library(boot)
library(broom.mixed)
library(collapse)
library(dataverse)
library(gutenbergr)
library(janitor)
library(marginaleffects)
library(modelsummary)
library(rstanarm)
library(tidybayes)
library(tidyverse)
library(tinytable)13 일반화 선형 모델
선수 지식
- 회귀 및 기타 이야기(Regression and Other Stories) 읽기(Gelman, Hill, and Vehtari 2020).
- 특히 일반화 선형 모델에 대한 상세한 가이드를 제공하는 13장 “로지스틱 회귀” 및 15장 “기타 일반화 선형 모델”을 중점적으로 읽어보세요.
- R을 활용한 통계 학습 입문(An Introduction to Statistical Learning with Applications in R) 읽기(James et al. [2013] 2021).
- 일반화 선형 모델을 색다른 관점에서 다루어 시야를 넓혀주는 4장 “분류(Classification)”를 집중적으로 살펴보세요.
- 우리는 네 명의 훌륭한 여론조사원에게 동일한 원시 데이터를 주었다. 그들은 네 가지 다른 결과를 얻었다(We Gave Four Good Pollsters the Same Raw Data. They Had Four Different Results) 기사 읽기(Cohn 2016).
- 완전히 동일한 데이터셋이 주어졌더라도, 분석가가 어떤 모델링 전략을 선택하느냐에 따라 도출되는 예측이 얼마나 극명하게 달라질 수 있는지 생생하게 보여줍니다.
핵심 개념 및 기술
- 우리가 배운 선형 회귀는 그 틀을 유지한 채 다양한 형태의 결과 변수(outcome variable)를 다룰 수 있도록 훌륭하게 일반화(generalized)될 수 있습니다.
- 결과 변수가 0 아니면 1인 이진(binary) 데이터일 때는 로지스틱 회귀(Logistic regression)를 사용합니다.
- 결과 변수가 물건의 개수나 횟수처럼 정수(integer) 형태의 카운트(count) 데이터일 때는 포아송 회귀(Poisson regression)를 사용합니다. 음이항 회귀(Negative binomial regression)는 포아송 회귀의 깐깐한 분산 가정을 완화해주기 때문에 실무에서 포아송 대신 종종 유연하게 고려되는 변형입니다.
- 다층 모델링(Multilevel modeling)은 데이터 내부에 잠재된 그룹 차원이나 위계 구조를 적극적으로 끌어안아 데이터를 훨씬 더 알뜰하고 강력하게 활용할 수 있게 해주는 선진적인 접근 방식입니다.
소프트웨어 및 패키지
- Base R (R Core Team 2024)
boot(Canty and Ripley 2021; Davison and Hinkley 1997)broom.mixed(Bolker and Robinson 2022)collapse(Krantz 2023)dataverse(Kuriwaki, Beasley, and Leeper 2023)gutenbergr(Johnston and Robinson 2022)janitor(Firke 2023)marginaleffects(Arel-Bundock 2023)modelsummary(Arel-Bundock 2022)rstanarm(Goodrich et al. 2023)tidybayes(Kay 2022)tidyverse(Wickham et al. 2019)tinytable(Arel-Bundock 2024)
13.1 서론
이전 장(Chapter 12)에서 다루었던 기본 선형 모델은 지난 세기 동안 눈부시게 발전했습니다. 앞서 Chapter 8 에서 언급한 프랜시스 골턴과 그의 동시대 학자들은 이미 1800년대 후반에서 1900년대 초반 무렵 선형 회귀 모형을 분석 도구로 널리 활용하기 시작했습니다. 하지만 연속적인 숫자 데이터뿐만 아니라 ’성공/실패’와 같은 이진(binary) 결과를 예측해야 하는 문제가 중요해지면서 새로운 수학적 처리 방식이 필요해졌습니다. 이는 1900년대 중반 로지스틱 회귀를 비롯한 다양한 방법론의 개발과 확산으로 이어졌습니다(Cramer 2003).
이후 1970년대에 넬더(Nelder)와 웨더번(Wedderburn)은 기존의 여러 모델을 하나로 우아하게 통합하는 틀을 제시했는데, 이것이 바로 일반화 선형 모델(Generalized Linear Model, GLM) 프레임워크입니다(Nelder and Wedderburn 1972). GLM은 기본 선형 회귀 모형이 다룰 수 있는 관측 결과의 범위를 대폭 확장합니다. 본질적으로 여전히 설명 변수들의 ’선형 조합(linear function)’을 사용하여 결과 변수를 모델링하지만, 결과 변수의 형태에는 훨씬 더 관대해집니다. 결과 변수는 지수족(exponential family)이라는 특정한 확률 분포 모임에 속하기만 하면 어떤 형태든 무방합니다. 데이터 과학에서 널리 쓰이는 대표적인 예가 이진 데이터를 다루는 ’로지스틱(이항) 분포’와 개수(count) 데이터를 다루는 ’포아송 분포’입니다. 여기서 더 나아가 1990년대 헤이스티와 티브시라니(Hastie and Tibshirani (1990))가 제창한 일반화 가법 모델(Generalized Additive Model, GAM)도 있습니다. GAM은 GLM의 뼈대를 유지하면서도 설명 변수 파트에 비선형(non-linear) 형태의 함수(additive function)를 허용하여 유연성을 높인 모델입니다.
저명한 일반화 선형 모델의 가족 중에서도, 이 장에서는 주로 가장 활용 빈도가 높은 ‘로지스틱 회귀’, ‘포아송 회귀’, 그리고 ’음이항 회귀’를 차례로 만나볼 것입니다. 단순 선형 모델과 일반화 선형 모델 모두에 찰떡같이 결합하여 사용할 수 있는 ’다층 모델링(Multilevel modeling)’에 대해서도 간략히 탐험할 예정입니다. 다층 모델링은 데이터셋 내부에 잠재해 있는 여러 위계적 그룹(예: 국가 내의 도시들, 학급 내의 학생들) 구조를 적극적으로 활용하여 추정의 질을 높이는 세련된 기법입니다.
13.2 로지스틱 회귀(Logistic Regression)
선형 회귀는 데이터를 깊이 있게 이해하고 인과를 시뮬레이션하는 데 대단히 직관적이며 유용한 방법입니다. 그러나 이는 결과 변수가 실수(real number) 선상의 모든 숫자, 즉 소수점 아래로 무한히 연속된 음수와 양수를 제한 없이 가질 수 있는 완벽한 형태의 ’연속 변수(continuous variable)’라는 매우 까다로운 전제 조건을 깔고 있습니다. 하지만 우리가 마주칠 현실 세계의 데이터, 가령 동전의 앞뒤나 질병의 유무처럼 이 가정을 도저히 충족할 수 없는 상황에서도 우리는 익숙하고 강력한 선형 모델의 메커니즘을 계속해서 활용하고 싶어 합니다. 따라서 결과 변수가 오직 두 가지뿐인 ’이진 데이터’일 때는 로지스틱 회귀로, 횟수나 명수를 세어야 하는 ’개수(count) 데이터’일 때는 포아송 회귀로 각각 엔진을 교체하여 대응하게 됩니다. 흥미로운 점은, 엔진을 교체했더라도 예측 변수(X)들은 여전히 더하기(+) 기호를 통해 수식에 ’선형적’으로 결합되므로 이들은 본질적으로 여전히 자랑스러운 선형 모델(Linear Models)의 일원이라는 사실입니다.
로지스틱 회귀와 그 유용한 변형들은 대통령 선거 결과 예측(Wang et al. 2015)부터 경마의 승률 베팅(Chellel 2018; Bolton and Chapman 1986)에 이르기까지 너무나 다채로운 환경에서 막강한 위력을 발휘합니다. 결과 변수가 오직 0 아니면 1, “예(Yes)” 아니면 “아니오(No)”와 같이 칼로 무 베듯 둘 중 하나로 나뉘는 이진 결과(binary outcome)일 때가 바로 로지스틱 회귀가 출격할 완벽한 타이밍입니다. 얼핏 생각하면 결과 변수가 둘 중 하나밖에 없는 상황이 턱없이 제한적으로 들릴 수도 있습니다. 하지만 조금만 주변을 둘러봐도 승리와 패배, 투표 지지와 반대, 이메일의 스팸 여부, 질병의 양성과 음성처럼 세상의 수많은 본질적인 관측 결과들이 이 이진법의 틀 안에 아주 자연스럽게 녹아들거나, 큰 무리 없이 두 가지 갈래로 조정 및 변환될 수 있음을 깨닫게 될 것입니다.
이러한 이진 논리의 근저를 지탱하는 수학적 초석은 바로 베르누이 분포(Bernoulli distribution)입니다. 동전을 한 번 던졌을 때의 결과를 상상하면 쉽습니다. “1(성공)”이라는 아주 특정한 결과가 발생할 확률을 \(p\)라고 한다면, 동전의 반대면이 나올 나머지 확률, 즉 “0(실패)”의 결과가 극명하게 나타날 확률은 필연적으로 \(1-p\)가 될 수밖에 없습니다. R에서는 단 한 번의 시도(size = 1)를 수행하는 rbinom() 함수를 가볍게 호출하여 이 베르누이 분포에서 가공의 이진 데이터들을 원하는 만큼 무작위로 추출(시뮬레이션)할 수 있습니다.
set.seed(853)
bernoulli_example <-
tibble(draws = rbinom(n = 20, size = 1, prob = 0.1))
bernoulli_example |> pull(draws) [1] 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0로지스틱 회귀를 사용하는 가장 핵심적인 이유는, 우리가 궁극적으로 모델링하고자 하는 대상이 어떤 사건이 일어날 ’확률(probability)’이라는 점에 있습니다. 확률은 정의상 반드시 0과 1 사이의 값만 가져야 하는데, 기존의 선형 회귀는 계산 결과로 음수나 1을 초과하는 황당한 값을 기꺼이 뱉어낼 수 있습니다. 이러한 문제를 우아하게 해결해 주는 로지스틱 회귀의 마법 같은 기초가 바로 로짓 함수(logit function)입니다.
수식을 보면 알 수 있듯, 로짓 함수는 0과 1 사이의 확률 값(\(x\))을 무한대로 뻗어 나가는 실수(real number) 선상으로 변환해 줍니다. 예를 들어 확률이 0.1이면 logit(0.1) = -2.2가 되고, 0.5라면 logit(0.5) = 0, 0.9라면 logit(0.9) = 2.2가 됩니다(Figure 13.1 참조). 이러한 변환을 담당하는 함수를 링크 함수(link function)라고 부릅니다. 링크 함수는 일반화 선형 모델에서 확률 분포의 특성과 선형 모델의 내부 메커니즘을 잇는 다리 역할을 합니다.
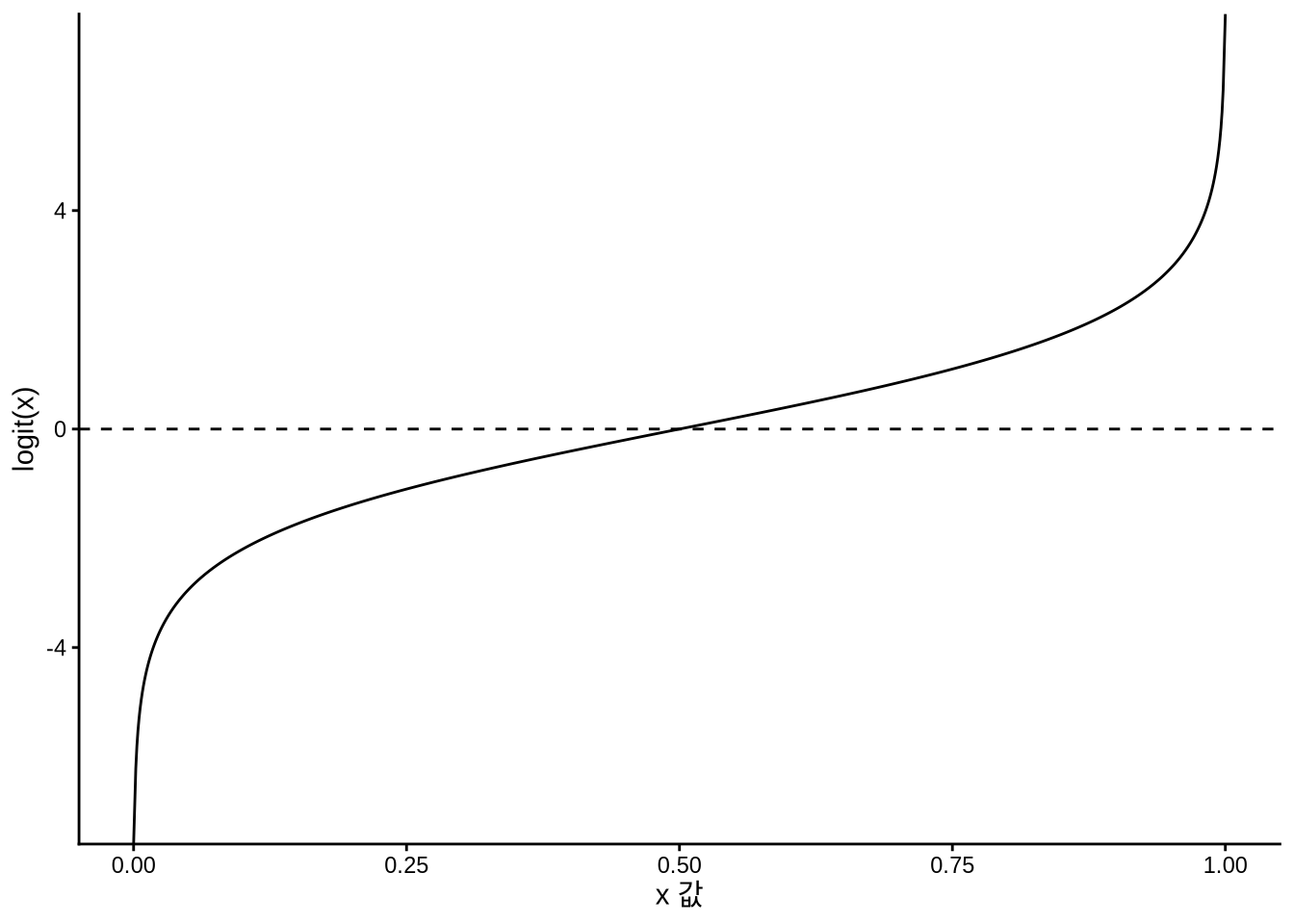
13.2.1 시뮬레이션 예시: 낮 또는 밤? 평일 또는 주말?
로지스틱 회귀의 작동 원리를 직관적으로 이해하기 위해, 창문 밖 도로 위를 굴러가는 ’자동차 수’만 보고 오늘이 ’평일’인지 아니면 ’주말’인지 맞혀야 하는 재미있는 상황을 시뮬레이션해 보겠습니다. 논리적으로는 당연히 사람들이 출퇴근하는 평일(weekday)에 도로가 훨씬 더 혼잡할 것이라고 가정할 수 있습니다.
set.seed(853)
week_or_weekday <-
tibble(
num_cars = sample.int(n = 100, size = 1000, replace = TRUE),
noise = rnorm(n = 1000, mean = 0, sd = 10),
is_weekday = if_else(num_cars + noise > 50, 1, 0)
) |>
select(-noise)
week_or_weekday# A tibble: 1,000 × 2
num_cars is_weekday
<int> <dbl>
1 9 0
2 64 1
3 90 1
4 93 1
5 17 0
6 29 0
7 84 1
8 83 1
9 3 0
10 33 1
# ℹ 990 more rowsR의 기본 glm() 함수를 사용하면 빠르게 추정할 수 있습니다. 이 예시에서는 관찰된 ’자동차 수’를 바탕으로 평일일 확률을 모델링하며, 추정 수식은 Equation 13.1 과 같습니다.
\[ \mbox{Pr}(y_i=1) = \mbox{logit}^{-1}\left(\beta_0+\beta_1 x_i\right) \tag{13.1}\]
여기서 결과 변수 \(y_i\)는 평일 여부(평일=1, 주말=0)를, 설명 변수 \(x_i\)는 자동차 수를 나타냅니다. (\(\mbox{logit}^{-1}\)는 로짓 변환을 되돌리는 역 로짓(inverse logit) 함수입니다.)
week_or_weekday_model <-
glm(
is_weekday ~ num_cars,
data = week_or_weekday,
family = "binomial"
)
summary(week_or_weekday_model)
Call:
glm(formula = is_weekday ~ num_cars, family = "binomial", data = week_or_weekday)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -9.48943 0.74492 -12.74 <2e-16 ***
num_cars 0.18980 0.01464 12.96 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1386.26 on 999 degrees of freedom
Residual deviance: 337.91 on 998 degrees of freedom
AIC: 341.91
Number of Fisher Scoring iterations: 7출력된 결과를 보면 자동차 수에 대한 추정 계수(\(\beta_1\))가 0.19로 나왔습니다. 여기서 주의할 점은, 로지스틱 회귀에서 추정된 계수를 해석하는 방식이 기존 선형 회귀보다 조금 더 까다롭다는 것입니다. 선형 회귀의 계수처럼 “확률이 0.19만큼 직관적으로 올라간다”라고 단순하게 해석하면 안 됩니다. 이 계수는 정확히 말하자면, 이진 결과에 대한 로그-오즈(log-odds)의 평균 변화량을 의미합니다. 즉, 0.19라는 추정치는 도로에서 자동차가 ‘한 대’ 더 관찰될 때마다 평일일 확률의 ’로그-오즈’가 평균적으로 0.19만큼 증가한다는 뜻입니다. 부호가 양수(+)이므로 자동차 수가 많을수록 평일일 확률이 높아진다는 전체적인 방향성은 일치합니다. 문제는 로그-오즈 변환이 ’비선형적(non-linear)’이기 때문에, 확률이 구체적으로 몇 퍼센트 오르는지 말하려면 ’현재 베이스라인이 어디쯤 있느냐(baseline level)’에 따라 값이 고무줄처럼 달라진다는 사실입니다. 쉽게 말해, 기본 로그-오즈가 0 (확률 50%) 근처에서 까딱거릴 때 계수로 인해 변하는 확률의 폭이, 로그-오즈가 2 (확률 88%) 쯤에서 이미 꽉 차 있을 때 변하는 확률 폭보다 훨씬 더 극적으로 크게 나타납니다.
다행히 우리는 약간의 연산을 통해 이 까다로운 로그-오즈 추정치를, 일정한 자동차 수 조건일 때 주어진 ’평일일 확률(probability)’로 훨씬 알기 쉽게 직관적으로 변환할 수 있습니다. marginaleffects 패키지의 predictions() 함수를 사용하면 우리가 관측한 모든 데이터 포인트에 대해 모델이 내놓은 암묵적인 ’평일일 확률’을 아주 새롭게 계산하여 덧붙여 줍니다.
week_or_weekday_predictions <-
predictions(week_or_weekday_model) |>
as_tibble()
week_or_weekday_predictions# A tibble: 1,000 × 9
rowid estimate p.value s.value conf.low conf.high num_cars is_weekday df
<int> <dbl> <dbl> <dbl> <dbl> <dbl> <int> <dbl> <dbl>
1 1 0.000417 1.40e-36 119. 0.000125 0.00139 9 0 Inf
2 2 0.934 9.33e-27 86.5 0.898 0.959 64 1 Inf
3 3 0.999 1.97e-36 119. 0.998 1.000 90 1 Inf
4 4 1.000 1.10e-36 119. 0.999 1.000 93 1 Inf
5 5 0.00190 1.22e-35 116. 0.000711 0.00508 17 0 Inf
6 6 0.0182 3.34e-32 105. 0.00950 0.0348 29 0 Inf
7 7 0.998 1.00e-35 116. 0.996 0.999 84 1 Inf
8 8 0.998 1.42e-35 116. 0.995 0.999 83 1 Inf
9 9 0.000134 5.22e-37 121. 0.0000338 0.000529 3 0 Inf
10 10 0.0382 1.08e-29 96.2 0.0222 0.0649 33 1 Inf
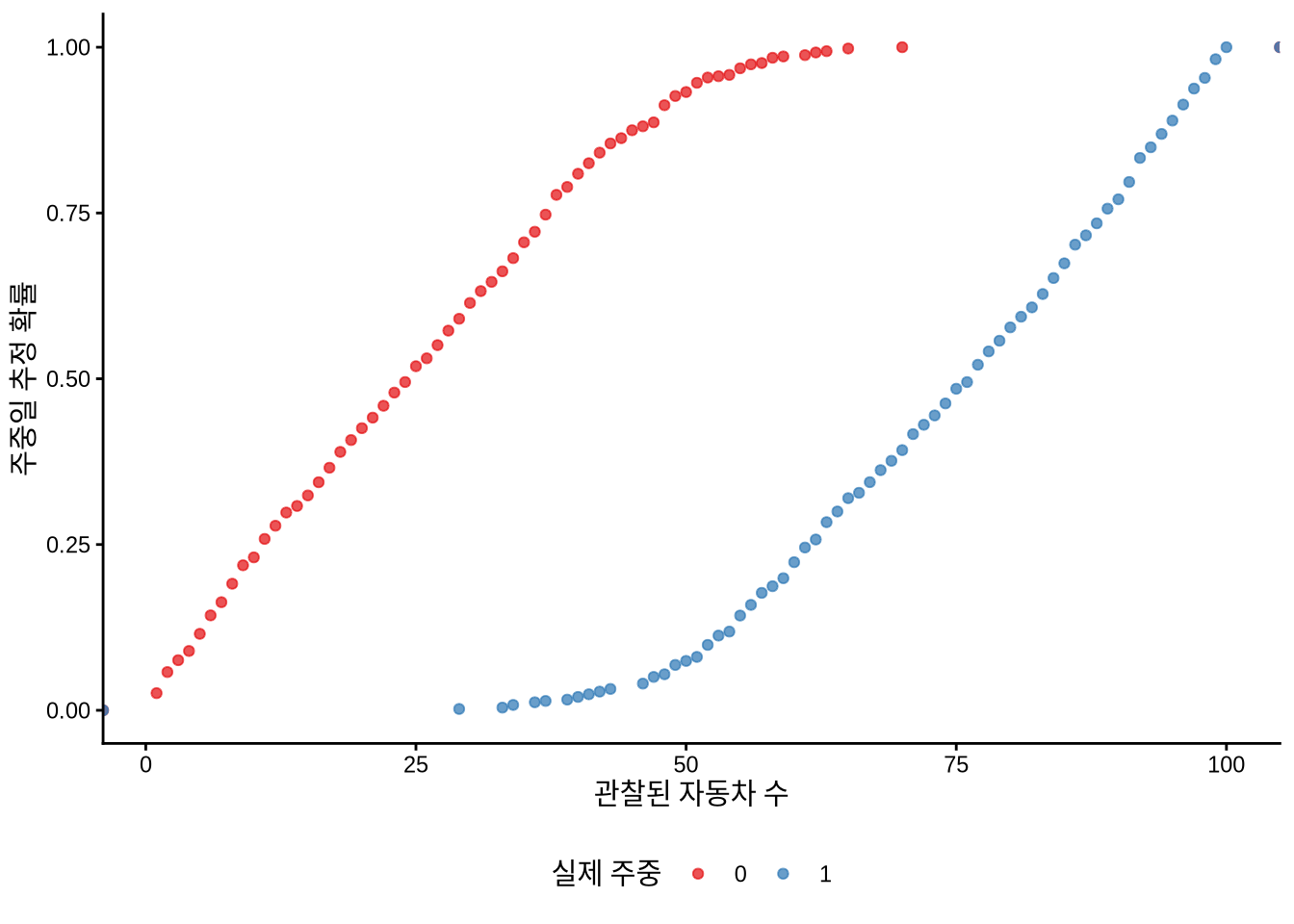
# ℹ 990 more rows구해진 확률값을 활용해 도로 위 자동차 수에 따라 모델이 평일일 확률을 어떻게 예측하는지 그래프로 그려볼 수 있습니다(Figure 13.2). 이는 모델이 데이터를 얼마나 잘 적합시켰는지 시각적으로 검토하는 과정입니다. 산점도를 그려보거나(Figure 13.2 (a)), 촘촘한 누적 분포를 보여주는 경험적 누적 분포 함수(ECDF) 곡선을 그려보는 방법이 유용합니다(Figure 13.2 (b)).
# 패널 (a)
week_or_weekday_predictions |>
mutate(is_weekday = factor(is_weekday)) |>
ggplot(aes(x = num_cars, y = estimate, color = is_weekday)) +
geom_jitter(width = 0.01, height = 0.01, alpha = 0.3) +
labs(
x = "관찰된 자동차 수",
y = "주중일 추정 확률",
color = "실제 주중"
) +
theme_classic() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")
# 패널 (b)
week_or_weekday_predictions |>
mutate(is_weekday = factor(is_weekday)) |>
ggplot(aes(x = num_cars, y = estimate, color = is_weekday)) +
stat_ecdf(geom = "point", alpha = 0.75) +
labs(
x = "관찰된 자동차 수",
y = "주중일 추정 확률",
color = "실제 주중"
) +
theme_classic() +
scale_color_brewer(palette = "Set1") +
theme(legend.position = "bottom")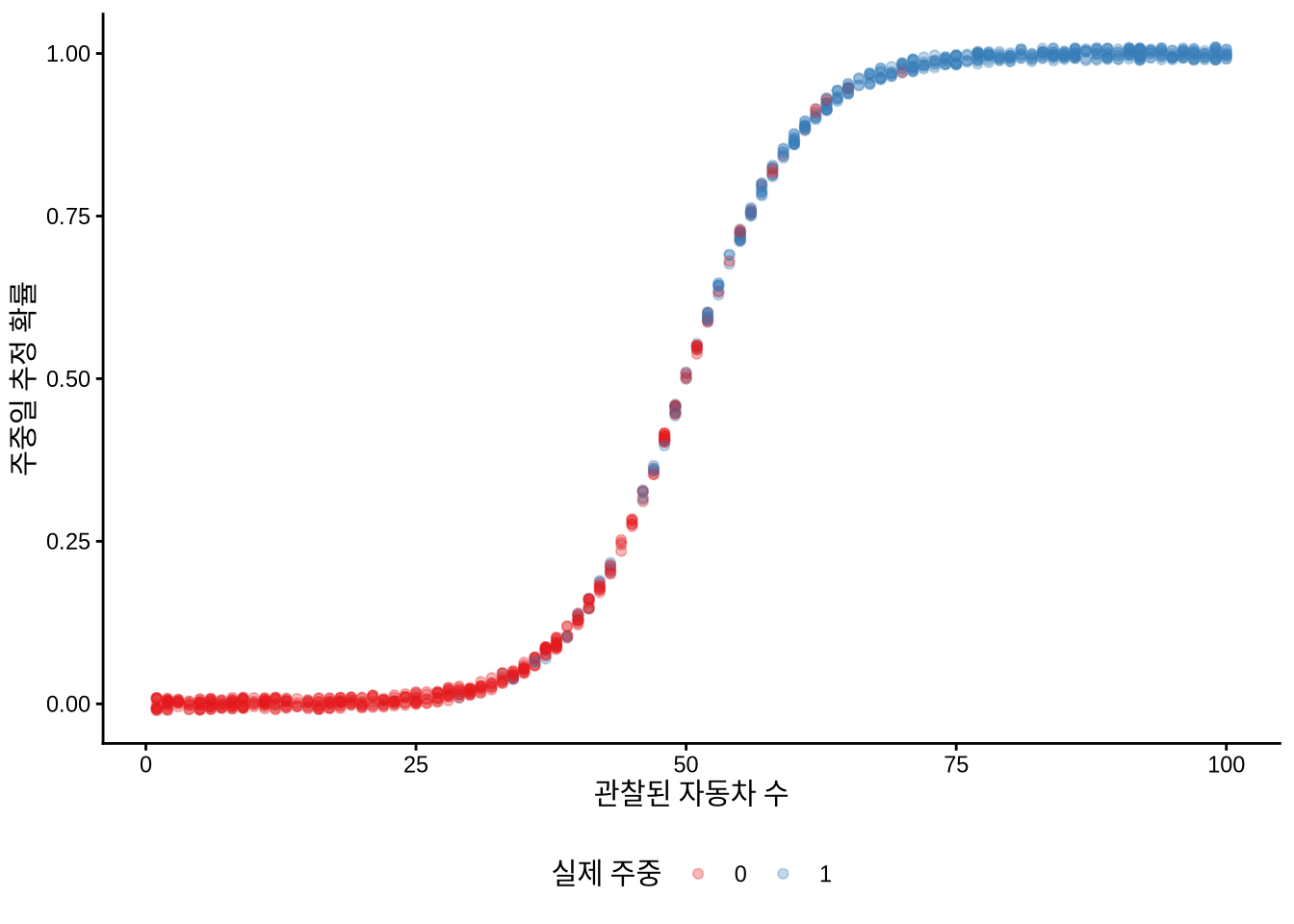
로지스틱 회귀 분석의 또 다른 유용한 도구는 확률의 변화 속도를 보여주는 한계 효과(marginal effects)입니다. 이를 통해 “자동차 50대를 목격했을 때(중앙값) 한 대가 더 지나간다면, 평일일 확률은 구체적으로 약 4.9%포인트 증가한다”는 식의 구체적인 해석이 가능합니다(Table 13.1).
slopes(week_or_weekday_model, newdata = "median") |>
select(term, estimate, std.error) |>
tt() |>
style_tt(j = 1:3, align = "lrr") |>
format_tt(digits = 3, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("항목", "추정치", "표준 오차"))| 항목 | 추정치 | 표준 오차 |
|---|---|---|
| num_cars | 0.047 | 0.004 |
베이즈(Bayesian) 기반의 로지스틱 모델도 구축할 수 있습니다. Chapter 12 에서 보았던 워크플로를 따라 사전 분포(prior)를 지정합니다. 여기서는 rstanarm의 기본 사전 분포를 활용하겠습니다.
\[ \begin{aligned} y_i|\pi_i & \sim \mbox{Bern}(\pi_i) \\ \mbox{logit}(\pi_i) & = \beta_0+\beta_1 x_i \\ \beta_0 & \sim \mbox{Normal}(0, 2.5)\\ \beta_1 & \sim \mbox{Normal}(0, 2.5) \end{aligned} \] 수식을 꼼꼼히 살펴보면, 여기서 \(y_i\)는 오늘이 실제 평일인지 여부(평일이면 1, 아니면 0)를, \(x_i\)는 수집된 도로 위의 자동차 수를 의미합니다. 그리고 가장 중요한 \(\pi_i\)는 우리가 그토록 호기심을 가졌던 관측치 \(i\) 시점이 ’평일’일 확률(probability)입니다.
week_or_weekday_rstanarm <-
stan_glm(
is_weekday ~ num_cars,
data = week_or_weekday,
family = binomial(link = "logit"),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 2.5, autoscale = TRUE),
seed = 853
)
saveRDS(
week_or_weekday_rstanarm,
file = "week_or_weekday_rstanarm.rds"
)베이즈 기반 결과는 빈도주의 모델의 결과와 매우 유사합니다(Table 13.2).
modelsummary(
list(
"낮 또는 밤" = week_or_weekday_rstanarm
)
)| 낮 또는 밤 | |
|---|---|
| (Intercept) | -9.464 |
| number_of_cars | 0.186 |
| Num.Obs. | 1000 |
| R2 | 0.779 |
| Log.Lik. | -177.899 |
| ELPD | -179.8 |
| ELPD s.e. | 13.9 |
| LOOIC | 359.6 |
| LOOIC s.e. | 27.9 |
| WAIC | 359.6 |
| RMSE | 0.24 |
Table 13.2 표를 보면, 이 단순한 사례에서는 빈도주의와 베이즈 중 어느 쪽을 택하든 동일한 결론에 이른다는 것을 알 수 있습니다. 효과의 방향성과 크기 모두 거의 일치합니다.
13.2.2 미국 정치적 지지 현황 예측하기
로지스틱 회귀가 현업 데이터 과학자들에게 가장 뜨겁게 사랑받고 자주 소환되는 분야 중 하나는 단연 정치 여론조사(Political polling)입니다. 선거에 뛰어든 유권자는 아무리 마음이 복잡하더라도 결국 투표용지 앞에서는 단 한 명의, 혹은 한 가지 선호도를 콕 찍어 선택해야 합니다. 따라서 복잡다단한 정치적 신념이라는 고차원적 문제도 투표소 문을 나설 무렵이면 적절하든 아니든 아주 차갑고 단순하게 “지지한다(1)” 또는 “지지하지 않는다(0)”의 이진법 세계로 완전히 쪼그라들게 됩니다.
이러한 문제를 풀기 위해 이 책이 끊임없이 옹호하고 권장해 온 견고한 분석 워크플로는 다음과 같습니다.
\(\mbox{계획} \rightarrow \mbox{시뮬레이션} \rightarrow \mbox{데이터 획득} \rightarrow \mbox{탐색} \rightarrow \mbox{지식 공유}\)
이 케이스 스터디에서는 미국의 정치적 지지 현황을 분석합니다. ‘교육 수준’과 ’성별’ 정보만으로 다가올 선거에서 바이든에게 투표할지 예측할 수 있을지 살펴보겠습니다. 분석 전 예상 데이터셋의 모습(Figure 13.3 (a))과 로지스틱 회귀 모델이 보여줄 결과(Figure 13.3 (b))를 미리 구상해 보는 것은 아이디어를 구체화하는 데 도움이 됩니다.
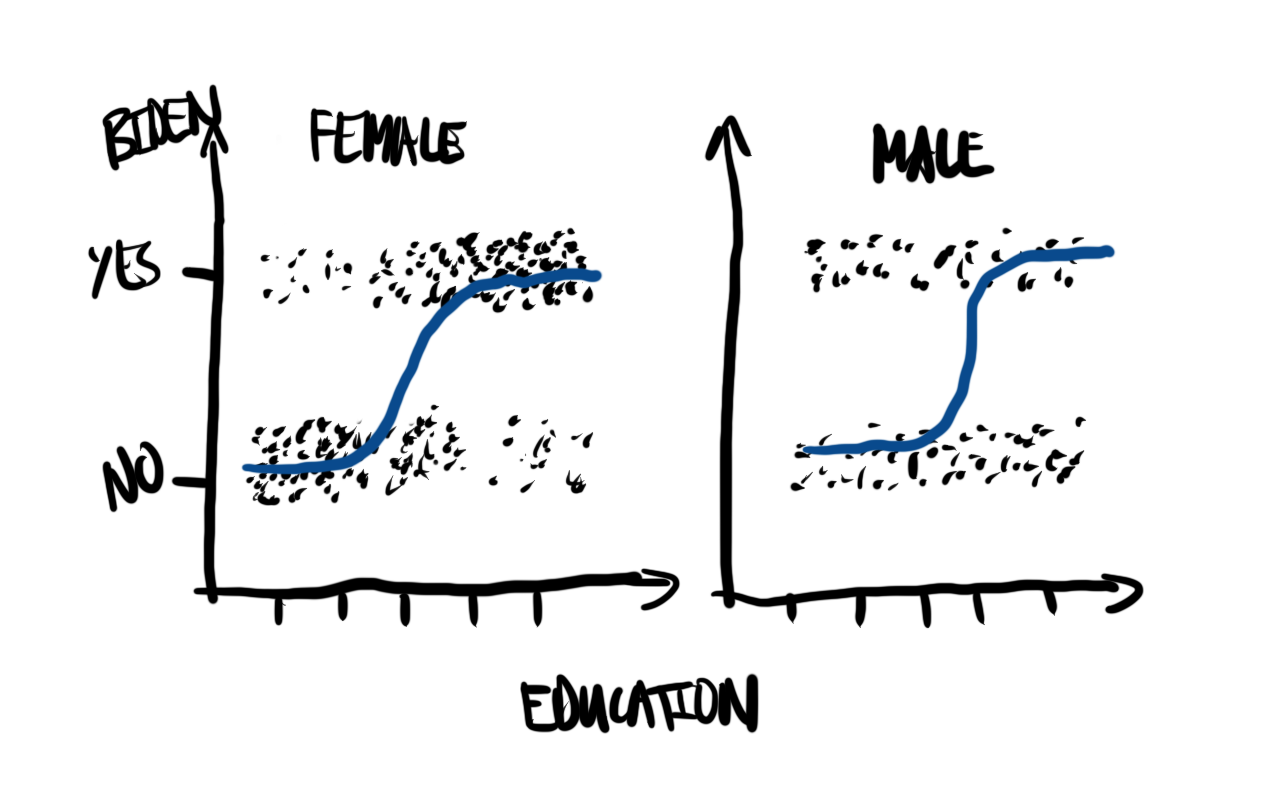
우리가 설정한 가설, 즉 개인이 바이든을 지지할 확률이 성별과 교육 수준에 따라 달라진다는 상황을 가정하는 모의 데이터셋을 아래와 같이 간단히 시뮬레이션해 봅니다.
set.seed(853)
num_obs <- 1000
us_political_preferences <- tibble(
education = sample(0:4, size = num_obs, replace = TRUE),
gender = sample(0:1, size = num_obs, replace = TRUE),
support_prob = ((education + gender) / 5),
) |>
mutate(
supports_biden = if_else(runif(n = num_obs) < support_prob, "yes", "no"),
education = case_when(
education == 0 ~ "< 고등학교",
education == 1 ~ "고등학교",
education == 2 ~ "일부 대학",
education == 3 ~ "대학",
education == 4 ~ "대학원"
),
gender = if_else(gender == 0, "남성", "여성")
) |>
select(-support_prob, supports_biden, gender, education)실제 분석에는 2020년 협동 선거 연구(Cooperative Election Study, CES) 데이터셋을 사용합니다(Schaffner, Ansolabehere, and Luks 2021). 미국 전역의 민심을 추적한 방대한 설문조사 결과입니다. R에서는 dataverse 패키지를 활용해 CES 데이터에 접근할 수 있습니다. 데이터 획득 방식은 Chapter 7 와 Chapter 10 에서 다룬 내용을 따릅니다.
ces2020 <-
get_dataframe_by_name(
filename = "CES20_Common_OUTPUT_vv.csv",
dataset = "10.7910/DVN/E9N6PH",
server = "dataverse.harvard.edu",
.f = read_csv
) |>
select(votereg, CC20_410, gender, educ)
write_csv(ces2020, "ces2020.csv")ces2020 <-
read_csv(
"ces2020.csv",
col_types =
cols(
"votereg" = col_integer(),
"CC20_410" = col_integer(),
"gender" = col_integer(),
"educ" = col_integer()
)
)
ces2020# A tibble: 61,000 × 4
votereg CC20_410 gender educ
<int> <int> <int> <int>
1 1 2 1 4
2 2 NA 2 6
3 1 1 2 5
4 1 1 2 5
5 1 4 1 5
6 1 2 1 3
7 2 NA 1 3
8 1 2 2 3
9 1 2 2 2
10 1 1 2 5
# ℹ 60,990 more rows실제 원시 데이터를 눈으로 직접 맞닥뜨려 보면, 애초에 머릿속으로 단순하게 스케치했던 것과는 사뭇 다른 지저분한 현실의 문제들이 고스란히 드러납니다. 이때 분석가의 가장 소중한 나침반인 ’코드북(codebook)’을 펼쳐 변수들의 진짜 정체를 더욱 철저히 파헤쳐야 합니다. 우리의 구체적인 타깃은 선거에 무관심한 사람들이 아니라 오직 투표 등록을 마친 유권자들이며, 그중에서도 바이든이나 트럼프에게 투표한 사람들의 응답만 온전히 분석에 사용할 계획입니다. 설문 항목 중 CC20_410 변수를 찾아보면 흥미롭게도 값이 1이면 응답자가 바이든을 지지했음을, 2이면 트럼프를 맹렬히 지지했음을 의미합니다. 이제 복잡한 데이터 프레임에서 이 조건에 딱 맞는 열성 응답자들만 체에 거르듯 필터링(filtering)해낸 다음, 나중에 헷갈리지 않도록 1과 2 대신 훨씬 더 유익하고 직관적인 텍스트 레이블을 친절하게 덧입혀 줄 것입니다.
CES 데이터셋에서는 남녀 성별 정보도 제공하는데, ‘gender’ 변수의 값이 1이면 “남성(Male)”을, 2이면 “여성(Female)”을 깔끔하게 의미합니다. 마지막으로 코드북을 조금 더 넘겨보면, 우리가 찾던 ‘educ’ 변수가 숫자가 1에서 6으로 쑥쑥 커질수록 그 응답자의 성취 교육 수준이 정비례하여 점진적으로 높아지는 구조임을 명확히 알려줍니다.
ces2020 <-
ces2020 |>
filter(votereg == 1,
CC20_410 %in% c(1, 2)) |>
mutate(
voted_for = if_else(CC20_410 == 1, "Biden", "Trump"),
voted_for = as_factor(voted_for),
gender = if_else(gender == 1, "남성", "여성"),
education = case_when(
educ == 1 ~ "고등학교 미만",
educ == 2 ~ "고등학교 졸업",
educ == 3 ~ "일부 대학",
educ == 4 ~ "2년제",
educ == 5 ~ "4년제",
educ == 6 ~ "대학원"
),
education = factor(
education,
levels = c(
"고등학교 미만",
"고등학교 졸업",
"일부 대학",
"2년제",
"4년제",
"대학원"
)
)
) |>
select(voted_for, gender, education)정제 과정을 거치면 총 43,554명의 응답자 데이터가 남습니다(Figure 13.4 참조).
ces2020 |>
ggplot(aes(x = education, fill = voted_for)) +
stat_count(position = "dodge") +
facet_wrap(facets = vars(gender)) +
theme_minimal() +
labs(
x = "최고 교육 수준",
y = "응답자 수",
fill = "투표 대상"
) +
coord_flip() +
scale_fill_brewer(palette = "Set1") +
theme(legend.position = "bottom")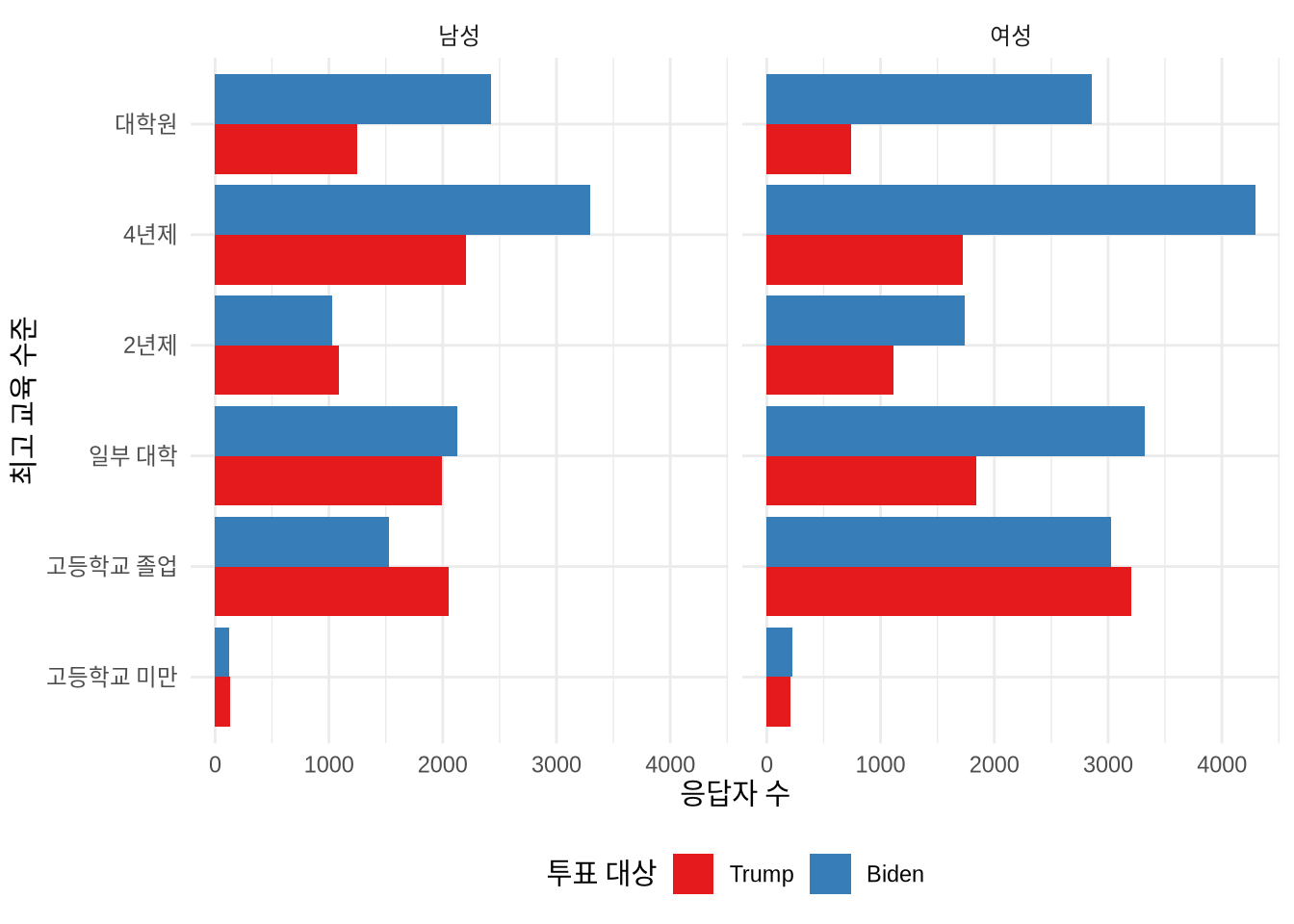
우리가 데이터를 통해 추정하고자 하는 구체적인 베이즈 모델의 뼈대는 다음과 같습니다.
\[ \begin{aligned} y_i|\pi_i & \sim \mbox{Bern}(\pi_i) \\ \mbox{logit}(\pi_i) & = \beta_0+\beta_1 \times \mbox{gender}_i + \beta_2 \times \mbox{education}_i \\ \beta_0 & \sim \mbox{Normal}(0, 2.5)\\ \beta_1 & \sim \mbox{Normal}(0, 2.5)\\ \beta_2 & \sim \mbox{Normal}(0, 2.5) \end{aligned} \]
위 수식에서 \(y_i\)는 해당 응답자의 최종 정치적 선택을 나타내며, 바이든을 지지했으면 1, 트럼프를 지지했으면 0의 값을 갖습니다. \(\mbox{gender}_i\)는 응답자의 성별이고, \(\mbox{education}_i\)는 응답자의 교육 수준입니다. 이 강력한 매개변수들은 rstanarm 패키지의 stan_glm() 함수를 호출하여 손쉽게 추정할 수 있습니다. 위 수식은 이해를 돕기 위해 간소화된 일반적인 약어 형태를 띠고 있습니다. 실제 R 내부에서 rstanarm이 작동할 때는, 범주형(categorical) 변수인 교육 수준 등을 여러 개의 가상의 지표 변수(indicator variables, 더미 변수)로 능목하게 변환하여 훨씬 더 많은 수의 세부 계수들을 한꺼번에 추정하게 됩니다. 게다가 4만 개가 넘는 전체 데이터셋을 그대로 베이즈 모델에 밀어 넣으면 MCMC 샘플링 실행 시간이 기하급수적으로 늘어날 수 있습니다. 따라서 이 장에서는 학습의 효율성을 고려하여, 아주 가벼운 1,000개의 관측치 샘플만 무작위로 추출(slice)하여 모델을 적합(fit)해 보겠습니다.
set.seed(853)
ces2020_reduced <-
ces2020 |>
slice_sample(n = 1000)
political_preferences <-
stan_glm(
voted_for ~ gender + education,
data = ces2020_reduced,
family = binomial(link = "logit"),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept =
normal(location = 0, scale = 2.5, autoscale = TRUE),
seed = 853
)
saveRDS(
political_preferences,
file = "political_preferences.rds"
)political_preferences <-
readRDS(file = "political_preferences.rds")추정된 모델 결과는 흥미로운 통찰을 줍니다. Table 13.3 표를 보면, 남성의 경우 바이든 지지 가능성이 상대적으로 낮으며, 교육 수준이 지지율에 유의미한 영향을 미친다는 점을 알 수 있습니다.
modelsummary(
list(
"바이든 지지 예측" = political_preferences
),
statistic = "mad"
)| 바이든 지지 예측 | |
|---|---|
| (Intercept) | -0.745 |
| (0.517) | |
| genderMale | -0.477 |
| (0.136) | |
| educationHigh school graduate | 0.617 |
| (0.534) | |
| educationSome college | 1.494 |
| (0.541) | |
| education2-year | 0.954 |
| (0.538) | |
| education4-year | 1.801 |
| (0.532) | |
| educationPost-grad | 1.652 |
| (0.541) | |
| Num.Obs. | 1000 |
| R2 | 0.064 |
| Log.Lik. | -646.335 |
| ELPD | -653.5 |
| ELPD s.e. | 9.4 |
| LOOIC | 1307.0 |
| LOOIC s.e. | 18.8 |
| WAIC | 1307.0 |
| RMSE | 0.48 |
각 예측 변수의 영향력 범위(신용 구간)를 그래프로 시각화하면 전달력이 높아집니다(Figure 13.5). 이 차트는 본문이나 부록에 첨부하기 좋은 자료입니다.
modelplot(political_preferences, conf_level = 0.9) +
labs(x = "90% 신용 구간")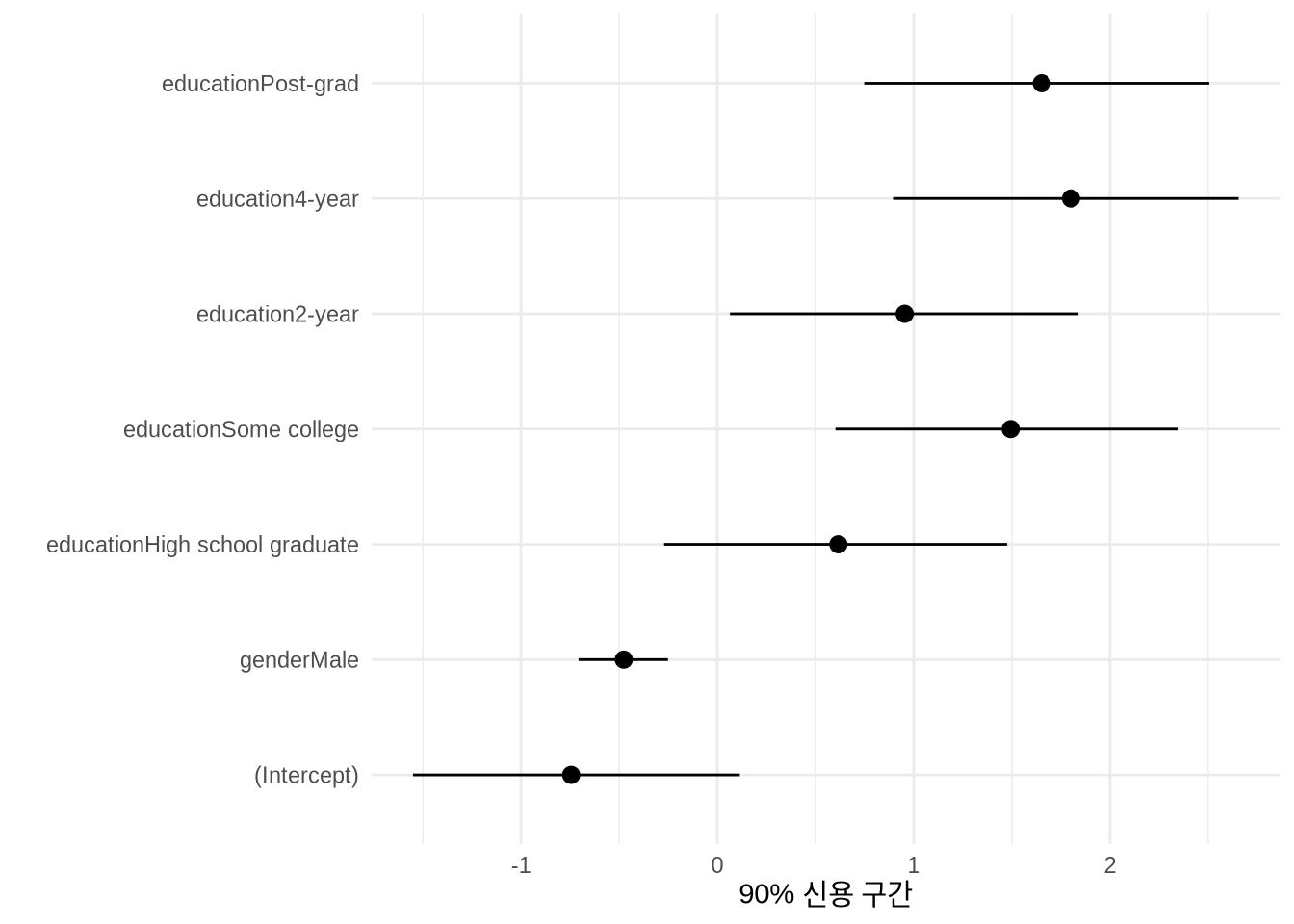
13.3 포아송 회귀(Poisson Regression)
만약 우리가 분석해야 할 데이터가 연속적인 실수가 아니라 ‘몇 명’, ‘몇 번’, ’몇 골’처럼 딱 떨어지는 개수(count) 데이터로 이루어져 있다면, 분석의 첫 단추로 가장 먼저 포아송 분포(Poisson distribution)를 떠올리는 것이 매우 현명한 선택입니다.
포아송 회귀가 맹활약하는 대표적인 분야 중 하나는 흥미롭게도 스포츠 경기 결과 모델링입니다. 예를 들어 보르흐(Burch (2023))는 축구 경기력을 모델링할 때 포아송 회귀의 선구자인 바이오(Baio and Blangiardo (2010))의 기법을 고스란히 차용하여, 하키 경기의 득점 수를 예측하는 정교한 포아송 모델을 구축하기도 했습니다.
수학적으로 포아송 분포는 오로지 단 하나의 특별한 매개변수, 곧 \(\lambda\)(람다)에 의해 모든 모양이 결정됩니다. 포아송은 항상 0보다 크거나 같은 음이 아닌 정수(0, 1, 2, 3…)에 대해서만 발생 확률을 할당하여 분포의 형태를 빚어냅니다. 그 결과 포아송 분포는 통계학적으로 아주 독특하면서도 골치 아픈 특징 하나를 갖게 되는데, 바로 ’분포의 평균(mean)이 그 고유한 분산(variance)과 완벽하게 동일하다’는 점입니다. 즉, 평균적으로 기대되는 발생 횟수가 커질수록, 데이터가 흔들리는 변동의 폭(분산) 또한 필연적으로 함께 커지는 구조입니다. 피트먼(Pitman (1993)) [p. 121]이 기술한 공식에 따르면, 특정 횟수 \(k\)번이 발생할 포아송 확률 질량 함수는 다음과 같습니다.
\[P_{\lambda}(k) = e^{-\lambda}\lambda^k/k!\mbox{, 단, }k=0,1,2,\dots\]
R에서는 놀랍도록 쉽게 rpois() 함수를 사용하여 \(\lambda\)가 3(평균적으로 3번 발생)인 포아송 분포로부터 가상의 개수 데이터 표본 \(n=20\)개를 순식간에 추출(시뮬레이션)할 수 있습니다.
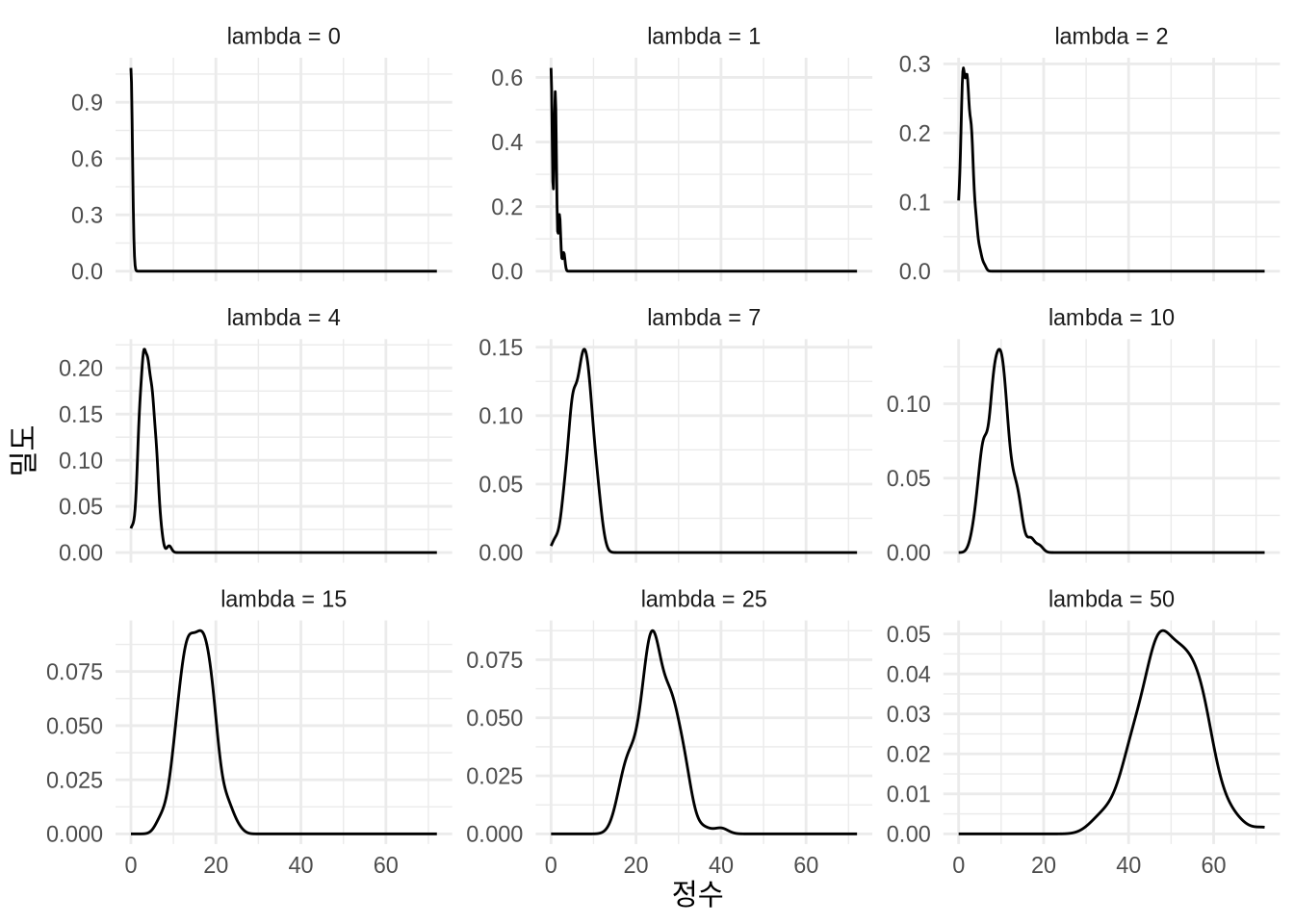
rpois(n = 20, lambda = 3) [1] 3 1 5 6 2 0 2 4 6 2 1 0 3 3 2 2 2 2 2 6핵심 매개변수인 \(\lambda\) 값이 커짐에 따라 분포의 모양이 어떻게 변화하는지 확인해 보십시오(Figure 13.6).
13.3.1 시뮬레이션 예시: 학과별 A 학점 부여 횟수 비교
포아송 회귀의 쓰임새를 명확히 이해하기 위해, 각 학과의 대학 인기 강의에서 한 학기 동안 학생들에게 ’A 학점’을 과연 몇 번이나 넉넉히 부여하는지 가상으로 가늠해 볼 수 있는 모의 데이터를 시뮬레이션해 보겠습니다. 이 시뮬레이션 시나리오에서는 총 3개의 학과를 설정하고, 각 학과 안에 수많은 강의들이 열려 있다고 가정합니다. 당연하게도, 각각의 강의들은 성적 부여 기준이나 난이도가 제각기 다르기 때문에 학기 말에 쏟아내는 A 학점의 수 역시 매우 다양할 것입니다.
set.seed(853)
class_size <- 26
count_of_A <-
tibble(
# Chris DuBois 코드 참고: https://stackoverflow.com/a/1439843
department =
c(rep.int("1", 26), rep.int("2", 26), rep.int("3", 26)),
course = c(
paste0("DEP_1_", letters),
paste0("DEP_2_", letters),
paste0("DEP_3_", letters)
),
number_of_As = c(
rpois(n = class_size, lambda = 5),
rpois(n = class_size, lambda = 10),
rpois(n = class_size, lambda = 20)
)
)count_of_A |>
ggplot(aes(x = number_of_As)) +
geom_histogram(aes(fill = department), position = "dodge") +
labs(
x = "부여된 A 학점 개수",
y = "해당하는 개수를 준 강의 수",
fill = "학과"
) +
theme_classic() +
scale_fill_brewer(palette = "Set1") +
theme(legend.position = "bottom")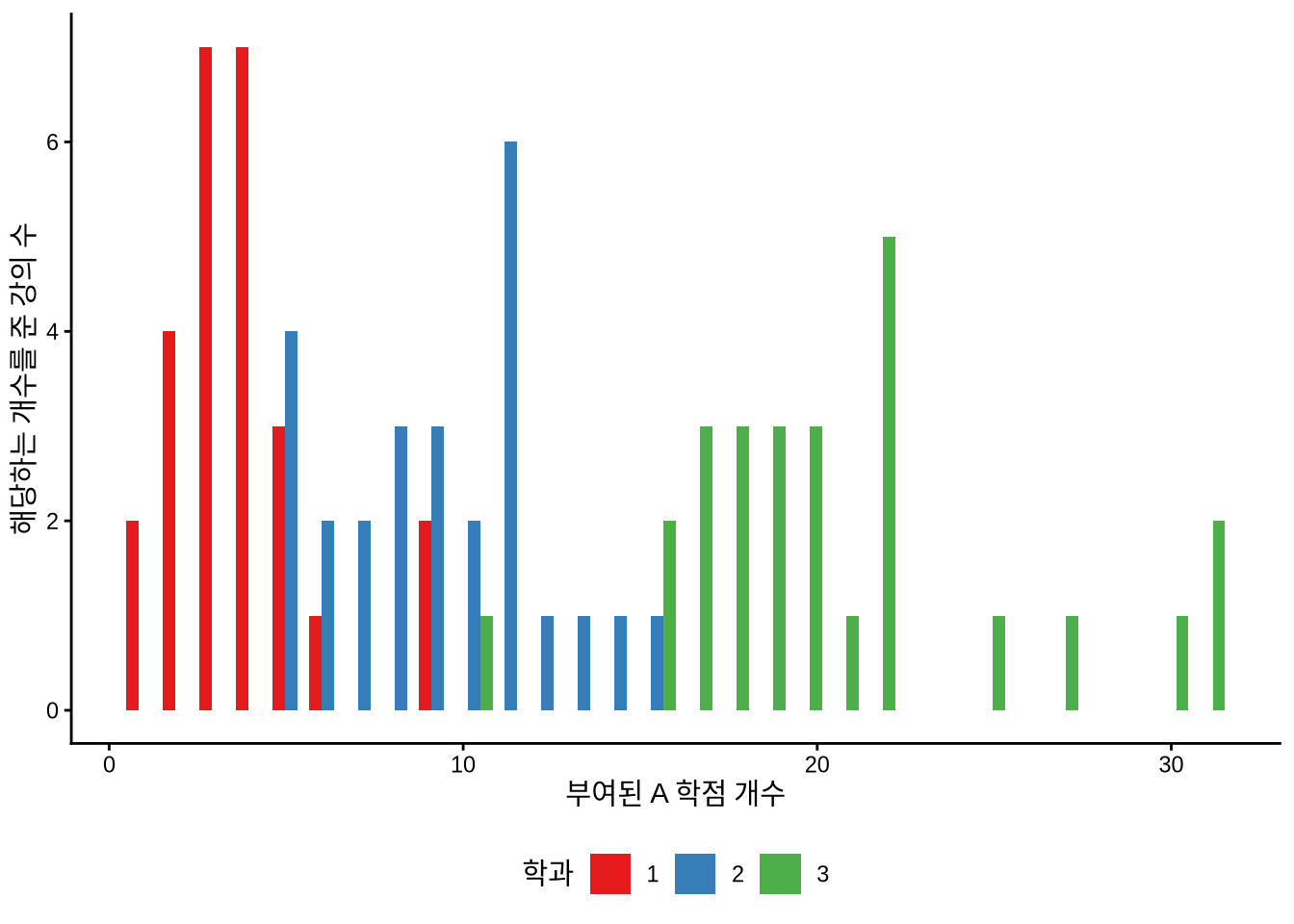
시뮬레이션된 데이터를 시각화하면(Figure 13.7), 학과 내 강의들이 갖는 학점 분포의 계층적 구조를 확인할 수 있습니다. Chapter 16 에서는 이러한 위계 구조를 다층 모델로 다루겠지만, 여기서는 학과 간의 거시적인 차이에 집중하겠습니다.
우리가 호기심을 안고 추정해 보려는 모델의 수식은 다음과 같습니다.
\[ \begin{aligned} y_i|\lambda_i &\sim \mbox{Poisson}(\lambda_i)\\ \log(\lambda_i) & = \beta_0 + \beta_1 \times \mbox{department}_i \end{aligned} \] 수식에서 결과 변수 \(y_i\)는 어떤 강의에서 최종적으로 부여된 A 학점의 진짜 개수이며, 우리의 유일한 목적은 이 개수가 ’어느 학과(\(\mbox{department}_i\))에 소속되어 있느냐’에 따라 어떻게 춤을 추는지 파악하는 것입니다.
R의 glm() 함수에 family = "poisson"을 지정해 포아송 회귀를 수행할 수 있습니다. 결과는 Table 13.4 의 첫 번째 열에 제시되어 있습니다.
grades_base <-
glm(
number_of_As ~ department,
data = count_of_A,
family = "poisson"
)
summary(grades_base)
Call:
glm(formula = number_of_As ~ department, family = "poisson",
data = count_of_A)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 1.3269 0.1010 13.135 < 2e-16 ***
department2 0.8831 0.1201 7.353 1.94e-13 ***
department3 1.7029 0.1098 15.505 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 426.201 on 77 degrees of freedom
Residual deviance: 75.574 on 75 degrees of freedom
AIC: 392.55
Number of Fisher Scoring iterations: 4계수 해석 시 주의가 필요합니다. 계수는 기준 그룹(학과 1) 대비 ’로그(log) 기대치’를 의미합니다. 지수 변환을 해보면 학과 1에 비해 학과 2는 약 2.4배, 학과 3은 약 5.5배 더 많은 A 학점을 부여할 것으로 예상됩니다(Table 13.4 참고).
마찬가지로 이 추론을 베이즈(Bayesian) 세계로 슬쩍 가져가서 rstanarm 패키지와 함께 고급스럽고 단단한 베이즈 모델을 세워볼 수도 있습니다(Table 13.4).
\[ \begin{aligned} y_i|\lambda_i &\sim \mbox{Poisson}(\lambda_i)\\ \log(\lambda_i) & = \beta_0 + \beta_1 \times\mbox{department}_i\\ \beta_0 & \sim \mbox{Normal}(0, 2.5)\\ \beta_1 & \sim \mbox{Normal}(0, 2.5) \end{aligned} \] 여기 수식에서도, \(y_i\)는 단일 강의에서 부여된 A 학점의 낱개 개수입니다.
grades_rstanarm <-
stan_glm(
number_of_As ~ department,
data = count_of_A,
family = poisson(link = "log"),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 2.5, autoscale = TRUE),
seed = 853
)
saveRDS(
grades_rstanarm,
file = "grades_rstanarm.rds"
)비교 가능한 모델 요약 결과표는 가독성을 위해 Table 13.4 에 정리되어 있습니다.
modelsummary(
list(
"A 학점 부여량 비교" = grades_rstanarm
)
)| A 학점 부여량 비교 | |
|---|---|
| (Intercept) | 1.321 |
| department2 | 0.884 |
| department3 | 1.706 |
| Num.Obs. | 78 |
| Log.Lik. | -193.355 |
| ELPD | -196.2 |
| ELPD s.e. | 7.7 |
| LOOIC | 392.4 |
| LOOIC s.e. | 15.4 |
| WAIC | 392.4 |
| RMSE | 3.41 |
marginaleffects 패키지의 slopes() 함수를 사용하면 포아송 계수의 직관적인 의미를 파악할 수 있습니다. 예를 들어 “학과 1에서 다른 학과로 옮길 때 A 학점 개수가 어떻게 변하는가?”와 같은 질문에 답할 수 있습니다. Table 13.5 을 보면, 학과 2는 학과 1보다 약 5개, 학과 3은 약 17개 더 많은 A 학점을 부여할 것으로 예상됩니다.
slopes(grades_rstanarm) |>
select(contrast, estimate, conf.low, conf.high) |>
unique() |>
tt() |>
style_tt(j = 1:4, align = "lrrr") |>
format_tt(digits = 2, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("학과 간의 짜릿한 비교", "추정증가분(개)", "2.5% 신용하한", "97.5% 신용상한"))| 학과 간의 짜릿한 비교 | 추정증가분(개) | 2.5% 신용하한 | 97.5% 신용상한 |
|---|---|---|---|
| 2 - 1 | 5.32 | 4.01 | 6.7 |
| 3 - 1 | 16.92 | 15.1 | 18.84 |
13.3.2 제인 에어 소설 속 알파벳 ’E’의 비밀
Edgeworth (1885) 는 버질의 서사시 아이네이스(Aeneid)에 등장하는 닥틸(dactyl)의 개수를 직접 세기도 했습니다(자세한 내용은 Stigler (1978, 301) 또는 HistData 패키지의 Dactyl 데이터셋을 참조하십시오(Friendly 2021)). 이러한 연구에 영감을 받아, 우리도 gutenbergr 패키지로 샬럿 브론테의 제인 에어(Jane Eyre) 원문을 분석해 보겠습니다. (Chapter 7 에서는 PDF 파일을 데이터셋으로 변환하는 과정을 다루었습니다.)
여기서는 각 챕터의 처음 10줄에서 단어 수와 알파벳 ’e’의 등장 횟수를 분석하여, 단어 수가 많아질수록 ’e’의 빈도도 비례해서 늘어나는지 살펴보겠습니다.
분석 전 예상 데이터셋(Figure 13.12 (a))과 포아송 모델의 결과(Figure 13.12 (b))를 미리 스케치해 보는 것은 분석의 방향을 잡는 데 도움이 됩니다.
데이터 수집 전, 포아송 분포를 따르는 가상의 텍스트 데이터셋을 시뮬레이션해 봅니다(Figure 13.9).
count_of_e_simulation <-
tibble(
chapter = c(rep(1, 10), rep(2, 10), rep(3, 10)),
line = rep(1:10, 3),
number_words_in_line = runif(min = 0, max = 15, n = 30) |> round(0),
number_e = rpois(n = 30, lambda = 10)
)
count_of_e_simulation |>
ggplot(aes(y = number_e, x = number_words_in_line)) +
geom_point() +
labs(
x = "해당 줄의 단어 수",
y = "처음 10줄에서 관찰된 e/E 개수"
) +
theme_classic() +
scale_fill_brewer(palette = "Set1")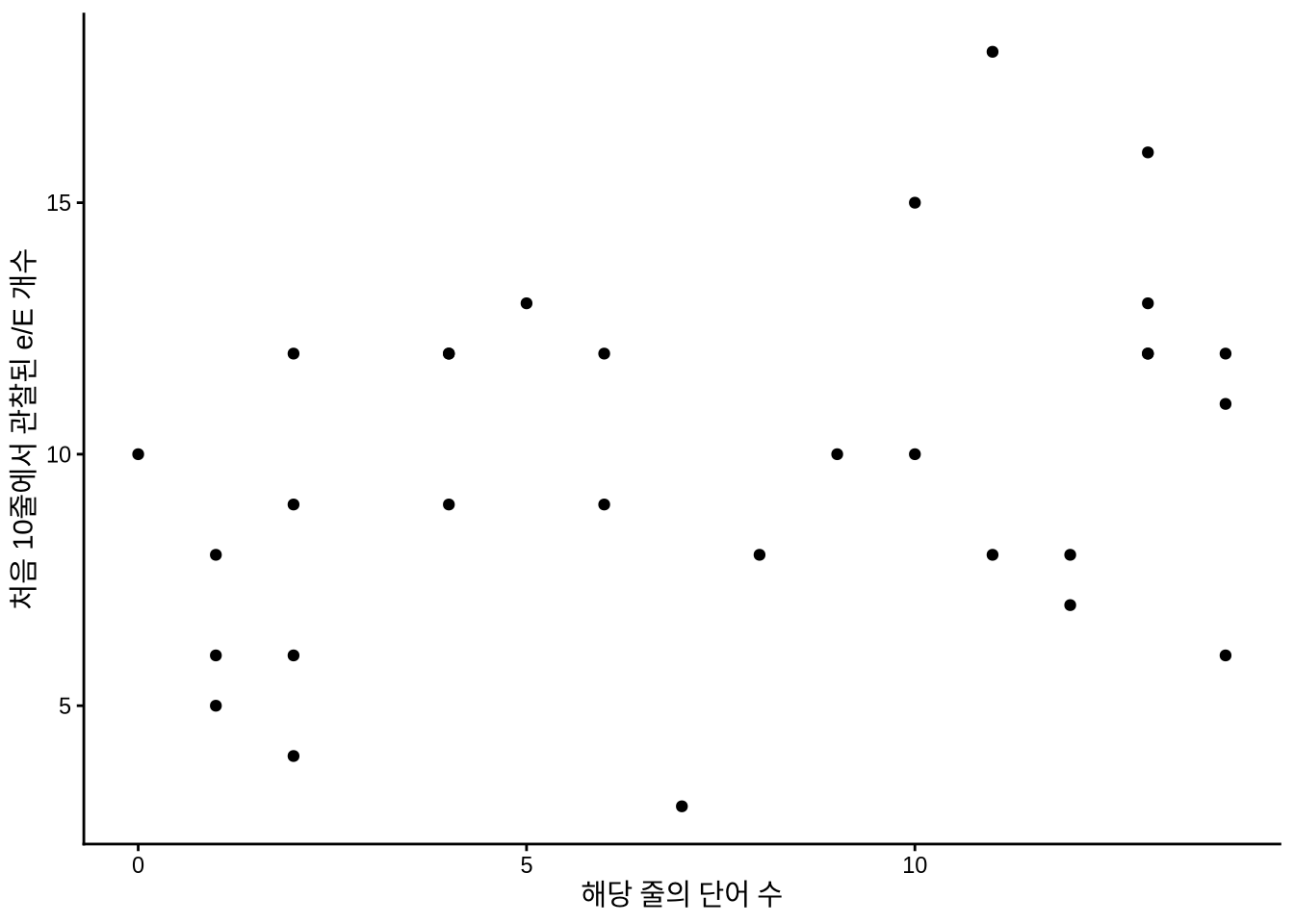
시뮬레이션을 통해 감을 잡았으니, 이제 드디어 진짜 제인 에어 데이터를 수집하고 정제할 차례입니다. gutenbergr 패키지의 명작인 gutenberg_download() 함수를 실행하면 전 세계의 지식 창고인 프로젝트 구텐베르크(Project Gutenberg)에서 방대한 텍스트를 무료로 순식간에 내 컴퓨터로 다운로드할 수 있습니다.
gutenberg_id_of_janeeyre <- 1260
jane_eyre <-
gutenberg_download(
gutenberg_id = gutenberg_id_of_janeeyre,
mirror = "https://gutenberg.pglaf.org/"
)
jane_eyre
write_csv(jane_eyre, "jane_eyre.csv")원문을 한 번 다운로드한 뒤에는, 자비로운 공공 프로젝트 구텐베르크의 공용 서버 장비에 무례하게 트래픽 부담을 주지 않도록 매번 로컬에 저장해 둔 사본(.csv)을 예의 바르게 불러와 분석을 진행할 것입니다.
jane_eyre <- read_csv(
"jane_eyre.csv",
col_types = cols(
gutenberg_id = col_integer(),
text = col_character()
)
)
jane_eyre# A tibble: 21,001 × 2
gutenberg_id text
<int> <chr>
1 1260 JANE EYRE
2 1260 AN AUTOBIOGRAPHY
3 1260 <NA>
4 1260 by Charlotte Brontë
5 1260 <NA>
6 1260 _ILLUSTRATED BY F. H. TOWNSEND_
7 1260 <NA>
8 1260 London
9 1260 SERVICE & PATON
10 1260 5 HENRIETTA STREET
# ℹ 20,991 more rows우리의 집중 과녁은 알파벳 문자가 실제로 존재하는 줄(line)이므로, 시각적 여백을 위해 소설에 삽입된 텅 빈 줄들은 filter를 이용해 모조리 청소합니다. 그런 다음 정규 표현식을 십분 활용해 각 장(chapter)의 시작 지점을 인식시키고, 모든 장의 맨 위에 해당하는 ’처음 10개 문장 줄’을 날카롭게 분리해 낸 뒤 그 안에서 e/E 문자가 정확히 몇 개 숨어 있는지 집계율을 올릴 수 있습니다. 예를 들어, 코드가 훑고 지나간 소설의 첫머리를 보면 1장 1번째 줄에는 알파벳 e/E가 5번, 2번째 줄에는 8번 출몰했다는 사실을 명명백백하게 확인할 수 있습니다.
jane_eyre_reduced <-
jane_eyre |>
filter(!is.na(text)) |> # 내용 없는 빈 줄 가차 없이 제거
mutate(chapter = if_else(str_detect(text, "CHAPTER") == TRUE,
text,
NA_character_)) |> # 각 장이 새롭게 시작되는 타이틀 위치 마킹
fill(chapter, .direction = "down") |>
mutate(chapter_line = row_number(),
.by = chapter) |> # 오직 그 챕터 안에서만 1부터 올라가는 고유 줄 번호 부여
filter(!is.na(chapter),
chapter_line %in% c(2:11)) |> # 잡다한 "CHAPTER I" 제목 줄을 버리고 순수 텍스트 처음 10줄만 확보
select(text, chapter) |>
mutate(
chapter = str_remove(chapter, "CHAPTER "),
chapter = str_remove(chapter, "—CONCLUSION"),
chapter = as.integer(as.roman(chapter))
) |> # 로마자 챕터 번호를 읽기 편한 정수로 완벽 변환
mutate(
count_e = str_count(text, "e|E"), # e나 E가 나올 때마다 카운트
word_count = str_count(text, "\\w+") # 띄어쓰기 기준으로 덩어리(단어) 개수 카운트
# 정규 표현식 팁 출처: https://stackoverflow.com/a/38058033
)jane_eyre_reduced |>
select(chapter, word_count, count_e, text) |>
head()# A tibble: 6 × 4
chapter word_count count_e text
<int> <int> <int> <chr>
1 1 13 5 There was no possibility of taking a walk that day…
2 1 11 8 wandering, indeed, in the leafless shrubbery an ho…
3 1 12 9 but since dinner (Mrs. Reed, when there was no com…
4 1 14 3 the cold winter wind had brought with it clouds so…
5 1 11 7 so penetrating, that further outdoor exercise was …
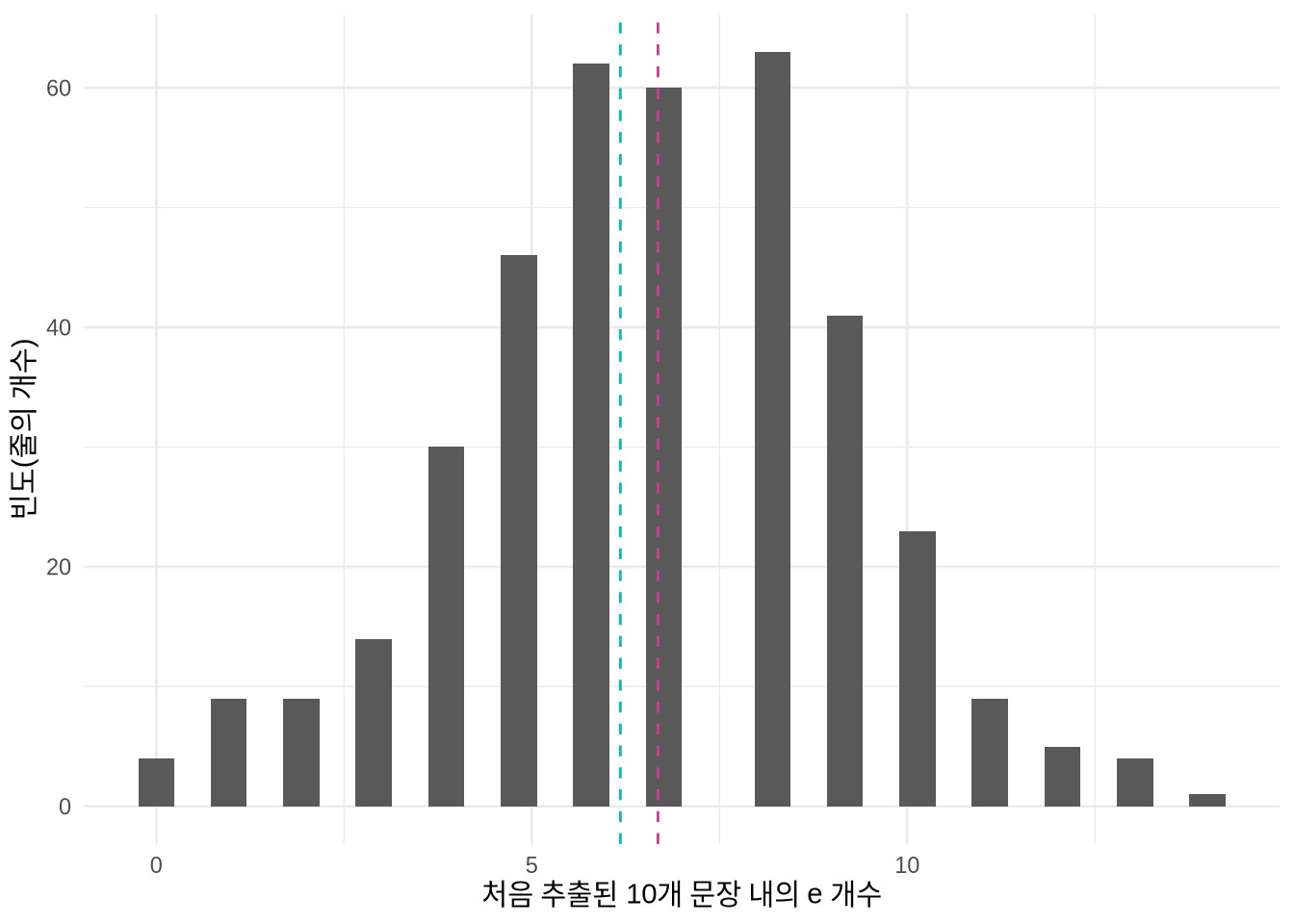
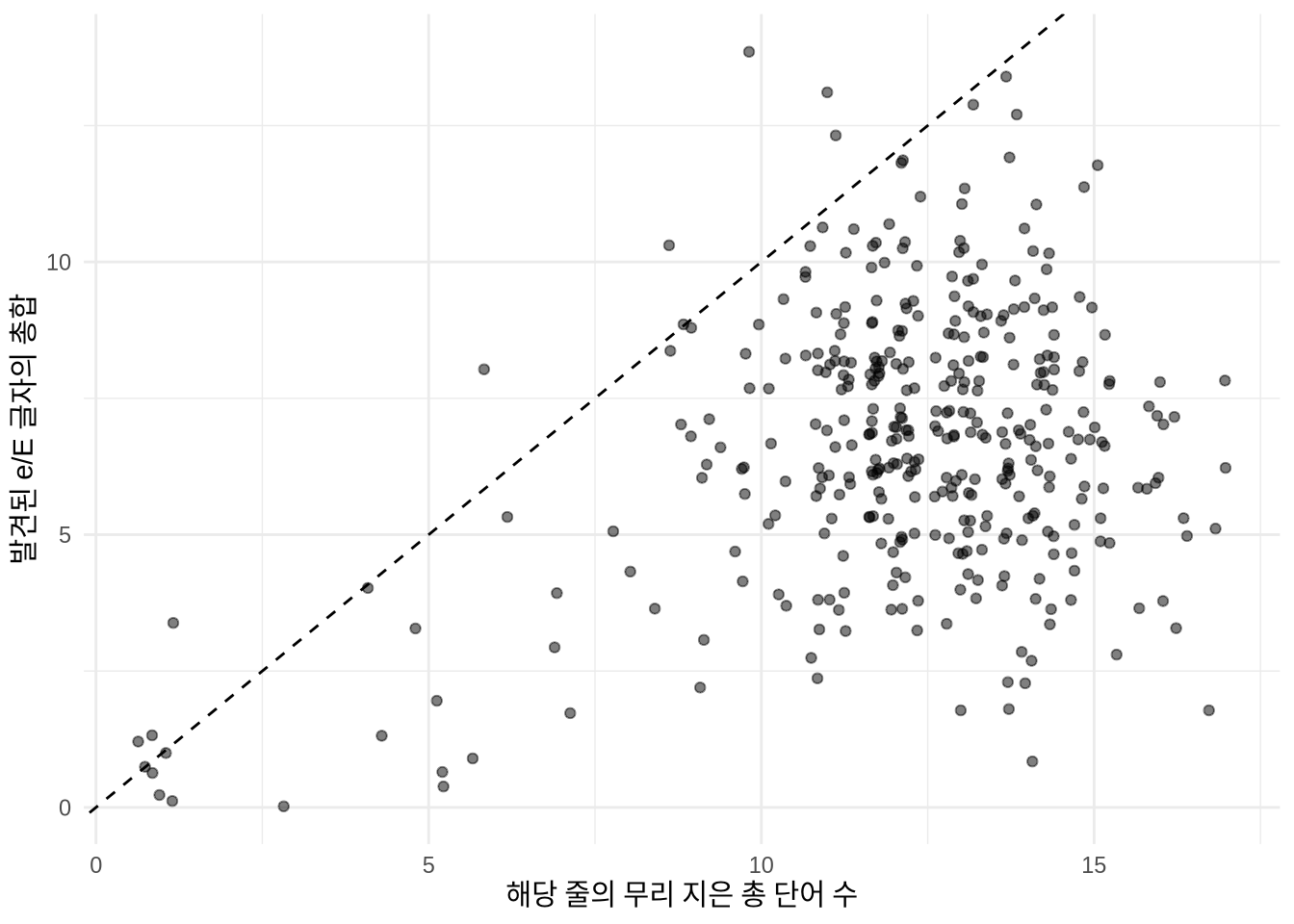
6 1 1 1 question. 알파벳 ’e’의 빈도 통계가 포아송 분포의 가정(평균과 분산이 비슷해야 함)을 충족하는지 탐색적 분석을 통해 확인해 봅니다(Figure 13.10). Figure 13.10 (b) 의 산점도에서 수많은 데이터 포인트가 기준선 아래에 있는 것을 보면, 단어 하나당 ’e’의 개수는 보통 1개 미만임을 알 수 있습니다.
mean_e <- mean(jane_eyre_reduced$count_e)
variance_e <- var(jane_eyre_reduced$count_e)
jane_eyre_reduced |>
ggplot(aes(x = count_e)) +
geom_histogram() +
geom_vline(xintercept = mean_e,
linetype = "dashed",
color = "#C64191") +
geom_vline(xintercept = variance_e,
linetype = "dashed",
color = "#0ABAB5") +
theme_minimal() +
labs(
y = "빈도(줄의 개수)",
x = "처음 추출된 10개 문장 내의 e 개수"
)
jane_eyre_reduced |>
ggplot(aes(x = word_count, y = count_e)) +
geom_jitter(alpha = 0.5) +
geom_abline(slope = 1, intercept = 0, linetype = "dashed") +
theme_minimal() +
labs(
x = "해당 줄의 무리 지은 총 단어 수",
y = "발견된 e/E 글자의 총합"
)
이처럼 아름답게 정제된 관측 증거들을 토대로, 마침내 우리는 베이스라인 모델을 설계할 권리를 획득합니다. 우리가 돌릴 베이즈 포아송 추정 모델(Model)의 수식은 이렇습니다:
\[
\begin{aligned}
y_i|\lambda_i &\sim \mbox{Poisson}(\lambda_i)\\
\log(\lambda_i) & = \beta_0 + \beta_1 \times \mbox{word\_count}_i\\
\beta_0 & \sim \mbox{Normal}(0, 2.5)\\
\beta_1 & \sim \mbox{Normal}(0, 2.5)
\end{aligned}
\] 수식에서 결과 변수인 \(y_i\)는 소설의 특정한 줄(문장) 하나에서 헤아린 무심한 낱자 e/E의 고유한 반복 횟수이고, 설명 변수는 그 줄 전체를 구성하는 ’단어의 총 개수(\(\mbox{word\_count}_i\))’입니다. 이제 rstanarm 패키지의 믿음직한 stan_glm() 함수 엔진을 가동하여 이 매개변수들의 숨은 베일을 벗겨볼 차례입니다.
jane_e_counts <-
stan_glm(
count_e ~ word_count,
data = jane_eyre_reduced,
family = poisson(link = "log"),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 2.5, autoscale = TRUE),
seed = 853
)
saveRDS(
jane_e_counts,
file = "jane_e_counts.rds"
)marginaleffects 패키지의 plot_predictions() 함수를 사용하면 포아송 모델이 예측한 값을 시각화할 수 있습니다. Figure 13.11 에서 단어 수와 ’e’의 등장 횟수 사이의 양(+)의 비례 관계가 나타납니다.
plot_predictions(jane_e_counts, condition = "word_count") +
labs(x = "해당 줄의 무리 지은 단어 수",
y = "처음 10줄 문단에서의 평균 e/E 개수") +
theme_classic()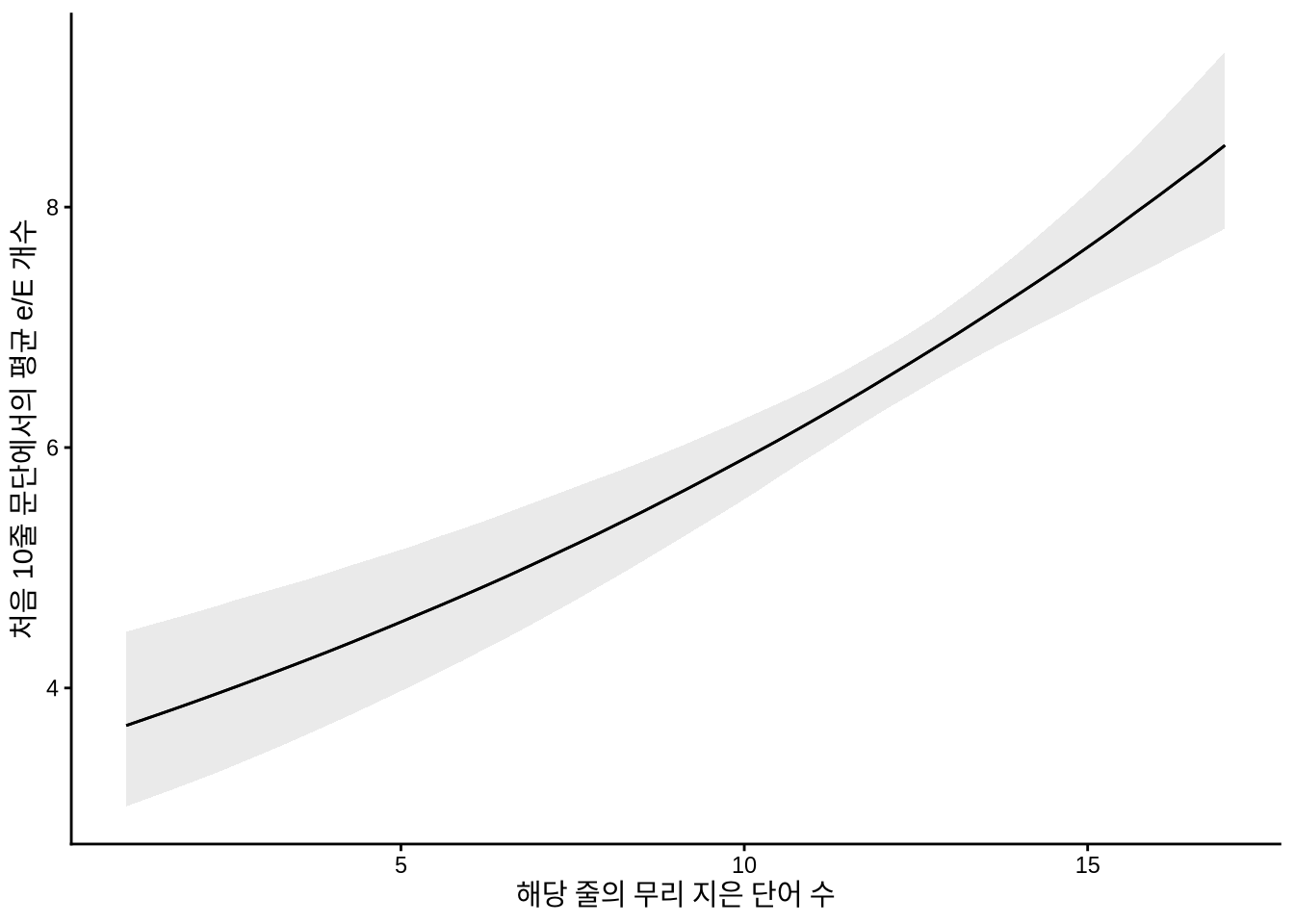
13.4 음이항 회귀 (Negative Binomial Regression)
앞서 우리가 찬양했던 모델인 포아송 회귀에도 치명적인 제약이 하나 숨어 있는데, 바로 발생 건수의 평균(mean)과 데이터의 흩어짐(분산, variance)이 반드시 동일해야 한다는 뻣뻣한 가정입니다. 하지만 골치 아픈 현실 세계의 데이터는 대개 평균보다 훨씬 널뛰는 큰 분산을 갖기 마련입니다. 이처럼 난감한 과분산(overdispersion) 현상을 너그럽게 품어주기 위해, 우리는 포아송과 형태는 유사하지만 훨씬 더 유연한 가정을 가진 음이항 회귀(negative binomial regression) 로 슬쩍 갈아타게 됩니다.
포아송 모델과 음이항 모델은 마치 친형제처럼 통계적으로 매우 밀접하게 얽혀 있습니다. 실무 분석가들은 이 두 가지 모델을 데이터에 나란히 적합(fit)시켜 본 다음, 과연 어느 쪽 옷이 더 데이터의 몸매에 잘 맞는지 까다롭게 비교하곤 합니다. 대표적인 비교 사례들은 다음과 같습니다:
- 마허(Maher) 등(Maher (1982))은 잉글랜드 축구 리그의 짜릿한 경기 결과를 예측하는 맥락에서 두 모델을 모두 링 위에 올린 뒤, 어떤 상황에서 음이항 모델이 포아송을 압도하며 더 적절한 투구로 인정받을 수 있는지 심도 있게 논의합니다.
- 조르노(Zorn)와 메이시(Macey)(Smith (2002))는 그 유명한 2000년 미국 대통령 선거 결과를 뜯어보면서, 포아송 분석을 들이댈 때 필연적으로 겪게 되는 골치 아픈 과분산(overdispersion) 문제를 집중적으로 조명했습니다.
- 오스굿(Osgood)(Osgood (2000))은 변동성이 널뛰는 사회 범죄 현상 데이터를 다룰 때 이 두 모델의 예측력을 날카롭게 비교대조했습니다.
13.4.1 캐나다 앨버타주의 사망 원인 파헤치기
대주제가 다소 어둡고 병적으로 들릴 수 있지만, 매년 각 개인에게는 궁극적으로 단 두 가지 운명만 주어집니다. 살아남거나, 혹은 사망하거나입니다. 이러한 통계적 관점을 드넓은 지리적 지역 단위로 확장하면, 우리는 보건 행정 기관으로부터 매년 안타깝게 목숨을 잃은 사람들의 사연(사망 원인)과 그 슬픈 숫자에 대한 방대한 집계 데이터를 얻어낼 수 있습니다. 실제로 캐나다 통계청에 따르면, 앨버타주(Alberta) 보건 당국은 지난 2001년부터 매년 도민들의 목숨을 앗아간 상위 30가지 치명적인 사망 원인들을 집요하게 추적하여 그 데이터를 일반 대중에게 투명하게 공개해오고 있습니다.
분석에 앞서 구상하는 데이터셋 구조(Figure 13.12 (a))와 모델의 목적(Figure 13.12 (b))을 미리 스케치해 보는 것을 권장합니다.
진짜 보건 데이터를 열어보기 전에 코딩 감각을 익히기 위해, 앞서 설명한 음이항 분포(negative binomial distribution) 의 통계적 패턴을 고스란히 따르는 가상의 앨버타주 사망 원인 데이터셋을 우선적으로 시뮬레이션해 볼 것입니다.
alberta_death_simulation <-
tibble(
cause = rep(x = c("심장 질환", "뇌졸중", "당뇨병"), times = 10),
year = rep(x = 2016:2018, times = 10),
deaths = rnbinom(n = 30, size = 20, prob = 0.1)
)
alberta_death_simulation# A tibble: 30 × 3
cause year deaths
<chr> <int> <int>
1 심장 질환 2016 241
2 뇌졸중 2017 197
3 당뇨병 2018 139
4 심장 질환 2016 136
5 뇌졸중 2017 135
6 당뇨병 2018 130
7 심장 질환 2016 194
8 뇌졸중 2017 211
9 당뇨병 2018 190
10 심장 질환 2016 142
# ℹ 20 more rows실제 데이터를 통해 앨버타주의 연도별·사인별 사망자 분포를 살펴봅니다(Figure 13.13). 데이터를 훑다 보면 어떤 질병 이름은 의학적으로 너무 길어서 분석 화면을 다 가려버릴 수 있으니, 요령껏 너무 긴 질병명 문자열의 뒷부분을 과감하게 잘라내어(truncation) 깔끔하게 다듬어 줍니다. 덧붙여 말하자면, 독감 같은 예기치 않은 질병의 특정 원인은 어떤 해에는 그 위세가 대단하여 상위 30위 사망 원인에 랭크업되지만, 또 다른 평온한 해에는 목록에서 아예 자취를 감추기도 합니다. 따라서 모든 사망 원인 데이터가 연도별로 똑같은 개수(빈도)만큼 온전히 살아남아 수집되지는 않는다는 뼈아픈 현실을 염두에 두어야 합니다.
alberta_cod <-
read_csv(
"https://open.alberta.ca/dataset/03339dc5-fb51-4552-97c7-853688fc428d/resource/3e241965-fee3-400e-9652-07cfbf0c0bda/download/deaths-leading-causes.csv",
skip = 2,
col_types = cols(
`Calendar Year` = col_integer(),
Cause = col_character(),
Ranking = col_integer(),
`Total Deaths` = col_integer()
)
) |>
clean_names() |>
add_count(cause) |>
mutate(cause = str_trunc(cause, 30))2021년 상위 10대 사망 원인을 살펴보면 흥미로운 점들이 발견됩니다(Table 13.6). 암이나 심장병은 꾸준히 상위권에 머무는 반면, “COVID-19”와 같은 원인은 특정 시기에만 나타납니다.
alberta_cod |>
filter(
calendar_year == 2021,
ranking <= 10
) |>
mutate(total_deaths = format(total_deaths, big.mark = ",")) |>
tt() |>
style_tt(j = 1:5, align = "lrrrr") |>
format_tt(digits = 0, num_mark_big = ",", num_fmt = "decimal") |>
setNames(c("연도", "치명적인 사망 원인", "발생 순위", "희생자 수(명)", "상위권 유지 연수(기간)"))| 연도 | 치명적인 사망 원인 | 발생 순위 | 희생자 수(명) | 상위권 유지 연수(기간) |
|---|---|---|---|---|
| 2,021 | Other ill-defined and unkno... | 1 | 3,362 | 3 |
| 2,021 | Organic dementia | 2 | 2,135 | 21 |
| 2,021 | COVID-19, virus identified | 3 | 1,950 | 2 |
| 2,021 | All other forms of chronic ... | 4 | 1,939 | 21 |
| 2,021 | Malignant neoplasms of trac... | 5 | 1,552 | 21 |
| 2,021 | Acute myocardial infarction | 6 | 1,075 | 21 |
| 2,021 | Other chronic obstructive p... | 7 | 1,028 | 21 |
| 2,021 | Diabetes mellitus | 8 | 728 | 21 |
| 2,021 | Stroke, not specified as he... | 9 | 612 | 21 |
| 2,021 | Accidental poisoning by and... | 10 | 604 | 9 |
분석의 집중도와 시각화의 단순성을 극대화하기 위해, 2021년 최상위 사망 원인들 중 지난 21년 내내 단 한 해도 빠짐없이 지속적으로 앨버타 주민들을 괴롭혀 온 치명적인 ‘고정 멤버’ 5가지 질병만 콕 집어 추려내어 시계열 트렌드를 살펴보겠습니다.
alberta_cod_top_five <-
alberta_cod |>
filter(
calendar_year == 2021,
n == 21
) |>
slice_max(order_by = desc(ranking), n = 5) |>
pull(cause)
alberta_cod <-
alberta_cod |>
filter(cause %in% alberta_cod_top_five)alberta_cod |>
ggplot(aes(x = calendar_year, y = total_deaths, color = cause)) +
geom_line() +
theme_minimal() +
scale_color_brewer(palette = "Set1") +
labs(x = "연도", y = "앨버타주의 연간 사망자 총합") +
facet_wrap(vars(cause), dir = "v", ncol = 1) +
theme(legend.position = "none")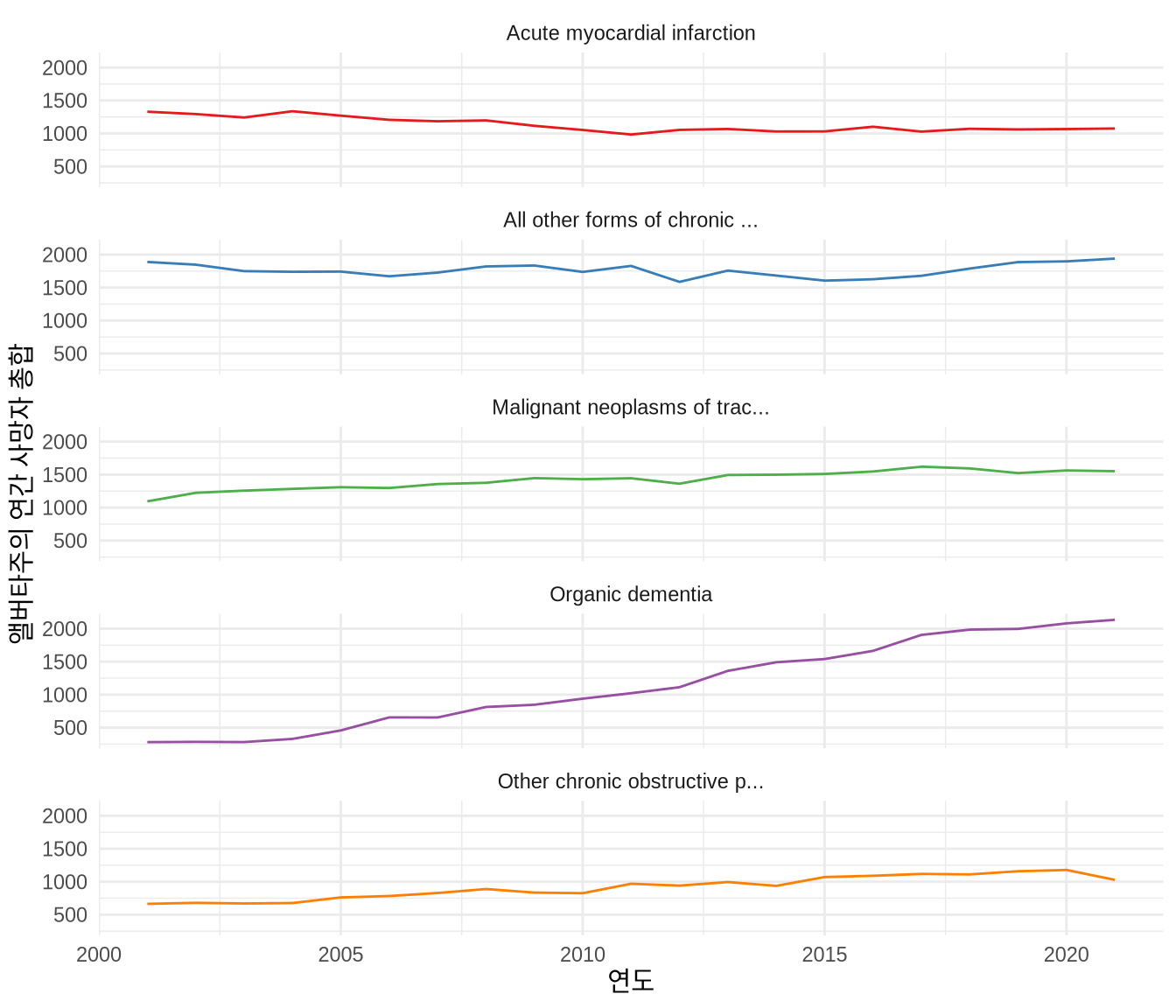
전체 데이터셋의 요약 통계(Table 13.7)를 보면, 사망자 수의 분산이 평균을 크게 상회하고 있음을 알 수 있습니다.
| Min | Mean | Max | SD | Var | N | |
|---|---|---|---|---|---|---|
| total_deaths | 280 | 1273 | 2135 | 427 | 182378 | 105 |
평균과 분산이 멱살을 잡고 싸울 만큼 이렇게 극적으로 다르다는 건, 앞서 논의했듯 평등을 사랑하는 전형적인 포아송 분포의 대전제(“평균=분산”)가 와장창 깨져버렸음을 의미하는 ’과분산(overdispersion)’의 강력한 신호입니다. 이를 구제하기 위해, 우리는 stan_glm() 함수를 호출할 때 family = neg_binomial_2(link = "log") 옵션을 당당히 지정하여 음이항 회귀 모델을 새롭게 출격시킬 수 있습니다. 학습을 위해 여기서는 억지를 부려 뼛속까지 포아송인 모델 한 개와 유연한 음이항 모델 한 개를 나란히 훈련(run)시켜 봅니다.
cause_of_death_alberta_poisson <-
stan_glm(
total_deaths ~ cause,
data = alberta_cod,
family = poisson(link = "log"),
seed = 853
)
cause_of_death_alberta_neg_binomial <-
stan_glm(
total_deaths ~ cause,
data = alberta_cod,
family = neg_binomial_2(link = "log"),
seed = 853
)두 모델의 매개변수 추정치를 Table 13.8 에 비교하여 정리했습니다.
coef_short_names <-
c("causeAll other forms of chronic ischemic heart disease"
= "기타 만성 허혈성 심장질환 등",
"causeMalignant neoplasms of trachea, bronchus and lung"
= "악성 신생물(폐암/기관지암)",
"causeOrganic dementia"
= "유기적 치매 증후군",
"causeOther chronic obstructive pulmonary disease"
= "기타 만성 폐쇄성 폐질환(COPD)"
)
modelsummary(
list(
"유연성 없는 포아송" = cause_of_death_alberta_poisson,
"관대한 음이항" = cause_of_death_alberta_neg_binomial
),
coef_map = coef_short_names
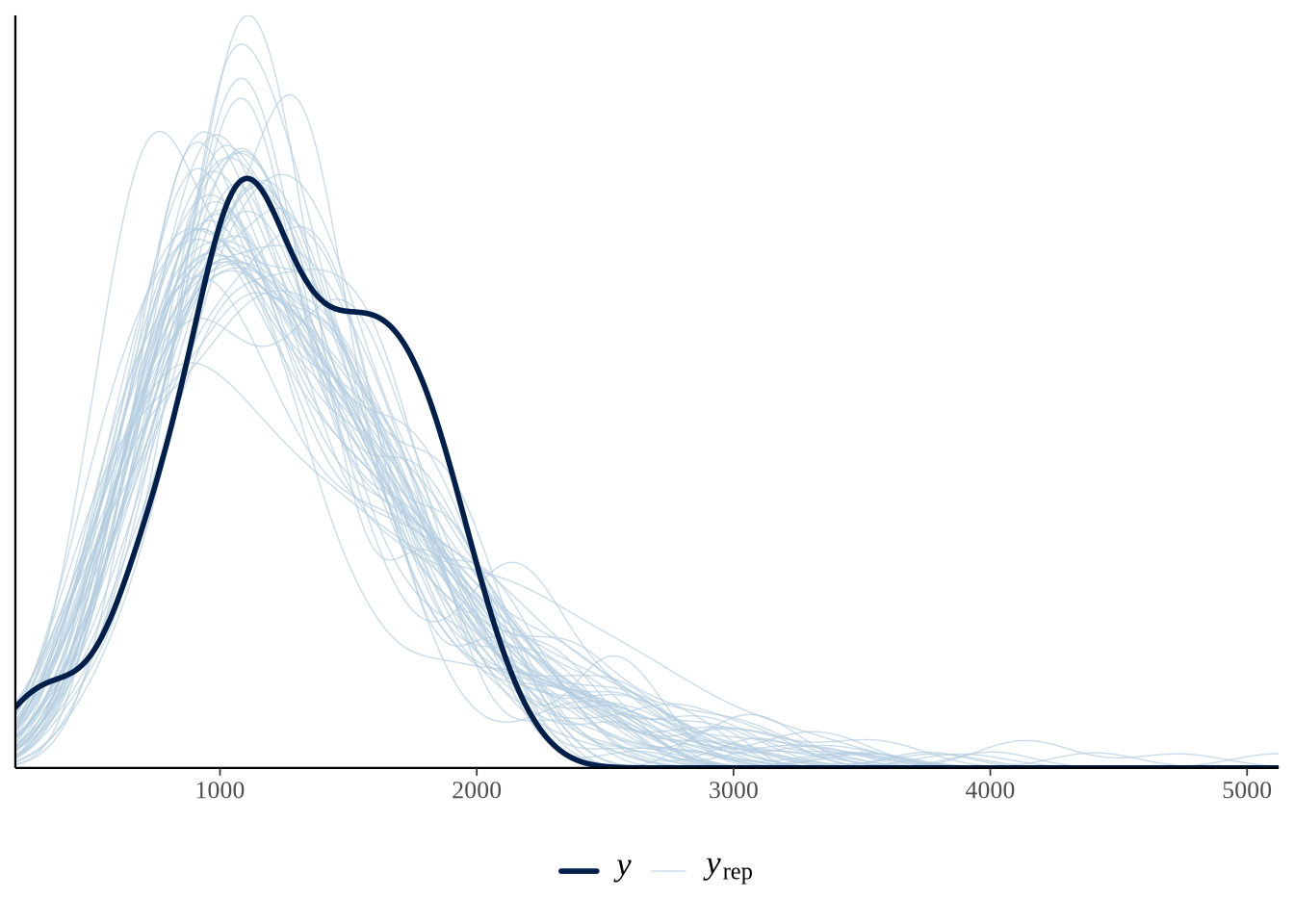
)어느 모델이 더 적절한지 판단하기 위해 Section 12.3.2 에서 소개한 사후 예측 검사(posterior predictive checks)를 수행합니다. Figure 13.14 을 보면, 분산이 큰 현실 데이터에는 음이항 모델이 훨씬 더 적합하다는 것을 알 수 있습니다.
pp_check(cause_of_death_alberta_poisson) +
theme(legend.position = "bottom")
pp_check(cause_of_death_alberta_neg_binomial) +
theme(legend.position = "bottom")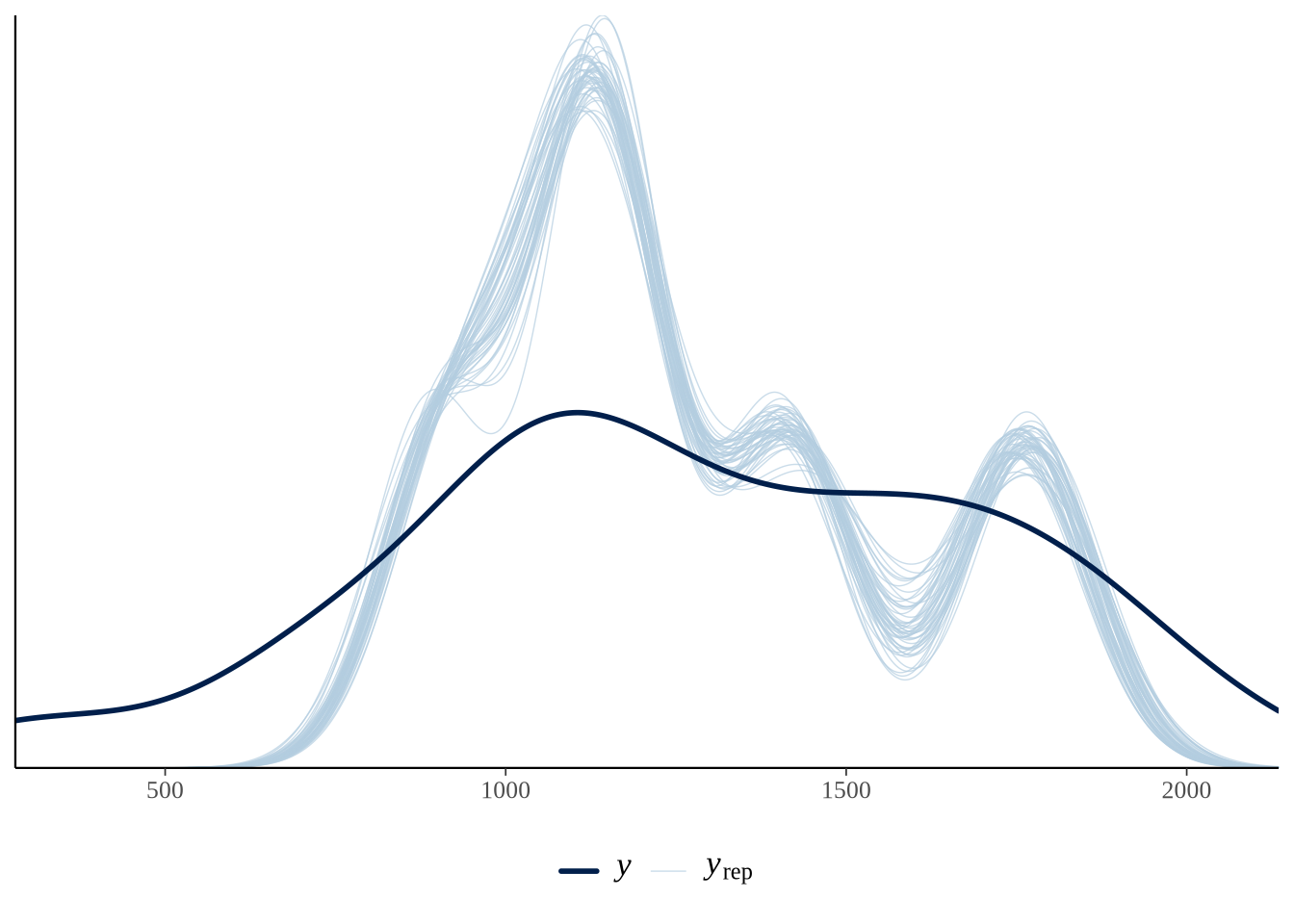
마지막으로 쐐기를 박기 위해, 우리는 리샘플링 기법인 단일 관측치 교차 검증(Leave-One-Out Cross-Validation, LOO-CV) 기법을 동원하여 두 모델의 예측력을 수치적으로 냉정하게 비교할 수 있습니다. LOO 기법은 전통적인 K-겹 교차 검증의 극한 버전으로, 데이터를 나누는 ’폴드(fold)’의 크기를 정확히 1개로 산정한 것입니다. 즉, 우리가 100행짜리 데이터셋을 쥐고 있다면, 이 LOO 기법은 데이터 1개를 숨겨두고 99개로 훈련시킨 뒤 1개를 예측하는 험난한 테스트를 무려 100번 반복하는 100-겹 교차 검증과 완벽히 동일한 원리입니다.
R에서는 며칠씩 돌아갈 수도 있는 이 무시무시한 연산을 rstanarm과 영리한 loo() 함수를 조합하여 효율적으로 근사(approximate) 처리할 수 있고, 뒤이어 loo_compare()를 호출하여 최종 승자를 가려냅니다. 점수(ELPD)는 당연히 높을수록 더 똑똑한 모델을 뜻합니다.1
교차 검증에 관한 가이드는 Chapter 14에서 확인할 수 있습니다.
poisson <- loo(cause_of_death_alberta_poisson, cores = 2)
neg_binomial <- loo(cause_of_death_alberta_neg_binomial, cores = 2)
loo_compare(poisson, neg_binomial) elpd_diff se_diff
cause_of_death_alberta_neg_binomial 0.0 0.0
cause_of_death_alberta_poisson -4536.2 1089.3출력된 비교 결과를 보면, 음이항 모델이 포아송 모델의 숨통을 끊을 정도로 압도적으로 더 데이터에 잘 적합(fit)한다는 것을 단번에 알 수 있습니다. 음이항 모델의 ELPD 점수가 비교할 수 없을 만큼 훨씬 더 크기 때문입니다.
13.5 다단계 모델링 (Multilevel Modeling)
이 강력한 통계적 스킬은 학술 분야에 따라 “계층적(hierarchical) 모델”, “혼합(mixed) 모델”, 또는 “임의 효과(random effects)”를 포함한 다양한 이름으로 화려하게 불립니다. 전공 분야의 뉘앙스에 따라 억양과 정의가 미세하게 다를 수는 있지만, 껍질을 벗겨보면 모두 동일하거나 아주 유사한 핵심 아이디어 하나를 관통하고 있습니다. 다단계 모델링이 내세우는 근본적인 통찰은 바로 “우리가 수집한 현실의 관측치들은 서로 완전히 무관한(독립적인) 남남이 아니며, 대신 어떠한 은밀한 구조나 소속(그룹)으로 묶여 있을 확률이 아주 높다”는 것입니다. 우리가 모델을 짤 때 이러한 데이터의 ’숨겨진 소속감(그룹화)’을 미리 눈치채고 모델에 똑똑하게 반영해주면, 예측력이 극적으로 향상되는 마법 같은 정보를 얻어낼 수 있습니다. 단적인 예를 하나 들어볼까요? 프로 운동선수의 연봉(수입)을 예측할 때, 그 선수가 몸담은 리그가 남성 종목인지 여성 종목인지에 따라 대우가 확연히 달라진다는 사실은 부인할 수 없습니다. 특정 선수의 개인적인 경기 성적(도루 수, 득점 등)만으로 그의 몸값을 예측하려 낑낑대는 것보다, 그 선수가 뛰고 있는 근본적인 종목 유형(그룹)이 무엇인지 아는 것은 회귀 모델이 현실적인 수입 예측선을 그리는 데 결정적인(혹은 압도적인) 도움을 줍니다.
거인의 어깨 위에 서서
피오나 스틸(Fiona Steele) 박사는 런던 정치경제대학교(LSE) 통계학과의 저명한 교수입니다. 1996년에 유서 깊은 사우샘프턴 대학교에서 통계학 박사 학위를 거머쥔 그녀는, LSE에 강사로 멋지게 데뷔한 뒤 런던 대학교와 브리스톨 대학교를 무대로 활약하다 2008년에 마침내 정교수(Full Professor) 타이틀을 따냈습니다. 이후 2013년 자신의 고향이나 다름없는 LSE로 화려하게 귀환했습니다. 그녀의 핵심 연구 무기는 단연 ’다단계 모델링(Multilevel modeling)’이며, 이 강력한 도구를 인구통계학, 교육학, 가족 심리학 및 보건의료 분야 등 인간의 복잡한 사회 현상을 해부하는 데 탁월하게 응용해 왔습니다. 일례로 그녀의 명저(Steele 등, Steele (2007))는 시간에 따라 추적한 종단(longitudinal) 데이터에 다단계 모델을 씌우는 정석을 보여주었으며, 또 다른 대표작(Steele, Vignoles, and Jenkins (2007))에서는 다단계 모델을 동원해 학교가 쏟아붓는 자원과 학생의 학업 성취도 사이에 얽힌 미묘한 함수관계를 날카롭게 분석했습니다. 이러한 눈부신 학문적 기여를 인정받아, 그녀는 2008년 통계학계의 노벨상으로 불리는 왕립통계학회(Royal Statistical Society)의 권위 있는 가이 메달(Guy Medal) 동상을 수상하는 영예를 안았습니다.
다단계 모델링의 세계로 들어가면 우리는 데이터를 묶어내는(Pooling) 방식에 따라 세 가지로 확연히 구분되는 철학적 태도를 취해야 합니다.
- 완전 풀링(Complete pooling): 데이터가 어디 출신이든 상관없이 모든 관측치를 싸그리 모아 단일한 하나의 거대한 집단에서 쏟아졌다고 퉁쳐서 우깁니다. (속이 쓰리겠지만, 사실 이것이 지금까지 우리가 순진하게 의존해 온 방식입니다.)
- 풀링 없음(No pooling): 모든 그룹을 무자비하게 쪼개서 각각 완벽히 남남으로 대우합니다. (가령 국가별 데이터를 분석할 때, 각 나라별로 회귀 모델을 아예 100개 따로 돌려버리는 극단적인 상황을 상상하면 됩니다.)
- 부분 풀링(Partial pooling): 이게 바로 다단계 모델링의 정수입니다. 전체 그룹의 기조(큰 그림)는 어느 정도 공유하면서도, 각 구성원이 속한 하위 그룹의 개별적인 특수성이 모델에 부드럽게 스며들어 영향을 미치도록 현명하게 타협합니다.
예를 들어 볼까요. 전 세계 국가들의 총생산(GDP)과 무서운 인플레이션율 사이의 상관관계를 한판 승부로 모델링한다고 가정해 봅시다. 당신이 고집스럽게 ‘완전 풀링’을 쓴다면 지구상의 모든 국가를 아무런 차별 없이 거대한 모델 하나에 욱여넣을 것입니다. 반대로 ’풀링 없음’을 선택한다면 북미, 유럽, 아프리카 등 대륙(그룹)마다 완전히 딴판인 별개의 회귀 모델을 고립시켜 실행할 것입니다. 이제 우리는 이 극단을 피하는 우아한 ’부분 풀링’ 접근법을 펼쳐 보일 때입니다.
부분 풀링을 현실의 수학 모델(코드)로 구현하는 메커니즘은 대략 두 가지 갈래로 나뉩니다.
- 각각의 그룹마다 출발선(기본 기대치)이 자유롭게 달라지도록 절편에 다양한 변동성(Varying intercepts)을 허용하기, 혹은
- 발생 원인이 집단마다 미치는 충격의 크기가 달라지도록 기울기에 다양한 변동성(Varying slopes)을 허용하기.
보다 깊이 있는 내용은 Gelman, Hill, and Vehtari (2020) , McElreath ([2015] 2020) , 또는 Johnson, Ott, and Dogucu (2022) 같은 문헌을 참고해 주시기 바랍니다.
13.5.1 시뮬레이션 예시: 복잡한 정치적 지지 현상
개인의 투표소 앞 변덕, 혹은 특정 정당(바이든)에 대한 지지 확률이란 것이 단순히 ‘본인의 성별’ පමණ만 아니라, ’자신이 현재 거주하고 있는 주(State)가 어딘지’라는 거대한 지리적·문화적 소속에 따라 근본적으로 출렁이는 현실적인 상황을 고려해 봅시다.
\[ \begin{aligned} y_i|\pi_i & \sim \mbox{Bern}(\pi_i) \\ \mbox{logit}(\pi_i) & = \beta_0 + \alpha_{g[i]}^{\mbox{gender}} + \alpha_{s[i]}^{\mbox{state}} \\ \beta_0 & \sim \mbox{Normal}(0, 2.5)\\ \alpha_{g}^{\mbox{gender}} & \sim \mbox{Normal}(0, 2.5)\mbox{ 단, }g=1, 2\\ \alpha_{s}^{\mbox{state}} & \sim \mbox{Normal}\left(0, \sigma_{\mbox{state}}^2\right)\mbox{ 단, }s=1, 2, \dots, S\\ \sigma_{\mbox{state}} & \sim \mbox{Exponential}(1) \end{aligned} \]
복잡해 보이는 수식을 하나씩 해체해 보면, \(\pi_i = \mbox{Pr}(y_i=1)\)는 그 사람(\(i\))이 궁극적으로 바이든(Biden)을 지지할 진짜 숨겨진 확률입니다. 통계 모형 안에는 딱 두 가지 성별 그룹만 세팅되어 있습니다. 이는 나중에 Chapter 16 챕터에서 우리가 다뤄야 할 실제 설문조사 데이터(CES)의 한계상 ‘남/여’ 두 성별 코드만 제공되므로 이를 반영한 것입니다. 모델 끝자락의 \(S\)는 미국 전역인 총 50개 주를 뜻합니다.
rstanarm의 stan_glmer() 함수를 사용해 이 모델을 구현할 수 있습니다. (1 | state) 항은 주(state)별 무작위 절편(random intercept)을 허용한다는 의미입니다. 즉, 주마다 바이든 지지 확률의 기준점이 달라질 수 있음을 모델에 반영합니다.
set.seed(853)
political_support <-
tibble(
state = sample(1:50, size = 1000, replace = TRUE),
gender = sample(c(1, 2), size = 1000, replace = TRUE),
noise = rnorm(n = 1000, mean = 0, sd = 10) |> round(),
supports = if_else(state + gender + noise > 50, 1, 0)
)
political_support# A tibble: 1,000 × 4
state gender noise supports
<int> <dbl> <dbl> <dbl>
1 9 1 11 0
2 26 1 3 0
3 29 2 7 0
4 17 2 13 0
5 37 2 11 0
6 29 2 9 0
7 50 2 3 1
8 20 2 3 0
9 19 1 -1 0
10 3 2 7 0
# ℹ 990 more rowsvoter_preferences <-
stan_glmer(
supports ~ gender + (1 | state),
data = political_support,
family = binomial(link = "logit"),
prior = normal(location = 0, scale = 2.5, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 2.5, autoscale = TRUE),
seed = 853
)
saveRDS(
voter_preferences,
file = "voter_preferences.rds"
)voter_preferencesstan_glmer
family: binomial [logit]
formula: supports ~ gender + (1 | state)
observations: 1000
------
Median MAD_SD
(Intercept) -4.4 0.7
gender 0.4 0.3
Error terms:
Groups Name Std.Dev.
state (Intercept) 2.5
Num. levels: state 50
------
* For help interpreting the printed output see ?print.stanreg
* For info on the priors used see ?prior_summary.stanreg실무에서 완전히 새로운 데이터를 마주하고 생소한 모델링 전투에 임할 때, 특히 당신의 핵심 임무나 미션이 ’정확한 설명(추론, Inference)’을 내놓는 것이라면, 무조건 핑곗거리를 찾아서라도 다단계 모델(Multilevel 모델)을 활용할 절호의 기회를 호시탐탐 엿보아야 합니다. 당신이 들여다보는 데이터의 이면에는, 우리가 눈치채지 못한 사이 모델에 훨씬 더 정교하고 입체적인 정보를 쏟아부어 줄 수 있는 일종의 ’그룹화(grouping, 소속성)’가 십중팔구 은밀하게 작동하고 있기 때문입니다.
다단계 모델링(stan_glmer)을 사용하다 보면 “발산 전환(divergent transitions)” 경고가 뜰 수 있습니다. 경고 횟수가 매우 적고 모든 계수의 Rhat 값이 1에 가깝다면(1.1 미만) 대체로 무시할 수 있습니다. 하지만 경고가 많거나 Rhat 값이 크다면 adapt_delta = 0.99와 같은 옵션을 사용해 샘플링 강도를 높여야 합니다(연산 시간은 길어집니다). Chapter 16 에서 이 전략이 어떻게 활용되는지 살펴보겠습니다.
다단계 모델링의 또 다른 예시로, 영국의 작가들(제인 오스틴, 샬럿 브론테, 찰스 디킨스, 윌리엄 셰익스피어)의 작품 길이를 분석해 봅니다. 소설가인 오스틴, 브론테, 디킨스는 극작가인 셰익스피어보다 평균적으로 더 긴 작품을 썼을 것으로 예상됩니다. 이때 다단계 모델을 사용하면 작가별 특성을 효과적으로 반영할 수 있습니다.
authors <- c("오스틴, 제인", "디킨스, 찰스",
"셰익스피어, 윌리엄", "브론테, 샬럿")
# 중복 및 원치 않는 문자에 대한 문서 값
dont_get_shakespeare <-
c(2270, 4774, 5137, 9077, 10606, 12578, 22791, 23041, 23042, 23043,
23044, 23045, 23046, 28334, 45128, 47518, 47715, 47960, 49007,
49008, 49297, 50095, 50559)
dont_get_bronte <- c(31100, 42078)
dont_get_dickens <-
c(25852, 25853, 25854, 30368, 32241, 35536, 37121, 40723, 42232, 43111,
43207, 46675, 47529, 47530, 47531, 47534, 47535, 49927, 50334)
books <-
gutenberg_works(
author %in% authors,
!gutenberg_id %in%
c(dont_get_shakespeare, dont_get_bronte, dont_get_dickens)
) |>
gutenberg_download(
meta_fields = c("title", "author"),
mirror = "https://gutenberg.pglaf.org/"
)
write_csv(books, "books-austen_bronte_dickens_shakespeare.csv")books <- read_csv(
"books-austen_bronte_dickens_shakespeare.csv",
col_types = cols(
gutenberg_id = col_integer(),
text = col_character(),
title = col_character(),
author = col_character()
)
)lines_by_author_work <-
books |>
summarise(number_of_lines = n(),
.by = c(author, title))
lines_by_author_work# A tibble: 125 × 3
author title number_of_lines
<chr> <chr> <int>
1 Austen, Jane Emma 16488
2 Austen, Jane Lady Susan 2525
3 Austen, Jane Love and Freindship [sic] 3401
4 Austen, Jane Mansfield Park 15670
5 Austen, Jane Northanger Abbey 7991
6 Austen, Jane Persuasion 8353
7 Austen, Jane Pride and Prejudice 14199
8 Austen, Jane Sense and Sensibility 12673
9 Brontë, Charlotte Jane Eyre: An Autobiography 21001
10 Brontë, Charlotte Shirley 25520
# ℹ 115 more rowsauthor_lines_rstanarm <-
stan_glm(
number_of_lines ~ author,
data = lines_by_author_work,
family = neg_binomial_2(link = "log"),
prior = normal(location = 0, scale = 3, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 3, autoscale = TRUE),
seed = 853
)
saveRDS(
author_lines_rstanarm,
file = "author_lines_rstanarm.rds"
)
author_lines_rstanarm_multilevel <-
stan_glmer(
number_of_lines ~ (1 | author),
data = lines_by_author_work,
family = neg_binomial_2(link = "log"),
prior = normal(location = 0, scale = 3, autoscale = TRUE),
prior_intercept = normal(location = 0, scale = 3, autoscale = TRUE),
seed = 853
)
saveRDS(
author_lines_rstanarm_multilevel,
file = "author_lines_rstanarm_multilevel.rds"
)modelsummary(
list(
"일반 음이항" = author_lines_rstanarm,
"다단계(작가별 혼합) 음이항" = author_lines_rstanarm_multilevel
)
)Table 13.9 표처럼 다단계 모델의 결과는 다소 복잡할 수 있습니다. 따라서 이를 효과적으로 전달하기 위해 그래프를 활용하는 것이 좋습니다(Chapter 16 에서 자세히 다룹니다).
Figure 13.15 은 tidybayes 패키지의 spread_draws() 함수를 사용하여 작가별 문장 길이에 대한 사후 분포를 시각화한 것입니다.
author_lines_rstanarm_multilevel |>
spread_draws(`(Intercept)`, b[, group]) |>
mutate(condition_mean = `(Intercept)` + b) |>
ggplot(aes(y = group, x = condition_mean)) +
stat_halfeye() +
theme_minimal() +
labs(x = "예상되는 평균 문장 수 (로그 스케일)", y = "저자(그룹)")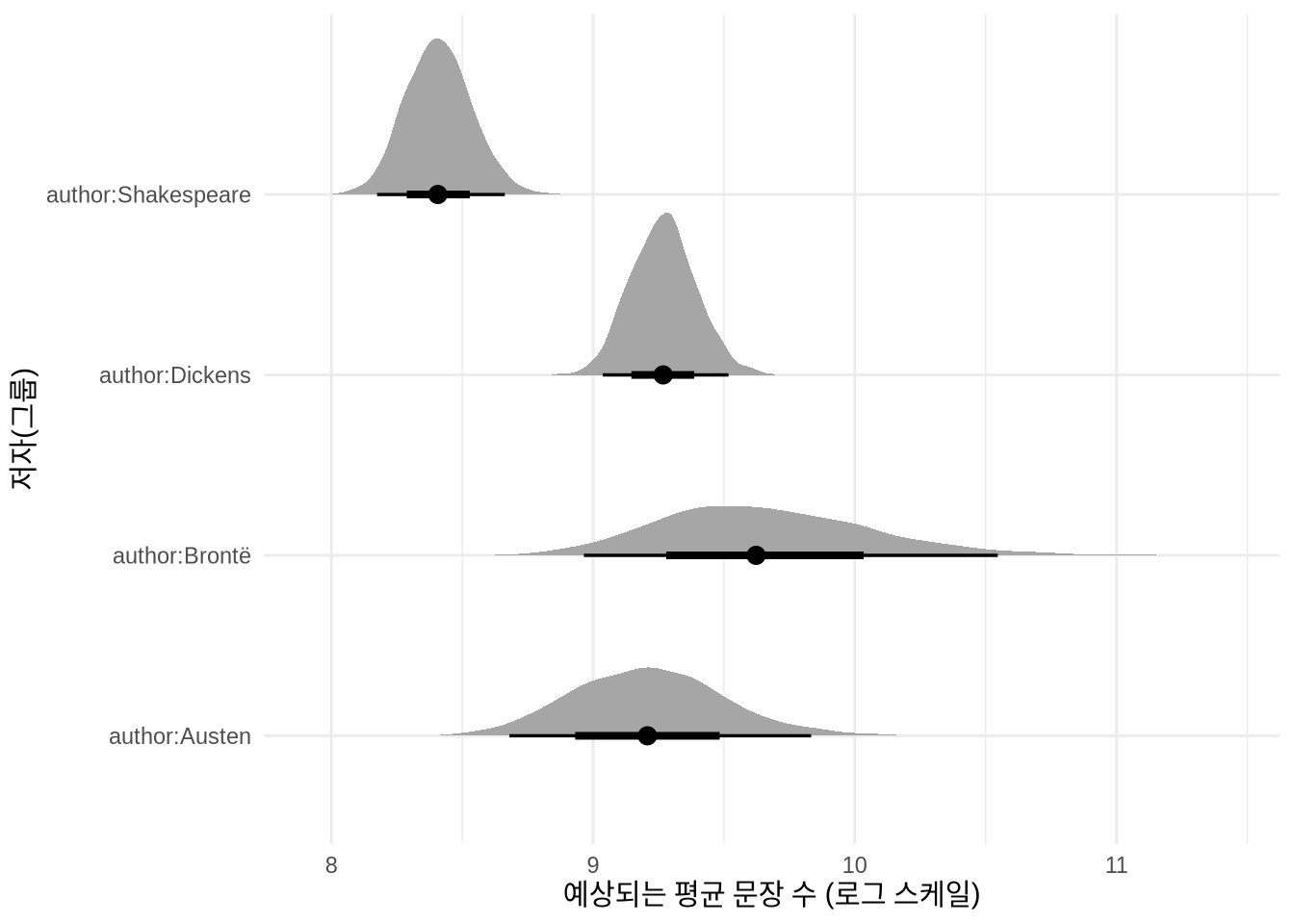
이 섬세한 다단계 그래프 분석을 통해, 우리는 세 명의 소설가 중에서도 유독 브론테(Bronte) 자매가 경쟁자들을 제치고 독보적으로 가장 호흡이 긴 두꺼운 책을 썼다는 뚜렷한 예측 결과를 확신할 수 있습니다. 반면 희곡을 주로 지은 셰익스피어는 우리의 짐작 한 치의 오차도 없이 네 명 중 가장 분량이 적은 얇은 작품들을 끊임없이 쏟아냈음을 한눈에 파악할 수 있습니다.
13.6 요약 및 결론
이 장에서는 일반화 선형 모델(GLM)과 다단계 모델링의 기초를 살펴보았습니다. Chapter 12 에서 다룬 기초를 바탕으로 더 복잡한 데이터를 다루는 방법을 배웠습니다. 더 깊은 내용은 Chapter 18 에서 추천하는 서적들을 참고하시기 바랍니다.
우리는 Chapter 12 과 Chapter 13 에서 다양한 베이즈 통계 모델링 기법을 익혔습니다. 물론, 세상의 모든 모델에 적용될 수 있는 완벽하고 절대적인 단일 교본을 이 얇은 책 안에 전부 쓸어 담지는 못했습니다.
사실 통계 분석에서 “이 정도면 충분하다”는 방어선을 명확하게 긋는 것은 불가능에 가깝습니다. 왜냐하면 모든 모델의 완성도는 당신이 처한 현실의 한계와 맥락(Context)에 철저히 종속되기 때문입니다. 그러나 최소한 학술 논문이나 보고서를 작성할 때, 앞선 장들에서 배운 개념들을 총동원하여 아래의 체크리스트를 철저히 지킨다면 심사관의 가혹한 공격을 막아낼 훌륭한 방패가 될 것입니다.
- 모델 수식 및 텍스트: 논문의 방법론(Model) 섹션 최상단에는 내가 세운 모델의 수학적 방정식을 명확하게 적고, 그 수식의 각 항을 친절하게 풀어서 설명하는 최소 두세 문단의 텍스트를 반드시 포함하십시오.
- 선택의 정당화: 왜 이 모델(예: 포아송 대신 음이항)을 굳이 선택했는지 설득력 있게 방어하고, 도입을 고려했다가 폐기한 대안 모델들의 단점을 간략하게 덧붙여 주십시오.
- 적합 및 진단: 실제 모델이 어떤 소프트웨어(예:
rstanarm패키지의stan_glmer())로 피팅되었는지 한 줄로 명시하십시오. 길고 복잡한 모델의 건강 진단서(MCMC 트레이스 플롯, Rhat 진단 플롯, 사후 예측 분포 및 사전 예측 검사 결과 등)는 본문에 우겨넣지 말고 교차 참조가 깔끔하게 된 ’부록(Appendix)’으로 우아하게 빼놓으십시오.
결과(Results) 섹션을 작성할 때는, 절대 터미널의 날것 그대로의 텍스트를 복사해서 붙여넣지 마십시오. 대신 modelsummary 패키지로 공들여 깎아낸 아름다운 비교 추정치 표를 중앙에 배치하고, marginaleffects 함수들의 든든한 지원을 받아 그 복잡한 한계 효과(역자 주: 변수 1단위 변화 효과)들을 독자들이 쉽게 이해할 수 있도록 글로 번역해 주십시오. 특히 다단계 모델링이라는 비싼 무기를 꺼내 들었다면, 딱딱한 표만 내밀지 말고 tidybayes 패키지의 도움을 받아 찬란한 시각적 결과 그래픽을 본문에 꼭 포함시켜야 합니다. * 워크플로: 무거운 모델 연산은 별도의 R 스크립트에서 수행하십시오. 실행 전 데이터 클래스와 관측치 수를 확인하는 테스트를 거치고, 완료 후에는 계수 값이 상식적인지 검증해야 합니다. 결과는 saveRDS()로 저장하고 Quarto에서는 readRDS()로 불러와 사용하십시오.
13.7 챕터 연습 문제
📝 심화 연습
- (분석 계획서) 다음과 같은 다소 어두운 리서치 시나리오를 머릿속으로 고려해 보십시오. 어떤 연구자가 호주 시드니에서 발생하는 암 환자 사망자 규모에 깊은 학문적 관심을 가지고 있습니다. 그는 이를 파헤치기 위해, 시드니에서 가장 규모가 큰 5개 대형 병원들을 돌아다니며 지난 20년간의 발생 데이터를 집요하게 수집했습니다. 당신이 이 연구자라면, 컴퓨터에 입력될 원시 데이터셋(Dataframe)이 어떤 행과 열을 가지고 있을지 스케치해 보십시오. 그런 다음 숨김없이 모든 관측 데이터 포인트들을 하나의 캔버스에 화려하게 뿌려 보여주기 위해 당신이 그릴 수 있는 훌륭한 시각화 차트는 어떤 모습일지 빈 종이에 끄적여 스케치해 보십시오.
- (데이터 시뮬레이션) 앞서 묘사된 1번의 시나리오를 더 깊이 고려하고, 무에서 유를 창조하듯 R을 켜서 그 상황을 시뮬레이션으로 완벽히 재현(Mock) 하십시오. 결과 변수인 ’원인별 연간 사망자 수’와 이를 설명해 줄 몇 가지 그럴듯한 예측 변수(성별, 연령대 등)를 모두 데이터 프레임 안에 포함시켜야 합니다. 시뮬레이션으로 방금 창조해 낸 가상의 데이터가 제대로 만들어졌는지 검증하기 위해,
stopifnot()혹은testthat을 활용하여 최소 10가지 이상의 데이터 정합성 테스트 코드 묶음을 꼼꼼하게 작성하여 포함시키십시오. - (데이터 수집 출처) 당신이 호주라는 국가에서 실제로 그러한 의료사망 통계 데이터셋을 구하려 한다면, 어떠한 공공기관, 단체, 웹사이트 등 가능한 데이터 출처의 이름을 구체적으로 설명해 보십시오.
- (탐색적 데이터 분석)
ggplot2패키지의 마법을 빌려, 앞선 1번 문항에서 연필로 끄적였던 당신의 스케치 그래프를 실제 화려한 코드로 구현해 내십시오. 그런 다음, 이 데이터를 학습시킬 수 있는 적절한 베이즈 모델 하나를rstanarm패키지를 사용하여 당당히 구축해 보십시오. - (전문적인 소통) 당신이 1번부터 4번까지 어떤 위대한 작업들을 해냈는지, 마치 당신의 상사나 깐깐한 클라이언트에게 보고서를 올리듯 전문적인 어투로 최소 두 문단 이상의 글을 매끄럽게 작성하십시오.
❓ 퀴즈
- 당신이 모델을 설계할 때 무조건 로지스틱 회귀(Logistic Regression)를 고려해야만 하는 운명적인 상황은 다음 중 언제입니까? (택 1)
- 결과 변수가 연속적으로 소수점까지 이어지는 값일 때.
- 결과 변수가 ‘성공/실패’ 등 완벽히 이분법적인(이진, Binary) 값일 때.
- 결과 변수가 개수를 세는(Count) 값일 때.
- 2020년 미국 대통령 선거전에서 국민들의 “투표 의향”이 그 국민의 각자 “개인 소득” 수준에 따라 과연 어떻게 흔들리는지 파헤치는 연구를 진행하려 합니다. 이런 강력한 상관관계를 밝혀내기 위해 당신은 아주 영리하게 로지스틱 회귀 모델의 뼈대를 엉성하게 세우고 있습니다. 당신이 설계한 이 연구 모델에서 예측해야 할 “결과(종속 변수)”로 삼을 만한 가장 타당한 변수는 다음 중 무엇일까요? (택 1)
- 응답자가 미국 시민권자인가? (예/아니오)
- 응답자의 개인 수입은 얼마인가? (고소득/저소득)
- 응답자가 이번 선거에서 바이든에게 투표할 의향이 있는가? (예/아니오)
- 응답자가 과거 2016년 선거 때 누구에게 투표했었나? (트럼프/클린턴)
- 방금 전 2번 문제의 미국 대선 2020 연구(투표 의향 vs 개인 소득)를 다시 들여다봅시다. 이 짜릿한 연구 모델에 훌륭한 재료로 투입할 만한 “예측(독립) 변수”에 해당하는 것은 다음 중 무엇일까요? (모두 고르시오)
- 응답자의 인종 카테고리 (백인/비백인)
- 응답자의 혼인 여부 (기혼/미혼)
- 응답자가 이번 선거에서 바이든에게 투표할 의향이 있는가? (예/아니오) # 주의: 번호매김 원본 그대로 유지 (c 누락, d 존재)
- 신비로운 포아송 분포도(Poisson Distribution)에서, 분포의 평균(Mean) 값은 언제나 다른 어떤 통계치와 수학적으로 완벽하게 동일합니까?
- 중앙값 (Median).
- 표준 편차 (Standard Deviation).
- 분산 (Variance).
- 이 장 중간에서 실행했던 미국 대선 유권자 정치 지지(
rstanarm사용) 예시 코드를 완전히 똑같이 다시 수행하되, 설명 변수를 딱 한 개 이상 추가하여 모델의 덩치를 더 키워보십시오. 당신이 연구자로서 고심 끝에 새로 추가한 변수는 무엇이었으며, 그 새로운 무기가 추가된 후 모델의 예측 성능 평가지표가 얼마나 더 우월하게 향상되었습니까? - 파라미터 \(\lambda = 75\)라는 묵직한 조건을 만족할 때, 과연 포아송 분포 곡선이 종이 위에 어떻게 그려질지 밀도 그래프(Density plot)를 완벽하게 플로팅해 보십시오.
- 전설적인 통계 구루들인 겔만과 동료들(Gelman, Hill, and Vehtari (2020))이 그들의 저서에서 가르치기를, 포아송 회귀 모델의 수식 안에서 은근슬쩍 등장하는 “오프셋(Offset)”이란 과연 무엇입니까?
- 영국의 고전 문학 제인 에어의 텍스트를 파헤쳤던 알파벳 수 세기 예시를 그대로 따라 하되, 이번에는 조금 비틀어서 대소문자를 포함한 “A/a” 만을 집요하게 겨냥해 보십시오.
- 20세기 영국의 천재적인 통계학자 조지 박스(George Box)는 후세에 길이 남을 엄청난 명언을 남겼습니다. “모든 모델은 틀렸으므로, 과학자는 모델이 중요하게 틀린 부분에만 날카롭게 주의해야 한다. 호랑이가 풀밭에서 으르렁거리며 돌아다니는데 고작 쥐구멍에서 튀어나오는 쥐를 걱정하느라 시간을 낭비하는 것은 부적절하다.”(Box 1976, 792). 이 심오하고 도발적인 인용구의 숨겨진 의미를 다양한 예시와 당신 논리를 섞어 심도 있게 논의해 보십시오.
👥 수업 활동 (팀플레이)
- (토론) 사람들은 거친 축구를 선호할까요, 아니면 차가운 얼음판 위의 하키를 선호할까요? 이 스포츠 선호가 그 사람의 연령, 성별, 살고 있는 지역(위치)과 과연 어떤 미묘한 끈적이는 인과관계로 얽혀 있는지 파헤쳐 내기 위해 거대한 다단계 베이즈 회귀 모델의 설계도를 허공에 그려봅시다. 열띤 시뮬레이션 토론에 앞서 아래 사항들을 조율하고 명확히 문서로 기록하십시오:
- 연구의 관심 결과 변수와 사용할 확률 분포(우도 함수).
- 수집한 결과를 설명해 줄 강력한 회귀 모델 방정식.
- 모델에서 쫓아가 추정해야 할 매개변수들에게 입혀줄 그럴듯한 사전 분포(Priors).
- (코딩 챌린지) Chapter 12 장에서 다룬 펭귄 데이터(
palmerpenguins)를 다시 활용해 보겠습니다. 부리 길이와 깊이 사이의 관계를 아델리, 턱끈, 젠투 종별로 탐구해 보십시오. 먼저 극단적인 ‘풀링 없음’ 기법을 이용해, 세 종류의 펭귄 각각에 대해 피가 튀기듯 3개의 완전 별개 모델을 추정하는 구역질 나는 노가다부터 시작해 보십시오. 그런 다음, 이들을 묶어 무식하게 ‘완전 풀링’ 단일 모델 한 개를 피팅해 보십시오. 모든 고통을 겪은 마지막으로, 진정한 구원인 ‘부분 풀링’ 엔진을 활성화한 다단계 혼합 회귀 모델을 우아하게 추정해 보십시오. - GitHub 스타터 폴더 저장소를 포크(Fork)하여 깨끗한 새 리포지토리를 예쁘게 파십시오. 수업 담당자 공유 Google Docs에 자랑스럽게 자신의 GitHub 리포지토리 링크를 새겨 넣으십시오.
- 우리는 학력수준, 나이대, 생물학적 성별, 그리고 그들이 발붙인 미국 각 50개 주의 위치를 기반으로 도대체 왜 시민들이 굳이 민주당이나 혹은 공화당을 결사적으로 지지하는지 무시무시한 통찰을 갈망하고 있습니다. 분석을 위한 가짜 상황(데이터)을 종이에 스케치한 뒤 R에서 마음껏 시뮬레이션해 보십시오.
- 뉴욕 타임스의 천재적인 선거 데이터 분석가들(Cohn (2016))이 수집한 기적 같은 여론조사 자료를 UpShot 하우스 저장소에서 무자비하게 긁어오십시오. 누구도 손대지 않은 날것 그대로의 편집되지 않은 데이터를 로컬에 고이 저장하고, 이를 먼지 하나 없는 분석용 데이터셋으로 가공해 내십시오(친절하게도 아래에 가공을 시작할 만한 마법 기호 코드를 몇 줄 드립니다). 각 독립적인 예측 변수의 흥미로운 생김새를 통계 그래프들로 그려 데이터 섹션에 붙이고, 변수끼리 어떻게 물고 물리며 얽히는지 보여주는 교차 산점도 그래프 또한 예술적으로 찍어내십시오.
- 사람들의 투표(vote 변수인 “vt_pres_2”) 결과를 오직 “성별(gender)”, “교육수준(educ)”, “나이(age)”라는 3가지의 차가운 수식으로 철저하게 설명하는 첫 번째 기준 모델(베이스라인 모델)을 빚어내십시오. 그런 다음 욕심을 한 단계 더 부려 각 개인의 “소속 거주 주(state)” 변동성 효과까지 짬뽕시킨 궁극의 두 번째 다단계 모델을 거침없이 밀어붙여 구축해 보십시오. 두 모델의 철학을 보고서의 방법론 섹션에 유려하게 묘사하고, 피팅 결과를 도출하여 결과 섹션에 멋지게 이식하십시오(다시 한번, 여러분이 출발선에서 쓰러지는 것을 방어하기 위해 밑에 일부 구급약 코드를 숨겨두었습니다).
vote_data <-
read_csv(
"https://raw.githubusercontent.com/TheUpshot/2016-upshot-siena-polls/master/upshot-siena-polls.csv"
)
cleaned_vote_data <-
vote_data |>
select(vt_pres_2, gender, educ, age, state) |>
rename(vote = vt_pres_2) |>
mutate(
gender = factor(gender),
educ = factor(educ),
state = factor(state),
age = as.integer(age)
) |>
mutate(
vote =
case_when(
vote == "Donald Trump, the Republican" ~ "0",
vote == "Hillary Clinton, the Democrat" ~ "1",
TRUE ~ vote
)
) |>
filter(vote %in% c("0", "1")) |>
mutate(vote = as.integer(vote))vote_model <-
stan_glm(
formula = vote ~ age + educ,
data = cleaned_vote_data,
family = gaussian(),
prior = normal(location = 0, scale = 2.5),
prior_intercept = normal(location = 0, scale = 2.5),
prior_aux = exponential(rate = 1),
seed = 853
)🔬 실전 프로젝트 과제
다음 중 끌리는 대작 논문 하나를 지목하여 깊이 파고들어 보십시오. Maher (1982)(영국 축구의 묘한 결과 승부 예측), Smith (2002)(조르노의 정치적 과분산 모델링 걸작), 또는 Cohn (2016)(미국 타임스의 날 선 선거 예측술). 거인들의 엄청난 데이터 분석 모델 방정식을 완전히 똑같이는 아니더라도, 훨씬 가지치기된 소박하고 가벼운 경량화 해적판 버전을 손을 부들부들 떨며 직접 코딩하여 설계해 보십시오.
그러기 위해서는 가장 최근 연도의 따끈따끈한 관련 데이터를 미친 듯이 스크래핑하거나 구글링해 긁어모은 다음, 당신의 그 훌륭한 경량화 모델을 피팅(추정)해야 합니다. 이 과정에서 결과 데이터를 로지스틱, 포아송, 혹은 극혐스런 음이항 회귀 중 대체 어떤 칼을 집어 들어 썰어내는 것이 가장 통계적으로 명분 있고 학문적으로 우월한 선택일지 뜨겁게 논쟁해 보십시오.
보고서는 반드시 Quarto 포맷으로 작성되어야 하며, 그 어떤 심사위원도 흠잡지 못할 적절한 헤더 제목, 논문 저자명, 작성 날짜, 당신의 피와 땀이 어린 코드가 널브러져 있는 GitHub 리포지토리 링크, 논리적인 섹션 구분, 그리고 적법한 인용구 및 참고문헌(Citation) 들을 완벽하게 세팅하십시오. 무엇보다, 당신이 사용한 수학적인 모델을 그 수식 하나하나가 빠짐없이 철저하고 우아하게 지정되도록 방어벽을 쌓으십시오.
📚 추천 관련 논문
모델링 훈련이 무르익은 지금, Appendix F에서 제공하는 Spadina 논문을 살펴보며 실제 데이터 분석 과정을 익히는 것을 추천합니다.
참고로,
loo()함수는 진짜로 모델을 100번씩 재적합하는 무식한 짓(LOO-CV 실연산)을 하지는 않습니다. 그렇게 하면 계산 비용 측면에서 파산할 것이 뻔하기 때문입니다. 대신 ’파레토 평활 중요도 샘플링(PSIS)’이라는 아주 세련된 수학적 근사법을 사용하여 예상 로그 점별 예측 밀도(Expected Log Pointwise Predictive Density, ELPD)라는 훌륭한 점수를 단숨에 계산해 줍니다. 더 깊은 원리가 궁금하다면rstanarm패키지의 공식 비네트(vignettes)를 살펴보십시오.↩︎