import pandas as pd
import numpy as np
pd.set_option("display.max_rows", 20)9장: Pandas를 사용한 고급 데이터 논쟁

학습 내용
학습 목표
Series.str속성의 메소드에 액세스하여 Pandas에서 문자열을 조작합니다.- 문자열을 랭글링하기 위해 Pandas에서 정규식을 사용하는 방법을 이해합니다.
Timestamp,Timedelta,Period,DateOffset과 같은 Pandas의 날짜/시간 개체를 구별합니다.pd.Timestamp(),pd.Period(),pd.date_range(),pd.기간_범위()와 같은 함수를 사용하여 이러한 날짜/시간 개체를 만듭니다.- 부분 문자열 인덱싱을 사용하여 날짜/시간 인덱스를 인덱싱합니다.
- 날짜 시간을 구성 부분(예:
연도,주중,초등)으로 분할하는 것과 같은 기본 날짜 시간 작업을 수행하고, 오프셋을 적용하고, 시간대를 변경하고,.resample()을 사용하여 리샘플링합니다. .plot속성에 액세스하거나pandas.plotting에서 함수를 가져와 Pandas에서 기본 플롯을 만듭니다.
1. 문자열 작업
텍스트 데이터로 작업하는 것은 데이터 과학에서 일반적입니다. 운 좋게도 Pandas Series 및 Index 개체에는 여기서 살펴볼 일련의 문자열 처리 방법이 장착되어 있습니다.
문자열 dtype
문자열 데이터는 혼합 데이터 또는 알 수 없는 크기의 데이터를 표현하기 위한 일반 dtype인 ‘object’ dtype을 사용하여 팬더에 표시됩니다. 전용 dtype을 갖는 것이 더 나을 것이며 Pandas는 방금 StringDtype을 도입했습니다. 그러나 Pandas는 string dtype을 계속 테스트하고 개선하기 위해 object는 문자열의 기본 dtype으로 남아 있습니다. Pandas 문서는 여기에서 ’StringDtype’에 대해 자세히 알아볼 수 있습니다.
문자열 메서드
우리는 NumPy 및 Pandas와 같은 라이브러리가 속도와 유용성을 높이기 위해 작업을 벡터화하는 방법을 확인했습니다.
x = np.array([1, 2, 3, 4, 5]) # noqa: F811
x * 2array([ 2, 4, 6, 8, 10])그러나 문자열 배열의 경우에는 그렇지 않습니다.
x = np.array(["Tom", "Mike", "Tiffany", "Joel", "Varada"]) # noqa: F811
x.upper()--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-3-acaefb05bf10> in <module> 1 x = np.array(['Tom', 'Mike', 'Tiffany', 'Joel', 'Varada']) ----> 2 x.upper() AttributeError: 'numpy.ndarray' object has no attribute 'upper'
대신 다음과 같은 루프를 사용하여 한 번에 하나씩 각 문자열 개체에 대해 작업을 수행해야 합니다.
[name.upper() for name in x]['TOM', 'MIKE', 'TIFFANY', 'JOEL', 'VARADA']그러나 배열에 누락된 값이 포함되어 있으면 이 방법도 실패합니다.
x = np.array(["Tom", "Mike", None, "Tiffany", "Joel", "Varada"]) # noqa: F811
[name.upper() for name in x]--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-5-b687bbdcc894> in <module> 1 x = np.array(['Tom', 'Mike', None, 'Tiffany', 'Joel', 'Varada']) ----> 2 [name.upper() for name in x] <ipython-input-5-b687bbdcc894> in <listcomp>(.0) 1 x = np.array(['Tom', 'Mike', None, 'Tiffany', 'Joel', 'Varada']) ----> 2 [name.upper() for name in x] AttributeError: 'NoneType' object has no attribute 'upper'
Pandas는 문자열 메서드를 사용하여 이러한 문제(벡터화 및 누락된 값)를 모두 해결합니다. 문자열 메서드는 Pandas Series 및 Index 개체의 .str 속성을 통해 액세스할 수 있습니다. 거의 모든 내장 문자열 연산(.upper(), .lower(), .split() 등)을 사용할 수 있습니다.
s = pd.Series(x) # noqa: F811
s0 Tom
1 Mike
2 None
3 Tiffany
4 Joel
5 Varada
dtype: objects.str.upper()0 TOM
1 MIKE
2 None
3 TIFFANY
4 JOEL
5 VARADA
dtype: objects.str.split("ff", expand=True)| 0 | 1 | |
|---|---|---|
| 0 | Tom | None |
| 1 | Mike | None |
| 2 | None | None |
| 3 | Ti | any |
| 4 | Joel | None |
| 5 | Varada | None |
s.str.len()0 3.0
1 4.0
2 NaN
3 7.0
4 4.0
5 6.0
dtype: float64Index 객체(예: 인덱스 또는 열 레이블)에 대해서도 작업을 수행할 수 있습니다.
df = pd.DataFrame( # noqa: F811
np.random.rand(5, 3), # noqa: F405, F811, F821
columns=["Measured Feature", "recorded feature", "PredictedFeature"], # noqa: F811
index=[f"ROW{_}" for _ in range(5)], # noqa: F811
)
df| Measured Feature | recorded feature | PredictedFeature | |
|---|---|---|---|
| ROW0 | 0.200112 | 0.790722 | 0.655438 |
| ROW1 | 0.866312 | 0.941067 | 0.179676 |
| ROW2 | 0.478350 | 0.844712 | 0.983463 |
| ROW3 | 0.028143 | 0.120413 | 0.396831 |
| ROW4 | 0.941455 | 0.526084 | 0.731475 |
type(df.columns)pandas.core.indexes.base.Index다음을 통해 해당 라벨을 정리해 보겠습니다. 1. “feature” 및 “feature”라는 단어 삭제 2. “ROW”를 소문자로 만들고 숫자와 문자 사이에 밑줄을 추가합니다.
df.columns = df.columns.str.capitalize().str.replace("feature", "").str.strip()df.index = df.index.str.lower().str.replace("w", "w_")df| Measured | Recorded | Predicted | |
|---|---|---|---|
| row_0 | 0.200112 | 0.790722 | 0.655438 |
| row_1 | 0.866312 | 0.941067 | 0.179676 |
| row_2 | 0.478350 | 0.844712 | 0.983463 |
| row_3 | 0.028143 | 0.120413 | 0.396831 |
| row_4 | 0.941455 | 0.526084 | 0.731475 |
잘됐네요! Pandas에서는 사용할 수 있는 문자열 작업이 너무 많습니다. 다음은 문서에서 가져온 Pandas에서 사용할 수 있는 모든 문자열 메서드의 전체 리스트입니다.
| 방법 | 설명 |
|---|---|
Series.str.cat |
문자열 연결 |
Series.str.split |
구분 기호로 문자열 분할 |
Series.str.rsplit |
문자열 끝에서 구분 기호로 문자열을 분할합니다. |
Series.str.get |
각 요소에 대한 색인(i번째 요소 검색) |
Series.str.join |
전달된 구분 기호를 사용하여 시리즈의 각 요소에 있는 문자열을 결합합니다 |
Series.str.get_dummies |
더미 변수의 DataFrame을 반환하는 구분 기호로 문자열을 분할합니다. |
Series.str.contains |
각 문자열에 패턴/정규식이 포함되어 있으면 불리언(Boolean) 배열을 반환합니다. |
Series.str.replace |
패턴/정규식/문자열 발생을 다른 문자열 또는 해당 발생에 따른 콜러블의 반환 값으로 바꾸기 |
시리즈.str.반복 |
중복된 값(s.str.repeat(3)은 x * 3과 동일) |
Series.str.pad |
“문자열의 왼쪽, 오른쪽 또는 양쪽에 공백 추가” |
Series.str.center |
str.center와 동일 |
Series.str.ljust |
str.ljust와 동일 |
Series.str.rjust |
str.rjust와 동일 |
Series.str.zfill |
str.zfill과 동일 |
Series.str.wrap |
긴 문자열을 주어진 너비보다 짧은 길이의 줄로 분할 |
Series.str.slice |
시리즈의 각 문자열을 슬라이스 |
Series.str.slice_replace |
각 문자열의 슬라이스를 전달된 값으로 바꾸기 |
Series.str.count |
패턴 발생 횟수 |
Series.str.startswith |
각 요소에 대해 str.startswith(pat)와 동일 |
Series.str.endswith |
각 요소에 대해 str.endswith(pat)와 동일 |
Series.str.findall |
각 문자열에 대한 모든 패턴/정규식 발생 리스트 계산 |
Series.str.match |
“각 요소에 대해 re.match를 호출하여 일치하는 그룹을 리스트으로 반환합니다.” |
Series.str.extract |
“각 요소에 대해 re.search를 호출하여 각 요소에 대해 하나의 행과 각 정규식 캡처 그룹에 대해 하나의 열이 있는 DataFrame을 반환합니다.” |
Series.str.extractall |
“각 요소에 대해 re.findall을 호출하여 각 일치 항목에 대해 하나의 행과 각 정규식 캡처 그룹에 대해 하나의 열이 있는 DataFrame을 반환합니다.” |
Series.str.len |
문자열 길이 계산 |
Series.str.strip |
str.strip과 동일 |
Series.str.rstrip |
str.rstrip과 동일 |
Series.str.lstrip |
str.lstrip과 동일 |
Series.str.partition |
str.partition과 동일 |
Series.str.rpartition |
str.rpartition과 동일 |
Series.str.lower |
str.lower와 동일 |
Series.str.casefold |
str.casefold와 동일 |
Series.str.upper |
str.upper와 동일 |
Series.str.find |
str.find와 동일 |
Series.str.rfind |
str.rfind와 동일 |
Series.str.index |
str.index와 동일 |
Series.str.rindex |
str.rindex와 동일 |
Series.str.capitalize |
str.capitalize와 동일 |
Series.str.swapcase |
str.swapcase와 동일 |
Series.str.normalize |
유니코드 정규 형식을 반환합니다. unicodedata.normalize와 동일 |
Series.str.translate |
str.translate와 동일 |
Series.str.isalnum |
str.isalnum과 동일 |
Series.str.isalpha |
str.isalpha와 동일 |
Series.str.isdigit |
str.isdigit와 동일 |
Series.str.isspace |
str.isspace와 동일 |
Series.str.islower |
str.islower와 동일 |
Series.str.isupper |
str.isupper와 동일 |
Series.str.istitle |
str.istitle과 동일 |
Series.str.isnumeric |
str.isnumeric과 동일 |
Series.str.isdecimal |
str.isdecimal과 동일 |
Error 500 (Server Error)!!1500.That’s an error.There was an error. Please try again later.That’s all we know.
df = pd.DataFrame({"col1": ["replace me", "b", "c"], "col2": [1, 99999, 3]}) # noqa: F811
df| col1 | col2 | |
|---|---|---|
| 0 | replace me | 1 |
| 1 | b | 99999 |
| 2 | c | 3 |
df.replace({"replace me": "a", 99999: 2})| col1 | col2 | |
|---|---|---|
| 0 | a | 1 |
| 1 | b | 2 |
| 2 | c | 3 |
정규 표현식
정규식(regex)은 검색 패턴을 정의하는 일련의 문자입니다. 보다 복잡한 문자열 연산의 경우 반드시 정규식을 사용하는 것이 좋습니다. 정규식 구문에 대한 훌륭한 치트시트가 있습니다. 저는 정규식 전문가가 아니라는 사실을 자명합니다. 저는 보통 RegExr.com으로 가서 제가 원하는 표현을 찾을 때까지 이리저리 돌아다닙니다. 많은 Pandas 문자열 함수는 정규식을 입력으로 받아들입니다. 다음은 제가 가장 자주 사용하는 함수입니다.
| 방법 | 설명 |
|---|---|
match() |
각 요소에 대해 re.match()를 호출하여 불리언(Boolean)을 반환합니다. |
extract() |
각 요소에 대해 re.match()를 호출하여 일치하는 그룹을 문자열로 반환합니다. |
findall() |
각 요소에 대해 re.findall()을 호출합니다. |
replace() |
패턴을 다른 문자열로 교체 |
contains() |
각 요소에 대해 re.search()를 호출하여 불리언 값을 반환합니다. |
count() |
패턴 발생 횟수 계산 |
split() |
str.split()과 동일하지만 정규식을 허용합니다. |
rsplit() |
str.rsplit()과 동일하지만 정규 표현식을 허용합니다. |
예를 들어, 시리즈에서 자음으로 시작하고 끝나는 모든 이름을 쉽게 찾을 수 있습니다.
s = pd.Series(["Tom", "Mike", None, "Tiffany", "Joel", "Varada"]) # noqa: F811
s0 Tom
1 Mike
2 None
3 Tiffany
4 Joel
5 Varada
dtype: objects.str.findall(r"^[^AEIOU].*[^aeiou]$")0 [Tom]
1 []
2 None
3 [Tiffany]
4 [Joel]
5 []
dtype: object해당 정규식을 분석해 보겠습니다.
| 부분 | 설명 |
|---|---|
^ |
문자열의 시작을 지정합니다. |
[^AEIOU] |
대괄호는 단일 문자와 일치합니다. ^가 대괄호 안에 사용되면 “not”을 의미하므로 “문자열의 첫 번째 문자는 A, E, I, O 또는 U(예: 모음)가 아니어야 합니다.” |
.* |
.는 모든 문자와 일치하고 *는 “0개 이상의 시간”을 의미합니다. 이는 기본적으로 문자열 중간에 임의의 수의 문자가 포함될 수 있음을 의미합니다 |
[^aeiou]$ |
$는 문자열의 끝과 일치하므로 마지막 문자가 소문자 모음이 되는 것을 원하지 않습니다 |
Regex는 정말 마법 같은 일을 할 수 있으므로 복잡한 텍스트 랭글링을 수행할 때 이를 염두에 두십시오. 사이클링 데이터세트에 대한 예를 하나 더 살펴보겠습니다.
df = pd.read_csv("data/cycling_data.csv", index_col=0) # noqa: F811
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
“Rain” 또는 “rain” 문자열이 포함된 모든 주석을 찾을 수 있습니다.
df.loc[df["Comments"].str.contains(r"[Rr]ain")]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 17 Sep 2019, 13:43:34 | Morning Ride | Ride | 2285 | 12.60 | Raining |
| 18 Sep 2019, 13:49:53 | Morning Ride | Ride | 2903 | 14.57 | Raining today |
| 26 Sep 2019, 00:13:33 | Afternoon Ride | Ride | 1860 | 12.52 | raining |
“Raining” 또는 “raining”을 포함하지 않으려면 다음을 수행할 수 있습니다.
df.loc[df["Comments"].str.contains(r"^[Rr]ain$")]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
예를 들어 구두점을 기준으로 문자열을 분할하고 새 열로 분리할 수도 있습니다.
df["Comments"].str.split(r"[.,!]", expand=True)| 0 | 1 | |
|---|---|---|
| Date | ||
| 10 Sep 2019, 00:13:04 | Rain | None |
| 10 Sep 2019, 13:52:18 | rain | None |
| 11 Sep 2019, 00:23:50 | Wet road but nice weather | None |
| 11 Sep 2019, 14:06:19 | Stopped for photo of sunrise | None |
| 12 Sep 2019, 00:28:05 | Tired by the end of the week | None |
| ... | ... | ... |
| 4 Oct 2019, 01:08:08 | Very tired | riding into the wind |
| 9 Oct 2019, 13:55:40 | Really cold | But feeling good |
| 10 Oct 2019, 00:10:31 | Feeling good after a holiday break | |
| 10 Oct 2019, 13:47:14 | Stopped for photo of sunrise | None |
| 11 Oct 2019, 00:16:57 | Bike feeling tight | needs an oil and pump |
33 rows × 2 columns
내 요점은 마음이 원하는 것은 무엇이든 할 수 있다는 것입니다!
2. 날짜/시간 작업
문자열과 마찬가지로 Pandas에는 시계열 데이터 작업을 위한 광범위한 함수이 있습니다.
Datetime dtype 및 Pandas 사용 동기
Python에는 datetime 모듈에 날짜/시간 형식, 즉 시간 및 날짜 정보가 포함된 객체에 대한 지원이 내장되어 있습니다.
from datetime import datetime, timedeltadate = datetime(year=2005, month=7, day=9, hour=13, minute=54) # noqa: F811
datedatetime.datetime(2005, 7, 9, 13, 54)문자열에서 직접 구문 분석할 수도 있습니다. 여기서 형식 코드를 참조하세요.
date = datetime.strptime("July 9 2005, 13:54", "%B %d %Y, %H:%M") # noqa: F811
datedatetime.datetime(2005, 7, 9, 13, 54)그런 다음 데이터에서 특정 정보를 추출할 수 있습니다.
print(f"Year: {date.strftime('%Y')}")
print(f"Month: {date.strftime('%B')}")
print(f"Day: {date.strftime('%d')}")
print(f"Day name: {date.strftime('%A')}")
print(f"Day of year: {date.strftime('%j')}")
print(f"Time of day: {date.strftime('%p')}")Year: 2005
Month: July
Day: 09
Day name: Saturday
Day of year: 190
Time of day: PM일주일 추가와 같은 기본 작업을 수행합니다.
date + timedelta(days=7)datetime.datetime(2005, 7, 16, 13, 54)그러나 문자열과 마찬가지로 Python에서 날짜/시간 배열로 작업하는 것은 어렵고 비효율적일 수 있습니다. 따라서 NumPy에는 날짜를 보다 효율적으로 사용할 수 있는 새로운 날짜/시간 개체가 포함되었습니다.
dates = np.array(["2020-07-09", "2020-08-10"], dtype="datetime64") # noqa: F811
datesarray(['2020-07-09', '2020-08-10'], dtype='datetime64[D]')np.arange()와 같은 다른 내장 함수를 사용하여 배열을 만들 수도 있습니다:
dates = np.arange("2020-07", "2020-12", dtype="datetime64[M]") # noqa: F811
datesarray(['2020-07', '2020-08', '2020-09', '2020-10', '2020-11'],
dtype='datetime64[M]')이제 우리는 시간 배열에 대한 작업을 쉽게 수행할 수 있습니다. 모든 날짜/시간 단위와 해당 형식은 여기 문서에서 확인할 수 있습니다.
dates + np.timedelta64(2, "M")array(['2020-09', '2020-10', '2020-11', '2020-12', '2021-01'],
dtype='datetime64[M]')그러나 numpy는 날짜/시간을 배열 세계로 가져오는 데 도움이 되지만 랭글링 작업에 일반적으로 원하거나 필요한 많은 함수이 누락되어 있습니다. 이것이 Pandas가 등장하는 곳입니다. Pandas는 datetime 모듈, numpy 및 scikits.timeseries와 같은 기타 라이브러리의 함수을 단일 장소로 통합하고 확장합니다. Pandas는 다음 섹션에서 살펴볼 4가지 주요 날짜/시간 개체를 제공합니다. 1. 타임스탬프(예: np.datetime64) 2. Timedelta(예: np.timedelta64) 3. 기간(일정한 날짜/시간 범위에 대한 사용자 정의 개체) 4. DateOffset(timedelta와 같은 사용자 정의 개체이지만 달력 규칙을 고려함)
날짜/시간 만들기
처음부터
가장 일반적으로 원하는 것은 다음과 같습니다. 1. pd.Timestamp()를 사용하여 단일 시점을 생성합니다(예: 2005-07-09 00:00:00) 2. pd.Period()를 사용하여 시간 범위를 생성합니다(예: 2020 Jan) 3. pd.date_range() 또는 pd.date_range()를 사용하여 날짜/시간 배열을 만듭니다.
print(pd.Timestamp("2005-07-09")) # parsed from string
print(pd.Timestamp(year=2005, month=7, day=9)) # pass data directly
print(pd.Timestamp(datetime(year=2005, month=7, day=9))) # from datetime object2005-07-09 00:00:00
2005-07-09 00:00:00
2005-07-09 00:00:00위의 내용은 특정 시점입니다. 아래에서는 pd.Period()를 사용하여 시간 범위(예: 하루)를 지정할 수 있습니다.
span = pd.Period("2005-07-09") # noqa: F811
print(span)
print(span.start_time)
print(span.end_time)2005-07-09
2005-07-09 00:00:00
2005-07-09 23:59:59.999999999point = pd.Timestamp("2005-07-09 12:00") # noqa: F811
span = pd.Period("2005-07-09") # noqa: F811
print(f"Point: {point}")
print(f" Span: {span}")
print(f"Point in span? {span.start_time < point < span.end_time}")Point: 2005-07-09 12:00:00
Span: 2005-07-09
Point in span? True단일 값뿐만 아니라 날짜/시간 배열을 생성하려는 경우가 많습니다. 날짜/시간 배열은 DatetimeIndex/PeriodIndex/TimedeltaIndex 클래스에 속합니다.
pd.date_range("2020-09-01 12:00", "2020-09-11 12:00", freq="D")DatetimeIndex(['2020-09-01 12:00:00', '2020-09-02 12:00:00',
'2020-09-03 12:00:00', '2020-09-04 12:00:00',
'2020-09-05 12:00:00', '2020-09-06 12:00:00',
'2020-09-07 12:00:00', '2020-09-08 12:00:00',
'2020-09-09 12:00:00', '2020-09-10 12:00:00',
'2020-09-11 12:00:00'],
dtype='datetime64[ns]', freq='D')pd.period_range("2020-09-01", "2020-09-11", freq="D")PeriodIndex(['2020-09-01', '2020-09-02', '2020-09-03', '2020-09-04',
'2020-09-05', '2020-09-06', '2020-09-07', '2020-09-08',
'2020-09-09', '2020-09-10', '2020-09-11'],
dtype='period[D]', freq='D')‘Timedelta’ 객체를 사용하여 시간을 더하거나 빼는 것과 같은 시간적 연산을 수행할 수 있습니다.
pd.date_range("2020-09-01 12:00", "2020-09-11 12:00", freq="D") + pd.Timedelta(
"1.5 hour"
)DatetimeIndex(['2020-09-01 13:30:00', '2020-09-02 13:30:00',
'2020-09-03 13:30:00', '2020-09-04 13:30:00',
'2020-09-05 13:30:00', '2020-09-06 13:30:00',
'2020-09-07 13:30:00', '2020-09-08 13:30:00',
'2020-09-09 13:30:00', '2020-09-10 13:30:00',
'2020-09-11 13:30:00'],
dtype='datetime64[ns]', freq='D')마지막으로 Pandas는 np.nan과 마찬가지로 NaT로 누락된 날짜 시간을 나타냅니다.
pd.Timestamp(pd.NaT)NaT기존 데이터를 변환하여
날짜 배열을 문자열로 갖는 것은 매우 일반적입니다. pd.to_datetime()을 사용하여 이를 날짜/시간으로 변환할 수 있습니다.
string_dates = ["July 9, 2020", "August 1, 2020", "August 28, 2020"] # noqa: F811
string_dates['July 9, 2020', 'August 1, 2020', 'August 28, 2020']pd.to_datetime(string_dates)DatetimeIndex(['2020-07-09', '2020-08-01', '2020-08-28'], dtype='datetime64[ns]', freq=None)더 복잡한 날짜/시간 형식의 경우 ‘format’ 인수를 사용하세요(도움말은 Python 형식 코드 참조).
string_dates = ["2020 9 July", "2020 1 August", "2020 28 August"] # noqa: F811
pd.to_datetime(string_dates, format="%Y %d %B")DatetimeIndex(['2020-07-09', '2020-08-01', '2020-08-28'], dtype='datetime64[ns]', freq=None)또는 딕셔너리을 사용하십시오.
dict_dates = pd.to_datetime( # noqa: F811
{"year": [2020, 2020, 2020], "month": [7, 8, 8], "day": [9, 1, 28]}
) # note this is a series, not an index!
dict_dates0 2020-07-09
1 2020-08-01
2 2020-08-28
dtype: datetime64[ns]pd.Index(dict_dates)DatetimeIndex(['2020-07-09', '2020-08-01', '2020-08-28'], dtype='datetime64[ns]', freq=None)외부 소스에서 직접 읽어옴
우리가 가장 좋아하는 사이클링 데이터 세트를 읽어서 연습해 보겠습니다.
df = pd.read_csv("data/cycling_data.csv", index_col=0) # noqa: F811
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
우리의 인덱스는 현재 string 날짜로 가득 찬 dtype object를 사용하는 평범한 오래된 인덱스입니다.
print(df.index.dtype)
type(df.index)objectpandas.core.indexes.base.Indexpd.to_datetime()을 사용하여 인덱스를 날짜/시간으로 수동으로 변환할 수 있습니다. 하지만 더 좋은 점은 pd.read_csv()에는 파일을 읽을 때 자동으로 이 작업을 수행할 수 있는 parse_dates 인수가 있다는 것입니다.
df = pd.read_csv("data/cycling_data.csv", index_col=0, parse_dates=True) # noqa: F811
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-10 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-11 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-11 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-12 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-10-04 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-09 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-11 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
type(df.index)pandas.core.indexes.datetimes.DatetimeIndexprint(df.index.dtype)
type(df.index)datetime64[ns]pandas.core.indexes.datetimes.DatetimeIndexparse_dates 인수는 매우 유연하며 읽기 어려운 날짜에 대해 날짜/시간 형식을 지정할 수 있습니다. 도움이 되는 date_parser, dayfirst 등과 같은 다른 관련 인수도 있습니다. 자세한 내용은 Pandas 문서를 확인하세요.
날짜/시간 인덱싱
날짜/시간 인덱스 개체는 일반 인덱스 개체와 동일하며 선택, 분할, 필터링 등이 가능합니다.
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-10 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-11 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-11 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-12 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-10-04 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-09 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-11 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
부분 문자열 인덱싱을 수행할 수 있습니다.
df.loc["2019-09"]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-10 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-11 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-11 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-12 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-09-25 13:35:41 | Morning Ride | Ride | 2124 | 12.65 | Stopped for photo of sunrise |
| 2019-09-26 00:13:33 | Afternoon Ride | Ride | 1860 | 12.52 | raining |
| 2019-09-26 13:42:43 | Morning Ride | Ride | 2350 | 12.91 | Detour around trucks at Jericho |
| 2019-09-27 01:00:18 | Afternoon Ride | Ride | 1712 | 12.47 | Tired by the end of the week |
| 2019-09-30 13:53:52 | Morning Ride | Ride | 2118 | 12.71 | Rested after the weekend! |
22 rows × 5 columns
정확한 일치:
df.loc["2019-10-10"]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
df.loc["2019-10-10 13:47:14"]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
그리고 슬라이싱:
df.loc["2019-10-01":"2019-10-13"]| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-10-01 00:15:07 | Afternoon Ride | Ride | 1732 | NaN | Legs feeling strong! |
| 2019-10-01 13:45:55 | Morning Ride | Ride | 2222 | 12.82 | Beautiful morning! Feeling fit |
| 2019-10-02 00:13:09 | Afternoon Ride | Ride | 1756 | NaN | A little tired today but good weather |
| 2019-10-02 13:46:06 | Morning Ride | Ride | 2134 | 13.06 | Bit tired today but good weather |
| 2019-10-03 00:45:22 | Afternoon Ride | Ride | 1724 | 12.52 | Feeling good |
| 2019-10-03 13:47:36 | Morning Ride | Ride | 2182 | 12.68 | Wet road |
| 2019-10-04 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-09 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-11 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
df.query()는 여기서도 작동합니다:
df.query("'2019-10-10'")| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
그리고 하루 두 번 사이의 모든 결과를 얻으려면 df.between_time()을 사용하세요:
df.between_time("00:00", "01:00")| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-11 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-12 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| 2019-09-17 00:15:47 | Afternoon Ride | Ride | 1973 | 12.45 | Legs feeling strong! |
| 2019-09-18 00:15:52 | Afternoon Ride | Ride | 2101 | 12.48 | Pumped up tires |
| 2019-09-19 00:30:01 | Afternoon Ride | Ride | 48062 | 12.48 | Feeling good |
| 2019-09-24 00:35:42 | Afternoon Ride | Ride | 2076 | 12.47 | Oiled chain, bike feels smooth |
| 2019-09-25 00:07:21 | Afternoon Ride | Ride | 1775 | 12.10 | Feeling really tired |
| 2019-09-26 00:13:33 | Afternoon Ride | Ride | 1860 | 12.52 | raining |
| 2019-10-01 00:15:07 | Afternoon Ride | Ride | 1732 | NaN | Legs feeling strong! |
| 2019-10-02 00:13:09 | Afternoon Ride | Ride | 1756 | NaN | A little tired today but good weather |
| 2019-10-03 00:45:22 | Afternoon Ride | Ride | 1724 | 12.52 | Feeling good |
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-11 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
1차원 배열
날짜/시간 조작
분해
시계열을 구성 요소로 쉽게 분해할 수 있습니다. 이러한 구성 요소를 정의하는 다양한 속성이 있습니다.
df.index.yearInt64Index([2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019,
2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019, 2019],
dtype='int64', name='Date')df.index.secondInt64Index([ 4, 18, 50, 19, 5, 48, 47, 34, 53, 52, 1, 9, 5, 41, 42, 24, 21,
41, 33, 43, 18, 52, 7, 55, 9, 6, 22, 36, 8, 40, 31, 14, 57],
dtype='int64', name='Date')df.index.weekdayInt64Index([1, 1, 2, 2, 3, 0, 1, 1, 2, 2, 3, 3, 4, 0, 1, 1, 2, 2, 3, 3, 4, 0,
1, 1, 2, 2, 3, 3, 4, 2, 3, 3, 4],
dtype='int64', name='Date')또한 다음과 같은 방법을 사용할 수 있습니다.
df.index.day_name()Index(['Tuesday', 'Tuesday', 'Wednesday', 'Wednesday', 'Thursday', 'Monday',
'Tuesday', 'Tuesday', 'Wednesday', 'Wednesday', 'Thursday', 'Thursday',
'Friday', 'Monday', 'Tuesday', 'Tuesday', 'Wednesday', 'Wednesday',
'Thursday', 'Thursday', 'Friday', 'Monday', 'Tuesday', 'Tuesday',
'Wednesday', 'Wednesday', 'Thursday', 'Thursday', 'Friday', 'Wednesday',
'Thursday', 'Thursday', 'Friday'],
dtype='object', name='Date')df.index.month_name()Index(['September', 'September', 'September', 'September', 'September',
'September', 'September', 'September', 'September', 'September',
'September', 'September', 'September', 'September', 'September',
'September', 'September', 'September', 'September', 'September',
'September', 'September', 'October', 'October', 'October', 'October',
'October', 'October', 'October', 'October', 'October', 'October',
'October'],
dtype='object', name='Date')DatetimeIndex 객체가 아닌 Series에서 작업하는 경우 .dt 속성을 통해 이 함수에 액세스할 수 있습니다.
s = pd.Series(pd.date_range("2011-12-29", "2011-12-31")) # noqa: F811
s.year # raises error--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-60-e24fea3644a8> in <module> 1 s = pd.Series(pd.date_range('2011-12-29', '2011-12-31')) ----> 2 s.year # raises error /opt/miniconda3/lib/python3.7/site-packages/pandas/core/generic.py in __getattr__(self, name) 5128 if self._info_axis._can_hold_identifiers_and_holds_name(name): 5129 return self[name] -> 5130 return object.__getattribute__(self, name) 5131 5132 def __setattr__(self, name: str, value) -> None: AttributeError: 'Series' object has no attribute 'year'
s.dt.year # works0 2011
1 2011
2 2011
dtype: int64오프셋 및 시간대
우리는 Timedelta를 사용하여 날짜/시간에 시간을 더하거나 빼는 방법을 이전에 보았습니다. ’Timedelta’는 절대 시간을 존중하는데, 이는 시간이 규칙적이지 않은 경우에 문제가 될 수 있습니다. 예를 들어, 3월 8일에 캐나다 일광 절약 시간제가 시작되어 시계가 1시간 앞으로 이동했습니다. 이 추가 “캘린더 시간”은 절대 시간으로 고려되지 않습니다.
t1 = pd.Timestamp("2020-03-07 12:00:00", tz="Canada/Pacific") # noqa: F811
t2 = t1 + pd.Timedelta("1 day") # noqa: F811
print(f"Original time: {t1}")
print(f" Plus one day: {t2}") # note that time has moved from 12:00 -> 13:00Original time: 2020-03-07 12:00:00-08:00
Plus one day: 2020-03-08 13:00:00-07:00대신 Dateoffset을 사용해야 합니다.
t3 = t1 + pd.DateOffset(days=1) # noqa: F811
print(f"Original time: {t1}")
print(f" Plus one day: {t3}") # note that time has stayed at 12:00Original time: 2020-03-07 12:00:00-08:00
Plus one day: 2020-03-08 12:00:00-07:00위에서 시간대 정보를 포함하기 시작했음을 알 수 있습니다. 기본적으로 datetime 객체는 “시간대를 인식하지 못합니다”. 시간을 시간대와 연관시키려면 tz 인수를 사용하거나 tz_localize() 메소드를 사용할 수 있습니다:
print(f" No timezone: {pd.Timestamp('2020-03-07 12:00:00').tz}")
print(
f" tz arg: {pd.Timestamp('2020-03-07 12:00:00', tz='Canada/Pacific').tz}"
)
print(
f".tz_localize method: {pd.Timestamp('2020-03-07 12:00:00').tz_localize('Canada/Pacific').tz}"
) No timezone: None
tz arg: Canada/Pacific
.tz_localize method: Canada/Pacific.tz_convert() 메소드를 사용하여 시간대 간을 변환할 수 있습니다. 제가 대학까지 차를 타고 가던 시절에 뭔가 재미있는 점을 눈치채셨을 것입니다.
df = pd.read_csv("data/cycling_data.csv", index_col=0, parse_dates=True) # noqa: F811
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-10 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-11 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-11 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-12 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-10-04 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-09 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-10 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-11 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
저는 자정 무렵에 자전거를 타지 않았다는 사실을 알고 있습니다. 이 데이터 세트의 시간대에 문제가 있습니다. 저는 라이딩을 기록하기 위해 ‘Strava’ 앱을 사용하고 있었는데, 캐나다 시간으로 기록하고 있었지만 호주 시간으로 변환하고 있었습니다. 계속해서 문제를 해결해 보겠습니다.
df.index = df.index.tz_localize("Canada/Pacific") # first specify the current timezone
df.index = df.index.tz_convert(
"Australia/Sydney"
) # then convert to the proper timezone
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-10 17:13:04+10:00 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-11 06:52:18+10:00 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-11 17:23:50+10:00 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-12 07:06:19+10:00 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-12 17:28:05+10:00 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-10-04 18:08:08+10:00 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-10 07:55:40+11:00 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-10 18:10:31+11:00 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-11 07:47:14+11:00 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-11 18:16:57+11:00 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
적용하려는 오프셋(이 경우 7시간)을 알고 있다면 DateOffset을 사용할 수도 있습니다.
df = pd.read_csv("data/cycling_data.csv", index_col=0, parse_dates=True) # noqa: F811
df.index = df.index + pd.DateOffset(hours=-7)
df| Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|
| Date | |||||
| 2019-09-09 17:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2019-09-10 06:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2019-09-10 17:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 2019-09-11 07:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 2019-09-11 17:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 2019-10-03 18:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 2019-10-09 06:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 2019-10-09 17:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 2019-10-10 06:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 2019-10-10 17:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
리샘플링 및 집계
시계열 작업 시 수행하려는 가장 일반적인 작업 중 하나는 시계열을 더 성기거나 더 미세한/일반 해상도로 리샘플링하는 것입니다. 예를 들어 일일 데이터를 주간 데이터로 다시 샘플링할 수 있습니다. .resample() 메소드를 사용하면 그렇게 할 수 있습니다. 예를 들어 불규칙한 사이클링 시계열을 정규 12시간 간격 시계열로 리샘플링해 보겠습니다.
df.indexDatetimeIndex(['2019-09-09 17:13:04', '2019-09-10 06:52:18',
'2019-09-10 17:23:50', '2019-09-11 07:06:19',
'2019-09-11 17:28:05', '2019-09-16 06:57:48',
'2019-09-16 17:15:47', '2019-09-17 06:43:34',
'2019-09-18 06:49:53', '2019-09-17 17:15:52',
'2019-09-18 17:30:01', '2019-09-19 06:52:09',
'2019-09-19 18:02:05', '2019-09-23 06:50:41',
'2019-09-23 17:35:42', '2019-09-24 06:41:24',
'2019-09-24 17:07:21', '2019-09-25 06:35:41',
'2019-09-25 17:13:33', '2019-09-26 06:42:43',
'2019-09-26 18:00:18', '2019-09-30 06:53:52',
'2019-09-30 17:15:07', '2019-10-01 06:45:55',
'2019-10-01 17:13:09', '2019-10-02 06:46:06',
'2019-10-02 17:45:22', '2019-10-03 06:47:36',
'2019-10-03 18:08:08', '2019-10-09 06:55:40',
'2019-10-09 17:10:31', '2019-10-10 06:47:14',
'2019-10-10 17:16:57'],
dtype='datetime64[ns]', name='Date', freq=None)df.resample("1D")<pandas.core.resample.DatetimeIndexResampler object at 0x153840d90>Resampler 객체는 이전 장에서 본 groupby 객체와 매우 유사합니다. groupby 객체에서 했던 것처럼 그룹화된 시계열에 집계 함수를 적용해야 합니다.
dfr = df.resample("1D").mean() # noqa: F811
dfr| Time | Distance | |
|---|---|---|
| Date | ||
| 2019-09-09 | 2084.0 | 12.620 |
| 2019-09-10 | 2197.0 | 12.775 |
| 2019-09-11 | 2041.5 | 12.660 |
| 2019-09-12 | NaN | NaN |
| 2019-09-13 | NaN | NaN |
| ... | ... | ... |
| 2019-10-06 | NaN | NaN |
| 2019-10-07 | NaN | NaN |
| 2019-10-08 | NaN | NaN |
| 2019-10-09 | 1995.0 | 12.645 |
| 2019-10-10 | 2153.0 | 12.290 |
32 rows × 2 columns
거기에 꽤 많은 NaN이 있나요? 어떤 날은 타지 않았지만 어떤 날은 주말에도 탈 수 있었습니다.
dfr["Weekday"] = dfr.index.day_name()
dfr.head(10)| Time | Distance | Weekday | |
|---|---|---|---|
| Date | |||
| 2019-09-09 | 2084.0 | 12.620 | Monday |
| 2019-09-10 | 2197.0 | 12.775 | Tuesday |
| 2019-09-11 | 2041.5 | 12.660 | Wednesday |
| 2019-09-12 | NaN | NaN | Thursday |
| 2019-09-13 | NaN | NaN | Friday |
| 2019-09-14 | NaN | NaN | Saturday |
| 2019-09-15 | NaN | NaN | Sunday |
| 2019-09-16 | 2122.5 | 12.450 | Monday |
| 2019-09-17 | 2193.0 | 12.540 | Tuesday |
| 2019-09-18 | 25482.5 | 13.525 | Wednesday |
Pandas는 지금까지 본 모든 시계열 함수에서 “비즈니스 시간” 작업과 형식 코드를 지원합니다. 자세한 내용은 문서를 확인하세요. 하지만 주말을 없애기 위해 여기에서 영업일을 지정하겠습니다.
dfr = df.resample("1B").mean() # "B" is business day # noqa: F811
dfr["Weekday"] = dfr.index.day_name()
dfr.head(10)| Time | Distance | Weekday | |
|---|---|---|---|
| Date | |||
| 2019-09-09 | 2084.0 | 12.620 | Monday |
| 2019-09-10 | 2197.0 | 12.775 | Tuesday |
| 2019-09-11 | 2041.5 | 12.660 | Wednesday |
| 2019-09-12 | NaN | NaN | Thursday |
| 2019-09-13 | NaN | NaN | Friday |
| 2019-09-16 | 2122.5 | 12.450 | Monday |
| 2019-09-17 | 2193.0 | 12.540 | Tuesday |
| 2019-09-18 | 25482.5 | 13.525 | Wednesday |
| 2019-09-19 | 2525.5 | 12.700 | Thursday |
| 2019-09-20 | NaN | NaN | Friday |
3. 계층적 인덱싱
계층적 인덱싱(“다중 인덱싱” 또는 “스택 인덱싱”이라고도 함)은 Pandas가 데이터를 “중첩”하는 방식입니다. 2D 데이터프레임에 고차원 데이터를 쉽게 저장하는 것이 아이디어입니다.

출처: Giphy
계층적 인덱스 만들기
동기를 부여하는 예부터 시작해 보겠습니다. Pandas 시리즈에서 각 데이터 과학 석사 강사가 수년 동안 가르친 강좌 수를 추적하고 싶다고 가정해 보겠습니다.
Note
이 사이트의 콘텐츠는 제가 브리티시 컬럼비아 대학의 데이터 과학 석사 프로그램을 위한 “DSCI 511 데이터 과학을 위한 Python 프로그래밍” 과정의 2020/2021 제공물을 가르치기 위해 사용한 자료에서 채택되었다는 점을 기억하세요.
적절한 인덱스를 만들기 위해 튜플을 사용할 수 있습니다:
index = [ # noqa: F811
("Tom", 2019),
("Tom", 2020),
("Mike", 2019),
("Mike", 2020),
("Tiffany", 2019),
("Tiffany", 2020),
]
courses = [4, 6, 5, 5, 6, 3] # noqa: F811
s = pd.Series(courses, index) # noqa: F811
s(Tom, 2019) 4
(Tom, 2020) 6
(Mike, 2019) 5
(Mike, 2020) 5
(Tiffany, 2019) 6
(Tiffany, 2020) 3
dtype: int64우리는 여전히 이 시리즈의 색인을 생성할 수 있습니다.
s.loc[("Tom", 2019) : ("Tom", 2019)](Tom, 2019) 4
dtype: int64그러나 2019년의 모든 값을 얻으려면 지저분한 반복을 수행해야 합니다.
s[[i for i in s.index if i[1] == 2019]](Tom, 2019) 4
(Mike, 2019) 5
(Tiffany, 2019) 6
dtype: int64이 문제를 설정하는 더 좋은 방법은 다중 인덱스(“계층적 인덱스”)를 사용하는 것입니다. pd.MultiIndex.from_tuple()을 사용하여 다중 인덱스를 만들 수 있습니다. .from_X의 다른 변형이 있지만 튜플이 가장 일반적입니다.
mi = pd.MultiIndex.from_tuples(index) # noqa: F811
miMultiIndex([( 'Tom', 2019),
( 'Tom', 2020),
( 'Mike', 2019),
( 'Mike', 2020),
('Tiffany', 2019),
('Tiffany', 2020)],
)s = pd.Series(courses, mi) # noqa: F811
sTom 2019 4
2020 6
Mike 2019 5
2020 5
Tiffany 2019 6
2020 3
dtype: int64이제 보다 효율적이고 논리적인 인덱싱을 수행할 수 있습니다.
s.loc["Tom"]2019 4
2020 6
dtype: int64s.loc[:, 2019]Tom 4
Mike 5
Tiffany 6
dtype: int64s.loc["Tom", 2019]4리스트 리스트과 같은 반복 가능 항목을 index 인수에 직접 전달하여 색인을 생성할 수도 있지만 pd.MultIndex를 사용하는 것만큼 명시적이거나 직관적이지는 않다고 생각합니다.
index = [ # noqa: F811
["Tom", "Tom", "Mike", "Mike", "Tiffany", "Tiffany"],
[2019, 2020, 2019, 2020, 2019, 2020],
]
courses = [4, 6, 5, 5, 6, 3] # noqa: F811
s = pd.Series(courses, index) # noqa: F811
sTom 2019 4
2020 6
Mike 2019 5
2020 5
Tiffany 2019 6
2020 3
dtype: int64스태킹/언스태킹
다중 인덱스 시리즈를 데이터프레임으로 표현할 수도 있다는 것을 눈치채셨을 것입니다. Pandas도 이 점을 인지하고 데이터 프레임과 다중 인덱스 시리즈 간 전환을 위한 .stack() 및 .unstack() 메서드를 제공합니다.
s = s.unstack() # noqa: F811
s| 2019 | 2020 | |
|---|---|---|
| Mike | 5 | 5 |
| Tiffany | 6 | 3 |
| Tom | 4 | 6 |
s.stack()Mike 2019 5
2020 5
Tiffany 2019 6
2020 3
Tom 2019 4
2020 6
dtype: int64계층적 인덱스 사용
위의 다중 인덱스 <-> 데이터프레임 동등성을 관찰하면 왜 다중 인덱스가 필요한지 궁금할 것입니다. 위에서는 2D 데이터만 다루었지만 다중 인덱스를 사용하면 임의의 수의 차원을 저장할 수 있습니다.
index = [ # noqa: F811
["Tom", "Tom", "Mike", "Mike", "Tiffany", "Tiffany"],
[2019, 2020, 2019, 2020, 2019, 2020],
]
courses = [4, 6, 5, 5, 6, 3] # noqa: F811
s = pd.Series(courses, index) # noqa: F811
sTom 2019 4
2020 6
Mike 2019 5
2020 5
Tiffany 2019 6
2020 3
dtype: int64pd.DataFrame(s).stack()Tom 2019 0 4
2020 0 6
Mike 2019 0 5
2020 0 5
Tiffany 2019 0 6
2020 0 3
dtype: int64s.loc["Tom"]2019 4
2020 6
dtype: int64tom = pd.DataFrame({"Courses": [4, 6], "Students": [273, 342]}, index=[2019, 2020]) # noqa: F811
mike = pd.DataFrame({"Courses": [5, 5], "Students": [293, 420]}, index=[2019, 2020]) # noqa: F811
tiff = pd.DataFrame({"Courses": [6, 3], "Students": [363, 190]}, index=[2019, 2020]) # noqa: F811여기에 함께 결합하고 싶은 3개의 2D 데이터프레임이 있습니다. 이를 수행할 수 있는 방법은 매우 많지만 저는 pd.concat()을 사용한 다음 keys 인수를 지정하겠습니다.
s3 = pd.concat((tom, mike, tiff), keys=["Tom", "Mike", "Tiff"], axis=0) # noqa: F811
s3| Courses | Students | ||
|---|---|---|---|
| Tom | 2019 | 4 | 273 |
| 2020 | 6 | 342 | |
| Mike | 2019 | 5 | 293 |
| 2020 | 5 | 420 | |
| Tiff | 2019 | 6 | 363 |
| 2020 | 3 | 190 |
이제 단일 구조에 3차원 정보가 있습니다!
s3.stack()Tom 2019 Courses 4
Students 273
2020 Courses 6
Students 342
Mike 2019 Courses 5
Students 293
2020 Courses 5
Students 420
Tiff 2019 Courses 6
Students 363
2020 Courses 3
Students 190
dtype: int64s3.loc["Tom"]| Courses | Students | |
|---|---|---|
| 2019 | 4 | 273 |
| 2020 | 6 | 342 |
s3.loc["Tom", 2019]Courses 4
Students 273
Name: (Tom, 2019), dtype: int64다양한 방법으로 더 깊은 수준에 접근할 수 있습니다.
s3.loc["Tom", 2019]["Courses"]4s3.loc[("Tom", 2019), "Courses"]4s3.loc[("Tom", 2019), "Courses"]4인덱스 열의 이름을 지정하면 .query()를 사용할 수도 있습니다.
s3 = s3.rename_axis(index=["Name", "Year"]) # noqa: F811
s3| Courses | Students | ||
|---|---|---|---|
| Name | Year | ||
| Tom | 2019 | 4 | 273 |
| 2020 | 6 | 342 | |
| Mike | 2019 | 5 | 293 |
| 2020 | 5 | 420 | |
| Tiff | 2019 | 6 | 363 |
| 2020 | 3 | 190 |
s3.query("Year == 2019")| Courses | Students | ||
|---|---|---|---|
| Name | Year | ||
| Tom | 2019 | 4 | 273 |
| Mike | 2019 | 5 | 293 |
| Tiff | 2019 | 6 | 363 |
또는 계층적 인덱스의 “스택” 버전을 선호할 수도 있습니다.
s3.stack()Name Year
Tom 2019 Courses 4
Students 273
2020 Courses 6
Students 342
Mike 2019 Courses 5
Students 293
2020 Courses 5
Students 420
Tiff 2019 Courses 6
Students 363
2020 Courses 3
Students 190
dtype: int64s3.stack().loc[("Tom", 2019, "Courses")]4그런데 계층적 데이터프레임에 대해 이전에 배운 모든 방법을 사용할 수도 있습니다.
s3.sort_index(ascending=False)| Courses | Students | ||
|---|---|---|---|
| Name | Year | ||
| Tom | 2020 | 6 | 342 |
| 2019 | 4 | 273 | |
| Tiff | 2020 | 3 | 190 |
| 2019 | 6 | 363 | |
| Mike | 2020 | 5 | 420 |
| 2019 | 5 | 293 |
s3.sort_values(by="Students")| Courses | Students | ||
|---|---|---|---|
| Name | Year | ||
| Tiff | 2020 | 3 | 190 |
| Tom | 2019 | 4 | 273 |
| Mike | 2019 | 5 | 293 |
| Tom | 2020 | 6 | 342 |
| Tiff | 2019 | 6 | 363 |
| Mike | 2020 | 5 | 420 |
한 가지 중요한 예외가 있습니다! 이제 ‘level’ 인수를 지정하여 함수를 적용할 다중 인덱스 레벨을 선택할 수 있습니다.
s3.mean()Courses 4.833333
Students 313.500000
dtype: float64s3.mean(level="Year")| Courses | Students | |
|---|---|---|
| Year | ||
| 2019 | 5.000000 | 309.666667 |
| 2020 | 4.666667 | 317.333333 |
4. DataFrame 시각화
Pandas는 여기서 간단히 보여주고 싶었던 Series 및 DataFrames에 .plot() 메서드를 제공합니다.
간단한 플롯
df = pd.read_csv("data/cycling_data.csv", index_col=0, parse_dates=True).dropna() # noqa: F811이제 내가 탔던 거리를 도표로 만들어 보겠습니다.
df["Distance"].plot.line();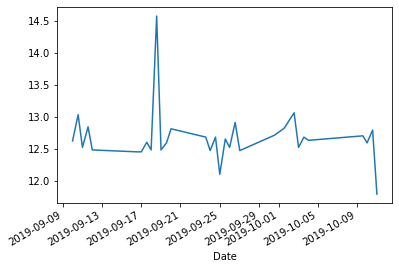
누적 거리가 더 유익할 수 있습니다.
df["Distance"].cumsum().plot.line();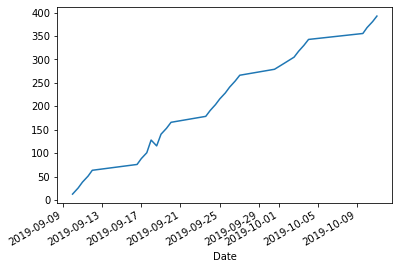
matplotlib 라이브러리를 빌드하는 이러한 플롯에 대한 많은 구성 옵션이 있습니다:
df["Distance"].cumsum().plot.line(fontsize=14, linewidth=2, color="r", ylabel="km");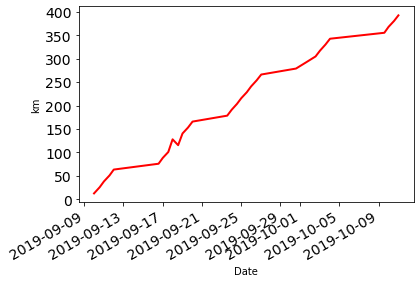
저는 실제로 플롯에 대해 많은 색상과 텍스트 형식을 지정하는 기본 제공 테마를 사용합니다.
import matplotlib.pyplot as plt
plt.style.use("ggplot")
plt.rcParams.update(
{"font.size": 16, "axes.labelweight": "bold", "figure.figsize": (8, 6)}
)df["Distance"].dropna().cumsum().plot.line(ylabel="km");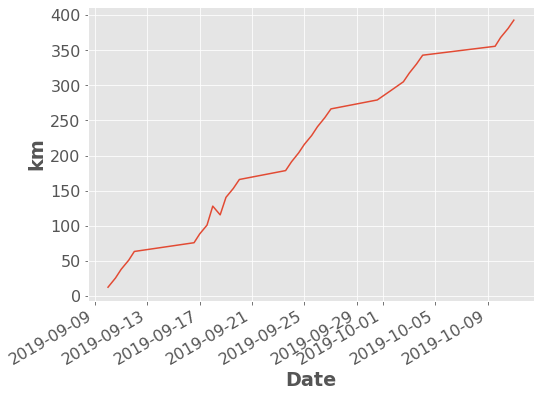
어떤 사람들은 다음과 같은 재미있는 사이버펑크 테마와 같은 맞춤 테마를 만들기도 했습니다.
import mplcyberpunk
plt.style.use("cyberpunk")
df["Distance"].plot.line(ylabel="km")
mplcyberpunk.add_glow_effects()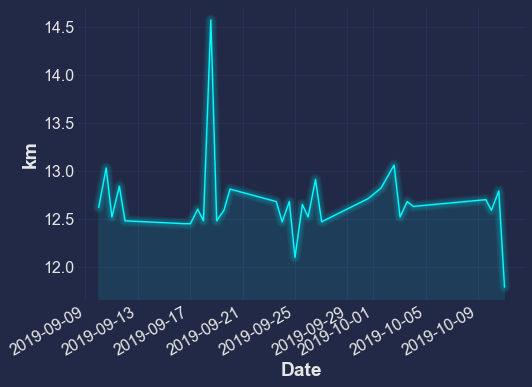
그 밖에도 다양한 유형의 플롯을 만들 수 있습니다.
| 방법 | 플롯 유형 |
|---|---|
bar 또는 barh |
막대 그래프 |
역사 |
히스토그램 |
상자 |
상자 그림 |
kde 또는 밀도 |
밀도 플롯 |
지역 |
면적 플롯 |
분산 |
산점도 |
헥스빈 |
육각형 빈 플롯 |
파이 |
파이 플롯 |
plt.style.use("ggplot")
plt.rcParams.update(
{"font.size": 16, "axes.labelweight": "bold", "figure.figsize": (8, 6)}
)
df["Distance"].plot.hist();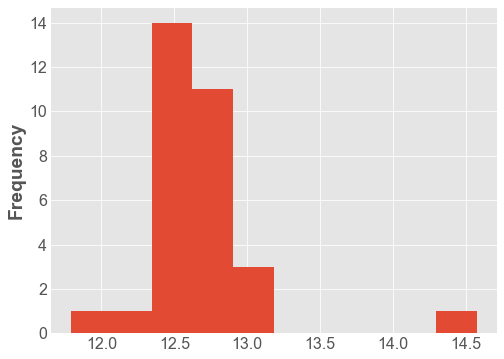
df["Distance"].plot.density();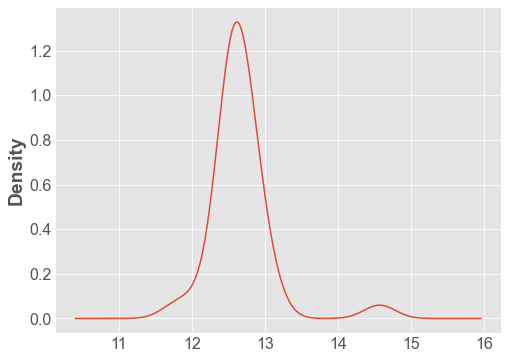
팬더 플로팅
Pandas는 pandas.plotting 모듈에서 몇 가지 고급 플로팅 함수도 지원합니다. Pandas 문서에서 볼 수 있습니다.
from pandas.plotting import scatter_matrixscatter_matrix(df);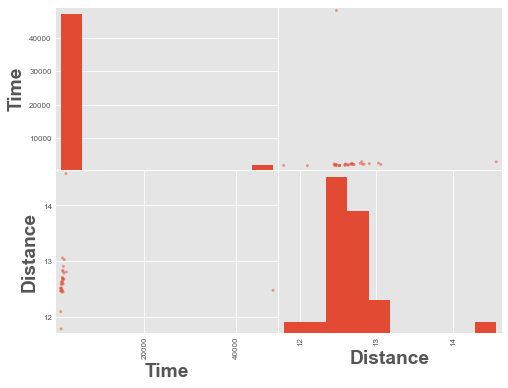
위 데이터에는 ~48,000의 시간 값인 이상치 시간이 있습니다. 그것을 제거하고 다시 플롯합시다.
scatter_matrix(df.query("Time < 4000"), alpha=1);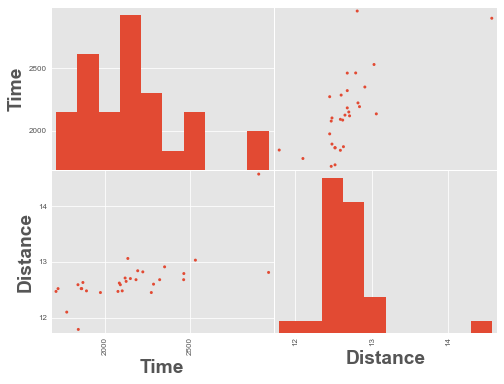
5. 팬더 프로파일링
Pandas 프로파일링은 요약 보고서를 생성하고 데이터 프레임에 대한 탐색적 데이터 분석을 수행하는 멋진 도구입니다. Pandas 프로파일링은 기본 Pandas의 일부가 아니지만 다음을 사용하여 설치할 수 있습니다.
conda install -c conda-forge ydata-profilingdf = pd.read_csv("data/cycling_data.csv") # noqa: F811
df.profile_report(progress_bar=False)