library(broom)
library(broom.mixed)
library(estimatr)
library(haven)
library(MatchIt)
library(modelsummary)
library(palmerpenguins)
library(rdrobust)
library(rstanarm)
library(scales)
library(tidyverse)
library(tinytable)15 관찰 데이터에서 인과 관계
선수 지식
- 데이터 분석가를 위한 인과 설계 패턴, (Riederer 2021)
- 이 블로그 게시물은 관찰 데이터에서 인과적 주장을 하는 다양한 접근 방식에 대한 개요를 제공합니다.
- 전국 대규모 백신 접종 환경에서의 BNT162b2 mRNA Covid-19 백신, (Dagan et al. 2021)
- 이 논문은 관찰 데이터에서 도출된 인과적 결론과 무작위 시험의 결론을 비교합니다.
- 효과: 연구 설계 및 인과 관계 소개, (Huntington-Klein 2021)
- 관찰 데이터에서 인과적 주장을 하는 세 가지 주요 접근 방식(차이-차이, 도구 변수, 회귀 불연속성)을 다룬 18~20장을 참고하십시오.
- 관찰 연구로서의 회귀 불연속성 설계 이해, (Sekhon and Titiunik 2017)
- 회귀 불연속성 설계 사용 시의 주의사항을 다룹니다.
핵심 개념 및 기술
- 완벽하게 통제된 실험을 수행하는 것이 항상 가능한 것은 아닙니다. 하지만 실험이 불가능한 ‘관찰 데이터’ 환경에서도 엄격한 통계적 모델링을 통해 인과 관계의 실마리를 찾아낼 수 있습니다.
- 데이터의 표면적인 모습에 속기 쉬운 ’심슨의 역설(Simpson’s paradox)’과 ’버크슨의 역설(Berkson’s paradox)’을 이해하고, 관찰 데이터의 한계를 보완하기 위한 매칭(Matching) 기법의 장점과 한계를 학습합니다.
- 서로 다른 시점과 집단(처리군 vs 대조군)을 비교하는 ‘차이-차이(Difference-in-Differences, DiD)’, 특정 임계값을 기준으로 나타나는 불연속적 변화를 포착하는 ‘회귀 불연속성 설계(Regression Discontinuity Design, RDD)’, 그리고 직접 관찰이 어려운 인과 관계를 간접적인 경로로 추적하는 ’도구 변수(Instrumental Variables, IV)’의 핵심 원리를 습득합니다.
- 이러한 인과 추론 기법을 사용할 때는 연구자가 설정한 가정이 현실과 부합하는지 끊임없이 질문해야 합니다. 우리가 통계적으로 검증할 수 있는 영역과 없는 영역의 경계를 명확히 인지하고, 모델의 가정이 성립하지 않을 때 발생할 수 있는 잠재적 위험을 비판적으로 검토하는 자세를 기릅니다.
소프트웨어 및 패키지
- Base R (R Core Team 2024)
broom(Robinson, Hayes, and Couch 2022)broom.mixed(Bolker and Robinson 2022)estimatr(Blair et al. 2021)haven(Wickham, Miller, and Smith 2023)MatchIt(Ho et al. 2011)modelsummary(Arel-Bundock 2022)palmerpenguins(Horst, Presmanes Hill, and Gorman 2020)rdrobust(Calonico et al. 2021)rstanarm(Goodrich et al. 2023)scales(Wickham and Seidel 2022)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
15.1 서론
변수 사이의 인과 관계(Causality)를 명확히 밝혀낼 수 있는 완벽한 실험 환경을 설계할 수 있다면 더할 나위 없을 것입니다. 하지만 현실에서는 윤리적, 비용적 혹은 물리적 제약으로 인해 실험이 불가능한 경우가 훨씬 더 많습니다. 다행히 실험이 아닌 환경에서 수집된 ‘관찰 데이터(Observational data)’ 또한 실험 데이터가 담지 못하는 고유한 가치를 지니고 있습니다. 이번 장에서는 관찰 데이터를 활용해 인과 관계의 사슬을 증명할 수 있는 구체적인 상황과 방법론을 논의합니다. 우리는 경제학, 정치학, 역학 등 여러 분야에서 정립된 분석 도구들을 활용해, 복잡한 데이터 속에 숨겨진 인과적 사실을 정교하게 추출해 내는 법을 배워볼 것입니다.
(Dagan et al. 2021) 은 화이자(Pfizer-BioNTech) 백신의 실질적인 효과를 입증하기 위해 방대한 관찰 데이터를 분석했습니다. 연구진이 직면한 가장 큰 과제는 바로 ‘혼란 변수(Confounder)’을 통제하는 것이었습니다. 혼란 변수란 예측 변수와 결과 변수 모두에 영향을 미치며, 실제로는 존재하지 않는 허위 관계(Spurious relationship)를 만들어내는 요인을 말합니다. 연구진은 백신 접종자와 비접종자를 연령, 성별, 거주 지역, 의료 기록 등에 따라 1:1로 정교하게 짝짓는 ‘매칭’ 기법을 통해 이 문제를 해결했습니다. 이러한 관찰 데이터 분석은 실험실 결과에 신뢰성을 더할 뿐만 아니라, 특정 연령대나 기저 질환군 같은 세부 집단에 대한 깊은 통찰을 제공합니다.
이번 장에서는 무작위 통제 실험(RCT)을 수행하기 어려운 환경에서도 분석가가 인과 관계를 설득력 있게 제시할 수 있도록 돕는 세 가지 핵심 기둥, 즉 차이-차이(DiD), 회귀 불연속성(RDD), 도구 변수(IV)를 차례로 살펴보겠습니다.
15.2 데이터의 함정: 두 가지 주요 역설
데이터가 보여주는 수치만으로 성급하게 결론을 내릴 때, 우리는 흔히 두 가지 치명적인 함정에 빠지곤 합니다. 바로 다음과 같은 역설들입니다.
- 심슨의 역설(Simpson’s paradox)
- 버크슨의 역설(Berkson’s paradox)
15.2.1 심슨의 역설: 집단과 개별 데이터 간의 충돌
심슨의 역설은 각각의 소집단에서 나타나는 경향성이 전체 집단을 합쳐서 보았을 때는 정반대로 나타나는 현상을 말합니다(Simpson 1951). 이는 집단 전체의 특성을 근거로 개별 구성원의 특성을 단언할 때 발생하는 ’생태학적 오류(Ecological fallacy)’의 전형적인 사례입니다.
예를 들어, 학과별로는 학부 성적과 대학원 성적이 뚜렷한 양(+)의 상관관계를 보이더라도, 여러 학과를 하나로 합쳐서 분석하면 마치 음(-)의 관계가 있는 것처럼 보일 수 있습니다. 시뮬레이션 데이터를 통해 이 현상을 직접 확인해 보겠습니다(Figure 15.1).
set.seed(853)
number_in_each <- 1000
department_one <-
tibble(
undergrad = runif(n = number_in_each, min = 0.7, max = 0.9),
noise = rnorm(n = number_in_each, 0, sd = 0.1),
grad = undergrad + noise,
type = "학과 1"
)
department_two <-
tibble(
undergrad = runif(n = number_in_each, min = 0.6, max = 0.8),
noise = rnorm(n = number_in_each, 0, sd = 0.1),
grad = undergrad + noise + 0.3,
type = "학과 2"
)
both_departments <- rbind(department_one, department_two)
both_departments# A tibble: 2,000 × 4
undergrad noise grad type
<dbl> <dbl> <dbl> <chr>
1 0.772 -0.0566 0.715 학과 1
2 0.724 -0.0312 0.693 학과 1
3 0.797 0.0770 0.874 학과 1
4 0.763 -0.0664 0.697 학과 1
5 0.707 0.0717 0.779 학과 1
6 0.781 -0.0165 0.764 학과 1
7 0.726 -0.104 0.623 학과 1
8 0.749 0.0527 0.801 학과 1
9 0.732 -0.0471 0.684 학과 1
10 0.738 0.0552 0.793 학과 1
# ℹ 1,990 more rowsboth_departments |>
ggplot(aes(x = undergrad, y = grad)) +
geom_point(aes(color = type), alpha = 0.1) +
geom_smooth(aes(color = type), method = "lm", formula = "y ~ x") +
geom_smooth(method = "lm", formula = "y ~ x", color = "black") +
labs(
x = "학부 성적",
y = "대학원 성적",
color = "학과"
) +
theme_minimal() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")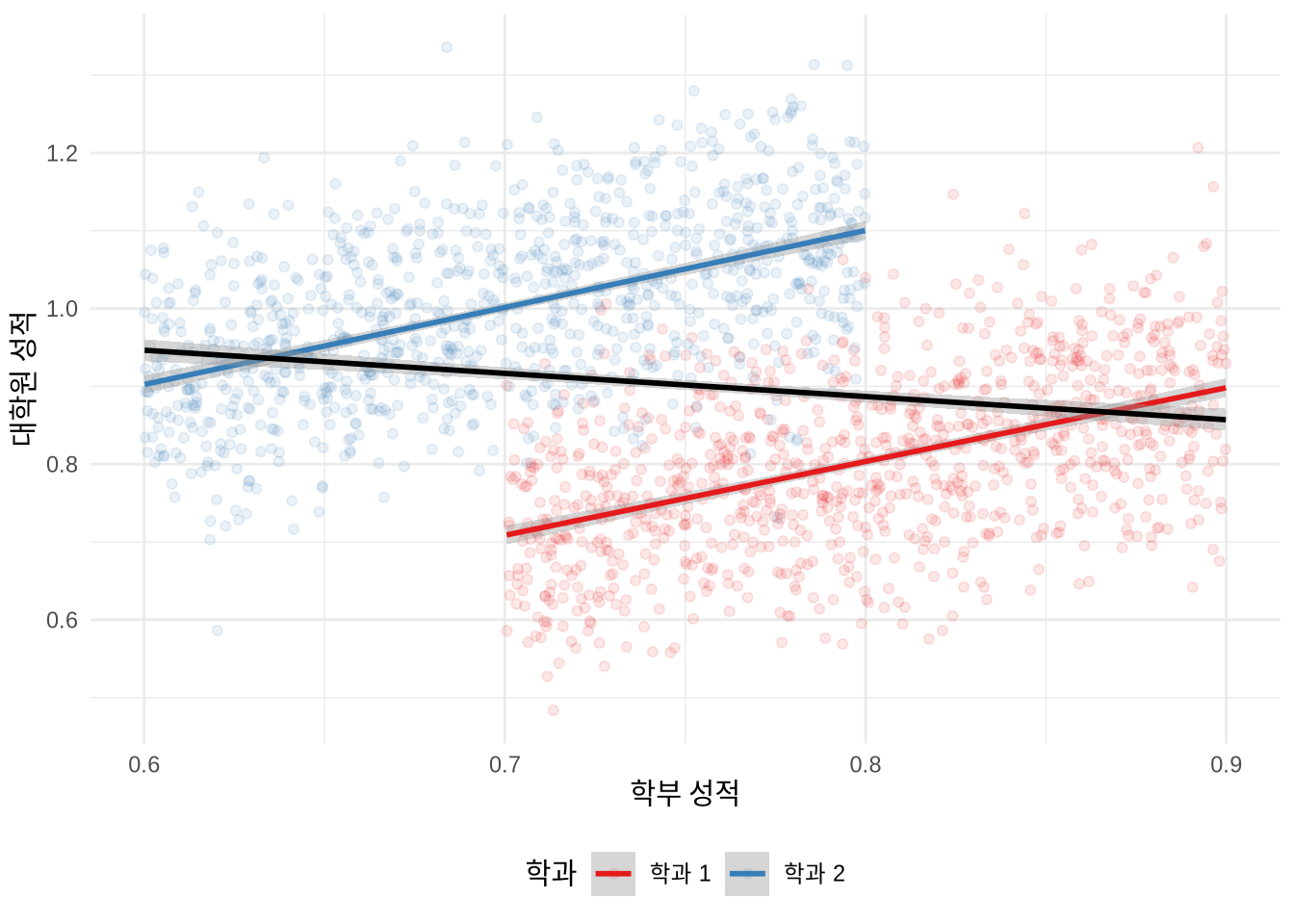
심슨의 역설은 캘리포니아 대학교 버클리의 입학 데이터 분석 사례로도 널리 알려져 있습니다(Bickel, Hammel, and O’Connell 1975). (Hernán, Clayton, and Keiding 2011) 은 인과 관계도(DAG)를 통해 이 역설이 발생하는 구조적 원인을 명쾌하게 설명했습니다.
최근에는 palmerpenguins 데이터셋에서 펭귄의 체질량과 부리 깊이 사이의 관계를 통해서도 심슨의 역설을 발견할 수 있습니다(Figure 15.2). 전체 펭귄을 대상으로 분석하면 음(-)의 상관관계가 나타나지만, 종별로 나누어 보면 각각 양(+)의 상관관계가 나타나는 것을 확인할 수 있습니다.
penguins |>
ggplot(aes(x = body_mass_g, y = bill_depth_mm)) +
geom_point(aes(color = species), alpha = 0.1) +
geom_smooth(aes(color = species), method = "lm", formula = "y ~ x") +
geom_smooth(
method = "lm",
formula = "y ~ x",
color = "black"
) +
labs(
x = "체질량 (g)",
y = "부리 깊이 (mm)",
color = "종"
) +
theme_minimal() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")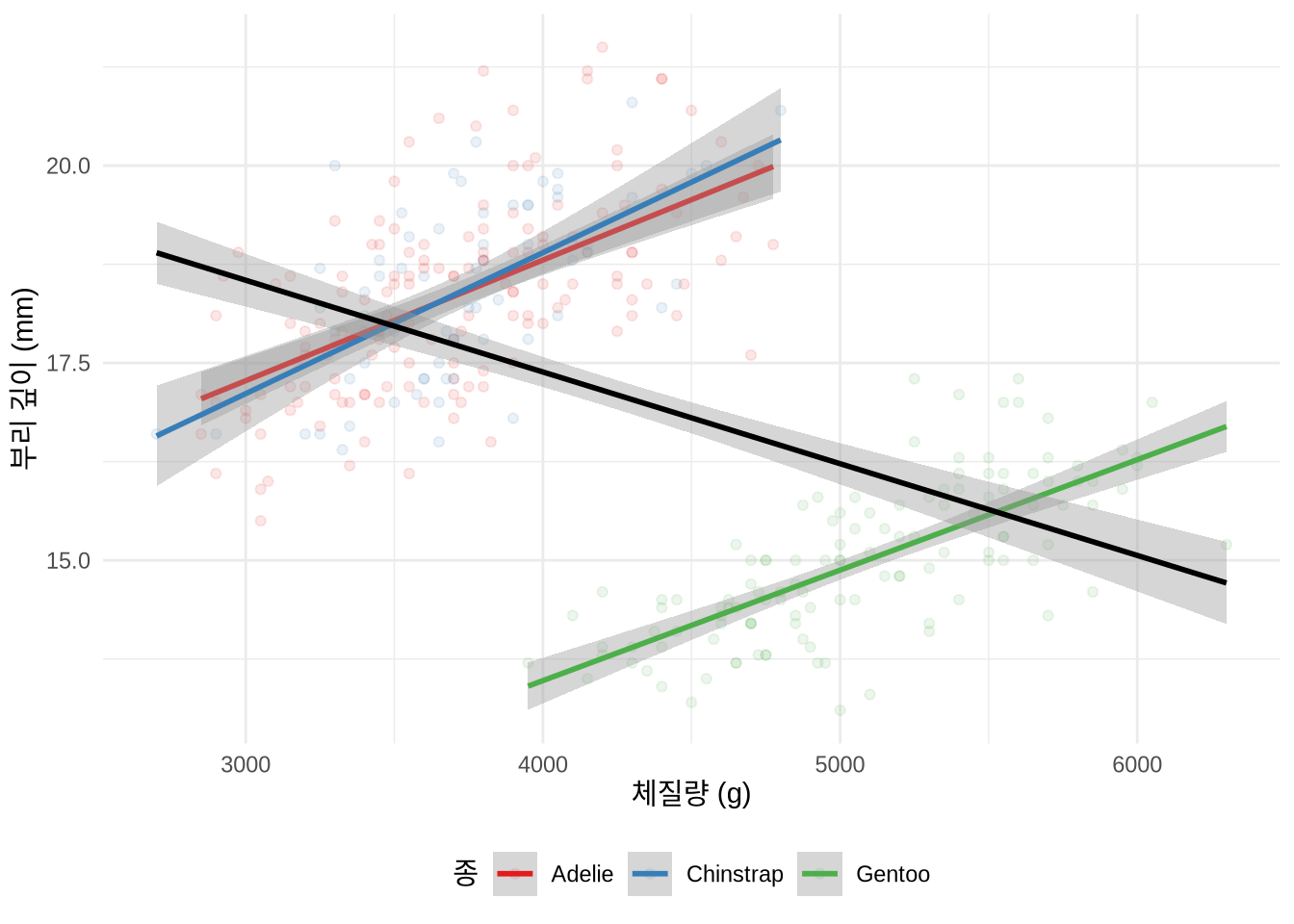
15.2.2 버크슨의 역설: 표본 선택에 의한 인과 왜곡
버크슨의 역설(Berkson’s paradox)은 분석 대상이 전체 모집단이 아닌 특수한 기준에 의해 선택된 집단일 때, 변수 간의 관계가 사실과 다르게 왜곡되어 나타나는 현상을 말합니다(Berkson 1946).
예를 들어, 프로 사이클 선수들만을 대상으로 조사하면 폐활량과 우승 확률 사이에 아무런 관련이 없는 것처럼 보일 수 있습니다(Coyle et al. 1988; Podlogar, Leo, and Spragg 2022). 이는 프로 선수들은 이미 매우 높은 폐활량을 가진 사람들로만 구성되어 있어, 그 집단 내부에서는 폐활량이 더 이상 승패를 가르는 변별력을 가지지 못하기 때문입니다. 이러한 표본 선택 편향이 가져오는 결론의 오류를 시뮬레이션(Figure 15.3)을 통해 살펴보겠습니다.
set.seed(853)
num_pros <- 100
num_public <- 1000
professionals <- tibble(
VO2 = runif(num_pros, 0.7, 0.9),
chance_of_winning = runif(num_pros, 0.7, 0.9),
type = "전문가"
)
general_public <- tibble(
VO2 = runif(num_public, 0.6, 0.8),
chance_of_winning = VO2 + rnorm(num_public, 0, 0.03) + 0.1,
type = "일반인"
)
professionals_and_public <- bind_rows(professionals, general_public)professionals_and_public |>
ggplot(aes(x = VO2, y = chance_of_winning)) +
geom_point(aes(color = type), alpha = 0.1) +
geom_smooth(aes(color = type), method = "lm", formula = "y ~ x") +
geom_smooth(method = "lm", formula = "y ~ x", color = "black") +
labs(
x = "최대 산소 섭취량(VO2 max)",
y = "자전거 경주 우승 확률",
color = "집단 유형"
) +
theme_minimal() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")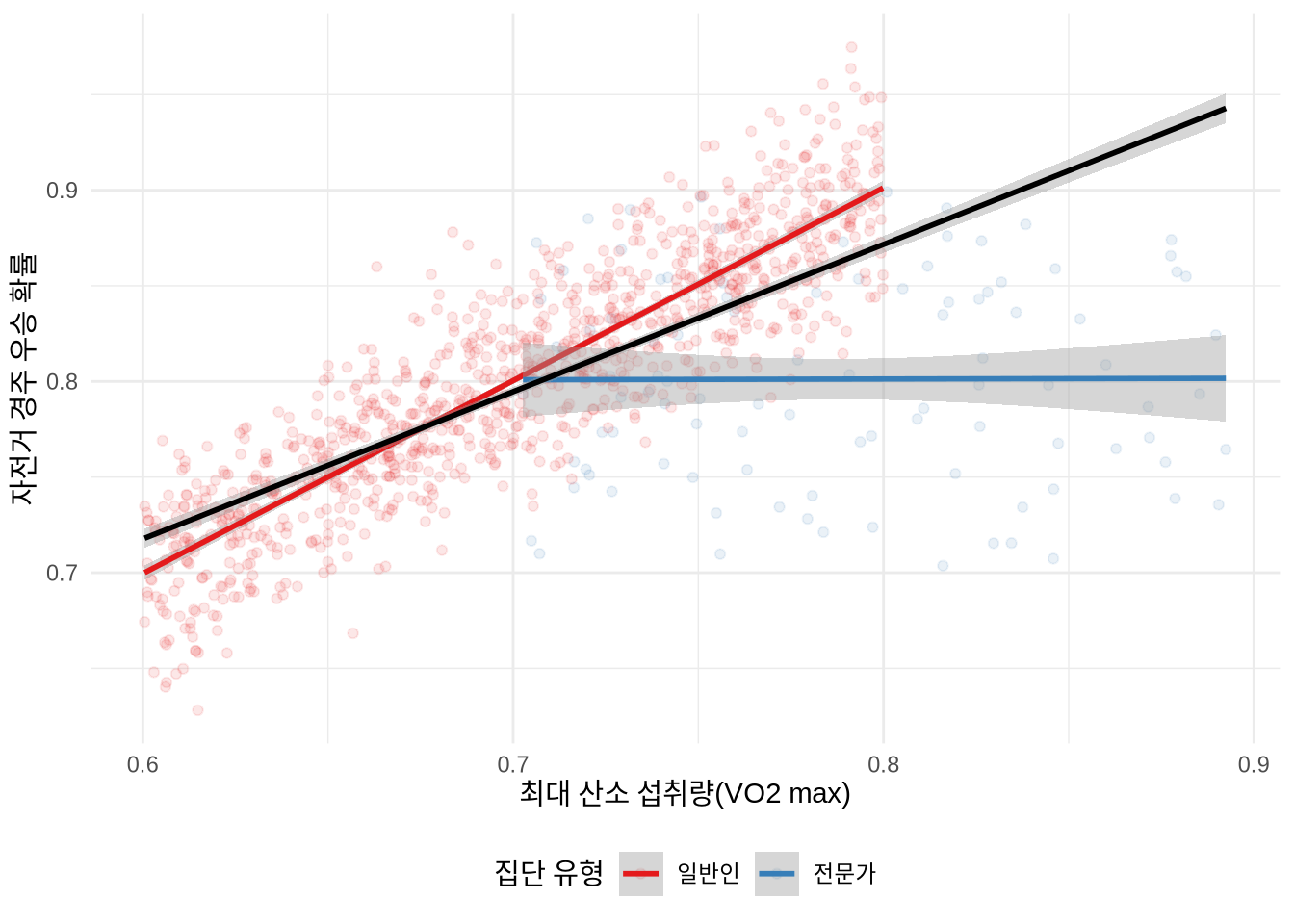
15.3 차이-차이 (Difference-in-Differences, DiD)
현실에서 완벽한 통제 실험을 수행하기란 매우 어렵습니다. 예를 들어, 넷플릭스가 요금제 개편의 효과를 측정하기 위해 우리에게 무작위 실험 권한을 무제한으로 내어줄까요? 설령 비용 문제가 해결되더라도, 어떤 실험은 윤리적인 이유로 아예 시도조차 할 수 없습니다. 이럴 때 분석가는 주어진 상황에서 최선의 대안을 찾아야 합니다. 무작위 배정을 통해 “처리를 제외하고는 완벽하게 같은 두 집단”을 확보하는 대신(반사실, Counterfactual), 우리는 “비록 처음에는 차이가 있었더라도, 변화의 흐름(Trend)만큼은 유사한” 대조군을 찾아낼 수 있습니다. 이 경우, 두 집단 사이에서 나타나는 ’격차의 변화’를 처리의 효과로 해석할 수 있게 됩니다.
관찰 데이터를 이용한 이 기법에서 가장 중요한 요건은 처리군과 대조군의 초기 차이가 일관되게 유지되어 왔으며, 처리가 없었더라도 그 격차가 평행하게 이어졌을 것이라는 ‘평행 추세 가정(Parallel Trends Assumption)’입니다. DiD는 그 강력한 논리에 비해 구현이 비교적 단순하며, (Tang 2015) 처럼 이진 변수를 이용한 선형 회귀만으로도 설득력 있는 주장을 펼칠 수 있습니다.
새로운 테니스 라켓이 서브 속도를 얼마나 높여주는지 확인하고 싶다고 가정해 봅시다. 세계적인 선수 로저 페더러의 ‘기존 라켓 서브’와 아마추어 빌의 ’새 라켓 서브’ 속도를 직접 비교하는 것은 무의미합니다. 두 사람의 엄청난 속도 차이가 라켓 때문인지, 신체적 능력의 차이 때문인지 구분할 방법이 없기 때문입니다. 그렇다고 빌이 새 라켓을 쓰기 전과 후의 속도만 비교하자니, 그사이에 빌의 서브 실력이 자연스럽게 향상되었을 가능성을 배제할 수 없습니다(자연적 성장 효과).
이때 DiD 기법은 두 세계를 결합하여 해답을 제시합니다. 먼저 페더러와 빌이 모두 기존 라켓을 사용할 때의 서브 속도 차이를 측정합니다(이것이 우리의 ’기준선’이 됩니다). 그다음 페더러는 기존 라켓을 유지하고 빌만 새 라켓으로 바꾼 뒤, 다시 속도 차이를 측정합니다. 이때 발생한 ‘격차의 변화량’이 바로 새 라켓이 가져온 순수한 효과에 대한 추정치가 됩니다. 이러한 분석이 유효하려면 다음 세 가지 질문을 면밀히 검토해야 합니다.
- 혼재 요인(Confounding Factors): 분석 기간 동안 오직 빌에게만 영향을 미치고 페더러에게는 영향을 주지 않은 다른 변수(예: 빌의 특별 개인 레슨)가 존재하는가?
- 평행 추세(Parallel Trends): 만약 새 라켓이 없었더라도 두 사람의 서브 속도는 앞으로도 유사한 궤적을 그리며 향상되었을 것인가? (DiD의 성패를 가르는 핵심 가정입니다.)
- 분산의 동질성: 페더러와 빌의 서브 속도 변동성(분산)이 통계적으로 허용 가능한 수준인가?
이러한 까다로운 조건에도 불구하고 DiD가 널리 쓰이는 이유는, 분석 전 두 집단이 반드시 동일할 필요가 없기 때문입니다. 두 집단이 ‘어떻게’ 달랐는지만 정확히 이해하고 있다면, 우리는 인과 관계의 실마리를 풀어낼 수 있습니다.
15.3.1 시뮬레이션 예시: 테니스 서브 속도
이론을 더 구체화하기 위해 데이터를 시뮬레이션해 보겠습니다. 초기 상태에서 두 집단의 서브 속도 차이가 1만큼 나고, 빌이 새 라켓을 사용한 뒤에는 그 차이가 6으로 벌어지는 시나리오를 가상해 보겠습니다. 시뮬레이션된 데이터의 모습은 ?fig-diffindifftennisracket과 같습니다.
set.seed(853)
simulated_diff_in_diff <-
tibble(
person = rep(c(1:1000), times = 2),
time = c(rep(0, times = 1000), rep(1, times = 1000)),
treat_group = rep(sample(x = 0:1, size = 1000, replace = TRUE ), times = 2)
) |>
mutate(
treat_group = as.factor(treat_group),
time = as.factor(time)
)
simulated_diff_in_diff <-
simulated_diff_in_diff |>
rowwise() |>
mutate(
serve_speed = case_when(
time == 0 & treat_group == 0 ~ rnorm(n = 1, mean = 5, sd = 1),
time == 1 & treat_group == 0 ~ rnorm(n = 1, mean = 6, sd = 1),
time == 0 & treat_group == 1 ~ rnorm(n = 1, mean = 8, sd = 1),
time == 1 & treat_group == 1 ~ rnorm(n = 1, mean = 14, sd = 1)
)
)
simulated_diff_in_diff# A tibble: 2,000 × 4
# Rowwise:
person time treat_group serve_speed
<int> <fct> <fct> <dbl>
1 1 0 0 4.43
2 2 0 1 6.96
3 3 0 1 7.77
4 4 0 0 5.31
5 5 0 0 4.09
6 6 0 0 4.85
7 7 0 0 6.43
8 8 0 0 5.77
9 9 0 1 6.13
10 10 0 1 7.32
# ℹ 1,990 more rowssimulated_diff_in_diff |>
ggplot(aes(x = time, y = serve_speed, color = treat_group)) +
geom_point(alpha = 0.2) +
geom_line(aes(group = person), alpha = 0.1) +
theme_minimal() +
labs(x = "기간", y = "서브 속도", color = "새 라켓 수혜 여부") +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")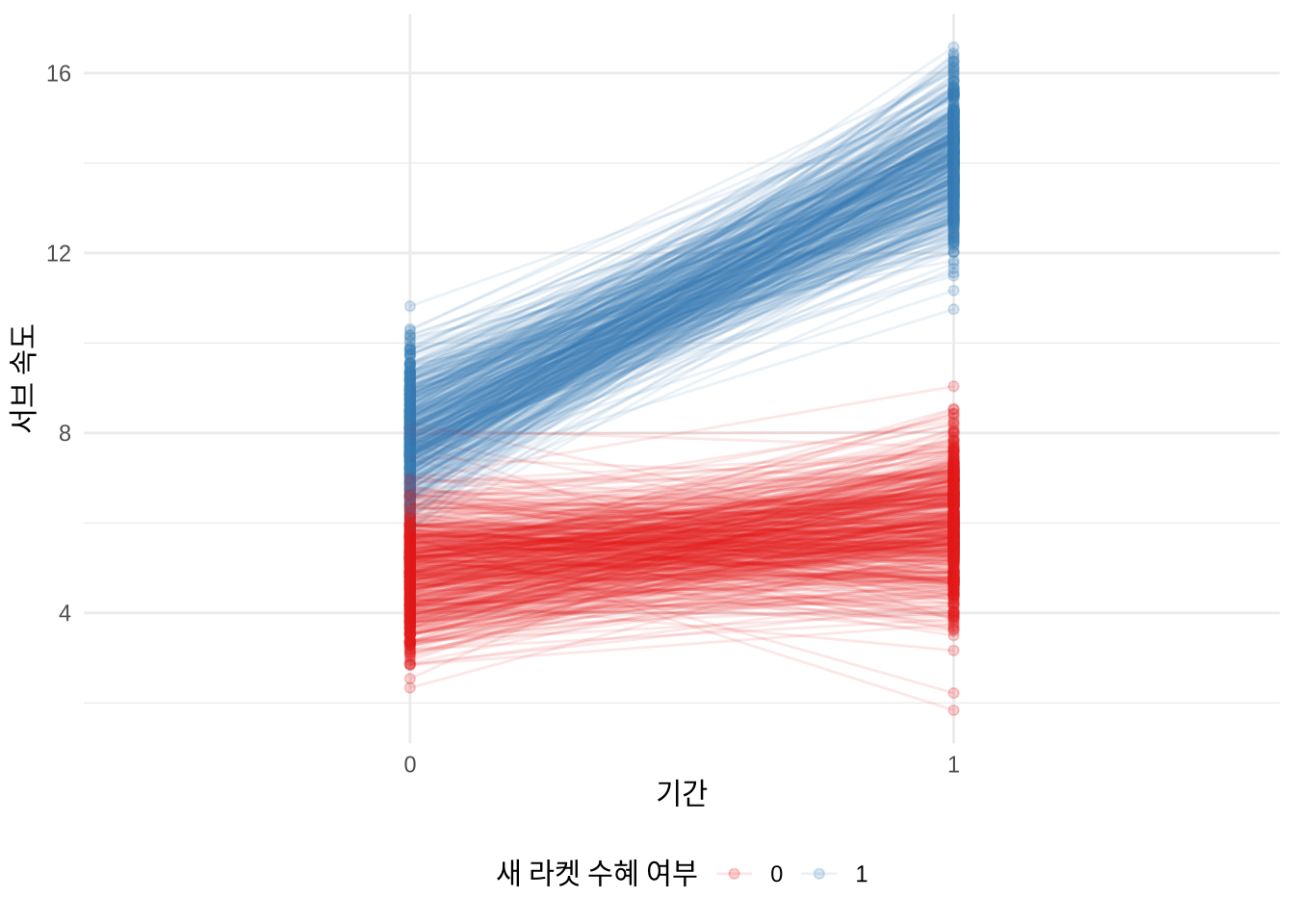
각 집단의 평균 변화를 비교해 보면 새 라켓의 효과가 약 5.06 정도로 추정되는 것을 확인할 수 있습니다. 이는 우리가 설정한 시뮬레이션 파라미터와 거의 일치합니다.
ave_diff <-
simulated_diff_in_diff |>
pivot_wider(
names_from = time,
values_from = serve_speed,
names_prefix = "time_"
) |>
mutate(difference = time_1 - time_0) |>
# 그룹 내에서 이전 및 새 라켓 서브 속도 간의 평균 차이
summarise(average_difference = mean(difference),
.by = treat_group)
# 각 그룹의 평균 차이 간의 차이 (차이의 차이)
ave_diff$average_difference[2] - ave_diff$average_difference[1][1] 5.058414이 ’차이의 차이’는 선형 회귀 모델을 통해서도 똑같이 얻어낼 수 있습니다. 우리가 추정하고자 하는 모델의 구조는 다음과 같습니다.
\[Y_{i,t} = \beta_0 + \beta_1\times\mbox{Target}_i + \beta_2\times\mbox{Time}_t + \beta_3\times(\mbox{Target} \times\mbox{Time})_{i,t} + \epsilon_{i,t}\]
여기서 우리가 가장 집중해야 할 숫자는 상호작용 항(Interaction term)의 계수인 \(\beta_3\)입니다. Table 15.1 을 보면 라켓의 효과가 5.06으로 명확하게 포착되는 것을 확인할 수 있습니다.
diff_in_diff_example_regression <-
stan_glm(
formula = serve_speed ~ treat_group * time,
data = simulated_diff_in_diff,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
diff_in_diff_example_regression,
file = "diff_in_diff_example_regression.rds"
)diff_in_diff_example_regression <-
readRDS(file = "diff_in_diff_example_regression.rds")modelsummary(
diff_in_diff_example_regression
)| (1) | |
|---|---|
| (Intercept) | 4.971 |
| treatment_group1 | 3.035 |
| time1 | 1.006 |
| treatment_group1 × time1 | 5.057 |
| Num.Obs. | 2000 |
| R2 | 0.927 |
| R2 Adj. | 0.927 |
| Log.Lik. | -2802.166 |
| ELPD | -2806.3 |
| ELPD s.e. | 32.1 |
| LOOIC | 5612.5 |
| LOOIC s.e. | 64.2 |
| WAIC | 5612.5 |
| RMSE | 0.98 |
15.3.2 DiD의 성패를 가르는 핵심 가정
차이-차이 분석이 논리적 힘을 얻으려면 몇 가지 엄격한 가정을 통과해야 합니다. 그중에서도 가장 중요하면서도 악명 높은 것이 바로 ‘평행 추세(Parallel Trends)’ 가정입니다. 이 가정은 우리가 결코 데이터로 직접 증명할 수 없기에 분석가를 늘 괴롭힙니다. 우리는 그저 데이터 주변의 정황 증거를 모아 독자를 설득할 수 있을 뿐입니다.
왜 증명이 불가능할까요? 새로운 경기장이 프로 스포츠 팀의 승률에 미치는 영향을 연구한다고 가정해 봅시다. 2019-20 시즌에 경기장을 옮긴 ’골든스테이트 워리어스’와 옮기지 않은 ’토론토 랩터스’를 비교하기 위해 지난 몇 시즌의 성적을 추적합니다. 여기서 랩터스는 우리의 ‘반사실(Counterfactual)’ 역할을 수행합니다. 즉, “만약 워리어스가 경기장을 옮기지 않았더라면, 그들의 승률 궤적은 랩터스와 평행하게 움직였을 거야”라고 가정하는 셈입니다. 하지만 인과 추론의 근본적인 한계(Fundamental problem of causal inference) 때문에, 우리는 일어나지 않은 미래를 결코 확신할 수 없습니다. 따라서 분석가는 가능한 모든 증거를 동원해 이 가정이 합리적임을 입증해야 합니다.
Cunningham (2021, 272–77)은 DiD의 타당성을 위협하는 네 가지 주요 요인을 다음과 같이 정리했습니다:
- 비평행 추세 (Non-parallel Trends): 처리군과 대조군이 애초에 서로 다른 길을 걷고 있었다면 평행 추세를 주장하기 어렵습니다. 이럴 때는 다른 변수를 통제하거나, 제3의 집단을 추가하는 ‘삼중 차이(Triple Differences)’ 기법을 고려해야 합니다.
- 구성적 차이 (Compositional Differences): ‘반복된 교차 단면(Repeated cross-section)’ 데이터를 다룰 때 주의해야 합니다. 집단의 구성원 자체가 시간이 흐르며 바뀌어버리는 경우입니다.
- 신뢰성 vs 장기 효과: 분석 기간을 길게 잡을수록 다른 돌발 변수가 개입할 여지가 커지고, 대조군 집단이 나중에 처리를 받게 될 위험도 커집니다. 반면, 너무 짧은 기간만 분석하면 그 효과가 일시적인 현상인지 장기적인 변화인지 확신할 수 없습니다.
- 함수 형태 의존성 (Functional Form Dependence): 두 집단의 초기 수치 차이가 너무 크면, 어떤 수학적 모델(예: 로그 변환 유무)을 쓰느냐에 따라 결과가 판이하게 달라질 수 있습니다.
Angelucci and Cagé (2019) 의 연구를 통해 DiD의 실전 응용을 살펴보겠습니다. 연구진은 1960년대 프랑스에 텔레비전 광고가 도입된 사건이 기존 신문 산업에 어떤 영향을 미쳤는지 추적했습니다.
과거 텔레비전의 등장은 신문 업계에 큰 위협이었습니다. 1967년 프랑스 정부는 공영 방송의 광고를 허용하기로 발표합니다. Angelucci and Cagé (2019) 는 이 발표가 광고 수익을 감소시켜 신문의 콘텐츠 품질과 가격에 영향을 주었을 것이라는 가설을 세웠습니다.
해당 연구의 공공 데이터셋은 ICPSR 하바드 데이터버스에서 구할 수 있습니다. Stata 형식(.dta)인 이 데이터는 haven 패키지의 read_dta() 함수로 쉽게 불러올 수 있습니다.
newspapers <- read_dta("Angelucci_Cage_AEJMicro_dataset.dta")분석 대상인 데이터셋(1960~1974년)에는 총 1,196개의 관측치와 52개의 변수가 포함되어 있습니다. 분석 기간 시작 시점에 14개였던 전국 신문은 기간 종료 시점에 12개로 줄어들었습니다. 핵심 분기점은 앞서 언급했듯 정부가 TV 광고 허용을 발표한 1967년입니다. 전국 신문은 TV 광고주들을 두고 직접 경쟁하는 관계였기에 ’처리군(Treatment group)’이 되었고, TV 광고의 영향력에서 비교적 자유로웠던 지역 신문은 ’대조군(Control group)’으로서 기능합니다.
우리는 이 방대한 연구의 핵심 지표인 ‘광고 수익’과 ’판매량’ 변화에 초점을 맞추어 DiD 분석을 재구성해 보겠습니다.
newspapers <-
newspapers |>
select(
year, id_news, after_national, local, national, ra_cst, ps_cst, qtotal
) |>
mutate(ra_cst_div_qtotal = ra_cst / qtotal,
across(c(id_news, after_national, local, national), as.factor),
year = as.integer(year))
newspapers# A tibble: 1,196 × 9
year id_news after_national local national ra_cst ps_cst qtotal
<int> <fct> <fct> <fct> <fct> <dbl> <dbl> <dbl>
1 1960 1 0 1 0 52890272 2.29 94478.
2 1961 1 0 1 0 56601060 2.20 96289.
3 1962 1 0 1 0 64840752 2.13 97313.
4 1963 1 0 1 0 70582944 2.43 101068.
5 1964 1 0 1 0 74977888 2.35 102103.
6 1965 1 0 1 0 74438248 2.29 105169.
7 1966 1 0 1 0 81383000 2.31 126235.
8 1967 1 0 1 0 80263152 2.88 128667.
9 1968 1 0 1 0 87165704 3.45 131824.
10 1969 1 0 1 0 102596384 3.28 132417.
# ℹ 1,186 more rows
# ℹ 1 more variable: ra_cst_div_qtotal <dbl>1967년 이후에 무슨 일이 일어났는지, 특히 광고 수익 측면에서, 그리고 전국 신문과 비교하여 지역 신문에 어떤 차이가 있었는지에 관심이 있습니다(Figure 15.5). y축을 조정하기 위해 scales를 사용합니다.
newspapers |>
mutate(type = if_else(local == 1, "지역", "전국")) |>
ggplot(aes(x = year, y = ra_cst)) +
geom_point(alpha = 0.5) +
scale_y_continuous(
labels = dollar_format(
prefix = "$",
suffix = "M",
scale = 0.000001)) +
labs(x = "연도", y = "광고 수익") +
facet_wrap(vars(type), nrow = 2) +
theme_minimal() +
geom_vline(xintercept = 1966.5, linetype = "dashed")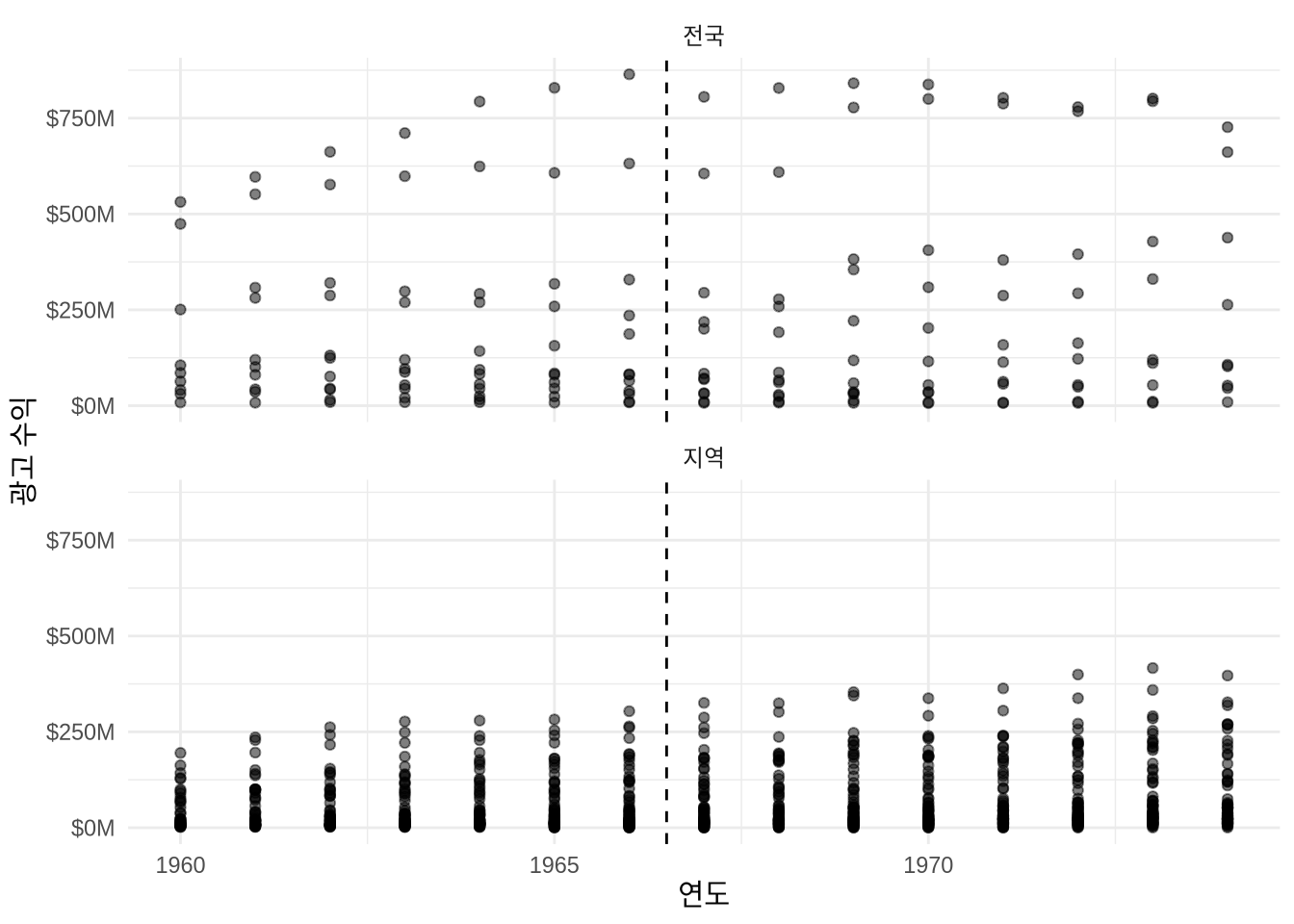
우리가 추정하는 데 관심 있는 모델은 다음과 같습니다.
\[\mbox{ln}(y_{n,t}) = \beta_0 + \beta_1\times(\mbox{전국 이진}\times\mbox{1967년 이후 이진}) + \lambda_n + \gamma_t + \epsilon\]
특히 관심 있는 것은 \(\beta_1\) 계수입니다. stan_glm()을 사용하여 모델을 추정합니다.
ad_revenue <-
stan_glm(
formula = log(ra_cst) ~ after_national + id_news + year,
data = newspapers,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
ad_revenue,
file = "ad_revenue.rds"
)
ad_revenue_div_circulation <-
stan_glm(
formula = log(ra_cst_div_qtotal) ~ after_national + id_news + year,
data = newspapers,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
ad_revenue_div_circulation,
file = "ad_revenue_div_circulation.rds"
)
# 소비자 측면
subscription_price <-
stan_glm(
formula = log(ps_cst) ~ after_national + id_news + year,
data = newspapers,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
subscription_price,
file = "subscription_price.rds"
)ad_revenue <-
readRDS(file = "ad_revenue.rds")
ad_revenue_div_circulation <-
readRDS(file = "ad_revenue_div_circulation")
subscription_price <-
readRDS(file = "subscription_price.rds")보시는 바와 같이 분석 결과(Table 15.2), 광고 수익과 판매 관련 지표들에서 일관되게 음(-)의 계수가 관찰됩니다. 즉, TV 광고 도입 이후 전국 신문의 광고 수입이 유의미하게 하락했음을 알 수 있습니다.
selected_variables <- c("year" = "연도", "after_national1" = "변경 후")
modelsummary(
models = list(
"광고 수익" = ad_revenue,
"순환 대비 광고 수익" = ad_revenue_div_circulation,
"구독 가격" = subscription_price
),
fmt = 2,
coef_map = selected_variables
)| 광고 수익 | 순환 대비 광고 수익 | 구독 가격 | |
|---|---|---|---|
| 연도 | 0.05 | 0.04 | 0.05 |
| 변경 후 | -0.23 | -0.15 | -0.04 |
| Num.Obs. | 1052 | 1048 | 1044 |
| R2 | 0.984 | 0.896 | 0.868 |
| R2 Adj. | 0.983 | 0.886 | 0.852 |
| Log.Lik. | 336.539 | 441.471 | 875.559 |
| ELPD | 257.4 | 362.3 | 793.5 |
| ELPD s.e. | 34.4 | 45.6 | 24.3 |
| LOOIC | -514.8 | -724.7 | -1587.0 |
| LOOIC s.e. | 68.9 | 91.1 | 48.6 |
| WAIC | -515.9 | -725.5 | -1588.9 |
| RMSE | 0.17 | 0.16 | 0.10 |
저자들은 이 주요 결과를 바탕으로 다양한 보조 분석을 수행했으며, 특히 1967년 이후부터 처리군과 대조군 사이의 격차가 뚜렷하게 벌어지는 것을 확인했습니다(Angelucci and Cagé 2019). 이 연구는 복잡한 시장 상황 속에서도 정교한 DiD 설계를 통해 외생적 충격(TV 광고)의 인과 효과를 추출해낸 사례입니다.
차이-차이(DiD)는 강력한 분석 프레임워크이지만, 적절한 대조군을 찾는 것이 어렵습니다. Alexander and Ward (2018) 는 이주 형제들을 비교했습니다. 한 형제는 본국에서, 다른 형제는 미국에서 교육을 받은 경우입니다. 형제는 여러 특성을 공유하므로 합리적인 대조군이 될 수 있습니다.
우리는 대개 연령이나 교육 수준처럼 ’관찰 가능한 변수’들을 기준으로 집단을 짝짓습니다. 예를 들어 A 도시의 18세 흡연율과 B 도시의 18세 흡연율을 비교하는 식입니다. 하지만 이는 다소 거친 매칭 방식입니다. 성별, 가정 환경, 학력 등 같은 연령대 내에서도 수많은 차이가 존재하기 때문입니다. 이를 해결하기 위해 ’고졸 학력을 가진 18세 남성’처럼 하위 그룹을 촘촘하게 쪼갤 수도 있겠지만, 이럴 경우 비교 대상(표본 크기)이 급격히 줄어들어 분석 자체가 불가능해질 수 있습니다. 또한 소득과 같은 연속 변수를 어떻게 처리할지도 까다로운 문제입니다.
이러한 한계를 극복하기 위해 등장한 기법이 바로 성향 점수 매칭(Propensity Score Matching, PSM)입니다. 이 기법은 각 관측치가 특정한 처리(Treatment)를 받을 확률을 계산하여, 이를 ‘성향 점수’라는 하나의 수치로 요약합니다. 이 점수는 실제로 처리를 받았는지와 상관없이, 그 사람이 가진 다차원적인 특성상 처리를 받을 법한 ’가능성’을 나타냅니다. 예를 들어 어떤 정책의 대상이 된 18세 남성과 대상이 되지 않은 19세 남성은 성향 점수 측면에서는 매우 비슷할 수 있습니다. PSM은 이렇게 성향 점수가 유사한 ’닮은꼴’들끼리 짝을 지어 결과를 비교함으로써, 마치 무작위 실험을 설계한 것과 유사한 통제 효과를 냅니다.
15.3.3 시뮬레이션 예시: 온라인 쇼핑몰의 무료 배송 효과
성향 점수 매칭의 큰 장점은 수많은 예측 변수를 로지스틱 회귀 모델을 통해 하나의 점수로 통합할 수 있다는 것입니다. 이를 확인하기 위해 데이터를 시뮬레이션해 보겠습니다. 당신이 대형 온라인 쇼핑몰의 데이터 분석가라고 가정해 봅시다. 특정 고객들에게 ‘무료 배송’ 혜택을 제공했을 때, 이들의 평균 구매 금액이 실제로 얼마나 증가하는지 정확히 측정해야 하는 과제를 맡았습니다.
set.seed(853)
sample_size <- 10000
purchase_data <-
tibble(
unique_person_id = 1:sample_size,
age = sample(x = 18:100, size = sample_size, replace = TRUE),
gender = sample(
x = c("여성", "남성", "기타/거부"),
size = sample_size,
replace = TRUE,
prob = c(0.49, 0.47, 0.02)
),
income = rnorm(n = sample_size, mean = 60000, sd = 15000) |> round(0)
)
purchase_data# A tibble: 10,000 × 4
unique_person_id age gender income
<int> <int> <chr> <dbl>
1 1 26 남성 68637
2 2 81 여성 71486
3 3 34 남성 75652
4 4 46 남성 68068
5 5 100 여성 73206
6 6 20 남성 41872
7 7 50 여성 75957
8 8 36 여성 56566
9 9 72 남성 54621
10 10 52 여성 40722
# ℹ 9,990 more rows다음으로 고객이 무료 배송 대상자로 선정될 확률을 추가합니다. 여기서는 나이가 젊고, 소득이 높으며, 남성인 고객이 무료 배송 혜택을 받을 가능성이 더 높도록 설정하겠습니다. 시뮬레이션 환경이기에 우리는 이 설정값을 알고 있지만, 실제 분석 현장에서는 이러한 배정 메커니즘을 미리 알 수 없습니다.
purchase_data <-
purchase_data |>
mutate(
# 특성을 범주형 수치로 변환
age_num = rank(1 / age, ties.method = "random") %/% 3000,
gender_num = case_when(
gender == "남성" ~ 3,
gender == "여성" ~ 2,
gender == "기타/거부" ~ 1
),
income_num = rank(income, ties.method = "random") %/% 3000
) |>
mutate(
sum_num = age_num + gender_num + income_num,
softmax_prob = exp(sum_num) / exp(max(sum_num) + 0.5),
free_shipping = rbinom(n = sample_size, size = 1, prob = softmax_prob)) |>
select(-(age_num:softmax_prob))마지막으로 각 고객의 평균 지출액 데이터를 생성합니다. 지출액은 소득에 비례하며, 특히 무료 배송 혜택을 받은 고객의 지출이 받지 않은 고객보다 평균적으로 높게 나타나도록 시뮬레이션하겠습니다.
purchase_data <-
purchase_data |>
mutate(
noise = rnorm(n = nrow(purchase_data), mean = 5, sd = 2),
spend = income / 1000 + noise,
spend = if_else(free_shipping == 1, spend + 10, spend),
spend = as.integer(spend)
) |>
select(-noise) |>
mutate(across(c(gender, free_shipping), as.factor))
purchase_data# A tibble: 10,000 × 6
unique_person_id age gender income free_shipping spend
<int> <int> <fct> <dbl> <fct> <int>
1 1 26 남성 68637 0 72
2 2 81 여성 71486 0 73
3 3 34 남성 75652 0 80
4 4 46 남성 68068 0 75
5 5 100 여성 73206 0 78
6 6 20 남성 41872 0 45
7 7 50 여성 75957 0 78
8 8 36 여성 56566 0 62
9 9 72 남성 54621 0 55
10 10 52 여성 40722 0 47
# ℹ 9,990 more rows단순히 무료 배송 수혜 집단과 비수혜 집단의 지출액 평균을 비교해 보면 상당한 차이가 관찰됩니다(Table 15.3). 하지만 여기서 “혜택을 받지 않았더라도, 원래 이 우량 고객들은 더 많은 쇼핑을 하지 않았을까?” 하는 질문이 생깁니다(역인과성 또는 혼란 변수 문제).
우리는 시뮬레이션을 통해 무료 배송 배정이 특정 조건(젊고 구매력이 높은 층)에 편향되어 있음을 알고 있습니다. 따라서 단순한 평균 비교는 왜곡된 결과를 낳습니다. 대신 성향 점수 매칭을 통해, 무료 배송을 받은 고객과 가장 ‘닮은’(성별, 나이, 소득 조건이 유사한) 비수혜 고객을 1:1로 추출하여 비교 대조군을 재구성합니다.
purchase_data |>
summarise(average_spend = round(mean(spend), 2), .by = free_shipping) |>
mutate(free_shipping = if_else(free_shipping == 0, "아니오", "예")) |>
tt() |>
style_tt(j = 1:2, align = "lr") |>
setNames(c("무료 배송 수혜 여부", "평균 지출액"))| 무료 배송 수혜 여부 | 평균 지출액 |
|---|---|
| 아니오 | 64.44 |
| 예 | 86.71 |
matched_groups <-
matchit(
free_shipping ~ age + gender + income,
data = purchase_data,
method = "nearest",
distance = "glm"
)
matched_groupsA `matchit` object
- method: 1:1 nearest neighbor matching without replacement
- distance: Propensity score
- estimated with logistic regression
- number of obs.: 10000 (original), 508 (matched)
- target estimand: ATT
- covariates: age, gender, incomematched_dataset <- match.data(matched_groups)
matched_dataset# A tibble: 508 × 9
unique_person_id age gender income free_shipping spend distance weights
<int> <int> <fct> <dbl> <fct> <int> <dbl> <dbl>
1 23 28 여성 65685 1 79 0.0334 1
2 24 67 남성 71150 0 76 0.0220 1
3 32 22 여성 86071 0 92 0.131 1
4 48 66 여성 100105 0 108 0.0473 1
5 59 25 남성 55548 1 68 0.0541 1
6 82 66 남성 70721 0 75 0.0224 1
7 83 58 남성 83443 0 88 0.0651 1
8 87 46 남성 59073 1 73 0.0271 1
9 119 89 기타/거부 72284 0 74 0.00301 1
10 125 51 여성 81164 1 96 0.0303 1
# ℹ 498 more rows
# ℹ 1 more variable: subclass <fct>이렇게 재평성된 ’매칭 데이터셋’을 바탕으로 선형 회귀 분석을 수행하여 순수한 처리 효과를 추출해 봅니다(Table 15.4).
propensity_score_regression <- lm(
spend ~ age + gender + income + free_shipping,
data = matched_dataset
)
modelsummary(propensity_score_regression)| (1) | |
|---|---|
| (Intercept) | 3.353 |
| (0.981) | |
| age | 0.007 |
| (0.005) | |
| gender남성 | 0.522 |
| (0.835) | |
| gender여성 | 0.509 |
| (0.847) | |
| income | 0.001 |
| (0.000) | |
| free_shipping1 | 10.073 |
| (0.180) | |
| Num.Obs. | 508 |
| R2 | 0.983 |
| R2 Adj. | 0.983 |
| AIC | 2167.6 |
| BIC | 2197.2 |
| Log.Lik. | -1076.811 |
| F | 5911.747 |
| RMSE | 2.02 |
매칭된 표본을 분석한 결과(Table 15.4), 무료 배송의 순수한 효과는 우리가 시뮬레이션 설정 시 부여했던 값인 ’10’에 매우 가깝게 나타났습니다. 이는 전체 데이터를 단순히 비교했던 ?tbl-heyheybigspender의 결과와 극명한 대조를 이루며, PSM이 어떻게 편향을 제거하는지 잘 보여줍니다.
PSM은 실무에서 활발히 사용되지만, 몇 가지 주의할 점이 있습니다. 분석의 투명성을 위해 연구자는 다음 사항을 반드시 인지해야 합니다(King and Nielsen 2019).
결론적으로, 관찰 불가능한 변수(Hidden bias)의 문제는 데이터를 분석하기 전까지는 완벽히 해소할 수 없으므로, 분석가는 결과의 타당성을 끊임없이 교차 검증해야 합니다. (McKenzie 2021) 가 제안하듯이, 때로는 물리적 용량 제한과 같은 외부 요인이 무작위성의 역할을 대신해 줄 수도 있습니다. 결국 이 장의 핵심은 통계 기법 자체보다도 데이터가 생성된 맥락과 비즈니스 상황에 대한 깊은 이해가 선행되어야 한다는 점입니다.
15.4 회귀 불연속성 설계 (Regression Discontinuity Design, RDD)
회귀 불연속성 설계(RDD)는 (Thistlethwaite and Campbell 1960) 에 의해 정립된 방법론으로, 처리를 결정하는 명확한 ’임계값(Cut-off)’이 존재하는 연속 변수가 있을 때 이 점을 중심으로 인과 효과를 추정하는 기법입니다.
예를 들어, 시험 점수 80점을 기준으로 장학금 수혜 여부가 갈린다면, 79점과 80점 학생의 지적 능력 차이는 거의 없겠지만 80점 학생만 장학금을 받게 됩니다. 이때 시험 점수는 ‘강제 변수(Forcing variable)’가 되고, 80점은 ‘임계값(Threshold)’ 혹은 ’절단점’이 됩니다. RDD는 이 임계값 부근에서 나타나는 불연속적인 결과의 변화를 통해 처리의 인과 효과를 포착합니다.
(Cunningham 2021) 은 이 강제 변수를 ’실행 변수(Running variable)’라고 부르기도 합니다.
15.4.1 시뮬레이션 예시: 학업 성적과 초기 소득
RDD의 원리를 더 구체적으로 이해하기 위해 데이터를 시뮬레이션해 보겠습니다. 성적과 소득 사이의 관계를 모델링하되, 학생이 80점 이상을 받으면 ’성적 장학금’이나 ’특별 채용’의 기회가 생겨 소득이 불연속적으로 점프하는 시나리오를 가정해 보겠습니다(Figure 15.6).
set.seed(853)
num_observations <- 1000
rdd_example_data <- tibble(
person = c(1:num_observations),
mark = runif(num_observations, min = 78, max = 82),
income = rnorm(num_observations, 10, 1)
)
## 80점 이상이면 소득이 점프하도록 설정합니다.
rdd_example_data <-
rdd_example_data |>
mutate(
noise = rnorm(n = num_observations, mean = 2, sd = 1),
income = if_else(mark >= 80, income + noise, income)
)
rdd_example_data# A tibble: 1,000 × 4
person mark income noise
<int> <dbl> <dbl> <dbl>
1 1 79.4 9.43 1.87
2 2 78.5 9.69 2.26
3 3 79.9 10.8 1.14
4 4 79.3 9.34 2.50
5 5 78.1 10.7 2.21
6 6 79.6 9.83 2.47
7 7 78.5 8.96 4.22
8 8 79.0 10.5 3.11
9 9 78.6 9.53 0.671
10 10 78.8 10.6 2.46
# ℹ 990 more rowsrdd_example_data |>
ggplot(aes(
x = mark,
y = income
)) +
geom_point(alpha = 0.2) +
geom_smooth(
data = rdd_example_data |> filter(mark < 80),
method = "lm",
color = "black",
formula = "y ~ x"
) +
geom_smooth(
data = rdd_example_data |> filter(mark >= 80),
method = "lm",
color = "black",
formula = "y ~ x"
) +
theme_minimal() +
labs(
x = "시험 점수",
y = "소득 ($)"
)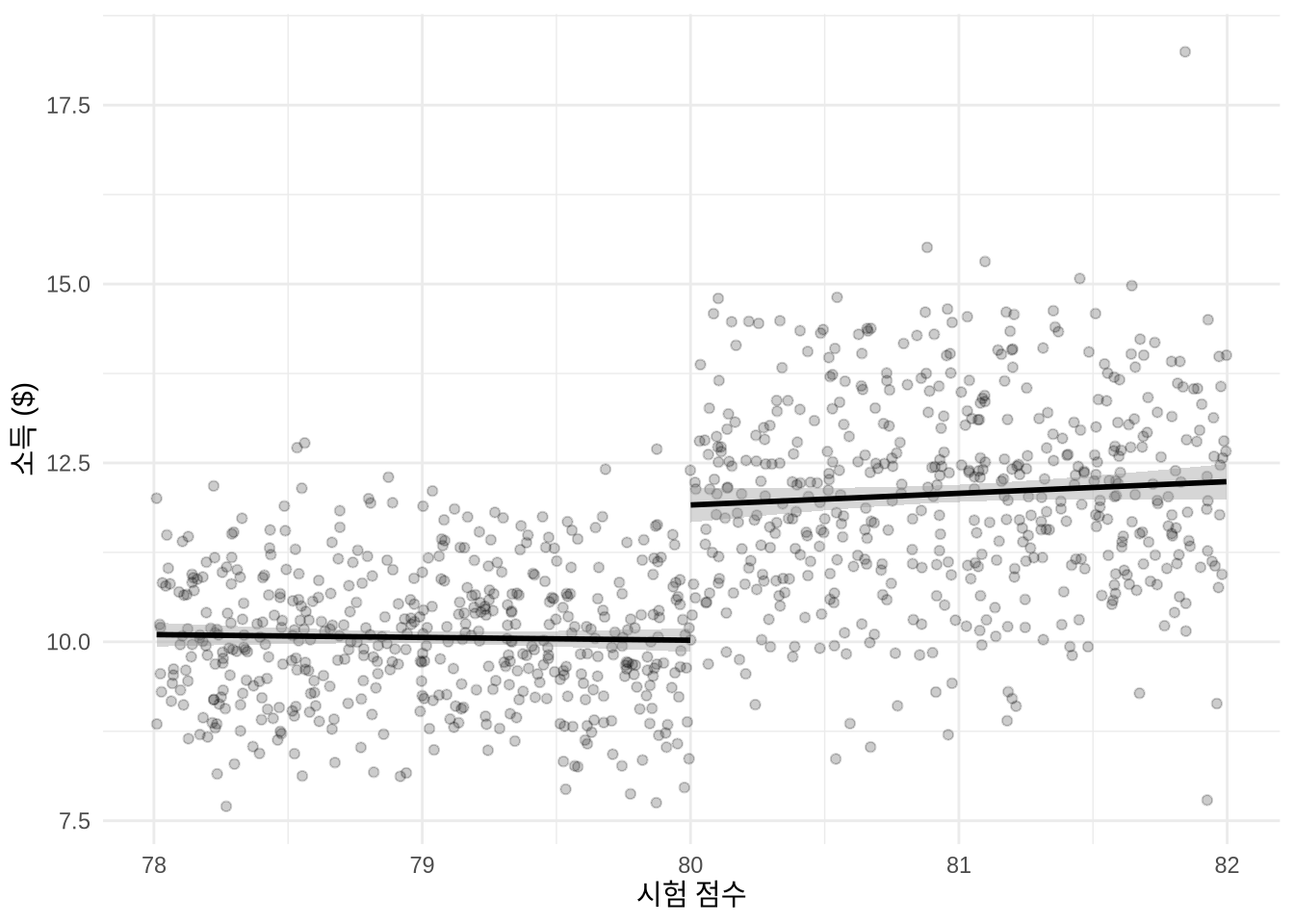
80점이라는 문턱을 넘은 것이 소득에 미치는 영향을 확인하기 위해, 해당 점수를 넘었는지 여부(이진 변수)를 독립 변수로 포함하여 선형 회귀를 실행합니다. 우리는 시뮬레이션 설정값과 유사한 약 2 정도의 소득 상승 효과를 기대하며, 실제 분석 결과도 이를 정확히 포착해 냅니다(Table 15.5).
rdd_example_data <-
rdd_example_data |>
mutate(mark_80_and_over = if_else(mark < 80, 0, 1))
rdd_example <-
stan_glm(
formula = income ~ mark + mark_80_and_over,
data = rdd_example_data,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
rdd_example,
file = "rdd_example.rds"
)rdd_example <-
readRDS(file = "rdd_example.rds")modelsummary(
models = rdd_example,
fmt = 2
)| (1) | |
|---|---|
| (Intercept) | 5.22 |
| mark | 0.06 |
| mark_80_and_over | 1.89 |
| Num.Obs. | 1000 |
| R2 | 0.417 |
| R2 Adj. | 0.415 |
| Log.Lik. | -1591.847 |
| ELPD | -1595.1 |
| ELPD s.e. | 25.4 |
| LOOIC | 3190.3 |
| LOOIC s.e. | 50.9 |
| WAIC | 3190.3 |
| RMSE | 1.19 |
실제 현장에서는 여러 제약이 따르겠지만, RDD는 적절히 설계될 경우 무작위 통제 실험(RCT)에 준하는 신뢰도를 가집니다 (Bloom, Bell, and Reiman 2020).
또한 rdrobust 패키지를 사용하여 RDD를 구현할 수도 있습니다. 이 패키지의 장점은 필터링이나 윈도우 크기 결정 등 다양한 고급 옵션을 제공한다는 것입니다.
rdrobust(
y = rdd_example_data$income,
x = rdd_example_data$mark,
c = 80,
h = 2,
all = TRUE
) |>
summary()Sharp RD estimates using local polynomial regression.
Number of Obs. 1000
BW type Manual
Kernel Triangular
VCE method NN
Number of Obs. 497 503
Eff. Number of Obs. 497 503
Order est. (p) 1 1
Order bias (q) 2 2
BW est. (h) 2.000 2.000
BW bias (b) 2.000 2.000
rho (h/b) 1.000 1.000
Unique Obs. 497 503
=======================================================================================
Method Coef. Std. Err. z P>|z| [ 95% C.I. ]
=======================================================================================
Conventional 1.913 0.161 11.876 0.000 [1.597 , 2.229]
Bias-Corrected 1.966 0.161 12.207 0.000 [1.650 , 2.282]
Robust 1.966 0.232 8.461 0.000 [1.511 , 2.422]
=======================================================================================15.4.2 RDD의 핵심 전제: 두 가지 기본 가정
RDD 분석이 타당성을 얻으려면 다음 두 가지 가정이 충족되어야 합니다 ((Cunningham 2021, 163)).
- 명확한 절단점: 임계값은 구체적이고 고정되어 있어야 하며, 분석 대상자들에게 사전에 공개되어 있어야 합니다.
- 연속성 가정(Continuity Assumption): 강제 함수(Forcing function)는 임계값 주변에서 부드럽게 이어져야 합니다.
첫 번째 가정은 이해관계자가 임의로 수치를 조작하여 임계값을 넘나들 수 없어야 함을 의미합니다. 두 번째 가정은 임계값 바로 왼쪽 집단과 오른쪽 집단이, 그 ’문턱’에 걸렸느냐 아니냐의 차이를 빼면 본질적으로 동일한 사람들이라는 확신을 줍니다.
앞선 장들을 복습해 봅시다. 무작위 통제 실험(RCT)은 처리를 무작위로 배정하여 두 집단을 동일하게 만들었습니다. 차이-차이(DiD)는 처음에 두 집단이 서로 달라도 되지만, 적어도 변화의 추세는 비슷하다고 가정했습니다. 매칭(PSM)은 서로 달라 보이는 사람들 중에서 닮은꼴을 골라내 비교 그룹을 만들었습니다.
반면 회귀 불연속성(RDD)은 완전히 다른 원리로 작동합니다. 두 집단은 강제 변수 기준으로 보면 절대 겹칠 수 없는, 서로 완전히 다른 사람들입니다. 하지만 임계값이라는 아주 좁은 경계선 위에서만큼은 두 그룹이 본질적으로 ’쌍둥이’와 같다고 가정하는 것입니다. 2019년 피 말리는 승부를 벌였던 NBA 토론토 랩터스와 필라델피아 76ers의 7차전 경기를 떠올려 봅시다. 마지막 순간 림을 네 번이나 튕기고 들어간 기적 같은 슛 하나로 승부가 갈렸습니다. 92대 90. 단 2점 차이로 승자와 패자가 갈렸지만, 과연 두 팀의 실력이 그만큼이나 극명하게 차이 난다고 할 수 있을까요? 그 찰나의 순간, 두 팀은 실력 면에서 거의 완벽하게 일치했다고 보는 것이 타당할 것입니다.
이러한 ‘연속성 가정’은 RDD의 생명과 같지만, 일어나지 않은 일을 가정하는 반사실의 영역이기에 데이터로 직접 증명할 수는 없습니다. 대신 분석가는 다음과 같은 정황 증거를 통해 독자를 설득해야 합니다.
- 별도의 테스트/훈련 데이터 설정을 사용합니다.
- 선형 모델 외에 2차 함수 등 다양한 모형을 시도하여 결과의 강건성(Robustness)을 검토합니다.
- 데이터의 다양한 하위 집단을 고려하여 분석을 수행합니다.
- 임계값의 좌우 범위를 어디까지로 설정할지(Window size) 여러 대안을 시도합니다.
- 시각화 시 신뢰 구간이나 불확실성 범위를 명확하게 표시합니다.
- 통제되지 않은 누락 변수가 결과에 영향을 미쳤을 가능성을 비판적으로 논의합니다.
또한 임계값의 위치도 중요합니다. 예를 들어, 해당 지점에서 실제 결과의 변화가 나타나는 것인지, 아니면 단순히 데이터의 비선형적 관계를 오해한 것인지 검증해야 합니다.
15.4.3 RDD의 한계와 실무적 고려 사항
RDD는 강력한 도구이지만 몇 가지 뚜렷한 약점도 존재합니다.
- 외부 타당성(External Validity)의 제약: RDD 결과는 오직 임계값 주변에서만 유효합니다. 학점 예시에서 보듯이, A-와 B+ 경계선의 학생들에게 통하는 이야기가 C와 D 경계선의 학생들에게는 전혀 맞지 않을 수 있습니다.
- 방대한 데이터 요구: 임계값 주변의 좁은 구간에 위치한 데이터가 주요 분석 대상이 되므로, 통계적 유의성을 확보하려면 상당한 양의 데이터가 필요합니다 (Green et al. 2009).
- 분석가의 재량과 투명성: 윈도우 크기 설정이나 함수 모델링 방식 등 분석가가 결정해야 할 요소가 매우 많습니다. 이는 의도치 않게 결과를 유리하게 해석하는 ’체리 피킹’의 유혹에 빠지기 쉬움을 뜻하며, 이를 방지하기 위해 분석 과정을 투명하게 공개하는 연구 윤리가 필수적입니다.
지금까지 우리는 임계값에 따라 처리가 칼같이 나뉘는 ‘샤프(Sharp) RDD’를 살펴보았습니다. 하지만 현실은 조금 더 복잡합니다. 임계값을 넘는다고 해서 처리가 즉각적으로 이루어지는 것이 아니라, 처리 받을 확률만이 변하는 ’퍼지(Fuzzy) RDD’ 상황이 더 자주 발생합니다.
또한, 임계값이 존재한다는 사실 자체가 사람들의 행동을 왜곡시키기도 합니다. 마라톤 선수가 특정 기록 달성을 위해 마지막 힘을 짜내거나, 교수가 B+를 주기보다는 성적 이의 제기가 없는 A-를 선뜻 내주는 ‘조작(Manipulation)’ 현상이 대표적입니다. 이를 확인하기 위해 임계값 주변의 데이터 밀도가 부자연스럽게 몰려 있는지 히스토그램 등을 통해 반드시 점검해야 합니다(Density test). Chapter 9 에서 다루었던 케냐 인구 조사 데이터의 연령대 뭉침 현상이 좋은 예입니다.
RDD 추정치는 모델 선택에 따라 결과가 크게 달라질 수 있습니다(Gelman 2019). 고차 다항식을 무리하게 사용하는 대신, 선형이나 2차 함수와 같이 부드럽고 단순한 모델을 사용하는 것이 권장됩니다(Gelman and Imbens 2019). 또한 RDD는 표준 오차가 과소 추정될 위험이 있으므로 결과 해석 시 신중을 기해야 합니다@stommessaysno.
15.4.4 사례 연구: 법적 음주 허용 연령과 범죄율
(Caughey and Sekhon 2011) 은 1942~2008년 미국 하원 선거 데이터를 분석하며 RDD의 강점을 강조했습니다. 또 다른 고전적인 사례는 법적 연령 기준입니다. (Carpenter and Dobkin 2015) 은 미국의 법적 음주 허용 연령인 21세를 기점으로 체포율이 불연속적으로 변화하는 현상을 포착하여, 알코올 접근성과 범죄 사이의 인과 관계를 분석했습니다. 재현 데이터는 (Carpenter and Dobkin 2014) 에서 확인할 수 있습니다.
carpenter_dobkin <-
read_dta(
"P01 Age Profile of Arrest Rates 1979-2006.dta"
)carpenter_dobkin_prepared <-
carpenter_dobkin |>
mutate(age = 21 + days_to_21 / 365) |>
select(age, assault, aggravated_assault, dui, traffic_violations) |>
pivot_longer(
cols = c(assault, aggravated_assault, dui, traffic_violations),
names_to = "arrested_for",
values_to = "number"
)
carpenter_dobkin_prepared |>
mutate(
arrested_for =
case_when(
arrested_for == "assault" ~ "단순 폭행",
arrested_for == "aggravated_assault" ~ "가중 폭행",
arrested_for == "dui" ~ "음주 운전",
arrested_for == "traffic_violations" ~ "교통 위반"
)
) |>
ggplot(aes(x = age, y = number)) +
geom_point(alpha = 0.05) +
facet_wrap(facets = vars(arrested_for), scales = "free_y") +
theme_minimal() +
labs(x = "연령", y = "체포 건수")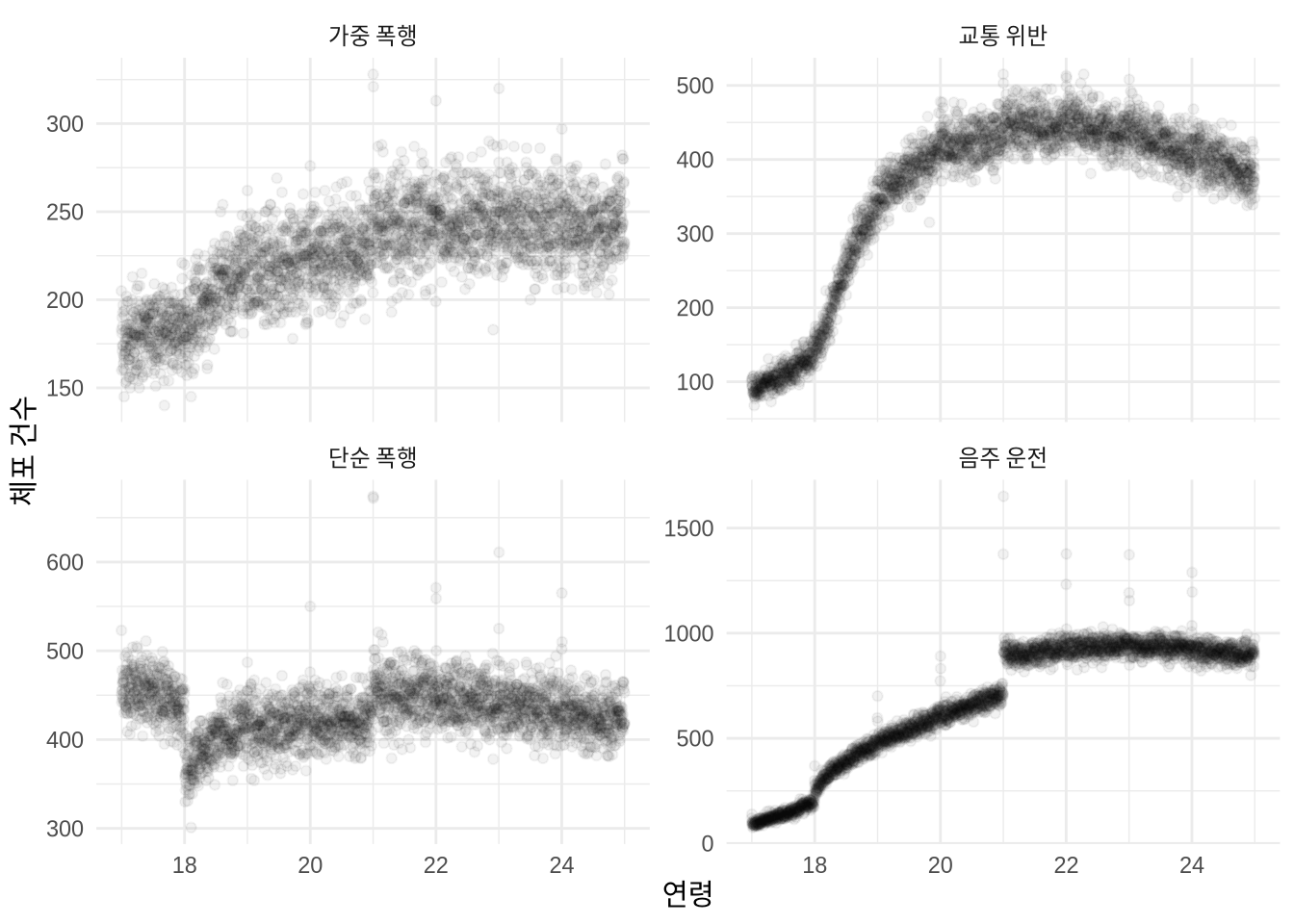
carpenter_dobkin_aggravated_assault_only <-
carpenter_dobkin_prepared |>
filter(
arrested_for == "가중 폭행",
abs(age - 21) < 2
) |>
mutate(is_21_or_more = if_else(age < 21, 0, 1))rdd_carpenter_dobkin <-
stan_glm(
formula = number ~ age + is_21_or_more,
data = carpenter_dobkin_aggravated_assault_only,
family = gaussian(),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(0, 2.5, autoscale = TRUE),
prior_aux = exponential(rate = 1, autoscale = TRUE),
seed = 853
)
saveRDS(
rdd_example,
file = "rdd_example.rds"
)rdd_carpenter_dobkin <-
readRDS(file = "rdd_carpenter_dobkin.rds")modelsummary(
models = rdd_carpenter_dobkin,
fmt = 2
)| (1) | |
|---|---|
| (Intercept) | 145.54 |
| age | 3.87 |
| is_21_or_more | 13.24 |
| Num.Obs. | 1459 |
| R2 | 0.299 |
| R2 Adj. | 0.297 |
| Log.Lik. | -6153.757 |
| ELPD | -6157.3 |
| ELPD s.e. | 32.9 |
| LOOIC | 12314.6 |
| LOOIC s.e. | 65.7 |
| WAIC | 12314.6 |
| RMSE | 16.42 |
rdrobust 패키지를 사용한 결과도 유사한 양상을 보입니다.
rdrobust(
y = carpenter_dobkin_aggravated_assault_only$number,
x = carpenter_dobkin_aggravated_assault_only$age,
c = 21,
h = 2,
all = TRUE
) |>
summary()15.5 도구 변수 (Instrumental Variables, IV)
도구 변수(Instrumental Variables, IV)는 인과 관계를 밝히는 과정에서 수많은 혼란 변수(Confounder)가 얽혀 있고, 이를 개별적으로 통제하기 어려운 상황에서 활용할 수 있는 매우 영리한 방법론입니다. 단순히 눈에 보이는 변수들을 통제하는 것만으로는 오염되지 않은 순수한 인과 효과를 추정하기 힘들 때, 우리는 다음 두 가지 조건을 동시에 충족하는 제3의 변수인 ‘도구 변수’를 찾아야 합니다.
- 관련성(Relevance): 도구 변수는 우리가 관심을 둔 처리 변수(Treatment)와 뚜렷한 상관관계를 가져야 합니다.
- 배제 제약(Exclusion Restriction): 도구 변수는 결과 변수(Outcome)와 직접적인 관련이 없어야 하며, 오직 처리 변수를 거쳐야만 결과에 영향을 미칠 수 있어야 합니다.
도구 변수는 처리 변수의 변동분 중에서 혼란 변수에 의해 오염되지 않은 ’깨끗한 부분’만을 걸러내는 필터 역할을 합니다. 비록 현실에서 이러한 가혹한 조건을 완벽히 충족하는 도구 변수를 찾기란 대단히 어렵지만, 일단 적절한 변수를 확보한다면 관찰 데이터에서 정교한 인과 관계를 추출해 내는 가장 강력한 도구가 됩니다.
가장 대표적인 예시는 흡연과 폐암 사이의 인과 관계 논쟁입니다. 과거에는 “흡연자가 폐암에 많이 걸리는 이유는 담배 때문이 아니라, 이들이 스트레스가 많거나 교육 수준이 낮은 환경에 처해 있기 때문일 수 있다”라는 주장이 있었습니다. 직접적인 인체 실험이 불가능한 상황에서 연구자들은 개별 흡연자의 신체적 특성이나 환경과는 무관하지만 흡연량에는 영향을 미치는 ‘담배 세금 인상 정책’을 도구 변수로 활용했습니다. 세금 인상은 흡연량을 줄이는 강력한 유인(관련성)이 되지만, 세금 그 자체가 폐암을 직접 유발하지는 않기 때문입니다(배제 제약).
도구 변수가 유효하려면 (Gelman and Hill 2007, 216) 이 제시한 네 가지 핵심 가정을 충족해야 합니다.
- 무시 가능성(Ignorability): 도구 변수 자체가 다른 혼란 변수와 직접적으로 얽혀 있지 않아야 합니다.
- 관련성(Relevance): 도구 변수가 처리 변수의 변동을 충분히 설명할 수 있어야 합니다.
- 단조성(Monotonicity): 도구 변수가 모든 대상에게 일관된 방향으로 작용해야 합니다 (예: 세금이 오르면 모두가 담배를 덜 피워야 하며, 반대로 더 많이 피우는 사람이 있으면 안 됩니다).
- 배제 제약(Exclusion Restriction): 도구 변수는 반드시 처리 변수를 통해서만 결과 변수에 영향을 미쳐야 합니다.
통계학의 여담: 부록 B의 미스터리 도구 변수의 역사는 1928년 필립 라이트(Philip Wright)의 저서 The Tariff on Animal and Vegetable Oils로 거슬러 올라갑니다. 동물성 및 식물성 기름의 관세가 가격에 미치는 영향을 분석하던 중, 가격과 수요 사이의 인과 관계를 풀기 위해 이 혁신적인 기법이 처음 등장했습니다. 흥미롭게도 이 위대한 발견은 본문이 아닌 ’부록 B’에 짧게 실렸습니다. 학계에서는 이 부록을 필립이 직접 썼는지, 아니면 통계학의 거장이자 그의 아들인 시월 라이트(Sewall Wright)가 쓴 것인지를 두고 오랜 논쟁이 있었습니다. (Stock and Trebbi 2003), (Cunningham 2021), 그리고 (Angrist and Krueger 2001) 등 여러 학자의 고증에 따르면, 아버지가 아들의 연구에서 힌트를 얻어 직접 저술했을 가능성이 높은 것으로 보입니다.
15.5.1 시뮬레이션 예시: 건강 상태, 흡연, 그리고 주별 세율
데이터 시뮬레이션을 통해 도구 변수의 작동 원리를 직접 확인해 보겠습니다. 우리는 흡연이 건강을 악화시킨다는 진실을 알고 있는 설계자이지만, 데이터에는 수많은 노이즈가 섞여 있어 인과 관계가 불분명하게 나타난다고 가정합니다. 이때 주(Province)별로 다른 ’담배 세율’을 도구 변수로 활용해 보겠습니다. 앨버타주는 세율이 낮고, 노바스코샤주는 세율이 매우 높은 환경을 설정합니다.
set.seed(853)
num_observations <- 10000
iv_example_data <- tibble(
person = c(1:num_observations),
smoker =
sample(x = c(0:1), size = num_observations, replace = TRUE)
)먼저 흡연 여부와 건강 등급을 연결합니다. 건강 상태는 정규 분포를 따르며, 흡연자의 평균 건강 등급이 비흡연자보다 낮게 나타나도록 모델링하겠습니다.
iv_example_data <-
iv_example_data |>
mutate(health = if_else(
smoker == 0,
rnorm(n = n(), mean = 1, sd = 1),
rnorm(n = n(), mean = 0, sd = 1)
))다음으로 주별 세율(도구 변수)과 흡연 습관 사이의 상관계수를 설정합니다. 세율이 높은 노바스코샤주에서는 비흡연자의 비중이 더 높도록 배정합니다.
iv_example_data <- iv_example_data |>
mutate(
province = case_when(
smoker == 0 ~ sample(
c("노바스코샤", "앨버타"),
size = n(),
replace = TRUE,
prob = c(1/2, 1/2)
),
smoker == 1 ~ sample(
c("노바스코샤", "앨버타"),
size = n(),
replace = TRUE,
prob = c(1/4, 3/4)
)
),
tax = case_when(province == "앨버타" ~ 0.3,
province == "노바스코샤" ~ 0.5,
TRUE ~ 9999999
)
)
iv_example_data# A tibble: 10,000 × 5
person smoker health province tax
<int> <int> <dbl> <chr> <dbl>
1 1 0 1.11 앨버타 0.3
2 2 1 -0.0831 앨버타 0.3
3 3 1 -0.0363 앨버타 0.3
4 4 0 2.48 앨버타 0.3
5 5 0 0.617 노바스코샤 0.5
6 6 0 0.748 앨버타 0.3
7 7 0 0.499 앨버타 0.3
8 8 0 1.05 노바스코샤 0.5
9 9 1 0.113 앨버타 0.3
10 10 1 -0.0105 앨버타 0.3
# ℹ 9,990 more rows시각화를 통해 주별, 흡연 여부별 건강 등급 분포를 확인해 봅니다.
iv_example_data |>
mutate(smoker = as_factor(smoker)) |>
ggplot(aes(x = health, fill = smoker)) +
geom_histogram(position = "dodge", binwidth = 0.2) +
theme_minimal() +
labs(
x = "건강 등급",
y = "인원수",
fill = "흡연 여부"
) +
scale_fill_brewer(palette = "Set1") +
theme(legend.position = "bottom") +
facet_wrap(vars(province))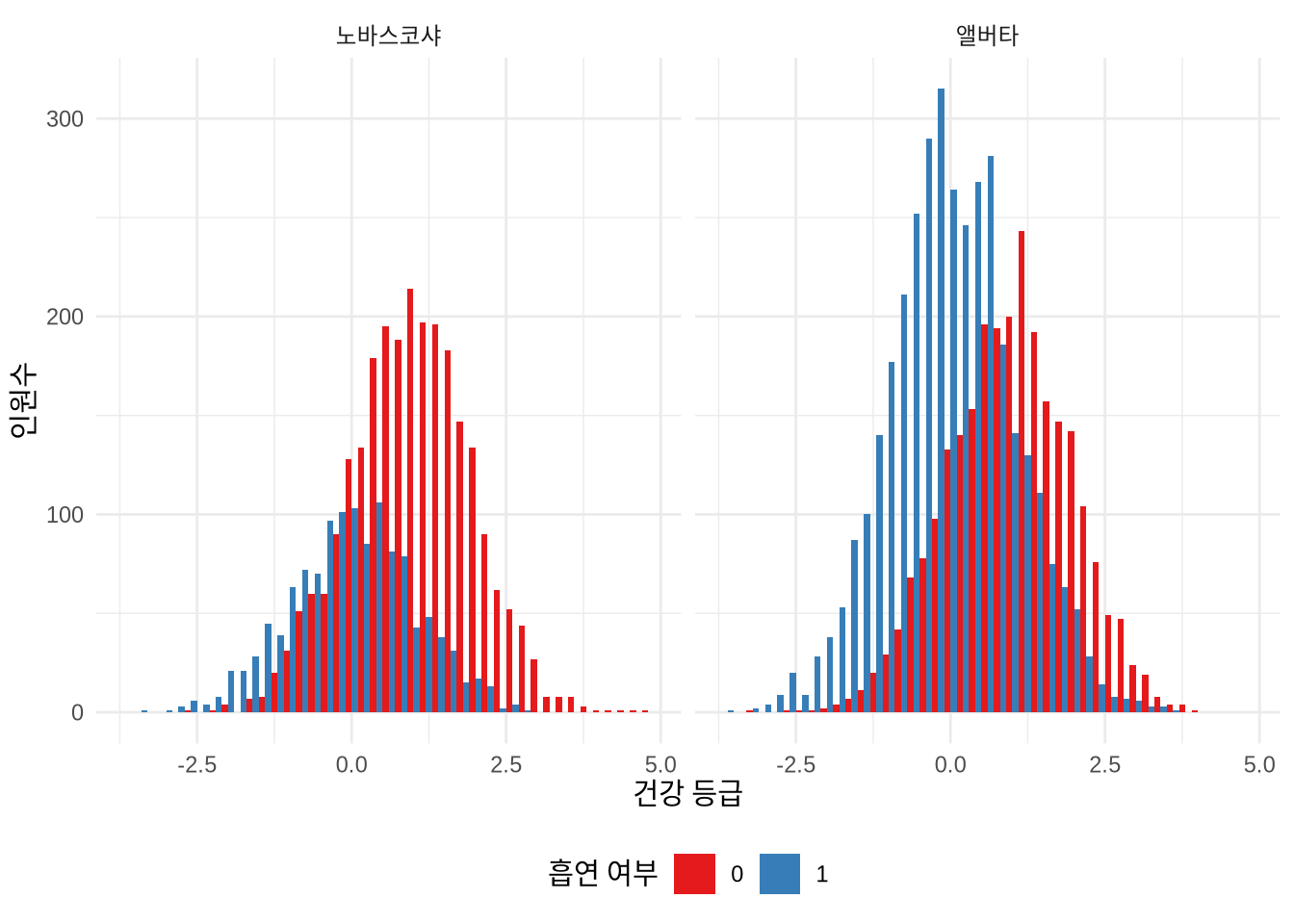
이제 세율(tax)을 도구 변수로 사용하여 흡연이 건강에 미치는 영향을 추정해 보겠습니다.
health_on_tax <- lm(health ~ tax, data = iv_example_data)
smoker_on_tax <- lm(smoker ~ tax, data = iv_example_data)
tibble(
coefficient = c("health ~ tax", "smoker ~ tax", "ratio"),
value = c(
coef(health_on_tax)["tax"],
coef(smoker_on_tax)["tax"],
coef(health_on_tax)["tax"] / coef(smoker_on_tax)["tax"]
)
)# A tibble: 3 × 2
coefficient value
<chr> <dbl>
1 health ~ tax 1.24
2 smoker ~ tax -1.27
3 ratio -0.980세율이 흡연 습관과 건강 지표 모두에 미치는 관계를 역으로 추산함으로써, 외부 노이즈에 오염되지 않은 흡연의 인과적 효과를 도출해낼 수 있습니다.
실무에서는 estimatr 패키지의 iv_robust() 함수를 사용하면 가중치 부여나 표준 오차 보정 등 복잡한 과정을 간결하게 수행할 수 있습니다(Table 15.7).
iv_robust(health ~ smoker | tax, data = iv_example_data) |>
modelsummary()| (1) | |
|---|---|
| (Intercept) | 0.977 |
| (0.041) | |
| smoker | -0.980 |
| (0.081) | |
| Num.Obs. | 10000 |
| R2 | 0.201 |
| R2 Adj. | 0.201 |
| AIC | 28342.1 |
| BIC | 28363.7 |
| RMSE | 1.00 |
15.5.2 IV의 핵심: 배제 제약과 관련성의 충동
도구 변수 분석의 성공 여부는 두 가지 핵심 기둥에 달려 있습니다.
- 배제 제약(Exclusion Restriction): 도구 변수가 우리가 관심 있는 처리 변수(흡연)를 통해서만 결과(건강)에 영향을 미쳐야 한다는 가정입니다.
- 관련성(Relevance): 도구 변수와 처리 변수 사이에 충분히 강력한 상관관계가 존재해야 합니다.
현실에서는 이 두 조건이 서로 충돌하는 경우가 많습니다. (Cunningham 2021, 211) 은 “좋은 도구 변수란, 처음 들었을 때는 어리둥절하다가도 논리적 설명을 듣고 나면 고개를 끄덕이게 만드는 매력이 있다”라고 설명했습니다.
관련성은 통계적 유의성으로 확인할 수 있지만, ’배제 제약’은 평행 추세 가정처럼 데이터만으로는 절대 증명할 수 없습니다. 오직 분석가의 논리적 설득력에 의존해야 합니다. 역설적이게도 좋은 도구 변수는 종종 결과 변수와는 겉보기에 아무런 상관이 없어 보일 때가 많습니다 (Cunningham 2021, 225).
최근에는 무작위 실험(A/B 테스트)의 한계를 보완하기 위해 IV를 활용하는 사례가 늘고 있습니다 (Taddy 2019, 162). 도구 변수를 사용하면 모든 대상자가 실험에 완벽히 순응하지 않는 환경(Non-compliance)에서도 처리의 효과를 비판 없이 추정할 수 있기 때문입니다.
과거에는 ’강우량’이나 ’날씨’를 도구 변수로 자주 사용했지만, 만약 날씨가 다른 사회경제적 변수와 얽혀 있다면 배제 제약 가정이 무너집니다. Mellon (2024) 는 이러한 방식의 잠재적 오류를 지적했습니다. 따라서 도구 변수를 선택할 때는 그 타당성을 끊임없이 의심해야 합니다. IV 기법은 분석가의 재량이 큰 만큼, 결과를 유리하게 해석하려는 ’P-값 해킹’의 위험에 노출되기 쉽기 때문입니다 (Brodeur, Cook, and Heyes 2020; Betz, Cook, and Hollenbach 2018).
15.6 연습 문제 및 과제
연습 문제
- (기획) 다음 시나리오를 구상해 보세요. “두 아이 모두 구급차가 지나갈 때는 쳐다보지만, 첫째 아이만 전차가 지나갈 때 쳐다보고, 막내 아이만 자전거가 지나갈 때 쳐다본다.” 이 데이터의 구조를 설계해 보고, 모든 데이터를 한눈에 보여줄 수 있는 그래프를 스케치해 보세요.
- (시뮬레이션) 위 시나리오를 바탕으로 데이터를 시뮬레이션해 보세요. 생성된 데이터를 검증하기 위해 최소 10개의 단위 테스트(Test code)를 포함하세요.
- (수집) 이와 유사한 성격의 데이터셋을 실제로 확보할 수 있는 공공 데이터나 오픈 소스가 어디일지 조사해 보세요.
- (탐색 및 모델링)
ggplot2를 사용하여 스케치한 그래프를 실제로 구현해 보세요. 그 다음rstanarm패키지 등을 활용해 인과 모델을 구축해 보세요. - (전달) 분석 과정과 주요 발견 사항에 대해 두 단락 내외의 짧은 요약 보고서를 작성해 보세요.
퀴즈
- 차이-차이(DiD) 분석이 성립하기 위해 반드시 충족되어야 하는 핵심 가정은 무엇입니까?
- (Varner and Sankin 2020) 기사를 읽고 보험 업계의 알고리즘 활용에 따른 통계적, 윤리적 쟁점에 대해 토론해 보세요.
- (Varner and Sankin 2020) 관련 GitHub 페이지를 방문하여 해당 조사 분석의 강점과 약점을 기술해 보세요.
- 회귀 불연속성 설계(RDD)의 정의와 이 분석이 가능하기 위한 필수 조건은 무엇입니까?
- RDD 추정치의 타당성을 위협하는 요인 중 ’조작(Manipulation)’이란 무엇입니까?
- (Meng 2021) 에 따르면 실증적 데이터 과학이 설득력을 얻기 위해 필요한 요소는 무엇입니까? (모두 선택)
- 고품질 데이터 수집을 통한 증거 확립
- 정교한 데이터 처리 및 분석 기법
- 분석 결과에 대한 정직하고 투명한 해석 전달
- 무조건적으로 큰 표본 크기 확보
- (Riederer 2021) 에 따르면 임계값 근처의 지역적 처리 효과(Local Treatment Effect)를 측정하는 데 가장 적합한 방법은 무엇입니까?
- 회귀 불연속성 설계(RDD)
- 성향 점수 매칭(PSM)
- 차이-차이(DiD)
- 이벤트 연구 방법(Event Study)
- (Riederer 2021) 에 따르면 인과 추론에 숙달하기 위해 필요한 핵심 역량은 무엇입니까? (모두 선택)
- 데이터 핸들링 기술
- 도메인 및 비즈니스 지식
- 확률적 사고 및 추론 능력
- 토론토에 거주하는 30~39세 호주인 남성(자녀 2명, 박사 학위 소지)의 행동을 분석하고자 합니다. 다음 중 통계적으로 가장 적합한 대조군은 누구이며, 그 이유를 1~2단락으로 설명하세요.
- 토론토 거주, 30~39세 호주인 남성, 자녀 1명, 학사 학위
- 토론토 거주, 30~39세 캐나다인 남성, 자녀 1명, 박사 학위
- 오타와 거주, 30~39세 호주인 남성, 자녀 1명, 박사 학위
- 토론토 거주, 18~29세 캐나다인 남성, 자녀 1명, 박사 학위
- 성향 점수 매칭(PSM)이란 무엇입니까? 당신이 특정 연구를 위해 대상자들을 매칭한다면 어떤 특성을 기준으로 삼겠습니까? 또한 민감한 개인 정보를 수집할 때 발생할 수 있는 윤리적 고려 사항은 무엇입니까?
- (Bronner 2020) 에서 설명된 ‘충돌 편향(Collider bias)’ 현상을 설명하는 인과 관계도(DAG)를 그려보세요.
- “인과 관계는 언제나 상관관계를 동반한다”는 주장에 대해, (Cunningham 2021, chap. 1) 의 내용을 참고하여 비판적으로 논의해 보세요.
수업 활동
- “가짜 면도 소동”: 세 살 아이가 면도하는 아빠 옆에서 수염을 깎는 시늉을 합니다. 아빠도 아이도 수염이 없지만 우리는 아이가 아빠를 ‘흉내’ 내고 있음을 압니다. 이 상황에서 인과 관계를 오해하게 만드는 요인은 무엇인지 DAG를 사용하여 설명해 보세요.
- “두 명의 외과 의사 역설”: 어느 병원에 두 명의 의사가 있습니다. 한 명은 초급 환자만 수술하여 사망률이 2%이고, 다른 한 명은 중증 환자만 전담하여 사망률이 10%입니다.
- 환자명, 담당 의사, 수술 결과가 포함된 가상의 데이터셋을 생성해 보세요.
- 단순 회귀 분석을 했을 때 “어떤 의사가 더 유능하다”는 결론이 나오는지 확인해 보세요.
- 이 분석에서 간과된 ’환자의 기저 질환 상태’를 포함한 DAG를 그려보세요.
- 기저 질환을 통제 변수로 넣었을 때 의사의 실력이 어떻게 재평가되는지 확인해 보세요.
- “생활 속의 역설”: 심슨의 역설이나 버크슨의 역설 중 하나를 선택하세요. 실생활에서 발생할 수 있는 구체적인 예시를 들어 설명하고, 데이터 전문가로서 이 문제를 어떻게 해결할지 토론해 보세요.
기말 과제
당신은 ’사회적 네트워크의 특성이 개인의 소득 수준에 미치는 영향’을 연구하고자 합니다. 한 대형 소셜 미디어 플랫폼에서 제공하는 타임라인 데이터(댓글, 태그, 상호 작용 등)를 확보했습니다.
- 표집 편향 논의: 소셜 미디어는 보편적이지만 모든 계층을 대변하지는 않습니다. 소셜 미디어 활동 데이터만을 사용하여 소득 수준을 추정할 때 발생할 수 있는 인구통계학적 편향에 대해 논의해 보세요.
- 데이터 보정 및 생태학적 오류: 확보한 데이터에는 실제 소득 정보가 없습니다. 대신 전체의 20%에 대해서만 인구 조사 블록 정보를 알고 있습니다. 당신은 다음 단계로 소득을 추정하기로 했습니다.
- 거주지 정보가 있는 20%의 데이터를 학습시켜 개인 특성별 소득 예측 모델을 만듭니다.
- 이 모델을 나머지 80%에 적용해 소득을 예측(Imputation)합니다. 이러한 방식의 타당성과 위험 요소를 최소 1,000자 내외로 서술하세요. 특히 ’집단 평균을 개인의 특성으로 오인’할 때 발생하는 생태학적 오류(Ecological Fallacy) 문제를 중점적으로 논의하세요.
- 오픈 사이언스: 기업 데이터는 외부 반출이 제한됩니다. 이런 제약 속에서도 당신의 연구 결과가 학계에서 신뢰를 얻고 재현될 수 있도록 하려면 어떤 연구 방법론적 대안을 세워야 할까요?
위 과제는 논리적인 근거를 갖추어 A4 용지 2페이지 내외의 보고서 형식으로 제출해야 합니다.