library(babynames)
library(carData)
library(datasauRus)
library(ggmap)
library(janitor)
library(knitr)
library(leaflet)
library(mapdeck)
library(maps)
library(mapproj)
library(modelsummary)
library(opendatatoronto)
library(patchwork)
library(tidygeocoder)
library(tidyverse)
library(tinytable)
library(troopdata)
library(shiny)
library(usethis)
library(WDI)5 그래프, 표, 그리고 지도
채프먼 앤 홀/CRC(Chapman and Hall/CRC)는 2023년 7월 이 책을 출간했습니다. 도서는 이곳에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 일부 내용이 반영되어 있습니다.
권장 학습 자료
- 데이터 과학을 위한 R(원제: R for Data Science) (Wickham, Çetinkaya-Rundel, and Grolemund [2016] 2023) 읽기.
- 특히
ggplot2의 전반적인 기능을 다룬 1장 “데이터 시각화”를 꼼꼼히 읽어보세요.
- 특히
- 데이터 시각화: 실무 입문(원제: Data Visualization: A Practical Introduction) (Healy 2018) 읽기.
- 또 다른 관점에서
ggplot2활용법을 설명하는 3장 “플롯 만들기”에 집중해 보시기 바랍니다.
- 또 다른 관점에서
- 그래픽의 매력(원제: The Glamour of Graphics) (Chase 2020) 시청하기.
ggplot2로 만든 차트를 더 아름답고 효과적으로 다듬는 구체적인 요령들을 배울 수 있습니다.
- 통계 차트 테스트: 무엇이 좋은 그래프를 만드는가? (Vanderplas, Cook, and Hofmann 2020) 읽기.
- 그래프 제작의 모범 사례를 상세히 다룬 기사입니다.
- 데이터 페미니즘(원제: Data Feminism) (D’Ignazio and Klein 2020) 읽기.
- 데이터가 왜 맥락 속에서 고려되어야 하는지 보여주는 3장 “신화적이고 가상적이며 불가능한 관점에서의 객관성”을 읽어보세요.
- 통계 데이터의 그래픽 표현에 관한 역사적 발전 (Funkhouser 1937) 읽기.
- 그래프의 기원과 발전 과정을 논의한 2장 “그래픽 방법의 기원”에 주목해 보시기 바랍니다.
- 범례를 없애야 전설이 된다(원제: Remove the legend to become one) (Wei 2017) 읽기.
- 그래프를 점진적으로 개선해 나가는 과정을 잘 보여줍니다. 선 그래프 관련 부분부터 흥미롭게 읽으실 수 있을 것입니다.
- R을 활용한 지리 정보 연산(원제: Geocomputation with R) 2장 “R의 지리 데이터” (Lovelace, Nowosad, and Muenchow 2019) 읽기.
R을 이용한 지도 제작의 기초를 다룹니다.
- Mastering Shiny 1장 “첫 번째 Shiny 앱” (Wickham 2021b) 읽기.
- Shiny 앱의 간단한 예제와 작동 방식을 친절하게 소개합니다.
핵심 개념 및 기술
- 시각화는 데이터를 깊이 있게 이해하고 그 결과를 독자에게 효과적으로 전달하는 핵심 수단입니다. 요약된 통계치에만 의존하지 않고, 데이터셋의 개별 관측치를 직접 플로팅해보는 태도가 무엇보다 중요합니다.
- 막대 차트, 산점도, 선 그래프, 히스토그램 등 다양한 그래프 유형의 특성을 이해하고 상황에 맞게 선택할 수 있어야 합니다. 위치 정보가 포함된 데이터라면 지도를 ’공간적 그래프’의 일종으로 활용할 수 있습니다.
- 표는 데이터를 체계적으로 요약할 때 쓰입니다. 주로 데이터셋의 일부 샘플이나 요약 통계량, 혹은 회귀 분석 결과 등을 보여줄 때 유용합니다.
소프트웨어 및 패키지
babynames(Wickham 2021a)- Base R (R Core Team 2024)
carData(Fox, Weisberg, and Price 2022)datasauRus(Davies, Locke, and D’Agostino McGowan 2022)ggmap(Kahle and Wickham 2013)janitor(Firke 2023)knitr(Xie 2023)leaflet(Cheng, Karambelkar, and Xie 2021)mapdeck(Cooley 2020)maps(Becker et al. 2022)mapproj(McIlroy et al. 2023)modelsummary(Arel-Bundock 2022)opendatatoronto(Gelfand 2022)patchwork(Pedersen 2022)shiny(Chang et al. 2021)tidygeocoder(Cambon and Belanger 2021)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)troopdata(Flynn 2022)usethis(Wickham, Bryan, and Barrett 2022)WDI(Arel-Bundock 2021)
5.1 서론
데이터로 이야기를 들려줄 때, 우리는 데이터가 독자를 설득하는 데 결정적인 역할을 해주길 기대합니다. 이때 논문은 메시지를 담는 그릇이고, 데이터는 그 속에 담길 핵심 메시지 그 자체입니다. 독자가 왜 이런 결론에 도달했는지 충분히 납득하게 하려면, 분석의 토대가 된 데이터를 투명하게 보여주어야 합니다. 이를 위해 우리는 그래프와 표, 그리고 지도를 활용합니다.
가급적 분석의 바탕이 되는 개별 관측치를 그대로 보여주려 노력해 보세요. 예를 들어 2,500명의 설문 응답을 분석한다면, 논문의 어딘가에는 이 2,500개의 응답이 모두 점으로 찍힌 플롯이 있어야 합니다. 우리는 이를 위해 ggplot2 패키지를 사용합니다. ggplot2는 tidyverse 핵심 라이브러리에 포함되어 있어 별도로 로드할 필요 없이 바로 쓸 수 있습니다. 이번 장에서는 막대 차트, 산점도, 선 그래프, 히스토그램 등 다양한 시각화 기법을 익히게 될 것입니다.
개별 관측치를 시각화하는 그래프와 달리, 표는 주로 데이터의 일부를 발췌해 보여주거나 요약 통계량, 회귀 분석 결과 등을 일목요연하게 전달할 때 사용합니다. 표 제작에는 주로 tinytable 패키지를 활용하며, 회귀 분석 결과표를 만들 때는 modelsummary 패키지가 훌륭한 도구가 될 것입니다.
마지막으로 지리 정보를 담은 데이터에 특화된 그래프의 변형인 지도를 다룹니다. tidygeocoder를 이용해 문자로 된 주소를 좌표 정보로 변환(지오코딩)하고, ggmap 등을 활용해 정교한 지도를 그려내는 방법을 살펴보겠습니다.
5.2 그래프의 힘
더 건전하고 풍요로운 문명으로 나아가는 세상은 차트로 나아가는 세상이 될 것입니다.
Karsten (1923, 684)
그래프는 설득력 있는 데이터 스토리를 구성하는 핵심 요소입니다. 좋은 그래프는 데이터에 담긴 거대한 흐름(Pattern)과 세밀한 부분(Detail)을 동시에 파악할 수 있게 해줍니다 (Cleveland [1985] 1994, 5). 또한 다른 어떤 분석 방법으로도 얻기 힘든 데이터에 대한 직관과 친숙함을 제공하죠. 따라서 분석에 활용하는 모든 핵심 변수는 반드시 그래프로 그려보아야 합니다.
그래프의 궁극적인 목표는 실제 데이터와 그 맥락을 독자에게 최대한 명확하게 전달하는 것입니다. 시각화는 일종의 정보 인코딩(Encoding) 과정이며, 작가는 청중에게 정보를 효과적으로 전달하기 위해 의도적인 시각적 도구를 구성합니다. 청중은 이 결과물을 해석해 정보를 디코딩(Decoding)하게 되죠. 그래프의 성공 여부는 이 인코딩과 디코딩 과정에서 얼마나 많은 정보가 손실 없이 전달되느냐에 달려 있습니다 (Cleveland [1985] 1994, 221). 결국 우리는 특정 목표 청중이 가장 쉽고 정확하게 이해할 수 있는 그래프를 만드는 데 집중해야 합니다.
시각화가 왜 중요한지 직접 확인해 볼까요? datasauRus 패키지를 설치하고 로드한 뒤 datasaurus_dozen 데이터셋을 살펴보겠습니다.
이 데이터셋에는 x축과 y축에 플로팅할 ‘x’와 ’y’ 값이 들어있습니다. ‘dataset’ 변수에는 ‘dino’(공룡), ‘star’, ‘away’, ‘bullseye’ 등 13가지 서로 다른 데이터 그룹이 포함되어 있죠. 우선 이 중 네 그룹을 골라 평균과 표준 편차 같은 요약 통계량을 계산해 보겠습니다 (Table 5.1).
# Based on: https://juliasilge.com/blog/datasaurus-multiclass/
datasaurus_dozen |>
filter(dataset %in% c("dino", "star", "away", "bullseye")) |>
summarise(across(c(x, y), list(mean = mean, sd = sd)),
.by = dataset) |>
tt() |>
style_tt(j = 2:5, align = "r") |>
format_tt(digits = 1, num_fmt = "decimal") |>
setNames(c("데이터 세트", "x 평균", "x 표준 편차", "y 평균", "y 표준 편차"))| 데이터 세트 | x 평균 | x 표준 편차 | y 평균 | y 표준 편차 |
|---|---|---|---|---|
| dino | 54.3 | 16.8 | 47.8 | 26.9 |
| away | 54.3 | 16.8 | 47.8 | 26.9 |
| star | 54.3 | 16.8 | 47.8 | 26.9 |
| bullseye | 54.3 | 16.8 | 47.8 | 26.9 |
네 가지 데이터 그룹의 요약 통계량이 거의 일치한다는 점에 주목하세요 (Table 5.1). 만약 이 숫자들만 본다면 네 그룹이 서로 매우 비슷할 것이라고 짐작하게 될 것입니다. 하지만 실제로 데이터를 그래프로 그려보면 전혀 예상치 못한 결과가 나타납니다 (Figure 5.1).
datasaurus_dozen |>
filter(dataset %in% c("dino", "star", "away", "bullseye")) |>
ggplot(aes(x = x, y = y, colour = dataset)) +
geom_point() +
theme_minimal() +
facet_wrap(vars(dataset), nrow = 2, ncol = 2) +
labs(color = "데이터 세트")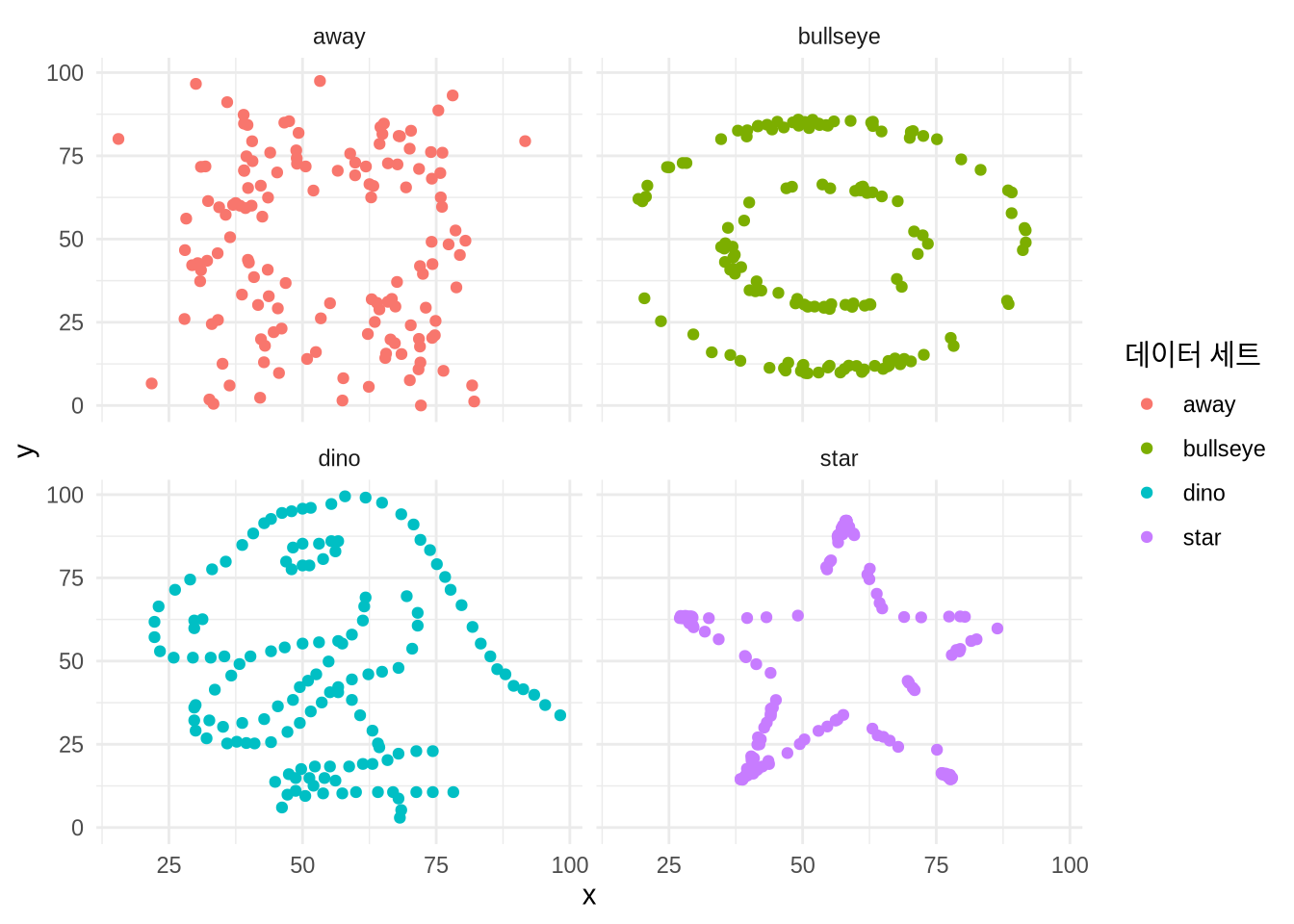
이와 같은 통찰은 20세기의 저명한 통계학자 프랭크 앤스콤(Frank Anscombe)이 고안한 ’앤스콤의 콰르텟(Anscombe’s Quartet)’에서도 찾아볼 수 있습니다. 핵심은 명쾌합니다. 요약 통계량에만 매몰되지 말고, 반드시 실제 데이터를 직접 눈으로 확인하라는 것입니다.
head(anscombe) x1 x2 x3 x4 y1 y2 y3 y4
1 10 10 10 8 8.04 9.14 7.46 6.58
2 8 8 8 8 6.95 8.14 6.77 5.76
3 13 13 13 8 7.58 8.74 12.74 7.71
4 9 9 9 8 8.81 8.77 7.11 8.84
5 11 11 11 8 8.33 9.26 7.81 8.47
6 14 14 14 8 9.96 8.10 8.84 7.04앤스콤의 콰르텟은 4개의 서로 다른 데이터셋에 대한 11개의 관측치로 구성되며, 각 관측치에는 x 및 y 값이 있습니다. 온라인 부록 A 에서 다루었듯이 이 데이터셋을 ‘정돈된(Tidy)’ 형식으로 만들기 위해 pivot_longer()를 사용해 가공해 보겠습니다.
# From: https://www.njtierney.com/post/2020/06/01/tidy-anscombe/
# And the pivot_longer() vignette.
tidy_anscombe <-
anscombe |>
pivot_longer(
everything(),
names_to = c(".value", "set"),
names_pattern = "(.)(.)"
)먼저 요약 통계를 생성한 뒤 (Table 5.2) 데이터를 플로팅해 보겠습니다 (Figure 5.2). 요약 통계에만 의존하지 않고 실제 데이터를 그래프로 나타내는 것이 얼마나 중요한지 다시 한번 실감할 수 있을 것입니다.
tidy_anscombe |>
summarise(
across(c(x, y), list(mean = mean, sd = sd)),
.by = set
) |>
tt() |>
style_tt(j = 2:5, align = "r") |>
format_tt(digits = 1, num_fmt = "decimal") |>
setNames(c("데이터 세트", "x 평균", "x 표준 편차", "y 평균", "y 표준 편차"))| 데이터 세트 | x 평균 | x 표준 편차 | y 평균 | y 표준 편차 |
|---|---|---|---|---|
| 1 | 9 | 3.3 | 7.5 | 2 |
| 2 | 9 | 3.3 | 7.5 | 2 |
| 3 | 9 | 3.3 | 7.5 | 2 |
| 4 | 9 | 3.3 | 7.5 | 2 |
tidy_anscombe |>
ggplot(aes(x = x, y = y, colour = set)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
theme_minimal() +
facet_wrap(vars(set), nrow = 2, ncol = 2) +
labs(colour = "데이터 세트") +
theme(legend.position = "bottom")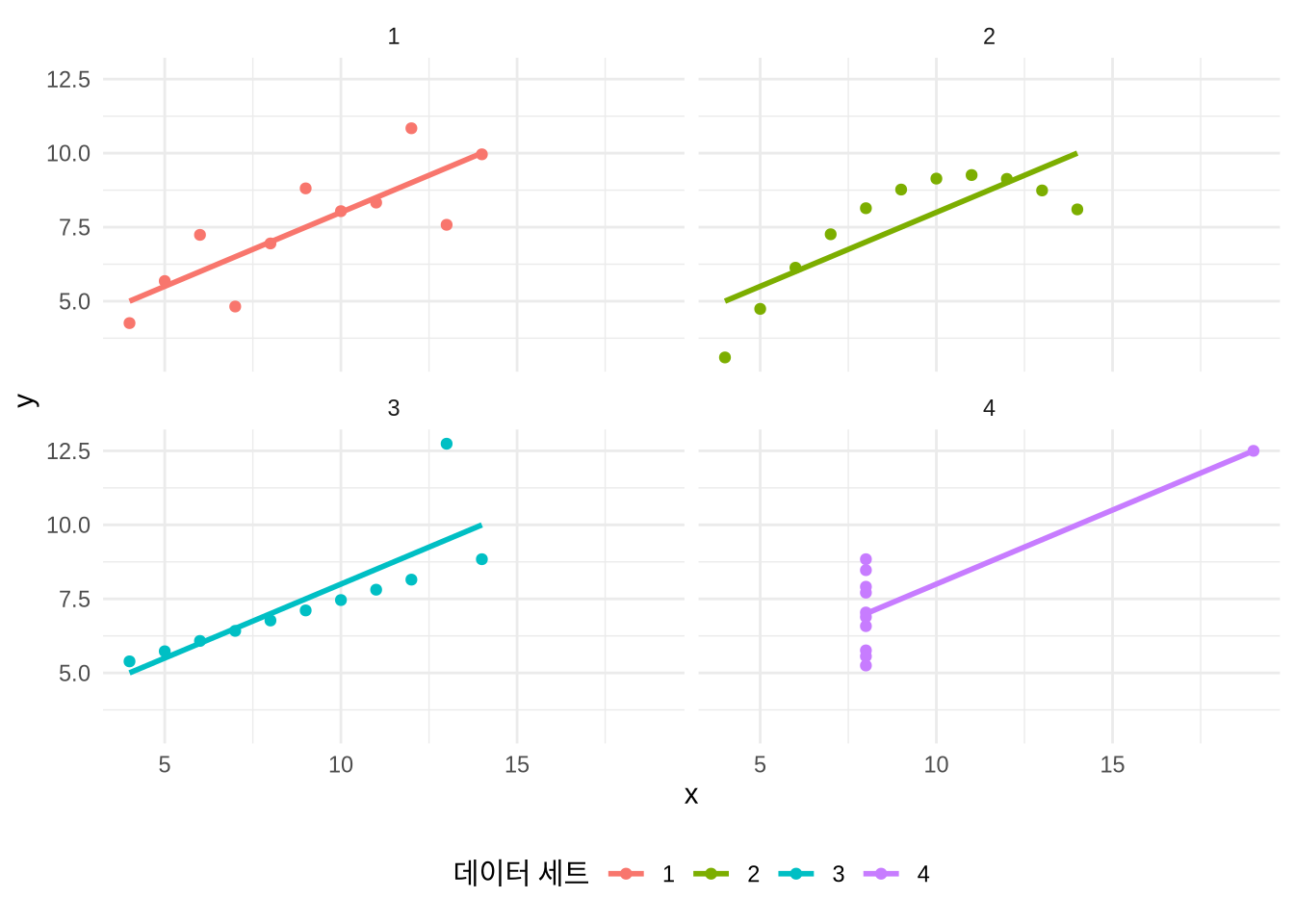
5.2.1 막대 차트
막대 차트(Bar Chart)는 주로 범주형 변수의 분포를 보여주려 할 때 사용합니다. 앞서 Chapter 2 에서 병원 침대 점유 수를 시각화할 때 이 방식을 쓴 적이 있죠. 가장 보편적인 함수인 geom_bar()를 기본으로 하되, 분석 상황에 따라 다양한 변형을 활용할 수 있습니다. 막대 차트 활용법을 익히기 위해 carData 패키지에 포함된 1997-2001년 영국 선거 패널 연구(British Election Panel Study, BEPS) 데이터를 써보겠습니다.
beps <-
BEPS |>
as_tibble() |>
clean_names() |>
select(age, vote, gender, political_knowledge)이 데이터셋은 응답자가 지지하는 정당과 인구 통계, 경제, 정치적 변수들로 이루어져 있습니다. 특히 응답자의 연령 정보가 담겨 있죠. 먼저 연령 데이터를 연령대 그룹으로 나눈 뒤 geom_bar()를 사용해 각 연령대의 빈도를 보여주는 막대 차트를 만들어 보겠습니다 (Figure 5.3 (a)).
beps <-
beps |>
mutate(
age_group =
case_when(
age < 35 ~ "<35",
age < 50 ~ "35-49",
age < 65 ~ "50-64",
age < 80 ~ "65-79",
age < 100 ~ "80-99"
),
age_group =
factor(age_group, levels = c("<35", "35-49", "50-64", "65-79", "80-99"))
)beps |>
ggplot(mapping = aes(x = age_group)) +
geom_bar() +
theme_minimal() +
labs(x = "연령 그룹", y = "관측치 수")
beps |>
count(age_group) |>
ggplot(mapping = aes(x = age_group, y = n)) +
geom_col() +
theme_minimal() +
labs(x = "연령 그룹", y = "관측치 수")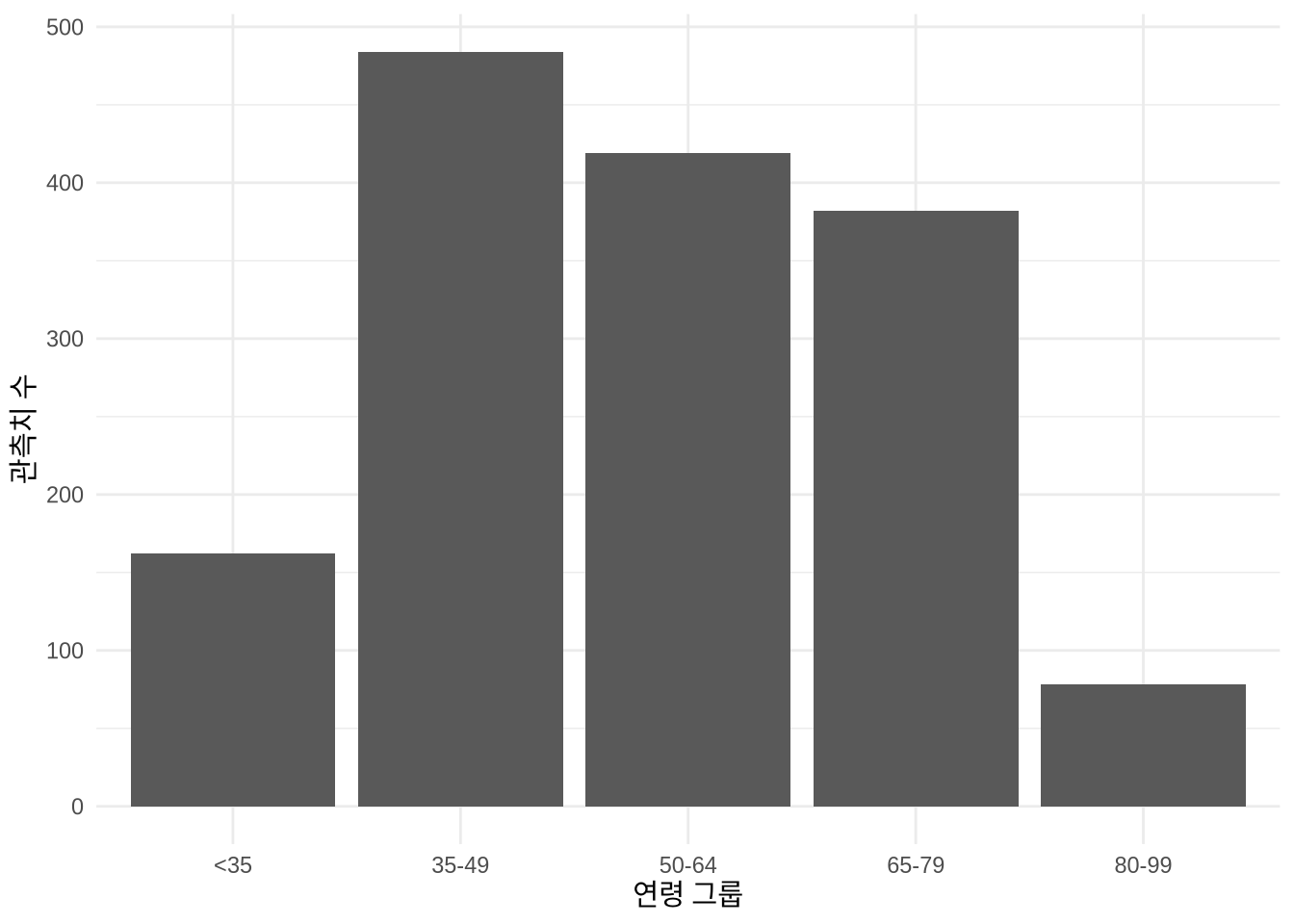
geom_bar() 사용
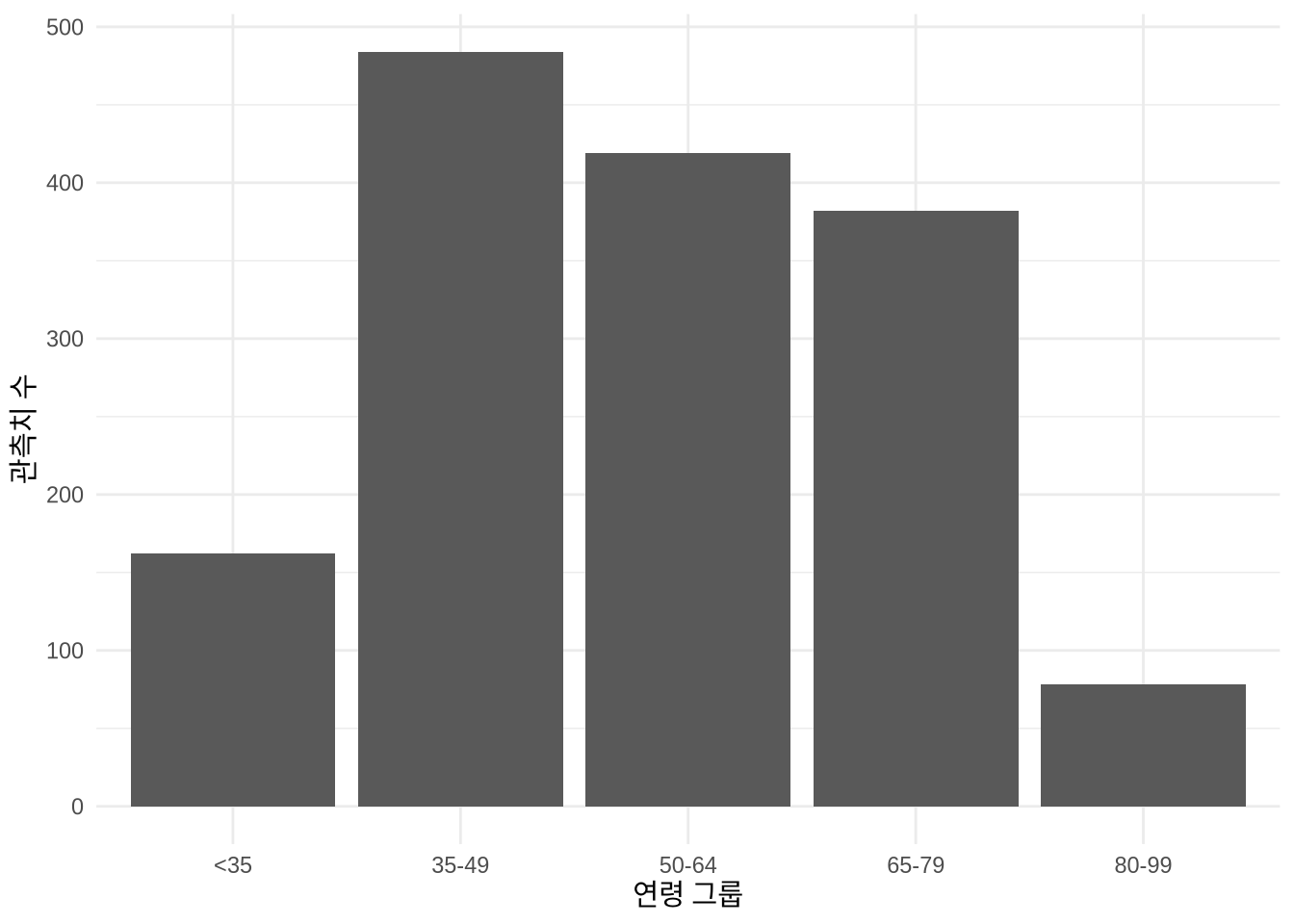
count() 및 geom_col() 사용
ggplot2에서 사용하는 기본 축 레이블은 변수 이름 그대로이므로, 더 친절한 설명을 덧붙이는 것이 좋습니다. labs() 함수를 이용해 축 이름을 지정할 수 있습니다. Figure 5.3 (a) 에서는 x축과 y축 레이블을 직접 입력해 주었습니다.
기본적으로 geom_bar()는 각 연령 그룹이 데이터셋에 나타나는 횟수를 스스로 계산합니다. 기본 통계 변환(stat) 설정이 “count”이기 때문이죠. 덕분에 우리가 직접 통계량을 만들 필요가 없습니다. 하지만 이미 카운트가 완료된 데이터를 가지고 있다면 (예: beps |> count(age_group)), y축 변수를 지정하고 geom_col()을 사용하면 됩니다 (Figure 5.3 (b)).
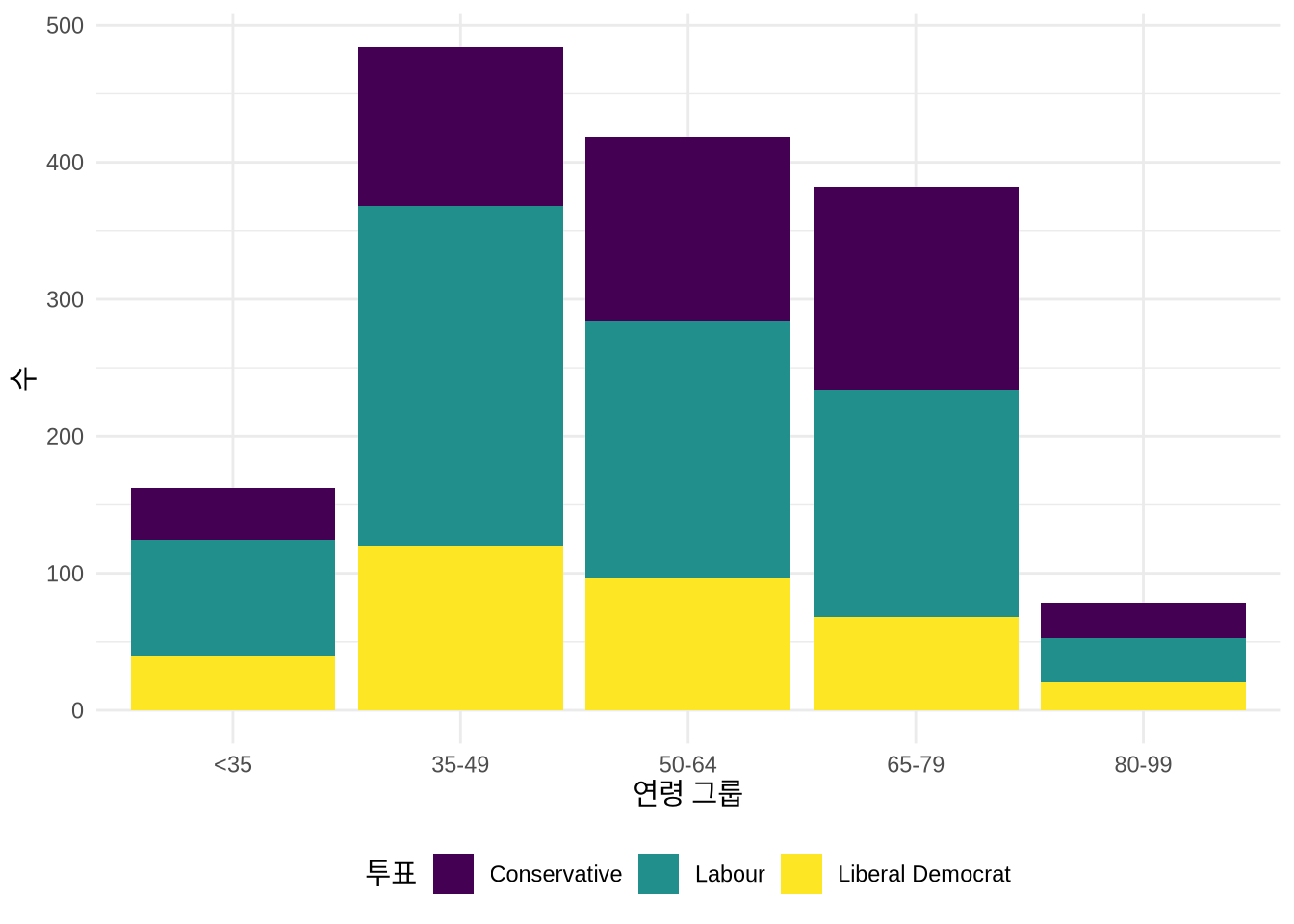
또 다른 통찰을 얻기 위해 데이터를 여러 그룹으로 나누어 살펴볼 수도 있습니다. 예를 들어 색상을 활용해 연령대별로 응답자가 지지하는 정당을 확인해 볼 수 있습니다 (Figure 5.4 (a)).
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
labs(x = "연령 그룹", y = "관측치 수", fill = "투표") +
theme(legend.position = "bottom")
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar(position = "dodge2") +
labs(x = "연령 그룹", y = "관측치 수", fill = "투표") +
theme(legend.position = "bottom")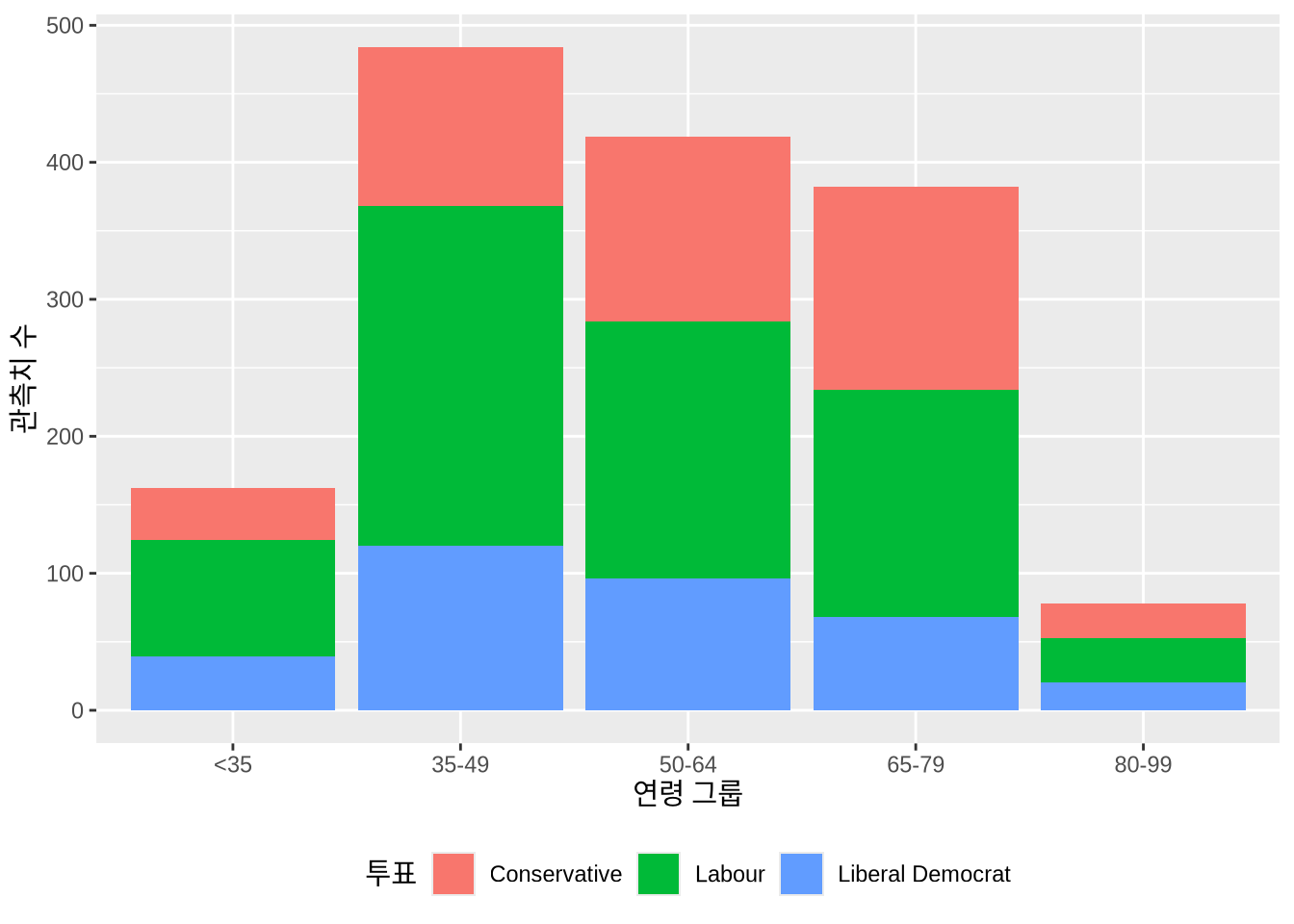
geom_bar() 사용
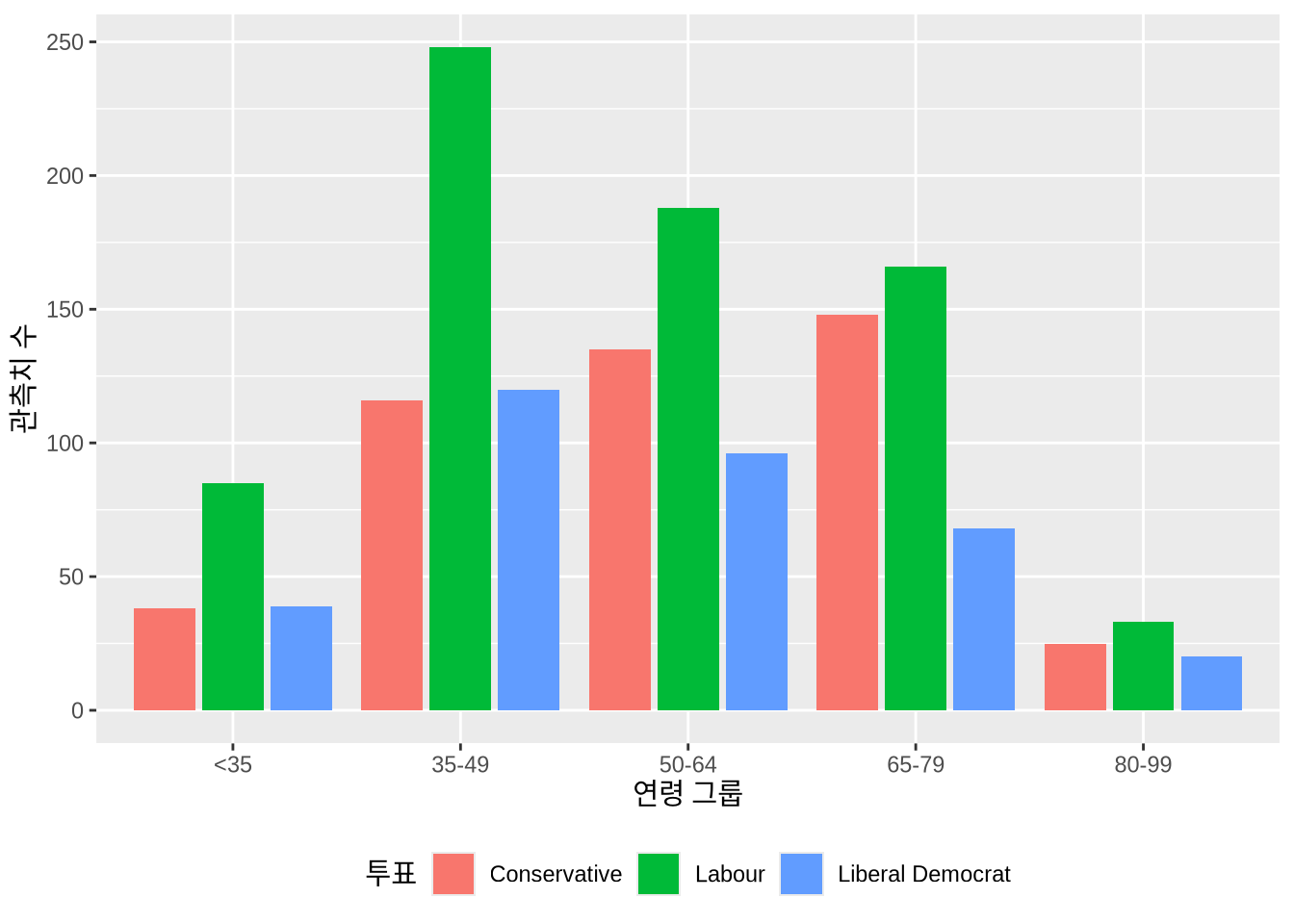
geom_bar()와 dodge2 사용
기본적으로는 그룹들이 위로 쌓여서 표시되지만, position = "dodge2" 옵션을 주면 막대들을 나란히 배치할 수 있습니다 (Figure 5.4 (b)). (“dodge” 대신 “dodge2”를 쓰면 막대 사이에 약간의 여백이 생겨 더 보기 좋습니다.)
5.2.1.1 테마 설정하기
그래프의 뼈대가 어느 정도 갖춰졌다면, 이제 전체적인 스타일을 결정할 차례입니다. ggplot2에는 다양한 테마(Theme)가 기본으로 내장되어 있습니다. 대표적으로 theme_bw(), theme_classic(), theme_dark(), theme_minimal() 등이 있으며, 전체 목록은 ggplot2 치트 시트에서 확인하실 수 있습니다. 이러한 테마는 그래프에 레이어처럼 간단히 추가할 수 있죠 (Figure 5.5). 더 나아가 ggthemes (Arnold 2021)나 hrbrthemes (Rudis 2020) 같은 외부 패키지를 쓰면 더욱 감각적인 스타일을 적용할 수 있고, 필요하다면 자신만의 고유한 테마를 설계할 수도 있습니다.
theme_bw <-
beps |>
ggplot(mapping = aes(x = age_group)) +
geom_bar(position = "dodge") +
theme_bw()
theme_classic <-
beps |>
ggplot(mapping = aes(x = age_group)) +
geom_bar(position = "dodge") +
theme_classic()
theme_dark <-
beps |>
ggplot(mapping = aes(x = age_group)) +
geom_bar(position = "dodge") +
theme_dark()
theme_minimal <-
beps |>
ggplot(mapping = aes(x = age_group)) +
geom_bar(position = "dodge") +
theme_minimal()
(theme_bw + theme_classic) / (theme_dark + theme_minimal)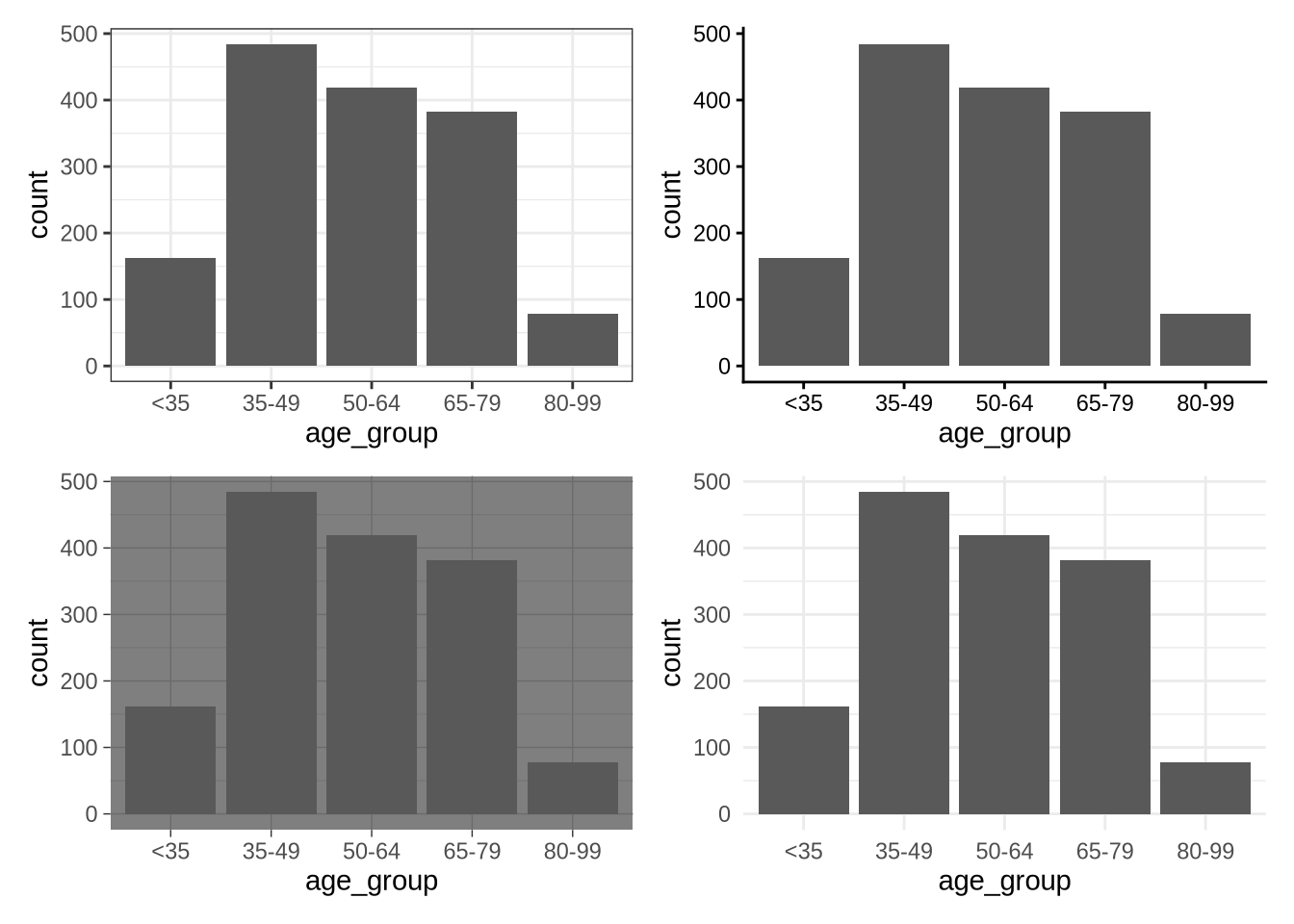
patchwork 사용법 설명
Figure 5.5 에서는 patchwork를 사용해 여러 그래프를 한데 모았습니다. 패키지를 로드한 뒤 그래프를 각각 변수에 할당하고, “+” 기호로 옆에 붙이거나 “/” 기호로 위아래로 쌓을 수 있습니다. 괄호를 써서 배치 우선순위를 정할 수도 있죠.
5.2.1.2 패싯 활용하기
패싯(Facet)은 하나 이상의 변수를 기준으로 데이터를 쪼개 여러 개의 작은 그래프로 나열하는 기법입니다 (Wilkinson 2005, 219). 이미 색상 등으로 특정 변수를 구분하고 있더라도, 또 다른 변수에 따른 변화를 동시에 보여주고 싶을 때 매우 유용하죠. 예를 들어 응답자의 연령과 성별에 따른 투표 성향을 한눈에 비교하고 싶다면 패싯을 써보세요 (Figure 5.6). 이때 x축 레이블이 겹치는 것을 막기 위해 guides(x = guide_axis(angle = 90)) 옵션으로 텍스트를 회전시키거나, theme(legend.position = "bottom")으로 범례 위치를 조정해 가독성을 높일 수 있습니다.
beps |>
ggplot(mapping = aes(x = age_group, fill = gender)) +
geom_bar() +
theme_minimal() +
labs(
x = "응답자 연령 그룹",
y = "응답자 수",
fill = "성별"
) +
facet_wrap(vars(vote)) +
guides(x = guide_axis(angle = 90)) +
theme(legend.position = "bottom")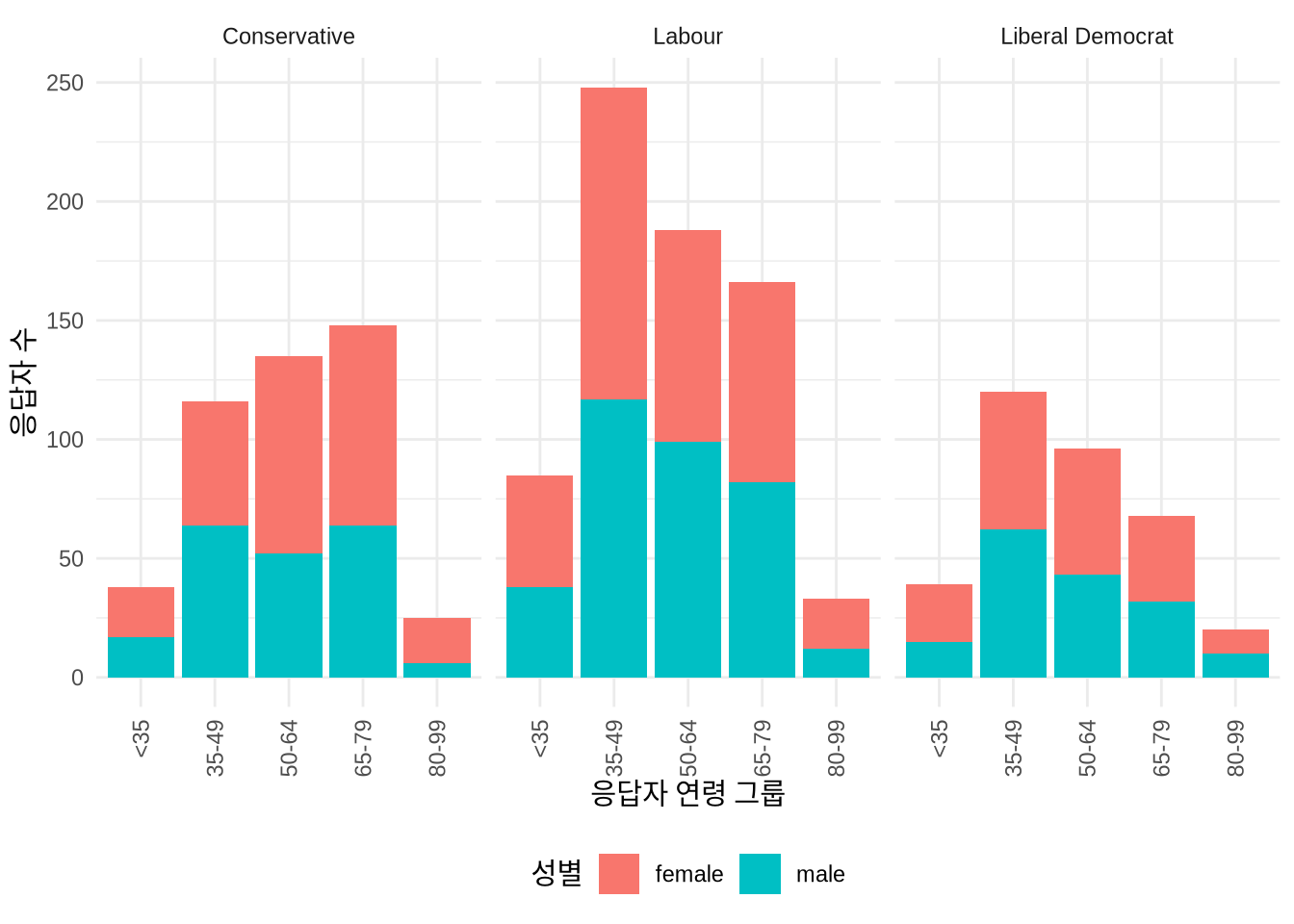
facet_wrap()에서 dir = "v" 옵션을 주면 수평 대신 수직으로 나열할 수 있습니다. 혹은 nrow나 ncol 인자로 행과 열의 개수를 직접 지정할 수도 있죠.
기본적으로 패싯은 모두 동일한 x축과 y축 범위를 가집니다. 만약 각 패싯마다 데이터 범위에 맞게 축을 따로 쓰고 싶다면 scales = "free"를, x축만 따로 쓰려면 scales = "free_x", y축만 따로 쓰려면 scales = "free_y" 옵션을 주면 됩니다 (Figure 5.7).
beps |>
ggplot(mapping = aes(x = age_group, fill = gender)) +
geom_bar() +
theme_minimal() +
labs(
x = "응답자 연령 그룹",
y = "응답자 수",
fill = "성별"
) +
facet_wrap(vars(vote), scales = "free") +
guides(x = guide_axis(angle = 90)) +
theme(legend.position = "bottom")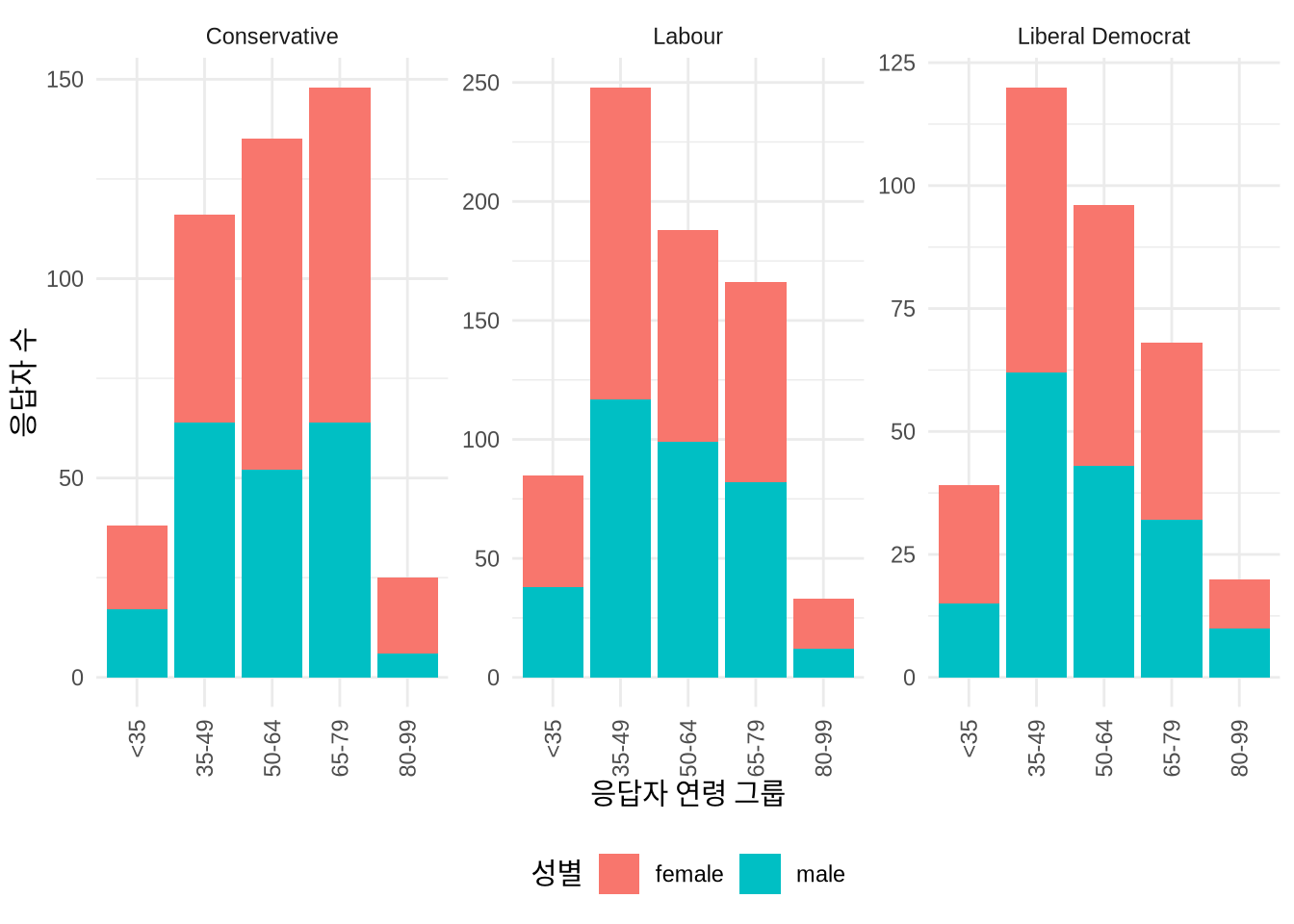
마지막으로 labeller()를 사용하면 패싯의 레이블 이름을 보기 좋게 바꿀 수 있습니다 (Figure 5.8).
new_labels <-
c("0" = "지식 없음", "1" = "낮은 지식",
"2" = "보통 지식", "3" = "높은 지식")
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(
x = "응답자 연령 그룹",
y = "응답자 수",
fill = "투표"
) +
facet_wrap(
vars(political_knowledge),
scales = "free",
labeller = labeller(political_knowledge = new_labels)
) +
guides(x = guide_axis(angle = 90)) +
theme(legend.position = "bottom")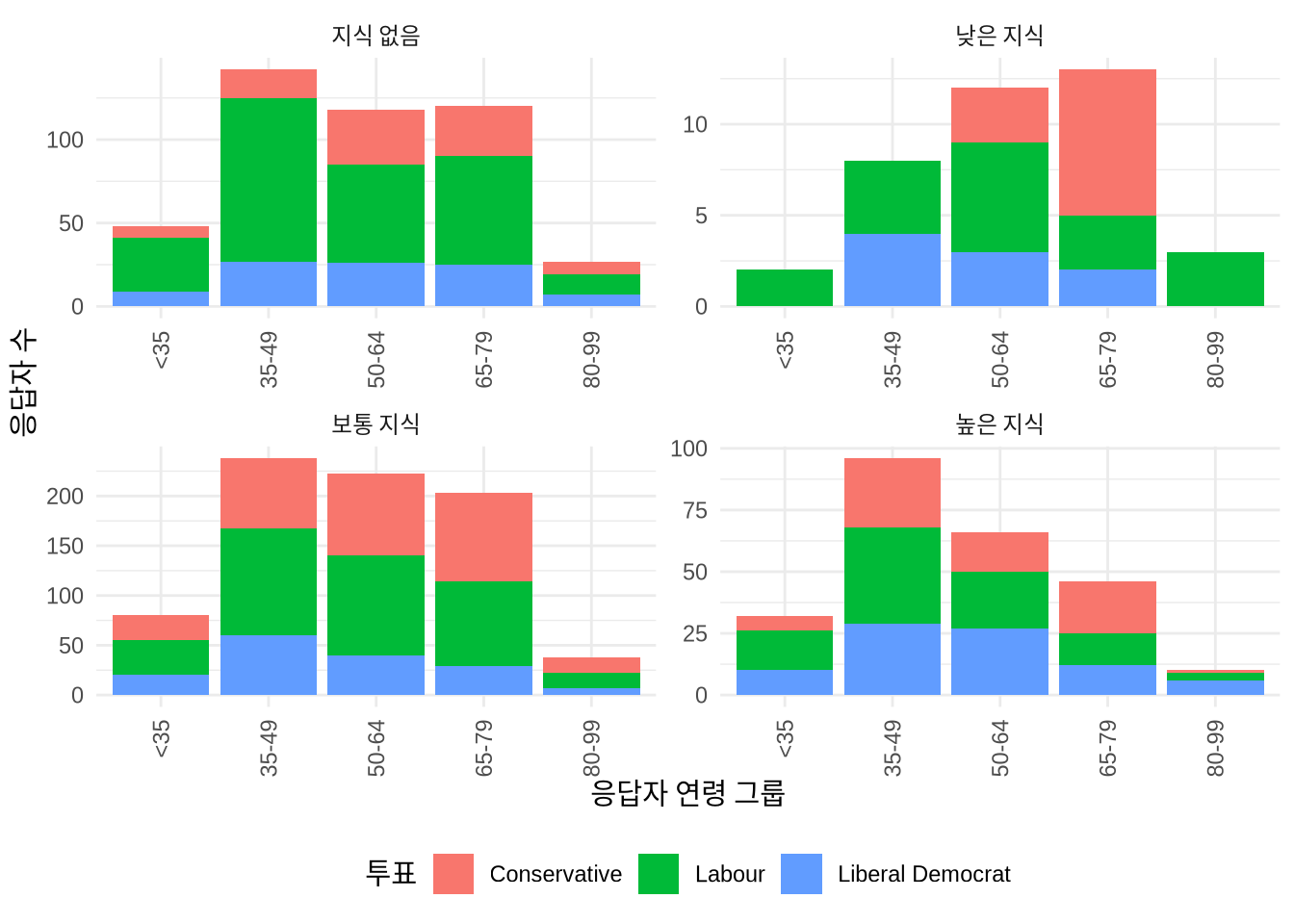
이제 여러 그래프를 결합하는 세 가지 방법을 알게 되었습니다. 하위 그림(Subplots), 패싯, 그리고 patchwork입니다. 상황에 맞춰 골라 쓰면 됩니다.
- 하위 그림: Chapter 3 에서 다루었듯, 서로 다른 변수를 고려할 때 유용합니다.
- 패싯: 범주형 변수에 따른 변화를 살필 때 제격입니다.
- patchwork: 성격이 완전히 다른 그래프들을 한데 모으고 싶을 때 아주 편리합니다.
5.2.1.3 색상 선택하기
그래프의 시각적 완성도를 결정짓는 핵심 요소 중 하나가 바로 색상입니다. ggplot2에서 색상을 바꾸는 방법은 매우 다양하죠. RColorBrewer (Neuwirth 2022) 패키지의 검증된 팔레트들은 scale_fill_brewer() 함수로 손쉽게 적용할 수 있습니다. 한편 viridis (Garnier et al. 2021) 패키지는 색맹인 독자들도 정보를 정확히 식별할 수 있도록 세심하게 설계된 팔레트를 제공하며, 이는 scale_fill_viridis_d() 함수로 쓸 수 있습니다 (Figure 5.9). 이 패키지들은 이미 tidyverse 라이브러리에 포함되어 있어 별도로 설치할 필요가 없습니다.
거인의 어깨 위에 서서: 신디 브루어
“Brewer” 팔레트의 명칭은 선구적인 지도학자 신디 브루어(Cynthia Brewer) (Miller 2014)의 이름에서 따온 것입니다. 1994년부터 펜실베이니아 주립 대학교 교수로 재직하며 시각화 분야에 지대한 공헌을 했죠. 그녀의 저서 더 나은 지도 만들기: GIS 사용자를 위한 가이드(원제: Designing Better Maps: A Guide for GIS Users) (Brewer 2015)는 이 분야의 고전으로 통합니다. 2019년, 그녀는 지도학 분야의 권위 있는 상인 O. M. 밀러 지도학 메달을 수상하는 영예를 안았습니다.
# Panel (a)
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(x = "연령 그룹", y = "수", fill = "투표") +
theme(legend.position = "bottom") +
scale_fill_brewer(palette = "Blues")
# Panel (b)
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(x = "연령 그룹", y = "수", fill = "투표") +
theme(legend.position = "bottom") +
scale_fill_brewer(palette = "Set1")
# Panel (c)
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(x = "연령 그룹", y = "수", fill = "투표") +
theme(legend.position = "bottom") +
scale_fill_viridis_d()
# Panel (d)
beps |>
ggplot(mapping = aes(x = age_group, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(x = "연령 그룹", y = "수", fill = "투표") +
theme(legend.position = "bottom") +
scale_fill_viridis_d(option = "magma")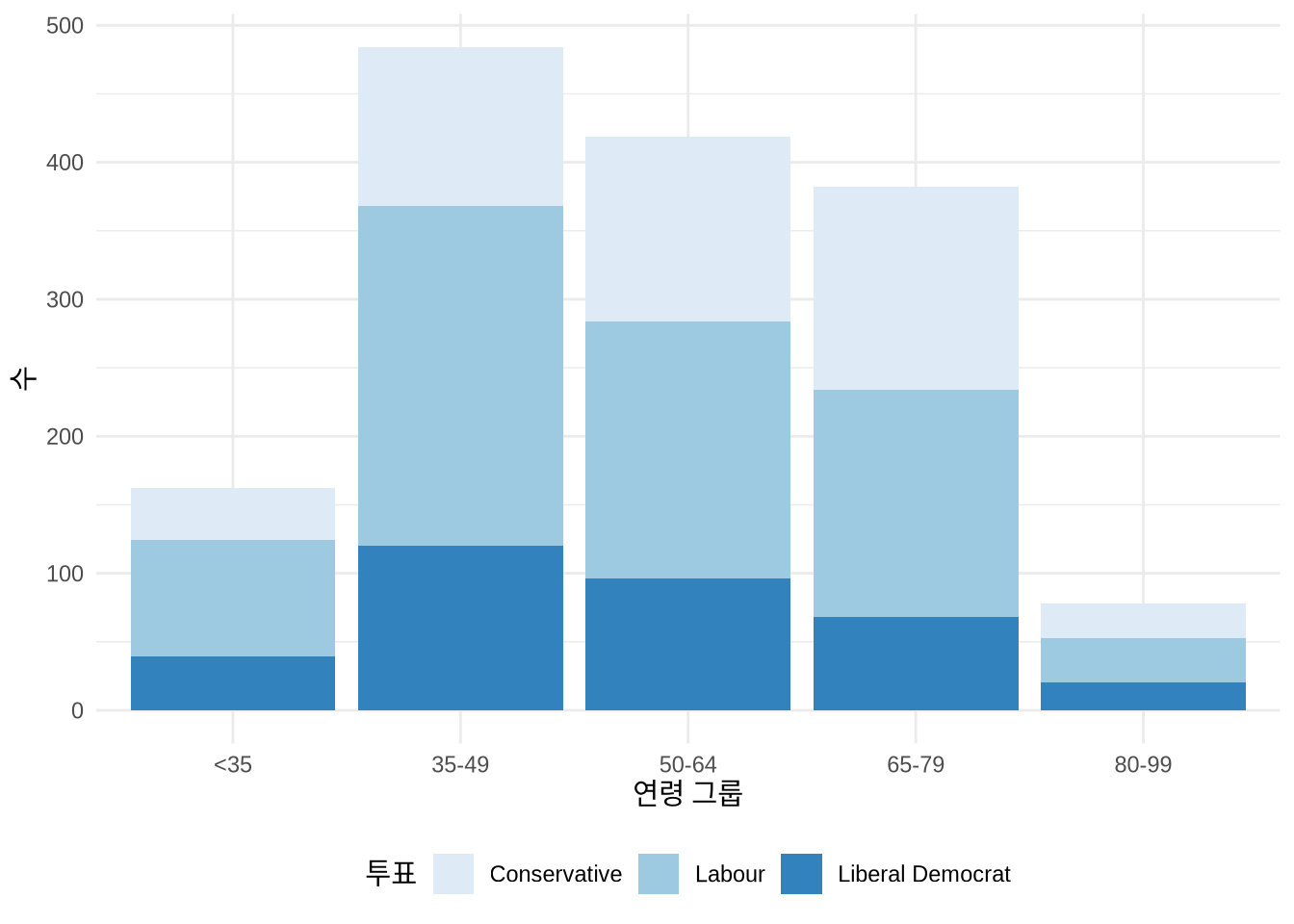
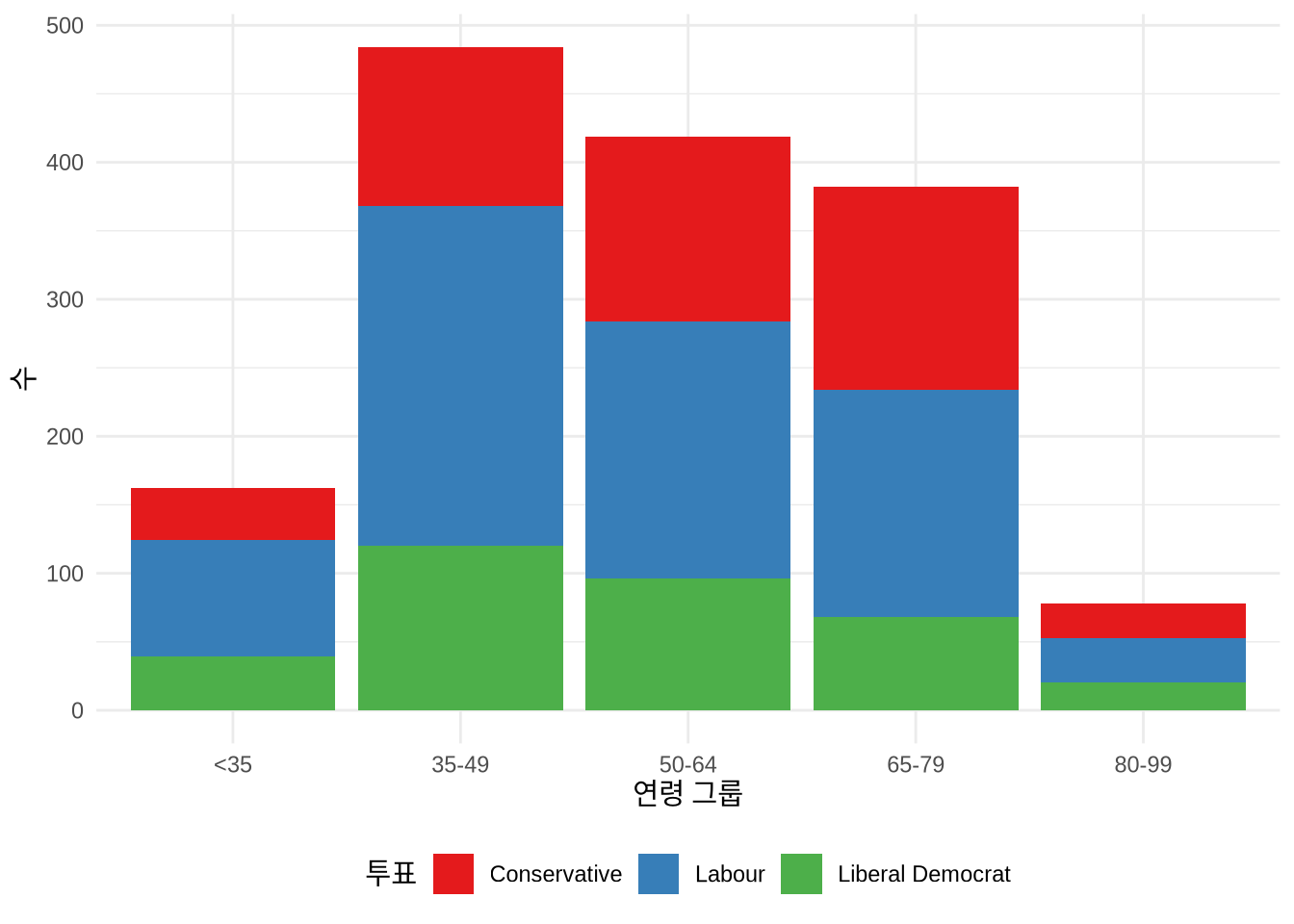
미리 만들어진 팔레트 외에 나만의 팔레트를 구성할 수도 있습니다. 하지만 색상은 아주 신중하게 사용해야 합니다. 색상은 단순히 예뻐 보이려는 게 아니라, 전달하는 정보의 양을 늘리는 도구가 되어야 하기 때문이죠 (Cleveland [1985] 1994). 불필요한 색 추가는 피해야 합니다. 즉 색상에는 분명한 ’역할’이 있어야 하죠. 대개 그 역할은 서로 다른 그룹을 구별하는 것이며, 이는 색상을 서로 대비되게 만드는 것을 뜻합니다. 변수와 색상 사이에 직관적인 관계가 있다면 금상첨화입니다. 예를 들어 망고와 라즈베리의 가격 그래프를 그릴 때 각각 노란색과 빨간색을 쓴다면 독자가 정보를 해석하는 데 큰 도움이 될 것입니다 (Franconeri et al. 2021, 121).
5.2.2 산점도
두 개의 숫자(연속형) 변수 사이의 관계를 탐구할 때 가장 즐겨 쓰는 방법은 산점도(Scatterplot)입니다. 산점도가 언제나 최선의 선택은 아닐지 몰라도, 데이터를 가장 정직하게 보여주기에 나쁜 선택이 되는 경우는 거의 없습니다 (Weissgerber et al. 2015). 많은 통계학자가 산점도를 가장 다재다능하고 강력한 시각화 도구로 꼽는 이유이기도 하죠 (Friendly and Wainer 2021, 121). 산점도의 위력을 확인하기 위해 WDI 패키지를 써서 세계은행(World Bank)에서 제공하는 국가별 경제 지표를 불러와 보겠습니다.
국내총생산(GDP): 숫자가 가려버리는 것들
국내총생산(GDP)은 특정 국가 내에서 생산된 모든 재화와 서비스의 가치를 합친 지표입니다. 20세기 경제학자 사이먼 쿠즈네츠가 정립한 이 개념은 국가의 경제 규모를 단 하나의 숫자로 보여준다는 점에서 매우 편리하죠. 하지만 모든 요약 통계가 그렇듯, 명확함 뒤에는 위험한 함정이 숨어 있습니다. 단일 숫자는 그 속에 담긴 복잡한 구성 요소와 격차를 지워버리며, 장기적 가치보다 단기적 성과에만 매달리게 만들기도 합니다 (Moyer and Dunn 2020). 또한 통계적 명확성에 매몰되다 보면, 그 수치가 불완전한 데이터와 상당한 오차 범위 위에서 아슬아슬하게 계산된 결과물임을 잊기 쉽습니다 (Kuznets, Epstein, and Jenks 1941, xxvi).
WDIsearch("gdp growth")
WDIsearch("inflation")
WDIsearch("population, total")
WDIsearch("Unemployment, total")world_bank_data <-
WDI(
indicator =
c("FP.CPI.TOTL.ZG", "NY.GDP.MKTP.KD.ZG", "SP.POP.TOTL","SL.UEM.TOTL.NE.ZS"),
country = c("AU", "ET", "IN", "US")
)변수 이름을 더 직관적으로 바꾸고 필요한 변수만 남겨 보겠습니다.
world_bank_data <-
world_bank_data |>
rename(
inflation = FP.CPI.TOTL.ZG,
gdp_growth = NY.GDP.MKTP.KD.ZG,
population = SP.POP.TOTL,
unem_rate = SL.UEM.TOTL.NE.ZS
) |>
select(country, year, inflation, gdp_growth, population, unem_rate)
head(world_bank_data)# A tibble: 6 × 6
country year inflation gdp_growth population unem_rate
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Australia 1960 3.73 NA 10276477 NA
2 Australia 1961 2.29 2.48 10483000 NA
3 Australia 1962 -0.319 1.29 10742000 NA
4 Australia 1963 0.641 6.22 10950000 NA
5 Australia 1964 2.87 6.98 11167000 NA
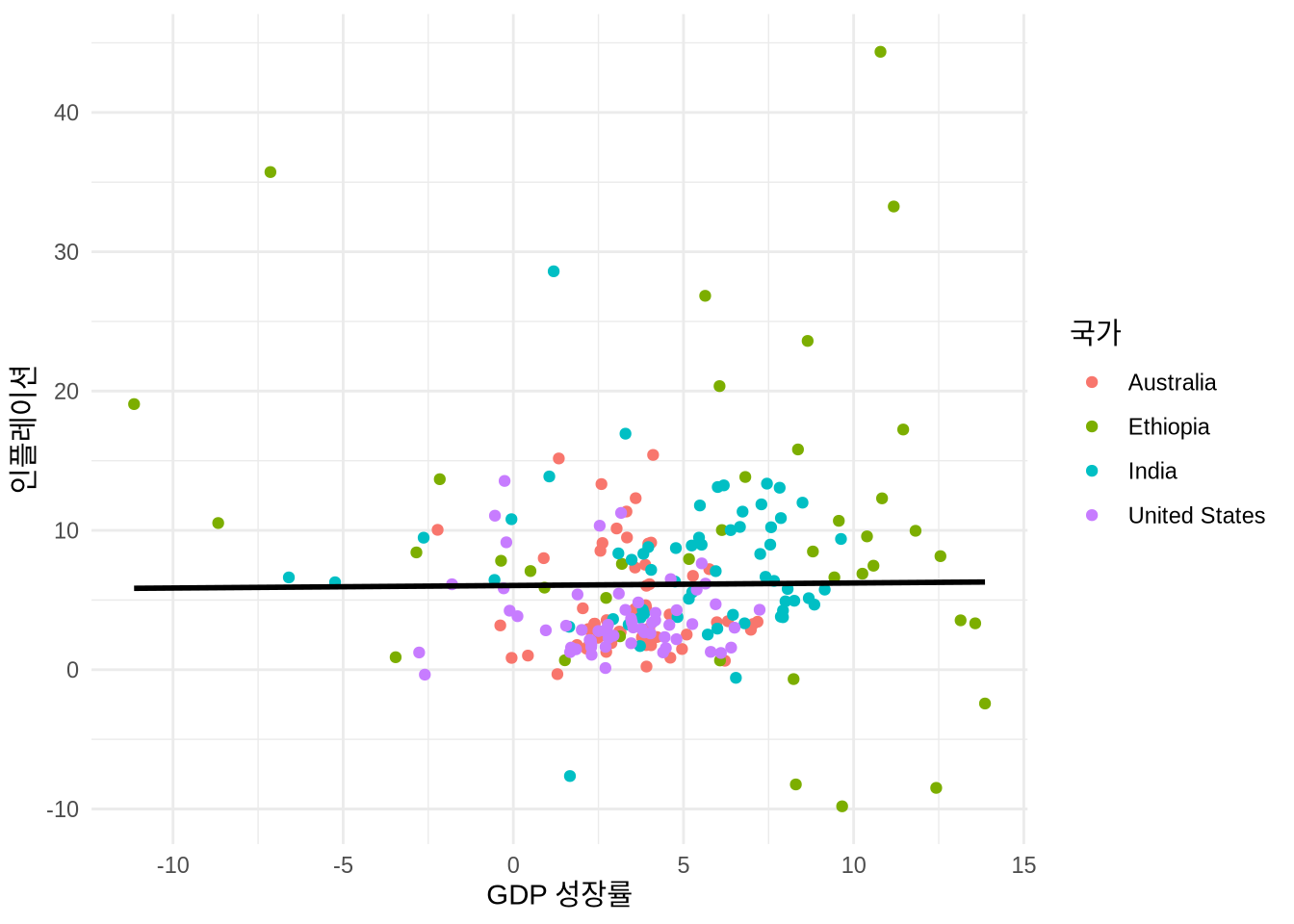
6 Australia 1965 3.41 5.98 11388000 NA우선 geom_point()를 사용해 국가별 GDP 성장률과 인플레이션 관계를 보여주는 산점도를 그려보겠습니다 (Figure 5.10 (a)).
# Panel (a)
world_bank_data |>
ggplot(mapping = aes(x = gdp_growth, y = inflation, color = country)) +
geom_point()
# Panel (b)
world_bank_data |>
ggplot(mapping = aes(x = gdp_growth, y = inflation, color = country)) +
geom_point() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")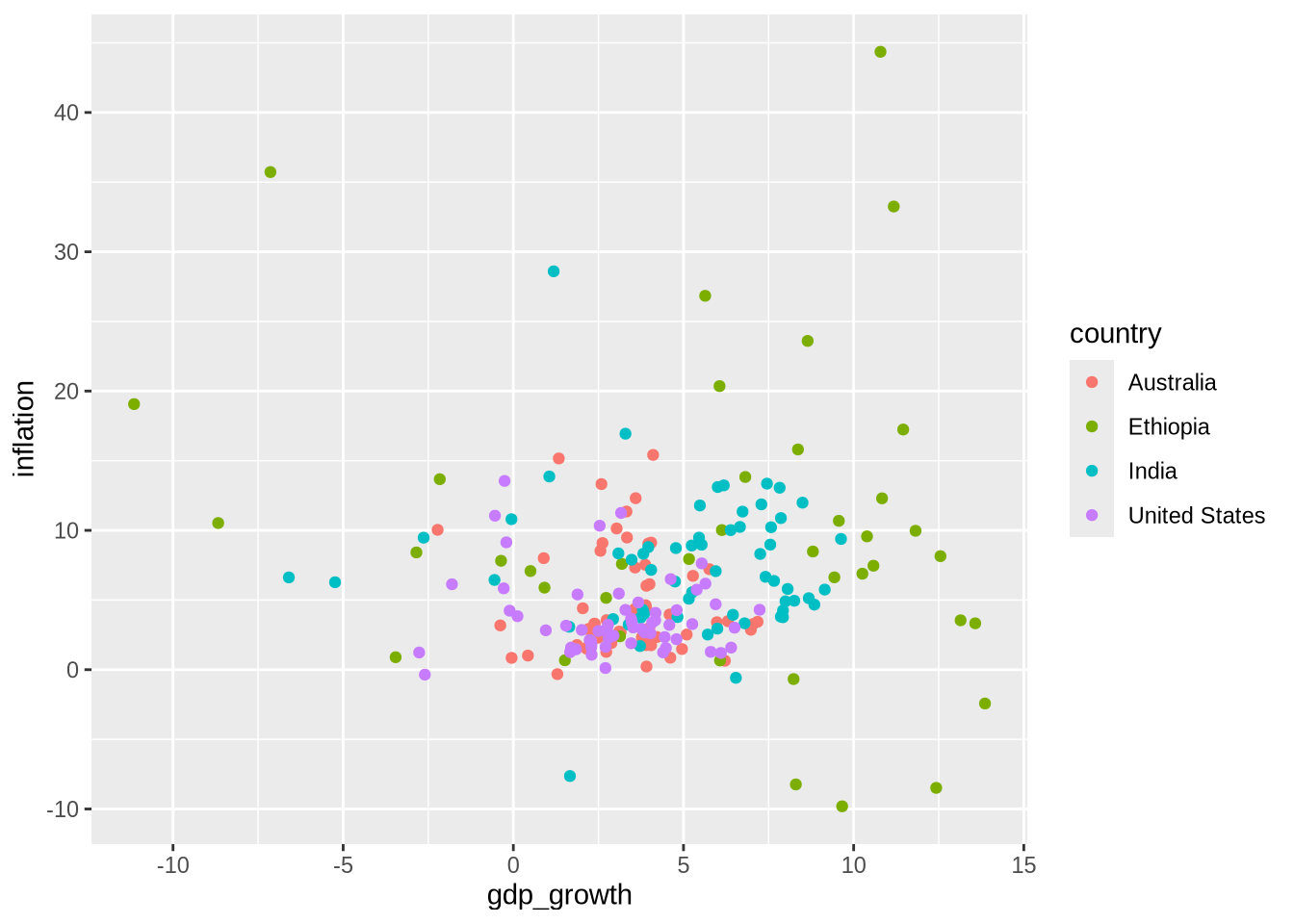
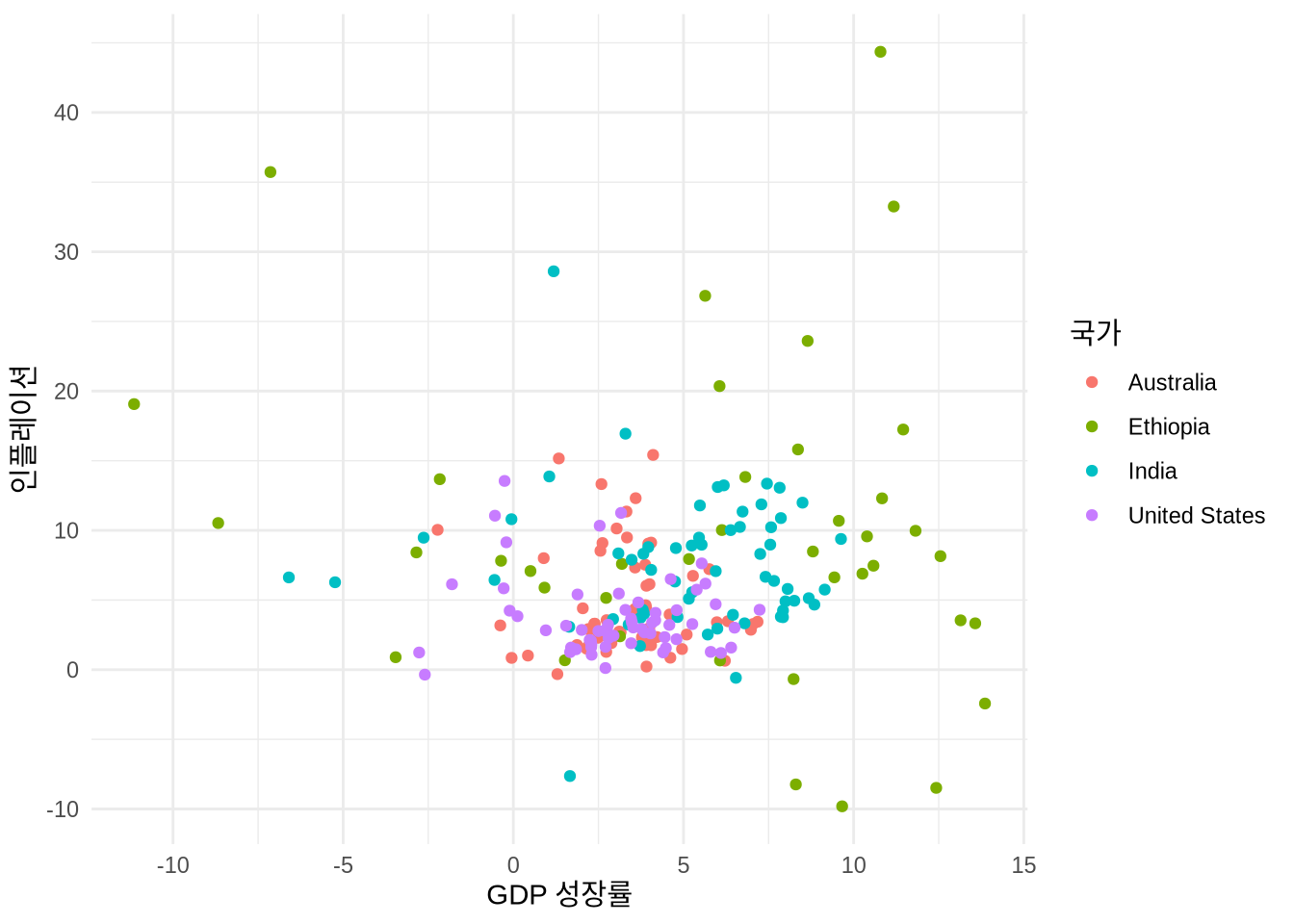
막대 차트 때와 마찬가지로 테마를 입히고 축 레이블을 다듬을 수 있습니다 (Figure 5.10 (b)).
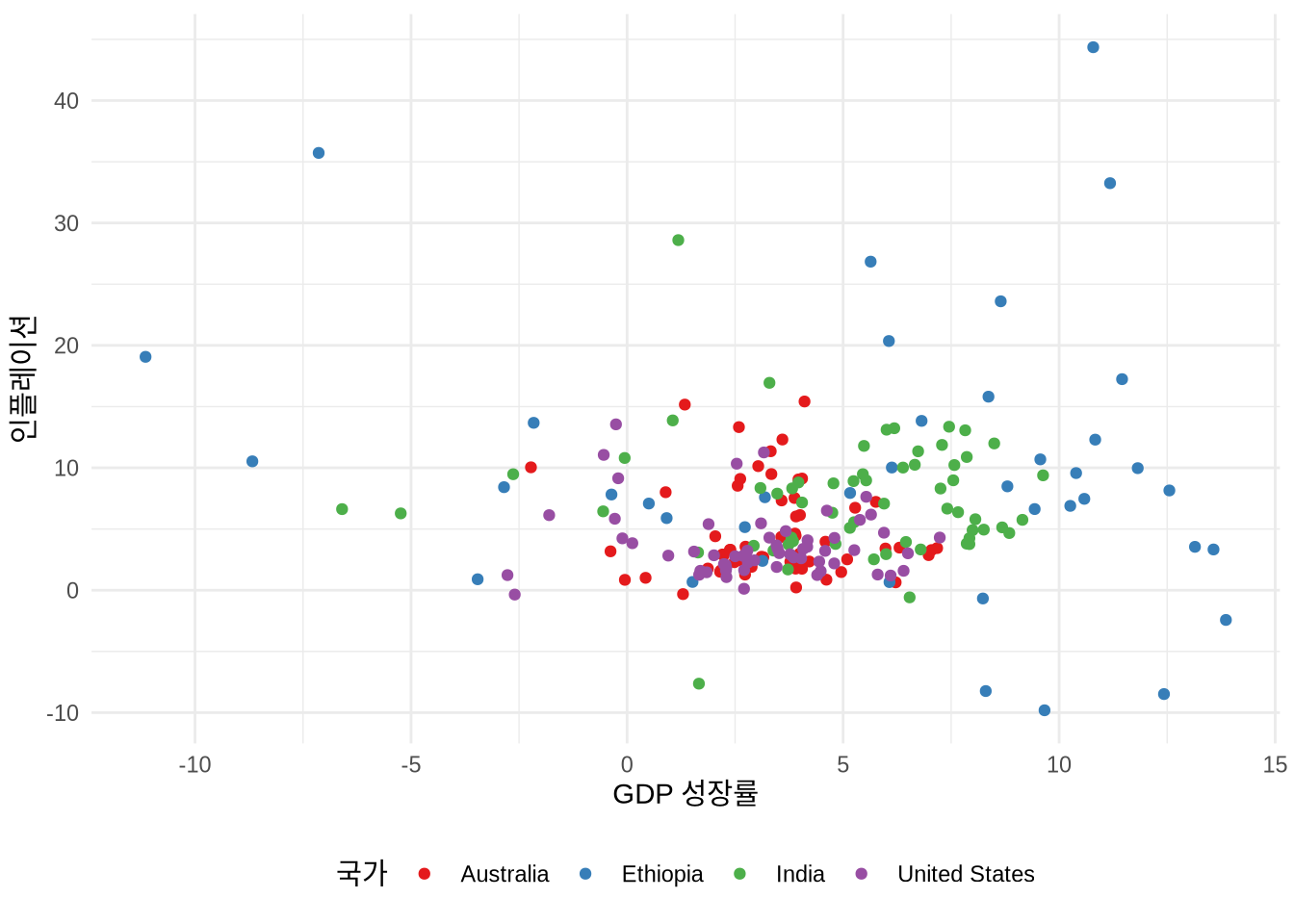
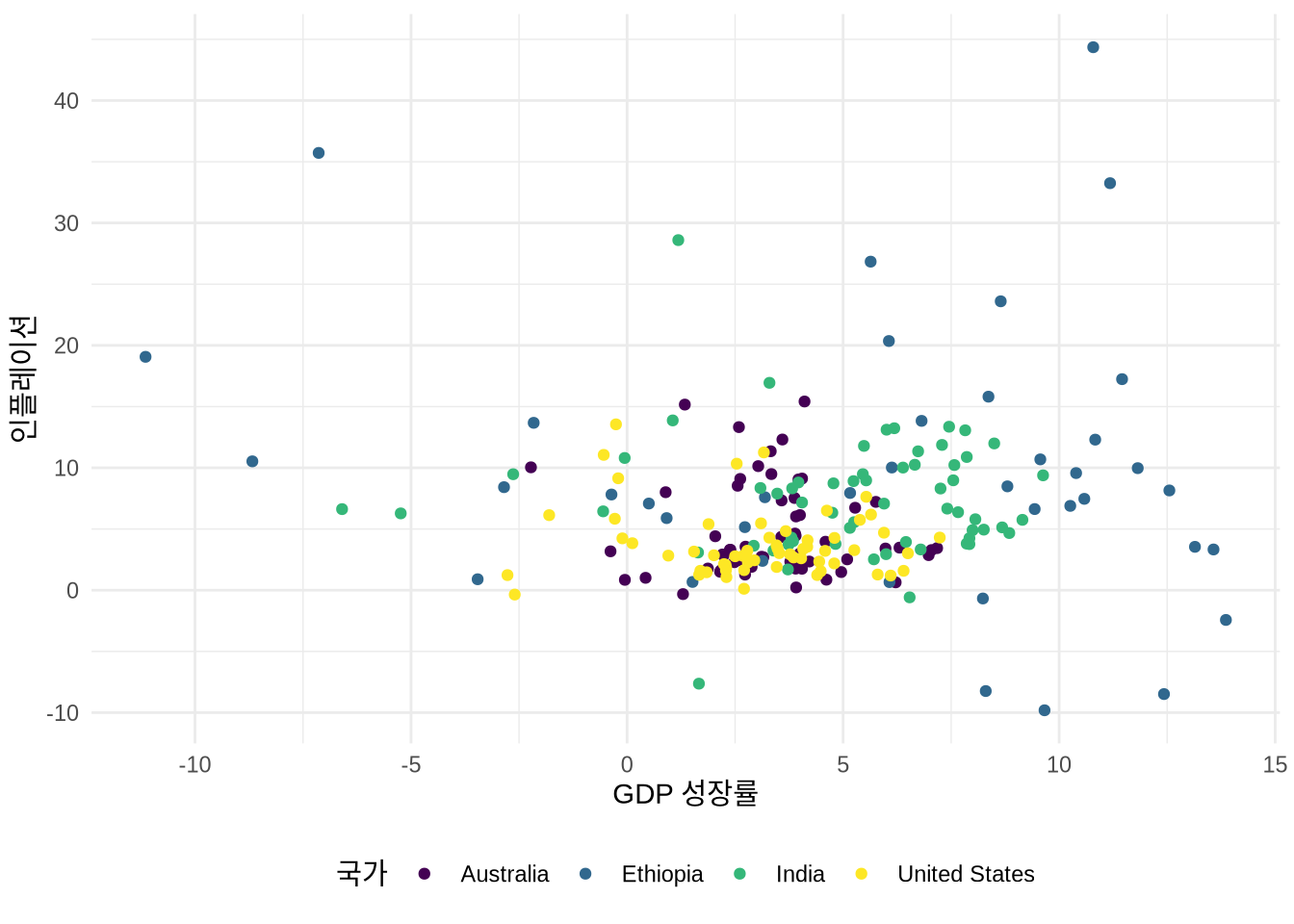
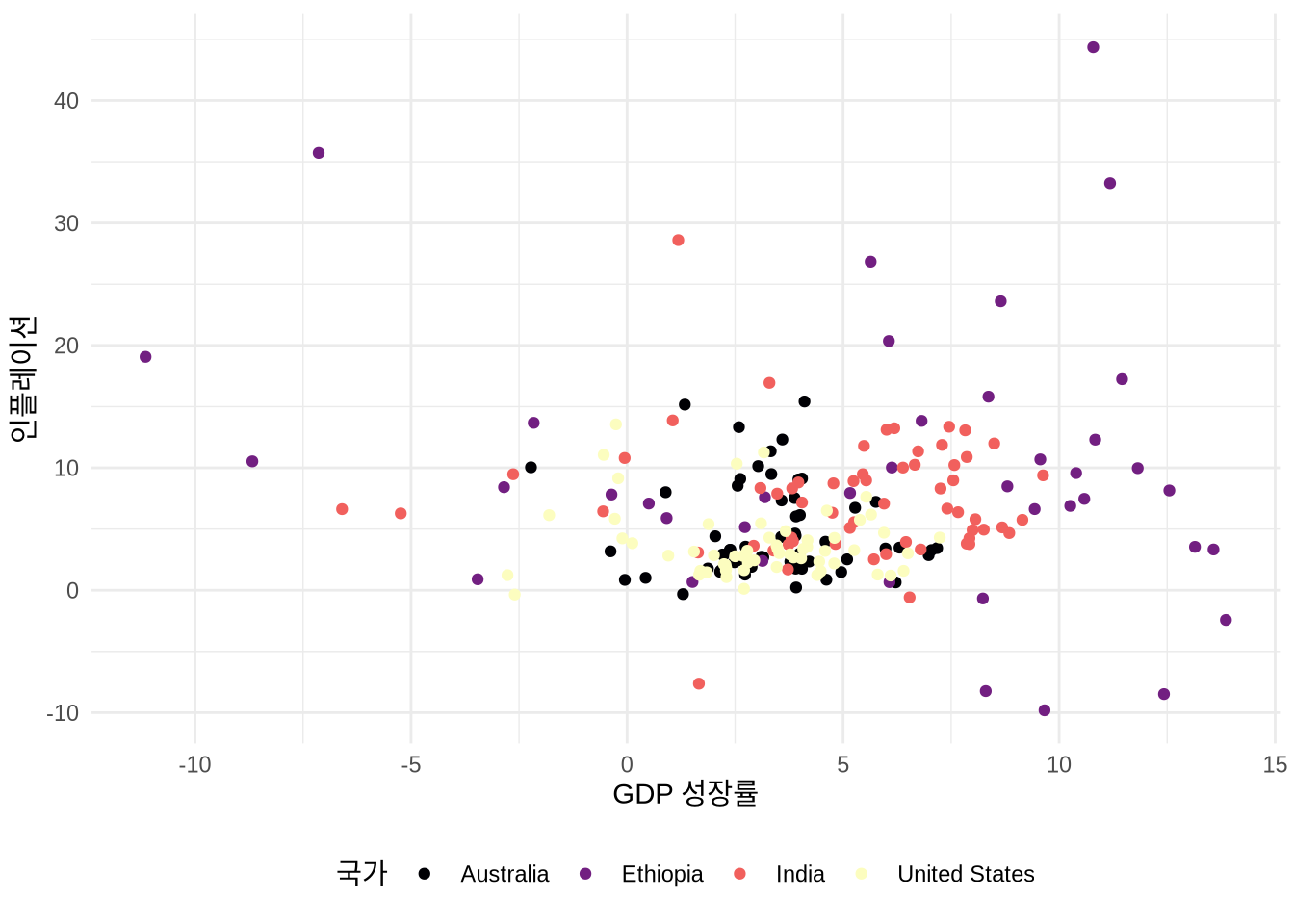
산점도에서는 막대 차트의 “fill” 대신 “color” 미학을 주로 사용합니다. 면이 아니라 점을 채색하기 때문이죠. 이는 팔레트를 적용하는 방식에도 차이를 줍니다 (Figure 5.11). 물론 shape = 21 같은 특정 점 모양에서는 테두리(color)와 내부(fill)를 모두 지정할 수도 있습니다.
# Panel (a)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_point() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가") +
theme(legend.position = "bottom") +
scale_color_brewer(palette = "Blues")
# Panel (b)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_point() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가") +
theme(legend.position = "bottom") +
scale_color_brewer(palette = "Set1")
# Panel (c)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_point() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가") +
theme(legend.position = "bottom") +
scale_colour_viridis_d()
# Panel (d)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_point() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가") +
theme(legend.position = "bottom") +
scale_colour_viridis_d(option = "magma")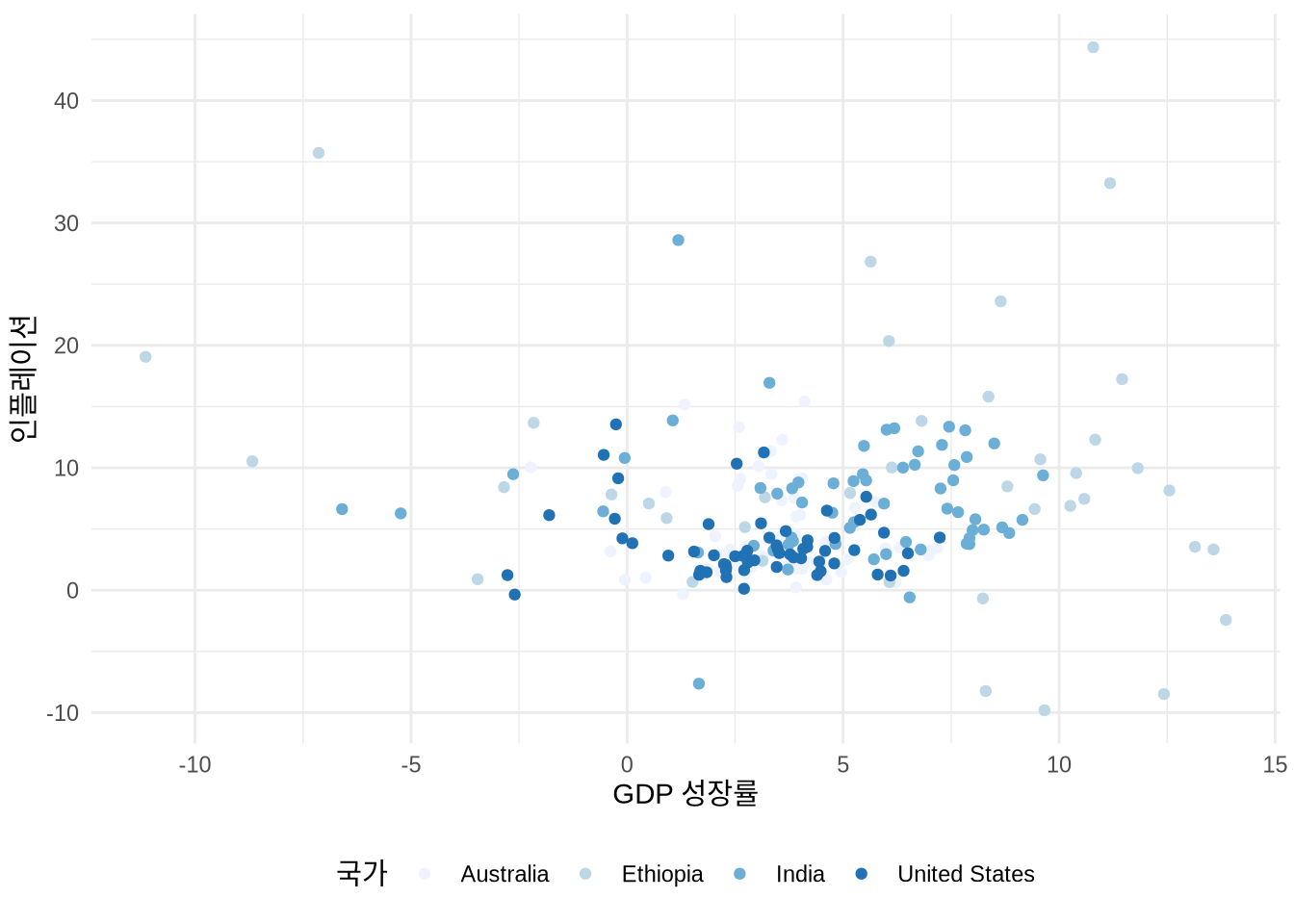
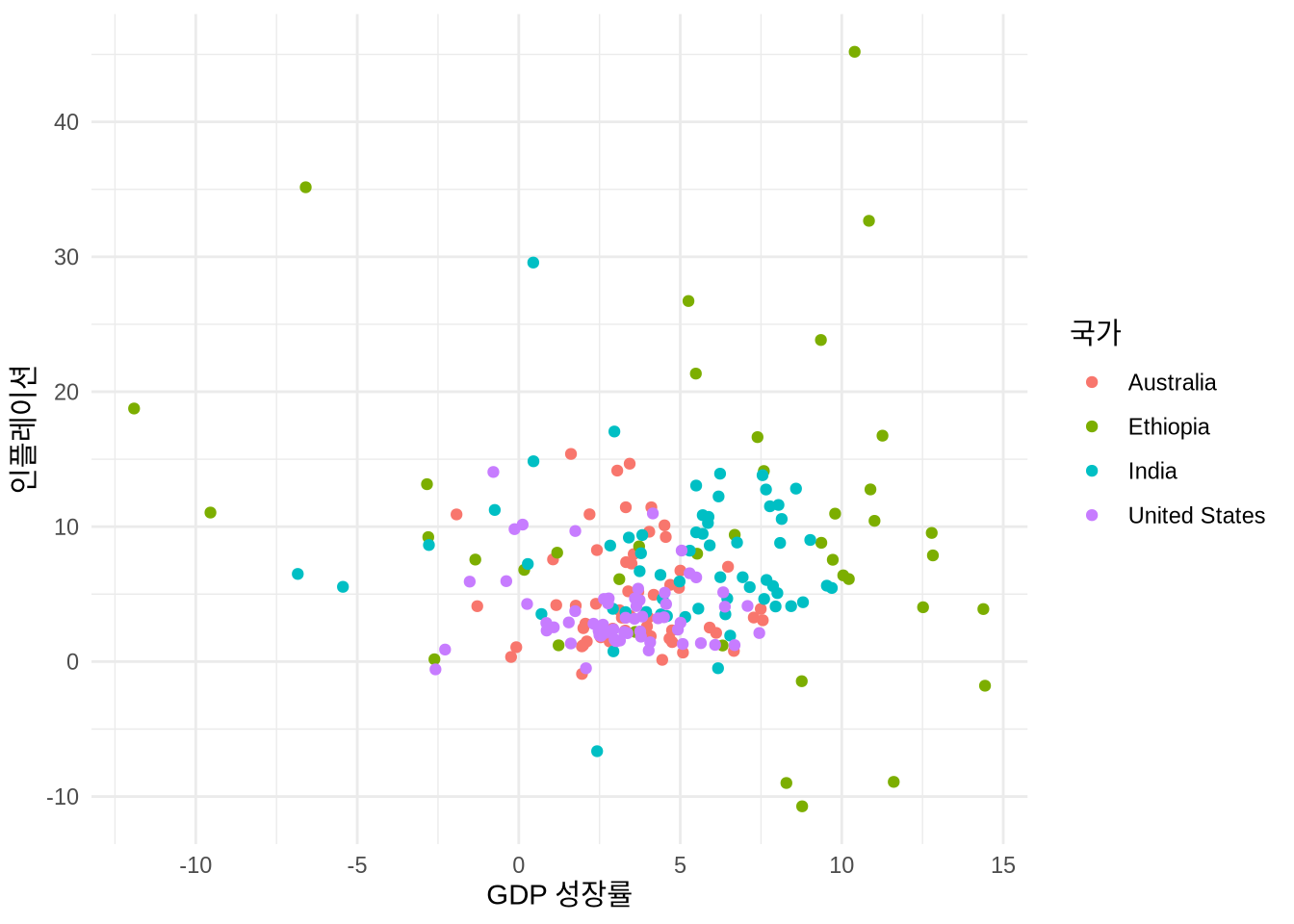
데이터가 많으면 점들이 겹쳐서 뭉쳐 보이는 현상이 생깁니다. 이를 해결하는 두 가지 방법이 있습니다 (Figure 5.12).
- “alpha” 값을 조절해 점에 투명도를 줍니다 (Figure 5.12 (a)). 0(완전 투명)에서 1(완전 불투명) 사이의 값을 사용합니다.
geom_jitter()를 사용해 점들을 아주 미세하게 무작위로 흩뿌립니다 (Figure 5.12 (b)). “width”나 “height” 인자로 흩어지는 정도를 조절할 수 있죠. 개별 점의 정확한 값보다 데이터의 밀집도를 보여주는 게 목적일 때 아주 유용합니다. 재현성을 위해 Chapter 2 에서 다룬 것처럼set.seed()로 시드를 설정하는 것을 권장합니다.
set.seed(853)
# Panel (a)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country )) +
geom_point(alpha = 0.5) +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")
# Panel (b)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_jitter(width = 1, height = 1) +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")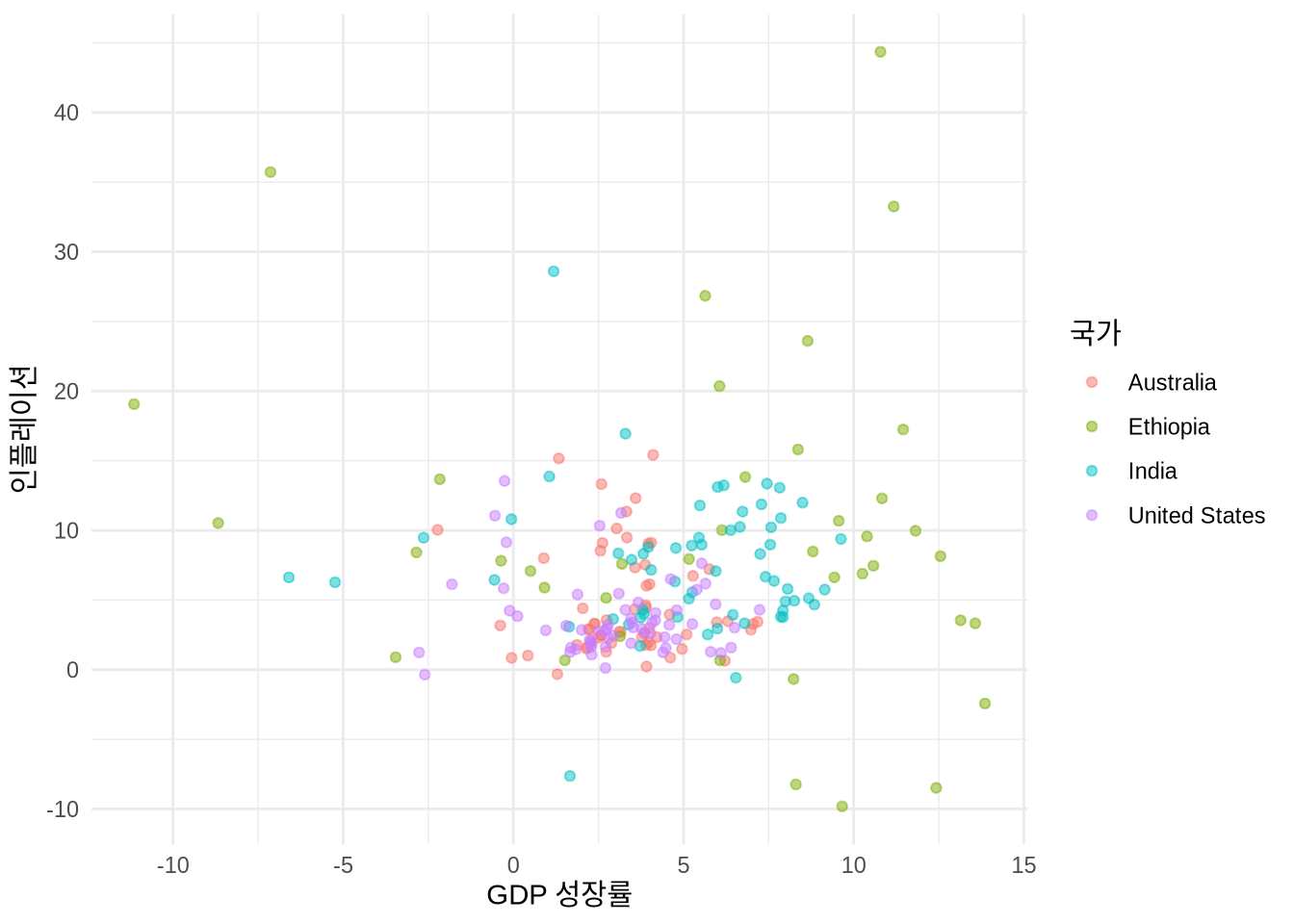
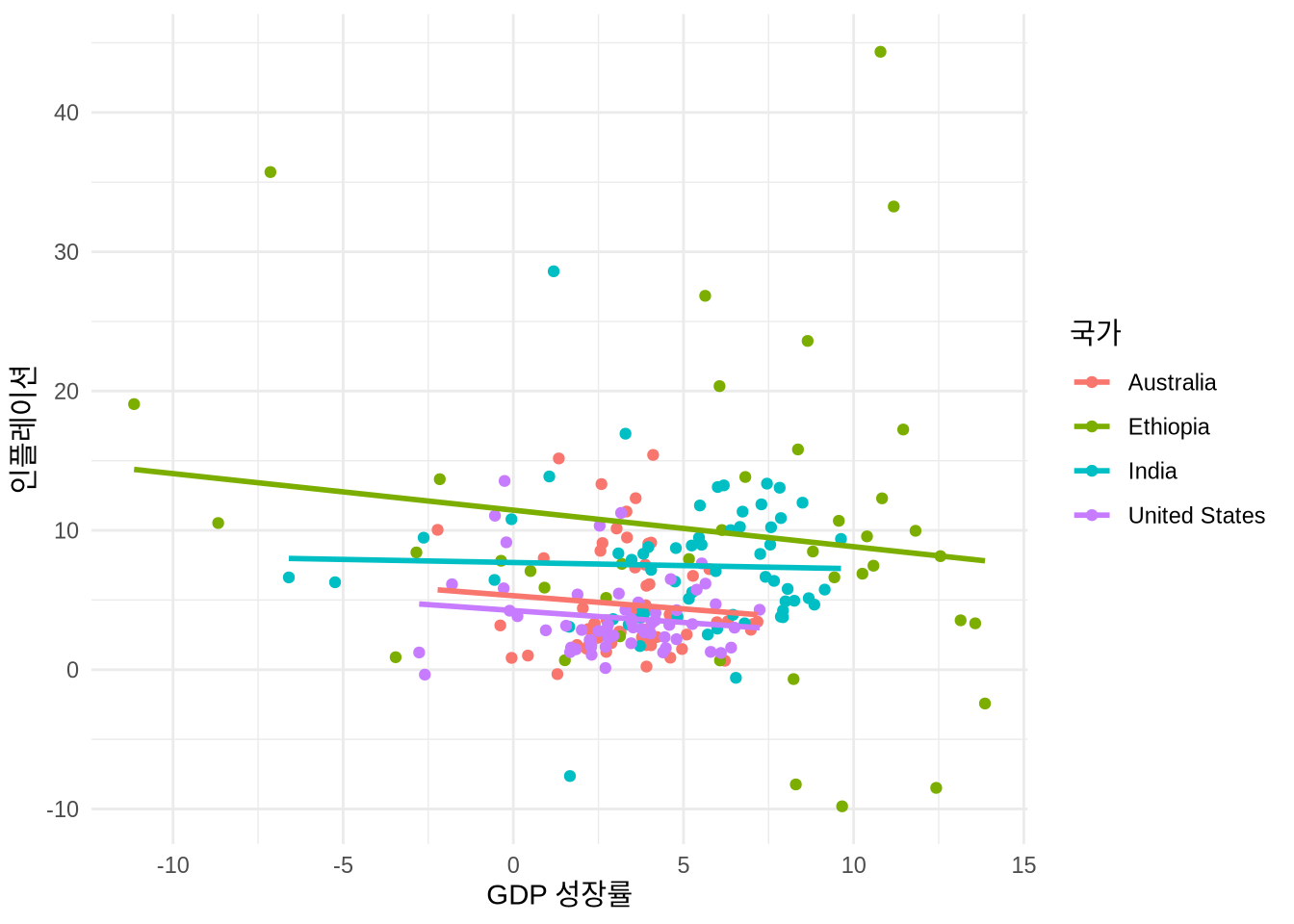
산점도를 그릴 때 두 변수 사이의 관계를 요약해 주는 선을 추가하면 이해를 돕기 좋습니다. geom_smooth() 함수를 쓰면 이른바 “최적 적합선”을 그릴 수 있죠 (Figure 5.13). “method”로 계산 방식을 지정하고, “se”로 표준 오차(신뢰 구간)를 표시할지 정할 수 있습니다. 가장 흔히 쓰이는 방식은 method = "lm"으로, 단순 선형 회귀선을 그려줍니다. geom_smooth()는 기본적으로 ggplot()에서 지정한 미학 설정을 상속받으므로, Figure 5.13 (a) 처럼 국가별로 다른 색의 선이 그려집니다. 모든 데이터를 아우르는 하나의 선만 보고 싶다면 특정 색상을 직접 지정해 상속을 끊어주면 됩니다 (Figure 5.13 (c)).
# Panel (a)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_jitter() +
geom_smooth() +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")
# Panel (b)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_jitter() +
geom_smooth(method = lm, se = FALSE) +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")
# Panel (c)
world_bank_data |>
ggplot(aes(x = gdp_growth, y = inflation, color = country)) +
geom_jitter() +
geom_smooth(method = lm, color = "black", se = FALSE) +
theme_minimal() +
labs(x = "GDP 성장률", y = "인플레이션", color = "국가")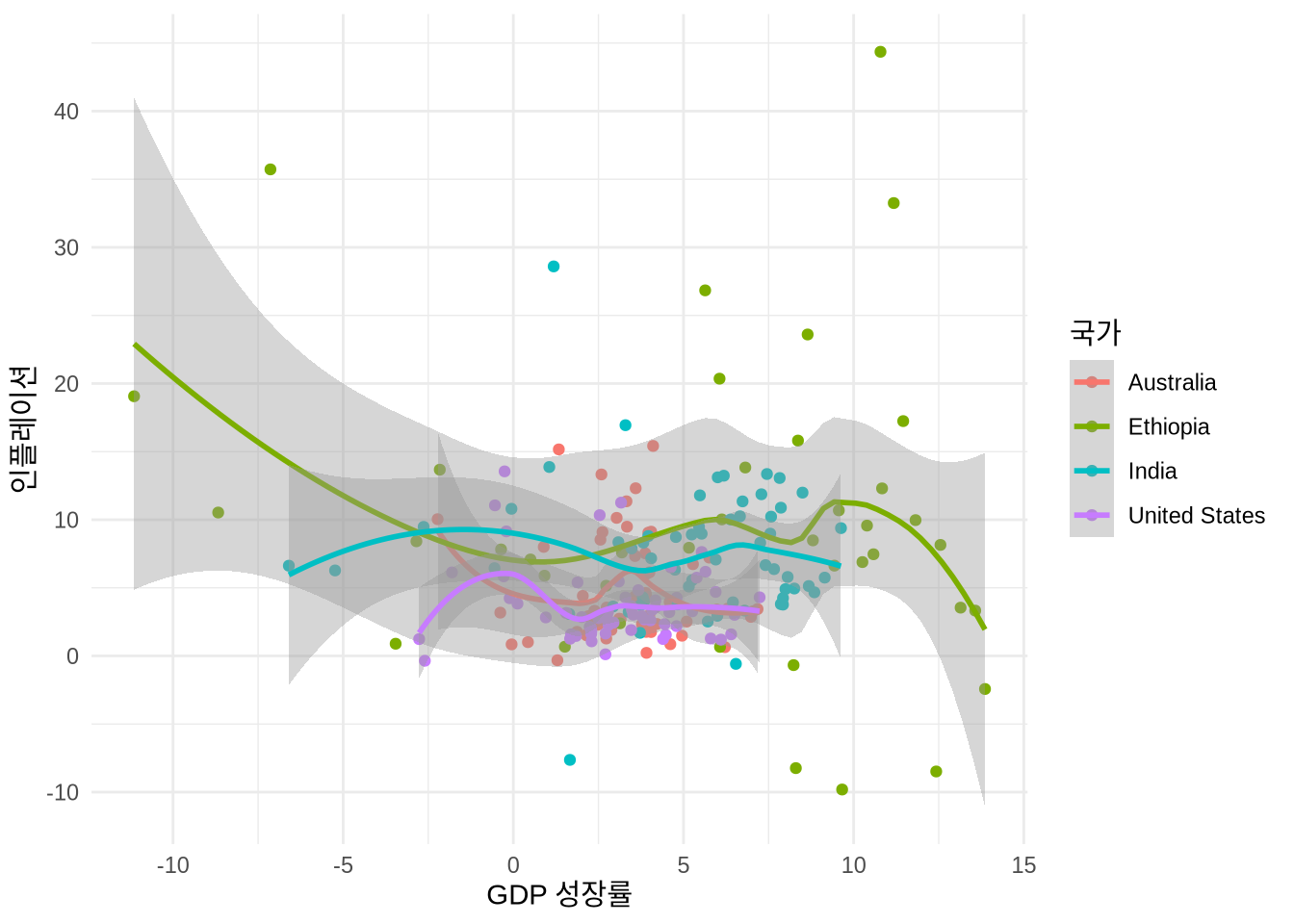
5.2.3 선 그래프
선 그래프(Line Plot)는 시계열 데이터처럼 특정 순서대로 연결된 데이터의 흐름을 보여줄 때 유용합니다. 세계은행 데이터로 미국의 GDP 성장률 추이를 시각화해 보겠습니다 (Figure 5.14 (a)). 이때 labs()의 caption 인자를 써서 데이터 출처를 명시하는 습관을 들이는 것이 좋습니다.
# Panel (a)
world_bank_data |>
filter(country == "United States") |>
ggplot(mapping = aes(x = year, y = gdp_growth)) +
geom_line() +
theme_minimal() +
labs(x = "연도", y = "GDP 성장률", caption = "데이터 출처: 세계은행.")
# Panel (b)
world_bank_data |>
filter(country == "United States") |>
ggplot(mapping = aes(x = year, y = gdp_growth)) +
geom_step() +
theme_minimal() +
labs(x = "연도",y = "GDP 성장률", caption = "데이터 출처: 세계은행.")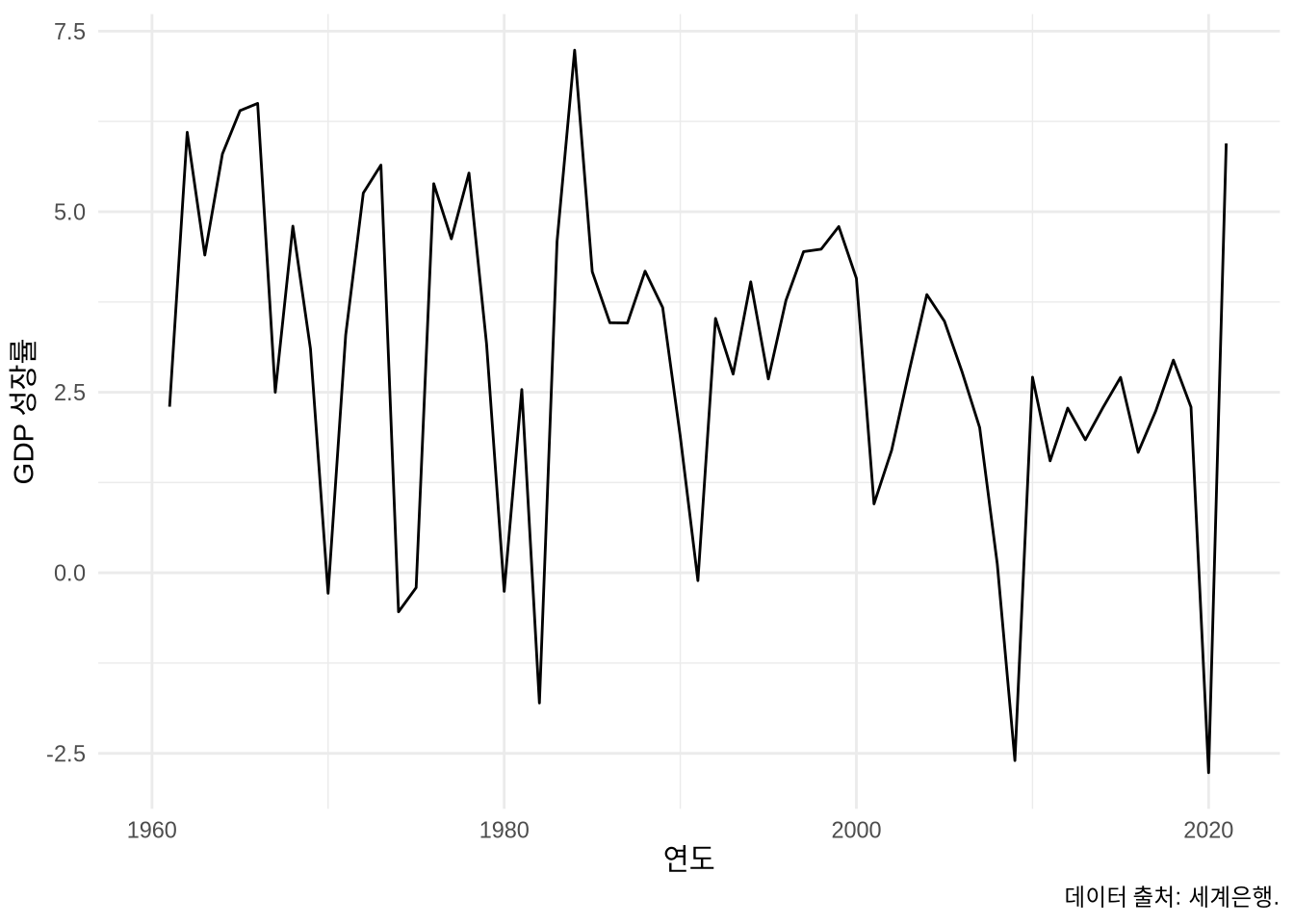
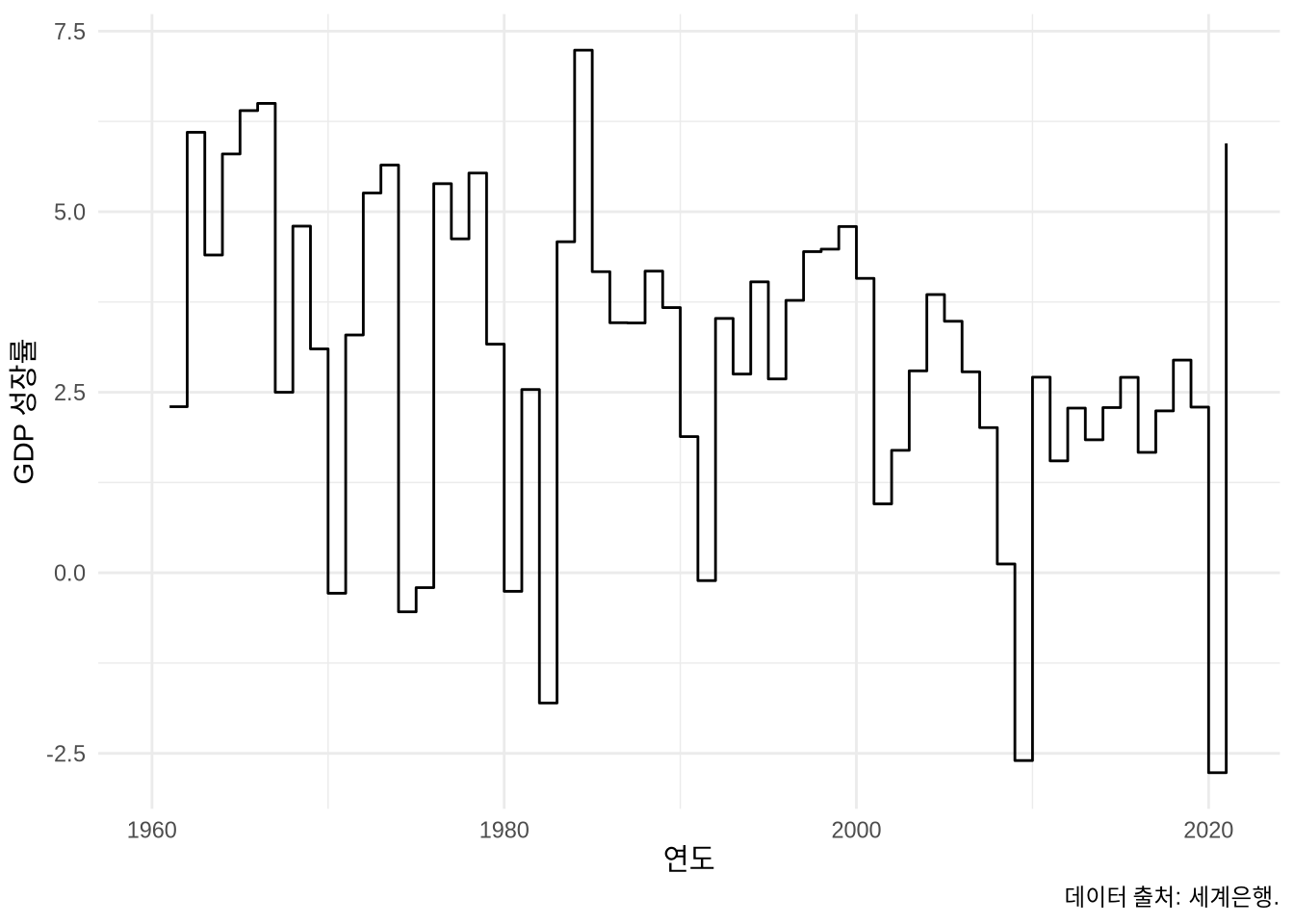
변화가 일어나는 지점을 더욱 선명하게 부각하고 싶다면 geom_line()의 변형인 geom_step()으로 계단식 그래프를 그려보세요 (Figure 5.14 (b)).
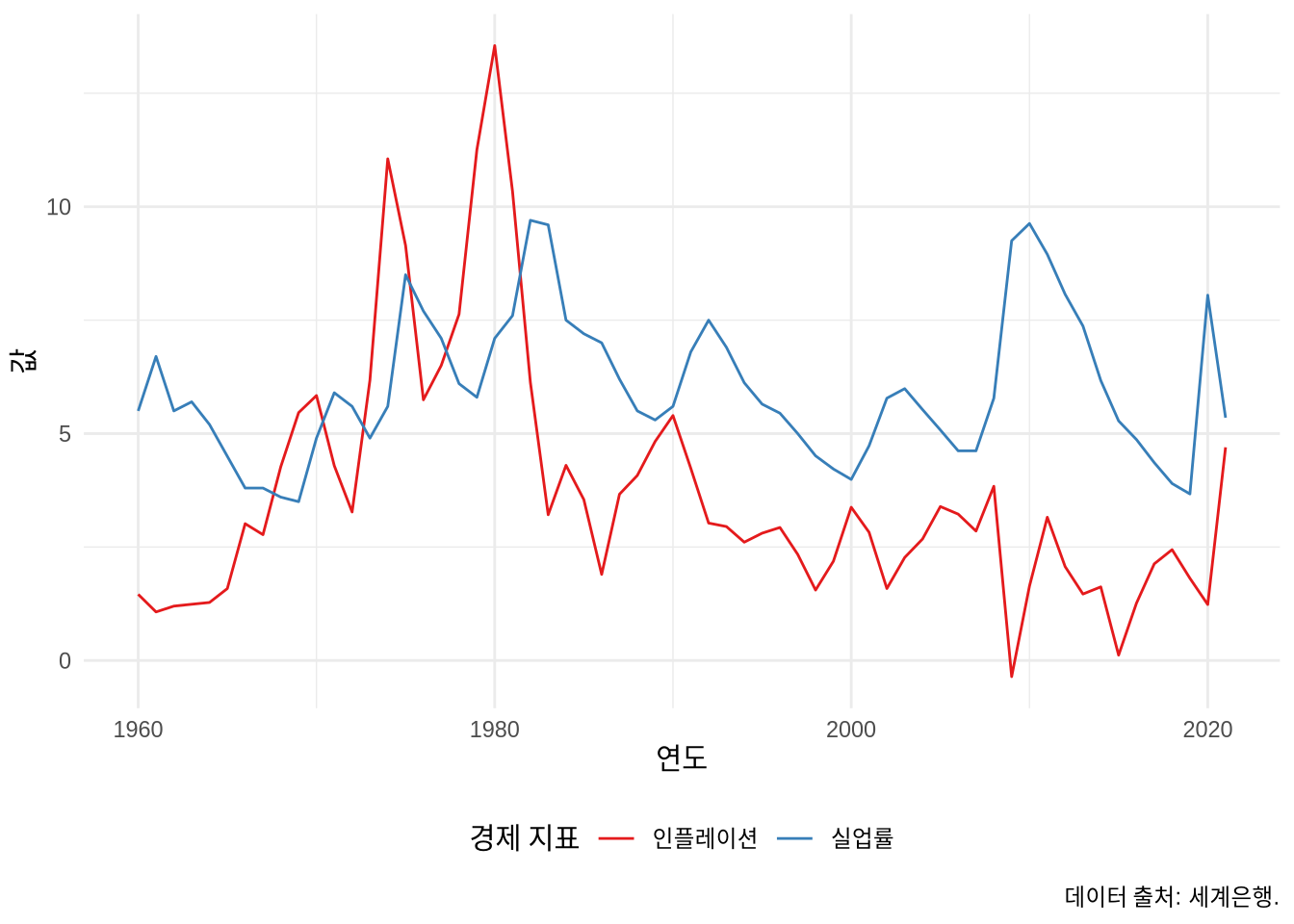
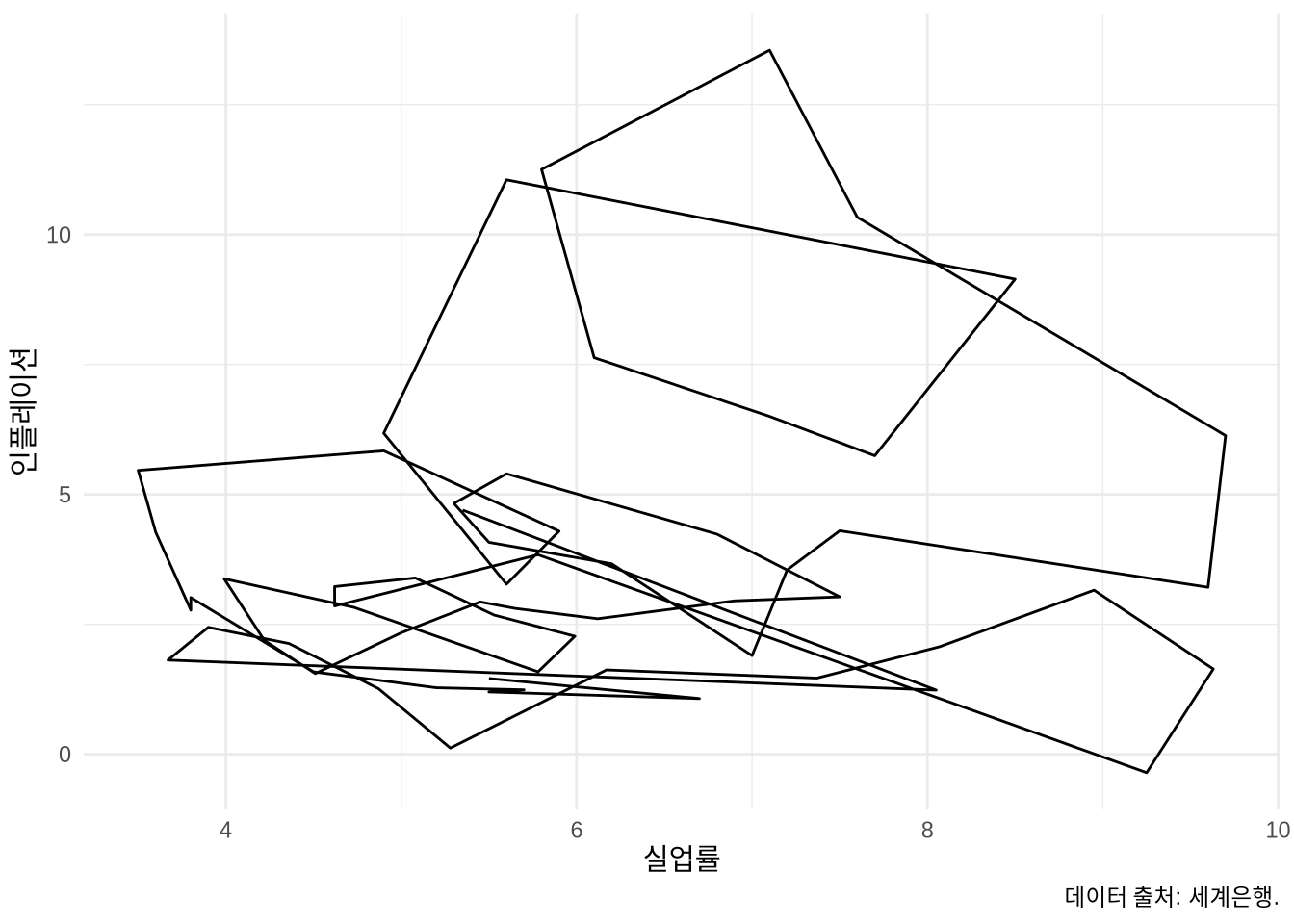
필립스 곡선(Phillips Curve)은 실업률과 인플레이션 사이의 역상관 관계를 보여주는 유명한 경제학 도표입니다. 윌리엄 필립스(A. W. Phillips)가 영국의 장기 데이터를 분석해 처음 제시했죠 (Phillips 1958). 우리는 ggplot2를 이용해 이 관계를 두 가지 방식으로 살펴볼 수 있습니다.
- 두 시계열 비교: 연도별 실업률과 인플레이션 선을 한 그래프에 겹쳐 그립니다 (Figure 5.15 (a)). 이를 위해선
pivot_longer()함수로 데이터를 시각화하기 좋은 ‘정돈된(Tidy)’ 형식으로 먼저 바꾸어야 합니다. (자세한 방법은 온라인 부록 A 를 참고하세요.) - 경로 그래프(Path Plot):
geom_path()를 쓰면 두 변수의 관계를 시계열 순서대로 선으로 연결할 수 있습니다 (Figure 5.15 (b)). 미국의 데이터를 보면, 이론적인 필립스 곡선만큼 매끄러운 역상관 관계가 나타나지는 않는다는 점이 흥미롭습니다.
world_bank_data |>
filter(country == "United States") |>
select(-population, -gdp_growth) |>
pivot_longer(
cols = c("inflation", "unem_rate"),
names_to = "series",
values_to = "value"
) |>
ggplot(mapping = aes(x = year, y = value, color = series)) +
geom_line() +
theme_minimal() +
labs(
x = "연도", y = "값", color = "경제 지표",
caption = "데이터 출처: 세계은행."
) +
scale_color_brewer(palette = "Set1", labels = c("인플레이션", "실업률")) +
theme(legend.position = "bottom")
world_bank_data |>
filter(country == "United States") |>
ggplot(mapping = aes(x = unem_rate, y = inflation)) +
geom_path() +
theme_minimal() +
labs(
x = "실업률", y = "인플레이션",
caption = "데이터 출처: 세계은행."
)
5.2.4 히스토그램
히스토그램(Histogram)은 연속형 변수의 분포 형태를 파악할 때 아주 유용한 도구입니다. 데이터의 전체 범위를 ’빈(Bin)’이라고 부르는 여러 구간으로 나누고, 각 구간에 속하는 데이터 개수를 막대로 쌓아 올리는 방식이죠. Figure 5.16 을 통해 에티오피아의 GDP 성장률 분포를 살펴보겠습니다.
world_bank_data |>
filter(country == "Ethiopia") |>
ggplot(aes(x = gdp_growth)) +
geom_histogram() +
theme_minimal() +
labs(
x = "GDP 성장률",
y = "빈도",
caption = "데이터 출처: 세계은행."
)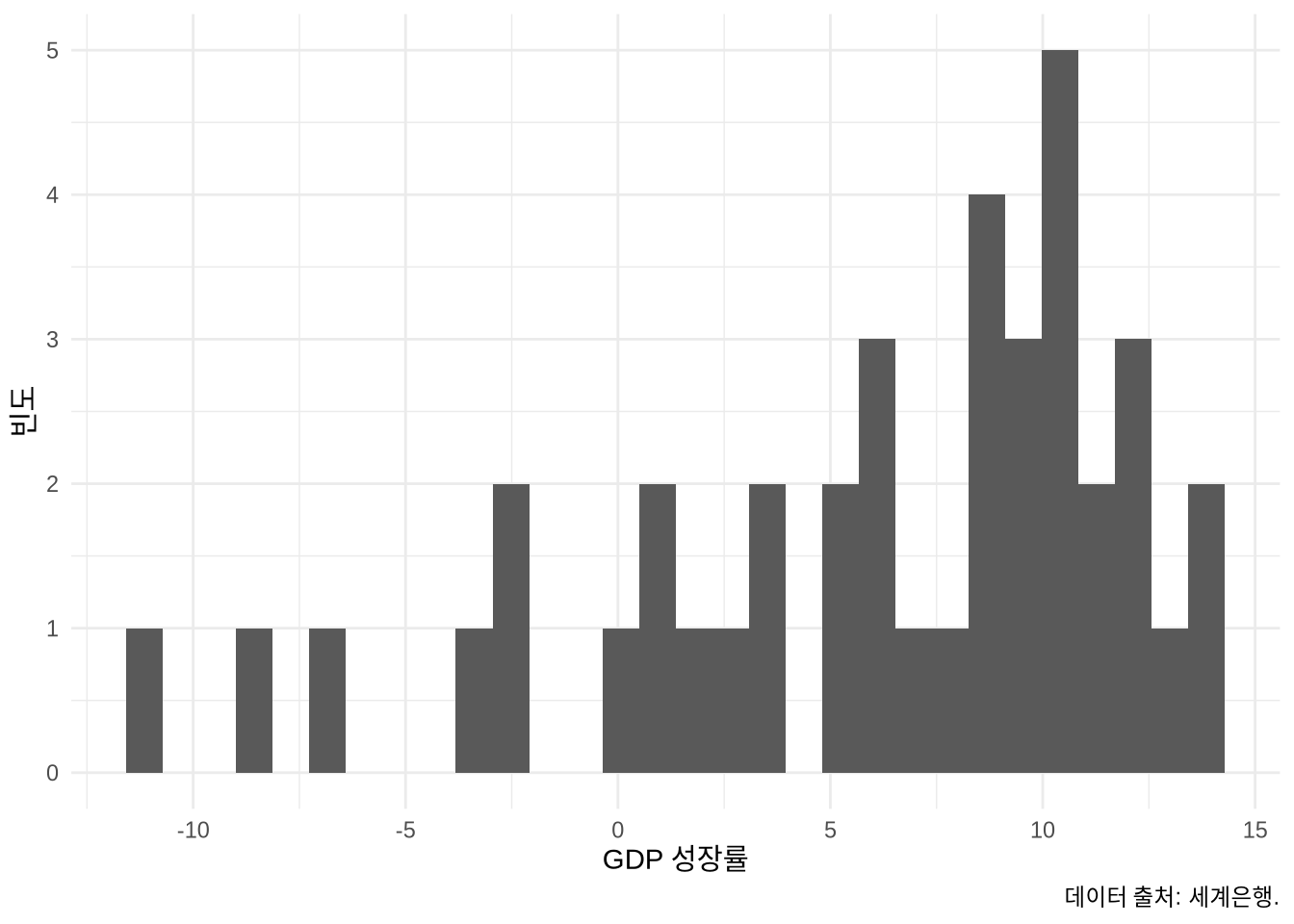
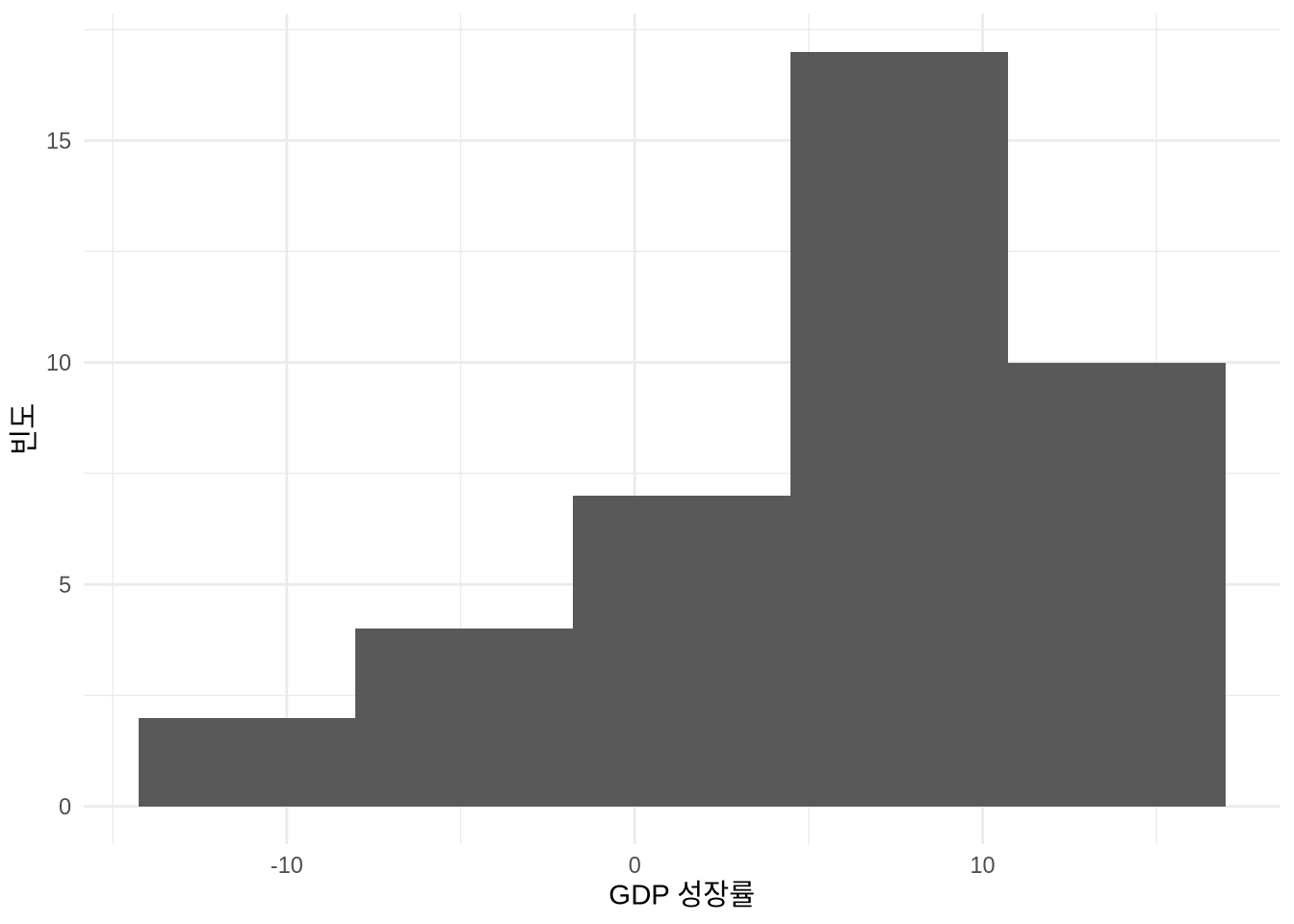
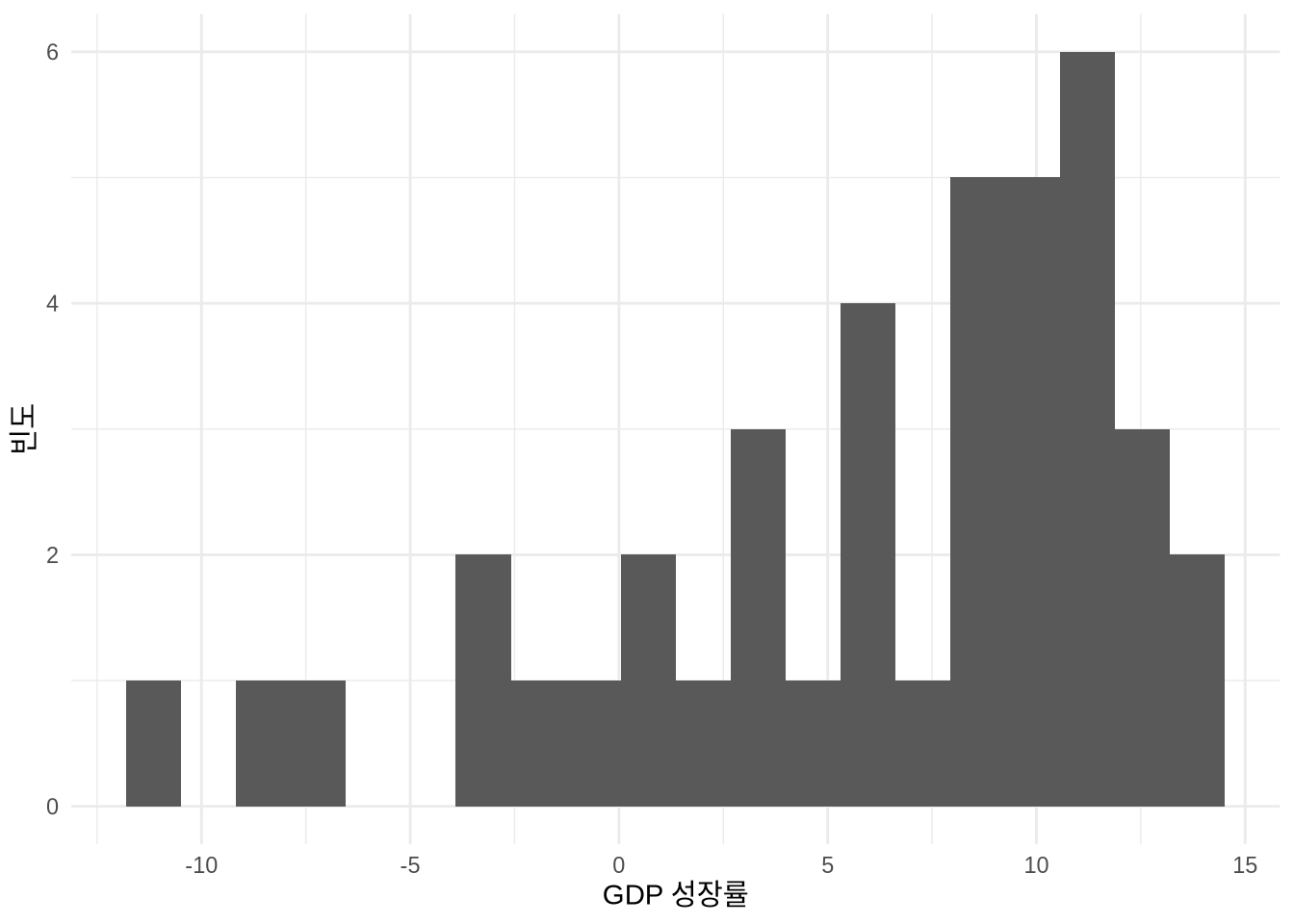
히스토그램의 모양을 결정짓는 핵심은 빈의 개수입니다. ggplot2에서는 다음 두 가지 방식 중 하나로 이를 조절할 수 있습니다 (Figure 5.17).
bins옵션으로 전체 구간의 개수를 직접 지정하기binwidth옵션으로 각 구간의 너비를 설정하기
# Panel (a)
world_bank_data |>
filter(country == "Ethiopia") |>
ggplot(aes(x = gdp_growth)) +
geom_histogram(bins = 5) +
theme_minimal() +
labs(
x = "GDP 성장률",
y = "빈도"
)
# Panel (b)
world_bank_data |>
filter(country == "Ethiopia") |>
ggplot(aes(x = gdp_growth)) +
geom_histogram(bins = 20) +
theme_minimal() +
labs(
x = "GDP 성장률",
y = "빈도"
)
# Panel (c)
world_bank_data |>
filter(country == "Ethiopia") |>
ggplot(aes(x = gdp_growth)) +
geom_histogram(binwidth = 2) +
theme_minimal() +
labs(
x = "GDP 성장률",
y = "빈도"
)
# Panel (d)
world_bank_data |>
filter(country == "Ethiopia") |>
ggplot(aes(x = gdp_growth)) +
geom_histogram(binwidth = 5) +
theme_minimal() +
labs(
x = "GDP 성장률",
y = "빈도"
)
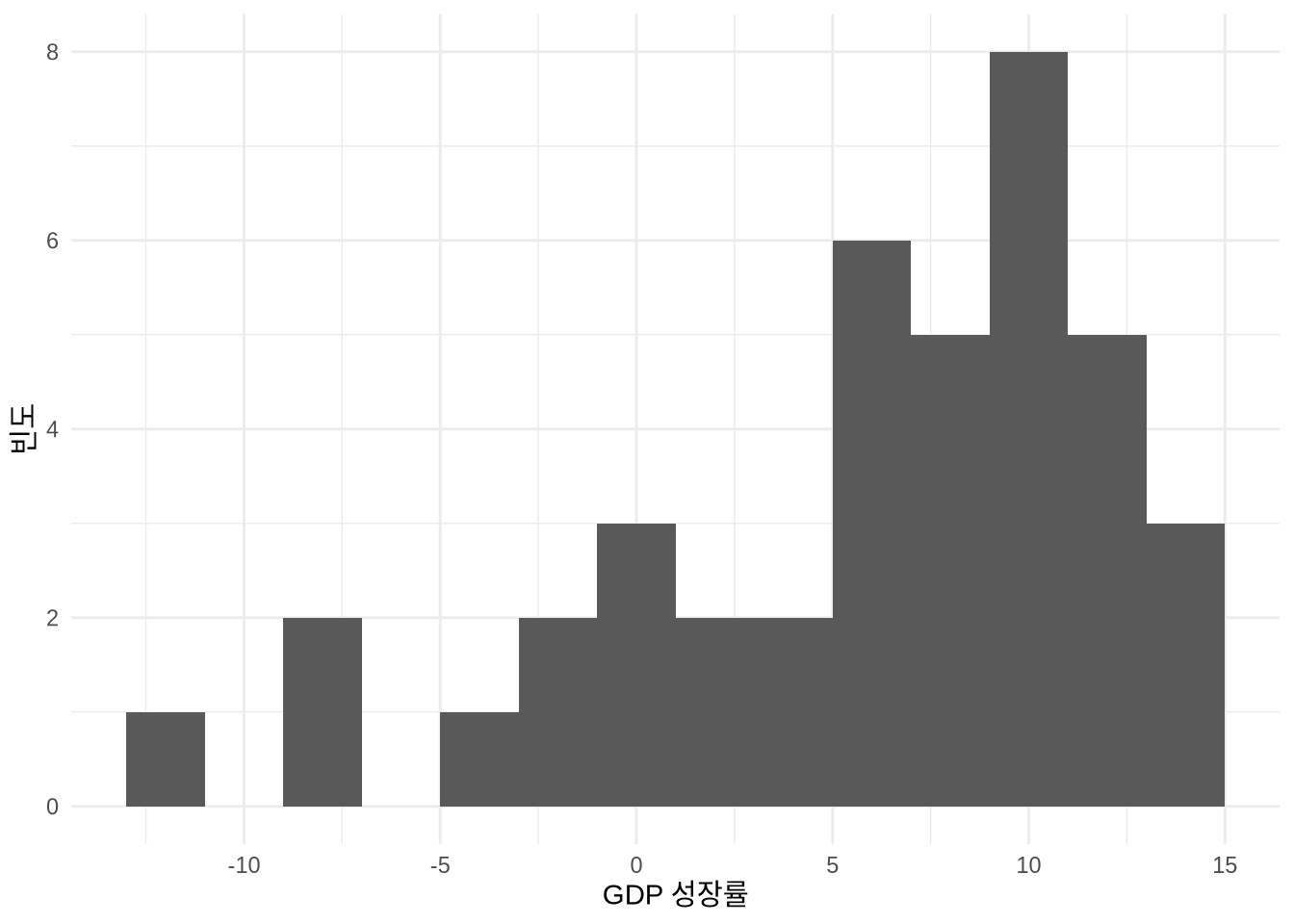
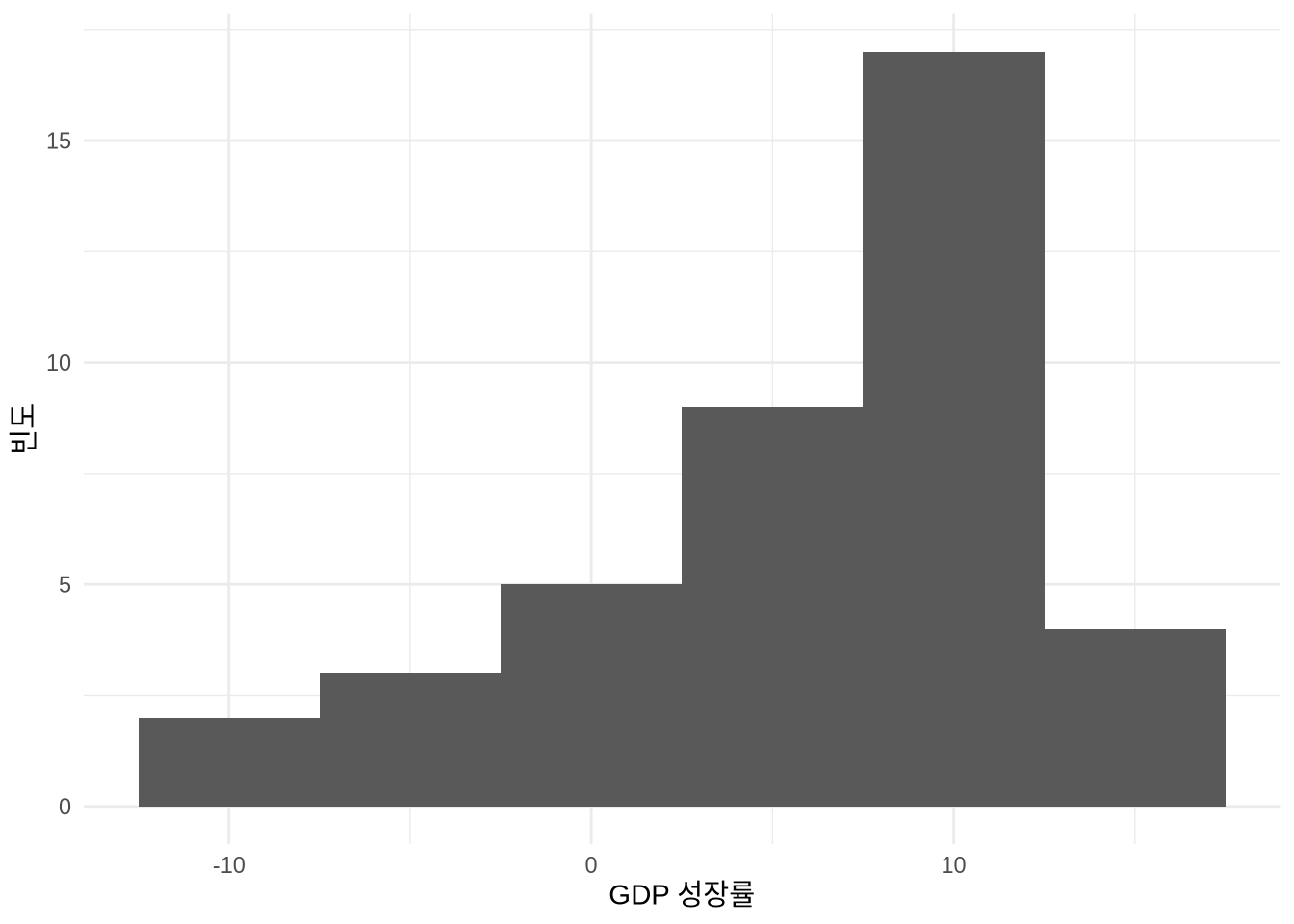
어떤 면에서 히스토그램은 데이터를 국소적으로 평균화해 보여주는 장치이며, 빈의 개수는 이 평활화(Smoothing)의 정도를 결정합니다. 빈이 너무 적으면 정보 손실이 크고 편향(Bias)이 발생하기 쉽습니다. 반대로 빈이 너무 많으면 미세한 노이즈까지 다 반영되어 전체적인 흐름을 읽기 어려운 높은 분산(Variance) 문제가 생기죠 (Wasserman 2005, 303). 따라서 적절한 빈의 개수를 정하는 일은 편향과 분산 사이의 균형점을 찾는 과정이며, 정답은 데이터의 성격에 따라 달라질 수 있습니다 (Cleveland [1985] 1994, 135). 이러한 유연성 덕분에 Denby and Mallows (2009) 는 히스토그램을 매우 가치 있는 탐색적 도구로 꼽습니다.
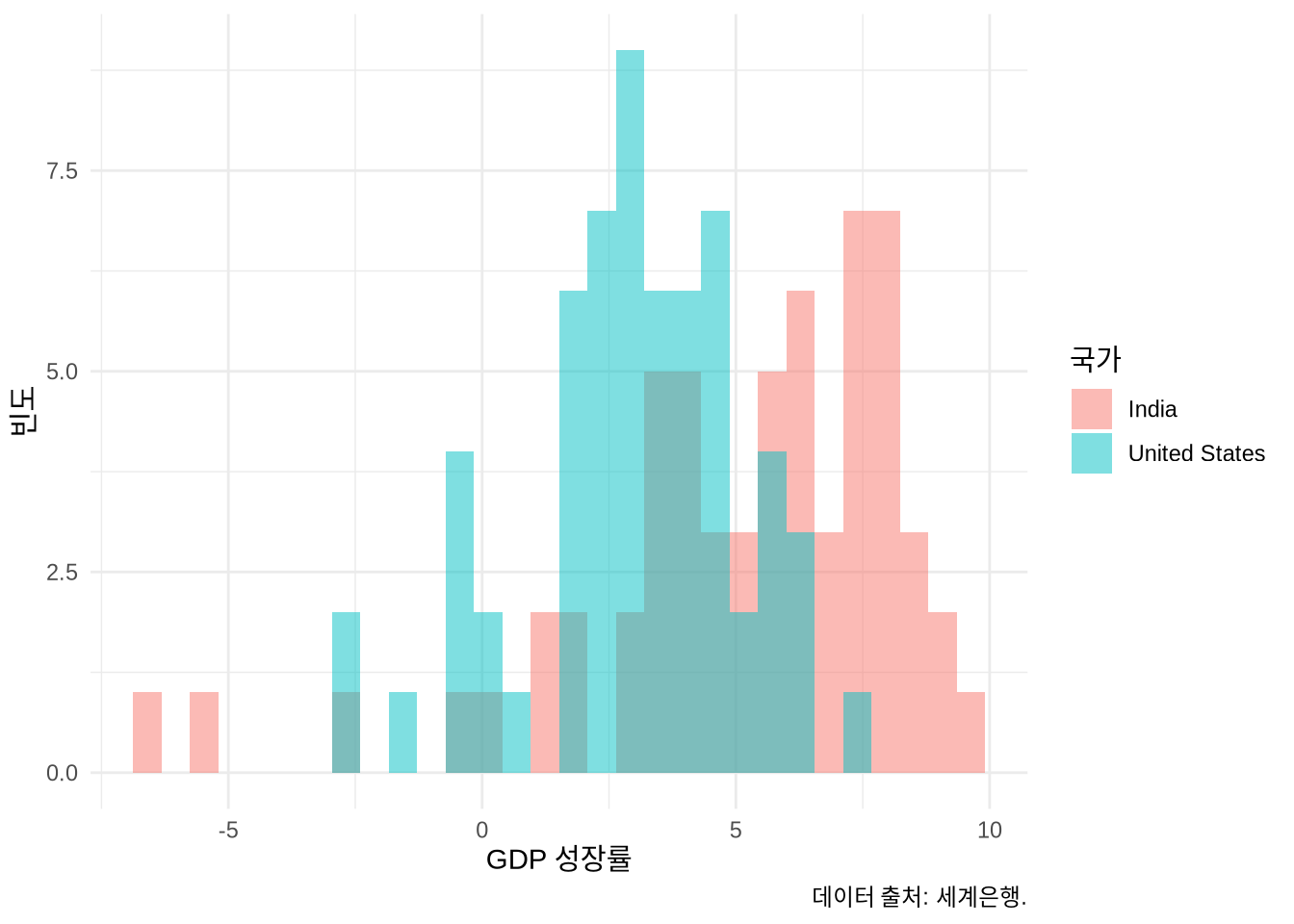
“fill” 미학을 써서 여러 그룹의 분포를 한꺼번에 그릴 수도 있지만, 자칫 지저분해 보이기 쉽습니다. 그럴 땐 다음과 같은 대안들을 고려해 보세요.
geom_freqpoly()로 분포의 윤곽선만 그리기 (Figure 5.18 (a))geom_dotplot()으로 점을 쌓아 올리기 (Figure 5.18 (b))- 투명도를 적절히 줘서 겹쳐 그리기 (Figure 5.18 (c))
# Panel (a)
world_bank_data |>
ggplot(aes(x = gdp_growth, color = country)) +
geom_freqpoly() +
theme_minimal() +
labs(
x = "GDP 성장률", y = "빈도",
color = "국가",
caption = "데이터 출처: 세계은행."
) +
scale_color_brewer(palette = "Set1")
# Panel (b)
world_bank_data |>
ggplot(aes(x = gdp_growth, group = country, fill = country)) +
geom_dotplot(method = "histodot") +
theme_minimal() +
labs(
x = "GDP 성장률", y = "빈도",
fill = "국가",
caption = "데이터 출처: 세계은행."
) +
scale_color_brewer(palette = "Set1")
# Panel (c)
world_bank_data |>
filter(country %in% c("India", "United States")) |>
ggplot(mapping = aes(x = gdp_growth, fill = country)) +
geom_histogram(alpha = 0.5, position = "identity") +
theme_minimal() +
labs(
x = "GDP 성장률", y = "빈도",
fill = "국가",
caption = "데이터 출처: 세계은행."
) +
scale_color_brewer(palette = "Set1")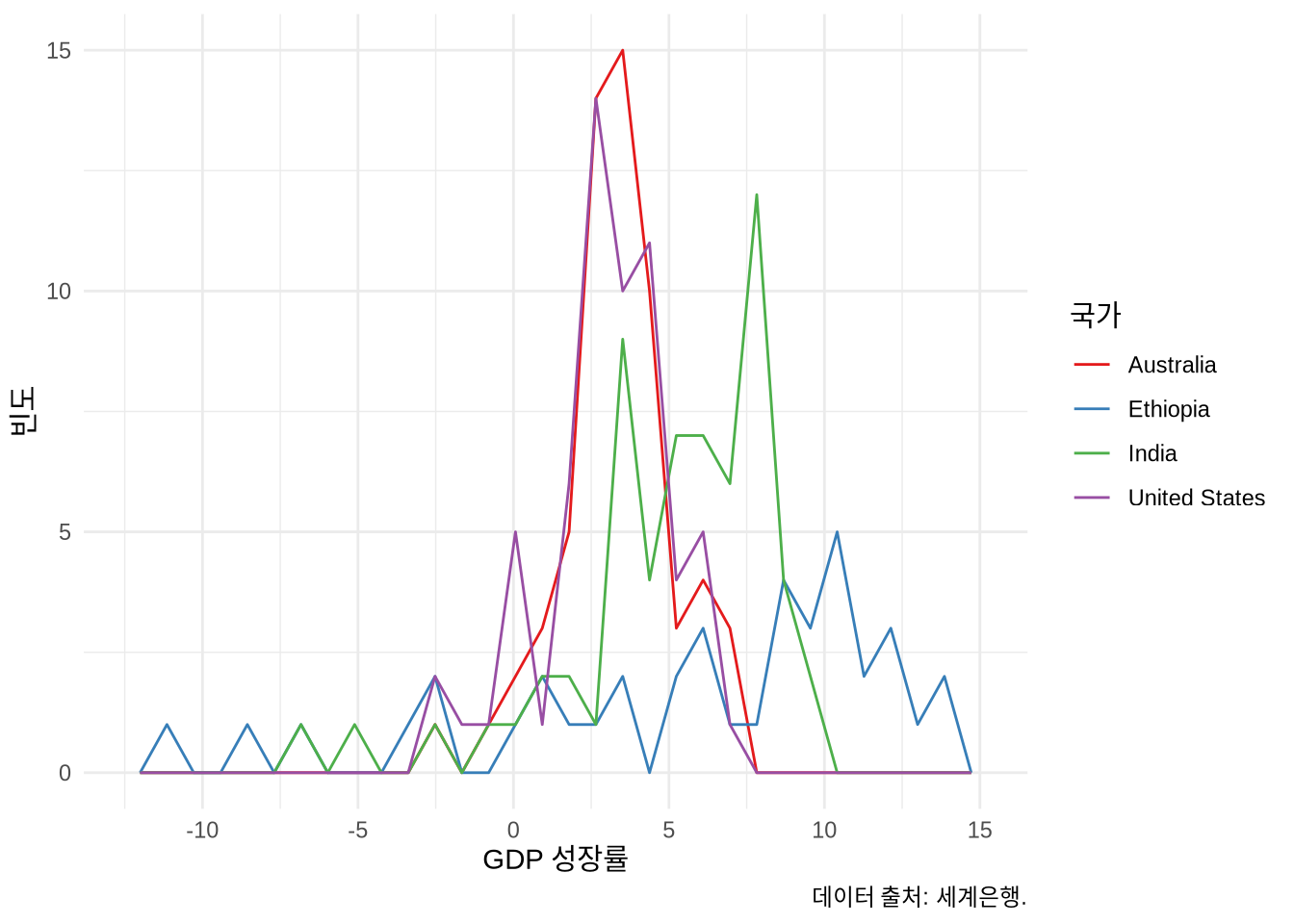
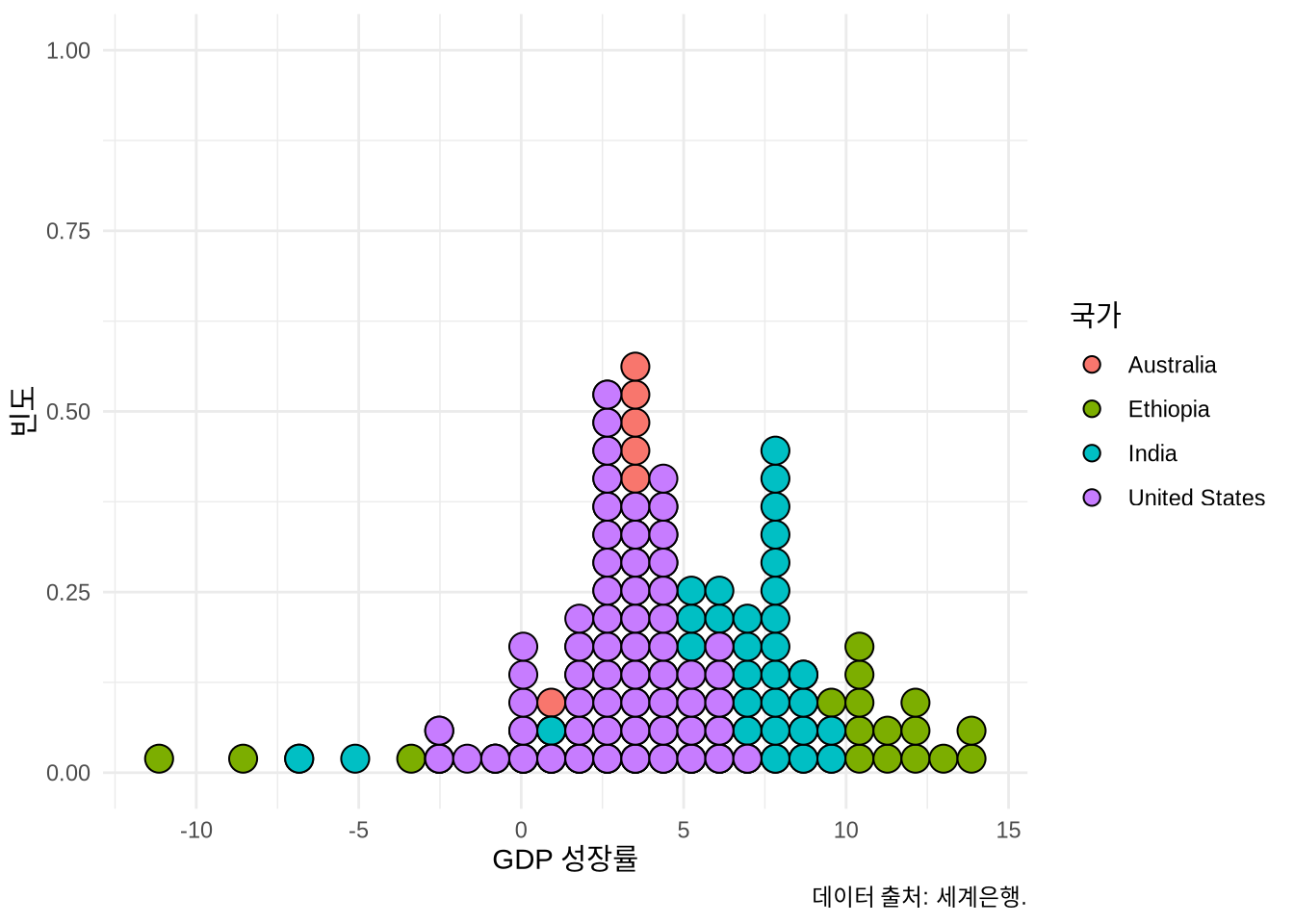
히스토그램의 또 다른 멋진 대안으로는 경험적 누적 분포 함수(Empirical Cumulative Distribution Function, ECDF)가 있습니다. 무엇을 선택할지는 청중의 통계적 숙련도에 달려 있습니다. 입문자에게 ECDF는 다소 낯설 수 있지만, 분석 전문가들에게는 히스토그램보다 임의적인 평활화가 적은 ECDF가 더 정확한 정보 전달 수단이 되기도 하죠. stat_ecdf() 함수로 이를 구현할 수 있습니다 (Figure 5.19).
world_bank_data |>
ggplot(mapping = aes(x = gdp_growth, color = country)) +
stat_ecdf(geom = "point") +
theme_minimal() +
labs(
x = "GDP 성장률", y = "비율", color = "국가",
caption = "데이터 출처: 세계은행."
) +
theme(legend.position = "bottom")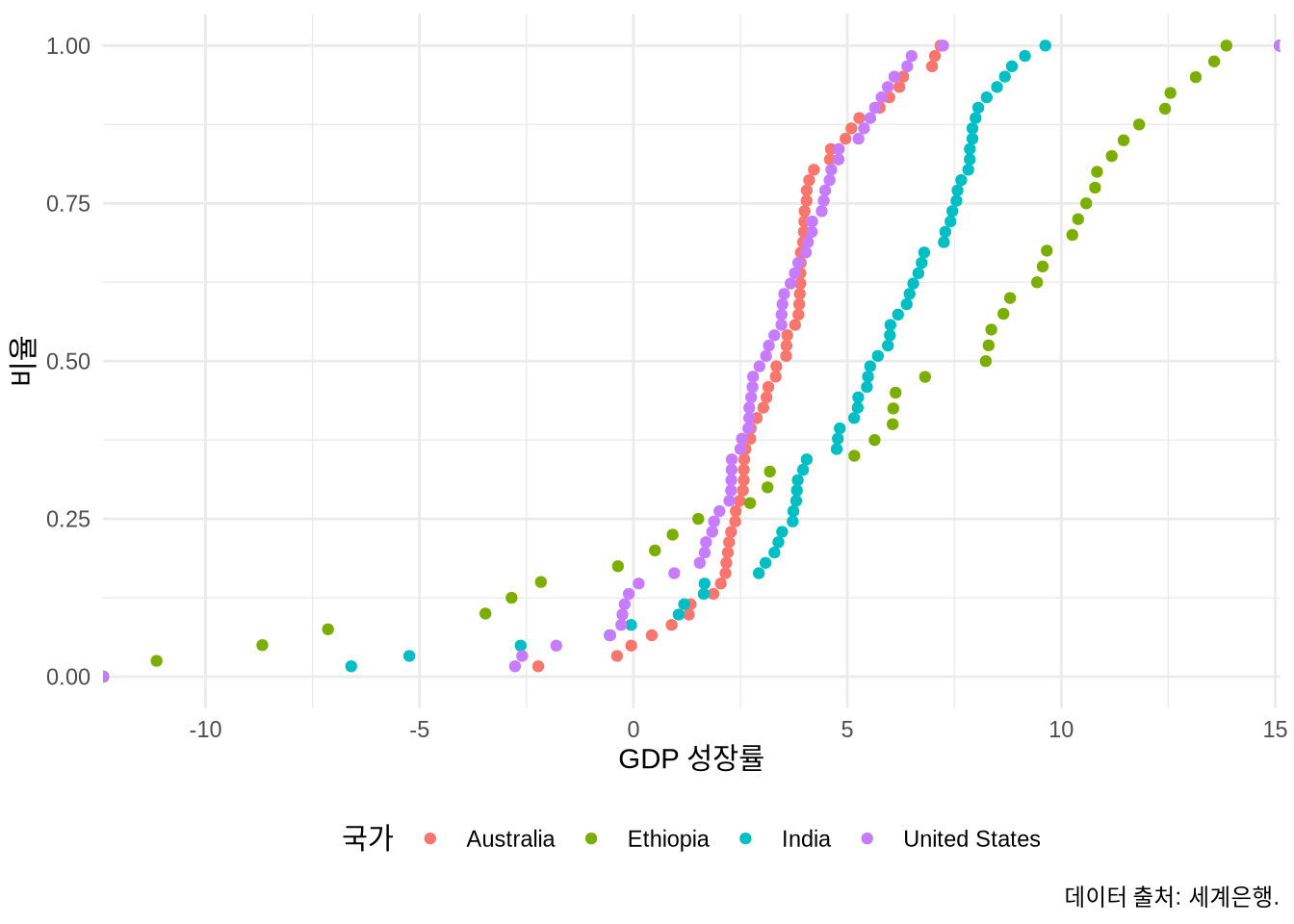
5.2.5 상자 그림
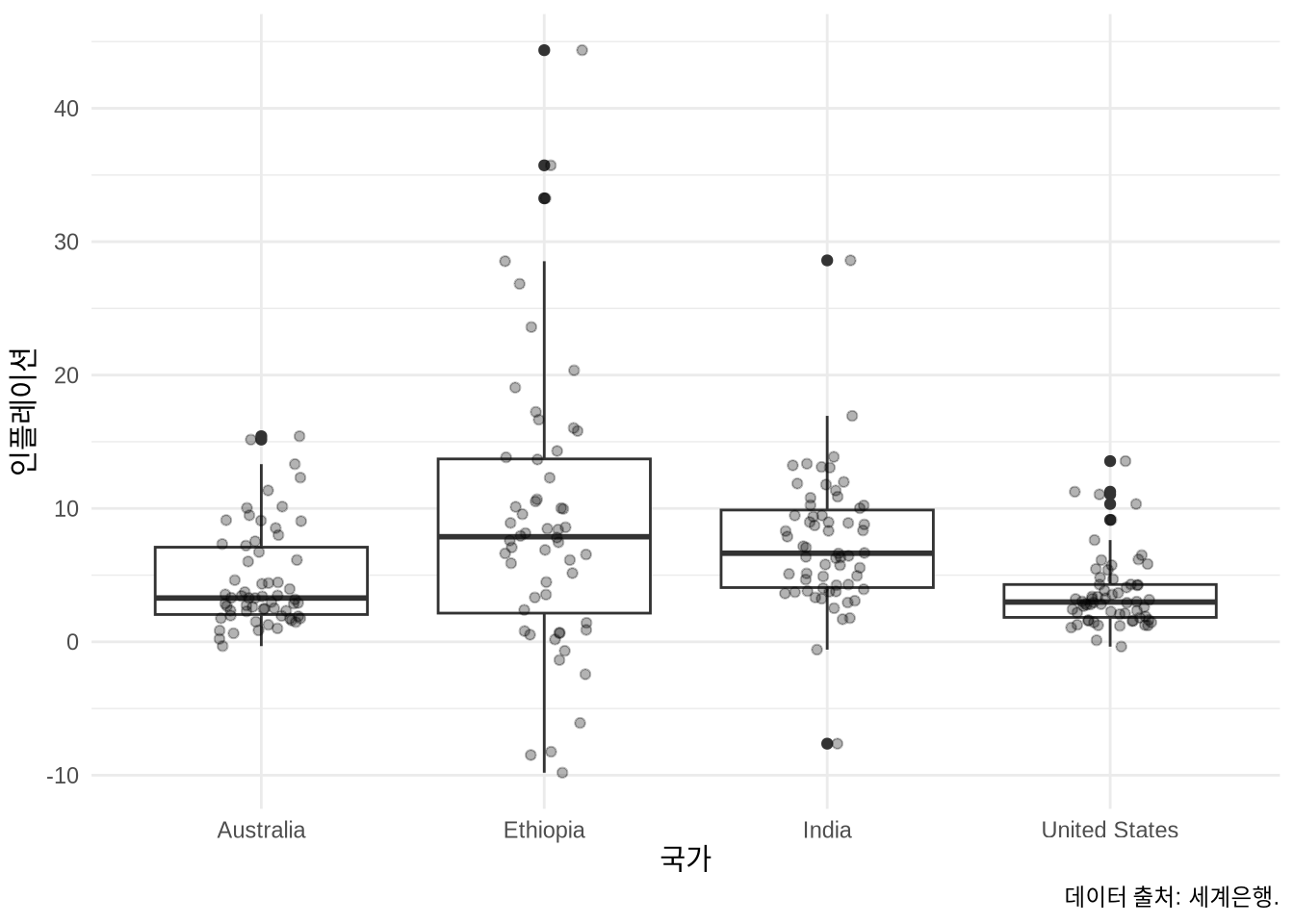
상자 그림(Boxplot)은 데이터의 분포를 다섯 가지 핵심 수치로 요약해 보여줍니다. 1) 중앙값, 2) 제1사분위수(25번째 백분위수), 3) 제3사분위수(75번째 백분위수)가 상자의 골격을 형성하죠. 상자 끝에서 뻗어 나온 선(Whiskers)은 대개 사분위수 범위(IQR)의 1.5배 이내에 있는 최댓값과 최솟값을 연결합니다. ggplot2의 geom_boxplot()이 이 방식을 따릅니다. 이러한 요약 방식은 (Spear 1952, 166) 에서 처음 제안되었고 (Tukey 1977) 에 의해 널리 보급되었습니다.
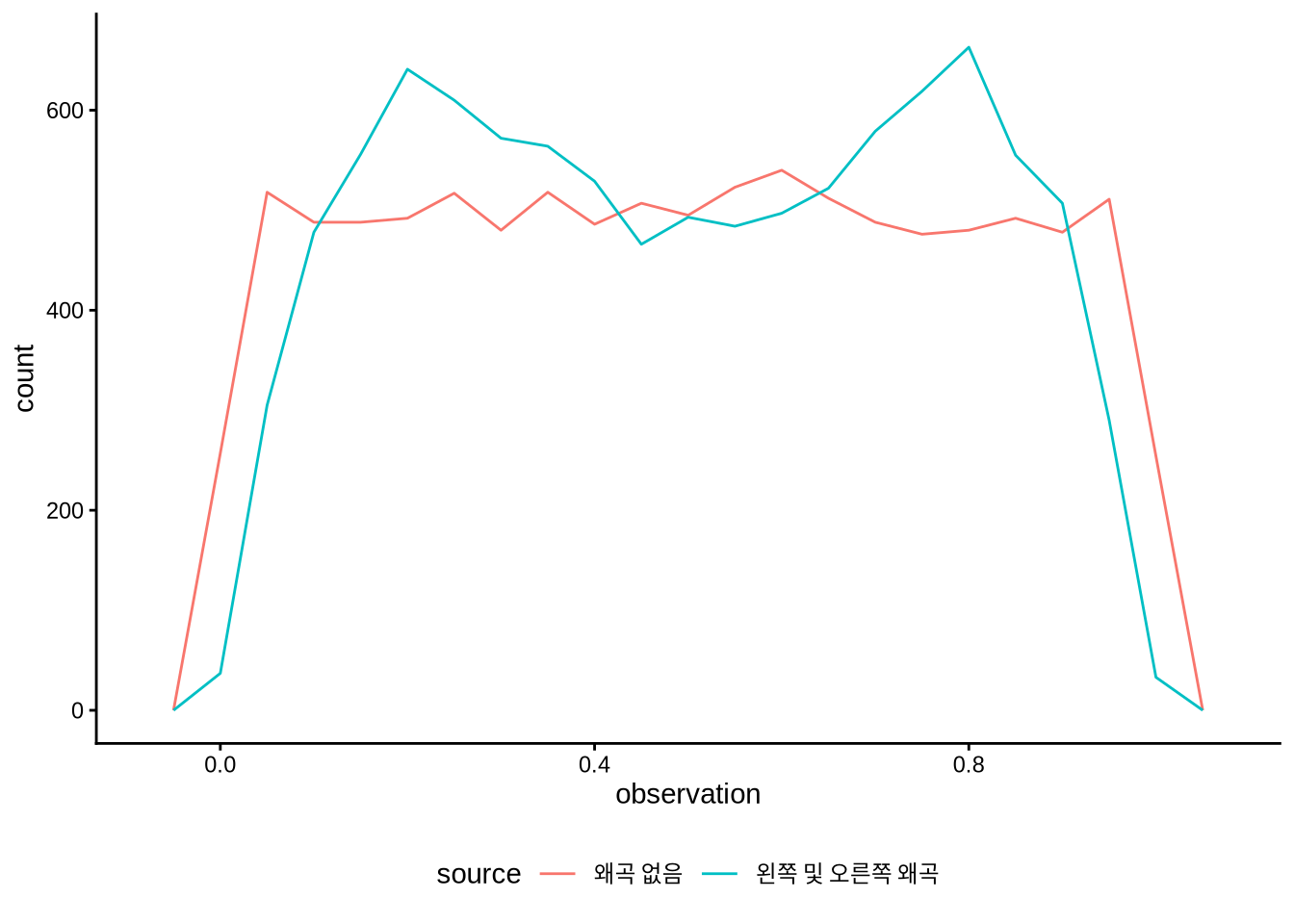
우리가 그래프를 그리는 중요한 이유 중 하나는 데이터의 복잡성을 단순화해 숨기는 게 아니라, 그 본연의 모습을 온전히 이해하기 위해서입니다 (Armstrong 2022). 상자 그림은 Bethlehem et al. (2022) 처럼 여러 변수의 요약치를 한눈에 비교할 때 매우 편리하죠. 하지만 상자 그림에만 의존하는 것은 위험할 수 있습니다. 분포의 세부적인 형태를 ‘감추는’ 성질이 있기 때문이죠. 서로 완전히 다른 형태의 분포가 동일한 상자 그림으로 나타날 수 있다는 사실을 이해하기 위해, 시뮬레이션된 베타 분포 데이터를 살펴보겠습니다.
set.seed(853)
number_of_draws <- 10000
both_left_and_right_skew <-
c(
rbeta(number_of_draws / 2, 5, 2),
rbeta(number_of_draws / 2, 2, 5)
)
no_skew <-
rbeta(number_of_draws, 1, 1)
beta_distributions <-
tibble(
observation = c(both_left_and_right_skew, no_skew),
source = c(
rep("왼쪽 및 오른쪽 왜곡", number_of_draws),
rep("왜곡 없음", number_of_draws)
)
)먼저 두 시리즈의 상자 그림을 비교해 볼까요? (Figure 5.20 (a)). 하지만 실제 데이터를 그려보면 얼마나 큰 차이가 있는지 곧바로 알 수 있습니다 (Figure 5.20 (b)).
beta_distributions |>
ggplot(aes(x = source, y = observation)) +
geom_boxplot() +
theme_classic()
beta_distributions |>
ggplot(aes(x = observation, color = source)) +
geom_freqpoly(binwidth = 0.05) +
theme_classic() +
theme(legend.position = "bottom")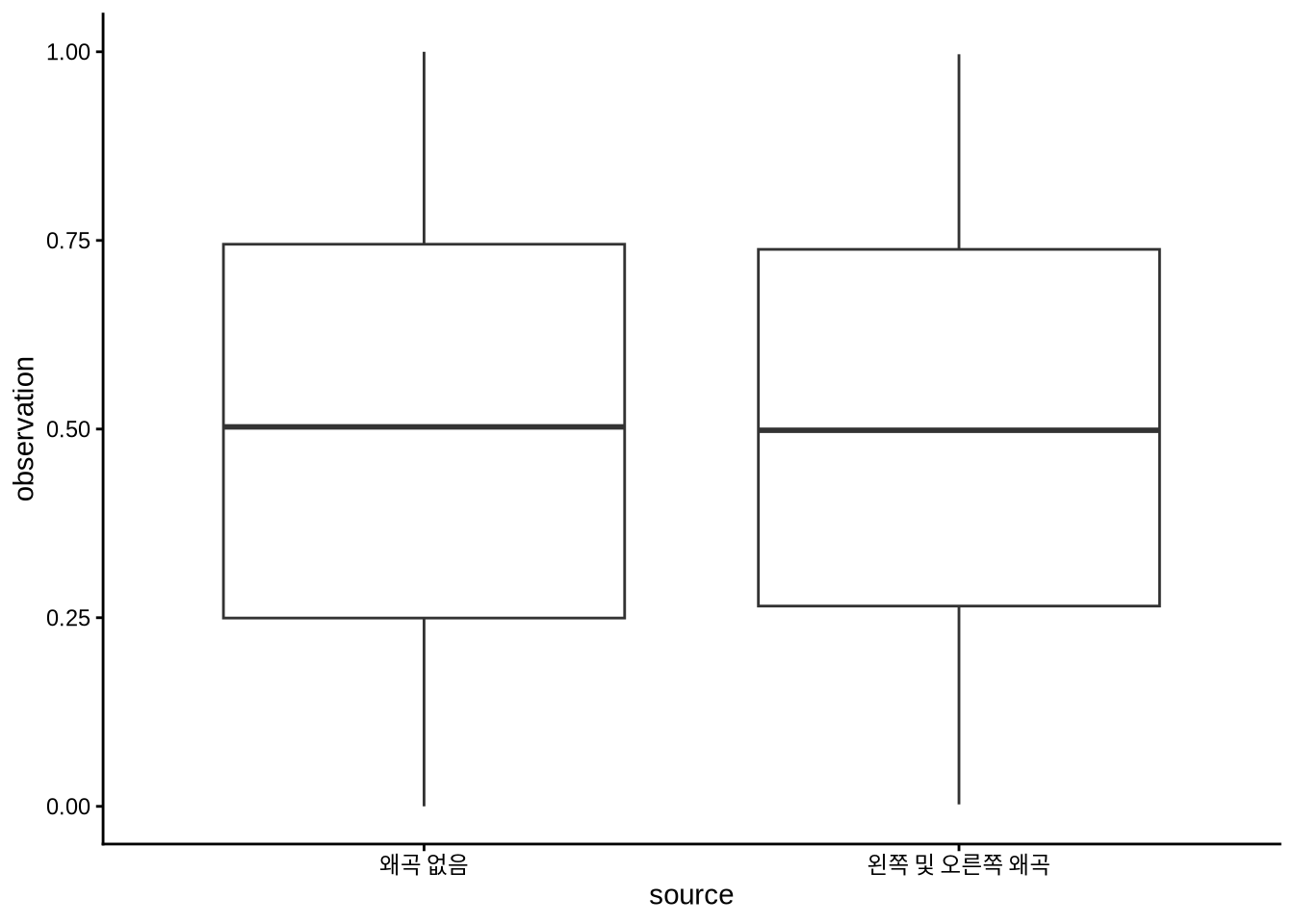
상자 그림을 써야 한다면, 그 위에 실제 데이터를 레이어로 겹쳐서 그리는 것이 좋은 해결책이 됩니다. 예를 들어 Figure 5.21 는 네 개 국가의 인플레이션 분포를 보여주는데, 실제 관측치와 요약 통계를 동시에 보여주기에 정보 손실을 최소화할 수 있습니다.
world_bank_data |>
ggplot(mapping = aes(x = country, y = inflation)) +
geom_boxplot() +
geom_jitter(alpha = 0.3, width = 0.15, height = 0) +
theme_minimal() +
labs(
x = "국가",
y = "인플레이션",
caption = "데이터 출처: 세계은행."
)
5.2.6 대화형 그래프
shiny (Chang et al. 2021) 패키지를 사용하면 R로 사용자와 상호작용하는 웹 애플리케이션을 만들 수 있습니다. 처음에는 조금 까다롭게 느껴질 수 있지만, 데이터 탐색의 차원을 넓혀주는 매우 강력한 도구입니다. 대화형 그래프가 왜 효과적인지에 대한 좋은 사례로 The Economist (2022) 가 만든 2022년 프랑스 대선 예측 모델을 들 수 있습니다. 사용자가 조건을 직접 바꿔가며 결과를 탐색하게 함으로써 훨씬 깊은 통찰을 제공하죠.
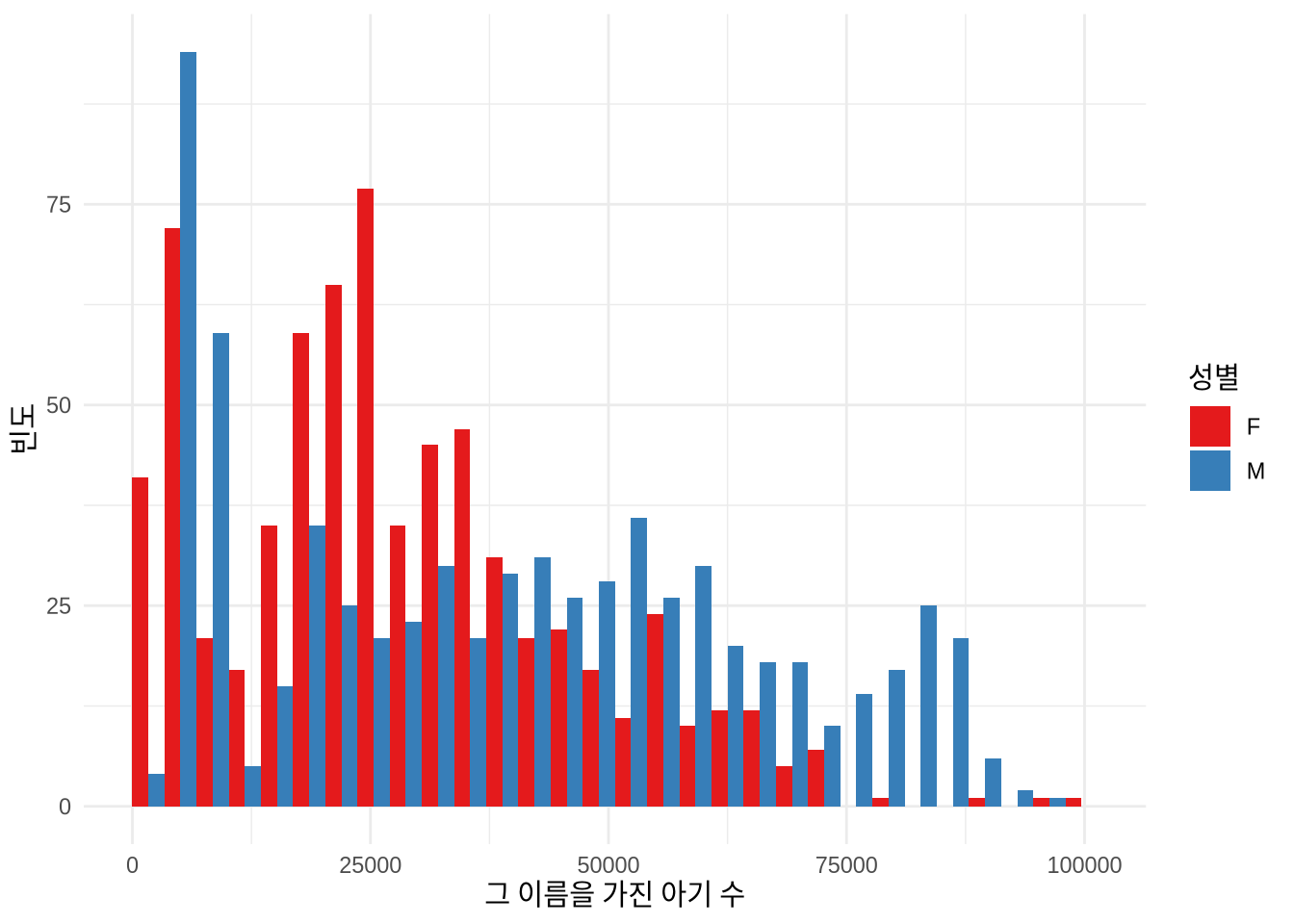
babynames (Wickham 2021a) 데이터셋을 기반으로 대화형 그래프를 만들어 보겠습니다. 우선 정적인 버전부터 시작하죠 (Figure 5.22).
top_five_names_by_year <-
babynames |>
arrange(desc(n)) |>
slice_head(n = 5, by = c(year, sex))
top_five_names_by_year |>
ggplot(aes(x = n, fill = sex)) +
geom_histogram(position = "dodge") +
theme_minimal() +
scale_fill_brewer(palette = "Set1") +
labs(
x = "그 이름을 가진 아기 수",
y = "빈도",
fill = "성별"
)
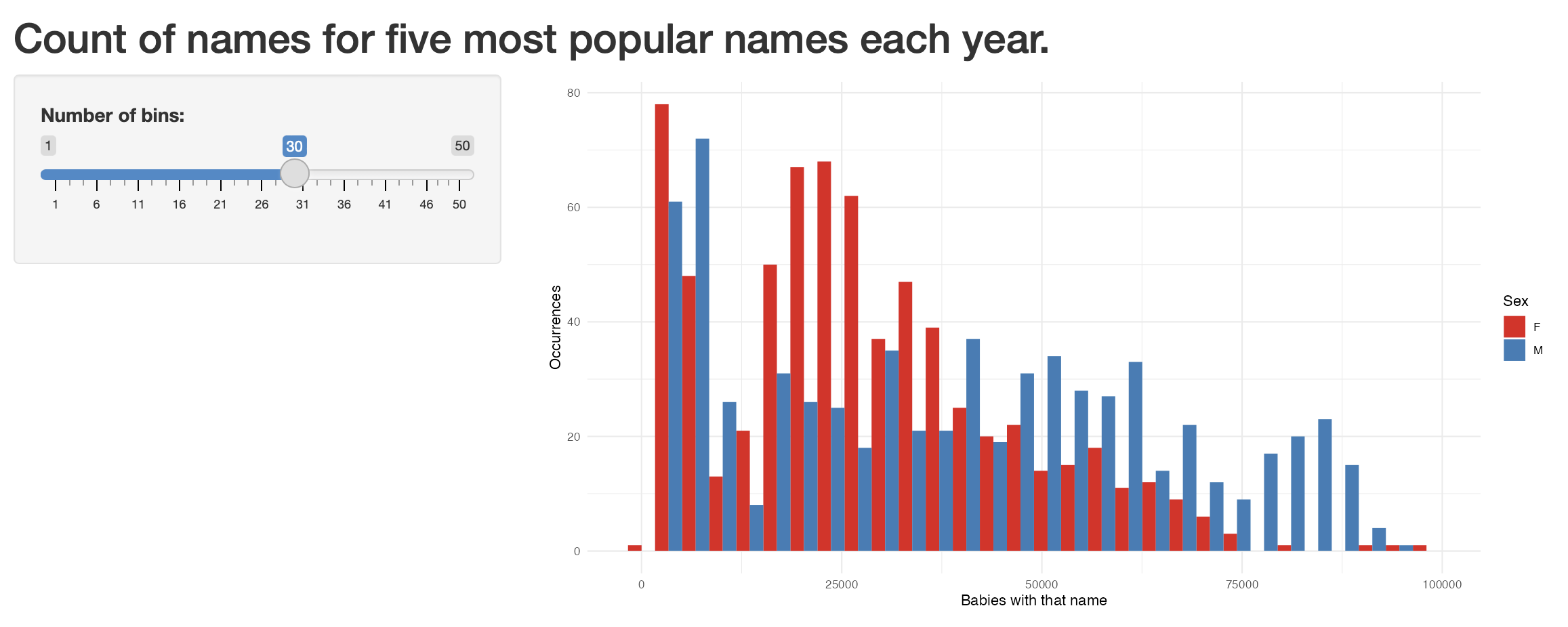
우리가 궁금할 수 있는 한 가지는 “bins” 매개변수의 값이 바뀌면 그래프가 어떻게 달라질까 하는 점입니다. 대화형 도구를 써서 이를 직접 탐색해 보겠습니다.
우선 새로운 shiny 앱을 만들어 보세요 (“File” -> “New File” -> “Shiny Web App”). 이름은 “my_first_shiny” 같은 것으로 정하고 다른 옵션은 그대로 둡니다. “app.R” 파일이 열리면 상단의 “Run App”을 클릭해 어떻게 생겼는지 확인해 보세요.
이제 “app.R”의 내용을 아래 코드로 바꾼 뒤 다시 “Run App”을 클릭해 보세요.
library(shiny)
# Define UI for application that draws a histogram
ui <- fluidPage(
# Application title
titlePanel("연도별 인기 아기 이름 빈도 분석"),
# Sidebar with a slider input for number of bins
sidebarLayout(
sidebarPanel(
sliderInput(
inputId = "number_of_bins",
label = "빈(bin)의 개수:",
min = 1,
max = 50,
value = 30
)
),
# Show a plot of the generated distribution
mainPanel(plotOutput("distPlot"))
)
)
# Define server logic required to draw a histogram
server <- function(input, output) {
output$distPlot <- renderPlot({
# Draw the histogram with the specified number of bins
top_five_names_by_year |>
ggplot(aes(x = n, fill = sex)) +
geom_histogram(position = "dodge", bins = input$number_of_bins) +
theme_minimal() +
scale_fill_brewer(palette = "Set1") +
labs(
x = "그 이름을 가진 아기 수",
y = "빈도",
fill = "성별"
)
})
}
# Run the application
shinyApp(ui = ui, server = server)빈의 개수를 실시간으로 조절할 수 있는 대화형 그래프가 완성되었습니다. Figure 5.23 처럼 보일 것입니다.
5.3 표
표(Table)는 데이터를 독자에게 전달하는 데 있어 그래프만큼이나 강력한 수단입니다. 그래프가 전반적인 패턴과 흐름을 보여주는 데 유리하다면, 표는 구체적인 수치 하나하나를 정밀하게 전달하는 데 최적화되어 있죠 (Andersen and Armstrong 2021). 이 책에서는 주로 다음과 같은 세 가지 목적으로 표를 사용합니다.
- 데이터셋 중 대표적인 일부 관측치를 그대로 보여줄 때
- 주요 변수들의 요약 통계량(평균, 표준편차 등)을 정리할 때
- 통계 분석의 핵심인 회귀 분석 결과를 보고할 때
5.3.1 데이터셋의 일부 노출하기
tinytable 패키지의 tt() 함수를 이용해 데이터셋 일부를 표로 만드는 방법을 알아보겠습니다. 세계은행 데이터에서 인플레이션, GDP 성장률, 인구수 변수를 중심으로 처음 10개 행을 추출해 보겠습니다.
world_bank_data <-
world_bank_data |>
select(-unem_rate)tinytable 패키지를 로드한 뒤 기본 tt() 설정으로 표를 생성할 수 있습니다.
world_bank_data |>
slice(1:10) |>
tt()| country | year | inflation | gdp_growth | population |
|---|---|---|---|---|
| Australia | 1960 | 3.7288136 | NA | 10276477 |
| Australia | 1961 | 2.2875817 | 2.482656 | 10483000 |
| Australia | 1962 | -0.3194888 | 1.294611 | 10742000 |
| Australia | 1963 | 0.6410256 | 6.216107 | 10950000 |
| Australia | 1964 | 2.8662420 | 6.980061 | 11167000 |
| Australia | 1965 | 3.4055728 | 5.980438 | 11388000 |
| Australia | 1966 | 3.2934132 | 2.379040 | 11651000 |
| Australia | 1967 | 3.4782609 | 6.304945 | 11799000 |
| Australia | 1968 | 2.5210084 | 5.094034 | 12009000 |
| Australia | 1969 | 3.2786885 | 7.045584 | 12263000 |
본문에서 표를 상호 참조하려면 Chapter 3 와 Section 3.2.7 에서 설명한 대로 Quarto 코드 청크 상단에 캡션(tbl-cap)과 레이블(label)을 추가해야 합니다. 또한 setNames()로 열 이름을 가독성 있게 바꾸고, format_tt()로 소수점 자릿수를 조절하면 훨씬 읽기 편한 표가 됩니다 (Table 5.3).
```{r}
#| label: tbl-gdpfirst
#| message: false
#| tbl-cap: "네 국가의 주요 경제 지표 데이터셋"
world_bank_data |>
slice(1:10) |>
tt() |>
style_tt(j = 2:5, align = "r") |>
format_tt(digits = 1, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("국가", "연도", "인플레이션", "GDP 성장률", "인구"))
```| 국가 | 연도 | 인플레이션 | GDP 성장률 | 인구 |
|---|---|---|---|---|
| Australia | 1,960 | 3.7 | NA | 10,276,477 |
| Australia | 1,961 | 2.3 | 2.5 | 10,483,000 |
| Australia | 1,962 | -0.3 | 1.3 | 10,742,000 |
| Australia | 1,963 | 0.6 | 6.2 | 10,950,000 |
| Australia | 1,964 | 2.9 | 7 | 11,167,000 |
| Australia | 1,965 | 3.4 | 6 | 11,388,000 |
| Australia | 1,966 | 3.3 | 2.4 | 11,651,000 |
| Australia | 1,967 | 3.5 | 6.3 | 11,799,000 |
| Australia | 1,968 | 2.5 | 5.1 | 12,009,000 |
| Australia | 1,969 | 3.3 | 7 | 12,263,000 |
5.3.2 서식 다듬기
style_tt() 함수의 align 인자에 “l”(왼쪽), “c”(가운데), “r”(오른쪽) 문자를 지정해 열별 정렬을 세밀하게 조절할 수 있습니다 (Table 5.4). 또한 숫자가 큰 경우 num_mark_big = "," 옵션을 주어 천 단위마다 쉼표를 넣어주면 가독성이 크게 올라갑니다.
world_bank_data |>
slice(1:10) |>
mutate(year = as.factor(year)) |>
tt() |>
style_tt(j = 1:5, align = "lccrr") |>
format_tt(digits = 1, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("국가", "연도", "인플레이션", "GDP 성장률", "인구"))| 국가 | 연도 | 인플레이션 | GDP 성장률 | 인구 |
|---|---|---|---|---|
| Australia | 1960 | 3.7 | NA | 10,276,477 |
| Australia | 1961 | 2.3 | 2.5 | 10,483,000 |
| Australia | 1962 | -0.3 | 1.3 | 10,742,000 |
| Australia | 1963 | 0.6 | 6.2 | 10,950,000 |
| Australia | 1964 | 2.9 | 7 | 11,167,000 |
| Australia | 1965 | 3.4 | 6 | 11,388,000 |
| Australia | 1966 | 3.3 | 2.4 | 11,651,000 |
| Australia | 1967 | 3.5 | 6.3 | 11,799,000 |
| Australia | 1968 | 2.5 | 5.1 | 12,009,000 |
| Australia | 1969 | 3.3 | 7 | 12,263,000 |
5.3.3 요약 통계량 전달하기
modelsummary 패키지의 datasummary_skim() 함수를 쓰면 데이터셋 전체의 요약 통계를 간편하게 표로 만들 수 있습니다.
이를 활용해 Table 5.5 같은 결과물을 얻을 수 있죠. 이는 Chapter 11 에서 다룰 탐색적 데이터 분석 과정에서 매우 유용합니다. (여기서는 지면을 아끼기 위해 인구 변수는 제외하고 히스토그램도 생략했습니다.)
world_bank_data |>
select(-population) |>
datasummary_skim(histogram = FALSE)| Unique | Missing Pct. | Mean | SD | Min | Median | Max | |
|---|---|---|---|---|---|---|---|
| year | 62 | 0 | 1990.5 | 17.9 | 1960.0 | 1990.5 | 2021.0 |
| inflation | 243 | 2 | 6.1 | 6.5 | -9.8 | 4.3 | 44.4 |
| gdp_growth | 224 | 10 | 4.2 | 3.7 | -11.1 | 3.9 | 13.9 |
| country | N | % | |||||
| Australia | 62 | 25.0 | |||||
| Ethiopia | 62 | 25.0 | |||||
| India | 62 | 25.0 | |||||
| United States | 62 | 25.0 |
기본적으로 datasummary_skim()은 수치형 변수를 요약하지만, 범주형 변수를 요청할 수도 있습니다 (Table 5.6). 상호 참조를 위해선 마찬가지로 “tbl-cap” 항목을 포함하고 코드 청크 이름을 지정해 주어야 합니다.
world_bank_data |>
datasummary_skim(type = "categorical")| country | N | % |
|---|---|---|
| Australia | 62 | 25.0 |
| Ethiopia | 62 | 25.0 |
| India | 62 | 25.0 |
| United States | 62 | 25.0 |
변수들 사이의 상관관계를 한눈에 보려면 datasummary_correlation()을 써보세요 (Table 5.7).
world_bank_data |>
datasummary_correlation()| year | inflation | gdp_growth | population | |
|---|---|---|---|---|
| year | 1 | . | . | . |
| inflation | .03 | 1 | . | . |
| gdp_growth | .11 | .01 | 1 | . |
| population | .25 | .06 | .16 | 1 |
실제 논문에는 흔히 ’기술 통계표’라고 부르는 요약표가 필요합니다 (Table 5.8). 앞서 본 Table 5.6 와 달리, 이는 논문의 주요 분석 결과를 뒷받침하기 위해 데이터를 정제해 보여주는 성격이 강합니다. notes 인자를 활용해 데이터 출처 등을 메모로 남길 수 있습니다.
datasummary_balance(
formula = ~country,
data = world_bank_data |>
filter(country %in% c("Australia", "Ethiopia")),
dinm = FALSE,
notes = "데이터 출처: 세계은행."
)| Australia (N=62) | Ethiopia (N=62) | |||
|---|---|---|---|---|
| Mean | Std. Dev. | Mean | Std. Dev. | |
| 데이터 출처: 세계은행. | ||||
| year | 1990.5 | 18.0 | 1990.5 | 18.0 |
| inflation | 4.7 | 3.8 | 9.1 | 10.6 |
| gdp_growth | 3.4 | 1.8 | 5.9 | 6.4 |
| population | 17351313.1 | 4407899.0 | 57185292.0 | 29328845.8 |
5.3.4 회귀 분석 결과 보고하기
회귀 분석 결과를 전문적으로 보고할 때는 modelsummary() 함수가 제격입니다. 여러 모델의 추정치를 나란히 배치해 비교할 수 있죠 (Table 5.9).
first_model <- lm(
formula = gdp_growth ~ inflation,
data = world_bank_data
)
second_model <- lm(
formula = gdp_growth ~ inflation + country,
data = world_bank_data
)
third_model <- lm(
formula = gdp_growth ~ inflation + country + population,
data = world_bank_data
)
modelsummary(list(first_model, second_model, third_model))| (1) | (2) | (3) | |
|---|---|---|---|
| (Intercept) | 4.147 | 3.676 | 3.611 |
| (0.343) | (0.484) | (0.482) | |
| inflation | 0.006 | -0.068 | -0.065 |
| (0.039) | (0.040) | (0.039) | |
| countryEthiopia | 2.896 | 2.716 | |
| (0.740) | (0.740) | ||
| countryIndia | 1.916 | -0.730 | |
| (0.642) | (1.465) | ||
| countryUnited States | -0.436 | -1.145 | |
| (0.633) | (0.722) | ||
| population | 0.000 | ||
| (0.000) | |||
| Num.Obs. | 223 | 223 | 223 |
| R2 | 0.000 | 0.111 | 0.127 |
| R2 Adj. | -0.004 | 0.095 | 0.107 |
| AIC | 1217.7 | 1197.5 | 1195.4 |
| BIC | 1227.9 | 1217.9 | 1219.3 |
| Log.Lik. | -605.861 | -592.752 | -590.704 |
| F | 0.024 | 6.806 | |
| RMSE | 3.66 | 3.45 | 3.42 |
소수점 자릿수는 “fmt” 인자로 조절할 수 있습니다 (Table 5.10). 단순히 자릿수가 많다고 신뢰도가 올라가는 건 아닙니다 (Howes 2022). 오히려 데이터 생성 과정을 고려해 적절한 수준으로 자릿수를 맞추는 것이 더 전문적인 태도입니다.
modelsummary(
list(first_model, second_model, third_model),
fmt = 1
)| (1) | (2) | (3) | |
|---|---|---|---|
| (Intercept) | 4.1 | 3.7 | 3.6 |
| (0.3) | (0.5) | (0.5) | |
| inflation | 0.0 | -0.1 | -0.1 |
| (0.0) | (0.0) | (0.0) | |
| countryEthiopia | 2.9 | 2.7 | |
| (0.7) | (0.7) | ||
| countryIndia | 1.9 | -0.7 | |
| (0.6) | (1.5) | ||
| countryUnited States | -0.4 | -1.1 | |
| (0.6) | (0.7) | ||
| population | 0.0 | ||
| (0.0) | |||
| Num.Obs. | 223 | 223 | 223 |
| R2 | 0.000 | 0.111 | 0.127 |
| R2 Adj. | -0.004 | 0.095 | 0.107 |
| AIC | 1217.7 | 1197.5 | 1195.4 |
| BIC | 1227.9 | 1217.9 | 1219.3 |
| Log.Lik. | -605.861 | -592.752 | -590.704 |
| F | 0.024 | 6.806 | |
| RMSE | 3.66 | 3.45 | 3.42 |
5.4 지도 그리기
지도는 x축이 위도, y축이 경도이고 배경에 지형이나 국경선이 깔린 특별한 형태의 그래프라고 볼 수 있습니다. 지도는 인류 역사에서 가장 오래되고 가장 직관적인 시각화 도구 중 하나죠 (Karsten 1923, 1). R을 쓰면 아주 간단한 지도를 금방 만들 수 있지만, 깊이 들어갈수록 상황은 꽤 복잡해집니다.
가장 먼저 할 일은 지리 데이터를 확보하는 것입니다. ggplot2에는 map_data()로 불러올 수 있는 기본 데이터가 내장되어 있고, maps 패키지의 world.cities 데이터셋을 쓰면 더 상세한 도시 정보를 얻을 수 있습니다.
france <- map_data(map = "france")
head(france) long lat group order region subregion
1 2.557093 51.09752 1 1 Nord <NA>
2 2.579995 51.00298 1 2 Nord <NA>
3 2.609101 50.98545 1 3 Nord <NA>
4 2.630782 50.95073 1 4 Nord <NA>
5 2.625894 50.94116 1 5 Nord <NA>
6 2.597699 50.91967 1 6 Nord <NA>french_cities <-
world.cities |>
filter(country.etc == "France")
head(french_cities) name country.etc pop lat long capital
1 Abbeville France 26656 50.12 1.83 0
2 Acheres France 23219 48.97 2.06 0
3 Agde France 23477 43.33 3.46 0
4 Agen France 34742 44.20 0.62 0
5 Aire-sur-la-Lys France 10470 50.64 2.39 0
6 Aix-en-Provence France 148622 43.53 5.44 0이 정보를 바탕으로 프랑스의 주요 도시들을 점으로 찍은 지도를 그려보겠습니다 (Figure 5.24). ggplot2의 geom_polygon()으로 영토 모양을 잡고, coord_map()으로 둥근 지구를 평면에 나타낼 때 생기는 왜곡을 보정해 줍니다.
ggplot() +
geom_polygon(
data = france,
aes(x = long, y = lat, group = group),
fill = "white",
colour = "grey"
) +
coord_map() +
geom_point(
aes(x = french_cities$long, y = french_cities$lat),
alpha = 0.3,
color = "black"
) +
theme_minimal() +
labs(x = "경도", y = "위도")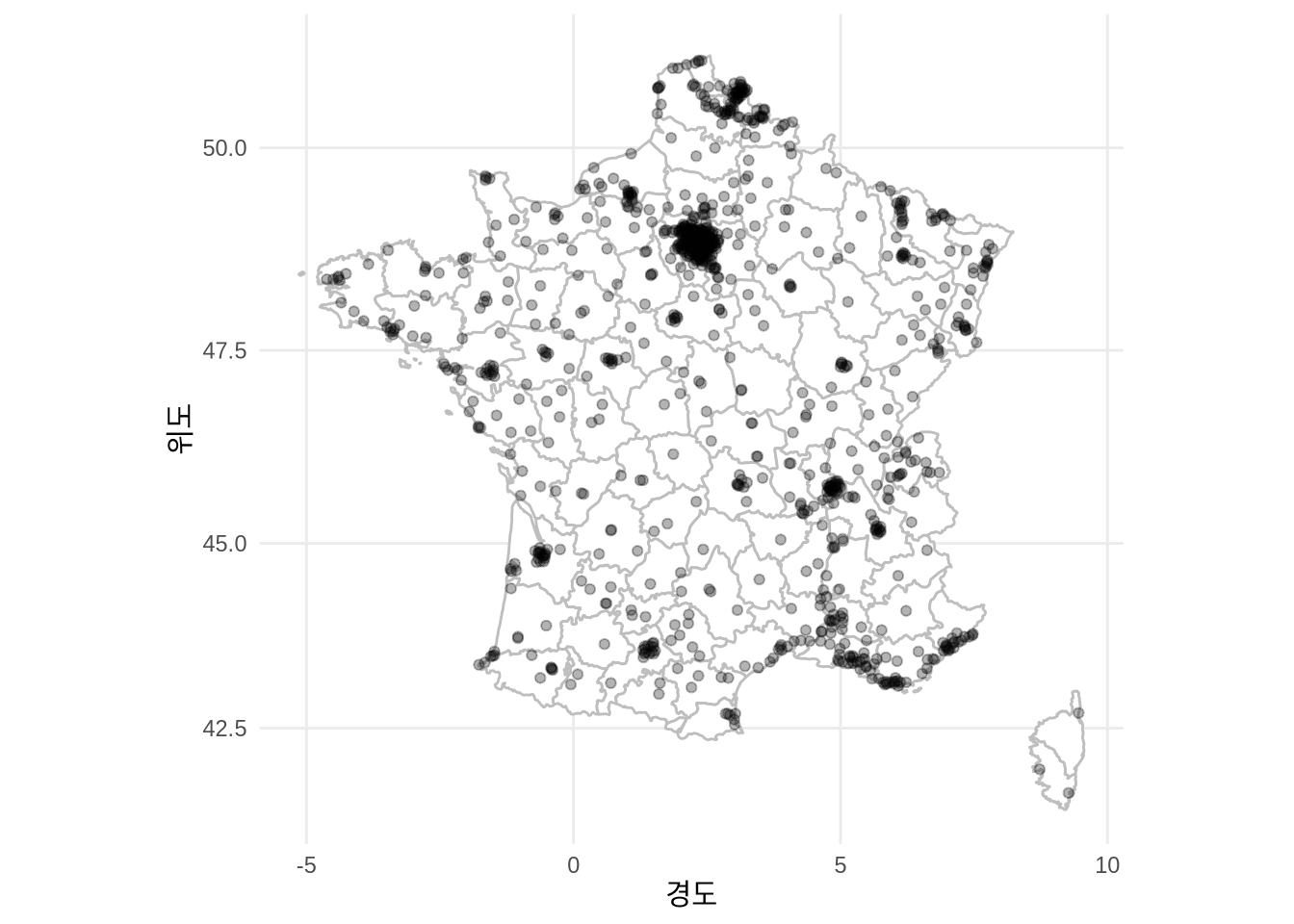
R에는 지도를 만드는 수많은 방법이 있습니다. ggplot2만 써도 충분하지만, ggmap 패키지를 쓰면 더욱 강력한 기능들을 활용할 수 있죠.
지도 제작에는 두 가지 필수 요소가 있습니다.
- 영토 경계선이나 배경 이미지 (흔히 타일(tile)이라고 합니다.)
- 그 배경 위에 얹을 관심 데이터 포인트
ggmap은 오픈 소스인 Stamen Maps의 타일을 가져와 그 위에 위도와 경도를 기준으로 데이터를 점으로 찍어줍니다.
5.4.1 정적 지도 제작
5.4.1.1 호주 투표소 위치도
호주에서는 투표를 하러 “부스(booths)”라는 곳에 가야 합니다. 이 부스들은 고유의 좌표(위도와 경도)를 가지고 있어 지도로 그릴 수 있죠. 이를 통해 투표소의 공간적 배치 패턴을 분석해 볼 수 있습니다.
먼저 배경이 될 지도 타일을 가져와야 합니다. ggmap 패키지를 통해 오픈스트리트맵(OpenStreetMap) 기반의 Stamen Maps 타일을 쓰겠습니다. 핵심은 우리가 보고 싶은 영역의 ’경계 상자(Bounding Box)’를 지정하는 것입니다. 즉 관심 영역의 끝 지점 좌표들이 필요하죠.
구글 지도 같은 플랫폼을 활용해 원하는 지역의 좌표를 찾으면 편리합니다. 여기서는 호주의 수도 캔버라를 중심으로 영역을 잡아보겠습니다.
bbox <- c(left = 148.95, bottom = -35.5, right = 149.3, top = -35.1)이 서비스는 무료지만 지도를 가져오려면 등록이 필요합니다. https://client.stadiamaps.com/signup/ 에서 계정을 만든 뒤 API 키를 발급받으세요. 그런 다음 register_stadiamaps(key = "여기에_키_입력", write = TRUE) 명령어를 실행하면 됩니다. 이제 경계 상자를 정의하고 get_stadiamap() 함수를 쓰면 해당 지역의 타일을 가져옵니다 (?fig-heyitscanberra). 확대 정도에 따라 타일 수가 결정되고, “toner-lite”, “terrain” 등 스타일도 고를 수 있습니다. 타일을 가져올 때는 인터넷 연결이 필수입니다.
canberra_stamen_map <- get_stadiamap(bbox, zoom = 11, maptype = "stamen_toner_lite")
ggmap(canberra_stamen_map)배경 지도가 준비되었다면 이제 그 위에 얹을 투표소 위치 데이터를 가져오겠습니다. 호주 선거 관리 위원회(AEC)에서 제공하는 데이터를 활용합니다.
booths <-
read_csv(
"https://results.aec.gov.au/24310/Website/Downloads/GeneralPollingPlacesDownload-24310.csv",
skip = 1,
guess_max = 10000
)이 데이터셋은 호주 전역을 아우르지만, 우리는 캔버라 인근의 투표소만 골라내어 시각화하겠습니다.
booths_reduced <-
booths |>
filter(State == "ACT") |>
select(PollingPlaceID, DivisionNm, Latitude, Longitude) |>
filter(!is.na(Longitude)) |> # 좌표 정보가 없는 데이터 제외
filter(Longitude < 165) # 노퍽 섬 등 외곽 지역 제외이제 배경 타일 위에 geom_point()로 개별 투표소 위치를 표시해 보겠습니다.
ggmap(canberra_stamen_map, extent = "normal", maprange = FALSE) +
geom_point(data = booths_reduced,
aes(x = Longitude, y = Latitude, colour = DivisionNm),
alpha = 0.7) +
scale_color_brewer(name = "2019 선거구", palette = "Set1") +
coord_map(
projection = "mercator",
xlim = c(attr(map, "bb")$ll.lon, attr(map, "bb")$ur.lon),
ylim = c(attr(map, "bb")$ll.lat, attr(map, "bb")$ur.lat)
) +
labs(x = "경도",
y = "위도") +
theme_minimal() +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank())완성된 지도는 ggsave()를 써서 파일로 저장해 둘 수 있습니다.
ggsave("my_map.pdf", width = 20, height = 10, units = "cm")구글 지도를 배경으로 쓸 수도 있습니다. 이를 위해선 구글 클라우드 플랫폼에 카드 정보를 등록하고 키를 받아야 하는데, 사용량이 많지 않으면 대개 무료입니다. ggmap 패키지의 get_googlemap()을 쓰면 좌표를 일일이 지정하지 않고 지명만으로도 지도를 가져올 수 있는 장점이 있습니다.
5.4.1.2 미국의 해외 군사 기지
또 다른 예로 troopdata 패키지를 활용해 미국의 해외 군사 기지 위치를 그려보겠습니다. get_basedata() 함수로 냉전 이후 미국의 기지 정보를 불러올 수 있습니다.
bases <- get_basedata()
head(bases)# A tibble: 6 × 9
countryname ccode iso3c basename lat lon base lilypad fundedsite
<chr> <dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 700 AFG Bagram AB 34.9 69.3 1 0 0
2 Afghanistan 700 AFG Kandahar Airfield 31.5 65.8 1 0 0
3 Afghanistan 700 AFG Mazar-e-Sharif 36.7 67.2 1 0 0
4 Afghanistan 700 AFG Gardez 33.6 69.2 1 0 0
5 Afghanistan 700 AFG Kabul 34.5 69.2 1 0 0
6 Afghanistan 700 AFG Herat 34.3 62.2 1 0 0독일, 일본, 호주에 있는 기지들을 살펴보죠. 데이터셋에는 이미 좌표값이 포함되어 있습니다. 우선 각 국가의 범위를 나타내는 경계 상자를 정의합니다.
# 참고: https://data.humdata.org/dataset/bounding-boxes-for-countries
bbox_germany <- c(left = 5.867, bottom = 45.967, right = 15.033, top = 55.133)
bbox_japan <- c(left = 127, bottom = 30, right = 146, top = 45)
bbox_australia <- c(left = 112.467, bottom = -45, right = 155, top = -9.133)그런 다음 배경 타일을 가져온 뒤 위치 정보를 얹으면 됩니다.
# Stadia Maps API 키가 필요한 실제 실행은 건너뛰고
# 레이아웃 렌더링을 위해 빈 ggplot 객체를 생성합니다.
german_stamen_map <- ggplot()
japan_stamen_map <- ggplot()
aus_stamen_map <- ggplot()마지막으로 독일 (Figure 5.25 (a)), 일본 (Figure 5.25 (b)), 호주 (Figure 5.25 (c))의 기지 지도를 완성해 보겠습니다.
german_stamen_map +
# geom_point(data = bases, aes(x = lon, y = lat)) +
labs(x = "경도",
y = "위도") +
theme_minimal()
japan_stamen_map +
# geom_point(data = bases, aes(x = lon, y = lat)) +
labs(x = "경도",
y = "위도") +
theme_minimal()
aus_stamen_map +
# geom_point(data = bases, aes(x = lon, y = lat)) +
labs(x = "경도",
y = "위도") +
theme_minimal()


5.4.2 지오코딩 기법
지금까지는 위도와 경도 좌표를 미리 알고 있다고 가정했습니다. 하지만 실제로는 ‘호주 시드니’, ‘가나 아크라’ 같은 지명만 있는 경우가 많죠. 이처럼 지명을 좌표 정보로 바꾸는 과정을 지오코딩이라고 합니다.
우리가 그곳을 정말 잘 안다고 생각하시나요?
자기가 사는 곳의 경계를 정확히 정의하는 게 의외로 어려울 수 있습니다. 특히 정부 기관마다 기준이 다르면 더 골치 아프죠. Bronner (2021) 에 따르면 미국 조지아주 애틀랜타의 경우 세 가지 이상의 공식 정의가 존재합니다.
- 대도시 통계 지역
- 도시화 지역
- 인구 조사 구역
어떤 기준을 쓰느냐에 따라 분석 결과가 판이하게 달라질 수 있습니다. 모두 똑같은 ’애틀랜타’를 말하고 있는데도 말이죠.
R에서 지오코딩을 수행하는 도구는 많지만 tidygeocoder 패키지가 특히 유용합니다. 우선 지명 데이터프레임을 만들어 보죠.
place_names <-
tibble(
city = c("시드니", "토론토", "아크라", "과야킬"),
country = c("호주", "캐나다", "가나", "에콰도르")
)
place_names# A tibble: 4 × 2
city country
<chr> <chr>
1 시드니 호주
2 토론토 캐나다
3 아크라 가나
4 과야킬 에콰도르place_names <-
geo(
city = place_names$city,
country = place_names$country,
method = "osm"
)
place_names이제 이 좌표들을 바탕으로 도시 위치를 지도로 나타낼 수 있습니다 (?fig-mynicemap).
world <- map_data(map = "world")
ggplot() +
geom_polygon(
data = world,
aes(x = long, y = lat, group = group),
fill = "white",
colour = "grey"
) +
geom_point(
aes(x = place_names$long, y = place_names$lat),
color = "black") +
geom_text(
aes(x = place_names$long, y = place_names$lat, label = place_names$city),
nudge_y = -5) +
theme_minimal() +
labs(x = "경도",
y = "위도")5.4.3 대화형 지도 활용
대화형 지도의 매력은 사용자가 자신에게 의미 있는 정보를 직접 찾아볼 수 있다는 데 있습니다. 토론토에 사는 독자는 캐나다 지역을, 오클랜드에 사는 독자는 뉴질랜드를 확대해 보고 싶어 하겠죠. 정적 지도를 수십 장 만드는 대신 대화형 지도를 하나 제공하면 모든 독자의 요구를 충족할 수 있습니다.
하지만 디지털 지도를 만들 때는 그 이면의 데이터 수집 과정에 대해서도 생각볼 필요가 있습니다. 구글 같은 거대 IT 기업의 행보에 대해 McQuire (2019) 은 다음과 같이 꼬집기도 했습니다.
구글은 세상을 데이터로 영문화(Capture)하고 정리하는 것을 넘어, 이제 인간 삶의 모든 요소를 ’생산적 자원’으로 변모시키고 있습니다. 유전학부터 이동성, 행동 방식에 이르기까지 모든 것이 수집되고 활용되는 세상이죠.
지도의 국경선 표현이 정치적 이해관계에 따라 달라지기도 한다는 사실을 인지하는 것도 중요합니다. 예를 들어 구글 지도는 분쟁 지역의 국경을 접속 국가에 따라 다르게 표시하기도 하죠 (Bensinger 2020).
5.4.3.1 리플릿 (Leaflet)
leaflet (Cheng, Karambelkar, and Xie 2021) 패키지는 R에서 대화형 지도를 만드는 가장 대중적인 도구입니다. 앞서 본 미국 해외 군사 기지 배치를 전 세계 규모의 대화형 지도로 다시 그려보겠습니다.
leaflet() 함수로 시작해 파이프 연산자(|>)를 써서 레이어를 쌓아 올립니다. addTiles()로 배경을 깔고 addMarkers()로 기지 위치를 표시합니다 (?fig-canhasbase).
bases <- get_basedata()
# 이름에 특수문자가 포함된 경우를 대비한 인코딩 처리
Encoding(bases$basename) <- "latin1"
leaflet(data = bases) |>
addTiles() |> # 기본 배경 타일 추가
addMarkers(
lng = bases$lon,
lat = bases$lat,
popup = bases$basename,
label = bases$countryname
)“popup”은 마커를 클릭했을 때 나타나는 텍스트이고, “label”은 마우스 커서를 올렸을 때 뜨는 정보입니다.
이번에는 기지 건설 비용 데이터를 점의 크기와 색상으로 표현해 보겠습니다. 비용에 따라 네 가지 범주로 나누어 시각화합니다 (?fig-canhasbaseandmoney).
build <-
get_builddata(startyear = 2008, endyear = 2019) |>
filter(!is.na(lon)) |>
mutate(
cost = case_when(
spend_construction > 100000 ~ "1억 달러 이상",
spend_construction > 10000 ~ "1천만 달러 이상",
spend_construction > 1000 ~ "1백만 달러 이상",
TRUE ~ "1백만 달러 이하"
)
)
pal <-
colorFactor("Dark2", domain = build$cost |> unique())
leaflet() |>
addTiles() |>
addCircleMarkers(
data = build,
lng = build$lon,
lat = build$lat,
color = pal(build$cost),
popup = paste(
"<b>위치:</b>", as.character(build$location), "<br>",
"<b>금액:</b>", as.character(build$spend_construction), "<br>"
)
) |>
addLegend(
"bottomright",
pal = pal,
values = build$cost |> unique(),
title = "비용 범주",
opacity = 1
)5.4.3.2 맵덱 (Mapdeck)
mapdeck (Cooley 2020) 은 WebGL 기술을 써서 그래픽 처리를 웹 브라우저에 맡깁니다. 덕분에 대량의 데이터셋도 아주 매끄럽게 시각화할 수 있죠.
이 패키지는 맵박스(Mapbox)의 타일을 씁니다. 무료 계정을 만들고 API 토큰을 발급받아 .Renviron 파일에 저장한 뒤 R을 다시 시작해 주세요. (자세한 설정 방법은 Chapter 7 를 참고하세요.)
MAPBOX_TOKEN <- "여기에_토큰_입력"토큰 설정이 끝났다면 건설 비용 데이터를 맵덱 지도로 그려보겠습니다 (?fig-canhasbaseandmoneymapdeck).
mapdeck(style = mapdeck_style("light")) |>
add_scatterplot(
data = build,
lat = "lat",
lon = "lon",
layer_id = "scatter_layer",
radius = 10,
radius_min_pixels = 5,
radius_max_pixels = 100,
tooltip = "location"
)5.5 결론
이번 장에서는 데이터를 타인에게 효과적으로 전달하기 위한 다양한 시각화 기법을 살펴보았습니다. 특히 방대한 정보를 직관적으로 압축해 보여주는 그래프에 많은 공을 들였죠. 아울러 정밀한 수치를 전달하는 표, 그리고 공간 정보를 담아내는 지도의 활용법도 익혔습니다. 시각화의 가장 큰 원칙은 ’독자를 현혹하지 않고, 데이터 본연의 모습을 투명하게 보여주는 것’임을 잊지 마시기 바랍니다.
5.6 연습 문제
실습
- (계획) 세 친구(에드워드, 휴고, 루시)가 주변 지인 20명의 키를 잽니다. 각자 조금씩 다른 방식으로 측정해 오차의 특성도 달라집니다. 이 데이터셋의 구조를 상상해 보고, 모든 관측치를 보여줄 수 있는 그래프를 스케치해 보세요.
- (시뮬레이션) 위 상황을 바탕으로 모든 변수가 서로 독립적인 상황을 시뮬레이션해 보세요. 시뮬레이션 데이터를 검증하는 테스트 코드 3개를 포함하십시오.
- (획득) 사람의 키와 관련된 실제 데이터 소스를 찾아보세요.
- (탐색) 시뮬레이션 데이터로 적절한 그래프와 표를 만드세요.
- (소통) 작성한 시각 자료를 설명하는 텍스트를 논리적으로 작성해 보세요. 코드는 R 스크립트와 Quarto 문서로 나누고, GitHub 리포지토리 링크를 제출하십시오.
퀴즈
- 데이터를 항상 플로팅해야 하는 주된 이유는 무엇입니까? (하나 선택)
- 데이터를 더 깊이 이해하기 위해.
- 데이터가 정규 분포인지 확인하려고.
- 결측값을 찾으려고.
- Wickham, Çetinkaya-Rundel, and Grolemund ([2016] 2023) 에 따르면 ’정돈된 데이터(tidy data)’의 특징은 무엇입니까? (하나 선택)
- 각 변수는 열에, 각 관측치는 행에 위치한다.
- 모든 데이터가 한 행에 있다.
- 한 셀에 여러 값이 있다.
- 모든 정보가 셀 하나에 저장된다.
- Healy (2018) 에 따르면
ggplot()의 첫 번째 인수는 무엇입니까? (하나 선택)- 데이터프레임.
- geom 함수.
- 범례.
- 미학적 매핑.
ggplot2에서+연산자는 무슨 역할을 합니까? (하나 선택)- 플롯 저장.
- 데이터 추가.
- 플롯의 레이어 결합.
- 요소 제거.
ggplot2의 “미학(mapping)”이란 무엇입니까? (하나 선택)- 차트 종류.
- 축 이름.
- 색상 설정.
- 변수를 시각적 속성에 연결하는 방식.
- “geom”이란 무엇입니까? (하나 선택)
- 데이터 변환 함수.
- 데이터를 나타내는 기하학적 객체.
- 제목 설정.
- 통계 변환.
- 산점도를 그릴 때 쓰는 geom은? (하나 선택)
geom_dotplot()geom_bar()geom_smooth()geom_point()
- 이미 카운트가 된 데이터로 막대 차트를 그리려면? (하나 선택)
geom_line()geom_bar()geom_histogram()geom_col()
- 히스토그램을 그릴 때 쓰는 geom은? (하나 선택)
geom_col()geom_bar()geom_density()geom_histogram()
- 아래 코드의 결과는 무엇입니까? (하나 선택)
- 수직선 2개.
- 수직선 3개.
- 수직선 4개.
- 수직선 5개.
datasaurus_dozen |>
filter(dataset == "v_lines") |>
ggplot(aes(x=x, y=y)) +
geom_point()- 변수를
color미학에 매핑하면 어떤 일이 생깁니까? (모두 선택)- 변수값에 따라 점 색상이 달라진다.
- 범례가 자동으로 생긴다.
- 점 크기가 변한다.
color와fill의 차이는 무엇입니까? (하나 선택)- 같은 말이다.
- color는 점과 선, fill은 면적 요소에 쓰인다.
- color는 글꼴, fill은 제목 색상이다.
- color는 배경, fill은 텍스트에 쓰인다.
- 점에 투명도를 주려면? (하나 선택)
alpha를 0~1 사이로 설정한다.- geom_point를 뺀다.
color = NULL로 둔다.
labs()함수의 역할은? (하나 선택)- 배경색 변경.
- 축 이름이나 범례 등 레이블 추가.
- 적합선 추가.
- 레이아웃 수정.
- 범례 제목을 바꾸려면
labs()에 무엇을 추가합니까? (하나 선택)scale = "투표"legend = "투표"color = "투표"fill = "투표"
beps |>
ggplot(mapping = aes(x = age, fill = vote)) +
geom_bar() +
theme_minimal() +
labs(x = "응답자 연령", y = "응답자 수")scale_colour_brewer()에서 ‘발산하는(diverging)’ 팔레트는? (하나 선택)- “GnBu”
- “Set1”
- “Accent”
- “RdBu”
- 축 선이 없는 깔끔한 테마는? (하나 선택)
theme_minimal()theme_classic()theme_bw()
- 막대를 나란히 배치하려면
position에 무엇을 씁니까? (하나 선택)- “adjacent”
- “side_by_side”
- “closest”
- “dodge2”
beps |>
ggplot(mapping = aes(x = age, fill = vote)) +
geom_bar()- Vanderplas, Cook, and Hofmann (2020) 가 강조한 인지 원칙 중 하나는? (하나 선택)
- 근접성.
- 부피 추정.
- 상대적 움직임.
- 축의 위치.
- 시각화에서 색상의 역할은 무엇입니까? (하나 선택)
- 디자인 개선.
- 변수 인코딩 및 요소 그룹화.
- 크기 식별.
- 빈(bin)이 가장 많이 생기는 설정은? (하나 선택)
binwidth = 2binwidth = 5
- 세 품종의 새 100마리 키 데이터가 있을 때, 분포를 확인하려면 어떤 그래프가 좋을까요? (한두 단락으로 설명)
data |> ggplot(aes(x = col_one)) |> geom_point()코드가 작동할까요? (하나 선택)- 아니요.
- 예.
- 패싯(facet)을 쓰는 목적은? (하나 선택)
- 투명도 조절.
- 레이블 추가.
- 변수별로 여러 개의 작은 플롯 만들기.
- 색상 변경.
- 막대 차트 내부를 채우는 미학 인자는? (하나 선택)
fillxysize
position = "dodge"의 효과는? (하나 선택)- 투명도 부여.
- 그룹별 막대를 나란히 배치.
- 막대 쌓기.
- 회색조 변경.
geom_point()와geom_jitter()의 차이는? (하나 선택)- jitter는 겹침을 방지하기 위해 점을 살짝 흩뜨린다.
- jitter는 연속형, point는 범주형에 쓴다.
- point는 투명도가 있고 jitter는 없다.
- point는 점, jitter는 선을 그린다.
- 산점도에 요약 선을 그리려면? (하나 선택)
geom_histogram()geom_smooth()geom_bar()geom_line()
- 신뢰 구간 없이 선형 회귀선을 그리려면? (하나 선택)
fit = lm, show_se = FALSEtype = "linear", ci = FALSEmodel = linear, error = FALSEmethod = lm, se = FALSE
- 빈의 개수나 너비를 바꾸면 무엇이 달라집니까? (하나 선택)
- 축 레이블.
- 점 크기.
- 색상.
- 분포의 매끄러운 정도.
- 상자 그림의 단점은? (하나 선택)
- 이상치를 못 본다.
- 계산이 느리다.
- 데이터의 실제 분포 형태를 가린다.
- 너무 화려하다.
- 그 단점을 보완하는 방법은? (하나 선택)
- 선을 없앤다.
- 색을 입힌다.
geom_jitter()로 실제 점들을 겹쳐 그린다.- 상자 너비를 키운다.
stat_ecdf()는 무엇을 그립니까? (하나 선택)- 누적 분포 함수.
- 오차 막대 산점도.
- 상자 그림.
- 히스토그램.
- 요약 통계표를 만드는 함수는? (하나 선택)
datasummary_balance()datasummary_skim()datasummary_descriptive()datasummary_crosstab()
- 지오코딩이란? (하나 선택)
- 좌표를 지명으로 바꾸기.
- 경계선 그리기.
- 투영법 선택.
- 지명을 좌표로 바꾸기.
- 벡터 데이터와 래스터 데이터의 차이는 무엇입니까? (한두 단락으로 설명)
- 마커 클릭 시 동작을 설정하는 인자는? (하나 선택)
layerIdiconpopuplabel
수업 활동
- 1875~1972년 휴런 호수 수위 산점도를 더 아름답고 알기 쉽게 개선해 보세요.
tibble(year = 1875:1972,
level = as.numeric(datasets::LakeHuron)) |>
ggplot(aes(x = year, y = level)) +
geom_point()- 블랙 체리 나무 31그루의 높이 분포 막대 차트를 적절한 시각화 기법으로 개선해 보세요.
datasets::trees |>
as_tibble() |>
ggplot(aes(x = Height)) +
geom_bar()- 병아리 체중 변화 선 그래프를 더 효과적으로 개선해 보세요.
datasets::ChickWeight |>
as_tibble() |>
ggplot(aes(x = Time, y = weight, group = Chick)) +
geom_line()- 1700~1988년 연간 흑점 수 히스토그램을 개선해 보세요.
tibble(year = 1700:1988,
sunspots = as.numeric(datasets::sunspot.year) |> round(0)) |>
ggplot(aes(x = sunspots)) +
geom_histogram()- Saloni Dattani의 코드를 참고해 관심 있는 두 국가의 연령별 사망률 그래프를 그려보세요.
palmerpenguins예제 코드를 수정해 세상에서 가장 보기 흉한 그래프를 만들어 보세요.