import numpy as np
import pandas as pd
import seaborn as sns
titanic = sns.load_dataset("titanic")피벗 테이블(Pivot Tables)
우리는 ‘groupby’ 추상화를 통해 데이터 세트 내의 관계를 탐색하는 방법을 살펴보았습니다. 피벗 테이블은 표 형식 데이터를 다루는 스프레드시트 및 기타 프로그램에서 흔히 볼 수 있는 유사한 작업입니다. 피벗 테이블은 간단한 열별 데이터를 입력으로 사용하고 항목을 데이터의 다차원 요약을 제공하는 2차원 테이블로 그룹화합니다. 피벗 테이블과 groupby의 차이점은 때때로 혼란을 야기합니다. 이는 피벗 테이블을 ‘groupby’ 집계의 다차원 버전으로 생각하는 데 도움이 됩니다. 즉, 분할-적용-결합을 수행하지만 분할과 결합은 모두 1차원 인덱스가 아닌 2차원 그리드에서 발생합니다.
피벗 테이블(Pivot Tables)에 동기를 부여하기
이 섹션에서는 Seaborn 라이브러리에서 제공하는 타이타닉(Titanic) 승객 데이터를 예제로 사용하겠습니다.(Visualization With Seaborn 참조).
titanic.head()| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
출력에서 볼 수 있듯이 여기에는 성별, 연령, 등급, 지불한 요금 등을 포함하여 불운한 항해의 각 승객에 대한 여러 데이터 포인트가 포함되어 있습니다.
직접 피벗 테이블 구현해보기
이 데이터에 대해 더 자세히 알아보려면 성별, 생존 상태 또는 이들의 조합에 따라 그룹화하는 것부터 시작합니다. 이전 장을 읽었다면 ‘groupby’ 연산을 적용하고 싶은 유혹을 느낄 수도 있습니다. 예를 들어 성별에 따른 생존율을 살펴보겠습니다.
titanic.groupby("sex")[["survived"]].mean()| survived | |
|---|---|
| sex | |
| female | 0.742038 |
| male | 0.188908 |
이는 우리에게 몇 가지 초기 통찰력을 제공합니다. 전반적으로 탑승한 여성 4명 중 3명이 생존한 반면, 남성은 5명 중 1명꼴로 생존했습니다.
이는 유용하지만 한 단계 더 깊이 들어가 성별, 계층별 생존율을 살펴보고 싶을 수도 있습니다. ’groupby’라는 용어를 사용하면 다음과 같은 프로세스를 진행합니다. 먼저 클래스와 성별로 그룹화한 다음, 생존을 선택하고, 평균 집계를 적용하고, 결과 그룹을 결합하고, 마지막으로 계층적 인덱스를 풀어 숨겨진 다차원성을 드러냅니다. 코드에서:
titanic.groupby(["sex", "class"])["survived"].aggregate("mean").unstack()| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
이를 통해 성별과 계급이 생존에 어떤 영향을 미치는지 더 잘 알 수 있지만 코드가 약간 왜곡되어 보이기 시작했습니다. 이 파이프라인의 각 단계는 이전에 논의한 도구를 고려하면 의미가 있지만 긴 코드 문자열은 특히 읽거나 사용하기 쉽지 않습니다. 이 2차원 groupby는 Pandas에 이러한 유형의 다차원 집계를 간결하게 처리하는 편의 루틴 pivot_table이 포함되어 있을 만큼 충분히 일반적입니다.
피벗 테이블(Pivot Tables) 구문
다음은 DataFrame.pivot_table 메서드를 사용한 이전 작업과 동일합니다.
titanic.pivot_table("survived", index="sex", columns="class", aggfunc="mean")| class | First | Second | Third |
|---|---|---|---|
| sex | |||
| female | 0.968085 | 0.921053 | 0.500000 |
| male | 0.368852 | 0.157407 | 0.135447 |
이 방식은 groupby를 직접 사용하는 것보다 훨씬 읽기 편하며, 결과는 동일합니다. 20세기 초 대서양 횡단 크루즈에서 기대할 수 있듯이 생존 기울기는 상류층과 여성으로 기록된 사람들 모두에게 유리합니다. 데이터. 일류 여성은 거의 확실하게 살아남은 반면(안녕, 로즈!), 삼류 남성은 여덟 명 중 한 명만이 살아남았습니다(미안해요, 잭!).
다단계 피벗 테이블
groupby에서와 마찬가지로 피벗 테이블에서도 여러 단계의 그룹화와 다양한 옵션을 지정합니다. 예를 들어 우리는 나이를 3차원으로 보는 데 관심이 있습니다. pd.cut 함수를 사용하여 나이를 비닝하겠습니다.
age = pd.cut(titanic["age"], [0, 18, 80])
titanic.pivot_table("survived", ["sex", age], "class")| class | First | Second | Third | |
|---|---|---|---|---|
| sex | age | |||
| female | (0, 18] | 0.909091 | 1.000000 | 0.511628 |
| (18, 80] | 0.972973 | 0.900000 | 0.423729 | |
| male | (0, 18] | 0.800000 | 0.600000 | 0.215686 |
| (18, 80] | 0.375000 | 0.071429 | 0.133663 |
열을 작업할 때도 동일한 전략을 적용합니다. 데이터를 분위수별로 나누기 위해 pd.qcut을 사용해 지불한 요금에 대한 정보를 추가해 보겠습니다.
fare = pd.qcut(titanic["fare"], 2)
titanic.pivot_table("survived", ["sex", age], [fare, "class"])| fare | (-0.001, 14.454] | (14.454, 512.329] | |||||
|---|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third | |
| sex | age | ||||||
| female | (0, 18] | NaN | 1.000000 | 0.714286 | 0.909091 | 1.000000 | 0.318182 |
| (18, 80] | NaN | 0.880000 | 0.444444 | 0.972973 | 0.914286 | 0.391304 | |
| male | (0, 18] | NaN | 0.000000 | 0.260870 | 0.800000 | 0.818182 | 0.178571 |
| (18, 80] | 0.0 | 0.098039 | 0.125000 | 0.391304 | 0.030303 | 0.192308 | |
결과물은 계층적 인덱스를 가진 4차원 집계 데이터가 됩니다(계층적 인덱싱 참조). 이는 값 간의 관계를 보여주는 그리드에 표시됩니다.
피벗 테이블의 추가 옵션
DataFrame.pivot_table 메서드의 전체 호출 서명은 다음과 같습니다.
``파이썬 # Pandas 1.3.5부터 호출 서명 DataFrame.pivot_table(데이터, 값=없음, 인덱스=없음, 열=없음, aggfunc=‘평균’, fill_value=없음, 여백=False, dropna=True, margins_name=‘모두’, 관찰됨=False, 정렬=참) ````
우리는 이미 처음 세 가지 주장의 예를 보았습니다. 여기에서는 나머지 항목 중 일부를 간략하게 살펴보겠습니다. 두 가지 옵션인 ’fill_value’와 ’dropna’는 누락된 데이터와 관련이 있으며 매우 간단합니다. 여기서는 그 예를 보여주지 않겠습니다.
aggfunc 키워드는 적용되는 집계 유형을 제어하며 이는 평균입니다. groupby와 마찬가지로 집계 사양은 여러 일반적인 선택('sum', 'mean', 'count', 'min', 'max' 등) 중 하나를 나타내는 문자열이거나 집계를 구현하는 함수(예: np.sum(), min(), sum() 등)일 수 있습니다. 또한 열을 원하는 옵션에 매핑하는 사전으로 지정합니다.
titanic.pivot_table(
index="sex", columns="class", aggfunc={"survived": sum, "fare": "mean"}
)| fare | survived | |||||
|---|---|---|---|---|---|---|
| class | First | Second | Third | First | Second | Third |
| sex | ||||||
| female | 106.125798 | 21.970121 | 16.118810 | 91 | 70 | 72 |
| male | 67.226127 | 19.741782 | 12.661633 | 45 | 17 | 47 |
여기서는 values 키워드를 생략했다는 점도 주목하세요. aggfunc에 대한 매핑을 지정할 때 이는 자동으로 결정됩니다.
각 그룹별로 합계를 계산하는 것이 유용한 경우가 있습니다. 이는 margins 키워드를 통해 수행합니다:
titanic.pivot_table("survived", index="sex", columns="class", margins=True)| class | First | Second | Third | All |
|---|---|---|---|---|
| sex | ||||
| female | 0.968085 | 0.921053 | 0.500000 | 0.742038 |
| male | 0.368852 | 0.157407 | 0.135447 | 0.188908 |
| All | 0.629630 | 0.472826 | 0.242363 | 0.383838 |
여기서는 성별에 따른 클래스 무관 생존율, 클래스별 성별 생존율, 전체 생존율 38%에 대한 정보를 자동으로 제공합니다. 여백 레이블은 margins_name 키워드로 지정합니다. 기본값은 "모두"입니다.
예제: 미국 출생률 데이터
또 다른 예로 미국 질병 통제 센터(CDC)에서 제공하는 무료로 제공되는 미국 출생 데이터를 살펴보겠습니다. 이 데이터는 https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csv에서 찾을 수 있습니다. (이 데이터 세트는 Andrew Gelman과 그의 그룹에 의해 상당히 광범위하게 분석되었습니다. 예를 들어 가우스 프로세스를 사용한 신호 처리에 대한 블로그 게시물을 참조하세요.)
# shell command to download the data:
# !cd data && curl -O \
# https://raw.githubusercontent.com/jakevdp/data-CDCbirths/master/births.csvbirths = pd.read_csv("data/births.csv")데이터를 살펴보면 비교적 간단하다는 것을 확인합니다. 여기에는 날짜와 성별별로 그룹화된 출생 수가 포함되어 있습니다.
births.head()| year | month | day | gender | births | |
|---|---|---|---|---|---|
| 0 | 1969 | 1 | 1.0 | F | 4046 |
| 1 | 1969 | 1 | 1.0 | M | 4440 |
| 2 | 1969 | 1 | 2.0 | F | 4454 |
| 3 | 1969 | 1 | 2.0 | M | 4548 |
| 4 | 1969 | 1 | 3.0 | F | 4548 |
피벗 테이블을 사용하면 이 데이터를 좀 더 이해합니다. ‘decade’ 열을 추가하고 10년의 함수로 남성과 여성의 출생을 살펴보겠습니다.
births["decade"] = 10 * (births["year"] // 10)
births.pivot_table("births", index="decade", columns="gender", aggfunc="sum")| gender | F | M |
|---|---|---|
| decade | ||
| 1960 | 1753634 | 1846572 |
| 1970 | 16263075 | 17121550 |
| 1980 | 18310351 | 19243452 |
| 1990 | 19479454 | 20420553 |
| 2000 | 18229309 | 19106428 |
매 10년마다 남성 출생이 여성 출생보다 많다는 것을 확인합니다. 이러한 추세를 좀 더 명확하게 보기 위해 다음 그림과 같이 Pandas에 내장된 플로팅 도구를 사용하여 연도별 총 출생 수를 시각화합니다(Matplotlib를 사용한 플로팅에 대한 논의는 Matplotlib 소개 참조).
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use("seaborn-whitegrid")
births.pivot_table("births", index="year", columns="gender", aggfunc="sum").plot()
plt.ylabel("total births per year");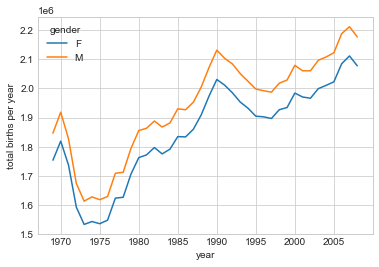
간단한 피벗 테이블과 plot 방식을 통해 성별에 따른 연간 출생아 추세를 즉시 확인합니다. 지난 50년 동안 남성 출생이 여성 출생보다 약 5% 더 많은 것으로 나타났습니다.
이것이 반드시 피벗 테이블과 관련이 있는 것은 아니지만 지금까지 다룬 Pandas 도구를 사용하여 이 데이터 세트에서 끌어낼 수 있는 몇 가지 흥미로운 기능이 더 있습니다. 먼저 데이터를 약간 정리하여 잘못 입력한 날짜(예: 6월 31일) 또는 누락된 값(예: 6월 99일)으로 인한 이상값을 제거해야 합니다. 이러한 모든 것을 한 번에 제거하는 쉬운 방법 중 하나는 이상값을 잘라내는 것입니다. 강력한 시그마 클리핑 작업을 통해 이를 수행합니다.
quartiles = np.percentile(births["births"], [25, 50, 75])
mu = quartiles[1]
sig = 0.74 * (quartiles[2] - quartiles[0])이 마지막 선은 표본 표준 편차의 강력한 추정치입니다. 여기서 0.74는 가우스 분포의 사분위수 범위에서 나옵니다(제가 Željko Ivezić, Andrew J. Connolly 및 Alexander Gray와 공동 집필한 책에서 시그마 클리핑 작업에 대해 자세히 알아볼 수 있습니다: Statistics, Data Mining, and Machine Learning in 천문학(프린스턴 대학 출판부)).
이를 통해 query 메서드(High-Performance Pandas: eval() 및 query()에서 자세히 설명)를 사용하여 이러한 값을 벗어나는 출생이 있는 행을 필터링합니다.
births = births.query("(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)")다음으로 ‘day’ 열을 정수로 설정합니다. 이전에는 데이터 세트의 일부 열에 'null' 값이 포함되어 있었기 때문에 문자열 열이었습니다.
# set 'day' column to integer; it originally was a string due to nulls
births["day"] = births["day"].astype(int)마지막으로 일, 월, 연도를 결합하여 날짜 인덱스를 생성합니다(시계열 작업 참조). 이를 통해 각 행에 해당하는 요일을 빠르게 계산합니다.
# create a datetime index from the year, month, day
births.index = pd.to_datetime(
10000 * births.year + 100 * births.month + births.day, format="%Y%m%d"
)
births["dayofweek"] = births.index.dayofweek이를 사용하여 수십 년 동안 평일별 출생을 계획합니다(다음 그림 참조).
import matplotlib.pyplot as plt
births.pivot_table("births", index="dayofweek", columns="decade", aggfunc="mean").plot()
plt.gca().set(
xticks=range(7), xticklabels=["Mon", "Tues", "Wed", "Thurs", "Fri", "Sat", "Sun"]
)
plt.ylabel("mean births by day");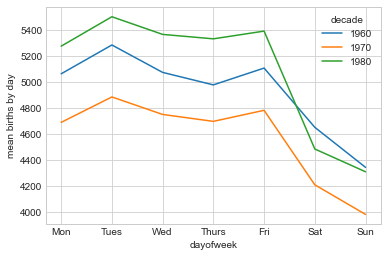
분명히 평일보다 주말에 출산이 약간 덜 일반적입니다! 1989년부터 CDC 데이터에 생년월일만 포함되어 있기 때문에 1990년대와 2000년대는 누락되었습니다.
또 다른 흥미로운 관점은 연중 평균 출생아 수를 표시하는 것입니다. 먼저 데이터를 월별, 일별로 그룹화해 보겠습니다.
births_by_date = births.pivot_table("births", [births.index.month, births.index.day])
births_by_date.head()| births | ||
|---|---|---|
| 1 | 1 | 4009.225 |
| 2 | 4247.400 | |
| 3 | 4500.900 | |
| 4 | 4571.350 | |
| 5 | 4603.625 |
그 결과는 몇 달과 며칠에 걸쳐 다중 인덱스가 됩니다. 이를 시각화 가능하게 만들기 위해 이러한 월과 일을 더미 연도 변수와 연결하여 날짜로 변환하겠습니다(2월 29일이 올바르게 처리되도록 윤년을 선택해야 합니다!).
from datetime import datetime
births_by_date.index = [
datetime(2012, month, day) for (month, day) in births_by_date.index
]
births_by_date.head()| births | |
|---|---|
| 2012-01-01 | 4009.225 |
| 2012-01-02 | 4247.400 |
| 2012-01-03 | 4500.900 |
| 2012-01-04 | 4571.350 |
| 2012-01-05 | 4603.625 |
월과 일에만 초점을 맞춰, 이제 연도별 평균 출생아 수를 반영하는 시계열을 갖게 되었습니다. 여기에서 ‘plot’ 메서드를 사용하여 데이터를 그릴 수 있습니다. 다음 그림에서 볼 수 있듯이 몇 가지 흥미로운 추세를 보여줍니다.
# Plot the results
fig, ax = plt.subplots(figsize=(12, 4))
births_by_date.plot(ax=ax);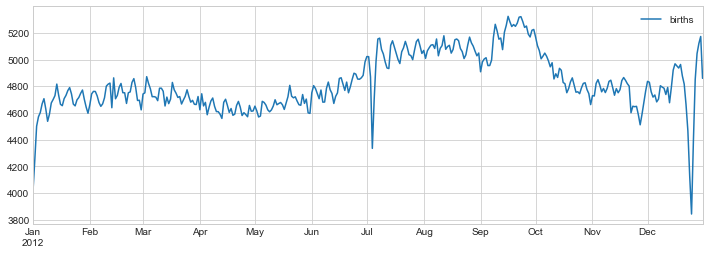
특히, 이 그래프의 눈에 띄는 특징은 미국 공휴일(예: 독립 기념일, 노동절, 추수감사절, 크리스마스, 설날)의 출산율 감소입니다. 그러나 이는 자연 출산에 대한 깊은 정신적 영향보다는 예정/유도 출산의 경향을 반영하는 것 같습니다. 이러한 추세에 대한 자세한 내용은 해당 주제에 대한 Andrew Gelman의 블로그 게시물의 분석 및 링크를 참조하세요. 예:-Effect-of-Holidays-on-US-Births에서 이 그림으로 돌아가서 Matplotlib의 도구를 사용하여 이 플롯에 주석을 달 것입니다.
이 짧은 예제에서 알 수 있듯, 지금까지 살펴본 파이썬과 Pandas의 여러 도구를 결합하면 다양한 데이터 세트에서 통찰력을 얻는 데 사용할 수 있음을 확인합니다. 우리는 다음 장에서 이러한 데이터 조작의 좀 더 정교한 적용을 보게 될 것입니다!