library(janitor)
library(lubridate)
library(mice)
library(modelsummary)
library(naniar)
library(opendatatoronto)
library(tidyverse)
library(tinytable)
library(arrow)11 탐색적 데이터 분석
권장 선행 학습
- 존 투키(John Tukey)의 저작 《데이터 분석의 미래》(원제: The Future of Data Analysis) (Tukey 1962) 읽기.
- 20세기 최고의 통계학자 중 한 명인 존 투키는 이 논문의 제1부 “일반적 고려 사항”을 통해 데이터를 통해 무언가를 배운다는 것이 무엇인지, 시대를 앞서간 통찰을 제시했습니다.
- 《데이터 정리를 위한 모범 사례》(원제: Best Practices in Data Cleaning) (Osborne 2012) 읽기.
- 특히 결측치나 불완전한 데이터를 다루는 법을 상세히 설명한 제6장 “결측 또는 불완전 데이터 처리”를 중점적으로 살펴보세요.
- 《데이터 과학을 위한 R》(원제: R for Data Science) (Wickham, Çetinkaya-Rundel, and Grolemund [2016] 2023) 읽기.
- 실질적인 EDA 작업 예시를 풍부하게 제공하는 제11장 “탐색적 데이터 분석”을 참고하세요.
- 비디오 강좌 《전체 게임》(원제: The Whole Game) (Wickham 2018) 시청하기.
- 전문가가 데이터를 탐색하며 어떻게 실수하고, 또 어떻게 그 실수를 바로잡아 나가는지 생생하게 볼 수 있는 훌륭한 자료입니다.
핵심 개념 및 기술
- 탐색적 데이터 분석(Exploratory Data Analysis, EDA)은 데이터를 면밀히 살펴보고 그래프, 표, 모델을 구성하며 새로운 데이터셋과 친밀해지는 과정입니다. 우리는 크게 세 가지 측면을 이해하고자 합니다.
- 개별 변수 자체의 통계적 특성 및 분포
- 변수 간의 관계 속에서 나타나는 상호작용과 의미
- 존재하지 않는 데이터(결측치)의 맥락과 원인
- EDA 과정을 통해 데이터셋의 잠재적인 문제점을 파악하며, 이것이 이후 분석 결정에 어떤 영향을 미칠지 이해합니다. 특히 결측치(Missing values)와 이상치(Outliers)를 식별하고 처리하는 법을 익힙니다.
소프트웨어 및 패키지
- 기본 R (R Core Team 2024)
arrow(Richardson et al. 2023)janitor(Firke 2023)lubridate(Grolemund and Wickham 2011)mice(van Buuren and Groothuis-Oudshoorn 2011)modelsummary(Arel-Bundock 2022)naniar(Tierney et al. 2021)opendatatoronto(Gelfand 2022)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
11.1 서론
데이터 분석의 미래는 큰 발전과 실질적인 어려움의 극복, 그리고 모든 과학 기술 분야에 대한 훌륭한 공헌을 포함할 수 있습니다. 그렇게 될 수 있을까요? 그것은 우리에게 달려 있습니다. 비현실적인 가정이나 자의적인 기준, 실제와 무관한 추상적인 결과라는 안락한 길 대신, 실제 문제라는 험난한 길을 기꺼이 택하려는 우리의 의지에 달려 있습니다. 과연 누가 이 도전에 나설까요?
Tukey (1962, 64).
탐색적 데이터 분석(Exploratory Data Analysis, EDA)은 분석이 완전히 끝날 때까지 멈추지 않는 연속적인 과정입니다. 이는 데이터를 적극적으로 탐색하며 데이터와 ‘친해지는’ 능동적인 여정이라 할 수 있습니다. 흙을 매만지며 그 상태를 살피는 농부처럼, 데이터 분석가 역시 데이터의 모든 굴곡과 특성을 속속들이 파악해야 합니다. 데이터가 어떻게 변하는지, 무엇을 말하고 무엇을 숨기는지, 그리고 그 한계가 어디까지인지 명확히 알아야 합니다. EDA는 바로 이러한 작업을 수행하는 비구조화된 과정입니다.
EDA는 그 자체로 목적이라기보다 최종 목표를 향해 나아가는 과정에 가깝습니다. EDA의 결과물은 최종 보고서나 논문의 ‘데이터’ 섹션을 구성하는 탄탄한 뼈대가 되지만, 분석 과정에서 생성한 수많은 그래프나 표가 모두 최종 본문에 실리지는 않습니다. 효과적인 EDA를 위해서는 별도의 Quarto 문서를 하나 더 열어 자유롭게 코드를 실행해 보고, 그 과정에서 스쳐 지나가는 데이터에 대한 의문이나 가설들을 즉시 메모해 두는 것이 좋습니다. 이전 코드를 지우지 않고 계속 덧붙여 나가며 기록하는 이 ‘노트북(Notebook)’ 방식은 장차 수행될 정밀 분석의 가장 든든한 가이드라인이 될 것입니다.
EDA는 정해진 공식이 있는 고수준의 작업이 아닙니다. 분석가는 시각화뿐만 아니라 활용 가능한 모든 수단을 동원해야 합니다 (Staniak and Biecek 2019). 데이터를 직접 훑어보고, 요약 통계량을 계산하며, 간단한 모델을 만들어 보는 과정이 반복되죠. 핵심은 세밀하게 깎아내는 완벽함보다는, 빠르게 반복(Iterate)하며 데이터를 다각도에서 입체적으로 이해하는 것입니다. 흥미로운 사실은, 현재 가진 데이터를 철저히 파악하려는 노력이 때로는 우리에게 ’지금 없는 데이터가 무엇인지’를 깨닫게 해준다는 점입니다.
성공적인 EDA를 위해 우리는 다음 세 가지 질문에 집중합니다.
- 개별 변수의 분포와 속성: 각 변수는 어떤 범위에 있으며 어떤 형태를 띠고 있는가?
- 변수 간의 관계: 어떤 변수들이 서로 밀접하게 연결되어 움직이는가?
- 존재하지 않는 것(Missingness): 무엇이 누락되었으며, 그 원인은 무엇인가?
EDA에는 정답이 없습니다. 과정과 도구는 데이터의 특성과 분석 목적에 따라 끊임없이 변합니다. 본 장에서는 미국 주의 인구 통계부터 토론토의 지하철 지연, 런던의 에어비앤비 목록까지 다양한 사례를 통해 EDA의 실전 접근법을 살펴보겠습니다. 또한 Chapter 6 에서 다루었던 결측 자아(Missing self)로 돌아가 데이터를 더 깊이 이해하는 법을 배웁니다.
11.2 1975년 미국 인구 및 소득 데이터
첫 번째 예시로 1975년 기준 미국 주 인구 데이터를 살펴보겠습니다. 이 데이터셋은 state.x77이라는 이름으로 R에 내장되어 있습니다.
us_populations <-
state.x77 |>
as_tibble() |>
clean_names() |>
mutate(state = rownames(state.x77)) |>
select(state, population, income)
us_populations# A tibble: 50 × 3
state population income
<chr> <dbl> <dbl>
1 Alabama 3615 3624
2 Alaska 365 6315
3 Arizona 2212 4530
4 Arkansas 2110 3378
5 California 21198 5114
6 Colorado 2541 4884
7 Connecticut 3100 5348
8 Delaware 579 4809
9 Florida 8277 4815
10 Georgia 4931 4091
# ℹ 40 more rows데이터를 빠르게 훑어보기 위한 첫 단추는 head()와 tail()로 데이터의 시작과 끝을 확인하고, 슬라이싱을 통해 중간 대목을 무작위로 추출해 보는 것입니다. 또한 glimpse()를 활용해 각 변수의 자료형과 대략적인 값을 입체적으로 파악해야 합니다. 특히 무작위 추출은 표본의 편향을 사전에 인지하는 데 매우 중요한 역할을 하므로 습관적으로 수행하는 것이 좋습니다.
us_populations |>
head()# A tibble: 6 × 3
state population income
<chr> <dbl> <dbl>
1 Alabama 3615 3624
2 Alaska 365 6315
3 Arizona 2212 4530
4 Arkansas 2110 3378
5 California 21198 5114
6 Colorado 2541 4884us_populations |>
tail()# A tibble: 6 × 3
state population income
<chr> <dbl> <dbl>
1 Vermont 472 3907
2 Virginia 4981 4701
3 Washington 3559 4864
4 West Virginia 1799 3617
5 Wisconsin 4589 4468
6 Wyoming 376 4566us_populations |>
slice_sample(n = 6)# A tibble: 6 × 3
state population income
<chr> <dbl> <dbl>
1 Vermont 472 3907
2 Virginia 4981 4701
3 New Mexico 1144 3601
4 Florida 8277 4815
5 South Carolina 2816 3635
6 Maryland 4122 5299us_populations |>
glimpse()Rows: 50
Columns: 3
$ state <chr> "Alabama", "Alaska", "Arizona", "Arkansas", "California", "…
$ population <dbl> 3615, 365, 2212, 2110, 21198, 2541, 3100, 579, 8277, 4931, …
$ income <dbl> 3624, 6315, 4530, 3378, 5114, 4884, 5348, 4809, 4815, 4091,…이어서 Base R의 summary() 함수를 사용하여 숫자 변수의 최솟값, 중앙값, 최댓값과 같은 주요 요약 통계량과 관측치 수를 확인합니다.
us_populations |>
summary() state population income
Length:50 Min. : 365 Min. :3098
Class :character 1st Qu.: 1080 1st Qu.:3993
Mode :character Median : 2838 Median :4519
Mean : 4246 Mean :4436
3rd Qu.: 4968 3rd Qu.:4814
Max. :21198 Max. :6315 요약 통계량을 살펴볼 때는 특히 극단값(Limits)에서의 변화를 관찰하는 것이 중요합니다. 한 가지 유용한 테크닉은 관측치 중 일부를 무작위로 제거해 본 뒤, 요약 통계량이 어떻게 변하는지 비교해 보는 것입니다. 예를 들어, 특정 주(State)를 제외했을 때 평균값이 요동친다면, 그 주가 전체 분석 결과에 매우 강력한 영향력(Leverage)을 행사하고 있음을 알 수 있습니다. 이러한 영향력 있는 관측치(Influential points)를 식별하는 것은 모델의 강건성을 검증하는 첫걸음입니다.
sample_means <- tibble(seed = c(), mean = c(), states_ignored = c())
for (i in 1:5) {
set.seed(i)
dont_get <- sample(x = state.name, size = 5)
sample_means <-
sample_means |>
rbind(tibble(
seed = i,
mean =
us_populations |>
filter(!state %in% dont_get) |>
summarise(mean = mean(population)) |>
pull(),
states_ignored = str_flatten_comma(dont_get)
))
}
sample_means |>
tt() |>
style_tt(j = 1:3, align = "lrr") |>
format_tt(digits = 0, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("시드", "평균 인구", "제외된 주"))| 시드 | 평균 인구 | 제외된 주 |
|---|---|---|
| 1 | 4,469 | Arkansas, Rhode Island, Alabama, North Dakota, Minnesota |
| 2 | 4,027 | Massachusetts, Iowa, Colorado, West Virginia, New York |
| 3 | 4,086 | California, Idaho, Rhode Island, Oklahoma, South Carolina |
| 4 | 4,391 | Hawaii, Arizona, Connecticut, Utah, New Jersey |
| 5 | 4,340 | Alaska, Texas, Iowa, Hawaii, South Dakota |
미국 주 인구 데이터의 경우, 캘리포니아나 뉴욕과 같이 인구가 많은 주들이 평균 추정치에 큰 영향을 미칠 것임을 짐작할 수 있습니다. Table 11.1 결과가 이를 뒷받침해 주는데, 시드 2와 3을 사용할 때 평균값이 상대적으로 낮게 나타나는 것을 볼 수 있습니다.
11.3 결측치 처리 (Missing Data)
우리는 이 책 전반에서, 특히 Chapter 6 장에서 결측치 문제를 비중 있게 다루었습니다. 여기서는 왜 결측치를 이해하는 것이 EDA의 핵심적인 초점이 되어야 하는지 다시 한번 짚어보겠습니다. 분석 과정에서 결측치를 발견하는 것은 지극히 흔한 일이며, 중요한 것은 우리가 어떤 유형의 결측 원인(기제)을 마주하고 있는지 파악하는 것입니다. Gelman, Hill, and Vehtari (2020, 323) 을 참고하여 데이터셋에서 나타나는 세 가지 주요 결측 유형을 살펴보겠습니다.
- 완전 무작위 결측 (Missing Completely At Random, MCAR): 데이터가 누락된 이유가 데이터셋 내부의 다른 변수(관측된 것이든 아니든)와 아무런 상관이 없는 경우입니다. 데이터가 MCAR일 때는 요약 통계량이나 추론 결과의 왜곡이 적지만, 현실 데이터에서 완벽한 MCAR은 매우 드뭅니다.
- 무작위 결측 (Missing At Random, MAR): 데이터의 결측 여부가 데이터셋 내의 다른 ‘관측된’ 변수와 관련이 있는 경우입니다. 예를 들어, 설문 조사에서 특정 성별이나 연령대가 소득 질문에 덜 응답하는 경향이 있다면 이는 MAR에 해당합니다.
- 비무작위 결측 (Missing Not At Random, MNAR): 데이터의 결측 여부가 관측되지 않은 변수나 혹은 결측된 값 그 자체와 관련이 있는 경우입니다. 예를 들어, 소득이 아주 높거나 아주 낮은 사람들이 의도적으로 소득을 기입하지 않는 경우가 이에 해당합니다.
데이터가 MCAR인 상황을 시뮬레이션해 보겠습니다. 예를 들어, 무작위로 선택된 3개 주의 인구 데이터를 누락시키는 코드는 다음과 같습니다.
set.seed(853)
remove_random_states <-
sample(x = state.name, size = 3, replace = FALSE)
us_states_MCAR <-
us_populations |>
mutate(
population =
if_else(state %in% remove_random_states, NA_real_, population)
)
summary(us_states_MCAR) state population income
Length:50 Min. : 365 Min. :3098
Class :character 1st Qu.: 1174 1st Qu.:3993
Mode :character Median : 2861 Median :4519
Mean : 4308 Mean :4436
3rd Qu.: 4956 3rd Qu.:4814
Max. :21198 Max. :6315
NA's :3 관측치가 무작위 결측(MAR)되는 상황은 데이터셋 내의 다른 변수와 연관된 방식으로 발생합니다. 예를 들어, 소득 순위가 가장 높은 3개 주의 인구 데이터를 누락시켜 MAR 데이터셋을 시뮬레이션할 수 있습니다.
highest_income_states <-
us_populations |>
slice_max(income, n = 3) |>
pull(state)
us_states_MAR <-
us_populations |>
mutate(population =
if_else(state %in% highest_income_states, NA_real_, population)
)
summary(us_states_MAR) state population income
Length:50 Min. : 376 Min. :3098
Class :character 1st Qu.: 1101 1st Qu.:3993
Mode :character Median : 2816 Median :4519
Mean : 4356 Mean :4436
3rd Qu.: 5147 3rd Qu.:4814
Max. :21198 Max. :6315
NA's :3 데이터가 비무작위로 결측(MNAR)될 때는 결측 여부가 관측되지 않은 변수나 혹은 결측된 값 그 자체와 관련이 있습니다. 통계적으로 가장 다루기 까다로운 상황이죠. 예를 들어, 인구가 아주 많은 주의 인구가 누락되거나, 소득이 극도로 높거나 낮은 사람들이 의도적으로 응답을 거부하는 경우입니다.
미국 주 데이터셋의 경우, 인구가 가장 많은 상위 3개 주를 누락시켜 MNAR 데이터셋을 시뮬레이션해 보겠습니다.
highest_population_states <-
us_populations |>
slice_max(population, n = 3) |>
pull(state)
us_states_MNAR <-
us_populations |>
mutate(population =
if_else(state %in% highest_population_states,
NA_real_,
population))
summary(us_states_MNAR) state population income
Length:50 Min. : 365.0 Min. :3098
Class :character 1st Qu.: 994.5 1st Qu.:3993
Mode :character Median : 2715.0 Median :4519
Mean : 3421.5 Mean :4436
3rd Qu.: 4678.0 3rd Qu.:4814
Max. :11860.0 Max. :6315
NA's :3 어떤 결측치 처리 방식을 택할지는 데이터의 성격과 분석 목적에 따라 결정해야 합니다. 우리는 시뮬레이션을 통해 특정 선택이 결과에 어떤 영향을 주는지 면밀히 검토해야 하죠. 크게 두 가지 방향이 있습니다. 결측치가 포함된 관측치를 아예 제거(Deletion)하거나, 적절한 값으로 ’대체(Imputation)’하는 것입니다. 어떤 방식을 택하든 그 한계와 가정을 명확히 인지하고 보고해야 합니다.
미국 주 인구 데이터셋을 활용해 대표적인 결측치 처리 전략 세 가지를 비교해 보겠습니다.
- 완전 제거(Listwise deletion): 결측치가 하나라도 있는 행을 분석에서 통째로 제외합니다.
- 평균 대체(Mean imputation): 결측치를 해당 변수의 평균값으로 채워 넣습니다.
- 다중 대체(Multiple imputation): 통계적 모델을 사용해 여러 개의 가능한 대체값을 생성하고 이를 종합합니다.
결측 데이터가 있는 관측치를 삭제하려면 mean() 함수의 na.rm = TRUE 옵션을 사용할 수 있습니다. 평균을 대체하려면 결측 데이터가 제거된 데이터셋에서 평균을 계산한 뒤, 이를 원본의 결측값에 채워 넣습니다. 다중 대체는 여러 개의 잠재적 데이터셋을 생성하여 추론을 수행한 뒤, 이를 결합하여 결과를 얻는 방식입니다 (Gelman and Hill 2007, 542). mice 패키지의 mice() 함수를 사용하여 이를 구현할 수 있습니다.
multiple_imputation <-
mice(
us_states_MCAR,
print = FALSE
)
mice_estimates <-
complete(multiple_imputation) |>
as_tibble()| 주 명칭 | 완전 제거 | 평균 대체 | 다중 대체 | 실제 값 |
|---|---|---|---|---|
| Florida | NA | 4,308 | 11,197 | 8,277 |
| Montana | NA | 4,308 | 4,589 | 746 |
| New Hampshire | NA | 4,308 | 813 | 812 |
| 전체 평균 | 4,308 | 4,308 | 4,382 | 4,246 |
Table 11.2 결과를 보면 어떤 접근 방식도 기계적으로 적용해서는 안 된다는 사실이 명확해집니다. 예를 들어, 실제 인구가 약 820만 명인 플로리다의 경우, 평균 대체법은 430만 명으로 너무 낮게 잡고 다중 대체법(mice)은 1,120만 명으로 너무 높게 추정했습니다. 만약 데이터셋의 상당 부분이 결측되어 대체의 신뢰도가 낮다면, 억지로 분석을 강행하기보다 연구 질문 자체를 변경하는 것이 더 현명한 판단일 수 있습니다.
결론적으로 결측 데이터를 완벽하게 보완할 수 있는 마법 같은 방법은 없습니다 (Manski 2022). 분석 상황에 따라 최선의 선택은 달라지며, 분석가는 자신이 내린 결정(제거 혹은 특정 방식의 대체)을 투명하게 문서화하고, 그 선택이 분석 결과에 미친 영향을 민감도 분석 등을 통해 검증해야 합니다. 또한 실제 데이터에서는 결측치가 “NA”가 아닌 특정 값(예: 소득 조사에서의 “888”, “999” 등)으로 인코딩되는 경우가 많으니, 범위를 벗어난 이상한 값들이 있는지 그래프와 표를 통해 끊임없이 의심해야 합니다.
11.4 사례 연구: 토론토 지하철(TTC) 운행 지연
EDA의 두 번째 사례로, Chapter 2 장에서 소개한 opendatatoronto 패키지와 tidyverse를 활용해 캐나다 토론토의 지하철 시스템 데이터를 탐색해 보겠습니다. 우리의 주된 관심사는 실제 발생하는 지연(Delay) 데이터의 특성을 파악하는 것입니다.
먼저 2021년 토론토 교통 위원회(TTC) 지하철 지연 데이터를 다운로드합니다. 데이터는 월별로 시트가 나누어진 Excel 파일 형태로 제공됩니다. 2021년 데이터만 필터링한 뒤 opendatatoronto의 get_resource()를 사용해 내려받고, bind_rows()로 월별 데이터를 하나로 합칩니다.
all_2021_ttc_data <-
list_package_resources("996cfe8d-fb35-40ce-b569-698d51fc683b") |>
filter(name == "ttc-subway-delay-data-2021") |>
get_resource() |>
bind_rows() |>
clean_names()
write_csv(all_2021_ttc_data, "all_2021_ttc_data.csv")
all_2021_ttc_data# A tibble: 16,370 × 10
date time day station code min_delay min_gap bound line
<dttm> <time> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
1 2021-01-01 00:00:00 00:33 Friday BLOOR … MUPAA 0 0 N YU
2 2021-01-01 00:00:00 00:39 Friday SHERBO… EUCO 5 9 E BD
3 2021-01-01 00:00:00 01:07 Friday KENNED… EUCD 5 9 E BD
4 2021-01-01 00:00:00 01:41 Friday ST CLA… MUIS 0 0 <NA> YU
5 2021-01-01 00:00:00 02:04 Friday SHEPPA… MUIS 0 0 <NA> YU
6 2021-01-01 00:00:00 02:35 Friday KENNED… MUIS 0 0 <NA> BD
7 2021-01-01 00:00:00 02:39 Friday VAUGHA… MUIS 0 0 <NA> YU
8 2021-01-01 00:00:00 06:00 Friday TORONT… MUO 0 0 <NA> YU
9 2021-01-01 00:00:00 06:00 Friday TORONT… MUO 0 0 <NA> SHP
10 2021-01-01 00:00:00 06:00 Friday TORONT… MRO 0 0 <NA> SRT
# ℹ 16,360 more rows
# ℹ 1 more variable: vehicle <dbl>데이터셋에는 다양한 열이 포함되어 있으며, 상세 정보를 위해 코드북과 지연 원인 설명서도 함께 확인하는 것이 좋습니다. 우리의 주요 관심 변수는 분 단위 지연 시간을 나타내는 min_delay입니다.
# 데이터 코드북 다운로드
delay_codebook <-
list_package_resources(
"996cfe8d-fb35-40ce-b569-698d51fc683b"
) |>
filter(name == "ttc-subway-delay-data-readme") |>
get_resource() |>
clean_names()
write_csv(delay_codebook, "delay_codebook.csv")
# 지연 코드 설명 다운로드
delay_codes <-
list_package_resources(
"996cfe8d-fb35-40ce-b569-698d51fc683b"
) |>
filter(name == "ttc-subway-delay-codes") |>
get_resource() |>
clean_names()
write_csv(delay_codes, "delay_codes.csv")EDA를 수행할 때 정해진 공식은 없지만, 대개 다음과 같은 핵심 질문들을 던지며 탐색을 시작합니다.
- 데이터의 구조와 자료형: 각 변수의 클래스는 무엇이며, 값의 범위가 상식적인가?
- 의외의 값과 결측: 이상치나 중복, 결측치가 발견되는가? 그 이유는 무엇인가?
- 분석 목표의 구체화: 특정 노선이나 시간대, 혹은 특정 역에서 지연이 더 빈번하게 발생하는가?
분석 과정을 꼼꼼히 기록하는 ‘연구 노트’ 습관을 들이세요. EDA 과정에서 발견한 모든 특이 사항과 가정을 문서화하는 것은 분석의 재현성과 신뢰성을 담보하는 가장 소중한 자산이 됩니다 (Ryan 2015).
11.4.1 개별 변수의 분포와 성격
먼저 각 변수가 실제 데이터의 정의와 일치하는지 확인해야 합니다. 자료형이 적절한지 점검하는 것이 첫걸음이죠. 이를 위해 unique()나 table() 함수를 유용하게 사용할 수 있습니다.
unique(all_2021_ttc_data$day)[1] "Friday" "Saturday" "Sunday" "Monday" "Tuesday" "Wednesday"
[7] "Thursday" unique(all_2021_ttc_data$line) [1] "YU" "BD" "SHP"
[4] "SRT" "YU/BD" NA
[7] "YONGE/UNIVERSITY/BLOOR" "YU / BD" "YUS"
[10] "999" "SHEP" "36 FINCH WEST"
[13] "YUS & BD" "YU & BD LINES" "35 JANE"
[16] "52" "41 KEELE" "YUS/BD" table(all_2021_ttc_data$day)
Friday Monday Saturday Sunday Thursday Tuesday Wednesday
2600 2434 2073 1942 2425 2481 2415 table(all_2021_ttc_data$line)
35 JANE 36 FINCH WEST 41 KEELE
1 1 1
52 999 BD
1 1 5734
SHEP SHP SRT
1 657 656
YONGE/UNIVERSITY/BLOOR YU YU / BD
1 8880 17
YU & BD LINES YU/BD YUS
1 346 18
YUS & BD YUS/BD
1 1 지하철 노선 데이터에서 몇 가지 오류가 발견됩니다. 일부는 명확한 해결책이 보이지만 전부는 아니죠. 부적절한 값을 삭제할 수도 있지만, 이러한 오류가 우리가 분석하고자 하는 핵심 요인과 상관관계가 있다면 소중한 정보를 잃게 될 수도 있습니다. 지금은 이 문제를 기록해 두고 탐색을 계속한 뒤 나중에 최종 결정을 내리겠습니다. 우선은 코드북에 명시된 올바른 노선 기호만 남기겠습니다.
delay_codebook |>
filter(field_name == "Line")# A tibble: 1 × 3
field_name description example
<chr> <chr> <chr>
1 Line TTC subway line i.e. YU, BD, SHP, and SRT YU all_2021_ttc_data_filtered_lines <-
all_2021_ttc_data |>
filter(line %in% c("YU", "BD", "SHP", "SRT"))결측치를 이해하는 일은 분석 전체의 신뢰도를 결정짓습니다. 먼저 각 변수별로 NA(결측치)가 얼마나 있는지 세어보겠습니다.
확인 결과 bound 변수에 결측치가 많고, line에도 두 개가 있네요. Chapter 6 장에서 논의했듯, 우리는 이 결측이 정말 우연히 발생한 것인지(무작위성), 아니면 어떤 체계적인 이유가 있는지 찾아내야 합니다.
데이터 중복 문제도 빼놓을 수 없습니다. 중복을 방치하면 분석 결과가 예상치 못한 방향으로 왜곡될 수 있죠. janitor 패키지의 get_dupes() 함수는 중복 행을 찾는 데 매우 효과적입니다.
get_dupes(all_2021_ttc_data_filtered_lines)# A tibble: 36 × 11
date time day station code min_delay min_gap bound line
<dttm> <time> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
1 2021-09-13 00:00:00 06:00 Monday TORONT… MRO 0 0 <NA> SRT
2 2021-09-13 00:00:00 06:00 Monday TORONT… MRO 0 0 <NA> SRT
3 2021-09-13 00:00:00 06:00 Monday TORONT… MRO 0 0 <NA> SRT
4 2021-09-13 00:00:00 06:00 Monday TORONT… MUO 0 0 <NA> SHP
5 2021-09-13 00:00:00 06:00 Monday TORONT… MUO 0 0 <NA> SHP
6 2021-09-13 00:00:00 06:00 Monday TORONT… MUO 0 0 <NA> SHP
7 2021-03-31 00:00:00 05:45 Wedne… DUNDAS… MUNCA 0 0 <NA> BD
8 2021-03-31 00:00:00 05:45 Wedne… DUNDAS… MUNCA 0 0 <NA> BD
9 2021-06-08 00:00:00 14:40 Tuesd… VAUGHA… MUNOA 3 6 S YU
10 2021-06-08 00:00:00 14:40 Tuesd… VAUGHA… MUNOA 3 6 S YU
# ℹ 26 more rows
# ℹ 2 more variables: vehicle <dbl>, dupe_count <int>이 데이터셋에는 중복 데이터가 꽤 많습니다. EDA 단계에서는 이를 나중에 다시 정밀하게 조사할 문제로 플래그를 달아두고, 일단은 distinct()를 사용해 중복을 제거한 뒤 진행하겠습니다.
all_2021_ttc_data_no_dupes <-
all_2021_ttc_data_filtered_lines |>
distinct()역(Station) 이름에도 오타나 일관성 없는 표기가 많습니다.
all_2021_ttc_data_no_dupes |>
count(station) |>
filter(str_detect(station, "WEST"))# A tibble: 17 × 2
station n
<chr> <int>
1 DUNDAS WEST STATION 198
2 EGLINTON WEST STATION 142
3 FINCH WEST STATION 126
4 FINCH WEST TO LAWRENCE 3
5 FINCH WEST TO WILSON 1
6 LAWRENCE WEST CENTRE 1
7 LAWRENCE WEST STATION 127
8 LAWRENCE WEST TO EGLIN 1
9 SHEPPARD WEST - WILSON 1
10 SHEPPARD WEST STATION 210
11 SHEPPARD WEST TO LAWRE 3
12 SHEPPARD WEST TO ST CL 2
13 SHEPPARD WEST TO WILSO 7
14 ST CLAIR WEST STATION 205
15 ST CLAIR WEST TO ST AN 1
16 ST. CLAIR WEST TO KING 1
17 ST.CLAIR WEST TO ST.A 1“ST. CLAIR”나 “ST. PATRICK” 같은 명칭을 통일하고, “WEST”가 포함된 역들을 구분하여 정리해 보겠습니다. stringr 패키지의 word() 함수를 쓰면 텍스트에서 특정 위치의 단어만 골라낼 수 있어 편리합니다.
all_2021_ttc_data_no_dupes <-
all_2021_ttc_data_no_dupes |>
mutate(
station_clean =
case_when(
str_starts(station, "ST") &
str_detect(station, "WEST") ~ word(station, 1, 3),
str_starts(station, "ST") ~ word(station, 1, 2),
str_detect(station, "WEST") ~ word(station, 1, 2),
TRUE ~ word(station, 1)
)
)
head(all_2021_ttc_data_no_dupes)# A tibble: 6 × 11
date time day station code min_delay min_gap bound line
<dttm> <time> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
1 2021-01-01 00:00:00 00:33 Friday BLOOR S… MUPAA 0 0 N YU
2 2021-01-01 00:00:00 00:39 Friday SHERBOU… EUCO 5 9 E BD
3 2021-01-01 00:00:00 01:07 Friday KENNEDY… EUCD 5 9 E BD
4 2021-01-01 00:00:00 01:41 Friday ST CLAI… MUIS 0 0 <NA> YU
5 2021-01-01 00:00:00 02:04 Friday SHEPPAR… MUIS 0 0 <NA> YU
6 2021-01-01 00:00:00 02:35 Friday KENNEDY… MUIS 0 0 <NA> BD
# ℹ 2 more variables: vehicle <dbl>, station_clean <chr>데이터를 제대로 이해하려면 시각화가 필수입니다. EDA 단계에서는 그래프의 미적 완성도보다는 ‘빠르게’ 데이터를 파악하는 데 집중합니다. 먼저 min_delay 변수의 분포를 살펴보죠.
all_2021_ttc_data_no_dupes |>
ggplot(aes(x = min_delay)) +
geom_histogram(bins = 30) +
theme_classic() +
labs(
x = "지연 (분)",
y = "관측치 수"
)
all_2021_ttc_data_no_dupes |>
ggplot(aes(x = min_delay)) +
geom_histogram(bins = 30) +
theme_classic() +
labs(
x = "지연 (분)",
y = "관측치 수"
) +
scale_x_log10()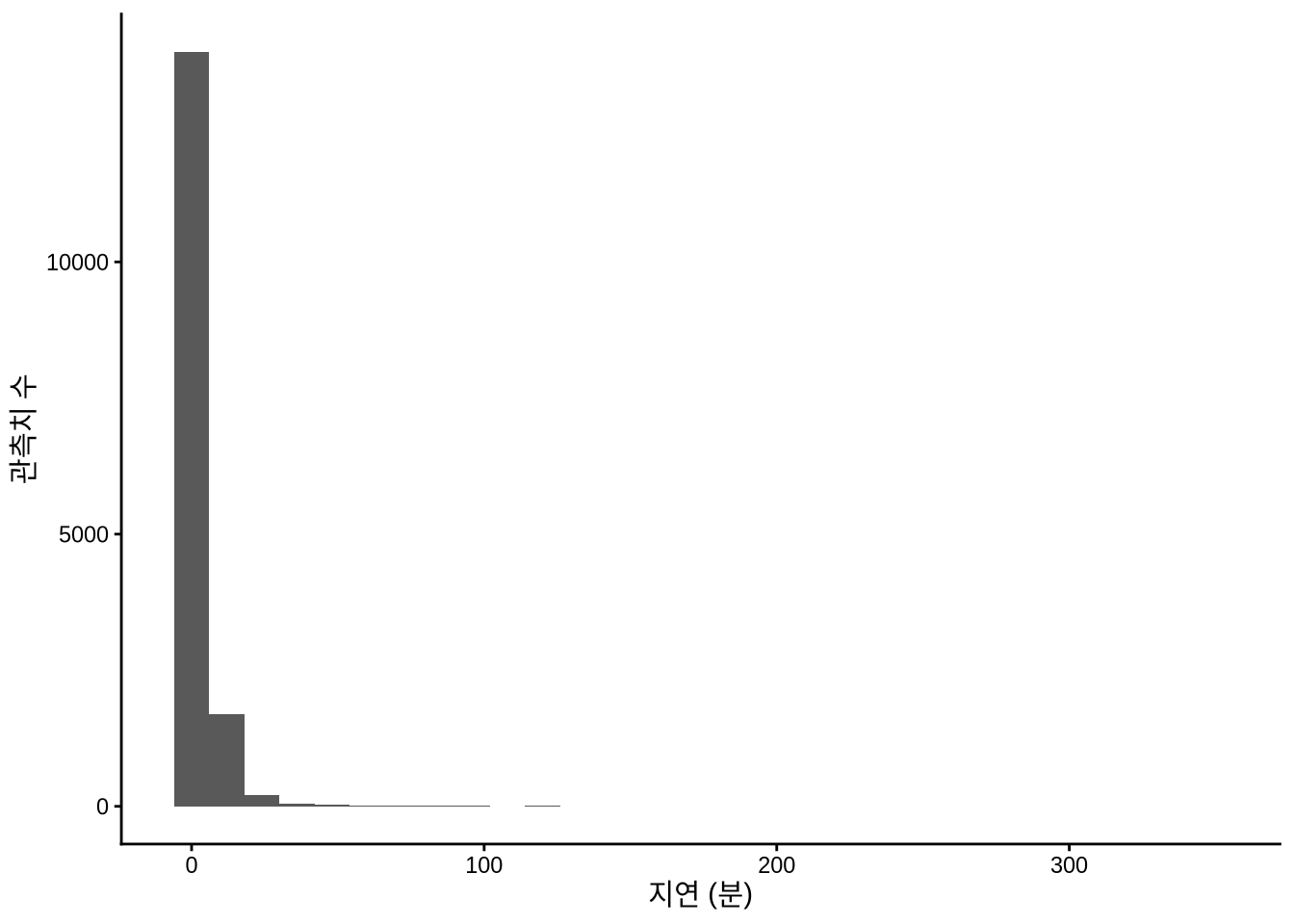
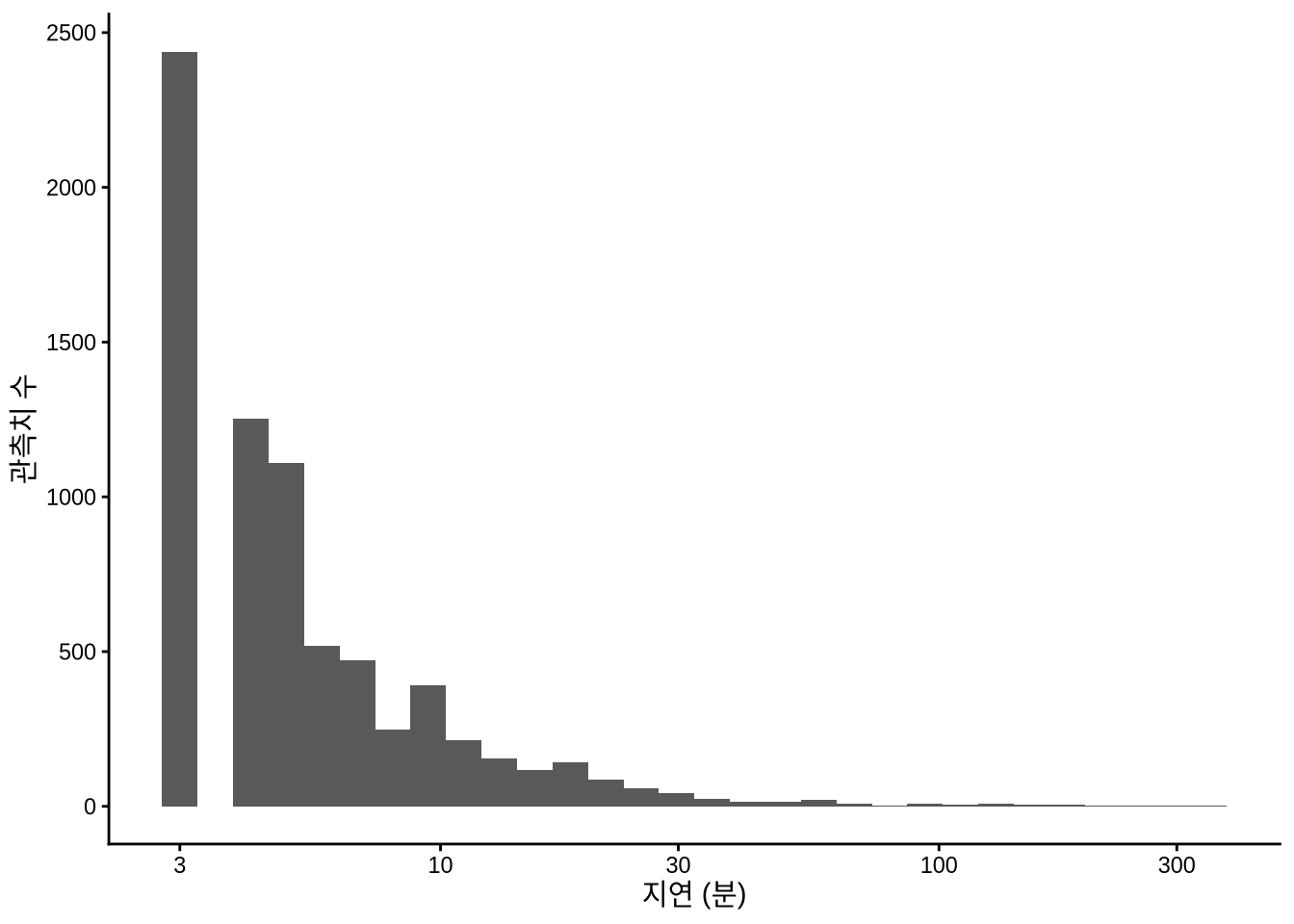
Figure 11.1 (a) 처럼 한쪽이 텅 빈 그래프는 강력한 이상치(Outliers)가 존재함을 암시합니다. 이를 더 자세히 보기 위해 x축에 로그 스케일을 적용해 보았습니다 (Figure 11.1 (b)). (0 분 값은 로그 계산에서 제외됨에 유의하세요.)
이러한 초기 탐색을 통해 몇몇 굉장히 긴 지연 사례들이 있음을 발견했습니다. 그 이유를 파악하기 위해 앞서 받은 지연 원인 코드(delay_codes)와 데이터를 결합해 보겠습니다.
fix_organization_of_codes <-
rbind(
delay_codes |>
select(sub_rmenu_code, code_description_3) |>
mutate(type = "sub") |>
rename(
code = sub_rmenu_code,
code_desc = code_description_3
),
delay_codes |>
select(srt_rmenu_code, code_description_7) |>
mutate(type = "srt") |>
rename(
code = srt_rmenu_code,
code_desc = code_description_7
)
)
all_2021_ttc_data_no_dupes_with_explanation <-
all_2021_ttc_data_no_dupes |>
mutate(type = if_else(line == "SRT", "srt", "sub")) |>
left_join(
fix_organization_of_codes,
by = c("type", "code")
)
all_2021_ttc_data_no_dupes_with_explanation |>
select(station_clean, code, min_delay, code_desc) |>
arrange(-min_delay) |>
head()# A tibble: 6 × 4
station_clean code min_delay code_desc
<chr> <chr> <dbl> <chr>
1 MUSEUM PUTTP 348 Traction Power Rail Related
2 EGLINTON PUSTC 343 Signals - Track Circuit Problems
3 WOODBINE MUO 312 Miscellaneous Other
4 MCCOWAN PRSL 275 Loop Related Failures
5 SHEPPARD WEST PUTWZ 255 Work Zone Problems - Track
6 ISLINGTON MUPR1 207 Priority One - Train in Contact With Person확인 결과, 348분의 지연은 “전력 레일 관련 장애” 때문이었고, 343분의 지연은 “신호 시스템 오류” 때문이었음을 알 수 있습니다.
또한 특정 그룹에 관측치가 너무 적은 경우 분석 결과가 그들에 의해 휘둘릴 수 있으므로 주의해야 합니다. 색상을 활용해 노선별 분포를 비교해 보죠.
all_2021_ttc_data_no_dupes_with_explanation |>
ggplot() +
geom_histogram(
aes(
x = min_delay,
y = ..density..,
fill = line
),
position = "dodge",
bins = 10
) +
scale_x_log10()
all_2021_ttc_data_no_dupes_with_explanation |>
ggplot() +
geom_histogram(
aes(x = min_delay, fill = line),
position = "dodge",
bins = 10
) +
scale_x_log10()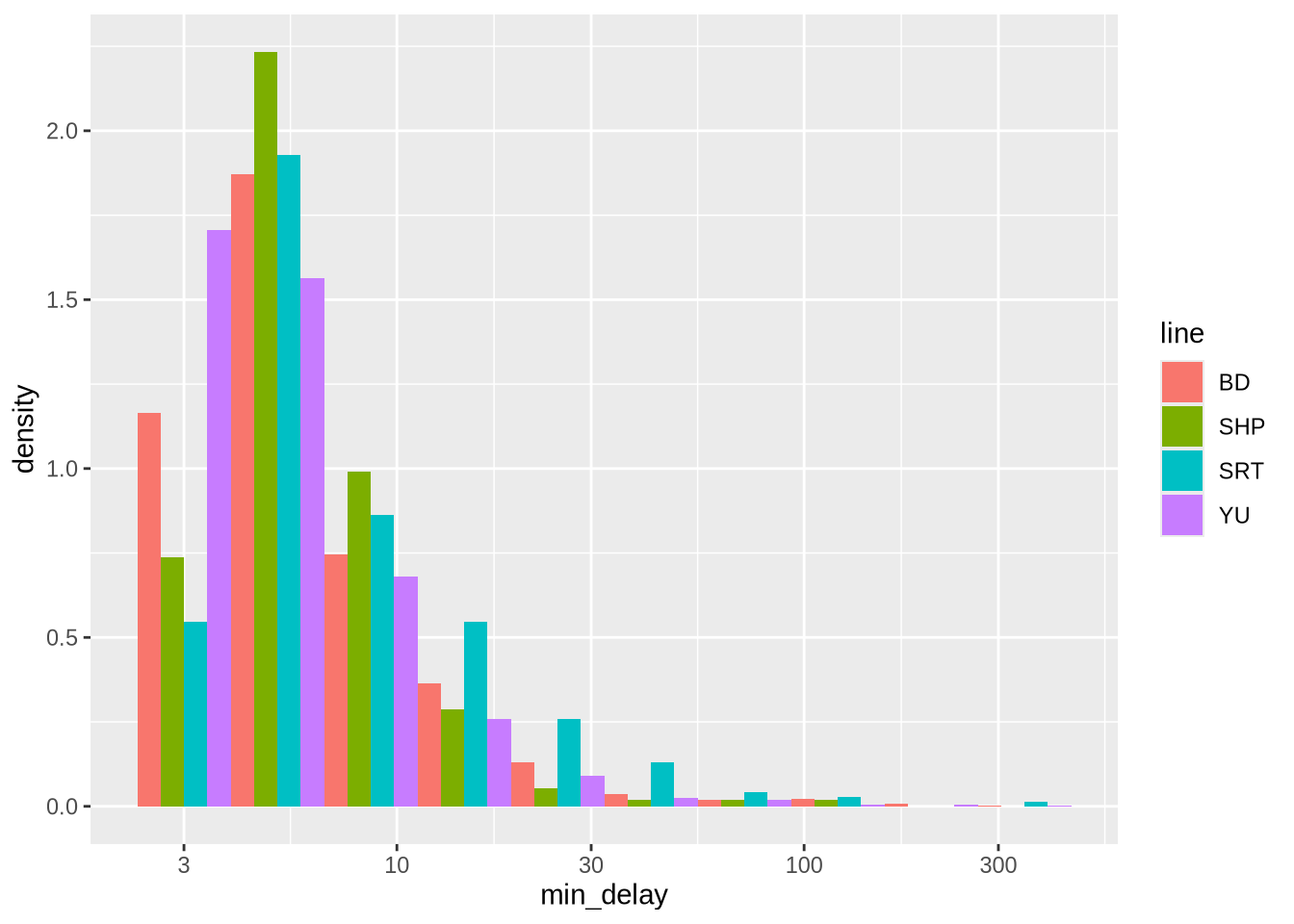
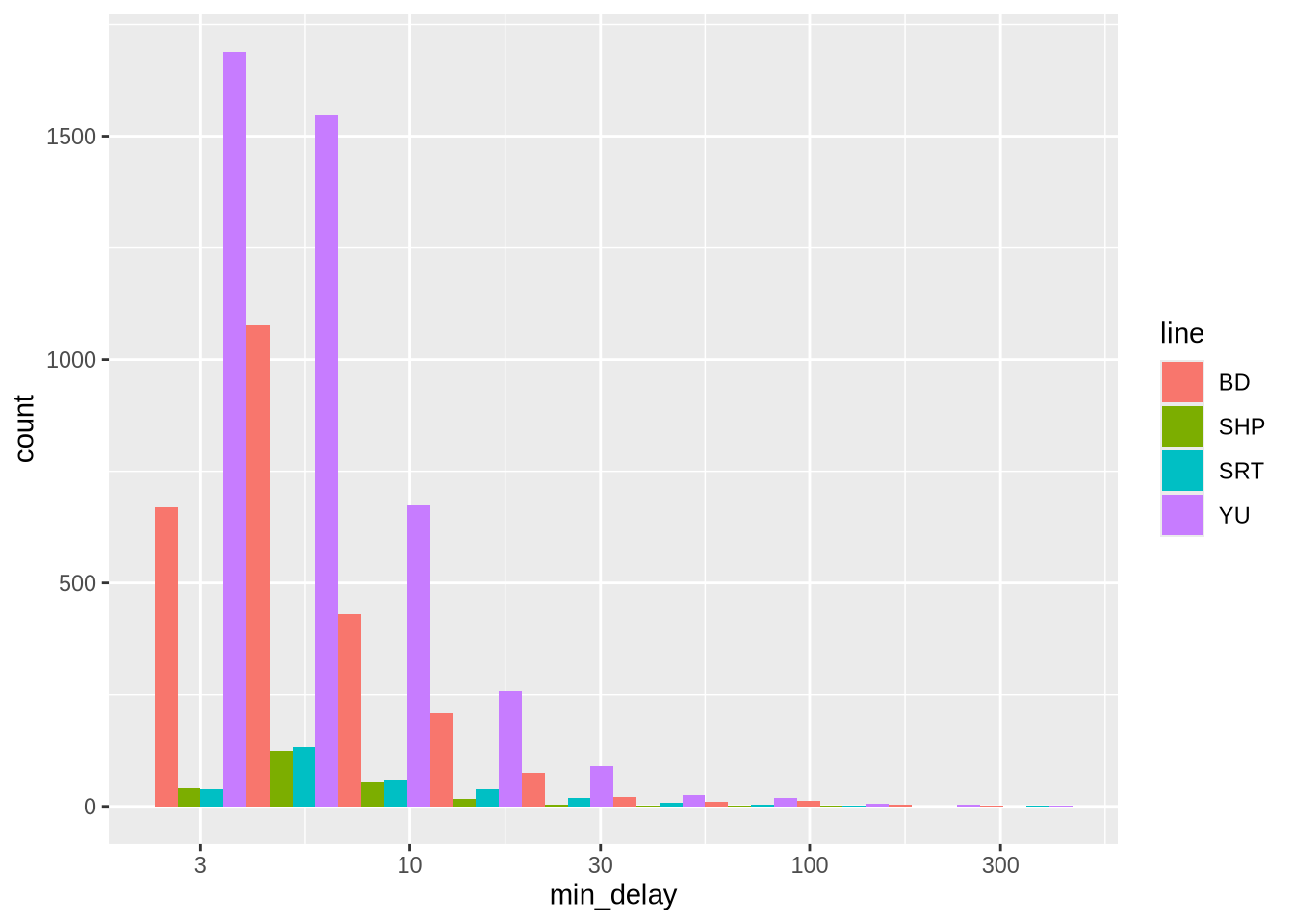
Figure 11.2 (a) 밀도 그래프는 노선 간의 상대적인 분포 비교에 유리하지만, 실제 표본 크기 차이를 보여주는 빈도 그래프 (Figure 11.2 (b)) 도 반드시 함께 보아야 합니다. 이 사례에서 “SHP”와 “SRT” 노선은 데이터 자체가 매우 적음을 알 수 있습니다.
더 정교한 비교를 위해 패싯(Facet) 기능을 활용해 일별 변화를 살펴보겠습니다 (Figure 11.3).
all_2021_ttc_data_no_dupes_with_explanation |>
ggplot() +
geom_histogram(
aes(x = min_delay, fill = line),
position = "dodge",
bins = 10
) +
scale_x_log10() +
facet_wrap(vars(day)) +
theme(legend.position = "bottom")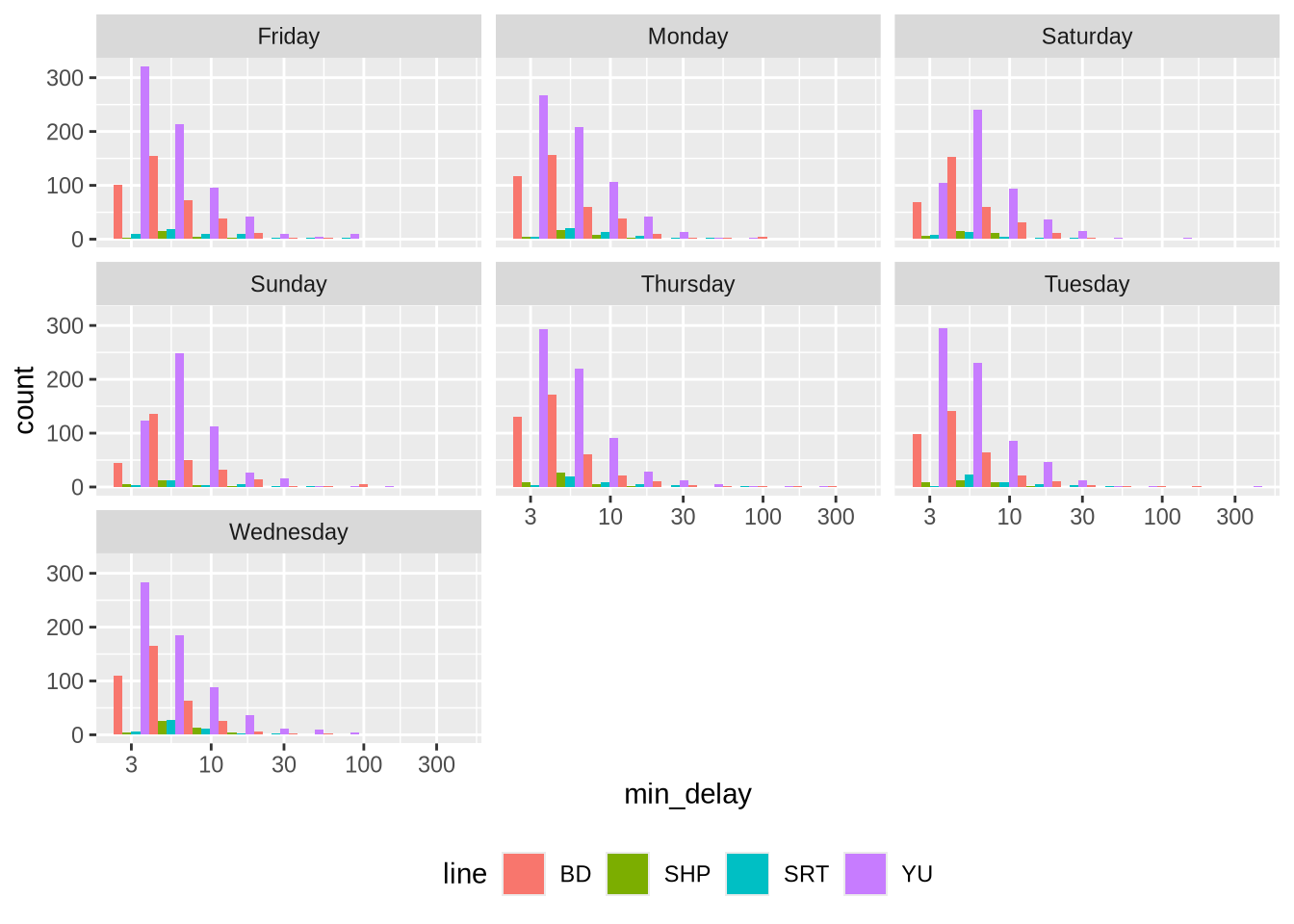
또한 노선별로 평균 지연 시간이 가장 긴 상위 5개 역을 플로팅할 수도 있습니다 (Figure 11.4). “YU” 노선의 “ZONE”이라는 데이터는 무엇을 뜻하는지 등, 추가적인 조사가 필요한 흥미로운 지점들이 포착되네요.
all_2021_ttc_data_no_dupes_with_explanation |>
summarise(mean_delay = mean(min_delay), n_obs = n(),
.by = c(line, station_clean)) |>
filter(n_obs > 1) |>
arrange(line, -mean_delay) |>
slice(1:5, .by = line) |>
ggplot(aes(reorder(station_clean, mean_delay), mean_delay)) +
geom_col() +
coord_flip() +
facet_wrap(vars(line), scales = "free_y") +
labs(x = "지하철 역", y = "평균 지연 (분)")
날짜 데이터는 언제나 말썽을 부리기 쉬우므로 EDA 단계에서 더 꼼꼼히 살펴야 합니다. lubridate 패키지의 week() 함수를 써서 연간 계절성이 있는지 주별 평균 지연 시간을 시각화해 보겠습니다 (Figure 11.5).
all_2021_ttc_data_no_dupes_with_explanation |>
filter(min_delay > 0) |>
mutate(week = week(date)) |>
summarise(mean_delay = mean(min_delay),
.by = c(week, line)) |>
ggplot(aes(week, mean_delay, color = line)) +
geom_point() +
geom_smooth(se = FALSE) +
facet_wrap(vars(line), scales = "free_y") +
theme_minimal()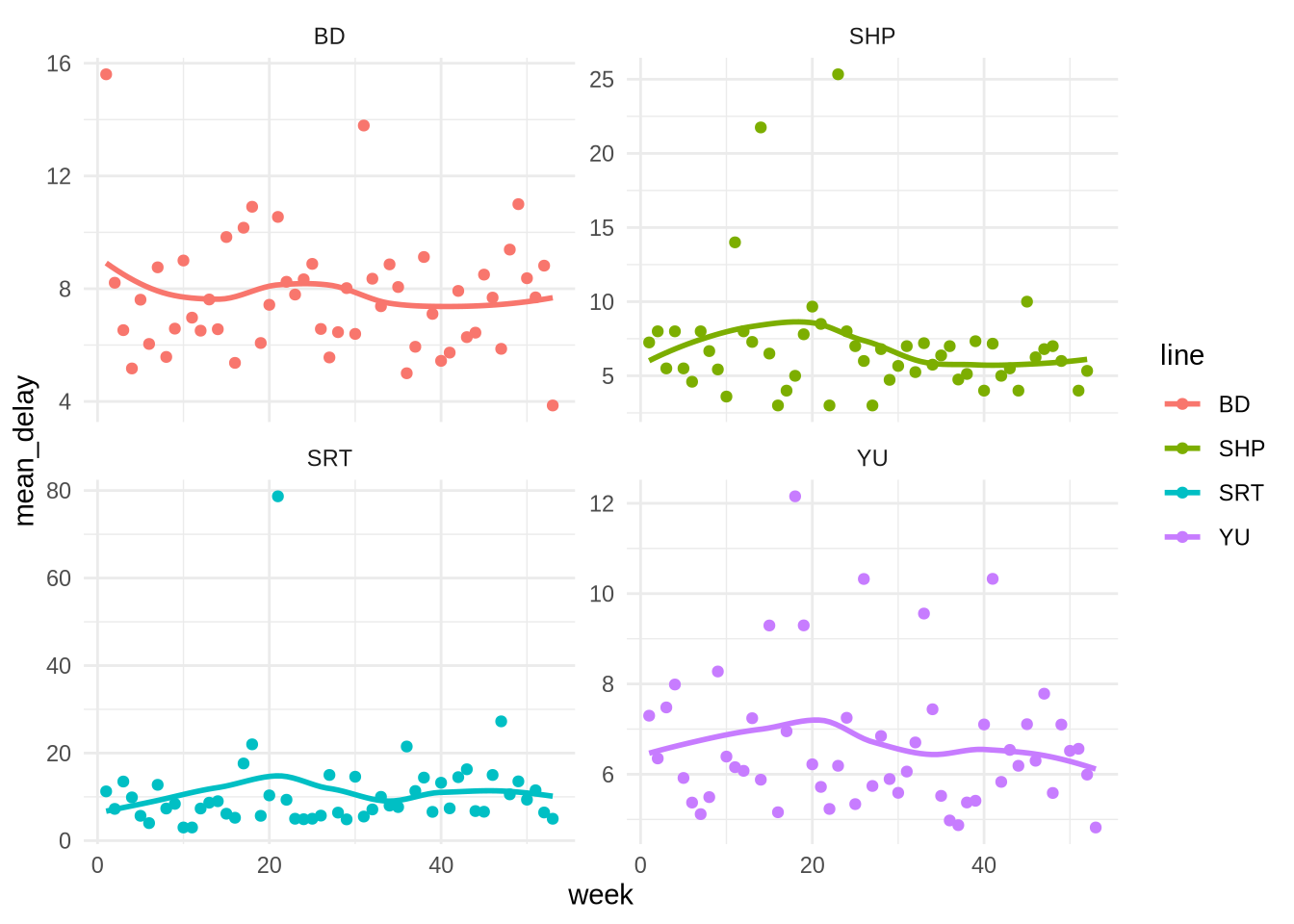
이번엔 좀 더 심각한 지연, 즉 10분 이상 지연된 사례들의 비중을 주별로 살펴보겠습니다 (Figure 11.6).
all_2021_ttc_data_no_dupes_with_explanation |>
mutate(week = week(date)) |>
summarise(prop_delay = sum(min_delay > 10) / n(),
.by = c(week, line)) |>
ggplot(aes(week, prop_delay, color = line)) +
geom_point() +
geom_smooth(se = FALSE) +
facet_wrap(vars(line), scales = "free_y") +
theme_minimal()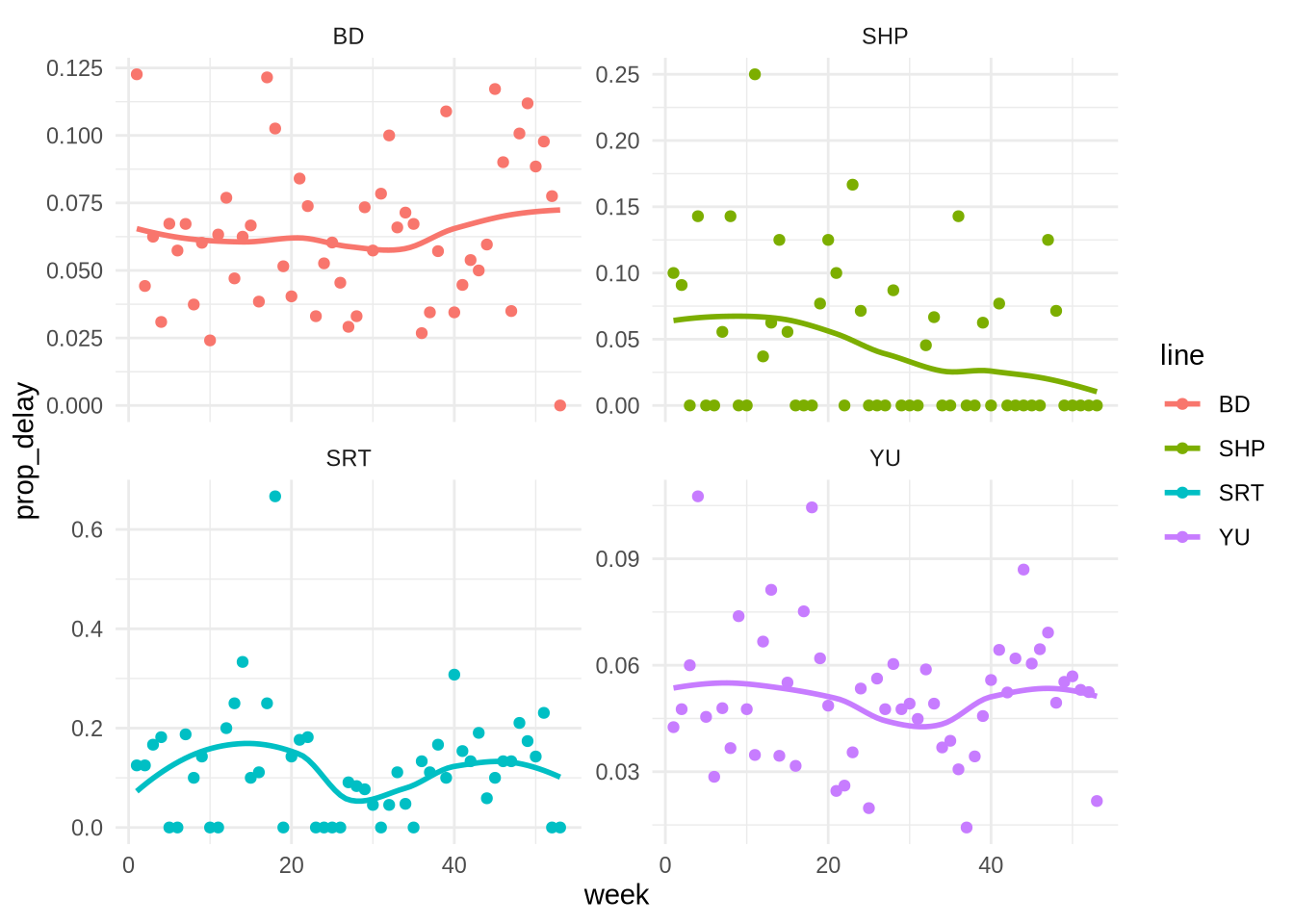
이러한 탐색 과정에서 생성된 모든 그림과 표가 최종 논문에 실리지는 않을 것입니다. 하지만 이 고된 과정을 통해 우리는 데이터와 깊이 소통하며 확신을 얻게 됩니다. 발견한 모든 특이점과 경고, 그리고 나중에 다시 파고들어야 할 문제들을 꼼꼼히 기록해 두는 것을 잊지 마세요.
11.4.2 변수 간의 관계 탐색
두 변수가 서로 어떤 영향을 주고받는지 살펴보는 것도 EDA의 핵심입니다. 시각화 기법에 대한 자세한 내용은 Chapter 5 장을 참고하세요. 산점도는 연속형 변수 간의 관계를 파악하는 데 제격이며, 모델링을 위한 훌륭한 예비 단계가 됩니다. 예를 들어 지연 시간(min_delay)과 열차 배차 간격(min_gap) 사이의 관계를 살펴볼까요? (Figure 11.7).
all_2021_ttc_data_no_dupes_with_explanation |>
ggplot(aes(x = min_delay, y = min_gap, alpha = 0.1)) +
geom_point() +
scale_x_log10() +
scale_y_log10() +
theme_minimal()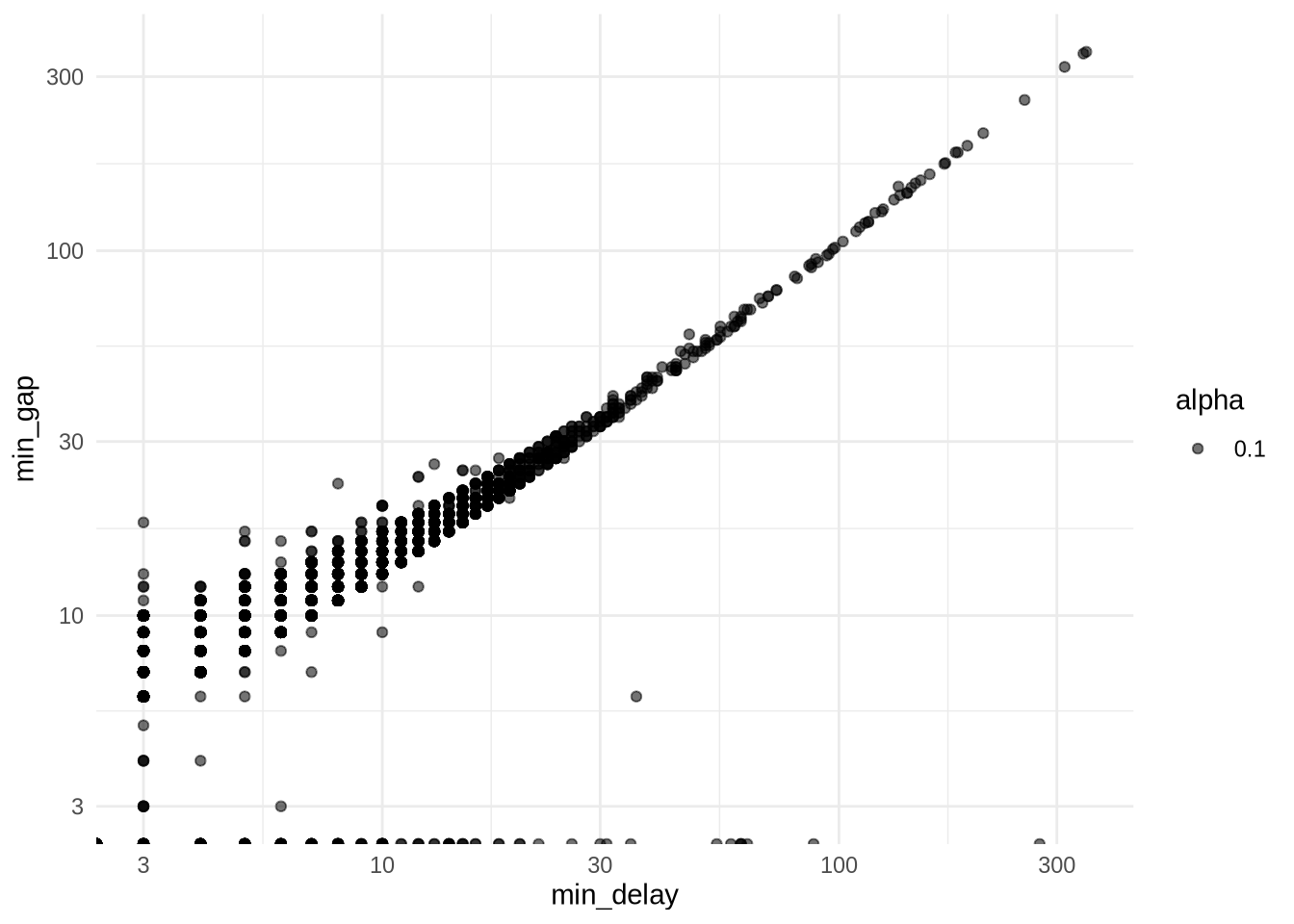
범주형 변수 간의 관계 파악은 조금 더 손이 많이 갑니다. 예컨대 노선별로 지연을 일으키는 주요 원인 상위 5가지를 비교해 볼 수 있겠죠. 노선마다 원인이 다른지, 그 차이가 통계적 모델로 설명 가능한 수준인지 가늠해 보는 과정입니다 (Figure 11.8).
all_2021_ttc_data_no_dupes_with_explanation |>
summarise(mean_delay = mean(min_delay),
.by = c(line, code_desc)) |>
arrange(-mean_delay) |>
slice(1:5, .by = line) |>
ggplot(aes(x = reorder(code_desc, mean_delay), y = mean_delay)) +
geom_col() +
facet_wrap(vars(line), scales = "free_y", nrow = 4) +
coord_flip() +
theme_minimal() +
labs(x = "지연 사유", y = "평균 지연 시간 (분)")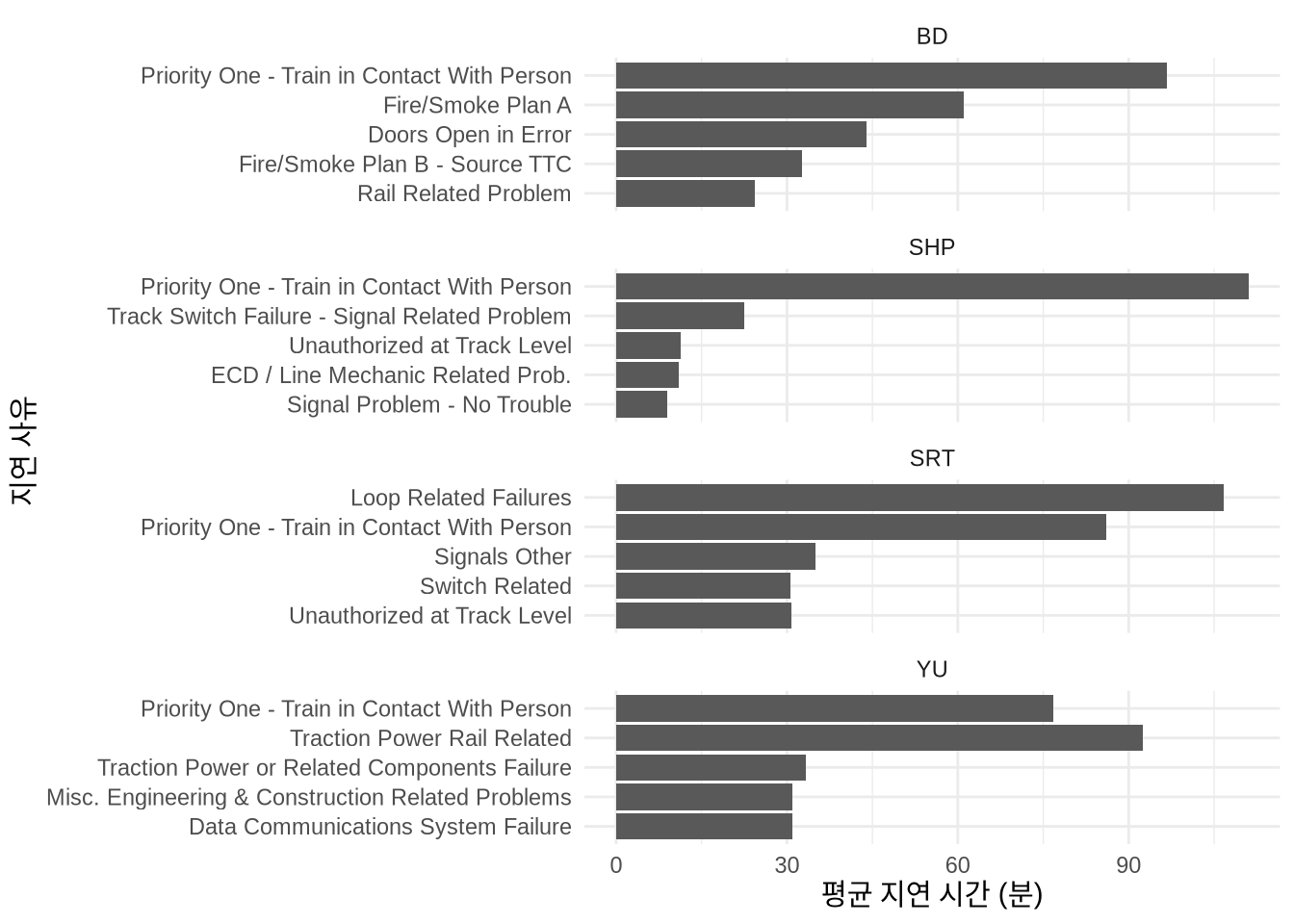
11.5 사례 연구: 런던 에어비앤비 숙소 목록
이번 사례 연구에서는 2023년 3월 14일 기준 영국 런던의 에어비앤비 숙소 데이터를 분석해 보겠습니다. 데이터는 Inside Airbnb 사이트에서 제공하는 공개 자료를 활용합니다 (Cox 2021). 웹사이트에서 실시간으로 데이터를 읽어올 수도 있지만, 재현성을 보장하고 서버 부하를 줄이기 위해 로컬에 사본을 저장해 두고 작업하는 방식을 권장합니다.
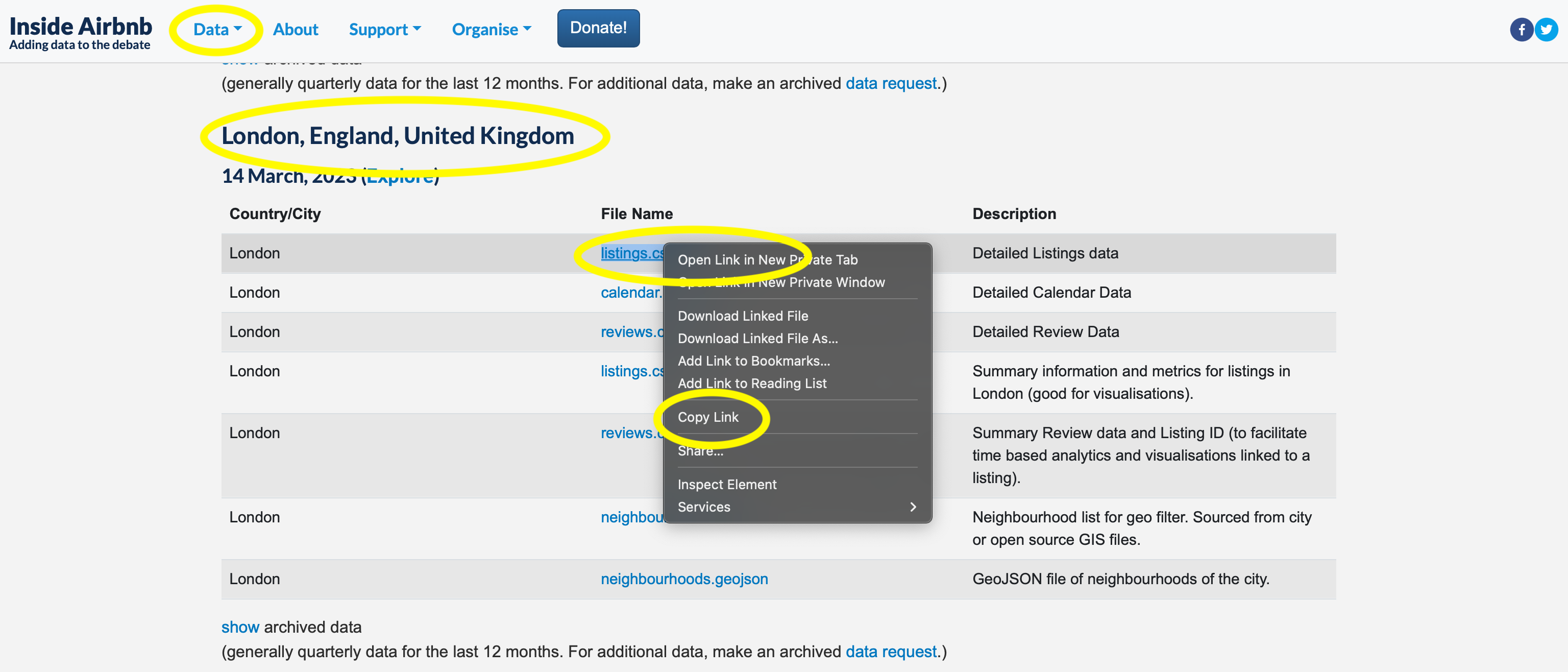
데이터는 Inside Airbnb의 “Get the Data” 메뉴에서 런던 섹션의 “listings.csv.gz” URL을 통해 가져올 수 있습니다 (Figure 11.9).
원본 데이터는 용량이 크고 저작권 문제가 얽혀 있을 수 있으므로, 재현성을 위해 로컬에 저장하되 GitHub에는 올라가지 않도록 설정(.gitignore)하는 것이 좋습니다. read_csv() 함수를 사용할 때 guess_max 인자를 넉넉히 설정하면, R이 데이터 앞부분만 보고 자료형을 잘못 추측하는 실수를 줄일 수 있습니다.
url <-
paste0(
"http://data.insideairbnb.com/united-kingdom/england/",
"london/2023-03-14/data/listings.csv.gz"
)
airbnb_data <-
read_csv(
file = url,
guess_max = 20000
)
write_csv(airbnb_data, "airbnb_data.csv")스크립트를 실행할 때마다 매번 에어비앤비 서버에 요청을 보내면 작업 속도가 느려지고 민폐가 될 수 있습니다. 한 번 다운로드한 뒤에는 로컬 파일을 읽어오도록 코드를 구성하세요.
원본 데이터셋은 100MB가 넘는 거대한 파일입니다. 원본은 그대로 보존하되, 탐색 분석에 필요한 변수들만 골라 효율적인 Parquet 형식으로 저장하겠습니다.
airbnb_data_selected <-
airbnb_data |>
select(
host_id,
host_response_time,
host_is_superhost,
host_total_listings_count,
neighbourhood_cleansed,
bathrooms,
bedrooms,
price,
number_of_reviews,
review_scores_rating,
review_scores_accuracy,
review_scores_value
)
write_parquet(
x = airbnb_data_selected,
sink =
"2023-03-14-london-airbnblistings-select_variables.parquet"
)
rm(airbnb_data)우선 숙박 가격(price) 변수부터 살펴보겠습니다. 원본 데이터에서 가격은 문자열(예: “$120.00”) 형태이므로, 기호와 쉼표를 제거하고 숫자형으로 변환해 주어야 합니다. 이 과정에서 자료형 변환으로 인해 엉뚱하게 결측치(NA)가 발생하지 않는지 주의 깊게 살펴야 합니다.
airbnb_data_selected$price |>
head()[1] "$100.00" "$65.00" "$132.00" "$100.00" "$120.00" "$43.00" airbnb_data_selected <-
airbnb_data_selected |>
mutate(
price = str_remove_all(price, "[\\$,]"),
price = as.integer(price)
)이제 가격 분포를 확인해 봅시다 (Figure 11.10 (a)). 이상치가 섞여 있으므로 로그 스케일을 적용해 보았습니다 (Figure 11.10 (b)).
airbnb_data_selected |>
ggplot(aes(x = price)) +
geom_histogram(binwidth = 10) +
theme_classic() +
labs(
x = "1박당 가격",
y = "숙소 수"
)
airbnb_data_selected |>
filter(price > 1000) |>
ggplot(aes(x = price)) +
geom_histogram(binwidth = 10) +
theme_classic() +
labs(
x = "1박당 가격",
y = "숙소 수"
) +
scale_y_log10()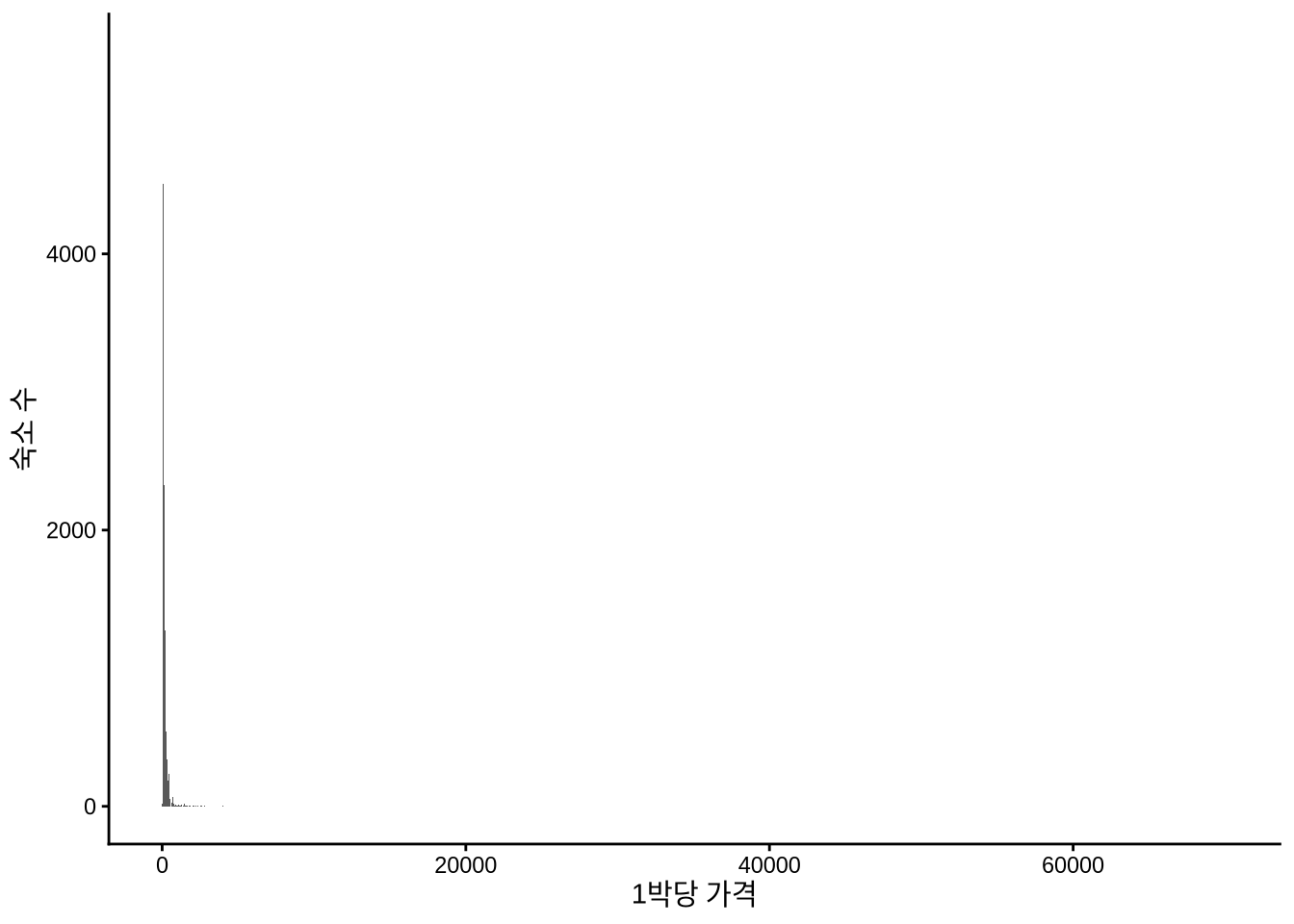
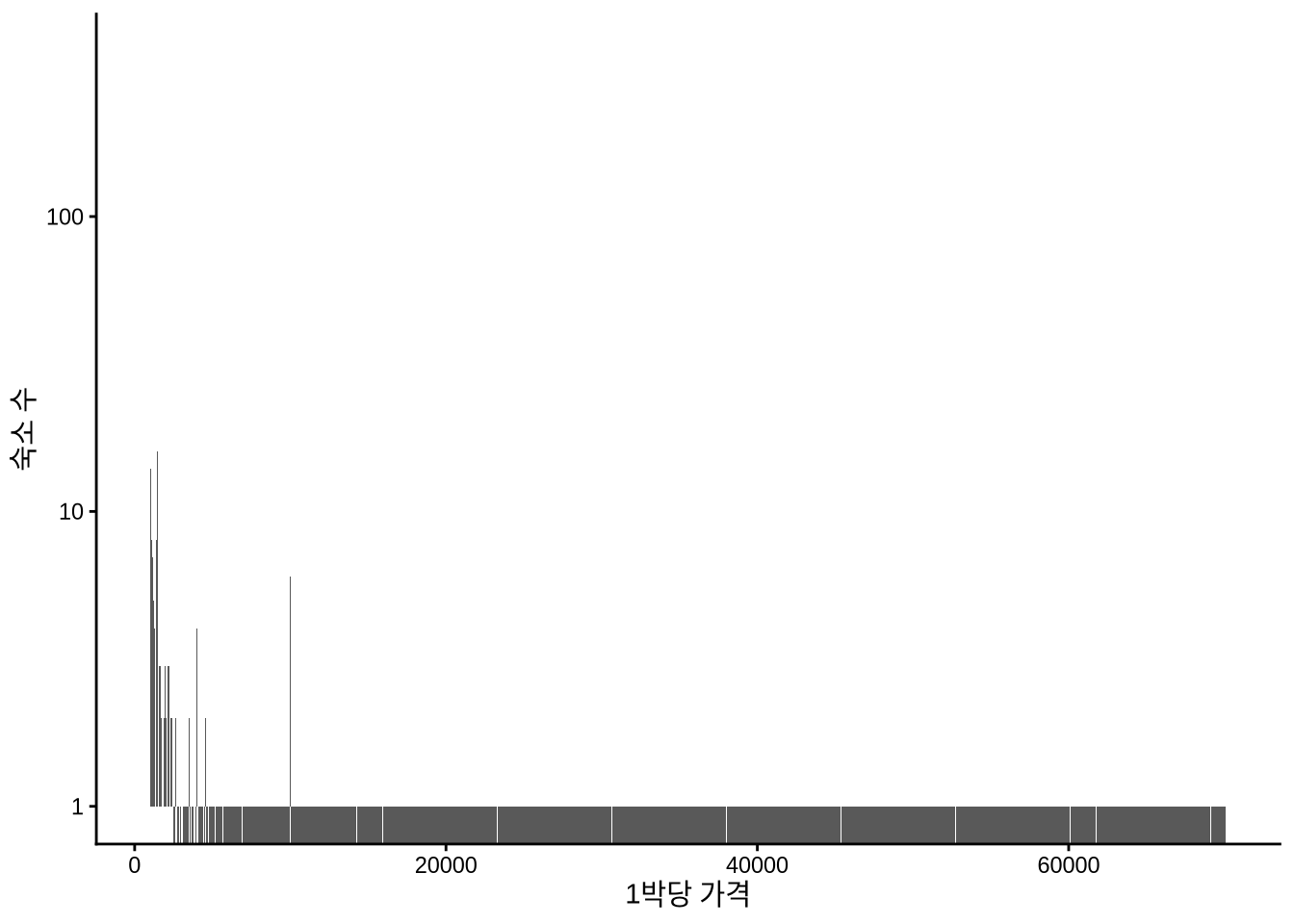
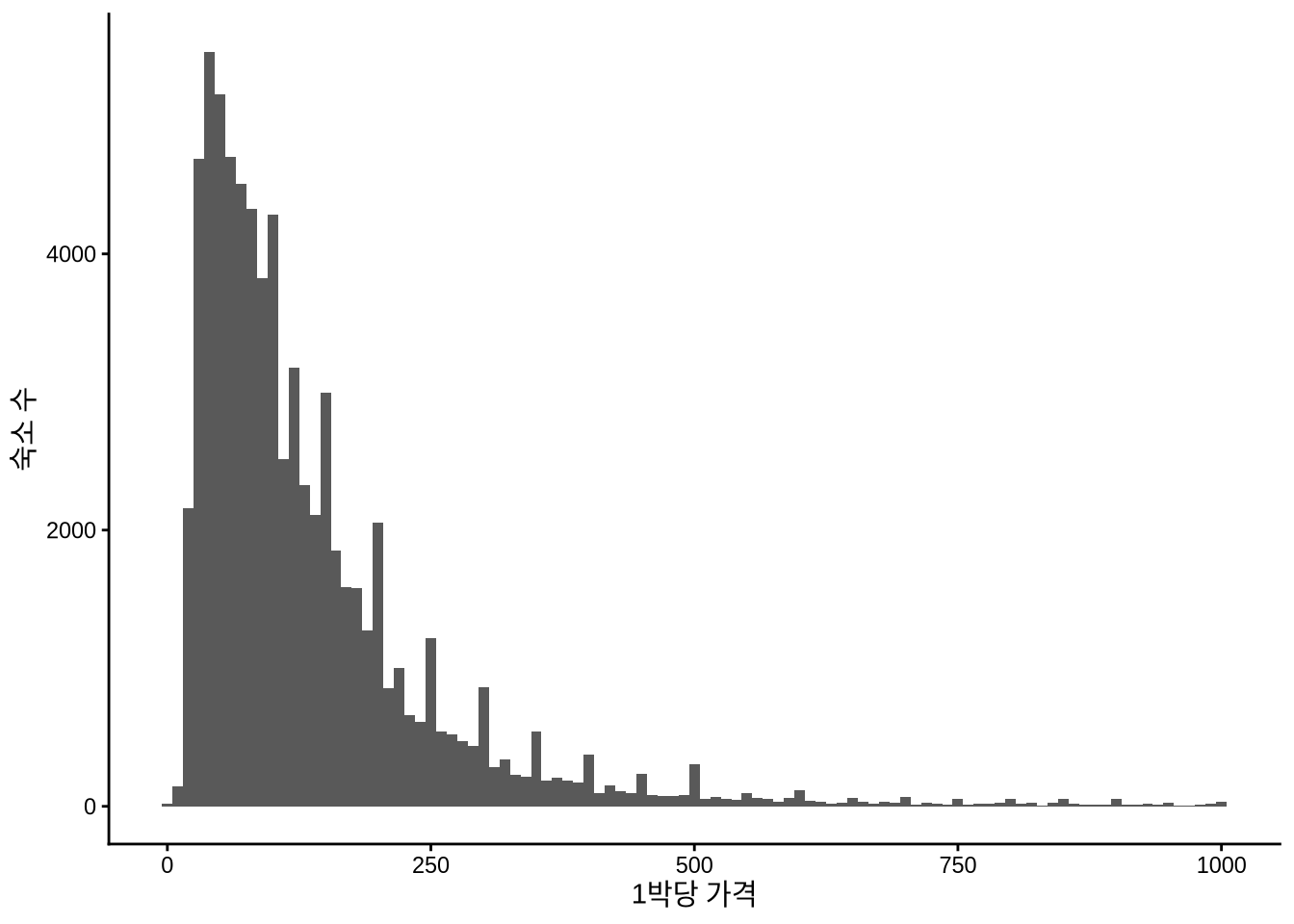
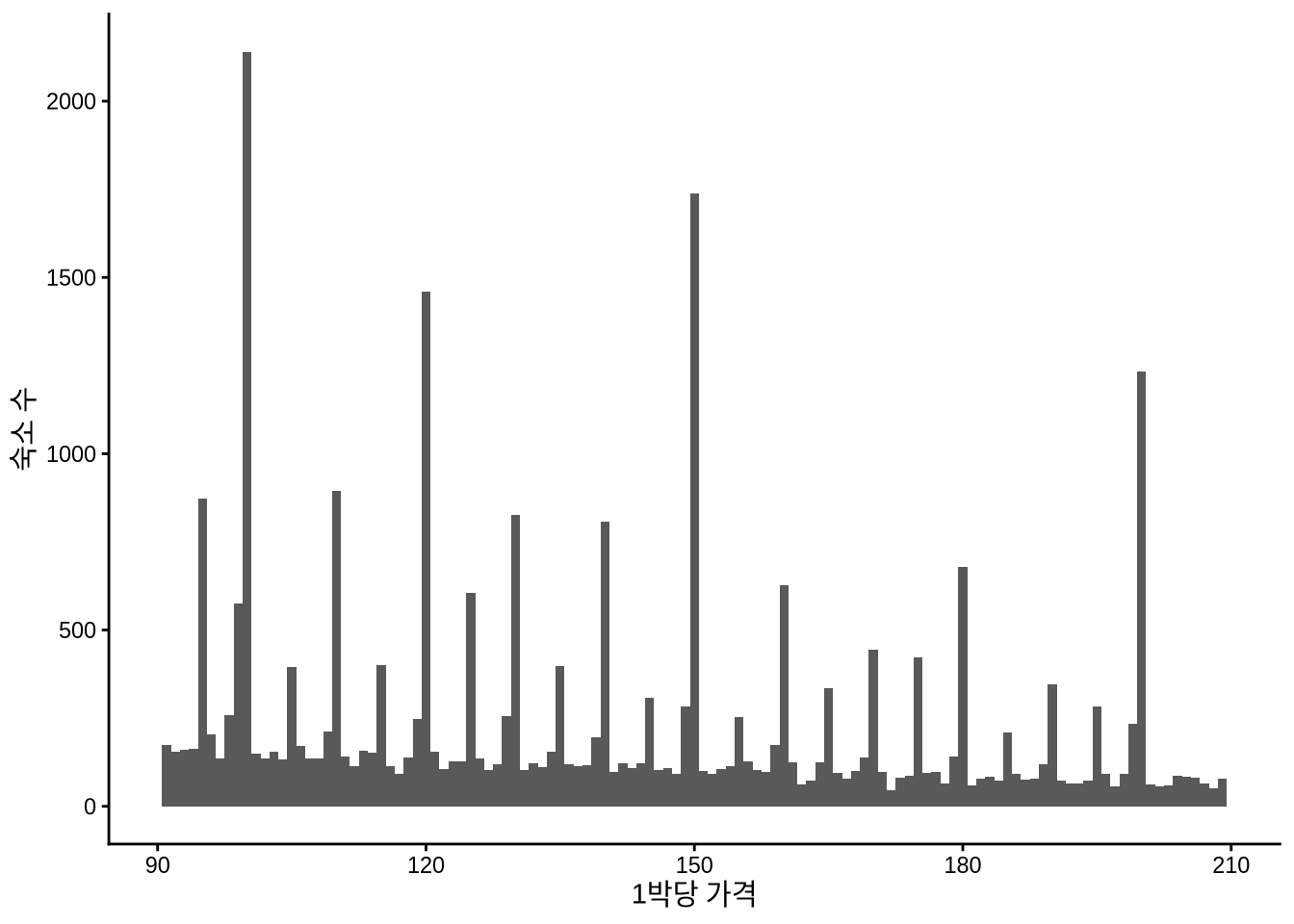
Figure 11.11 의 왼쪽 그래프를 보면 대부분의 숙소 가격이 1박당 250달러 미만에 집중되어 있음을 알 수 있습니다. Chapter 9 장에서 다루었던 연령 데이터처럼, 가격 데이터에서도 특정 숫자에 값이 몰리는 뭉침(Bunching) 현상이 나타납니다. 호스트들이 가격을 설정할 때 $100, $150처럼 딱 떨어지는 숫자를 선호하기 때문이죠. 오른쪽 그래프에서 90~210달러 구간을 확대해 보면 이러한 경향이 더 명확히 드러납니다.
airbnb_data_selected |>
filter(price < 1000) |>
ggplot(aes(x = price)) +
geom_histogram(binwidth = 10) +
theme_classic() +
labs(
x = "1박당 가격",
y = "숙소 수"
)
airbnb_data_selected |>
filter(price > 90) |>
filter(price < 210) |>
ggplot(aes(x = price)) +
geom_histogram(binwidth = 1) +
theme_classic() +
labs(
x = "1박당 가격",
y = "숙소 수"
)
지금은 999달러를 초과하는 고가 숙소 데이터는 제외하고 분석을 진행하겠습니다.
airbnb_data_less_1000 <-
airbnb_data_selected |>
filter(price < 1000)’슈퍼호스트’는 숙련된 경험과 우수한 평가를 받은 호스트를 말합니다. 호스트는 슈퍼호스트이거나 아니거나 둘 중 하나이므로 결측치(NA)가 없어야 정상이지만, 실제 데이터에는 NA가 존재합니다. 호스트가 정보를 삭제했거나 다른 사유가 있을 수 있는데, 이는 정밀 조사가 필요한 대목입니다.
airbnb_data_less_1000 |>
filter(is.na(host_is_superhost)) |>
nrow()[1] 13모델링의 편의를 위해 슈퍼호스트 여부를 나타내는 참/거짓 값을 0과 1의 이진 변수로 변환하고, 결측치가 있는 행은 제거하겠습니다.
airbnb_data_no_superhost_nas <-
airbnb_data_less_1000 |>
filter(!is.na(host_is_superhost)) |>
mutate(
host_is_superhost_binary =
as.numeric(host_is_superhost)
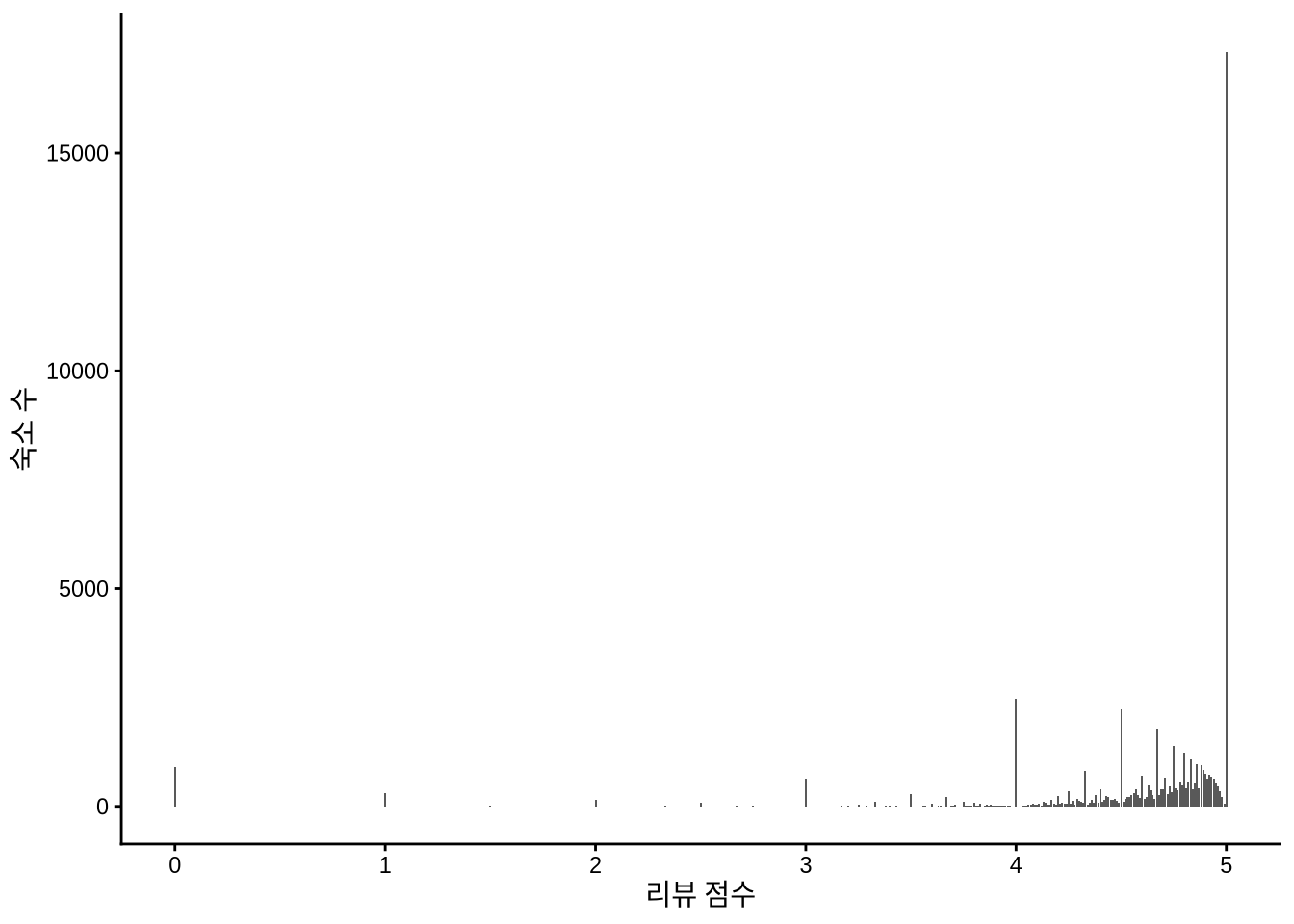
)에어비앤비 게스트는 다양한 항목에 대해 1~5점의 별점을 남깁니다. 하지만 실제 데이터를 그려보면 놀랍게도 거의 모든 점수가 5점에 쏠려 있는 이진적인 분포를 보입니다 (Figure 11.12).
airbnb_data_no_superhost_nas |>
ggplot(aes(x = review_scores_rating)) +
geom_bar() +
theme_classic() +
labs(
x = "리뷰 점수",
y = "숙소 수"
)
리뷰 점수의 결측치(NA) 처리는 꽤 복잡한 문제입니다. 단순히 리뷰가 아직 작성되지 않았기 때문일 수도 있죠.
airbnb_data_no_superhost_nas |>
filter(is.na(review_scores_rating)) |>
nrow()[1] 17681airbnb_data_no_superhost_nas |>
filter(is.na(review_scores_rating)) |>
select(number_of_reviews) |>
table()number_of_reviews
0
17681 리뷰 점수가 없는 숙소의 약 20%는 실제로 리뷰 개수가 0개입니다. 이러한 결측이 체계적으로 발생하고 있는지 확인하고 싶을 수 있습니다. 예를 들어 특정 노선이나 유형에서만 집중적으로 나타나는지 보는 것이죠.
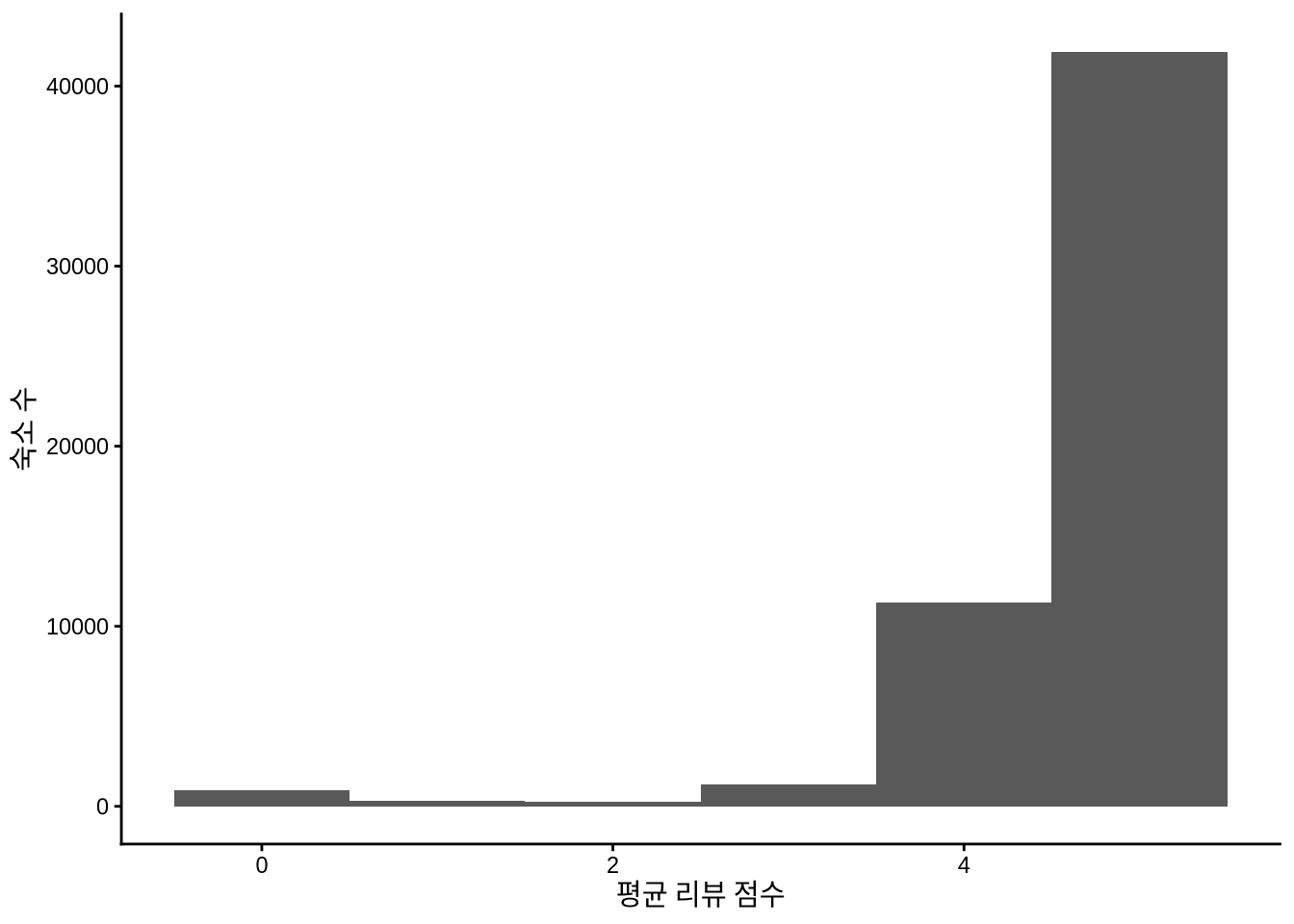
한 가지 전략은 일단 결측치가 없는 데이터와 핵심 리뷰 점수에만 집중해 보는 것입니다 (Figure 11.13).
airbnb_data_no_superhost_nas |>
filter(!is.na(review_scores_rating)) |>
ggplot(aes(x = review_scores_rating)) +
geom_histogram(binwidth = 1) +
theme_classic() +
labs(
x = "평균 리뷰 점수",
y = "숙소 수"
)
지금은 리뷰 점수가 누락된 약 20%의 관측치를 과감히 제거하겠습니다. 만약 이 데이터를 실제 연구에 활용한다면, 이러한 선택이 결과에 어떤 편향을 줄 수 있는지 부록 등에서 충분히 설명해야 합니다.
airbnb_data_has_reviews <-
airbnb_data_no_superhost_nas |>
filter(!is.na(review_scores_rating))호스트의 응답 속도도 중요한 요인입니다. 에어비앤비 데이터에서 “N/A”라는 텍스트로 표기된 응답 시간은 실제 결측치(NA)로 다시 코딩하고 요인(Factor)형으로 변환합니다.
airbnb_data_has_reviews <-
airbnb_data_has_reviews |>
mutate(
host_response_time = if_else(
host_response_time == "N/A",
NA_character_,
host_response_time
),
host_response_time = factor(host_response_time)
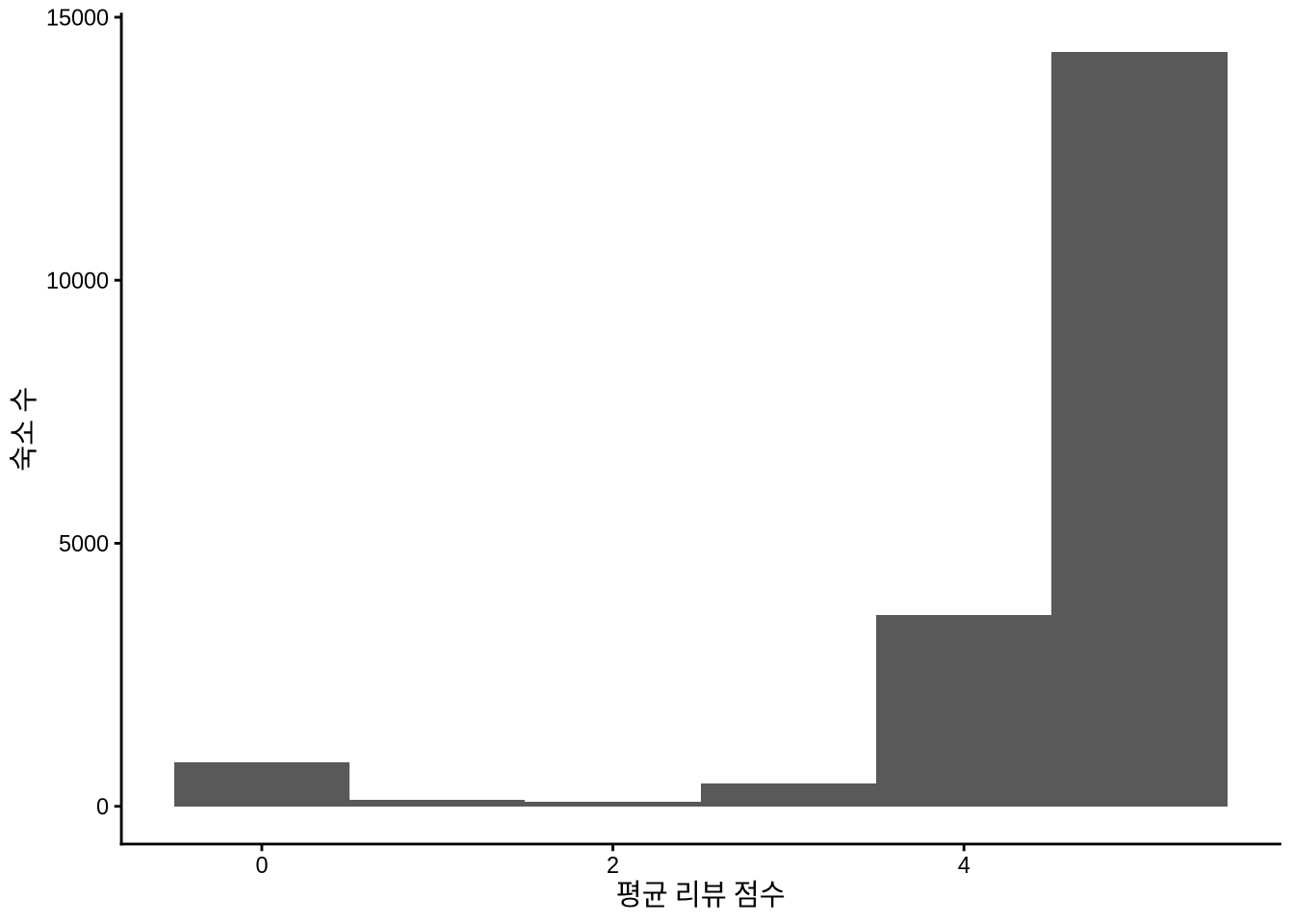
)응답 시간의 결측치가 리뷰 점수와 어떤 관계가 있는지 시각적으로 확인해 봅니다 (Figure 11.14). naniar 패키지의 geom_miss_point()를 쓰면 결측 데이터를 그래프 상에 효과적으로 표시할 수 있습니다 (Figure 11.15).
airbnb_data_has_reviews |>
filter(is.na(host_response_time)) |>
ggplot(aes(x = review_scores_rating)) +
geom_histogram(binwidth = 1) +
theme_classic() +
labs(
x = "평균 리뷰 점수",
y = "숙소 수"
)
airbnb_data_has_reviews |>
ggplot(aes(
x = host_response_time,
y = review_scores_accuracy
)) +
geom_miss_point() +
labs(
x = "호스트 응답 시간",
y = "리뷰 정확도 점수",
color = "결측치입니까?"
) +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust=1))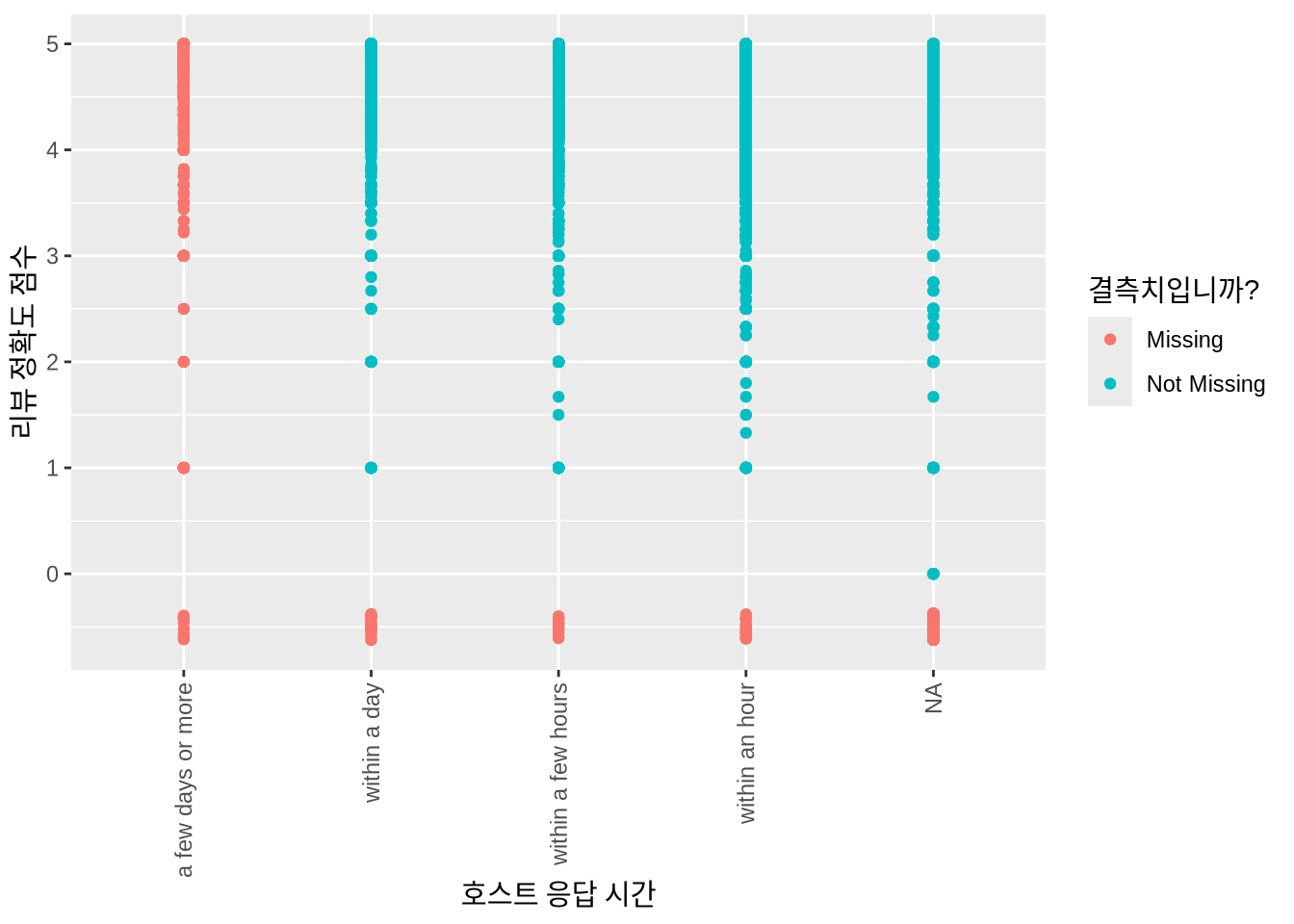
이번 분석에서는 응답 시간이 누락된 데이터를 다시 한번 제외하겠습니다. 이렇게 하면 원래의 약 20%가 또 줄어들게 되죠.
airbnb_data_selected <-
airbnb_data_has_reviews |>
filter(!is.na(host_response_time))호스트가 운영하는 총 숙소 수의 분포도 흥미롭습니다 (Figure 11.16).
airbnb_data_selected |>
ggplot(aes(x = host_total_listings_count)) +
geom_histogram() +
scale_x_log10() +
labs(
x = "호스트별 총 숙소 수",
y = "호스트 수"
)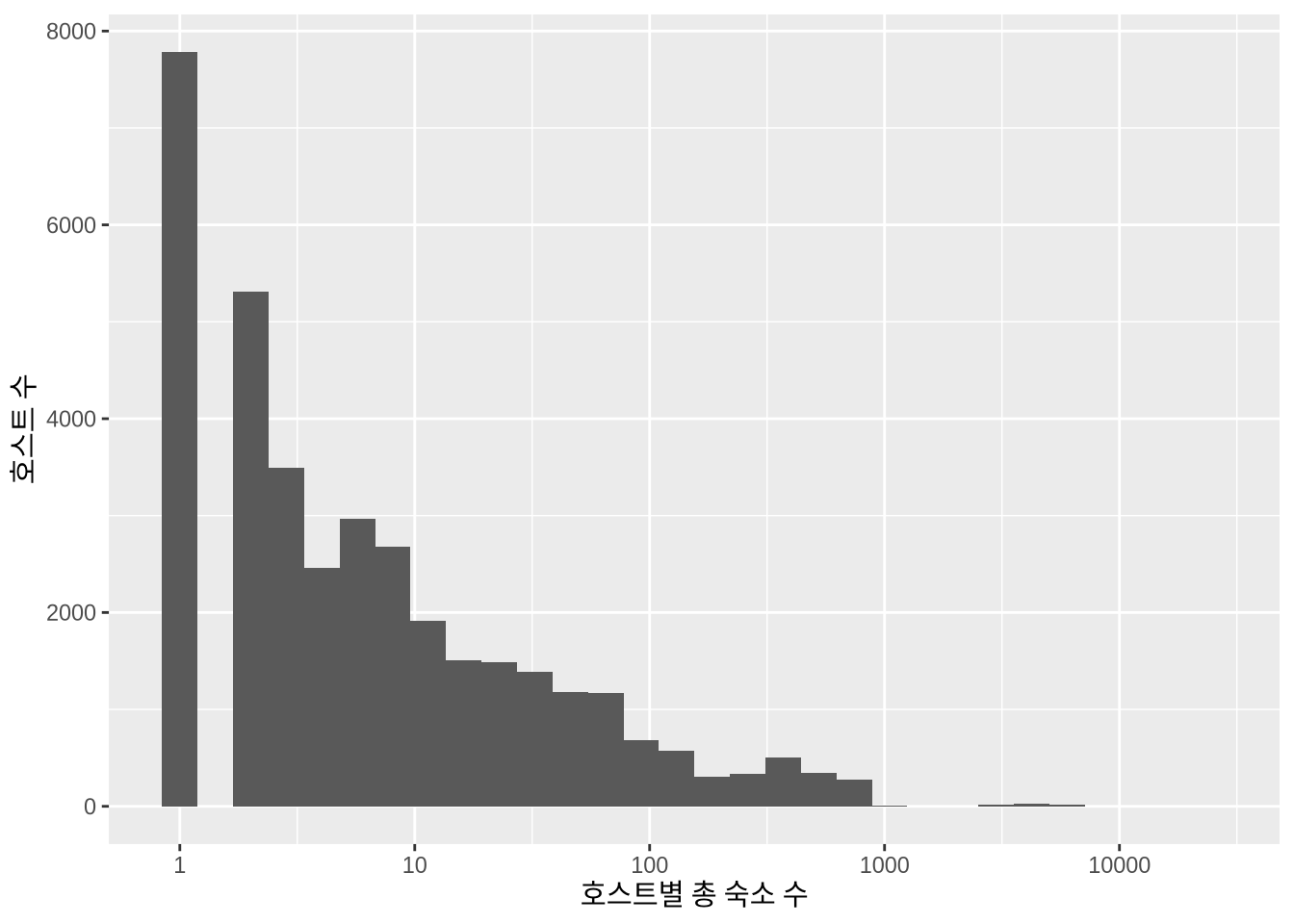
분포의 긴 꼬리 부분을 보면 500개 이상의 숙소를 관리하는 전문 호스트들이 포착됩니다. 이번 분석의 목적을 ’개인 호스트’로 한정하기 위해, 운영 숙소가 단 하나인 호스트의 데이터만 남기겠습니다.
airbnb_data_selected <-
airbnb_data_selected |>
add_count(host_id) |>
filter(n == 1) |>
select(-n)11.5.1 변수 간의 관계 탐색
이제 정제된 변수들 사이의 관계를 들여다볼 차례입니다. 가격과 리뷰 점수, 그리고 슈퍼호스트 여부가 서로 어떻게 얽혀 있는지 산점도로 그려보겠습니다 (Figure 11.17).
airbnb_data_selected |>
filter(number_of_reviews > 1) |>
ggplot(aes(x = price, y = review_scores_rating,
color = host_is_superhost)) +
geom_point(size = 1, alpha = 0.1) +
theme_classic() +
labs(
x = "1박당 가격",
y = "평균 리뷰 점수",
color = "슈퍼호스트"
) +
scale_color_brewer(palette = "Set1")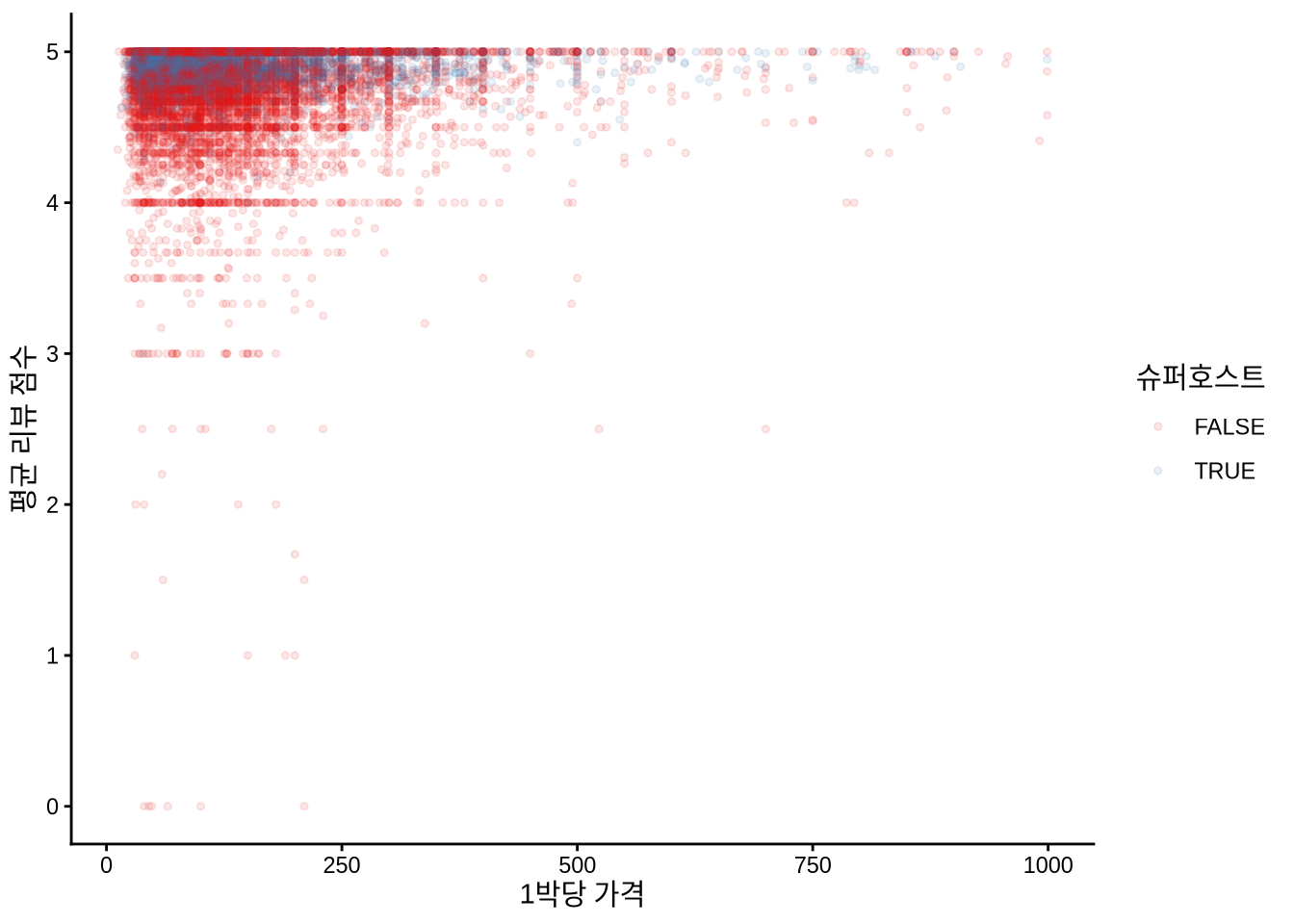
호스트의 응답 속도와 슈퍼호스트 선정 사이의 관계도 janitor의 tabyl() 함수로 일목요연하게 정리해 보았습니다. 1시간 이내에 응답하지 않는 호스트는 슈퍼호스트가 될 확률이 희박하다는 사실이 명확히 드러나네요.
airbnb_data_selected |>
tabyl(host_response_time, host_is_superhost) |>
adorn_percentages("col") |>
adorn_pct_formatting(digits = 0) |>
adorn_ns() |>
adorn_title() host_is_superhost
host_response_time FALSE TRUE
a few days or more 5% (489) 0% (8)
within a day 22% (2,322) 11% (399)
within a few hours 23% (2,440) 25% (928)
within an hour 50% (5,229) 64% (2,337)마지막으로 지역별(이웃) 숙소 수를 집계해 보았습니다.
airbnb_data_selected |>
tabyl(neighbourhood_cleansed) |>
adorn_pct_formatting() |>
arrange(-n) |>
filter(n > 100) |>
adorn_totals("row") |>
head() neighbourhood_cleansed n percent
Hackney 1172 8.3%
Westminster 965 6.8%
Tower Hamlets 956 6.8%
Southwark 939 6.6%
Lambeth 914 6.5%
Wandsworth 824 5.8%준비된 데이터로 간단한 모델을 실행해 보겠습니다. 모델링에 대해서는 Chapter 12 에서 자세히 다루겠지만, EDA 단계에서도 변수 간의 대략적인 관계를 파악하기 위해 모델을 활용할 수 있습니다. 예를 들어, 어떤 요인이 ‘슈퍼호스트’ 여부를 결정하는지 궁금할 수 있습니다. 결과값이 이진(Yes/No)이므로 로지스틱 회귀 분석이 적합합니다. 우리는 숙소에 대한 응답 속도가 빠르고 리뷰 점수가 높을수록 슈퍼호스트일 확률이 높을 것이라고 가설을 세울 수 있습니다. 구체적인 모델식은 다음과 같습니다.
\[\mbox{Prob}(\mbox{superhost}=1) = \mbox{logit}^{-1}\left( \beta_0 + \beta_1 \mbox{response\_time} + \beta_2 \mbox{review\_rating} + \epsilon\right)\]
glm 함수를 사용하여 모델을 추정합니다.
logistic_reg_superhost_response_review <-
glm(
host_is_superhost ~
host_response_time +
review_scores_rating,
data = airbnb_data_selected,
family = binomial
)modelsummary 패키지의 modelsummary() 함수를 사용하여 결과를 빠르게 살펴보겠습니다 (Table 11.3).
modelsummary(logistic_reg_superhost_response_review)| (1) | |
|---|---|
| (Intercept) | -16.369 |
| (0.673) | |
| host_response_timewithin a day | 2.230 |
| (0.361) | |
| host_response_timewithin a few hours | 3.035 |
| (0.359) | |
| host_response_timewithin an hour | 3.279 |
| (0.358) | |
| review_scores_rating | 2.545 |
| (0.116) | |
| Num.Obs. | 14152 |
| AIC | 14948.4 |
| BIC | 14986.2 |
| Log.Lik. | -7469.197 |
| F | 197.407 |
| RMSE | 0.42 |
분석 결과, 빠른 응답 속도와 높은 리뷰 점수 모두 슈퍼호스트 선정 확률과 뚜렷한 양의 상관관계를 보였습니다. 특히 1시간 이내 응답 여부가 결정적인 역할을 하고 있네요.
이제 분석에 사용된 최종 데이터셋을 저장하겠습니다.
write_parquet(
x = airbnb_data_selected,
sink = "2023-05-05-london-airbnblistings-analysis_dataset.parquet"
)11.6 결론
이 장에서 우리는 탐색적 데이터 분석(EDA)의 정수를 살펴보았습니다. EDA는 수동적으로 데이터를 읽어 들이는 과정이 아니라, 결측치와 변수의 분포, 그리고 변수 간의 역동적인 관계를 직접 파헤치며 데이터와 소통하는 능동적인 과정입니다. 우리는 이를 위해 그래프와 표라는 강력한 도구를 자유자재로 활용해 보았습니다.
EDA의 접근 방식은 데이터셋의 고유한 문제나 특징, 그리고 분석의 맥락에 따라 유연하게 변해야 합니다. 회귀 모델을 통한 예비 분석이나 차원 축소 기법 등 더 고도화된 기술들도 EDA의 훌륭한 무기가 될 수 있습니다.
11.7 연습 문제
실습
- (계획) 다음 시나리오를 구상해 보세요. “어느 소셜 미디어 플랫폼이 사용자 연령 데이터를 보유하고 있으며, 이 플랫폼에는 미국 인구의 약 80%가 가입되어 있다.” 이 데이터셋의 구조를 설계해 보고, 전체 관측치를 효과적으로 보여줄 수 있는 그래프를 스케치해 보세요.
- (시뮬레이션) 위 시나리오를 바탕으로 가상의 데이터를 생성해 보세요. 데이터 규모를 고려하여 Parquet 형식을 사용하고, 데이터의 무결성을 검증하기 위한 테스트 코드 10개를 포함하세요.
- (수집) 이와 같은 실제 데이터를 얻을 수 있는 현실적인 통로가 있다면 무엇인지 기술해 보세요.
- (탐색)
ggplot2를 사용하여 직접 스케치한 그래프를 구현해 보세요. - (소통) 분석 과정과 결과를 요약하고, 해당 표본을 기반으로 한 추론이 가질 수 있는 잠재적 위험 요소들에 대해 논의해 보세요.
퀴즈
- 투키의 논문 (Tukey (1962)) 을 읽고 요약한 뒤, 이를 현대 데이터 과학의 관점에서 비판적으로 재해석해 보세요.
- 본인이 생각하는 탐색적 데이터 분석(EDA)의 정의를 인용과 예시를 곁들여 서술해 보세요.
- “my_data”라는 이름의 데이터셋이 있고 “first_col”, “second_col”이라는 두 개의 열이 있을 때, 이를 시각화하는 R 코드를 작성해 보세요.
- 500개의 관측치와 3개의 변수로 이루어진 데이터셋에서 특정 열의 100개 행이 결측된 경우를 가정해 봅시다. 이 상황에서 데이터 제거와 대체 중 어떤 방식을 택하겠습니까? 데이터 규모가 10,000행으로 늘어난다면 결정이 달라질까요?
- 특이값(Unusual values)을 식별하는 세 가지 방법을 각각 설명해 보세요.
- 범주형 변수와 연속형 변수의 결정적인 차이점은 무엇입니까?
- Factor 변수와 Integer 변수의 차이점은 무엇입니까?
- 데이터 수집 과정에서 특정 집단이 ’체계적으로 배제’되는 상황에 대해 본인의 견해를 밝혀 보세요.
opendatatoronto패키지를 사용하여 2014년 토론토 시장 선거 기부금 데이터를 분석해 보세요.- 데이터 전처리를 수행하세요.
- 변수별 결측치 현황을 파악하고 논의하세요.
- 기부 금액의 분포를 시각화하고 이상치를 식별해 보세요.
- 총 기부액 기준 상위 5명의 후보자를 나열하세요.
- 본인 기부금을 제외했을 때 결과 변화를 확인하세요.
- 중복 기부자의 비중을 계산해 보세요.
ggplot2에서 막대 그래프를 그릴 수 있는 세 가지geom함수를 나열하세요.- 10,000개의 관측치와 27개의 변수가 있고, 모든 행에 최소 하나 이상의 결측치가 있는 데이터셋을 마주했다면 어떤 순서로 분석을 진행하겠습니까?
- 데이터셋에 ‘기록되지 않은’ 데이터가 결과에 어떤 편향을 불러올 수 있는지 비판적으로 논의해 보세요.
수업 활동
- 파일 명명 규칙: 다음 프로젝트 폴더의 파일 이름들을 더 나은 방식으로 수정해 보세요.
example_project/
├── .gitignore
├── Example project.Rproj
├── scripts
│ ├── simulate data.R
│ ├── DownloadData.R
│ ├── data-cleaning.R
│ ├── test(new)data.R- 앤스컴의 콰르텟: Chapter 5 에서 소개한 앤스컴의 콰르텟 데이터를 활용해 결측치 연습을 수행해 보세요. 무작위로 일부 데이터를 삭제한 뒤, 본 장에서 배운 대체 기법을 적용하여 실제값과 대체값을 비교해 보세요.
set.seed(853)
tidy_anscombe <-
anscombe |>
pivot_longer(everything(),
names_to = c(".value", "set"),
names_pattern = "(.)(.)")
tidy_anscombe_MCAR <-
tidy_anscombe |>
mutate(row_number = row_number()) |>
mutate(
x = if_else(row_number %in% sample(
x = 1:nrow(tidy_anscombe), size = 10
), NA_real_, x),
y = if_else(row_number %in% sample(
x = 1:nrow(tidy_anscombe), size = 10
), NA_real_, y)
) |>
select(-row_number)
tidy_anscombe_MCAR# A tibble: 44 × 3
set x y
<chr> <dbl> <dbl>
1 1 10 8.04
2 2 10 9.14
3 3 NA NA
4 4 8 NA
5 1 8 6.95
6 2 8 8.14
7 3 8 6.77
8 4 8 5.76
9 1 NA 7.58
10 2 13 8.74
# ℹ 34 more rows# 여기에 코드 추가- 비무작위 결측(MNAR) 상황에서 동일한 연습을 반복해 보고, MCAR 결과와 어떤 차이가 있는지 토론해 보세요.
tidy_anscombe_MNAR <-
tidy_anscombe |>
arrange(desc(x)) |>
mutate(
ordered_x_rows = 1:nrow(tidy_anscombe),
x = if_else(ordered_x_rows %in% 1:10, NA_real_, x)
) |>
select(-ordered_x_rows) |>
arrange(desc(y)) |>
mutate(
ordered_y_rows = 1:nrow(tidy_anscombe),
y = if_else(ordered_y_rows %in% 1:10, NA_real_, y)
) |>
arrange(set) |>
select(-ordered_y_rows)
tidy_anscombe_MNAR# A tibble: 44 × 3
set x y
<chr> <dbl> <dbl>
1 1 NA NA
2 1 NA NA
3 1 9 NA
4 1 11 8.33
5 1 10 8.04
6 1 NA 7.58
7 1 6 7.24
8 1 8 6.95
9 1 5 5.68
10 1 7 4.82
# ℹ 34 more rows# 여기에 코드 추가- 페어 프로그래밍(5분마다 교대)을 통해 Bombieri et al. (2023) 의 데이터셋을 읽어 들이고 Quarto 문서로 탐색해 보세요.
download.file(url = "https://doi.org/10.1371/journal.pbio.3001946.s005",
destfile = "data.xlsx")
data <-
read_xlsx(path = "data.xlsx",
col_types = "text") |>
clean_names() |>
mutate(date = convert_to_date(date))과제
다음 옵션 중 하나를 선택해 수행하고, Quarto로 작성한 PDF 보고서(제목, 저자, 날짜, GitHub 링크 포함)를 제출하세요.
옵션 1: 미국 주 및 인구 결측 데이터 연습을 palmerpenguins 패키지의 penguins 데이터셋 중 bill_length_mm 변수에 대해 반복하세요. 대체값과 실제값을 비교 분석한 소감을 최소 두 페이지 분량으로 작성하세요.
옵션 2: 프랑스 파리에 대한 에어비앤비 데이터로 EDA를 수행하세요.
옵션 3: “결측 데이터란 무엇이며 어떻게 처리해야 하는가?”라는 주제에 대해 자신의 견해를 담아 최소 두 페이지 분량의 에세이를 작성하세요.