import numpy as np
import pandas as pd8장: 팬더와 기본 데이터 논쟁

학습 내용
학습 목표
df.head(),df.tail(),df.info(),df.describe()를 사용하여 데이터프레임을 검사합니다.df.info()및df.describe()를 사용하여 데이터프레임 요약을 얻습니다.pd.set_option("display.max_rows", n)과 같은 Pandas 구성 옵션을 수정하여 Jupyter에서 데이터프레임이 표시되는 방식을 조작합니다.df.rename()함수를 사용하거나df.columns속성에 액세스하여 데이터프레임의 열 이름을 바꿉니다..set_index(),.reset_index(),df.index.name,.index를 사용하여 데이터프레임의 인덱스 이름과 인덱스 값을 수정합니다.df.melt()및df.pivot()을 사용하여 데이터프레임의 모양을 변경하고, 특히 깔끔한 데이터프레임을 만드세요.df.merge()및pd.concat()을 사용하여 데이터프레임을 결합하고 이러한 다양한 방법을 언제 사용해야 하는지 알아보세요.- 데이터 프레임
df.apply()및df.applymap()에 함수 적용 df.groupby()및df.agg()를 사용하여 그룹화 및 집계 작업을 수행합니다.df.agg()를 사용하여 데이터 프레임에서 값의 최소값, 최대값 및 합계를 찾는 등 그룹화되거나 그룹화되지 않은 개체에 대해 집계 방법을 수행합니다.df.dropna()및df.fillna()를 사용하여 데이터프레임에서 누락된 값을 제거하거나 채웁니다.
1. 데이터프레임 특성
지난 장에서는 데이터프레임을 생성하는 방법을 살펴보았습니다. 이제 데이터프레임을 볼 수 있는 몇 가지 유용한 방법을 살펴보겠습니다.
머리/꼬리
.head() 및 .tail() 메서드를 사용하면 데이터프레임의 상단/하단 n(기본값 5) 행을 볼 수 있습니다. 지난 장의 사이클링 데이터 세트를 로드하여 시험해 보겠습니다.
df = pd.read_csv("data/cycling_data.csv") # noqa: F811
df.head()| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
기본 반환 값은 5개 행이지만 원하는 숫자를 전달할 수 있습니다. 예를 들어 상위 10개 행을 살펴보겠습니다.
df.head(10)| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| 5 | 16 Sep 2019, 13:57:48 | Morning Ride | Ride | 2272 | 12.45 | Rested after the weekend! |
| 6 | 17 Sep 2019, 00:15:47 | Afternoon Ride | Ride | 1973 | 12.45 | Legs feeling strong! |
| 7 | 17 Sep 2019, 13:43:34 | Morning Ride | Ride | 2285 | 12.60 | Raining |
| 8 | 18 Sep 2019, 13:49:53 | Morning Ride | Ride | 2903 | 14.57 | Raining today |
| 9 | 18 Sep 2019, 00:15:52 | Afternoon Ride | Ride | 2101 | 12.48 | Pumped up tires |
또는 아래쪽 5개 행:
df.tail()| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
데이터프레임 요약
데이터프레임의 상위 수준 요약을 얻는 데 매우 유용한 세 가지 속성/함수는 다음과 같습니다. - .shape -.info() - .describe()
.shape는 이전에 본 ndarray 속성과 같습니다. 데이터프레임의 모양(행, 열)을 제공합니다.
df.shape(33, 6).info()는 dtype, 메모리 사용량, null이 아닌 값 등과 같은 데이터프레임 자체에 대한 정보를 인쇄합니다.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 33 entries, 0 to 32
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 33 non-null object
1 Name 33 non-null object
2 Type 33 non-null object
3 Time 33 non-null int64
4 Distance 31 non-null float64
5 Comments 33 non-null object
dtypes: float64(1), int64(1), object(4)
memory usage: 1.7+ KB.describe()는 데이터프레임 내 값의 요약 통계를 제공합니다.
df.describe()| Time | Distance | |
|---|---|---|
| count | 33.000000 | 31.000000 |
| mean | 3512.787879 | 12.667419 |
| std | 8003.309233 | 0.428618 |
| min | 1712.000000 | 11.790000 |
| 25% | 1863.000000 | 12.480000 |
| 50% | 2118.000000 | 12.620000 |
| 75% | 2285.000000 | 12.750000 |
| max | 48062.000000 | 14.570000 |
기본적으로 .describe()는 숫자 함수의 요약만 인쇄합니다. include='all' 인수를 사용하여 모든 함수에 대한 요약을 제공하도록 강제할 수 있습니다(비록 말이 안 될 수도 있지만!):
df.describe(include="all")| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| count | 33 | 33 | 33 | 33.000000 | 31.000000 | 33 |
| unique | 33 | 2 | 1 | NaN | NaN | 25 |
| top | 20 Sep 2019, 01:02:05 | Afternoon Ride | Ride | NaN | NaN | Rested after the weekend! |
| freq | 1 | 17 | 33 | NaN | NaN | 3 |
| mean | NaN | NaN | NaN | 3512.787879 | 12.667419 | NaN |
| std | NaN | NaN | NaN | 8003.309233 | 0.428618 | NaN |
| min | NaN | NaN | NaN | 1712.000000 | 11.790000 | NaN |
| 25% | NaN | NaN | NaN | 1863.000000 | 12.480000 | NaN |
| 50% | NaN | NaN | NaN | 2118.000000 | 12.620000 | NaN |
| 75% | NaN | NaN | NaN | 2285.000000 | 12.750000 | NaN |
| max | NaN | NaN | NaN | 48062.000000 | 14.570000 | NaN |
데이터프레임 표시하기
데이터프레임을 효과적으로 표시하는 것은 작업 흐름에서 중요한 부분이 될 수 있습니다. 데이터프레임에 60개 이상의 행이 있는 경우 Pandas는 처음 5개와 마지막 5개 행만 표시합니다.
pd.DataFrame(np.random.rand(100)) # noqa: F405, F811, F821| 0 | |
|---|---|
| 0 | 0.643224 |
| 1 | 0.617756 |
| 2 | 0.650490 |
| 3 | 0.289595 |
| 4 | 0.469394 |
| ... | ... |
| 95 | 0.549403 |
| 96 | 0.187836 |
| 97 | 0.016904 |
| 98 | 0.733392 |
| 99 | 0.875343 |
100 rows × 1 columns
행이 60개 미만인 데이터프레임의 경우 Pandas는 전체 데이터프레임을 인쇄합니다.
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| 5 | 16 Sep 2019, 13:57:48 | Morning Ride | Ride | 2272 | 12.45 | Rested after the weekend! |
| 6 | 17 Sep 2019, 00:15:47 | Afternoon Ride | Ride | 1973 | 12.45 | Legs feeling strong! |
| 7 | 17 Sep 2019, 13:43:34 | Morning Ride | Ride | 2285 | 12.60 | Raining |
| 8 | 18 Sep 2019, 13:49:53 | Morning Ride | Ride | 2903 | 14.57 | Raining today |
| 9 | 18 Sep 2019, 00:15:52 | Afternoon Ride | Ride | 2101 | 12.48 | Pumped up tires |
| 10 | 19 Sep 2019, 00:30:01 | Afternoon Ride | Ride | 48062 | 12.48 | Feeling good |
| 11 | 19 Sep 2019, 13:52:09 | Morning Ride | Ride | 2090 | 12.59 | Getting colder which is nice |
| 12 | 20 Sep 2019, 01:02:05 | Afternoon Ride | Ride | 2961 | 12.81 | Feeling good |
| 13 | 23 Sep 2019, 13:50:41 | Morning Ride | Ride | 2462 | 12.68 | Rested after the weekend! |
| 14 | 24 Sep 2019, 00:35:42 | Afternoon Ride | Ride | 2076 | 12.47 | Oiled chain, bike feels smooth |
| 15 | 24 Sep 2019, 13:41:24 | Morning Ride | Ride | 2321 | 12.68 | Bike feeling much smoother |
| 16 | 25 Sep 2019, 00:07:21 | Afternoon Ride | Ride | 1775 | 12.10 | Feeling really tired |
| 17 | 25 Sep 2019, 13:35:41 | Morning Ride | Ride | 2124 | 12.65 | Stopped for photo of sunrise |
| 18 | 26 Sep 2019, 00:13:33 | Afternoon Ride | Ride | 1860 | 12.52 | raining |
| 19 | 26 Sep 2019, 13:42:43 | Morning Ride | Ride | 2350 | 12.91 | Detour around trucks at Jericho |
| 20 | 27 Sep 2019, 01:00:18 | Afternoon Ride | Ride | 1712 | 12.47 | Tired by the end of the week |
| 21 | 30 Sep 2019, 13:53:52 | Morning Ride | Ride | 2118 | 12.71 | Rested after the weekend! |
| 22 | 1 Oct 2019, 00:15:07 | Afternoon Ride | Ride | 1732 | NaN | Legs feeling strong! |
| 23 | 1 Oct 2019, 13:45:55 | Morning Ride | Ride | 2222 | 12.82 | Beautiful morning! Feeling fit |
| 24 | 2 Oct 2019, 00:13:09 | Afternoon Ride | Ride | 1756 | NaN | A little tired today but good weather |
| 25 | 2 Oct 2019, 13:46:06 | Morning Ride | Ride | 2134 | 13.06 | Bit tired today but good weather |
| 26 | 3 Oct 2019, 00:45:22 | Afternoon Ride | Ride | 1724 | 12.52 | Feeling good |
| 27 | 3 Oct 2019, 13:47:36 | Morning Ride | Ride | 2182 | 12.68 | Wet road |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
저는 60개 행 임계값이 약간 과하다고 생각합니다. 저는 20개 정도를 더 선호합니다. pd.set_option("display.max_rows", 20)을 사용하여 설정을 변경하면 20개 이상의 행이 있는 항목은 이전처럼 첫 번째와 마지막 5개 행으로 요약됩니다.
pd.set_option("display.max_rows", 20)
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
표시되는 열 수, 숫자 형식 지정 방법 등 변경할 수 있는 다른 표시 옵션도 있습니다. 자세한 내용은 공식 문서를 참조하세요.
제가 지적할 표시 옵션 중 하나는 Pandas를 사용하면 음수 값을 강조 표시하거나 데이터 프레임에 조건부 색상 맵을 추가하는 등 테이블 스타일을 지정할 수 있다는 것입니다. 아래에서는 음수(보라색)에서 양수(노란색)까지의 값을 기준으로 값의 스타일을 지정하겠습니다. 더 많은 예를 보려면 스타일링 문서를 참조하세요.
test = pd.DataFrame( # noqa: F811
np.random.randn(5, 5), # noqa: F405, F811, F821
index=[f"row_{_}" for _ in range(5)], # noqa: F811
columns=[f"feature_{_}" for _ in range(5)], # noqa: F811
)
test.style.background_gradient(cmap="plasma")| feature_0 | feature_1 | feature_2 | feature_3 | feature_4 | |
|---|---|---|---|---|---|
| row_0 | -0.519284 | -0.553179 | -1.768810 | 1.023342 | -0.668625 |
| row_1 | -1.064582 | 0.205538 | 0.350555 | -1.942761 | 1.594635 |
| row_2 | 1.057886 | 0.074919 | -0.998969 | -0.030725 | 0.677628 |
| row_3 | 0.898228 | -0.697138 | -0.134935 | -1.592920 | -2.127225 |
| row_4 | 0.039582 | 0.372877 | -0.299539 | -2.132972 | 2.194797 |
조회수와 매수
이전 장에서 우리는 뷰(기존 객체의 일부를 “보는 것”)와 복사본(메모리에 객체의 새로운 복사본을 만드는 것)에 대해 논의했습니다. Pandas에서는 이러한 것들이 약간 추상화되어 “…뷰 또는 복사본을 반환할지 예측하기가 매우 어렵습니다”(이는 Pandas 문서의 전용 섹션에서 인용문입니다).
기본적으로 수행하려는 작업, 데이터 프레임 구조 및 기본 배열의 메모리 레이아웃에 따라 다릅니다. 하지만 걱정하지 마세요. 여러분이 알아야 할 모든 것을 알려드리겠습니다. 첫째, Pandas에서 접하게 되는 가장 일반적인 경고는 ’SettingWithCopy’입니다. Pandas는 자신이 하고 있다고 생각하는 작업을 수행하지 않을 수도 있다는 경고로 이를 발생시킵니다. 예를 살펴보겠습니다. 우리 데이터프레임에 하나의 이상치 ’Time’이 있다는 것을 기억하실 것입니다.
df[df["Time"] > 4000]| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 10 | 19 Sep 2019, 00:30:01 | Afternoon Ride | Ride | 48062 | 12.48 | Feeling good |
이것을 ’2000’으로 변경하고 싶다고 상상해 보세요. 아마도 다음과 같이 할 것입니다:
df[df["Time"] > 4000]["Time"] = 2000/opt/miniconda3/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.곱셈이나 제곱과 같은 계열에 대한 표준 연산을 수행할 수도 있습니다. NumPy는 또한 시리즈가 numpy 배열로 구축되었기 때문에 대부분의 함수에 대한 인수로 시리즈를 허용합니다(나중에 자세히 설명).
df[df["Time"] > 4000]| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 10 | 19 Sep 2019, 00:30:01 | Afternoon Ride | Ride | 48062 | 12.48 | Feeling good |
아니, 그렇지 않았습니다. 아마도 당신은 그렇다고 생각했지만요. 위에서 일어난 일은 df[df['Time'] > 4000]이 먼저 실행되어 데이터프레임의 복사본을 반환했다는 것입니다. id()를 사용하여 확인할 수 있습니다.
print(f"The id of the original dataframe is: {id(df)}")
print(f" The id of the indexed dataframe is: {id(df[df['Time'] > 4000])}")The id of the original dataframe is: 5762156560
The id of the indexed dataframe is: 5781171152그런 다음 ['Time'] = 2000을 추가하여 이 새 객체에 값을 설정하려고 했습니다. Pandas는 원본 데이터프레임의 복사본에서 해당 작업을 수행하고 있다고 경고하는데 이는 아마도 우리가 원하는 것이 아닐 것입니다. 이 문제를 해결하려면 .loc[]를 사용하여 한 번에 색인을 생성해야 합니다. 예를 들면 다음과 같습니다.
df.loc[df["Time"] > 4000, "Time"] = 2000이번에는 오류가 없습니다! 그리고 변경 사항을 확인해 보겠습니다.
df[df["Time"] > 4000]| Date | Name | Type | Time | Distance | Comments |
|---|
두 번째로 알아야 할 것은 무엇인가가 뷰인지 복사본인지 확실하지 않은 경우 .copy() 메서드를 사용하여 데이터프레임의 복사본을 강제로 만들 수 있다는 것입니다. 다음과 같습니다:
df2 = df[df["Time"] > 4000].copy() # noqa: F811이렇게 하면 원하는 대로 수정할 수 있는 복사본이 보장됩니다.
2. 기본 DataFrame 조작
열 이름 바꾸기
두 가지 방법으로 열 이름을 바꿀 수 있습니다. 1. .rename() 사용(선택적으로 열 이름 변경) 2. .columns 속성을 설정하여 (모든 열 이름을 한 번에 변경하려면)
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
한번 시도해 봅시다:
df.rename(columns={"Date": "Datetime", "Comments": "Notes"})
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
기다리다? 무슨 일이에요? 아무것도 바뀌지 않았나요? 위의 코드에서는 실제로 데이터프레임의 열 이름을 바꾸었지만 데이터프레임을 수정하지 않고 복사본을 만들었습니다. 영구적인 데이터프레임 변경에는 일반적으로 두 가지 옵션이 있습니다. - 1. 대부분의 함수/메소드에서 사용할 수 있는 inplace=True 인수(예: df.rename(..., inplace=True))를 사용합니다. - 2. 재할당(예: df = df.rename(...)) Pandas 팀에서는 몇 가지 이유로 인해 방법 2(재할당)을 권장합니다(대부분 내부적으로 메모리가 할당되는 방식과 관련이 있음).
df = df.rename(columns={"Date": "Datetime", "Comments": "Notes"}) # noqa: F811
df| Datetime | Name | Type | Time | Distance | Notes | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
데이터프레임의 모든 열을 변경하려면 .columns 속성을 설정하면 됩니다.
df.columns = [f"Column {_}" for _ in range(1, 7)]
df| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
색인 변경
세 가지 주요 방법으로 데이터프레임의 인덱스 레이블을 변경할 수 있습니다. 1. 데이터 프레임의 열 중 하나를 인덱스로 만드는 .set_index() 2. df.index.name을 직접 수정하여 인덱스 이름 변경 3. .reset_index()는 현재 인덱스를 열로 이동하고 0부터 시작하는 정수 레이블로 인덱스를 재설정합니다. 4. .index() 속성을 직접 수정합니다.
df| Column 1 | Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
아래에서는 인덱스를 Column 1로 설정하고 인덱스 이름을 “New Index”로 바꿉니다.
df = df.set_index("Column 1") # noqa: F811
df.index.name = "New Index"
df| Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | |
|---|---|---|---|---|---|
| New Index | |||||
| 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... |
| 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 5 columns
.reset_index()를 사용하여 인덱스를 다시 열로 보내고 기본 정수 인덱스를 가질 수 있습니다.
df = df.reset_index() # noqa: F811
df| New Index | Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
열 이름과 마찬가지로 인덱스를 직접 수정할 수도 있지만 이렇게 한 기억은 없습니다. 일반적으로 .set_index()를 사용합니다.
df.indexRangeIndex(start=0, stop=33, step=1)df.index = range(100, 133, 1)
df| New Index | Column 2 | Column 3 | Column 4 | Column 5 | Column 6 | |
|---|---|---|---|---|---|---|
| 100 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 101 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 102 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 103 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 104 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 128 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 129 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 130 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 131 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 132 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
열 추가/제거
데이터프레임의 열을 추가/제거하는 두 가지 주요 방법이 있습니다. 1. []를 사용하여 열을 추가하세요. 2. .drop()을 사용하여 열을 삭제합니다.
사이클링 데이터세트의 새로운 사본을 다시 읽어보겠습니다.
df = pd.read_csv("data/cycling_data.csv") # noqa: F811
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
새 열 이름과 값과 함께 []를 사용하면 데이터프레임에 새 열을 추가할 수 있습니다.
df["Rider"] = "Tom Beuzen"
df["Avg Speed"] = df["Distance"] * 1000 / df["Time"] # avg. speed in m/s
df| Date | Name | Type | Time | Distance | Comments | Rider | Avg Speed | |
|---|---|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain | Tom Beuzen | 6.055662 |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain | Tom Beuzen | 5.148163 |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather | Tom Beuzen | 6.720344 |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise | Tom Beuzen | 5.857664 |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week | Tom Beuzen | 6.599683 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind | Tom Beuzen | 6.754011 |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good | Tom Beuzen | 5.909725 |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! | Tom Beuzen | 6.838675 |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise | Tom Beuzen | 5.192854 |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump | Tom Beuzen | 6.397179 |
33 rows × 8 columns
df = df.drop(columns=["Rider", "Avg Speed"]) # noqa: F811
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
행 추가/제거
데이터프레임에 행을 수동으로 추가하는 경우는 많지 않습니다(일반적으로 연결/조인을 통해 행을 추가합니다. 이에 대해서는 다음에 설명하겠습니다). 다음 두 가지 방법으로 데이터프레임의 행을 추가/제거할 수 있습니다. 1. .append()를 사용하여 행을 추가합니다. 2. .drop()을 사용하여 행을 삭제합니다.
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
이 데이터프레임의 맨 아래에 새 행을 추가해 보겠습니다.
another_row = pd.DataFrame( # noqa: F811
[
[
"12 Oct 2019, 00:10:57",
"Morning Ride",
"Ride",
2331,
12.67,
"Washed and oiled bike last night",
]
],
columns=df.columns, # noqa: F811
index=[33], # noqa: F811
)
df = df.append(another_row) # noqa: F811
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
| 33 | 12 Oct 2019, 00:10:57 | Morning Ride | Ride | 2331 | 12.67 | Washed and oiled bike last night |
34 rows × 6 columns
.drop()을 사용하여 인덱스 30 위의 모든 행을 삭제할 수 있습니다.
df.drop(index=range(30, 34))| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 25 | 2 Oct 2019, 13:46:06 | Morning Ride | Ride | 2134 | 13.06 | Bit tired today but good weather |
| 26 | 3 Oct 2019, 00:45:22 | Afternoon Ride | Ride | 1724 | 12.52 | Feeling good |
| 27 | 3 Oct 2019, 13:47:36 | Morning Ride | Ride | 2182 | 12.68 | Wet road |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
30 rows × 6 columns
3. 데이터프레임 재구성
Tidy 데이터는 “데이터세트의 구조를 의미(의미)와 연결”에 관한 것입니다. 이는 다음과 같이 정의됩니다. 1. 각 변수는 열을 형성합니다. 2. 각 관측치가 행을 형성합니다. 3. 각 유형의 관측 단위가 테이블을 구성합니다.
데이터프레임을 깔끔하게 만들기 위해(또는 다른 목적으로) 데이터프레임의 모양을 변경해야 하는 경우가 많습니다.

출처: r4ds
용융 및 피벗
Pandas .melt(), .pivot() 및 .pivot_table()은 데이터프레임 재구성에 도움이 될 수 있습니다. - .melt(): 넓은 데이터를 길게 만듭니다. - .pivot(): 데이터 폭을 길게 만듭니다. - .pivot_table(): .pivot()과 동일하지만 여러 인덱스를 처리할 수 있습니다.
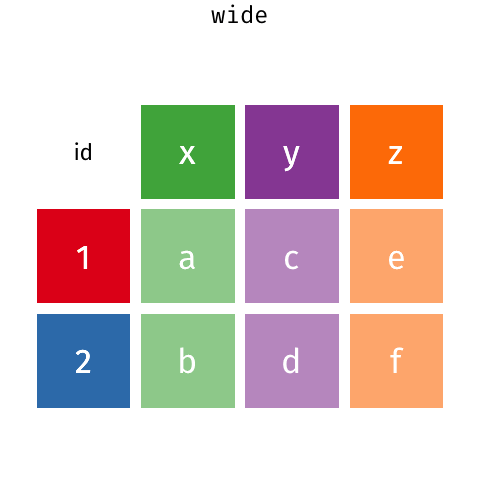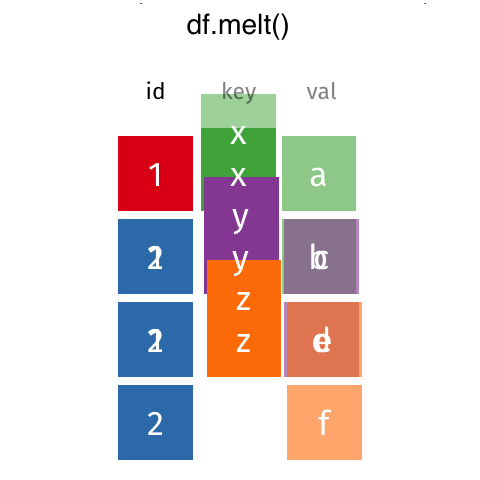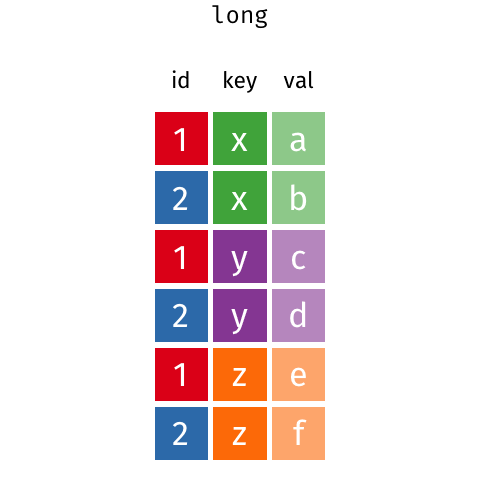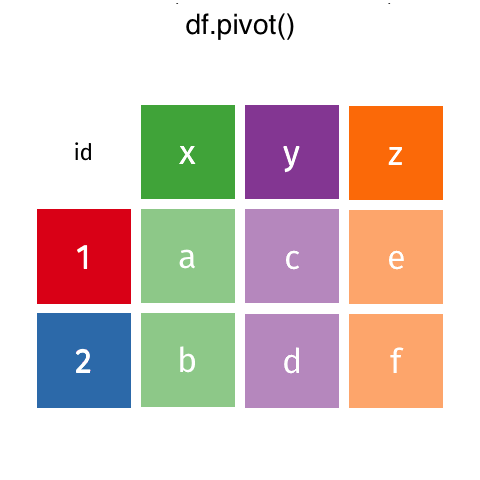
아래 데이터는 다양한 강사가 다양한 연도에 걸쳐 가르친 강좌 수를 보여줍니다. 당신이 대답하고 싶은 질문이 “연도에 따라 가르치는 과목의 수가 달라지나요?”와 같은 것이라면, 다음은 한 행에 1년 동안 진행된 과정에 대한 관찰이 여러 개 있기 때문에 아마도 정리된 것으로 간주되지 않을 것입니다(즉, 2018, 2019 및 2020에 대한 데이터가 단일 행에 있음).
df = pd.DataFrame( # noqa: F811
{
"Name": ["Tom", "Mike", "Tiffany", "Varada", "Joel"],
"2018": [1, 3, 4, 5, 3],
"2019": [2, 4, 3, 2, 1],
"2020": [5, 2, 4, 4, 3],
}
)
df| Name | 2018 | 2019 | 2020 | |
|---|---|---|---|---|
| 0 | Tom | 1 | 2 | 5 |
| 1 | Mike | 3 | 4 | 2 |
| 2 | Tiffany | 4 | 3 | 4 |
| 3 | Varada | 5 | 2 | 4 |
| 4 | Joel | 3 | 1 | 3 |
.melt()로 깔끔하게 만들어 보겠습니다. .melt()는 몇 가지 인수를 취하는데, 가장 중요한 것은 “식별자”가 되어야 하는 열을 나타내는 id_vars입니다.
df_melt = df.melt(id_vars="Name", var_name="Year", value_name="Courses") # noqa: F811
df_melt| Name | Year | Courses | |
|---|---|---|---|
| 0 | Tom | 2018 | 1 |
| 1 | Mike | 2018 | 3 |
| 2 | Tiffany | 2018 | 4 |
| 3 | Varada | 2018 | 5 |
| 4 | Joel | 2018 | 3 |
| 5 | Tom | 2019 | 2 |
| 6 | Mike | 2019 | 4 |
| 7 | Tiffany | 2019 | 3 |
| 8 | Varada | 2019 | 2 |
| 9 | Joel | 2019 | 1 |
| 10 | Tom | 2020 | 5 |
| 11 | Mike | 2020 | 2 |
| 12 | Tiffany | 2020 | 4 |
| 13 | Varada | 2020 | 4 |
| 14 | Joel | 2020 | 3 |
value_vars 인수를 사용하면 “용해”하려는 특정 변수를 선택할 수 있습니다(value_vars를 지정하지 않으면 식별자가 아닌 모든 열이 사용됩니다). 예를 들어 아래에서는 2018 열을 생략했습니다.
df.melt(
id_vars="Name",
value_vars=["2019", "2020"],
var_name="Year",
value_name="Courses", # noqa: F811
)| Name | Year | Courses | |
|---|---|---|---|
| 0 | Tom | 2019 | 2 |
| 1 | Mike | 2019 | 4 |
| 2 | Tiffany | 2019 | 3 |
| 3 | Varada | 2019 | 2 |
| 4 | Joel | 2019 | 1 |
| 5 | Tom | 2020 | 5 |
| 6 | Mike | 2020 | 2 |
| 7 | Tiffany | 2020 | 4 |
| 8 | Varada | 2020 | 4 |
| 9 | Joel | 2020 | 3 |
때로는 .pivot()을 사용하여 긴 데이터를 넓게 만들고 싶을 때가 있습니다. .pivot()을 사용할 때 피벗할 인덱스와 더 넓은 데이터프레임의 새 열을 만드는 데 사용될 열을 지정해야 합니다.
df_pivot = df_melt.pivot(index="Name", columns="Year", values="Courses") # noqa: F811
df_pivot| Year | 2018 | 2019 | 2020 |
|---|---|---|---|
| Name | |||
| Joel | 3 | 1 | 3 |
| Mike | 3 | 4 | 2 |
| Tiffany | 4 | 3 | 4 |
| Tom | 1 | 2 | 5 |
| Varada | 5 | 2 | 4 |
Pandas는 지정된 index를 새 데이터 프레임의 인덱스로 설정하고 열의 레이블을 유지한다는 것을 알 수 있습니다. 이러한 이름을 쉽게 제거하고 인덱스를 재설정하여 데이터프레임을 원래처럼 보이게 만들 수 있습니다.
df_pivot = df_pivot.reset_index() # noqa: F811
df_pivot.columns.name = None
df_pivot| Name | 2018 | 2019 | 2020 | |
|---|---|---|---|---|
| 0 | Joel | 3 | 1 | 3 |
| 1 | Mike | 3 | 4 | 2 |
| 2 | Tiffany | 4 | 3 | 4 |
| 3 | Tom | 1 | 2 | 5 |
| 4 | Varada | 5 | 2 | 4 |
.pivot()은 종종 원하는 것을 얻을 수 있지만 다음과 같은 경우에는 작동하지 않습니다. - 여러 인덱스를 사용하거나(다음 장) - 중복된 인덱스/열 레이블이 있습니다.
이러한 경우 .pivot_table()을 사용해야 합니다. 여기서는 pivot()에 대해 먼저 배우는 것이 좋기 때문에 여기서는 너무 많이 집중하지 않겠습니다.
df = pd.DataFrame( # noqa: F811
{
"Name": ["Tom", "Tom", "Mike", "Mike"],
"Department": ["CS", "STATS", "CS", "STATS"],
"2018": [1, 2, 3, 1],
"2019": [2, 3, 4, 2],
"2020": [5, 1, 2, 2],
}
).melt(id_vars=["Name", "Department"], var_name="Year", value_name="Courses")
df| Name | Department | Year | Courses | |
|---|---|---|---|---|
| 0 | Tom | CS | 2018 | 1 |
| 1 | Tom | STATS | 2018 | 2 |
| 2 | Mike | CS | 2018 | 3 |
| 3 | Mike | STATS | 2018 | 1 |
| 4 | Tom | CS | 2019 | 2 |
| 5 | Tom | STATS | 2019 | 3 |
| 6 | Mike | CS | 2019 | 4 |
| 7 | Mike | STATS | 2019 | 2 |
| 8 | Tom | CS | 2020 | 5 |
| 9 | Tom | STATS | 2020 | 1 |
| 10 | Mike | CS | 2020 | 2 |
| 11 | Mike | STATS | 2020 | 2 |
위의 경우 이름에 중복이 있으므로 pivot()이 작동하지 않습니다. ValueError: Index에 중복 항목이 포함되어 있어 모양을 변경할 수 없습니다가 발생합니다.
df.pivot(index="Name", columns="Year", values="Courses")--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-41-585e29950052> in <module> 1 df.pivot(index="Name", 2 columns="Year", ----> 3 values="Courses") /opt/miniconda3/lib/python3.7/site-packages/pandas/core/frame.py in pivot(self, index, columns, values) 6669 from pandas.core.reshape.pivot import pivot 6670 -> 6671 return pivot(self, index=index, columns=columns, values=values) 6672 6673 _shared_docs[ /opt/miniconda3/lib/python3.7/site-packages/pandas/core/reshape/pivot.py in pivot(data, index, columns, values) 475 else: 476 indexed = data._constructor_sliced(data[values]._values, index=index) --> 477 return indexed.unstack(columns) 478 479 /opt/miniconda3/lib/python3.7/site-packages/pandas/core/series.py in unstack(self, level, fill_value) 3888 from pandas.core.reshape.reshape import unstack 3889 -> 3890 return unstack(self, level, fill_value) 3891 3892 # ---------------------------------------------------------------------- /opt/miniconda3/lib/python3.7/site-packages/pandas/core/reshape/reshape.py in unstack(obj, level, fill_value) 423 return _unstack_extension_series(obj, level, fill_value) 424 unstacker = _Unstacker( --> 425 obj.index, level=level, constructor=obj._constructor_expanddim, 426 ) 427 return unstacker.get_result( /opt/miniconda3/lib/python3.7/site-packages/pandas/core/reshape/reshape.py in __init__(self, index, level, constructor) 118 raise ValueError("Unstacked DataFrame is too big, causing int32 overflow") 119 --> 120 self._make_selectors() 121 122 @cache_readonly /opt/miniconda3/lib/python3.7/site-packages/pandas/core/reshape/reshape.py in _make_selectors(self) 167 168 if mask.sum() < len(self.index): --> 169 raise ValueError("Index contains duplicate entries, cannot reshape") 170 171 self.group_index = comp_index ValueError: Index contains duplicate entries, cannot reshape
그러한 경우 .pivot_table()을 사용합니다. 중복 항목에 집계 함수를 적용합니다. 이 경우에는 ’sum()’을 사용합니다.
df.pivot_table(index="Name", columns="Year", values="Courses", aggfunc="sum")| Year | 2018 | 2019 | 2020 |
|---|---|---|---|
| Name | |||
| Mike | 4 | 6 | 4 |
| Tom | 3 | 5 | 6 |
부서별 번호를 유지하려면 Name과 Department를 모두 여러 인덱스로 지정할 수 있습니다.
df.pivot_table(index=["Name", "Department"], columns="Year", values="Courses")| Year | 2018 | 2019 | 2020 | |
|---|---|---|---|---|
| Name | Department | |||
| Mike | CS | 3 | 4 | 2 |
| STATS | 1 | 2 | 2 | |
| Tom | CS | 1 | 2 | 5 |
| STATS | 2 | 3 | 1 |
위의 결과는 다중 인덱스 또는 “계층적으로 인덱스된” 데이터 프레임입니다(다음 장에서 자세히 설명). 사용해야 하는 경우 문서에서 pivot_table()에 대해 자세히 알아볼 수 있습니다.
4. 여러 DataFrame으로 작업하기
함께 묶거나 병합하려는 여러 데이터프레임을 사용하여 작업하는 경우가 많습니다. df.merge() 및 df.concat()은 데이터프레임 결합에 대해 알아야 할 전부입니다. Pandas 문서는 이러한 함수에 매우 유용하지만 이해하기가 매우 쉽습니다.
Note
이 섹션에 표시된 조인 예는 Jenny Bryan의 STAT 545 자료의 15장에서 영감을 받았습니다.
pd.concat()을 사용하여 데이터프레임 고정
pd.concat()을 사용하여 데이터프레임을 서로 붙일 수 있습니다: - 수직: 동일한 열이 있는 경우 또는 - 가로: 동일한 행이 있는 경우
df1 = pd.DataFrame({"A": [1, 3, 5], "B": [2, 4, 6]}) # noqa: F811
df2 = pd.DataFrame({"A": [7, 9, 11], "B": [8, 10, 12]}) # noqa: F811df1| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
df2| A | B | |
|---|---|---|
| 0 | 7 | 8 |
| 1 | 9 | 10 |
| 2 | 11 | 12 |
pd.concat((df1, df2), axis=0) # axis=0 specifies a vertical stick, i.e., on the columns| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
| 0 | 7 | 8 |
| 1 | 9 | 10 |
| 2 | 11 | 12 |
인덱스가 단순히 서로 결합되었다는 점에 주목하세요. 이것은 당신이 원하는 것일 수도 있고 아닐 수도 있습니다. 인덱스를 재설정하려면 ‘ignore_index=True’ 인수를 지정하면 됩니다.
pd.concat((df1, df2), axis=0, ignore_index=True)| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
| 3 | 7 | 8 |
| 4 | 9 | 10 |
| 5 | 11 | 12 |
가로로 서로 붙이려면 axis=1을 사용하세요.
pd.concat((df1, df2), axis=1, ignore_index=True)| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1 | 2 | 7 | 8 |
| 1 | 3 | 4 | 9 | 10 |
| 2 | 5 | 6 | 11 | 12 |
두 개의 데이터프레임으로 제한되지 않고 원하는 만큼 연결할 수 있습니다.
pd.concat((df1, df2, df1, df2), axis=0, ignore_index=True)| A | B | |
|---|---|---|
| 0 | 1 | 2 |
| 1 | 3 | 4 |
| 2 | 5 | 6 |
| 3 | 7 | 8 |
| 4 | 9 | 10 |
| 5 | 11 | 12 |
| 6 | 1 | 2 |
| 7 | 3 | 4 |
| 8 | 5 | 6 |
| 9 | 7 | 8 |
| 10 | 9 | 10 |
| 11 | 11 | 12 |
pd.merge()를 사용하여 DataFrame 결합하기
pd.merge()는 다른 규칙을 사용하여 데이터프레임을 “결합”하는 함수을 제공합니다(SQL에 익숙하다면 SQL과 마찬가지로). df.merge()를 사용하여 공유 키 열을 기반으로 데이터프레임을 조인할 수 있습니다. 방법은 다음과 같습니다. - “내부 조인” - “외부 조인” - “왼쪽 조인” - “오른쪽 가입”
자세한 내용은 이 훌륭한 치트 시트 및 이 훌륭한 애니메이션을 참조하세요.
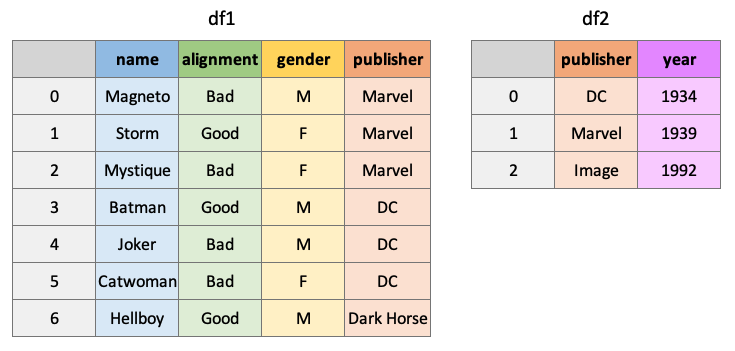
df1 = pd.DataFrame( # noqa: F811
{
"name": [
"Magneto",
"Storm",
"Mystique",
"Batman",
"Joker",
"Catwoman",
"Hellboy",
],
"alignment": ["bad", "good", "bad", "good", "bad", "bad", "good"],
"gender": ["male", "female", "female", "male", "male", "female", "male"],
"publisher": [
"Marvel",
"Marvel",
"Marvel",
"DC",
"DC",
"DC",
"Dark Horse Comics",
],
}
)
df2 = pd.DataFrame( # noqa: F811
{"publisher": ["DC", "Marvel", "Image"], "year_founded": [1934, 1939, 1992]}
)
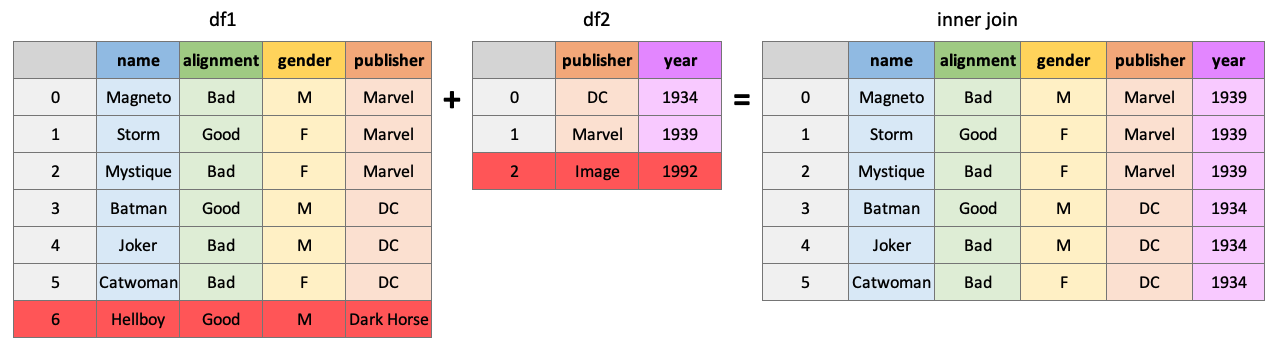
‘내부’ 조인은 df2에서 ’publisher’에 대한 일치 값이 발견된 df1의 모든 행을 반환합니다.
pd.merge(df1, df2, how="inner", on="publisher")| name | alignment | gender | publisher | year_founded | |
|---|---|---|---|---|---|
| 0 | Magneto | bad | male | Marvel | 1939 |
| 1 | Storm | good | female | Marvel | 1939 |
| 2 | Mystique | bad | female | Marvel | 1939 |
| 3 | Batman | good | male | DC | 1934 |
| 4 | Joker | bad | male | DC | 1934 |
| 5 | Catwoman | bad | female | DC | 1934 |
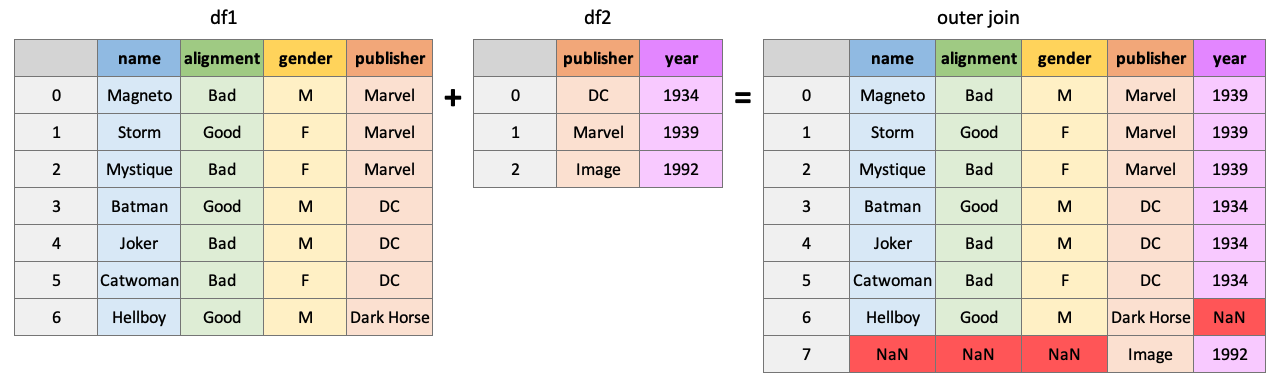
“외부” 조인은 df1 및 df2의 모든 행을 반환하여 정보를 사용할 수 없는 곳에 NaN을 배치합니다.
pd.merge(df1, df2, how="outer", on="publisher")| name | alignment | gender | publisher | year_founded | |
|---|---|---|---|---|---|
| 0 | Magneto | bad | male | Marvel | 1939.0 |
| 1 | Storm | good | female | Marvel | 1939.0 |
| 2 | Mystique | bad | female | Marvel | 1939.0 |
| 3 | Batman | good | male | DC | 1934.0 |
| 4 | Joker | bad | male | DC | 1934.0 |
| 5 | Catwoman | bad | female | DC | 1934.0 |
| 6 | Hellboy | good | male | Dark Horse Comics | NaN |
| 7 | NaN | NaN | NaN | Image | 1992.0 |
df1의 모든 행과 df1 및 df2의 모든 열을 반환하며, 일치하는 부분이 채워집니다.
pd.merge(df1, df2, how="left", on="publisher")| name | alignment | gender | publisher | year_founded | |
|---|---|---|---|---|---|
| 0 | Magneto | bad | male | Marvel | 1939.0 |
| 1 | Storm | good | female | Marvel | 1939.0 |
| 2 | Mystique | bad | female | Marvel | 1939.0 |
| 3 | Batman | good | male | DC | 1934.0 |
| 4 | Joker | bad | male | DC | 1934.0 |
| 5 | Catwoman | bad | female | DC | 1934.0 |
| 6 | Hellboy | good | male | Dark Horse Comics | NaN |
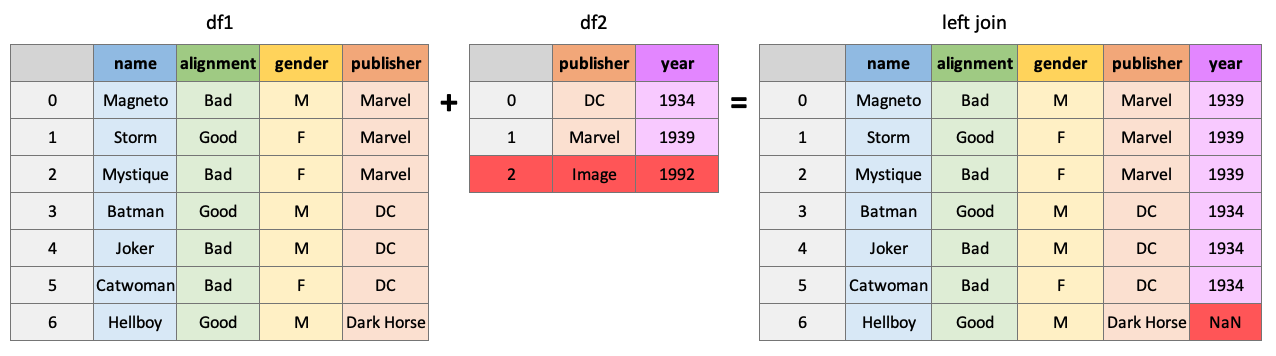
pd.merge(df1, df2, how="right", on="publisher")| name | alignment | gender | publisher | year_founded | |
|---|---|---|---|---|---|
| 0 | Batman | good | male | DC | 1934 |
| 1 | Joker | bad | male | DC | 1934 |
| 2 | Catwoman | bad | female | DC | 1934 |
| 3 | Magneto | bad | male | Marvel | 1939 |
| 4 | Storm | good | female | Marvel | 1939 |
| 5 | Mystique | bad | female | Marvel | 1939 |
| 6 | NaN | NaN | NaN | Image | 1992 |
데이터프레임을 조인하기 위해 ‘키’를 지정하는 방법은 여러 가지가 있습니다. 인덱스 값, 다른 항목, 열 이름 등에 대해 조인할 수 있습니다. 또 다른 유용한 인수는 데이터프레임에서 일치 항목이 발견된 위치를 알려주는 결과에 열을 추가하는 ’indicator’ 인수입니다.
pd.merge(df1, df2, how="outer", on="publisher", indicator=True)| name | alignment | gender | publisher | year_founded | _merge | |
|---|---|---|---|---|---|---|
| 0 | Magneto | bad | male | Marvel | 1939.0 | both |
| 1 | Storm | good | female | Marvel | 1939.0 | both |
| 2 | Mystique | bad | female | Marvel | 1939.0 | both |
| 3 | Batman | good | male | DC | 1934.0 | both |
| 4 | Joker | bad | male | DC | 1934.0 | both |
| 5 | Catwoman | bad | female | DC | 1934.0 | both |
| 6 | Hellboy | good | male | Dark Horse Comics | NaN | left_only |
| 7 | NaN | NaN | NaN | Image | 1992.0 | right_only |
그런데 pd.concat()을 사용하면 여러 데이터드램에서 간단한 “내부” 또는 “외부” 조인을 동시에 수행할 수 있습니다. 병합보다 유연성은 떨어지지만 때로는 유용할 수 있습니다.
5. 추가 DataFrame 작업
사용자 정의 함수 적용
Pandas에 내장되지 않은 함수을 적용하고 싶을 때가 있을 것입니다. 이를 위해 다음과 같은 방법도 있습니다. - df.apply(), 데이터프레임 전체에 걸쳐 열 방향 또는 행 방향으로 함수를 적용합니다(함수는 배열을 허용/반환할 수 있어야 합니다). - df.applymap(), 요소별로 함수를 적용합니다(한 번에 단일 값을 허용/반환하는 함수의 경우). - series.apply()/series.map(), 위와 동일하지만 Pandas 시리즈용
예를 들어 데이터프레임의 열에 numpy 함수를 사용한다고 가정해 보겠습니다.
df = pd.read_csv("data/cycling_data.csv") # noqa: F811
df[["Time", "Distance"]].apply(np.sin)| Time | Distance | |
|---|---|---|
| 0 | -0.901866 | 0.053604 |
| 1 | -0.901697 | 0.447197 |
| 2 | -0.035549 | -0.046354 |
| 3 | -0.739059 | 0.270228 |
| 4 | -0.236515 | -0.086263 |
| ... | ... | ... |
| 28 | -0.683372 | 0.063586 |
| 29 | 0.150056 | 0.133232 |
| 30 | 0.026702 | 0.023627 |
| 31 | -0.008640 | 0.221770 |
| 32 | 0.897861 | -0.700695 |
33 rows × 2 columns
또는 사용자 정의 함수을 적용할 수도 있습니다.
def seconds_to_hours(x): # noqa: F811
return x / 3600
df[["Time"]].apply(seconds_to_hours)| Time | |
|---|---|
| 0 | 0.578889 |
| 1 | 0.703056 |
| 2 | 0.517500 |
| 3 | 0.608889 |
| 4 | 0.525278 |
| ... | ... |
| 28 | 0.519444 |
| 29 | 0.596944 |
| 30 | 0.511389 |
| 31 | 0.684167 |
| 32 | 0.511944 |
33 rows × 1 columns
이것은 람다 함수로 더 좋았을 수도 있습니다 …
df[["Time"]].apply(lambda x: x / 3600)| Time | |
|---|---|
| 0 | 0.578889 |
| 1 | 0.703056 |
| 2 | 0.517500 |
| 3 | 0.608889 |
| 4 | 0.525278 |
| ... | ... |
| 28 | 0.519444 |
| 29 | 0.596944 |
| 30 | 0.511389 |
| 31 | 0.684167 |
| 32 | 0.511944 |
33 rows × 1 columns
추가 인수가 필요한 함수를 사용할 수도 있습니다. .apply()에 인수를 지정하기만 하면 됩니다.
def convert_seconds(x, to="hours"): # noqa: F811
if to == "hours":
return x / 3600
elif to == "minutes":
return x / 60
df[["Time"]].apply(convert_seconds, to="minutes")| Time | |
|---|---|
| 0 | 34.733333 |
| 1 | 42.183333 |
| 2 | 31.050000 |
| 3 | 36.533333 |
| 4 | 31.516667 |
| ... | ... |
| 28 | 31.166667 |
| 29 | 35.816667 |
| 30 | 30.683333 |
| 31 | 41.050000 |
| 32 | 30.716667 |
33 rows × 1 columns
일부 함수는 스칼라만 허용/반환합니다.
int(3.141)3float([3.141, 10.345])--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-62-97f9c30c3ff1> in <module> ----> 1 float([3.141, 10.345]) TypeError: float() argument must be a string or a number, not 'list'
이를 위해서는 .applymap()이 필요합니다:
df[["Time"]].applymap(int)| Time | |
|---|---|
| 0 | 2084 |
| 1 | 2531 |
| 2 | 1863 |
| 3 | 2192 |
| 4 | 1891 |
| ... | ... |
| 28 | 1870 |
| 29 | 2149 |
| 30 | 1841 |
| 31 | 2463 |
| 32 | 1843 |
33 rows × 1 columns
그러나 이와 같은 일반적인 함수의 “벡터화된” 버전이 이미 사용 가능하여 훨씬 더 빠른 경우가 많습니다. 위의 경우 .astype()을 사용하여 전체 열의 dtype을 빠르게 변경할 수 있습니다.
time_applymap = %timeit -q -o -r 3 df[['Time']].applymap(float) # noqa: F811
time_builtin = %timeit -q -o -r 3 df[['Time']].astype(float) # noqa: F811
print(
f"'astype' is {time_applymap.average / time_builtin.average:.2f} faster than 'applymap'!"
)'astype' is 1.98 faster than 'applymap'!그룹화
종종 우리는 데이터의 특정 그룹을 조사하는 데 관심이 있습니다. df.groupby()를 사용하면 변수를 기준으로 데이터를 그룹화할 수 있습니다.
df = pd.read_csv("data/cycling_data.csv") # noqa: F811
df| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
33 rows × 6 columns
이 데이터프레임을 ‘이름’ 열에 그룹화해 보겠습니다.
dfg = df.groupby(by="Name") # noqa: F811
dfg<pandas.core.groupby.generic.DataFrameGroupBy object at 0x1577bb150>DataFrameGroupBy 객체란 무엇입니까? 여기에는 데이터프레임 그룹에 대한 정보가 포함됩니다.
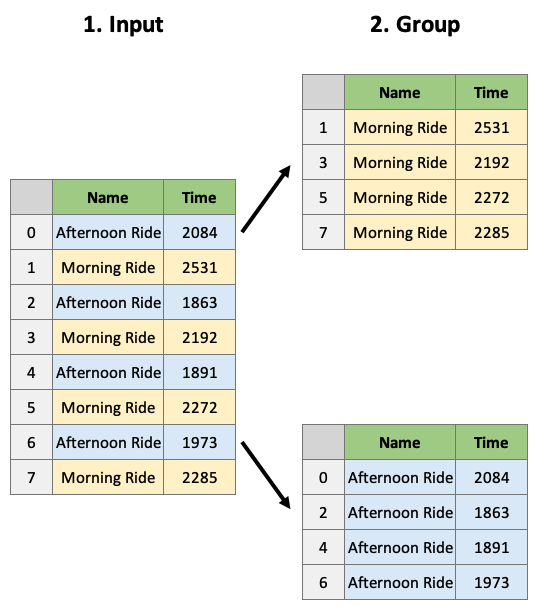
groupby 객체는 실제로 인덱스 매핑 딕셔너리이며, 원하는 경우 다음을 볼 수 있습니다.
dfg.groups{'Afternoon Ride': [0, 2, 4, 6, 9, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32], 'Morning Ride': [1, 3, 5, 7, 8, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31]}.get_group() 메소드를 사용하여 그룹에 접근할 수도 있습니다:
dfg.get_group("Afternoon Ride")| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| 6 | 17 Sep 2019, 00:15:47 | Afternoon Ride | Ride | 1973 | 12.45 | Legs feeling strong! |
| 9 | 18 Sep 2019, 00:15:52 | Afternoon Ride | Ride | 2101 | 12.48 | Pumped up tires |
| 10 | 19 Sep 2019, 00:30:01 | Afternoon Ride | Ride | 48062 | 12.48 | Feeling good |
| 12 | 20 Sep 2019, 01:02:05 | Afternoon Ride | Ride | 2961 | 12.81 | Feeling good |
| 14 | 24 Sep 2019, 00:35:42 | Afternoon Ride | Ride | 2076 | 12.47 | Oiled chain, bike feels smooth |
| 16 | 25 Sep 2019, 00:07:21 | Afternoon Ride | Ride | 1775 | 12.10 | Feeling really tired |
| 18 | 26 Sep 2019, 00:13:33 | Afternoon Ride | Ride | 1860 | 12.52 | raining |
| 20 | 27 Sep 2019, 01:00:18 | Afternoon Ride | Ride | 1712 | 12.47 | Tired by the end of the week |
| 22 | 1 Oct 2019, 00:15:07 | Afternoon Ride | Ride | 1732 | NaN | Legs feeling strong! |
| 24 | 2 Oct 2019, 00:13:09 | Afternoon Ride | Ride | 1756 | NaN | A little tired today but good weather |
| 26 | 3 Oct 2019, 00:45:22 | Afternoon Ride | Ride | 1724 | 12.52 | Feeling good |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
그러나 일반적으로 해야 할 일은 groupby 객체에 집계 함수를 적용하는 것입니다.
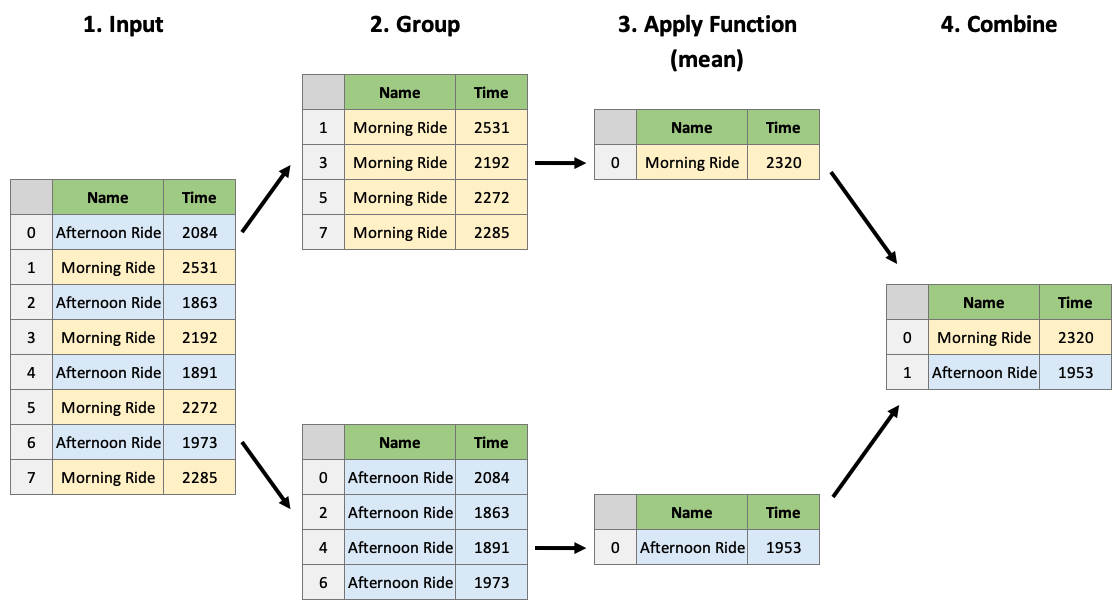
dfg.mean()| Time | Distance | |
|---|---|---|
| Name | ||
| Afternoon Ride | 4654.352941 | 12.462 |
| Morning Ride | 2299.875000 | 12.860 |
.aggregate()를 사용하여 여러 함수를 적용할 수 있습니다.
dfg.aggregate(["mean", "sum", "count"])| Time | Distance | |||||
|---|---|---|---|---|---|---|
| mean | sum | count | mean | sum | count | |
| Name | ||||||
| Afternoon Ride | 4654.352941 | 79124 | 17 | 12.462 | 186.93 | 15 |
| Morning Ride | 2299.875000 | 36798 | 16 | 12.860 | 205.76 | 16 |
그리고 다른 열에 다른 함수을 적용할 수도 있습니다.
def num_range(x): # noqa: F811
return x.max() - x.min()
dfg.aggregate({"Time": ["max", "min", "mean", num_range], "Distance": ["sum"]})| Time | Distance | ||||
|---|---|---|---|---|---|
| max | min | mean | num_range | sum | |
| Name | |||||
| Afternoon Ride | 48062 | 1712 | 4654.352941 | 46350 | 186.93 |
| Morning Ride | 2903 | 2090 | 2299.875000 | 813 | 205.76 |
그런데 그룹화되지 않은 데이터 프레임에도 집계를 사용할 수 있습니다. 이것은 df.describe가 내부적으로 수행하는 작업과 거의 같습니다:
df.agg(["mean", "min", "count", num_range])| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| min | 1 Oct 2019, 00:15:07 | Afternoon Ride | Ride | 1712.000000 | 11.790000 | A little tired today but good weather |
| count | 33 | 33 | 33 | 33.000000 | 31.000000 | 33 |
| mean | NaN | NaN | NaN | 3512.787879 | 12.667419 | NaN |
| num_range | NaN | NaN | NaN | 46350.000000 | 2.780000 | NaN |
누락된 값 처리
누락된 값은 일반적으로 ’NaN’으로 표시됩니다. df.isnull()을 사용하여 데이터프레임에서 누락된 값을 찾을 수 있습니다. 데이터프레임의 각 요소에 대해 불리언(Boolean)을 반환합니다.
df.isnull()| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | False | False | False | False | False | False |
| 1 | False | False | False | False | False | False |
| 2 | False | False | False | False | False | False |
| 3 | False | False | False | False | False | False |
| 4 | False | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | False | False | False | False | False | False |
| 29 | False | False | False | False | False | False |
| 30 | False | False | False | False | False | False |
| 31 | False | False | False | False | False | False |
| 32 | False | False | False | False | False | False |
33 rows × 6 columns
하지만 일반적으로 .any() 또는 .info() 메서드를 사용하여 행이나 열별로 이 정보를 얻는 것이 더 도움이 됩니다.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 33 entries, 0 to 32
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 33 non-null object
1 Name 33 non-null object
2 Type 33 non-null object
3 Time 33 non-null int64
4 Distance 31 non-null float64
5 Comments 33 non-null object
dtypes: float64(1), int64(1), object(4)
memory usage: 1.7+ KBdf[df.isnull().any(axis=1)]| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 22 | 1 Oct 2019, 00:15:07 | Afternoon Ride | Ride | 1732 | NaN | Legs feeling strong! |
| 24 | 2 Oct 2019, 00:13:09 | Afternoon Ride | Ride | 1756 | NaN | A little tired today but good weather |
누락된 값이 있는 경우 일반적으로 해당 값을 삭제하거나 대치합니다.df.dropna()를 사용하여 누락된 값을 삭제할 수 있습니다.
df.dropna()| Date | Name | Type | Time | Distance | Comments | |
|---|---|---|---|---|---|---|
| 0 | 10 Sep 2019, 00:13:04 | Afternoon Ride | Ride | 2084 | 12.62 | Rain |
| 1 | 10 Sep 2019, 13:52:18 | Morning Ride | Ride | 2531 | 13.03 | rain |
| 2 | 11 Sep 2019, 00:23:50 | Afternoon Ride | Ride | 1863 | 12.52 | Wet road but nice weather |
| 3 | 11 Sep 2019, 14:06:19 | Morning Ride | Ride | 2192 | 12.84 | Stopped for photo of sunrise |
| 4 | 12 Sep 2019, 00:28:05 | Afternoon Ride | Ride | 1891 | 12.48 | Tired by the end of the week |
| ... | ... | ... | ... | ... | ... | ... |
| 28 | 4 Oct 2019, 01:08:08 | Afternoon Ride | Ride | 1870 | 12.63 | Very tired, riding into the wind |
| 29 | 9 Oct 2019, 13:55:40 | Morning Ride | Ride | 2149 | 12.70 | Really cold! But feeling good |
| 30 | 10 Oct 2019, 00:10:31 | Afternoon Ride | Ride | 1841 | 12.59 | Feeling good after a holiday break! |
| 31 | 10 Oct 2019, 13:47:14 | Morning Ride | Ride | 2463 | 12.79 | Stopped for photo of sunrise |
| 32 | 11 Oct 2019, 00:16:57 | Afternoon Ride | Ride | 1843 | 11.79 | Bike feeling tight, needs an oil and pump |
31 rows × 6 columns
또는 .fillna()를 사용하여 이를 대치(“채우기”)할 수 있습니다. 이 방법에는 채우기를 위한 다양한 옵션이 있으며 고정 값, 열의 평균, 이전의 nan이 아닌 값 등을 사용할 수 있습니다.
df = pd.DataFrame( # noqa: F811
[
[np.nan, 2, np.nan, 0],
[3, 4, np.nan, 1],
[np.nan, np.nan, np.nan, 5],
[np.nan, 3, np.nan, 4],
],
columns=list("ABCD"), # noqa: F811
)
df| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | NaN | NaN | NaN | 5 |
| 3 | NaN | 3.0 | NaN | 4 |
df.fillna(0) # fill with 0| A | B | C | D | |
|---|---|---|---|---|
| 0 | 0.0 | 2.0 | 0.0 | 0 |
| 1 | 3.0 | 4.0 | 0.0 | 1 |
| 2 | 0.0 | 0.0 | 0.0 | 5 |
| 3 | 0.0 | 3.0 | 0.0 | 4 |
df.fillna(df.mean()) # fill with the mean| A | B | C | D | |
|---|---|---|---|---|
| 0 | 3.0 | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | 3.0 | 3.0 | NaN | 5 |
| 3 | 3.0 | 3.0 | NaN | 4 |
df.fillna(method="bfill") # backward (upwards) fill from non-nan values| A | B | C | D | |
|---|---|---|---|---|
| 0 | 3.0 | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | NaN | 3.0 | NaN | 5 |
| 3 | NaN | 3.0 | NaN | 4 |
df.fillna(method="ffill") # forward (downward) fill from non-nan values| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | 3.0 | 4.0 | NaN | 5 |
| 3 | 3.0 | 3.0 | NaN | 4 |
마지막으로 때로는 시각화를 사용하여 누락된 값을 식별(패턴)하는 데 도움을 줍니다. 제가 자주 하는 일 중 하나는 누락된 값이 어디에 있는지 파악하기 위해 데이터프레임의 히트맵을 인쇄하는 것입니다. 이 코드를 실행하려면 seaborn을 설치해야 할 수도 있습니다.
``쉬 conda 설치 seaborn ````
import seaborn as sns
sns.set(rc={"figure.figsize": (7, 7)})df| A | B | C | D | |
|---|---|---|---|---|
| 0 | NaN | 2.0 | NaN | 0 |
| 1 | 3.0 | 4.0 | NaN | 1 |
| 2 | NaN | NaN | NaN | 5 |
| 3 | NaN | 3.0 | NaN | 4 |
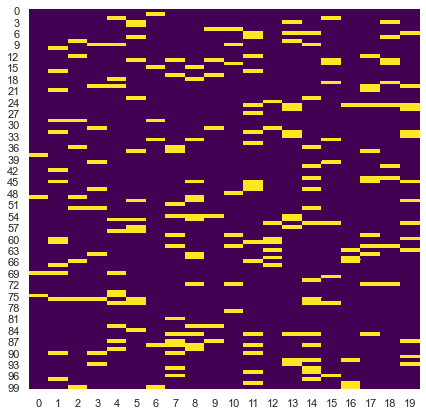
sns.heatmap(df.isnull(), cmap="viridis", cbar=False);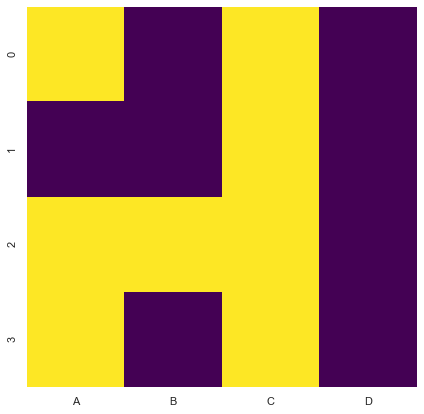
# Generate a larger synthetic dataset for demonstration
np.random.seed(2020) # noqa: F405, F811, F821
npx = np.zeros((100, 20)) # noqa: F811
mask = np.random.choice([True, False], npx.shape, p=[0.1, 0.9]) # noqa: F405, F811, F821
npx[mask] = np.nan
sns.heatmap(pd.DataFrame(npx).isnull(), cmap="viridis", cbar=False);