 이산적 | 4 이산적 | 이산 단위의 일 | 숫자. 가장 반적으로 정수이지만 반드시 그런 것은 아닙니다. 예를 들어 숫자 0.5, 1.0, 1.5는 주어진 데이터 세트에 중간 값이 존재할 수 없는 경우 이산적으로 처리될 수도 있습니다. |
| 정성적/범주형 개, 고양이 정렬되지 않음 | , 물고기 이산적 | 순서 없는 | 범주. 고유한 순서가 없는 이산적이고 고유한 범주입니다. 이러한 변수는 요인이라고도 합니다. |
| 정성적/범주형 좋음, 보통 정렬됨 | , 나쁨 이산적 | 순서 있는 범 이 | 주. 순서가 있는 산적이고 고유한 범주입니다. 예를 들어 “보통”은 항상 “좋음”과 “나쁨” 사이에 있습니다. 이러한 변수는 정렬된 요인이라고도 합니다. |
| 날짜 또는 시간 | 2018년 1월 5일, 오전 | 8:03 연속적 또는 이산 | 적 특정 날짜 및/또는 시간. 또한 7월 4일 또는 12월 25일과 같은 일반적인 날짜(연도 없음). |
| 텍스트 | 빠른 갈색 여우가 없 게으른 개를 뛰어넘습니 시나리오에서 접하는 변 | 음 또는 이산적 자유 다. 수 유형. {#tbl-basic-dat | 형식 텍스트. 필요한 경우 범주형으로 처리할 수 있습니다. a-types} |
| 이러한 다양한 데이터 유형 | 의 구체적인 예시는 표 | ?tbl-data-example에서 확 | 인할 수 있습니다. 이 표는 미국 4개 지역의 일일 기온 정상값(30년 평균치)을 보여주는 데이터 세트의 처음 몇 행입니다. 여기에는 월, 일, 위치, 관측소 ID, 기온(화씨)의 5가지 변수가 포함되어 있습니다. 월은 ‘정렬된 요인’, 일은 ‘이산형 수치’, 위치와 관측소 ID는 ‘정렬되지 않은 요인’, 그리고 기온은 ‘연속형 수치’ 변수입니다. |
| 월 일 위치 관측소 | ID 기온 |
1월 1 시카고 USW00014819 25.6 1월 1 샌디에이고 USW00093107 55.2 1월 1 휴스턴 USW00012918 53.9 1월 1 데스밸리 USC00042319 51.0 1월 2 시카고 USW00014819 25.5 1월 2 샌디에이고 USW00093107 55.3 1월 2 휴스턴 USW00012918 53.8 1월 2 데스밸리 USC00042319 51.2 1월 3 시카고 USW00014819 25.3 1월 3 샌디에이고 USW00093107 55.3 1월 3 데스밸리 USC00042319 51.3 1월 3 휴스턴 USW00012918 53.8 ——- —– ———— ———— ————- : 4개 기상 관측소의 일일 기온 정상값을 나열하는 데이터 세트의 처음 12개 행. 데이터 출처: NOAA. {#tbl-data-example}
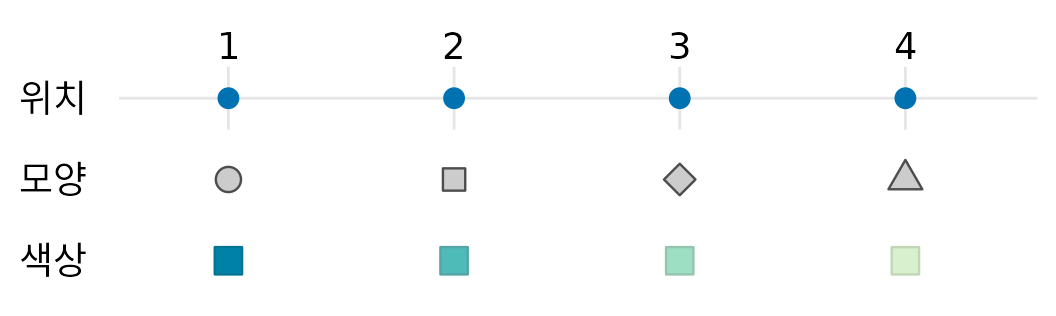
데이터 값을 미학적 요소에 매핑하려면, 어떤 데이터 값이 어떤 시각적 특징에 대응하는지 정의해야 합니다. 예를 들어 그래프에 x축이 있다면, 어떤 데이터 값이 축의 어느 위치에 놓일지 지정해야 합니다. 마찬가지로 어떤 데이터 값이 어떤 모양이나 색으로 표현될지도 결정해야 하죠. 데이터 값과 미학적 요소 사이의 이러한 연결 고리를 척도(scale)라고 합니다. 척도는 데이터와 시각적 요소 간의 일대일 대응 관계를 정의합니다(그림 Figure 2). 여기서 일대일 대응은 매우 중요합니다. 각 데이터 값에 대해 단 하나의 미학적 값이 존재해야 시각화 결과에 모호함이 생기지 않기 때문입니다.
(ref:basic-scales-example) 척도는 데이터 값을 미학적 요소로 연결해주는 가교 역할을 합니다. 여기서는 숫자 1부터 4까지를 위치, 모양, 색상 척도에 매핑했습니다. 각 척도 안에서 숫자는 저마다 고유한 위치, 모양, 색상에 대응합니다.
이제 실제 사례를 살펴봅시다. 표 ?tbl-data-example의 데이터를 기반으로, 기온을 y축에, 날짜를 x축에, 위치를 선의 색상에 매핑하여 실선 그래프로 시각화해보겠습니다. 그 결과 4개 지역의 기온이 일 년 동안 어떻게 변하는지 보여주는 전형적인 꺾은선 그래프가 만들어집니다(그림 Figure 3).
(ref:temp-normals-vs-time) 미국 내 4개 지역의 일일 기온 정상값. 기온은 y축, 날짜는 x축, 그리고 위치는 선의 색상에 매핑되었습니다. 데이터 출처: NOAA.
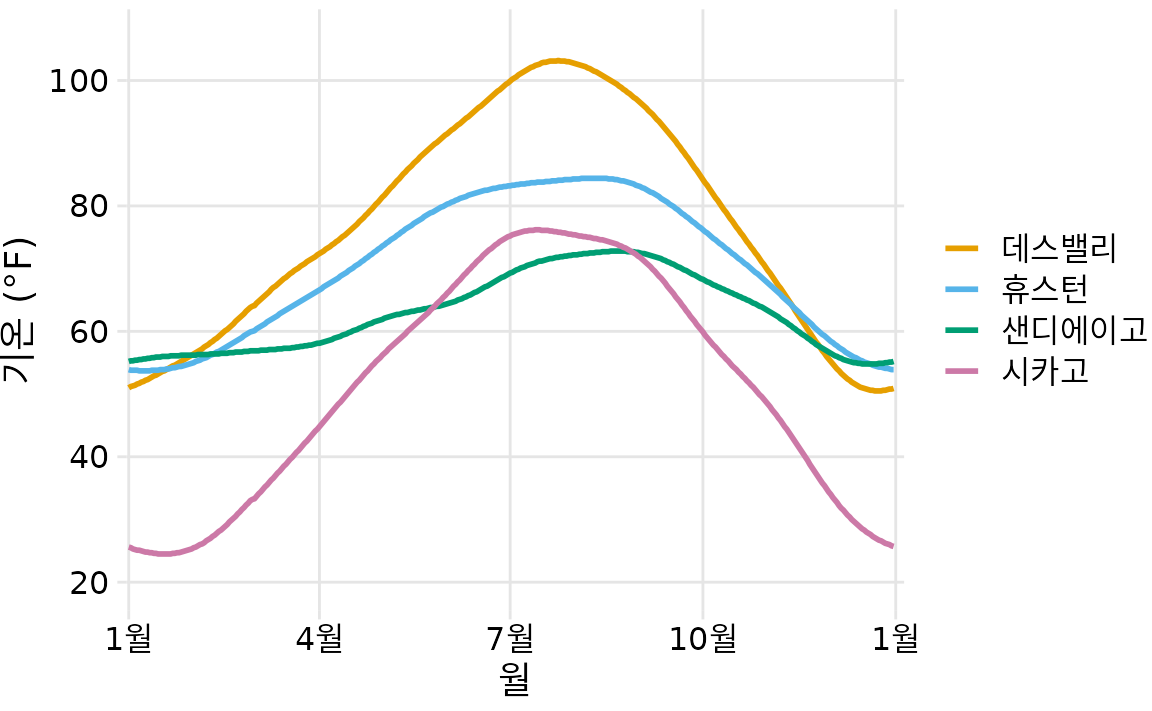
그림 ?fig-temp-normals-vs-time은 기온 데이터의 아주 표준적인 시각화 방식이며, 많은 데이터 분석가가 직관적으로 가장 먼저 선택할 만한 형태입니다. 하지만 어떤 변수를 어떤 척도에 매핑할지는 순전히 우리의 선택에 달려 있습니다. 예를 들어, 기온을 y축이 아닌 ’색상’에 매핑하고 위치를 y축에 매핑할 수도 있습니다. 이 경우 주요 정보인 기온이 색으로 표현되므로, 독자의 눈에 정보가 잘 들어오도록 충분히 넓은 영역을 색으로 채우는 것이 좋습니다(Stone, Albers Szafir, and Setlur 2014). 따라서 여기서는 선이 아닌 정사각형 격자(타일)를 사용하고, 각 달의 평균 기온에 따라 색상을 입혔습니다(그림 Figure 4).
(ref:four-locations-temps-by-month) 미국 4개 지역의 월별 정상 평균 기온. 데이터 출처: NOAA
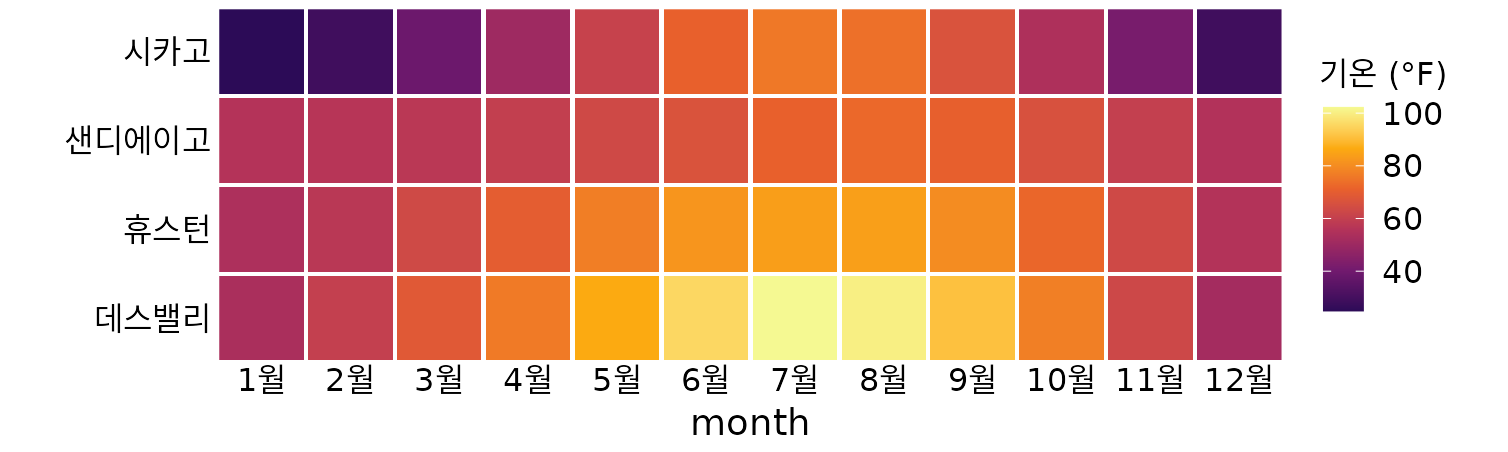
여기서 강조하고 싶은 점은, 그림 ?fig-four-locations-temps-by-month에서 두 개의 위치 척도(x축의 달, y축의 위치) 중 어느 것도 ‘연속형’ 척도가 아니라는 사실입니다. 달은 12개의 수준을 가진 ’정렬된 요인’이고, 위치는 4개의 수준을 가진 ’정렬되지 않은 요인’입니다. 따라서 두 위치 척도 모두 ’이산형’입니다. 이산형 위치 척도의 경우, 대개 각 수준을 축을 따라 일정한 간격으로 배치합니다. 요인이 정렬되어 있다면(달의 경우처럼) 수준을 적절한 순서대로 배치해야 하고, 정렬되지 않았다면(위치의 경우처럼) 순서는 임의로 정할 수 있습니다. 저는 가장 추운 시카고부터 가장 더운 데스밸리 순으로 위치를 배치하여 색상 변화가 자연스럽게 보이도록 했습니다. 물론 다른 순서를 선택했더라도 그래프 자체는 유효했을 것입니다.
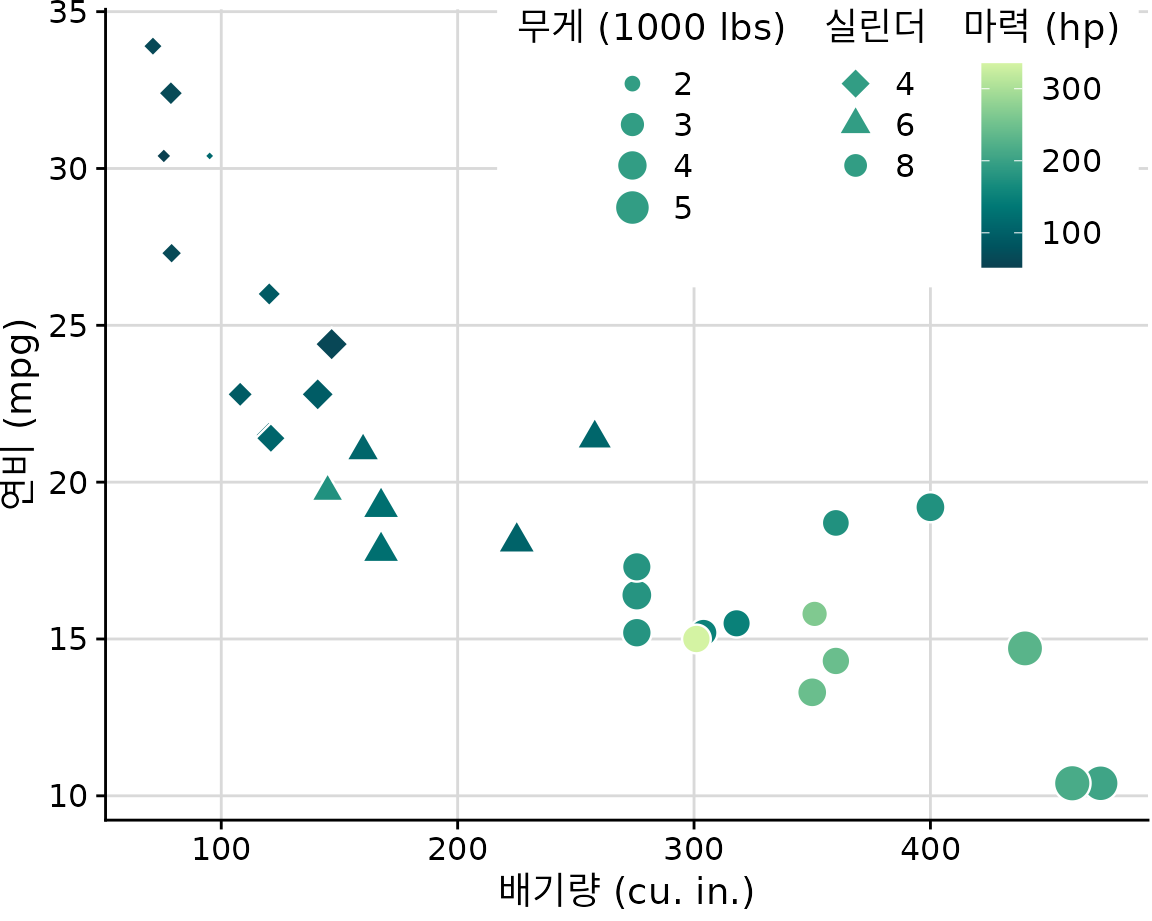
그림 ?fig-temp-normals-vs-time과 Figure 4 모두 총 3개의 척도(위치 척도 2개, 색상 척도 1개)를 사용했습니다. 이는 기본적인 시각화에서 흔히 볼 수 있는 구성이지만, 원한다면 한 번에 더 많은 척도를 사용할 수도 있습니다. 그림 ?fig-mtcars-five-scale은 위치 2개, 색상 1개, 크기 1개, 모양 1개 등 총 5개의 척도를 사용하여 데이터 세트의 각기 다른 5가지 변수를 하나의 그림에 담아냈습니다.
(ref:mtcars-five-scale) 32개 차종(1973-74년 모델)의 연비 대비 배기량 그래프. 이 그림은 총 5가지 척도를 사용하여 데이터를 표현합니다. (i) x축(배기량), (ii) y축(연비), (iii) 점의 색상(마력), (iv) 점의 크기(무게), (v) 점의 모양(실린더 수). 5가지 변수 중 4가지(배기량, 연비, 마력, 무게)는 수치형 연속 변수이며, 나머지 하나(실린더 수)는 수치형 이산 변수 혹은 정성적 순서 변수로 볼 수 있습니다. 데이터 출처: Motor Trend, 1974.
Stone, M., D. Albers Szafir, and V. Setlur. 2014. “An Engineering Model for Color Difference as a Function of Size.” In 22nd Color and Imaging Conference. Society for Imaging Science and Technology.