import numpy as np배열 계산: 브로드캐스팅
우리는 NumPy 배열 계산: 범용 함수에서 NumPy의 범용 함수를 활용해 벡터화 연산을 수행함으로써 느린 파이썬 루프를 제거하는 방법을 확인했습니다. 이번 장에서는 브로드캐스팅을 살펴봅니다. 브로드캐스팅은 NumPy에서 크기와 모양이 서로 다른 배열 간에 이진 연산(예: 덧셈, 뺄셈, 곱셈 등)을 적용하기 위한 규칙들입니다.
브로드캐스팅 소개
크기가 같은 배열 간의 이진 연산은 요소별(element-wise)로 수행됩니다.
a = np.array([0, 1, 2])
b = np.array([5, 5, 5])
a + barray([5, 6, 7])브로드캐스팅을 사용하면 크기가 다른 배열 간에도 이러한 이진 연산을 수행합니다. 예를 들어, 스칼라(0차원 배열)를 다른 배열에 간단히 더합니다.
a + 5array([5, 6, 7])이 과정은 값 5를 [5, 5, 5] 배열로 확장하거나 복제한 뒤 결과를 더하는 작업으로 이해합니다.
이러한 개념은 고차원 배열로도 확장 가능합니다. 2차원 배열에 1차원 배열을 더할 때 어떤 결과가 나오는지 살펴보겠습니다.
M = np.ones((3, 3))
Marray([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])M + aarray([[1., 2., 3.],
[1., 2., 3.],
[1., 2., 3.]])여기서 1차원 배열 a는 M의 모양과 일치하도록 두 번째 차원에 맞춰 확장(브로드캐스팅)됩니다.
위 예제는 비교적 이해하기 쉽지만, 더 복잡한 상황에서는 두 배열 모두 브로드캐스팅이 일어날 수도 있습니다. 다음 예제를 살펴보겠습니다.
a = np.arange(3)
b = np.arange(3)[:, np.newaxis]
print(a)
print(b)[0 1 2]
[[0]
[1]
[2]]a + barray([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])앞서 다른 배열의 모양에 맞춰 하나의 배열을 확장했던 것처럼, 여기서는 a와 b를 둘 다 늘려서 공통된 모양을 맞췄습니다. 그 결과로 2차원 배열이 생성됩니다! 이러한 과정의 기하학적 구조는 다음 그림에서 시각적으로 확인합니다. (그림을 생성하는 코드는 온라인 부록에 있으며, astroML 문서의 소스를 허가 하에 수정하여 사용했습니다.)

밝게 표시된 박스는 브로드캐스팅된 값을 나타냅니다. 이러한 방식이 메모리를 비효율적으로 사용하지 않을까 걱정할 수도 있지만, NumPy는 브로드캐스팅 시 값을 실제로 메모리에 복제하지 않으므로 안심하셔도 됩니다. 다만 이 방식은 브로드캐스팅을 이해하는 데 매우 유용한 개념적 모델이 됩니다.
브로드캐스팅 규칙
NumPy의 브로드캐스팅은 두 배열 간의 상호작용을 결정하는 엄격한 규칙을 따릅니다.
- 규칙 1: 두 배열의 차원 수가 다르면, 차원 수가 더 적은 배열의 형상(shape) 앞쪽(왼쪽)을 1로 채웁니다.
- 규칙 2: 두 배열의 형상이 특정 차원에서 일치하지 않는 경우, 해당 차원의 크기가 1인 배열을 다른 배열의 형상에 맞춰 늘립니다.
- 규칙 3: 어떤 차원에서든 크기가 일치하지 않고 둘 다 1이 아니라면 오류가 발생합니다.
이 규칙들을 명확히 이해하기 위해 몇 가지 예제를 자세히 살펴보겠습니다.
방송예시 1
1차원 배열에 2차원 배열을 추가한다고 가정해 보겠습니다.
M = np.ones((2, 3))
a = np.arange(3)다음과 같은 모양을 갖는 두 배열에 대한 작업을 고려해 보겠습니다.
M.shape는(2, 3)입니다.a.shape은(3,)입니다.
규칙 1을 통해 배열 ’a’의 차원이 더 적다는 것을 알 수 있으므로 왼쪽을 1로 채웁니다.
M.shape는(2, 3)로 유지됩니다.a.shape는(1, 3)이 됩니다.
규칙 2에 따르면 이제 첫 번째 차원이 일치하지 않는다는 것을 알 수 있으므로 일치하도록 이 차원을 늘립니다.
M.shape는(2, 3)로 유지됩니다.a.shape는(2, 3)이 됩니다.
이제 모양이 일치하며 최종 모양은 ’(2, 3)’이 됩니다.
M + aarray([[1., 2., 3.],
[1., 2., 3.]])방송 예시 2
이제 두 배열을 모두 브로드캐스트해야 하는 예를 살펴보겠습니다.
a = np.arange(3).reshape((3, 1))
b = np.arange(3)다시 한번 배열의 모양을 결정하는 것부터 시작하겠습니다.
a.shape은(3, 1)입니다.b.shape은(3,)입니다.
규칙 1은 b의 모양을 1로 채워야 한다고 말합니다.
a.shape는(3, 1)로 유지됩니다.b.shape는(1, 3)이 됩니다.
그리고 규칙 2는 다른 배열의 해당 크기와 일치하도록 이러한 1 각각을 업그레이드해야 함을 알려줍니다.
a.shape는(3, 3)이 됩니다.b.shape는(3, 3)이 됩니다.
결과가 일치하므로 이러한 모양은 호환됩니다. 우리는 이것을 여기서 볼 수 있습니다:
a + barray([[0, 1, 2],
[1, 2, 3],
[2, 3, 4]])방송 예시 3
다음으로 두 어레이가 호환되지 않는 예를 살펴보겠습니다.
M = np.ones((3, 2))
a = np.arange(3)이는 첫 번째 예와는 약간 다른 상황입니다. 행렬 ’M’이 전치됩니다. 이것이 계산에 어떤 영향을 미치나요? 배열의 모양은 다음과 같습니다.
M.shape는(3, 2)입니다.a.shape은(3,)입니다.
다시, 규칙 1은 a의 모양을 1로 채워야 한다고 말합니다.
M.shape는(3, 2)로 유지됩니다.a.shape는(1, 3)이 됩니다.
규칙 2에 따라 ’a’의 첫 번째 차원은 ’M’의 차원과 일치하도록 확장됩니다.
M.shape는(3, 2)로 유지됩니다.a.shape는(3, 3)이 됩니다.
이제 규칙 3에 도달했습니다. 최종 모양이 일치하지 않으므로 이 두 배열은 호환되지 않습니다. 이 작업을 시도하면 확인합니다.
M + a--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-13-8cac1d547906> in <module> ----> 1 M + a ValueError: operands could not be broadcast together with shapes (3,2) (3,)
여기에서 잠재적인 혼란을 주목하십시오: 예를 들어 a의 모양을 왼쪽이 아닌 오른쪽에 패딩하여 a와 M을 호환 가능하게 만드는 것을 상상합니다. 하지만 이것은 방송 규칙이 작동하는 방식이 아닙니다! 이러한 종류의 유연성은 어떤 경우에는 유용할 수 있지만 잠재적으로 모호한 영역으로 이어질 수 있습니다. 오른쪽 패딩을 원하는 경우 배열을 재구성하여 이를 명시적으로 수행합니다(이를 위해 NumPy 배열의 기본에 소개된 np.newaxis 키워드를 사용합니다):
a[:, np.newaxis].shape(3, 1)M + a[:, np.newaxis]array([[1., 1.],
[2., 2.],
[3., 3.]])또한 여기서는 ‘+’ 연산자에 중점을 두었지만 이러한 브로드캐스팅 규칙은 모든 바이너리 ufunc에 적용됩니다. 예를 들어 다음은 순진한 접근 방식보다 더 정확하게 log(exp(a) + exp(b))를 계산하는 logaddexp(a, b) 함수입니다.
np.logaddexp(M, a[:, np.newaxis])array([[1.31326169, 1.31326169],
[1.69314718, 1.69314718],
[2.31326169, 2.31326169]])사용 가능한 다양한 범용 함수에 대한 자세한 내용은 NumPy 배열 계산: 범용 함수를 참조하세요.
방송실습
방송 작업은 이 책 전반에 걸쳐 보게 될 많은 예제의 핵심을 구성합니다. 이제 이것이 유용할 수 있는 몇 가지 사례를 살펴보겠습니다.
배열 중심 맞추기
NumPy 배열에 대한 계산: 범용 함수에서 우리는 ufuncs를 사용하면 NumPy 사용자가 느린 파이썬(Python) 루프를 명시적으로 작성할 필요가 없다는 것을 확인했습니다. 방송은 이 능력을 확장합니다. 데이터 과학(Data Science)에서 흔히 볼 수 있는 예 중 하나는 데이터 배열에서 행별 평균을 빼는 것입니다. 각각 3개의 값으로 구성된 10개의 관측값 배열이 있다고 가정해 보겠습니다. 표준 규칙(Scikit-Learn의 데이터 표현 참조)을 사용하여 이를 \(10 \times 3\) 배열에 저장합니다.
rng = np.random.default_rng(seed=1701)
X = rng.random((10, 3))첫 번째 차원에서 ‘평균’ 집계를 사용하여 각 열의 평균을 계산합니다.
Xmean = X.mean(0)
Xmeanarray([0.38503638, 0.36991443, 0.63896043])이제 평균을 빼서 X 배열을 중앙에 배치합니다(이것은 브로드캐스트 작업입니다).
X_centered = X - Xmean이 작업을 올바르게 수행했는지 다시 확인하기 위해 중앙 배열의 평균이 0에 가까운지 확인합니다.
X_centered.mean(0)array([ 4.99600361e-17, -4.44089210e-17, 0.00000000e+00])기계 정밀도 내에서 평균은 이제 0입니다.
2차원 함수 그래프 그리기
방송이 종종 유용하게 활용되는 곳 중 하나는 2차원 기능을 기반으로 이미지를 표시하는 것입니다. \(z = f(x, y)\) 함수를 정의하려면 브로드캐스팅을 사용하여 그리드 전체에 걸쳐 함수를 계산합니다.
# x and y have 50 steps from 0 to 5
x = np.linspace(0, 5, 50)
y = np.linspace(0, 5, 50)[:, np.newaxis]
z = np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)다음 그림과 같이 Matplotlib를 사용하여 이 2차원 배열을 플롯합니다(이러한 도구는 밀도 및 등고선 플롯에서 자세히 설명합니다).
%matplotlib inline
import matplotlib.pyplot as pltplt.imshow(z, origin="lower", extent=[0, 5, 0, 5])
plt.colorbar();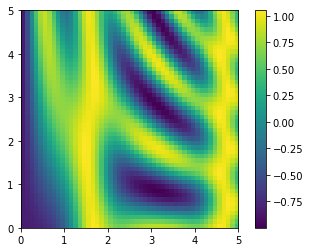
그 결과 2차원 함수가 눈에 띄게 시각화되었습니다.