library(babynames)
library(gh)
library(here)
library(httr)
library(janitor)
library(jsonlite)
library(lubridate)
library(pdftools)
library(purrr)
library(rvest)
library(spotifyr)
# library(tesseract)
library(tidyverse)
library(tinytable)
library(usethis)
library(xml2)7 API와 스크래핑, 그리고 파싱
채프먼 앤 홀/CRC(Chapman and Hall/CRC)는 2023년 7월 이 책을 출간했습니다. 도서는 이곳에서 구매하실 수 있습니다. 온라인 버전에는 인쇄본 출간 이후 업데이트된 최신 내용이 일부 포함되어 있습니다.
권장 선행 학습
- Cirone and Spirling (2021), “Turning History into Data: Data Collection, Measurement, and Inference at the HPE” 읽기.
- 데이터셋을 구축하는 과정에서 마주하게 되는 실무적인 어려움들을 깊이 있게 다룹니다.
- Johnson (2021), “Two Regimes of Box-Score Data Collection” 읽기.
- 시대에 따른 NBA 경기 기록(Box-score) 데이터 수집 방식의 변화와 그 의미를 비교 분석합니다.
- Crawford (2021), “The Atlas of AI” 읽기.
- 특히 3장 “데이터”를 중심으로 데이터의 유래(Provenance)를 명확히 이해하는 것이 왜 중요한지 살펴봅니다.
핵심 개념 및 기술
- 분석에 꼭 필요한 데이터라도 처음부터 깔끔한 데이터셋 형태로 제공되지 않는 경우가 많습니다. 우리는 세상에 흩어진 데이터를 직접 찾아 ’수집’하는 기술을 익혀야 합니다.
- 비정형 데이터 소스에서 정보를 추출하고 정제하는 과정은 꽤 번거롭고 시간이 많이 걸리기도 합니다. 하지만 그렇게 공들여 얻은 ’정돈된 데이터(Tidy data)’는 종종 그 무엇보다 흥미롭고 유익한 통찰을 선사합니다.
- 이번 장에서는 API(직접 요청 혹은 R 패키지 활용)를 통해 반정형 데이터를 확보하는 법을 배웁니다. 또한 윤리적 원칙을 지키며 웹 스크래핑을 수행하고, PDF 문서 속에 잠든 데이터를 깨우는 파싱 기술도 함께 익히게 될 것입니다.
소프트웨어 및 패키지
- 기본 R (R Core Team 2024)
babynames(Wickham 2021)gh(Bryan and Wickham 2021)here(Müller 2020)httr(Wickham 2023)janitor(Firke 2023)jsonlite(Ooms 2014)lubridate(Grolemund and Wickham 2011)pdftools(Ooms 2022a)purrr(Wickham and Henry 2022)rvest(Wickham 2022)spotifyr(Thompson et al. 2022) (이 패키지는 CRAN에 없으므로install.packages("devtools")실행 후devtools::install_github("charlie86/spotifyr")로 설치하세요.)tesseract(Ooms 2022b)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)usethis(Wickham, Bryan, and Barrett 2022)xml2(Wickham, Hester, and Ooms 2021)
7.1 서론
이번 장에서는 우리가 직접 발로 뛰어 수집해야 하는 데이터를 다룹니다. 분석에 필요한 관측치가 세상 어딘가에 존재하긴 하지만, 이를 활용 가능한 데이터셋으로 바꾸려면 데이터를 가져와 파싱(Parsing)하고 다듬는(Wrangling) 고된 과정이 필요하다는 뜻입니다. Chapter 6 에서 배운 ’경작 데이터(Farmed Data)’와 달리, 이러한 데이터들은 대개 분석을 목적으로 공개된 것이 아닙니다. 따라서 문서화 과정이나 표본의 선택 기준, 결측치 처리, 그리고 무엇보다 ’윤리적 수집’에 각별한 주의를 기울여야 합니다.
직접 수집한 데이터가 보여주는 힘은 놀랍습니다. Cummins (2022) 는 1892년부터 1992년까지 영국의 유언 검인 기록을 일일이 파싱해 새로운 데이터셋을 구축했습니다. 이를 통해 상류층의 상속 중 약 3분의 1이 교묘하게 가려져 왔음을 밝혀냈죠. 또한 Taflaga and Kerby (2019) 는 호주 장관들의 전화번호부를 분석해 직무 책임에 관한 체계적인 데이터를 만들었고, 그 과정에서 뚜렷한 성별 차이를 발견하기도 했습니다. 유언장이나 전화번호부 모두 처음부터 데이터 분석을 위해 만들어진 것은 아닙니다. 하지만 연구자가 존중하는 마음으로 데이터에 접근한다면, 다른 방법으로는 결코 얻을 수 없는 깊은 통찰을 얻게 됩니다. 이것이 바로 우리가 “데이터 수집(Data Gathering)”이라 부르는 여정입니다.
프로젝트를 시작할 때는 팀이 지향할 가치를 먼저 세워야 합니다. 예를 들어 Hugging Face는 투명성, 재현성, 공정성, 자기 비판, 그리고 동료의 공로 인정 등을 핵심 가치로 둡니다 (Saulnier et al. 2022). 특히 ’공로 인정’을 중시한다면 출처(Attribution) 표기와 라이선스 준수에 완벽을 기해야 합니다. 우리가 직접 수집한 원본 데이터는 대개 우리의 소유가 아닐 가능성이 크기에 더욱 조심스럽게 다루어야 하죠.
데이터 과학의 결과물은 결코 입력 데이터의 품질을 넘어설 수 없습니다 (Bailey 2008). 아무리 화려하고 정교한 통계 기법을 동원하더라도, 애초에 잘못 수집된 데이터를 사후에 수습하기란 불가능에 가깝습니다. 그래서 팀 프로젝트에서 데이터 수집 단계는 반드시 선임 분석가가 직접 감독하거나 수행해야 할 만큼 막중한 책임이 따릅니다. 혼자 작업할 때도 이 단계에 가장 많은 정성과 주의를 쏟으시기 바랍니다.
이번 장에서는 데이터를 수집하는 다양한 길을 안내합니다. 가장 먼저 API와 JSON, XML 같은 반정형 데이터 형식을 살펴봅니다. API를 쓴다는 것은 데이터 제공자가 정한 규칙에 따라 정중하게 정보를 요청하는 것과 같습니다. 수집 과정을 자동화하고 대규모로 확장할 수 있어 매우 효율적이죠. 실제 사례로 Wong (2020) 는 페이스북의 정치 광고 API를 활용해 2020년 트럼프 캠페인 광고 약 22만 개를 분석한 바 있습니다.
다음으로는 웹 스크래핑(Web Scraping)을 배웁니다. 웹사이트에 가치 있는 정보가 눈에는 보이지만, 편리한 API가 제공되지 않을 때 사용하는 최후의 수단입니다. 서버에 부담을 줄 수 있으므로 명확한 윤리 원칙 아래 수행되어야 하죠. 팬데믹 초기 수많은 코로나19 대시보드가 웹 스크래핑으로 실시간 데이터를 모아 방역에 기여했던 사례가 대표적입니다 (Eisenstein 2022).
마지막으로 PDF 문서에서 데이터를 추출하는 법을 알아봅니다. 정부 보고서나 오래된 고서 속에 잠든 귀중한 데이터들을 깨우는 작업입니다. 많은 국가가 정보를 공개하고는 있지만, 정작 데이터가 CSV가 아닌 PDF로 제공되는 경우가 많아 데이터 과학자에게는 필수적인 기술입니다.
직접 데이터를 수집하는 과정은 이미 잘 차려진 밥상인 ’경작 데이터’를 쓰는 것보다 훨씬 힘들고 고된 작업일 수 있습니다. 하지만 이 과정을 마스터하면, 다른 누구도 던지지 못한 질문에 스스로 답할 수 있는 독보적인 데이터셋을 갖게 될 것입니다.
7.2 API 활용하기
일상적인 대화에서, 그리고 이 책의 목적상 API(Application Programming Interface)란 누군가가 자신의 서버에 특정 파일을 설정해 두고, 우리가 정해진 규칙(Protocol)을 따라 데이터를 가져올 수 있게 만든 통로를 뜻합니다. 예를 들어 슬랙(Slack)에서 고양이 짤을 검색해 올린다고 해보죠. 이때 슬랙은 백그라운드에서 Giphy 서버에 특정 이미지를 요청하고, Giphy 서버는 요청에 맞는 GIF를 보내주며, 슬랙은 이를 채팅창에 띄워줍니다. 슬랙과 Giphy가 정보를 주고받는 이 구체적인 약속이 바로 Giphy의 API입니다. 기술적으로 보면 API는 HTTP 프로토콜을 이용해 특정 서버의 애플리케이션에 접근하여 데이터를 요청하고 받는 규약이라 할 수 있습니다.
우리는 데이터 수집을 위한 API 활용에 집중하겠습니다. 이 맥락에서 API는 사람이 아닌 ’다른 컴퓨터’가 데이터를 쉽게 가져가도록 설계된 웹사이트라고 이해하면 쉽습니다. 브라우저를 켜고 Google Maps에 접속해 캔버라 지도를 검색할 수도 있지만, 브라우저에서 일일이 클릭하는 대신 이 링크와 같은 특정 URL을 서버에 ’요청(Request)’하면 그에 맞는 데이터를 ’응답(Response)’으로 돌려받을 수 있죠. 이것이 바로 API의 작동 원리입니다.
API의 가장 큰 장점은 데이터 제공자가 공개 범위와 사용 조건을 미리 명시해 두었다는 점입니다. 여기에는 속도 제한(Rate Limit)(예: “1분에 100번만 요청 가능”)이나 활용 방식(예: “상업적 재배포 금지”) 등이 포함됩니다. 정해진 통로를 통하므로 웹사이트 구조가 갑자기 바뀌거나 법적 문제에 휘말릴 위험이 상대적으로 적습니다. 따라서 데이터 수집 시 API가 존재한다면 웹 스크래핑보다 API를 쓰는 것이 훨씬 현명한 선택입니다.
이제 실제 API 활용 사례를 살펴보겠습니다. 먼저 httr 패키지로 API에 직접 요청을 보내는 법을 배우고, 이어서 spotifyr 패키지처럼 API를 더 쓰기 쉽게 감싼 도구들을 활용하는 법을 익히겠습니다.
7.2.1 arXiv, NASA, 그리고 Dataverse
httr 패키지를 로드한 뒤 GET() 함수로 API에 데이터를 요청해 봅시다. 이 함수의 핵심은 데이터를 가져올 주소인 url입니다. 앞서 구글 맵 사례처럼 URL을 통해 특정 정보를 요청하는 것과 같은 논리입니다.
7.2.1.1 arXiv 데이터 수집
첫 번째 사례로 학술 논문 저장소인 arXiv API를 써보겠습니다. arXiv에는 저널 심사 전의 논문들이 ‘프리프린트(Preprint)’ 형태로 올라옵니다. 특정 논문의 정보를 가져오기 위해 다음과 같이 요청을 보냅니다.
arxiv <- GET("http://export.arxiv.org/api/query?id_list=2310.01402")
status_code(arxiv)응답 결과는 status_code() 함수로 확인합니다. 200이면 성공, 404는 페이지를 찾을 수 없음, 400대는 보통 사용자 측의 요청 오류를 뜻합니다. 성공적으로 데이터를 받았다면 content() 함수로 내용을 확인하면 됩니다.
arXiv API는 XML 형식의 데이터를 반환합니다. XML은 항목들이 태그(Tag)로 구분되며 태그 안에 다른 태그가 중첩될 수 있는 구조입니다. 이를 분석하기 좋게 읽어오려면 xml2 패키지의 read_xml()을 사용합니다. XML은 반정형 구조이므로 본격적인 파싱 전에 html_structure()로 전체적인 트리를 훑어보는 것이 좋습니다.
content(arxiv) |>
read_xml() |>
html_structure()이 XML 트리에서 필요한 부분만 골라 데이터셋을 만들어 봅시다. 예를 들어 8번째 자식 노드인 ‘entry’ 안에서 4번째 항목인 제목(‘title’)과 9번째 항목인 링크(‘link’)를 추출할 수 있습니다.
data_from_arxiv <-
tibble(
title = content(arxiv) |>
read_xml() |>
xml_child(search = 8) |>
xml_child(search = 4) |>
xml_text(),
link = content(arxiv) |>
read_xml() |>
xml_child(search = 8) |>
xml_child(search = 9) |>
xml_attr("href")
)
data_from_arxiv7.2.1.2 NASA ‘오늘의 천문학 사진’
NASA는 APOD API를 통해 매일 한 장씩 ’오늘의 천문학 사진’을 제공합니다. GET()을 사용해 특정 날짜의 사진 URL을 얻어와 보죠.
NASA_APOD_20190719 <-
GET("https://api.nasa.gov/planetary/apod?api_key=DEMO_KEY&date=2019-07-19")받아온 데이터를 뜯어보면 날짜, 제목, 설명, 그리고 이미지 URL 등 다양한 정보가 담겨 있습니다.
# 2019년 7월 19일 APOD 정보 확인
content(NASA_APOD_20190719)$date[1] "2019-07-19"content(NASA_APOD_20190719)$title[1] "Tranquility Base Panorama"content(NASA_APOD_20190719)$explanation[1] "On July 20, 1969 the Apollo 11 lunar module Eagle safely touched down on the Moon. It landed near the southwestern corner of the Moon's Mare Tranquillitatis at a landing site dubbed Tranquility Base. This panoramic view of Tranquility Base was constructed from the historic photos taken from the lunar surface. On the far left astronaut Neil Armstrong casts a long shadow with Sun is at his back and the Eagle resting about 60 meters away ( AS11-40-5961). He stands near the rim of 30 meter-diameter Little West crater seen here to the right ( AS11-40-5954). Also visible in the foreground is the top of the camera intended for taking stereo close-ups of the lunar surface."content(NASA_APOD_20190719)$url[1] "https://apod.nasa.gov/apod/image/1907/apollo11TranquilitybasePan600h.jpg"knitr의 include_graphics() 함수에 해당 URL을 넣으면 그림을 직접 띄울 수 있습니다(Figure 7.1).

7.2.1.3 Dataverse와 JSON 파싱
마지막으로 API 응답에서 가장 흔히 쓰이는 JSON 형식을 살펴보겠습니다. JSON은 컴퓨터가 읽기 편하면서도 사람이 이해하기 좋게 만들어진 텍스트 데이터 형식입니다. 우리가 익숙한 표(CSV) 형식과 달리 JSON은 키-값(Key-Value) 쌍으로 정보를 묶어 관리하죠.
{
"firstName": "Rohan",
"lastName": "Alexander",
"age": 36,
"favFoods": {
"first": "Pizza",
"second": "Bagels",
"third": null
}
}politics_datasets <-
fromJSON("https://demo.dataverse.org/api/search?q=politics")복잡한 JSON 데이터는 RStudio의 View() 함수로 계층 구조를 펼쳐가며 살펴보는 게 좋습니다. 요소 위에 마우스를 올리고 나타나는 녹색 화살표를 누르면, 해당 위치까지 도달하는 R 코드를 자동으로 생성해 주어 아주 편리합니다 (Figure 7.2).
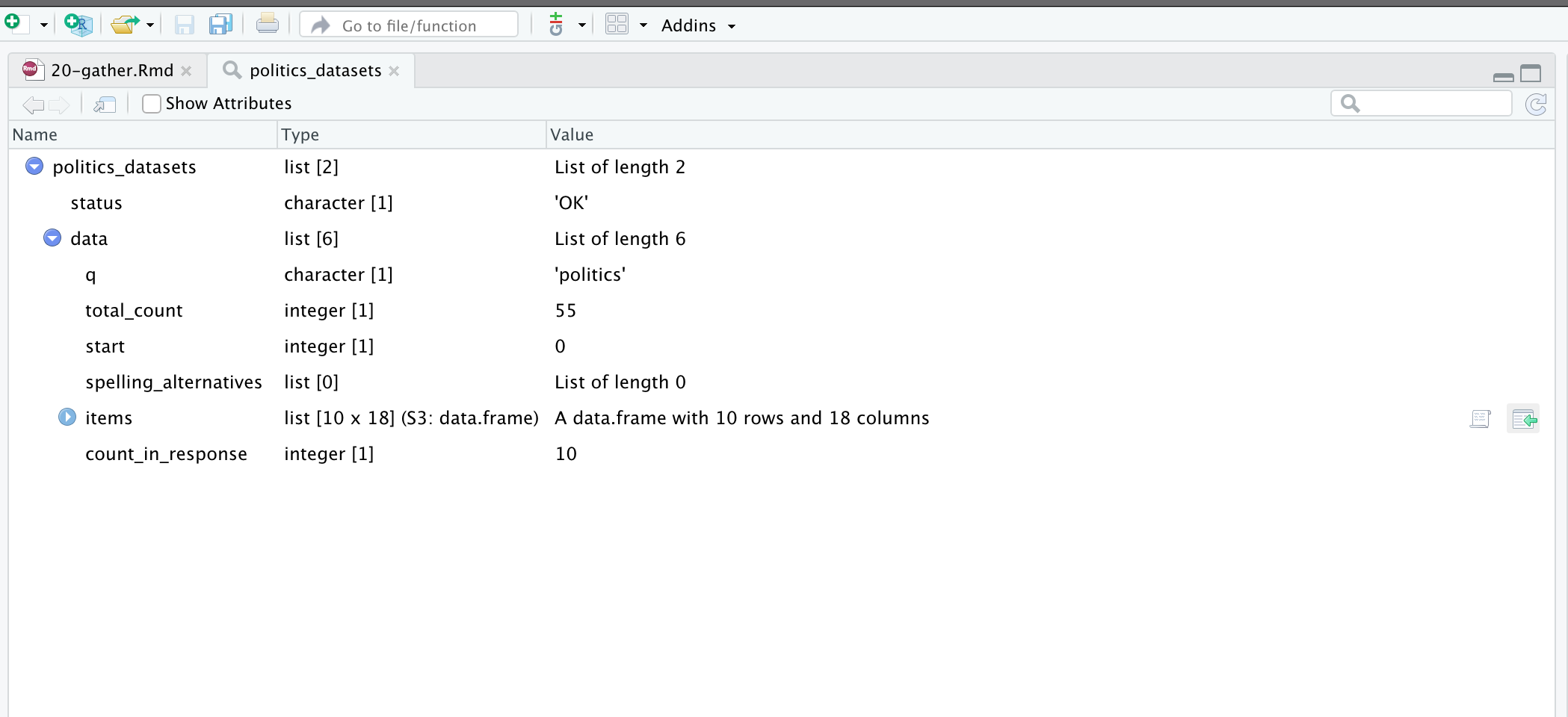
이를 활용해 관심 있는 데이터셋을 추출해 보겠습니다.
as_tibble(politics_datasets[["data"]][["items"]])7.2.2 Spotify API 활용하기
특정 API를 아주 쉽게 쓸 수 있도록 잘 만들어진 전용 패키지들도 있습니다. 스포티파이(Spotify) API를 R에서 편하게 다루게 해주는 spotifyr 패키지가 대표적이죠. 이런 도구를 쓸 때도 데이터 활용 가이드를 꼼꼼히 확인하는 자세가 필요합니다.
스포티파이 API를 쓰려면 먼저 Spotify for Developers 대시보드에서 계정을 만들어야 합니다. 로그인을 마치고 개발자 약관에 동의하는 과정을 거치게 되죠 (Figure 7.3).
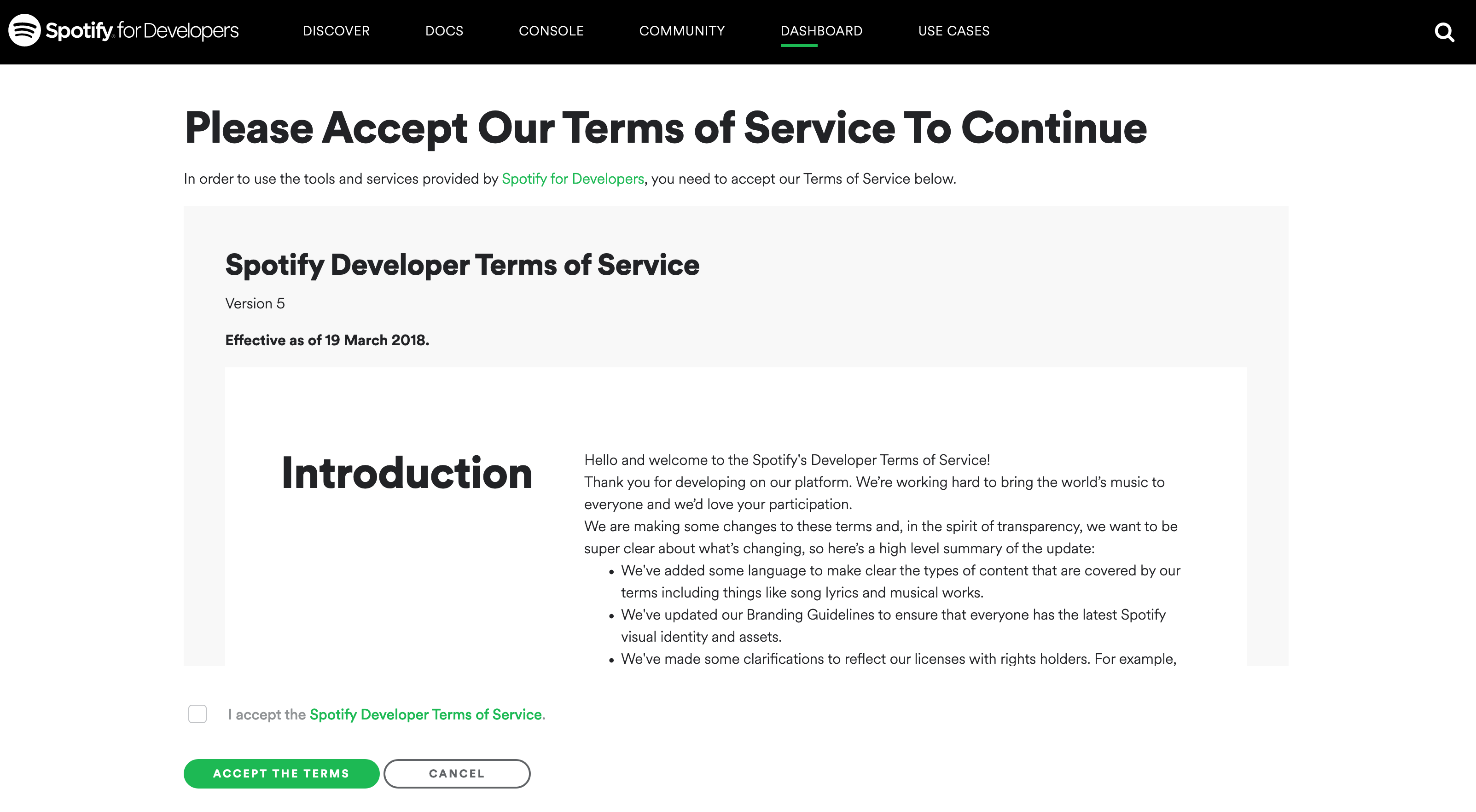
가입 시 프로젝트 목적을 묻는데, 우리는 비상업적(Non-commercial) 용도를 선택하면 됩니다. 등록을 마치면 가장 중요한 두 정보인 클라이언트 ID(Client ID)와 클라이언트 시크릿(Client Secret)이 발급됩니다. 이는 일종의 암호이므로 절대 남에게 노출해서는 안 됩니다.
이런 비밀 키를 코드에 직접 적지 않고 안전하게 관리하는 좋은 방법은 시스템 환경 변수로 저장하는 것입니다. 이렇게 하면 코드를 GitHub에 공유해도 키 정보가 새 나가지 않죠. usethis 패키지의 edit_r_environ() 함수로 R의 환경 설정 파일인 .Renviron을 열어보세요.
edit_r_environ()이제 열린 파일에 발급받은 키 정보를 아래와 같이 입력합니다. spotifyr 패키지가 정해진 이름의 변수를 찾아 읽어 가므로, 변수명을 정확히 똑같이 적어야 합니다. (주의: 값 주위에 작은따옴표를 써야 합니다.)
SPOTIFY_CLIENT_ID = '여러분의_클라이언트_ID'
SPOTIFY_CLIENT_SECRET = '여러분의_클라이언트_시크릿'파일 저장 후 설정이 적용되도록 R을 다시 시작하세요 (Session > Restart R). 이제부터는 코드에 키를 적지 않아도 함수들이 자동으로 환경 변수에서 키를 읽어와 인증을 마칠 것입니다.
준비가 되었으니 영국 밴드 라디오헤드(Radiohead)의 음악 정보를 가져와 보겠습니다. get_artist_audio_features() 함수는 아티스트의 모든 곡에 대한 음악적 특징을 데이터프레임으로 돌려줍니다.
radiohead <- get_artist_audio_features("radiohead")
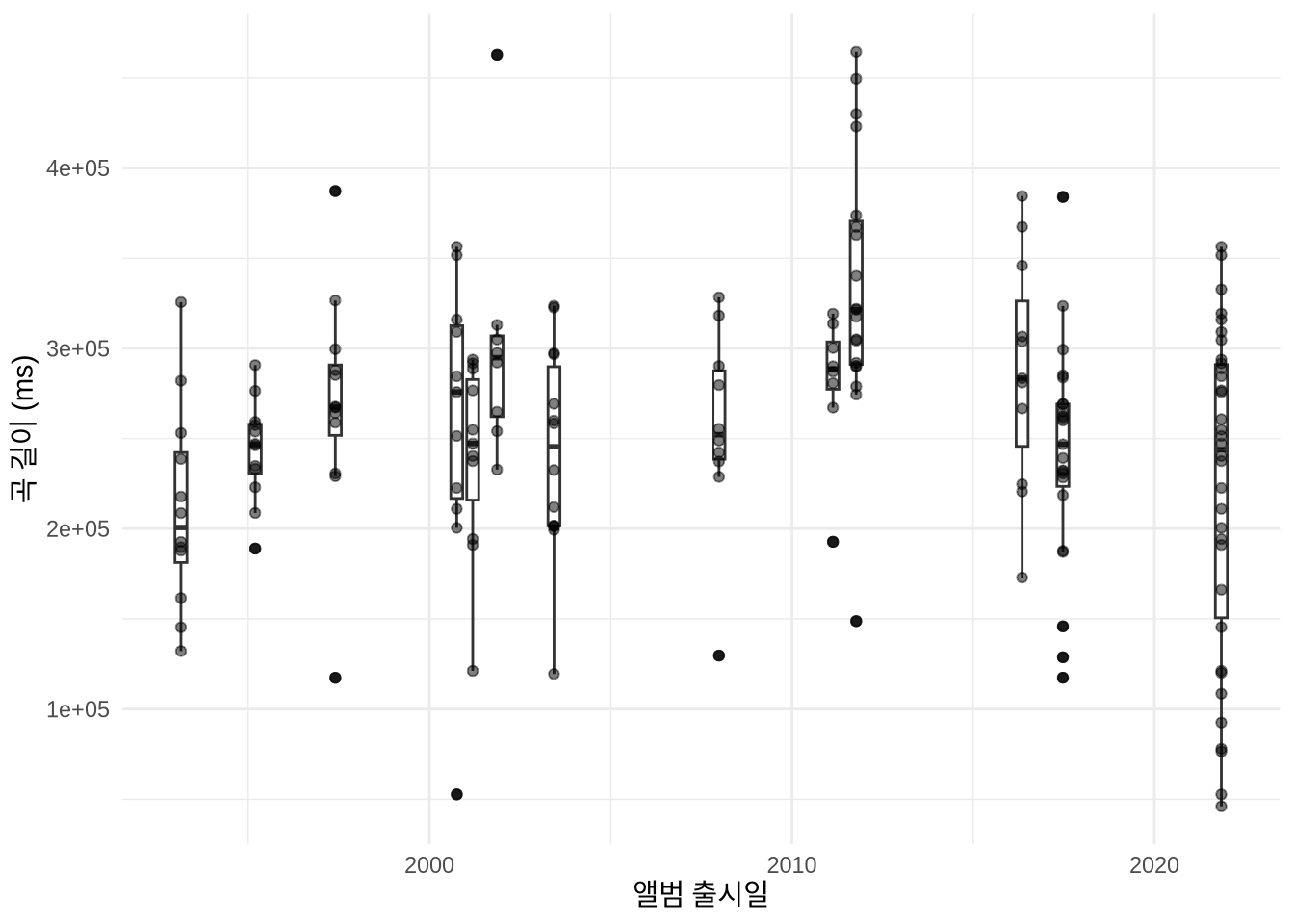
saveRDS(radiohead, "radiohead.rds")radiohead <- readRDS("radiohead.rds")수집된 데이터에는 노래마다 다양한 변수가 담겨 있습니다. 예를 들어 라디오헤드 노래들이 시간이 흐를수록 점점 길어지는 추세인지 궁금할 수 있죠 (Figure 7.4). Chapter 5 에서 배운 시각화 원칙을 살려 앨범별 분포를 보여주는 박스 플롯과 개별 곡을 나타내는 지터 플롯을 함께 그려보겠습니다.
radiohead <- as_tibble(radiohead)
radiohead |>
mutate(album_release_date = ymd(album_release_date)) |>
ggplot(aes(
x = album_release_date,
y = duration_ms,
group = album_release_date
)) +
geom_boxplot() +
geom_jitter(alpha = 0.5, width = 0.3, height = 0) +
theme_minimal() +
labs(
x = "앨범 출시일",
y = "곡 길이 (ms)"
)
스포티파이는 각 곡에 대해 ‘Valence’라는 흥미로운 수치를 제공합니다. 스포티파이 문서에 따르면 이 값은 0에서 1 사이로, 음악의 ’긍정성’을 나타냅니다. 값이 높을수록 밝고 행복한 느낌의 곡이라는 뜻이죠. 라디오헤드, 미국의 록 밴드 더 내셔널(The National), 그리고 팝스타 테일러 스위프트(Taylor Swift)의 음악이 시간에 따라 어떻게 변했는지 valence 값을 비교해 봅시다.
분석 결과 테일러 스위프트와 라디오헤드는 오랜 활동 기간에도 불구하고 비교적 일관된 정서를 유지해 온 반면, 더 내셔널의 음악은 시간이 갈수록 valence 값이 서서히 낮아지는 경향을 보였습니다.
거의 비용을 들이지 않고 전 세계 음악 라이브러리에 접근해 이런 정교한 분석을 할 수 있다는 점이 정말 놀랍지 않나요? Pavlik (2019) 은 이런 데이터를 활용해 음악 장르를 자동 분류하고, (The Economist 2022)는 언어와 스트리밍 횟수 사이의 상관관계를 밝혀내기도 했습니다. 과거에는 엄청난 규모의 실험을 해야 얻을 수 있었던 통찰을, 이제는 단 몇 줄의 코드로 관측 데이터에서 뽑아낼 수 있게 된 것입니다(예: Salganik, Dodds, and Watts (2006)).
물론 주의할 점도 있습니다. ’Valence’라는 숫자 하나가 음악의 복잡한 감성을 완벽히 요약할 수 있을까요? 스포티파이의 산출 공식은 비공개이므로 측정의 타당성에 늘 의문을 가져야 합니다. 또한 스포티파이에 등록되지 않은 수많은 아티스트의 목소리가 누락되어 있다는 점도 잊지 말아야 하죠. 이는 앞서 배운 측정과 표본 추출의 문제가 우리가 다루는 모든 데이터에 깊숙이 스며들어 있음을 보여주는 훌륭한 사례입니다.
7.3 웹 스크래핑
7.3.1 기본 원칙
웹 스크래핑(Web Scraping)이란 웹사이트에 게시된 정보를 코드로 자동 수집하는 기술입니다. 브라우저에서 직접 복사해 저장하는 지루한 과정을 자동화하는 것이죠. 스크래핑은 방대한 데이터를 다울 수 있게 해주지만, 대개 웹사이트 운영자가 데이터 수집을 목적으로 페이지를 만든 게 아니라는 점을 명심해야 합니다. 따라서 스크래핑을 할 때는 항상 존중하는 태도가 필요합니다. 스크래핑 자체가 불법은 아닌 경우가 많지만, 상업적 경쟁이나 서비스 약관 위반 여부에 따라 법적·윤리적 문제가 불거질 수 있습니다 (Luscombe, Dick, and Walby 2021).
특히 개인정보 보호에 각별히 유의해야 합니다. 공개된 정보라고 해서 마음대로 긁어모아 새로운 데이터셋으로 배포해도 된다는 뜻은 아닙니다. Kirkegaard and Bjerrekær (2016) 는 데이팅 앱 OKCupid의 프로필 약 7만 개를 스크래핑해 공개했다가 큰 윤리적 비판을 받기도 했죠 (Hackett 2016). Zimmer (2018) 은 ’피해 최소화’와 ’정보에 입각한 동의’의 가치를 강조하며, 데이터가 공개된 ’맥락’이 바뀔 때 발생할 수 있는 위험을 경고합니다. 사용자가 특정 플랫폼에 올린 정보는 그 안에서만 쓰일 것을 전제로 한 것이지, 불특정 연구자들이 분석하도록 허락한 게 아닐 수 있기 때문입니다.
“데이터가 있다”는 착각
경찰의 공권력 남용 문제는 사회적 신뢰와 직결된 아주 민감한 사안입니다. 하지만 이에 대한 정확한 정부 공식 통계는 찾기가 매우 어렵습니다 (Thomson-DeVeaux, Bronner, and Sharma 2021). 사건의 맥락을 데이터셋으로 단순화하는 것이 조심스럽기 때문이죠. 현재 가장 널리 쓰이는 경찰 폭력 관련 데이터셋들은 모두 웹 스크래핑으로 구축되었습니다.
- Mapping Police Violence
- The Fatal Force Database
Bor et al. (2018) 은 이 데이터를 분석해 비무장 흑인에 대한 경찰의 치명적 무력 사용이 공동체의 정신 건강에 심각한 악영향을 미친다는 사실을 규명했습니다. 반면 Nix and Lozada (2020) 은 동일한 데이터를 쓰면서도 코딩 방식(예: ‘장난감 총을 든 경우를 무장으로 볼 것인가’)에 따라 결론이 달라질 수 있음을 지적하며 신중한 접근을 당부했죠. 이는 정성적 맥락이 강한 사건을 정량적 데이터로 바꿀 때 피할 수 없는 ’단순화’의 문제입니다 (The Washington Post 2023; Jenkins et al. 2022; Comer and Ingram 2022).
웹 스크래핑은 서버에 부하를 줄 수 있습니다. 매너 있는 데이터 과학자가 지켜야 할 스크래핑 7원칙을 기억하세요.
- 최후의 수단으로 써라: API가 있다면 API를 먼저 쓰세요.
- robots.txt를 준수하라: 주소 뒤에
/robots.txt를 붙여보세요.Disallow에 적힌 폴더는 피하고,Crawl-delay만큼 기다려야 합니다. - 서버 부하를 최소화하라:
Sys.sleep()으로 요청 사이에 쉬는 시간을 두세요. 대량 수집은 밤 시간대에 천천히 하는 게 좋습니다. - 꼭 필요한 것만 가져가라: 위키피디아 전체를 긁지 말고 필요한 페이지만 수집하세요.
- 한 번만 긁어라: 수집한 원본 데이터는 로컬에 저장해 두세요. 코드를 고칠 때마다 서버에 다시 요청하는 건 낭비입니다.
- 페이지 내용을 통째로 재배포하지 마라: 원본 전체를 공개하는 건 저작권 위반 소지가 큽니다.
- 책임감 있게 행동하라: 수집 스크립트에 본인의 연락처를 남기거나 대규모 수집 전에는 미리 허락을 구하는 것이 예의입니다.
7.3.2 HTML과 CSS의 이해
웹 스크래핑은 웹페이지가 HTML(HyperText Markup Language)이라는 구조로 짜여 있다는 점을 활용합니다. 원하는 데이터가 어떤 태그(Tag) 안에 숨어 있는지 찾으려면 브라우저의 ‘검사(Inspect)’ 기능을 활용하거나 페이지 소스를 직접 확인해야 하죠.
HTML은 꺾쇠괄호(<>) 태그들이 중첩된 구조입니다. 예를 들어 글자를 굵게 표시하려면 다음과 같이 씁니다.
<b>이 글자는 굵게 표시됩니다.</b>목록을 만들 때는 이런 식이죠.
<ul>
<li>첫 번째 항목</li>
<li>두 번째 항목</li>
</ul>스크래핑의 핵심은 이 태그들을 찾아 그 안의 알맹이(텍스트)만 쏙 뽑아내는 것입니다.
가장 대중적인 R 패키지인 rvest를 사용해 봅시다. rvest는 태그 정보를 ’노드(Node)’라고 부릅니다. read_html()로 페이지를 읽고, html_elements()로 특정 태그를 찾은 뒤 html_text()로 내용을 추출하는 게 기본 흐름입니다.
스크래핑은 한 페이지로 끝나지 않는 경우가 많습니다. 보통 목록을 먼저 가져오는 인덱스 스크래핑(Index scraping)과 개별 링크를 따라가 상세 내용을 담는 콘텐츠 스크래핑(Content scraping)의 두 단계로 진행되죠. 대규모 작업이라면 서버에 예의를 갖추는 polite 패키지를 쓰거나 GitHub Actions로 자동화하는 방법도 고려해 보세요 (Luscombe, Duncan, and Walby 2022; Perepolkin 2022).
website_extract <- "<p>안녕하세요, 저는 <b>로한</b> 알렉산더입니다.</p>"rvest 패키지를 로드한 뒤 read_html()로 데이터를 읽어 들입니다.
rohans_data <- read_html(website_extract)
rohans_data{html_document}
<html>
[1] <body><p>안녕하세요, 저는 <b>로한</b> 알렉산더입니다.</p></body>rvest는 태그를 찾을 때 ’node’라는 표현을 씁니다. 여기서는 굵은 노드(b)에 집중해 보죠. html_elements()는 태그 정보까지 돌려주고, html_text()는 텍스트만 추출합니다.
rohans_data |>
html_elements("b"){xml_nodeset (1)}
[1] <b>로한</b>rohans_data |>
html_elements("b") |>
html_text()[1] "로한"7.3.3 사례 연구: 도서 목록 수집하기
이번 실습에서는 Rohan’s Books 웹사이트의 도서 목록을 스크래핑해 보겠습니다. 수집한 데이터를 정리해 저자 성(Last name)의 첫 글자가 어떻게 분포되어 있는지 시각화하는 게 목표입니다. 페이지 다운로드 \(\rightarrow\) 노드 탐색 \(\rightarrow\) 정보 추출 \(\rightarrow\) 데이터 정제 순으로 진행합니다.
먼저 rvest로 웹사이트를 불러옵니다. 스크래핑을 할 때는 서버에 계속 접근하는 대신 로컬 사본을 만들어 작업하는 것이 서버에 대한 예의입니다.
books_data <- read_html("https://rohansbooks.com")
write_html(books_data, "raw_data.html")이제 저장된 HTML 파일에서 정보를 뽑아낼 차례입니다. 추출한 데이터는 가능한 한 빨리 티블(tibble) 형태로 바꾸는 게 좋습니다. 그래야 tidyverse 도구들을 곧장 활용할 수 있기 때문이죠.
익숙하지 않다면 온라인 부록 A을 참고하세요.
books_data <- read_html("raw_data.html")데이터를 확인해 봅시다.
books_data{html_document}
<html>
[1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UTF-8 ...
[2] <body>\n <h1>Books</h1>\n\n <p>\n This is a list of books that ...웹사이트 화면과 소스 코드를 대조해 데이터가 어디 있는지 찾습니다 (Figure 7.5). 도서 제목과 저자가 목록(<li>) 태그 안에 담겨 있음을 알 수 있네요.

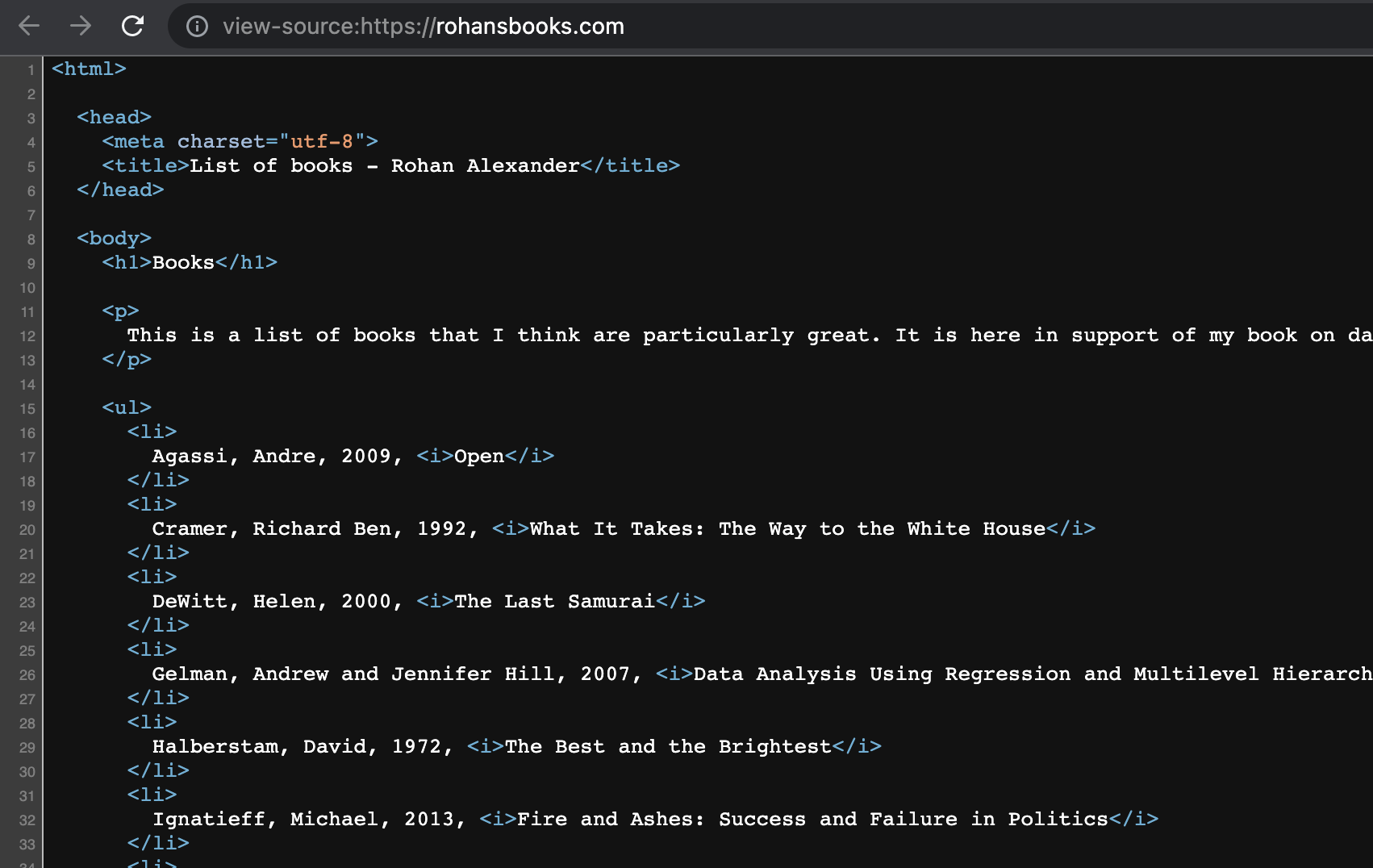
<li> 태그를 활용해 도서 정보를 골라내 보겠습니다.
text_data <-
books_data |>
html_elements("li") |>
html_text()
all_books <-
tibble(books = text_data)
head(all_books)# A tibble: 6 × 1
books
<chr>
1 "\n Agassi, Andre, 2009, Open\n "
2 "\n Cramer, Richard Ben, 1992, What It Takes: The Way to the White Hou…
3 "\n DeWitt, Helen, 2000, The Last Samurai\n "
4 "\n Gelman, Andrew and Jennifer Hill, 2007, Data Analysis Using Regres…
5 "\n Halberstam, David, 1972, The Best and the Brightest\n "
6 "\n Ignatieff, Michael, 2013, Fire and Ashes: Success and Failure in P…이제 날것의 데이터를 다듬을 차례입니다. separate() 함수로 한 덩어리로 된 제목, 저자, 발표 연도를 각각의 열로 분리해 보겠습니다.
all_books <-
all_books |>
mutate(books = str_squish(books)) |>
separate(books, into = c("author", "title"), sep = "\\, [[:digit:]]{4}\\, ")
head(all_books)# A tibble: 6 × 2
author title
<chr> <chr>
1 Agassi, Andre Open
2 Cramer, Richard Ben What It Takes: The Way to the White House
3 DeWitt, Helen The Last Samurai
4 Gelman, Andrew and Jennifer Hill Data Analysis Using Regression and Multileve…
5 Halberstam, David The Best and the Brightest
6 Ignatieff, Michael Fire and Ashes: Success and Failure in Polit…마지막으로 저자 이름 첫 글자의 분포를 확인해 봅니다 (Table 7.1).
all_books |>
mutate(
first_letter = str_sub(author, 1, 1)
) |>
count(first_letter) |>
tt() |>
style_tt(j = 1:2, align = "lr") |>
format_tt(digits = 0, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("첫 글자", "빈도"))| 첫 글자 | 빈도 |
|---|---|
| A | 1 |
| C | 1 |
| D | 1 |
| G | 1 |
| H | 1 |
| I | 1 |
| L | 1 |
| M | 1 |
| P | 3 |
| R | 1 |
| V | 2 |
| W | 4 |
| Y | 1 |
7.3.4 사례 연구: 영국 총리의 생애
이번에는 영국 총리들이 태어난 해를 기준으로 얼마나 오래 살았는지 알아보겠습니다. 위키피디아에서 데이터를 스크래핑해 정리한 뒤 그래프를 그려보죠. 웹사이트 구조는 언제든 바뀔 수 있으니 스크래핑 코드는 늘 유연하게 대처해야 합니다.
먼저 시뮬레이션 데이터를 만들어 봅니다. 이름, 출생 및 사망 연도, 수명 정보가 담긴 표를 구상해 보죠.
set.seed(853)
simulated_dataset <-
tibble(
prime_minister = babynames |>
filter(prop > 0.01) |>
distinct(name) |>
unlist() |>
sample(size = 10, replace = FALSE),
birth_year = sample(1700:1990, size = 10, replace = TRUE),
years_lived = sample(50:100, size = 10, replace = TRUE),
death_year = birth_year + years_lived
) |>
select(prime_minister, birth_year, death_year, years_lived) |>
arrange(birth_year)
simulated_dataset# A tibble: 10 × 4
prime_minister birth_year death_year years_lived
<chr> <int> <int> <int>
1 Kevin 1813 1908 95
2 Karen 1832 1896 64
3 Robert 1839 1899 60
4 Bertha 1846 1915 69
5 Jennifer 1867 1943 76
6 Arthur 1892 1984 92
7 Donna 1907 2006 99
8 Emma 1957 2031 74
9 Ryan 1959 2053 94
10 Tyler 1990 2062 72시뮬레이션을 먼저 하면 좋은 점은 팀원들이 데이터를 모으는 동안 다른 한쪽에서는 그래프 코드를 미리 짤 수 있다는 것입니다. 우리는 Figure 7.6 같은 그래프를 최종 목표로 삼습니다.
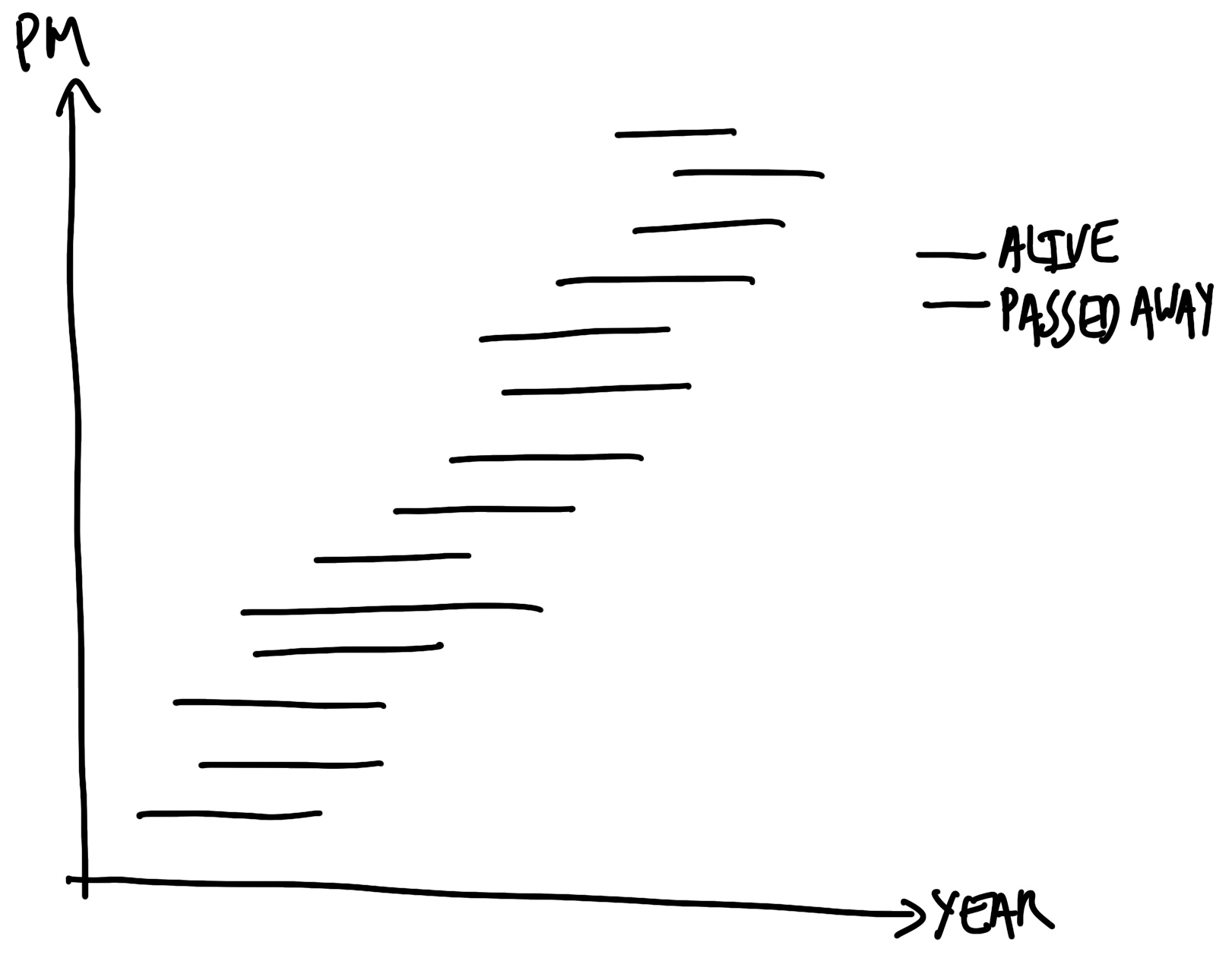
영국 총리 목록 위키피디아 페이지는 정보가 정확하고 표 구조가 잘 잡혀 있어 아주 좋은 소스입니다. read_html()로 페이지를 로컬에 저장해 두고 작업을 시작합니다.
raw_data <-
read_html(
"https://en.wikipedia.org/wiki/List_of_prime_ministers_of_the_United_Kingdom"
)
write_html(raw_data, "pms.html")이때 SelectorGadget을 쓰면 원하는 정보가 담긴 CSS 선택자를 마우스 클릭만으로 쉽게 찾을 수 있습니다 (Figure 7.7).
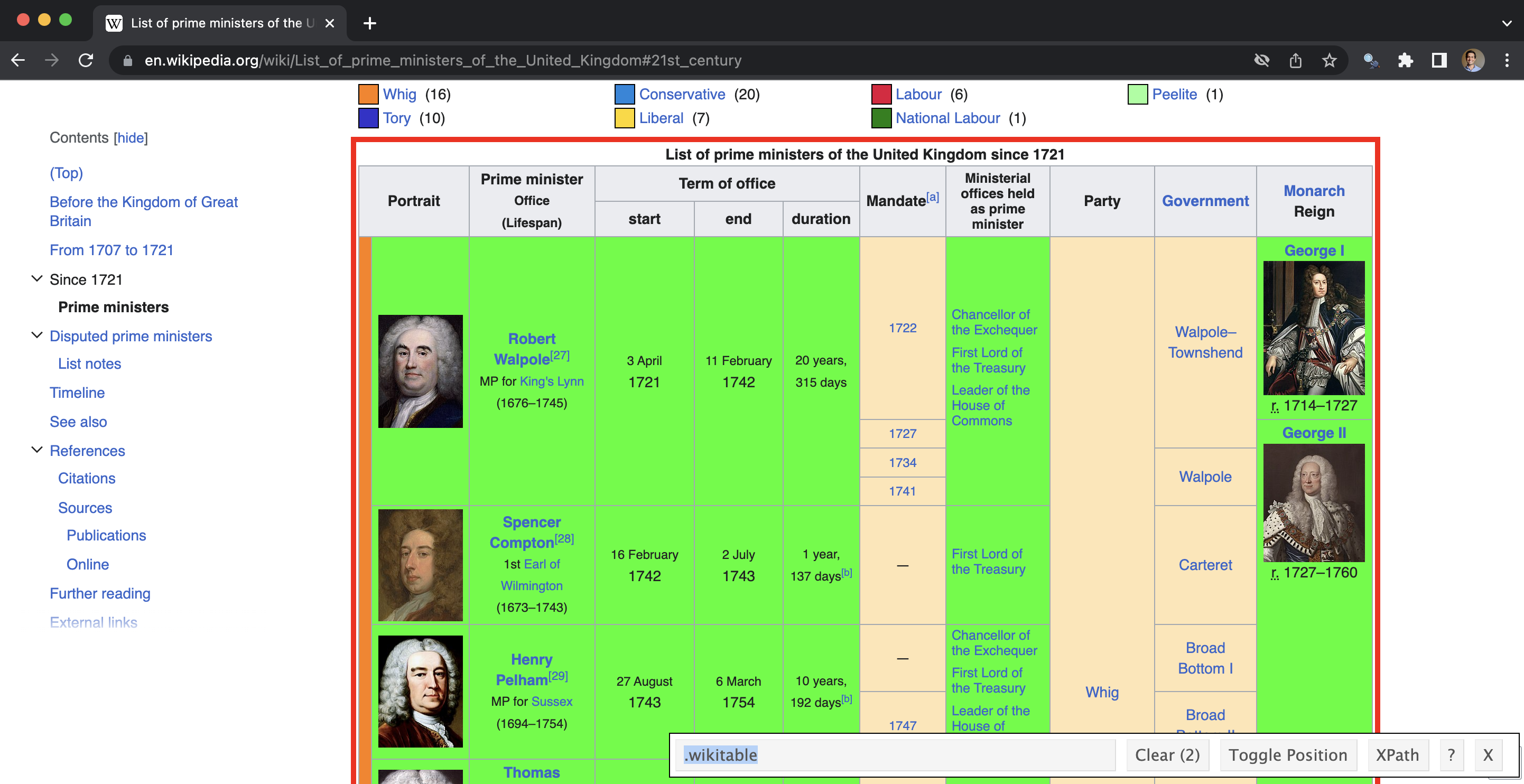
parse_data_selector_gadget <-
raw_data |>
html_element(".wikitable") |>
html_table()
head(parse_data_selector_gadget)# A tibble: 6 × 11
Portrait Portrait Prime ministerOffice(L…¹ `Term of office` `Term of office`
<chr> <chr> <chr> <chr> <chr>
1 Portrait "Portrait" Prime ministerOffice(Li… start end
2 "" Robert Walpole[27]MP fo… 3 April1721 11 February1742
3 "" Robert Walpole[27]MP fo… 3 April1721 11 February1742
4 "" Robert Walpole[27]MP fo… 3 April1721 11 February1742
5 "" Robert Walpole[27]MP fo… 3 April1721 11 February1742
6 "" Spencer Compton[28]1st … 16 February1742 2 July1743
# ℹ abbreviated name: ¹`Prime ministerOffice(Lifespan)`
# ℹ 6 more variables: `Term of office` <chr>, `Mandate[a]` <chr>,
# `Ministerial offices held as prime minister` <chr>, Party <chr>,
# Government <chr>, MonarchReign <chr>가져온 표 데이터에는 불필요한 내용이 섞여 있게 마련입니다. 필요한 열만 골라 정규 표현식을 활용해 텍스트를 나누고 정제해 줍니다.
parsed_data <-
parse_data_selector_gadget |>
clean_names() |>
rename(raw_text = prime_minister_office_lifespan) |>
select(raw_text) |>
filter(raw_text != "Prime ministerOffice(Lifespan)") |>
distinct()
initial_clean <-
parsed_data |>
separate(
raw_text, into = c("name", "not_name"), sep = "\\[", extra = "merge",
) |>
mutate(date = str_extract(not_name, "[[:digit:]]{4}–[[:digit:]]{4}"),
born = str_extract(not_name, "born[[:space:]][[:digit:]]{4}")
) |>
select(name, date, born)
head(initial_clean)# A tibble: 6 × 3
name date born
<chr> <chr> <chr>
1 Robert Walpole 1676–1745 <NA>
2 Spencer Compton 1673–1743 <NA>
3 Henry Pelham 1694–1754 <NA>
4 Thomas Pelham-Holles 1693–1768 <NA>
5 William Cavendish 1720–1764 <NA>
6 Thomas Pelham-Holles 1693–1768 <NA> 사망한 총리와 생존한 총리의 날짜 형식이 다르므로 이를 꼼꼼히 보정해 줍니다. 마침내 깔끔한 데이터셋이 완성되었습니다 (Table 7.2).
# 정제 과정은 본문 코드 참고이제 총리들의 생애 주기를 그래프로 그려봅시다 (?fig-pmslives). 생존 중인 총리는 색상을 다르게 해 현재 시점까지 선을 이었습니다.
7.3.5 수집 과정 자동화하기
실제 프로젝트에서는 수백 개의 파일을 자동으로 내려받아야 할 때가 많습니다. 호주 중앙은행(RBA)의 통화 정책 성명서를 예로 들어보죠. 우리는 purrr 패키지의 함수들을 활용해 이 반복 작업을 스마트하게 처리할 수 있습니다.
먼저 다운로드할 URL 목록을 담은 티블을 만듭니다.
first_bit <- "https://www.rba.gov.au/publications/smp/2023/"
last_bit <- "/pdf/overview.pdf"
statements_of_interest <-
tibble(
address =
c(
paste0(first_bit, "feb", last_bit),
paste0(first_bit, "may", last_bit)
),
local_save_name = c("2023-02.pdf", "2023-05.pdf")
)단순히 다운로드만 하는 게 아니라 작업 상황을 알려주고 서버 부하를 줄이기 위해 잠시 쉬어주는 함수를 작성합니다.
visit_download_and_wait <-
function(address_to_visit,
where_to_save_it_locally) {
download.file(url = address_to_visit,
destfile = where_to_save_it_locally)
print(paste("완료:", address_to_visit, "시간:", Sys.time()))
Sys.sleep(sample(5:10, 1))
}이제 walk2() 함수로 목록을 순회하며 파일을 저장합니다. 대량 수집 시에는 heapsofpapers 패키지를 활용하는 것도 아주 좋은 방법입니다 (Alexander and Mahfouz 2021).
7.4 PDF 파싱
어도비가 개발한 PDF(Portable Document Format)는 어느 환경에서든 문서 레이아웃을 똑같이 보여주기에 아주 훌륭하지만, 데이터를 추출하기에는 꽤나 까다로운 형식입니다. 분석을 위해서는 이 틀 안에 갇힌 데이터를 ’구출’해내야 하죠.
PDF 파싱 시 기억해야 할 두 원칙은 다음과 같습니다.
- 목표를 먼저 그리세요: 어떤 형태의 표를 원하는지 미리 스케치해야 헛수고를 줄입니다.
- 작게 시작해 넓히세요: 처음부터 전체를 다루지 말고 한 줄, 한 페이지만이라도 제대로 불러오는 코드부터 짜보세요.
7.4.1 사례 1: ‘제인 에어’ 텍스트 추출
‘제인 에어’ 소설 PDF에서 텍스트를 가져오려면 pdftools 패키지의 pdf_text()를 씁니다. 읽어온 결과는 각 페이지가 요소인 문자 벡터가 되죠. 이를 가능한 한 빨리 우리가 익숙한 티블 형식으로 변환해 tidyverse 도구들로 처리하는 게 정석입니다.
# 텍스트 읽기 및 티블 변환 예시는 본문 참고7.4.2 사례 2: 미국 총 출산율(TFR) 데이터 구축
미국 생명 통계 보고서의 표 데이터를 파싱해 깔끔한 데이터셋을 만들어 봅시다. 마법 같은 한 방은 없습니다. 수동으로 데이터를 확인하고 규칙성을 찾아내는 끈질긴 과정이 필요하죠.
우리는 미리 조사된 URL과 페이지 정보가 담긴 메타데이터를 활용할 것입니다.
PDF를 다운로드해 문자 벡터로 읽은 뒤 separate_rows()로 줄을 나누고, 공통 패턴(주와 숫자 사이의 점 등)을 찾아 열을 분리해 줍니다. 정교한 정규 표현식 활용이 관건입니다.
정제가 끝나면 마침내 유타주가 가장 높고 버몬트주가 가장 낮은, 미국의 주별 출산율 분포를 한눈에 보여주는 데이터셋이 탄생합니다 (?tbl-tfrforthewin, ?fig-smalldhsexample).
7.4.3 광학 문자 인식 (OCR)
이미지로 된 PDF나 사진 속 글자는 기계에게 그저 점들의 집합일 뿐입니다. 광학 문자 인식(OCR)은 이를 실제 텍스트 데이터로 바꿔주는 마법 같은 기술이죠 (Cheriet et al. 2007). 이번엔 오픈 소스 엔진인 Tesseract를 활용해 이미지 속 텍스트를 추출해 보겠습니다.
’제인 에어’의 첫 페이지 스캔 이미지를 OCR 해보면 결과가 꽤 훌륭합니다. 물론 완벽하진 않으니 오타가 있는지 늘 검토해야 합니다. 결과가 아쉽다면 이미지 대비를 높이는 등의 전처리가 도움이 됩니다.
7.5 연습 문제
실습
- (계획) 다섯 명의 학생이 100일간 독서량을 기록하는 시나리오를 구상해 보세요. 데이터 구조를 스케치하고 이를 잘 보여줄 그래프를 그려보세요.
- (시뮬레이션) 위 시나리오를 코드로 구현하고 데이터 검증 테스트 5개를 작성하세요.
- (수집) 유사한 실제 데이터를 찾아 수집하고 테스트 코드를 적용해 보세요.
- (탐색) 수집한 데이터로 의미 있는 그래프와 표를 만드세요.
- (소통) 분석 보고서를 Quarto로 작성해 GitHub 링크와 함께 제출하세요.
퀴즈
- 데이터 수집에서 API란 무엇인가요? (하나 선택)
- 정답: d. 다른 사람이 코드를 사용해 정해진 규칙대로 데이터를 요청하고 받을 수 있게 서버가 제공하는 인터페이스.
- API 인증 시 주로 쓰는 방법은? (하나 선택)
- 정답: a. 요청 시 API 키나 토큰을 함께 전달한다.
- 웹 스크래핑 시
robots.txt를 존중해야 하는 이유는? (하나 선택)- 정답: b. 운영자가 정한 규칙을 준수해 서비스 약관을 위반하지 않으려고.
- 웹 스크래핑 매너가 아닌 것은? (하나 선택)
- 정답: c. 나중에 쓸지 모르니 일단 사이트 전체를 다 긁어모은다. (X)
- 정규 표현식에서 마침표(.) 자체를 찾으려면? (하나 선택)
- 정답: b.
\\.
- 정답: b.
- HTML 목록 항목 태그는? (하나 선택)
- 정답: a.
<li>
- 정답: a.
- 문자열을 분리하는 함수는? (하나 선택)
- 정답: c.
separate()
- 정답: c.
- OCR이란 무엇인가요? (하나 선택)
- 정답: b. 텍스트 이미지 파일을 기계가 읽을 수 있는 텍스트 데이터로 바꾸는 기술.
- PDF 데이터 추출의 근본적 어려움은? (하나 선택)
- 정답: b. 데이터 추출이 아니라 시각적 일관성을 위해 설계되었기 때문.
- Cirone and Spirling (2021) 가 말한 역사적 정치경제학의 ’술꾼의 검색 문제’란? (하나 선택)
- 정답: a. 대표성보다 단순히 입수하기 쉬운 데이터만 선택하는 현상.