library(haven)
# library(labelled)
library(tidyverse)
library(tinytable)8 실험 및 설문 조사
채프먼 앤 홀/CRC(Chapman and Hall/CRC)는 2023년 7월 이 책을 출간했습니다. 도서는 이곳에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 최신 내용이 일부 반영되어 있습니다.
권장 선행 학습
- Impact Evaluation in Practice (Gertler et al. 2016) 읽기.
- 인과 추론과 무작위 배정에 대해 폭넓게 다루는 3장과 4장을 중심으로 읽어보세요.
- The Psychology of Survey Response (Tourangeau, Rips, and Rasinski 2000) 읽기.
- 설문 문구 설계의 심리학적 원칙을 논의하는 2장 “참가자의 설문 질문 이해”에 집중해 보시기 바랍니다.
- “How to run a survey” (Stantcheva 2023) 읽기.
- 설문 조사 설계 및 실제 운영 시 고려해야 할 실무적 쟁점들을 체계적으로 정리한 논문입니다.
- “Q&A: How Pew Research Center surveyed nearly 30,000 people in India” (Letterman 2021) 읽기.
- 종교적 신념에 관한 대규모 설문 조사 과정에서 마주했던 생생한 현장의 목소리와 현실적인 문제들을 다룹니다.
- “Statistics and Causal Inference” (Holland 1986) 읽기.
- 루빈(Rubin) 모델 등 통계 모델을 이용해 인과 관계를 파악하는 방법을 설명하는 1~3부를 정독하세요.
- “Big Tech is Testing You” (Fry 2020) 읽기.
- 빅테크 기업들이 사용자 데이터를 바탕으로 A/B 테스트를 어떻게 활용하는지 흥미롭게 소개합니다.
- “Challenges of Causal Inference in Industry: Perspectives from Experiences at LinkedIn” (Xu 2020) 시청하기.
- A/B 테스트의 개요와 실무적 도전을 다루는 영상의 전반부를 시청해 보세요.
핵심 개념 및 기술
- 무작위 배정(Randomization): 처리군과 대조군을 설정하는 핵심 기술입니다. 처치(Treatment) 이외의 모든 조건이 동일한 집단을 구성함으로써, 처치가 가져온 평균적인 효과를 측정할 수 있게 합니다.
- 내적 타당성(Internal Validity) vs 외적 타당성(External Validity): 실험 결과가 실험 내에서 얼마나 정확한지(내적), 그리고 그 결과가 현실 세계로 얼마나 확장될 수 있는지(외적)를 구분하여 이해합니다.
- 윤리적 고려: 실험 전 ’정보에 입각한 동의(Informed Consent)’를 구하는 절차와 실험의 필요성을 도덕적으로 정당화하는 법을 배웁니다.
- A/B 테스트: 실무 환경에서 이루어지는 실험의 특징과 그 이면에 숨겨진 미묘한 차이들을 분석합니다.
- 설문 조사 설계: 설문 문항 구성부터 실제 구현까지의 전 과정을 익힙니다.
소프트웨어 및 패키지
- 기본 R (R Core Team 2024)
haven(Wickham, Miller, and Smith 2023)labelled(Larmarange 2023)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
8.1 서론
이번 장에서는 실험(Experiments)과 설문 조사(Surveys)를 통해 데이터를 ‘능동적으로’ 수집하는 방법을 다룹니다. 실험이란 우리가 관심을 두고 있는 요인을 직접 제어하고 변경할 수 있는 상황을 말합니다. 실험의 가장 큰 장점은 특정 요인의 효과를 식별하고 추정하는 과정이 매우 명확하다는 것입니다. 우리는 실험 대상이 되는 처리군(Treatment group)과 그렇지 않은 대조군(Control group)을 설정합니다. 이때 두 그룹을 무작위로 나누면, 실험이 끝난 후 나타나는 차이는 오직 ‘처리’ 때문에 발생한 것이라고 결론 내릴 수 있습니다. 물론 실제 세상에서 이 과정이 늘 순조로운 것만은 아닙니다. 처리군과 대조군이 정말로 비슷하게 구성되었는지에 대한 논쟁은 끊이지 않으며, 정작 우리가 측정하고 싶은 핵심 지표 자체가 측정하기 까다로운 경우도 많습니다.
실험의 원리를 이해하기 위해 흥미로운 사례를 하나 들어보겠습니다. 2014년 샌프란시스코로 이사한 어떤 사람이 있는데, 그가 이사하자마자 샌프란시스코 자이언츠가 월드 시리즈에서 우승했습니다. 그 후 그가 시카고로 옮겨가자 시카고 컵스가 100년 만에 월드 시리즈 정상에 올랐고, 다시 토론토로 이사가자마자 랩터스가 NBA 챔피언이 되었습니다. 이 정도면 도시들이 그에게 이사 비용을 대주면서라도 영입해야 할 ’우승 요정’이라고 불러야 할까요? 아니면 그저 우연의 일치일까요?
정답을 찾으려면 엄격한 실험이 필요합니다. 스포츠 팀이 있는 여러 도시를 목록으로 만들고 주사위를 굴려 그를 무작위로 특정 도시에 살게 한 뒤, 팀의 성적을 측정하는 것입니다. 하지만 현실적으로 한 사람이 동시에 여러 도시에 살 수도 없고, 인생은 유한하기에 이런 실험은 불가능합니다. 이것이 바로 인과 추론의 근본적인 문제(Fundamental problem of causal inference)입니다. 즉, 한 개인에 대해 처리가 가해진 상태와 가해지지 않은 상태를 동시에 관찰할 수 없다는 것이죠 . 그래서 우리는 무작위 대조 시험(Randomized Controlled Trial, RCT) 을 통해 처리를 무작위로 할당함으로써, ’다른 모든 조건이 동일하다’는 가정 아래 인과 효과를 추론하려 노력합니다. 이를 위해 우리는 네이만-루빈 잠재적 결과 프레임워크(Neyman-Rubin potential outcomes framework)라는 논리적 틀을 사용합니다 (Holland 1986).
여기서 처치(Treatment) \(t\)는 보통 0(대조군)과 1(처리군)의 값을 갖는 이진 변수입니다 . 우리는 각 개인 \(i\)에 대해 측정하고자 하는 결과(Outcome) \(Y_i\)를 가집니다.
처리의 진정한 효과는 \((Y_i|t=0) \neq (Y_i|t=1)\)인 경우, 즉 처리를 받았을 때와 받지 않았을 때 한 사람의 결과가 다르게 나타날 때 존재합니다 . 하지만 앞서 언급했듯 우리는 한 사람에게서 두 결과(잠재적 결과)를 모두 볼 수 없습니다. 따라서 우리는 반사실(Counterfactual), 즉 “만약 이 사람이 처리를 받지 않았다면 어땠을까?”라는 가상 상황을 추론해야 합니다 . 인과 추론은 본질적으로 이 반사실 데이터가 빠져 있는 결측 데이터 문제(Missing data problem)라고 볼 수 있습니다.
개인 수준에서 처치와 대조를 비교할 수 없으므로, 우리는 대신 집단(Group)의 평균을 비교합니다. 우리에게 불가능한 개인 단위의 반사실을 집단 단위의 평균으로 대신 추정하려는 것입니다. 이 과정에서 우리는 완벽한 확실성을 포기하는 대신 무작위 배정(Randomization) 과 확률적 기댓값이라는 도구에 의존하게 됩니다.
우리는 일반적으로 효과가 없다는 기본 가정을 고려하고, 우리의 생각을 바꾸게 할 증거를 찾습니다. 우리는 그룹에서 일어나는 일에 관심이 있으므로, 우리 자신을 표현하기 위해 기대와 확률 개념으로 전환합니다. 따라서 우리는 평균적으로 적용되는 주장을 할 것입니다. 재미있는 양말을 신는 것이 정말로 행운의 날을 만들 수도 있지만, 그룹 전체의 평균으로는 그렇지 않을 것입니다. 평균 효과에만 관심이 있을 필요는 없다는 점을 지적할 가치가 있습니다. 중앙값, 분산 또는 무엇이든 고려할 수 있습니다. 그럼에도 불구하고, 평균 효과에 관심이 있다면 진행하는 한 가지 방법은 다음과 같습니다.
- 데이터셋을 두 개로 나눕니다. 즉, 처리된 것과 처리되지 않은 것, 그리고 이진 효과 변수(행운의 날 또는 아님)를 가집니다.
- 변수를 합산한 다음 변수의 길이로 나눕니다.
- 두 그룹 간의 이 값을 비교합니다.
이것은 Chapter 4 에서 소개된 추정량으로, 관심 있는 것을 추측하는 방법입니다. 추정 대상은 관심 있는 것이며, 이 경우 평균 효과이고, 추정치는 우리의 추측이 무엇이든 간에 나타나는 것입니다. 상황을 설명하기 위해 데이터를 시뮬레이션할 수 있습니다.
set.seed(853)
treat_control <-
tibble(
group = sample(x = c("Treatment", "Control"), size = 100, replace = TRUE),
binary_effect = sample(x = c(0, 1), size = 100, replace = TRUE)
)
treat_control# A tibble: 100 × 2
group binary_effect
<chr> <dbl>
1 Treatment 0
2 Control 1
3 Control 1
4 Treatment 1
5 Treatment 1
6 Treatment 0
7 Treatment 1
8 Treatment 1
9 Control 0
10 Control 0
# ℹ 90 more rowstreat_control |>
summarise(
treat_result = sum(binary_effect) / length(binary_effect),
.by = group
)# A tibble: 2 × 2
group treat_result
<chr> <dbl>
1 Treatment 0.552
2 Control 0.333이 경우, 우리는 처리군과 대조군 각각에 대해 0 또는 1을 100번 추출하며, 처리된 것의 평균 효과 추정치는 0.22입니다.
더 넓게 보면, 인과적 이야기를 하기 위해서는 이론과 우리가 관심 있는 것에 대한 상세한 지식을 결합해야 합니다 (Cunningham 2021, 4). Chapter 7 우리가 세상에 대해 관찰한 데이터를 수집하는 것에 대해 논의했습니다. 이 장에서는 세상을 우리가 필요한 데이터로 바꾸는 것에 대해 더 적극적으로 다룰 것입니다. 연구자로서 우리는 무엇을 측정하고 어떻게 측정할지 결정해야 하며, 우리가 관심 있는 것이 무엇인지 정의해야 합니다. 우리는 데이터 생성 과정에 적극적으로 참여할 것입니다. 즉, 이 데이터를 사용하고 싶다면 연구자로서 직접 그것을 찾아 나서야 합니다.
이 밖에도 본 장에서는 오리건주 건강 보험 실험(Oregon Health Insurance Experiment), 지갑 정직성 실험(Civic Honesty) 등 다양한 사례를 통해 실험의 설계와 분석법을 살펴봅니다. 또한 현대 마케팅과 서비스 개선에 필수적인 A/B 테스트와 그 이면의 윤리적 문제를 심도 있게 다룹니다.
본격적인 논의에 앞서 한 가지 짚고 넘어갈 점이 있습니다. 통계학의 거장인 로널드 피셔(Ronald Fisher) 나 프랜시스 골턴(Francis Galton) 은 이 장에서 다루는 많은 이론적 토대를 닦은 인물들입니다. 하지만 동시에 그들은 우생학을 지지하는 등 오늘날의 관점에서 보면 매우 부적절한 학문적·윤리적 태도를 보이기도 했습니다. 마치 위대한 예술가의 범죄 사실을 인정하면서도 그의 작품 세계가 미친 영향을 분석하듯, 우리도 통계학의 어두운 과거를 인지하면서도 그들이 남긴 유산을 선별적으로 수용하여 더 나은 미래를 설계하는 데 활용해야 합니다.
8.2 현장 실험 및 무작위 대조 시험
8.2.1 무작위 배정의 힘
어떤 상황에서는 변수 사이의 상관관계를 파악하는 것만으로도 충분할 수 있습니다 (Hill 1965). 하지만 환경이 변할 때 어떤 결과가 나타날지 정확히 예측하려면, 무엇이 원인이고 결과인지 즉, ’인과 관계’를 반드시 이해해야 합니다 . 경제학에서는 2000년대에 소위 신뢰성 혁명(Credibility revolution)이 일어났습니다 (Angrist and Pischke 2010). 과거의 연구 방식이 충분히 신뢰할 만하지 않다는 반성 아래, 연구 설계와 실험을 통한 인과 관계 식별에 더 큰 공을 들이기 시작한 것입니다. 이러한 흐름은 정치학 등 다른 사회과학 분야로도 빠르게 퍼져나갔습니다 (Druckman and Green 2021).
핵심은 역시 반사실(Counterfactual)입니다 . 처리가 없었을 때 일어났을 일을 정확히 파악하는 것이 목표입니다. 이상적으로는 세상의 다른 모든 조건을 똑같이 유지한 채, 무작위로 두 그룹을 나누어 한쪽(처리군)에만 변화를 주고 다른 쪽(대조군)은 그대로 두는 것입니다. 두 그룹이 충분히 크다면, 무작위로 나누는 것만으로도 두 그룹의 특성은 모집단과 동일해집니다. 따라서 실험 후 나타나는 두 그룹의 차이는 오직 처리에 의한 것이라고 확신할 수 있습니다. 무작위 대조 시험(RCT) 이나 A/B 테스트 는 우리가 도달할 수 있는 가장 신뢰할 만한 ’표준(Gold standard)’에 가깝습니다.
그렇다고 RCT가 만능이라는 뜻은 아닙니다. 단지 다른 대안들에 비해 ‘상대적으로’ 낫다는 의미입니다. 앞으로 살펴볼 관찰 데이터(Observational data) 기반의 연구 방식들은 실험을 할 수 없는 상황에서 최선의 선택이지만, 본질적으로는 차선책일 수밖에 없습니다 (Gordon et al. 2019). RCT는 메커니즘을 규명하는 연구를 직접 설계할 수 있다는 강력한 이점이 있지만, 한편으로는 비용이 많이 들고 실제 세상에 적용하기에 한계가 있다는 비판도 존재합니다 (Deaton 2010).
실험 설계에서 중요한 원칙 중 하나는 맹검(Blinded) 입니다. 참가자가 자신이 어느 그룹에 속해 있는지 모르게 하는 것입니다. 특히 주관적인 만족도를 조사할 때 맹검이 깨지면 실험 결과의 신뢰도가 크게 떨어집니다. 가장 이상적인 것은 연구자조차 누가 어느 그룹인지 모르는 이중 맹검(Double-blinded) 방식입니다. 1835년 동종 요법 연구에서 이미 이 방식이 사용된 사례가 있습니다 (Stolberg 2006). 물론 손 씻기의 중요성을 발견한 젬멜바이스(Semmelweis)의 사례처럼 맹검 없이도 위대한 발견이 일어날 수 있지만, 현대적 실험에서 맹검은 매우 중요한 요소입니다. 또한 실험 결과가 실험실 밖의 실제 세상에서도 성립하는지(일반화 가능성)도 늘 고민해야 할 숙제입니다.
8.2.2 시뮬레이션 사례: 고양이와 개
우리가 바라는 이상적인 상황은 처리(Treatment) 외에는 모든 면에서 동일한 처리군과 대조군 을 구성하는 것입니다. 대조군은 우리가 실제로 보지 못한 ’반사실’을 가늠하게 해주는 기준점이 됩니다. 만약 무작위로 집단을 나누지 않는다면, 참가자가 스스로 특정 그룹을 선택함으로써 발생하는 선택 편향(Selection bias) 이나 외부 환경의 변화가 결과에 섞여 들어갈 수 있습니다. 무작위 배정은 이러한 편향된 추정치 문제를 해결하는 가장 강력한 무기입니다.
먼저 가상의 모집단을 시뮬레이션해 봅시다 . 인구의 절반은 파란색을 좋아하고 나머지 절반은 흰색을 좋아한다고 가정하겠습니다. 한 걸음 더 나아가, 파란색을 좋아하는 사람은 대부분 개를 선호하고, 흰색을 좋아하는 사람은 대부분 고양이를 선호한다고 설정해 보겠습니다. 시뮬레이션은 데이터 분석 워크플로에서 매우 중요한 단계입니다. 정답을 미리 알고 있는 상태에서 분석 코드를 짜기 때문에, 예상치 못한 결과가 나왔을 때 이것이 분석 과정의 오류인지 아니면 데이터의 특성인지 명확히 알 수 있기 때문입니다. 또한 데이터 수집이 끝나기 전에도 분석 작업을 시작할 수 있게 해준다는 실무적인 장점도 있습니다.
set.seed(853)
num_people <- 5000
population <- tibble(
person = 1:num_people,
favorite_color = sample(c("Blue", "White"), size = num_people, replace = TRUE),
prefers_dogs = if_else(favorite_color == "Blue",
rbinom(num_people, 1, 0.9),
rbinom(num_people, 1, 0.1))
)
population |>
count(favorite_color, prefers_dogs)# A tibble: 4 × 3
favorite_color prefers_dogs n
<chr> <int> <int>
1 Blue 0 256
2 Blue 1 2291
3 White 0 2239
4 White 1 214Chapter 6 소개된 용어와 개념을 바탕으로, 이제 목표 모집단의 약 80%를 포함하는 표집 틀을 구성합니다.
set.seed(853)
frame <-
population |>
mutate(in_frame = rbinom(n = num_people, 1, prob = 0.8)) |>
filter(in_frame == 1)
frame |>
count(favorite_color, prefers_dogs)# A tibble: 4 × 3
favorite_color prefers_dogs n
<chr> <int> <int>
1 Blue 0 201
2 Blue 1 1822
3 White 0 1803
4 White 1 177지금은 개 또는 고양이 선호도를 제쳐두고, 좋아하는 색상만으로 처리군과 대조군을 만드는 데 집중하겠습니다.
set.seed(853)
sample <-
frame |>
select(-prefers_dogs) |>
mutate(
group =
sample(x = c("Treatment", "Control"), size = nrow(frame), replace = TRUE
))두 그룹의 평균을 보면, 파란색 또는 흰색을 선호하는 비율이 우리가 지정한 것과 매우 유사함을 알 수 있습니다(Table 8.1).
sample |>
count(group, favorite_color) |>
mutate(prop = n / sum(n),
.by = group) |>
tt() |>
style_tt(j = 1:4, align = "llrr") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("그룹", "선호", "수", "비율"))| 그룹 | 선호 | 수 | 비율 |
|---|---|---|---|
| Control | Blue | 987 | 0.5 |
| Control | White | 997 | 0.5 |
| Treatment | Blue | 1,036 | 0.51 |
| Treatment | White | 983 | 0.49 |
우리는 좋아하는 색상만으로 무작위화했습니다. 그러나 동시에 개 또는 고양이 선호도라는 특성 또한 자연스럽게 가져왔으며, 이를 통해 개를 고양이보다 선호하는 사람들의 ‘대표적인’ 비율을 확보하게 됩니다. 데이터셋을 통해 이를 확인할 수 있습니다(Table 8.2).
sample |>
left_join(
frame |> select(person, prefers_dogs),
by = "person"
) |>
count(group, prefers_dogs) |>
mutate(prop = n / sum(n),
.by = group) |>
tt() |>
style_tt(j = 1:4, align = "llrr") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c(
"그룹",
"개를 고양이보다 선호",
"수",
"비율"
))| 그룹 | 개를 고양이보다 선호 | 수 | 비율 |
|---|---|---|---|
| Control | 0 | 1,002 | 0.51 |
| Control | 1 | 982 | 0.49 |
| Treatment | 0 | 1,002 | 0.5 |
| Treatment | 1 | 1,017 | 0.5 |
‘관찰 불가능한’ 것에 대한 대표적인 비율을 얻는다는 것은 매우 흥미로운 일입니다. (이 사례에서는 편의상 ‘관찰’ 가능한 변수로 설정했지만, 실제로는 우리가 명시적으로 선택하지 않은 변수들까지 무작위화를 통해 균형이 맞춰진다는 점이 핵심입니다.) 이는 변수들 간의 상관관계 덕분이죠. 물론 이 원리는 실험 규모가 작거나 특정 변수(예: 개 품종)가 극단적으로 편중된 상황에서는 무너질 수 있습니다. 두 그룹이 통계적으로 동일한지 확인하려면 이론, 경험, 전문가의 의견을 바탕으로 평균 외의 다른 지표들도 꼼꼼히 살펴야 합니다.
이것은 통계학에서 전통적인 분산 분석(ANOVA)으로 이어집니다. ANOVA 는 약 100년 전 로널드 피셔 가 농업 연구 도중 고안한 방식입니다 . 역사적으로 통계학의 많은 혁신은 “어떤 비료가 더 효과적인가?”와 같은 농업 현장의 질문에서 시작되었습니다 (Yoshioka 1998). 논밭을 구획지어 처리군과 대조군으로 나누는 것은 비교적 명확했기 때문입니다. 하지만 100년 전의 도구가 현대의 복잡한 데이터 분석에도 늘 최선의 선택인 것은 아닙니다. ANOVA를 기계적으로 적용하기보다는, 분석의 목적에 맞게 직접 회귀 모델을 구축하는 것이 더 나은 경우가 많으며 이에 대해서는 Chapter 12 에서 자세히 다루겠습니다.
8.2.3 처리군과 대조군
처리군과 대조군 이 처치 여부를 제외한 모든 면에서 동일하고, 실험 과정에서도 그 상태가 유지된다면 우리는 내적 타당성(Internal validity)을 확보했다고 말합니다. 이는 우리의 대조군이 완벽한 반사실 역할을 수행하며, 실험 결과로 나타난 두 그룹 간의 차이가 온전히 처치 때문임을 보증한다는 뜻입니다. 즉, 내적 타당성 은 실험 내에서 인과 관계를 정확히 추론할 수 있는 능력을 의미합니다.
만약 실험에 참여한 집단이 더 넓은 모집단을 잘 대표하고, 실험 환경이 실제 현실과 유사하다면 우리는 추가로 외적 타당성(External validity)을 가질 수 있습니다 . 이는 실험에서 발견한 사실이 실험실 밖의 실제 세상에도 적용될 수 있음을 의미합니다. 내적 타당성이 ’실험 자체의 정확성’이라면, 외적 타당성은 ’결과의 일반화 가능성’인 셈입니다. 이러한 일반화를 가능하게 하는 핵심 도구 또한 무작위 배정 입니다. 현대의 연구자들은 단 하나의 실험으로 모든 결론을 내리기보다는, 수많은 실험 결과를 쌓아 올리며 증거의 토대를 마련해 나갑니다 (Duflo 2020).
거인의 어깨 위에서: 에스더 뒤플로
에스더 뒤플로(Esther Duflo) 박사는 MIT의 빈곤 퇴치 및 개발 경제학 교수입니다. 2003년 29세의 나이로 MIT 정교수가 되었으며, 무작위 대조 시험(RCT)을 경제학 연구, 특히 빈곤 문제 해결에 본격적으로 도입한 선구자입니다 . 저서 가난한 사람이 더 합리적이다(Poor Economics) (Banerjee and Duflo 2011) 로 잘 알려져 있으며, 2019년에는 빈곤 퇴치를 위한 실험적 접근법의 공로를 인정받아 최연소로 노벨 경제학상을 수상했습니다.
하지만 이는 우리가 무작위화를 두 번 수행해야 함을 의미합니다. 첫째는 실험 대상을 선정할 때이고, 둘째는 그들을 처리군과 대조군으로 나눌 때입니다. 이 무작위화 과정이 얼마나 정교하냐에 따라 연구의 신뢰도가 결정됩니다.
우리는 처리가 가져오는 효과에 집중합니다. 처리는 가격 설정처럼 연속형일 수도 있고, 웹사이트 버튼 색상처럼 이산형일 수도 있습니다. 어떤 경우든 두 그룹이 처리 외에는 동일하다는 확신이 필요하죠. 이를 검증하는 한 가지 방법은 처리 변수를 잠시 무시하고, 다른 변수들(Microsoft vs Apple 사용자, 브라우저 종류, 접속 기기, 위치 등)을 기준으로 그룹 간에 유의미한 차이가 있는지 살펴보는 것입니다. 예를 들어 뒷부분에서 살펴볼 Nationscape 설문 조사는 Firefox 사용자의 응답 품질을 우려하여 해당 데이터를 분석에서 제외하기도 했습니다 (Vavreck and Tausanovitch 2021, 5).
처리가 모집단과 독립적으로 적절히 이루어졌다면, 우리는 평균 처리 효과(Average Treatment Effect, ATE)를 추정할 수 있습니다. 이진 처리 상황에서 ATE는 다음과 같이 정의됩니다.
\[\mbox{ATE} = \mathbb{E}[Y|t=1] - \mathbb{E}[Y|t=0].\]
8.2.4 오리건 건강 보험 실험
현실에서 인과 효과를 측정하는 것이 얼마나 중요한지 보여주는 대표적인 사례가 오리건 건강 보험 실험(Oregon Health Insurance Experiment)입니다. 당시 오리건주는 저소득층을 위한 건강 보험인 메디케이드(Medicaid)의 가입 대상을 확대하고 싶었지만 예산이 부족했습니다. 이에 공평하게 추첨(Lottery)을 통해 가입 대상자를 선정했습니다. 연구자들에게는 완벽한 자연 실험(Natural experiment) 환경이 조성된 셈입니다.
연구팀은 추첨에 당첨된 처리군이 그렇지 않은 대조군에 비해 의료 서비스를 더 많이 이용하고, 본인 부담 의료비 지출은 줄었으며, 전반적인 신체적·정신적 건강 상태가 개선되었음을 발견했습니다 (Finkelstein et al. 2012). 이 실험은 건강 보험의 혜택이라는 복잡한 주제에 대해 RCT를 통해 매우 신뢰도 높은 인과적 결론을 내놓으며 큰 주목을 받았습니다.
8.2.5 전 세계 시민 정직성 실험
타인에 대한 ’신뢰’는 눈에 보이지 않지만, 우리 사회와 경제를 지탱하는 가장 근본적인 토대입니다 . 예를 들어, 우리는 한 달 동안 열심히 일한 뒤 월급을 받을 것이라고 고용주를 믿습니다. 만약 서로를 믿지 못해 모든 거래마다 엄청난 확인 절차가 필요하다면 사회적 비용은 상상할 수 없을 만큼 커질 것입니다.
하지만 국가마다, 사회마다 이 ’정직성’의 정도가 얼마나 다른지 측정하는 것은 매우 어렵습니다. 사람들에게 대뜸 “당신은 얼마나 정직합니까?”라고 물어본들, 정직하지 않은 사람이 진실을 말할 리 없기 때문입니다. 이러한 역선택(Adverse selection) 문제를 해결하기 위해, 연구자들은 실제 현장에서 실험을 진행했습니다 (Akerlof 1970).
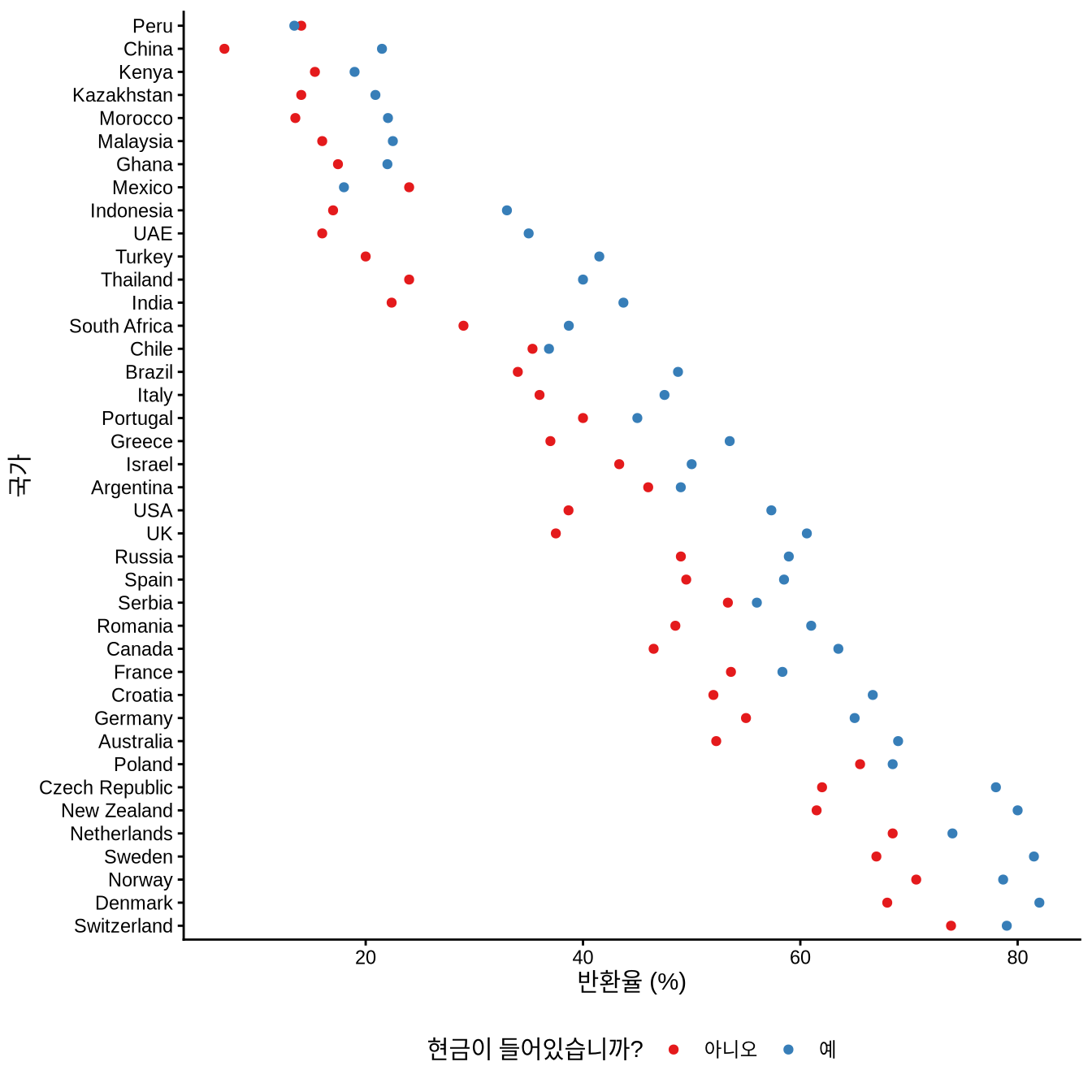
Cohn et al. (2019a) 은 전 세계 40개국 355개 도시에서 ’지갑 분실 실험’을 수행했습니다. 이들은 빈 지갑, 혹은 소액의 현금이 들어있는 지갑을 박물관, 호텔, 은행, 경찰서 등 공공기관의 안내 데스크에 “길에서 주웠다”며 맡겼습니다 . 그리고 지갑 안에 남겨진 주인 연락처(이메일)로 지갑을 돌려주겠다는 연락이 오는지 관찰했습니다.
실험 설계에서 가장 흥미로운 점은 지갑 안에 든 ’현금’이었습니다. 상식적으로는 돈이 많이 들었을수록 지갑을 가로챌 유인이 커질 것 같지만, 실험 결과는 정반대였습니다. 거의 모든 국가에서 현금이 든 지갑이 빈 지갑보다 반환율이 더 높게 나타났습니다 (Cohn et al. 2019a, 1). 지갑에는 현금 외에도 열쇠, 식료품 목록, 명함 등이 들어있었습니다. 열쇠는 오직 주인에게만 가치가 있으므로, 지갑을 돌려주는 행위가 순수한 이타주의에서 비롯된 것인지 아니면 다른 득실을 따진 것인지 확인하기 위한 장치였습니다.
실험의 핵심 처리는 지갑 속 현금의 유무였고, 결과 지표는 지갑 반환 시도 여부였습니다. 연락이 오는 데 걸린 시간은 중앙값 기준 26분이었으며, 대부분 이메일 전송 후 하루 이내에 연락이 왔습니다 (Cohn et al. 2019b, 10).
Figure 8.1 를 보면 국가별로 반환율에 큰 차이가 있음을 알 수 있습니다. 그럼에도 공통적인 사실은 ’돈이 든 지갑’을 더 많이 돌려주었다는 점입니다. 연구팀은 왜 이런 현상이 발생하는지 이해하기 위해 추가 설문 조사를 진행했습니다. 그 결과, 지갑에 돈이 많이 들었을수록 이를 돌려주지 않았을 때 스스로를 ’도둑’이라고 느끼는 심리적 가책(Psychological cost)이 커지기 때문이라는 점을 확인했습니다. 즉, 사람들은 단순히 이기적인 이득을 취하기보다 스스로를 정직한 사람으로 인식하려는 자아상을 지키는 것을 더 중요하게 여긴다는 것입니다.
8.3 A/B 테스트
지난 20년 동안 인류 역사상 가장 방대한 규모의 실험이 매일같이 수행되고 있습니다. 바로 구글, 아마존, 페이스북 같은 빅테크 기업들이 진행하는 A/B 테스트 덕분입니다 . 과거에는 웹사이트의 글꼴이나 버튼 색상 하나를 정할 때도 소위 ’HIPPO(Highest Paid Person’s Opinion, 가장 높은 연봉을 받는 사람의 의견)’에 의존하는 경우가 많았습니다 (Christian 2012). 하지만 오늘날에는 데이터에 기반한 실험이 그 자리를 대신하고 있습니다.
A/B 테스트란 간단히 말해 사용자 집단을 무작위로 두 개(A와 B)로 나누고, 서로 다른 버전의 서비스를 제공한 뒤 어떤 결과가 더 나은지 비교하는 실험 방식입니다 (Salganik 2018, 185). 실험군이 여러 개인 경우에는 ’멀티-암드 밴딧(Multi-armed bandit)’과 같은 더 복잡한 최적화 기법을 쓰기도 합니다.
빅테크 기업들의 실험이 활발해지면서 새로운 윤리적 문제도 대두되었습니다 . 대다수 기업에는 대학이나 연구소 같은 공식적인 ’윤리위원회(IRB)’가 없으며, 실험의 목적이 수익 극대화에 치우치는 경우가 많기 때문입니다. 예를 들어, 식료품 앱이 가독성을 높이는 실험을 하는 것은 문제가 없겠지만, 도박 사이트가 사용자가 돈을 더 따게끔(혹은 잃게끔) 유도하는 실험을 한다면 사회적인 비판을 피하기 어려울 것입니다.
본질적으로 A/B 테스트는 무작위 대조 시험(RCT)과 같지만, 온라인 환경 특유의 고려 사항들이 있습니다.
- 조직 내의 정치적 역학: 기업 내에 실험 문화를 도입하는 것은 통계적인 문제만큼이나 정치적인 과제입니다 . 관리자를 설득하고 조직 전체의 의사결정 방식을 바꾸는 과정이 필요하기 때문입니다. 때로는 ’데이터가 모든 것을 말해준다’는 믿음이 기존의 위계질서와 충돌하기도 합니다.
- 배포와 전달 메커니즘: 웹사이트는 수시로 업데이트가 가능해 실험이 쉽지만, 스마트폰 앱은 앱스토어 심사나 사용자의 업데이트 여부에 따라 실험 환경이 달라질 수 있습니다 .
- 계측(Instrumentation): 전통적 실험은 설문 조사로 데이터를 얻지만, A/B 테스트는 쿠키(Cookie)나 서버 로그 등의 센서를 활용해 사용자 행동을 자동으로 측정합니다 .
- 무작위 배정의 단위: 페이지 방문마다 무작위로 바꿀 것인지, 세션(접속) 단위로 바꿀 것인지, 아니면 사용자 ID 단위로 고정할 것인지를 결정해야 합니다 . 예를 들어 상품 가격을 실험한다면, 한 사용자가 접속할 때마다 가격이 바뀌어 당황하지 않도록 사용자 단위로 고정하는 것이 상식적일 것입니다.
- A/A 테스트: 실제 실험을 하기 전, 두 그룹에 똑같은 버전을 보여주어 무작위 배정 시스템 자체가 편향 없이 제대로 작동하는지 검증하는 절차입니다.
가장 경계해야 할 것은 단기적인 최적화의 함정입니다 . 예를 들어, 음식 배달 앱에서 ’배달 속도’만을 최적화하기 위해 실험한다면 운전자들은 보온 상자를 쓰지 않고 속도를 높일 수도 있습니다. 단기적으로는 배달이 빨라져 지표가 개선되겠지만, 결국 고객은 식은 음식을 받게 되어 앱을 떠나게 될 것입니다. 페이스북 또한 알림을 남발해 단기 클릭률을 높이는 것보다, 적절한 알림으로 장기적인 사용자 만족도를 유지하는 것이 더 중요하다는 사실을 발견하기도 했습니다 (Chen et al. 2022).
거인의 어깨 위에서: 수잔 애시
수잔 애시(Susan Athey) 박사는 스탠포드 대학교의 기술 경제학 교수입니다 . 그녀는 경제학 박사 학위를 받은 후 MIT와 스탠포드에서 가르치며 응용 경제학 분야의 권위자가 되었습니다. 특히 학술 연구뿐만 아니라 마이크로소프트와 같은 빅테크 기업의 자문역을 맡아 실무 현장에 실험 경제학을 도입하는 데 결정적인 역할을 했습니다. 2007년에는 ’경제학계의 노벨상’으로 불리는 존 베이츠 클라크 메달(John Bates Clark Medal)을 수상했습니다.
8.3.1 미디어 최적화 사례: Upworthy
A/B 테스트의 가장 큰 장벽 중 하나는 민간 기업의 데이터라 외부에서 접근하기 어렵다는 점입니다. 하지만 미디어 웹사이트인 Upworthy 는 자신들이 콘텐츠 최적화를 위해 수행했던 수만 건의 A/B 테스트 데이터셋을 연구용으로 공개했습니다.
Upworthy는 소위 ’낚시성 제목(Clickbait)’으로 유명해지기도 했지만, 그 이면에는 어떤 헤드라인과 이미지가 사용자의 클릭을 더 많이 유도하는지에 대한 철저한 실험이 있었습니다. 이제 이 데이터를 활용해 직접 분석해 보겠습니다.
upworthy <- read_csv("https://osf.io/vy8mj/download")upworthy |>
names() [1] "...1" "created_at" "updated_at"
[4] "clickability_test_id" "excerpt" "headline"
[7] "lede" "slug" "eyecatcher_id"
[10] "impressions" "clicks" "significance"
[13] "first_place" "winner" "share_text"
[16] "square" "test_week" upworthy |>
head()# A tibble: 6 × 17
...1 created_at updated_at clickability_test_id excerpt
<dbl> <dttm> <dttm> <chr> <chr>
1 11 2014-11-20 11:33:26 2016-04-02 16:25:54 546dd17e26714c82cc00001c Things…
2 12 2014-11-20 15:00:01 2016-04-02 16:25:54 546e01d626714c6c4400004e Things…
3 13 2014-11-20 11:33:51 2016-04-02 16:25:54 546dd17e26714c82cc00001c Things…
4 14 2014-11-20 11:34:12 2016-04-02 16:25:54 546dd17e26714c82cc00001c Things…
5 15 2014-11-20 11:34:33 2016-04-02 16:25:54 546dd17e26714c82cc00001c Things…
6 16 2014-11-20 11:34:48 2016-04-02 16:25:54 546dd17e26714c82cc00001c Things…
# ℹ 12 more variables: headline <chr>, lede <chr>, slug <chr>,
# eyecatcher_id <chr>, impressions <dbl>, clicks <dbl>, significance <dbl>,
# first_place <lgl>, winner <lgl>, share_text <chr>, square <chr>,
# test_week <dbl>데이터셋에서 각 행은 ’패키지(Package)’라고 불리는 헤드라인과 이미지의 조합입니다. 하나의 테스트 내에서 여러 패키지가 사용자들에게 무작위로 노출됩니다. 우리는 다음 변수들에 집중할 것입니다.
created_at: 테스트 생성 시각clickability_test_id: 각 테스트를 식별하는 고유 IDheadline: 뉴스 헤드라인 텍스트impressions: 해당 패키지가 노출된 횟수clicks: 실제 클릭이 발생한 횟수
우리의 가설은 다음과 같습니다: “물음표(?)가 포함된 질문형 헤드라인이 일반 평서문 헤드라인보다 더 많은 클릭을 유도할까?”
upworthy_restricted <-
upworthy |>
select(
created_at, clickability_test_id, headline, impressions, clicks
)head(upworthy_restricted)# A tibble: 6 × 5
created_at clickability_test_id headline impressions clicks
<dttm> <chr> <chr> <dbl> <dbl>
1 2014-11-20 11:33:26 546dd17e26714c82cc00001c Let’s See … H… 3118 8
2 2014-11-20 15:00:01 546e01d626714c6c4400004e People Sent T… 4587 130
3 2014-11-20 11:33:51 546dd17e26714c82cc00001c $3 Million Is… 3017 19
4 2014-11-20 11:34:12 546dd17e26714c82cc00001c The Fact That… 2974 26
5 2014-11-20 11:34:33 546dd17e26714c82cc00001c Reason #351 T… 3050 10
6 2014-11-20 11:34:48 546dd17e26714c82cc00001c I Was Already… 3061 20먼저 헤드라인에 물음표가 포함되어 있는지 여부를 나타내는 이진 변수(asks_question)를 만듭니다. 그 후, 동일한 테스트 ID 내에서 질문형 헤드라인과 평서문 헤드라인의 평균 클릭 수를 비교해 보겠습니다.
upworthy_restricted <-
upworthy_restricted |>
mutate(
asks_question =
str_detect(string = headline, pattern = "\\?")
)
upworthy_restricted |>
count(asks_question)# A tibble: 2 × 2
asks_question n
<lgl> <int>
1 FALSE 89559
2 TRUE 15992모든 테스트와 이미지 조합에 대해, 질문 형식이 클릭 수에 미친 영향력을 파악해 보겠습니다.
question_or_not <-
upworthy_restricted |>
summarise(
ave_clicks = mean(clicks),
.by = c(clickability_test_id, asks_question)
)
question_or_not |>
pivot_wider(names_from = asks_question,
values_from = ave_clicks,
names_prefix = "ave_clicks_") |>
drop_na(ave_clicks_FALSE, ave_clicks_TRUE) |>
mutate(difference_in_clicks = ave_clicks_TRUE - ave_clicks_FALSE) |>
summarise(average_differce = mean(difference_in_clicks))# A tibble: 1 × 1
average_differce
<dbl>
1 -4.16간단한 요약표를 통해 결과를 확인해 보죠(Table 8.3).
question_or_not |>
summarise(mean = mean(ave_clicks),
.by = asks_question) |>
tt() |>
style_tt(j = 1:2, align = "lr") |>
format_tt(digits = 0, num_mark_big = ",", num_fmt = "decimal") |>
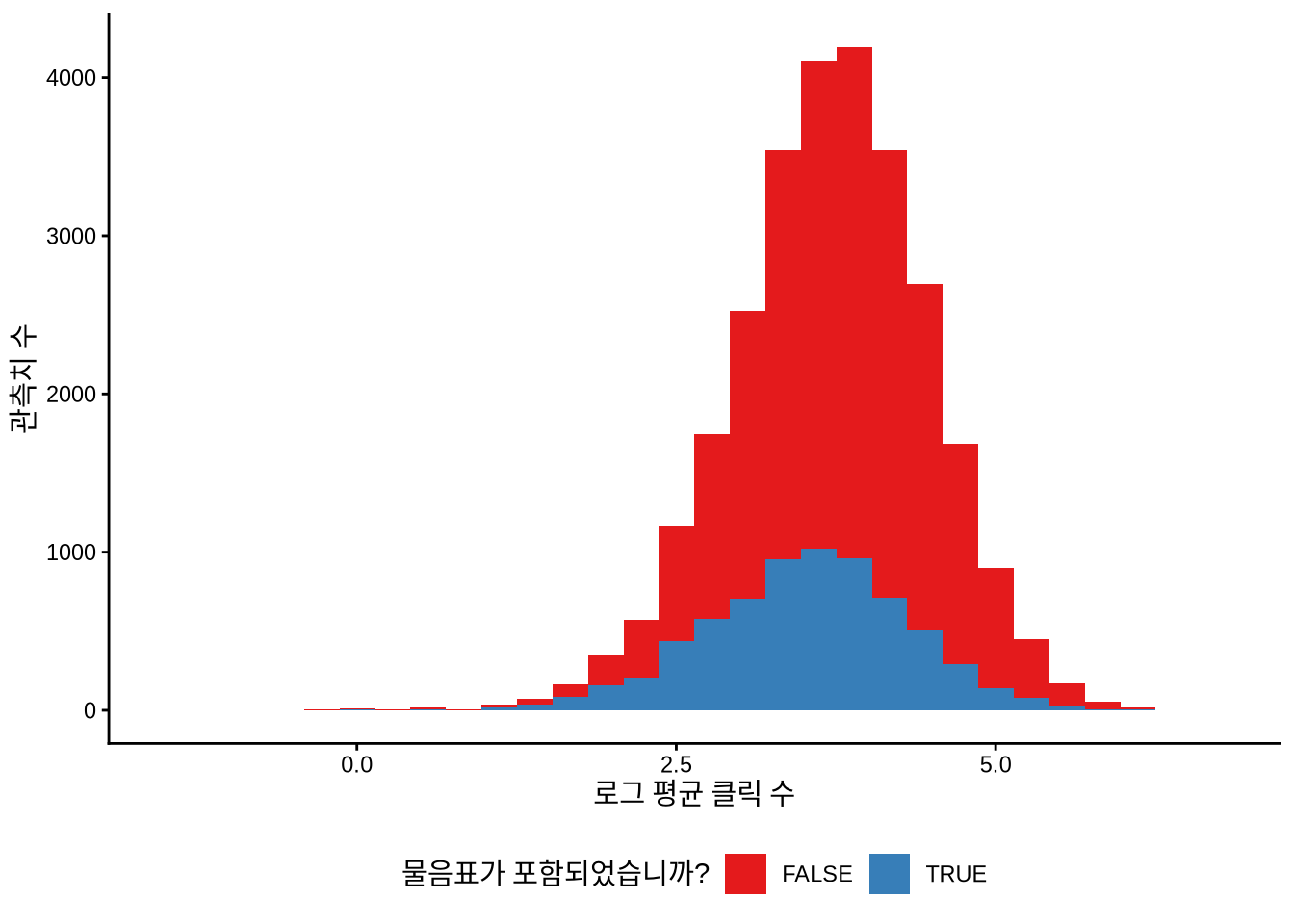
setNames(c("질문형입니까?", "평균 클릭 수"))| 질문형입니까? | 평균 클릭 수 |
|---|---|
| TRUE | 45 |
| FALSE | 57 |
분석 결과, 놀랍게도 Upworthy 데이터에서는 질문형 헤드라인이 평서문보다 클릭 수가 약간 더 적게 나타나는 경향이 있었습니다 (Figure 8.2). 물론 이 차이가 통계적으로 항상 유의미하거나 모든 맥락에 적용되는 것은 아니지만, 우리의 직관(질문이 더 호기심을 자극할 것이다)이 실제 데이터와는 다를 수 있음을 보여주는 흥미로운 사례입니다.
8.4 윤리적 고려 사항
실험은 인간을 대상으로 직접적인 변화를 가하는 행위이기에, 언제나 엄격한 윤리적 기준이 뒤따라야 합니다 . 사실 통계학의 초기 역사에는 현재의 관점으로 도저히 용납할 수 없는 비윤리적인 실험들이 존재했습니다 .
가장 악평이 높은 사례 중 하나는 터스키기 매독 연구(Tuskegee Syphilis Study)입니다 . 1930년대부터 40년 동안 수행된 이 연구에서, 미국 보건 당국은 흑인 남성들에게 매독의 진행 과정을 관찰한다는 명목으로 치료제인 페니실린이 개발된 후에도 이를 처방하지 않았습니다. 이는 인종차별과 의학적 방임이 결합된 인류 역사상 가장 수치스러운 실험 중 하나로 기록되어 있습니다 (Brandt 1978).
이러한 비극적 사례들을 거치며 현대의 연구 윤리는 다음 세 가지 핵심 원칙을 확립했습니다 .
- 인간 존중(Respect for persons): 모든 참가자는 실험의 내용과 위험성을 충분히 인지한 상태에서 자발적으로 참여해야 합니다. 이를 정보에 입각한 동의(Informed consent)라고 합니다 .
- 선의(Beneficence): 실험의 잠재적 이득이 위험보다 커야 하며, 참가자에게 해를 끼치지 않아야 합니다.
- 정의(Justice): 실험의 혜택과 부담이 특정 집단에 치우치지 않고 공평하게 분배되어야 합니다.
최근에는 대학이나 공공기관뿐만 아니라 빅테크 기업들도 자체적인 윤리 가이드라인을 수립하고 있습니다. 실험의 범위가 전 세계로 확장된 만큼, 연구 설계 단계부터 발생할 수 있는 부작용을 면밀히 검토하는 것이 데이터 과학자의 필수 덕목이 되었습니다.
8.5 연습 문제
실습
- (계획) 다음 시나리오를 구상해 봅시다. “한 정치 후보가 선거 운동 기간 동안 두 가지 여론 조사 지표(지지율과 당선 기대감)의 변화를 추적하고 싶어 합니다. 두 지표는 백분율로 측정되며 밀접한 상관관계를 보입니다. 특히 후보자 간 토론회가 열릴 때마다 수치가 크게 출렁이는 경향이 있습니다.” 이 데이터셋의 구조를 상상해 보고, 전체 흐름을 한눈에 보여줄 수 있는 그래프를 스케치해 보세요.
- (시뮬레이션) 위 시나리오를 바탕으로 데이터를 시뮬레이션해 보세요. 그리고 생성된 데이터가 논리적으로 타당한지 확인할 수 있는 검증 테스트 코드를 작성해 보세요.
- (수집) 실제 선거 여론 조사와 유사한 공개 데이터를 찾아 수집하고, 앞서 만든 테스트 코드를 적용해 보세요.
- (탐색) 수집한 데이터를 활용해 R로 의미 있는 그래프와 표를 만들어 보세요.
- (소통) Quarto를 사용하여 분석 결과에 대한 짧은 보고서를 작성하고, GitHub 리포지토리 링크를 제출하세요.
퀴즈
- 다음 중 ’인과 추론의 근본적인 문제’를 가장 잘 설명한 것은 무엇입니까?
- 무작위 배정만으로는 실험의 모든 편향을 완벽히 제거할 수 없다.
- 설문 조사는 개인의 내밀한 선호도를 정확히 측정하기 어렵다.
- 한 개인에 대해 처리가 가해진 상태와 가해지지 않은 상태를 동시에 관찰할 수 없다.
- 어떤 실험 결과도 실험실 밖의 현실 세계로 확장하는 것은 불가능하다.
- 네이만-루빈 잠재적 결과 프레임워크를 활용한 실험의 주된 목적은 무엇입니까?
- 처리군과 대조군의 결과를 비교하여 처치의 인과적 효과를 추정하는 것.
- 내부 타당성보다 외부 타당성을 확보하는 데 모든 역량을 집중하는 것.
- 통계적 검정력을 높이기 위해 표본의 크기를 무조건 최대로 늘리는 것.
- 모든 참가자가 실험 기간 중 한 번씩은 반드시 처리를 경험하게 하는 것.
- Gertler et al. (2016) 에 따르면, 영향 평가의 기본 공식인 \(\Delta = (Y_i|t=1) - (Y_i|t=0)\)은 무엇을 뜻합니까?
- 처치를 받은 경우와 받지 않았을 경우의 결과값 차이.
- 참가자들의 평균 소득 수준 변화량.
- 외부 환경 요인이 결과에 미친 영향의 총합.
- 프로그램 운영에 투입된 전체 예산 규모.
- 실험 설계에서 ’무작위 배정’이 핵심적인 이유는 무엇입니까?
- 추출된 표본이 모집단을 완벽히 대표하도록 보장하기 때문.
- 실험에서 대조군을 따로 두어야 하는 번거로움을 덜어주기 때문.
- 실험 결과의 외적 타당성을 무조건적으로 담보하기 때문.
- 처치 여부를 제외하고 두 집단의 특성을 통계적으로 유사하게 만들어주기 때문.
- Gertler et al. (2016) 에 따르면, ’반사실’을 측정할 때 마주하는 현실적인 난관은 무엇입니까?
- 오직 무작위 대조 시험(RCT)을 통해서만 반사실을 얻을 수 있다는 믿음.
- 대조군에 대해 수집된 데이터는 언제나 실제보다 부정확하다는 점.
- 동일한 대상에게서 처리가 있는 결과와 없는 결과를 동시에 관찰하는 것이 불가능하다는 점.
- 대부분의 정책 프로그램에는 실험에 참여할 충분한 인원이 없다는 점.
- Gertler et al. (2016) 에 따르면, ’선택 편향’은 어떤 상황에서 발생합니까?
- 연구를 진행할 충분한 예산이 확보되지 않았을 때.
- 정책 프로그램이 특정 지역이 아닌 전국 단위로 시행될 때.
- 실험 참가자들이 무작위가 아닌 자의적인 기준에 의해 할당되었을 때.
- 데이터 수집 과정에서 일부 응답이 누락되었을 때.
- ’외부 타당성’이란 무엇을 의미합니까?
- 여러 번의 반복 실험을 통해 일관된 결과를 얻어낸 상태.
- 실험 환경 내에서 도출된 결과가 통계적으로 유효한 상태.
- 분석에 쓰인 모든 코드와 데이터가 외부에 투명하게 공개된 상태.
- 실험에서 발견된 사실이 다른 대상이나 환경 등 실험 밖에서도 유효한 상태.
- ’내적 타당성’이란 무엇을 의미합니까?
- 외부 연구자가 실험 데이터를 활용해 동일한 결론에 도달할 수 있는 상태.
- 실험 결과가 수년이 지난 후에도 변함없이 유지되는 상태.
- 실험 설계와 수행 과정이 엄격하여 실험 내에서 인과 관계를 정확히 추론한 상태.
- 실험 결과가 현실의 정책 결정에 즉각 반영될 수 있는 상태.
- Gertler et al. (2016) 에 따르면, 영향 평가에서 ’내적 타당성’의 핵심은 무엇입니까?
- 프로그램이 가져온 인과적 효과를 얼마나 정확하게 측정했는가.
- 해당 결과를 다른 모집단으로 얼마나 잘 일반화할 수 있는가.
- 프로그램 운영 인력들의 업무 효율성이 얼마나 높은가.
- 프로그램이 장기적으로 재정적 자립을 이룰 수 있는가.
- Gertler et al. (2016) 에 따르면, 영향 평가에서 ’외적 타당성’의 핵심은 무엇입니까?
- 프로그램 운영에 소요되는 총 관리 비용.
- 실험 결과를 원래 의도했던 전체 대상 모집단으로 일반화할 수 있는가.
- 무작위 대조 시험(RCT)이 얼마나 빠르고 저렴하게 수행되었는가.
- 정책 변화에 따라 결과값이 얼마나 민감하게 반응하는가.
- 다음 넷플릭스 데이터셋에서, 사람들을 두 그룹 중 하나에 무작위로 할당하는 R 코드를 작성해 보세요.
netflix_data <-
tibble(
person = c("Ian", "Ian", "Roger", "Roger",
"Roger", "Patricia", "Patricia", "Helen"
),
tv_show = c(
"Broadchurch", "Line of Duty", "Broadchurch", "Line of Duty",
"Shetland", "Broadchurch", "Shetland", "Line of Duty"
),
hours = c(6.8, 8.0, 0.8, 9.2, 3.2, 4.0, 0.2, 10.2)
)- Gertler et al. (2016) 에 따르면, ’유효한 비교 그룹’이 갖추어야 할 요건이 아닌 것은 무엇입니까?
- 처치 그룹과 인구 통계학적 특성이 평균적으로 동일해야 함.
- 처치가 없었을 경우, 처치 그룹과 동일한 궤적으로 결과가 변했을 것이어야 함.
- 정책 프로그램의 영향을 직간접적으로 받아 결과값이 변했어야 함.
- 동일한 처치가 주어졌을 때, 처치 그룹과 유사한 반응을 보여야 함.
- Gertler et al. (2016) 에 따르면, 단순한 ‘전후 비교’ 분석이 종종 잘못된 결론을 내리는 이유는 무엇입니까?
- 분석 과정에 무작위 배정 절차가 포함되지 않았기 때문.
- 정책 결정자에게 중요하지 않은 지표들에만 집중하기 때문.
- 분석을 위해 지나치게 많은 양의 데이터가 필요하기 때문.
- 처치 이외의 요인에 의한 시간의 흐름 효과를 무시하기 때문.
- Gertler et al. (2016) 에 따르면, 어떤 상황에서 무작위 배정을 통한 프로그램 할당이 윤리적으로 정당화될 수 있습니까?
- 모든 대상자가 소득 수준에 따라 선착순으로 등록되었을 때.
- 지원을 원하는 모든 사람을 수용할 만큼 프로그램 예산이 넉넉할 때.
- 프로그램이 특정 소수 집단에게만 혜택을 주도록 설계되었을 때.
- 프로그램의 수용 인원보다 지원 자격을 갖춘 신청자가 훨씬 더 많을 때.
- 터스키기 매독 연구는 다음 중 어떤 윤리적 원칙을 가장 심각하게 위반했습니까?
- 데이터 기밀 유지 및 보안 수칙
- 통계적 검정력 확보를 위한 노력
- 정보에 입각한 동의와 참가자 선의의 원칙
- 참가자들에 대한 적절한 금전적 보상
- 임상 시험에서 평형 상태(Equipoise)란 무엇을 의미합니까?
- 실험군과 대조군의 표본 크기가 수학적으로 동일한 상태
- 실험에 참여한 모든 사람의 경제적 배경이 일치하는 상태
- 처치로 인한 부작용이 전혀 발견되지 않은 이상적인 상태
- 특정 치료법의 우열에 대해 전문가 집단 내에 진정한 불확실성이 존재하는 상태
- Ware (1989) 은 생사가 위급한 영아 대상 실험에서 부모의 심리적 고통을 배려해 ‘지연된 동의’ 절차를 언급했습니다. 당시 연구진이 정보 일부를 나중에 알리기로 했던 결정에 대해 여러분의 윤리적 견해는 어떠합니까?
- 설문 조사 문항을 설계할 때 가장 경계해야 할 태도는 무엇입니까?
- 응답자가 이해하기 쉬운 일상적인 용어를 사용하는 것
- 실제 배포 전 파일럿 테스트를 통해 문항을 다듬는 것
- 응답자를 특정 방향의 답변으로 유도하는 편향된 질문을 던지는 것
- 응답자의 피로도를 고려해 질문의 개수를 최소화하는 것
- 실험에서 교란 변수(Confounding variable)란 무엇을 의미합니까?
- 연구자의 지시 사항을 따르지 않는 불성실한 참가자
- 연구자가 효과를 확인하기 위해 의도적으로 조작하는 변수
- 연구자가 통제하지 못했지만 결과에 영향을 줄 수 있는 제3의 변수
- 데이터 입력 과정에서 실수로 발생한 단순한 수치 오류
- 오리건 건강 보험 실험의 근본적인 목적은 무엇이었습니까?
- 저소득층에게 메디케이드를 무작위로 제공하여 보건 의료 혜택의 인과적 영향을 측정함
- 신규 민간 건강 보험 상품에 대한 잠재 고객들의 선호도를 조사함
- 병원들의 업무 효율성을 평가하여 정부 예산을 절감할 방안을 찾음
- 다양한 치료법 중 어떤 것이 특정 질병에 더 효과적인지 임상적으로 비교함
- 설문 조사 설계 시 사전 검사(Pilot study)를 수행하는 주된 이유는 무엇입니까?
- 모든 잠재적 응답자에게 연구 가설을 미리 교육하기 위해
- 실제 배포 전 질문의 모호함을 제거하고 응답 흐름을 개선하기 위해
- 통계적 유의성을 확보하기 위해 미리 더 많은 데이터를 모으기 위해
- 학술지 게재에 필요한 예비 분석 결과를 확보하기 위해
- A/B 테스트에서 A/A 테스트를 수행하는 가장 큰 이유는 무엇입니까?
- 대조군 처치가 가진 절대적인 성능을 측정하기 위해
- 무작위 배정 알고리즘이 두 그룹을 편향 없이 제대로 나누었는지 확인하기 위해
- 완전히 다른 두 가지 신기능을 한꺼번에 테스트해 보기 위해
- 전체 실험 기간을 단축하여 개발 비용을 절감하기 위해
- 민간 기업의 대규모 A/B 테스트와 관련하여 자주 제기되는 비판은 무엇입니까?
- 실험을 설계하고 데이터를 저장하는 데 드는 비용이 너무 크다는 점
- 단기적인 지표 개선에만 매몰되어 서비스의 본질을 해칠 수 있다는 점
- 사용자로부터 명시적인 ’정보에 입각한 동의’를 구하지 않는 경우가 많다는 점
- 수집된 사용자 데이터의 양이 통계 분석을 하기에 턱없이 부족하다는 점
- 여러분이 대형 IT 컨설팅 회사의 분석가라고 가정해 봅시다. 귀사는 정부와 협력하여 국경 보안을 위한 안면 인식 시스템을 구축하는 프로젝트를 맡았습니다. 이와 관련하여 발생할 수 있는 윤리적 쟁점들을 세 단락 이상의 에세이 형식으로 서술해 보세요. (실제 사례나 참고 문헌을 인용하면 좋습니다.)
- 평균 처치 효과(ATE)에 대한 정확한 설명은 무엇입니까?
- 실험에 참여한 특정 개인에게 나타난 고유한 변화량
- 처치를 받지 않은 대조군에서 관찰된 결과값의 평균
- 처리군과 대조군 사이의 결과값 차이를 전체 표본에 대해 평균낸 수치
- 실험 중 관찰된 모든 개별적인 효과들의 단순한 합계
- 실험 설계에서 맹검(Blinded)이란 무엇을 뜻합니까?
- 복잡한 통계 기법을 동원해 데이터의 원천을 완전히 숨기는 것
- 참가자가 자신이 어느 집단(처리 혹은 대조)인지 모르게 하여 심리적 편향을 막는 것
- 분석 과정에서 표본의 구체적인 크기를 연구자에게 비밀로 하는 것
- 기록을 남기지 않고 오로지 육안 관찰로만 실험 결과를 기록하는 것
- 실제 데이터 분석 전 시뮬레이션을 수행하는 가장 큰 이유는 무엇입니까?
- 시뮬레이션 결과가 실제 현장 데이터보다 언제나 더 신뢰할 만하기 때문
- 복잡한 수식 계산을 대신해주어 전체 분석 시간을 획기적으로 줄여주기 때문
- 실제 데이터를 수집해야 하는 번거로운 과정을 생략하기 위해
- 데이터의 잠재적인 특성을 이해하고 분석 코드의 오류를 미리 잡아내기 위해
- 선택 편향(Selection Bias)에 대한 올바른 설명은 무엇입니까?
- 추출된 표본이 목표 모집단의 특성을 완벽하게 반영하고 있는 상태
- 핵심 처치 변수 외에 모든 외부 요인이 철저히 통제된 이상적인 상황
- 실험 과정에서 참가자들이 무작위로 연구 참여를 중단하는 현상
- 참가자를 모집하거나 배정하는 방식 때문에 표본이 모집단을 대변하지 못하는 상태
- Upworthy 데이터를 활용해, 물음표(?) 대신 느낌표(!)가 들어간 제목의 클릭률 차이를 분석해 보세요. 클릭 수의 차이는 대략 얼마로 나타납니까?
- -8.3
- -7.2
- -5.6
- -4.5
- Letterman (2021) 에 따르면, 인도 내 소수 종교 집단의 목소리를 대표성 있게 담아내기 위해 사용한 표집 방식은 무엇입니까?
- 눈덩이 표집(Snowball sampling)
- 할당 표집(Quota sampling)
- 무작위 전화 걸기(RDD)
- 복합 크기 측정 비례 표집(Composite size measure)
- 퓨 리서치 센터(Pew Research Center)는 해당 조사가 윤리적으로 수행되었음을 어떻게 입증했습니까?
- 인도 현지의 저명한 연구 윤리 위원회(IRB)로부터 공식 승인을 받음
- 오직 자발적으로 지원한 시민들만을 대상으로 조사를 한정함
- 인구 통계학적 정보를 아예 묻지 않아 철저한 익명성을 보장함
- 참가한 모든 응답자에게 파격적인 수준의 금전적 대가를 지급함
- Stantcheva (2023) 에 따르면 설문 조사에서 포괄 범위 오류(Coverage error)란 무엇입니까?
- 응답자들이 질문 의도를 오해해 엉뚱한 답변을 내놓는 현상
- 우리가 알고자 하는 전체 모집단과 실제 연락 가능한 명단 사이의 불일치
- 특정 계층의 의견을 더 많이 듣기 위해 의도적으로 과다 표집을 하는 행위
- 원래 목표로 했던 표본 수와 실제 응답을 완료한 사람 수의 차이
- 중간 응답 편향(Satisficing / Mid-point bias)이란 무엇을 의미합니까?
- 질문 내용과 상관없이 무의식적으로 ’보통’이나 중간 선택지만을 고집하는 경향
- 설문지의 질문 순서에 따라 응답자의 태도가 시시각각 변하는 현상
- 척도의 가장 낮은 값이나 가장 높은 값만을 골라서 선택하는 경향
- 조사자가 원하는 답이 무엇인지 짐작하여 그에 맞춰 답변하는 경향
- 온라인 설문 조사에서 사회적 바람직성 편향(Social desirability bias)을 줄이려면 어떻게 해야 합니까?
- 성실한 답변을 전제로 매우 높은 보상을 약속함
- 응답 내용이 철저히 비밀로 유지되며 익명성이 보장됨을 반복하여 강조함
- 응답자의 신원을 투명하게 공개하도록 하여 답변의 책임감을 높임
- 질문을 최대한 복잡하게 꼬아서 응답자가 질문의 의도를 모르게 함
- 응답 순서 편향(Response order bias)이란 무엇입니까?
- 응답자가 대답하기 곤란한 민감한 질문들을 그냥 넘어가는 경향
- 척도의 양 끝단에 있는 극단적인 선택지만을 주로 클릭하는 경향
- 질문의 어휘가 너무 어려워 질문 자체를 이해하지 못해 생기는 오류
- 여러 선택지 중 앞부분이나 뒷부분에 놓인 항목을 더 자주 선택하는 경향
- 설문 조사를 실무적으로 운영할 때 거쳐야 하는 과정이 아닌 것은 무엇입니까?
- 수집된 데이터의 형식과 정합성을 실시간으로 확인하는 일
- 전체적인 응답 진행 현황과 이탈률을 모니터링하는 일
- 데이터 수집이 완료되기도 전에 가설 검정부터 수행하는 일
- 소수의 인원에게 먼저 배포해 문제를 찾는 ‘소프트 론칭’ 과정
- 질문의 순서에 따른 편향을 막기 위해 문항을 무작위로 섞는 방식이 얼마나 효과적이라고 보십니까? 여러분의 생각을 적어보세요.
- 온라인 설문에서 응답률을 높이기 위한 가장 바람직한 권장 사항은 무엇입니까?
- 참가자들이 거절하기 힘든 매우 높은 수준의 금전적 유인을 제공함
- 설문의 의도를 숨기기 위해 초기 안내 단계에서는 정보를 최소화함
- 초대 메시지의 제목에 설문의 핵심 주제와 가치를 명확히 드러냄
- 더 정교한 분석을 위해 문항의 개수가 매우 많다는 점을 사전에 강조함
- 설문 조사에서 중도 이탈(Attrition)이란 무엇을 뜻합니까?
- 설문 초대를 보낸 전체 잠재 대상자의 총 숫자
- 수집된 데이터가 통계적으로 얼마나 정확한지를 나타내는 지표
- 설문 완료자와 미응답자 사이의 인구 통계학적 특성 차이
- 설문을 시작하기는 했으나 모든 문항을 마치기 전에 응답을 중단한 비율
수업 활동
- 리포지토리 설정: 스타터 폴더를 활용해 본인만의 GitHub 리포지토리를 생성하고, 링크를 공유 문서에 업로드하세요.
- 차 시음 실험(Lady Tasting Tea): 통계학의 고전인 피셔의 실험을 재현해 봅시다. 먼저 각 실험 결과를 요약할 수 있는 데이터 표와 그래프를 상상해 그려보세요. 그 후 R로 해당 상황을 시뮬레이션해 봅니다. 마지막으로 소그룹별로 실제 차(혹은 다른 음료) 시음 실험을 진행하고, 전체 반의 결과를 합산해 시각화해 보세요.
- 개인 웹사이트 제작: Chapter 3 의 가이드를 따라 개인 웹사이트를 만들고 GitHub Pages를 통해 전 세계에 공개해 보세요.
- A/B 테스트 실무: 웹사이트를 하나 더 만들고 Google Analytics를 연동해 보세요. Netlify로 배포한 뒤, 특정 요소를 변경한 새 브랜치를 만들어 Netlify의 A/B 테스트 기능을 직접 경험해 보세요.
- 논문 비평: Hammond et al. (2022) 을 정독하고 실험 설계의 타당성, 동의 절차의 적절성, 그리고 평형 상태(Equipoise) 개념에 대해 본인의 생각을 담아 2쪽 내외의 보고서를 작성하세요.
과제
Journal of Survey Statistics and Methodology의 무응답률 및 조정 관련 특별 호 수록 논문 중 하나를 골라보세요. 논문의 핵심 주장을 관련 연구들과 연결 지어 최소 2쪽 분량으로 논의하세요. Quarto를 활용해 제목, 저자, 날짜, GitHub 링크, 인용 정보가 포함된 PDF 보고서를 제출하세요.
에세이 및 프로젝트
이 장을 마친 후, 온라인 부록 F 의 Howrah 관련 논문을 읽고 비판적으로 분석해 보길 권장합니다.