library(astrologer)
# library(beepr)
library(fs)
# library(gutenbergr)
# library(quanteda)
# library(stm)
library(tidytext)
library(tidyverse)
library(tinytable)17 데이터로서의 텍스트
선수 지식
- 데이터로서의 텍스트: 개요, (Benoit 2020)
- 텍스트를 정량적 데이터로 활용하는 전반적인 개념을 소개합니다.
- R을 사용한 텍스트 분석을 위한 지도 기계 학습, (Hvitfeldt and Silge 2021)
- 텍스트 데이터를 활용한 선형 및 일반화 선형 모델 구현을 다루는 6장(회귀)과 7장(분류)을 중점적으로 살펴보세요.
- 벌거벗은 진실: 6,816개 파운데이션 제품명이 드러낸 뷰티 산업의 편향, (Amaka and Thomas 2021)
- 화장품 제품 설명 텍스트를 분석한 흥미로운 사례 연구입니다.
핵심 개념 및 기술
- 텍스트를 분석 가능한 데이터 소스로 인식하면, 기존의 정형 데이터만으로는 풀 수 없었던 수많은 흥미로운 질문들에 답할 수 있습니다.
- 텍스트 데이터는 전처리 방식에 따라 결과가 판이하게 달라질 수 있습니다. 텍스트 정제 및 준비(Text cleaning and preparation) 단계에서 내리는 수많은 결정은 분석 결과에 결정적인 영향을 미칩니다.
- 텍스트 데이터셋을 분석하는 한 가지 방법은 특정 문서를 다른 문서와 구별 짓는 핵심 단어들을 찾아내는 것입니다 (TF-IDF 등).
- 또 다른 강력한 방법은 방대한 문서 집합 속에 숨겨진 핵심 주제들을 추출해내는 것입니다 (주제 모델링).
소프트웨어 및 패키지
- Base R (R Core Team 2024)
astrologer(Gelfand 2022) (이 패키지는 CRAN에 없으므로devtools::install_github("sharlagelfand/astrologer")로 설치하세요)beepr(Bååth 2018)fs(Hester, Wickham, and Csárdi 2021)gutenbergr(Johnston and Robinson 2022)quanteda(Benoit et al. 2018)stm(Roberts, Stewart, and Tingley 2019)tidytext(Silge and Robinson 2016)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
17.1 서론
텍스트는 우리 일상 어디에나 존재합니다. 어쩌면 우리는 숫자를 배우기 전부터 텍스트라는 데이터를 가장 먼저 접하며 세상을 이해하기 시작했을지도 모릅니다. 최근 컴퓨팅 성능의 비약적인 발전과 새로운 분석 기법의 등장, 그리고 방대한 디지털 텍스트 자료의 축적은 ‘데이터로서의 텍스트’에 대한 폭발적인 관심을 불러일으켰습니다. 텍스트 분석은 우리에게 매우 독특하고 가치 있는 통찰을 제공합니다. 예를 들어:
- 아프리카 국가들의 국영 신문 기사를 분석하여 정부의 여론 조작이나 선전 활동을 포착할 수 있습니다(Hassan 2022).
- 영국의 일간지 텍스트를 활용해 GDP나 인플레이션 등 경제 지표를 더 정확하게 예측할 수 있으며(Kalamara et al. 2022), 마찬가지로 뉴욕 타임즈 자료로 미국 경제의 불확실성 지수를 산출할 수도 있습니다(Alexopoulos and Cohen 2015).
- 전자 건강 기록(EHR)에 담긴 의사의 진료 메모를 분석하여 질병 예측 모델의 성능을 획기적으로 높일 수 있습니다(Gronsbell et al. 2019).
- 미국 의회 회의록 분석을 통해 여성 의원들이 남성 동료들에게 얼마나 자주 발언을 방해받는지를 정량적으로 보여줄 수 있습니다(Miller and Sutherland 2022).
초기 텍스트 분석 기법은 문맥(context)을 무시하고 단어의 빈도를 숫자로 변환하는 방식에 치중했습니다. 이렇게 수치화된 데이터는 그저 로지스틱 회귀와 같은 전통적인 통계 모델에 투입되곤 했습니다. 하지만 최신 기법들은 텍스트에 내재된 구조(structure)를 파악하여 더 깊은 의미를 끌어내고자 합니다. 이러한 차이는 마치 단순히 색상만 보고 ’악어와 나무는 모두 초록색’이라고 분류하는 것과, ’악어는 위험한 동물이고 나무는 식물’이라는 본질적인 범주와 속성을 이해하는 것의 차이와 같습니다.
텍스트는 일반적인 정형 데이터와 유사한 면이 많으면서도 훨씬 다루기 까다로운 데이터입니다. 가장 큰 차이는 보통 수만 개 이상의 변수(단어 또는 토큰)가 존재하는 초고차원 희소(sparse) 데이터로 시작한다는 점입니다. 우리는 보통 이를 분석하기 위해 특정 단어와 그 빈도를 매칭시키는 긴 형태(long format)의 데이터로 변환합니다. 텍스트를 데이터로 다루려면 필연적으로 문맥으로부터 일정한 수준의 추상화가 필요합니다. 하지만 이 과정에서 주의해야 할 지점이 있습니다. 알고리즘과 데이터가 기존의 사회적 불평등을 고착화하거나 영속화할 위험이 있기 때문입니다. 예를 들어, 코네케(Koenecke et al. (2020)) 등은 자동 음성 인식 시스템이 흑인 화자에 대해 백인보다 현저히 낮은 성능을 보인다는 사실을 발견했습니다. 또한 데이비슨(Davidson, Bhattacharya, and Weber (2019)) 등은 흑인 영어(AAVE)를 사용하는 트윗이 표준 영어 트윗보다 혐오 발언으로 더 자주 오분류되는 편향성을 지적했습니다.
텍스트 데이터의 흥미로운 특징 중 하나는, 대부분의 텍스트가 애초에 분석을 목적으로 생성되지 않았다는 점입니다. 이 때문에 우리가 분석할 수 있는 형태로 가공하기 위한 전처리(Data cleaning and preparation) 과정에 엄청난 노력이 수반되며, 이 단계에서 내리는 수많은 주관적 결정들이 최종 결과에 영향을 미칩니다.
텍스트 데이터셋의 규모가 커질수록, 작은 규모에서 먼저 시뮬레이션해 보고 점진적으로 분석을 확대하는 전략이 매우 중요합니다. 풍부한 가용성과 다양성 덕분에 텍스트 분석은 매우 매력적이지만, 그만큼 데이터는 거칠고 지저분합니다. 따라서 재현 가능하고 효율적인 데이터 워크플로우를 구축하고 분석 결과를 명확하게 전달하는 역량이 필수적입니다. 그럼에도 불구하고, 텍스트가 전해주는 이야기는 그 어떤 데이터보다도 흥미진진한 탐구 영역입니다.
거인의 어깨 위에 서서: 케네스 브누아 (Kenneth Benoit)
케네스 브누아 박사는 런던 경제 정치 대학(LSE)의 전산사회과학 교수이며, 데이터 과학 연구소(Data Science Institute) 소장을 맡고 있습니다. 1998년 하바드 대학교에서 게리 킹(Gary King)과 케네스 셰플(Kenneth Shepsle)의 지도를 받아 정부학 박사 학위를 취득했습니다.
그는 정량적 텍스트 분석, 특히 정치적 텍스트와 소셜 미디어 데이터를 활용한 분석 분야의 세계적인 석학입니다. 라버(Laver, Benoit, and Garry (2003)) 등과 함께 집필한 선구적인 논문은 텍스트에서 정책적 입장을 추출하는 기법을 정립하여 정치학 내에 ‘데이터로서의 텍스트’라는 하위 분야를 단단히 다지는 데 크게 기여했습니다. 또한 그는 전문가 설문 조사와 수동 코딩 분석을 비교하는 등 정책 입장 추정 방법론 전반에 걸쳐 광범위한 연구 성과를 남겼습니다.
그의 가장 핵심적인 공헌 중 하나는 R 패키지 quanteda(Benoit et al. 2018) 패키지 제품군을 설계하고 개발한 것입니다. 이 패키지는 텍스트 데이터를 효율적으로 처리하고 정교하게 분석할 수 있는 표준적인 도구로 널리 사용되고 있습니다.
이 장에서는 먼저 텍스트 데이터를 어떻게 준비하고 가공하는지 살펴봅니다. 이어서 단어의 중요도를 평가하는 TF-IDF 방식과 대규모 문서 집합에서 주제를 찾아내는 주제 모델링(Topic Modeling)에 대해 학습하겠습니다.
17.2 텍스트 정제 및 준비
텍스트를 모델링하는 작업은 매우 흥미롭지만, 실제로는 데이터를 정제하고 분석 가능한 형태로 준비하는 과정이 모델링 자체만큼이나 (혹은 그보다 더) 까다롭고 중요합니다. 여기서는 텍스트 처리를 위한 핵심적인 기초 단계들을 살펴보겠습니다.
첫 번째 단계는 물론 데이터를 확보하는 것입니다. Chapter 7 에서 다양한 데이터 수집 방식을 다루었으며, 다음과 같은 텍스트 전문 출처들을 언급한 바 있습니다:
- 숙소 리뷰 텍스트를 제공하는 Inside Airbnb
- 저작권이 만료된 클래식 도서들을 제공하는 Project Gutenberg
- 위키피디아 등 웹 사이트 스크래핑(Scraping)자료
텍스트 정제 및 준비에 가장 널리 쓰이는 도구는 tidyverse에 포함된 stringr 패키지와, 앞서 소개한 quanteda 패키지입니다.
구체적인 설명을 위해 세 권의 소설 도입부 문구로 구성된 간단한 코퍼스(Corpus, 말뭉치)를 만들어 보겠습니다: 토니 모리슨의 빌러브드, 헬렌 드윗의 마지막 사무라이, 그리고 샬럿 브론테의 제인 에어.
last_samurai <- "우리 아버지의 아버지는 감리교 목사였다."
beloved <- "124번지는 악의로 가득했다. 아기의 독으로 충만했다."
jane_eyre <- "그날은 산책을 할 수 있는 형편이 아니었다."
bookshelf <-
tibble(
book = c("마지막 사무라이", "빌러브드", "제인 에어"),
first_sentence = c(last_samurai, beloved, jane_eyre)
)
bookshelf# A tibble: 3 × 2
book first_sentence
<chr> <chr>
1 마지막 사무라이 우리 아버지의 아버지는 감리교 목사였다.
2 빌러브드 124번지는 악의로 가득했다. 아기의 독으로 충만했다.
3 제인 에어 그날은 산책을 할 수 있는 형편이 아니었다. 우리의 최종 목표는 보통 문서-특징 행렬(Document-Feature Matrix, DFM)을 구축하는 것입니다. 이 행렬은 각 행이 문서(Document)를, 각 열이 특정 단어 등의 특징(Feature)을 나타내며, 각 칸에는 해당 단어가 문서에 등장한 빈도수가 들어갑니다. 예를 들어 코퍼스가 ’에어비앤비 리뷰’라면, 개별 리뷰가 각 문서가 되고 “숙소”, “청결”, “좋았다” 등이 각 열의 특징이 됩니다. 이때 텍스트를 구성하는 개별 단위를 문맥에 따라 단어보다는 조금 더 넓은 의미인 토큰(Token)이라는 용어로 부르기도 합니다.
books_corpus <-
corpus(bookshelf,
docid_field = "book",
text_field = "first_sentence")
books_corpusquanteda(Benoit et al. 2018)의 dfm()을 사용하여 코퍼스의 토큰을 사용하여 문서-특징 행렬(DFM)을 구성합니다.
books_dfm <-
books_corpus |>
tokens() |>
dfm()
books_dfm이처럼 문서-특징 행렬(DFM)을 구축하는 과정에는 분석가의 수많은 판단이 개입됩니다. 명확한 정답이 정해져 있는 것은 아니며, 데이터셋의 성격과 분석의 목적에 따라 최선의 선택을 내려야 합니다. 이제 그 주요 고려 사항들을 하나씩 살펴보겠습니다.
17.2.1 불용어 (Stop words)
불용어(Stop words)는 “은/는”, “이/가”, “a”, “the”, “and” 처럼 문법적 역할을 수행하지만 그 자체로는 구체적인 의미를 거의 담고 있지 않은 단어들을 말합니다. 예전에는 컴퓨팅 자원의 한계로 인해 이러한 단어들이 불필요한 노이즈로 간주되어 분석 전 단계에서 무조건 제거되곤 했습니다. 하지만 최근 연구에 따르면, 이러한 불용어조차도 화자의 문체나 감정, 문맥을 파악하는 데 중요한 단서가 될 수 있음이 밝혀졌습니다(Schofield, Magnusson, and Mimno 2017). 따라서 불용어 제거 여부는 분석의 목적에 따라 신중하게 결정해야 합니다.
R에서 quanteda의 stopwords() 함수를 사용하면 미리 정의된 불용어 목록을 쉽게 확인할 수 있습니다.
stopwords(source = "snowball")[1:10]가장 단순한 방식으로는 str_replace_all() 함수를 사용하여 텍스트에서 이러한 불용어들을 공백으로 치환해 제거할 수 있습니다.
stop_word_list <-
paste(stopwords(source = "snowball"), collapse = " | ")
bookshelf |>
mutate(no_stops = str_replace_all(
string = first_sentence,
pattern = stop_word_list,
replacement = " ")
) |>
select(no_stops, first_sentence)현재 “snowball”, “nltk” 등 다양한 기관에서 구축한 불용어 사전들이 존재합니다. 실무에서는 이러한 표준 사전만으로는 부족한 경우가 많아, 분석 중인 도메인에 특화된 특정 단어들을 추가하여 사전을 보강하곤 합니다.
stop_word_list_updated <-
paste(
"목사 |",
"악의 |",
"산책 |",
stop_word_list,
collapse = " | "
)
bookshelf |>
mutate(no_stops = str_replace_all(
string = first_sentence,
pattern = stop_word_list_updated,
replacement = " ")
) |>
select(no_stops)quanteda를 사용할 때는 DFM을 생성하는 과정에서 dfm_remove() 함수를 활용해 불용어를 한 번에 걸러낼 수 있습니다.
books_dfm |>
dfm_remove(stopwords(source = "snowball"))불용어 제거는 데이터셋을 인위적으로 가공하는 행위임을 명심해야 합니다. 과거에는 계산 능력 부족 때문에 필수 코스로 여겨졌지만, 쥬라프스키와 마틴(Jurafsky and Martin ([2000] 2023, 62)) 등의 연구에 따르면 불용어 제거가 텍스트 분류 성능을 항상 향상시키는 것은 아닙니다. 스코필드(Schofield, Magnusson, and Mimno (2017)) 또한 주제 모델링 등에서 불용어 제거가 전체 결과에 미치는 영향이 매우 미미함을 지적했습니다. 만약 불용어를 제거해야 한다면, 분석 초기가 아닌 주제나 특징이 모두 추출된 이후 단계에서 고려하는 것이 권장됩니다.
17.2.2 대소문자, 숫자 및 구두점
때로는 단어의 의미 자체가 중요할 뿐, 대소문자나 구두점은 분석에 방해가 되는 노이즈일 수 있습니다. 특히 텍스트 코퍼스가 매우 지저분하거나 특정 키워드의 존재 여부가 핵심인 경우, 구두점을 제거하고 대소문자를 통일함으로써 데이터를 단순화하고 분석의 효율성을 높일 수 있습니다. R의 str_to_lower() 함수로 모든 문자를 소문자로 바꾸거나, str_replace_all()에서 정규표현식 [:punct:]와 [:digit:]를 사용해 구두점과 숫자를 제거할 수 있습니다.
bookshelf |>
mutate(lower_sentence = str_to_lower(string = first_sentence)) |>
select(lower_sentence)# A tibble: 3 × 1
lower_sentence
<chr>
1 우리 아버지의 아버지는 감리교 목사였다.
2 124번지는 악의로 가득했다. 아기의 독으로 충만했다.
3 그날은 산책을 할 수 있는 형편이 아니었다. bookshelf |>
mutate(no_punctuation_numbers = str_replace_all(
string = first_sentence,
pattern = "[:punct:]|[:digit:]",
replacement = " "
)) |>
select(no_punctuation_numbers)# A tibble: 3 × 1
no_punctuation_numbers
<chr>
1 "우리 아버지의 아버지는 감리교 목사였다 "
2 " 번지는 악의로 가득했다 아기의 독으로 충만했다 "
3 "그날은 산책을 할 수 있는 형편이 아니었다 " 참고로 str_replace_all()에서 [:graph:]를 활용하면 문자, 숫자, 구두점을 한꺼번에 처리할 수 있습니다. 교재 예제에서는 드물지만, 실제 데이터셋에는 예상치 못한 기괴한 기호들이 포함된 경우가 많으므로 유용하게 쓰입니다. 우리가 익숙한 모든 패턴을 제거하고 분석에 필요한 것만 남기는 전략입니다.
또한 quanteda의 tokens() 함수 내 인수를 활용하면 토큰화 과정에서 이를 간편하게 처리할 수 있습니다.
books_corpus |>
tokens(remove_numbers = TRUE, remove_punct = TRUE)17.2.3 오타 및 희귀 단어
다음으로는 오타(Typo)나 거의 등장하지 않는 희귀 단어들을 어떻게 처리할지 결정해야 합니다. 실제 세계의 모든 텍스트에는 오타가 존재합니다. 의미 전달을 위해 명확한 오타는 수정해야 할 수도 있지만, 때로는 오타 자체가 정보가 되기도 합니다. 예를 들어 특정 작가나 집단이 반복적으로 저지르는 고유한 실수는 저자를 식별하는 강력한 증거가 될 수 있습니다. 또한 Chapter 7 에서 언급했듯, OCR 기술을 사용해 문서를 디지털화할 때 “the”가 “thc”로 잘못 인식되는 등의 체계적인 오류가 발생할 수 있습니다.
오타 수정은 불용어 처리와 마찬가지로 ’수정 목록(Replace list)’을 활용할 수 있습니다. 한편, 너무 드물게 나타나는 단어들은 분석 전체의 일반성을 해칠 수 있는데, dfm_trim() 함수를 써서 이를 걸러낼 수 있습니다. 예를 들어 최소 2회 이상 등장하지 않는 단어(min_termfreq = 2)나 전체 문서의 5% 미만에서만 나타나는 단어(min_docfreq = 0.05), 혹은 반대로 너무 흔해서 변별력이 없는 단어(max_docfreq = 0.90)를 제거하여 모델의 복잡도를 줄일 수 있습니다.
books_corpus |>
tokens(remove_numbers = TRUE, remove_punct = TRUE) |>
dfm(tolower = TRUE) |>
dfm_trim(min_termfreq = 2)17.2.4 N-그램 (N-grams)
텍스트 분석에서 토큰화(Tokenization)를 수행할 때 보통 공백을 기준으로 단어를 분리합니다. 하지만 “New York”이나 “United Kingdom”처럼 여러 단어가 하나의 고유한 의미를 형성하는 경우가 많습니다. 이러한 단어 뭉치를 N-그램(N-grams) 또는 튜플(Tuples)이라고 부릅니다. 두 단어 뭉치는 바이그램(Bigrams), 세 단어는 트라이그램(Trigrams)이라고 합니다.
지명 분석에서 이는 특히 중요한 문제입니다. “British”와 “Columbia”가 따로 떨어지면 원래의 의미인 ’브리티시 컬럼비아 주’라는 맥락이 사라져 버립니다. 이를 해결하는 한 가지 방법은 미리 정의된 지명 목록을 활용해 str_replace_all()로 “British_Columbia”처럼 밑줄을 추가해 하나의 단어로 연결하는 것입니다. quanteda 패키지의 tokens_compound() 함수를 사용하면 이를 더욱 우아하게 처리할 수 있습니다.
some_places <- c("British Columbia",
"New Hampshire",
"United Kingdom",
"Port Hedland")
a_sentence <-
c("밴쿠버는 브리티시 컬럼비아에 있고 뉴햄프셔는 아니다.")
tokens(a_sentence) |>
tokens_compound(pattern = phrase(some_places))만약 코퍼스에 어떤 주요 N-그램이 있는지 미리 알 수 없다면, tokens_ngrams() 함수를 사용해 데이터에서 자주 포착되는 단어 조합을 식별할 수 있습니다. 예를 들어 소설 제인 에어의 텍스트에서 자주 등장하는 바이그램을 찾아보겠습니다.
jane_eyre <- read_csv(
"jane_eyre.csv",
col_types = cols(
gutenberg_id = col_integer(),
text = col_character()
)
)
jane_eyre# A tibble: 21,001 × 2
gutenberg_id text
<int> <chr>
1 1260 JANE EYRE
2 1260 AN AUTOBIOGRAPHY
3 1260 <NA>
4 1260 by Charlotte Brontë
5 1260 <NA>
6 1260 _ILLUSTRATED BY F. H. TOWNSEND_
7 1260 <NA>
8 1260 London
9 1260 SERVICE & PATON
10 1260 5 HENRIETTA STREET
# ℹ 20,991 more rows먼저 분석에 방해가 되는 빈 줄을 제거합니다.
jane_eyre <-
jane_eyre |>
filter(!is.na(text))jane_eyre_text <- tibble(
book = "제인 에어",
text = paste(jane_eyre$text, collapse = " ") |>
str_replace_all(pattern = "[:punct:]",
replacement = " ") |>
str_replace_all(pattern = stop_word_list,
replacement = " ")
)
jane_eyre_corpus <-
corpus(jane_eyre_text, docid_field = "book", text_field = "text")
ngrams <- tokens_ngrams(tokens(jane_eyre_corpus), n = 2)
ngram_counts <-
tibble(ngrams = unlist(ngrams)) |>
count(ngrams, sort = TRUE)
head(ngram_counts)이 과정을 통해 “Mr Rochester”나 “St John” 같은 이름들이 빈번하게 등장하는 것을 확인할 수 있으며, 이러한 바이그램들은 분석 과정에서 하나의 토큰으로 유지하는 것이 바람직합니다.
17.2.5 어간 추출(Stemming) 및 표제어 추출(Lemmatization)
데이터셋의 차원을 축소하고 유사한 의미를 가진 단어들을 하나로 묶기 위해 어간 추출(Stemming)과 표제어 추출(Lemmatization)이 자주 활용됩니다.
- 어간 추출(Stemming): 단어의 어미를 단순히 잘라내어 공통된 ’어간’을 찾아내는 방식입니다. 예를 들어, “fishing”, “fished”, “fisher”는 모두 “fish”라는 어간으로 통합됩니다. 영어의 경우 “Canadians”, “Canadian”, “Canada”는 모두 “Canad”로 어간이 추출됩니다.
- 표제어 추출(Lemmatization): 단순히 어미를 자르는 것이 아니라 단어의 철자와 사전적 의미를 고려하여 ’기본형(Lemma)’으로 변환하는 좀 더 정교한 방식입니다. 예를 들어, “am”, “are”, “is”의 표제어는 “be”가 됩니다.
dfm_wordstem() 함수를 사용하면 이러한 작업을 수행할 수 있습니다. 다음 예제에서 “minister”가 “minist”로 어간 추출된 것을 볼 수 있습니다.
char_wordstem(c("Canadians", "Canadian", "Canada"))
books_corpus |>
tokens(remove_numbers = TRUE, remove_punct = TRUE) |>
dfm(tolower = TRUE) |>
dfm_wordstem()이러한 단계는 텍스트 분석의 표준적인 절차로 여겨지기도 하지만, 스코필드(Schofield et al. (2017)) 등은 주제 모델링과 같은 특정 분석 맥락에서 어간 추출이 결과에 거의 영향을 미치지 않으며, 반드시 수행할 필요는 없다는 연구 결과를 발표하기도 했습니다.
17.2.6 중복 데이터 처리
텍스트 데이터셋은 그 규모가 매우 크기 때문에 중복(Duplication) 문제가 빈번하게 발생합니다. 반디(Bandy and Vincent (2021)) 등은 유명한 ‘BookCorpus’ 데이터셋의 약 30%가 부적절하게 중복된 데이터임을 밝혀냈습니다. 중복 데이터는 분석 결과를 심각하게 왜곡할 수 있으나, 이를 진단하는 것은 매우 어렵습니다. 예를 들어, 셰익스피어 전집을 분석할 때 개별 희곡 데이터와 선집(Anthology) 데이터를 모두 포함하면 동일한 대사들이 여러 번 카운트되는 오류가 발생할 수 있습니다. 따라서 대규모 코퍼스를 구축할 때는 데이터 소스의 구성 요소를 면밀히 검토해야 합니다.
17.3 용어 빈도-역 문서 빈도 (TF-IDF)
17.3.1 점성술 데이터로 보는 TF-IDF
텍스트 분석의 실제 활용례를 살펴보기 위해, 점성술 운세 데이터가 담긴 astrologer 패키지를 활용해 보겠습니다.
이 패키지에서 제공하는 horoscopes 데이터셋을 불러옵니다.
horoscopes# A tibble: 1,272 × 4
startdate zodiacsign horoscope url
<date> <fct> <chr> <chr>
1 2015-01-05 Aries Considering the fact that this past week (espec… http…
2 2015-01-05 Taurus It's time Taurus. You aren't one to be rushed a… http…
3 2015-01-05 Gemini Soon it will be time to review what you know, t… http…
4 2015-01-05 Cancer Feeling feelings and being full of flavorful s… http…
5 2015-01-05 Leo Look, listen, watch, meditate and engage in pra… http…
6 2015-01-05 Virgo Last week's astrology is still reverberating th… http…
7 2015-01-05 Libra Get out your markers and your glue sticks. Get … http…
8 2015-01-05 Scorpio Time to pay extra attention to the needs of you… http…
9 2015-01-05 Sagittarius Everything right now is about how you say it, h… http…
10 2015-01-05 Capricorn The full moon on January 4th/5th was a healthy … http…
# ℹ 1,262 more rows이 데이터셋에는 “startdate(시작일)”, “zodiacsign(별자리)”, “horoscope(운세 문구)”, “url”의 네 가지 변수가 포함되어 있습니다. 우리의 목표는 각 별자리별 운세에서 특별히 강조되거나 차별화되는 단어들이 무엇인지 찾아내는 것입니다.
horoscopes |>
count(zodiacsign)# A tibble: 12 × 2
zodiacsign n
<fct> <int>
1 Aries 106
2 Taurus 106
3 Gemini 106
4 Cancer 106
5 Leo 106
6 Virgo 106
7 Libra 106
8 Scorpio 106
9 Sagittarius 106
10 Capricorn 106
11 Aquarius 106
12 Pisces 106각 별자리별로 106개씩의 운세 텍스트가 존재합니다. 이제 텍스트를 단어 단위로 토큰화하고, 각 별자리별로 단어 빈도를 집계하겠습니다. 여기서는 강력한 텍스트 분석 도구인 tidytext 패키지를 활용합니다.
horoscopes_by_word <-
horoscopes |>
select(-startdate,-url) |>
unnest_tokens(output = word,
input = horoscope,
token = "words")
horoscopes_counts_by_word <-
horoscopes_by_word |>
count(zodiacsign, word, sort = TRUE)
horoscopes_counts_by_word# A tibble: 41,847 × 3
zodiacsign word n
<fct> <chr> <int>
1 Cancer to 1440
2 Sagittarius to 1377
3 Aquarius to 1357
4 Aries to 1335
5 Pisces to 1313
6 Leo to 1302
7 Libra to 1270
8 Sagittarius you 1264
9 Virgo to 1262
10 Scorpio to 1260
# ℹ 41,837 more rows단순 빈도를 확인해 보면, “you”, “your”, “the” 처럼 모든 별자리에서 공통적으로 많이 쓰이는 단어들이 상위권을 차지하고 있습니다. 하지만 우리가 알고 싶은 것은 특정 별자리의 운세만이 가지는 고유한 특징입니다.
이때 TF-IDF (Term Frequency-Inverse Document Frequency) 기법이 필요합니다.
- 용어 빈도 (TF, Term Frequency): 특정 문서(여기서는 특정 별자리)에서 해당 단어가 얼마나 자주 등장하는지를 나타냅니다.
- 역 문서 빈도 (IDF, Inverse Document Frequency): 해당 단어가 전체 문서군(전체 별자리)에서 얼마나 흔하게 등장하는지를 고려합니다. 모든 별자리에서 흔하게 쓰이는 단어에는 벌점(Penalty)을 주고, 특정 별자리에서만 집중적으로 쓰이는 단어에 가중치를 부여합니다.
즉, TF-IDF 값이 높을수록 그 단어는 해당 문서를 대표하는 변별력 높은 핵심어라고 볼 수 있습니다. tidytext의 bind_tf_idf() 함수로 이 값을 계산해 보겠습니다.
horoscopes_counts_by_word_tf_idf <-
horoscopes_counts_by_word |>
bind_tf_idf(
term = word,
document = zodiacsign,
n = n
) |>
arrange(-tf_idf)
horoscopes_counts_by_word_tf_idf# A tibble: 41,847 × 6
zodiacsign word n tf idf tf_idf
<fct> <chr> <int> <dbl> <dbl> <dbl>
1 Capricorn goat 6 0.000236 2.48 0.000585
2 Pisces pisces 14 0.000531 1.10 0.000584
3 Sagittarius sagittarius 10 0.000357 1.39 0.000495
4 Cancer cancer 10 0.000348 1.39 0.000483
5 Gemini gemini 7 0.000263 1.79 0.000472
6 Taurus bulls 5 0.000188 2.48 0.000467
7 Aries warns 5 0.000186 2.48 0.000463
8 Cancer organize 7 0.000244 1.79 0.000437
9 Cancer overwork 5 0.000174 2.48 0.000432
10 Taurus let's 10 0.000376 1.10 0.000413
# ℹ 41,837 more rowsTable 17.1 는 각 별자리의 운세를 가장 잘 구별해주는 단어들을 보여줍니다. 재미있는 점은 많은 경우 별자리 이름 그 자체가 핵심어로 추출된다는 사실입니다. 분석 목적에 따라 이를 제거할 수도 있겠지만, 반대로 별자리 이름이 모든 운세 문구에 포함되는 것은 아니라는 사실 자체가 해당 텍스트의 구성 방식을 보여주는 중요한 단서가 되기도 합니다.
horoscopes_counts_by_word_tf_idf |>
slice(1:5,
.by = zodiacsign) |>
select(zodiacsign, word) |>
summarise(all = paste0(word, collapse = "; "),
.by = zodiacsign) |>
tt() |>
style_tt(j = 1:2, align = "lr") |>
setNames(c("별자리", "핵심 단어 (TF-IDF 상위 5개)"))| 별자리 | 핵심 단어 (TF-IDF 상위 5개) |
|---|---|
| Capricorn | goat; capricorn; capricorns; signify; neighborhood |
| Pisces | pisces; wasted; missteps; node; shoes |
| Sagittarius | sagittarius; rolodex; distorted; coat; reinvest |
| Cancer | cancer; organize; overwork; procrastinate; scuttle |
| Gemini | gemini; mood; output; admit; faces |
| Taurus | bulls; let's; painfully; virgin; taurus |
| Aries | warns; vesta; aries; fearful; chase |
| Virgo | digesting; trace; liberate; someone's; final |
| Libra | proof; inevitably; recognizable; reference; disguise |
| Scorpio | skate; advocate; knots; bottle; meditating |
| Aquarius | saves; consult; yearnings; sexy; athene |
| Leo | trines; blessed; regrets; leo; agree |
17.4 주제 모델 (Topic Models)
주제 모델(Topic Models)은 방대한 양의 문서 집합 속에서 유사한 단어 뭉치들을 찾아내어 공통된 ’주제’를 추출하고 싶을 때 매우 유용한 도구입니다. 우리는 비슷한 단어들의 집합을 하나의 주제로 정의합니다. 각 문서가 어떤 주제들을 비중 있게 다루고 있는지 파악하기 위해 가장 널리 쓰이는 기법 중 하나는 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)입니다. (참고로 이 장에서 LDA는 선형 판별 분석이 아닌 잠재 디리클레 할당을 의미합니다.)
LDA 모델의 핵심 가정은 “사람이 글을 쓸 때 먼저 어떤 주제들에 대해 쓸지 결정하고, 그 주제에 어울리는 단어들을 골라 문장을 완성한다”는 생성 과정을 상상하는 것입니다. 여기서 주제는 특정 단어들의 묶음이며, 문서는 여러 주제의 혼합체로 간주됩니다. 이러한 주제들은 분석가가 미리 정해주는 것이 아니라, 알고리즘이 텍스트 데이터 내부의 패턴을 스스로 학습하여 찾아내는 결과물입니다. 단어들은 여러 주제에 걸쳐 나타날 수 있으며, 하나의 문서는 여러 주제를 동시에 포함할 수 있습니다. 이는 단순히 단어 빈도를 세는 방식보다 훨씬 유연하고 정교한 분석을 가능하게 합니다.
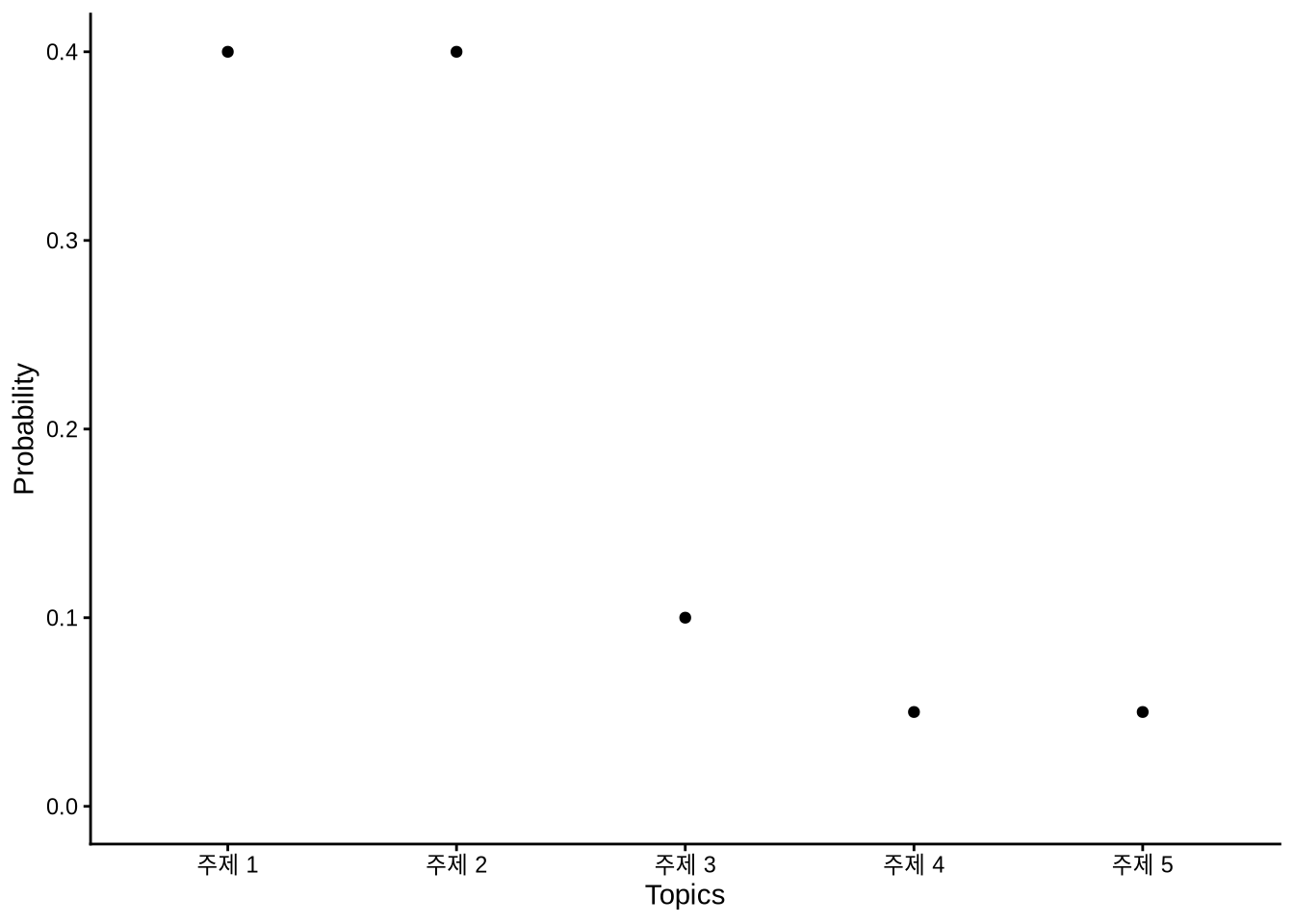
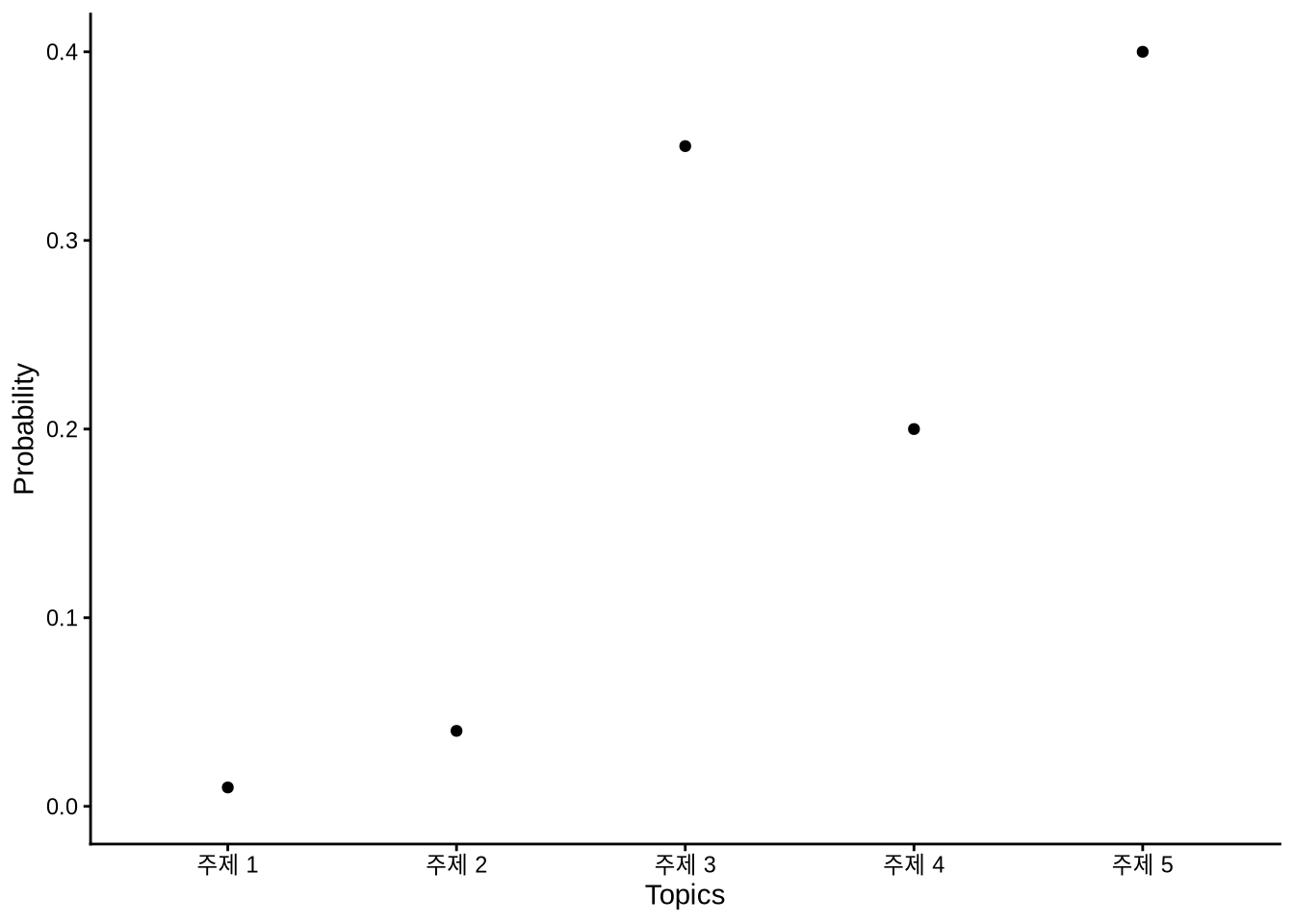
LDA는 각 문서가 주제들의 확률 분포 위에 세워졌다고 봅니다. 예를 들어, 5개의 주제가 있고 2개의 문장이 있다면, 첫 번째 문장은 1번과 2번 주제를 주로 다루고, 두 번째 문장은 3번이나 4번 주제에 집중할 수 있습니다(Figure 17.1).
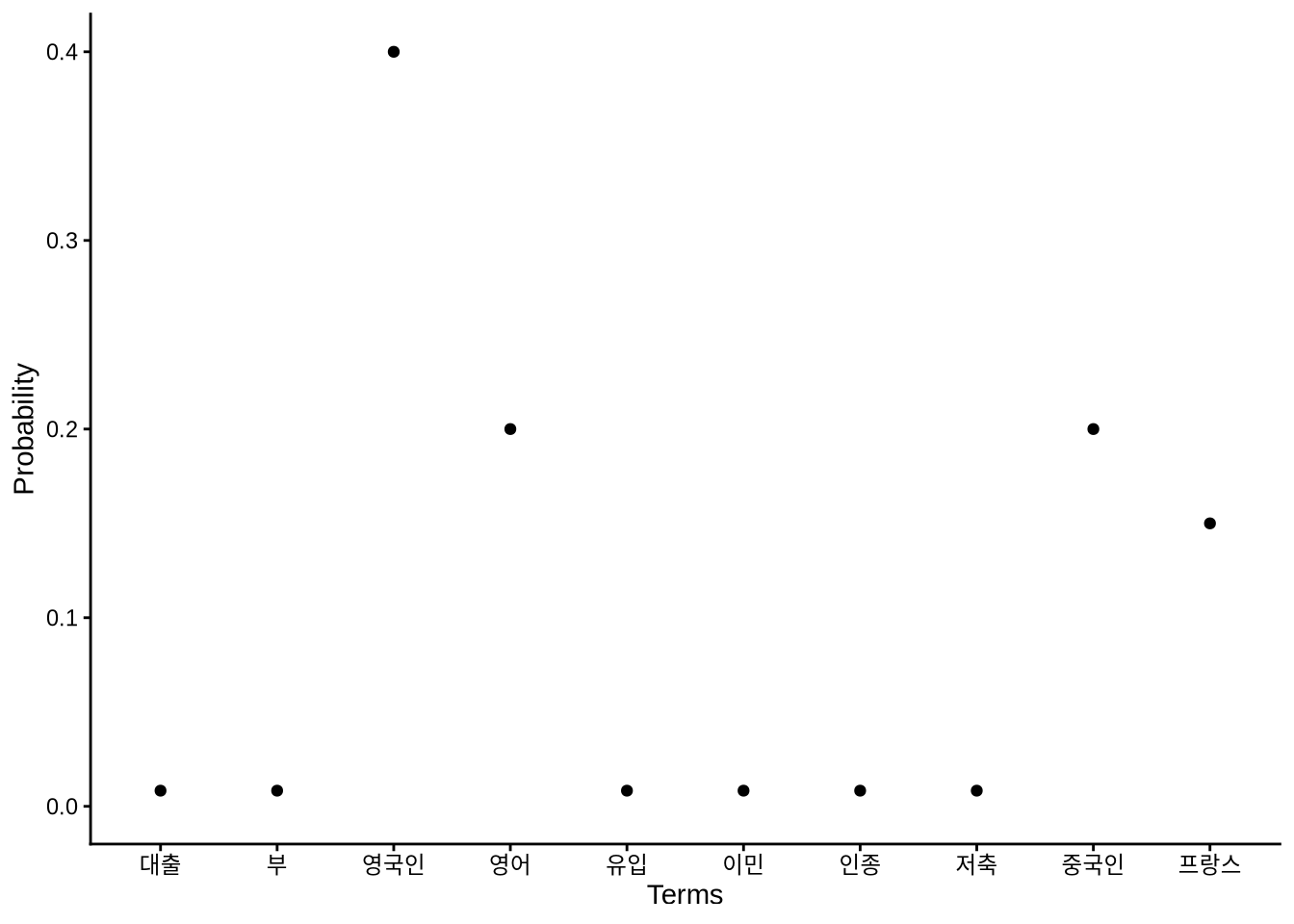
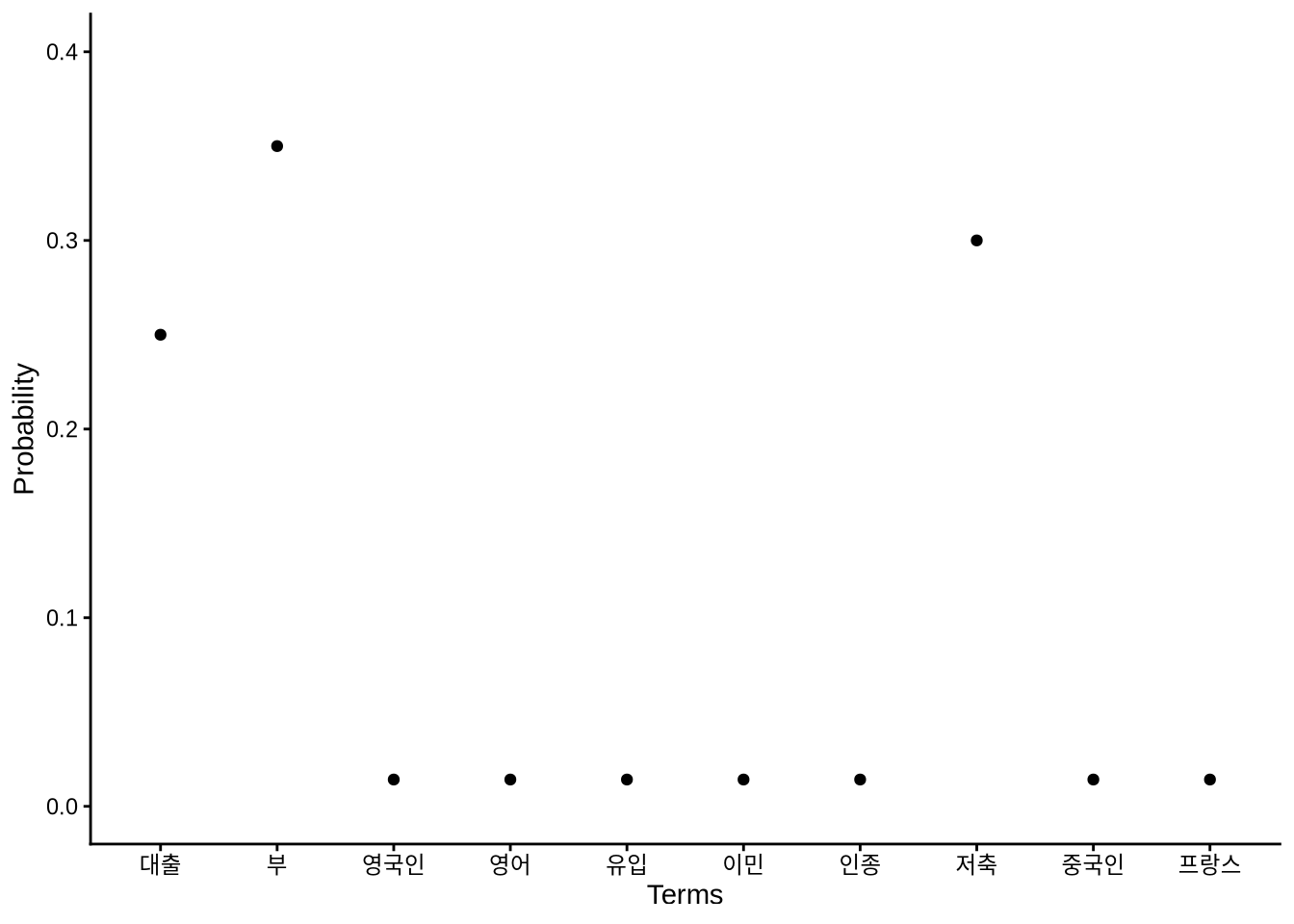
마찬가지로, 각 주제는 단어들의 확률 분포로 설명됩니다. 화자는 특정 주제에 대해 말하기 위해 해당 주제에 어울리는 단어들을 적절한 비율로 선택합니다. 예를 들어 1번 주제는 ‘이민’, ‘인종’ 같은 단어에 높은 가중치를 두고, 2번 주제는 ‘대출’, ‘부’, ‘저축’ 같은 경제 단어에 높은 비중을 둘 수 있습니다(Figure 17.2).
우리가 관찰할 수 있는 결과물은 ’문서에 포함된 단어들’뿐입니다. 이 단어들이 어떤 주제를 형성하고 있고, 문서가 어떤 주제의 혼합물인지는 겉으로 드러나지 않는 ‘잠재(Latent)’ 영역입니다. 주제 모델링의 목표는 이 문서 생성 과정을 역으로 추적하여, 단어들의 묶음을 바탕으로 숨겨진 주제의 구조(Figure 17.1 및 Figure 17.2 의 분포)를 찾아내는 것입니다.
배경 지식으로, 디리클레 분포는 범주형 및 다항 변수에 대한 사전 분포로 일반적으로 사용되는 베타 분포의 변형입니다. 두 가지 범주만 있다면 디리클레 분포와 베타 분포는 동일합니다. 대칭 디리클레 분포의 특수한 경우인 \(\eta=1\)일 때, 이는 균일 분포와 동일합니다. \(\eta<1\)이면 분포는 희소하고 더 적은 수의 값에 집중되며, 이 수는 \(\eta\)가 감소함에 따라 감소합니다. 이 용법에서 하이퍼파라미터는 사전 분포의 매개변수입니다.
문서가 생성된 후, 그것들이 우리가 분석할 수 있는 전부입니다. 각 문서의 용어 사용은 관찰되지만, 주제는 숨겨져 있거나 “잠재적”입니다. 우리는 각 문서의 주제를 모르고, 용어가 주제를 어떻게 정의했는지도 모릅니다. 즉, Figure 17.1 또는 Figure 17.2 확률 분포를 모릅니다. 어떤 의미에서 우리는 문서 생성 프로세스를 역전시키려고 노력하고 있습니다. 즉, 용어를 가지고 있고, 주제를 발견하고 싶습니다.
각 문서의 용어를 관찰하면 주제의 추정치를 얻을 수 있습니다(Steyvers and Griffiths 2006). LDA 프로세스의 결과는 확률 분포입니다. 이 분포가 주제를 정의합니다. 각 용어는 특정 주제의 구성원일 확률을 부여받고, 각 문서는 특정 주제에 관한 것일 확률을 부여받습니다.
코퍼스 문서가 주어졌을 때 LDA를 구현할 때의 초기 실용적인 단계는 일반적으로 불용어를 제거하는 것입니다. 비록 앞서 언급했듯이 이것이 필수는 아니며, 그룹이 생성된 후에 수행하는 것이 더 나을 수 있습니다. 우리는 종종 구두점과 대소문자도 제거합니다. 그런 다음 quanteda의 dfm()을 사용하여 문서-특징 행렬을 구성합니다.
17.4.1 LDA 모델의 추정 및 한계
실전에서 LDA를 구현할 때 보통 불용어 정제, 구두점 및 대소문자 제거 등의 전처리를 먼저 거칩니다. 그 다음 quanteda의 dfm() 함수로 문서-특징 행렬을 만든 뒤, stm 패키지 등을 활용해 주제의 사후 분포를 추정합니다.
이 모델은 깁스 샘플링(Gibbs Sampling) 이라는 기법을 즐겨 사용합니다. 이는 매우 방대한 단어와 주제들의 관계를 하나씩 훑어보며 최적의 할당을 찾아가는 과정입니다. 처음에는 모든 단어에 무작위로 주제를 할당한 뒤, 수만 번에 걸친 반복 연산을 통해 각 단어가 어떤 주제에 속할 때 가장 자연스러운지를 찾아내며 전역적인 해답에 수렴해 갑니다.
가장 중요한 결정 중 하나는 ‘주제 수(\(k\))’를 몇 개로 설정할 것인가 하는 점입니다. 분석가가 도메인 지식을 바탕으로 특정 숫자를 지정할 수도 있지만, 본질적으로 이는 정답이 없는 문제입니다. 대개는 훈련 데이터셋과 테스트 데이터셋을 나누어 다양한 \(k\)값을 시도해 보며 모델의 성능(예: Perplexity 등)이 최적화되는 지점을 선택합니다.
LDA 기법의 대표적인 약점 중 하나는 단어의 순서를 무시하는 ‘단어 가방(Bag-of-Words, BoW)’ 모델에 기반한다는 점입니다. 문맥상의 전후 관계보다는 단순히 한 문서 안에 특정 단어들이 공존(co-occurrence)하는지 여부만을 따집니다. 이를 보완하기 위해 단어 순서나 단어 간 상관관계를 고려하는 다양한 확장 모델들도 연구되고 있습니다.
17.4.2 사례 연구: 캐나다 의회에서는 무엇을 논의하는가?
캐나다 의회의 회의록 역시 영국 의회의 전통을 따라 ‘한사드(Hansard)’라고 불립니다. 문자 그대로의 녹취록은 아니지만, 의원들의 발언을 거의 그대로 충실하게 기록하고 있습니다. 이 방대한 기록은 베일런(Beelen et al. (2017)) 등이 구축한 LiPaD 프로젝트를 통해 CSV 형태로 누구나 이용할 수 있습니다.
우리는 2018년 캐나다 의회에서 어떤 주제들이 중요하게 논의되었는지 살펴보겠습니다. 데이터 사이트에서 전체 코퍼스를 내려받은 뒤 2018년 자료만 슬라이싱하여 분석에 활용합니다.
files_of_interest <-
dir_ls(path = "2018/", glob = "*.csv", recurse = 2)
hansard_canada_2018 <-
read_csv(
files_of_interest,
col_types = cols(
basepk = col_integer(),
speechdate = col_date(),
speechtext = col_character(),
speakerparty = col_character(),
speakerriding = col_character(),
speakername = col_character()
),
col_select =
c(basepk, speechdate, speechtext, speakername, speakerparty,
speakerriding)) |>
filter(!is.na(speakername))
hansard_canada_2018# A tibble: 33,105 × 6
basepk speechdate speechtext speakername speakerparty speakerriding
<int> <date> <chr> <chr> <chr> <chr>
1 4732776 2018-01-29 "Mr. Speaker, I wo… Julie Dabr… Liberal Toronto—Danf…
2 4732777 2018-01-29 "Mr. Speaker, I wa… Matthew Du… New Democra… Beloeil—Cham…
3 4732778 2018-01-29 "Mr. Speaker, I am… Stephanie … Conservative Calgary Midn…
4 4732779 2018-01-29 "Resuming debate.\… Anthony Ro… Liberal Nipissing—Ti…
5 4732780 2018-01-29 "Mr. Speaker, we a… Alain Rayes Conservative Richmond—Art…
6 4732781 2018-01-29 "The question is o… Anthony Ro… Liberal Nipissing—Ti…
7 4732782 2018-01-29 "Agreed.\n No." Some hon. … <NA> <NA>
8 4732783 2018-01-29 "All those in favo… Anthony Ro… Liberal Nipissing—Ti…
9 4732784 2018-01-29 "Yea." Some hon. … <NA> <NA>
10 4732785 2018-01-29 "All those opposed… Anthony Ro… Liberal Nipissing—Ti…
# ℹ 33,095 more rows데이터의 첫 머리에는 종종 “하원은 2017년 11월 9일부터 동의안 심의를 재개했습니다”와 같은 의사 진행 지시 사항이 포함되기도 합니다. 이와 같은 비연설 요소를 걸러내기 위해 filter()를 적절히 사용한 뒤 코퍼스를 구축합니다.
hansard_canada_2018_corpus <-
corpus(hansard_canada_2018,
docid_field = "basepk",
text_field = "speechtext")
hansard_canada_2018_corpus이제 코퍼스를 토큰화하여 문서-특징 행렬(DFM)을 생성합니다. 계산 효율성을 높이기 위해 전체에서 2회 이상 등장하지 않은 단어나, 단 2개 미만의 문서에서만 쓰인 아주 희귀한 단어들은 제거(dfm_trim)합니다. 또한 앞서 배운 불용어 제거 처리를 병행합니다.
hansard_dfm <-
hansard_canada_2018_corpus |>
tokens(
remove_punct = TRUE,
remove_symbols = TRUE
) |>
dfm() |>
dfm_trim(min_termfreq = 2, min_docfreq = 2) |>
dfm_remove(stopwords(source = "snowball"))
hansard_dfm준비된 DFM을 바탕으로 이제 본격적인 LDA 주제 모델링을 수행합니다. 이때 우리가 찾고자 하는 주제 수(\(K\))를 지정해야 합니다. 주제 모델은 방대한 텍스트를 인간이 이해할 수 있는 수준으로 요약해주는 지도 역할을 합니다. 여기서는 탐색적 목적으로 \(K=10\)을 지정해 보겠습니다.
이 고된 분석 과정은 약 15~30분 이상 소요될 수 있으므로, 완료 알림을 위해 beepr 패키지를 활용하고 결과를 write_rds()로 저장해 두는 지혜가 필요합니다.
hansard_topics <- stm(documents = hansard_dfm, K = 10)
beepr::beep()
write_rds(
hansard_topics,
file = "hansard_topics.rda"
)저장된 모델은 언제든 불러와서 labelTopics() 함수를 통해 각 주제가 어떤 핵심 단어들로 구성되어 있는지 살펴보며 해석할 수 있습니다. 각 주제를 보며 “주제 1은 예산에 관한 것”, “주제 2는 외교 정책에 관한 것” 등 의미를 명명해 보세요.
17.5 연습 문제
연습
- (계획) 다음 시나리오를 구상해 봅시다: 당신은 뉴스 웹사이트 배포를 앞두고 있으며, 익명 댓글 허용 여부를 결정해야 합니다. 이를 위해 A/B 테스트를 실시하기로 했습니다. 모든 조건은 동일하게 유지하되, 한 그룹의 사용자에게만 익명 댓글 기능을 제공합니다. 이때 얻을 수 있는 텍스트 데이터셋이 어떤 구조일지 설계해 보세요. 또한 분석 결과를 효과적으로 시각화하기 위해 어떤 그래프를 그릴 수 있을지 스케치해 보세요.
- (시뮬레이션) 위 시나리오에 따라 가상의 데이터를 시뮬레이션해 보세요. 최소 10개의 테스트 케이스를 포함하는 시뮬레이션 데이터를 생성해 봅시다.
- (수집) 이러한 분석을 수행하기 위해 실제로 데이터를 확보할 수 있는 온/오프라인 출처들을 나열해 보세요.
- (탐색)
ggplot2를 사용해 앞서 스케치한 시각화 그래프를 실제로 구현해 보세요. 또한rstanarm을 활용해 익명성이 댓글의 성격에 미치는 영향을 분석하는 모델을 구축해 봅시다. - (통찰) 수행한 분석 과정과 그 결과로부터 얻은 통찰을 두 개의 문단으로 정리해 보세요.
퀴즈
str_replace_all()함수에서 구두점을 제거하기 위해 사용하는 정규표현식은 무엇입니까?- “[:punct:]”
- “[:digit:]”
- “[:alpha:]”
- “[:lower:]”
- ‘nltk’ 불용어 목록에서 아홉 번째로 등장하는 단어는 무엇입니까? (힌트:
stopwords(source = "nltk")활용)- “her”
- “my”
- “you”
- “i”
quanteda패키지에서 코퍼스 데이터를 토큰 단위로 나누어주는 함수는 무엇입니까?tokenizer()token()tokenize()tokens()
dfm_trim()함수에서 최소 2회 이상 나타나는 단어만 남기기 위해 사용하는 인수는 무엇입니까?- “min_wordfreq”
- “min_termfreq”
- “min_term_occur”
- “min_occurrence”
- 당신이 가장 좋아하는 ’트라이그램(Trigram)’의 예시는 무엇인가요? (세 단어로 된 어구)
- 본문에서 다룬 게자리(Cancer) 운세 데이터에서 두 번째로 자주 등장하는 단어는 무엇입니까?
- to
- your
- the
- you
- 물고기자리(Pisces) 운세 데이터에서 여섯 번째로 흔한 단어는 무엇이며, 이 별자리에만 고유하게 나타나는 단어는 무엇입니까?
- shoes
- prayer
- fishes
- pisces
- 캐나다 의회 주제 모델링을 다시 실행하되, 주제의 수(\(K\))를 5개로 설정해 보세요. 각 주제를 구성하는 단어들을 살펴보고, 각 주제가 구체적으로 어떤 정책 분야를 다루는지 설명해 보세요.
수업 활동
- 아이들이 “개”, “고양이”, “새” 중 가장 먼저 배우는 단어는 무엇일까요? ‘Wordbank’ 데이터베이스를 활용해 실제 언어 습득 데이터를 분석해 봅시다.
과제
R을 사용한 텍스트 분석을 위한 지도 기계 학습의 5.2장 “단어 임베딩의 이해”(Hvitfeldt and Silge 2021) 파트의 예제 코드를 참고하여, LiPaD 캐나다 의회 데이터(최근 1년 치)를 활용해 자신만의 단어 임베딩(Word Embedding) 모델을 직접 구현하고 시각화해 보세요.