library(cancensus)
library(canlang)
library(maps)
library(tidycensus)
library(tidyverse)
library(tinytable)6 측정과 인구 조사, 그리고 표본 추출
채프먼 앤 홀/CRC(Chapman and Hall/CRC)는 2023년 7월 이 책을 출간했습니다. 도서는 이곳에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 최신 내용이 일부 반영되어 있습니다.
권장 선행 학습
- 표본 추출 및 무작위화 소개(Introduction to Sampling and Randomization) 시청하기 (Register 2020):
- 주요 표본 추출 기법의 핵심 원리와 실질적인 활용 사례들을 다룹니다.
- 리딩의 노동자 계층 가구(Working-class Households in Reading) 읽어보기 (Bowley 1913):
- 1900년대 초 영국에서 수행된 설문 조사를 바탕으로 체계적 표집(Systematic Sampling)에 대해 심도 있게 논의한 역사적인 논문입니다.
- 대표 방법의 두 가지 측면에 관하여(On the Two Different Aspects of the Representative Method) 읽어보기 (Neyman 1934):
- 층화 표집(Stratified Sampling)의 기초를 다룹니다. 특히 1장 “서론”, 3장 “대표 방법의 다른 측면”, 5장 “결론” 및 보울리(Bowley)와의 논의 부분을 주의 깊게 살펴보시기 바랍니다.
- 인구 조사 안내서(Guide to the Census) 읽어보기 (Statistics Canada 2023):
- 10장 “데이터 품질 평가”에 집중해 보세요. 캐나다 정부가 작성한 자료이지만, 거의 모든 설문 조사에서 공통적으로 발생하는 문제와 품질 관리 방안을 잘 설명해줍니다.
- 그, 그녀, 그들: 설문 조사에서 성별 구분(He, She, They: Using Gender in Survey Adjustment) 읽어보기 (Kennedy et al. 2022):
- 설문 조사에서 생물학적 성(Sex)과 사회적 성(Gender)을 고려할 때 마주하는 현실적인 어려움과 대안을 제시합니다.
핵심 개념 및 기술
- 데이터셋이 탄생하려면 먼저 측정(Measurement)이 이루어져야 합니다. 하지만 이 과정에는 수많은 도전 과제가 따르죠.
- 인구 조사(Census)는 특정 측면에서 완전성을 목표로 설계된 데이터셋입니다. 비록 완벽할 수는 없겠지만, 정부가 막대한 예산을 들여 관리하는 인구 조사와 공식 통계는 매우 훌륭한 기초 데이터 소스입니다.
- 전수 조사가 불가능한 상황에서도 표본 추출(Sampling)을 통해 모집단에 대한 합리적인 추론을 이끌어낼 수 있습니다.
- 확률 표집과 비확률 표집의 차이를 이해하고, 목표 모집단, 표집 틀, 표본, 단순 무작위 표집, 체계적 표집, 층화 표집, 군집 표집과 같은 핵심 용어를 익힙니다.
주요 패키지 및 함수
- 기본 R (R Core Team 2024)
cancensus(von Bergmann, Shkolnik, and Jacobs 2021)canlang(Timbers 2020) (이 패키지는 CRAN에 없으므로install.packages("devtools")실행 후devtools::install_github("ttimbers/canlang")로 설치하세요.)maps(Becker et al. 2022)tidycensus(Walker and Herman 2022)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
6.1 서론
우리가 세상을 이해하고 그에 관한 이야기를 들려줄 때 가장 큰 난관 중 하나는, 복잡다단하고 아름다운 세상을 분석 가능한 형태의 데이터셋으로 압축해 담아내는 과정입니다. 이 과정에서 우리가 무엇을 놓치고 있는지 끊임없이 자각해야 하며, 데이터화 과정 전반에 걸쳐 신중하고 사려 깊은 태도를 유지해야 합니다. 어떤 이들은 데이터셋이 워낙 방대하니 개별 데이터 포인트 하나쯤은 중요하지 않다고 생각할지도 모릅니다. 하지만 과연 그럴까요? 만약 여러분의 어머니가 다른 분이었다면 여러분의 삶이 얼마나 달라졌을지 한 번 상상해 보십시오 (Crawford 2021, 94).
우리는 종종 데이터셋을 통해 미래를 예측하거나 더 넓은 세상에 대한 주장을 펼치고 싶어 합니다. 하지만 세상을 어떻게 데이터로 치환하든, 우리가 손에 넣는 것은 대개 전체 중 일부인 표본(Sample)뿐입니다. 통계학은 이러한 제약 조건을 인지한 상태에서 데이터에 담긴 의미를 파악하는 체계적인 방법론을 제공합니다. 하지만 통계학 자체가 수집된 데이터로부터 누가 혜택을 받는지, 혹은 데이터에 누구의 권력이 투영되어 있는지와 같은 윤리적·사회적 문제에 정답을 주지는 않습니다.
이번 장에서는 먼저 측정 과정에서 마주하는 고민들을 살펴봅니다. 이어 모집단 전체를 파악하려는 인구 조사와 유기적으로 생산되는 정부 공식 통계, 그리고 장기 설문 조사 데이터를 다룹니다. 우리는 이러한 유형의 데이터셋을 “경작 데이터(Farmed Data)”라고 부르기로 하겠습니다.
마치 농장에서 식량을 생산하기 위해 수많은 노력을 기울이면 소비자는 요리만 하면 되는 것처럼, 경작 데이터셋도 구조가 잘 잡혀 있고 문서화가 철저합니다. 데이터를 수집하고 가공하여 정리하는 고된 작업이 이미 완료되어 있어, 우리는 분석에만 집중할 수 있다는 것이 큰 장점이죠. 또한 일정한 주기에 따라 규칙적으로 발표됩니다. 예를 들어 주요 국가는 실업률 및 인플레이션 데이터를 매월, GDP를 매 분기, 인구 조사를 5~10년마다 공표합니다.
다음으로는 분석의 기초가 되는 표본 추출의 통계적 개념을 소개합니다. 지난 100여 년 동안 통계학자들은 표본을 다루는 정교한 기법들을 발전시켜 왔으며, 그 과정에서 수많은 논쟁을 거쳤습니다 (Brewer 2013). 여기서는 확률 표집과 비확률 표집을 살펴보고 주요 핵심 용어들을 정리하겠습니다.
데이터는 결코 중립적이지 않습니다. 기록학자들에 따르면 기록 보관소는 단순히 사실을 모아둔 곳이 아니라, 특정 맥락(특히 국가의 의도)에 의해 생산된 사실의 파편들을 담은 공간입니다 (Stoler 2002). 따라서 데이터셋에 누가 포함되고 누가 체계적으로 배제되었는지 파악하는 것이 무엇보다 중요합니다. 데이터를 수집하고 분류하고 명명하는 행위는 본질적으로 세상을 구축하는 권력의 반영이며, 사회적·역사적·재정적·법적 힘을 내포하고 있습니다 (Crawford 2021, 121).
예를 들어 설문 조사에서 생물학적 성(Sex)과 사회적 성(Gender)의 구분을 생각해 보십시오. 생물학적 성은 출생 시 지정되는 신체적 속성에 기반하지만, 사회적 성은 문화적 요인에 의해 구성됩니다 (Lips 2020, 7). 연구자가 실제 알고 싶은 것은 생물학적 차이가 아니라 사회적 성에 따른 결과의 차이일 수 있습니다. 하지만 공식 통계에서 이러한 미묘한 구분을 반영한 것은 그리 오래된 일이 아닙니다. 생물학적 성만을 고집하거나 이분법적 성별만을 제공하는 설문 조사는 그 범주에 속하지 않는 수많은 응답자의 삶을 누락하게 되죠. 설문 조사 결과를 처리할 때 윤리성과 정확성, 유연성을 어떻게 확보할지에 대해 Kennedy et al. (2022) 이 가이드를 제공하지만 정답이 정해져 있지는 않습니다. 다만 응답자에 대한 존중을 최우선으로 두어야 한다는 점만큼은 명확합니다 (Kennedy et al. 2022, 16).
때로는 “복잡한 세상을 왜 굳이 분류하고 그룹화해야 하는가?”라는 의문이 생길 수도 있습니다. Scott (1998) 은 이를 국가가 통치를 위해 사회를 ‘읽기 쉽게’ 만들려는 욕망 때문이라고 분석합니다. 예를 들어 성씨(Surname)를 사용하는 관습도 세금을 징수하고 부동산을 관리하며 인센티브를 주거나 징집하기 위한 현대 국가의 필요에서 비롯된 것이 많죠. 이러한 가독성에 대한 욕구는 자연스럽게 측정의 표준화를 불러왔습니다. 현대의 계측학(Metrology)은 프랑스 혁명기의 표준 단위 도입에서 싹텄고, 나폴레옹 시대에 이르러 국가 체제 구축의 일환으로 더욱 견고해졌습니다 (Scott 1998, 30). 지식이 “파편적이고 지역적인 것”에서 “보편적이고 수치화된 것”으로 이동한 셈입니다 (Prévost and Beaud 2015, 154). 하지만 이러한 측정 기준 없이는 데이터를 대규모로 수집하는 것 자체가 불가능합니다. 여기서 주의할 점은 이러한 측정 기준이 인위적으로 ’구성’된 것임을 잊고, 마치 절대적인 진리인 양 믿어버리는 재구체화(Reification)의 함정입니다.
모든 데이터셋에는 한계가 있습니다. 이번 장에서는 경작 데이터를 다루는 데 익숙해지는 시간을 가질 것입니다. 다시 한번 강조하자면, 경작 데이터란 데이터 분석이라는 목적을 위해 정교하게 설계되고 축적된 데이터셋을 뜻합니다.
경작 데이터셋은 누군가 미리 만들어 두었기에 얻기는 쉽지만, 그 내부 구조와 구성 과정을 철저히 이해하는 것은 분석가의 몫입니다. 19세기의 제임스 밀(James Mill)은 인도 땅을 한 번도 밟아보지 않고도 방대한 《영국령 인도사(The History of British India)》를 쓴 것으로 유명하죠. 그는 다음과 같이 주장했습니다.
인도에서 보고 들을 가치가 있는 모든 지식은 글로 기록될 수 있다. 중요한 정보들이 기록으로 남겨지는 순간, 자질을 갖춘 학자는 영국 서재에 앉아 단 1년 만에 인도 현장에서 평생을 바친 이보다 더 깊은 지식을 얻을 수 있다.
Mill (1817, xv)
당시 그가 전문가로 대접받았다는 사실이 지금으로서는 놀랍게 느껴질 수도 있습니다. 하지만 현대의 우리도 물가를 직접 조사하지 않고 인플레이션 통계를 믿으며, 모든 유권자를 만나지 않고도 여론조사 결과를 분석합니다. 또한 개별 이미지에 직접 라벨을 붙여보지 않고 대규모 데이터셋을 활용하곤 하죠. 데이터의 세부 사항을 파고들고 그 이면을 이해하려는 노력은 시대를 불문하고 데이터 과학자가 갖춰야 할 핵심 윤리입니다.
6.2 측정의 기초
측정(Measurement)은 인류의 아주 오래된 관심사입니다. 아리스토텔레스는 일찍이 양(Quantity)과 질(Quality)을 구분한 바 있습니다 (Tal 2020). 측정은 모든 정량 분석의 기초이지만, 무엇을 어떻게 측정할지 결정하는 일은 결코 간단치 않습니다.
측정은 생각보다 훨씬 까다로운 작업입니다. 예를 들어 아이오와 주립대학교의 데이비드 피터슨(David Peterson) 교수는 음악계의 ’원히트 원더(One-hit wonder)’를 정의하는 것이 얼마나 어려운지 보여주었습니다. 당장 떠오르는 가수들도 자세히 살펴보면 차트에서 성공한 곡이 한두 곡 더 있는 경우가 많기 때문입니다 (Molanphy 2012). 다른 분야도 마찬가지입니다. 단임 정부를 분석할 때 임기를 다 채우지 못한 정부는 포함해야 할까요? 단 한 달, 혹은 일주일만 지속된 정부는 어떨까요? 정부 지원의 상당 부분이 현금이 아닌 현물 급여일 때 그 규모를 어떻게 측정할 수 있을까요 (Garfinkel, Rainwater, and Smeeding 2006)? 민주주의에서 시민이 얼마나 잘 대변되고 있는지는 어떻게 수치화할까요 (Achen 1978)? 또한 세계보건기구(WHO)가 산모 사망을 분만 후 42일 이내 발생 건으로 제한할 때, 그 정의가 추정치에 어떤 영향을 끼칠지 고민해 보셨나요 (Gazeley et al. 2022)?
철학적 관점은 측정의 정의에 깊이를 더해주지만 (Tal 2020), 실용적으로는 “대상의 특성에 합리적으로 귀속될 수 있는 값을 실험적으로 얻는 과정”으로 정의할 수 있습니다 (International Organization Of Legal Metrology 2007, 44). 여기서 값은 “숫자와 참조 단위의 조합”을 의미하며, 이는 “측정 결과의 용도와 절차, 교정된 시스템 등을 전제로 한 비교 과정”을 내포합니다. 이 정의를 통해 우리는 측정에 있어 참조 단위(Units)가 얼마나 중요한지, 그리고 타당도(Validity)와 신뢰도(Reliability)가 보장된 측정이 왜 핵심인지를 알 수 있습니다.
계측(Instrumentation or Metrology)은 측정을 수행하는 도구와 체계를 의미합니다. 어떤 도구를 쓰느냐에 따라 우리가 무엇을 측정할 수 있는지가 결정되죠. 예를 들어 16세기 현미경의 발명은 모세혈관(1661년), 세포(1665년), 박테리아(1677년)의 관찰로 이어지며 인류의 지평을 넓혔습니다 (Morange 2016, 63; Lane 2015). 시간 측정의 역사도 흥미롭습니다. 초기 해시계로는 한 시간 단위를 정확히 맞추기 어려웠지만, 정밀한 기계식 시계와 원자시계의 등장은 스포츠 경기를 1,000분의 1초 단위로 가르고 GPS를 통해 오차 범위 수 미터 내의 항법을 가능케 했습니다.
“정확한 데이터가 있다”는 착각
시간은 우리 삶에서 가장 중요한 측정 단위 중 하나입니다. 포뮬러 1(F1) 경주에서는 랩 타임을 1,000분의 1초 단위로 측정하며, 수영 황제 마이클 펠프스는 베이징 올림픽에서 단 100분의 1초 차이로 금메달을 거머쥐었습니다. 정밀한 시간 측정은 겉보기에 동시에 일어난 것처럼 보이는 일들 사이의 선후 관계를 밝혀주죠. Chambliss (1989) 의 수영 선수 사례에서 보듯, 기록이 없다면 누가 더 탁월한지 증명하기란 불가능했을 것입니다. 금융 시장에서도 거래 시점은 자산 가치와 직결되는 핵심 요소입니다.
하지만 “지금 몇 시인가?”라는 단순한 질문에 답하는 것은 의외로 복잡합니다. 개인의 시계는 저마다 기준이 다를 수 있기 때문이죠. 1970년대 이후 인류는 원자 시간을 표준으로 삼았습니다. 1초의 정의는 “세슘 133 원자의 바닥 상태에 있는 두 초미세 준위 사이의 전이에 대응하는 복사선의 9,192,631,770주기 지속 시간”입니다 (Levine, Tavella, and Milton 2022, 4). 하지만 원자시계가 알려주는 시간을 전 세계 수많은 컴퓨터에 어떻게 동일하게 동기화할 것인가 하는 문제는 여전히 남아 있습니다. 이에 대해 (Hopper 2022) 와 Mills (1991) 은 인터넷 망을 통해 시각을 맞추는 NTP(Network Time Protocol)의 원리와 한계를 설명합니다. 또한 지구 자전을 기준으로 하는 천문 시간과 원자 시간 사이의 오차를 교정하기 위해 도입된 ‘윤초(Leap second)’ 제도는 최근 디지털 인프라에 혼란을 줄 수 있다는 우려로 폐지 수순을 밟고 있습니다 (Levine, Tavella, and Milton 2022; Gibney 2022; Mitchell 2022).
사회과학에서 가장 보편적인 측정 도구는 설문 조사입니다 (Chapter 8 참조). 자연과학이나 공학에서는 센서가 그 역할을 대신하죠. 기후 과학자는 온습도와 기압 센서를 활용하고, 동물의 움직임을 분석하는 연구자는 가속도계(Accelerometer) 데이터를 분석합니다 (Leos-Barajas et al. 2016). 인공위성의 센서는 지표면 이미지를 촬영하며, 물리학 연구는 데이터 저장 용량이 한계에 다다를 만큼 방대한 양의 정보를 쏟아냅니다. 예를 들어 CERN의 ATLAS 검출기는 입자 충돌 시 초당 80TB의 데이터를 발생시키는데, 이를 모두 저장할 수 없어 필요한 정보만 골라내는 고도의 필터링 과정을 거칩니다 (Colombo et al. 2016).
마케팅 분야의 A/B 테스트에서는 쿠키나 비콘, 행동 로그 등을 통해 사용자의 반응을 측정합니다. 이때 측정 도구를 대상에게 어떻게 전달할지도 중요한 문제입니다. 설문 조사의 경우 우편, 전화, 온라인 중 어떤 방식을 택할지, 응답자가 직접 기입하게 할지 조사원이 개입할지에 따라 결과가 달라질 수 있습니다.
또한 측정을 위해서는 반드시 단위(Units)라는 참조 기준이 필요합니다. 단위의 선택은 연구 질문과 도구의 정밀도에 달려 있죠. 만약 식물의 성장을 측정한다면 ‘킬로미터’보다는 ’밀리미터’가 적절하며, 정밀한 캘리퍼스를 쓴다면 ’마이크로미터’ 단위까지 고려할 수 있을 것입니다.
6.2.1 측정의 핵심 속성
타당도(Validity) 있는 측정이란 우리가 측정하는 값이 실제 알고자 하는 연구 질문(추정량)과 밀접하게 연관되어 있음을 뜻합니다. 이는 “우리가 정말로 재야 할 것을 재고 있는가?”에 관한 적절성의 문제입니다. Chapter 4 에서 다룬 추정량(Estimand)은 흡연이 기대 수명에 미치는 실제 영향과 같은 ’객관적 실체’입니다. 따라서 우리는 단순히 흡연에 대한 개인의 주관적 견해가 아니라 그가 피운 담배 개수와 실제 수명 같은 관련 정보를 정확히 측정해야 합니다.
미터(m)나 초(s)처럼 정의가 확고한 단위는 측정의 타당성에 의문이 적습니다. 하지만 ‘은총’이나 ’미덕’, ‘지능’, 혹은 ’대학의 질’과 같은 추상적인 개념을 수치화하려 할 때는 타당도가 핵심적인 쟁점이 됩니다. 중세에도 은총을 측정하려는 시도가 있었고 (Crosby 1997, 14), 현대에도 복잡한 지적 능력을 IQ라는 단일 지표로 가두려 합니다. 이러한 가치들이 실재하지 않는다는 뜻은 아니지만, 이를 측정하는 방식에 대해서는 항상 비판적인 시각이 필요합니다.
대표적인 사례가 U.S. News & World Report의 대학 순위입니다. 이들은 학급 규모, 교수진 학위 등 여러 지표를 조합해 대학의 질을 서열화하죠. 하지만 이러한 인위적 지표는 구성원들의 행동을 왜곡하는 부작용을 낳기도 합니다. 컬럼비아 대학교가 1988년 18위에서 2022년 2위로 수직 상승한 배경에 대해, 이 대학 소속 마이클 태디어스(Michael Thaddeus) 교수는 대학 측이 보고한 데이터와 실제 데이터 사이에 유리한 왜곡이 있음을 폭로하기도 했습니다 (Hartocollis 2022).
심리학 분야에서도 명확한 척도가 없는 개념을 다루기에 타당도와 신뢰도 문제가 큰 비중을 차지합니다. Fried, Flake, and Robinaugh (2022) 가 우울증 측정 도구들을 검토한 결과, 상당수의 도구가 타당성과 신뢰성이 부족하다는 사실을 밝혀냈습니다. 그렇다고 측정을 포기할 것이 아니라 측정 기준을 정하는 과정을 더 투명하게 공개해야 합니다. Flake and Fried (2020) 은 새로운 척도를 만들 때마다 연구자가 개념 정의, 결정 과정, 대안 검토, 정량화 방식 등에 관한 구체적인 질문에 답할 것을 제안합니다. 이는 연구자가 원하는 결과를 얻기 위해 유리한 척도를 자의적으로 선택하는 일을 방지하기 위함입니다.
신뢰도(Reliability)는 측정의 ’일관성’을 의미합니다. 동일한 대상을 여러 번 반복 측정하더라도 결과가 비슷하게 나와야 한다는 뜻이죠. 예를 들어 두 명의 조사원이 같은 거리의 상점 수를 셌는데 값이 다르다면, 한 명이 지침을 오해했거나 폐업한 가게를 포함하는 등 측정 상의 오류가 있었을 가능성이 큽니다. 국제 통계에서도 A국의 B국행 이민자 수와 B국이 집계한 A국발 입국자 수가 일치하지 않는 등 신뢰도 문제는 빈번하게 발생합니다.
“정확한 데이터가 있다”는 착각
비행기 조종사가 승객에게 현재 고도를 안내하는 것은 흔한 일입니다. 하지만 ’고도’라는 개념을 정의하고 측정하는 과정은 생각보다 훨씬 복잡하며, 모든 측정은 특정한 맥락 안에서 이루어진다는 사실을 잘 보여줍니다 (Vanhoenacker 2015).
예를 들어 ’비행기와 지면 사이의 거리’를 고도라고 한다면 기준점을 조종석으로 잡아야 할까요(이는 안내 방송에 적합할 것입니다), 아니면 바퀴 아래로 잡아야 할까요(이는 착륙에 필수적일 것입니다)? 만약 비행기가 거대한 산맥 위를 지나간다면 어떻게 될까요? 비행기 자체는 고도를 유지하며 수평 비행 중이더라도 지면과의 거리는 급격히 줄어들 것입니다. 그렇다고 비행기가 하강했다고 말하기는 어렵죠.
이 때문에 항공 분야에서는 조석에 따라 변화하는 해수면 대신 기압을 기준으로 고도를 측정하는 방식을 주로 사용합니다. 하지만 기압 역시 날씨와 계절, 위치에 따라 수시로 변하기 때문에 동일한 기압 고도라도 실제 지면으로부터의 거리는 천차만별일 수 있습니다. 결국 비행기에서 사용하는 고도 측정법은 ’비행기 간의 충돌을 방지하고 안전한 운항을 보장한다’는 실용적인 목적에 맞게 설계된 타협점인 셈입니다.
6.2.2 측정 오차의 이해
측정 오차(Measurement Error)는 우리가 관찰한 값과 실제 참값 사이의 차이를 말합니다. 특정한 경우에는 응답의 진위를 확인할 수 있는데, 확인 가능한 샘플에서 오차의 패턴이 일정하다면 전체 데이터의 오차 정도를 추정할 수 있습니다. 예를 들어 Sakshaug, Yan, and Tourangeau (2010) 은 대학 동문 조사에서 응답자가 말한 성적과 실제 대학 기록을 대조했습니다. 그 결과 사람이 직접 전화로 묻는지, 컴퓨터가 묻는지, 혹은 온라인 설문인지에 따라 오차의 수준이 달라진다는 흥미로운 사실을 발견했죠.
이러한 오차는 조사원이 응답자를 대신해 설문지를 작성할 때 더 심해질 수 있으며, 특히 인종 문제와 결합할 때 민감하게 작용합니다. Davis (1997, 177)은 미국의 흑인 응답자들이 백인 면접관 앞에서는 자신의 정치적·인종적 신념을 가감 없이 드러내지 않을 가능성이 있다고 지적합니다.
오차의 또 다른 유형으로 검열된 데이터(Censored Data)가 있습니다. 실제 값에 대해 부분적인 정보만 알고 있는 경우를 말하죠. 우측 검열(Right-censoring)은 실제 값이 관찰된 값보다 ’크다’는 것은 알지만 정확히 얼마나 큰지 모르는 상황입니다. 1986년 체르노빌 원전 사고 당시 현장에 투입된 방사능 측정기들은 최대 측정 한계가 있었습니다. 기계가 최대치를 가리키고 있다면 실제 방사능 수치는 그보다 훨씬 높았을 것임을 짐작할 수 있죠.
우측 검열은 의료 연구에서도 흔히 발생합니다. 어떤 환자를 10년간 추적 관찰했을 때 연구 종료 시점까지 생존해 있다면 우리가 알 수 있는 것은 그가 ’최소 10년은 살았다’는 사실일 뿐, 정확한 전체 수명은 아닙니다. 반대로 실제 값이 관찰된 값보다 작을 때 발생하는 좌측 검열(Left-censoring)도 있습니다. 예를 들어 영하로 내려가지 않는 온도계는 실제 기온이 영하 10도라 하더라도 0도로 표시할 것입니다.
검열과 비슷하지만 조금 다른 개념으로 윈저화(Winsorizing)가 있습니다. 이는 극단적인 값이 통계 분석에 미치는 영향을 줄이기 위해 관찰된 값을 의도적으로 덜 극단적인 값으로 변환하는 기법입니다. 예를 들어 100세가 넘는 고령자의 나이를 모두 100세로 처리하는 식이죠.
절단된 데이터(Truncated Data)는 아예 일정 범위를 벗어나는 관측치를 기록조차 하지 않는 경우입니다. 어린이의 나이와 키의 관계를 연구할 때 “나이가 어떻게 되세요?”라고 물어보고 성인이라면 아예 키를 재지 않고 데이터에서 제외하는 상황이 이에 해당합니다. 절단된 데이터는 선택 편향(Selection Bias)과 밀접한 관련이 있습니다. 강의 중간에 자퇴한 학생의 의견이 강의 평가 데이터에 누락되는 것이 전형적인 사례입니다.
이러한 개념들의 차이를 이해하기 위해 신생아 몸무게 데이터를 시뮬레이션해 보겠습니다. 실제 신생아 몸무게는 평균 3.5kg인 정규 분포를 따른다고 가정하죠. 이때 세 가지 가상 시나리오를 설정합니다.
- 실제 데이터(Actual): 모든 아기의 몸무게가 정확히 측정됨.
- 검열된 데이터(Censored): 저울 결함으로 2.75kg 이하의 아기는 모두 2.75kg로 기록됨.
- 절단된 데이터(Truncated): 고위험군(4.25kg 이상) 아기는 다른 병원으로 이송되어 우리 데이터셋에서 완전히 제외됨.
Figure 6.1 는 이 세 시나리오의 분포 차이를 보여주며, Table 6.1 는 이로 인해 평균값이 어떻게 왜곡(편향)되는지 보여줍니다.
set.seed(853)
newborn_weight <-
tibble(
weight = rep(
x = rnorm(n = 1000, mean = 3.5, sd = 0.5),
times = 3),
measurement = rep(
x = c("Actual", "Censored", "Truncated"),
each = 1000)
)
newborn_weight <-
newborn_weight |>
mutate(
weight = case_when(
weight <= 2.75 & measurement == "Censored" ~ 2.75,
weight >= 4.25 & measurement == "Truncated" ~ NA_real_,
TRUE ~ weight
)
)
newborn_weight |>
ggplot(aes(x = weight)) +
geom_histogram(bins = 50) +
facet_wrap(vars(measurement)) +
theme_minimal()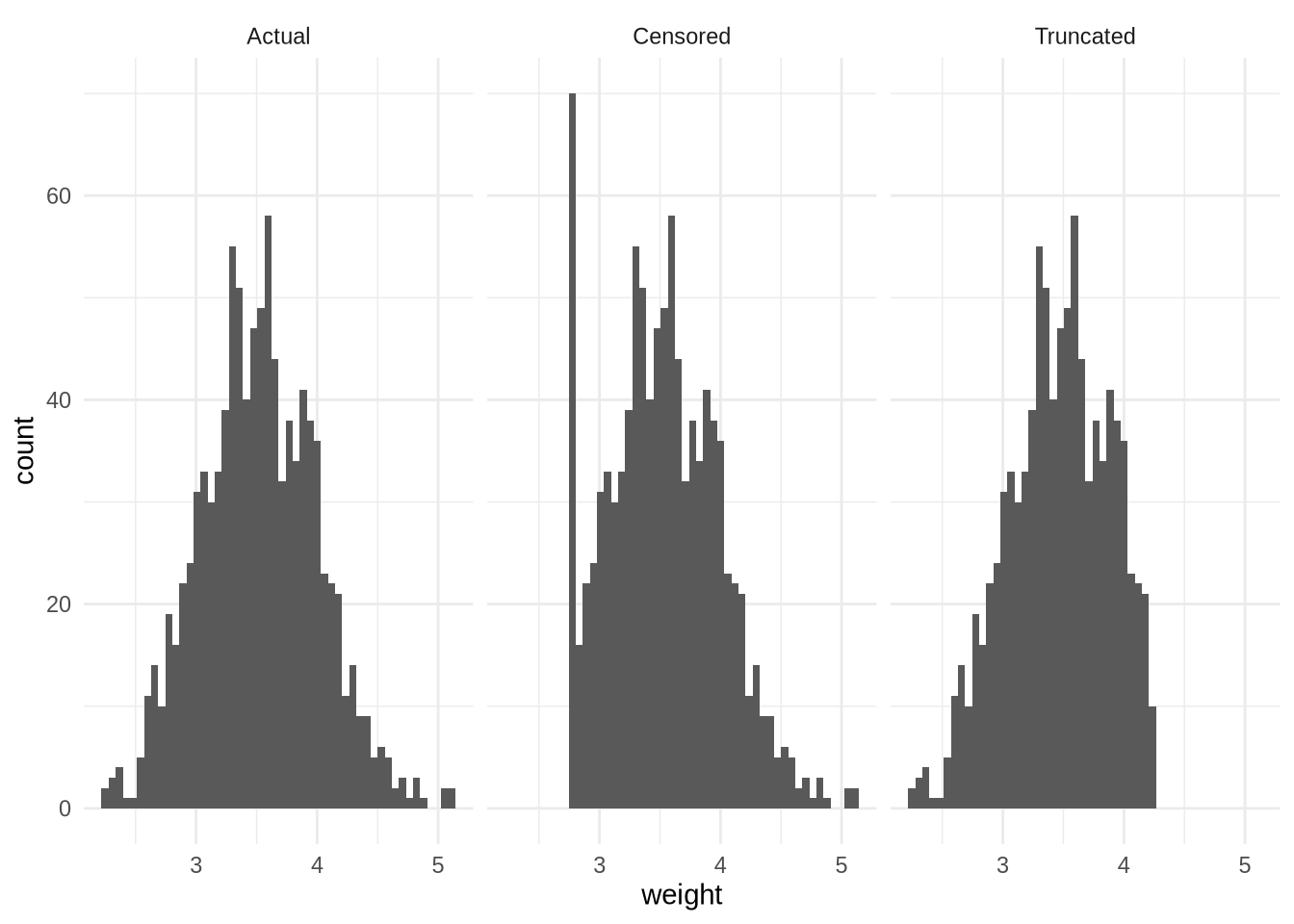
newborn_weight |>
summarise(mean = mean(weight, na.rm = TRUE),
.by = measurement) |>
tt() |>
style_tt(j = 1:2, align = "lr") |>
format_tt(digits = 3, num_fmt = "decimal") |>
setNames(c("측정 방식", "평균값"))| 측정 방식 | 평균값 |
|---|---|
| Actual | 3.521 |
| Censored | 3.53 |
| Truncated | 3.455 |
6.2.3 결측 데이터의 문제
아무리 완벽한 설문 조사라도 결측 데이터(Missing Data)는 발생하기 마련입니다. 우리가 얻지 못한 관측치가 있다는 사실을 인지하는 것이 중요합니다. 하지만 더 무서운 것은 우리가 결측되었다는 사실조차 모르는 데이터입니다. 즉 아예 변수 항목으로 고려되지 않아 ’짖지 않는 개’처럼 존재를 감추고 있는 데이터들이죠. 이를 방지하기 위해서는 연구 설계 단계에서 주제 전문가와 협력하여 데이터의 흐름을 시뮬레이션하고 꼼꼼히 스케치해 보는 과정이 필수적입니다.
무응답(Non-response)은 측정 오차의 특수한 형태입니다 설문 조사 자체를 거부하는 것부터 특정 질문에만 답하지 않는 것까지 그 층위가 다양하죠. 특히 비확률 표본에서 무응답은 치명적인데, 응답한 집단과 그렇지 않은 집단 사이에 체계적인 차이가 있을 가능성이 크기 때문입니다. Gelman et al. (2016) 은 선거 기간의 여론 변화가 유권자의 변심 때문이라기보다, 지지 후보의 형세에 따라 응답 확률이 달라지는 ‘차등적 무응답’ 때문일 수 있다고 지적합니다. 다행히 사전 통지나 리마인더 발송 등의 기법으로 무응답률을 낮추려는 노력을 기울일 수 있습니다 (Koitsalu et al. 2018; Frandell et al. 2021).
무응답 편향이 국가적 비교에 영향을 준 사례로 PISA(국제 학업성취도 평가)를 들 수 있습니다. 캐나다는 학생들의 성적이 우수한 국가로 꼽히지만, Anders et al. (2020) 에 따르면 2015년 조사 당시 캐나다의 15세 학생 표본 참여율은 약 50%에 불과했습니다. 반면 다른 고성과 국가들은 90% 이상이 참여했죠. 연구팀은 참여율을 동일하게 맞출 경우 캐나다의 성적 우위가 상당 부분 사라진다는 사실을 밝혀냈습니다.
데이터가 결측되는 양상은 크게 세 가지로 나뉩니다 (Newman 2014).
- MCAR (완전 무작위 결측): 어떤 변수와도 상관없이 정말 우연히 빠진 경우입니다. 가장 이상적이지만 현실에선 거의 드뭅니다.
- MAR (무작위 결측): 특정 변수(예: 성별)에 따라 결측 확률이 달라지지만, 결측된 값 자체(예: 정치적 지향)와는 상관없는 경우입니다. 예를 들어 남성이 설문 응답을 더 귀찮아하지만, 응답한 남성과 하지 않은 남성의 정치 성향이 비슷하다면 성별 가중치를 주어 보정할 수 있습니다.
- MNAR (비무작위 결측): 결측된 이유가 결측된 값 자체와 연관된 경우입니다. 정치 성향이 너무 극단적이어서 아예 응답을 거부하는 경우가 이에 해당하며 보정이 매우 까다롭습니다.
이러한 결측치 문제에 대해서는 Chapter 11 에서 더 자세히 다루겠습니다.
6.3 인구 조사와 정부 데이터
데이터 분석을 위해 국가적 차원에서 체계적으로 생산된 가장 대표적인 소스는 인구 조사(Census)입니다. 역사적으로 인구 조사는 매우 오래된 전통을 가지고 있습니다. Whitby (2020, 30–31)에 따르면 기록상 가장 오래된 인구 조사는 중국 황하 유역에서 실시되었습니다 인구 조사의 주요 동기 중 하나는 세금 징수였으며, Jones (1953) 는 기원후 3~4세기경 로마에서 새로운 조세 제도를 뒷받침하기 위해 작성된 상세한 인구 기록을 설명합니다.
하지만 인구 조사의 정교한 기록이 비극적으로 악용된 사례도 있습니다. Luebke and Milton (1994, 25)은 나치가 인구 조사와 경찰 등록 데이터를 활용해 유대인 등 박해 대상을 선별하고 학살지로 이송한 과정을 고발합니다. 또한 Bowen (2022, 17)은 제2차 세계대전 당시 미국 인구 조사국이 일본계 미국인을 수용소에 감금하는 데 필요한 정보를 제공했음을 밝히고 있습니다. 이에 대해 1990년대 빌 클린턴 대통령은 공식적으로 사과한 바 있죠.
정부가 생산하는 또 다른 핵심 데이터는 실업률, 물가 상승률, 국내총생산(GDP)과 같은 공식 통계입니다. 흥미롭게도 이러한 경제 지표들이 처음부터 국가 주도로 개발된 것은 아니었습니다 (Rockoff 2019). 하지만 현재는 국가의 인적·재정적 자원이 뒷받침된 인구 조사와 정부 설문 조사가 그 어떤 민간 데이터보다 강력한 신뢰성과 포괄성을 자랑합니다. 2020년 미국 인구 조사에만 무려 156억 달러의 예산이 투입된 것으로 추정됩니다 (Hawes 2020). 물론 막대한 자본이 투입되었다고 해서 데이터가 완벽하다는 뜻은 아닙니다. 모든 데이터와 마찬가지로 인구 조사 역시 누락이나 중복, 오보 등의 오류에서 자유울 수 없으며 통계학자들은 이러한 품질을 평가하기 위해 끊임없이 노력합니다 (Statistics Canada 2023).
“정확한 데이터가 있다”는 착각
인구 조사는 국가 정책의 기초가 되지만 결코 무결하지 않습니다. Anderson and Fienberg (1999) 에 따르면 미국 인구 조사의 역사는 곧 ’누락(Undercount)’의 역사이기도 합니다. 조지 워싱턴조차도 1790년대 첫 조사 당시 누락이 너무 많다며 불만을 터뜨렸을 정도니까요. 실제 누락 정도를 파악하기 위해 통계학자들은 제2차 세계대전 당시의 징집 병역 등록 시스템과 인구 조사 데이터를 비교했습니다. 그 결과 징집 대상 남성 수가 인구 조사 기록보다 약 50만 명이나 더 많다는 사실이 발견되었습니다. 이는 인종에 따라 더 심각한 차이를 보였는데, 전체 평균 누락률은 3%였지만 징집 연령대 흑인 남성들의 누락률은 무려 13%에 달했습니다 (Anderson and Fienberg 1999, 29). 인종별 인구 집계는 데이터의 객관적 수치를 넘어 계급, 법률, 정치적 이해관계가 얽힌 복잡한 사회적 산물이기도 합니다 (Nobles 2002, 48).
거인의 어깨 위에서
마고 앤더슨(Margo Anderson)은 위스콘신-밀워키 대학교의 역사 및 도시 연구 특훈 교수입니다. 럿거스 대학교에서 역사학 박사 학위를 취득한 뒤 미국의 인구 조사 제도와 역사에 관한 독보적인 연구 성과를 쌓아왔습니다. 주요 저서로는 Anderson and Fienberg (1999) 와 Anderson ([1988] 2015) 가 있으며, 1998년에는 미국 통계 협회(ASA) 펠로우로 선출되기도 했습니다.
정부 데이터의 또 다른 축은 장기적인 사회 설문 조사들입니다. 정부가 직접 수행하기도 하지만 대개 정부의 재정 지원을 받는 전문 연구 기관들이 정기적으로 실시합니다. 캐나다 선거 연구(Canadian Election Study)나 영국 선거 연구(British Election Study)가 대표적이며, 이들은 수십 년간의 데이터를 축적해 시민들의 정치적 태도 변화를 추적할 수 있게 해줍니다.
최근 전 세계적으로 불고 있는 공공 데이터 개방(Open Data) 운동도 주목할 만합니다. 정부가 보유한 데이터를 시민에게 투명하게 공개해야 한다는 원칙은 민주주의의 기본이죠. 하지만 정부가 ‘입맛에 맞는’ 데이터만 골라 공개하거나 정부의 성과를 홍보하기 위해 데이터를 가공할 위험성도 상존합니다 (Kalgin 2014; Zhang et al. 2019; Berdine, Geloso, and Powell 2018). 이럴 때 시민 사회가 활용할 수 있는 강력한 도구가 정보공개청구(Freedom of Information, FOI)입니다 (Walby and Luscombe 2019). 실제로 Cardoso (2020) 는 정보공개청구를 통해 입수한 데이터를 분석하여 캐나다 교도소 시스템 내부의 체계적인 인종 차별 실태를 세상에 알린 바 있습니다.
과거에는 이러한 방대한 데이터셋을 다루는 것이 전문가들만의 영역이었지만, 이제는 R 패키지를 통해 누구나 손쉽게 접근할 수 있습니다. 다음은 그중 특히 유용한 도구들입니다.
6.3.1 캐나다의 사례
캐나다 최초의 인구 조사는 1666년에 실시되었습니다. 이는 모든 개인의 이름을 기록한 최초의 현대적 인구 조사였지만 원주민은 포함하지 않았죠 (Godfrey 1918, 179). 당시 3,215명의 주민이 집계되었으며 연령과 성별, 결혼 여부 및 직업을 조사했습니다 (Statistics Canada 2023). 1867년 캐나다 연방 결성 당시에는 새로운 의회의 정치적 대표성을 할당하기 위해 10년마다 인구 조사를 실시하도록 규정했고, 그 이후 정기적인 조사가 이어져 오고 있습니다.
canlang 패키지를 사용하면 2016년 인구 조사에서 나타난 캐나다 내 사용 언어 데이터를 탐색할 수 있습니다. 이 패키지는 CRAN에는 없지만 GitHub을 통해 설치할 수 있습니다.
패키지를 로드한 뒤 can_lang 데이터셋을 살펴보겠습니다. 캐나다인들이 사용하는 214개 언어별 인구수를 확인할 수 있습니다.
can_lang# A tibble: 214 × 6
category language mother_tongue most_at_home most_at_work lang_known
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Aboriginal langu… Aborigi… 590 235 30 665
2 Non-Official & N… Afrikaa… 10260 4785 85 23415
3 Non-Official & N… Afro-As… 1150 445 10 2775
4 Non-Official & N… Akan (T… 13460 5985 25 22150
5 Non-Official & N… Albanian 26895 13135 345 31930
6 Aboriginal langu… Algonqu… 45 10 0 120
7 Aboriginal langu… Algonqu… 1260 370 40 2480
8 Non-Official & N… America… 2685 3020 1145 21930
9 Non-Official & N… Amharic 22465 12785 200 33670
10 Non-Official & N… Arabic 419890 223535 5585 629055
# ℹ 204 more rows모국어로 가장 많이 쓰이는 상위 10개 언어를 빠르게 확인해 볼까요?
can_lang |>
slice_max(mother_tongue, n = 10) |>
select(language, mother_tongue)# A tibble: 10 × 2
language mother_tongue
<chr> <dbl>
1 English 19460850
2 French 7166700
3 Mandarin 592040
4 Cantonese 565270
5 Punjabi (Panjabi) 501680
6 Spanish 458850
7 Tagalog (Pilipino, Filipino) 431385
8 Arabic 419890
9 German 384040
10 Italian 375635region_lang과 region_data 두 데이터셋을 결합하면 가장 큰 지역인 토론토와 가장 작은 지역 중 하나인 벨빌 사이에 가장 흔한 5개 언어의 비중이 어떻게 다른지 비교할 수 있습니다.
region_lang |>
left_join(region_data, by = "region") |>
slice_max(c(population)) |>
slice_max(mother_tongue, n = 5) |>
select(region, language, mother_tongue, population) |>
mutate(prop = mother_tongue / population)# A tibble: 5 × 5
region language mother_tongue population prop
<chr> <chr> <dbl> <dbl> <dbl>
1 Toronto English 3061820 5928040 0.516
2 Toronto Cantonese 247710 5928040 0.0418
3 Toronto Mandarin 227085 5928040 0.0383
4 Toronto Punjabi (Panjabi) 171225 5928040 0.0289
5 Toronto Italian 151415 5928040 0.0255region_lang |>
left_join(region_data, by = "region") |>
slice_min(c(population)) |>
slice_max(mother_tongue, n = 5) |>
select(region, language, mother_tongue, population) |>
mutate(prop = mother_tongue / population)# A tibble: 5 × 5
region language mother_tongue population prop
<chr> <chr> <dbl> <dbl> <dbl>
1 Belleville English 93655 103472 0.905
2 Belleville French 2675 103472 0.0259
3 Belleville German 635 103472 0.00614
4 Belleville Dutch 600 103472 0.00580
5 Belleville Spanish 350 103472 0.00338토론토에서는 영어를 모국어로 쓰는 사람의 비율이 50%를 조금 넘는 반면, 벨빌에서는 약 90%에 달하는 등 지역 간에 상당한 차이가 있음을 알 수 있습니다.
캐나다의 인구 조사 데이터는 다른 국가들에 비해 정부 기관을 통한 접근이 아주 쉬운 편은 아닙니다. 하지만 나중에 다룰 IPUMS(통합 공공 이용 마이크로데이터 시리즈)를 통해 일부 데이터를 얻을 수 있죠. 캐나다 통계청은 2016년 인구 조사의 ’개인 파일’을 공공 이용 마이크로데이터 파일(PUMF) 형태로 제공하지만, 요청 시에만 승인을 거쳐 지급합니다. 또한 이는 전체의 2.7% 표본이며 세부 정보도 제한적입니다.
그럼에도 캐나다 통계청은 여전히 방대한 데이터를 제공하며 cansim 패키지 를 통해 이를 R로 직접 불러올 수 있습니다. 특정 테이블 ID를 알고 있다면 바로 호출이 가능하죠. 예를 들어 테이블 “17-10-0005-01”은 지역별 인구 추계 정보를 담고 있습니다. 이 패키지는 데이터를 깔끔한(Tidy) 형식으로 변환해주어 별도의 정제 과정 없이 시각화 등에 바로 활용할 수 있다는 것이 큰 장점입니다.
캐나다 인구 조사 데이터에 접근하는 또 다른 방법은 cancensus를 활용하는 것입니다. API 키가 필요하며, 웹사이트에서 계정을 만든 뒤 발급받을 수 있습니다. 키를 .Renviron 파일에 등록해 두면 편리하며, 자세한 방법은 Chapter 7 에서 설명하겠습니다.
get_census() 함수를 사용하면 원하는 지역과 변수를 지정해 인구 조사 데이터를 가져올 수 있습니다. 예컨대 온타리오주의 2016년 인구 데이터를 얻는 코드는 다음과 같습니다.
set_api_key("여기에_API_키_입력", install = TRUE)
ontario_population <-
get_census(
dataset = "CA16",
level = "Regions",
vectors = "v_CA16_1",
regions = list(PR = c("35"))
)
ontario_population# A tibble: 1 × 9
GeoUID Type `Region Name` `Area (sq km)` Population Dwellings Households
<dbl> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 35 PR Ontario 986722. 13448494 5598391 5169174
# ℹ 2 more variables: C_UID <chr>, `v_CA16_1: Age Stats` <dbl>list_census_datasets()로 접근 가능한 연도별 데이터를 확인하고, list_census_regions()와 list_census_vectors()를 통해 지역 및 변수 정보를 미리 파악할 수 있습니다.
6.3.2 미국의 사례
6.3.2.1 인구 조사
미국 헌법은 인구 조사를 명문화하고 있으며, 1639년 초 매사추세츠 지역에서는 이미 출생과 사망 기록을 법적으로 등록해야 했습니다 (Gutman 1958).
미국 인구 조사국 데이터는 tidycensus 패키지 (Walker and Herman 2022)를 통해 아주 편리하게 이용할 수 있습니다. 5년 단위 미국 지역사회 조사(ACS)와 인구 조사 데이터를 R 데이터프레임으로 불러와 주죠. 특히 공간 정보(Geometry)를 함께 가져오는 기능이 강력해 ?sec-graphs-tables-maps 에서 다룬 지도를 만들 때 매우 유용합니다. 사용을 위해서는 API 키 발급이 필요합니다.
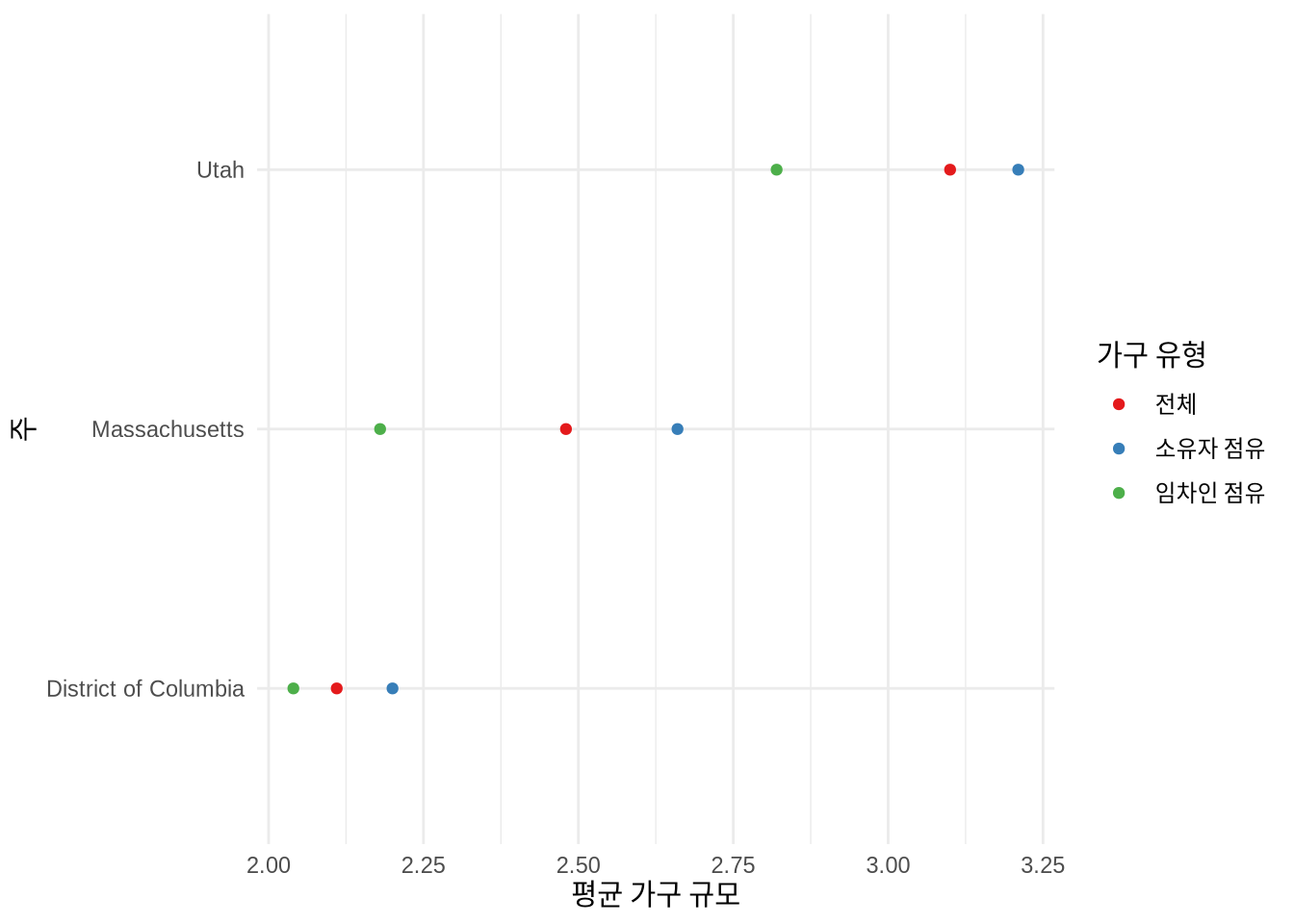
get_decennial() 함수를 쓰면 10년 단위 인구 조사 데이터를 얻을 수 있습니다. 예를 들어 2010년 특정 주의 가구 점유 형태별 가구 규모를 비교해 볼 수 있죠 (Figure 6.2).
census_api_key("여기에_API_키_입력")
us_ave_household_size_2010 <-
get_decennial(
geography = "state",
variables = c("H012001", "H012002", "H012003"),
year = 2010
)
us_ave_household_size_2010 |>
filter(NAME %in% c("District of Columbia", "Utah", "Massachusetts")) |>
ggplot(aes(y = NAME, x = value, color = variable)) +
geom_point() +
theme_minimal() +
labs(
x = "평균 가구 규모", y = "주", color = "가구 유형"
) +
scale_color_brewer(
palette = "Set1", labels = c("전체", "소유자 점유", "임차인 점유")
)
Walker (2022) 는 R을 활용한 미국 인구 조사 데이터 분석법을 더 상세히 설명해 줍니다.
6.3.2.2 미국 지역사회 조사 (ACS)
미국은 정부 통계 기관 웹사이트를 뒤적이는 것보다 훨씬 효율적인 데이터 접근 수단을 가지고 있습니다 바로 IPUMS입니다. 특히 미국 지역사회 조사(ACS)는 정기 인구 조사와 유사한 내용을 매년 조사하여 수백만 건의 응답을 제공합니다 인구 조사보다 규모는 작지만 훨씬 최신 정보를 제공한다는 것이 큰 장점이죠. 우리는 IPUMS를 통해 이 데이터에 접근합니다.
거인의 어깨 위에서
스티븐 러글스(Steven Ruggles) 교수는 미네소타 대학교의 역사 및 인구 연구 특훈 교수이며 IPUMS를 이끌고 있습니다 1984년 펜실베이니아 대학교에서 역사 인구학 박사 학위를 받은 뒤 IPUMS를 세계 최대 규모의 인구 데이터 저장소로 성장시켰죠. 1993년 첫 데이터 출시 이후 현재 수많은 국가의 사회·경제 데이터를 아우르고 있습니다. 그는 2022년에 맥아더 재단 펠로우십을 수상했습니다.
6.3.3 IPUMS 데이터 활용하기
전 세계 각국의 인구 조사와 대규모 설문 조사 결과를 통합해 제공하는 IPUMS(Integrated Public Use Microdata Series)는 데이터 과학자들에게는 그야말로 보물창고와 같습니다. 정부가 발표하는 공식 통계가 이미 집계된 요약표라면, IPUMS는 개별 응답자의 정보를 담은 미시 데이터(Microdata)를 제공하죠. 물론 개인정보 보호를 위한 비식별 처리가 되어 있지만, 연구자가 원하는 방식대로 직접 데이터를 집계하고 분석할 수 있다는 점에서 활용도가 매우 높습니다.
IPUMS 데이터를 다룰 때는 ipumsr 패키지가 필수입니다. 웹사이트에서 내려받은 데이터 파일(.dat)과 메타데이터(.xml)를 읽어와 R 데이터프레임으로 변환해주죠. 특히 파일 내의 다양한 코드 정보(예: ‘1’은 ’기혼’)를 R의 레이블 속성으로 자동 처리해주어 분석이 훨씬 수월해집니다.
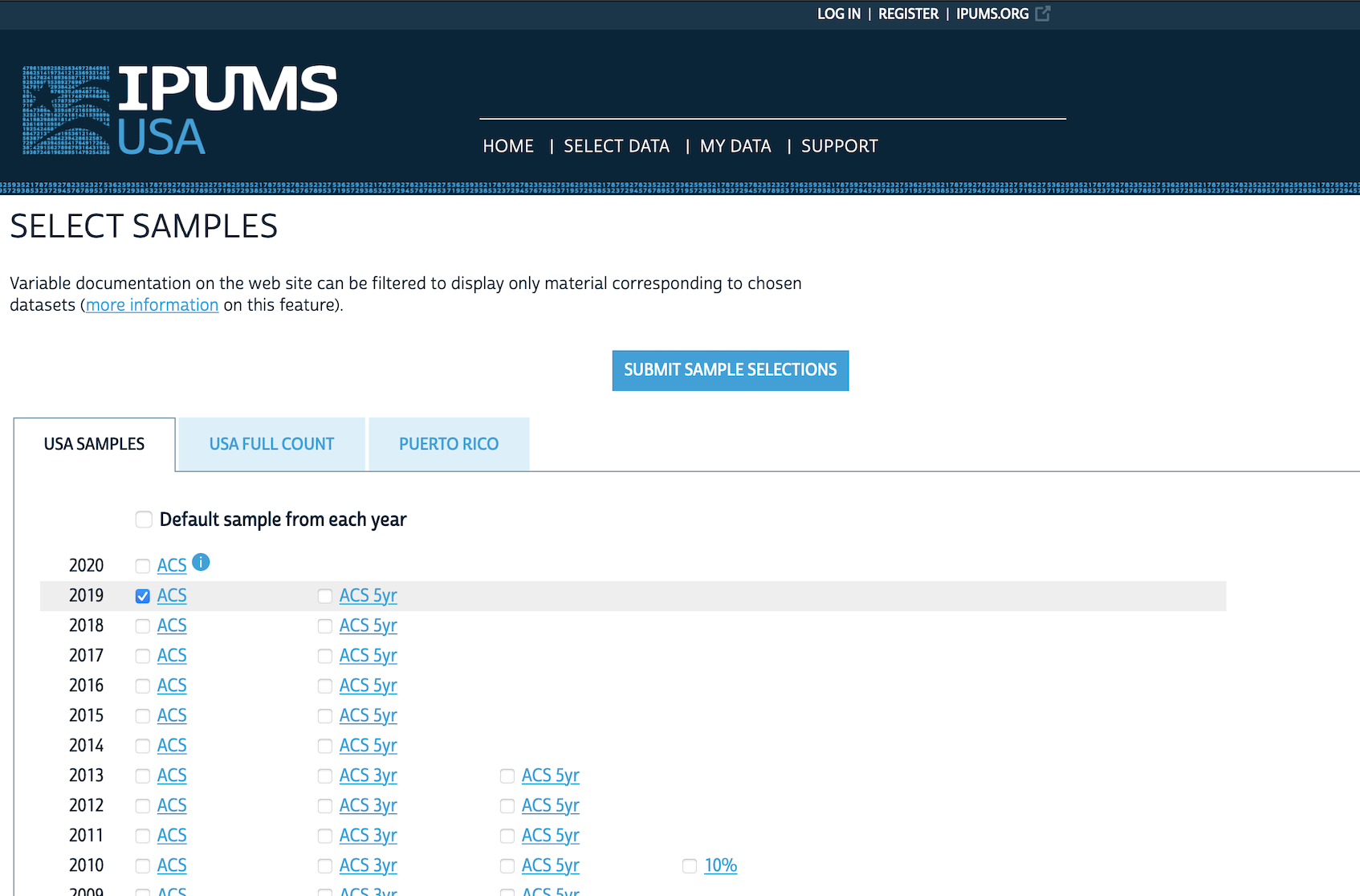
IPUMS 웹사이트에서 “IPUMS USA” -> “Get Data”로 이동해 보세요. 표본 선택(Select Samples)에서 “2019 ACS”를 선택하고 제출합니다 (Figure 6.3 (a)).
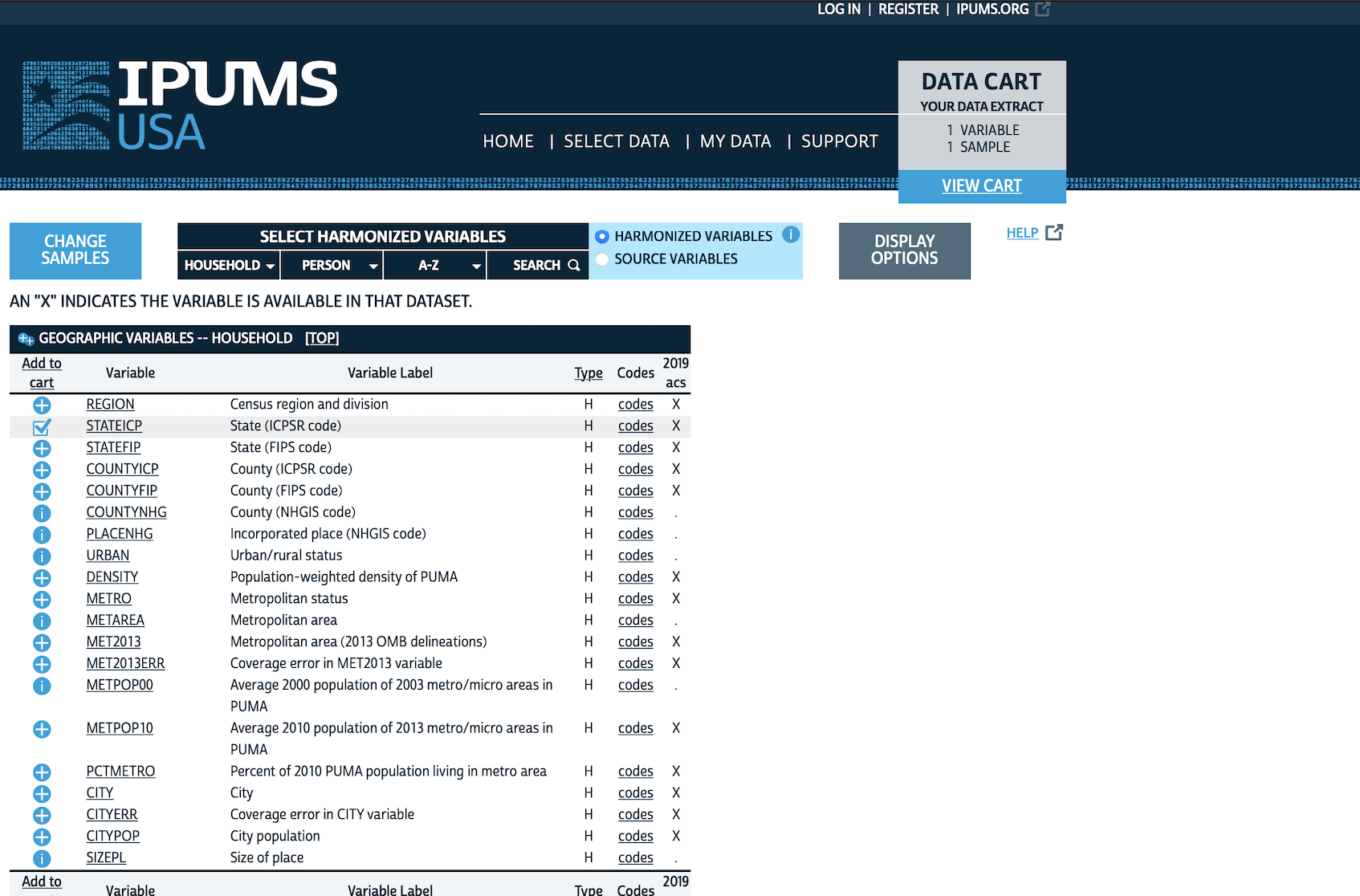
주별 데이터가 필요하다면 “HOUSEHOLD” 항목의 “GEOGRAPHIC”에서 “STATEICP”를 찾아 장바구니에 담으세요 (Figure 6.3 (b), Figure 6.3 (c)). 인구 통계 변수인 연령(AGE), 성별(SEX), 교육 수준(EDUC)도 함께 추가합니다.
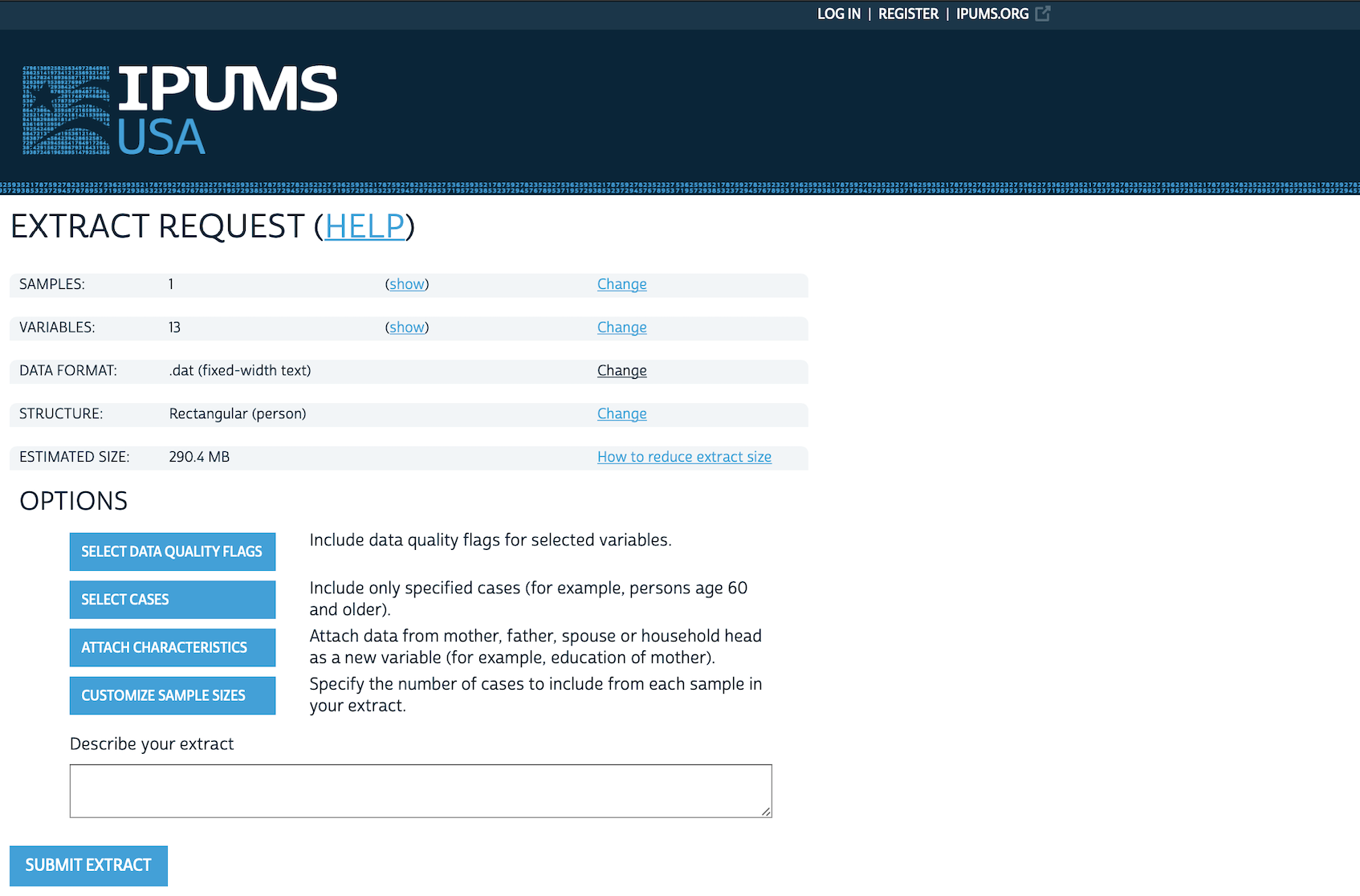
완료 후 “View Cart” -> “Create Data Extract”를 클릭하세요. 이때 다음 두 가지를 변경하는 것이 좋습니다.
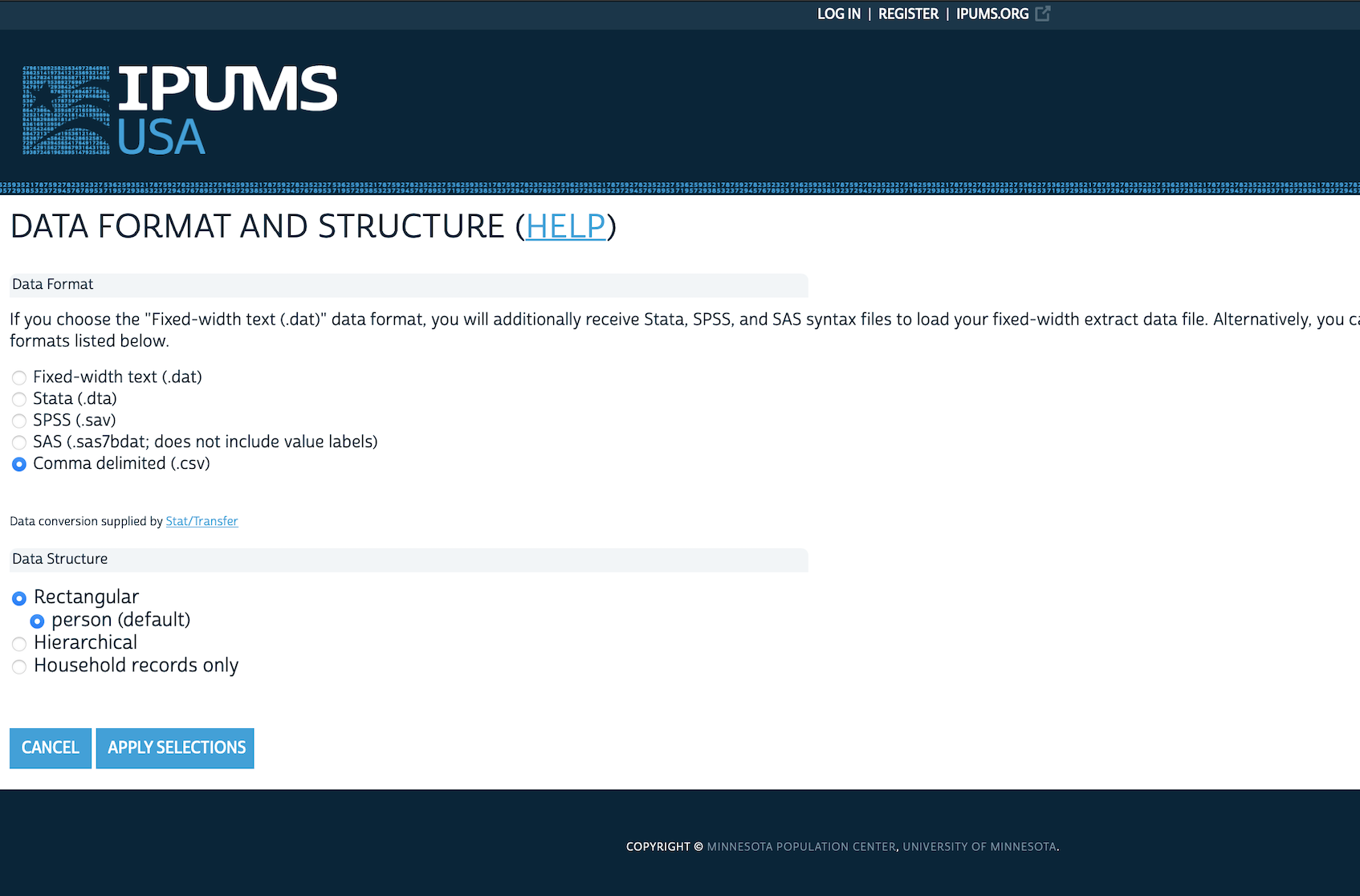
- 데이터 형식을 “.dat”에서 “.dta”로 바꿉니다 (Figure 6.3 (e)).
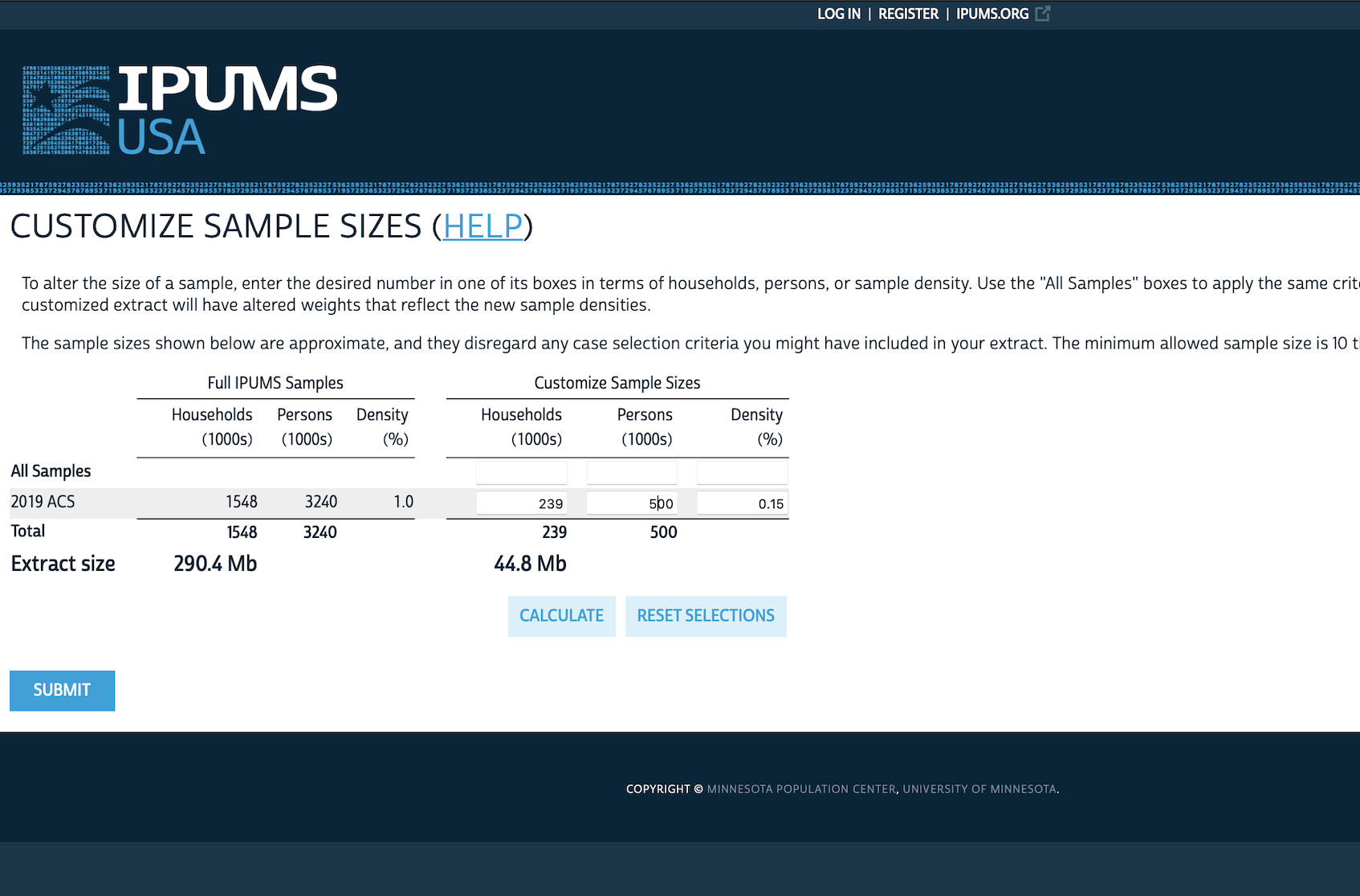
- 300만 건이 넘는 전체 응답이 다 필요 없다면 표본 크기를 적절히(예: 50만 건) 줄입니다 (Figure 6.3 (f)).
요청 용량이 40MB를 너무 넘지 않는지 확인한 뒤, 추출물에 적절한 이름(예: “2023-05-15: 주, 연령, 성별, 교육”)을 붙여 제출하세요. 추출이 완료되면 이메일로 알림이 오며, 파일을 내려받아 R로 읽어오면 됩니다.
데이터를 사용할 때는 인용하는 습관이 중요합니다. BibTeX 형식의 예시는 다음과 같습니다.
@misc{ipumsusa,
author = {Ruggles, Steven and Flood, Sarah and Foster, Sophia and Goeken, Ronald and Pacas, Jose and Schouweiler, Megan and Sobek, Matthew},
year = 2021,
title = {IPUMS USA: Version 11.0},
publisher = {Minneapolis, MN: IPUMS},
doi = {10.18128/d010.v11.0},
url = {https://usa.ipums.org},
language = {en},
}
Chapter 16 에서 이 데이터를 활용할 예정이므로, Mitrovski, Yang, and Wankiewicz (2020) 의 코드를 참고해 간단히 정제해 두겠습니다.
ipums_extract <- read_dta("usa_00015.dta")
ipums_extract <-
ipums_extract |>
select(stateicp, sex, age, educd) |>
to_factor()
ipums_extract# A tibble: 500,221 × 4
stateicp sex age educd
* <fct> <fct> <fct> <fct>
1 alabama male 77 grade 9
2 alabama male 62 1 or more years of college credit, no degree
3 alabama male 25 ged or alternative credential
4 alabama female 20 1 or more years of college credit, no degree
5 alabama male 37 1 or more years of college credit, no degree
6 alabama female 19 regular high school diploma
7 alabama female 67 regular high school diploma
8 alabama female 20 1 or more years of college credit, no degree
9 alabama male 66 grade 8
10 alabama male 58 regular high school diploma
# ℹ 500,211 more rowscleaned_ipums <-
ipums_extract |>
mutate(age = as.numeric(age)) |>
filter(age >= 18) |>
rename(gender = sex) |>
mutate(
age_group = case_when(
age <= 29 ~ "18-29",
age <= 44 ~ "30-44",
age <= 59 ~ "45-59",
age >= 60 ~ "60+",
TRUE ~ "Trouble"
),
education_level = case_when(
educd %in% c(
"nursery school, preschool", "kindergarten", "grade 1",
"grade 2", "grade 3", "grade 4", "grade 5", "grade 6",
"grade 7", "grade 8", "grade 9", "grade 10", "grade 11",
"12th grade, no diploma", "regular high school diploma",
"ged or alternative credential", "no schooling completed"
) ~ "High school or less",
educd %in% c(
"some college, but less than 1 year",
"1 or more years of college credit, no degree"
) ~ "Some post sec",
educd %in% c("associate's degree, type not specified",
"bachelor's degree") ~ "Post sec +",
educd %in% c(
"master's degree",
"professional degree beyond a bachelor's degree",
"doctoral degree"
) ~ "Grad degree",
TRUE ~ "Trouble"
)
) |>
select(gender, age_group, education_level, stateicp) |>
mutate(across(c(
gender, stateicp, education_level, age_group),
as_factor)) |>
mutate(age_group =
factor(age_group, levels = c("18-29", "30-44", "45-59", "60+")))
cleaned_ipums# A tibble: 407,354 × 4
gender age_group education_level stateicp
<fct> <fct> <fct> <fct>
1 male 60+ High school or less alabama
2 male 60+ Some post sec alabama
3 male 18-29 High school or less alabama
4 female 18-29 Some post sec alabama
5 male 30-44 Some post sec alabama
6 female 18-29 High school or less alabama
7 female 60+ High school or less alabama
8 female 18-29 Some post sec alabama
9 male 60+ High school or less alabama
10 male 45-59 High school or less alabama
# ℹ 407,344 more rows저장된 데이터는 나중에 다시 사용하겠습니다.
write_csv(x = cleaned_ipums,
file = "cleaned_ipums.csv")정제된 데이터의 특성을 시각적으로 확인해 볼 수 있습니다 (Figure 6.4).
cleaned_ipums |>
ggplot(mapping = aes(x = age_group, fill = gender)) +
geom_bar(position = "dodge2") +
theme_minimal() +
labs(
x = "응답자 연령 그룹",
y = "응답자 수",
fill = "교육 수준"
) +
facet_wrap(vars(education_level)) +
guides(x = guide_axis(angle = 90)) +
theme(legend.position = "bottom") +
scale_fill_brewer(palette = "Set1")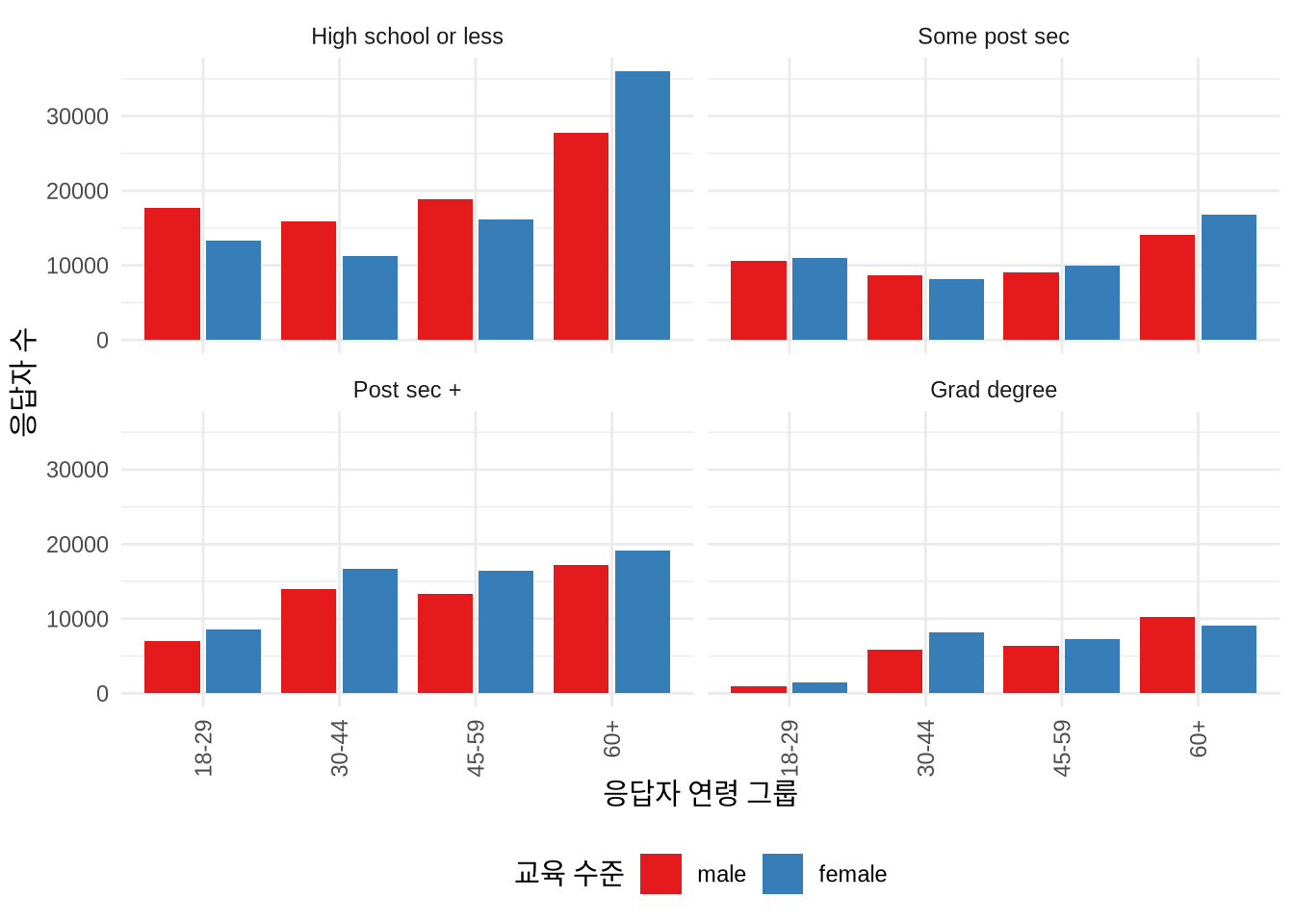
IPUMS는 1850~1940년 사이의 미국 인구 조사 전체 데이터(1890년 제외)와 1990년까지의 1% 표본 데이터를 제공합니다. 역사적인 인구 변화를 연구하기에 더할 나위 없는 자원이죠.
6.4 표본 추출의 핵심 원리
모집단 전체를 조사하는 전수 조사는 이상적이지만, 시간과 비용 면에서 불가능할 때가 많습니다. 이때 우리는 표본 추출(Sampling)이라는 강력한 대안을 활용합니다. 잘 떠낸 한 스푼의 국이 냄비 전체의 맛을 알려주듯, 적절히 추출된 표본은 모집단의 특성을 놀라울 정도로 정확히 반영하죠.
하지만 표본 추출은 단순히 ’무작위’로 뽑는 것 이상의 정교한 설계가 필요합니다. 잘못된 설계는 심각한 편향을 초래하며, 이는 100년 전이나 지금이나 데이터 분석에서 가장 경계해야 할 대목입니다 (Brewer 2013). 표본 추출을 이해하기 위한 세 가지 핵심 용어를 명확히 짚고 넘어가겠습니다.
- 목표 모집단(Target Population): 우리가 정말로 알고 싶어 하는 전체 집단입니다 (예: “투표권이 있는 모든 성인”).
- 표집 틀(Sampling Frame): 모집단에 접근하기 위해 사용하는 실제 명부나 수단입니다 (예: “유선전화 가입자 리스트”).
- 표본(Sample): 표집 틀에서 실제로 선정되어 조사에 응한 데이터들의 집합입니다.
이론적으로 모집단이란 우리가 정확히 알 수는 없지만 확률 분포를 통해 그 특성을 설명할 수 있는 가상의 무한한 그룹을 의미합니다 (Chapter 12 에서 다시 다룹니다). Fisher ([1925] 1928, 41)는 모든 통계 작업의 기초가 이러한 가상의 모집단 개념 위에 세워져 있다고 말했습니다.
목표 모집단을 명확히 정의하는 일은 생각보다 까다롭습니다. 대학생의 소비 습관을 조사할 때, 직장에 다니는 야간 대학생이나 고령의 만학도를 포함해야 할까요? Gelman, Hill, and Vehtari (2020, 24)은 누군가를 “흡연자”로 분류할 때 15세의 흡연 기록과 90세의 기록을 똑같은 잣대로 평가할 수 있는지 묻습니다. 이처럼 경계가 모호한 지점들을 어떻게 처리하느냐가 연구의 성격을 규정하죠.
표집 틀과 모집단이 일치하지 않는 경우도 흔합니다. 독일에 사는 브라질인들의 태도를 알고 싶을 때, 페이스북 사용자 명부를 표집 틀로 쓴다면 페이스북을 하지 않는 브라질인들은 원천적으로 배제됩니다. 이처럼 목표 모집단과 표집 틀, 그리고 실제 표본 사이의 간극을 이해하는 것이 분석의 시작입니다.
6.4.1 역사적 사례: 더블린과 리딩
표본 추출 기법의 발전을 보여주는 두 가지 역사적 사례를 살펴보겠습니다.
6.4.1.1 1798년 더블린 인구 조사
1798년 제임스 휘틀로 목사는 아일랜드 더블린의 인구를 집계하기 위해 조사를 실시했습니다. Whitelaw (1805) 에 따르면 당시 인구 추정치는 기관마다 천차만별이었다고 하죠. 휘틀로는 처음에는 가구주가 명단을 문에 붙여두게 하는 방식을 기대했지만, 명단이 부실하다는 사실을 깨닫고 조수들을 동원해 직접 가가호호 방문하며 수를 셌습니다 (Figure 6.5). 그가 추정한 인구는 182,370명이었습니다.
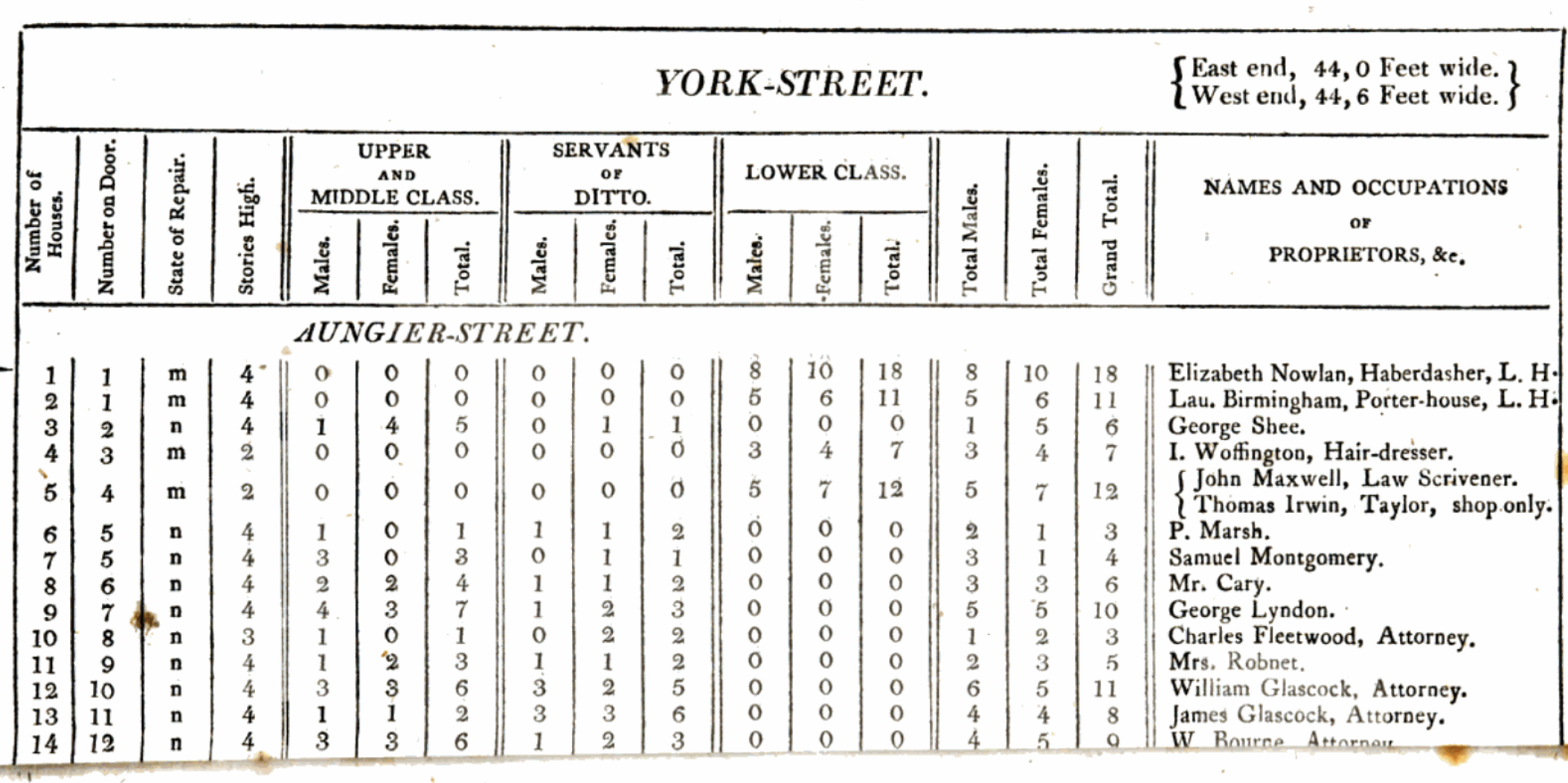
흥미로운 점은 그가 계급 정보를 포함했다는 것입니다. 그는 상류층 집안에는 목록 작성이 능숙한 이들이 늘 상주했지만, 하층 계급은 상황이 전혀 달랐다고 기록했습니다. 통계적 정교함은 부족했을지 몰라도, 전수 조사를 향한 집념이 돋보이는 사례입니다.
6.4.1.2 1912년 리딩의 노동자 가구 조사
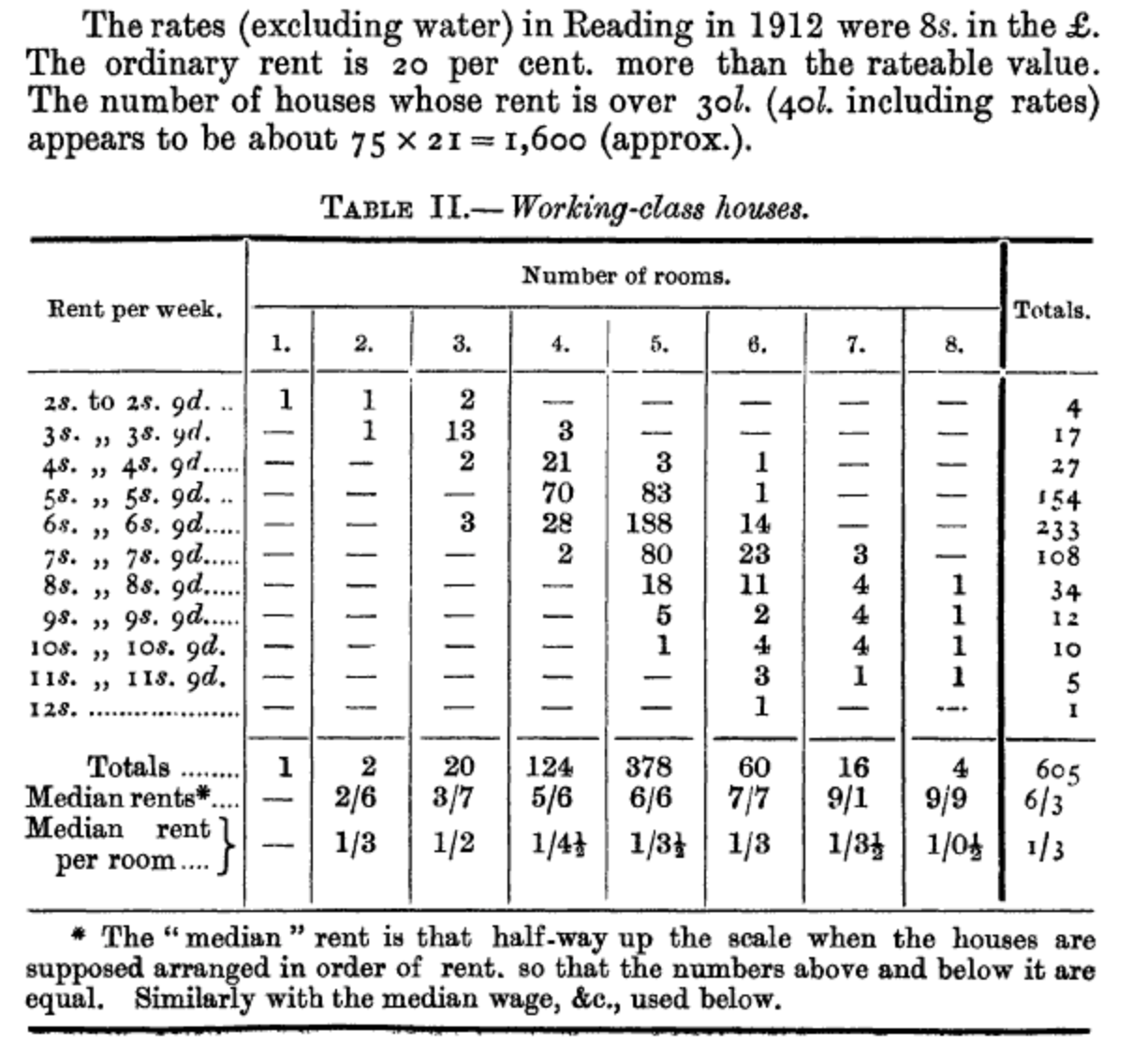
휘틀로의 조사 이후 100년이 흘러 Bowley (1913) 은 영국 리딩 지역의 노동자 계층 가구를 조사했습니다. 보울리는 현대적인 표본 추출 방식의 효시가 된 절차를 사용했죠. 그는 지역 주소록에서 알파벳순으로 열 번째 건물마다 표시를 한 뒤, 그중 주거용 건물만을 골라내 최종적으로 20가구 중 하나를 추출하는 방식을 택했습니다.
Bowley (1913) 은 622가구의 정보를 확보해 이들이 매주 지불하는 임대료 등을 추정했습니다 (Figure 6.6). 그는 조사원들에게 “정보를 얻기 힘들다고 해서 마음대로 다른 집으로 대체하지 말 것”을 엄격히 지시했는데, 이는 표본의 무작위성을 확보하기 위함이었습니다. 그는 표본 데이터에 승수를 적용해 지역 전체의 인구를 추정해냈죠.
6.4.2 확률 표집 방식
확률 표집(Probability Sampling)은 모집단의 모든 구성원이 표본에 포함될 확률이 0보다 크고, 그 확률을 우리가 미리 알 수 있는 방식을 말합니다. 통계 이론의 견고한 뒷받침을 받기에 표본 오차 범위를 과학적으로 계산할 수 있다는 큰 장점이 있죠.
6.4.2.1 단순 무작위 표집 (SRS)
단순 무작위 표집(Simple Random Sampling)은 가장 기초적인 방식입니다. 제비뽑기처럼 모든 구성원이 뽑힐 확률이 동일(1/N)한 경우죠. 1부터 100까지의 숫자 중에서 20%를 무작위로 뽑는 시뮬레이션을 해보겠습니다.
set.seed(853)
illustrative_sampling <- tibble(
unit = 1:100,
simple_random_sampling =
sample(x = c("In", "Out"),
size = 100,
replace = TRUE,
prob = c(0.2, 0.8))
)
illustrative_sampling |>
count(simple_random_sampling)# A tibble: 2 × 2
simple_random_sampling n
<chr> <int>
1 In 14
2 Out 866.4.2.2 체계적 표집
체계적 표집(Systematic Sampling)은 목록에서 일정한 간격마다 표본을 추출하는 방식입니다. 예를 들어 무작위로 시작점을 정한 뒤 매 5번째 데이터마다 추출하는 식이죠. 목록이 무작위로 섞여 있다면 단순 무작위 표집과 유사한 효과를 내며 실행이 간편합니다.
set.seed(853)
starting_point <- sample(x = c(1:5), size = 1)
illustrative_sampling <-
illustrative_sampling |>
mutate(
systematic_sampling =
if_else(unit %in% seq.int(from = starting_point, to = 100, by = 5),
"In",
"Out"
)
)
illustrative_sampling |>
count(systematic_sampling)# A tibble: 2 × 2
systematic_sampling n
<chr> <int>
1 In 20
2 Out 806.4.2.3 층화 표집
모집단을 연령이나 지역처럼 서로 겹치지 않는 그룹(층, Strata)으로 나눈 뒤, 각 층에서 독립적으로 무작위 추출을 하는 방식입니다. 각 그룹의 대표성을 골고루 확보하고 싶을 때 유용하죠. 예컨대 인구가 아주 적은 특정 지역의 목소리도 놓치지 않고 담아내기 위해 층화 구조를 활용할 수 있습니다.
set.seed(853)
picked_in_strata <-
illustrative_sampling |>
mutate(strata = (unit - 1) %/% 10) |>
slice_sample(n = 2, by = strata) |>
pull(unit)
illustrative_sampling <-
illustrative_sampling |>
mutate(stratified_sampling =
if_else(unit %in% picked_in_strata, "In", "Out"))
illustrative_sampling |>
count(stratified_sampling)# A tibble: 2 × 2
stratified_sampling n
<chr> <int>
1 In 20
2 Out 806.4.2.4 군집 표집
개인이 아니라 ‘그룹’(군집, Cluster) 단위로 무작위 추출을 하는 방식입니다. 전국 초등학생을 조사할 때 먼저 몇몇 학교를 무작위로 뽑은 뒤, 그 학교 학생들만 조사하는 식이 전형적인 군집 표집입니다. 조사 비용을 크게 줄여주지만, 끼리끼리 모여 있는 집단의 특성상 단순 무작위 표집보다는 통계적 정밀도가 떨어질 수 있습니다.
set.seed(853)
picked_clusters <-
sample(x = c(0:9), size = 2)
illustrative_sampling <-
illustrative_sampling |>
mutate(
cluster = (unit - 1) %/% 10,
cluster_sampling = if_else(cluster %in% picked_clusters, "In", "Out")
) |>
select(-cluster)
illustrative_sampling |>
count(cluster_sampling)# A tibble: 2 × 2
cluster_sampling n
<chr> <int>
1 In 20
2 Out 80각 방식의 차이를 시각적으로 비교해 보겠습니다 (Figure 6.7, ?fig-samplingexamplesworld). 층화 표집과 군집 표집이 특정 영역에 집중하면서도 전체적인 그림과 어떻게 절충하는지 확인할 수 있습니다.
new_labels <- c(
simple_random_sampling = "단순 무작위 표집",
systematic_sampling = "체계적 표집",
stratified_sampling = "층화 표집",
cluster_sampling = "군집 표집"
)
illustrative_sampling_long <-
illustrative_sampling |>
pivot_longer(
cols = names(new_labels), names_to = "sampling_method",
values_to = "in_sample"
) |>
mutate(sampling_method =
factor(sampling_method,levels = names(new_labels)))
illustrative_sampling_long |>
filter(in_sample == "In") |>
ggplot(aes(x = unit, y = in_sample)) +
geom_point() +
facet_wrap(vars(sampling_method), dir = "v", ncol = 1,
labeller = labeller(sampling_method = new_labels)
) +
theme_minimal() +
labs(x = "관측 단위", y = "표본 포함 여부") +
theme(axis.text.y = element_blank())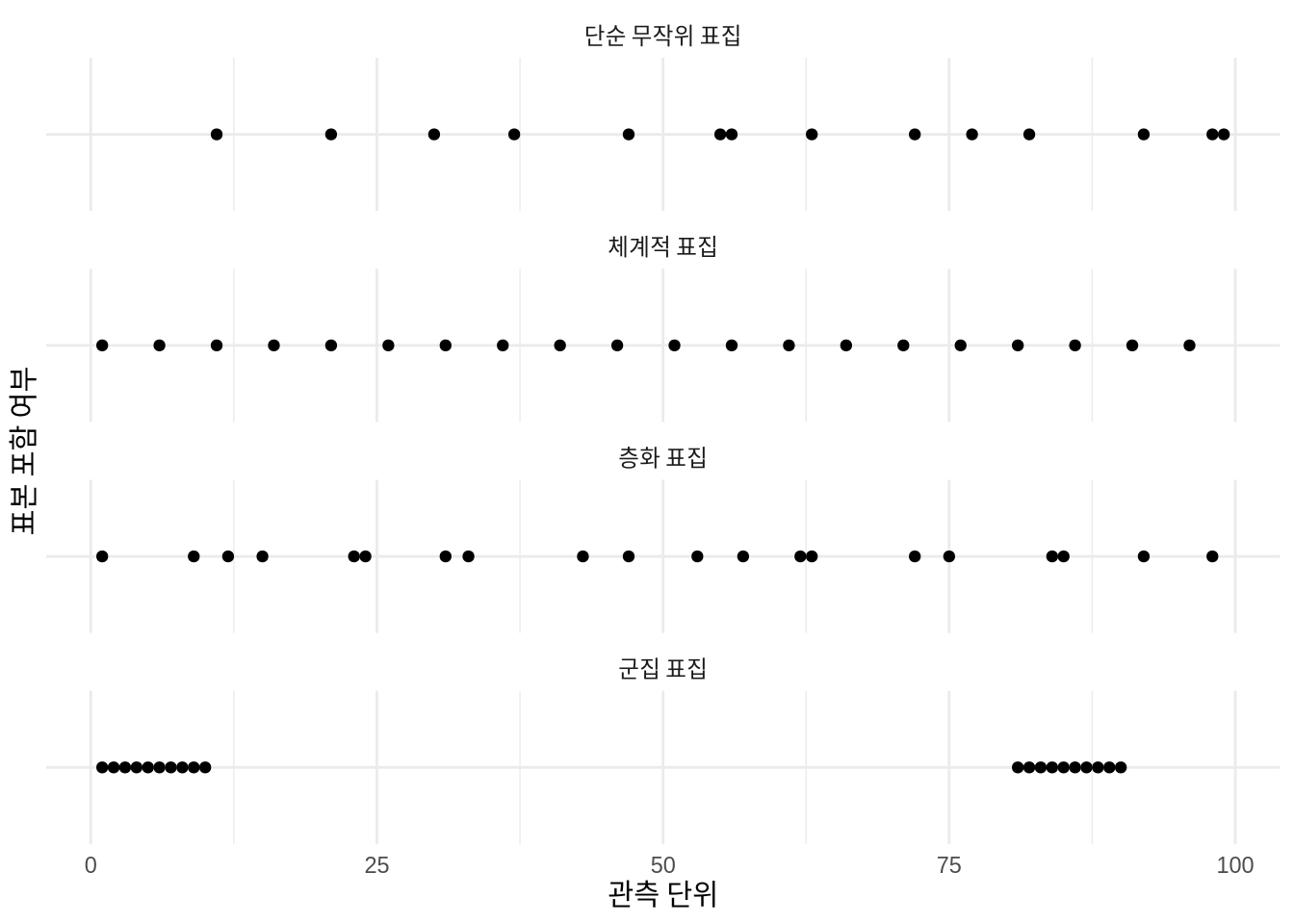
6.4.2.5 확률 표본을 통한 추론
표본을 얻고 나면 이를 통해 모집단의 특성(평균, 분산 등)을 추정하게 됩니다. Neyman (1934, 561)는 이를 통계적 추정의 문제라고 정의했습니다. 우리는 표본 평균(\(\hat{\mu}\))과 표본 분산(\(\hat{\sigma}^2\))을 계산해 모집단의 실제 모습에 다가가려 노력하죠.
앞서 본 1부터 100까지의 숫자 합계 사례에서, 표본 데이터를 바탕으로 모집단 전체의 합계(5,050)를 얼마나 잘 예측하는지 비교해 보겠습니다 (Table 6.2). 층화 표집과 체계적 표집이 실제 값에 아주 가깝게 도달한 것을 볼 수 있습니다.
| 표집 방법 | 표본 합계 | 모집단 추정 합계 |
|---|---|---|
| 체계적 표집 | 970 | 4,850 |
| 층화 표집 | 979 | 4,895 |
| 군집 표집 | 910 | 4,550 |
| 단순 무작위 표집 | 840 | 4,200 |
비율 추정량(Ratio estimator)은 두 평균의 비율을 이용해 미지의 값을 추정하는 유용한 도구입니다. 1802년 라플라스는 전국의 출생아 수와 특정 지역의 인구 비율을 이용해 프랑스 전체 인구를 추정하기도 했죠. 부모와 유아의 수면 시간 관계를 시뮬레이션해 보아도 이 비율 추정 방식이 상당히 정확함을 알 수 있습니다 (?tbl-averagesleepestimate).
생태학에서 쓰이는 포획-재포획(Capture-Recapture)법 역시 비율 추정의 흥미로운 변형입니다. 동물을 잡아 표식을 남긴 뒤 풀어주고 다시 잡아 그 비중을 따져보는 이 기법은, 최근 웹 데이터를 활용한 인구 조사 보완 등 사회과학 분야에서도 새롭게 조명받고 있습니다.
6.4.3 비확률 표집 방식
비확률 표집(Non-probability Sampling)은 구성원이 표본에 포함될 확률을 미리 알 수 없는 방식입니다. 편의 표집이나 자발적 응답 표집 등이 해당하죠. 과거에는 통계적 근거가 약하다는 이유로 외면받기도 했지만, 인터넷의 발달로 방대한 데이터를 얻기 쉬워진 현대에는 이를 어떻게 잘 보정해 활용할지가 핵심 과제가 되었습니다.
1936년 미국 대선 당시 리터러리 다이제스트가 엄청난 양의 설문으로도 예측에 실패한 반면, 갈럽은 훨씬 적은 확률 표본으로 결과를 맞춘 사례는 표본의 ’크기’보다 ’추출 방식’이 얼마나 중요한지 잘 보여줍니다. 최근에는 낮은 응답률 문제를 해결하기 위해 비확률 표본의 편향을 모집단 통계(인구 조사 등)로 보정하는 다층 모형 및 사후 층화(MRP) 기법이 각광받고 있습니다.
- 편의 표집: 길거리 인터뷰처럼 접근하기 쉬운 대상만 조사하는 방식입니다. 빠르고 저렴하지만 대표성 확보가 어렵고 편향될 위험이 큽니다.
- 할당 표집: 모집단 성비 등을 맞추기 위해 그룹별 할당량을 정해두고 추출하는 방식입니다. 무작위성이 부족해 편향될 수 있지만 특정 계층의 목소리를 의도적으로 담아내기에 유리합니다.
- 눈덩이 표집: 초기 응답자가 주변 사람을 추천하며 표본을 키워나가는 방식입니다. 접근하기 어려운 숨겨진 집단을 연구할 때 매우 효과적입니다.
거인의 어깨 위에서
네이먼(Jerzy Neyman)은 현대 통계학의 토대를 닦은 거인입니다. 1934년 발표한 논문 (Neyman 1934)을 통해 확률 표집이 비확률 표집보다 논리적으로 우월함을 입증하며 현대 여론조사의 표준을 세웠죠. 또한 신뢰 구간과 가설 검정 등 우리가 오늘날 당연하게 사용하는 통계적 도구들을 정립하는 데 크게 기여했습니다.
6.5 결론
이번 장에서는 세상을 데이터로 박제하고 보존하는 과정, 즉 ’경작 데이터’의 세계를 살펴보았습니다. 데이터는 결코 하늘에서 떨어진 객관적인 진리가 아닙니다. 수집 과정에는 누군가의 의도와 권력이 개입되며, 측정 도구의 한계로 인해 언제나 오차가 발생하기 마련이죠.
인구 조사와 공식 통계는 막대한 노력의 산물이지만 그 이면에 숨겨진 누락과 편향을 읽어낼 수 있어야 합니다. 또한 전수 조사가 불가능한 상황에서 표본 추출이 모집단을 어떻게 대변하는지, 그리고 각 방식의 장단점이 무엇인지 이해하는 것은 데이터 과학자의 필수적인 기초 체력입니다.
우리는 이제 잘 가꾸어진 농장(Farmed Data)을 떠나, 더 거칠고 방대한 야생의 데이터(Scraped/Found Data)를 수집하는 방법으로 나아갈 준비가 되었습니다.
6.6 연습 문제
실습
- (계획) 특정 대학교 학부생들의 ’정치적 지향’을 조사한다고 가정해 봅시다.
- 목표 모집단과 표집 틀을 어떻게 정의하시겠습니까?
- 포괄 오차(Coverage error)가 발생할 수 있는 구체적인 사례를 들어보세요.
- (시뮬레이션) Figure 6.1 에서 다룬 신생아 몸무게 시나리오를 R로 직접 시뮬레이션해 보세요. 표본 크기가 늘어남에 따라 각 시나리오의 평균값이 이론적 참값(3.5kg)에 수렴하는 양상을 비교해 보십시오.
- (획득)
tidycensus패키지를 사용해 관심 있는 미국 지역의 인구 밀도 데이터를 시각화해 보세요. - (탐색) IPUMS 웹사이트에 접속해 1950년대 미국 인구 조사 데이터의 변수들을 살펴보세요. 현대 데이터와 비교해 어떤 항목이 사라지거나 추가되었나요? 그 이유는 무엇이라고 생각하십니까?
- (소통) 분석 결과를 설명하는 텍스트를 작성해 보세요. 코드는 R 스크립트와 Quarto 문서로 나누어 관리하고, 고품질의 GitHub 리포지토리 링크를 제출하십시오.
퀴즈
- 세상의 현상을 데이터셋으로 변환할 때 가장 어려운 점은 무엇입니까? (하나 선택)
- 데이터 저장 비용의 과다.
- 편향되지 않은 데이터의 과잉.
- 데이터 수집 도구의 부재.
- 무엇을, 어떻게 적절하게 측정할지 결정하는 문제.
- Daston (2000) 를 참고해 GDP와 인구수라는 개념이 ’발명’된 것인지 ’발견’된 것인지 토론해 보세요.
- 계측학(Metrology)의 관점에서 측정을 가장 잘 정의한 것은? (하나 선택)
- 예측 모델을 통한 미지수 추정.
- 분석 시 통계적 유의성 계산.
- 대상에 임의로 숫자를 부여하는 행위.
- 현상의 속성에 귀속될 수 있는 양 값을 실험적으로 얻는 과정.
- 본인의 언어로 측정 오차를 정의하고 실생활의 사례를 들어 두 단락 내외로 설명해 보세요.
- Gargiulo (2022) 를 참고해 현실 세계에서 측정의 어려움에 대해 논의해 보세요.
- 측정의 ’타당성(Validity)’이란 무엇을 의미합니까? (하나 선택)
- 결과의 통계적 유의성.
- 측정이 의도한 개념을 얼마나 정확히 반영하는지의 정도.
- 데이터 수집의 속도.
- 측정 재현의 정밀도.
- Kennedy et al. (2022) 은 윤리를 어떻게 정의했나요? (하나 선택)
- 개별 응답자의 관점과 존엄성을 존중하는 것.
- 일반 인구에 대한 추정치를 생성하는 것.
- 복잡한 절차를 통해 유용한 기능을 제공하는 것.
- 측정 오차를 가장 잘 설명한 것은? (하나 선택)
- 관찰된 값과 실제 참값 사이의 차이.
- 비정규 분포에서만 생기는 오류.
- 더 좋은 기계로 완전히 없앨 수 있는 오류.
- 의도적인 데이터 조작.
- 검열된 데이터(Censored data)란 무엇입니까? (하나 선택)
- 손상되어 읽을 수 없는 정보.
- 개인정보 문제로 삭제된 데이터.
- 실제 값을 부분적으로만 알 수 있는 데이터.
- 승인되지 않은 데이터.
- 절단된 데이터(Truncated data)와 검열된 데이터의 차이는? (하나 선택)
- 절단은 과대평가, 검열은 과소평가를 다룬다.
- 절단은 특정 범위 밖의 데이터가 아예 누락된 것이고, 검열은 값이 불완전하게 알려진 것이다.
- 절단이 덜 정확하다.
- 완전 무작위 결측(MCAR)의 의미는? (하나 선택)
- 모델로 쉽게 예측 가능한 결측.
- 관찰되지 않은 변수와 연관된 결측.
- 관찰된 변수와 연관된 결측.
- 어떤 변수와도 상관없이 정말 우연히 발생한 결측.
- 인구 조사가 중요한 이유는 무엇입니까? (하나 선택)
- 드물게 수행되므로 희소성이 있다.
- 모집단 전체를 파악해 분석용 포괄 데이터를 제공하는 것이 목적이기 때문.
- 독점적인 정보를 담은 비공개 데이터이기 때문.
- 농업 데이터에만 집중하기 때문.
- Statistics Canada (2023) 에서 인구 조사 품질을 평가하는 이유는? (하나 선택)
- 비용 절감을 위해.
- 데이터 보급을 막으려고.
- 보안 강화를 위해.
- 데이터가 신뢰할 만하고 사용자 요구를 충족하는지 확인하기 위해.
- 표본 추출 오차의 주된 원인은? (하나 선택)
- 개인의 무응답.
- 모집단 대신 표본을 사용하기 때문.
- 데이터 입력 실수.
- 주거지 분류 오류.
- 사람이나 주택이 누락되거나 중복 집계되어 생기는 오류는? (하나 선택)
- 무응답 오류.
- 포괄 범위 오류.
- 표본 추출 오류.
- 처리 오류.
- 응답자나 조사원의 오해로 인해 생기는 오류는? (하나 선택)
- 표본 추출 오류.
- 응답 오류.
- 처리 오류.
- 포괄 범위 오류.
- Statistics Canada (2023) 에서 주거지 분류 조사(DCS)의 목적은? (하나 선택)
- 설문지 문항 개선.
- 신축 주택 분류.
- 가구 소득 조사.
- 주거지 분류 과정의 오류 연구.
- 과소 집계 연구(CUS)는 무엇을 추정합니까? (하나 선택)
- 조사에서 누락된 인구수.
- 표본 오차의 분산.
- 결측치 대체율.
- 무응답률.
- 과대 집계 연구(COS)는 무엇을 찾아냅니까? (하나 선택)
- 주거지 오분류.
- 중복 집계된 인구.
- 누락된 인구.
- 입력 오류.
- 총 무응답(TNR)률의 정의는? (하나 선택)
- 대체된 값의 수.
- 부정확한 응답의 비율.
- 부분 응답 비율.
- 설문지가 최소 요건을 충족하지 못한 가구의 비율.
- Chen et al. (2019) 및 Martı́nez (2022) 를 참고해 정부 통계를 어느 정도 신뢰할 수 있는지 두 국가 이상을 비교해 작성해 보세요.
- 2021년 캐나다 인구 조사의 성별 관련 질문 방식에 대해 Statistics Canada (2020) 을 참고해 토론해 보세요. 적절한 방식이라고 생각하시나요?
- IPUMS 2020 ACS 데이터를 활용해 캘리포니아주(STATEICP)에서 박사 학위(EDUC) 소지 응답자 수를 찾아보세요.
- IPUMS 1940 1% 표본에서 5년 이상 대학교육을 받은 캘리포니아 응답자 수는 몇 명입니까?
- Dean (2022) 를 참고해 확률 표집과 비확률 표집의 차이를 논의해 보세요.
- 목표 모집단의 정의는? (하나 선택)
- 우리가 결론을 내리려는 전체 그룹.
- 조사 가능한 모든 단위의 명부.
- 접근하기 쉬운 일부 하위 그룹.
- 참여 동의자 명단.
- 표집 틀(Sampling frame)이란? (하나 선택)
- 데이터 수집 방법.
- 표본을 뽑을 수 있는 전체 단위의 목록.
- 조사 기간.
- 연구자가 관심을 둔 그룹 전체.
- 확률 표집과 비확률 표집의 가장 큰 차이는? (하나 선택)
- 확률 표집은 명부가 필요 없다.
- 확률 표집이 무조건 저렴하다.
- 확률 표집은 추출 확률을 알 수 있지만, 비확률 표집은 그렇지 않다.
- 비확률 표집이 더 정확하다.
- Beaumont (2020) 를 참고해 확률 조사의 미래에 대해 어떻게 생각하는지 두 단락 내외로 쓰세요.
- 모든 관측치가 선택될 확률이 동일한 방식은? (하나 선택)
- 체계적 표집.
- 층화 표집.
- 단순 무작위 표집.
- 군집 표집.
- 첫 번째는 무작위로, 나머지는 일정한 간격으로 뽑는 방식은? (하나 선택)
- 체계적 표집.
- 편의 표집.
- 층화 표집.
- 군집 표집.
- 층화 표집의 특징은? (하나 선택)
- 하위 그룹으로 나눈 뒤 각 그룹에서 무작위 추출.
- 네트워크를 통한 모집.
- 무작위로 뽑힌 군집의 모든 단위 조사.
- 무작위로 뽑힌 군집의 일부 조사.
- 군집 표집에서 단위는 어떻게 선택됩니까? (하나 선택)
- 층별 무작위 추출.
- 군집을 무작위로 뽑은 뒤 그 안의 단위를 조사.
- n번째마다 추출.
- 할당량 기준 추출.
- 군집 표집을 사용하는 주된 이유는? (모두 선택)
- 응답의 균형 확보.
- 관리상 편의.
- 비용 효율성.
- 1~100 사이 숫자 중 단 10개로 중앙값을 추정하려 할 때 가장 적절한 방식은? (하나 선택)
- 단순 무작위 표집.
- 체계적 표집.
- 군집 표집.
- 층화 표집.
- 1~100 사이 숫자에서 20개 군집 표본으로 평균을 추정하는 R 코드를 작성하고 이를 100번 반복해 분포를 확인해 보세요. 어떤 사실을 알 수 있나요?
- 보울리의 1912년 리딩 조사는 어떤 표집 방식을 썼나요? (하나 선택)
- 군집 표집.
- 단순 무작위 표집.
- 층화 표집.
- 체계적 표집.
- 보울리가 전체 인구를 추정하기 위해 사용한 수치는? (하나 선택)
- 비례 데이터.
- 중간 소득.
- 승수(multiplier).
- 네이먼이 강조한 층화 표집의 주요 목표는? (하나 선택)
- 무작위성 축소.
- 모집단의 모든 층이 대표되도록 보장.
- 편향 증가.
- 편의 표집(Convenience sampling)을 가장 잘 설명한 것은? (하나 선택)
- 비례 대표 표집.
- 무작위 숫자 기반 표집.
- 가장 접근하기 쉬운 참가자 선택.
- 알고리즘 기반 표집.
- 눈덩이 표집은 언제 주로 쓰이나요? (하나 선택)
- 모집단 명부가 완벽할 때.
- 접근하기 어려운 숨겨진 집단을 연구할 때.
- 모든 그룹의 균등한 대표성을 위해.
- 개체 수 추정 시.
- “전체 모집단을 다 가지고 있으니 불확실성은 없다”는 주장에 대해 어떻게 생각하십니까?
- Meng (2018) 을 참고해 “응답자가 백만 명이면 무작위성은 중요하지 않다”는 주장을 비판해 보세요.
수업 활동
usethis::git_vaccinate()함수는 무슨 일을 하나요?- 지능 측정의 타당성과 신뢰성에 대해 토론해 보세요.
- 시뮬레이션에서
set.seed()설정이 왜 중요한지 설명해 보세요. - 수입과 수출 데이터가 일치하지 않는 ‘측정의 불일치’ 사례를 찾아 토론해 보세요.
- 확률 표집 방식을 활용해 우리 반 학생들의 평균 키를 추정해 보세요.
- “라보이스의 실수”: 전수 조사가 반드시 편향으로부터 자유롭지 못한 이유를 설명해 보세요. (병원 방문과 사망률의 관계 사례 등)
과제 I
IPUMS 2022 ACS 데이터를 활용해 보세요. 각 주(STATEICP)별로 박사 학위(EDUC) 소지 응답자 수를 구하고, 이를 이용해 라플라스의 비율 추정 방식으로 각 주의 전체 응답자 수를 추측해 보세요. 실제 수치와 비교해 보고 왜 차이가 나는지, 비율 추정 방식의 장단점은 무엇인지 논술해 보세요.
과제 II
UK 바이오뱅크 데이터를 시뮬레이션해 보세요. 단순 무작위 표집과 가족 기반의 군집 표집 방식을 비교 분석하는 논문을 작성해 보세요. 유전 질환과 특정 게놈 시퀀스의 연관성을 찾는 능력이 표집 방식에 따라 어떻게 달라지는지 토론해 보세요. 확률 표집과 비확률 표집의 경계에 대해서도 고민해 보시기 바랍니다.