%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("seaborn-whitegrid")심층 분석: 서포트 벡터 머신
SVM(지원 벡터 머신)은 분류 및 회귀 모두를 위한 특히 강력하고 유연한 지도 알고리즘 클래스입니다. 이번 장에서는 SVM의 이면에 있는 직관과 분류 문제에서의 SVM 사용법을 살펴보겠습니다.
표준 가져오기부터 시작합니다.
서포트 벡터 머신에 동기를 부여하기
베이지안 분류에 대한 논의의 일환으로(심층: Naive Bayes 분류 참조) 각 기본 클래스의 분포를 설명하는 간단한 종류의 모델에 대해 배웠고 이를 사용하여 새로운 점에 대한 레이블을 확률적으로 결정하는 실험을 했습니다. 이는 생성 분류의 예였습니다. 여기서는 차별적 분류를 대신 고려하겠습니다. 즉, 각 클래스를 모델링하는 대신 클래스를 서로 나누는 선이나 곡선(2차원) 또는 다양체(다차원)를 간단히 찾을 것입니다.
이에 대한 예로서, 두 클래스의 포인트가 잘 분리되어 있는 분류 작업의 간단한 사례를 생각해 보십시오(다음 그림 참조).
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=50, centers=2, random_state=0, cluster_std=0.60)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn");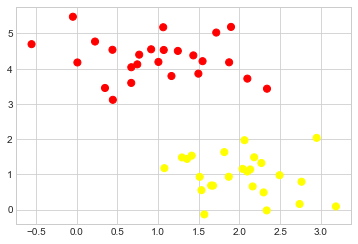
선형 판별 분류기는 두 데이터 세트를 분리하는 직선을 그려 분류 모델을 생성하려고 시도합니다. 여기에 표시된 것과 같은 2차원 데이터의 경우 이는 우리가 직접 수행할 수 있는 작업입니다. 그러나 즉시 우리는 문제를 발견합니다. 두 클래스를 완벽하게 구별할 수 있는 구분선이 두 개 이상 있습니다!
우리는 그 중 일부를 다음과 같이 그릴 수 있습니다. 다음 그림은 결과를 보여줍니다.
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plt.plot([0.6], [2.1], "x", color="red", markeredgewidth=2, markersize=10)
for m, b in [(1, 0.65), (0.5, 1.6), (-0.2, 2.9)]:
plt.plot(xfit, m * xfit + b, "-k")
plt.xlim(-1, 3.5);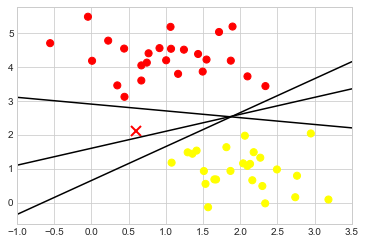
그럼에도 불구하고 이 세 가지 매우 다른 분리기는 이러한 샘플을 완벽하게 구별합니다. 선택한 항목에 따라 새 데이터 포인트(예: 이 플롯에서 “X”로 표시된 데이터 포인트)에 다른 레이블이 할당됩니다! 분명히 “클래스 사이에 선을 긋는 것”에 대한 우리의 단순한 직관만으로는 충분하지 않으며 좀 더 깊이 생각할 필요가 있습니다.
서포트 벡터 머신: 마진 최대화
서포트 벡터 머신은 이를 개선할 수 있는 한 가지 방법을 제공합니다. 직관은 다음과 같습니다. 단순히 클래스 사이에 너비가 0인 선을 그리는 대신 각 선 주위에 가장 가까운 지점까지 어느 정도 너비의 여백을 그릴 수 있습니다. 다음은 이것이 어떻게 보이는지에 대한 예입니다(다음 그림 참조).
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, "-k")
plt.fill_between(
xfit, yfit - d, yfit + d, edgecolor="none", color="lightgray", alpha=0.5
)
plt.xlim(-1, 3.5);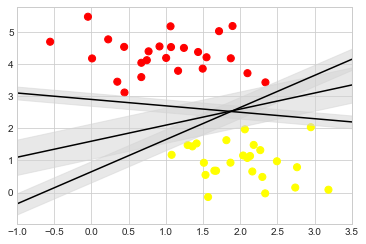
이 마진을 최대화하는 선이 우리가 최적 모델로 선택할 선입니다.
서포트 벡터 머신 피팅
이 데이터에 대한 실제 적합 결과를 살펴보겠습니다. Scikit-Learn의 지원 벡터 분류기(SVC)를 사용하여 이 데이터에 대한 SVM 모델을 교육합니다. 당분간 우리는 선형 커널을 사용하고 C 매개변수를 매우 큰 숫자로 설정하겠습니다(이 값의 의미에 대해서는 잠시 후에 더 자세히 논의하겠습니다).
from sklearn.svm import SVC # "Support vector classifier"
model = SVC(kernel="linear", C=1e10)
model.fit(X, y)SVC(C=10000000000.0, kernel='linear')여기서 일어나는 일을 더 잘 시각화하기 위해 SVM 결정 경계를 표시하는 빠른 편의 함수를 만들어 보겠습니다(다음 그림 참조).
def plot_svc_decision_function(model, ax=None, plot_support=True):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
xlim = ax.get_xlim()
ylim = ax.get_ylim()
# create grid to evaluate model
x = np.linspace(xlim[0], xlim[1], 30)
y = np.linspace(ylim[0], ylim[1], 30)
Y, X = np.meshgrid(y, x)
xy = np.vstack([X.ravel(), Y.ravel()]).T
P = model.decision_function(xy).reshape(X.shape)
# plot decision boundary and margins
ax.contour(
X, Y, P, colors="k", levels=[-1, 0, 1], alpha=0.5, linestyles=["--", "-", "--"]
)
# plot support vectors
if plot_support:
ax.scatter(
model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300,
linewidth=1,
edgecolors="black",
facecolors="none",
)
ax.set_xlim(xlim)
ax.set_ylim(ylim)plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(model);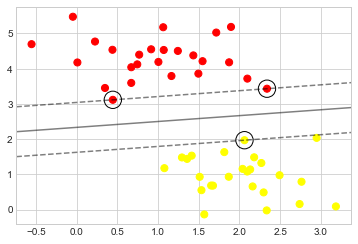
이는 두 점 세트 사이의 마진을 최대화하는 구분선입니다. 훈련 포인트 중 일부는 여백에 닿아 있습니다. 다음 그림에서는 원으로 표시되어 있습니다. 이 점은 이 핏의 중추적인 요소입니다. 이는 지원 벡터로 알려져 있으며 알고리즘에 이름을 부여합니다. Scikit-Learn에서 이러한 포인트의 ID는 분류기의 support_Vectors_ 속성에 저장됩니다.
model.support_vectors_array([[0.44359863, 3.11530945],
[2.33812285, 3.43116792],
[2.06156753, 1.96918596]])이 분류기 성공의 핵심은 적합성에 있어서 서포트 벡터의 위치만 중요하다는 것입니다. 올바른 면에 있는 여백에서 더 멀리 있는 점은 맞춤을 수정하지 않습니다. 기술적으로 이는 이러한 점들이 모델을 맞추는 데 사용되는 손실 함수에 기여하지 않기 때문에 마진을 넘지 않는 한 위치와 개수는 중요하지 않습니다.
예를 들어 이 데이터 세트의 처음 60개 포인트와 처음 120개 포인트에서 학습된 모델을 플롯하면 이를 확인합니다(다음 그림 참조).
def plot_svm(N=10, ax=None):
X, y = make_blobs(n_samples=200, centers=2, random_state=0, cluster_std=0.60)
X = X[:N]
y = y[:N]
model = SVC(kernel="linear", C=1e10)
model.fit(X, y)
ax = ax or plt.gca()
ax.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
ax.set_xlim(-1, 4)
ax.set_ylim(-1, 6)
plot_svc_decision_function(model, ax)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, N in zip(ax, [60, 120]):
plot_svm(N, axi)
axi.set_title("N = {0}".format(N))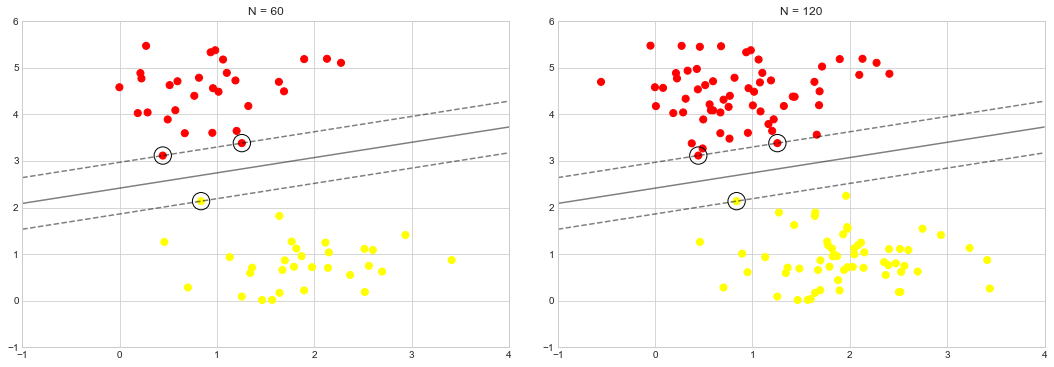
왼쪽 패널에는 60개의 훈련 포인트에 대한 모델과 지원 벡터가 표시됩니다. 오른쪽 패널에서는 훈련 포인트 수를 두 배로 늘렸지만 모델은 변경되지 않았습니다. 왼쪽 패널의 세 가지 지원 벡터는 오른쪽 패널의 지원 벡터와 동일합니다. 멀리 있는 지점의 정확한 동작에 대한 이러한 둔감성은 SVM 모델의 강점 중 하나입니다.
이 노트북을 라이브로 실행하는 경우 IPython의 대화형 위젯을 사용하여 SVM 모델의 이 기능을 대화형으로 살펴볼 수 있습니다.
from ipywidgets import interact, fixed
interact(plot_svm, N=(10, 200), ax=fixed(None));선형 경계 너머: 커널 SVM
SVM이 커널과 결합될 때 매우 강력해질 수 있습니다. 우리는 이전에 In Depth: Linear Regression의 기본 함수 회귀에서 커널 버전을 본 적이 있습니다. 거기서 우리는 데이터를 다항식과 가우스 기반 함수로 정의된 고차원 공간에 투영하여 선형 분류기를 사용하여 비선형 관계에 적합할 수 있었습니다.
SVM 모델에서는 동일한 아이디어 버전을 사용합니다. 커널의 필요성을 높이기 위해 선형 분리가 불가능한 일부 데이터를 살펴보겠습니다(다음 그림 참조).
from sklearn.datasets import make_circles
X, y = make_circles(100, factor=0.1, noise=0.1)
clf = SVC(kernel="linear").fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(clf, plot_support=False);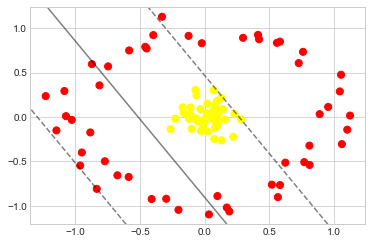
어떠한 선형 차별도 절대로 이 데이터를 분리할 수 없다는 것은 분명합니다. 하지만 심층: 선형 회귀의 기본 함수 회귀에서 교훈을 얻을 수 있으며, 선형 구분 기호가 충분하도록 데이터를 더 높은 차원으로 투영할 수 있는 방법에 대해 생각해 살펴볼 수 있습니다. 예를 들어 우리가 사용할 수 있는 간단한 투영 중 하나는 중간 덩어리를 중심으로 하는 방사형 기본 함수(RBF)를 계산하는 것입니다.
r = np.exp(-(X**2).sum(1))다음 그림과 같이 3차원 플롯을 사용하여 이 추가 데이터 차원을 시각화합니다.
ax = plt.subplot(projection="3d")
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap="autumn")
ax.view_init(elev=20, azim=30)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r");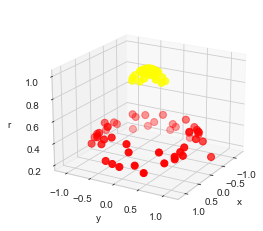
이 추가 차원을 사용하면 r=0.7에서 분리 평면을 그려 데이터가 간단하게 선형으로 분리 가능해짐을 확인합니다.
이 경우 우리는 투영을 선택하고 신중하게 조정해야 했습니다. 방사형 기저 함수의 중심을 올바른 위치에 두지 않았다면 이렇게 깨끗하고 선형적으로 분리 가능한 결과를 볼 수 없었을 것입니다. 일반적으로 그러한 선택을 해야 하는 필요성이 문제가 됩니다. 우리는 사용할 최상의 기본 기능을 어떻게든 자동으로 찾고 싶습니다.
이를 위한 한 가지 전략은 데이터 세트의 모든 지점을 중심으로 하는 기본 함수를 계산하고 SVM 알고리즘이 결과를 선별하도록 하는 것입니다. 이러한 유형의 기본 함수 변환은 각 점 쌍 간의 유사성 관계(또는 커널)를 기반으로 하기 때문에 커널 변환으로 알려져 있습니다.
\(N\) 포인트를 \(N\) 차원으로 투영하는 이 전략의 잠재적인 문제는 \(N\)이 커짐에 따라 계산 집약적이 될 수 있다는 것입니다. 그러나 커널 트릭으로 알려진 깔끔한 작은 절차 덕분에 커널 변환 데이터에 대한 피팅이 암시적으로, 즉 커널 투영의 전체 \(N\) 차원 표현을 구축하지 않고도 수행될 수 있습니다. 이 커널 트릭은 SVM에 내장되어 있으며 이 방법이 매우 강력한 이유 중 하나입니다.
Scikit-Learn에서는 ‘커널’ 모델 하이퍼파라미터를 사용하여 선형 커널을 RBF 커널로 변경함으로써 간단히 커널화된 SVM을 적용합니다.
clf = SVC(kernel="rbf", C=1e6)
clf.fit(X, y)SVC(C=1000000.0)이전에 정의한 함수를 사용하여 피팅을 시각화하고 서포트 벡터를 식별해 보겠습니다(다음 그림 참조).
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(clf)
plt.scatter(
clf.support_vectors_[:, 0],
clf.support_vectors_[:, 1],
s=300,
lw=1,
facecolors="none",
);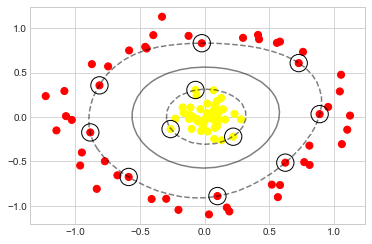
이 커널화된 지원 벡터 머신을 사용하여 적절한 비선형 결정 경계를 학습합니다. 이 커널 변환 전략은 특히 커널 트릭을 사용할 수 있는 모델의 경우 빠른 선형 방법을 빠른 비선형 방법으로 전환하기 위해 머신러닝(Machine Learning)에서 자주 사용됩니다.
SVM 조정: 여백 완화
지금까지 우리의 논의는 완벽한 결정 경계가 존재하는 매우 깨끗한 데이터 세트를 중심으로 이루어졌습니다. 하지만 데이터에 어느 정도 겹치는 부분이 있으면 어떻게 될까요? 예를 들어 다음과 같은 데이터가 있습니다(다음 그림 참조).
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=1.2)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn");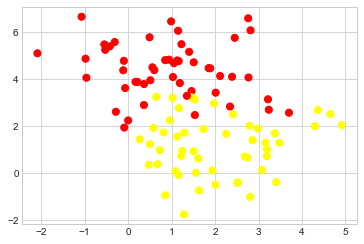
이 경우를 처리하기 위해 SVM 구현에는 여백을 “부드럽게” 하는 약간의 퍼지 요소가 있습니다. 즉, 더 나은 적합성을 허용하는 경우 일부 포인트가 여백 안으로 들어갈 수 있도록 허용합니다. 마진의 경도는 가장 흔히 ’C’로 알려진 조정 매개변수에 의해 제어됩니다. 매우 큰 ’C’의 경우 여백이 단단하고 점이 그 안에 있을 수 없습니다. 더 작은 ’C’의 경우 여백은 더 부드러워지고 일부 지점을 포함하도록 커질 수 있습니다.
다음 그림에 표시된 플롯은 ‘C’ 변경이 여백 완화를 통해 최종 맞춤에 어떤 영향을 미치는지 시각적으로 보여줍니다.
X, y = make_blobs(n_samples=100, centers=2, random_state=0, cluster_std=0.8)
fig, ax = plt.subplots(1, 2, figsize=(16, 6))
fig.subplots_adjust(left=0.0625, right=0.95, wspace=0.1)
for axi, C in zip(ax, [10.0, 0.1]):
model = SVC(kernel="linear", C=C).fit(X, y)
axi.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="autumn")
plot_svc_decision_function(model, axi)
axi.scatter(
model.support_vectors_[:, 0],
model.support_vectors_[:, 1],
s=300,
lw=1,
facecolors="none",
)
axi.set_title("C = {0:.1f}".format(C), size=14)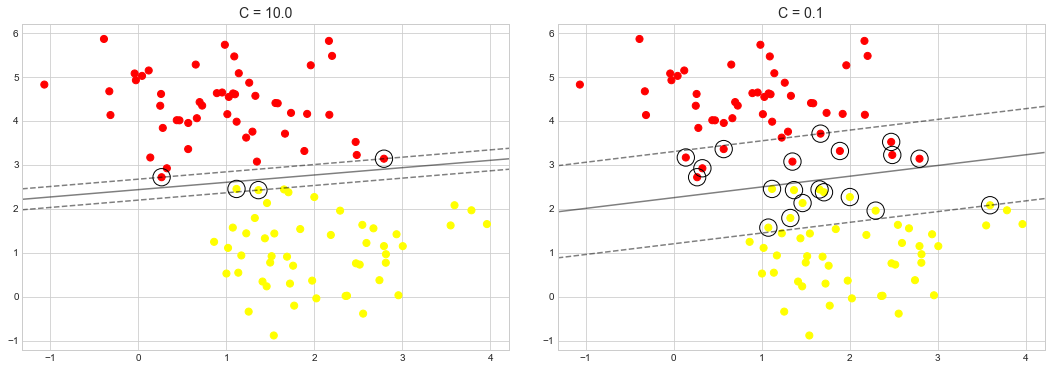
’C’의 최적 값은 데이터 세트에 따라 다르며 교차 검증 또는 유사한 절차를 사용하여 이 매개변수를 조정해야 합니다(하이퍼파라미터 및 모델 검증 참조).
예: 얼굴 인식
작동 중인 서포트 벡터 머신의 예로 얼굴 인식 문제를 살펴보겠습니다. 우리는 다양한 공인의 수천 장의 사진으로 구성된 Labeled Faces in the Wild 데이터 세트를 사용할 것입니다. 데이터 세트 가져오기 도구는 Scikit-Learn에 내장되어 있습니다.
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=60)
print(faces.target_names)
print(faces.images.shape)['Ariel Sharon' 'Colin Powell' 'Donald Rumsfeld' 'George W Bush'
'Gerhard Schroeder' 'Hugo Chavez' 'Junichiro Koizumi' 'Tony Blair']
(1348, 62, 47)우리가 작업 중인 내용을 확인하기 위해 이러한 면 중 몇 가지를 플롯해 보겠습니다(다음 그림 참조).
fig, ax = plt.subplots(3, 5, figsize=(8, 6))
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap="bone")
axi.set(xticks=[], yticks=[], xlabel=faces.target_names[faces.target[i]])
각 이미지에는 62 × 47 또는 약 3,000픽셀이 포함되어 있습니다. 단순히 각 픽셀 값을 특징으로 사용하여 진행할 수도 있지만, 더 의미 있는 특징을 추출하기 위해 일종의 전처리기를 사용하는 것이 더 효과적인 경우가 많습니다. 여기서는 주성분 분석(심층: 주성분 분석 참조)을 사용하여 지원 벡터 머신 분류기에 입력할 150개의 기본 구성요소를 추출합니다. 전처리기와 분류기를 단일 파이프라인으로 패키징하여 이 작업을 가장 간단하게 수행합니다.
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.pipeline import make_pipeline
pca = PCA(n_components=150, whiten=True, svd_solver="randomized", random_state=42)
svc = SVC(kernel="rbf", class_weight="balanced")
model = make_pipeline(pca, svc)분류기 출력을 테스트하기 위해 데이터를 훈련 세트와 테스트 세트로 분할합니다.
from sklearn.model_selection import train_test_split
Xtrain, Xtest, ytrain, ytest = train_test_split(
faces.data, faces.target, random_state=42
)마지막으로 그리드 검색 교차 검증을 사용하여 매개변수 조합을 탐색합니다. 여기서는 C(마진 경도 제어)와 gamma(방사형 기저 함수 커널의 크기 제어)를 조정하고 최상의 모델을 결정합니다.
from sklearn.model_selection import GridSearchCV
param_grid = {"svc__C": [1, 5, 10, 50], "svc__gamma": [0.0001, 0.0005, 0.001, 0.005]}
grid = GridSearchCV(model, param_grid)
%time grid.fit(Xtrain, ytrain)
print(grid.best_params_)CPU times: user 1min 19s, sys: 8.56 s, total: 1min 27s
Wall time: 36.2 s
{'svc__C': 10, 'svc__gamma': 0.001}최적의 값은 그리드 중앙에 위치합니다. 가장자리에 떨어지면 그리드를 확장하여 진정한 최적값을 찾았는지 확인해야 합니다.
이제 이 교차 검증 모델을 사용하여 모델이 아직 확인하지 못한 테스트 데이터의 레이블을 예측합니다.
model = grid.best_estimator_
yfit = model.predict(Xtest)몇 가지 테스트 이미지와 예측 값을 살펴보겠습니다(다음 그림 참조).
fig, ax = plt.subplots(4, 6)
for i, axi in enumerate(ax.flat):
axi.imshow(Xtest[i].reshape(62, 47), cmap="bone")
axi.set(xticks=[], yticks=[])
axi.set_ylabel(
faces.target_names[yfit[i]].split()[-1],
color="black" if yfit[i] == ytest[i] else "red",
)
fig.suptitle("Predicted Names; Incorrect Labels in Red", size=14);
이 작은 샘플 중에서 우리의 최적 추정기는 단 하나의 얼굴에만 잘못 레이블을 붙였습니다(Bush의 맨 아래 줄의 얼굴은 블레어 총리로 잘못 표시되었습니다. 레이블별로 복구 통계 레이블을 나열하는 분류 보고서를 사용하여 추정기의 성능을 더 잘 이해합니다.
from sklearn.metrics import classification_report
print(classification_report(ytest, yfit, target_names=faces.target_names)) precision recall f1-score support
Ariel Sharon 0.65 0.73 0.69 15
Colin Powell 0.80 0.87 0.83 68
Donald Rumsfeld 0.74 0.84 0.79 31
George W Bush 0.92 0.83 0.88 126
Gerhard Schroeder 0.86 0.83 0.84 23
Hugo Chavez 0.93 0.70 0.80 20
Junichiro Koizumi 0.92 1.00 0.96 12
Tony Blair 0.85 0.95 0.90 42
accuracy 0.85 337
macro avg 0.83 0.84 0.84 337
weighted avg 0.86 0.85 0.85 337
또한 이러한 클래스 간의 혼동 행렬을 표시할 수도 있습니다(다음 그림 참조).
from sklearn.metrics import confusion_matrix
import seaborn as sns
mat = confusion_matrix(ytest, yfit)
sns.heatmap(
mat.T,
square=True,
annot=True,
fmt="d",
cbar=False,
cmap="Blues",
xticklabels=faces.target_names,
yticklabels=faces.target_names,
)
plt.xlabel("true label")
plt.ylabel("predicted label");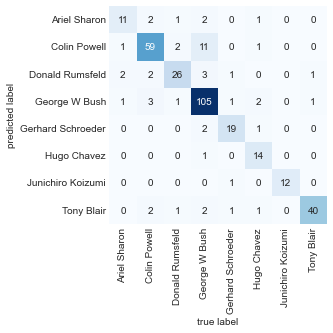
이는 추정자가 어떤 레이블을 혼동할 가능성이 있는지 파악하는 데 도움이 됩니다.
사진이 멋진 그리드로 미리 잘리지 않는 실제 얼굴 인식 작업의 경우 얼굴 분류 체계의 유일한 차이점은 특징 선택입니다. 즉, 얼굴을 찾고 픽셀화와 무관한 특징을 추출하려면 더 정교한 알고리즘을 사용해야 합니다. 이러한 종류의 응용 프로그램의 경우 한 가지 좋은 옵션은 OpenCV를 사용하는 것입니다. 여기에는 일반적인 이미지와 특히 얼굴에 대한 최첨단 특징 추출 도구의 사전 학습된 구현이 포함되어 있습니다.
요약
지금까지 서포트 벡터 머신의 기본 원칙을 간략하고 직관적으로 소개했습니다. 이러한 모델은 다음과 같은 여러 가지 이유로 강력한 분류 방법입니다.
- 상대적으로 적은 수의 지원 벡터에 의존한다는 것은 크기가 작고 메모리를 거의 차지하지 않는다는 것을 의미합니다.
- 모델이 훈련되면 예측 단계가 매우 빠릅니다.
- 여백 근처의 점에만 영향을 받기 때문에 고차원 데이터, 즉 다른 알고리즘에서는 어려운 샘플보다 차원이 더 많은 데이터에서도 잘 작동합니다.
- 커널 방법과의 통합으로 인해 다양한 유형의 데이터에 적응할 수 있어 매우 다재다능합니다.
그러나 SVM에는 다음과 같은 몇 가지 단점도 있습니다.
- 샘플 수 \(N\)에 따른 스케일링은 최악의 경우 \(\mathcal{O}[N^3]\)이거나 효율적인 구현을 위한 \(\mathcal{O}[N^2]\)입니다. 훈련 샘플 수가 많으면 이 계산 비용이 엄청날 수 있습니다.
- 결과는 연화 매개변수 ’C’에 대한 적절한 선택에 따라 크게 달라집니다. 이는 교차 검증을 통해 신중하게 선택해야 하며, 데이터 세트의 크기가 커짐에 따라 비용이 많이 들 수 있습니다.
- 결과는 직접적인 확률론적 해석을 가지지 않습니다. 이는 내부 교차 검증(
SVC의확률매개변수 참조)을 통해 추정할 수 있지만 이 추가 추정에는 비용이 많이 듭니다.
이러한 특성을 염두에 두고 일반적으로 다른 더 간단하고 빠르며 튜닝 집약적이지 않은 방법이 제 요구 사항에 충분하지 않다는 것이 밝혀진 후에만 SVM을 사용합니다. 그럼에도 불구하고 데이터에 대한 SVM 교육 및 교차 검증에 전념할 CPU 주기가 있는 경우 이 방법을 사용하면 탁월한 결과를 얻을 수 있습니다.