%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("seaborn-white")
rng = np.random.default_rng(1701)
data = rng.normal(size=1000)히스토그램, 비닝 및 밀도
간단한 히스토그램은 데이터 세트를 이해하는 데 있어 훌륭한 첫 번째 단계가 될 수 있습니다. 앞서 우리는 일반 상용구 가져오기가 완료되면 한 줄에 기본 히스토그램을 생성하는 Matplotlib의 히스토그램 함수(비교, 마스크 및 부울 논리에서 설명)의 미리 보기를 보았습니다(다음 그림 참조).
plt.hist(data);
hist 함수에는 계산과 표시를 모두 조정할 수 있는 다양한 옵션이 있습니다. 다음 그림에 표시된 보다 맞춤화된 히스토그램의 예는 다음과 같습니다.
plt.hist(
data,
bins=30,
density=True,
alpha=0.5,
histtype="stepfilled",
color="steelblue",
edgecolor="none",
);
plt.hist 문서화 문자열에는 사용 가능한 다른 사용자 정의 옵션에 대한 자세한 정보가 있습니다. 저는 histtype='stepfilled'와 일부 투명도 alpha의 조합이 여러 분포의 히스토그램을 비교할 때 도움이 된다는 것을 알았습니다(다음 그림 참조):
x1 = rng.normal(0, 0.8, 1000)
x2 = rng.normal(-2, 1, 1000)
x3 = rng.normal(3, 2, 1000)
kwargs = dict(histtype="stepfilled", alpha=0.3, density=True, bins=40)
plt.hist(x1, **kwargs)
plt.hist(x2, **kwargs)
plt.hist(x3, **kwargs);
히스토그램을 계산하고 싶지만 표시하지 않으려는 경우(즉, 주어진 빈에 있는 포인트 수 계산) ‘np.histogram’ 함수를 사용합니다.
counts, bin_edges = np.histogram(data, bins=5)
print(counts)[ 23 241 491 224 21]2차원 히스토그램 및 비닝
수직선을 빈(bin)으로 나누어 1차원 히스토그램을 만드는 것처럼, 2차원 빈 사이의 점을 나누어 2차원 히스토그램을 만들 수도 있습니다. 여기서는 이를 수행하는 몇 가지 방법을 간략하게 살펴보겠습니다. 다변량 가우스 분포에서 가져온 ‘x’ 및 ‘y’ 배열과 같은 일부 데이터를 정의하는 것부터 시작하겠습니다.
mean = [0, 0]
cov = [[1, 1], [1, 2]]
x, y = rng.multivariate_normal(mean, cov, 10000).Tplt.hist2d: 2차원 히스토그램
2차원 히스토그램을 그리는 간단한 방법 중 하나는 Matplotlib의 ‘plt.hist2d’ 함수를 사용하는 것입니다(다음 그림 참조).
plt.hist2d(x, y, bins=30)
cb = plt.colorbar()
cb.set_label("counts in bin")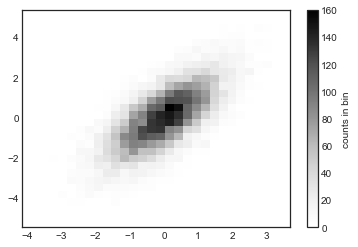
plt.hist와 마찬가지로 plt.hist2d에는 플롯과 비닝을 미세 조정할 수 있는 여러 추가 옵션이 있으며, 이는 함수 docstring에 잘 설명되어 있습니다. 또한 plt.hist에 np.histogram에 대응되는 부분이 있는 것처럼 plt.hist2d에는 np.histogram2d에 대응되는 부분이 있습니다.
counts, xedges, yedges = np.histogram2d(x, y, bins=30)
print(counts.shape)(30, 30)차원이 2개 이상일 때 이 히스토그램 비닝을 일반화하려면 ‘np.histogramdd’ 함수를 참조하세요.
plt.hexbin: 육각형 비닝
2차원 히스토그램은 축을 따라 사각형의 테셀레이션을 만듭니다. 이러한 테셀레이션의 또 다른 자연스러운 모양은 정육각형입니다. 이를 위해 Matplotlib는 육각형 그리드 내에 비닝된 2차원 데이터 세트를 나타내는 ‘plt.hexbin’ 루틴을 제공합니다(다음 그림 참조).
plt.hexbin(x, y, gridsize=30)
cb = plt.colorbar(label="count in bin")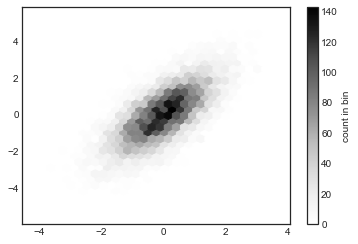
plt.hexbin에는 각 포인트에 대한 가중치를 지정하고 각 bin의 출력을 NumPy 집계(가중치 평균, 가중치 표준 편차 등)로 변경하는 기능을 포함하여 다양한 추가 옵션이 있습니다.
커널 밀도 추정
다차원에서 밀도를 추정하고 표현하는 또 다른 일반적인 방법은 커널 밀도 추정(KDE)입니다. 이에 대해서는 심층: 커널 밀도 추정에서 더 자세히 논의할 것입니다. 그러나 지금은 KDE가 공간의 점을 “번짐”하고 그 결과를 합산하여 부드러운 함수를 얻는 방법으로 생각할 수 있다는 점만 언급하겠습니다. 매우 빠르고 간단한 KDE 구현이 scipy.stats 패키지에 있습니다. 다음은 KDE를 사용하는 간단한 예입니다(다음 그림 참조):
from scipy.stats import gaussian_kde
# fit an array of size [Ndim, Nsamples]
data = np.vstack([x, y])
kde = gaussian_kde(data)
# evaluate on a regular grid
xgrid = np.linspace(-3.5, 3.5, 40)
ygrid = np.linspace(-6, 6, 40)
Xgrid, Ygrid = np.meshgrid(xgrid, ygrid)
Z = kde.evaluate(np.vstack([Xgrid.ravel(), Ygrid.ravel()]))
# Plot the result as an image
plt.imshow(
Z.reshape(Xgrid.shape), origin="lower", aspect="auto", extent=[-3.5, 3.5, -6, 6]
)
cb = plt.colorbar()
cb.set_label("density")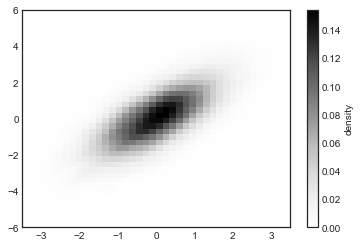
KDE에는 세부 사항과 부드러움 사이를 효과적으로 이동하는 평활화 길이가 있습니다(편향-분산 절충의 한 예). 적절한 평활화 길이 선택에 관한 문헌은 방대합니다. ’gaussian_kde’는 경험 법칙을 사용하여 입력 데이터에 대해 거의 최적의 평활화 길이를 찾으려고 시도합니다.
SciPy 생태계 내에서 다른 KDE 구현을 사용할 수 있으며 각각 고유한 장점과 단점이 있습니다. 예를 들어 sklearn.neighbors.KernelDensity 및 statsmodels.nonparametric.KDEMultivariate를 참조하세요. KDE 기반 시각화의 경우 Matplotlib을 사용하면 지나치게 장황해지는 경향이 있습니다. Visualization With Seaborn에서 논의된 Seaborn 라이브러리는 KDE 기반 시각화 생성을 위한 훨씬 더 컴팩트한 API를 제공합니다.