곡선형 축을 가진 좌표계
어떤 종류의 데이터 시각화를 만들든, 우리는 데이터 값이 그래픽의 어디에 놓일지 결정하는 ’위치 척도’를 정의해야 합니다. 데이터 포인트를 서로 다른 위치에 배치하지 않고는 시각화 자체가 불가능하기 때문입니다. 설령 선을 따라 데이터를 한 줄로 늘어놓기만 하더라도 위치 정보는 필수적입니다. 일반적인 2차원 시각화의 경우, 한 점의 위치를 고유하게 지정하려면 두 개의 숫자가 필요하며, 따라서 두 개의 위치 척도가 동원됩니다. 대개 이 두 척도는 그래프의 x축과 y축이 되지만, 항상 그런 것은 아닙니다. 또한 이 척도들이 기하학적으로 어떻게 배열되는지도 지정해야 합니다. 보통 x축은 수평으로, y축은 수직으로 그리지만 상황에 따라 다른 방식을 택할 수도 있습니다. 예를 들어 y축이 x축에 대해 비스듬하게 그려지거나, 한 축이 원형으로 돌고 다른 한 축이 중심에서 바깥으로 뻗어나가는 방사형으로 그려질 수도 있습니다. 이처럼 위치 척도들의 집합과 그 기하학적 배치 방식을 통틀어 좌표계(coordinate system)라고 부릅니다.
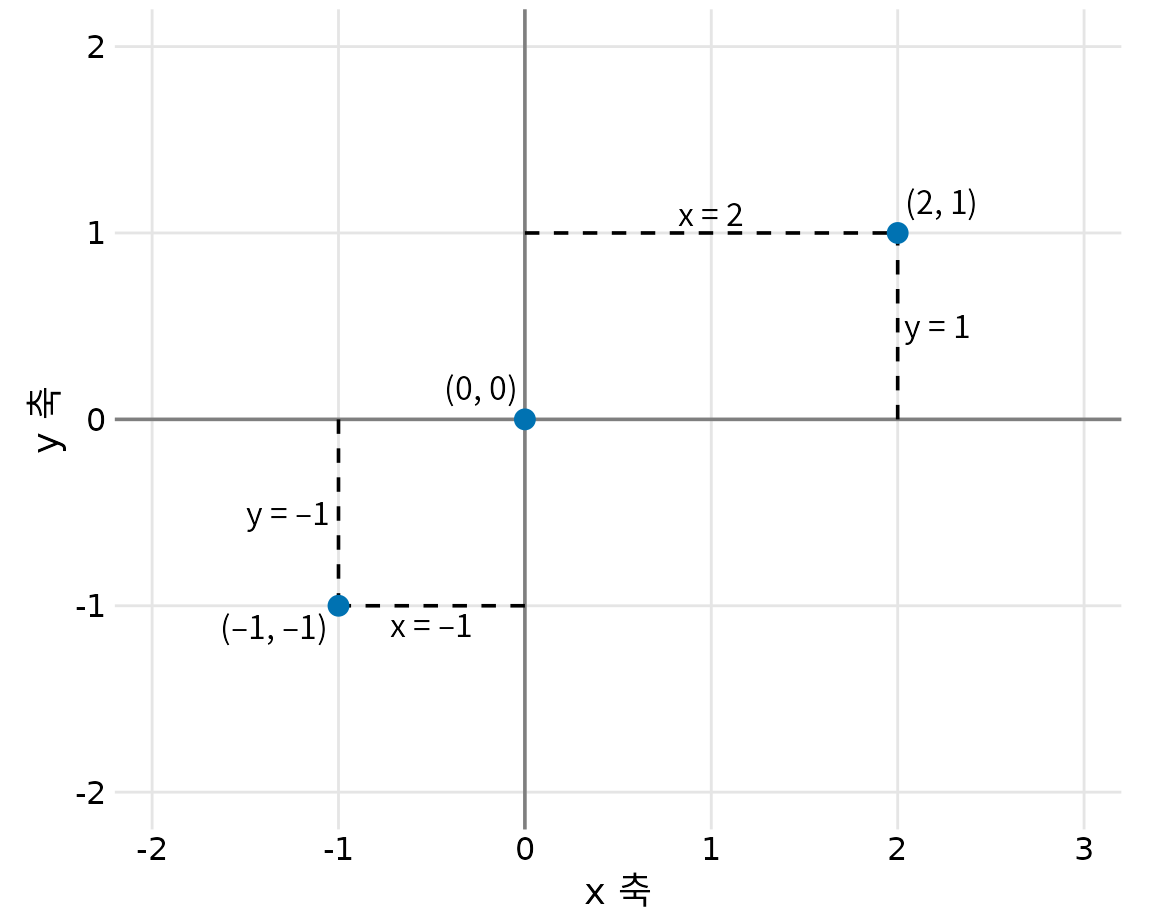
데이터 시각화에서 가장 널리 쓰이는 좌표계는 2차원 데카르트 좌표계(Cartesian coordinate system)입니다. 각 위치는 x와 y 값에 의해 고유하게 결정됩니다. x축과 y축은 서로 직각을 이루며, 데이터 값은 두 축을 따라 균일한 간격으로 배치됩니다(그림 Figure 5.1). 이 두 축은 물리적으로 연속적인 위치 척도이며 양수와 음수 실수를 모두 표현할 수 있습니다. 좌표계를 온전히 정의하려면 각 축이 담아낼 숫자 범위를 지정해야 합니다. 그림 ?fig-cartesian-coord에서 x축은 -2.2에서 3.2까지, y축은 -2.2에서 2.2까지의 범위를 갖습니다. 이 범위 안에 있는 데이터 값들은 그래프상의 해당 위치에 표시되며, 범위를 벗어나는 데이터는 제외됩니다.
(ref:cartesian-coord) 표준 데카르트 좌표계. 관례적으로 수평 축은 x, 수직 축은 y라고 부릅니다. 두 축은 일정한 간격의 격자를 형성합니다. 여기서는 x와 y 격자선이 각각 1단위씩 떨어져 있습니다. 점 (2, 1)은 원점 (0, 0)에서 오른쪽으로 2단위(x), 위쪽으로 1단위(y)만큼 떨어져 있습니다. 점 (-1, -1)은 원점에서 왼쪽으로 1단위, 아래쪽으로 1단위만큼 떨어져 있습니다.
하지만 데이터 값은 단순한 숫자가 아니라 고유한 ’단위’를 가집니다. 온도를 잰다면 섭씨(℃)나 화씨(℉)가 단위가 될 것이고, 거리는 킬로미터(km)나 마일(mile), 시간은 분, 시간, 일 등으로 측정될 것입니다. 데카르트 좌표계에서 축 위의 격자선 간격은 바로 이러한 데이터 단위의 이산적인 단계를 나타냅니다. 예를 들어 온도 척도에서는 10도마다, 거리 척도에서는 5킬로미터마다 격자선이 그어질 수 있습니다.
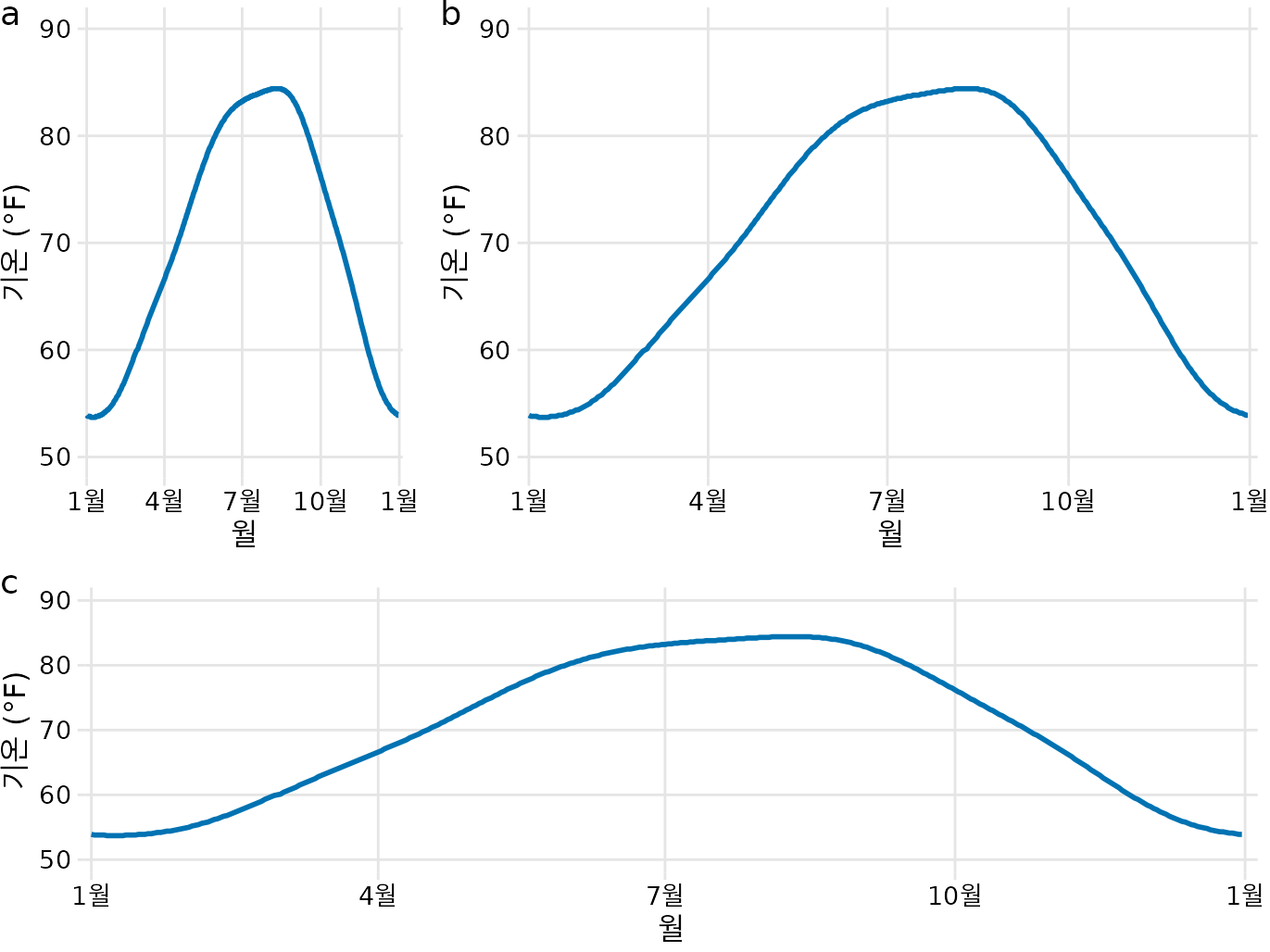
데카르트 좌표계의 두 축은 서로 다른 단위를 나타낼 수 있습니다. 이는 서로 다른 유형의 변수를 x와 y에 매핑할 때 매우 흔하게 일어납니다. 예를 들어 그림 ?fig-temp-normals-vs-time에서는 날짜별 기온을 그렸습니다. y축은 화씨 온도로 20도마다 격자선이 있고, x축은 월 단위로 3개월마다 격자선이 있습니다. 이처럼 두 축의 단위가 다를 때는 한 축을 늘리거나 줄여도 시각화 자체는 유효합니다(그림 Figure 5.2). 어떤 비율을 택할지는 전달하려는 이야기에 달려 있습니다. 세로로 긴 그림은 y축의 변화(기온 변화)를 강조하고, 가로로 넓은 그림은 그 반대가 될 것입니다. 위치 간의 중요한 차이가 눈에 잘 띄도록 적절한 종횡비(aspect ratio)를 선택하는 것이 이상적입니다.
(ref:temperature-normals-Houston) 텍사스주 휴스턴의 일일 기온 정상값. 기온은 y축, 날짜는 x축에 매핑되었습니다. (a), (b), (c)는 같은 데이터를 서로 다른 종횡비로 시각화한 예시입니다. 세 형태 모두 온도 데이터를 시각화하는 올바른 방법입니다. 데이터 출처: NOAA.
반대로 x축과 y축이 같은 단위를 나타낼 때는 두 축의 격자 간격이 동일해야 합니다. 그래야만 x축이나 y축 방향으로 같은 물리적 거리만큼 이동했을 때, 그것이 같은 데이터 단위의 변화를 의미하게 됩니다. 예를 들어 휴스턴의 일일 기온을 샌디에이고의 기온과 비교하여 그릴 때(그림 Figure 5.3 (a)), 두 축 모두 같은 온도 단위를 사용하므로 격자선이 정확한 정사각형을 이루도록 해야 합니다.
(ref:temperature-normals-Houston-San-Diego) 텍사스주 휴스턴과 캘리포니아주 샌디에이고의 일일 기온 정상값 비교. 1, 4, 7, 10월의 첫날을 강조하여 시간적 흐름을 표시했습니다. (a) 화씨 기온 기준. (b) 섭씨 기온 기준. 데이터 출처: NOAA.
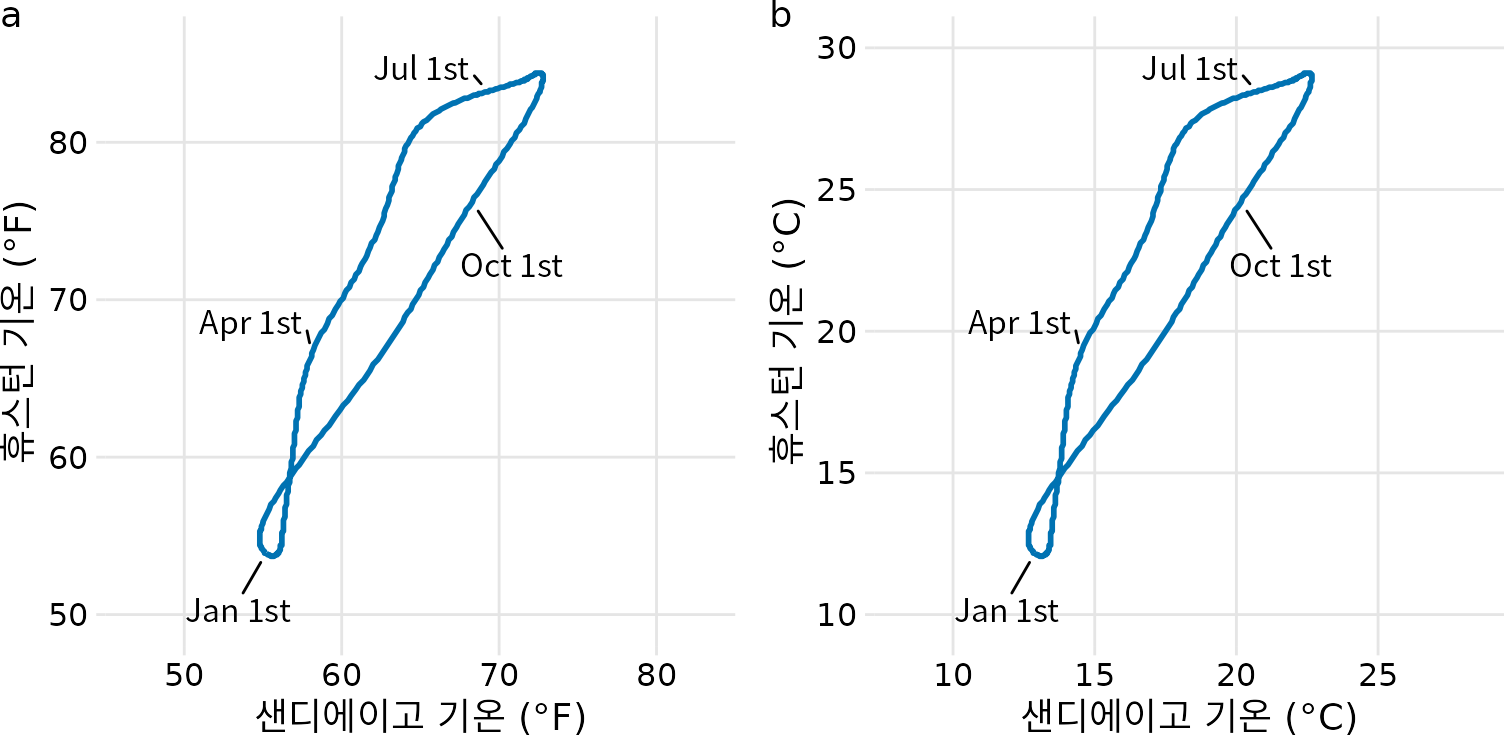
데이터의 단위를 바꾸면 어떻게 될지 궁금할 수 있습니다. 사실 단위란 것은 어느 정도 인위적인 것이고, 사람마다 선호하는 단위가 다를 수 있죠. 단위를 바꾸는 일은 대개 선형 변환(모든 데이터에 상수를 더하거나 빼기, 혹은 곱하기)에 해당합니다. 다행히 데카르트 좌표계는 이러한 선형 변환에 대해 불변하는 성질이 있습니다. 즉, 데이터의 단위를 바꾸고 그에 맞춰 축을 조정하면 결과물인 그림 자체는 변하지 않습니다. 그림 ?fig-temperature-normals-Houston-San-Diego의 (a)부분과 (b)부분을 비교해보세요. 둘 다 같은 데이터를 보여주지만 (a)는 화씨를, (b)는 섭씨를 사용했습니다. 격자선의 위치와 축의 숫자는 다르지만, 데이터가 그려진 모습은 완벽하게 일치합니다.
데카르트 좌표계에서 축을 따라 그어진 격자선들은 데이터 단위 기준로나 시각화 결과로나 일정한 간격을 유지합니다. 이러한 위치 척도를 선형(linear) 척도라고 합니다. 선형 척도는 대개 데이터를 정확하게 보여주지만, 때로는 비선형(non-linear) 척도가 더 적합한 경우도 있습니다. 비선형 척도에서는 데이터 단위의 일정한 변화가 시각적으로는 일정하지 않게 나타나거나, 반대로 시각적인 일정한 간격이 데이터의 비일정한 변화를 의미하게 됩니다.
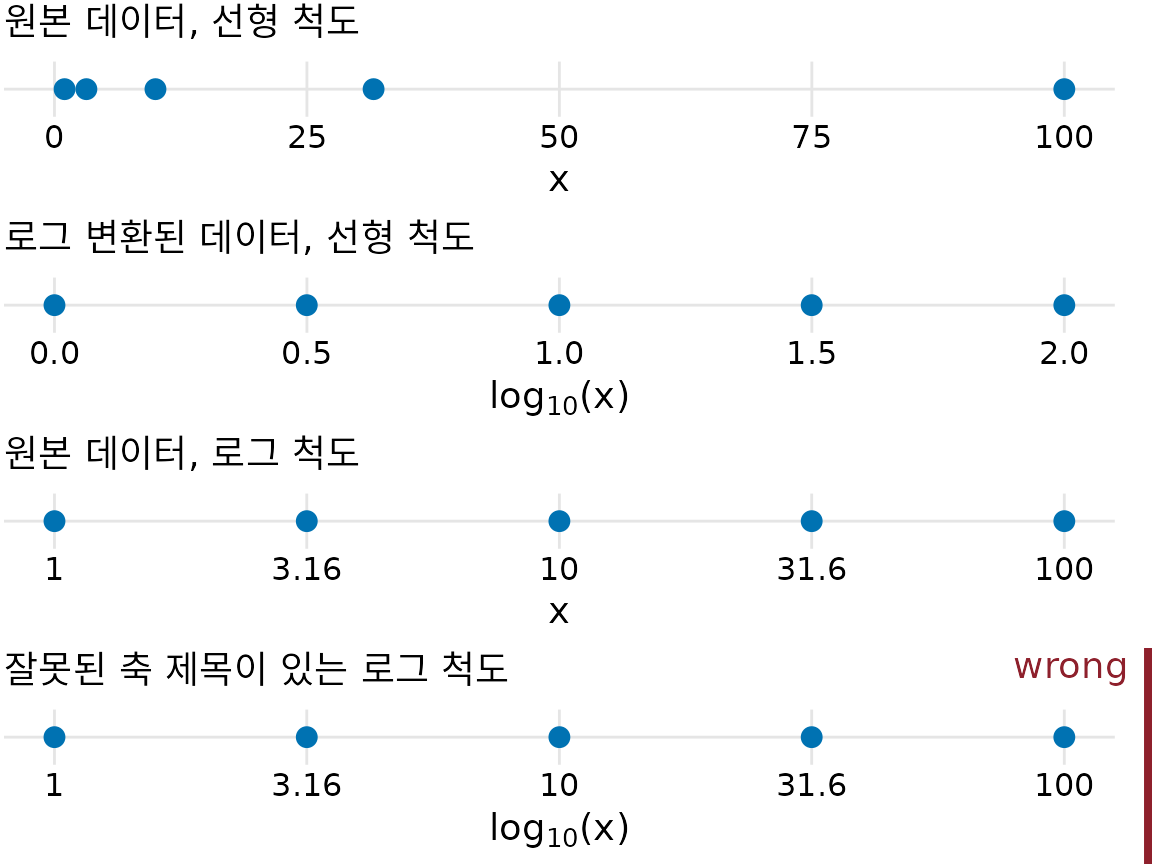
가장 흔히 쓰이는 비선형 척도는 로그 척도(logarithmic scale)입니다. 로그 척도는 곱셈 관계를 선형적으로 보여주므로, 한 단위의 이동은 일정한 비율의 곱을 의미합니다. 로그 척도를 만들려면 데이터 값에 로그를 취하고 축의 레이블을 다시 지수화하는 과정을 거칩니다. 이 과정은 그림 ?fig-linear-log-scales에 잘 나타나 있으며, 여기서 숫자 1, 3.16, 10, 31.6, 100이 선형 척도와 로그 척도에서 어떻게 배치되는지 볼 수 있습니다. 3.16이나 31.6이 생뚱맞아 보일 수 있지만, 이들은 로그 척도상에서 1과 10 사이, 그리고 10과 100 사이의 정확히 중간 지점입니다. \(10^{0.5} = \sqrt{10} \approx 3.16\)이며, \(3.16 \times 3.16 \approx 10\)이 성립하기 때문입니다. 마찬가지로 \(10^{1.5} = 10 \times 10^{0.5} \approx 31.6\)입니다.
(ref:linear-log-scales) 선형 척도와 로그 척도의 관계. 점들은 데이터 값 1, 3.16, 10, 31.6, 100을 나타냅니다. 이들은 로그 척도상에서 같은 간격으로 놓입니다. 이 점들을 선형 척도에 그대로 그리거나, 로그 변환 후 선형 척도에 그리거나, 혹은 로그 척도 자체에 그릴 수 있습니다. 여기서 주의할 점은 로그 척도를 쓸 때 축 제목은 ’log(x)’가 아니라 원래 변수 이름인 ’x’여야 한다는 것입니다.
수학적으로만 보면 로그 변환된 데이터를 선형 척도에 그리는 것과, 원래 데이터를 로그 척도에 그리는 것 사이에는 차이가 없습니다(그림 Figure 5.4). 하지만 실제로는 로그 척도를 사용하는 것이 훨씬 바람직합니다. 축의 눈금 레이블이 원래의 숫자 형태를 유지하므로 독자가 데이터를 해석하는 데 힘을 덜 써도 되기 때문입니다. 또한 로그의 밑(base)에 대한 혼동도 줄일 수 있습니다. 로그 변환된 데이터는 자연로그(ln)를 썼는지 밑이 10인 상용로그를 썼는지 헷갈리기 쉽고, ’log(x)’처럼 밑을 표시하지 않은 모호한 레이블도 흔합니다. 따라서 로그 척도를 쓸 때는 항상 어떤 밑을 썼는지 확인하고, 축 레이블에 명확히 명시하는 것이 중요합니다.
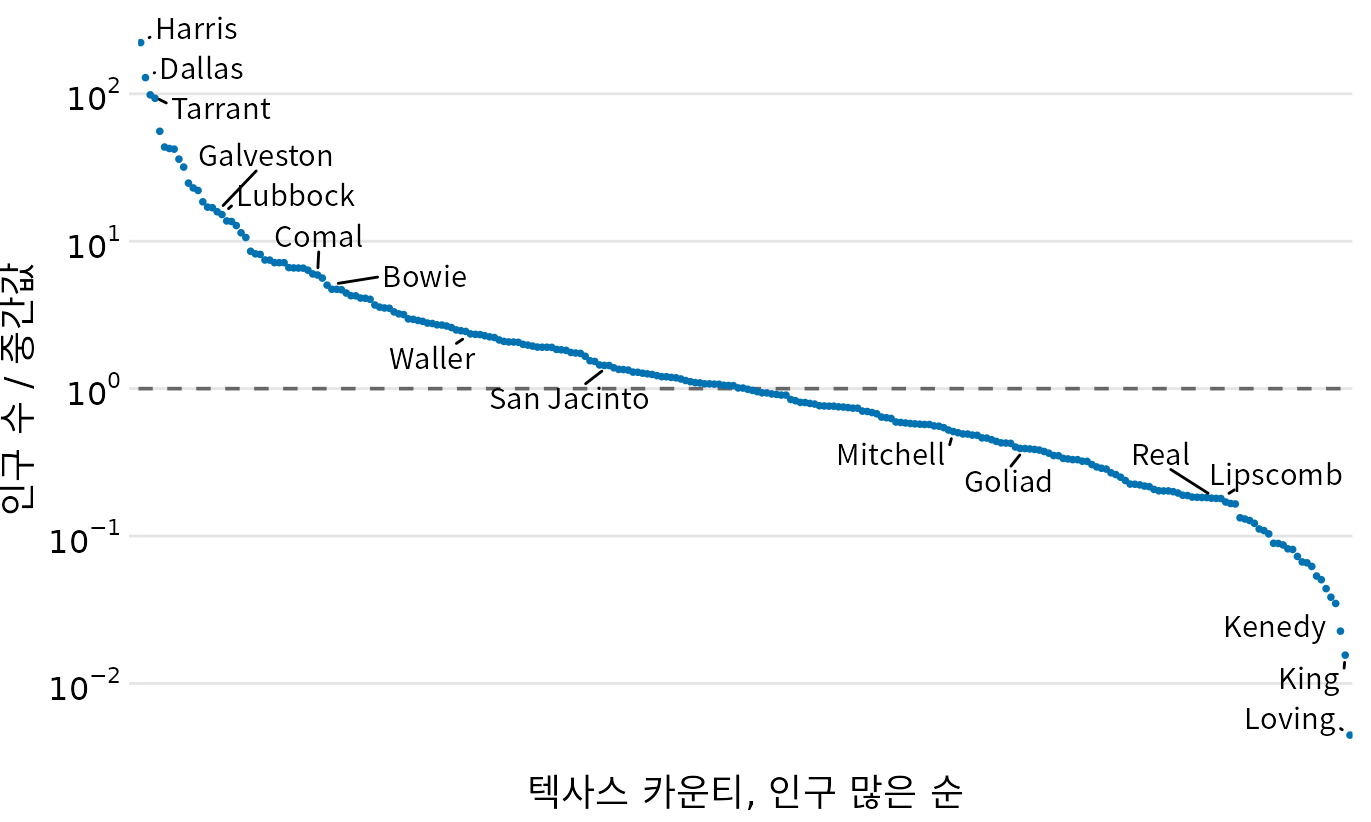
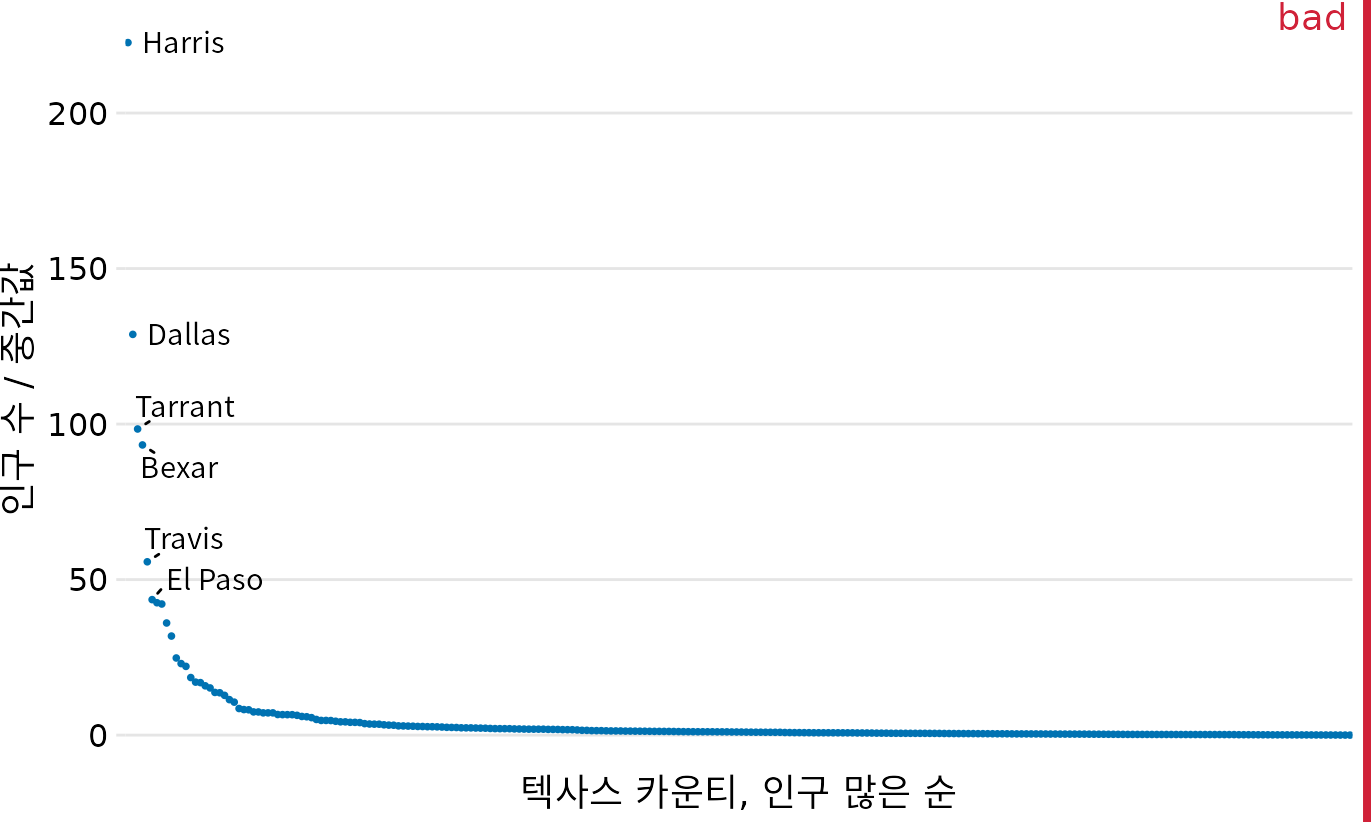
로그 척도 위의 곱셈은 선형 척도 위의 덧셈처럼 보이므로, 로그 척도는 곱셈이나 나눗셈을 통해 얻은 데이터를 표현할 때 자연스러운 선택이 됩니다. 특히 비율(ratio) 데이터는 대개 로그 척도에 그려야 합니다. 예를 들어 텍사스주의 각 카운티 인구수를 중앙값으로 나눈 비율 데이터를 생각해 봅시다. 이 비율은 1보다 클 수도 작을 수도 있으며, 1인 경우는 정확히 중앙값 인구를 가졌음을 뜻합니다. 이 비율을 로그 척도에 시각화하면 텍사스 카운티의 인구 분포가 중앙값을 기준으로 대칭적으로 퍼져 있음을 한눈에 알 수 있습니다. 인구가 가장 많은 곳은 중앙값의 100배가 넘고, 가장 적은 곳은 100분의 1도 안 된다는 사실이 명확히 드러나죠(그림 Figure 5.5). 반면 선형 척도는 인구가 아주 많은 카운티만 부각할 뿐, 중앙값 근처나 그보다 적은 카운티들의 세세한 차이는 뭉뚱그려버립니다(그림 Figure 5.6).
(ref:texas-counties-pop-ratio-log) 텍사스주 카운티 인구와 중앙값의 비율. 몇몇 카운티 이름을 강조했습니다. 점선은 비율 1(중앙값)을 나타냅니다. 인구가 가장 많은 곳은 중앙값보다 약 100배 더 많고, 가장 적은 곳은 약 100배 더 적습니다. 데이터 출처: 2010년 미국 인구조사.
(ref:texas-counties-pop-ratio-lin) 텍사스주 카운티 인구 규모와 중앙값의 비율. 선형 척도로 그리면 1보다 큰 값만 과하게 강조되고, 1보다 작은 값의 차이는 거의 보이지 않습니다. 일반적으로 비율 데이터는 선형 척도에 그려서는 안 됩니다. 데이터 출처: 2010년 미국 인구조사.
로그 척도에서 값 1은 선형 척도의 0과 같은 자연스러운 기준점입니다. 1보다 크면 곱셈을, 1보다 작으면 나눗셈을 의미한다고 볼 수 있기 때문입니다(\(10 = 1 \times 10, 0.1 = 1 / 10\)). 반면 로그 척도에서는 0을 표시할 수 없습니다. 0은 1로부터 무한히 멀리 떨어져 있기 때문입니다(\(\log(0) = -\infty\)). 1에서 0에 도달하려면 유한한 값으로 무한 번 나누거나, 무한대로 한 번 나누어야 합니다(\(1/\infty = 0\)).
로그 척도는 데이터의 수치 범위가 매우 넓을 때 자주 쓰입니다. 앞에 나온 텍사스 카운티만 봐도 가장 인구가 많은 해리스(Harris) 카운티는 약 400만 명이지만, 가장 적은 러빙(Loving) 카운티는 고작 82명뿐입니다. 비율로 바꾸지 않았더라도 로그 척도는 적절한 선택이었을 것입니다. 그렇다면 만약 인구가 0명인 카운티가 있다면 어떨까요? 그곳은 로그 척도의 음의 무한대에 위치하므로 그래프에 그릴 수 없습니다. 이럴 때는 로그 대신 제곱근 척도(square root scale)를 쓰기도 합니다(그림 Figure 5.7). 로그처럼 큰 숫자를 압축해주면서도, 0 값을 허용한다는 장점이 있습니다.
(ref:sqrt-scales) 선형 척도와 제곱근 척도의 관계. 점들은 0에서 7까지의 제곱수인 0, 1, 4, 9, 16, 25, 36, 49를 나타내며, 이들은 제곱근 척도 위에서 같은 간격으로 놓입니다.
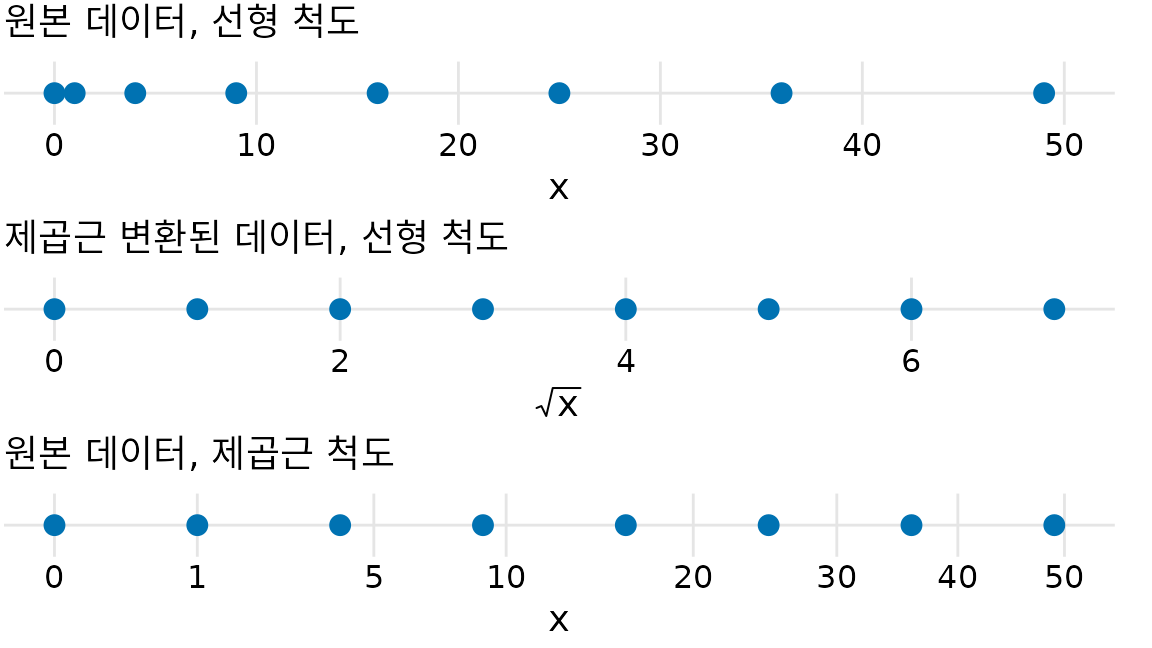
제곱근 척도에는 두 가지 난제가 있습니다. 첫째, 선형 척도에서의 한 칸 이동은 ’일정한 값을 더함’을 뜻하고 로그 척도에서는 ’일정한 비율을 곱함’을 뜻하는 반면, 제곱근 척도에서는 그러한 명확한 규칙이 없습니다. 다시 말해 한 칸의 의미가 현재 위치에 따라 달라집니다. 둘째, 축 눈금을 어디에 두어야 할지 모호합니다. 눈금을 일정한 모양으로 배치하려면 제곱수 위치에 두어야 하는데, 0, 4, 25, 49, 81 같은 숫자는 직관적이지 않죠. 그렇다고 선형 간격(10, 20, 30…)으로 눈금을 두면 척도의 낮은 쪽은 눈금이 너무 적고 높은 쪽은 너무 많아집니다. 그림 ?fig-sqrt-scales에서는 0, 1, 5, 10, 20, 30, 40, 50 위치에 눈금을 두었는데, 이는 데이터 범위를 적절히 보여주기 위한 임의의 선택입니다.
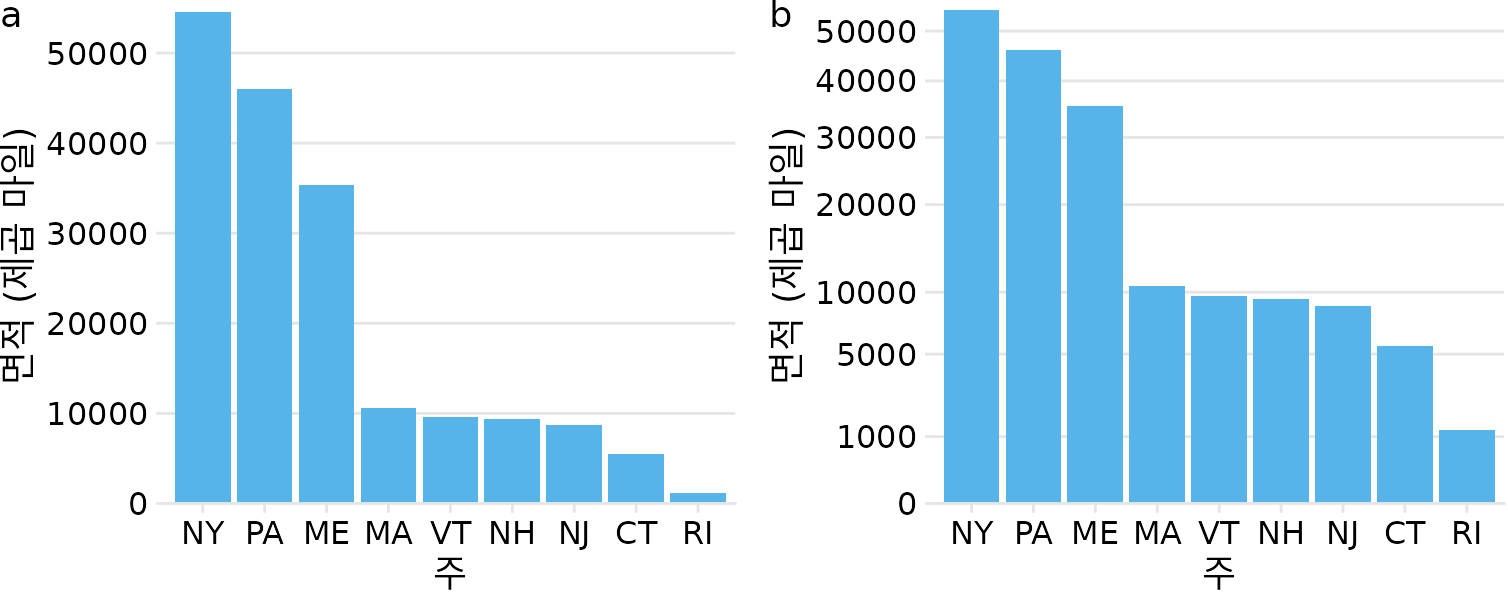
이러한 단점에도 불구하고 제곱근 척도는 나름의 쓰임새가 있습니다. 로그 척도가 ’비율’에 적합하듯, 제곱근 척도는 ’제곱’의 성질을 가진 데이터에 자연스럽게 어울립니다. 대표적인 사례가 바로 ’지리적 면적’입니다. 주(state)나 국가의 면적에 제곱근을 취해 그리면, 그 지역을 가로지르는 선형적 거리(동서나 남북 길이)를 강조하게 됩니다. 이는 예를 들어 그 지역을 자동차로 가로지르는 데 걸리는 시간과 관련이 있을 것입니다. 그림 ?fig-northeast-state-areas는 미국 북동부 주들의 면적을 선형 척도와 제곱근 척도로 보여줍니다. 주들의 실제 면적 차이는 매우 크지만(그림 a), 각 주를 운전해서 지나가는 체감 거리는 제곱근 척도(그림 b)에서 더 균형 있게 느껴질 것입니다.
(ref:northeast-state-areas) 미국 북동부 주의 면적. (a) 선형 척도에 표시된 면적. (b) 제곱근 척도에 표시된 면적. 데이터 출처: Google.
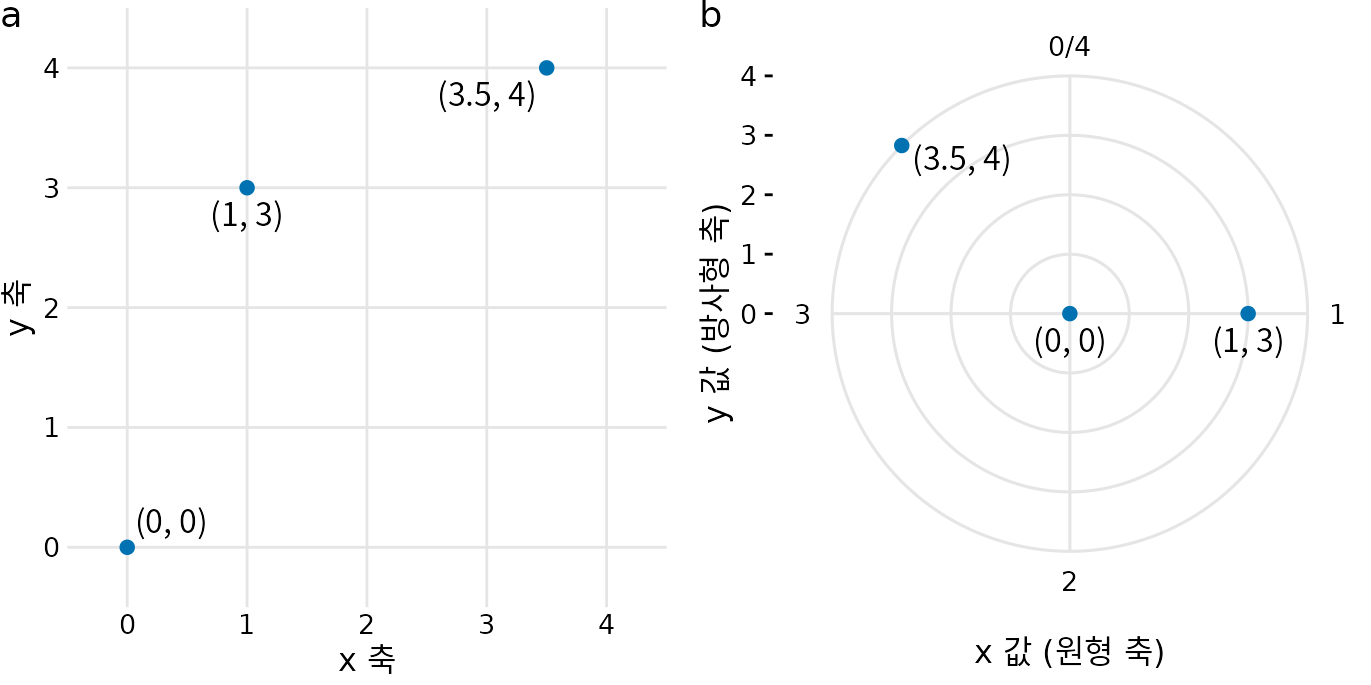
지금까지의 좌표계는 축 자체의 매핑 방식(선형 혹은 비선형)이 무엇이든 간에, 항상 두 축이 직각으로 만나는 직선 형태였습니다. 하지만 축 자체가 곡선인 좌표계도 존재합니다. 대표적인 것이 극좌표계(polar coordinate system)입니다. 극좌표계에서는 각도와 원점으로부터의 거리(방사형 거리)로 위치를 지정하며, 따라서 각도 축은 원 모양을 띄게 됩니다(그림 Figure 5.9).
(ref:polar-coord) 데카르트 좌표와 극좌표의 관계. (a) 데카르트 좌표계의 세 점. (b) 같은 점들을 극좌표계에 나타낸 모습. (a)의 x좌표는 각도로, y좌표는 반지름으로 쓰였습니다. 이 예에서 원형 축은 0에서 4까지의 범위를 가지며, 0과 4는 같은 위치가 됩니다.
극좌표는 주기성을 가진 데이터를 표현할 때 유용합니다. 척도의 시작과 끝이 논리적으로 연결되기 때문입니다. 일 년의 ’날짜’를 예로 들어보죠. 12월 31일은 한 해의 마지막 날인 동시에, 첫날인 1월 1일의 바로 전날이기도 합니다. 일 년 동안 특정 수치가 어떻게 변하는지 보여주려 할 때, 날짜를 각도로 변환해 극좌표에 그리면 이러한 주기적 성질을 잘 살릴 수 있습니다. 이 개념을 앞서 본 기온 데이터에 적용해보겠습니다. 기온 정상값은 장기 평균치이므로, 12월 31일과 1월 1일은 시각적으로 맞닿아 있는 것이 자연스럽습니다. 기온 데이터를 극좌표에 그리면 바로 이러한 연결성이 강조됩니다(그림 Figure 5.10). 특히 늦가을부터 초봄까지 데스밸리, 휴스턴, 샌디에이고의 기온이 얼마나 비슷하게 움직이는지 한눈에 보입니다. 데카르트 좌표계에서는 12월 말과 1월 초의 데이터가 그림의 양 끝으로 갈라져 있어 이러한 유사성을 파악하기 어려웠던 것과 대조적입니다.
(ref:temperature-normals-polar) 미국 내 4개 지역의 일일 기온 정상값을 극좌표로 시각화한 예. 중심에서의 거리는 화씨 기온을 나타내며, 날짜는 1월 1일을 6시 방향에서 시작하여 시계 반대 방향으로 배치했습니다.
곡선형 축을 마주하게 되는 또 다른 중요한 분야는 바로 ’지도’입니다. 지구상의 위치는 위도와 경도로 표시되지만, 지구가 둥글기 때문에 위경도를 단순한 데카르트 축에 그리는 것은 권장되지 않습니다(그림 ?fig-worldmap-four-projections). 대신 지구상의 실제 모양, 면적, 혹은 각도 사이의 균형을 맞추기 위한 다양한 투영법(projection)을 사용하게 됩니다.
(ref:worldmap-four-projections) 서로 다른 네 가지 투영법으로 그린 세계지도. ‘데카르트 위경도’ 방식은 위도와 경도를 평면에 그대로 옮긴 것으로, 극지방으로 갈수록 모양과 면적이 심하게 왜곡됩니다. ‘구드 호몰로사인’ 투영법은 면적을 정확하게 보여주지만 육지를 여러 조각으로 떼어놓는 단점이 있습니다. ‘로빈슨’과 ’빈켈 트리펠’ 투영법은 각도와 면적의 왜곡 사이에서 균형을 잡은 형태로, 전 세계지도를 그릴 때 흔히 쓰입니다.