%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use("seaborn-whitegrid")심층 분석: 나이브 베이즈 분류
이전 4개 장에서는 머신러닝(Machine Learning) 개념에 대한 일반적인 개요를 제공했습니다. 이 장과 다음 장에서 우리는 먼저 지도 학습을 위한 네 가지 알고리즘을 자세히 살펴보세요. 그리고 비지도 학습을 위한 네 가지 알고리즘이 있습니다. 여기서는 첫 번째 지도 방법인 Naive Bayes 분류부터 시작합니다.
Naive Bayes 모델은 매우 고차원 데이터 세트에 적합한 매우 빠르고 간단한 분류 알고리즘 그룹입니다. 속도가 매우 빠르고 조정 가능한 매개변수가 거의 없기 때문에 분류 문제에 대한 빠르고 간단한 기준으로 유용하게 사용됩니다. 이번 장에서는 Naive Bayes 분류기가 작동하는 방식에 대한 직관적인 설명을 제공하고 일부 데이터 세트에서 작동하는 몇 가지 예를 제공합니다.
베이지안 분류
Naive Bayes 분류기는 베이지안 분류 방법을 기반으로 구축되었습니다. 이는 통계량의 조건부 확률 관계를 설명하는 방정식인 베이즈 정리에 의존합니다. 베이지안 분류에서는 \(P(L~|~{\rm feature})\)로 쓸 수 있는 일부 관찰된 특징이 주어지면 \(L\) 레이블의 확률을 찾는 데 관심이 있습니다. 베이즈의 정리는 이를 보다 직접적으로 계산할 수 있는 수량으로 표현하는 방법을 알려줍니다.
\[ P(L~|~{\rm 특징}) = \frac{P({\rm 특징}~|~L)P(L)}{P({\rm 특징})} \]
두 레이블(\(L_1\) 및 \(L_2\)) 중에서 결정하려는 경우 이 결정을 내리는 한 가지 방법은 각 레이블에 대한 사후 확률의 비율을 계산하는 것입니다.
\[ \frac{P(L_1~|~{\rm 기능})}{P(L_2~|~{\rm 기능})} = \frac{P({\rm 기능}~|~L_1)}{P({\rm 기능}~|~L_2)}\frac{P(L_1)}{P(L_2)} \]
이제 우리에게 필요한 것은 각 레이블에 대해 \(P({\rm feature}~|~L_i)\)를 계산할 수 있는 모델입니다. 이러한 모델은 데이터를 생성하는 가상의 무작위 프로세스를 지정하므로 생성 모델이라고 합니다. 각 레이블에 대해 이 생성 모델을 지정하는 것이 베이지안 분류기 훈련의 주요 부분입니다. 이러한 훈련 단계의 일반적인 버전은 매우 어려운 작업이지만, 이 모델의 형태에 대한 몇 가지 단순화된 가정을 사용하여 더 간단하게 만들 수 있습니다.
여기서 “순진한 베이즈”의 “순진한”이 등장합니다. 각 레이블의 생성 모델에 대해 매우 순진한 가정을 하면 각 클래스에 대한 생성 모델의 대략적인 근사치를 찾은 다음 베이지안 분류를 진행합니다. 다양한 유형의 나이브 베이즈 분류기는 데이터에 대한 다양한 나이브 가정을 기반으로 하며 다음 섹션에서 이들 중 몇 가지를 검토할 것입니다.
표준 가져오기부터 시작합니다.
가우스 나이브 베이즈
아마도 이해하기 가장 쉬운 순진한 베이즈 분류기는 가우스 순진한 베이즈일 것입니다. 이 분류기를 사용하면 각 레이블의 데이터가 단순 가우스 분포에서 추출된다고 가정합니다. 그림 41-1에 표시된 다음 데이터가 있다고 상상해 보십시오.
from sklearn.datasets import make_blobs
X, y = make_blobs(100, 2, centers=2, random_state=2, cluster_std=1.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="RdBu");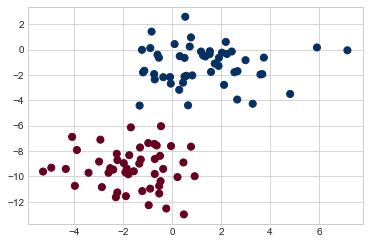
가장 간단한 가우스 모델은 데이터가 차원 간 공분산 없이 가우스 분포로 설명된다고 가정하는 것입니다. 이 모델은 각 레이블 제 점의 평균 및 표준 편차를 계산하여 적합할 수 있으며, 이는 이러한 분포를 정의하는 데 필요한 전부입니다. 이 순진한 가우스 가정의 결과는 다음 그림에 나와 있습니다.

여기의 타원은 각 레이블에 대한 가우스 생성 모델을 나타내며 타원 중심으로 갈수록 확률이 더 높습니다. 각 클래스에 대해 이 생성 모델을 적용하면 모든 데이터 포인트에 대한 우도 \(P({\rm feature}~|~L_1)\)를 계산하는 간단한 방법이 있으므로 사후 비율을 빠르게 계산하고 주어진 포인트에 대해 가장 가능성이 높은 레이블을 결정합니다.
이 절차는 Scikit-Learn의 sklearn.naive_bayes.GaussianNB 추정기에서 구현됩니다.
from sklearn.naive_bayes import GaussianNB
model = GaussianNB()
model.fit(X, y);새로운 데이터를 생성하고 레이블을 예측해 보겠습니다.
rng = np.random.RandomState(0)
Xnew = [-6, -14] + [14, 18] * rng.rand(2000, 2)
ynew = model.predict(Xnew)이제 이 새로운 데이터를 플롯하여 결정 경계가 어디에 있는지 알 수 있습니다(다음 그림 참조).
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap="RdBu")
lim = plt.axis()
plt.scatter(Xnew[:, 0], Xnew[:, 1], c=ynew, s=20, cmap="RdBu", alpha=0.1)
plt.axis(lim);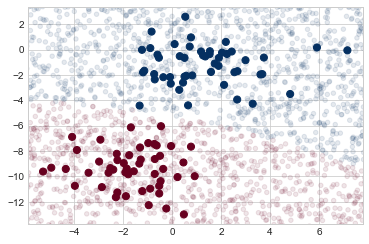
분류에서 약간 구부러진 경계를 살펴볼 수 있습니다. 일반적으로 Gaussian Naive Bayes 모델에 의해 생성된 경계는 2차입니다.
이 베이지안 형식의 좋은 점은 ‘predict_proba’ 방법을 사용하여 계산할 수 있는 확률적 분류를 자연스럽게 허용한다는 것입니다.
yprob = model.predict_proba(Xnew)
yprob[-8:].round(2)array([[0.89, 0.11],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[1. , 0. ],
[0. , 1. ],
[0.15, 0.85]])열은 각각 첫 번째 레이블과 두 번째 레이블의 사후 확률을 제공합니다. 분류의 불확실성 추정치를 찾고 있다면 이와 같은 베이지안 접근 방식이 좋은 시작점이 될 수 있습니다.
물론 최종 분류는 이를 도출하는 모델 가정만큼만 우수하므로 Gaussian Naive Bayes는 종종 좋은 결과를 생성하지 못합니다. 그럼에도 불구하고 많은 경우, 특히 특징 수가 많아질수록 이 가정은 Gaussian Naive Bayes가 신뢰할 수 있는 방법이 되는 것을 방해할 만큼 해롭지 않습니다.
다항식 나이브 베이즈
방금 설명한 가우스 가정은 결코 각 레이블에 대한 생성 분포를 지정하는 데 사용할 수 있는 유일한 간단한 가정이 아닙니다. 또 다른 유용한 예는 다항식 Naive Bayes입니다. 여기서 특징은 단순 다항 분포에서 생성된 것으로 가정됩니다. 다항 분포는 여러 범주 중에서 개수를 관찰할 확률을 설명하므로 개수 또는 개수 비율을 나타내는 특성에는 다항 순진 베이즈가 가장 적합합니다.
최적의 가우스 분포를 사용하여 데이터 분포를 모델링하는 대신 최적의 다항 분포를 사용하여 모델링한다는 점을 제외하면 아이디어는 이전과 정확히 동일합니다.
예: 텍스트 분류
다항식 나이브 베이즈가 자주 사용되는 곳 중 하나는 텍스트 분류입니다. 여기서 기능은 분류할 문서 내의 단어 수 또는 빈도와 관련됩니다. 우리는 Feature Engineering의 텍스트에서 이러한 기능을 추출하는 방법을 논의했습니다. 여기서는 Scikit-Learn을 통해 제공되는 20개 뉴스그룹 코퍼스의 희소 단어 수 기능을 사용하여 이러한 짧은 문서를 카테고리로 분류하는 방법을 보여줍니다.
데이터를 다운로드하고 대상 이름을 살펴보겠습니다.
from sklearn.datasets import fetch_20newsgroups
data = fetch_20newsgroups()
data.target_names['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']여기서는 단순화를 위해 이러한 범주 중 몇 가지만 선택하고 훈련 및 테스트 세트를 다운로드하겠습니다.
categories = [
"talk.religion.misc",
"soc.religion.christian",
"sci.space",
"comp.graphics",
]
train = fetch_20newsgroups(subset="train", categories=categories)
test = fetch_20newsgroups(subset="test", categories=categories)다음은 데이터의 대표적인 항목입니다.
print(train.data[5][48:])Subject: Federal Hearing
Originator: dmcgee@uluhe
Organization: School of Ocean and Earth Science and Technology
Distribution: usa
Lines: 10
Fact or rumor....? Madalyn Murray O'Hare an atheist who eliminated the
use of the bible reading and prayer in public schools 15 years ago is now
going to appear before the FCC with a petition to stop the reading of the
Gospel on the airways of America. And she is also campaigning to remove
Christmas programs, songs, etc from the public schools. If it is true
then mail to Federal Communications Commission 1919 H Street Washington DC
20054 expressing your opposition to her request. Reference Petition number
2493.
이 데이터를 머신러닝(Machine Learning)에 사용하려면 각 문자열의 내용을 숫자 벡터로 변환할 수 있어야 합니다. 이를 위해 TF-IDF 벡터화기(Feature Engineering에 도입됨)를 사용하고 이를 다항식 Naive Bayes 분류기에 연결하는 파이프라인을 생성합니다.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
model = make_pipeline(TfidfVectorizer(), MultinomialNB())이 파이프라인을 사용하면 모델을 훈련 데이터에 적용하고 테스트 데이터의 레이블을 예측합니다.
model.fit(train.data, train.target)
labels = model.predict(test.data)이제 테스트 데이터의 레이블을 예측했으므로 이를 평가하여 추정기의 성능을 알아살펴볼 수 있습니다. 예를 들어 테스트 데이터에 대한 실제 레이블과 예측 레이블 사이의 혼동 행렬을 살펴보겠습니다(다음 그림 참조).
from sklearn.metrics import confusion_matrix
mat = confusion_matrix(test.target, labels)
sns.heatmap(
mat.T,
square=True,
annot=True,
fmt="d",
cbar=False,
xticklabels=train.target_names,
yticklabels=train.target_names,
cmap="Blues",
)
plt.xlabel("true label")
plt.ylabel("predicted label");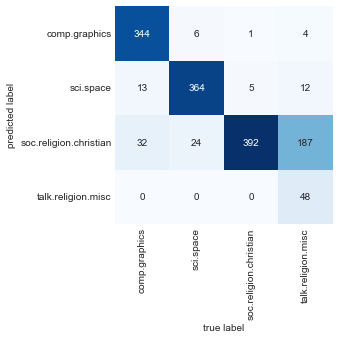
분명히 이 매우 간단한 분류자조차도 컴퓨터 토론과 우주 토론을 성공적으로 분리할 수 있지만 종교에 관한 토론과 기독교에 관한 토론을 혼동하게 됩니다. 이는 아마도 예상할 수 있는 일입니다!
여기서 멋진 점은 이제 이 파이프라인의 predict 메서드를 사용하여 모든 문자열의 범주를 결정하는 도구가 있다는 것입니다. 다음은 단일 문자열에 대한 예측을 반환하는 유틸리티 함수입니다.
def predict_category(s, train=train, model=model):
pred = model.predict([s])
return train.target_names[pred[0]]시도해 봅시다:
predict_category("sending a payload to the ISS")'sci.space'predict_category("discussing the existence of God")'soc.religion.christian'predict_category("determining the screen resolution")'comp.graphics'이는 문자열에 있는 각 단어의 (가중치) 빈도에 대한 단순한 확률 모델보다 더 정교한 것은 아니라는 점을 기억하십시오. 그럼에도 불구하고 결과는 놀랍습니다. 매우 순진한 알고리즘이라도 신중하게 사용하고 대규모 고차원 데이터 세트에 대해 학습하면 놀라울 정도로 효과적일 수 있습니다.
Naive Bayes를 사용해야 하는 경우
나이브 베이즈 분류기는 데이터에 대해 엄격한 가정을 하기 때문에 일반적으로 더 복잡한 모델만큼 성능을 발휘하지 못합니다. 즉, 다음과 같은 몇 가지 장점이 있습니다.
- 훈련과 예측 모두 빠릅니다.
- 간단한 확률적 예측을 제공합니다. Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know. Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.
이러한 장점은 Naive Bayes 분류기가 초기 기준 분류로 좋은 선택이 되는 경우가 많다는 것을 의미합니다. 적절하게 수행된다면 축하합니다. 문제에 대한 매우 빠르고 해석 가능한 분류기를 갖게 된 것입니다. 성능이 좋지 않으면 모델이 얼마나 잘 수행되어야 하는지에 대한 기본 지식을 바탕으로 보다 정교한 모델 탐색을 시작합니다.
Naive Bayes 분류기는 다음과 같은 상황에서 특히 잘 작동하는 경향이 있습니다.
- 순진한 가정이 실제로 데이터와 일치하는 경우(실제로는 매우 드뭅니다)
- 매우 잘 구분된 범주의 경우 모델 복잡성이 덜 중요한 경우
- 매우 고차원적인 데이터의 경우 모델 복잡성이 덜 중요한 경우
마지막 두 점은 별개로 보이지만 실제로는 서로 관련이 있습니다. 데이터 세트의 차원이 커짐에 따라 두 점이 서로 가깝게 발견될 가능성이 훨씬 줄어듭니다. 결국 두 점이 전체적으로 가까워지려면 모든 단일 차원에서 가까워야 합니다. 이는 새로운 차원이 실제로 정보를 추가한다고 가정할 때 높은 차원의 클러스터가 낮은 차원의 클러스터보다 평균적으로 더 분리되는 경향이 있음을 의미합니다. 이러한 이유로 여기에서 논의된 것과 같은 단순한 분류자는 차원이 커짐에 따라 더 복잡한 분류자보다 잘 작동하거나 더 잘 작동하는 경향이 있습니다. 데이터가 충분하면 간단한 모델도 매우 강력합니다.