library(janitor)
library(lubridate)
#library(opendatatoronto)
library(tidyverse)
library(tinytable)2 소방 호스로 물 마시기
채프먼 앤 홀/CRC(Chapman and Hall/CRC)는 2023년 7월 이 책을 출간했습니다. 도서는 여기에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 내용이 일부 포함되어 있습니다.
권장 학습 자료
- 탁월함의 평범함: 올림픽 수영 선수들에 대한 사회학적 보고서 (Chambliss 1989) 읽기.
- 탁월함이란 특별한 재능의 산물이 아니라, 구체적인 기술과 훈련, 그리고 태도가 켜켜이 쌓여 만들어지는 것임을 보여주는 논문입니다.
- 원자 습관으로서의 데이터 과학 (Barrett 2021) 읽기.
- 작고 꾸준한 행동을 통해 데이터 과학이라는 거대한 산을 정복하는 방법을 제안합니다.
- AI 편향이 발생하는 실제 과정과 이를 고치기 어려운 이유 (Hao 2019) 읽기.
- 분석 모델이 어떻게 기존의 사회적 편향을 고착화하는지 생생한 사례를 통해 경고하는 기사입니다.
핵심 개념 및 기술
- R은 데이터를 활용해 흥미로운 이야기를 들려줄 수 있는 강력한 도구입니다. 여느 언어와 마찬가지로 기초를 다지고 능숙해지기까지는 절대적인 시간이 필요합니다.
- 프로젝트를 수행할 때는 계획(Plan) - 시뮬레이션(Simulate) - 획득(Acquire) - 탐색(Explore) - 공유(Share)로 이어지는 워크플로를 따릅니다.
- R을 배우는 지름길은 작은 프로젝트부터 직접 시작해 보는 것입니다. 목표를 아주 세밀한 단계로 쪼개고, 다른 이의 코드를 참고하며 한 걸음씩 나아가세요. 프로젝트를 하나씩 완수할 때마다 여러분의 실력은 눈에 띄게 성장할 것입니다.
소프트웨어 및 패키지
- 기본 R (R Core Team 2024)
- 핵심
tidyverse(Wickham et al. 2019)dplyr(Wickham et al. 2022)ggplot2(Wickham 2016)tidyr(Wickham, Vaughan, and Girlich 2023)stringr(Wickham 2022)readr(Wickham, Hester, and Bryan 2022)
janitor(Firke 2023)lubridate(Grolemund and Wickham 2011)opendatatoronto(Gelfand 2022)tinytable(Arel-Bundock 2024)
2.1 안녕하세요, 세상! (Hello, World!)
무언가를 시작하는 가장 좋은 방법은 일단 뛰어드는 것입니다. 이 장에서는 데이터 과학 워크플로의 전체 과정을 처음부터 끝까지 가볍게 훑어보겠습니다. 워크플로는 다음 단계로 진행됩니다.
\[ \mbox{계획(Plan)} \rightarrow \mbox{시뮬레이션(Simulate)} \rightarrow \mbox{획득(Acquire)} \rightarrow \mbox{탐색(Explore)} \rightarrow \mbox{공유(Share)} \]
R이나 통계학이 처음이라면 코드와 개념이 낯설게 느껴질 수 있습니다. 하지만 너무 걱정하지 마세요. 실습을 거듭하다 보면 금세 익숙해질 것입니다.
데이터로 이야기하는 법을 익히는 유일한 방법은 직접 이야기를 시작해 보는 것입니다. 즉, 아래 예제들을 여러분의 컴퓨터에서 직접 실행해 보시라는 뜻입니다. 스케치를 그려보고, 모든 코드를 직접 타이핑해 보세요. 로컬 환경에 R을 설치하지 않았다면 Posit Cloud가 훌륭한 대안이 될 것입니다. 처음에는 모든 것이 막막할 수 있지만, 이는 배움의 과정에서 지극히 자연스러운 일입니다.
새로운 도구를 배울 때 한동안 서툰 것은 당연합니다. 누구나 겪는 일이며, 단지 지나가는 단계일 뿐이니 안심하세요.
해들리 위컴(Hadley Wickham), Barrett (2021) 재인용.
이 장의 안내를 차근차근 따라오세요. 데이터를 통해 결과물을 만들어낼 때 느끼는 희열이 학습의 고단함을 이겨내고 꾸준히 나아가는 원동력이 되길 바랍니다.
워크플로의 첫 단추는 계획입니다. 분석 도중 목표가 바뀔 수도 있지만, 우선은 최종 목적지를 정해두는 것이 중요합니다. 그다음은 시뮬레이션입니다. 시뮬레이션은 계획의 세부 내용을 구체화하도록 돕습니다. 획득 단계는 단순히 데이터셋을 내려받는 것처럼 간단할 수도 있지만, 직접 설문조사를 설계하는 경우처럼 분석의 성패를 가르는 핵심 작업이 되기도 합니다. 이후 다양한 정량적 방법론으로 데이터를 탐색하며 깊이 있게 이해하고, 마지막으로 청중의 눈높이에 맞춰 여러분의 통찰을 공유합니다.
실습을 위해 Posit Cloud에 가입해 주세요. 무료 계정으로도 충분합니다. 환경 설정의 번거로움을 줄이기 위해 초기 실습은 Posit Cloud를 기준으로 설명합니다. 로그인하면 Figure 2.1 (a) 과 같은 화면을 만나게 됩니다.
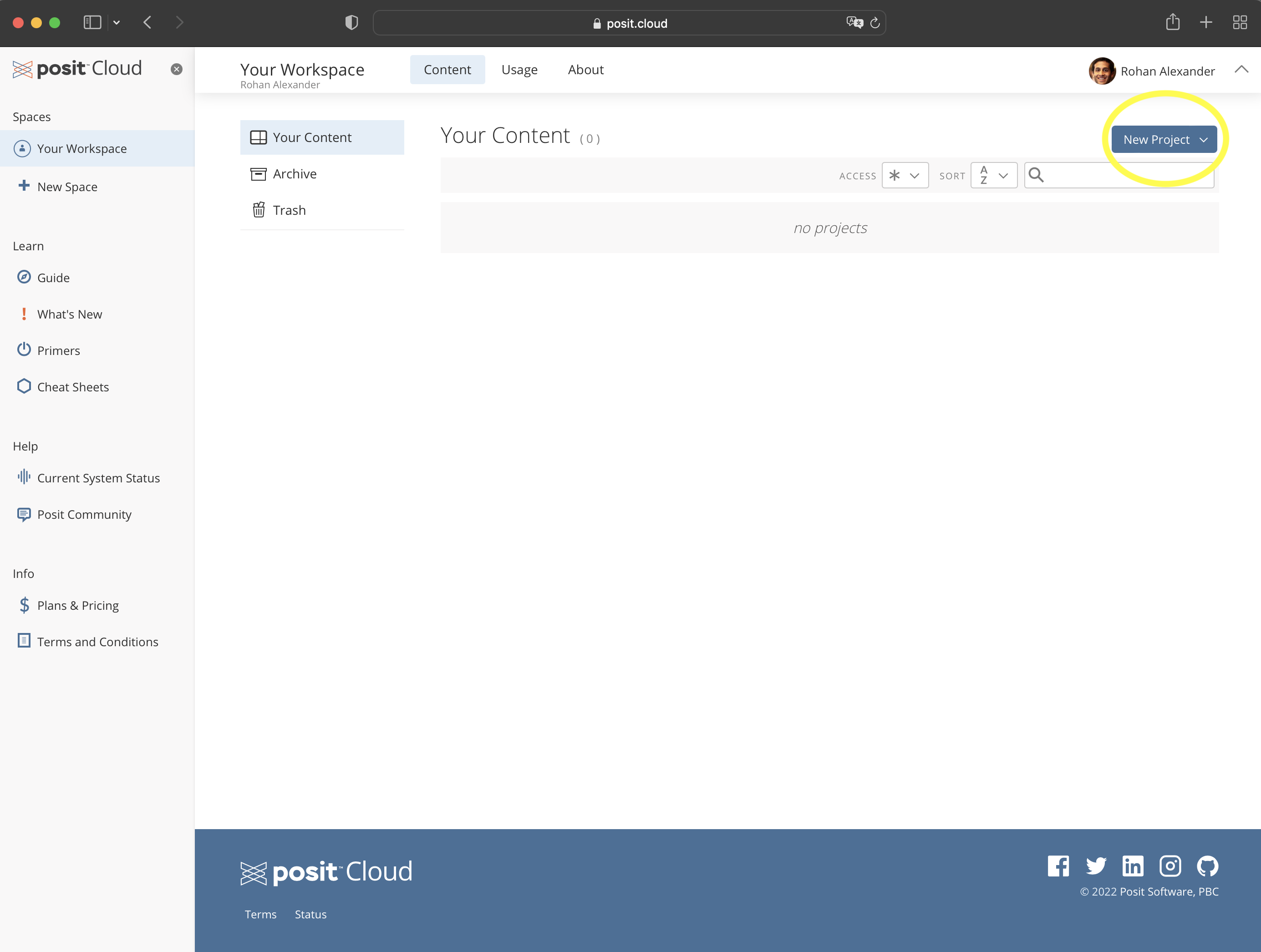
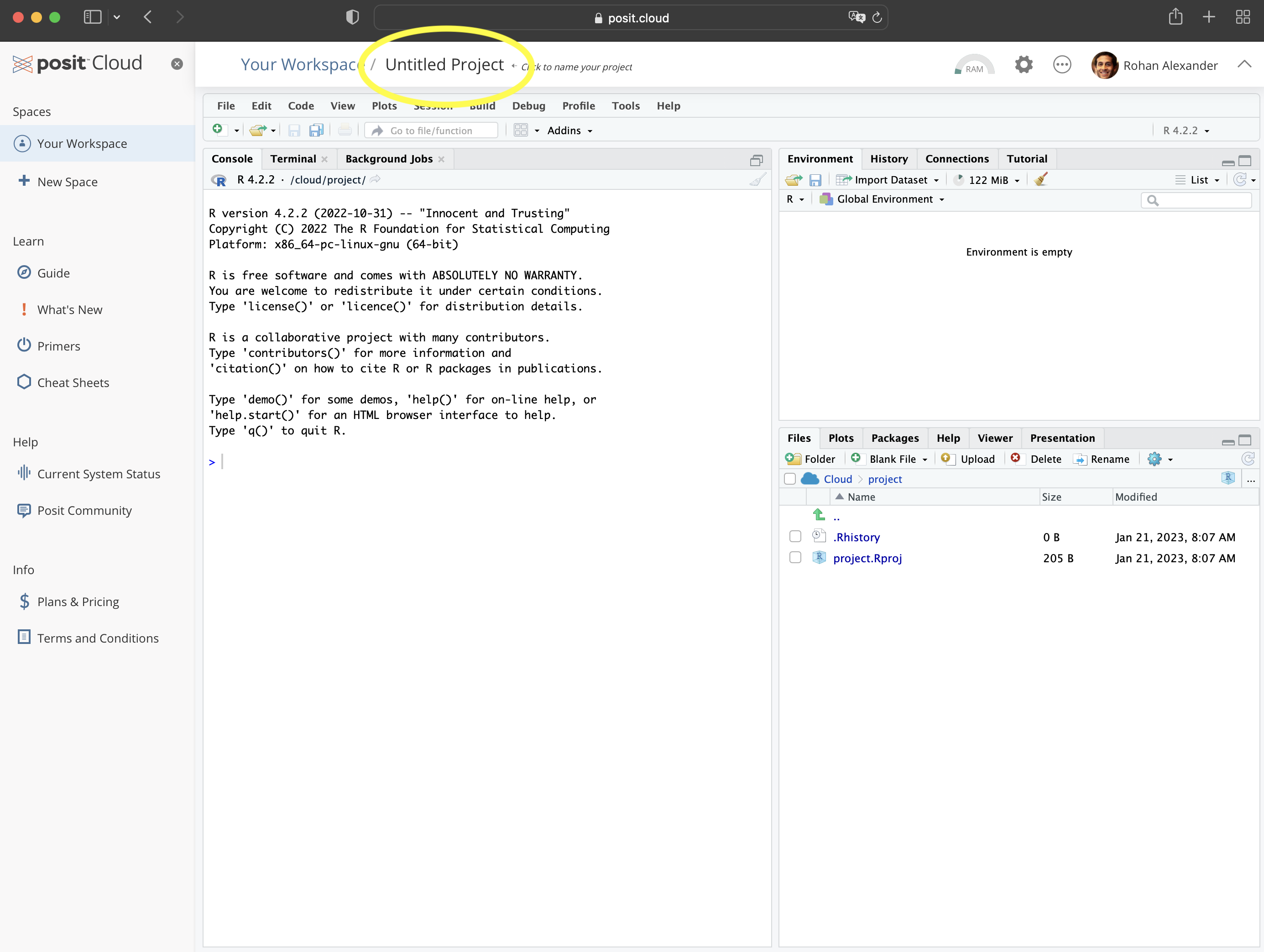
Posit Cloud에 로그인한 후 “Your workspace”에서 “New Project” \(\rightarrow\) “New RStudio Project”를 클릭해 새 프로젝트를 시작하세요(Figure 2.1 (b)). 상단의 “Untitled Project”를 눌러 프로젝트 이름을 자유롭게 정할 수 있습니다.
이제 세 가지 사례를 살펴보겠습니다. 호주 연방 선거, 토론토 쉼터 사용량, 그리고 신생아 사망률입니다. 뒤로 갈수록 조금씩 복잡해지겠지만, 모든 사례의 본질은 ’데이터로 이야기를 전달하는 것’입니다. 여기서는 도구와 개념을 간략히 짚고 넘어가며, 자세한 내용은 책의 후반부에서 심도 있게 다루겠습니다.
2.2 사례 1: 호주 연방 선거
호주는 하원(House of Representatives) 151석을 기반으로 정부가 구성되는 의회 민주주의 국가입니다. 주요 정당으로는 자유당(Liberal)과 노동당(Labor)이 있으며, 국민당(National), 녹색당(Greens) 등 소수 정당과 무소속 의원들이 함께 활동합니다. 이번 예제에서는 2022년 호주 연방 선거 결과를 정당별 의석수로 시각화해 보겠습니다.
2.2.1 계획 (Plan)
여기서는 두 가지를 계획해야 합니다. 하나는 데이터셋의 구조이고, 다른 하나는 최종 결과물인 그래프의 형태입니다.
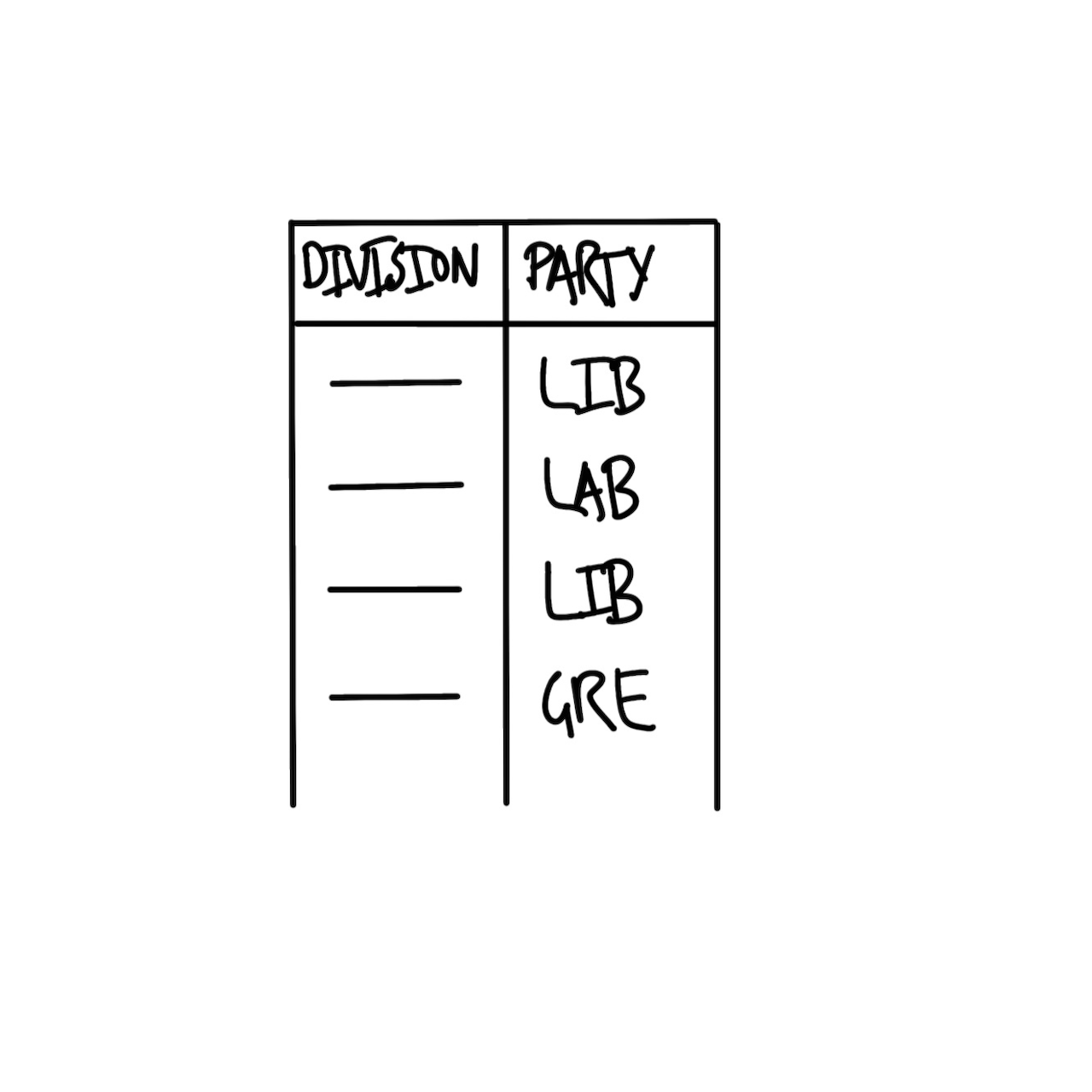
데이터셋에는 각 선거구(Division) 명칭과 당선 의원의 소속 정당 정보가 담겨야 합니다. 우리가 목표로 하는 데이터셋의 밑그림은 Figure 2.2 (a) 와 같습니다.
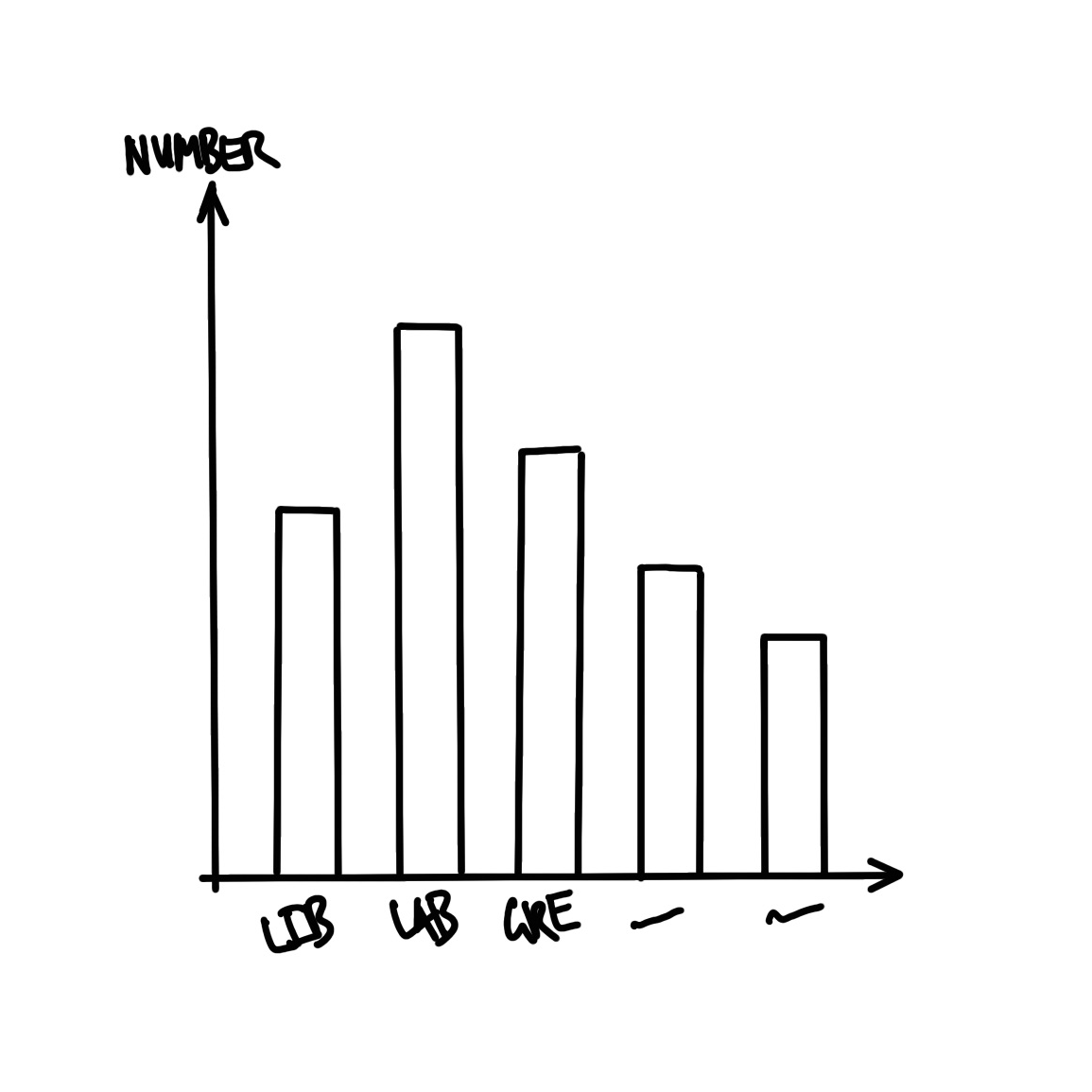
결과물을 어떻게 보여줄지도 미리 구상해야 합니다. 여기서는 정당별 의석수를 한눈에 비교할 수 있는 막대그래프를 그려보겠습니다(Figure 2.2 (b)).
2.2.2 시뮬레이션 (Simulate)
기획한 스케치를 구체화하기 위해 가상의 데이터를 만들어 보겠습니다.
먼저 Posit Cloud에서 새로운 Quarto 문서를 만듭니다. File \(\rightarrow\) New File \(\rightarrow\) Quarto Document…를 클릭하세요. 제목은 “2022년 호주 선거 결과 탐색”으로 정하고 저자명을 입력합니다. “Use visual markdown editor” 옵션은 체크를 해제하고 Create를 누릅니다(?fig-quarto-australian-elections-clcik).
이제 시뮬레이션 코드를 작성할 준비가 되었습니다.
만약 “rmarkdown 패키지 설치”를 요청하는 창이 뜬다면(?fig-quarto-australian-elections-wtfquarto) Install을 눌러 진행하세요. 모든 과정은 하나의 Quarto 문서 안에서 이루어집니다. 문서를 “australian_elections.qmd”라는 이름으로 저장하세요 (File \(\rightarrow\) Save As…).
기본 예시 내용을 모두 지우고, 문서 상단 메타데이터(YAML) 영역 바로 아래에 새로운 R 코드 청크(R code chunk)를 삽입합니다 (Code \(\rightarrow\) Insert Chunk). 그리고 문서의 개요를 설명하는 머리말(Preamble) 주석을 다음과 같이 작성합니다.
- 분석 목적
- 작성자 및 연락처
- 작성일 또는 최종 수정일
- 선행 조건
#### 머리말 ####
# 목적: 2022년 호주 연방 선거 데이터를 불러와
# 정당별 의석수를 시각화합니다.
# 작성자: Rohan Alexander
# 이메일: rohan.alexander@utoronto.ca
# 작성일: 2023년 1월 1일
# 선행 조건: 호주 선거 데이터의 출처를 파악하고 있어야 합니다.R에서 #으로 시작하는 문장은 주석(Comment)입니다. 컴퓨터는 이 부분을 무시하므로, 사람이 읽기 위한 메모를 남길 때 유용합니다. 머리말의 모든 줄은 #으로 시작해야 하며, #### 같은 기호를 사용해 영역을 구분하면 가독성이 좋아집니다(?fig-quarto-australian-elections-3).
다음은 작업 환경 설정입니다. 필요한 패키지를 설치하고 불러오는 과정입니다. 패키지 설치는 컴퓨터에 한 번만 하면 되지만, 불러오는 작업은 R을 새로 실행할 때마다 매번 수행해야 합니다. 여기서는 tidyverse와 janitor를 사용합니다.
거인의 어깨 위에 서서
해들리 위컴(Hadley Wickham)은 데이터 과학 도구 제작사 Posit의 수석 과학자입니다. 아이오와 주립 대학교에서 통계학 박사 학위를 받았으며, 전 세계 데이터 과학자들이 애용하는 tidyverse 생태계를 구축했습니다. 저명한 통계학 도서인 R for Data Science (Wickham, Çetinkaya-Rundel, and Grolemund [2016] 2023)를 집필했으며, 2019년에는 통계학계의 노벨상이라 불리는 COPSS 회장상을 수상했습니다.
패키지 설치 코드는 다음과 같습니다. 코드 청크 오른쪽의 작은 녹색 화살표를 눌러 실행하세요(?fig-quarto-australian-elections-4).
#### 작업 환경 설정 ####
install.packages("tidyverse")
install.packages("janitor")설치가 끝났다면 패키지를 불러옵니다. 앞서 말했듯 설치는 일회성이므로, 설치 코드는 주석 처리하거나 지워두는 것이 좋습니다. 콘솔에 출력된 복잡한 메시지들도 지우면 화면이 깔끔해집니다(?fig-quarto-australian-elections-5).
#### 작업 환경 설정 ####
# install.packages("tidyverse")
# install.packages("janitor")
library(tidyverse)
library(janitor)상단의 Render 버튼을 누르면 전체 문서를 완성할 수 있습니다(?fig-quarto-australian-elections-6). 추가 패키지 설치 요청이 오면 승인해 주세요. 과정이 끝나면 깔끔한 HTML 문서가 생성됩니다.
R 패키지들은 상세한 도움말을 포함하고 있습니다. 궁금한 함수나 패키지 이름 앞에 물음표(?)를 붙여 콘솔에 입력해 보세요. 예: ?tidyverse
이제 데이터를 시뮬레이션해 보겠습니다. ’선거구(Division)’와 ’정당(Party)’이라는 두 개의 열로 구성된 데이터셋을 만듭니다. ’Division’은 1부터 151까지 숫자로 채우고, ’Party’에는 주요 정당 이름을 무작위로 할당하겠습니다.
#### 데이터 시뮬레이션 ####
set.seed(853) # 무작위 결과를 재현하기 위해 시드를 고정합니다.
simulated_data <-
tibble(
# 선거구 이름 대신 1부터 151까지 번호를 사용합니다.
"Division" = 1:151,
# 151개 선거구에 대해 5개 정당 중 하나를 무작위로 선택합니다.
"Party" = sample(
x = c("Liberal", "Labor", "National", "Green", "Other"),
size = 151,
replace = TRUE
)
)
simulated_data# A tibble: 151 × 2
Division Party
<int> <chr>
1 1 Liberal
2 2 Labor
3 3 Other
4 4 Liberal
5 5 Other
6 6 Other
7 7 Labor
8 8 Green
9 9 National
10 10 National
# ℹ 141 more rows학습하다 보면 코드가 막혀 도움을 청해야 할 때가 생깁니다. 이때 코드의 일부분만 캡처해서 보내는 것은 좋지 않습니다. 문제의 전체 맥락을 파악하기 어렵기 때문입니다. 가장 좋은 방법은 상대방이 자신의 컴퓨터에서 바로 실행해 볼 수 있도록 전체 코드를 공유하는 것입니다.
이럴 때 GitHub의 Gist 서비스가 유용합니다. 계정이 없다면 먼저 가입하세요(Figure 2.3 (a)). 아이디는 전문가다운 인상을 줄 수 있도록 실제 이름과 관련되거나 정중한 것으로 정하길 권합니다. 로그인 후 오른쪽 상단 + 버튼을 눌러 New Gist를 선택합니다(Figure 2.3 (b)).
Gist 본문에 오류가 난 부분을 포함한 전체 코드를 복사해 넣으세요. 파일 이름은 australian_elections.R처럼 확장자(.R)를 포함해 명확히 짓습니다. Figure 2.3 (c) 는 패키지 이름의 대소문자를 틀려 오류가 발생한 예시입니다(library(tidyverse)가 정답).
Create public gist를 클릭해 생성된 주소를 질문과 함께 공유하세요. 어떤 결과를 기대했는지, 현재 상황은 어떤지 상세히 설명한다면 훨씬 정확한 도움을 받을 수 있습니다.
2.2.3 획득 (Acquire)
이제 실제 데이터를 가져올 차례입니다. 호주 선거 관리 위원회(AEC)의 공개 데이터를 사용하겠습니다. readr 패키지의 read_csv() 함수로 웹사이트의 데이터를 직접 읽어와 raw_elections_data 객체에 담습니다.
#### 데이터 읽기 ####
raw_elections_data <-
read_csv(
file =
"https://results.aec.gov.au/27966/website/Downloads/HouseMembersElectedDownload-27966.csv",
show_col_types = FALSE,
skip = 1
)
# 원본 데이터를 파일로 저장합니다. 나중에 웹사이트 주소가 바뀌더라도
# 분석을 계속할 수 있어 안전합니다.
write_csv(
x = raw_elections_data,
file = "australian_voting.csv"
)데이터의 구성을 빠르게 보려면 head()나 tail()을 사용하세요. 각각 처음과 마지막 6개 행을 보여줍니다.
head(raw_elections_data)# A tibble: 6 × 8
DivisionID DivisionNm StateAb CandidateID GivenNm Surname PartyNm PartyAb
<dbl> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
1 179 Adelaide SA 36973 Steve GEORGANAS Austral… ALP
2 197 Aston VIC 36704 Alan TUDGE Liberal LP
3 198 Ballarat VIC 36409 Catherine KING Austral… ALP
4 103 Banks NSW 37018 David COLEMAN Liberal LP
5 180 Barker SA 37083 Tony PASIN Liberal LP
6 104 Barton NSW 36820 Linda BURNEY Austral… ALP tail(raw_elections_data)# A tibble: 6 × 8
DivisionID DivisionNm StateAb CandidateID GivenNm Surname PartyNm PartyAb
<dbl> <chr> <chr> <dbl> <chr> <chr> <chr> <chr>
1 152 Wentworth NSW 37451 Allegra SPENDER Indepen… IND
2 153 Werriwa NSW 36810 Anne Maree STANLEY Austral… ALP
3 150 Whitlam NSW 36811 Stephen JONES Austral… ALP
4 178 Wide Bay QLD 37506 Llew O'BRIEN Liberal… LNP
5 234 Wills VIC 36452 Peter KHALIL Austral… ALP
6 316 Wright QLD 37500 Scott BUCHHOLZ Liberal… LNP 실제 분석에 활용하려면 앞서 기획한 구조(Figure 2.2 (a))에 맞게 데이터를 정제해야 합니다. 과정은 논리적이고 투명해야 합니다. 먼저 저장한 CSV를 불러온 뒤, janitor의 clean_names() 함수로 복잡한 변수 이름들을 다루기 좋게 바꿉니다.
#### 기본 정제 ####
raw_elections_data <-
read_csv(
file = "australian_voting.csv",
show_col_types = FALSE
)# 열 이름을 소문자와 밑줄(_) 형식으로 통일합니다.
cleaned_elections_data <-
clean_names(raw_elections_data)
# 바뀐 이름을 확인해 봅니다.
head(cleaned_elections_data)# A tibble: 6 × 8
division_id division_nm state_ab candidate_id given_nm surname party_nm
<dbl> <chr> <chr> <dbl> <chr> <chr> <chr>
1 179 Adelaide SA 36973 Steve GEORGANAS Australian …
2 197 Aston VIC 36704 Alan TUDGE Liberal
3 198 Ballarat VIC 36409 Catherine KING Australian …
4 103 Banks NSW 37018 David COLEMAN Liberal
5 180 Barker SA 37083 Tony PASIN Liberal
6 104 Barton NSW 36820 Linda BURNEY Australian …
# ℹ 1 more variable: party_ab <chr>RStudio의 자동 완성 기능을 쓰면 변수 이름을 일일이 치지 않아도 됩니다. 이름의 앞 글자만 넣고 Tab을 누르세요.
원본 데이터에는 정보가 너무 많으므로, 선거구(division_nm)와 정당(party_nm) 열만 남기겠습니다. select() 함수와 파이프 연산자(|>)를 사용합니다. 파이프 연산자는 앞 단계의 결과를 다음 단계의 재료로 전달해 주어 코드를 읽기 쉽게 만듭니다.
cleaned_elections_data <-
cleaned_elections_data |>
select(
division_nm,
party_nm
)
head(cleaned_elections_data)# A tibble: 6 × 2
division_nm party_nm
<chr> <chr>
1 Adelaide Australian Labor Party
2 Aston Liberal
3 Ballarat Australian Labor Party
4 Banks Liberal
5 Barker Liberal
6 Barton Australian Labor Party이름이 여전히 투박하므로 rename()으로 알기 쉽게 바꿔줍니다.
cleaned_elections_data <-
cleaned_elections_data |>
rename(
division = division_nm,
elected_party = party_nm
)
head(cleaned_elections_data)# A tibble: 6 × 2
division elected_party
<chr> <chr>
1 Adelaide Australian Labor Party
2 Aston Liberal
3 Ballarat Australian Labor Party
4 Banks Liberal
5 Barker Liberal
6 Barton Australian Labor Party이제 어떤 정당들이 있는지 unique()로 확인해 볼까요?
cleaned_elections_data$elected_party |>
unique()[1] "Australian Labor Party"
[2] "Liberal"
[3] "Liberal National Party of Queensland"
[4] "The Greens"
[5] "The Nationals"
[6] "Independent"
[7] "Katter's Australian Party (KAP)"
[8] "Centre Alliance" 실제 정당 이름은 시뮬레이션 때보다 훨씬 복잡합니다. case_match()를 사용해 이름을 단순하게 묶어보겠습니다.
cleaned_elections_data <-
cleaned_elections_data |>
mutate(
elected_party =
case_match(
elected_party,
"Australian Labor Party" ~ "Labor",
"Liberal National Party of Queensland" ~ "Liberal",
"Liberal" ~ "Liberal",
"The Nationals" ~ "Nationals",
"The Greens" ~ "Greens",
"Independent" ~ "Other",
"Katter's Australian Party (KAP)" ~ "Other",
"Centre Alliance" ~ "Other"
)
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `elected_party = case_match(...)`.
Caused by warning:
! `case_match()` was deprecated in dplyr 1.2.0.
ℹ Please use `recode_values()` instead.head(cleaned_elections_data)# A tibble: 6 × 2
division elected_party
<chr> <chr>
1 Adelaide Labor
2 Aston Liberal
3 Ballarat Labor
4 Banks Liberal
5 Barker Liberal
6 Barton Labor 이제 데이터셋이 기획안(Figure 2.2 (a))과 일치하게 정리되었습니다. 이 데이터를 별도 파일로 저장해 두면 다음 단계에서 편리하게 쓸 수 있습니다.
write_csv(
x = cleaned_elections_data,
file = "cleaned_elections_data.csv"
)2.2.4 탐색 (Explore)
정리된 데이터를 바탕으로 탐색을 시작합니다. 시각화는 데이터를 이해하는 가장 강력한 도구입니다. 기획 스케치(Figure 2.2 (b))를 실제 그래프로 구현해 볼까요?
먼저 정제된 데이터를 불러옵니다.
#### 데이터 탐색 ####
cleaned_elections_data <-
read_csv(
file = "cleaned_elections_data.csv",
show_col_types = FALSE
)count()로 정당별 의석수를 빠르게 집계해 봅니다.
cleaned_elections_data |>
count(elected_party)# A tibble: 5 × 2
elected_party n
<chr> <int>
1 Greens 4
2 Labor 77
3 Liberal 48
4 Nationals 10
5 Other 12이제 ggplot2로 그래프를 그립니다. ggplot2는 도화지에 레이어를 하나씩 덧칠하는 방식으로 작동하며, 각 레이어는 + 기호로 연결합니다. 막대그래프는 geom_bar()를 사용합니다(Figure 2.4 (a)).
cleaned_elections_data |>
ggplot(aes(x = elected_party)) + # aes는 시각적 요소의 매핑을 담당합니다.
geom_bar()
cleaned_elections_data |>
ggplot(aes(x = elected_party)) +
geom_bar() +
theme_minimal() + # 깔끔한 미니멀 테마 적용
labs(x = "정당", y = "의석수") # 한글 레이블 추가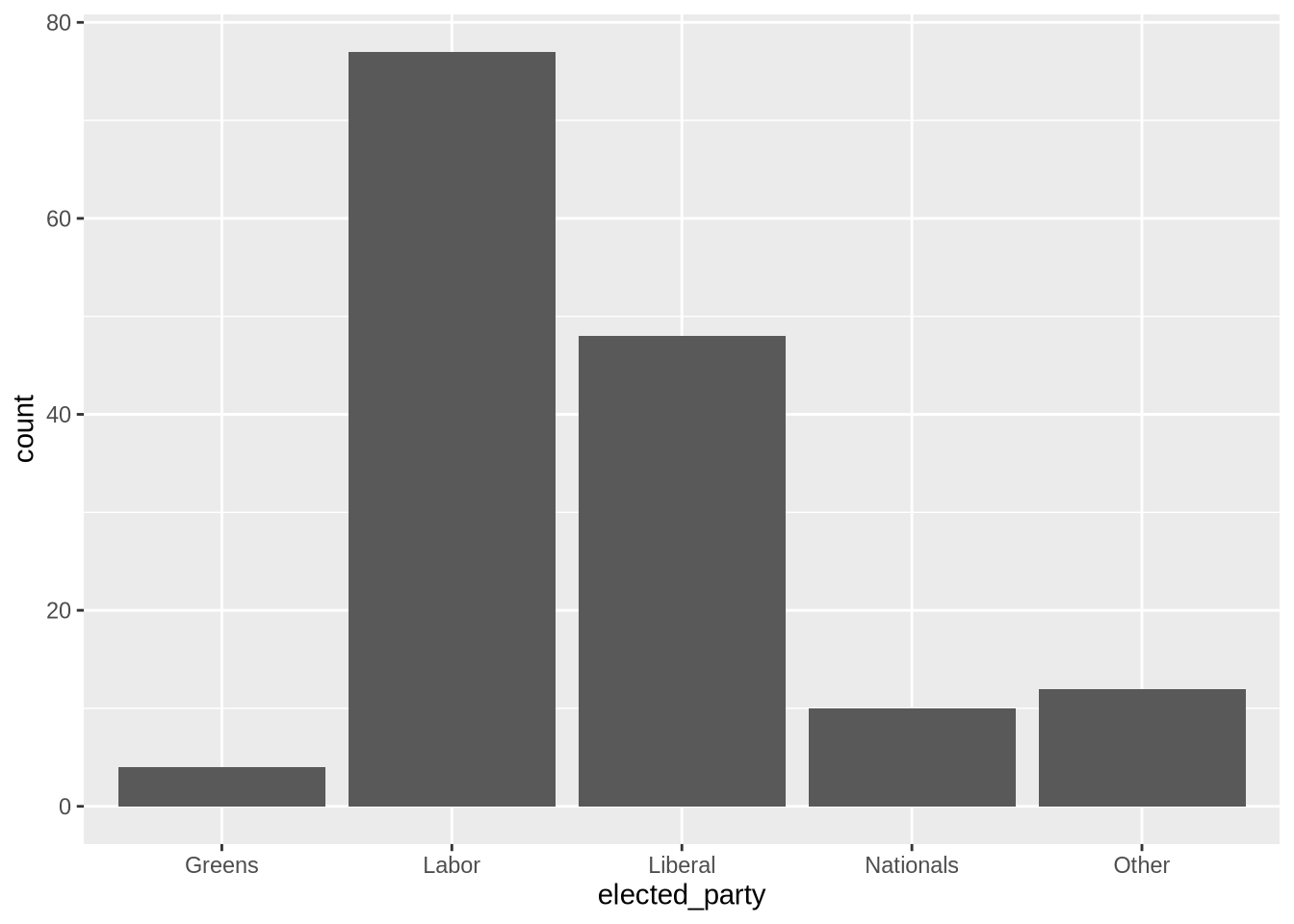
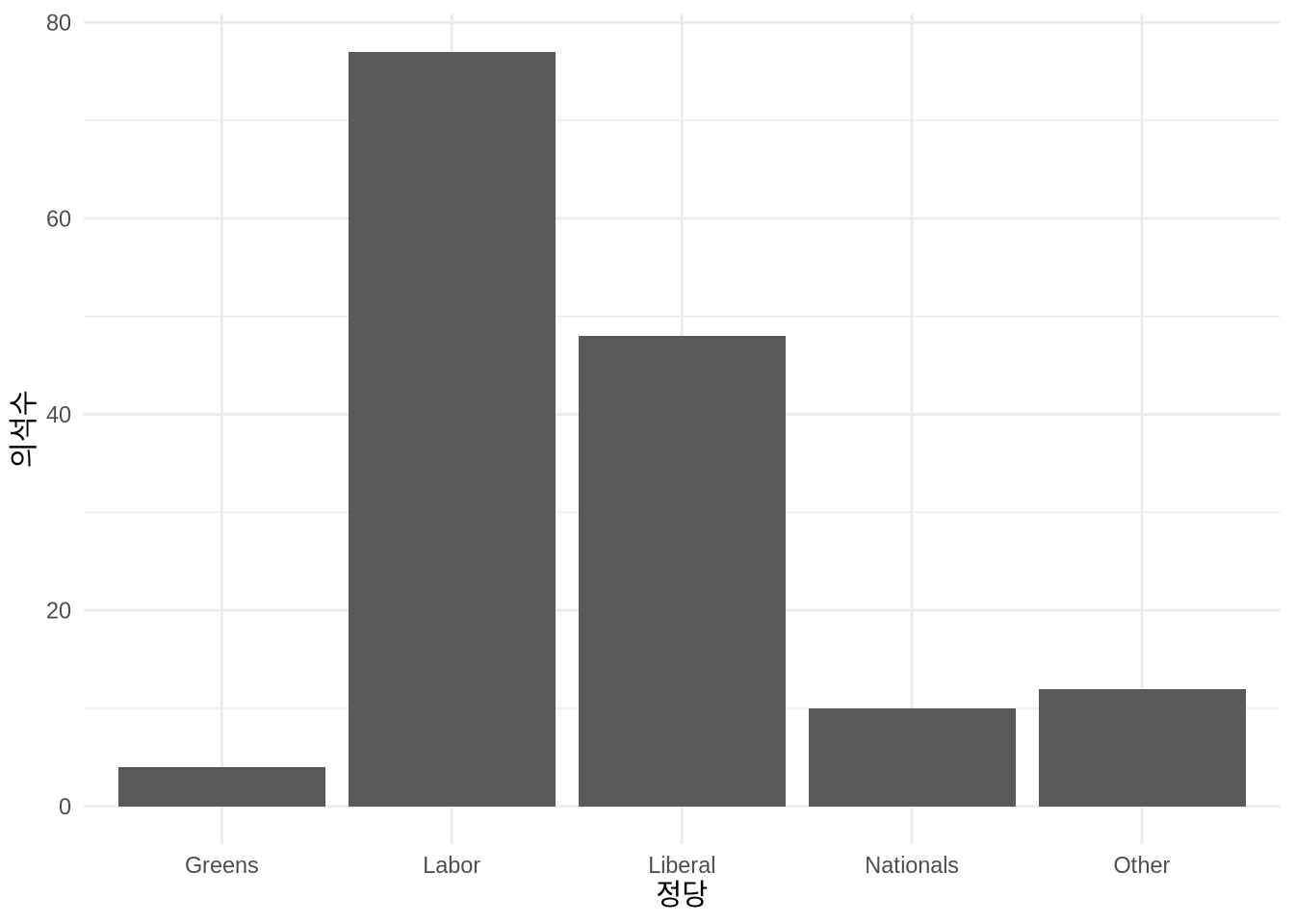
Figure 2.4 (a) 은 목표했던 모습 그대로입니다. 여기에 테마를 입히고 레이블을 다듬으면 훨씬 전문적인 결과물이 완성됩니다(Figure 2.4 (b)).
2.3 사례 2: 토론토 노숙인 현황
캐나다 토론토에는 많은 노숙인이 거주하고 있습니다 (City of Toronto 2021). 토론토의 혹독한 겨울을 생각하면, 쉼터(Shelter)의 안정적인 운영은 생존과 직결된 문제입니다. 이번에는 2021년 토론토 쉼터 이용 데이터를 사용해 월별 평균 이용 현황을 비교해 보겠습니다. 겨울철(12월) 이용률이 여름철(7월)보다 높을 것이라는 가설을 확인하는 것이 목표입니다.
2.3.1 계획 (Plan)
필요한 정보는 날짜, 쉼터 이름, 그리고 점유 침대 수(Occupied beds)입니다. 분석용 데이터셋의 구조(Figure 2.5 (a))와 최종적으로 만들 요약표(Figure 2.5 (b))의 스케치를 먼저 그려봅니다.
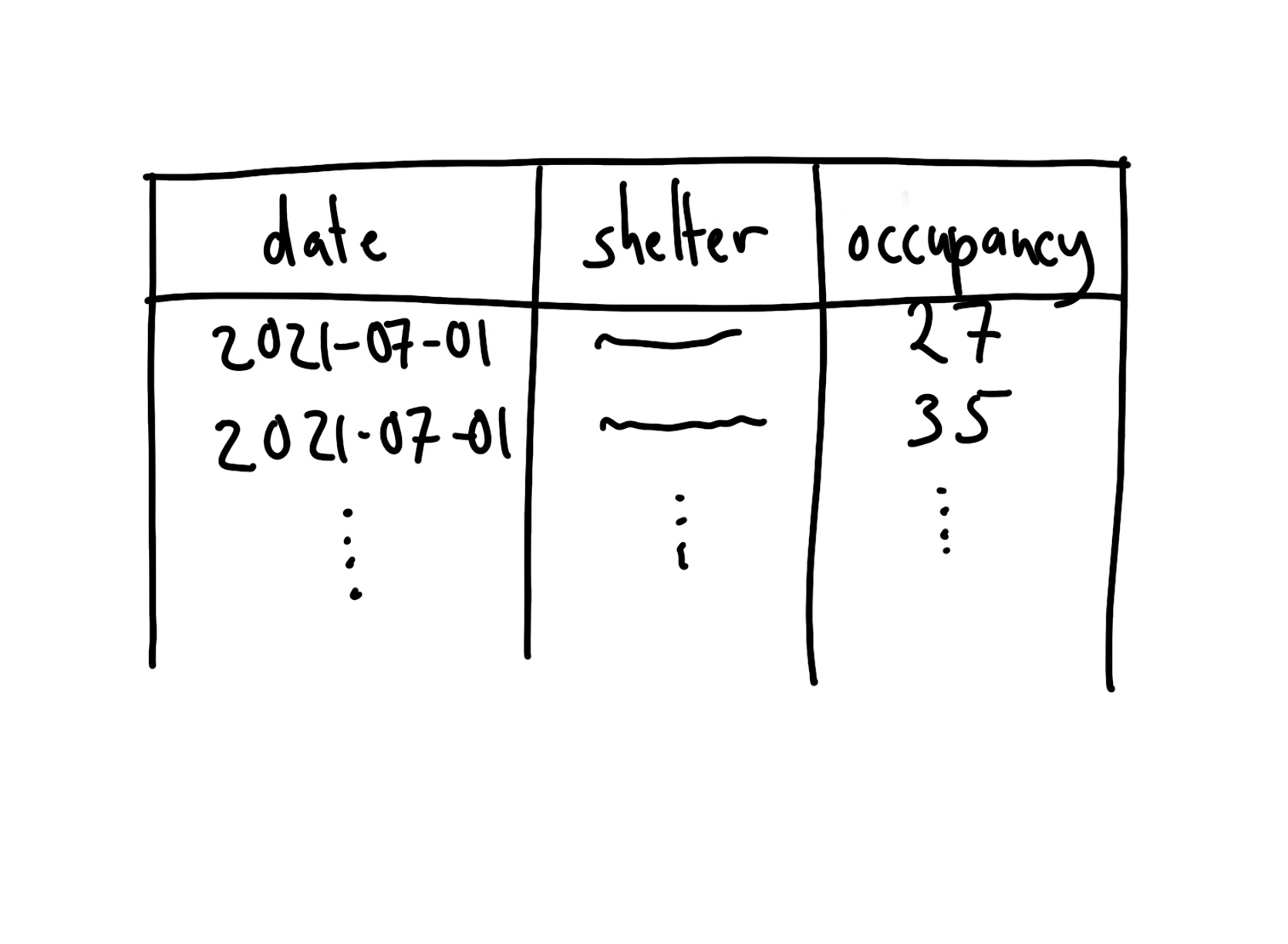
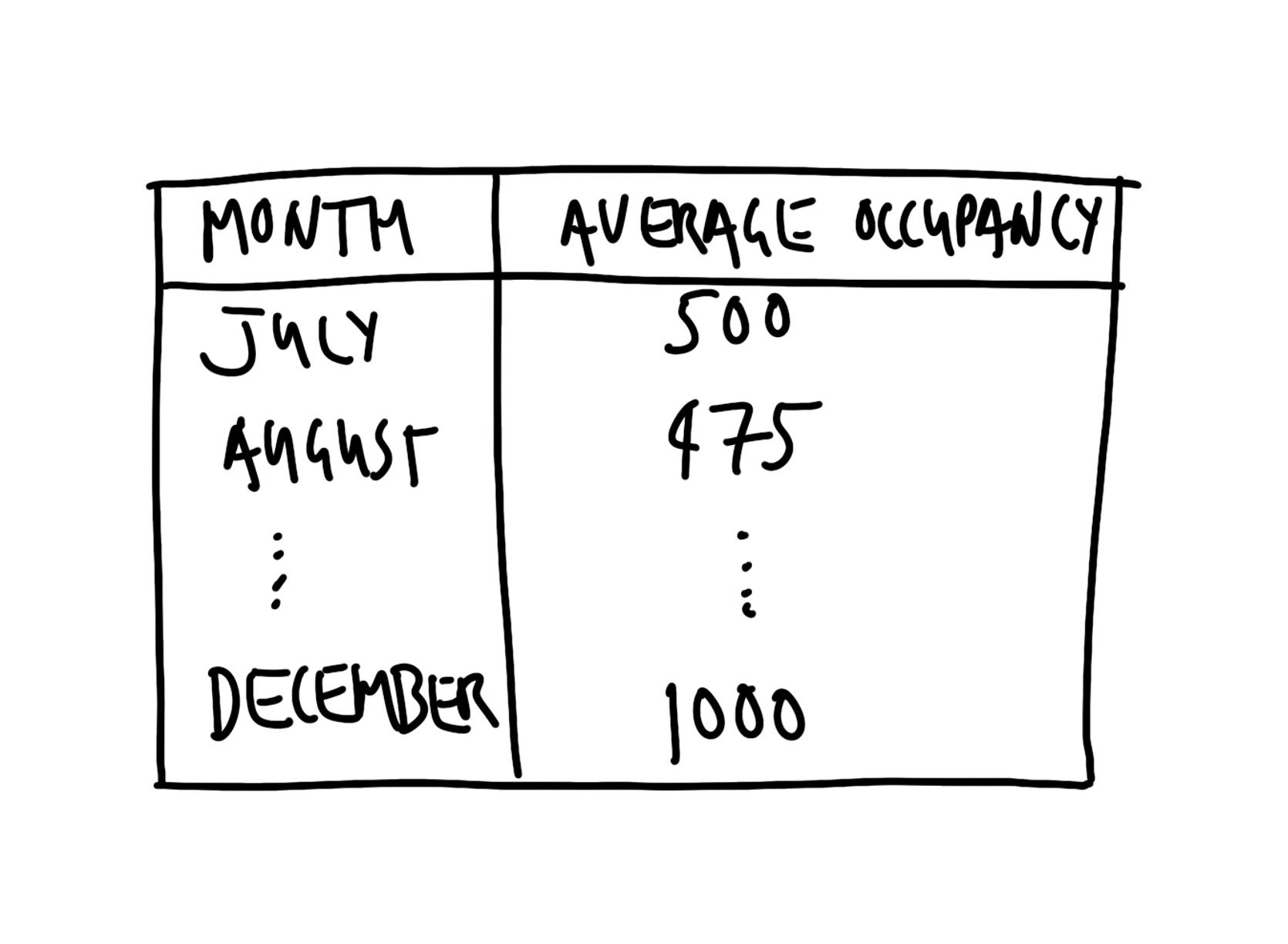
2.3.2 시뮬레이션 (Simulate)
실제 분석에 앞서 가상의 데이터를 시뮬레이션해 봅니다. 이 과정은 데이터가 생성되는 원리(Data generation process)를 깊이 있게 고민하게 하며, 실제 데이터를 다룰 때 훌륭한 나침반이 됩니다. 시뮬레이션 없이 분석에 뛰어드는 것은 목적지 없이 길을 나서는 것과 같습니다.
새로운 Quarto 문서를 만들고 머리말을 작성하세요. tidyverse와 janitor 외에 날짜를 다루기 위한 lubridate, 토론토 시 데이터를 가져올 opendatatoronto, 표를 예쁘게 출력할 knitr 패키지가 필요합니다.
#### 머리말 ####
# 목적: 2021년 토론토 쉼터 이용 데이터를 확보하고 월별 요약표를 만듭니다.
# 작성자: Rohan Alexander
# 이메일: rohan.alexander@utoronto.ca
# 작성일: 2022년 7월 1일
#### 작업 환경 설정 ####
# library(knitr)
# library(janitor)
# library(lubridate)
# library(opendatatoronto)
# library(tidyverse)패키지는 전 세계 개발자들이 미리 만들어 둔 유용한 도구상자입니다. 설치는 한 번, 사용은 매번 library()로 불러오는 것을 잊지 마세요.
거인의 어깨 위에 서서
로버트 젠틀맨(Robert Gentleman)은 R 언어의 공동 창시자입니다. 워싱턴 대학교에서 통계학 박사 학위를 받았으며, 유전자 분석 기업 23andMe 등을 거쳐 현재 하버드 의과대학에서 계산 생의학 분야를 이끌고 있습니다.
거인의 어깨 위에 서서
로스 이아카(Ross Ihaka)는 R 언어의 또 다른 창시자입니다. UC 버클리에서 박사 학위를 받았으며, 오클랜드 대학교에서 통계학 발전에 평생을 헌신했습니다. 2008년 뉴질랜드 왕립 학회로부터 피커링 메달을 수상한 바 있습니다.
수많은 이의 헌신으로 만들어진 R과 패키지들을 분석에 활용할 때는 적절히 인용하는 것이 예의입니다. citation() 함수로 정보를 확인할 수 있습니다.
citation() # R 언어 인용 정보
citation("ggplot2") # 특정 패키지 인용 정보시뮬레이션으로 돌아와 날짜, 쉼터, 점유수 세 가지 변수를 생성합니다. set.seed()로 무작위 숫자를 고정해 결과를 재현 가능하게 만들고, rep() 함수로 데이터를 반복 생성하겠습니다.
#### 데이터 시뮬레이션 ####
set.seed(853)
simulated_occupancy_data <-
tibble(
# 2021년 날짜를 3번 반복합니다 (쉼터가 3곳이라 가정).
date = rep(x = as.Date("2021-01-01") + c(0:364), times = 3),
# 3개 쉼터의 이름을 각각 365번씩 할당합니다.
shelter = c(
rep(x = "쉼터 1", times = 365),
rep(x = "쉼터 2", times = 365),
rep(x = "쉼터 3", times = 365)
),
# 점유수를 포아송 분포에서 무작위로 추출합니다 (평균 30명 가정).
number_occupied =
rpois(
n = 365 * 3,
lambda = 30
)
)
head(simulated_occupancy_data)# A tibble: 6 × 3
date shelter number_occupied
<date> <chr> <int>
1 2021-01-01 쉼터 1 28
2 2021-01-02 쉼터 1 29
3 2021-01-03 쉼터 1 35
4 2021-01-04 쉼터 1 25
5 2021-01-05 쉼터 1 21
6 2021-01-06 쉼터 1 30위 코드에서 점유수는 포아송 분포(Poisson distribution)를 사용했습니다. 이는 일정 시간이나 공간 내에서 발생하는 사건의 횟수를 모델링할 때 자주 쓰이는 확률 분포입니다.
2.3.3 획득 (Acquire)
토론토 시의 오픈 데이터 포털(Open Data Toronto)에서 제공하는 쉼터 이용 현황 데이터를 사용합니다. opendatatoronto 패키지를 이용해 2021년 데이터를 불러와 저장하겠습니다.
#### 데이터 획득 ####
toronto_shelters <-
list_package_resources("21c83b32-d5a8-4106-a54f-010dbe49f6f2") |>
filter(name ==
"daily-shelter-overnight-service-occupancy-capacity-2021.csv") |>
get_resource()
write_csv(
x = toronto_shelters,
file = "toronto_shelters.csv"
)
head(toronto_shelters)head(toronto_shelters)# A tibble: 6 × 32
X_id OCCUPANCY_DATE ORGANIZATION_ID ORGANIZATION_NAME SHELTER_ID
<dbl> <chr> <dbl> <chr> <dbl>
1 1 21-01-01 24 COSTI Immigrant Services 40
2 2 21-01-01 24 COSTI Immigrant Services 40
3 3 21-01-01 24 COSTI Immigrant Services 40
4 4 21-01-01 24 COSTI Immigrant Services 40
5 5 21-01-01 24 COSTI Immigrant Services 40
6 6 21-01-01 24 COSTI Immigrant Services 40
# ℹ 27 more variables: SHELTER_GROUP <chr>, LOCATION_ID <dbl>,
# LOCATION_NAME <chr>, LOCATION_ADDRESS <chr>, LOCATION_POSTAL_CODE <chr>,
# LOCATION_CITY <chr>, LOCATION_PROVINCE <chr>, PROGRAM_ID <dbl>,
# PROGRAM_NAME <chr>, SECTOR <chr>, PROGRAM_MODEL <chr>,
# OVERNIGHT_SERVICE_TYPE <chr>, PROGRAM_AREA <chr>, SERVICE_USER_COUNT <dbl>,
# CAPACITY_TYPE <chr>, CAPACITY_ACTUAL_BED <dbl>, CAPACITY_FUNDING_BED <dbl>,
# OCCUPIED_BEDS <dbl>, UNOCCUPIED_BEDS <dbl>, UNAVAILABLE_BEDS <dbl>, …가져온 데이터를 분석하기 좋게 다듬습니다(Figure 2.5 (a)). 이름을 정리하고 날짜 형식을 변환한 뒤 필요한 정보만 추려냅니다.
toronto_shelters_clean <-
clean_names(toronto_shelters) |>
mutate(occupancy_date = ymd(occupancy_date)) |>
select(occupancy_date, occupied_beds)
head(toronto_shelters_clean)# A tibble: 6 × 2
occupancy_date occupied_beds
<date> <dbl>
1 2021-01-01 NA
2 2021-01-01 NA
3 2021-01-01 NA
4 2021-01-01 NA
5 2021-01-01 NA
6 2021-01-01 6정리된 데이터를 저장해 둡니다.
write_csv(
x = toronto_shelters_clean,
file = "toronto_shelters_clean.csv"
)2.3.4 탐색 (Explore)
가공된 데이터에서 월별 평균 점유 침대 수를 계산해 보겠습니다. month() 함수로 월 이름을 추출하고, drop_na()로 결측치를 제거한 뒤 summarise()로 평균값을 구합니다. 마지막으로 tinytable의 tt()를 사용해 깔끔한 표를 완성합니다(Table 2.1).
toronto_shelters_clean |>
mutate(occupancy_month = month(
occupancy_date,
label = TRUE,
abbr = FALSE
)) |>
arrange(month(occupancy_date)) |>
drop_na(occupied_beds) |>
summarise(number_occupied = mean(occupied_beds),
.by = occupancy_month) |>
tt(digits = 1) |>
style_tt(j = 2, align = "r") |>
setNames(c("월", "일평균 점유 침대 수"))2.4 사례 3: 신생아 사망률 (Neonatal Mortality Rate)
신생아 사망률(Neonatal Mortality Rate, NMR)은 생후 28일 이내에 사망하는 영유아의 비율을 출생아 1,000명당 숫자로 나타낸 지표입니다 (UN IGME 2021). 이번 사례에서는 아르헨티나, 호주, 캐나다, 케냐 4개국의 지난 50년간 NMR 변화 추이를 비교해 보겠습니다.
2.4.1 계획 (Plan)
국가명, 연도, NMR 추정치를 포함하는 데이터셋과 이를 시각화한 선 그래프를 기획합니다(Figure 2.6).
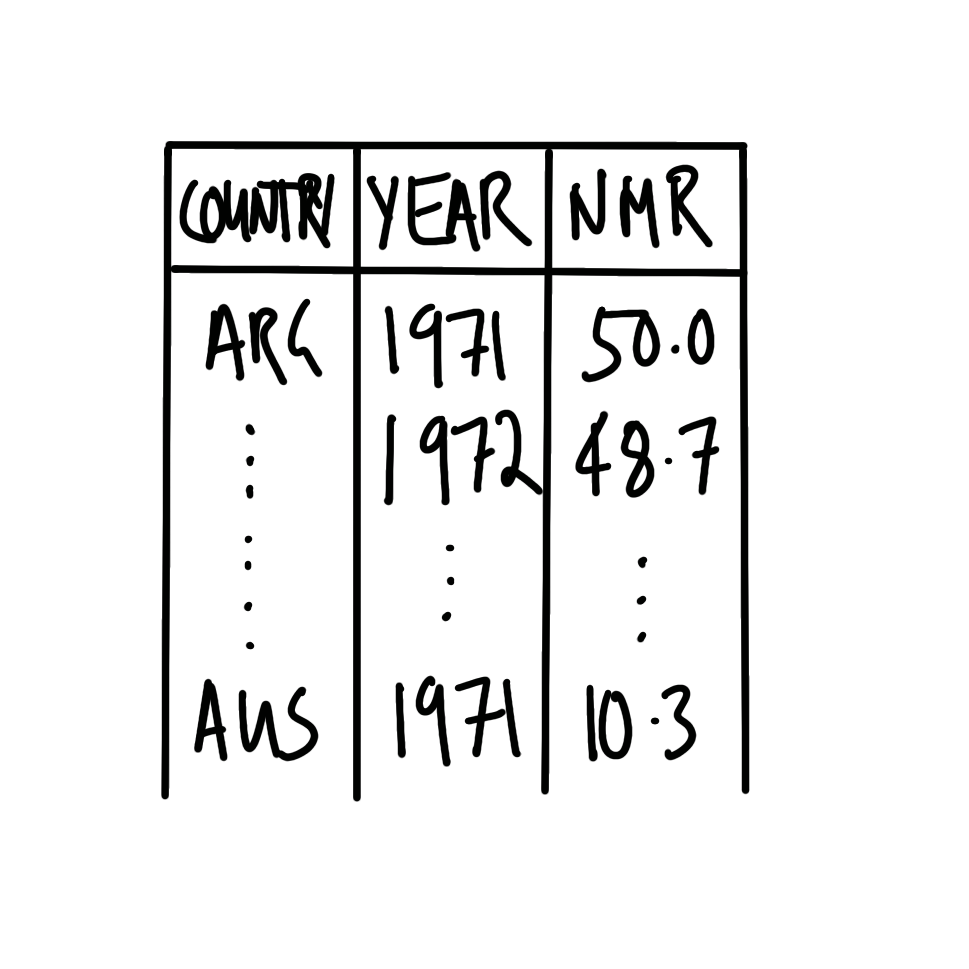
2.4.2 시뮬레이션 (Simulate)
가상의 데이터를 시뮬레이션해 봅니다. 이번에는 분석 기간을 변수로 선언해 코드를 더 유연하게 짜보겠습니다.
#### 데이터 시뮬레이션 ####
set.seed(853)
number_of_years <- 50 # 기간을 변수로 설정해 관리가 쉽도록 합니다.
simulated_nmr_data <-
tibble(
country = rep(c("Argentina", "Australia", "Canada", "Kenya"), each = number_of_years),
year = rep(1971:(1971 + number_of_years - 1), times = 4),
nmr = runif(n = number_of_years * 4, min = 0, max = 100)
)
head(simulated_nmr_data)# A tibble: 6 × 3
country year nmr
<chr> <int> <dbl>
1 Argentina 1971 35.9
2 Argentina 1972 12.0
3 Argentina 1973 48.4
4 Argentina 1974 31.6
5 Argentina 1975 3.74
6 Argentina 1976 40.4 실제 데이터를 다루기 전, 데이터가 상식적인 범위에 있는지 확인하는 검증 테스트(Validation testing)가 필수입니다. 국가 이름이 정확한지, 연도 범위가 맞는지, 사망률이 음수이거나 비정상적으로 높지 않은지 확인하는 코드를 작성합니다.
# 국가 이름 및 개수 확인
simulated_nmr_data$country |> unique() == c("Argentina", "Australia", "Canada", "Kenya")
simulated_nmr_data$country |> unique() |> length() == 4
# 연도 및 NMR 값 범위 확인
simulated_nmr_data$year |> range() == c(1971, 2020)
simulated_nmr_data$nmr |> min() >= 0 & simulated_nmr_data$nmr |> max() <= 10002.4.3 획득 (Acquire)
유엔 영유아 사망률 추정 기관 간 그룹(UN IGME)의 데이터를 활용합니다.
분석 목적에 맞게 데이터를 필터링하고 다듬습니다. ‘Total’(전체), ‘UN IGME estimate’, 지표는 ’Neonatal mortality rate’인 행만 골라내고 필요한 열을 선택합니다.
cleaned_igme_data <-
clean_names(raw_igme_data) |>
filter(
sex == "Total",
series_name == "UN IGME estimate",
geographic_area %in% c("Argentina", "Australia", "Canada", "Kenya"),
indicator == "Neonatal mortality rate"
) |>
mutate(
year = as.integer(str_remove(time_period, "-06")),
nmr = obs_value
) |>
filter(year >= 1971) |>
select(geographic_area, year, nmr) |>
rename(country = geographic_area)
head(cleaned_igme_data)# A tibble: 6 × 3
country year nmr
<chr> <int> <dbl>
1 Argentina 1971 24.7
2 Argentina 1972 24.6
3 Argentina 1973 24.6
4 Argentina 1974 24.5
5 Argentina 1975 24.1
6 Argentina 1976 23.3모든 테스트를 통과했다면 이제 시각화할 준비가 된 것입니다.
2.4.4 탐색 (Explore)
국가별 NMR 변화 추이를 그래프로 그려봅니다(Figure 2.7).
cleaned_igme_data |>
ggplot(aes(x = year, y = nmr, color = country)) +
geom_line() + # 흐름을 보기 위해 선 그래프를 사용합니다.
theme_minimal() +
labs(x = "연도", y = "신생아 사망률 (NMR)", color = "국가") +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")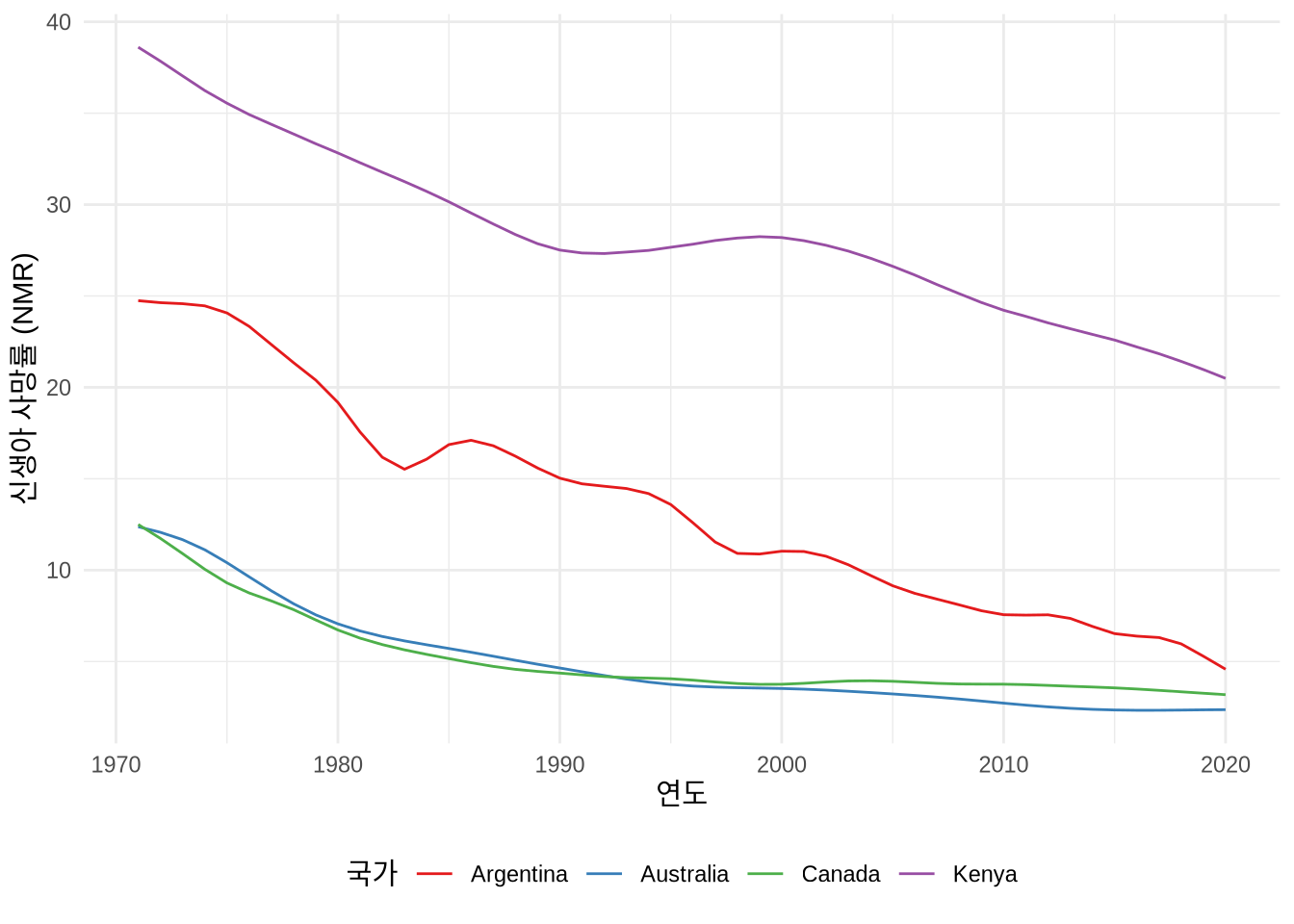
2.4.5 공유 (Share)
지난 50년간 분석 대상인 4개국 모두 신생아 사망률이 눈에 띄게 감소하며 영유아 보건 환경이 개선되었음을 확인했습니다(Figure 2.7). 특히 아르헨티나와 케냐의 가파른 하락세는 전 지구적 보건 수준의 발전을 상징합니다.
다만 이러한 낙관적인 데이터 너머에 존재하는 ‘데이터의 이중고(Double burden of data)’에 주목해야 합니다. 보건 상황이 열악한 지역일수록 오히려 이를 정확히 포착할 고품질 데이터가 부족하다는 역설이 존재합니다. 우리의 분석 결과 역시 이러한 데이터의 불완전성을 내포하고 있음을 잊지 말아야 합니다.
이 장에서 우리는 데이터 과학 워크플로의 전체 과정을 세 번이나 반복했습니다. 모든 코드를 단번에 이해하지 못했더라도 괜찮습니다. 가장 좋은 공부법은 직접 코드를 타이핑하며 오류와 싸워보는 것입니다.
단 몇 시간의 실습만으로 우리는 데이터를 통해 세상을 들여다보는 첫걸음을 뗐습니다. 기술이 발전할수록 분석 결과가 세상에 미칠 영향에 대해서도 더 깊이 고민해야 합니다.
“전문가들이 알아서 할 테니 우리는 사회적 영향을 걱정할 필요가 없다”는 생각은 매우 위험합니다. 저는 제가 사랑하던 연구가 군사적 용도나 프라이버시 침해에 쓰이는 것을 목격한 후 과감히 그만두었습니다. 과학이 비정치적이고 도덕적으로 무결하다는 신화에서 깨어나야 할 때입니다.
조 레드먼(Joe Redmon), 2020년 2월 20일
데이터 과학은 때로 “인간성을 차가운 숫자로 축소하는 것” (Keyes 2019)이라는 비판을 받기도 합니다. 하지만 역설적으로 데이터 과학이 각광받는 이유는 분석의 중심에 ’개인’이 서 있기 때문입니다.
우리는 프라이버시와 동의, 그리고 윤리적 책임을 항상 우선순위에 두어야 합니다. 유전공학이나 의학계가 과거의 뼈아픈 실수에서 배워 엄격한 윤리 강령을 만든 것처럼, 데이터 과학 역시 자신의 작업에 대한 깊은 자각(Self-awareness)을 가져야 합니다(Figure 2.8). 우리는 단순히 숫자를 다루는 사람이 아니라, 그 숫자를 통해 누군가의 삶을 이야기하는 스토리텔러이기 때문입니다.

2.5 연습 문제
퀴즈
- 여러분의 언어로 ’데이터 과학’을 정의해 보세요.
- Register (2020) 에 따르면 데이터 관련 결정은 누구에게 영향을 미칩니까? (a. 실제 사람)
- Keyes (2019) 는 데이터 과학을 어떻게 정의했나요? (c. 인간성을 숫자로 비인간적으로 축소하는 것)
- 모든 데이터를 표준화된 범주로 분류하려는 시도의 결과는 무엇입니까? (d. 개인의 정체성과 고유한 경험의 말소)
- Healy (2020) 은 데이터를 다루는 행위에 대해 어떤 답변을 내놓았나요? (a. 데이터 작업은 우리를 본질적인 사회적 ’의미’에 대한 질문과 마주하게 한다.)
- 윤리가 데이터 과학의 핵심 요소인 이유는 무엇입니까? (c. 데이터셋은 결국 인간의 삶과 연결되어 있으며, 그 맥락을 고려해야 하기 때문.)
- R에서 패키지 이름이나 함수명을 입력할 때 시간을 절약해 주는 기능은 무엇인가요? (Tab 자동 완성)
- 코드의 재현성을 확보하기 위해 무작위 결과값을 고정하는 함수는 무엇인가요? (
set.seed()) - ’데이터의 이중고’란 무엇을 의미합니까? (결과가 좋지 않은 지역일수록 오히려 데이터 품질이 낮아 정확한 파악이 어려운 현상)
- 분석 과정을 공유할 때 가장 중요한 것은 무엇입니까? (명확하고 정직한 커뮤니케이션)