# library(beepr)
library(broom)
library(broom.mixed)
library(modelsummary)
library(purrr)
library(rstanarm)
library(testthat)
# library(tictoc)
library(tidyverse)
library(tinytable)12 선형 모델
권장 선행 학습
- 회귀 및 기타 이야기(원제: Regression and Other Stories) (Gelman, Hill, and Vehtari 2020) 읽기.
- 선형 모델에 대한 친절한 가이드를 제공하는 6장 “회귀 모델링 배경”, 7장 “단일 예측 변수를 사용한 선형 회귀”, 10장 “다중 예측 변수를 사용한 선형 회귀”를 중심으로 살펴보세요.
- R을 활용한 통계 학습 입문(원제: An Introduction to Statistical Learning with Applications in R) (James et al. [2013] 2021) 읽기.
- 또 다른 관점에서 선형 모델을 심도 있게 다루는 3장 “선형 회귀”에 집중해 보시기 바랍니다.
- 대부분의 출판된 연구 결과가 거짓인 이유 (Ioannidis 2005) 읽기.
- 통계 모델에서 도출된 결론을 약화시킬 수 있는 다양한 요인들을 날카롭게 짚어낸 논문입니다.
핵심 개념 및 기술
- 선형 모델은 통계적 추론의 핵심 기둥이며, 방대한 데이터를 빠르게 탐색할 수 있게 해줍니다.
- 단순 및 다중 선형 회귀는 각각 하나 또는 여러 개의 예측 변수를 활용해 연속형 결과 변수를 모델링하는 기법입니다.
- 선형 모델은 관계의 원인을 밝히는 ‘추론’이나 미래를 내다보는 ’예측’ 중 어디에 무게를 두느냐에 따라 활용 방식이 달라집니다.
소프트웨어 및 패키지
- 기본 R (R Core Team 2024)
beepr(Bååth 2018)broom(Robinson, Hayes, and Couch 2022)broom.mixed(Bolker and Robinson 2022)modelsummary(Arel-Bundock 2022)purrr(Wickham and Henry 2022)rstanarm(Goodrich et al. 2023)testthat(Wickham 2011)tictoc(Izrailev 2022)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
12.1 서론
선형 모델은 오랜 세월 다양한 분야에서 옷을 갈아입으며 활용되어 왔습니다. 스티글러(Stigler (1986)) [p.16]에 따르면, 단순 선형 회귀의 핵심인 최소제곱법은 1700년대 천문학의 난제들을 풀기 위해 처음 고안되었습니다. 달의 궤도를 계산하거나 목성과 토성의 불규칙한 움직임을 보정하는 과정에서 싹튼 것이죠. 초기 통계학자들은 서로 다른 조건에서 얻은 관측치를 하나로 묶는 것을 꺼렸으나, 천문학자들은 데이터 사이의 공통점을 믿고 이를 기꺼이 수용했습니다.
Stigler (1986, 28)는 이러한 인식의 차이를 18세기의 두 학자를 통해 설명합니다. Chapter 6 장에서 언급했던 수학자 오일러(Leonhard Euler)는 관측치를 모을수록 오차가 쌓여 결과가 왜곡될까 걱정했습니다. 반면 천문학자 마이어(Tobias Mayer)는 오차가 무작위적이라면 서로 상쇄되어 데이터가 많아질수록 오히려 더 정확한 진실에 다가갈 것이라고 믿었죠.
사회과학자들이 선형 모델의 위력을 깨닫고 받아들이기까지는 천문학자들보다 훨씬 긴 시간이 걸렸습니다. 사회과학 데이터는 천문학 데이터만큼 균일하지 않았고, 성격이 다른 데이터를 하나의 모델로 뭉뚱그리는 것에 대한 본능적인 거부감이 컸기 때문입니다. 천문학자는 자신이 예측한 천체의 움직임을 밤하늘의 실물과 직접 대조하며 검증할 수 있었지만, 사회과학자에게는 그런 명쾌한 심판대가 없었습니다 (Stigler 1986, 163).
통계 모델을 세운다고 해서 세상의 “진실”이 한 번에 눈앞에 나타나는 것은 아닙니다. 애초에 모델은 현실을 완벽하게 비추는 거울이 될 수 없습니다. 우리는 그저 주어진 데이터를 훑어보고, 복잡한 세상을 조금이라도 더 명확히 이해하기 위한 ’유용한 지팡이’로서 모델을 짚고 나아갈 뿐입니다. 따라서 세상에 ’정답인 모델’은 존재하지 않습니다. 오직 우리가 데이터로부터 무언가를 배우게 하고, 그 데이터가 태어난 현실에 대해 새로운 통찰을 주는 모델들이 있을 뿐입니다. 모델로 세상을 보려 할 때, 우리가 취하는 관점에는 필연적으로 한계가 따릅니다. 컴퓨터에 데이터를 쏟아붓는다고 모델이 알아서 모든 숙제를 해결해 주지는 않습니다. 모델은 스스로 생각하지 못하기 때문입니다.
“회귀 분석은 실로 신탁(oracle)과도 같지만, 동시에 잔인한 신탁입니다. 늘 수수께끼 같은 대답을 던지며, 우리가 잘못된 질문을 던졌을 때 여지없이 우리를 벌주는 것을 즐깁니다.”
— 맥엘리스(McElreath ([2015] 2020)) [p. 162]
우리는 모델이라는 렌즈로 세상을 들여다보려 합니다. 모델을 이리저리 찔러보고, 극한의 상황에 몰아넣으며 그 한계를 시험합니다. 공들여 만든 모델의 정교함에 감탄하다가도, 치명적인 결함을 발견하면 미련 없이 부숴버리기도 하죠. 하지만 이 치열한 과정 자체가 연구의 본질입니다. 바로 이 소란스러운 과정 속에서 우리는 세상을 조금씩 더 깊이 이해하게 되기 때문입니다. 비록 최종 모델 그 자체는 우연한 결과물일지라도 말입니다. 모델을 세울 때는 모델이 묘사하는 좁은 세계와, 우리가 궁극적으로 말하고자 하는 넓은 현실 세계를 동시에 시야에 두어야 합니다. 우리가 쥔 데이터셋은 대개 모집단을 완벽히 대변하지 못하고 저마다의 편향을 품고 있기 마련입니다. 그렇다고 해서 불완전한 데이터로 만든 모델이 무가치한 것은 아닙니다. 다만 맹신은 금물입니다. “이 모델은 우리 데이터에 대해 무엇을 말해주는가?” 그리고 “우리 데이터는 우리가 결론을 내리려는 현실을 얼마나 정직하게 반영하는가?” 이 두 가지 질문을 늘 가슴에 새겨두어야 합니다.
오늘날 우리가 쓰는 많은 통계 기법은 천문학이나 농업처럼 비교적 통제된 환경을 위해 태어났습니다. Chapter 8 에서 소개한 로널드 피셔(Ronald Fisher)가 농업 연구소 시절 펴낸 연구자를 위한 통계적 방법(Fisher ([1925] 1928))이 대표적인 예입니다. 하지만 현대 데이터 과학이 마주하는 현실은 과거 농장 실험과는 차원이 다른 복잡성을 띱니다. 통계적 타당성은 엄격한 수학적 가정이 전제될 때 빛을 발하지만, 실제 데이터가 이를 완벽히 충족하기란 하늘의 별 따기입니다. 분석은 매끄러운 길이 아닙니다. 끊임없이 시도하고, 추측하고, 결과를 검증하며 직관에 따라 방향을 트는 여정입니다. 이 과정에서 p-값(p-value)이나 검정력(power) 같은 전통적인 개념들이 본래의 의미를 잃고 흔들리기도 합니다. 우리는 이 기초적인 도구들을 명확히 이해해야 하지만, 동시에 현실의 복잡함 앞에서 교과서적인 틀을 벗어날 수 있는 유연함도 갖추어야 합니다.
모델링 과정 전반에 걸쳐 다양한 통계적 검사(statistical tests)가 수행되지만, 코드(code)와 데이터(data) 자체에 대한 자동화된 테스트 또한 그에 못지않게 중요합니다. 예를 들어, 웨이크필드 외(Knutson et al. (2022))는 팬데믹 기간의 초과 사망자 수를 추정하기 위해 정교한 모델을 구축했습니다. 수작업으로 꼼꼼히 검토를 거친 초기 모델이 발표되었으나, 이후 다른 학자들의 피드백을 수렴하는 과정에서 특정 가정 때문에 독일과 스웨덴의 추정치가 현실과 동떨어지게 나타난다는 사실이 뒤늦게 발견되었습니다. 연구팀은 즉시 이를 바로잡았지만, 만약 초기에 ’모델이 도출한 계수값이 현실적인 상식의 범위를 벗어나지 않는지’를 점검하는 ’자동화된 단위 테스트’를 코드에 심어두었더라면 어땠을까요? 그랬다면 오류를 훨씬 일찍 잡아내어 모델에 대한 신뢰를 처음부터 더 단단히 쌓을 수 있었을 것입니다.
이 장에서는 가장 기초적인 단순 선형 회귀부터 시작해, 여러 요인을 동시에 살피는 다중 선형 회귀로 보폭을 넓혀가겠습니다. 둘의 차이는 오직 모델에 넣는 ‘설명 변수’의 개수뿐입니다. 우리는 이 두 회귀 분석에 대해 두 가지 접근 방식을 살펴볼 것입니다. 첫째는 탐색적 데이터 분석(EDA) 과정에서 모델을 빠르고 가볍게 돌려볼 때 유용한 lm()이나 glm() 같은 기본 R 함수들입니다. 둘째는 결과의 불확실성을 더 깊이 있게 파고드는 ’추론(inference)’에 무게를 둘 때 사용하는 rstanarm 패키지입니다. 대개 통계 모델은 관계를 밝히는 ’추론’이나 미래 값을 맞추는 ’예측(prediction)’ 중 하나에 특화됩니다. 특히 ’예측’은 현대 머신러닝의 핵심 분야죠. R 생태계에서는 이를 위해 tidymodels(Kuhn and Wickham 2020)라는 훌륭한 도구를 제공합니다. 파이썬 활용법에 대해서는 Chapter 14 장에서 ’예측’에 초점을 둔 다양한 기법들을 상세히 다룰 것입니다. 어떤 도구나 접근 방식을 택하든 잊지 말아야 할 본질이 있습니다. 우리가 하는 정교한 모델링은 결국 ’세련된 방식으로 평균을 내는 것’이며, 그 결과는 필연적으로 우리가 입력한 데이터셋이 지닌 편향과 특성을 고스란히 반영한다는 사실입니다.
마지막으로 용어와 표기법을 정리하겠습니다. 통계학과 머신러닝은 역사적 배경이 달라 똑같은 개념을 제각각 부르곤 합니다. 혼동을 막기 위해 이 책에서는 Gelman, Hill, and Vehtari (2020) 의 관례를 따라 주로 “결과(outcome)”와 “예측 변수(predictor)”라는 용어를 사용하겠습니다. 또한 빈도주의 모델은 James et al. ([2013] 2021) 의 표기법을, 베이즈 모델은 McElreath ([2015] 2020) 의 명세 방식을 따르겠습니다.
12.2 단순 선형 회귀
연속형 결과 변수 \(y\)와 예측 변수 \(x\) 사이의 관계가 궁금할 때 가장 먼저 떠올리는 것이 단순 선형 회귀입니다. 이는 정규 분포(또는 “가우스” 분포)에 뿌리를 두고 있지만, 변수 자체가 반드시 정규 분포를 따라야 한다는 뜻은 아닙니다. 정규 분포는 평균 \(\mu\)와 표준 편차 \(\sigma\)라는 두 개의 매개변수에 의해 그 형태가 결정됩니다 (Pitman 1993, 94).
\[y = \frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{1}{2}z^2},\] 여기서 \(z = (x - \mu)/\sigma\)는 관측치 \(x\)가 평균에서 표준 편차의 몇 배만큼 떨어져 있는지를 나타내는 표준화된 수치입니다. Altman and Bland (1995) 는 정규 분포에 대한 훌륭한 개요를 제공합니다.
부록 A에서 배웠듯이, rnorm() 함수를 사용해 정규 분포를 따르는 데이터를 시뮬레이션해 보겠습니다.
set.seed(853)
normal_example <-
tibble(draws = rnorm(n = 20, mean = 0, sd = 1))
normal_example |> pull(draws) [1] -0.35980342 -0.04064753 -1.78216227 -1.12242282 -1.00278400 1.77670433
[7] -1.38825825 -0.49749494 -0.55798959 -0.82438245 1.66877818 -0.68196486
[13] 0.06519751 -0.25985911 0.32900796 -0.43696568 -0.32288891 0.11455483
[19] 0.84239206 0.34248268위 코드는 평균(\(\mu\))이 0이고 표준 편차(\(\sigma\))가 1인 표준 정규 분포에서 20개의 표본을 무작위로 추출(draw)한 결과입니다. 하지만 실제 데이터를 분석할 때 우리는 이 ‘참값’들을 알 수 없습니다. 오직 데이터를 통해 간접적으로 추정할 뿐이죠. 우리는 수집된 데이터를 바탕으로 평균 추정치 \(\hat{\mu}\)와 표준 편차 추정치 \(\hat{\sigma}\)를 계산합니다. (통계학에서 문자 위의 ’햇(hat, \(\hat{}\))’ 기호는 그것이 데이터로부터 얻은 ’추정치’임을 뜻합니다.)
\[ \begin{aligned} \hat{\mu} &= \frac{1}{n} \times \sum_{i = 1}^{n}x_i\\ \hat{\sigma} &= \sqrt{\frac{1}{n-1} \times \sum_{i = 1}^{n}\left(x_i - \hat{\mu}\right)^2} \end{aligned} \]
우리가 구한 \(\hat{\sigma}\)가 모집단의 표준 편차를 잘 반영한다고 가정하면, 추정된 평균 \(\hat{\mu}\)의 불확실성을 나타내는 표준 오차(SE, Standard Error)는 다음과 같이 구합니다.
\[\mbox{SE}(\hat{\mu}) = \frac{\hat{\sigma}}{\sqrt{n}}.\]
이름이 비슷해 헷갈리기 쉽지만, 표준 오차(SE)는 ’추정한 평균값이 실제 참값과 얼마나 다를 수 있는지’를, 표준 편차(SD)는 ’데이터 자체가 평균 주변에 얼마나 퍼져 있는지’를 나타내는 척도입니다1
이제 시뮬레이션 데이터로 평균, 표준 편차, 표준 오차를 직접 계산해 보며, 20개의 표본만으로도 원래 설정했던 값(0과 1)에 얼마나 근접하는지 확인해 보겠습니다.
estimated_mean <-
sum(normal_example$draws) / nrow(normal_example)
normal_example <-
normal_example |>
mutate(diff_square = (draws - estimated_mean) ^ 2)
estimated_standard_deviation <-
sqrt(sum(normal_example$diff_square) / (nrow(normal_example) - 1))
estimated_standard_error <-
estimated_standard_deviation / sqrt(nrow(normal_example))
tibble(mean = estimated_mean,
sd = estimated_standard_deviation,
se = estimated_standard_error) |>
tt() |>
style_tt(j = 1:3, align = "lrr") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c(
"추정 평균",
"추정 표준 편차",
"추정 표준 오차"
))| 추정 평균 | 추정 표준 편차 | 추정 표준 오차 |
|---|---|---|
| -0.21 | 0.91 | 0.2 |
Table 12.1 을 보면 추정치가 “참값”인 0과 1에서 약간씩 어긋나 있습니다. 표본이 20개뿐이니 당연한 결과입니다. 표본이 많아질수록 데이터는 매끄러운 종 모양을 갖추고, 추정치는 모집단의 진실에 수렴하게 됩니다 (Figure 12.1). 래리 와서먼(Wasserman (2005)) [p. 76]은 이를 대수의 법칙(Law of Large Numbers)이라 부르며 “확률론의 위대한 성취”라고 치켜세웠죠. 반면 사이먼 우드(Wood (2015)) [p. 15]는 이를 “필연적인 물리적 현상”으로 담담하게 설명하기도 합니다.
set.seed(853)
normal_takes_shapes <-
map_dfr(c(2, 5, 10, 50, 100, 500, 1000, 10000, 100000),
~ tibble(
number_draws = rep(paste(.x, "개 표본"), .x),
draws = rnorm(.x, mean = 0, sd = 1)
))
normal_takes_shapes |>
mutate(number_draws = as_factor(number_draws)) |>
ggplot(aes(x = draws)) +
geom_density() +
theme_minimal() +
facet_wrap(vars(number_draws),
scales = "free_y") +
labs(x = "값", y = "밀도")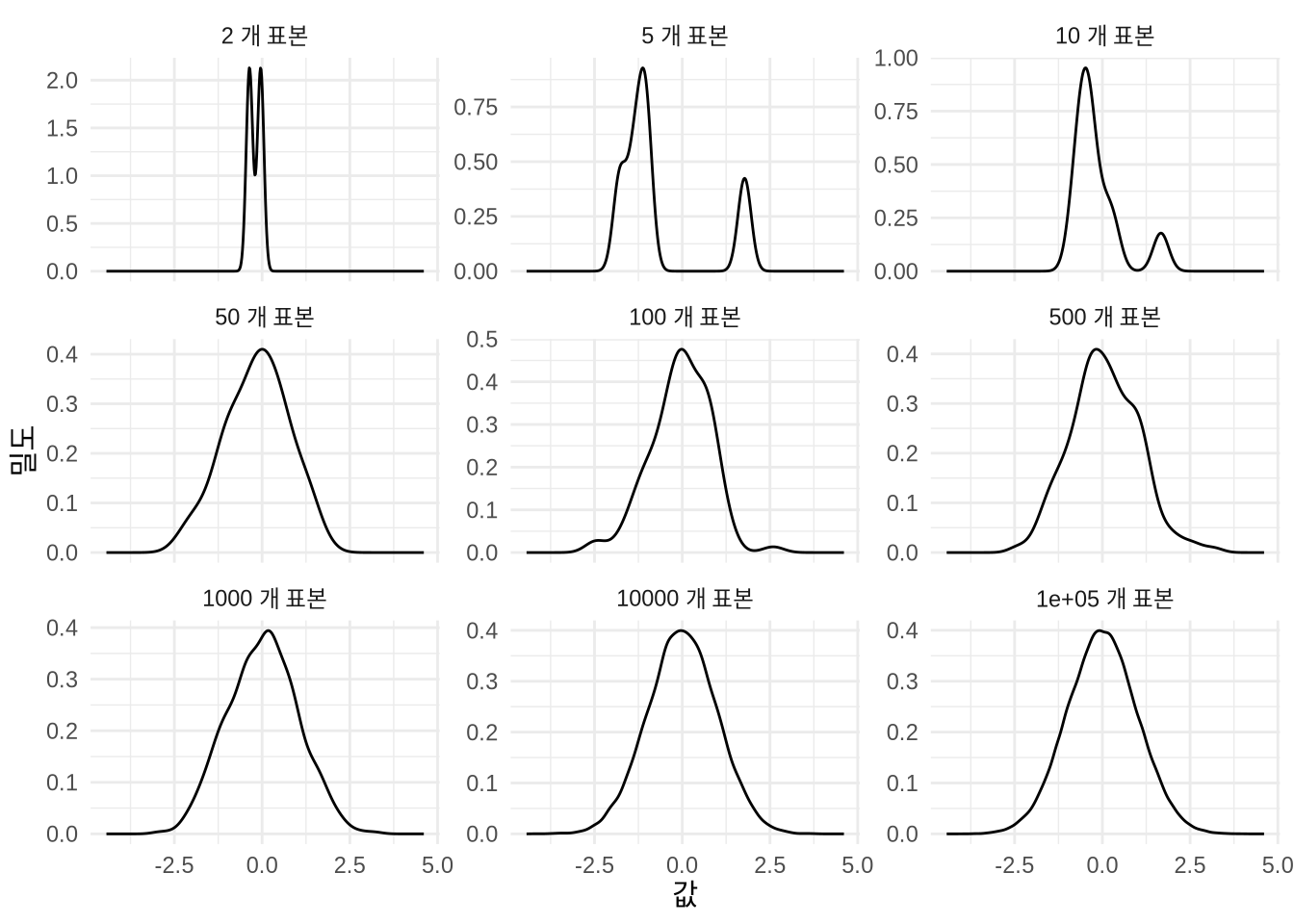
단순 선형 회귀를 시작할 때, 우리는 두 변수 \(Y\)와 \(X\) 사이의 관계가 특정한 수학적 질서를 따른다고 과감하게 ’가정’합니다. 그 관계는 다음과 같은 수식으로 표현됩니다.
\[ Y = \beta_0 + \beta_1 X + \epsilon. \tag{12.1}\] 여기서 \(\beta_0\)(절편)와 \(\beta_1\)(기울기)은 우리가 찾아내야 할 핵심 매개변수(계수)입니다. \(X\)가 0일 때 \(Y\)의 기댓값은 \(\beta_0\)이고, \(X\)가 1단위 증가할 때마다 \(Y\)의 기댓값은 \(\beta_1\)만큼 변한다는 뜻입니다. 수식 끝의 \(\epsilon\)은 선형 관계만으로는 설명할 수 없는 ’잡음(노이즈)’을 나타냅니다. 고전적인 회귀 분석에서는 이 노이즈가 정규 분포를 따른다고 가정하며, 이는 결과 변수 \(Y\) 또한 평균이 \(\beta\)에 의해 결정되는 정규 분포를 따른다는 결론으로 이어집니다.
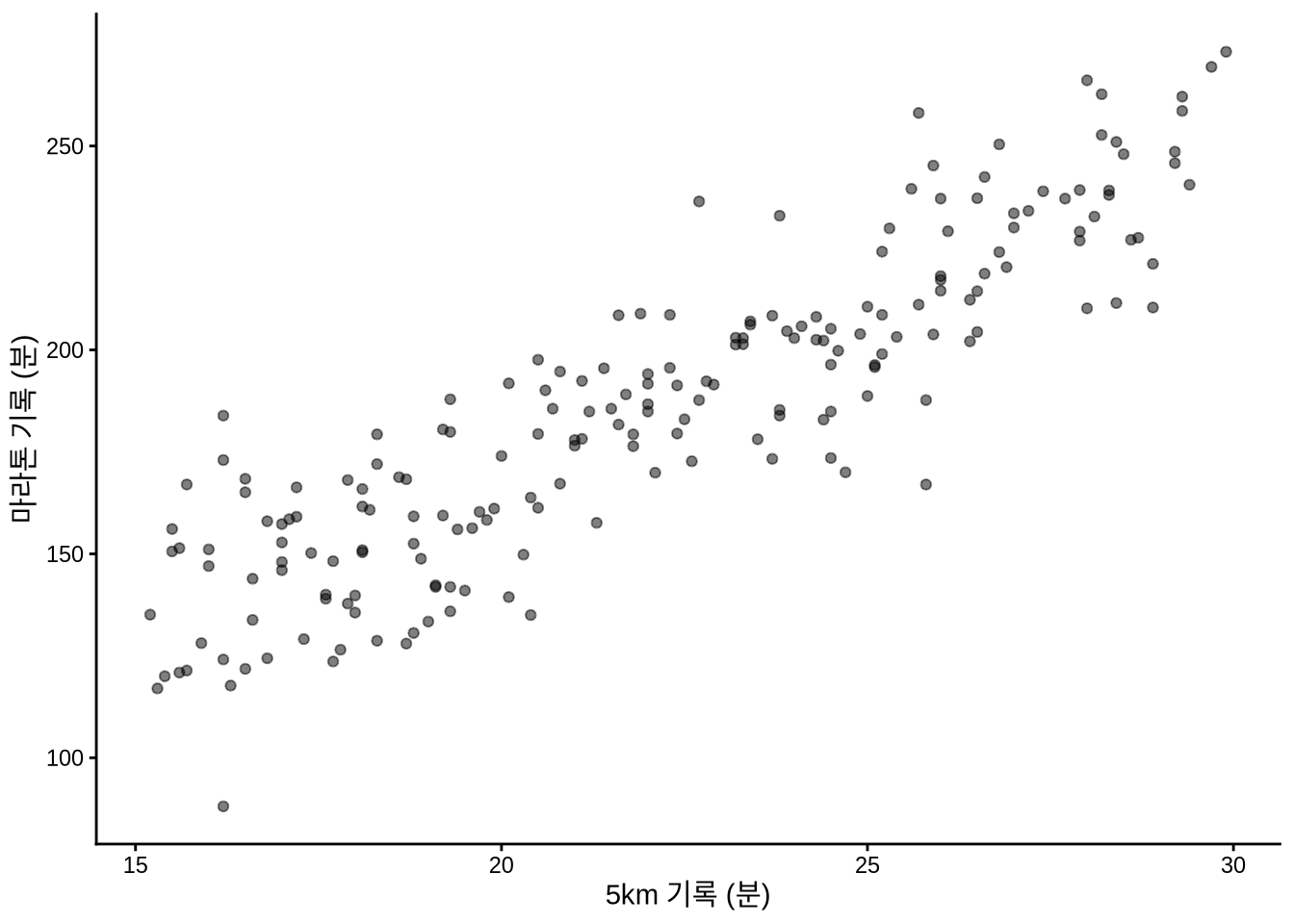
추상적인 수식을 현실로 가져오기 위해, 앞서 다뤘던 5km 달리기 기록과 마라톤 완주 기록의 관계를 다시 살펴보겠습니다 (Figure 12.2 (a)).
set.seed(853)
num_observations <- 200
expected_relationship <- 8.4
fast_time <- 15
good_time <- 30
sim_run_data <-
tibble(
five_km_time =
runif(n = num_observations, min = fast_time, max = good_time),
noise = rnorm(n = num_observations, mean = 0, sd = 20),
marathon_time = five_km_time * expected_relationship + noise
) |>
mutate(
five_km_time = round(x = five_km_time, digits = 1),
marathon_time = round(x = marathon_time, digits = 1)
) |>
select(-noise)base_plot <-
sim_run_data |>
ggplot(aes(x = five_km_time, y = marathon_time)) +
geom_point(alpha = 0.5) +
labs(
x = "5km 기록 (분)",
y = "마라톤 기록 (분)"
) +
theme_classic()
# 패널 (a)
base_plot
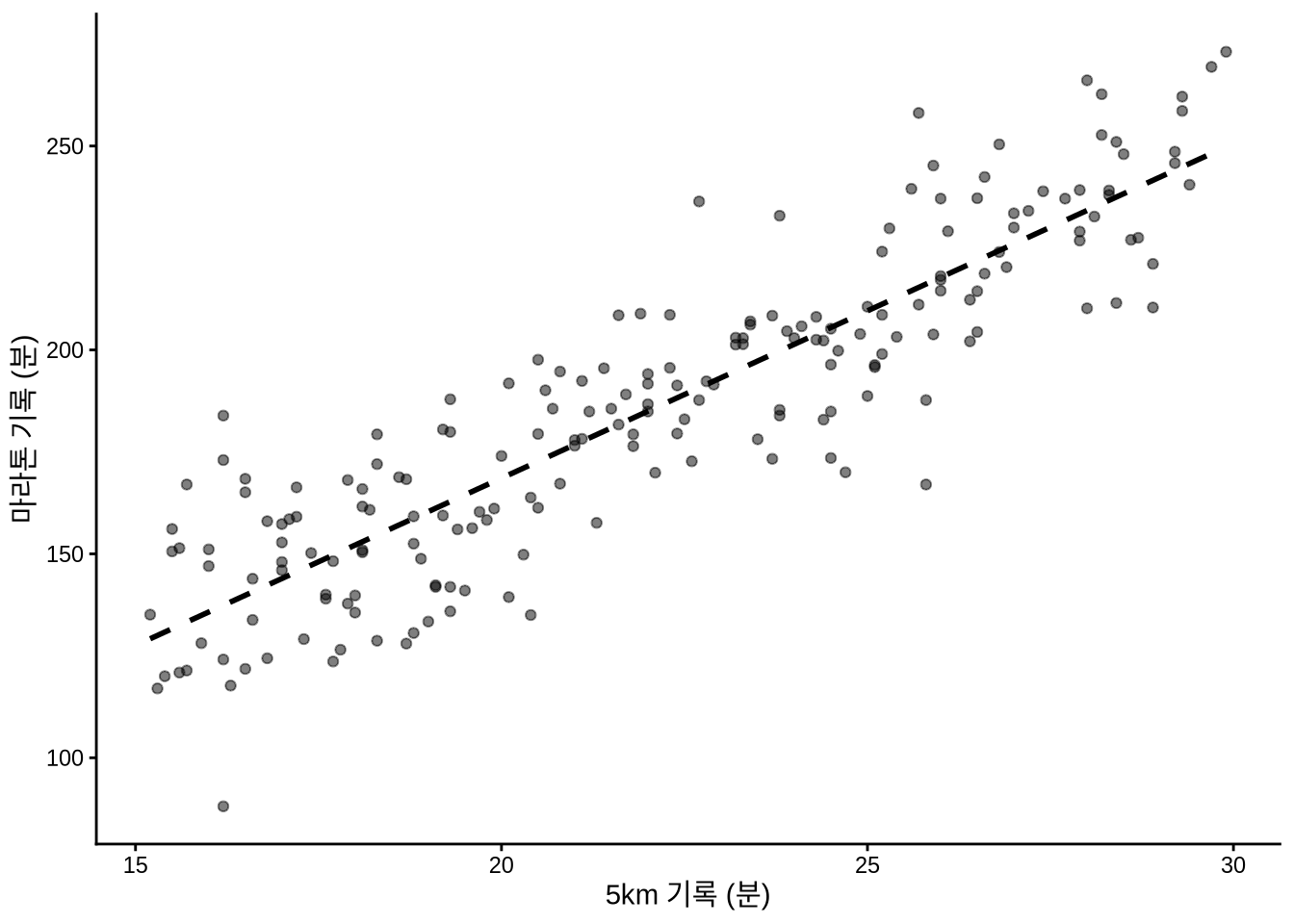
# 패널 (b)
base_plot +
geom_smooth(
method = "lm",
se = FALSE,
color = "black",
linetype = "dashed",
formula = "y ~ x"
)
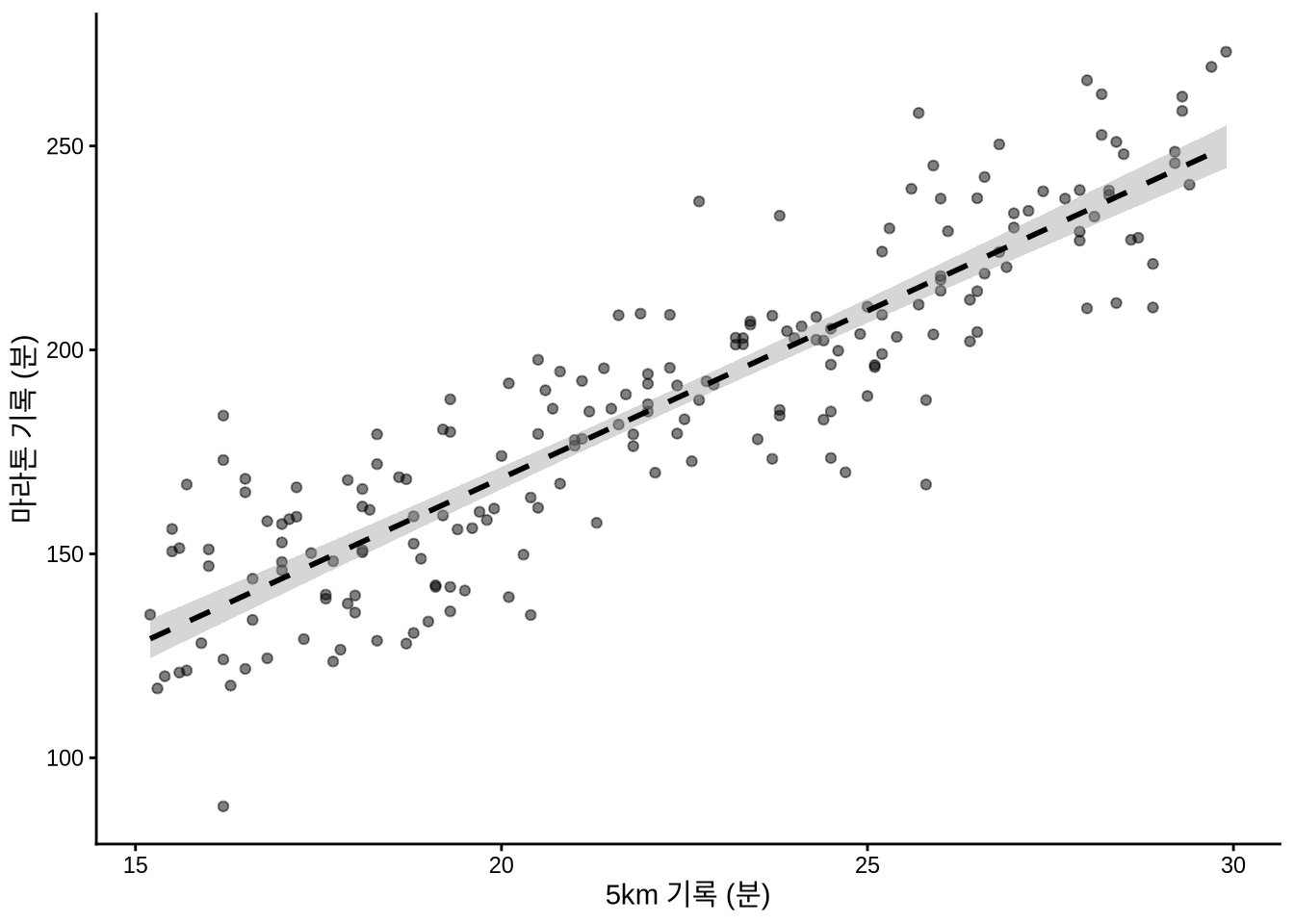
# 패널 (c)
base_plot +
geom_smooth(
method = "lm",
se = TRUE,
color = "black",
linetype = "dashed",
formula = "y ~ x"
)
시뮬레이션 데이터에서 우리는 \(\beta_0\)가 0이고 \(\beta_1\)이 8.4라는 ’진실’을 알고 있습니다. 분석가의 임무는 오직 데이터만을 가지고 이 숨겨진 값들을 얼마나 정확히 찾아낼 수 있는지(추정) 시험하는 것입니다 (James et al. [2013] 2021, 61).
\[\hat{y} = \hat{\beta}_0 + \hat{\beta}_1 x.\]
모델링의 핵심은 베일에 싸인 \(\beta_0\)와 \(\beta_1\)을 추정하는 일입니다. 산점도 위에 그을 수 있는 직선은 무수히 많지만, 어떤 선이 데이터를 가장 잘 설명할까요? 통계학의 표준은 잔차 제곱합(Residual Sum of Squares, RSS)을 최소화하는 선을 찾는 것입니다. 우선 임의의 \(\hat{\beta}_0, \hat{\beta}_1\) 값을 정해 예측치 \(\hat{y}\)를 구합니다. 그러고 나서 실제 관측치 \(y_i\)와의 차이인 ’잔차(residual)’를 각 데이터 포인트마다 계산하죠 (James et al. [2013] 2021, 62).
\[e_i = y_i - \hat{y}_i.\]
모든 데이터 포인트에서 발생한 잔차를 제곱해 모조리 더한 값이 바로 RSS입니다 (James et al. [2013] 2021, 62).
\[\mbox{RSS} = e^2_1+ e^2_2 +\dots + e^2_n.\]
RSS를 최소화하는 수학적 과정을 거치면 데이터에 가장 잘 들어맞는 단 하나의 최적 적합선(line of best fit)이 탄생합니다 (Figure 12.2 (b)). 하지만 수식을 풀었다고 끝이 아닙니다. 이 매끈한 선 하나를 얻기 위해 우리가 내렸던 수많은 가정을 되돌아봐야 합니다.
단순 선형 회귀의 기저에는 \(X\)와 \(Y\) 사이에 어떤 “참된” 관계가 있으며, 그것이 선형적이라는 믿음이 깔려 있습니다. 우리는 결코 그 진실을 완벽히 알 수 없습니다. 오직 표본(Sample)을 통해 추론할 뿐이죠. 하지만 우리가 얻는 통찰은 표본의 특성에 크게 휘둘리므로, 매번 다른 데이터를 뽑을 때마다 계수값은 조금씩 요동칠 수밖에 없습니다.
수식 끝의 \(\epsilon\)은 모델이 설명하지 못한 ’나머지 영역’을 뜻합니다. 데이터셋이라는 좁은 틀 안에서 우리 모델이 얼마나 부족한지 보여주는 지표죠. 하지만 이 수치가 모델이 현실 세계에서도 잘 작동할지(외적 타당성)를 보장해 주지는 않습니다. 그것은 분석가의 몫입니다. (Chapter 8 에서 다룬 내적·외적 타당성을 떠올려 보세요.)
R의 기본 함수인 lm()을 쓰면 선형 회귀를 아주 쉽게 실행할 수 있습니다. 결과 변수(\(Y\))를 앞에 쓰고 ~ 기호 뒤에 예측 변수(\(X\))를 적어주면 됩니다.
모델을 돌리기 전, 데이터 타입과 관측치 개수가 상식적인지 단위 테스트로 확인하는 습관을 들이세요. 또한 도출된 계수값이 물리적인 상식(예: 5km와 마라톤의 거리 비인 6~10 사이)을 벗어나지 않는지도 점검해야 합니다.
# 입력 데이터 검증
stopifnot(
class(sim_run_data$marathon_time) == "numeric",
class(sim_run_data$five_km_time) == "numeric",
nrow(sim_run_data) == 200
)
# 모델 적합
sim_run_data_first_model <-
lm(
marathon_time ~ five_km_time,
data = sim_run_data
)
# 결과 계수값의 합리성 검증
stopifnot(between(
sim_run_data_first_model$coefficients[2],
6,
10
))결과 요약은 summary() 함수나, 좀 더 깔끔한 표를 만들어주는 modelsummary 패키지의 modelsummary() 함수를 활용합니다 (Table 12.2).
modelsummary(
list(
"기본 모델" = sim_run_data_first_model,
"중심화 모델" = sim_run_data_centered_model
),
fmt = 2
)| 기본 모델 | 중심화 모델 | |
|---|---|---|
| (Intercept) | 4.47 | 185.73 |
| (6.75) | (1.23) | |
| five_km_time | 8.20 | |
| (0.30) | ||
| centered_time | 8.20 | |
| (0.30) | ||
| Num.Obs. | 200 | 200 |
| R2 | 0.790 | 0.790 |
| R2 Adj. | 0.789 | 0.789 |
| AIC | 1714.7 | 1714.7 |
| BIC | 1724.6 | 1724.6 |
| Log.Lik. | -854.341 | -854.341 |
| F | 745.549 | 745.549 |
| RMSE | 17.34 | 17.34 |
Table 12.2 의 계수값 중 절편(Intercept)을 해석할 때는 주의가 필요합니다. 기본 모델의 절편은 5km를 ’0분’에 달리는 가상의 선수가 기록할 마라톤 시간을 뜻하는데, 이는 현실적으로 불가능한 상황입니다. 우리 데이터가 15~30분 구간에만 몰려 있었기에 생기는 현상이죠.
더 직관적인 해석을 위해 5km 시간의 평균을 빼서(중심화, mean-centering) 회귀를 돌리는 방법을 씁니다. Table 12.2 의 “중심화 모델” 열을 보면, 절편이 “평균적인 5km 기록을 가진 사람의 예상 마라톤 시간”이라는 명확한 의미를 갖게 됨을 알 수 있습니다. 이때 기울기(slope) 값은 전혀 변하지 않는다는 점에 주목하세요.
겔만 외(Gelman, Hill, and Vehtari (2020)) [p. 84]의 조언처럼, 회귀 계수를 기계적인 ’인과적 효과’로 읽기보다는 두 집단 간의 ‘비교(Comparison)’로 이해하는 것이 좋습니다. “우리 데이터셋에서 5km 기록이 1분 차이 나는 두 사람을 비교하면, 평균적으로 마라톤 기록은 약 8분 정도 차이가 난다”는 식으로 조심스럽게 설명하는 태도가 필요합니다.
broom 패키지의 augment() 함수를 쓰면 모델의 예측치와 잔차를 원본 데이터에 붙여서 진단 그래프를 그리기 편해집니다 (Figure 12.3).
sim_run_data <-
augment(
sim_run_data_first_model,
data = sim_run_data
)# 패널 a)
ggplot(sim_run_data, aes(x = .resid)) +
geom_histogram(binwidth = 1) +
theme_classic() +
labs(y = "빈도", x = "잔차")
# 패널 b)
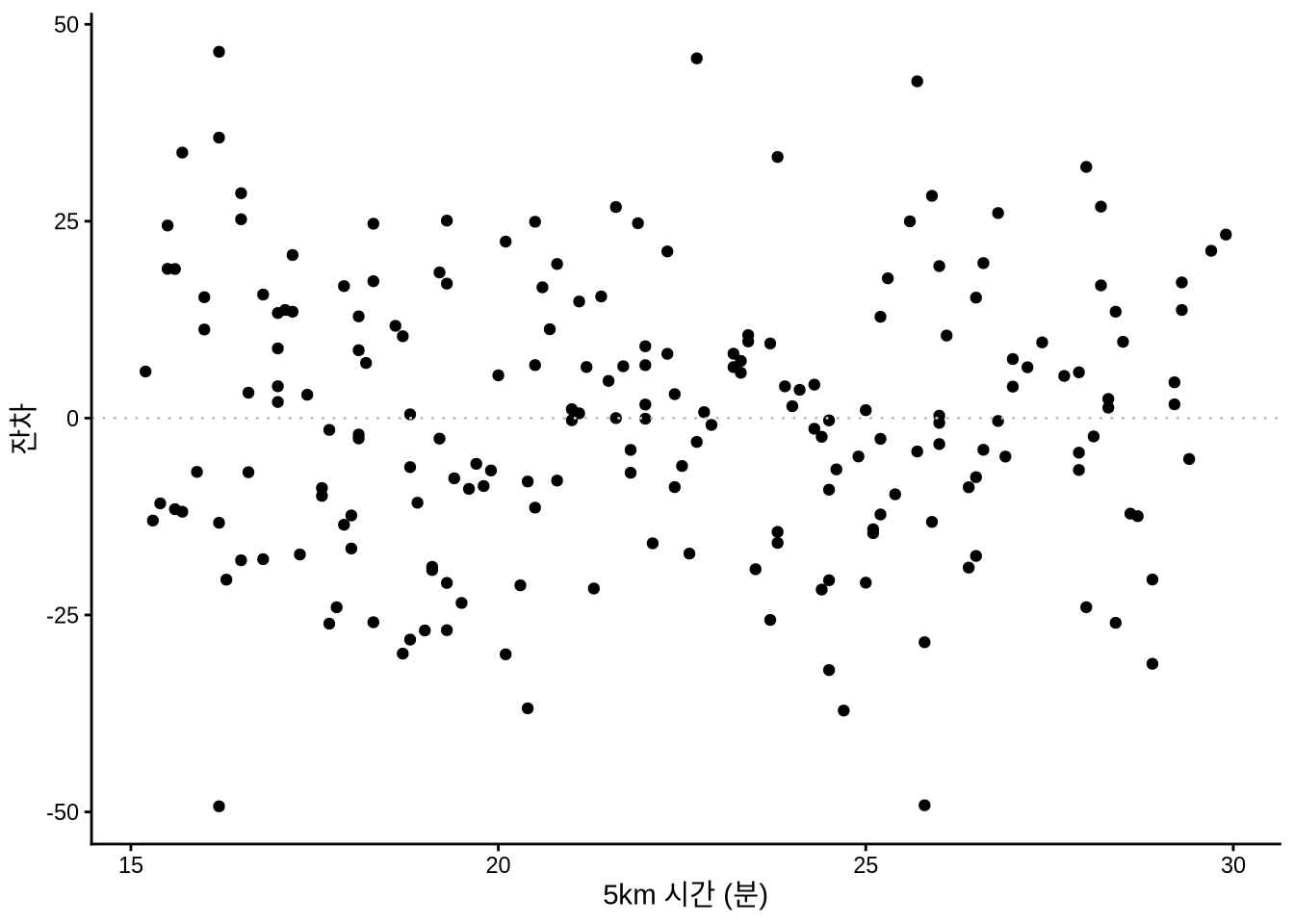
ggplot(sim_run_data, aes(x = five_km_time, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dotted", color = "grey") +
theme_classic() +
labs(y = "잔차", x = "5km 시간 (분)")
# 패널 c)
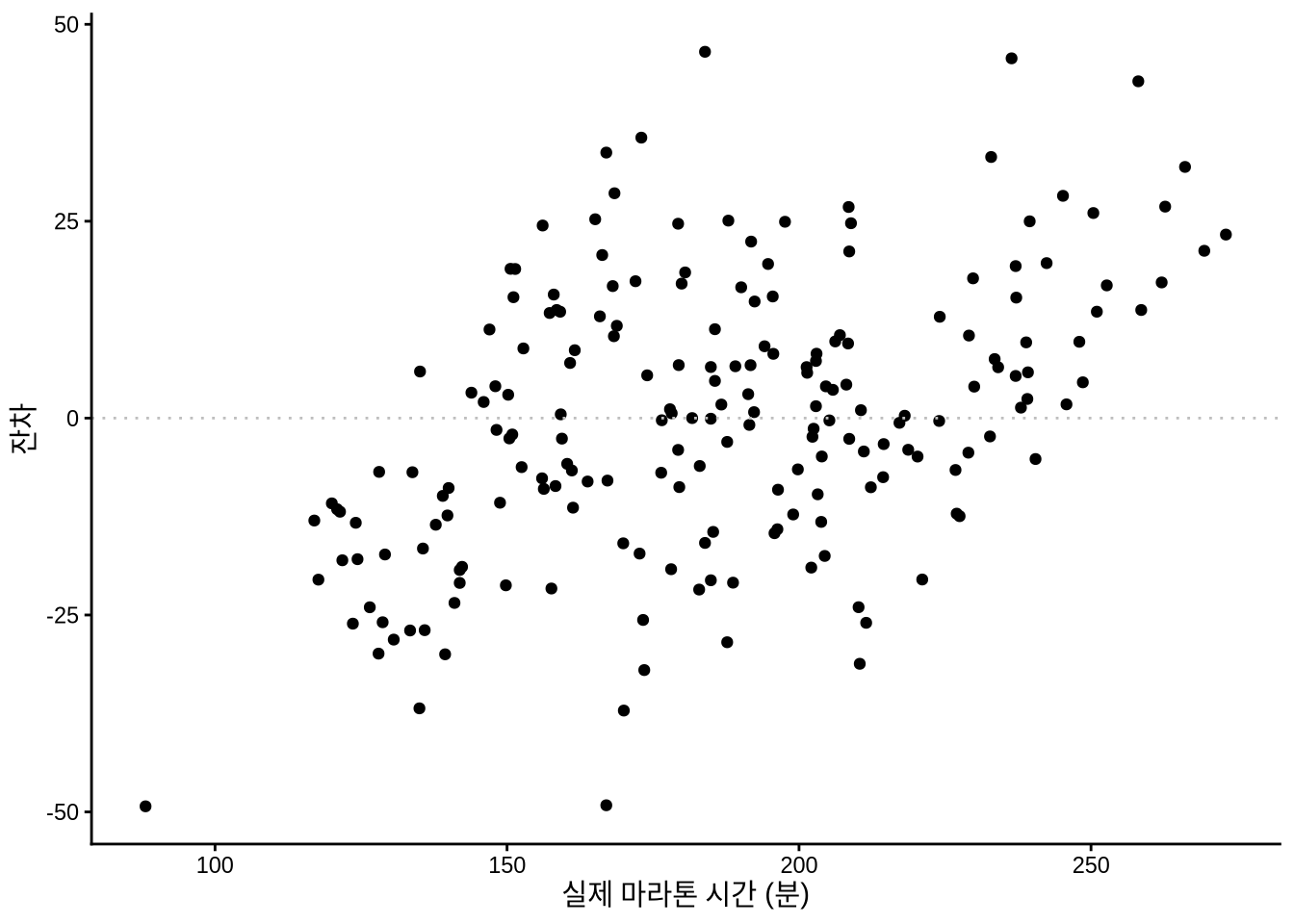
ggplot(sim_run_data, aes(x = marathon_time, y = .resid)) +
geom_point() +
geom_hline(yintercept = 0, linetype = "dotted", color = "grey") +
theme_classic() +
labs(y = "잔차", x = "실제 마라톤 시간 (분)")
# 패널 d)
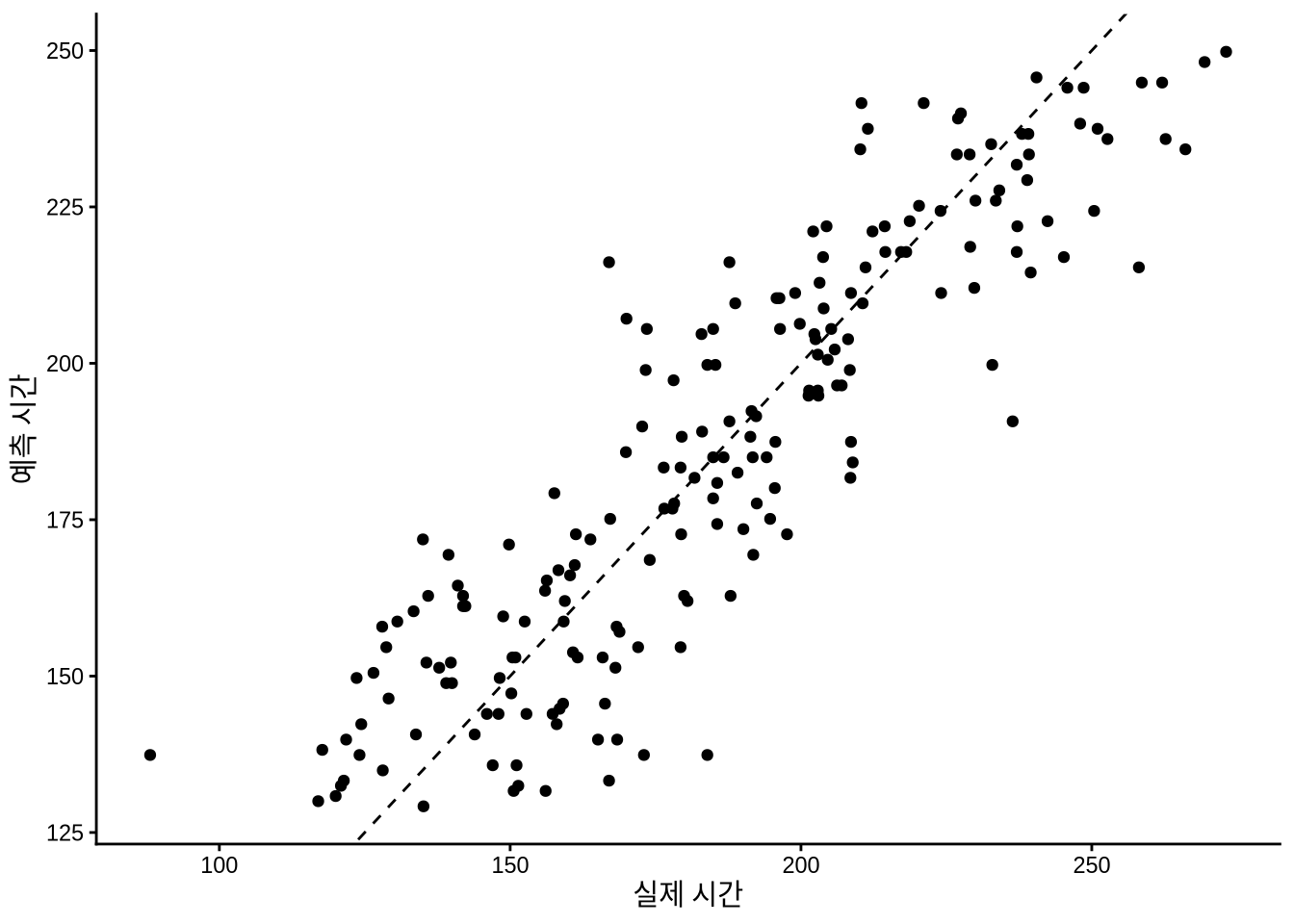
ggplot(sim_run_data, aes(x = marathon_time, y = .fitted)) +
geom_point() +
geom_abline(intercept = 0, slope = 1, linetype = "dashed") +
theme_classic() +
labs(y = "예측 시간", x = "실제 시간")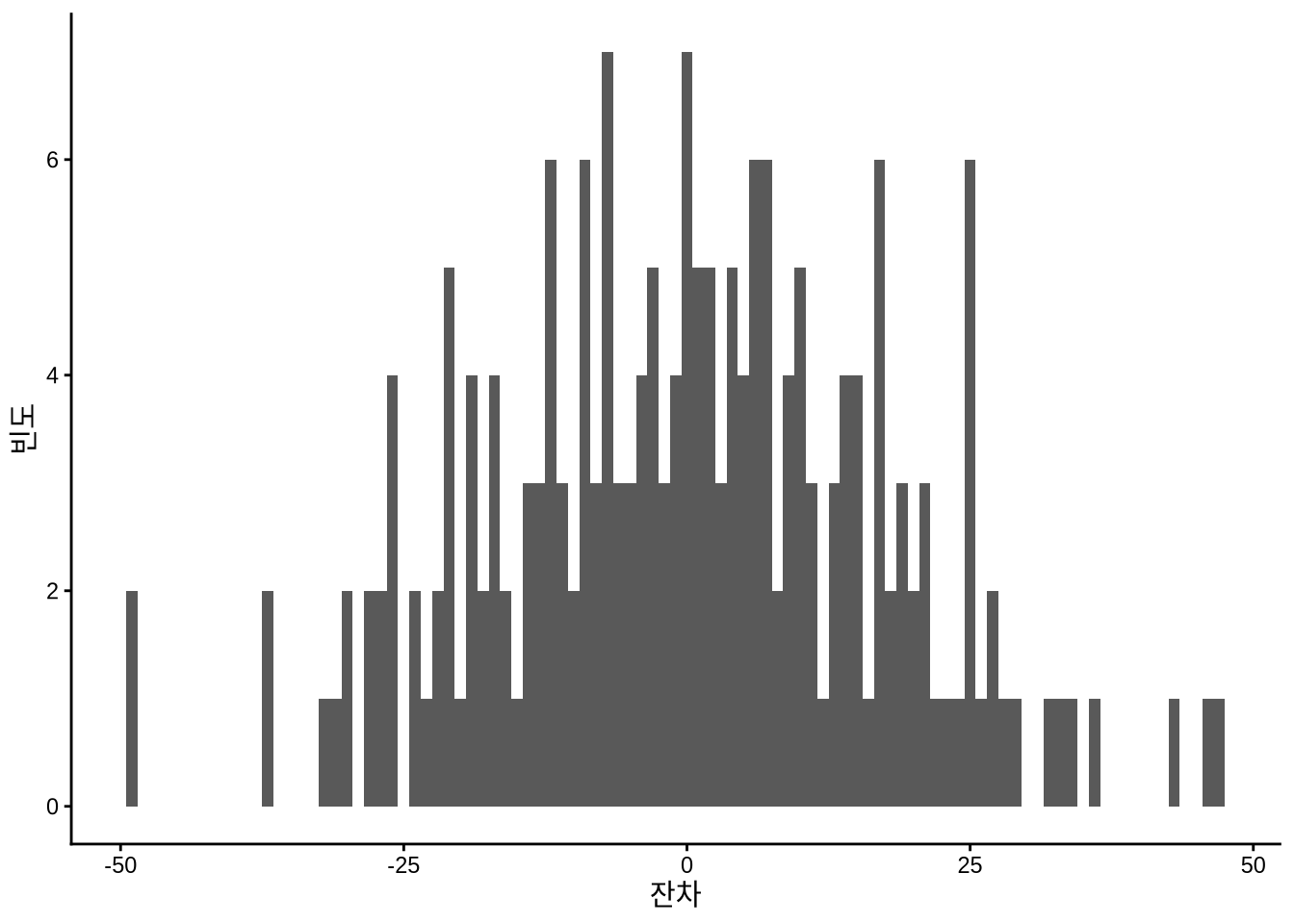
우리는 표본 데이터를 통해 모집단의 진실을 엿보고자 하므로, 추정치가 얼마나 믿을 만한지 ’표준 오차(standard error)’를 통해 측정해야 합니다. 데이터를 많이 모을수록 모델의 확신이 커지고 표준 오차는 줄어듭니다 (Figure 12.2 (c)).
이 불확실성을 가장 잘 보여주는 도구가 ’신뢰 구간(confidence interval)’입니다. 95% 신뢰 구간이란, “이런 식으로 표본 추출과 구간 생성을 무한히 반복하면, 그중 95%의 구간 안에는 우리가 모르는 진짜 매개변수가 포함되어 있을 것”이라는 의미입니다 (James et al. [2013] 2021, 66).
95% 신뢰 구간의 하한과 상한은 대략 \(\hat{\beta_1} \pm 2 \times \mbox{SE}\left(\hat{\beta_1}\right)\) 공식으로 구합니다. 마라톤 예시에 대입해 보면 하한 7.66, 상한 8.82가 나오며, 이 범위 안에 진실인 8.4가 잘 안착해 있음을 볼 수 있습니다.
이 원리로 가설 검정(test)을 수행합니다. 핵심은 추정한 \(\hat{\beta}_1\) 값이 0에서 ‘충분히 멀리’ 떨어져 있는지 판단하는 것이죠. 우리가 만든 t-통계량을 t-분포 곡선과 비교하여, 이런 결과가 순전히 우연일 확률인 p-값(p-value)을 계산합니다 (Gelman, Hill, and Vehtari 2020, 57).
하지만 이 책은 p-값에 대한 맹신을 경계합니다. p-값은 “과학적 추론에 별 도움이 되지 않는다”는 비판을 받기도 하죠 (Nelder 1999, 257). p-값 하나에는 데이터 수집부터 전처리까지 우리가 내린 수많은 가정이 통째로 녹아 있습니다. 만약 가정 중 하나라도 어긋났다면 p-값은 본래의 의미를 잃고 맙니다 (Greenland et al. 2016, 339). 멩 외(Meng (2018))와 브래들리 외(Bradley et al. (2021))의 연구처럼, 단순히 표본 크기를 늘려 p-값을 낮추는 데만 골몰하기보다 ’데이터 자체가 신뢰할 수 있는 품질인가’를 먼저 묻는 것이 데이터 과학자의 참된 의무입니다.
거인의 어깨 위에 서서: 낸시 리드(Nancy Reid)
낸시 리드(Nancy Reid) 박사는 토론토 대학교 통계학과 교수입니다. 1979년 스탠포드 대학교에서 박사 학위를 받은 후 전 세계 통계학계에서 독보적인 업적을 쌓아왔습니다 (Staicu 2017). 그녀의 연구는 특히 표본이 작은 상황에서 정확한 추론을 얻어내는 법과, 계산이 까다로운 복잡한 모델의 해법을 찾는 데 중점을 둡니다. 콕스(Cox)와 함께한 매개변수 재구조화 연구 (Cox and Reid 1987) 등이 대표적입니다. 리드 박사는 이러한 공로로 1992년 COPSS 회장상을 비롯해 수많은 훈장을 받은, 이 시대의 위대한 통계학자입니다.
12.3 다중 선형 회귀
현실의 문제는 대개 여러 요인이 복잡하게 얽혀 있습니다. 다중 선형 회귀는 여러 개의 설명 변수를 동시에 모델에 넣어 분석하는 기법입니다. 단순히 여러 번의 단순 회귀를 돌리는 것과 다른 결정적 이점은, 다른 변수들의 영향을 ’통제(조정)’한 상태에서 특정 변수의 순수한 연관성을 뽑아낼 수 있다는 점입니다.
범주형 변수도 ‘더미 변수’ 처리를 통해 모델에 넣을 수 있습니다. 예를 들어 “성별”이나 “시간대” 같은 변수들이죠. R은 문자형 데이터를 입력받으면 자동으로 0과 1의 이진 변수로 변환해 처리합니다. 범주가 세 개 이상이면 여러 개의 이진 변수 조합으로 처리되며, 그중 하나는 기준(baseline)이 되어 절편 속에 녹아들게 됩니다.
12.3.1 시뮬레이션: 비가 오면 달리기가 얼마나 느려질까?
앞선 마라톤 예시에 “우천 여부”라는 새로운 변수를 더해보겠습니다. “비가 오면 화창할 때보다 완주 시간이 10분 더 걸린다”는 명확한 규칙을 시뮬레이션 데이터에 심어보겠습니다.
slow_in_rain <- 10
sim_run_data <-
sim_run_data |>
mutate(was_raining = sample(
c("Yes", "No"),
size = num_observations,
replace = TRUE,
prob = c(0.2, 0.8)
)) |>
mutate(
marathon_time = if_else(
was_raining == "Yes",
marathon_time + slow_in_rain,
marathon_time
)
) |>
select(five_km_time, marathon_time, was_raining)lm() 함수에서 + 기호를 써서 변수를 추가합니다. 이번에도 데이터 타입과 결측치 여부를 확인하는 단위 테스트를 잊지 마세요. 비가 오면 시간이 늘어날 것이 자명하므로, 우천 변수의 계수가 반드시 양수여야 한다는 논리적 테스트도 추가할 수 있습니다.
stopifnot(
class(sim_run_data$marathon_time) == "numeric",
class(sim_run_data$five_km_time) == "numeric",
class(sim_run_data$was_raining) == "character",
all(complete.cases(sim_run_data)),
nrow(sim_run_data) == 200
)
sim_run_data_rain_model <-
lm(
marathon_time ~ five_km_time + was_raining,
data = sim_run_data
)
stopifnot(
between(sim_run_data_rain_model$coefficients[3], 0, 20)
)
summary(sim_run_data_rain_model)
Call:
lm(formula = marathon_time ~ five_km_time + was_raining, data = sim_run_data)
Residuals:
Min 1Q Median 3Q Max
-50.760 -11.942 0.471 11.719 46.916
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 3.8791 6.8385 0.567 0.571189
five_km_time 8.2164 0.3016 27.239 < 2e-16 ***
was_rainingYes 11.8753 3.2189 3.689 0.000291 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 17.45 on 197 degrees of freedom
Multiple R-squared: 0.791, Adjusted R-squared: 0.7889
F-statistic: 372.8 on 2 and 197 DF, p-value: < 2.2e-16Table 12.3 의 결과를 보면, 비가 오는 날 달린 선수는 평균적으로 약 10분 정도 완주가 늦어지는 경향을 보입니다. 이는 시각화 결과와도 일치하죠 (Figure 12.4 (a)).
중복되는 테스트 코드를 관리하기 위해 testthat 패키지를 활용하는 것이 좋습니다. 예를 들어 “test_class.R”, “test_observations.R” 같은 별도 파일에 테스트를 모아두고 필요할 때마다 호출하는 방식입니다.
# 별도 파일에 저장할 테스트 예시
test_that("자료형 및 관측치 수 검증", {
expect_type(sim_run_data$marathon_time, "double")
expect_equal(nrow(sim_run_data), 200)
expect_true(all(complete.cases(sim_run_data)))
})계수값 검증 테스트를 짤 때는 상식적인 기준을 먼저 세워야 합니다. 만약 모델 결과가 테스트를 통과하지 못했다면, 그것은 모델이 틀렸다는 뜻일 수도 있고, 우리가 세운 ’상식의 기준’을 수정해야 한다는 신호일 수도 있습니다.
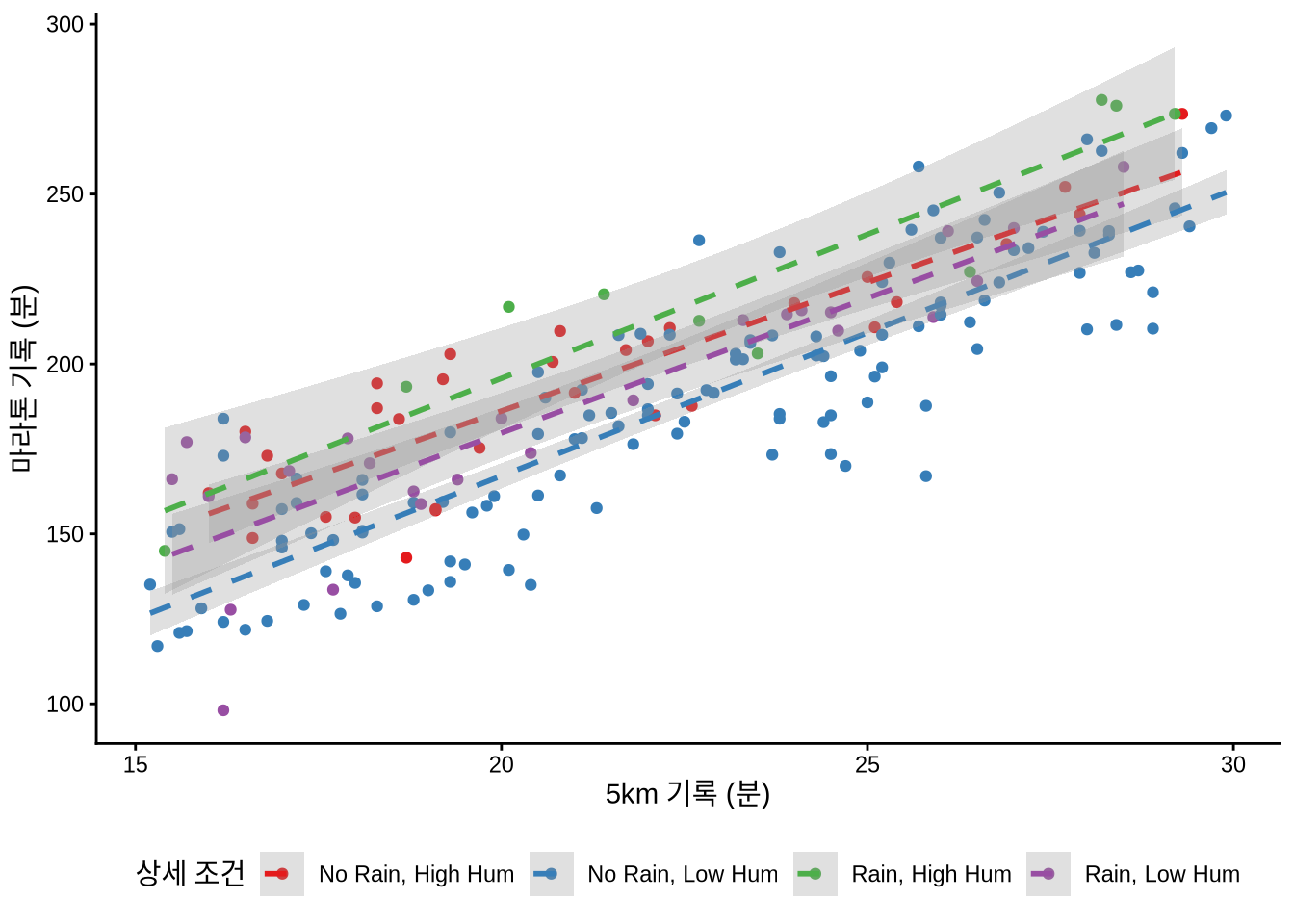
때로는 변수들끼리 서로 영향을 주고받기도 합니다. 비가 오는데 습도까지 높다면 마라톤 기록에 미치는 영향은 훨씬 강력해질 수 있죠. 이를 ’상호 작용(Interaction)’이라고 하며, lm() 수식에서 * 기호를 써서 간단히 표현할 수 있습니다. 그 결과는 Table 12.3 의 세 번째 열에서 확인할 수 있습니다.
slow_in_humidity <- 15
sim_run_data <- sim_run_data |>
mutate(
humidity = sample(c("High", "Low"), size = num_observations,
replace = TRUE, prob = c(0.2, 0.8)),
marathon_time =
marathon_time + if_else(humidity == "High", slow_in_humidity, 0),
weather_conditions = case_when(
was_raining == "No" & humidity == "Low" ~ "No Rain, Low Hum",
was_raining == "Yes" & humidity == "Low" ~ "Rain, Low Hum",
was_raining == "No" & humidity == "High" ~ "No Rain, High Hum",
was_raining == "Yes" & humidity == "High" ~ "Rain, High Hum"
)
)base <-
sim_run_data |>
ggplot(aes(x = five_km_time, y = marathon_time)) +
labs(
x = "5km 기록 (분)",
y = "마라톤 기록 (분)"
) +
theme_classic() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")
base +
geom_point(aes(color = was_raining)) +
geom_smooth(
aes(color = was_raining),
method = "lm",
alpha = 0.3,
linetype = "dashed",
formula = "y ~ x"
) +
labs(color = "비가 왔나요?")
base +
geom_point(aes(color = weather_conditions)) +
geom_smooth(
aes(color = weather_conditions),
method = "lm",
alpha = 0.3,
linetype = "dashed",
formula = "y ~ x"
) +
labs(color = "상세 조건")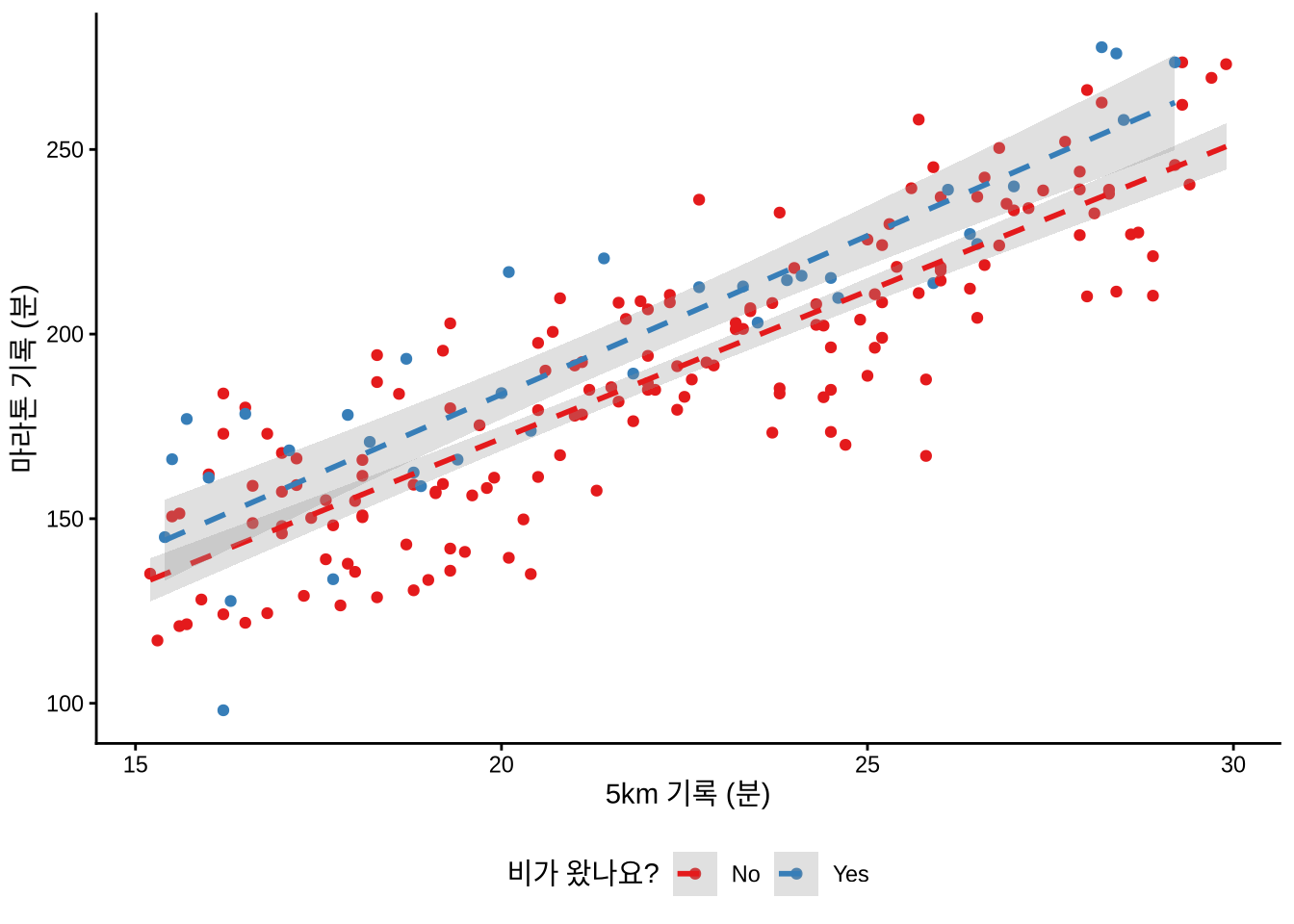
sim_run_data_rain_and_humidity_model <-
lm(
marathon_time ~ five_km_time + was_raining * humidity,
data = sim_run_data
)
modelsummary(
list(
"기본" = sim_run_data_first_model,
"우천 추가" = sim_run_data_rain_model,
"상호작용 추가" = sim_run_data_rain_and_humidity_model
),
fmt = 2
)| 기본 | 우천 추가 | 상호작용 추가 | |
|---|---|---|---|
| (Intercept) | 4.47 | 3.88 | 20.68 |
| (6.75) | (6.84) | (7.12) | |
| five_km_time | 8.20 | 8.22 | 8.24 |
| (0.30) | (0.30) | (0.31) | |
| was_rainingYes | 11.88 | 11.00 | |
| (3.22) | (6.36) | ||
| humidityLow | -18.01 | ||
| (3.45) | |||
| was_rainingYes × humidityLow | 0.92 | ||
| (7.47) | |||
| Num.Obs. | 200 | 200 | 200 |
| R2 | 0.790 | 0.791 | 0.795 |
| R2 Adj. | 0.789 | 0.789 | 0.791 |
| AIC | 1714.7 | 1716.3 | 1719.4 |
| BIC | 1724.6 | 1729.5 | 1739.2 |
| Log.Lik. | -854.341 | -854.169 | -853.721 |
| F | 745.549 | 372.836 | 189.489 |
| RMSE | 17.34 | 17.32 | 17.28 |
회귀 분석 결과를 신뢰하기 위해 반드시 점검해야 할 ‘통계적 진단’ 항목들이 있습니다.
- 선형성(Linearity): 설명 변수와 결과 변수가 정말 직선적인 관계인지 산점도로 확인하세요.
- 등분산성(Homoscedasticity): 오차의 폭이 일정하게 유지되는지 잔차도 (Figure 12.3 (b))로 점검하세요.
- 독립성(Independence): 관측치들이 서로 독립적인지, 특히 시계열 데이터에서 이전 오차가 다음 오차에 영향을 주지 않는지 살펴야 합니다.
- 이상치 경계: 단 몇 개의 특이한 데이터가 전체 회귀선의 기울기를 주도하는지 의심해 보아야 합니다.
이러한 기술적 진단도 중요하지만, 무엇보다 이 모델이 원래 던졌던 ’현실의 연구 질문’과 얼마나 논리적으로 잘 맞닿아 있는지 고민하는 것이 데이터 과학자의 가장 큰 과제입니다.
거인의 어깨 위에 서서: 다니엘라 위튼(Daniela Witten)
다니엘라 위튼(Daniela Witten) 박사는 워싱턴 대학교의 통계학 및 생물통계학 교수입니다. 2010년 스탠포드 대학에서 박사 학위를 받은 후 최단 기간에 정교수 반열에 오른 천재 학자이죠. 그녀의 연구는 특히 복잡한 데이터에서 유의미한 변수를 골라내는 기법에 특화되어 있습니다 (Gao, Bien, and Witten 2022). 무엇보다 그녀는 전 세계 데이터 과학도들의 교과서인 Introduction to Statistical Learning (James et al. [2013] 2021)의 공동 저자로 아주 잘 알려져 있습니다.
12.3.2 베이즈 모델링을 통한 추론
레오 브라이만(Breiman (2001))은 통계적 모델링에 ’두 가지 문화’가 있다고 말했습니다. 하나는 현상의 원인을 밝히는 ’추론(Inference)’이고, 다른 하나는 정확한 정답을 맞히는 ’예측(Prediction)’입니다. 과거에는 둘이 완전히 남남처럼 지냈지만, 현대 데이터 과학에서는 이 둘의 경계가 무너지고 있습니다. 하지만 여전히 간극은 존재하죠. 공학자들은 “머신러닝”을 즐겨 쓰고, 통계학자들은 같은 원리를 다루면서도 굳이 “통계 학습”이라는 말을 고집하곤 합니다.
이 책은 ’추론’에 조금 더 무게를 두며, 이를 위해 베이즈(Bayesian) 프레임워크와 rstanarm 패키지를 적극 활용할 것입니다. 예측 중심의 파이썬 기반 워크플로는 온라인 부록 14에서 따로 다룹니다. 처음 입문할 때는 한 가지 도구와 문화를 깊이 파고드는 것이 유리하지만, 숙련된 후에는 R과 파이썬이라는 두 언어를 자유자재로 구사하는 ’다국어 능력자’가 되어야 합니다.
베이즈 회귀 분석의 논리는 앞서 본 lm()과 놀라울 정도로 비슷합니다. 가장 큰 차이는 ‘매개변수(\(\beta\))’를 고정된 상수가 아닌 확률 변수로 본다는 점입니다. 따라서 데이터를 보기 전에 우리가 가진 배경지식을 ’사전 분포(Prior)’로 먼저 정의해야 하죠. 이 과정은 우리가 이전 장들에서 반복했던 ’시뮬레이션’ 워크플로와 완벽하게 일맥상통합니다.
\[ \begin{aligned} y_i|\mu_i, \sigma &\sim \mbox{Normal}(\mu_i, \sigma) \\ \mu_i &= \beta_0 +\beta_1x_i\\ \beta_0 &\sim \mbox{Normal}(0, 2.5) \\ \beta_1 &\sim \mbox{Normal}(0, 2.5) \\ \sigma &\sim \mbox{Exponential}(1) \\ \end{aligned} \]
베이즈 모델은 수많은 샘플을 추출하는 ‘샘플링’ 과정을 거치므로 연산 속도가 느린 편입니다. 따라서 무거운 모델은 별도 스크립트에서 돌린 뒤 saveRDS()로 저장하고, Quarto 문서에서는 readRDS()로 결과만 불러와 쓰는 것이 실무적인 팁입니다.
# 베이즈 모델 실행 및 저장 예시
sim_run_data_first_model_rstanarm <-
stan_glm(
formula = marathon_time ~ five_km_time + was_raining,
data = sim_run_data,
family = gaussian(),
seed = 853
)
saveRDS(sim_run_data_first_model_rstanarm, "my_model.rds")12.3.3 사전 분포의 선택
베이즈 분석에서 ’사전 분포’를 정하는 것은 매우 중요한 일입니다. 입문 단계에서는 rstanarm이 제공하는 훌륭한 기본값들을 활용하세요. 다만 어떤 설정이 쓰였는지 prior_summary()로 확인하고 코드에 명시해두는 것이 좋은 프로그래밍 습관입니다.
데이터를 넣기 전, 우리가 설정한 사전 분포가 과연 상식적인 세상을 상상하고 있는지 점검하는 사전 예측 검증(prior predictive check)도 필수입니다. 5km 기록이 1분 늘어날 때 마라톤 기록이 8분 늘어난다는 우리의 상식을 반영해 분포의 중심을 조정해 주면 훨씬 합리적인 모델을 얻을 수 있습니다 (?fig-secondworstmodelever). 구체적인 수치가 막막하다면 autoscale = TRUE 옵션을 써서 모델이 데이터 규모에 맞게 사전 분포를 스스로 조정하게 할 수도 있습니다.
modelsummary(
list(
"기본 사전 분포" = sim_run_data_first_model_rstanarm,
"조정된 사전 분포" = sim_run_data_second_model_rstanarm
),
fmt = 2
)Warning:
`modelsummary` uses the `performance` package to extract goodness-of-fit
statistics from models of this class. You can specify the statistics you wish
to compute by supplying a `metrics` argument to `modelsummary`, which will then
push it forward to `performance`. Acceptable values are: "all", "common",
"none", or a character vector of metrics names. For example: `modelsummary(mod,
metrics = c("RMSE", "R2")` Note that some metrics are computationally
expensive. See `?performance::performance` for details.
This warning appears once per session.| 기본 사전 분포 | 조정된 사전 분포 | |
|---|---|---|
| (Intercept) | -67.50 | 8.66 |
| five_km_time | 3.47 | 7.90 |
| was_rainingYes | 0.12 | 9.23 |
| Num.Obs. | 100 | 100 |
| R2 | 0.015 | 0.797 |
| R2 Adj. | -1.000 | 0.790 |
| Log.Lik. | -678.336 | -425.193 |
| ELPD | -679.5 | -429.0 |
| ELPD s.e. | 3.3 | 8.9 |
| LOOIC | 1359.0 | 858.0 |
| LOOIC s.e. | 6.6 | 17.8 |
| WAIC | 1359.0 | 857.9 |
| RMSE | 175.52 | 16.85 |
12.3.4 사후 분포와 진단
데이터를 학습한 모델이 들려주는 이야기는 ’사후 분포(Posterior)’에 담겨 있습니다. pp_check() 함수로 모델이 실제 데이터의 윤곽을 잘 따라가고 있는지 사후 예측 검증을 수행하세요 (?fig-ppcheckandposteriorvsprior-1). 또한 posterior_vs_prior()를 통해 데이터가 우리의 초기 믿음을 어떻게 변화시켰는지 시각적으로 확인할 수 있습니다.
베이즈 모델은 결과로 하나의 숫자가 아닌 ‘확률 분포’ 자체를 돌려줍니다. 따라서 결과 보고 시에도 표보다는 분포 그래프를 직접 보여주는 것이 훨씬 유익합니다 (?fig-credibleintervals).
마지막 관문은 진단(Diagnostics)입니다. 샘플링 엔진이 성실히 일했는지 트레이스 플롯으로 확인하고, 여러 연산 체계가 하나로 잘 수렴했는지 Rhat 플롯으로 점검하세요 (?fig-stanareyouokay). Rhat 값은 반드시 1.1 미만이어야 합니다.
계산이 너무 느리다면 여러 개의 코어를 동시에 쓰는 병렬 처리(Parallel Processing) 기술을 도입하세요. tictoc 패키지로 병목 지점을 찾고, future 생태계를 활용해 연산 속도를 획기적으로 높일 수 있습니다.
12.4 결론
이번 장에서는 선형 회귀라는 친숙한 도구로 데이터 모델링의 첫 단추를 꿰었습니다. 모델 설정부터 베이즈 추론의 오묘한 매력까지 살펴보았죠. 하지만 이것은 시작일 뿐입니다. 다음 장에서 다룰 일반화 선형 모델(GLM)까지 익혀야 비로소 모델링의 큰 그림이 완성됩니다.
훌륭한 분석 보고서란 무엇일까요? 명확한 모델 설정 근거를 밝히고, 기술적 세부 사항을 투명하게 공개하며, 무엇보다 그 결과가 현실의 언어로 어떻게 풀이되는지 친절하게 설명하는 글입니다. 이 장에서 배운 체크리스트를 등대 삼아 여러분만의 데이터 이야기를 시작해 보시기 바랍니다.
12.5 연습 문제
퀴즈
- 예측 변수인 “인종”과 “성별”이 “투표 선호도”에 불완전하게 영향을 주는 상황을 시뮬레이션해 보세요.
- 결과 변수 \(Y\)와 예측 변수 \(X\)의 선형 관계식을 작성해 보세요. 각 기호가 의미하는 바(절편, 기울기 등)를 설명하고, ‘모자(hat)’ 기호가 붙었을 때의 의미 변화를 서술해 보세요.
- 최소 제곱 기준(Least squares criterion)과 RSS의 개념을 설명하고, 회귀 분석의 궁극적인 목표가 무엇인지 논의해 보세요.
- p-값의 본질적인 의미와 한계를 그린랜드 외(Greenland et al. (2016))의 논문을 참고해 서술해 보세요. 특히 p-값이 매우 작게 나왔을 때 발생할 수 있는 오류들을 짚어보세요.
- 검정력(Power)이란 통계적으로 무엇을 의미합니까?
- McElreath ([2015] 2020) 의 “회귀 분석은 잔인한 신탁이다”라는 인용구의 의미를 본인만의 예시를 들어 논의해 보세요.
수업 활동
palmerpenguins데이터를 활용해 펭귄 부리 길이와 깊이의 관계를 분석하는 전체 워크플로(스케치-시뮬레이션-데이터-모델-결과)를 Quarto 문서로 완성해 보세요.- 미국 카운티별 데이터 분석 시 ’FIPS 코드’를 숫자형 변수로 그대로 모델에 넣었을 때 발생할 수 있는 문제에 대해 토론해 보세요.
- “카시우스의 경고”: 연구 결과 표에 기계적으로 찍히는 ’별표(*)’와 p-값의 남용이 가져올 수 있는 위험성에 대해 이오아니디스(Ioannidis (2005))의 주장을 곁들여 논의해 보세요.
과제
데이터 생성 과정이 정규 분포(평균 1, 표준편차 1)를 따르는 가상의 세계가 있습니다. 하지만 데이터 수집과 정리 과정에서 다음과 같은 사고가 발생했습니다. 1) 측정 기기 결함으로 마지막 100개 데이터가 초기 100개 데이터의 복사본으로 덮어씌워졌습니다. 2) 아르바이트생의 실수로 음수 데이터의 절반이 부호가 바뀌어 양수가 되었습니다. 3) 특정 구간(1.0~1.1)의 소수점 위치가 모두 잘못 찍혔습니다.
이 엉망이 된 데이터를 가지고 원래의 참값이 “0보다 컸는지”를 입증하기 위한 사투를 벌여보세요. 시뮬레이션 과정과 그로 인한 왜곡의 실체, 그리고 이를 방지하기 위해 어떤 ’단위 테스트’를 도입해야 할지 보고서로 작성해 제출하세요. 동료와의 상호 피드백 과정을 반드시 포함하시기 바랍니다.
여기서는 표본 크기가 20으로 매우 작아 엄밀히는 ’유한 모집단 수정’이 필요하지만, 일반적인 분석 관행에 따라 기본 공식을 사용하겠습니다.↩︎