import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
plt.style.use('seaborn-whitegrid')심층 분석: 다양한 학습
이전 장에서 우리는 차원 축소에 PCA를 사용하여 포인트 간의 필수 관계를 유지하면서 데이터 세트의 기능 수를 줄이는 방법을 살펴보았습니다. PCA는 유연하고 빠르며 쉽게 해석할 수 있지만 데이터 내에 비선형 관계가 있는 경우에는 제대로 작동하지 않습니다. 이에 대한 몇 가지 예는 곧 살펴보겠습니다.
이러한 결함을 해결하기 위해 우리는 데이터 세트를 고차원 공간에 내장된 저차원 다양체로 설명하려는 비지도 추정기 클래스인 다양체 학습 알고리즘을 사용합니다. 다양체를 생각할 때 종이 한 장을 상상해 보시기 바랍니다. 이것은 우리에게 친숙한 3차원 세계에 살고 있는 2차원 물체입니다.
다양체 학습의 용어로 이 시트를 3차원 공간에 내장된 2차원 다양체라고 생각합니다. 3차원 공간에서 종이 조각을 회전하거나 방향을 바꾸거나 늘려도 평면 형상은 변경되지 않습니다. 이러한 작업은 선형 임베딩과 유사합니다. 종이를 구부리거나 말리거나 구겨도 종이는 여전히 2차원 다양체이지만 3차원 공간에 매립되는 방식은 더 이상 선형이 아닙니다. 다양한 학습 알고리즘은 종이가 3차원 공간을 채우기 위해 왜곡되더라도 종이의 근본적인 2차원 특성에 대해 학습하려고 합니다.
여기서는 다차원 스케일링(MDS), 국소 선형 임베딩(LLE) 및 등각 매핑(Isomap)과 같은 기술의 하위 집합을 가장 깊이 살펴보는 다양한 방법을 살펴보겠습니다.
표준 가져오기부터 시작합니다.
다양한 학습: “안녕하세요”
이러한 개념을 더 명확하게 하기 위해 다양체를 정의하는 데 사용할 수 있는 2차원 데이터를 생성하는 것부터 시작하겠습니다. 다음은 “HELLO”라는 단어 형태로 데이터를 생성하는 함수입니다.
from matplotlib.image import imread
def make_hello(N=1000, rseed=42):
# Make a plot with "HELLO" text; save as PNG
fig, ax = plt.subplots(figsize=(4, 1))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1)
ax.axis('off')
ax.text(0.5, 0.4, 'HELLO', va='center', ha='center', weight='bold', size=85)
fig.savefig('hello.png')
plt.close(fig)
# Open this PNG and draw random points from it
data = imread('hello.png')[::-1, :, 0].T
rng = np.random.RandomState(rseed)
X = rng.rand(4 * N, 2)
i, j = (X * data.shape).astype(int).T
mask = (data[i, j] < 1)
X = X[mask]
X[:, 0] *= (data.shape[0] / data.shape[1])
X = X[:N]
return X[np.argsort(X[:, 0])]함수를 호출하고 결과 데이터를 시각화해 보겠습니다(다음 그림 참조).
X = make_hello(1000)
colorize = dict(c=X[:, 0], cmap=plt.cm.get_cmap('rainbow', 5))
plt.scatter(X[:, 0], X[:, 1], **colorize)
plt.axis('equal')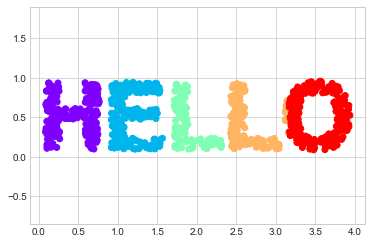
출력은 2차원이며 “HELLO”라는 단어 모양으로 그려진 점으로 구성됩니다. 이 데이터 형식은 이러한 알고리즘이 수행하는 작업을 시각적으로 확인하는 데 도움이 됩니다.
다차원 스케일링
이와 같은 데이터를 살펴보면 데이터 세트의 x 및 y 값의 특정 선택이 데이터에 대한 가장 기본적인 설명이 아니라는 것을 확인합니다. 데이터를 확장, 축소 또는 회전할 수 있으며 “HELLO”는 여전히 분명합니다. 예를 들어 회전 행렬을 사용하여 데이터를 회전하면 x 및 y 값이 변경되지만 데이터는 여전히 동일합니다(다음 그림 참조).
def rotate(X, angle):
theta = np.deg2rad(angle)
R = [[np.cos(theta), np.sin(theta)],
[-np.sin(theta), np.cos(theta)]]
return np.dot(X, R)
X2 = rotate(X, 20) + 5
plt.scatter(X2[:, 0], X2[:, 1], **colorize)
plt.axis('equal')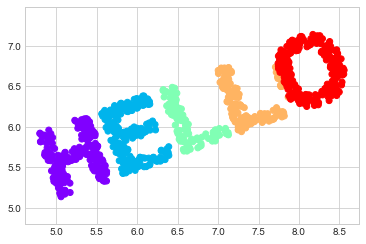
이는 x 및 y 값이 데이터 관계의 기본이 아닐 수도 있음을 확인합니다. 이 경우 가장 중요한 것은 데이터 세트 내의 각 지점 사이의 거리입니다. 이를 표현하는 일반적인 방법은 거리 행렬을 사용하는 것입니다. \(N\) 점에 대해 \((i, j)\) 항목에 \(i\) 점과 \(j\) 사이의 거리가 포함되도록 \(N \times N\) 배열을 구성합니다. Scikit-Learn의 효율적인 pairwise_distances 함수를 사용하여 원본 데이터에 대해 이 작업을 수행해 보겠습니다.
from sklearn.metrics import pairwise_distances
D = pairwise_distances(X)
D.shape(1000, 1000)약속한 대로 N=1,000 포인트에 대해 1000 × 1000 행렬을 얻습니다. 이는 다음과 같이 시각화합니다(다음 그림 참조).
plt.imshow(D, zorder=2, cmap='viridis', interpolation='nearest')
plt.colorbar()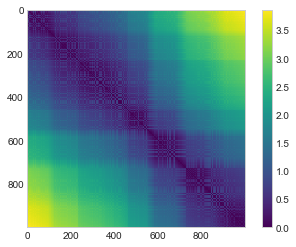
회전 및 변환된 데이터에 대해 유사하게 거리 행렬을 구성하면 동일한 것을 확인합니다.
D2 = pairwise_distances(X2)
np.allclose(D, D2)True이 거리 행렬은 회전과 평행 이동에 변하지 않는 데이터 표현을 제공하지만 다음 그림의 행렬 시각화는 완전히 직관적이지 않습니다. 여기에 표시된 표현에서는 이전에 본 “HELLO”라는 데이터의 흥미로운 구조에 대한 가시적 신호가 손실되었습니다.
또한 (x, y) 좌표에서 이 거리 행렬을 계산하는 것은 간단하지만 거리를 다시 x 및 y 좌표로 변환하는 것은 다소 어렵습니다. 이것이 바로 다차원 스케일링 알고리즘의 목표입니다. 즉, 점 사이의 거리 행렬이 주어지면 데이터의 \(D\) 차원 좌표 표현을 복구합니다. 거리 행렬을 전달한다는 것을 지정하기 위해 미리 계산된 비유사성을 사용하여 거리 행렬에 대해 이것이 어떻게 작동하는지 살펴보겠습니다(다음 그림).
from sklearn.manifold import MDS
model = MDS(n_components=2, dissimilarity='precomputed', random_state=1701)
out = model.fit_transform(D)
plt.scatter(out[:, 0], out[:, 1], **colorize)
plt.axis('equal')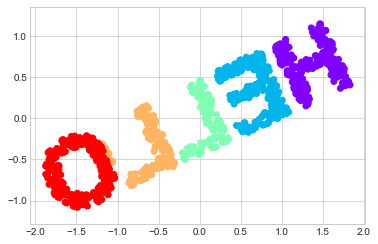
MDS 알고리즘은 데이터 포인트 간의 관계를 설명하는 \(N\times N\) 거리 행렬 만 사용하여 데이터의 가능한 2차원 좌표 표현 중 하나를 복구합니다.
다양한 학습으로서의 MDS
모든 차원의 데이터로부터 거리 행렬을 계산할 수 있다는 사실을 고려할 때 이 방법의 유용성은 더욱 분명해집니다. 따라서 예를 들어 단순히 2차원 평면에서 데이터를 회전하는 대신 다음 함수를 사용하여 데이터를 3차원으로 투영합니다(본질적으로 앞서 사용된 회전 행렬의 3차원 일반화).
def random_projection(X, dimension=3, rseed=42):
assert dimension >= X.shape[1]
rng = np.random.RandomState(rseed)
C = rng.randn(dimension, dimension)
e, V = np.linalg.eigh(np.dot(C, C.T))
return np.dot(X, V[:X.shape[1]])
X3 = random_projection(X, 3)
X3.shape(1000, 3)이러한 점을 시각화하여 우리가 작업 중인 내용을 살펴보겠습니다(다음 그림).
ax = plt.axes(projection='3d')
ax.scatter3D(X3[:, 0], X3[:, 1], X3[:, 2],
**colorize)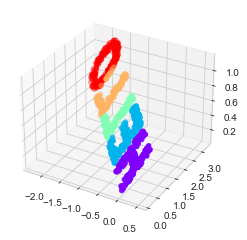
이제 ‘MDS’ 추정기에 이 3차원 데이터를 입력하고 거리 행렬을 계산한 다음 이 거리 행렬에 대한 최적의 2차원 임베딩을 결정하도록 요청합니다. 결과는 다음 그림과 같이 원본 데이터의 표현을 복구합니다.
model = MDS(n_components=2, random_state=1701)
out3 = model.fit_transform(X3)
plt.scatter(out3[:, 0], out3[:, 1], **colorize)
plt.axis('equal')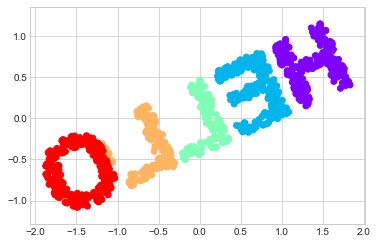
이는 본질적으로 매니폴드 학습 추정기의 목표입니다. 고차원 임베디드 데이터가 주어지면 데이터 내의 특정 관계를 유지하는 데이터의 저차원 표현을 찾습니다. MDS의 경우 보존되는 양은 모든 점 쌍 사이의 거리입니다.
비선형 임베딩: MDS가 실패하는 경우
지금까지 논의한 내용은 데이터를 고차원 공간으로 회전, 변환 및 크기 조정하는 것으로 구성된 선형 임베딩을 고려했습니다. MDS가 분해되는 곳은 임베딩이 비선형일 때입니다. 즉, 이 단순한 작업 세트를 넘어서는 경우입니다. 입력을 가져와 3차원에서 “S” 모양으로 변환하는 다음 임베딩을 고려해보세요.
def make_hello_s_curve(X):
t = (X[:, 0] - 2) * 0.75 * np.pi
x = np.sin(t)
y = X[:, 1]
z = np.sign(t) * (np.cos(t) - 1)
return np.vstack((x, y, z)).T
XS = make_hello_s_curve(X)이는 다시 3차원 데이터이지만 다음 그림에서 볼 수 있듯이 임베딩은 훨씬 더 복잡합니다.
ax = plt.axes(projection='3d')
ax.scatter3D(XS[:, 0], XS[:, 1], XS[:, 2],
**colorize)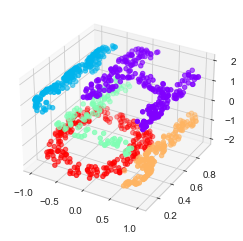
데이터 포인트 사이의 기본적인 관계는 여전히 존재하지만 이번에는 데이터가 비선형 방식으로 변환되었습니다. 즉, “S” 모양으로 포장되었습니다.
이 데이터에 대해 간단한 MDS 알고리즘을 시도하면 이 비선형 임베딩을 “해제”할 수 없으며 포함된 다양체의 기본 관계를 추적할 수 없습니다(다음 그림 참조).
from sklearn.manifold import MDS
model = MDS(n_components=2, random_state=2)
outS = model.fit_transform(XS)
plt.scatter(outS[:, 0], outS[:, 1], **colorize)
plt.axis('equal')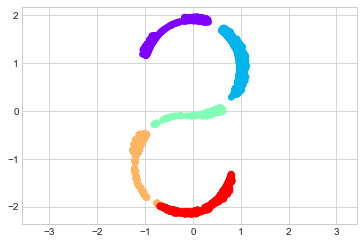
최고의 2차원 선형 임베딩은 S 곡선을 펼치지 않고 대신 원래 y축을 삭제합니다.
비선형 다양체: 국소 선형 임베딩
여기서 어떻게 앞으로 나아갈 수 있습니까? 한발 물러나서, 문제의 원인은 MDS가 임베딩을 구성할 때 멀리 있는 지점 사이의 거리를 유지하려고 시도한다는 것임을 확인합니다. 하지만 대신 가까운 지점 사이의 거리만 보존하도록 알고리즘을 수정하면 어떻게 될까요? 결과 임베딩은 우리가 원하는 것에 더 가깝습니다.
시각적으로 보면 다음 그림과 같이 생각합니다.

여기서 각각의 희미한 선은 임베딩에서 유지되어야 하는 거리를 나타냅니다. 왼쪽에는 MDS에서 사용하는 모델이 표시됩니다. MDS는 데이터 세트의 각 점 쌍 사이의 거리를 보존하려고 시도합니다. 오른쪽에는 로컬 선형 임베딩이라는 다양한 학습 알고리즘이 사용하는 모델이 표시됩니다. 모든 거리를 보존하는 대신 이웃 지점 사이의 거리만 보존하려고 합니다(이 경우 각 지점에서 가장 가까운 100개 이웃).
왼쪽 패널을 생각하면 MDS가 실패하는 이유를 확인합니다. 두 점 사이에 그려진 모든 선의 길이를 적절하게 유지하면서 이 데이터를 전개할 방법이 없습니다. 반면에 오른쪽 패널의 경우 상황이 좀 더 낙관적으로 보입니다. 선의 길이를 거의 동일하게 유지하는 방식으로 데이터를 펼치는 것을 상상합니다. 이것이 바로 이 논리를 반영하는 비용 함수의 전역 최적화를 통해 LLE가 수행하는 작업입니다.
LLE는 다양한 형태로 제공됩니다. 여기서는 수정된 LLE 알고리즘을 사용하여 내장된 2차원 다양체를 복구할 것입니다. 일반적으로 수정된 LLE는 왜곡이 거의 없이 잘 정의된 다양체를 복구하는 데 있어 다른 알고리즘보다 더 나은 성능을 발휘합니다(다음 그림 참조).
from sklearn.manifold import LocallyLinearEmbedding
model = LocallyLinearEmbedding(
n_neighbors=100, n_components=2,
method='modified', eigen_solver='dense')
out = model.fit_transform(XS)
fig, ax = plt.subplots()
ax.scatter(out[:, 0], out[:, 1], **colorize)
ax.set_ylim(0.15, -0.15)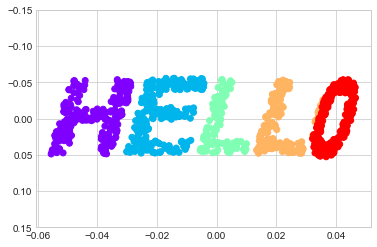
결과는 원래 다양체에 비해 다소 왜곡된 상태로 남아 있지만 데이터의 필수 관계를 포착합니다!
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.
이러한 예가 매력적일 수 있지만 실제로 다양한 학습 기술은 고차원 데이터의 단순한 질적 시각화 이상의 용도로는 거의 사용되지 않을 정도로 까다롭습니다.
다음은 PCA와 잘 대조되지 않는 다양한 학습의 특정 과제 중 일부입니다.
- 매니폴드 학습에서는 누락된 데이터를 처리하기 위한 좋은 프레임워크가 없습니다. 대조적으로, PCA에는 누락된 데이터를 처리하기 위한 간단한 반복 접근 방식이 있습니다.
- 다양체 학습에서 데이터에 노이즈가 있으면 다양체가 “단락”되어 임베딩이 크게 변경될 수 있습니다. 이와 대조적으로 PCA는 가장 중요한 구성 요소에서 자연스럽게 노이즈를 필터링합니다.
- 매니폴드 임베딩 결과는 일반적으로 선택된 이웃 수에 크게 의존하며 일반적으로 최적의 이웃 수를 선택하는 확실한 정량적 방법은 없습니다. 대조적으로, PCA는 그러한 선택을 포함하지 않습니다.
- 매니폴드 학습에서는 전역적으로 최적의 출력 차원 수를 결정하기가 어렵습니다. 대조적으로, PCA를 사용하면 설명된 분산을 기반으로 출력 차원의 수를 찾을 수 있습니다.
- 매니폴드 학습에서는 내장된 차원의 의미가 항상 명확하지는 않습니다. PCA에서 주요 구성 요소는 매우 명확한 의미를 갖습니다.
- 다양체 학습에서 다양체 방법의 계산 비용은 \(O[N^2]\) 또는 \(O[N^3]\)로 확장됩니다. PCA의 경우 일반적으로 훨씬 더 빠른 무작위 접근 방식이 있습니다(다양한 학습의 확장 가능한 구현에 대해서는 megaman 패키지 참조).
이 모든 것을 고려하면 PCA에 비해 다양한 학습 방법의 유일한 확실한 장점은 데이터의 비선형 관계를 보존하는 능력입니다. 그런 이유로 저는 먼저 PCA로 데이터를 탐색한 후에 다양한 방법으로 데이터를 탐색하는 경향이 있습니다.
Scikit-Learn은 LLE 및 Isomap을 넘어 다양한 학습의 여러 가지 일반적인 변형을 구현합니다(이전 장에서 몇 개 사용했으며 다음 섹션에서 살펴보겠습니다). Scikit-Learn 문서에는 그들에 대한 좋은 토론 및 비교가 있습니다. 제 경험을 바탕으로 다음과 같은 권장 사항을 제시합니다.
- 이전에 본 S-곡선과 같은 장난감 문제의 경우 LLE와 그 변형(특히 수정된 LLE)이 매우 잘 수행됩니다. 이는
sklearn.manifold.LocallyLinearEmbedding에서 구현됩니다. - 실제 소스의 고차원 데이터의 경우 LLE는 종종 좋지 않은 결과를 생성하며 Isomap은 일반적으로 더 의미 있는 임베딩으로 이어지는 것으로 보입니다. 이는
sklearn.manifold.Isomap에서 구현됩니다. - 고도로 클러스터된 데이터의 경우 t-분산 확률적 이웃 임베딩(t-SNE)이 매우 잘 작동하는 것으로 보이지만 다른 방법에 비해 속도가 매우 느릴 수 있습니다. 이는
sklearn.manifold.TSNE에 구현되어 있습니다.
이러한 작동 방식에 대해 알아보고 싶다면 이 섹션의 데이터에 대해 각 메서드를 실행해 보는 것이 좋습니다.
예: 면의 등위도표
매니폴드 학습이 자주 사용되는 곳 중 하나는 고차원 데이터 포인트 간의 관계를 이해하는 것입니다. 고차원 데이터의 일반적인 경우는 이미지입니다. 예를 들어 각각 1,000픽셀로 구성된 이미지 세트는 1,000차원의 점 모음으로 간주할 수 있으며, 각 이미지의 각 픽셀 밝기는 해당 차원의 좌표를 정의합니다.
설명을 위해 이전에 심층: 지원 벡터 머신 및 심층: 주성분 분석에서 본 Wild 데이터 세트의 Labeled Faces의 일부 데이터에 Isomap을 적용해 보겠습니다. 이 명령을 실행하면 데이터 세트가 다운로드되어 나중에 사용할 수 있도록 홈 디렉터리에 캐시됩니다.
from sklearn.datasets import fetch_lfw_people
faces = fetch_lfw_people(min_faces_per_person=30)
faces.data.shape(2370, 2914)우리는 각각 2,914픽셀을 가진 2,370개의 이미지를 가지고 있습니다. 즉, 이미지는 2,914차원 공간의 데이터 포인트라고 생각합니다!
우리가 작업 중인 내용을 상기시키기 위해 이러한 이미지 중 몇 개를 표시해 보겠습니다(다음 그림 참조).
fig, ax = plt.subplots(4, 8, subplot_kw=dict(xticks=[], yticks=[]))
for i, axi in enumerate(ax.flat):
axi.imshow(faces.images[i], cmap='gray')
심층: 주요 구성 요소 분석에서 이 데이터를 발견했을 때 우리의 목표는 본질적으로 압축이었습니다. 구성 요소를 사용하여 저차원 표현에서 입력을 재구성하는 것입니다.
PCA는 다재다능하여 이미지 간의 기본 관계를 학습하기 위해 2,914차원 데이터의 저차원 임베딩을 플롯하려는 이러한 맥락에서도 사용합니다. 설명된 분산 비율을 다시 살펴보겠습니다. 이를 통해 데이터를 설명하는 데 필요한 선형 특성 수에 대한 아이디어를 얻을 수 있습니다(다음 그림 참조).
from sklearn.decomposition import PCA
model = PCA(100, svd_solver='randomized').fit(faces.data)
plt.plot(np.cumsum(model.explained_variance_ratio_))
plt.xlabel('n components')
plt.ylabel('cumulative variance')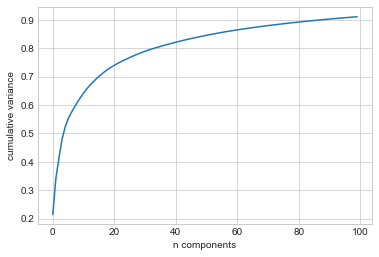
이 데이터의 경우 분산의 90%를 유지하려면 거의 100개의 구성 요소가 필요하다는 것을 확인합니다. 이는 데이터가 본질적으로 매우 고차원적이라는 것을 말해줍니다. 즉, 몇 가지 구성 요소만으로 선형적으로 설명할 수는 없습니다.
이 경우 LLE 및 Isomap과 같은 비선형 다양체 임베딩이 도움이 될 수 있습니다. 이전에 표시된 것과 동일한 패턴을 사용하여 이러한 면에 Isomap 임베딩을 계산합니다.
from sklearn.manifold import Isomap
model = Isomap(n_components=2)
proj = model.fit_transform(faces.data)
proj.shape(2370, 2)출력은 모든 입력 이미지의 2차원 투영입니다. 투영이 우리에게 알려주는 내용을 더 잘 이해하기 위해 투영 위치에 이미지 축소판을 출력하는 함수를 정의해 보겠습니다.
from matplotlib import offsetbox
def plot_components(data, model, images=None, ax=None,
thumb_frac=0.05, cmap='gray'):
ax = ax or plt.gca()
proj = model.fit_transform(data)
ax.plot(proj[:, 0], proj[:, 1], '.k')
if images is not None:
min_dist_2 = (thumb_frac * max(proj.max(0) - proj.min(0))) ** 2
shown_images = np.array([2 * proj.max(0)])
for i in range(data.shape[0]):
dist = np.sum((proj[i] - shown_images) ** 2, 1)
if np.min(dist) < min_dist_2:
# don't show points that are too close
continue
shown_images = np.vstack([shown_images, proj[i]])
imagebox = offsetbox.AnnotationBbox(
offsetbox.OffsetImage(images[i], cmap=cmap),
proj[i])
ax.add_artist(imagebox)이제 이 함수를 호출하면 다음 그림과 같은 결과를 살펴볼 수 있습니다.
fig, ax = plt.subplots(figsize=(10, 10))
plot_components(faces.data,
model=Isomap(n_components=2),
images=faces.images[:, ::2, ::2])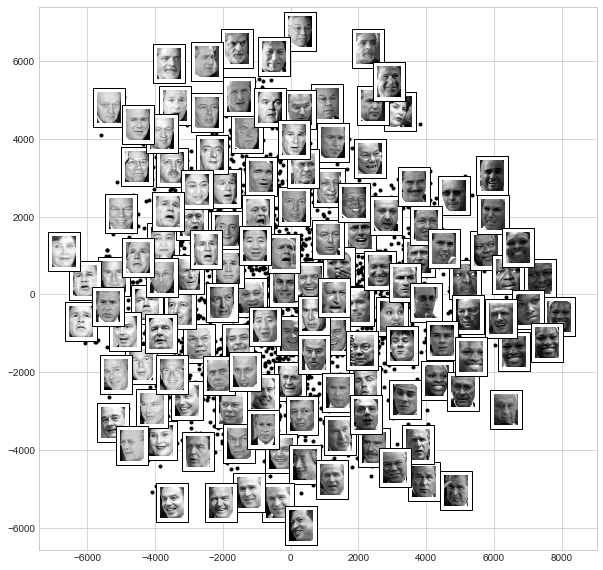
결과는 흥미롭습니다. 처음 두 개의 Isomap 차원은 전반적인 이미지 특징, 즉 왼쪽에서 오른쪽으로 이미지의 전체 밝기와 아래에서 위로 얼굴의 일반적인 방향을 설명하는 것으로 보입니다. 이는 데이터의 기본 기능 중 일부를 시각적으로 잘 보여줍니다.
그런 다음 심층: 지원 벡터 머신에서 했던 것처럼 여기에서 계속해서 이 데이터를 분류합니다(아마도 분류 알고리즘에 대한 입력으로 다양한 기능을 사용하여).
예: 숫자로 구조 시각화
시각화를 위해 매니폴드 학습을 사용하는 또 다른 예로 MNIST 필기 숫자 데이터 세트를 살펴보겠습니다. 이는 심층: 의사결정 트리 및 랜덤 포레스트에서 본 숫자 데이터 세트와 유사하지만 이미지당 픽셀이 더 많습니다. Scikit-Learn 유틸리티를 사용하여 http://openml.org/에서 다운로드합니다.
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784')
mnist.data.shape(70000, 784)데이터 세트는 각각 784픽셀(즉, 이미지 크기는 28 × 28)인 70,000개의 이미지로 구성됩니다. 이전과 마찬가지로 처음 몇 개의 이미지를 살펴볼 수 있습니다(다음 그림 참조).
mnist_data = np.asarray(mnist.data)
mnist_target = np.asarray(mnist.target, dtype=int)
fig, ax = plt.subplots(6, 8, subplot_kw=dict(xticks=[], yticks=[]))
for i, axi in enumerate(ax.flat):
axi.imshow(mnist_data[1250 * i].reshape(28, 28), cmap='gray_r')
이를 통해 데이터 세트의 다양한 필기 스타일에 대한 아이디어를 얻을 수 있습니다.
데이터 전체에 걸쳐 다양한 학습 예측을 계산해 보겠습니다. 여기서는 속도를 위해 데이터의 1/30(약 2,000포인트)만 사용하겠습니다. (매니폴드 학습의 상대적으로 낮은 확장성 때문에 전체 계산으로 이동하기 전에 상대적으로 빠른 탐색을 위해 수천 개의 샘플로 시작하는 것이 좋은 숫자라는 것을 알았습니다.) 다음 그림은 결과를 보여줍니다.
# Use only 1/30 of the data: full dataset takes a long time!
data = mnist_data[::30]
target = mnist_target[::30]
model = Isomap(n_components=2)
proj = model.fit_transform(data)
plt.scatter(proj[:, 0], proj[:, 1], c=target, cmap=plt.cm.get_cmap('jet', 10))
plt.colorbar(ticks=range(10))
plt.clim(-0.5, 9.5)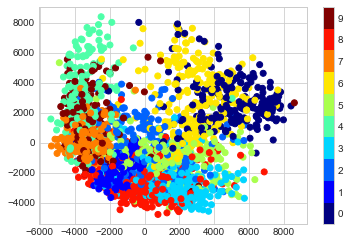
결과 산점도에는 데이터 포인트 간의 관계 중 일부가 표시되지만 약간 복잡합니다. 한 번에 하나의 숫자만 보면 더 많은 통찰력을 얻을 수 있습니다(다음 그림 참조).
# Choose 1/4 of the "1" digits to project
data = mnist_data[mnist_target == 1][::4]
fig, ax = plt.subplots(figsize=(10, 10))
model = Isomap(n_neighbors=5, n_components=2, eigen_solver='dense')
plot_components(data, model, images=data.reshape((-1, 28, 28)),
ax=ax, thumb_frac=0.05, cmap='gray_r')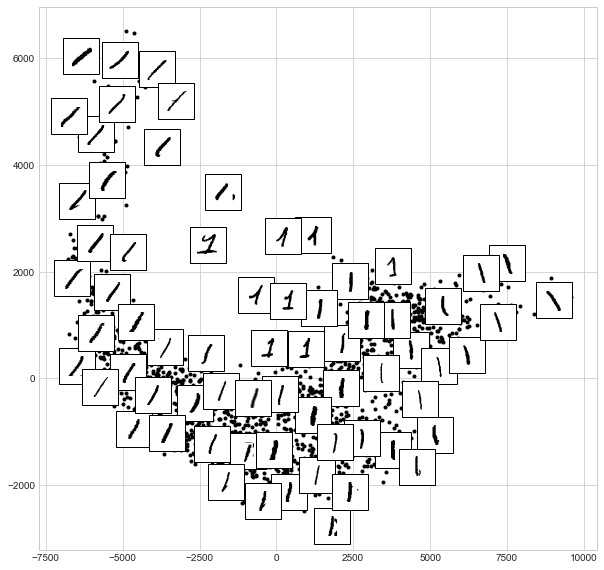
결과를 통해 데이터 세트 내에서 숫자 1이 취할 수 있는 다양한 형태에 대한 아이디어를 얻을 수 있습니다. 데이터는 투영된 공간의 넓은 곡선을 따라 놓여 있으며, 이는 숫자의 방향을 추적하는 것처럼 보입니다. 플롯을 위로 이동하면 모자 및/또는 베이스가 있는 1을 찾을 수 있지만 이는 데이터 세트 내에서 매우 드물습니다. 투영을 통해 데이터 문제가 있는 이상값을 식별합니다. 예를 들어 추출된 이미지에 몰래 들어간 이웃 숫자 조각이 있습니다.
이제 이 자체는 숫자 분류 작업에 유용하지 않을 수 있지만 데이터를 이해하는 데 도움이 되며 분류 파이프라인을 구축하기 전에 데이터를 전처리하는 방법과 같은 앞으로 나아갈 방법에 대한 아이디어를 제공합니다.