library(knitr)
library(tidyverse)
library(tinytable)4 연구 보고서 작성하기
이 책은 2023년 7월 채프먼 앤 홀/CRC(Chapman and Hall/CRC)에서 출간되었습니다. 도서는 이곳에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 일부 내용이 반영되어 있습니다.
권장 선행 학습
- 고등 교육 연구 계획하기(원제: By Design: Planning Research on Higher Education) (Light, Singer, and Willett 1990) 읽기.
- 특히 좋은 연구 질문을 던지기 위한 전략을 다룬 2장 “당신의 질문은 무엇인가”를 꼼꼼히 읽어보세요.
- 글쓰기 법칙(원제: On Writing Well) (Zinsser 1976) 읽기. (판본 무관)
- 효과적인 글쓰기 스타일의 ’원칙’과 ’방법’을 다룬 1부와 2장에 집중해 보시기 바랍니다.
- 소설가 코맥 매카시의 훌륭한 과학 논문 작성법 (Savage and Yeh 2019) 읽기.
- 과학적 글쓰기를 실질적으로 개선할 수 있는 구체적인 조언들을 얻을 수 있습니다.
- 출판, 그리고 출판(원제: Publication, publication) (G. King 2006) 읽기.
- 단순한 복제 연구 수준을 넘어 학술지에 게재 가능한 논문으로 나아가는 전략을 상세히 설명합니다.
- 정량적 편집 (Bronner 2021) 시청하기.
- 데이터 저널리즘 매체 ’FiveThirtyEight’의 정량 편집자로서 겪은 생생한 경험과 글쓰기 전략이 담겨 있습니다.
- 흡연과 폐암(원제: Smoking and carcinoma of the lung) (Doll and Hill 1950) 읽기.
- 데이터 섹션을 어떻게 구성해야 하는지 보여주는 아주 훌륭한 모범 사례입니다.
- 유용한 글을 쓰는 법(원제: How to write usefully) (Graham 2020) 읽기.
- 독자가 아직 모르는 ’진실되고 중요한 사실’을 전달하는 방법에 관한 글입니다.
- 다음 중 관심 있는 정량 분석 논문을 골라 한 편 이상 읽어보세요.
- Asset prices in an exchange economy, (Lucas 1978)
- Individuals, institutions, and innovation in the debates of the French Revolution, (Barron et al. 2018)
- Modeling: optimal marathon performance on the basis of physiological factors, (Joyner 1991)
- On reproducible econometric research, (Koenker and Zeileis 2009)
- Prevented mortality and greenhouse gas emissions from historical and projected nuclear power, (Kharecha and Hansen 2013)
- Seeing like a market, (Fourcade and Healy 2017)
- Simpson’s paradox and the hot hand in basketball, (Wardrop 1995)
- Some studies in machine learning using the game of checkers, (Samuel 1959)
- Statistical methods for assessing agreement between two methods of clinical measurement, (Bland and Altman 1986)
- Surgical Skill and Complication Rates after Bariatric Surgery, (Birkmeyer et al. 2013)
- The mundanity of excellence: An ethnographic report on stratification and Olympic swimmers, (Chambliss 1989)
- The probable error of a mean, (Student 1908)
- 다음 중 The New Yorker 기사를 한 편 이상 골라 읽어보세요.
- Funny Like a Guy, Tad Friend, 2011년 4월 4일
- Going the Distance, David Remnick, 2014년 1월 19일
- How the First Gravitational Waves Were Found, Nicola Twilley, 2016년 2월 11일
- Happy Feet, Alexandra Jacobs, 2009년 9월 7일
- Levels of the Game, John McPhee, 1969년 5월 31일
- Reporting from Hiroshima, John Hersey, 1946년 8월 23일
- The Catastrophist, Elizabeth Kolbert, 2009년 6월 22일
- The Quiet German, George Packer, 2014년 11월 24일
- The Pursuit of Beauty, Alec Wilkinson, 2015년 2월 1일
- 다음 중 다른 매체에 실린 기사를 한 편 이상 골라 읽어보세요.
- Blades of Glory, Holly Anderson, Grantland
- Born to Run, Walt Harrington, The Washington Post
- Dropped, Jason Fagone, Grantland
- Federer as Religious Experience, David Foster Wallace, The New York Times Magazine
- Generation Why?, Zadie Smith, The New York Review of Books
- One hundred years of arm bars, David Samuels, Grantland
- Out in the Great Alone, Brian Phillips, ESPN
- Pearls Before Breakfast, Gene Weingarten, The Washington Post
- Resurrecting The Champ, J.R. Moehringer, Los Angeles Times
- The Cult of “Jurassic Park”, Bryan Curtis, Grantland
- The House that Hova Built, Zadie Smith, The New York Times
- The Re-Education of Chris Copeland, Flinder Boyd, SB Nation
- The Sea of Crisis, Brian Phillips, Grantland
- The Webb Space Telescope Will Rewrite Cosmic History. If It Works., Natalie Wolchover, Quanta Magazine
핵심 개념 및 기술
- 글쓰기는 데이터 분석에 필요한 모든 기술 중에서도 어쩌면 가장 중요할지 모릅니다. 글쓰기 실력을 키우는 유일한 비결은 ’매일 쓰는 것’뿐입니다.
- 글쓰기를 통해 얻는 통찰은 작가 자신에게도 유익하지만, 글 자체는 철저히 독자를 위해 써야 합니다. 독자의 눈높이에서 생각하고, 전달하고자 하는 메시지를 하나로 명확히 정하세요.
- 초고는 가급적 빨리 완성하는 것이 좋습니다. 아무리 엉성하더라도 초고가 일단 존재해야 진정한 ’다시 쓰기’를 시작할 수 있습니다. 수정 단계에서는 불필요한 단어를 과감히 걷어내고 내용을 선명하게 다듬는 데 집중하세요.
- 대개 우리는 관심 분야에서 출발해 연구 질문을 던지고, 데이터를 확보하며 분석 과정을 거치는 동안 생각을 끊임없이 반복하며 발전시킵니다. 이 과정을 통과해야만 비로소 자신이 하려는 일이 무엇인지 선명하게 이해하게 됩니다.
소프트웨어 및 패키지
knitr(Xie 2023)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
4.1 서론
작가가 되고 싶다면 무엇보다 두 가지를 반드시 해야 합니다. 바로 많이 읽고, 많이 쓰는 것입니다. 제가 아는 한 이 두 가지를 대신할 수 있는 지름길이나 다른 방법은 전혀 없습니다.
우리는 대개 데이터를 수단 삼아 글로 이야기를 들려줍니다. 이때 글쓰기는 효율적인 소통의 도구이자, 우리가 무엇을 믿고 있는지 스스로 점검하는 과정이며, 타인으로부터 아이디어에 대한 피드백을 받는 소중한 통로가 됩니다. 잘 쓴 논문은 간결하고 체계적이며 이야기가 물 흐르듯 자연스럽게 이어집니다. 올바른 문장 구조와 철자, 적절한 어휘 선택과 문법은 독자가 내용에만 온전히 집중할 수 있게 도와주므로 매우 중요합니다.
이번 장에서는 글쓰기를 다룹니다. 이 장을 마치고 나면, 독자의 소중한 시간을 아끼면서도 전달하려는 바를 명확히 담은 정량적 연구 논문을 작성하는 법을 익히게 될 것입니다. 우리는 자신이 아니라 독자를 위해 글을 씁니다. 구체적으로는 독자에게 ‘유용한’ 글을 써야 하죠. 이는 새롭고 진실하며 중요한 내용을 투명하게 전달하는 것을 뜻합니다 (Graham 2020). 이와 동시에 글쓰기의 가장 큰 수혜자는 종종 작가 자신이기도 합니다. 글을 쓰는 과정 자체가 사고를 정교하게 다듬어주고, 왜 그런 결론에 도달했는지 논리적으로 재구성할 기회를 주기 때문입니다.
이 장의 내용이 다소 열거식으로 느껴질 수도 있습니다. 처음에는 가볍게 훑어본 뒤, 실제 논문을 작성할 때 필요한 부분을 다시 찾아보는 방식으로 활용하시길 권합니다.
4.2 글쓰기 과정
글을 쓰는 법은 세 번 혹은 네 번 반복해서 고쳐 쓰는 것이지, 한 번에 끝내는 것이 아닙니다. 제게 가장 어려운 작업은 무엇이 되었든 일단 결과물을 내놓는 일입니다. 때로는 조급한 마음에 마치 벽에 진흙을 던지듯 단어들을 쏟아내기도 합니다. 무엇이 되었든 일단 내뱉고 쏟아내고 지껄여보십시오.
글을 쓰는 과정은 곧 ‘다시 쓰는’ 과정과 같습니다. 가장 중요한 과제는 최대한 빨리 초고를 마치는 것입니다. 아무리 엉망이라도 일단 전체 분량이 나오기 전까지는 이미 쓴 내용을 고치는 데 시간을 낭비하지 않는 것이 좋습니다. 일단 끝까지 써 내려가십시오. (물론 이 조언은 주로 글쓰기 경험이 부족한 분들을 위한 것이며, 숙련될수록 자신만의 방식이 자연스럽게 생길 것입니다.)
빈 페이지를 마주하는 일은 누구에게나 두렵습니다. 이를 극복하는 한 가지 요령은 ‘서론’, ‘데이터’, ‘모델’, ‘결과’, ’논의’와 같은 소제목을 미리 달아두는 것입니다. 그리고 문서 상단에 제목, 날짜, 저자, 초록 같은 항목을 채워 넣으세요. 이렇게 하면 논문의 전체적인 윤곽이 잡히는데, 이는 요리에서 재료를 미리 손질해 두는 ’미장 플라스(Mise en place)’와 같은 역할을 합니다. 전문 주방에서 요리를 시작하기 전 필요한 재료를 미리 배열해 두어 지체 없이 조리에 집중하듯, 논문 쓰기에서도 전체 개요를 미리 잡아두면 불필요한 고민을 줄일 수 있습니다 (McPhee 2017).
이러한 개요가 마련되었다면 연구 질문에 대해 깊이 고민하며 탐구하려는 내용을 구체화해야 합니다. 이론적으로는 연구 질문을 완벽히 정하고 답을 찾은 뒤에 글을 써야 할 것 같지만, 실제로는 글을 쓰는 과정에서 생각이 더 선명해지는 경우가 아주 많습니다 (Franklin 2005). 질문과 답변에 대한 막연한 아이디어가 글쓰기를 통해 구체적인 논리로 바뀌는 것이죠 (S. King 2000, 131). 연구 질문에 대한 생각이 정리되면 각 섹션에 핵심 내용을 불렛 포인트로 적고, 필요에 따라 하위 섹션을 추가해 보세요. 그런 다음 이 불렛 포인트들을 단락으로 확장해 나가는 것입니다.
초고를 쓰는 동안만큼은 ‘내가 정말 잘할 수 있을까?’ 하는 의구심이나 부족한 느낌을 철저히 무시해야 합니다. 그냥 쓰십시오. 아무리 엉성하더라도 일단 종이 위에 단어들이 채워져야 하기 때문입니다. 초고는 바로 그 목적을 달성하는 단계입니다. 모든 방해 요소를 차단하고 오로지 쓰는 행위에만 집중하세요. 완벽주의는 초고의 적입니다. 아주 이른 새벽에 글을 쓰거나 스스로 마감 기한을 정하는 등 자신을 몰아붙이는 환경을 만들어보시기 바랍니다. 적절한 인용이나 그래프 삽입은 나중으로 미루고 ‘[TODO: 인용 추가]’, ‘[TODO: 연도별 그래프 추가]’ 같은 표시만 해둔 채 속도를 내는 것이 도움이 됩니다. 어떤 방식으로든 끝까지 내용을 채워 넣었다면 그것으로 초고는 완성입니다.
당연히 이 초고는 볼품없고 엉성할 것입니다. 하지만 이 ‘부족한 초고’가 있어야만 비로소 ’괜찮은 두 번째 초고’, ‘훌륭한 세 번째 초고’, 그리고 마침내 ’탁월한 결과물’로 나아갈 수 있습니다 (Lamott 1994, 20). 초고는 너무 길 수도 있고, 논리가 맞지 않거나 터무니없는 주장을 포함할 수도 있습니다. 만약 자신의 초고가 조금도 부끄럽게 느껴지지 않는다면, 그것은 아직 충분히 과감하게 쓰지 않았다는 뜻일지도 모릅니다.
이제 ‘삭제’ 키와 ‘잘라내기’, ‘붙여넣기’ 기능을 마음껏 활용해 첫 번째 초고를 두 번째 초고로 탈바꿈시키십시오. 초고를 인쇄한 뒤 빨간 펜으로 단어와 문장, 단락 전체를 옮기거나 삭제하는 과정이 특히 큰 도움이 됩니다. 초고에서 두 번째 초고로 넘어가는 과정은 이야기의 흐름과 일관성을 유지하기 위해 가급적 한 호흡에 수행하는 것이 좋습니다. 이 첫 번째 다시 쓰기 단계의 한 축이 전달하려는 이야기를 더 풍성하게 만드는 것이라면, 다른 한 축은 이야기와 상관없는 모든 요소를 걷어내는 작업입니다 (S. King 2000, 57).
글의 흐름에 잘 맞지 않더라도 애착이 가는 내용을 삭제하는 일은 고통스러울 수 있습니다. 이 고통을 덜어주는 한 가지 요령은 임시 문서, 예를 들어 ‘debris.qmd’ 같은 파일을 만들어 원치 않는 단락을 삭제하는 대신 그곳에 따로 저장해 두는 것입니다. 혹은 단락을 주석 처리하는 방법도 있습니다. 그렇게 하면 원본 파일의 흐름을 방해하지 않으면서도 나중에 유용할 수 있는 아이디어를 남겨둘 수 있습니다.
각 섹션의 내용을 검토할 때는 전체 이야기가 발전해 나가는 방식에 특히 주의를 기울이며 의미를 부여하세요. 이 수정 과정이야말로 글쓰기의 본질입니다 (McPhee 2017, 160). 또한 참고문헌을 정리하고 실제 그래프와 표를 추가해야 합니다. 이 다시 쓰기 과정을 거치면서 논문의 핵심 메시지가 정교해지고 연구 질문에 대한 답변도 명확해지는 경향이 있습니다. 이 시점에 이르면 서론을 다시 살피거나 마지막으로 초록을 작성할 수 있습니다. 오타나 사소한 실수들은 작업의 신뢰성에 큰 영향을 주므로 두 번째 초고 단계에서 반드시 바로잡아야 합니다.
이제 초고는 어느 정도 형체를 갖추기 시작했을 것입니다. 이제는 그것을 훌륭하게 다듬는 것이 목표입니다. 다시 인쇄해서 종이로 검토해 보세요. 이야기에 기여하지 않는 모든 요소는 제거하십시오. 이 단계쯤 되면 자신의 글에 너무 익숙해져 객관성을 잃기 쉽습니다. 따라서 다른 사람에게 의견을 구하기에 아주 좋은 타이밍입니다. 논리의 약점에 대해 피드백을 요청하세요. 피드백을 반영한 후에는 논문을 다시 한번 읽어보는 것이 좋은데, 이때는 소리 내어 읽어보시길 권합니다. 논문은 결코 완벽하게 ’완료’되지 않습니다. 다만 정해진 시간이 다 되었거나 작가 스스로 지쳐서 멈추게 되는 경우가 더 많을 뿐입니다.
4.3 질문 던지기
질적 연구와 양적 연구 모두 각자의 역할이 있습니다. 이 책에서는 양적 접근 방식에 중점을 두지만, 질적 연구 역시 매우 중요하며 종종 가장 흥미로운 작업은 이 두 가지를 조화롭게 아우를 때 탄생합니다. 양적 분석을 수행할 때는 데이터 품질이나 측정 방식, 관련성 같은 문제들에 직면하게 됩니다. 특히 인과 관계를 파악하는 일에 큰 관심을 두게 되죠. 이 모든 고민은 결국 우리가 세상에 대해 무언가를 배우려는 노력이며, 연구 질문은 이러한 측면들을 모두 고려해야 합니다.
거칠게 요약하자면 연구를 수행하는 방식에는 크게 두 가지가 있습니다.
- 데이터 우선(Data-first)
- 질문 우선(Question-first)
물론 이 둘은 이분법적으로 나뉘지 않으며, 실제 연구는 연구 주제를 중심으로 데이터와 질문 사이를 끊임없이 오가는 반복적인 과정으로 이루어집니다 (Gustafsson and Hagström 2017). (Light, Singer, and Willett 1990, 39) 는 이 과정을 \(\mbox{이론}\rightarrow\mbox{데이터}\rightarrow\mbox{이론}\rightarrow\mbox{데이터}\) 와 같이 나선형으로 순환하며 발전하는 형태로 설명합니다. 예를 들어 질문 우선 방식이라도 이론 중심일 수도, 데이터 중심일 수도 있으며 데이터 우선 방식 역시 마찬가지입니다. 다른 관점으로는 개별 사실에서 일반적 법칙을 찾아내는 귀납적 접근과 일반적 원리에서 구체적 사실을 이끌어내는 연역적 접근으로 나누어 볼 수도 있습니다.
두 가지 사례를 통해 살펴봅시다.
- (Mok et al. 2022) 은 10만 명의 Spotify 사용자로부터 수집한 80억 건의 청취 기록을 조사해 사용자들이 콘텐츠를 탐색하는 방식을 연구했습니다. 그 결과 나이와 행동 사이에 명확한 상관관계가 있음을 발견했죠. 젊은 층은 소비하는 콘텐츠가 더 다양함에도 불구하고 고령층보다 낯선 콘텐츠를 탐색하는 경향은 오히려 낮았습니다. 이 논문은 발견과 탐색에 관한 연구 질문이 핵심이지만, 방대한 데이터셋이 없었다면 연구 자체가 불가능했을 것입니다. 즉, 잠재적 질문과 데이터셋 사이를 끊임없이 오가는 반복적 과정을 통해 최종적인 결론에 도달한 셈입니다.
- Chapter 2 에서 소개한 신생아 사망률(NMR)을 탐색한다고 가정해 봅시다. 20년 뒤 사하라 이남 아프리카의 NMR 수치가 어떨지 궁금해하는 것은 질문 우선 접근 방식입니다. 하지만 이 안에도 생물학적 관계를 기반으로 예측하는 이론 중심적 측면이나, 가능한 한 많은 데이터를 모아 예측력을 높이려는 데이터 중심적 측면이 공존할 수 있습니다. 완전히 데이터 중심적인 방식이라면, 일단 확보 가능한 NMR 데이터를 살펴본 뒤 거기서 무엇을 알아낼 수 있을지 고민하는 식이 될 것입니다.
4.3.1 데이터 우선 방식
데이터 우선(Data-first) 전략을 취할 때 핵심은 확보한 데이터로 답변할 수 있는 ’타당한 질문’이 무엇인지 찾아내는 것입니다. 이때 다음 네 가지 요소를 고려하면 도움이 됩니다.
- 이론: 인과 관계를 합리적으로 설명할 수 있는 근거가 있습니까? 예를 들어 마크 크리스텐슨은 주식 시장의 흐름을 맞히는 일이 목적이라면 차트를 보는 것보다 고대 유적에서 황소 내장을 읽으며 점을 치는 게 나을 수도 있다고 농담하곤 했습니다. 적어도 점괘가 틀려도 하루 끝에 먹을 고기는 남기 때문이죠. 질문은 허구적인 관계를 피할 수 있도록 그럴듯한 이론적 근거를 갖춰야 합니다. 데이터를 기반으로 이론을 세울 때는 “이것은 무엇에 관한 사례인가?”를 자문해 보는 것이 좋습니다 (Rosenau 1999, 7). 이를 통해 특정 상황을 넘어 일반화된 통찰을 얻을 수 있기 때문입니다. 예를 들어 특정 내전 상황을 모든 내전이 가진 일반적 속성의 하나로 바라보는 식입니다.
- 중요성: 답변 가능한 사소한 질문은 얼마든지 많지만, 작가나 독자의 시간을 낭비하지 않는 것이 중요합니다. 중요한 질문을 던지는 것은 데이터 정제나 코드 디버깅에 몇 주씩 매달려야 하는 고된 과정에서 동기부여를 유지하는 데 큰 힘이 됩니다. 산업계라면 유능한 인재와 자금을 유치하는 데도 유리하겠죠. 다만 현실성과의 균형이 필요합니다. 질문은 답을 찾을 가능성이 충분해야 하며, 거대한 시대적 질문은 여러 단계로 나누어 접근하는 것이 현명합니다.
- 지속성: 앞으로 추가적인 데이터가 계속 제공될 가능성이 있습니까? 이는 관련 질문에 계속 답하며 하나의 논문을 장기적인 연구 의제로 확장할 수 있게 해줍니다.
- 반복 가능성: 이번 분석이 일회성으로 끝나는 것입니까, 아니면 여러 번 반복해서 수행할 수 있는 것입니까? 반복 가능하다면 연구 질문을 지속적으로 다듬어 나갈 수 있습니다. 하지만 데이터에 단 한 번만 접근할 수 있다면 더 광범위하고 포괄적인 질문을 던져야 합니다.
샤오리 멩 교수는 모든 통계 문제는 결국 결측 데이터(Missing data)의 문제라고 말하곤 합니다. 역설적이게도 데이터 우선 질문을 던지는 또 다른 방법은 우리가 ‘가지고 있지 않은’ 데이터에 대해 생각해보는 것입니다. 앞서 언급한 사망률 예시로 돌아가 보면, 사망 원인에 관한 완전한 데이터가 없다는 점이 큰 걸림돌입니다. 만약 그 데이터가 있다면 정확한 사망자 수를 셀 수 있겠죠. (Castro et al. (2023) 은 사망 원인들이 서로 독립적이지 않은 경우가 많기에 실제로는 훨씬 복잡할 것이라고 지적합니다.) 이처럼 결측 데이터의 실체가 파악되면 데이터 중심의 접근이 가능해집니다. 우리가 가진 데이터를 살피며 가상의 완벽한 데이터셋을 얼마나 잘 근사할 수 있는지 묻는 연구 질문을 던지는 것이죠.
거인의 어깨 위에서
일부 연구자들은 특정 지리적 환경이나 역사적 맥락의 데이터에 대한 전문성을 쌓는 방식으로 데이터 우선 전략을 택하기도 합니다. 예를 들어 현대 영국이나 19세기 일본의 데이터에 정통한 전문가가 되는 식이죠. 그런 다음 다른 연구자들이 다른 상황에서 던진 흥미로운 질문들을 가져와 자신의 데이터에 적용해 봅니다. 미국에 대해 처음 제기된 질문을 바탕으로 영국, 캐나다, 호주 등 다른 국가의 데이터를 분석해 답변하는 방식이 흔한 사례입니다.
물론 데이터 우선 방식은 불확실성이 크고 특정 조건이 반영된 데이터로 인한 선택 효과 때문에 외부 타당성을 확보하기 어렵다는 단점도 있습니다. 이 방식의 변형으로는 특정 통계 기법의 전문가가 되어 이를 적절한 맥락에 적용하는 모델 중심 연구가 있습니다.
4.3.2 질문 우선 방식
질문 우선(Question-first) 전략을 취할 때는 데이터 확보 가능성을 역으로 고민해야 하는 과제가 따릅니다. 의학 분야에서는 연구 질문을 정교하게 다듬기 위해 ’FINER 프레임워크’를 자주 활용합니다. 스스로 다음과 같은 질문을 던져보는 것이죠. 실현 가능하고(Feasible), 흥미롭고(Interesting), 새롭고(Novel), 윤리적이며(Ethical), 관련성 있는(Relevant) 질문인가? (Hulley et al. 2007). (Farrugia et al. 2010) 는 여기에 PICOT 요소를 더해 구체성을 높일 것을 권장합니다. 대상(Population), 개입(Intervention), 비교군(Comparison group), 결과(Outcome), 기간(Time)을 명확히 하는 것입니다.
좋은 질문을 만드는 일이 막막하다면 아주 구체적인 지점부터 출발해 보세요. 또한 자신의 분석이 기술적(Descriptive), 예측적(Predictive), 추론적(Inferential), 인과적(Causal) 분석 중 어디에 속하는지 정하는 것도 도움이 됩니다. 목적에 따라 질문의 성격이 완전히 달라지기 때문입니다.
- 기술적 분석: “\(x\)는 어떤 모습인가?”
- 예측 분석: “\(x\)에 앞으로 어떤 일이 일어날까?”
- 추론적 분석: “\(x\)의 특성을 어떻게 설명할 수 있는가?”
- 인과적 분석: “\(x\)가 \(y\)에 실제로 어떤 영향을 미치는가?”
이 모든 분석은 저마다의 가치를 지닙니다. 인과 관계 혁명 (Angrist and Pischke 2010) 이후 특정 방법론을 활용한 인과적 질문이 주류가 되었지만 그 이면의 한계도 분명 존재합니다. 때로는 정밀한 인과 분석보다 정성껏 수행된 기술적 분석이 더 깊은 통찰을 주기도 하죠 (Sen 1980). 중요한 것은 방법론 그 자체보다 여러분이 그 질문의 답을 찾는 과정에 얼마나 진심으로 관심이 있느냐 하는 점입니다.
시간은 언제나 제약 요인이 되며 이는 연구 질문의 세부 내용을 규정하기도 합니다. 유명인의 발표가 주식 시장에 미치는 영향이 궁금하다면 발표 전후의 주가를 살피면 그만입니다. 하지만 암 치료제가 장기적으로 어떤 영향을 주는지 알고 싶다면 어떨까요? 효과가 나타나는 데 20년이 걸린다면 그만큼 기다리거나 20년 전에 치료받은 사람들을 찾아내야 합니다. 이는 오늘날 약을 투여하는 경우와 비교했을 때 선택 효과나 환경적 차이라는 또 다른 문제를 낳습니다. 종종 통계 모델을 구축하는 것이 유일한 해법이 되기도 하지만 이 역시 새로운 도전 과제들을 동반합니다.
4.4 질문에 답변하기
4.4.1 반사실과 편향
질문에 답할 때는 반사실(Counterfactual)의 관점에서 생각해보는 것이 매우 중요합니다. 반사실이란 “만약 ~했다면 어땠을까?”라는 가정형 문장에서 전제가 되는 사실이 실제와는 다른 경우를 말합니다. 루이스 캐럴의 거울 나라의 앨리스에 등장하는 험프티 덤프티의 대화를 떠올려 보십시오.
“정말 쉬운 수수께끼를 내시는군요!” 험프티 덤프티가 으르렁거렸다. “전혀 그렇게 생각하지 않아요! 만약 제가 떨어졌다면—그럴 일은 없겠지만—만약 떨어졌다면—” 여기서 그는 입술을 오므리고 너무나 진지하고 위엄 있는 표정을 지어 앨리스는 웃음을 참을 수 없었습니다. “만약 제가 떨어졌다면,” 그가 말을 이었습니다. “왕께서 제게 약속하셨답니다—본인이 직접요—”
Carroll (1871)
험프티는 자신이 결코 떨어지지 않을 것이라고 확신하면서도 만약 떨어졌을 때 일어날 일에 대해서는 아주 만족스러워합니다. 연구에서 질문의 답을 결정짓는 핵심은 바로 이 ’비교 그룹’입니다. 예를 들어 Chapter 15 에서 다루는 사이클 선수의 우승 확률을 생각해 봅시다. 일반인 전체와 비교한다면 최대 산소 섭취량(VO2 max)은 매우 중요한 변수가 됩니다. 하지만 이미 잘 훈련된 엘리트 선수들 사이에서만 비교한다면 이미 다들 우수한 상태이기에 그 중요도는 상대적으로 낮아질 수밖에 없습니다.
연구 질문을 정할 때 특히 경계해야 할 두 가지 편향은 선택 편향(Selection bias)과 측정 편향(Measurement bias)입니다.
선택 편향은 결과값이 표본에 누가 포함되느냐에 따라 달라질 때 발생합니다. 선택 편향이 까다로운 점은 그 존재를 미리 알아차리지 못하면 손쓸 방법이 없다는 것입니다. 기본적인 진단만으로는 이를 식별하기 어렵죠. Chapter 8 에서 다루는 A/B 테스트의 변형인 A/A 테스트는 처치를 적용하기 전 그룹들을 미리 비교해 봅니다. 그룹이 처음부터 동질적인지 확인하려는 이런 노력은 선택 편향을 찾아내는 데 도움이 됩니다. 좀 더 일반적으로는 연령, 성별 등 표본의 특성을 전체 모집단의 특성과 비교해 보는 것도 유용합니다. 하지만 관측 데이터의 근본적인 문제는 데이터가 확보된 사람들은 그렇지 않은 사람들과 최소한 한 가지 면에서는 분명히 다르다는 사실입니다. 다만 그 차이가 어떤 면에서 나타나는지 우리가 다 알지 못할 뿐입니다.
선택 편향은 분석의 전 과정에 스며들 수 있습니다. 처음에는 대표성이 있던 표본도 시간이 흐르며 편향될 수 있죠. 예를 들어 Chapter 6 에서 다루는 설문 조사 패널 데이터는 응답을 중단하는 사람들이 생기기 때문에 주기적으로 업데이트해 주어야 합니다.
주의해야 할 또 다른 오류는 측정 편향(Measurement bias)입니다. 이는 데이터를 수집하는 방식 그 자체가 결과에 영향을 줄 때 발생합니다. 예를 들어 소득을 물어볼 때 온라인 설문 조사와 대면 인터뷰에서 응답자가 내놓는 답변은 체계적으로 다를 수 있습니다.
4.4.2 추정량, 추정기, 추정치
우리는 데이터를 통해 질문의 답을 찾으려 하지만 이때 사용하는 개념들을 명확히 구분하는 것이 중요합니다. 예를 들어 흡연이 기대 수명에 미치는 영향이 궁금하다고 가정해 보죠. 이때 우리가 정말로 알고자 하는 ‘실제 효과’ 그 자체를 추정량(Estimand)이라고 부릅니다 (Little and Lewis 2021). 논문을 쓸 때는 가급적 서론에서 이 추정량을 명확히 정의하는 것이 좋습니다 (Lundberg, Johnson, and Stewart 2021). 분석 과정의 세부 사항이 조금만 바뀌어도 자칫 의도와는 다른 것을 추정하게 될 위험이 크기 때문입니다 (Kahan et al. 2022). 최근 일부 의약품 규제 기관에서는 이를 의무적으로 요구하기도 합니다 (Kahan et al. 2024). 추정량은 그 효과가 무엇을 의미하는지 전문 용어가 아닌 일반 언어로도 명확히 설명할 수 있어야 합니다 (Kahan et al. 2023). 이 추정량을 구하기 위해 데이터를 활용하는 규칙이나 수식은 추정기(Estimator)라고 하며, 실제로 데이터를 넣어 계산된 구체적인 결과값은 추정치(Estimate)라고 부릅니다. (Efron and Morris 1977) 는 이 개념들과 관련 문제들을 잘 설명해 줍니다.
Bueno de Mesquita and Fowler (2021, 94)은 이들의 관계를 다음과 같이 명쾌하게 요약합니다.
\[\mbox{추정치 = 추정량 + 편향 + 노이즈}\]
편향(Bias)은 추정기가 실제 추정량과 지속적으로 차이를 보이게 만드는 계통적 오차를 뜻하며 노이즈(Noise)는 무작위로 발생하는 비계통적 오차를 의미합니다. 예를 들어 표준정규분포에서 추출한 데이터의 평균을 알고자 한다면 여기서 평균(0)이 바로 우리의 추정량이 됩니다. 이제 이 분포에서 데이터를 10번 뽑아 봅시다. 추정치를 구하는 한 가지 추정기는 ’모든 값을 더해 개수로 나누는 것’이고 다른 하나는 ’값을 순서대로 세워 중간값을 찾는 것’일 수 있습니다. 이 상황을 코드로 시뮬레이션해 보면 다음과 같습니다 (Table 4.1).
set.seed(853)
tibble(
num_draws = c(
rep(10, times = 10),
rep(100, times = 100),
rep(1000, times = 1000),
rep(10000, times = 10000)
),
draw = rnorm(
n = length(num_draws),
mean = 0,
sd = 1)
) |>
summarise(
estimator_one = sum(draw) / unique(num_draws),
estimator_two = sort(draw)[round(unique(num_draws) / 2, 0)],
.by = num_draws
) |>
tt() |>
style_tt(j = 2:3, align = "r") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("추출 횟수", "추정기 1", "추정기 2"))| 추출 횟수 | 추정기 1 | 추정기 2 |
|---|---|---|
| 10 | -0.58 | -0.82 |
| 100 | -0.06 | -0.07 |
| 1,000 | 0.06 | 0.04 |
| 10,000 | -0.01 | -0.01 |
추출 횟수가 늘어날수록 노이즈의 영향이 줄어들면서 추정치는 해당 추정기가 가진 편향의 정도를 드러냅니다. 이 사례에서는 정답을 알고 있지만 실제 데이터 분석에서는 무엇이 진실인지 알기 훨씬 어렵습니다. 따라서 추정치를 도출하기 전 우리가 정말로 구하려는 추정량이 무엇인지 명확히 정립하는 과정이 필수적입니다.
4.4.3 방향성 비순환 그래프 (DAG)
분석에 사용할 변수를 정할 때 각 변수 사이의 관계를 시각적으로 그려보는 것이 큰 도움이 됩니다. 관측 데이터만 보고 있으면 자칫 스스로를 속이기 쉽기 때문이죠. 데이터에 내재된 인과 구조를 깊이 있게 고민하기 위한 도구로 방향성 비순환 그래프(Directed Acyclic Graph, DAG)를 활용해 보십시오. DAG는 변수 사이의 관계를 화살표와 선으로 나타낸 일종의 흐름도입니다.
이를 구현하기 위해 Quarto에 내장된 Graphviz를 활용해 보겠습니다. 코드는 dot 청크로 감싸야 하며 옵션 표시에는 #| 대신 //|를 사용합니다. (대안으로 DiagrammeR이나 ggdag 패키지를 쓸 수도 있습니다.) 우선 가장 기본적인 인과 관계를 그려봅시다.
?fig-dot-firstdag-quarto 에서 우리는 x가 y의 원인이라고 생각합니다.
좀 더 복잡한 상황의 DAG를 그려보죠. 이해를 돕기 위해 소득과 행복 사이의 관계, 그리고 여기에 영향을 줄 수 있는 제3의 변수를 고려해 보겠습니다. 첫 번째 예시는 소득, 행복, 그리고 교육 사이의 관계입니다 (?fig-dot-educationasconfounder-quarto).
?fig-dot-educationasconfounder-quarto 우리는 소득이 높으면 더 행복해진다고 생각합니다. 하지만 동시에 교육 수준이 높을수록 행복도가 높아지고 소득도 올라간다고 볼 수 있죠. 이러한 인과 구조는 ’백도어 경로(Backdoor path)’를 형성합니다. 회귀 분석에서 교육을 조정하지 않으면 소득과 행복의 관계를 과대평가하거나 아예 존재하지 않는 허위 관계를 만들어낼 수도 있습니다. 즉, 행복의 변화가 사실은 소득이 아니라 교육 때문에 일어난 것일 수도 있다는 뜻입니다. 이처럼 두 변수 모두에 공통으로 영향을 주는 변수를 교란 변수(Confounder)라고 합니다.
Hernán and Robins (2023, 83)은 한 연구자가 어떤 사람이 하늘을 올려다보는 행위가 주변 사람들도 따라보게 만드는지 조사한 흥미로운 사례를 소개합니다. 두 사람의 반응 사이에는 분명한 관계가 있었죠. 하지만 그 순간 하늘에 큰 소음이 났던 경우도 있었습니다. 두 번째 사람이 첫 번째 사람을 따라본 것인지 아니면 둘 다 소음 때문에 본 것인지가 불분명해진 것이죠. 실험 데이터라면 무작위화를 통해 이런 문제를 피할 수 있지만 관측 데이터에서는 불가능합니다. 데이터가 많다고 해결되는 문제도 아니죠. 오직 상황에 대한 신중한 고민만이 답을 줄 수 있으며 이때 DAG가 훌륭한 도구가 됩니다.
교란 변수가 존재할 때 인과 효과를 정확히 파악하려면 이를 조정해야 합니다. 한 가지 방법은 회귀 모델에 포함하는 것입니다. 다만 Gelman and Hill (2007, 169)은 모든 교란 변수를 포함하고 올바른 모델 설계를 갖췄을 때만 추정치가 의미 있는 평균 인과 효과를 보여줄 것이라고 경고합니다. 결국 교란 변수를 놓치지 않고 식별해내는 것은 연구자의 전문성과 이론적 통찰이 빛을 발해야 하는 영역입니다.
?fig-dot-luxuryasmediator-quarto 이번에는 소득이 행복에 미치는 영향 사이에 ’자녀’라는 변수가 있는 경우를 살펴봅시다.
?fig-dot-luxuryasmediator-quarto 여기서 자녀는 매개 변수로 작용합니다. 소득이 행복에 미치는 전체적인 효과를 알고 싶다면 자녀 변수를 조정하지 않는 것이 좋습니다.
마지막으로 ?fig-dot-residenceascollider-quarto 를 보죠. 소득과 행복이 모두 ’운동’에 영향을 주는 구조입니다.
이 상황에서 운동은 충돌 변수가 되며 이를 조건화하여 모델에 넣게 되면 결과가 왜곡될 위험이 큽니다.
분명히 말씀드릴 수 있는 것은 모델을 구성하는 것과 마찬가지로 DAG 역시 여러분이 직접 그려야 한다는 사실입니다. 자동으로 그려주는 도구는 없습니다. 상황에 대해 깊이 고민해야 한다는 뜻이죠. DAG는 그 고민을 도와주는 훌륭한 나침반 역할을 합니다. McElreath ([2015] 2020, 180)은 이를 ’유령 DAG’라고 설명하기도 했습니다. 보이지 않는 인과 구조를 가시화하는 과정 자체가 연구의 핵심이 됩니다.
모델을 만들 때 가급적 많은 변수를 넣고 싶은 유혹이 들곤 합니다. 하지만 DAG는 왜 우리가 신중해야 하는지 명확히 보여줍니다. 교란 변수는 넣어야 하지만 충돌 변수는 빼야 하는 것처럼 말이죠. 우리는 결코 완벽한 진실을 알 수 없지만 이론과 연구 설계, 데이터의 한계 등을 통해 진실에 가까워지려 노력합니다. 한계를 아는 것 또한 결과를 보고하는 것만큼이나 중요합니다. 결함이 있는 데이터나 모델이라도 그 결함을 솔직히 인정한다면 충분히 가치 있는 정보가 될 수 있기 때문입니다. 상황을 이해하려는 노력은 끝이 없으며 동료 연구자들과의 소통을 통해 보완됩니다. 모든 연구 과정을 재현 가능한 방식으로 기록해야 하는 이유이기도 합니다.
4.5 논문의 구성 요소
나는 정식 교수가 되기 전까지는 아무것도 발표하지 않았다. 하지만 거의 쓰자마자 폐기했던 수많은 서툰 시도들을 거치면서, 한때 동경했던 화려하고 장황한 문체 대신 평범하고 소박한 글쓰기를 선호하게 되었다.
샬럿 브론테, 교수(The Professor) (Brontë 1857)
제목, 초록, 서론, 데이터, 결과, 논의, 그리고 그림과 표, 수식 같은 논문의 핵심 요소들을 살펴보겠습니다.1 논문을 쓸 때는 항상 간결하고 구체적이어야 합니다. 대다수 독자는 제목만 보고 지나치며 초록까지 읽는 사람도 그리 많지 않습니다. 따라서 각 섹션의 제목과 그래프/표의 캡션만 보고도 전체 맥락을 파악할 수 있도록 ’자체 완결성’을 갖추는 것이 무엇보다 중요합니다 (Keshav 2007).
4.5.1 제목
제목은 독자를 우리의 이야기로 끌어들이는 첫 번째 기회입니다. 이상적인 제목은 논문에서 무엇을 발견했는지 독자에게 정확히 알려줍니다. 제목이 매력적이지 않으면 독자들은 논문을 그냥 지나칠지도 모릅니다. 제목이 반드시 ‘재치’ 있을 필요는 없지만 의미가 선명해야 합니다. 즉, 이야기가 무엇인지 한눈에 보여주어야 합니다.
예를 들어 “2016년 브렉시트 국민투표 연구”라는 제목은 충분히 나쁘지 않습니다. 독자가 무엇에 관한 논문인지 알 수 있으니까요. 하지만 딱히 정보를 주거나 흥미를 유발하지는 않죠. “2016년 브렉시트 국민투표의 탈퇴 투표 결과 분석”이라고 하면 좀 더 구체적인 정보가 담깁니다. 하지만 가장 좋은 제목은 아마 이런 식일 겁니다. “2016년 브렉시트 국민투표, 농촌 지역에서 탈퇴 투표율이 더 높았다: 베이즈 계층 모델을 통한 증거”. 이 제목을 읽으면 독자는 논문의 방법론과 핵심 결론을 즉시 파악할 수 있습니다.
효과적인 제목의 사례들을 더 볼까요? Hug et al. (2019) 은 “1990~2017년 신생아 사망률의 국가별·지역별 추세 및 2030년까지의 시나리오 기반 예측: 체계적 분석”이라는 제목을 썼습니다. 주제와 방법이 명확하죠. R. Alexander and Alexander (2021) 은 “1901~2018년 호주 연방 의회 논의 주제에 미친 선거 및 총리 교체의 영향력 증대”라는 제목으로 핵심 발견을 담았습니다. M. Alexander, Kiang, and Barbieri (2018) 는 “1979~2015년 미국 흑인 및 백인의 아편류 사망률 추세”를, Frei and Welsh (2022) 는 “미국 세금 허점 폐쇄가 투자자 포트폴리오에 미치는 영향”을 제목으로 썼습니다. 아마도 역대 최고의 제목 중 하나는 Bickel, Hammel, and O’Connell (1975) 의 “대학원 입학에서의 성별 편향: 버클리 데이터: 편향 측정은 통념보다 어려우며 증거는 예상과 다를 수 있다”일 것입니다. 이는 Chapter 15 에서 다시 다루게 됩니다.
제목은 대개 논문 작성의 가장 마지막 단계에서 완성됩니다. 초고를 쓰는 동안에는 임시 제목을 사용하다가 다시 쓰기 과정을 거치며 다듬게 되죠. 제목은 결국 논문의 최종 이야기를 반영해야 하는데 이는 글을 시작할 때 미리 알 수 있는 것이 아니기 때문입니다. 독자가 논문을 읽고 싶게 만드는 흥미와 내용을 충분히 전달하는 유익함 사이에서 균형을 잡아야 합니다 (Hayot 2014).
한 가지 유용한 전략은 ‘흥미로운 문구: 구체적인 내용’ 형식을 사용하는 것입니다. 예를 들어 “초심으로 돌아가기: 2016년 브렉시트 국민투표에서의 탈퇴 지지 현황 검토”와 같은 식이죠. Kennedy and Gelman (2021) 가 쓴 “인구와 모델을 이해하라: 모델 기반 회귀 및 사후 계층화를 활용한 표본 외 일반화”나 Craiu (2019) 의 “채용의 수: 데이터 과학 인재를 찾아서” 같은 제목이 좋은 예입니다. 질문 형식을 빌려 “왜 원조는 가장 가난한 이들에게 전달되지 않는가?” (Briggs 2021) 처럼 호기심을 자극할 수도 있습니다. 때로는 “성별, 지방 정당 정치, 그리고 몬트리올 최초의 여성 시장” (Tolley and Paquet 2021) 처럼 핵심 키워드를 나열하는 방식도 효과적입니다.
필요하다면 부제목을 활용해 구체적인 정량적 결과의 일부를 노출할 수도 있습니다. 물론 적절한 수준의 추상화와 구체성을 확보하기 위해서는 여러 번 고쳐 쓰고 동료의 조언을 구하는 과정이 필요할 것입니다.
4.5.2 초록
10~15쪽 분량의 논문이라면 좋은 초록은 서너 문장으로 이루어진 한 단락이면 충분합니다. 초록은 논문의 전체 이야기를 명확히 드러내야 합니다. 무엇을 연구했고 그게 왜 중요한지 전달하는 것이 핵심이죠. 이를 위해 맥락, 목표, 접근 방식, 그리고 발견한 사실을 차례로 담습니다.
초록을 작성하는 좋은 레시피를 제안하자면 이렇습니다. 첫 번째 문장: 연구의 일반적인 분야를 명시해 독자의 관심을 끕니다. 두 번째 문장: 사용한 데이터셋과 방법론을 개괄적으로 설명합니다. 세 번째 문장: 핵심 연구 결과를 제시합니다. 네 번째 문장: 그 결과가 갖는 함의를 설명하며 마무리합니다.
실제 사례를 볼까요? Tolley and Paquet (2021) 는 400년 만에 선출된 첫 여성 시장 이야기를 꺼내며 독자를 끌어들입니다. 이어 무엇을 연구했는지 어떤 설문 조사를 활용했는지 설명한 뒤 성별이 유권자에게는 큰 변수가 아니었으나 캠페인 조직에는 영향을 미쳤다는 결론을 내립니다. 마지막으로는 이 승리가 고정관념을 깬 전략 덕분이었다는 주장을 덧붙이죠.
2017년 몬트리올은 400년 역사상 처음으로 여성 시장인 발레리 플랑트를 선출했습니다. 이 선거를 사례 연구로 활용하여 우리는 성별이 결과에 어떻게 기여했는지 혹은 기여하지 않았는지를 분석합니다. 몬트리올 유권자 설문 조사 결과 성별은 투표 선택의 결정적 요인이 아니었던 것으로 나타났습니다. 하지만 유권자 태도와 달리 캠페인과 정당 조직 과정에서는 성별이 중요한 변수로 작용했습니다. 우리는 플랑트의 승리가 리더 중심적이지 않은 정당 조직과 여성 리더십에 대한 고정관념을 상쇄한 ‘탈성별화’ 캠페인 전략에 힘입은 바가 크다고 주장합니다.
마찬가지로 Sides, Vavreck, and Warshaw (2021) 는 단 다섯 문장으로 무엇을 어떻게 연구했고 무엇을 발견했는지 그리고 그게 왜 중요한지를 명쾌하게 설명합니다.
우리는 2000~2018년 미국 선거 결과에 미친 TV 광고의 영향력을 종합적으로 평가합니다. 대통령부터 상·하원 의원, 주지사에 이르는 방대한 선거 데이터를 포함하며 광고의 인과 효과를 식별하기 위해 이중차분법과 단절회귀 설계를 모두 활용했습니다. 분석 결과 TV 캠페인 광고의 영향력은 전반적으로 유효했으나 대통령 선거보다는 하위 선거에서 훨씬 더 강력한 것으로 나타났습니다. 또한 광고의 핵심 메커니즘은 당파적 동원이 아닌 ’설득’에 있음을 보여줍니다. 이 결과는 선거 연구뿐 아니라 유권자의 의사결정 방식에 대한 중요한 통찰을 제공합니다.
최고의 초록은 단어 하나하나에 담긴 정보 밀도가 매우 높아서 때로는 다소 딱딱하게 느껴질 정도입니다. Touvron et al. (2023) 의 초록은 낭비되는 단어가 단 하나도 없으며 단 네 문장으로 엄청난 양의 정보를 전달하죠.
우리는 70억~650억 개의 매개변수를 가진 기초 언어 모델 컬렉션인 LLaMA를 소개합니다. 수조 개의 토큰으로 모델을 훈련했으며 폐쇄적인 데이터가 아닌 공개된 데이터셋만으로도 최첨단 모델을 훈련할 수 있음을 입증했습니다. 특히 LLaMA-13B는 대부분의 벤치마크에서 GPT-3(175B)를 능가하며 LLaMA-65B는 Chinchilla-70B나 PaLM-540B 같은 최고 수준의 모델과 대등하게 경쟁합니다. 우리는 모든 모델을 연구 커뮤니티에 공개합니다.
과학 저널 Nature는 초록 구성의 가이드라인으로 6개 부분을 권장합니다. 1) 광범위한 독자가 이해할 수 있는 도입, 2) 상세한 배경 설명, 3) 구체적인 문제 제기, 4) 주요 결과 요약 및 설명, 5) 일반적인 맥락 속의 의미, 6) 좀 더 넓은 관점에서의 함의입니다.
초록의 첫 문장에서 누구나 아는 당연한 소리를 늘어놓는 것은 금물입니다. 독자가 제목을 보고 초록까지 읽기 시작했다면 첫 문장은 이 논문을 끝까지 읽게 만들 수 있는 절호의 기회입니다. 초록만 읽어도 논문의 핵심을 충분히 파악할 수 있을 때까지 다듬고 또 다듬으십시오. 대다수 독자에게 여러분의 논문은 ‘초록’ 그 자체로 기억될 것이기 때문입니다.
4.5.3 서론
서론은 그 자체로 완결성을 갖춰야 하며 독자가 알아야 할 정보를 모두 담고 있어야 합니다. 논문은 미스터리 소설이 아닙니다. 가장 중요한 요점을 먼저 시원하게 알려주어야 하죠. 10~15쪽 분량의 논문이라면 서론은 대개 두세 단락이면 충분합니다. Hayot (2014, 90)은 서론의 목표가 독자의 흥미를 유발하고 연구를 적절한 배경 속에 위치시키며 앞으로 전개될 내용을 예고하는 것이라고 설명합니다. 철저히 독자 중심의 관점에서 써야 합니다.
서론에서는 연구 배경을 설정하고 독자에게 필요한 정보를 제공합니다. 조금 넓은 범위에서 시작해 연구의 맥락을 짚어주고 논문이 그 맥락 속에서 어떤 역할을 하는지 설명하세요. 그런 다음 핵심적인 연구 결과를 요약해 보여줍니다. 초록보다는 자세하지만 전체 내용을 다 보여주지는 않는 수준이 적당합니다. 이어 한두 문장으로 향후 과제를 언급하고 논문의 전체 구조를 간략히 소개하며 마무리합니다.
가상의 사례를 한 번 볼까요?
영국 보수당은 전통적으로 농촌 지역에서 강세를 보여왔습니다. 2016년 브렉시트 국민투표 역시 도시와 농촌 간의 뚜렷한 표심 차이를 드러냈습니다. 하지만 보수적 성향의 농촌 지역이라는 점을 고려하더라도 “탈퇴(Vote Leave)”에 대한 지지세는 이례적으로 강력했습니다. 탈퇴 지지는 이스트 미들랜드와 잉글랜드 동부에서 가장 두드러졌던 반면 “잔류(Remain)” 지지는 런던에서 가장 압도적이었습니다.
본 논문에서는 2016년 브렉시트 투표에서 탈퇴 지지율이 농촌성과 그토록 밀접한 상관관계를 보인 원인을 추적합니다. 우리는 투표 지역별 탈퇴 지지율이 해당 지역의 농가 수, 인터넷 보급률, 연령 중앙값 등에 의해 설명되는 모델을 구축했습니다. 분석 결과 지역의 연령 중앙값이 높아질수록 탈퇴를 지지할 확률이 14%포인트 감소하는 것으로 나타났습니다. 향후 연구에서는 개별 의원들의 영향력을 분석함으로써 이러한 효과를 더 정교하게 이해할 수 있을 것입니다.
이어지는 논문의 구성은 다음과 같습니다. 2절에서는 데이터를, 3절에서는 분석 모델을 설명합니다. 4절에서는 주요 연구 결과를 제시하고 마지막 5절에서는 발견한 사실들의 의미와 연구의 한계를 논의하며 마무리합니다.
독자는 서론만 읽고도 논문의 전체적인 그림을 정확히 그릴 수 있어야 합니다. 서론에 그래프나 표를 넣는 일은 드물며 논문의 구조를 암시하며 끝내는 것이 일반적인 관례입니다.
4.5.4 데이터 섹션
린든 존슨의 전기를 쓴 로버트 카로는 글을 쓸 때 “장소의 감각”을 전달하는 것이 얼마나 중요한지 강조합니다 (Caro 2019, 141). 그는 이를 “작품 속 사건이 벌어지는 물리적 환경을 아주 선명하고 세밀하게 묘사하여 독자가 마치 그 현장에 있는 것처럼 느끼게 만드는 것”이라고 정의하죠. 그가 묘사한 다음 대목을 보십시오.
레베카가 작은 집의 현관문을 나섰을 때 눈앞에는 아무것도 없었습니다. 가끔 바위 뒤를 잽싸게 지나가는 길달리기새나 덤불 속으로 사라지는 토끼의 하얀 꼬리 말고는 정말 아무것도 보이지 않았습니다. 드문드문 서 있는 나무 잎사귀가 흔들리는 소리, 그리고 끊임없이 속삭이는 바람 소리 말고는 어떤 움직임도 소리도 없었죠. … 레베카가 절망적인 마음으로 집 뒤 언덕에 올랐을 때 본 것은 그저 끝없이 펼쳐진, 집 한 채 보이지 않는 언덕뿐이었습니다. … 아무것도 움직이지 않는 텅 빈 언덕 위로 조용히 원을 그리며 맴도는 매 한 마리가 유일한 사건이었습니다. 무엇보다 사람의 흔적이라곤 찾아볼 수 없었고 말을 섞을 이조차 없었습니다.
Caro (2019, 146)
존슨의 어머니 레베카가 마주했던 그 막막한 상황이 눈앞에 그려지시나요? 논문을 쓸 때 우리도 카로가 묘사한 ’장소의 감각’을 우리의 데이터에 대해서 성취해야 합니다. 최대한 명확하고 세밀하게 설명해야 한다는 뜻입니다. 대개 별도의 데이터 섹션을 두는 이유는 우리의 이야기를 뒷받침하는 실제 데이터의 실체를 독자에게 생생하게 보여주기 위해서입니다.
데이터 섹션을 작성할 때는 “당신은 이 사실을 어떻게 알게 되었는가?”라는 독자의 근본적인 질문에 답해야 합니다 (McPhee 2017, 78). Doll and Hill (1950) 은 좋은 모범 사례입니다. 그들은 흡연의 효과를 연구하며 데이터셋을 명확히 정의하고 관련 교차표와 그래프를 활용해 집단 간의 차이를 선명하게 대조해 보여주었습니다.
여기서는 사용하는 변수들을 철저히 분석하고 설명해야 합니다. 활용할 수 있었지만 제외한 데이터가 있다면 그 이유를 밝히고 변수를 새롭게 구성하거나 결합했다면 그 과정과 동기를 상세히 적으십시오.
독자가 결과의 바탕이 된 데이터가 실제로 어떤 모습인지 이해할 수 있어야 합니다. 즉 분석에 쓰인 개별 데이터들을 가급적 가감 없이 그래프로 보여주어야 하죠. 요약 통계표도 필수입니다. 만약 데이터가 설문 응답에서 비롯되었다면 주요 설문 문항들을 부록에 담아두는 것도 좋은 방법입니다.
어떤 그림과 표를 본문에 넣을지는 연구자의 판단에 달려 있습니다. 독자가 세부 사항을 파악할 기회를 주되 너무 지엽적인 내용은 부록으로 돌리는 지혜가 필요합니다. 그림과 표는 독자를 설득하는 가장 강력한 무기입니다. 그래프로는 데이터의 실체를 보여주고 표로는 전체적인 흐름을 요약하세요. 모든 변수는 최소한 한 번씩은 그래프나 표로 다뤄져야 합니다. 본문의 그림과 표는 반드시 번호가 매겨져야 하며 본문 텍스트 내에서 “그림 1에서 보듯…”, “표 1은 ~을 설명합니다”와 같이 상호 참조되어야 합니다. 또한 모든 시각 자료에는 그 의미를 설명하는 텍스트가 곁들여져야 하죠.
Chapter 5 에서 제목과 레이블을 다루겠지만 여기서 강조하고 싶은 것은 캡션(Caption)입니다. 캡션은 그 자체로 정보를 충분히 담고 있어야 하며 독자적인 완결성을 갖춰야 합니다. Borkin et al. (2015) 에 따르면 독자는 캡션만 보고도 시각 자료의 핵심 메시지를 파악할 수 있어야 합니다. Cleveland ([1985] 1994, 57)는 그래프와 캡션, 텍스트 사이의 상호작용이 매우 섬세한 작업이라고 말합니다. 캡션이 두 줄 이상으로 길어지는 것을 주저하지 마세요. 그래프의 모든 요소를 충분히 설명하는 것이 우선입니다. Bowley (1901, 151)가 제시한 Figure 4.1 (a) 와 Figure 4.1 (b) 는 아주 좋은 본보기입니다.
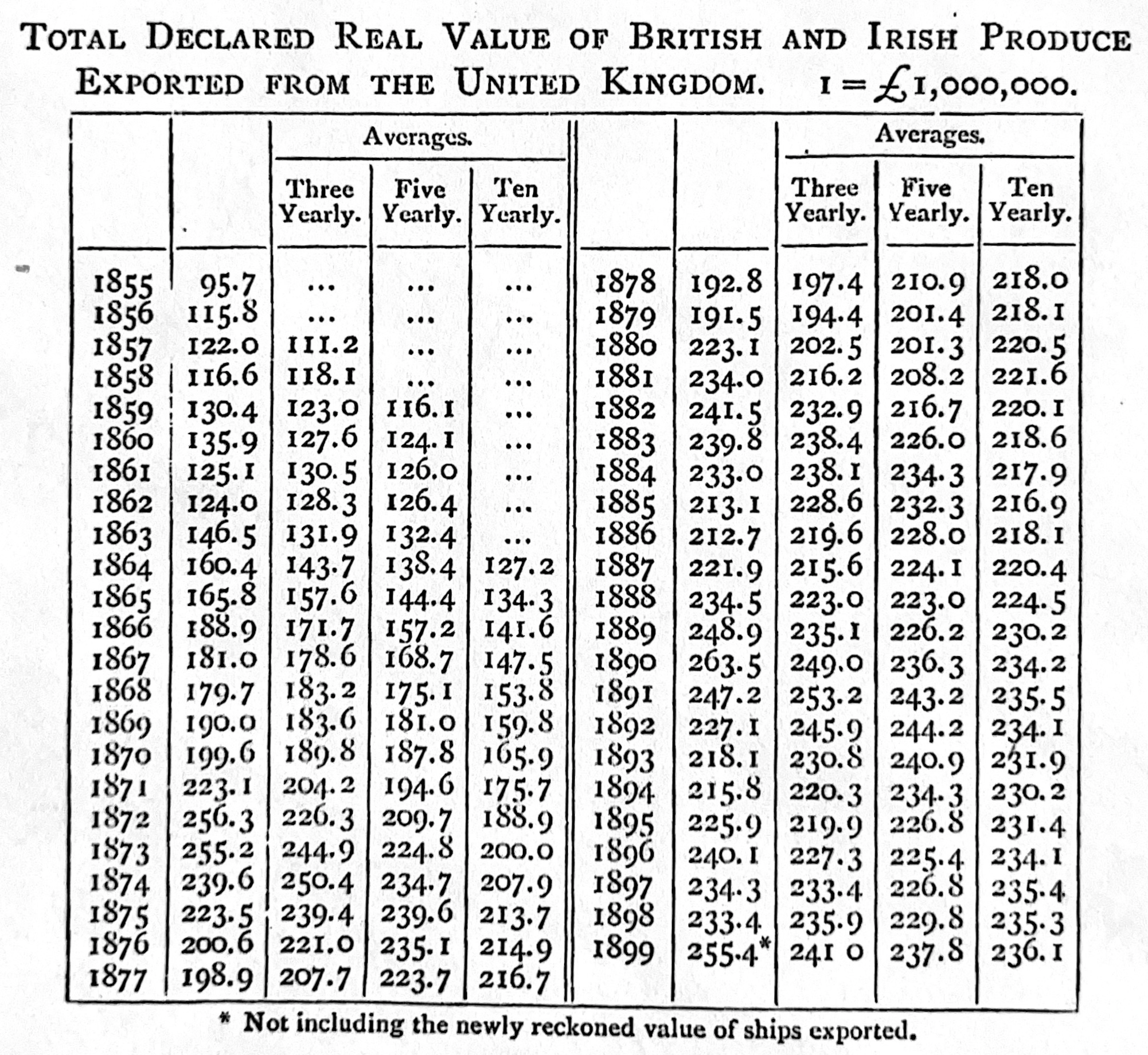
표와 그래프 중 무엇을 선택할지는 전달하려는 정보의 성격에 달려 있습니다. 요약 통계량처럼 구체적인 수치를 확인해야 할 때는 표가 좋고 추세나 비교를 보여주려 할 때는 그래프가 훨씬 효과적입니다 (Gelman, Pasarica, and Dodhia 2002).
4.5.5 모델 섹션
데이터 분석에 통계 모델을 활용했다면 이를 설명하는 별도의 섹션이 필요합니다. 최소한 모델의 구조를 보여주는 수식을 제시하고 각 구성 요소를 일반 언어로 상세히 설명해야 합니다.
모델 섹션은 보통 모델의 수식을 적고 그 의미와 선정 이유를 정당화하는 것으로 시작합니다. 독자의 수준에 맞춰 필요한 배경지식을 적절히 제공하세요. 수식에 사용된 기호(표기법) 하나하나를 명확히 정의하는 것은 모델의 신뢰성을 높여줍니다. 모델의 변수들은 앞서 데이터 섹션에서 설명한 변수들과 일관성을 유지해야 하며 이 둘 사이의 연결 고리를 명확히 밝혀주어야 합니다.
특정한 변수를 모델에 포함한 이유도 설명해야 합니다. 예를 들어 이런 질문들에 답해주는 것이죠.
- 왜 연령을 연속형이 아닌 범주형 그룹으로 나누었는가?
- 왜 지역 효과를 모델에 반영했는가?
- 성별 변수를 범주형으로 처리한 이유는 무엇인가?
결국 독자에게 이 모델이 데이터의 특성을 가장 잘 반영하고 있다는 확신을 주어야 합니다.
마지막으로 모델의 기반이 되는 가정들을 논의하고 고려했던 대안 모델들이나 한계점에 대해서도 간략히 언급하세요. 독자가 이 모델을 선택한 타당한 이유를 알게 하는 것이 목표입니다. 사용한 소프트웨어를 명시하고 모델이 적절하지 않을 수 있는 예외 상황에 대한 통찰도 곁들이면 좋습니다. 모델의 수렴 여부나 진단 결과 같은 기술적인 증거도 필요하며 너무 상세한 내용은 부록으로 돌릴 수 있습니다.
기술 용어를 쓸 때는 낯선 독자를 위해 친절한 설명을 덧붙이세요. M. Alexander (2019) 가 지니 계수를 설명한 방식이 아주 좋은 예입니다.
이름의 집중도를 살펴보기 위해 각 국가와 연도별 지니 계수를 계산했습니다. 지니 계수는 수치들의 불균형이나 불평등 정도를 나타내는 지표로 0에서 1 사이의 값을 갖습니다. 소득 분포로 치면 1은 한 사람이 모든 소득을 독점한 상태를, 0은 모두가 평등하게 나누는 상태를 뜻하죠. 아기 이름의 경우 지니 계수가 1에 가까울수록 모든 아기가 같은 이름을 가진다는 뜻이고 0에 가까울수록 이름이 골고루 분산되어 있다는 뜻입니다.
통계 모델이 없는 논문이라면 이 섹션을 ‘방법론’ 섹션으로 대체해 시뮬레이션 과정이나 일반적인 분석 접근 방식을 설명하면 됩니다.
4.5.6 결과 섹션
결과 섹션의 훌륭한 사례로는 Kharecha and Hansen (2013) 와 Kiang et al. (2021) 을 꼽을 수 있습니다. 여기서는 분석 결과를 명확히 전달하는 데 집중해야 하며 해석이나 함의에 대한 논의는 가급적 자제하는 것이 좋습니다. 결과 섹션에는 요약 통계량과 표, 그래프가 조화롭게 배치되어야 합니다. 각 시각 자료는 본문에서 상호 참조되어야 하며 무엇이 보이는지 상세히 설명하는 텍스트가 수반되어야 하죠. 다시 말해 결과가 무엇을 ’의미’하는지보다는 결과가 ’무엇’인지 그 자체를 보여주는 데 충실해야 합니다.
모델을 통해 도출된 계수 추정치나 그래프를 제시하고 모델 간의 차이나 데이터의 하위 그룹별 특성을 설명하세요. 모든 표와 그래프에는 일반 언어로 된 설명이 덧붙여져야 합니다. 대략적인 기준을 잡자면 텍스트의 분량이 시각 자료가 차지하는 공간만큼은 되어야 합니다. 예를 들어 계수 표를 보여주는 데 한 페이지를 썼다면 그 표를 설명하는 텍스트도 한 페이지 정도는 되어야 한다는 뜻입니다.
4.5.7 논의 섹션
논의(Discussion) 섹션은 논문의 마침표를 찍는 부분으로 대개 네다섯 개의 하위 섹션으로 구성됩니다.
먼저 연구 내용을 간략히 요약하며 시작합니다. 그런 다음 이 연구를 통해 세상에 대해 새롭게 알게 된 사실이 무엇인지 핵심 내용을 두세 개의 하위 섹션에 걸쳐 깊이 있게 다룹니다. 이 대목이야말로 여러분이 들려주려는 이야기의 가치를 증명할 가장 중요한 기회입니다. 새로운 그래프나 표를 넣기보다는 앞서 제시한 결과로부터 어떤 통찰을 얻었는지 설명하는 데 집중하세요. 여러분의 연구 결과가 기존 연구들과 일치하는지 혹은 다르다면 왜 그런 차이가 생겼는지 논의하는 과정도 꼭 필요합니다.
핵심 통찰을 다룬 뒤에는 연구의 한계를 짚어보는 하위 섹션을 둡니다. 데이터의 제약이나 분석 모델의 약점 등을 솔직하게 인정하세요. 특히 기계 학습 모델을 썼다면 Smith et al. (2022) 의 가이드를 참고해 결과에 영향을 줄 수 있는 요인들을 꼼꼼히 따져보아야 합니다. 마지막으로 이번 연구를 통해 배운 점과 향후 연구 방향을 정리하며 마무리합니다.
일반적으로 논의 섹션은 전체 논문 분량의 최소 4분의 1 이상을 차지하는 것이 좋습니다. 8쪽짜리 논문이라면 최소 2쪽 정도는 깊이 있는 논의에 할애해야 한다는 뜻입니다.
4.5.8 간결성, 오타, 문법
글쓰기에서 간결함(Conciseness)은 최고의 미덕입니다. 이는 단순히 독자의 시간을 아껴주기 때문만이 아닙니다. 작가 스스로 논문의 핵심이 무엇인지, 주장이 탄탄한지, 약점은 무엇인지 치열하게 고민하게 만들기 때문입니다. 캐나다 전 총리 장 크레티앙은 공무원들에게 모든 보고서를 두세 쪽으로 요약하고 나머지는 부록으로 돌리라고 지시했습니다 (Chrétien 2007, 105). 그는 “자기가 무슨 말을 하려는지 스스로 모르는 사람만이 요약을 어려워한다”고 일침을 가했죠.
이런 태도는 훌륭한 리더들의 공통점이기도 합니다. 영국의 전 내각 장관 올리버 렛윈은 장황한 보고서들을 보고 “분량을 4분의 1로 줄이라”고 요구했는데 부처들은 핵심 내용을 하나도 빠뜨리지 않고 이를 완수해냈습니다. 윈스턴 처칠 역시 제2차 세계대전 당시 “핵심을 짧게 전달하는 훈련은 사고를 명료하게 해준다”며 간결함을 강조했죠. 세상을 바꾼 아인슈타인의 편지도 고작 두 쪽에 불과했습니다.
Zinsser (1976) 는 좋은 글쓰기의 비결을 “모든 문장을 가장 순수한 요소로 걸러내는 것”이라고 말합니다. 주장에 기여하지 않는 불필요한 단어나 문장은 과감히 깎아내야 합니다.
오타나 문법 오류 역시 주장의 신뢰도를 갉아먹는 주범입니다. 맞춤법 하나 제대로 확인하지 않는 저자가 복잡한 통계 수치는 정확하게 다뤘을지 독자는 의문을 가질 수밖에 없습니다. RStudio 내장 맞춤법 검사기나 워드, 구글 문서의 검사 기능을 적극 활용하세요.
완벽한 문법 이론에 얽매일 필요는 없습니다. 그보다는 우리가 대화할 때 쓰는 자연스러운 문장 구조를 지향하십시오 (S. King 2000, 118). 좋은 글을 많이 읽고 자신의 글을 소리 내어 읽어보는 것만으로도 어색한 표현을 많이 잡아낼 수 있습니다. 참고로 학술적 관례상 1에서 10까지의 숫자는 문자로(예: ‘세 명’), 11 이상의 숫자는 아라비아 숫자로 쓰는 것이 일반적입니다.
4.5.9 글쓰기 10계명
조지 오웰의 원칙 (Orwell 1946)과 이코노미스트지의 재해석 (The Economist 2013)을 바탕으로 데이터 스토리텔링을 위한 글쓰기 원칙을 정리해 보았습니다.
- 철저히 독자와 그들의 필요에 집중하세요. 나머지는 부차적인 문제입니다.
- 탄탄한 구조를 세우고 그 흐름에 몸을 실으세요.
- 초고는 가급적 빨리 완성하십시오.
- 그 초고가 너덜너덜해질 때까지 고쳐 쓰고 또 쓰십시오.
- 간결하고 직접적으로 표현하세요. 군더더기는 가차 없이 덜어내야 합니다.
- 단어를 정확하게 선택하십시오. (예: 주가는 ’개선’되는 게 아니라 ’상승’하거나 ’하락’하는 것입니다.)
- 문장은 가급적 짧게 끊어 쓰세요.
- 불필요한 전문 용어는 피하십시오.
- 신문 1면의 머릿기사를 쓴다는 마음가짐으로 임하십시오.
- “내가 최초다”라는 식의 과시는 삼가세요. 세상 아래 새로운 것은 없으며 언제나 선구자는 존재합니다.
Savage and Yeh (2019) 는 글을 다 쓴 뒤 “이 단어나 문장, 섹션을 통째로 들어내도 원래 메시지가 전달되는가?”를 자문해 보라고 권합니다 (Savage and Yeh 2019, 442). 만약 그렇다면 그 부분은 과감히 삭제해야 할 부분입니다.
여러분이 정말 만족할 수 있는 가장 완벽한 버전을 쓰기 위해 노력하십시오. 모든 독자를 만족시킬 수는 없어도 스스로는 떳떳해야 합니다. 여러분이 정성껏 쓴 논문은 미래의 독자들을 위한 소중한 기록이 될 것입니다.
4.6 연습 문제
실습
- (계획) 다음 시나리오를 구상해 봅시다. “한 아이와 부모가 아파트 창가에서 전차(tram)가 지나가는 것을 구경합니다. 그들은 8시간 동안 매시간 지나가는 전차 대수를 기록합니다.” 이 데이터셋의 구조를 상상해 보고 전체 관측치를 효과적으로 보여줄 수 있는 그래프를 스케치해 보세요.
- (시뮬레이션) 위 시나리오를 바탕으로 데이터를 시뮬레이션해 보세요. 그리고 생성된 데이터가 논리적으로 타당한지 확인할 수 있는 5가지 테스트를 작성해 보세요.
- (획득) 관심 있는 도시의 교통 관련 실제 데이터 소스(API, 공공데이터 포털 등)를 하나 찾아보세요.
- (탐색) 시뮬레이션한 데이터를 활용해 R로 그래프와 표를 만들어 보세요.
- (공유) 생성한 그래프와 표를 설명하는 짧은 글을 써보세요. 실제 연구 보고서의 일부라고 가정하고 위에서 배운 글쓰기 원칙들을 적용해 보십시오.
퀴즈
- 좋은 연구 질문의 세 가지 특징은 무엇입니까? (한두 단락으로 작성)
- (Light, Singer, and Willett 1990) 는 광범위한 주제에서 연구를 상세히 계획하는 방법으로 무엇을 권장합니까? (하나 선택)
- 전문가와 대화.
- 사용 가능한 데이터 식별.
- 구체적인 연구 질문 세트 명확화.
- (Light, Singer, and Willett 1990) 는 연구 질문이 왜 그토록 중요하다고 믿습니까? (모두 선택)
- 합리적인 계획 결정을 내리는 유일한 근거입니다.
- 표본을 추출할 대상 모집단을 식별합니다.
- 적절한 집계 수준을 결정합니다.
- 결과 변수를 식별합니다.
- 주요 예측 변수를 식별합니다.
- 측정 및 데이터 수집에 대한 과제를 제기합니다.
- (Light, Singer, and Willett 1990) 에 따르면 연구에서 “이론과 데이터의 나선”의 목적은 무엇입니까? (하나 선택)
- 이론을 세우기 전 데이터를 먼저 수집하기 위해.
- 이론과 데이터 사이를 오가며 반복적으로 다듬기 위해.
- 데이터 수집이 이론 분석 전 완료되도록 보장하기 위해.
- 데이터 없이 이론적 틀에만 집중하기 위해.
- 연구 접근 방식에서 ’데이터 우선’은 무엇을 뜻합니까? (하나 선택)
- 데이터 가용성을 고려하지 않고 질문을 개발하는 것.
- 특정 질문에 답하기 위해 특별히 설계된 데이터를 수집하는 것.
- 경험적 증거보다 이론적 틀을 우선시하는 것.
- 사용 가능한 데이터에서 출발해 답변 가능한 질문을 찾는 것.
- 데이터 우선 접근 방식의 장점은 무엇입니까? (하나 선택)
- 이론적 틀의 필요성을 없애줍니다.
- 사용 가능한 데이터를 기반으로 질문을 공식화할 수 있게 해줍니다.
- 인과 관계 설정을 보장합니다.
- 연구의 모든 편향을 방지합니다.
- 데이터 우선 접근 방식의 단점은 무엇입니까? (하나 선택)
- “가로등 아래에서 열쇠 찾기”와 같은 한계에 대한 우려.
- 이론 기여도에 대한 우려.
- 인과 관계 파악의 어려움에 대한 우려.
- 외부 타당성에 대한 우려.
- 반사실이란 무엇입니까? (예시와 참조를 포함해 최소 세 단락으로 작성)
- 반사실은 무엇입니까? (하나 선택)
- 주 이론과 모순되는 대안 가설.
- 전제가 거짓인 “만약 ~라면” 문장.
- 논문의 주요 주장에 반대되는 사실.
- 교란 변수를 조정하는 통계적 방법.
- “FINER” 프레임워크는 무엇의 약자입니까? (하나 선택)
- Flexible, Innovative, Neutral, Empirical, Reproducible.
- Formal, Interpretive, Novel, Experimental, Robust.
- Focused, Integrative, Natural, Efficient, Reliable.
- Feasible, Interesting, Novel, Ethical, Relevant.
- 추정량(Estimand)이란 무엇입니까? (하나 선택)
- 측정 오차가 있는 변수.
- 편향된 추정기.
- 추정치를 계산하는 과정.
- 우리가 추정하고자 하는 실제 효과나 관심 대상.
- 추정량은 무엇입니까? (하나 선택)
- 데이터를 기반으로 추정치를 계산하는 규칙.
- 탐구하려는 대상 그 자체.
- 특정 데이터와 접근 방식이 주어졌을 때의 결과값.
- 추정기(Estimator)란 무엇입니까? (하나 선택)
- 데이터를 기반으로 추정치를 계산하는 수식이나 규칙.
- 탐구하려는 대상 그 자체.
- 특정 데이터와 접근 방식이 주어졌을 때의 결과값.
- 추정기의 역할은 무엇입니까? (하나 선택)
- 우리가 추정하고자 하는 진정한 효과입니다.
- 데이터에서 추정치를 계산하기 위한 규칙이나 방법입니다.
- 데이터와 방법이 주어졌을 때 계산된 값입니다.
- 통계 모델의 오차항입니다.
- 추정치(Estimate)란 무엇입니까? (하나 선택)
- 데이터를 기반으로 추정치를 계산하는 규칙.
- 탐구하려는 대상 그 자체.
- 특정 데이터와 접근 방식이 주어졌을 때 도출된 결과값.
- 선택 편향이란 무엇입니까? (하나 선택)
- 참가자가 시간이 지나며 연구에서 이탈할 때.
- 측정 방식에 따라 결과가 달라질 때.
- 표본이 모집단을 대표하지 못할 때.
- 실험에서 변수 통제가 제대로 되지 않을 때.
- 측정 편향이란 무엇입니까? (하나 선택)
- 장비 고장으로 데이터가 잘못 기록될 때.
- 데이터 수집 방법이 체계적으로 실제 값을 왜곡할 때.
- 측정 과정 자체가 결과에 영향을 줄 때.
- 표본 크기가 너무 작아 결론을 내리기 어려울 때.
- 방향성 비순환 그래프(DAG)의 목적은 무엇입니까? (하나 선택)
- 무작위 표본을 생성하기 위해.
- 비선형 데이터의 통계 테스트를 위해.
- 통계 모델을 자동 생성하기 위해.
- 변수 간의 인과 관계를 시각적으로 나타내기 위해.
- DAG를 구축하는 것의 이점은 무엇입니까? (하나 선택)
- 인과 관계를 자동으로 식별해줍니다.
- 통계 분석의 필요성을 없애줍니다.
- 연구자가 변수 간 관계를 깊이 고민하도록 돕습니다.
- 인과 효과의 정확한 수치를 제공합니다.
- 교란 변수란 무엇입니까? (하나 선택)
- 예측 변수와 결과 변수 모두에 의해 영향을 받는 변수.
- 예측 변수와 결과 변수 모두에 영향을 미치는 변수.
- 예측 변수에 영향을 받고 결과 변수에 영향을 주는 변수.
- 매개 변수란 무엇입니까? (하나 선택)
- 예측 변수와 결과 변수 모두에 의해 영향을 받는 변수.
- 예측 변수와 결과 변수 모두에 영향을 미치는 변수.
- 예측 변수에 영향을 받고 결과 변수에 영향을 주는 변수.
- 충돌 변수란 무엇입니까? (하나 선택)
- 예측 변수와 결과 변수 모두에 의해 영향을 받는 변수.
- 예측 변수와 결과 변수 모두에 영향을 미치는 변수.
- 예측 변수에 영향을 받고 결과 변수에 영향을 주는 변수.
- Zinsser (1976) 2장에 따르면 좋은 글쓰기의 비결은 무엇입니까? (하나 선택)
- 올바른 문장 구조와 문법.
- 수동태와 부사, 긴 단어의 활용.
- 모든 문장을 가장 순수한 구성 요소로 걸러내는 것.
- 철저한 계획.
- Zinsser (1976) 에 따르면 작가는 스스로에게 끊임없이 무엇을 물어야 합니까? (하나 선택)
- 누구를 위해 글을 쓰고 있는가?
- 무엇을 말하려는 것인가?
- 이것을 어떻게 고쳐 쓸 것인가?
- 이것이 왜 중요한가?
- 논문 작성 과정에서 가장 중요한 과제는 무엇입니까? (하나 선택)
- 글을 쓰기 전 최대한 많은 데이터를 모으는 것.
- 초고의 각 문장을 완벽하게 만드는 데 공을 들이는 것.
- 가능한 한 빨리 초고를 완성하는 것.
- 글쓰기 전 정교한 그래프와 표를 만드는 데 집중하는 것.
- 초고를 빨리 쓰는 것이 왜 중요합니까? (하나 선택)
- 초고에서 실수가 생기지 않도록 보장합니다.
- 수정하고 개선할 수 있는 전체적인 결과물을 제공합니다.
- 진행하며 각 문장을 완벽하게 다듬을 수 있게 해줍니다.
- 글쓰기에 드는 전체 시간을 줄여줍니다.
- “자신이 아끼는 문장을 죽여라”는 무엇을 의미합니까? (하나 선택)
- 논란이 되는 주제를 피하기 위해.
- 혹독한 비판을 통해 작업을 개선하기 위해.
- 좋아하지만 이야기의 흐름에 방해되는 불필요한 내용을 제거하기 위해.
- 초고 전체를 처음부터 다시 쓰기 위해.
- 작가에게 있어 글쓰기의 가장 큰 이점은 무엇입니까? (하나 선택)
- 다시 쓰기의 번거로움을 피하게 해줍니다.
- 자신이 무엇을 왜 믿는지 스스로 명확히 깨닥게 해줍니다.
- 동료들의 피드백을 받을 필요성을 줄여줍니다.
- 논문 게재를 보장해줍니다.
- Zinsser (1976) 가 강조하는 조언을 특징짓는 두 단어는 무엇입니까? (하나 선택)
- 다시 쓰기, 다시 쓰기.
- 단순화, 단순화.
- 제거, 제거.
- 간결하게, 간결하게.
- 불필요한 단어와 오타, 문법 오류를 제거해야 하는 주된 이유는 무엇입니까? (하나 선택)
- 단어 수 제한을 맞추기 위해.
- 어려운 어휘로 심사위원을 감동시키기 위해.
- 논문 분량을 늘리기 위해.
- 주장의 신뢰성을 높이기 위해.
- 다음 중 가장 적절한 제목은 무엇입니까? (하나 선택)
- “작은 표본 추정치의 표준 오차 분석”
- “표준 오차”
- “과제 2”
- 효과적인 제목 작성을 위한 전략은 무엇입니까? (하나 선택)
- 전문 용어를 사용해 전문가임을 과시합니다.
- 일반적인 주제와 핵심 발견에 대한 구체적 정보를 함께 담습니다.
- 가급적 한두 단어로 짧게 만듭니다.
- 독자의 호기심을 위해 질문 형식으로만 만듭니다.
- Fourcade and Healy (2017) 의 새로운 제목을 지어보세요.
- 초록 작성 시 권장되지 않는 사항은 무엇입니까? (하나 선택)
- 핵심 요점을 설명하기 위해 그림이나 표를 넣는 것.
- 주요 결과와 함의를 포함하는 것.
- 정확하고 간결한 언어를 사용하는 것.
- 초록 자체로 완결성을 갖게 만드는 것.
- 초록의 일반적인 구조는 무엇입니까? (하나 선택)
- 함의로 시작해 방법, 맥락 순으로 끝냅니다.
- 연구 분야 도입, 방법 설명, 핵심 결과 제시, 함의 설명 순서.
- 한계점 고백 후 데이터 소스, 결과 순으로 씁니다.
- 논문이 답해야 할 질문들을 나열합니다.
- XKCD Simple Writer를 활용해 가장 많이 쓰이는 1,000개 단어만으로 Chambliss (1989) 의 초록을 다시 써보세요.
- G. King (2006) 에 따르면 소제목의 역할은 무엇입니까? (하나 선택)
- 논문을 문헌 속에 통합하기 위해 약어를 씁니다.
- 논문의 중요성을 과시하기 위해 화려하게 씁니다.
- 졸다가 깬 독자도 자신이 어디를 읽고 있는지 금방 알 수 있게 합니다.
- 데이터 섹션에서 달성해야 할 목표는 무엇입니까? (하나 선택)
- 데이터의 복잡성을 과시해 독자를 압도합니다.
- 데이터를 상세히 설명해 ’장소의 감각’을 만들어냅니다.
- 가급적 많은 그래프와 표를 욱여넣습니다.
- 데이터의 약점을 교묘히 가립니다.
- 연구 논문 데이터 섹션의 주된 목표는 무엇입니까? (하나 선택)
- 최대한 많은 시각 자료를 보여주는 것.
- 독자가 결과의 토대를 이해하도록 데이터를 철저히 설명하는 것.
- 분석의 난도를 독자에게 납득시키는 것.
- 사용하지 않은 데이터 소스까지 모두 나열하는 것.
- G. King (2006) 에 따르면 표준 오차가 0.05일 때 계수값을 어떻게 표기하는 것이 부적절합니까? (모두 선택)
- 2.7182818
- 2.718282
- 2.71828
- 2.7183
- 2.718
- 2.72
- 2.7
- 3
- 좋은 캡션은 어떤 역할을 해야 합니까? (하나 선택)
- 가급적 한 줄로 짧게 끝냅니다.
- 그 자체로 완결성을 갖고 핵심 요점을 설명합니다.
- 전문성을 보여주기 위해 복잡한 용어를 씁니다.
- 본문을 읽게 만들기 위해 최소한의 정보만 줍니다.
- 모델 섹션에 반드시 포함되어야 할 것은 무엇입니까? (하나 선택)
- 기존 문헌에서 쓰인 모델들의 요약.
- 수식 없이 최종 결과만 제시.
- 수학 기호 없는 일반적인 설명.
- 모델 수식과 각 구성 요소에 대한 정의 및 설명.
- 모델 섹션에서 대안 모델을 언급하는 것이 왜 중요합니까? (하나 선택)
- 신중한 검토 과정을 보여주고 선택한 모델을 정당화하기 위해.
- 다른 모델이 얼마나 부족한지 깎아내리기 위해.
- 여러 옵션을 보여주어 독자를 혼란스럽게 하기 위해.
- 논문의 분량을 늘리기 위해.
- 결과 섹션의 목적은 무엇입니까? (하나 선택)
- 결과를 해석하고 함의를 논의하는 것.
- 다른 연구자의 결과와 비교해 비판하는 것.
- 향후 연구 방향을 제안하는 것.
- 과한 해석 없이 분석 결과 그 자체를 명확히 제시하는 것.
- 결과 섹션에서 그래프와 표는 어떻게 다뤄야 합니까? (하나 선택)
- 텍스트 설명 없이 독립적으로 둡니다.
- 혼란을 피하기 위해 최소한으로 줄입니다.
- 본문 텍스트에서 반드시 상호 참조하고 논의해야 합니다.
- 흐름을 방해하지 않게 모두 부록으로 뺍니다.
- 논의 섹션의 목적은 무엇입니까? (하나 선택)
- 연구 결과를 단순히 반복하는 것.
- 상세한 방법론을 다시 설명하는 것.
- 결과를 해석하고 함의를 짚으며 연구의 한계를 인정하는 것.
- 대안 없이 한계점만 나열하는 것.
- Savage and Yeh (2019) 가 “이게 없어도 메시지가 전달되는가?”를 자문하라고 한 이유는 무엇입니까? (하나 선택)
- 오류를 줄이기 위해.
- 명확성을 확보하기 위해.
- 논문을 짧게 만들기 위해.
- 다시 쓰기 과정의 핵심 요소는 무엇입니까? (모두 선택)
- 빨간 펜으로 불필요한 단어를 깎아내는 것.
- 종이로 인쇄해 직접 읽어보는 것.
- 흐름 개선을 위해 문장을 옮기고 붙이는 것.
- 소리 내어 읽어보는 것.
- 타인과 바꿔 읽어보는 것.
- 오타나 문법 오류가 논문의 신뢰성에 영향을 주는 이유는 무엇입니까? (하나 선택)
- 논문의 편안한 분위기를 위해 필요합니다.
- 논문 분량을 줄여주기 때문입니다.
- 세심함이 부족하다는 인상을 주기 때문입니다.
- 내용만 좋다면 전혀 상관없습니다.
수업 활동
- 연구에 대한 자신의 선호 방식(데이터 우선 vs 질문 우선)과 그 이유를 토론해 보세요.
- 추정량, 추정기, 추정치의 개념을 적절한 예시와 함께 설명해 보세요.
- ’선택 편향’의 정의를 M. Alexander (2019) 가 지니 계수를 설명한 것처럼 일반인도 알기 쉽게 한 문장으로 정의해 보세요.
- LLM(ChatGPT 등)을 활용해 “선택 효과란 무엇인가?”에 대한 답을 얻어보세요. 그런 다음 파트너와 함께 맥락과 참고 문헌을 추가해 내용을 더 정확하고 풍성하게 다듬어 보세요. 1) 초기 프롬프트, 2) 원본 답변, 3) 개선된 답변을 비교해 보세요.
- 정량 분석 논문 중 한 편을 골라 다음을 수행해 보세요.
- 원본 제목을 분석해 보세요. 장단점은 무엇인가요? 새로운 제목을 지어보세요.
- 초록을 분석해 보세요. 장단점은 무엇인가요?
- LLM에게 대안 초록을 만들게 시켜보세요. (프롬프트 공유)
- 이를 바탕으로 최종 개선된 초록을 작성하고 토론해 보세요.
- G. King (2006) 을 참고해 이번 학기 말까지 완성할 연구 논문의 계획을 세워보세요. (박사 과정생이라면 투고할 저널 3곳을 선정하고 그 이유를 적으세요.)
- Gerring (2012) 를 읽고 한 쪽 분량의 서평을 작성해 보세요.
과제
로버트 카로 (Caro 2019, xii)는 거의 매일 최소 1,000단어를 씁니다. 여러분도 이번 기회에 글쓰기 훈련을 해봅시다. 권장 논문 중 하나를 골라 다음 일주일간의 과제를 수행하세요.
- 1일차: 서론 전체를 그대로 필사해 보세요.
- 2일차: 필사한 서론을 10% 정도 분량으로 줄여서 다시 써보세요.
- 3일차: 초록 전체를 그대로 필사해 보세요.
- 4일차: 논문에 대한 새로운 초록을 네 문장으로 작성해 보세요.
- 5일차: 가장 많이 쓰이는 1,000개 단어만 사용해 초록의 두 번째 버전을 써보세요.
- 6일차: 논문 작성 방식에서 마음에 드는 세 가지 점을 분석해 보세요.
- 7일차: 논문 작성 방식에서 아쉬운 점 한 가지를 분석해 보세요.
Quarto를 활용해 일주일간의 기록을 하나의 PDF로 만드십시오. 매일 작업 내용을 커밋하고 푸시하며 정보가 담긴 커밋 메시지를 남기세요.
별도의 문헌 검토(Literature Review) 섹션이 필요할 수도 있지만, 관련 연구들을 논문 전체에 걸쳐 적재적소에 녹여내는 방식도 권장할 만합니다. 예를 들어 데이터 관련 연구는 데이터 섹션에서, 모델 관련 연구는 모델 섹션에서 언급하는 식이죠.↩︎