둘 이상의 정량적 변수 간의 연관성 시각화
대부분의 데이터 세트는 두 개 이상의 정량적 변수를 포함하며, 우리는 종종 이 변수들이 서로 어떤 관계를 맺고 있는지 알고 싶어 합니다. 예를 들어 동물의 키, 몸무게, 몸길이, 일일 에너지 섭취량 등이 기록된 데이터를 생각해 봅시다. 이 중 두 변수(예: 키와 몸무게) 사이의 관계를 보여줄 때는 보통 산점도(scatterplot)를 사용합니다. 한 번에 세 개 이상의 변수를 표현해야 한다면 버블 차트, 산점도 행렬, 혹은 상관도(correlogram) 등을 선택할 수 있습니다. 데이터의 차원이 매우 높은 경우에는 주성분 분석(PCA) 같은 기법을 동원해 차원을 축소하여 시각화하는 것이 유용합니다.
산점도
123마리의 파랑어치(blue jay)를 측정한 데이터를 통해 산점도의 기본과 변형을 살펴보겠습니다. 이 데이터에는 각 새의 머리 길이(부리 끝부터 머리 뒤쪽까지), 두개골 크기(머리 길이에서 부리를 제외한 부분), 그리고 체질량이 기록되어 있습니다. 상식적으로 이 변수들 사이에는 밀접한 관계가 있을 것입니다. 예를 들어 부리가 긴 새는 두개골도 클 가능성이 높고, 덩치가 큰(체질량이 높은) 새는 전반적인 머리 크기도 클 것입니다.
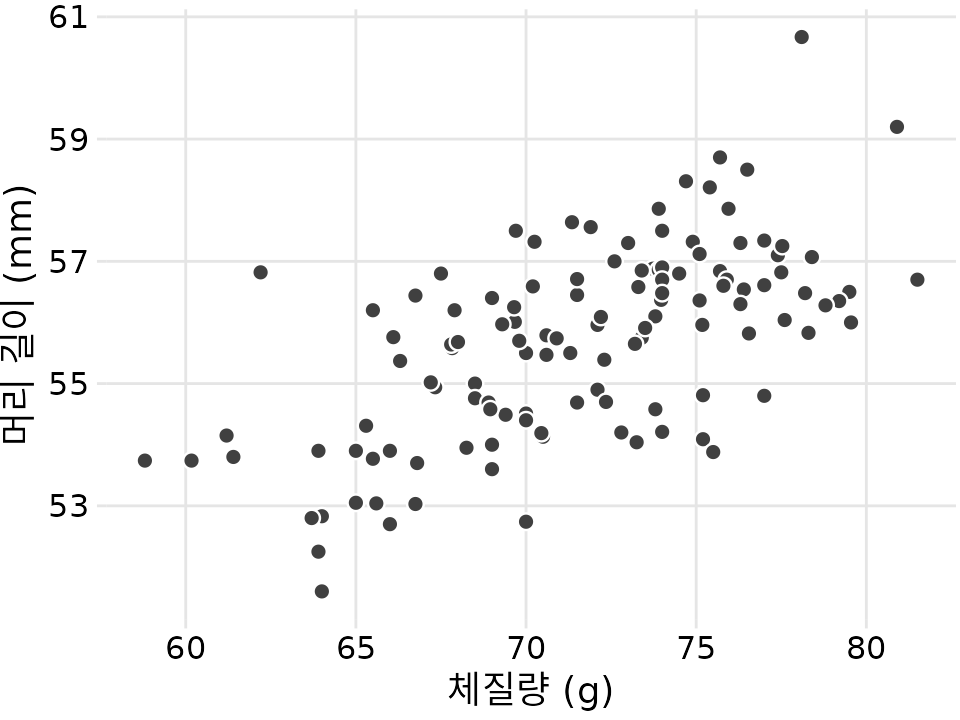
이런 관계를 파악하기 위해 먼저 ’체질량’과 ’머리 길이’를 축으로 하는 그래프를 그려봅시다(그림 Figure 14.1). 가로축(x축)에는 체질량을, 세로축(y축)에는 머리 길이를 할당하고 각 새를 하나의 점으로 표시했습니다. 점들이 구름처럼 흩어져 있다고 해서 이를 산점도라고 부릅니다. 그래프를 보면 체질량이 늘어날수록 머리 길이도 길어지는 뚜렷한 경향성을 확인할 수 있습니다.
(ref:blue-jays-scatter) 파랑어치 123마리의 체질량과 머리 길이의 관계. 몸무게가 많이 나가는 새일수록 머리 길이도 긴 경향이 있습니다. (데이터 출처: Keith Tarvin, Oberlin College)
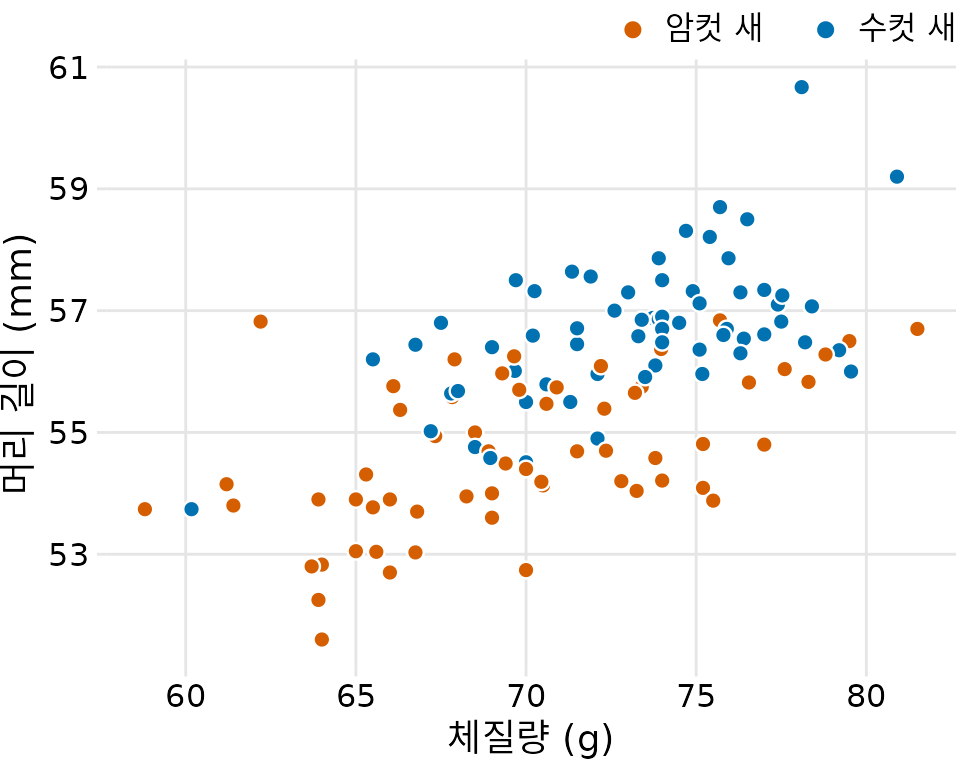
파랑어치 암수의 특성 차이가 이 관계에 어떤 영향을 주는지도 궁금할 수 있습니다. 이를 확인하기 위해 점의 색상을 성별에 따라 나누어 보았습니다(그림 Figure 14.2). 이를 통해 머리 길이와 체질량의 관계가 성별에 따라 다르게 나타난다는 사실을 알 수 있습니다. 같은 체중일 때 암컷(주황색)이 수컷(파란색)보다 머리가 짧은 편이며, 암컷이 전반적으로 수컷보다 몸무게도 덜 나가는 경향이 있습니다.
(ref:blue-jays-scatter-sex) 성별에 따른 파랑어치의 체질량과 머리 길이 관계. 같은 몸무게라면 수컷(파란색)이 암컷(주황색)보다 머리가 더 긴 경향을 보입니다. (데이터 출처: Keith Tarvin, Oberlin College)
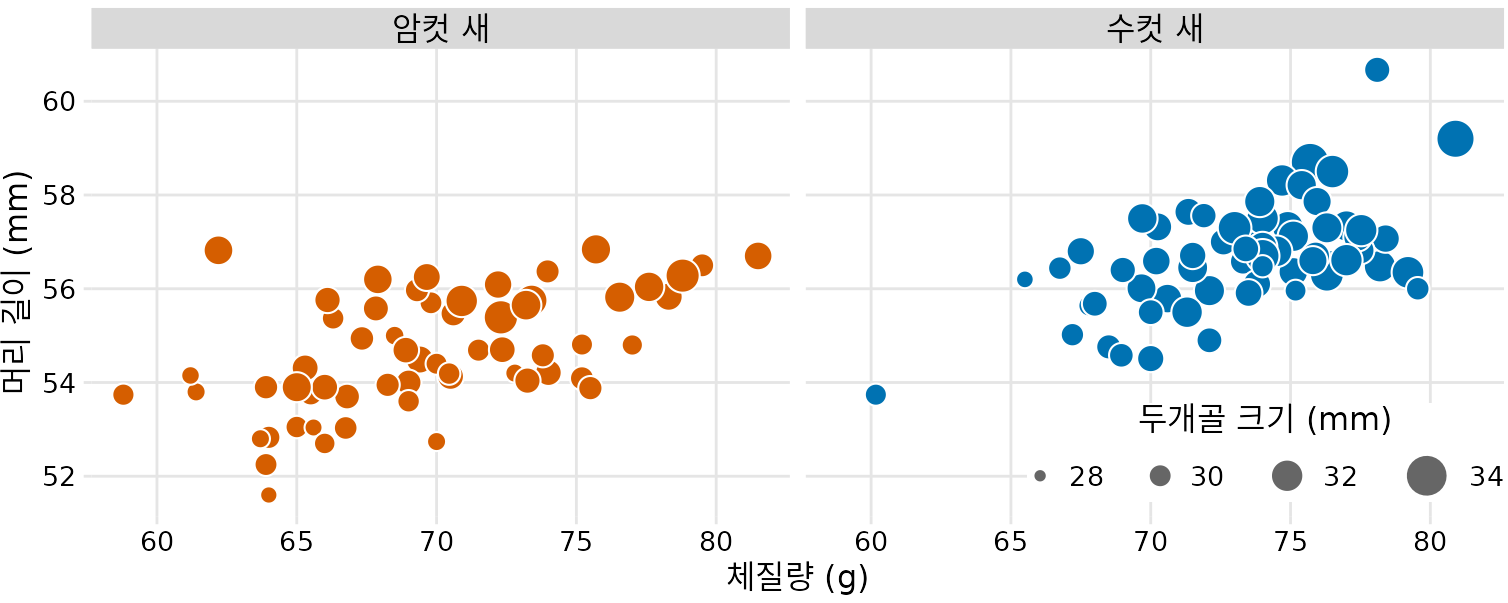
머리 길이는 부리 끝부터 머리 뒤쪽까지의 길이이므로, 머리가 길다는 것은 부리가 길거나 두개골이 크다는 뜻이 될 수 있습니다. 이제 ’두개골 크기’라는 또 다른 변수를 추가해 봅시다. 이미 x축, y축, 색상을 사용하고 있으므로, 새로운 변수를 표현하기 위해 점의 크기를 활용할 수 있습니다. 이렇게 점의 크기로 정보를 나타내는 그래프를 버블 차트(bubble chart)라고 합니다(그림 Figure 14.3).
(ref:blue-jays-scatter-bubbles) 체질량, 머리 길이, 성별에 더해 두개골 크기를 점의 크기로 표현한 버블 차트. 머리 길이와 두개골 크기는 대체로 비례하지만, 두개골에 비해 유난히 부리가 긴 개체도 존재함을 알 수 있습니다. (데이터 출처: Keith Tarvin, Oberlin College)
버블 차트에는 치명적인 단점이 있습니다. 위치(x, y)와 크기라는 서로 다른 방식의 척도를 동시에 사용하기 때문에, 변수 간의 연관 강도를 직관적으로 비교하기가 매우 어렵습니다. 우리 눈은 위치의 차이보다 크기의 차이를 훨씬 덜 정교하게 인식합니다. 또한 버블이 너무 커지면 그래프를 가리기 때문에 크기의 변화 폭을 크게 잡기도 어렵습니다. 그림 ?fig-blue-jays-scatter-bubbles에서도 두개골 크기 차이를 강조하기 위해 크기를 조절해 보았으나, 여전히 두개골 크기와 다른 변수들 사이의 관계를 한눈에 파악하기는 힘듭니다.
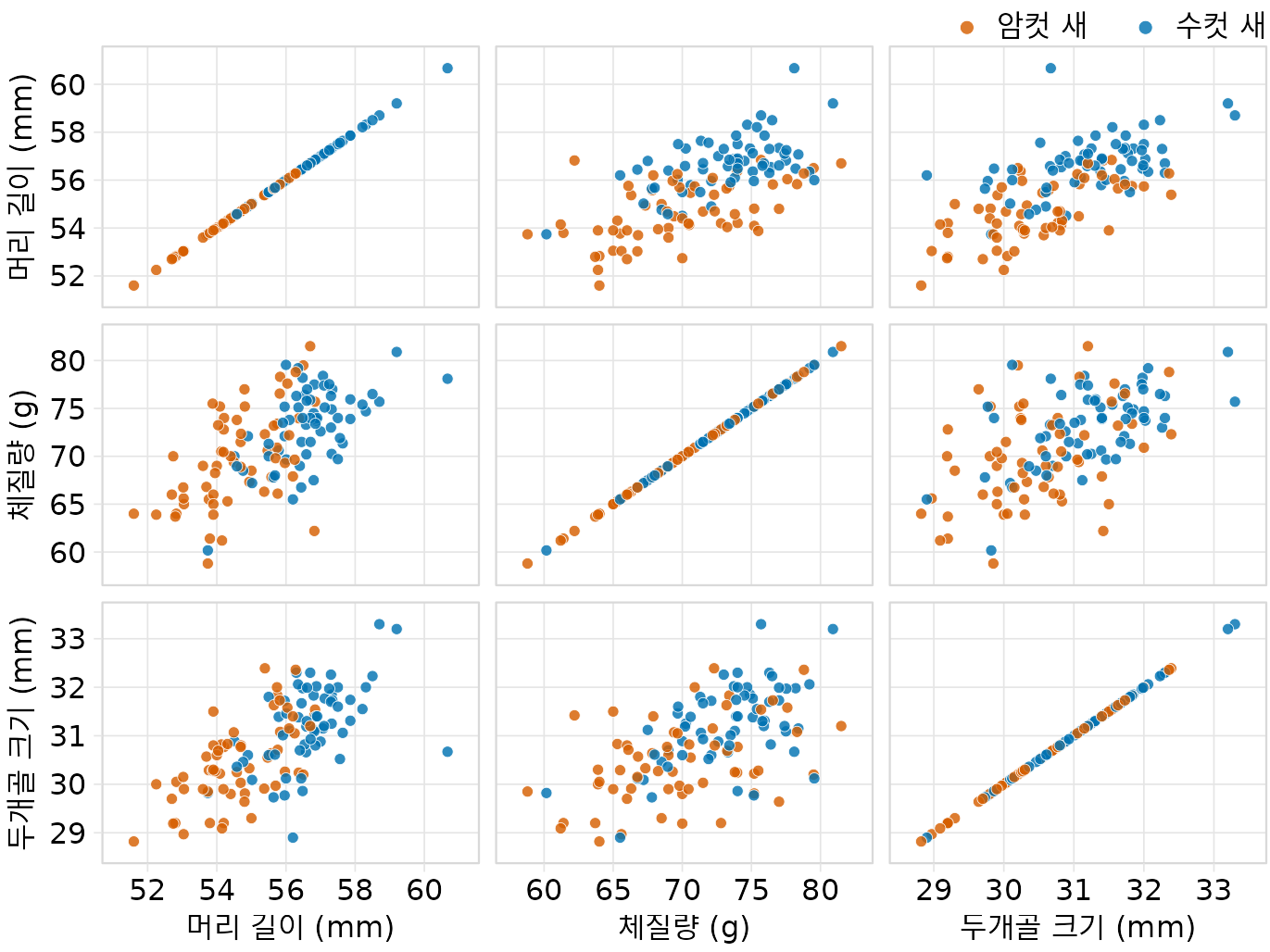
그래서 버블 차트보다는 모든 변수의 조합을 격자 형태로 보여주는 산점도 행렬(scatterplot matrix)을 만드는 것이 훨씬 더 바람직합니다(그림 Figure 14.4). 이 그래프를 통하면, 두개골 크기와 체질량의 관계는 암수 구분이 덜한 반면, 머리 길이와 체질량의 관계는 성별에 따라 확연히 갈린다는 사실을 명확히 알 수 있습니다. 즉, 조건이 같다면 수컷이 암컷보다 부리가 더 길다는 결론에 쉽게 도달할 수 있습니다.
(ref:blue-jays-scatter-all) 파랑어치의 머리 길이, 체질량, 두개골 크기에 대한 산점도 행렬. 버블 차트(Figure 14.3)와 같은 데이터를 보여주지만, 위치 비교를 통해 변수 간의 상관관계를 훨씬 명확하게 파악할 수 있게 해줍니다. (데이터 출처: Keith Tarvin, Oberlin College)
상관도
비교해야 할 정량적 변수가 4개 이상으로 늘어나면 산점도 행렬도 너무 복잡해져서 읽기 힘들어집니다. 이럴 때는 원시 데이터 점을 일일이 보여주기보다는, 변수 쌍 사이의 연관성 정도를 수치화하여 시각화하는 것이 효과적입니다. 이때 가장 많이 쓰이는 통계량이 상관 계수(correlation coefficient, \(r\))입니다. 상관 계수는 두 변수가 함께 변하는 정도를 -1에서 1 사이의 숫자로 나타냅니다. 0은 아무런 관계가 없음을, 1이나 -1에 가까울수록 아주 밀접한 관계가 있음을 뜻합니다. 부호가 (+)면 비례 관계, (-)면 반비례 관계를 의미합니다. 그림 ?fig-correlations는 상관 계수에 따라 점들의 분포가 어떻게 달라지는지 보여줍니다.
(ref:correlations) 상관 계수 \(r\)의 크기와 방향에 따른 분포 양상. 윗줄은 양의 상관관계(비례), 아랫줄은 음의 상관관계(반비례)를 나타내며, 왼쪽에서 오른쪽으로 갈수록 관계가 강해집니다.

상관 계수는 다음과 같이 정의됩니다.
\[ r = \frac{\sum_i (x_i - \bar x)(y_i - \bar y)}{\sqrt{\sum_i (x_i-\bar x)^2}\sqrt{\sum_i (y_i-\bar y)^2}}, \] 여기서 \(x_i\)와 \(y_i\)는 두 개의 관찰 집합이고 \(\bar x\)와 \(\bar y\)는 해당 표본 평균입니다. 이 공식에서 몇 가지 관찰을 할 수 있습니다. 첫째, 공식은 \(x_i\)와 \(y_i\)에 대해 대칭적이므로 x와 y의 상관 관계는 y와 x의 상관 관계와 동일합니다. 둘째, 개별 값 \(x_i\)와 \(y_i\)는 해당 표본 평균과의 차이 맥락에서만 공식에 들어가므로 전체 데이터 세트를 상수만큼 이동하면(예: 일부 상수 \(C\)에 대해 \(x_i\)를 \(x_i' = x_i + C\)로 대체) 상관 계수는 변경되지 않습니다. 셋째, 데이터를 다시 스케일링하면(\(x_i' = C x_i\)) 상수 \(C\)가 공식의 분자와 분모 모두에 나타나므로 상쇄되므로 상관 계수도 변경되지 않습니다.
상관 계수를 행렬 형태로 시각화한 것을 상관도(correlogram)라고 합니다. 법의학 현장에서 수집한 유리 조각들의 성분 데이터를 예로 들어봅시다. 7가지 광물 산화물의 함량을 측정했으므로, 총 21가지의 상관 계수 조합이 나옵니다. 이를 그림 ?fig-forensic-correlations1처럼 색칠된 타일 행렬로 표현하면, 마그네슘(Mg)이 다른 성분들과 전반적으로 반비례 관계에 있고 알루미늄(Al)과 바륨(Ba)은 강한 비례 관계에 있다는 등의 패턴을 순식간에 파악할 수 있습니다.
(ref:forensic-correlations1) 유리 조각 214개 샘플의 광물 함량 상관도. 색상은 각 성분 쌍 사이의 상관 계수를 나타냅니다. (데이터 출처: B. German)
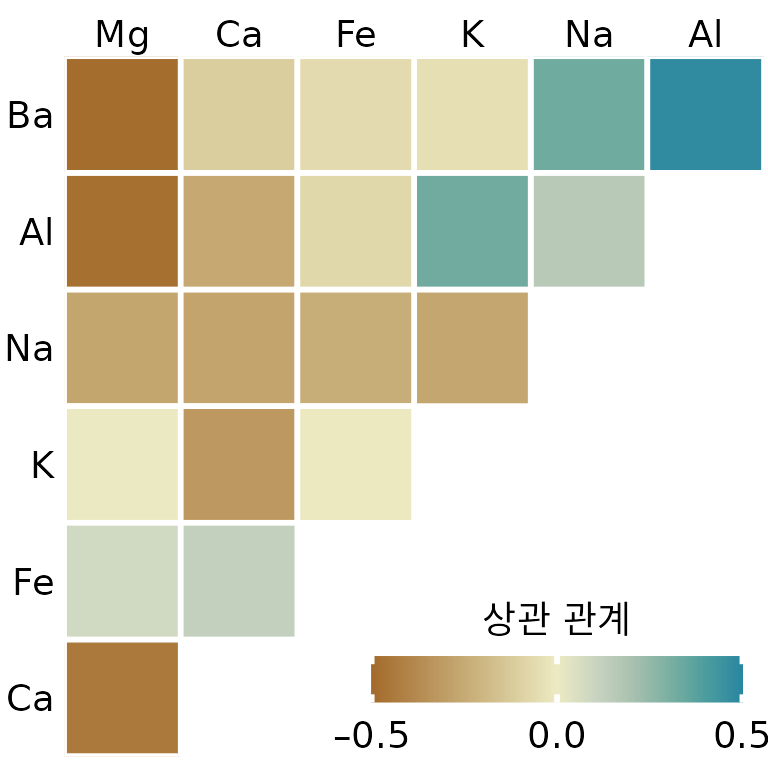
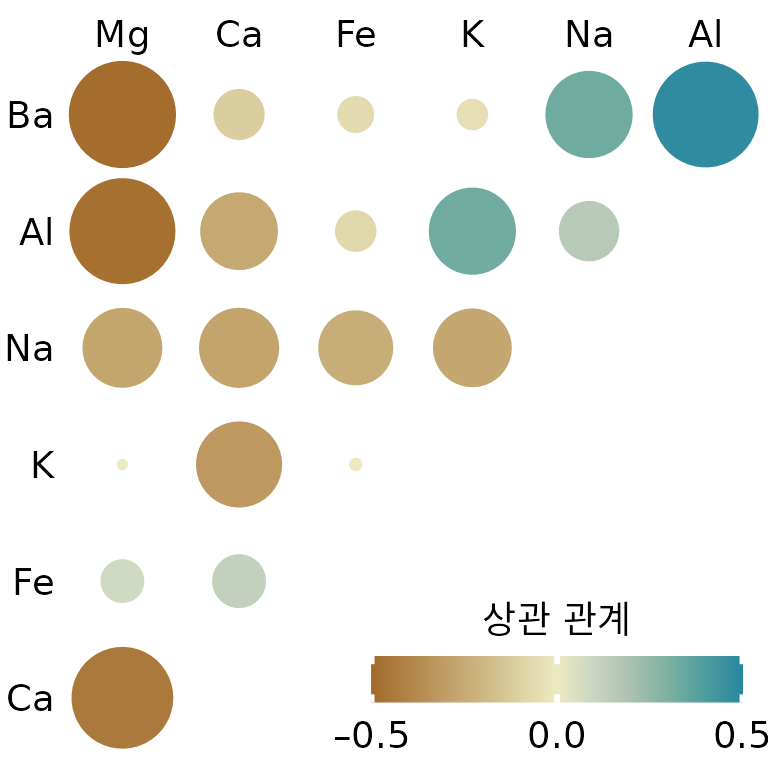
그림 ?fig-forensic-correlations1처럼 타일의 색상만 쓰면 상관관계가 낮은(0에 가까운) 항목들이 시각적으로 잘 억제되지 않는다는 단점이 있습니다. 이를 보완하기 위해 색상뿐 아니라 원의 크기를 상관 계수의 절댓값에 비례하도록 그릴 수 있습니다(그림 Figure 14.7). 이렇게 하면 관계가 옅은 항목은 작게 표시되어 무시하기 쉬워지고, 중요한 관계들만 뚜렷하게 도드라집니다.
(ref:forensic-correlations2) 색상과 원의 크기를 동시에 활용한 유리 샘플 상관도. 원의 크기를 통해 관계가 약한 항목들을 시각적으로 억제함으로써, 중요한 패턴이 더 잘 드러나게 했습니다. (데이터 출처: B. German)
상관도는 데이터를 통계적으로 요약해서 보여준다는 장점이 있지만, 실제 데이터 점들을 모두 숨겨버리기 때문에 자칫 잘못된 결론으로 이끌 위험이 있습니다. 가능한 한 원본 데이터를 직접 보여주는 것이 늘 바람직하며, 그 대안으로 ‘차원 축소’ 기법을 활용하면 원시 데이터의 느낌을 살리면서도 중요한 패턴을 효과적으로 추출할 수 있습니다.
차원 축소
차원 축소(dimension reduction)는 고차원 데이터의 여러 변수가 사실 서로 얽혀 있어서, 몇 가지 핵심적인 요소(차원)만으로도 전체 정보를 충분히 설명할 수 있다는 점에 착안한 기법입니다. 사람의 신체 치수를 예로 들어봅시다. 키, 몸무게, 팔다리 길이, 허리둘레 등 수많은 측정값이 있겠지만, 이들은 결국 그 사람의 ’전체적인 덩치(사이즈)’라는 하나의 핵심 차원과 밀접하게 연결되어 있습니다. 키가 큰 사람은 다리도 길고 몸무게도 더 나갈 확률이 높은 식입니다. 그 다음으로 중요한 차원은 ’성별’일 것입니다. 비슷한 체구라 하더라도 남녀에 따라 골격이나 신체 비율이 다르기 때문입니다.
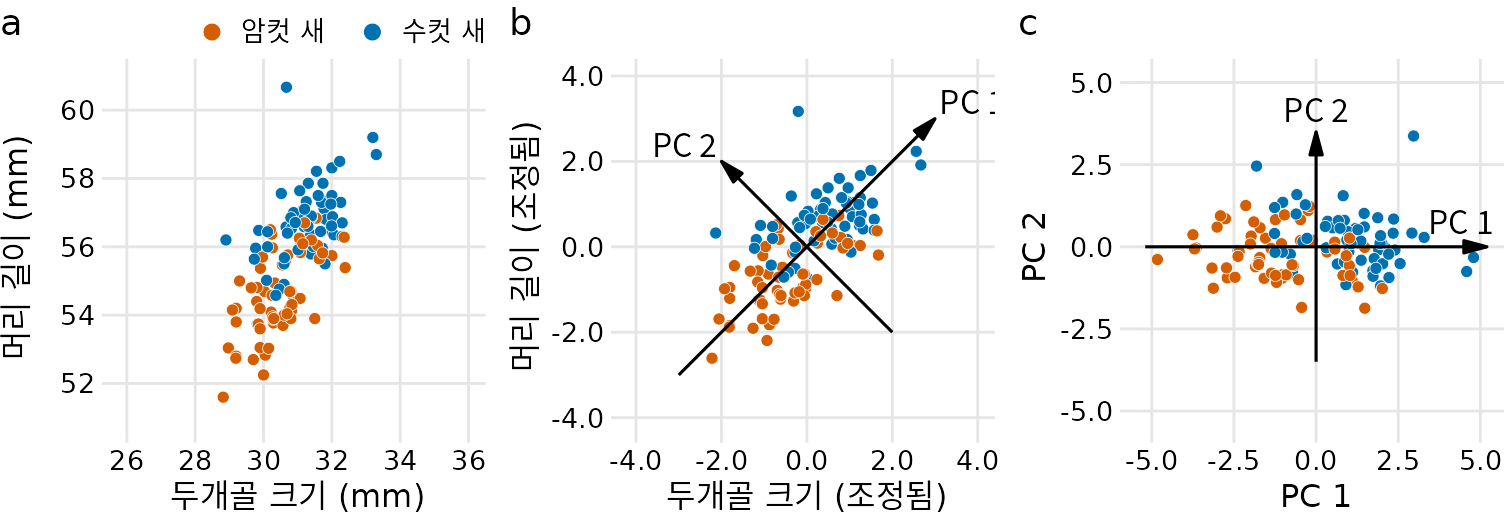
수많은 차원 축소 기법 중 가장 널리 쓰이는 것이 주성분 분석(Principal Component Analysis, PCA)입니다. PCA는 변수들을 조합해 서로 상관관계가 없는 새로운 가공의 변수들(주성분, PC)을 만들어냅니다. 첫 번째 주성분(PC1)이 데이터의 가장 큰 변동을 설명하며, 뒤로 갈수록 나머지 자잘한 변동을 설명합니다. 대개 처음 두세 개의 주성분만으로도 데이터의 본질적인 특징을 충분히 시각화할 수 있습니다.
(ref:blue-jays-PCA) 2차원 주성분 분석(PCA)의 원리. (a) 파랑어치의 머리 길이와 두개골 크기 원본 데이터. (b) 데이터를 표준화한 후, 변동이 가장 큰 방향을 따라 주성분 축(PC1, PC2)을 설정합니다. (c) 설정한 주성분 축으로 데이터를 투영(회전)한 결과입니다.
PCA 결과를 해석할 때는 보통 두 가지에 주목합니다. 하나는 ’주성분이 어떤 원래 변수들로 구성되었는가’이고, 다른 하나는 ’주성분 공간 상에서 데이터 점들이 어디에 위치하는가’입니다. 유리 성분 데이터를 통해 이 둘을 살펴봅시다.
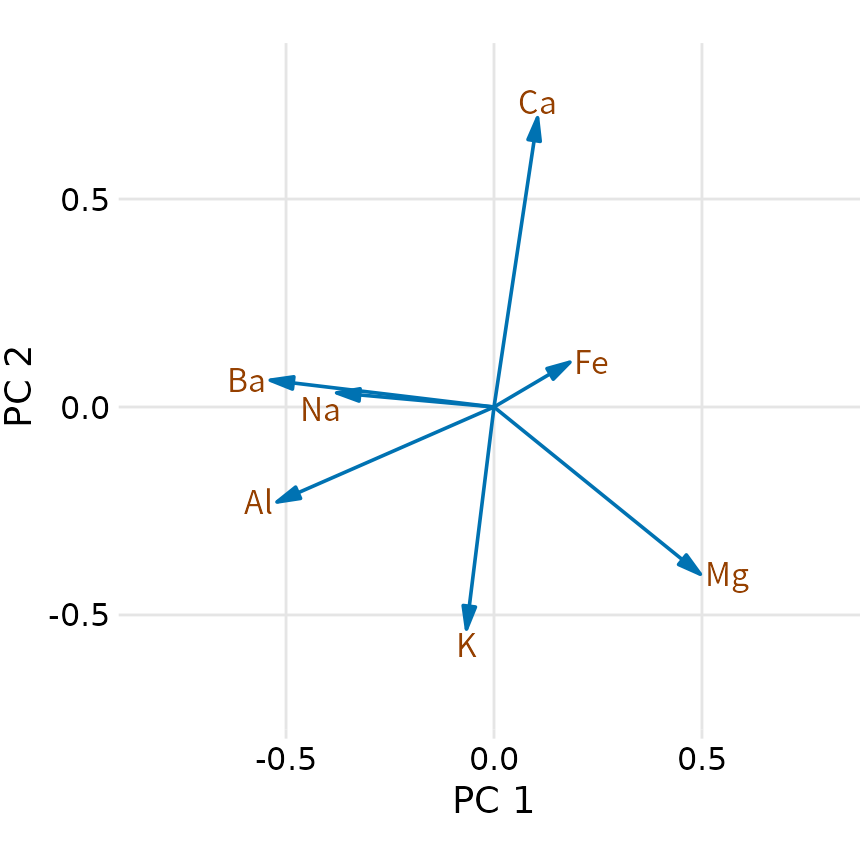
먼저 주성분의 구성을 보면(그림 Figure 14.9), 첫 번째 주성분(PC1)에는 주로 바륨과 나트륨 성분이 큰 영향을 주었고, 두 번째 주성분(PC2)에는 칼슘과 칼륨 성분이 결정적인 역할을 했음을 알 수 있습니다. 화살표의 방향과 길이는 각 성분이 주성분을 결정하는 데 얼마나 기여했는지를 시각적으로 보여줍니다.
(ref:forensic-PCA-rotation) 유리 데이터 PCA에서 처음 두 주성분(PC1, PC2)의 구성 성분. 각 화살표는 원래의 성분이 해당 주성분에 기여하는 정도를 나타냅니다.
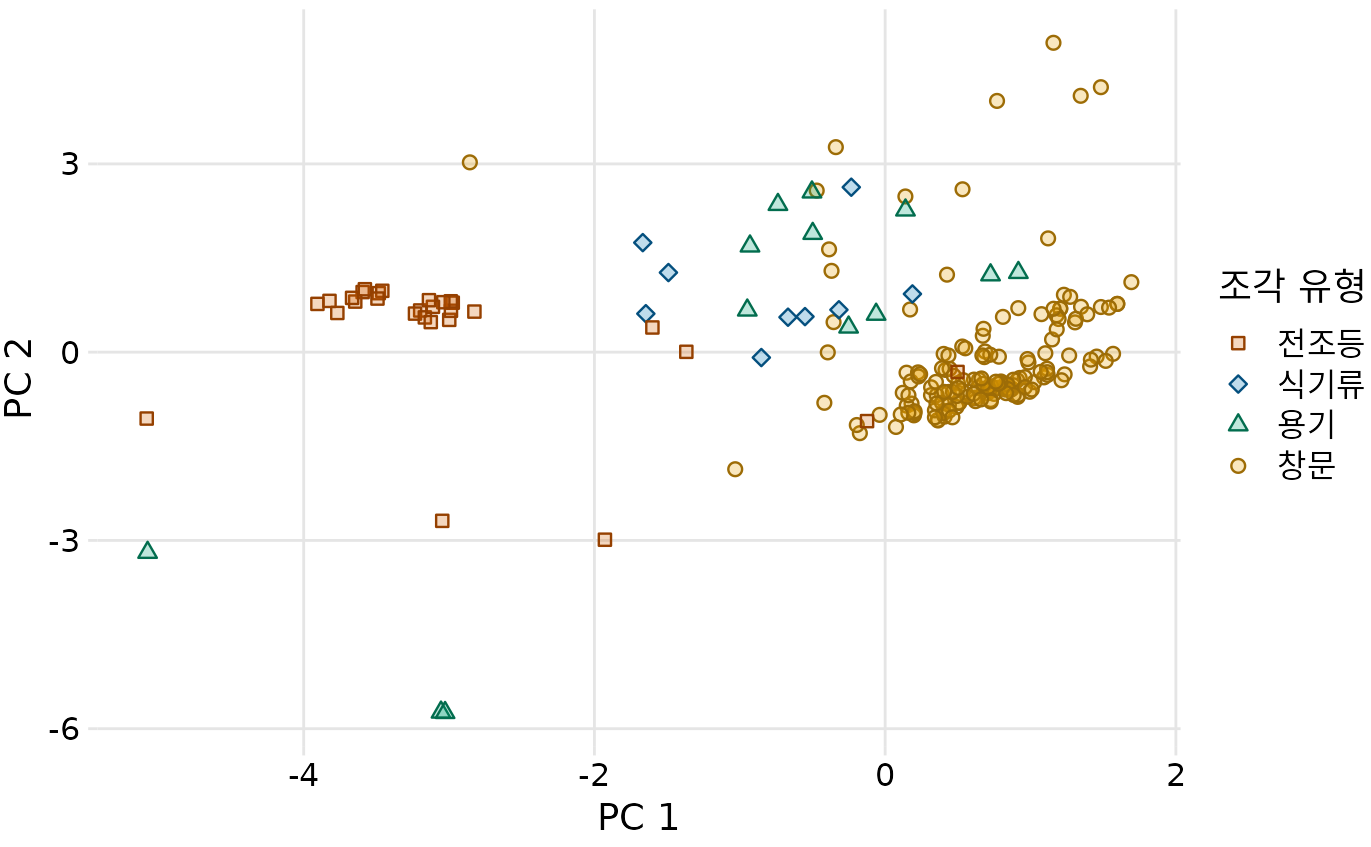
이제 실제 데이터 점들을 이 주성분 공간에 뿌려봅니다(그림 Figure 14.10). 놀랍게도 성분 데이터만으로 전조등 유리, 창문 유리 등이 서로 다른 군집을 형성하는 것을 볼 수 있습니다. 이를 통해 “창문 유리는 마그네슘 함량이 높고 바륨이나 나트륨은 적은 편이지만, 전조등 유리는 정반대의 특성을 가진다”는 식의 통찰력 있는 결론을 내릴 수 있습니다.
(ref:forensic-PCA) 주성분 공간 상에 투영된 유리 조각 데이터. 성분 데이터만으로 전조등, 창문 등 유리의 용도별로 뚜렷한 군집이 형성되는 것을 확인할 수 있습니다.
쌍을 이룬 데이터
다변량 데이터의 특수한 사례로 쌍을 이룬 데이터(paired data)가 있습니다. 동일한 대상을 서로 다른 두 조건에서 측정했거나(예: 한 사람의 왼팔과 오른팔 길이), 시간 차를 두고 반복 측정한 경우(예: 다이어트 전후 몸무게)가 이에 해당합니다. 이런 데이터는 다른 데이터들끼리 비교하는 것보다 ’한 쌍 내에서의 차이’를 보여주는 것이 훨씬 효율적입니다.
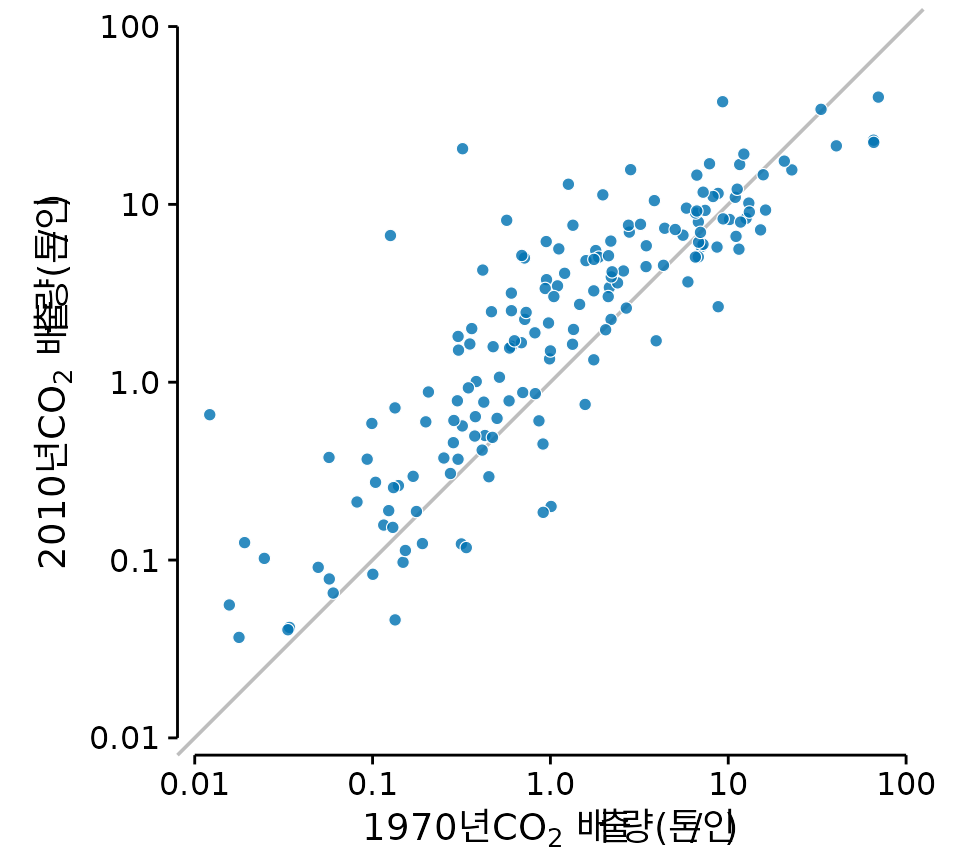
이때 가장 좋은 방법은 \(x = y\) 대각선이 그려진 산점도를 활용하는 것입니다. 만약 두 측정값 사이에 아무런 차이가 없다면 모든 점은 대각선 위에 놓일 것입니다. 하지만 어떤 계통적인 변화가 일어났다면 점들은 대각선 위나 아래로 쏠리게 됩니다. 그림 ?fig-CO2-paired-scatter는 1970년과 2010년의 국가별 1인당 탄소 배출량을 비교한 것입니다. 점들이 대각선보다 뚜렷하게 위쪽으로 치우쳐 있는 것을 볼 수 있는데, 이는 40년 사이 대부분의 국가에서 탄소 배출량이 늘어났음을 한눈에 보여줍니다.
(ref:CO2-paired-scatter) 1970년과 2010년 국가별 1인당 탄소(\(CO_2\)) 배출량 비교. 대각선보다 위쪽에 있는 점들은 2010년의 배출량이 더 많아졌음을 뜻합니다. (데이터 출처: CDIAC)
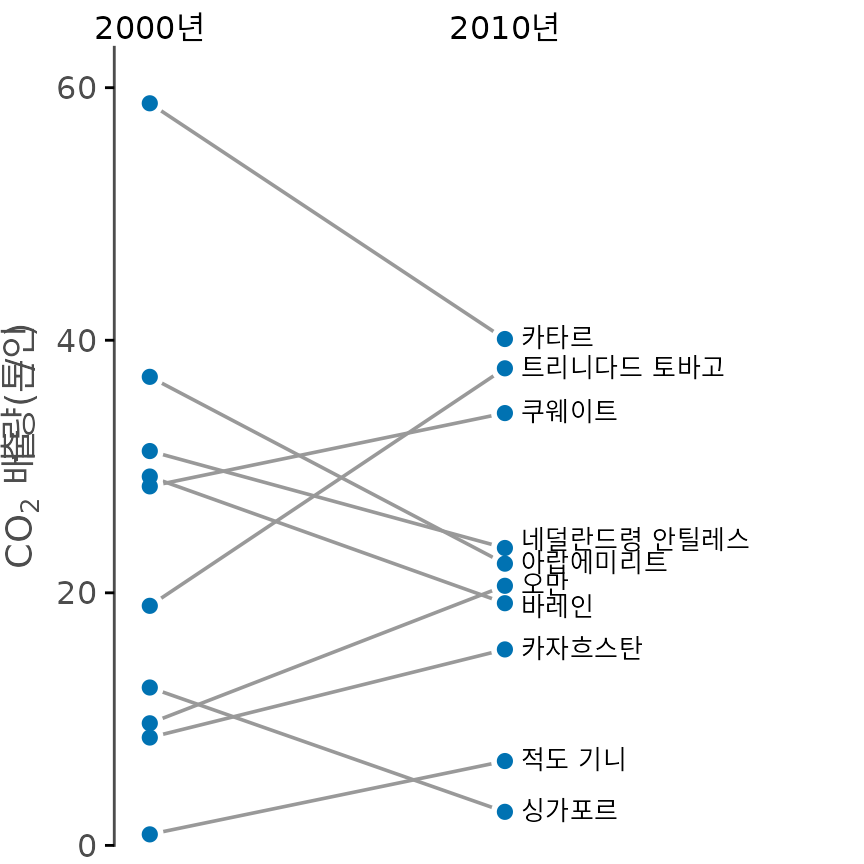
데이터 포인트가 너무 많지 않고 개별 사례의 변화에 더 주목하고 싶다면 경사 그래프(slopegraph)가 훌륭한 대안입니다. 양쪽 열에 점을 찍고 이를 선으로 연결하여 변화의 방향과 크기를 강조하는 방식입니다. 그림 ?fig-CO2-slopegraph는 2000년부터 2010년 사이 탄소 배출량 변화가 가장 컸던 10개국의 사례를 보여줍니다.
(ref:CO2-slopegraph) 2000년과 2010년 사이 1인당 탄소 배출량 변화가 가장 컸던 10개국의 경사 그래프. (데이터 출처: CDIAC)
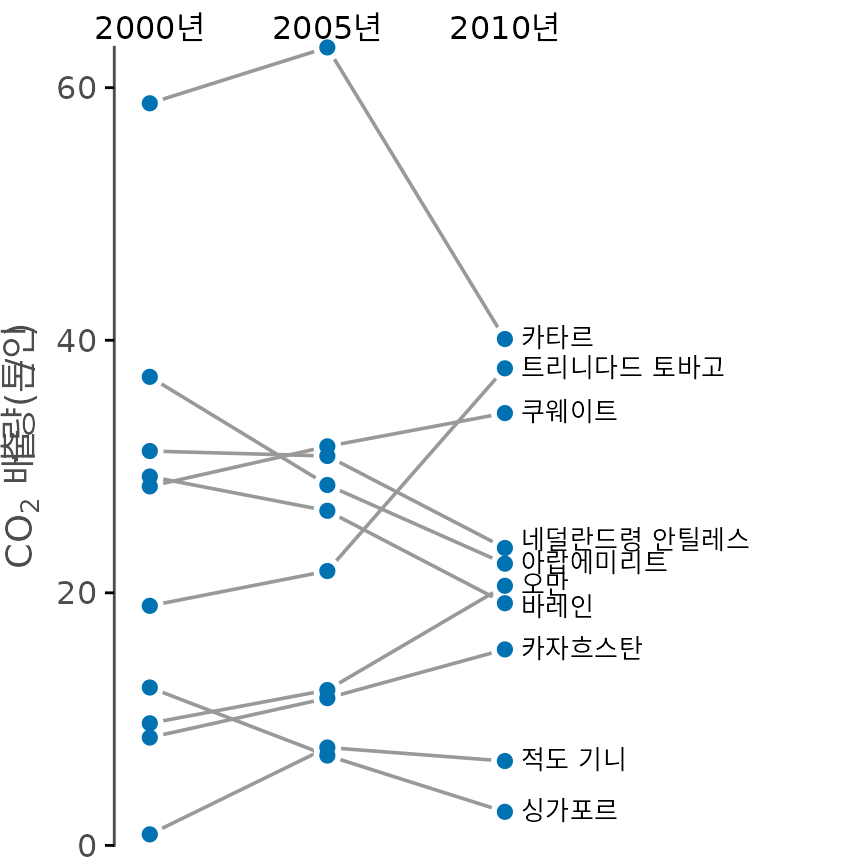
경사 그래프의 또 다른 장점은 셋 이상의 시점도 한 번에 비교할 수 있다는 것입니다. 그림 ?fig-CO2-slopegraph-three-year처럼 2000년, 2005년, 2010년의 데이터를 나열하면, 전체적인 추세는 물론 특정 기간에 배출량이 급격히 변한 국가(예: 카타르나 트리니다드 토바고)를 쉽게 찾아낼 수 있습니다.
(ref:CO2-slopegraph-three-year) 2000년, 2005년, 2010년 세 시점을 비교한 탄소 배출량 경사 그래프. (데이터 출처: CDIAC)