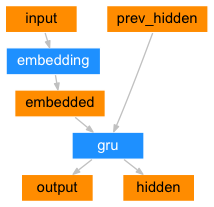
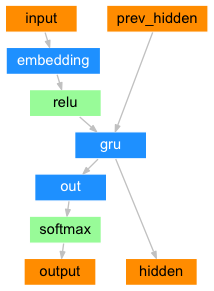
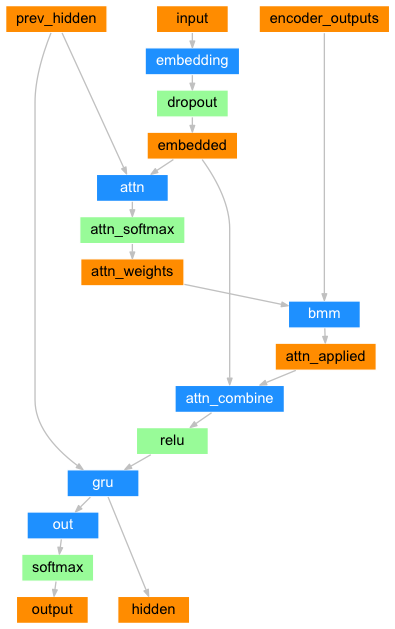
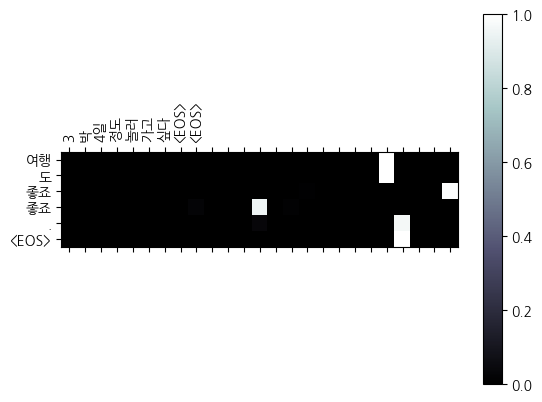
class AttentionDecoder(nn.Module):
def __init__(self, num_vocabs, hidden_size, embedding_dim, dropout_p=0.1, max_length=MAX_LENGTH):
super(AttentionDecoder, self).__init__()
self.hidden_size = hidden_size
self.max_length = max_length
self.embedding = nn.Embedding(num_vocabs, embedding_dim)
self.attn = nn.Linear(hidden_size + embedding_dim , max_length)
self.attn_combine = nn.Linear(hidden_size + embedding_dim, hidden_size)
self.dropout = nn.Dropout(dropout_p)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, num_vocabs)
def forward(self, x, hidden, encoder_outputs):
# x: (1, 1) 1개의 토큰
embedded = self.embedding(x).view(1, 1, -1)
# embedded: (1, 1, 1)
embedded = self.dropout(embedded)
# embedded[0]: (1, embedding_dim)
# hidden[0]: (1, hidden_size)
attn_in = torch.cat((embedded[0], hidden[0]), 1)
# attn_in: (1, embedding_dim + hidden_size)
attn = self.attn(attn_in)
# attn: (1, max_length)
attn_weights = F.softmax(attn)
# attn_weights: (1, max_length)
# (1, 1, max_length), (1, max_length, hidden_size)
attn_applied = torch.bmm(attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))
# attn_applied: (1, 1, hidden_size)
# embedded[0]: (1, embedding_dim)
# attn_applied[0]: (1, hidden_size)
output = torch.cat((embedded[0], attn_applied[0]), 1)
# output: (1, embedding_dim + hidden_size)
output = self.attn_combine(output)
# output: (1, hidden_size)
output = output.unsqueeze(0)
# output: (1, 1, hidden_size)
output = F.relu(output)
# output: (1, 1, hidden_size)
# output: (1, 1, hidden_size)
# hidden: (1, 1, hidden_size)
output, hidden = self.gru(output, hidden)
# output: (1, 1, hidden_size)
# hidden: (1, 1, hidden_size)
# output[0]: (1, hidden_size)
output = self.out(output[0])
# output: (1, number of vocabs)
# output[0]: (number of vocabs)
# hidden: (1, 1, hidden_size)
# attn_weights: (1, max_length)
return output[0], hidden, attn_weights
def initHidden(self, device):
# (Bidirectional(1) x number of layers(1), batch_size, hidden_size(32))
return torch.zeros(1, 1, self.hidden_size, device=device)