import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
plt.style.use('seaborn-whitegrid')심층 분석: 선형 회귀
Naive Bayes(심층: Naive Bayes 분류에서 논의)가 분류 작업의 좋은 시작점인 것처럼 선형 회귀 모델은 회귀 작업의 좋은 시작점입니다. 이러한 모델은 신속하게 적합할 수 있고 해석하기 쉽기 때문에 인기가 있습니다. 여러분은 이미 가장 간단한 형태의 선형 회귀 모델(즉, 2차원 데이터에 직선을 맞추는 것)에 익숙하지만 이러한 모델을 확장하여 더 복잡한 데이터 동작을 모델링합니다.
이번 장에서는 이 잘 알려진 문제 뒤에 있는 수학을 빠르게 살펴보는 것부터 시작하여 데이터의 더 복잡한 패턴을 설명하기 위해 선형 모델을 일반화하는 방법을 살펴보겠습니다.
표준 가져오기부터 시작합니다.
단순 선형 회귀
가장 친숙한 선형 회귀, 즉 데이터에 대한 직선 적합부터 시작하겠습니다. 직선 맞춤은 다음과 같은 형태의 모델입니다. \[ y = 도끼 + b \] 여기서 \(a\)는 일반적으로 기울기로 알려져 있고 \(b\)는 일반적으로 절편으로 알려져 있습니다.
기울기가 2이고 절편이 –5인 선 주위에 흩어져 있는 다음 데이터를 고려해 보세요(다음 그림 참조).
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = 2 * x - 5 + rng.randn(50)
plt.scatter(x, y);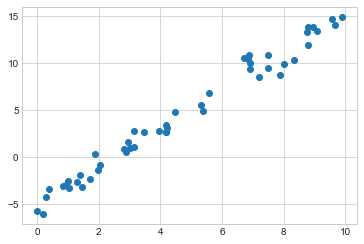
다음 그림과 같이 Scikit-Learn의 LinearRegression 추정기를 사용하여 이 데이터를 맞추고 가장 적합한 선을 구성합니다.
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(x[:, np.newaxis], y)
xfit = np.linspace(0, 10, 1000)
yfit = model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);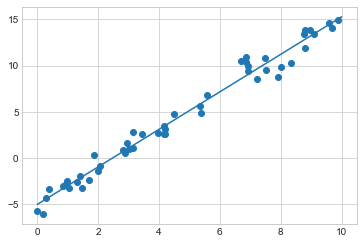
데이터의 기울기와 절편은 모델의 맞춤 매개변수에 포함되어 있으며 Scikit-Learn에서는 항상 밑줄로 표시됩니다. 여기서 관련 매개변수는 coef_ 및 intercept_입니다.
print("Model slope: ", model.coef_[0])
print("Model intercept:", model.intercept_)Model slope: 2.0272088103606953
Model intercept: -4.998577085553204우리가 바라는 대로 결과가 데이터를 생성하는 데 사용된 값과 매우 유사하다는 것을 확인합니다.
‘LinearRegression’ 추정기는 이보다 훨씬 더 많은 기능을 제공하지만 단순한 직선 피팅 외에도 다음 형식의 다차원 선형 모델도 처리합니다. \[ y = a_0 + a_1 x_1 + a_2 x_2 + \cdots \] \(x\) 값이 여러 개 있는 경우. 기하학적으로 이는 평면을 3차원 점에 맞추거나 초평면을 더 높은 차원 점에 맞추는 것과 유사합니다.
이러한 회귀의 다차원적 특성으로 인해 시각화하기가 더 어렵지만 NumPy의 행렬 곱셈 연산자를 사용하여 몇 가지 예제 데이터를 구축하면 이러한 적합성 중 하나가 실제로 작동하는 것을 살펴볼 수 있습니다.
rng = np.random.RandomState(1)
X = 10 * rng.rand(100, 3)
y = 0.5 + np.dot(X, [1.5, -2., 1.])
model.fit(X, y)
print(model.intercept_)
print(model.coef_)0.50000000000001
[ 1.5 -2. 1. ]여기서 \(y\) 데이터는 세 개의 임의 \(x\) 값의 선형 조합으로 구성되며 선형 회귀는 데이터를 구성하는 데 사용된 계수를 복구합니다.
이러한 방식으로 단일 LinearRegression 추정기를 사용하여 선, 평면 또는 초평면을 데이터에 맞출 수 있습니다. 여전히 이 접근 방식은 변수 간의 엄격한 선형 관계로 제한되는 것처럼 보이지만 이를 완화할 수도 있는 것으로 나타났습니다.
기초 함수 회귀
변수 간의 비선형 관계에 선형 회귀를 적용하는 데 사용할 수 있는 한 가지 방법은 기저 함수에 따라 데이터를 변환하는 것입니다. 우리는 이전에 초매개변수 및 모델 검증 및 기능 엔지니어링에 사용된 PolynomialRegression 파이프라인에서 이 버전 중 하나를 본 적이 있습니다. 아이디어는 다차원 선형 모델을 취하는 것입니다. \[
y = a_0 + a_1 x_1 + a_2 x_2 + a_3 x_3 + \cdots
\] 1차원 입력 \(x\)에서 \(x_1, x_2, x_3,\) 등을 만듭니다. 즉, \(x_n = f_n(x)\)라고 합니다. 여기서 \(f_n()\)은 데이터를 변환하는 함수입니다.
예를 들어 \(f_n(x) = x^n\)이면 모델은 다항식 회귀가 됩니다. \[ y = a_0 + a_1 x + a_2 x^2 + a_3 x^3 + \cdots \] 이것은 여전히 선형 모델입니다. 선형성은 \(a_n\) 계수가 서로 곱하거나 나누어지지 않는다는 사실을 나타냅니다. 우리가 효과적으로 수행한 작업은 1차원 \(x\) 값을 가져와 더 높은 차원에 투영하여 선형 맞춤이 \(x\)와 \(y\) 사이의 더 복잡한 관계에 맞도록 하는 것입니다.
다항식 기저 함수
이 다항식 투영은 PolynomialFeatures 변환기를 사용하여 Scikit-Learn에 내장될 만큼 유용합니다.
from sklearn.preprocessing import PolynomialFeatures
x = np.array([2, 3, 4])
poly = PolynomialFeatures(3, include_bias=False)
poly.fit_transform(x[:, None])array([[ 2., 4., 8.],
[ 3., 9., 27.],
[ 4., 16., 64.]])여기서는 변환기가 1차원 배열을 3차원 배열로 변환했으며, 각 열에는 지수화된 값이 포함되어 있음을 확인합니다. 이 새로운 고차원 데이터 표현은 선형 회귀에 연결될 수 있습니다.
Feature Engineering에서 본 것처럼 이를 수행하는 가장 깔끔한 방법은 파이프라인을 사용하는 것입니다. 이런 식으로 7차 다항식 모델을 만들어 보겠습니다.
from sklearn.pipeline import make_pipeline
poly_model = make_pipeline(PolynomialFeatures(7),
LinearRegression())이 변환을 사용하면 선형 모델을 사용하여 \(x\)와 \(y\) 사이의 훨씬 더 복잡한 관계를 맞출 수 있습니다. 예를 들어 노이즈가 있는 사인파는 다음과 같습니다(다음 그림 참조).
rng = np.random.RandomState(1)
x = 10 * rng.rand(50)
y = np.sin(x) + 0.1 * rng.randn(50)
poly_model.fit(x[:, np.newaxis], y)
yfit = poly_model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit);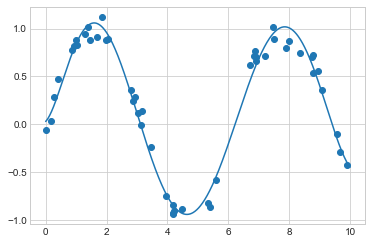
우리의 선형 모델은 7차 다항식 기반 함수를 사용하여 이 비선형 데이터에 탁월한 적합성을 제공합니다!
가우스 기반 함수
물론, 다른 기본 기능도 가능합니다. 예를 들어 유용한 패턴 중 하나는 다항식 베이스의 합이 아니라 가우스 베이스의 합인 모델을 피팅하는 것입니다. 결과는 다음 그림과 유사합니다.

플롯에서 음영 처리된 영역은 스케일링된 기본 함수이며, 함께 추가되면 데이터 전체에서 부드러운 곡선을 재현합니다. 이러한 가우스 기반 함수는 Scikit-Learn에 내장되어 있지 않지만 여기에 표시되고 다음 그림에 설명된 대로 이를 생성할 사용자 정의 변환기를 작성합니다(Scikit-Learn 변환기는 파이썬(Python) 클래스로 구현됩니다. Scikit-Learn의 소스를 읽는 것은 생성 방법을 확인하는 좋은 방법입니다).
from sklearn.base import BaseEstimator, TransformerMixin
class GaussianFeatures(BaseEstimator, TransformerMixin):
"""Uniformly spaced Gaussian features for one-dimensional input"""
def __init__(self, N, width_factor=2.0):
self.N = N
self.width_factor = width_factor
@staticmethod
def _gauss_basis(x, y, width, axis=None):
arg = (x - y) / width
return np.exp(-0.5 * np.sum(arg ** 2, axis))
def fit(self, X, y=None):
# create N centers spread along the data range
self.centers_ = np.linspace(X.min(), X.max(), self.N)
self.width_ = self.width_factor * (self.centers_[1] - self.centers_[0])
return self
def transform(self, X):
return self._gauss_basis(X[:, :, np.newaxis], self.centers_,
self.width_, axis=1)
gauss_model = make_pipeline(GaussianFeatures(20),
LinearRegression())
gauss_model.fit(x[:, np.newaxis], y)
yfit = gauss_model.predict(xfit[:, np.newaxis])
plt.scatter(x, y)
plt.plot(xfit, yfit)
plt.xlim(0, 10);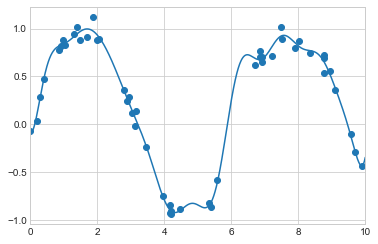
다항식 기저 함수에는 마술 같은 것이 없다는 점을 분명히 하기 위해 이 예를 포함시켰습니다. 데이터 생성 과정에 대해 일종의 직관이 있어 하나의 기저 또는 다른 기저가 적절할 수 있다고 생각하게 만드는 경우 대신 이를 사용합니다.
정규화
선형 회귀에 기본 함수를 도입하면 모델이 훨씬 더 유연해지지만 매우 빠르게 과적합으로 이어질 수도 있습니다(이에 대한 자세한 내용은 하이퍼파라미터 및 모델 검증을 참조하세요). 예를 들어 다음 그림은 다수의 가우스 기반 함수를 사용하면 어떤 일이 발생하는지 보여줍니다.
model = make_pipeline(GaussianFeatures(30),
LinearRegression())
model.fit(x[:, np.newaxis], y)
plt.scatter(x, y)
plt.plot(xfit, model.predict(xfit[:, np.newaxis]))
plt.xlim(0, 10)
plt.ylim(-1.5, 1.5);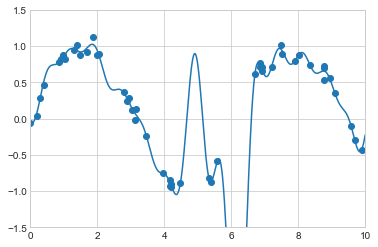
데이터를 30차원 기반으로 투영하면 모델의 유연성이 너무 높아 데이터의 제약을 받는 위치 사이에서 극단값으로 이동합니다. 다음 그림과 같이 위치에 대한 가우스 베이스의 계수를 플롯하면 그 이유를 확인합니다.
def basis_plot(model, title=None):
fig, ax = plt.subplots(2, sharex=True)
model.fit(x[:, np.newaxis], y)
ax[0].scatter(x, y)
ax[0].plot(xfit, model.predict(xfit[:, np.newaxis]))
ax[0].set(xlabel='x', ylabel='y', ylim=(-1.5, 1.5))
if title:
ax[0].set_title(title)
ax[1].plot(model.steps[0][1].centers_,
model.steps[1][1].coef_)
ax[1].set(xlabel='basis location',
ylabel='coefficient',
xlim=(0, 10))
model = make_pipeline(GaussianFeatures(30), LinearRegression())
basis_plot(model)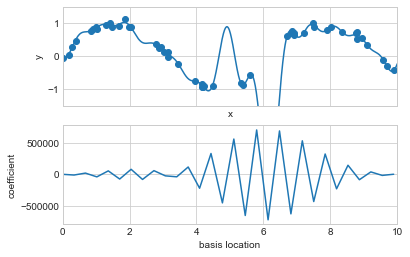
이 그림의 아래쪽 패널은 각 위치의 기본 함수의 진폭을 보여줍니다. 이는 기저 함수가 겹칠 때의 전형적인 과적합 동작입니다. 인접한 기저 함수의 계수가 서로 폭발하고 상쇄됩니다. 우리는 그러한 행동이 문제가 있다는 것을 알고 있으며, 모델 매개변수의 큰 값에 불이익을 주어 모델에서 그러한 급증을 명시적으로 제한할 수 있다면 좋을 것입니다. 이러한 처벌은 정규화로 알려져 있으며 여러 형태로 나타납니다.
능형 회귀(\(L_2\) 정규화)
아마도 가장 일반적인 정규화 형태는 능선 회귀 또는 \(L_2\) 정규화(Tikhonov 정규화라고도 함)일 것입니다. 이는 모델 계수 \(\theta_n\)의 제곱합(2-norms)에 페널티를 적용하여 진행됩니다. 이 경우 모델 적합성에 대한 페널티는 다음과 같습니다. \[ P = \alpha\sum_{n=1}^N \theta_n^2 \] 여기서 \(\alpha\)는 페널티의 강도를 제어하는 자유 매개변수입니다. 이러한 유형의 페널티 모델은 ‘Ridge’ 추정기를 사용하여 Scikit-Learn에 내장되어 있습니다(다음 그림 참조).
from sklearn.linear_model import Ridge
model = make_pipeline(GaussianFeatures(30), Ridge(alpha=0.1))
basis_plot(model, title='Ridge Regression')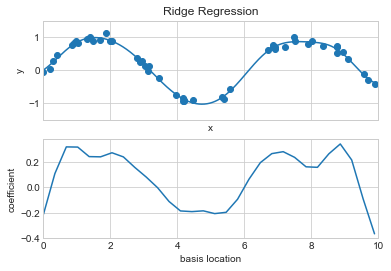
\(\alpha\) 매개변수는 본질적으로 결과 모델의 복잡성을 제어하는 손잡이입니다. \(\alpha\to 0\) 한계에서 표준 선형 회귀 결과를 복구합니다. \(\alpha\to\infty\) 한도에서는 모든 모델 응답이 억제됩니다. 특히 능선 회귀의 한 가지 장점은 매우 효율적으로 계산할 수 있다는 것입니다. 원래 선형 회귀 모델보다 계산 비용이 거의 들지 않습니다.
올가미 회귀(\(L_1\) 정규화)
또 다른 일반적인 유형의 정규화는 올가미 회귀 또는 L1 정규화로 알려져 있으며 회귀 계수의 절대값(1-노름)의 합에 페널티를 적용하는 것과 관련됩니다. \[ P = \alpha\sum_{n=1}^N |\theta_n| \] 이는 개념적으로 능선 회귀와 매우 유사하지만 결과는 놀랍게도 다를 수 있습니다. 예를 들어 올가미 회귀는 구조상 가능한 경우 희소 모델을 선호하는 경향이 있습니다. 즉, 많은 모델 계수를 정확히 0으로 우선 설정합니다.
L1 정규화된 계수를 사용하여 이전 예제를 복제하면 이 동작을 볼 수 있습니다(다음 그림 참조).
from sklearn.linear_model import Lasso
model = make_pipeline(GaussianFeatures(30), Lasso(alpha=0.001, max_iter=2000))
basis_plot(model, title='Lasso Regression')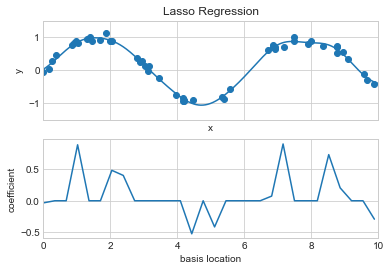
올가미 회귀 페널티를 사용하면 대부분의 계수가 정확히 0이며 기능적 동작은 사용 가능한 기본 함수의 작은 하위 집합으로 모델링됩니다. 능선 정규화와 마찬가지로 \(\alpha\) 매개변수는 페널티의 강도를 조정하며 교차 검증 등을 통해 결정해야 합니다(이에 대한 자세한 내용은 하이퍼파라미터 및 모델 검증을 참조하세요).
예: 자전거 교통량 예측
예를 들어 날씨, 계절 및 기타 요인을 기반으로 시애틀의 프리몬트 브리지를 통과하는 자전거 여행 횟수를 예측할 수 있는지 살펴보겠습니다. 우리는 이미 Working With Time Series에서 이 데이터를 보았지만 여기서는 자전거 데이터를 다른 데이터 세트와 결합하여 날씨와 계절 요인(온도, 강수량, 일광 시간)이 이 통로를 통과하는 자전거 교통량에 영향을 미치는 정도를 결정하려고 합니다. 다행히 미국 국립해양대기청(NOAA)에서는 일일 기상 관측소 데이터를 제공하고 있으며(저는 관측소 ID USW00024233을 사용했습니다) Pandas를 사용하여 두 데이터 소스를 쉽게 결합합니다. 우리는 이러한 매개변수 중 하나의 변화가 특정 날짜의 라이더 수에 어떤 영향을 미치는지 추정하기 위해 날씨 및 기타 정보를 자전거 수와 연관시키는 간단한 선형 회귀를 수행할 것입니다.
특히 이는 모델의 매개변수가 해석 가능한 의미를 갖는 것으로 가정되는 통계 모델링 프레임워크에서 Scikit-Learn 도구를 어떻게 사용할 수 있는지 보여주는 예입니다. 이전에 논의한 것처럼 이는 머신러닝(Machine Learning) 제 표준 접근 방식은 아니지만 일부 모델에서는 이러한 해석이 가능합니다.
날짜별로 인덱싱하여 두 개의 데이터 세트를 로드하는 것부터 시작해 보겠습니다.
# url = 'https://raw.githubusercontent.com/jakevdp/bicycle-data/main'
# !curl -O {url}/FremontBridge.csv
# !curl -O {url}/SeattleWeather.csvimport pandas as pd
counts = pd.read_csv('FremontBridge.csv',
index_col='Date', parse_dates=True)
weather = pd.read_csv('SeattleWeather.csv',
index_col='DATE', parse_dates=True)단순화를 위해 시애틀의 통근 패턴에 큰 영향을 미친 코로나19 팬데믹의 영향을 피하기 위해 2020년 이전의 데이터를 살펴보겠습니다.
counts = counts[counts.index < "2020-01-01"]
weather = weather[weather.index < "2020-01-01"]다음으로 일일 총 자전거 교통량을 계산하고 이를 자체 DataFrame에 넣습니다.
daily = counts.resample('d').sum()
daily['Total'] = daily.sum(axis=1)
daily = daily[['Total']] # remove other columns우리는 이전에 사용 패턴이 일반적으로 날마다 다르다는 것을 확인했습니다. 요일을 나타내는 이진 열을 추가하여 데이터에 이를 설명하겠습니다.
days = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
for i in range(7):
daily[days[i]] = (daily.index.dayofweek == i).astype(float)마찬가지로 우리는 라이더가 휴일에 다르게 행동할 것으로 예상합니다. 이에 대한 표시도 추가해 보겠습니다.
from pandas.tseries.holiday import USFederalHolidayCalendar
cal = USFederalHolidayCalendar()
holidays = cal.holidays('2012', '2020')
daily = daily.join(pd.Series(1, index=holidays, name='holiday'))
daily['holiday'].fillna(0, inplace=True)우리는 또한 일광 시간이 탑승하는 사람 수에 영향을 미칠 것이라고 의심할 수도 있습니다. 표준 천문학적 계산을 사용하여 이 정보를 추가해 보겠습니다(다음 그림 참조).
def hours_of_daylight(date, axis=23.44, latitude=47.61):
"""Compute the hours of daylight for the given date"""
days = (date - pd.datetime(2000, 12, 21)).days
m = (1. - np.tan(np.radians(latitude))
* np.tan(np.radians(axis) * np.cos(days * 2 * np.pi / 365.25)))
return 24. * np.degrees(np.arccos(1 - np.clip(m, 0, 2))) / 180.
daily['daylight_hrs'] = list(map(hours_of_daylight, daily.index))
daily[['daylight_hrs']].plot()
plt.ylim(8, 17)
또한 평균 기온과 총 강수량을 데이터에 추가할 수도 있습니다. 강수량 인치 외에 하루가 건조한지(강수량이 0인지) 나타내는 플래그를 추가해 보겠습니다.
weather['Temp (F)'] = 0.5 * (weather['TMIN'] + weather['TMAX'])
weather['Rainfall (in)'] = weather['PRCP']
weather['dry day'] = (weather['PRCP'] == 0).astype(int)
daily = daily.join(weather[['Rainfall (in)', 'Temp (F)', 'dry day']])마지막으로, 1일부터 증가하고 몇 년이 지났는지 측정하는 카운터를 추가해 보겠습니다. 이를 통해 일일 횡단 횟수의 연간 증가 또는 감소를 관찰합니다.
daily['annual'] = (daily.index - daily.index[0]).days / 365.이제 데이터가 정리되었으므로 살펴보겠습니다.
daily.head()| Total | Mon | Tue | Wed | Thu | Fri | Sat | Sun | holiday | daylight_hrs | Rainfall (in) | Temp (F) | dry day | annual | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Date | ||||||||||||||
| 2012-10-03 | 14084.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 11.277359 | 0.0 | 56.0 | 1 | 0.000000 |
| 2012-10-04 | 13900.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 11.219142 | 0.0 | 56.5 | 1 | 0.002740 |
| 2012-10-05 | 12592.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 11.161038 | 0.0 | 59.5 | 1 | 0.005479 |
| 2012-10-06 | 8024.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 11.103056 | 0.0 | 60.5 | 1 | 0.008219 |
| 2012-10-07 | 8568.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 11.045208 | 0.0 | 60.5 | 1 | 0.010959 |
이를 통해 사용할 열을 선택하고 선형 회귀 모델을 데이터에 맞출 수 있습니다. 일일 플래그는 자체 날짜별 인터셉트로 작동하므로 fit_intercept=False를 설정합니다.
# Drop any rows with null values
daily.dropna(axis=0, how='any', inplace=True)
column_names = ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun',
'holiday', 'daylight_hrs', 'Rainfall (in)',
'dry day', 'Temp (F)', 'annual']
X = daily[column_names]
y = daily['Total']
model = LinearRegression(fit_intercept=False)
model.fit(X, y)
daily['predicted'] = model.predict(X)마지막으로 전체 자전거 통행량과 예상 자전거 통행량을 시각적으로 비교합니다(다음 그림 참조).
daily[['Total', 'predicted']].plot(alpha=0.5);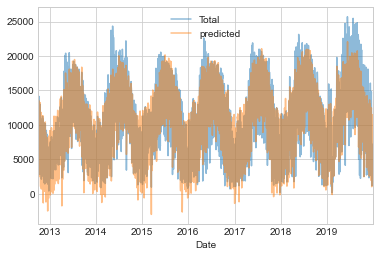
데이터와 모델 예측이 정확히 일치하지 않는다는 사실을 보면 몇 가지 핵심 기능을 놓친 것이 분명합니다. 우리의 기능이 완전하지 않거나(예: 사람들이 이러한 기능보다 더 많은 것을 기반으로 출근할지 여부를 결정함), 우리가 고려하지 못한 일부 비선형 관계가 있습니다(예: 고온 및 저온 모두에서 사람들이 덜 타는 경우). 그럼에도 불구하고 대략적인 근사치는 몇 가지 통찰력을 제공하기에 충분하며 선형 모델의 계수를 살펴보고 각 기능이 일일 자전거 수에 얼마나 기여하는지 추정합니다.
params = pd.Series(model.coef_, index=X.columns)
paramsMon -3309.953439
Tue -2860.625060
Wed -2962.889892
Thu -3480.656444
Fri -4836.064503
Sat -10436.802843
Sun -10795.195718
holiday -5006.995232
daylight_hrs 409.146368
Rainfall (in) -2789.860745
dry day 2111.069565
Temp (F) 179.026296
annual 324.437749
dtype: float64이 숫자는 불확실성을 측정하지 않으면 해석하기 어렵습니다. 데이터의 부트스트랩 리샘플링을 사용하여 이러한 불확실성을 신속하게 계산합니다.
from sklearn.utils import resample
np.random.seed(1)
err = np.std([model.fit(*resample(X, y)).coef_
for i in range(1000)], 0)이러한 오류를 추정한 후 결과를 다시 살펴보겠습니다.
print(pd.DataFrame({'effect': params.round(0),
'uncertainty': err.round(0)})) effect uncertainty
Mon -3310.0 265.0
Tue -2861.0 274.0
Wed -2963.0 268.0
Thu -3481.0 268.0
Fri -4836.0 261.0
Sat -10437.0 259.0
Sun -10795.0 267.0
holiday -5007.0 401.0
daylight_hrs 409.0 26.0
Rainfall (in) -2790.0 186.0
dry day 2111.0 101.0
Temp (F) 179.0 7.0
annual 324.0 22.0대략적으로 말하면 여기의 ‘효과’ 열은 문제의 기능 변경이 라이더 수에 어떤 영향을 미치는지 보여줍니다. 예를 들어 요일의 경우에는 분명한 차이가 있습니다. 주말에는 평일보다 라이더가 수천 명 더 적습니다. 우리는 또한 일광 시간이 추가될 때마다 409 ± 26명의 사람들이 더 많은 사람들이 자전거를 타는 것을 선택한다는 것을 확인합니다. 화씨 1도의 온도 상승으로 인해 179±7명의 사람들이 자전거를 움켜쥐게 됩니다. 건조한 날은 평균 2,111 ± 101명의 라이더가 더 많다는 것을 의미합니다. 비가 내릴 때마다 2,790 ± 186명의 라이더가 다른 운송 수단을 선택하게 됩니다. 이러한 모든 효과를 고려하면 매년 324 ± 22명의 새로운 일일 라이더가 조금씩 증가하는 것을 살펴볼 수 있습니다.
우리의 간단한 모델에는 일부 관련 정보가 누락된 것이 거의 확실합니다. 예를 들어 앞에서 언급한 것처럼 비선형 효과(예: 강수량 및 추운 기온의 영향)와 각 변수 내의 비선형 추세(예: 매우 추운 날씨와 매우 더운 기온에서 운전을 꺼리는 경향)는 간단한 선형 모델에서 설명할 수 없습니다. 또한, 우리는 보다 세밀한 정보(예: 비오는 아침과 비오는 오후의 차이)를 버렸고 요일 간 상관관계(예: 비오는 화요일이 수요일 숫자에 미치는 영향 또는 연속 비오는 날 이후 예상치 못한 맑은 날의 효과 등)를 무시했습니다. 이것들은 모두 잠재적으로 흥미로운 효과이며, 원하는 경우 이제 탐색을 시작할 수 있는 도구가 있습니다!