import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
plt.style.use('seaborn-whitegrid')심층 분석: k-평균 클러스터링
이전 장에서는 차원 축소를 위한 비지도 머신러닝 모델을 살펴보았습니다. 이제 우리는 비지도 머신러닝(Machine Learning) 모델의 또 다른 클래스인 클러스터링 알고리즘으로 넘어갈 것입니다. 클러스터링 알고리즘은 데이터 속성을 통해 점 그룹의 최적 분할 또는 이산 레이블링을 학습하려고 합니다.
많은 클러스터링 알고리즘은 Scikit-Learn 및 다른 곳에서 사용할 수 있지만 아마도 가장 이해하기 쉬운 알고리즘은 sklearn.cluster.KMeans에 구현된 k-평균 클러스터링으로 알려진 알고리즘일 것입니다.
표준 가져오기부터 시작합니다.
k-평균 소개
k-평균 알고리즘은 레이블이 지정되지 않은 다차원 데이터 세트 내에서 미리 결정된 개수의 클러스터를 검색합니다. 최적의 클러스터링이 어떤 것인지에 대한 간단한 개념을 사용하여 이를 수행합니다.
- 클러스터 중심은 클러스터에 속한 모든 포인트의 산술 평균입니다.
- 각 지점은 다른 클러스터 중심보다 자체 클러스터 중심에 더 가깝습니다.
이 두 가지 가정은 k-평균 모델의 기초입니다. 우리는 곧 알고리즘이 이 해에 정확히 어떻게 도달하는지 알아볼 것입니다. 하지만 지금은 간단한 데이터 세트를 살펴보고 k-평균 결과를 살펴보겠습니다.
먼저, 4개의 개별 블롭을 포함하는 2차원 데이터 세트를 생성해 보겠습니다. 이것이 비지도 알고리즘이라는 점을 강조하기 위해 시각화에서 레이블을 제외하겠습니다(다음 그림 참조).
from sklearn.datasets import make_blobs
X, y_true = make_blobs(n_samples=300, centers=4,
cluster_std=0.60, random_state=0)
plt.scatter(X[:, 0], X[:, 1], s=50);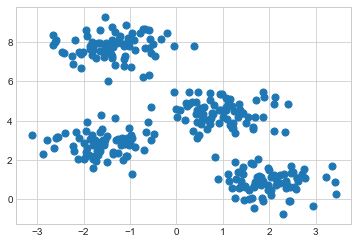
눈으로 보면 4개의 클러스터를 찾아내는 것이 상대적으로 쉽습니다. k-평균 알고리즘은 이를 자동으로 수행하며 Scikit-Learn에서는 일반적인 추정기 API를 사용합니다.
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=4)
kmeans.fit(X)
y_kmeans = kmeans.predict(X)이러한 레이블로 색상이 지정된 데이터를 플로팅하여 결과를 시각화해 보겠습니다(다음 그림). 또한 k-평균 추정기에 의해 결정된 대로 클러스터 중심을 표시합니다.
plt.scatter(X[:, 0], X[:, 1], c=y_kmeans, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='black', s=200);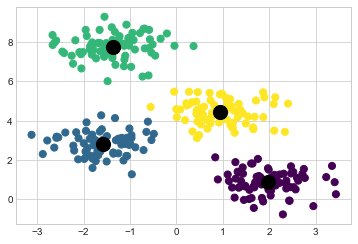
좋은 소식은 k-평균 알고리즘(적어도 이 간단한 경우)이 눈으로 포인트를 할당하는 방법과 매우 유사하게 클러스터에 포인트를 할당한다는 것입니다. 그러나 이 알고리즘이 어떻게 이러한 클러스터를 그렇게 빨리 찾는지 궁금할 것입니다. 결국 클러스터 할당의 가능한 조합 수는 데이터 포인트 수에 따라 기하급수적으로 증가합니다. 철저한 검색에는 비용이 매우 많이 듭니다. 다행스럽게도 이러한 철저한 검색은 필요하지 않습니다. 대신 k-평균에 대한 일반적인 접근 방식에는 기대값-최대화로 알려진 직관적인 반복 접근 방식이 포함됩니다.
기대 – 극대화
기대-최대화(E-M)는 데이터 과학(Data Science) 내의 다양한 맥락에서 나타나는 강력한 알고리즘입니다. k-평균은 특히 간단하고 이해하기 쉬운 알고리즘 적용이므로 여기서 간단히 살펴보겠습니다. 간단히 말해서, 기대치 최대화 접근법은 다음 절차로 구성됩니다.
- 클러스터 센터를 추측해 보세요.
- 수렴될 때까지 반복합니다.
- E-단계: 가장 가까운 클러스터 중심에 포인트를 할당합니다.
- M-단계: 클러스터 중심을 할당된 포인트의 평균으로 설정합니다.
여기서 E-단계 또는 기대 단계는 각 포인트가 속한 클러스터에 대한 기대를 업데이트하는 것과 관련되어 있기 때문에 그렇게 명명되었습니다. M-단계 또는 최대화 단계는 군집 중심의 위치를 정의하는 일부 적합성 함수의 최대화를 포함하기 때문에 그렇게 명명되었습니다. 이 경우 최대화는 각 군집에 있는 데이터의 간단한 평균을 취하여 수행됩니다.
이 알고리즘에 대한 문헌은 방대하지만 다음과 같이 요약합니다. 일반적인 상황에서 E-단계와 M-단계를 반복할 때마다 항상 클러스터 특성을 더 잘 추정합니다.
다음 그림과 같이 알고리즘을 시각화합니다. 여기에 표시된 특정 초기화의 경우 클러스터는 단 세 번의 반복으로 수렴됩니다. (이 그림의 대화형 버전은 온라인 부록의 코드를 참조하세요.)

k-평균 알고리즘은 몇 줄의 코드로 작성할 수 있을 정도로 간단합니다. 다음은 매우 기본적인 구현입니다(다음 그림 참조).
from sklearn.metrics import pairwise_distances_argmin
def find_clusters(X, n_clusters, rseed=2):
# 1. Randomly choose clusters
rng = np.random.RandomState(rseed)
i = rng.permutation(X.shape[0])[:n_clusters]
centers = X[i]
while True:
# 2a. Assign labels based on closest center
labels = pairwise_distances_argmin(X, centers)
# 2b. Find new centers from means of points
new_centers = np.array([X[labels == i].mean(0)
for i in range(n_clusters)])
# 2c. Check for convergence
if np.all(centers == new_centers):
break
centers = new_centers
return centers, labels
centers, labels = find_clusters(X, 4)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');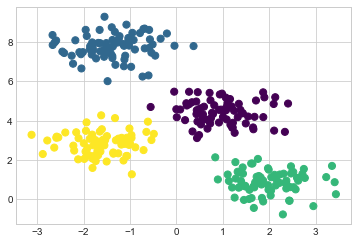
대부분의 잘 테스트된 구현은 내부적으로 이보다 약간 더 많은 작업을 수행하지만 앞의 함수는 기대치 최대화 접근 방식의 요점을 제공합니다.
기대값 최대화 알고리즘을 사용할 때 주의해야 할 몇 가지 주의 사항이 있습니다.
전체적으로 최적의 결과를 얻지 못할 수도 있습니다.
첫째, E-M 절차는 각 단계에서 결과 개선을 보장하지만 글로벌 최고의 솔루션으로 이어질 것이라는 보장은 없습니다. 예를 들어 간단한 절차에서 다른 무작위 시드를 사용하는 경우 특정 시작 추측으로 인해 결과가 좋지 않습니다(다음 그림 참조).
centers, labels = find_clusters(X, 4, rseed=0)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');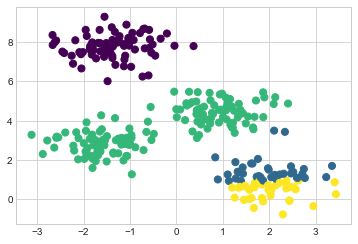
여기서 E–M 접근 방식은 수렴되었지만 전체적으로 최적의 구성으로 수렴되지는 않았습니다. 이러한 이유로 실제로 Scikit-Learn이 수행하는 것처럼 알고리즘은 여러 시작 추측에 대해 실행되는 것이 일반적입니다(숫자는 n_init 매개변수에 의해 설정되며 기본값은 10입니다).
클러스터 수를 미리 선택해야 합니다.
k-의미의 또 다른 일반적인 문제는 예상되는 클러스터 수를 알려주어야 한다는 것입니다. 즉, 데이터에서 클러스터 수를 학습할 수 없습니다. 예를 들어 알고리즘에 6개의 클러스터를 식별하도록 요청하면 그림 47-6과 같이 계속 진행하여 가장 좋은 6개의 클러스터를 찾습니다.
labels = KMeans(6, random_state=0).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');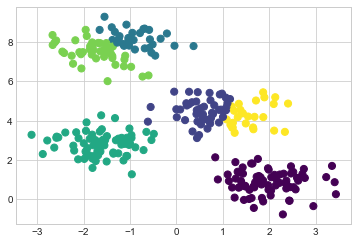
결과가 의미가 있는지 여부는 확실하게 대답하기 어려운 질문입니다. 다소 직관적이지만 여기서는 더 이상 논의하지 않을 접근 방식 중 하나를 실루엣 분석이라고 합니다.
또는 클러스터 수당 적합도를 더 정량적으로 측정하는 더 복잡한 클러스터링 알고리즘을 사용할 수도 있습니다(예: 가우스 혼합 모델, 심층: 가우스 혼합 모델 참조). 또는 적절한 수의 클러스터를 선택할 수 있습니다(예: DBSCAN, 평균 이동 또는 친화도 전파). sklearn.cluster 하위 모듈).
k-평균은 선형 클러스터 경계로 제한됩니다.
k-평균(포인트가 다른 포인트보다 자체 클러스터 중심에 더 가까움)에 대한 기본 모델 가정은 클러스터에 복잡한 형상이 있는 경우 알고리즘이 종종 비효율적이라는 것을 의미합니다.
특히 k-평균 클러스터 사이의 경계는 항상 선형이므로 더 복잡한 경계에서는 실패합니다. 일반적인 k-평균 접근 방식으로 찾은 클러스터 레이블과 함께 다음 데이터를 고려하십시오(다음 그림 참조).
from sklearn.datasets import make_moons
X, y = make_moons(200, noise=.05, random_state=0)labels = KMeans(2, random_state=0).fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');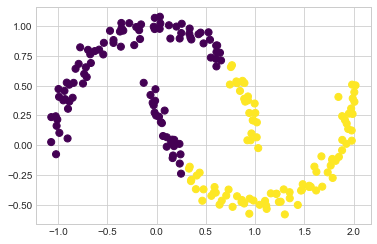
이 상황은 심층: 지원 벡터 머신의 논의를 연상시킵니다. 여기서 우리는 커널 변환을 사용하여 데이터를 선형 분리가 가능한 더 높은 차원으로 투영했습니다. k-수단이 비선형 경계를 발견할 수 있도록 동일한 트릭을 사용하는 것을 상상합니다.
이 커널화된 k-평균의 한 버전은 SpectralClustering 추정기 내의 Scikit-Learn에서 구현됩니다. 가장 가까운 이웃 그래프를 사용하여 데이터의 고차원 표현을 계산한 다음 k-평균 알고리즘을 사용하여 레이블을 할당합니다(다음 그림 참조).
from sklearn.cluster import SpectralClustering
model = SpectralClustering(n_clusters=2, affinity='nearest_neighbors',
assign_labels='kmeans')
labels = model.fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=labels,
s=50, cmap='viridis');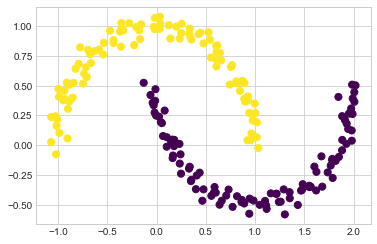
이 커널 변환 접근 방식을 사용하면 커널화된 k-평균이 클러스터 간의 더 복잡한 비선형 경계를 찾을 수 있음을 확인합니다.
k-평균은 샘플 수가 많으면 느릴 수 있습니다.
k-평균의 각 반복은 데이터 세트의 모든 포인트에 액세스해야 하기 때문에 샘플 수가 증가함에 따라 알고리즘이 상대적으로 느려질 수 있습니다. 각 반복에서 모든 데이터를 사용해야 하는 이 요구 사항을 완화할 수 있는지 궁금할 것입니다. 예를 들어 데이터의 하위 집합을 사용하여 각 단계에서 클러스터 중심을 업데이트합니다. 이것이 배치 기반 k-평균 알고리즘의 기본 아이디어이며, 그 중 한 형태가 sklearn.cluster.MiniBatchKMeans에 구현되어 있습니다. 이에 대한 인터페이스는 표준 KMeans와 동일합니다. 토론을 계속하면서 그 사용 예를 살펴보겠습니다.
예
알고리즘의 이러한 제한 사항에 주의하여 다양한 상황에서 k-평균을 유리하게 사용합니다. 이제 몇 가지 예를 살펴보겠습니다.
예 1: 숫자의 k-평균
시작하려면 심층: 의사결정 트리 및 랜덤 포레스트 및 심층: 주성분 분석에서 본 것과 동일한 단순 숫자 데이터에 k-평균을 적용하는 방법을 살펴보겠습니다. 여기서는 k-원래 레이블 정보를 사용하지 않고* 유사한 숫자를 식별하려고 시도한다는 의미를 사용하려고 합니다. 이는 선험적 레이블 정보가 없는 새 데이터 세트에서 의미를 추출하는 첫 번째 단계와 유사합니다.
먼저 데이터 세트를 로드한 다음 클러스터를 찾습니다. 숫자 데이터 세트는 64개의 특징을 가진 1,797개의 샘플로 구성되어 있으며, 여기서 64개의 특징 각각은 8 × 8 이미지에서 한 픽셀의 밝기입니다.
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape(1797, 64)클러스터링은 이전과 같이 수행합니다.
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits.data)
kmeans.cluster_centers_.shape(10, 64)결과는 64차원의 10개 클러스터입니다. 클러스터 중심 자체는 64차원 지점이며 클러스터 내의 “일반적인” 숫자를 나타내는 것으로 해석될 수 있습니다. 이러한 클러스터 센터가 어떻게 생겼는지 살펴보겠습니다(다음 그림 참조).
fig, ax = plt.subplots(2, 5, figsize=(8, 3))
centers = kmeans.cluster_centers_.reshape(10, 8, 8)
for axi, center in zip(ax.flat, centers):
axi.set(xticks=[], yticks=[])
axi.imshow(center, interpolation='nearest', cmap=plt.cm.binary)
레이블이 없어도 KMeans는 1과 8을 제외하고 중심이 인식 가능한 숫자인 클러스터를 찾을 수 있음을 확인합니다.
k는 클러스터의 ID에 대해 아무것도 모르기 때문에 0-9 레이블이 순열될 수 있습니다. 학습된 각 클러스터 레이블을 클러스터에서 발견된 실제 레이블과 일치시켜 이 문제를 해결합니다.
from scipy.stats import mode
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]이제 비지도 클러스터링이 데이터 내에서 유사한 숫자를 찾는 데 얼마나 정확한지 확인합니다.
from sklearn.metrics import accuracy_score
accuracy_score(digits.target, labels)0.7935447968836951간단한 k-평균 알고리즘을 사용하여 입력 숫자의 80%에 대한 올바른 그룹화를 발견했습니다! 다음 그림에 시각화된 혼동 행렬을 확인해 보겠습니다.
from sklearn.metrics import confusion_matrix
import seaborn as sns
mat = confusion_matrix(digits.target, labels)
sns.heatmap(mat.T, square=True, annot=True, fmt='d',
cbar=False, cmap='Blues',
xticklabels=digits.target_names,
yticklabels=digits.target_names)
plt.xlabel('true label')
plt.ylabel('predicted label');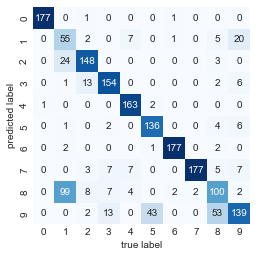
이전에 시각화한 클러스터 중심에서 예상할 수 있듯이 혼동의 주요 지점은 8과 1 사이입니다. 그러나 이것은 여전히 k-수단을 사용하면 알려진 레이블을 참조하지 않고 숫자 분류기를 구축할 수 있음을 보여줍니다!
재미삼아 이것을 더욱 발전시켜 보도록 하겠습니다. t-분포 확률론적 이웃 임베딩 알고리즘(심층: 다양체 학습에 언급됨)을 사용하여 k-평균을 수행하기 전에 데이터를 전처리합니다. t-SNE는 클러스터 내의 지점을 보존하는 데 특히 적합한 비선형 임베딩 알고리즘입니다. 어떻게 되는지 살펴보겠습니다:
from sklearn.manifold import TSNE
# Project the data: this step will take several seconds
tsne = TSNE(n_components=2, init='random',
learning_rate='auto',random_state=0)
digits_proj = tsne.fit_transform(digits.data)
# Compute the clusters
kmeans = KMeans(n_clusters=10, random_state=0)
clusters = kmeans.fit_predict(digits_proj)
# Permute the labels
labels = np.zeros_like(clusters)
for i in range(10):
mask = (clusters == i)
labels[mask] = mode(digits.target[mask])[0]
# Compute the accuracy
accuracy_score(digits.target, labels)0.9415692821368948레이블을 사용하지 않고도 분류 정확도가 94%입니다. 이것이 주의 깊게 사용될 때 비지도 학습의 힘입니다. 즉, 손이나 눈으로 추출하기 어려울 수 있는 정보를 데이터 세트에서 추출합니다.
예 2: 색상 압축을 위한 k-평균
클러스터링의 흥미로운 적용 중 하나는 이미지 제 색상 압축입니다. 이 예는 Scikit-Learn의 “K-Means를 사용한 색상 양자화”에서 채택되었습니다. 예를 들어 수백만 가지 색상의 이미지가 있다고 가정해 보겠습니다. 대부분의 이미지에서는 많은 색상이 사용되지 않으며 이미지의 많은 픽셀이 유사하거나 동일한 색상을 갖습니다.
예를 들어 Scikit-Learn datasets 모듈의 다음 그림에 표시된 이미지를 고려해 보세요(이 작업을 위해서는 PIL 파이썬(Python) 패키지가 설치되어 있어야 합니다). (이 이미지와 다음 이미지의 컬러 버전을 보려면 이 책의 온라인 버전을 참조하세요.)
from sklearn.datasets import load_sample_image
# Note: this requires the PIL package to be installed
china = load_sample_image("china.jpg")
ax = plt.axes(xticks=[], yticks=[])
ax.imshow(china);
이미지 자체는 ‘(높이, 너비, RGB)’ 크기의 3차원 배열에 저장되며 0에서 255까지의 정수로 빨간색/파란색/녹색 기여도를 포함합니다.
china.shape(427, 640, 3)이 픽셀 세트를 볼 수 있는 한 가지 방법은 3차원 색상 공간의 점 구름으로 보는 것입니다. 데이터를 [n_samples, n_features]로 재구성하고 색상 크기를 0과 1 사이에 있도록 다시 조정합니다.
data = china / 255.0 # use 0...1 scale
data = data.reshape(-1, 3)
data.shape(273280, 3)효율성을 위해 10,000픽셀의 하위 집합을 사용하여 이 색상 공간에서 이러한 픽셀을 시각화합니다(다음 그림 참조).
def plot_pixels(data, title, colors=None, N=10000):
if colors is None:
colors = data
# choose a random subset
rng = np.random.default_rng(0)
i = rng.permutation(data.shape[0])[:N]
colors = colors[i]
R, G, B = data[i].T
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
ax[0].scatter(R, G, color=colors, marker='.')
ax[0].set(xlabel='Red', ylabel='Green', xlim=(0, 1), ylim=(0, 1))
ax[1].scatter(R, B, color=colors, marker='.')
ax[1].set(xlabel='Red', ylabel='Blue', xlim=(0, 1), ylim=(0, 1))
fig.suptitle(title, size=20)plot_pixels(data, title='Input color space: 16 million possible colors')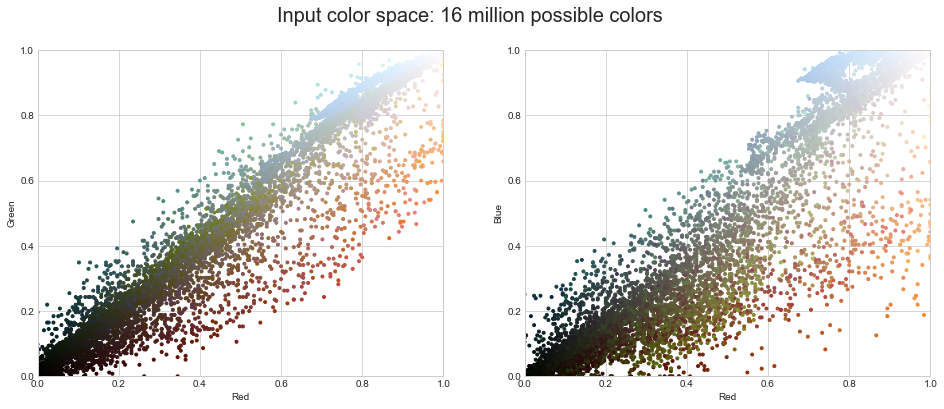
이제 픽셀 공간 전체에 걸쳐 클러스터링을 의미하는 k를 사용하여 이러한 1,600만 색상을 단 16개 색상으로 줄이겠습니다. 우리는 매우 큰 데이터 세트를 다루고 있기 때문에 데이터의 하위 집합에 대해 작동하는 미니 배치 k-평균을 사용하여 표준 k-평균 알고리즘보다 훨씬 빠르게 결과(다음 그림 참조)를 계산합니다.
from sklearn.cluster import MiniBatchKMeans
kmeans = MiniBatchKMeans(16)
kmeans.fit(data)
new_colors = kmeans.cluster_centers_[kmeans.predict(data)]
plot_pixels(data, colors=new_colors,
title="Reduced color space: 16 colors")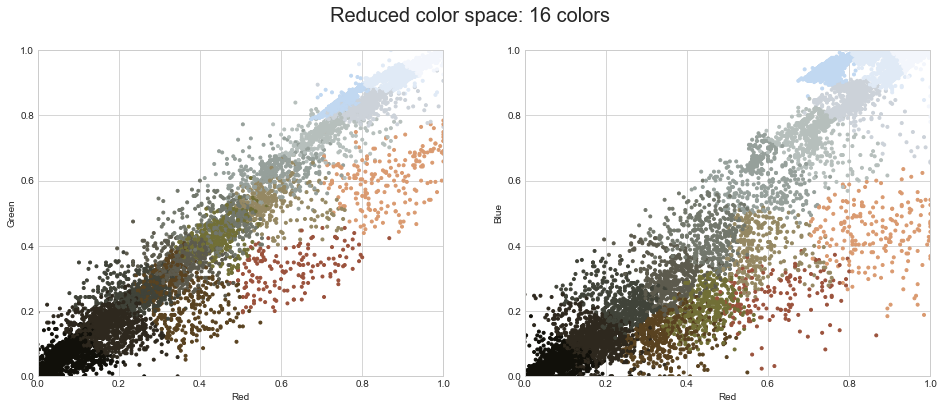
결과적으로 원본 픽셀이 다시 칠해지고, 각 픽셀에는 가장 가까운 클러스터 중심의 색상이 할당됩니다. 픽셀 공간이 아닌 이미지 공간에 이러한 새로운 색상을 플로팅하면 이에 따른 효과가 표시됩니다(다음 그림 참조).
china_recolored = new_colors.reshape(china.shape)
fig, ax = plt.subplots(1, 2, figsize=(16, 6),
subplot_kw=dict(xticks=[], yticks=[]))
fig.subplots_adjust(wspace=0.05)
ax[0].imshow(china)
ax[0].set_title('Original Image', size=16)
ax[1].imshow(china_recolored)
ax[1].set_title('16-color Image', size=16);
가장 오른쪽 패널에서는 일부 세부 사항이 확실히 손실되었지만 전체 이미지는 여전히 쉽게 알아살펴볼 수 있습니다. 원시 데이터를 저장하는 데 필요한 바이트 측면에서 오른쪽 이미지는 약 100만 개의 압축 계수를 달성합니다! 이제 이런 종류의 접근 방식은 JPEG와 같이 특별히 제작된 이미지 압축 체계의 충실도와 일치하지 않지만 이 예는 k-평균과 같은 비지도 방법을 사용하여 고정관념에서 벗어난 사고의 힘을 보여줍니다.