import numpy as np6장: NumPy 구현 세부 사항

학습 내용
학습 목표
- NumPy 배열이 메모리에 저장되는 방식을 높은 수준에서 이해합니다.
- NumPy의 “스트라이드” 개념을 설명하세요.
- NumPy로 데이터에 효율적으로 액세스하려면 스트라이드를 사용하세요.
1. 개요
이 장에서는 NumPy가 메모리에서 배열을 관리하고 저장하는 방법에 대해 자세히 설명합니다. 메모리가 처리되고 액세스되는 방식과 같은 NumPy 내부에 대한 철저한 이해는 매우 최적화된 알고리즘을 작업하는 개발자나 이러한 종류의 작업에 관심이 있는 개발자에게 더 도움이 된다는 점을 강조하겠습니다. 이러한 구현 세부 사항에 관심이 없는 데이터 과학자는 이 장을 건너뛰고 계속해서 배열을 N차원 데이터 구조로 시각화하고 사용할 수 있습니다. 결국 NumPy의 요점은 기술 구현 세부 사항을 추상화하여 이러한 사용자가 코드 작성 및 데이터 랭글링에 집중할 수 있도록 하는 것입니다!
이 장에서는 다음에 제시된 훌륭한 자료를 활용합니다. - NumPy 문서. - NumPy 가이드, Travis Oliphant 작성, 2006년.
2. Numpy 배열
N차원 배열(“ndarray”)은 단지 동질적인 요소 집합이라는 점을 기억하세요. “벡터”(1차원 배열) 또는 “행렬”(2차원 배열)이라는 용어가 더 익숙할 것입니다. 특정 ndarray를 설명하는 두 가지 주요 정보가 있습니다.
- 배열의 형태 그리고,
- 배열 요소의 데이터 타입.
배열 모양
ndarray의 모양을 각 차원의 “길이”로 생각할 수 있습니다. 예를 들어, 6개의 요소와 ‘(6,)’ 모양을 가진 다음 벡터를 생각해 보세요.
a = np.array([1, 2, 3, 4, 5, 6]) # noqa: F811
aarray([1, 2, 3, 4, 5, 6])이 벡터에는 6개 요소로 구성된 1차원이 있습니다.
print(f"The shape of this ndarray is: {a.shape}")
print(f" The number of dimensions is: {a.ndim}")
print(f" The number of elements is: {a.size}")The shape of this ndarray is: (6,)
The number of dimensions is: 1
The number of elements is: 6이 벡터를 ‘(2, 3)’ 모양의 다음 행렬과 비교합니다.
a = np.array([[1, 2, 3], [4, 5, 6]]) # noqa: F811
aarray([[1, 2, 3],
[4, 5, 6]])print(f"The shape of this ndarray is: {a.shape}")
print(f" The number of dimensions is: {a.ndim}")
print(f" The number of elements is: {a.size}")The shape of this ndarray is: (2, 3)
The number of dimensions is: 2
The number of elements is: 6마지막으로 4차원 배열이 있습니다(시각화해 보세요! 🤷♂️).
a = np.arange(36).reshape(2, 3, 3, 2) # noqa: F811
aarray([[[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]]],
[[[18, 19],
[20, 21],
[22, 23]],
[[24, 25],
[26, 27],
[28, 29]],
[[30, 31],
[32, 33],
[34, 35]]]])print(f"The shape of this ndarray is: {a.shape}")
print(f" The number of dimensions is: {a.ndim}")
print(f" The number of elements is: {a.size}")The shape of this ndarray is: (2, 3, 3, 2)
The number of dimensions is: 4
The number of elements is: 36배열 데이터 타입
모든 ndarray는 동질적입니다. 즉, 모든 요소는 정확히 동일한 양의 메모리를 차지하는 동일한 데이터 타입(예: 정수, 부동 소수점, 문자열 등)을 가집니다.
예를 들어, 8비트 정수(int8)로 가득 찬 다음 1d 배열을 생각해 보세요.
a = np.array([1, 2, 3, 4, 5, 6], dtype="int8") # noqa: F811
aarray([1, 2, 3, 4, 5, 6], dtype=int8)1바이트는 8비트와 같습니다(여기에서 비트와 바이트에 대해 새로 고침). 따라서 이 int8 데이터 타입 배열의 경우 각 요소가 1바이트를 차지할 것으로 예상됩니다. 다음을 사용하여 확인할 수 있습니다.
a.itemsize1
int8,int16,int32등의 차이점에 대해서는 따로 설명합니다. 여기서 숫자는 각 정수를 나타내는 데 사용되는 비트 수를 나타냅니다. 예를 들어int8은 1바이트(1바이트 = 8비트)로 표현되는 정수입니다. 비트는 컴퓨터가 사용하는 정보의 기본 단위인 “0/1”임을 기억하세요. 따라서int8데이터 타입으로 보유할 수 있는 최대 부호 없는 숫자는 2^8입니다(그러나 Python은 0부터 색인을 생성하므로int8의 부호 없는 범위는 0에서 257입니다). 음수를 가지려면 해당 비트 중 하나를 사용하여 부호를 표시해야 하며 숫자를 만들려면 2^7비트가 남으므로int8의 부호 있는 범위는 -128에서 +127입니다. 마찬가지로int16에는 0 ~ 65,535(2^16)의 부호 없는 범위 또는 -32,768 ~ +32,767 등의 부호 있는 범위가 있습니다. 저장하려는 숫자를 지원하지 않는 dtype을 사용하려고 하면 어떤 일이 발생하는지 지켜보는 것은 흥미롭습니다.
np.array([126, 127, 128, 129, 130, 131, 132], dtype="int8")array([ 126, 127, -128, -127, -126, -125, -124], dtype=int8)위에서, 정수 127(‘int8’ 부호 있는 범위의 최대값)을 초과했을 때 NumPy가 부호 있는 범위(-128)의 최소값부터 세어 자동으로 이 숫자를 표시하는 방법에 주목하세요. 시원한! 물론
int16을 사용하면 문제가 되지 않습니다:
np.array([126, 127, 128, 129, 130, 131, 132], dtype="int16")array([126, 127, 128, 129, 130, 131, 132], dtype=int16)마지막으로 기술적으로 배열(예: 이종 배열)에 혼합된 데이터 타입을 갖는 것이 가능하지만 이 경우 배열은 여전히 각 요소를 동일한 것으로 “인식”합니다. 일부 Python 객체에 대한 참조이고 dtype은 “객체”입니다.
a = np.array([["a", "b", "c"], 1, 3.14159], dtype="object") # noqa: F811
aarray([list(['a', 'b', 'c']), 1, 3.14159], dtype=object)위에는 ndarray의 객체가 있는데, 각 객체는 자체 데이터 타입을 가진 다른 Python 객체에 대한 참조입니다.
list(map(type, a))[list, int, float]이와 같은 배열을 사용하면 함께 제공되는 최적화된 함수이 대부분 무효화되며 “이기종 배열”을 사용한 적이 기억나지 않습니다. 혼합 데이터 타입의 경우 일반적으로 리스트이나 딕셔너리과 같은 다른 구조를 사용합니다.
3. 메모리 레이아웃 및 스트라이드
이제 ndarray의 기본 개념을 다루었으므로 배열이 메모리에서 어떻게 표현되는지 더 자세히 설명할 수 있습니다. ndarray는 특정 위치에서 시작하는 단일 메모리 “청크”로 저장됩니다. N차원 인덱스(ndarray의 경우)를 해당 1차원 표현으로 매핑하는 데 도움이 될 수 있는 “멋진 인덱싱”을 사용하여 메모리의 1차원 시퀀스로 생각하는 것이 도움이 됩니다.
NumPy를 사용한 배열 프로그래밍 문서의 아래 개념 그림에서 “패널 a”를 고려하여 데이터 타입 ‘int64’(8바이트)의 2D 배열이 메모리에서 단일 청크로 표현되는 방식을 보여줍니다.
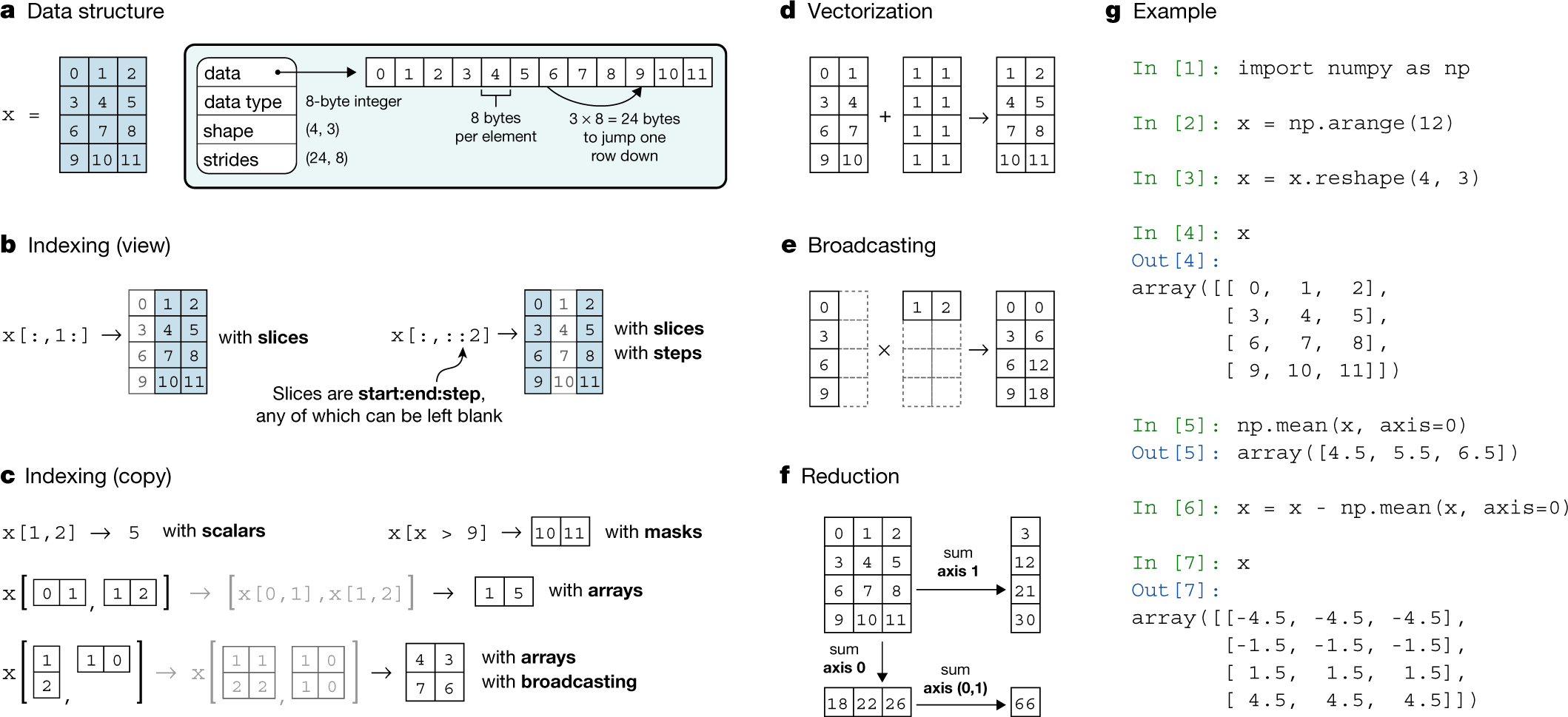
strides라는 단어는 배열을 탐색할 때 각 차원에서 단계적으로 이동해야 하는 바이트 수입니다. 예제에서 볼 수 있듯이 stride 정보는 메모리 청크를 n차원 배열 구조로 다시 매핑하는 데 특히 중요합니다. 따라서 위의 경우 스트라이드는 24바이트(8바이트 int64 요소 3개)와 8바이트(8바이트 int64 요소 1개)를 의미하는 (24, 8)입니다. 즉, 요소 3개마다 첫 번째 차원(즉, 다음 행으로 이동)이 증가하고 요소 1개마다 두 번째 차원(즉, 다음 열로 이동)이 증가한다는 의미입니다.
또 다른 예를 살펴보겠습니다.
a = np.array([[1, 2], [3, 4], [5, 6]], dtype="int16") # noqa: F811
aarray([[1, 2],
[3, 4],
[5, 6]], dtype=int16)여기에 (3, 2) 모양의 ndarray가 있고 dtype은 int16(배열의 요소당 2바이트)입니다. 우리는 스트라이드가 (4, 2)일 것으로 예상합니다(여기서 int16에 대한 2개의 요소인 4바이트마다 새 행을 시작하고 여기서는 1개의 요소인 2바이트마다 새 열을 시작합니다). 다음을 통해 확인할 수 있습니다.
a.strides(4, 2)정돈된! 실제로 보폭 정보를 변경하여 ndarray가 메모리 블록에서 다시 ndarray로 매핑되는 방식을 변경할 수 있습니다.
a.strides = (2, 4)
aarray([[1, 3],
[2, 4],
[3, 5]], dtype=int16)요점을 더 자세히 설명하기 위해 1D 배열의 발전이 어떻게 될 것으로 예상하십니까? 이 경우 통과할 차원은 하나뿐이므로 스트라이드는 단지 1개 요소의 바이트 수 (2,)(즉, 2바이트마다 하나의 int16 요소임)가 될 것으로 예상됩니다. 확인해 봅시다:
a = a.flatten() # noqa: F811
aarray([1, 3, 2, 4, 3, 5], dtype=int16)a.strides(2,)마지막으로 크기가 ’(3,3,2)’이지만 데이터 타입이 ’int8’인 다음 3D 배열의 스트라이드를 살펴보겠습니다(1바이트 = 1 요소이므로 스트라이드를 좀 더 쉽게 해석할 수 있음). 3D 배열을 시각화하는 것이 조금 더 까다로워지기 시작하지만 저는 이를 빵 조각처럼 서로 쌓인 행렬이나 서로 쌓인 여러 체스판으로 생각합니다.
a = np.arange(18, dtype="int8").reshape(3, 3, 2) # noqa: F811
aarray([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]]], dtype=int8)a.strides(6, 2, 1)설치된 패키지 가져오기
4. 우리는 왜 관심을 갖는가?
재형성
NumPy에서 때때로 혼란스러운 주제 중 하나는 ndarray가 어떻게 재구성되는지 이해하는 것입니다. 하지만 이제 ndarray가 메모리에 어떻게 표현되는지 이해했으므로 NumPy에서도 재구성이 어떻게 작동하는지 더 잘 이해할 수 있습니다! 기본적으로 모양 변경은 메모리의 “덩어리”를 다른 방식으로 보는 것으로 생각할 수 있습니다(다른 모양으로 읽지만 메모리의 데이터 순서는 유지함). 앞서 본 것과 동일한 2D 배열을 생각해 보세요. 하지만 데이터 타입이 ’int8’입니다(1 바이트 = 1 요소이므로 스트라이드를 좀 더 쉽게 해석할 수 있습니다).
a = np.array([[1, 2], [3, 4], [5, 6]], dtype="int8") # noqa: F811
aarray([[1, 2],
[3, 4],
[5, 6]], dtype=int8)a.strides(2, 1)배열의 모양을 바꿀 때 배열을 평면화하는 것으로 생각하십시오.
a.flatten()array([1, 2, 3, 4, 5, 6], dtype=int8)그런 다음 해당 데이터를 다른 보폭으로 다른 모양으로 다시 읽습니다. 아래에서는 모양을 ‘(2, 3)’으로 변경하겠습니다. 즉,’(3, 1)’의 스트라이드가 필요합니다(3개 요소마다 행 한 개 증가, 요소 1개마다 배열에서 열 증가).
a.shape = (2, 3)
a.strides = (3, 1)
aarray([[1, 2, 3],
[4, 5, 6]], dtype=int8)위에서는
a.strides를 할 필요가 없었습니다. 모양을 ’(2, 3)’으로 변경했을 때 NumPy가 이미 보폭 변경을 처리했지만 데모용으로 표시하고 있습니다.
2차원이 넘는 ndarray를 재구성하는 경우에도 동일한 논리가 적용됩니다. 예를 들어:
a = np.arange(18, dtype="int8") # noqa: F811
aarray([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17], dtype=int8)a = a.reshape(3, 3, 2) # noqa: F811
aarray([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]]], dtype=int8)a.strides(6, 2, 1)위의 예에서는 3개의 2D 행렬이 함께 쌓여 있습니다(“슬라이스”라고 부르겠습니다). 평면화된 배열의 처음 6개 요소를 사용하여 첫 번째 “슬라이스”를 채우고 해당 2D 슬라이스 내에서 해당 요소는 스트라이드에 따라 행과 열로 배열됩니다(즉, 2개의 요소마다 행이 증가하고 1개의 요소마다 열이 증가합니다). 처음 6개 요소를 사용한 후에는 차원 “슬라이스”를 탐색하고 다음 6개 요소를 사용하여 해당 2D 슬라이스를 채웁니다. 그런 다음 마지막 “슬라이스”에 대해 한 번 더 반복합니다.
이 시점에서 두 가지가 궁금할 것입니다.
- 위의 배열이 3x3 행렬의 2조각이 아닌 3x2 행렬의 조각 3개로 구성된 이유는 무엇입니까?
- NumPy는 어떻게 각 2D 행렬 슬라이스를 요소로 먼저 채우기로 결정했는데, “깊이” 차원을 먼저 채우는 것은 어떨까요?
이러한 질문은 관련이 있으며 실제로 예상보다 훨씬 더 깊습니다. NumPy 문서 및 Travis Oliphant의 책 Guide to NumPy 책의 2.3 ndarray의 메모리 레이아웃 섹션에 자세히 설명되어 있지만 기본적인 구현과 관련이 있습니다. NumPy가 메모리에서 데이터를 읽는 방법에 대해 설명합니다.
간단히 말해서, NumPy는 메모리에서 데이터를 읽을 때 “행 주요” 인덱싱을 사용합니다. 이는 기본적으로 “그룹화”가 가장 왼쪽 인덱스부터 시작된다는 의미입니다. 따라서 2D 배열의 경우 순서는 ‘(행, 열)’이고, 3D 배열의 경우 순서는’(깊이, 행, 열)‘이고, 4D 배열의 경우’(4차원, 깊이, 행, 열)’입니다. 제가 생각하는 방식은 ndarray가 컨테이너이고, 3D의 경우 누적된 행렬로 구성된 큐브라고 생각합니다. 컨테이너(“차원”)에 대해 이를 입력하고 매트릭스를 볼 수 있습니다. 다음 컨테이너는 각 “열”에 대해 하나의 작은 컨테이너로 구성된 값의 “행”입니다. 메모리에서 데이터를 읽는 방식을 결정하는 두 가지 중요한 스타일이 있는데, “C 스타일”과 “포트란 스타일”입니다. NumPy는 기본적으로 위에서 본 “C 스타일”을 사용합니다.
a = np.arange(18, dtype="int8").reshape(3, 3, 2, order="C") # noqa: F811
aarray([[[ 0, 1],
[ 2, 3],
[ 4, 5]],
[[ 6, 7],
[ 8, 9],
[10, 11]],
[[12, 13],
[14, 15],
[16, 17]]], dtype=int8)그러나 아래 예에서 볼 수 있고 ‘깊이’ 차원을 먼저 채우는 것처럼 보이는 order 인수를 사용하여 지정할 수 있는 “포트란 스타일”도 있습니다.
a = np.arange(18, dtype="int8").reshape(3, 3, 2, order="F") # noqa: F811
aarray([[[ 0, 9],
[ 3, 12],
[ 6, 15]],
[[ 1, 10],
[ 4, 13],
[ 7, 16]],
[[ 2, 11],
[ 5, 14],
[ 8, 17]]], dtype=int8)이러한 구현 세부 사항은 컴퓨터 메모리와 직접 인터페이스하는 NumPy와 같은 개발 알고리즘이나 패키지가 아니면 실제로 알 필요가 없습니다.
초고속 코드
ndarray가 메모리에 저장되는 방식과 스트라이드가 무엇인지 알면 매우 멋진 트릭을 활용하여 numpy 코드 속도를 높이는 데 도움이 될 수 있습니다. 이미지 픽셀에 “가중치” 필터 창을 전달하여 2D 이미지에서 컨볼루션을 수행하는 것을 고려해보세요. 예를 들면:
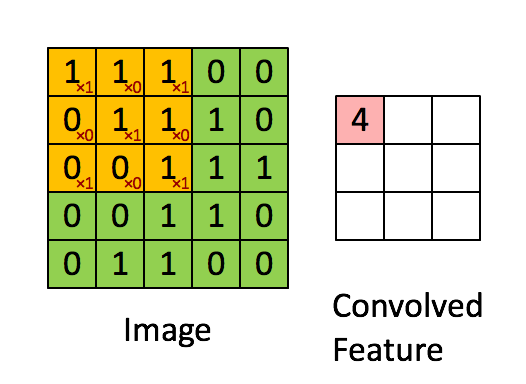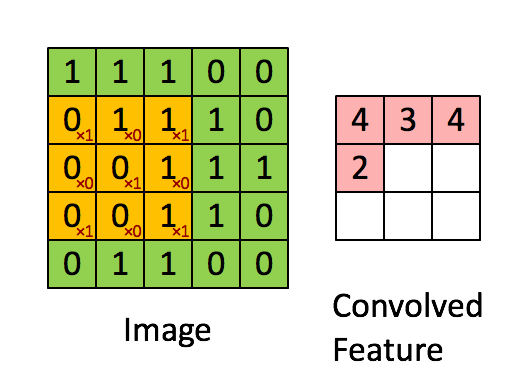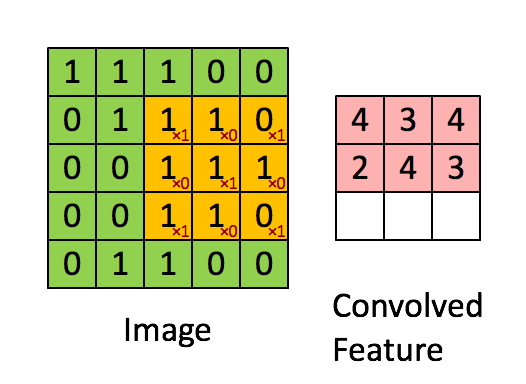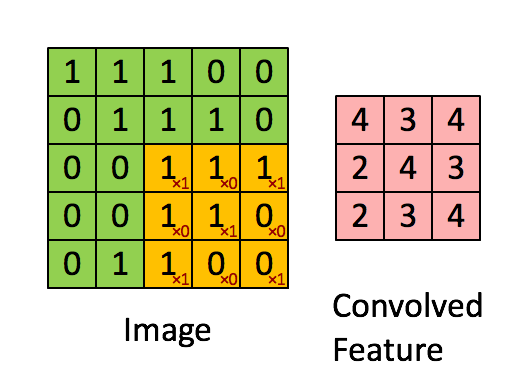
출처: hackernoon.com
이 문제를 해결하는 방법은 많습니다. 목표는 실제로 배열의 창 세그먼트에 필터를 적용하는 것입니다. Windows에서 배열을 “볼” 수 있는 한 가지 방법은 strides와 numpy.lib.stride_tricks 모듈을 사용하는 것입니다. 다음은 귀하의 실제 400 x 400 픽셀 이미지입니다.
import time
import matplotlib.pyplot as plt
from numpy.lib.stride_tricks import as_strided
plt.style.use("ggplot")
plt.rcParams.update({"font.size": 16, "figure.figsize": (8, 6), "axes.grid": False})image = plt.imread("img/chapter6/tomas_beuzen.png")[:, :, 0] # noqa: F811
plt.imshow(image, cmap="gray");--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-1-65e80ed6e478> in <module> ----> 1 image = plt.imread('img/chapter6/tomas_beuzen.png')[:,:,0] 2 plt.imshow(image, cmap='gray'); NameError: name 'plt' is not defined
이미지에 적용하려는 필터는 다음과 같습니다.
f = np.array([[-2, -1, 0], [-1, 1, 1], [0, 1, 2]]) # noqa: F811이제 스트라이드를 사용하여 이미지를 3 x 3 창으로 표시하므로 모든 단일 창에 필터를 적용할 수 있습니다. 기본적으로 여기서 목표는 배열을 일련의 3x3 창으로 보는 것입니다. 따라서 이를 이미지의 각 픽셀에 대해 생각해 보면 해당 픽셀 주위에 3x3 창을 표시하려고 합니다. 우리는 400x400 픽셀을 가지고 있고 각 픽셀에 대해 3x3 창이 있다면 ‘(400, 400, 3, 3)’ 모양의 배열의 4D 보기를 갖게 됩니다. 이 경우 이미지 가장자리에 3x3 창을 가질 수 없으므로 최종 모양이 ‘(398, 398, 3, 3)’이 되도록 잘라내겠습니다(하지만 원하는 경우 가장자리에 필터를 적용하기 위해 이미지를 0으로 채울 수도 있습니다). 4D 보기가 있으면 각 3x3 창에 필터를 적용하고 각 창의 숫자를 합산할 수 있습니다. ’for’ 루프는 복잡한 함수가 필요하지 않습니다!
start = time.time() # start time # noqa: F811
size = f.shape[0] # filter size # noqa: F811
win_img = as_strided( # Now use as_strided to get a windowed view of the array # noqa: F811
image, # image to view as windows
shape=( # noqa: F811
image.shape[0] - size + 1,
image.shape[1] - size + 1,
size,
size,
), # the shape of the new view (398, 398, 3, 3), the edge pixels are cut-off, but we could always pad if we wanted to here
strides=image.strides # noqa: F811
* 2, # this just duplicates the strides as we are now working in 4 dimensions, strides will be (6400, 16, 6400, 16)
)
filtered_image = (win_img * f).sum( # noqa: F811
axis=(2, 3) # noqa: F811
) # apply filter to each window (the 3rd and 4th dimensions of win_img)
plt.imshow(filtered_image, cmap="gray")
print(f"Wall time taken for convolution: {time.time() - start:.4f}s")Wall time taken for convolution: 0.0329s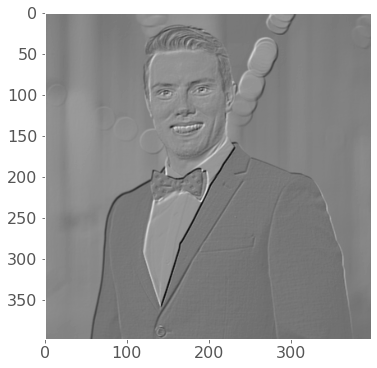
그것은 사악하고 빠른 컨볼루션입니다! 🚀
지금 당장 그 예가 너무 부담스럽다면 Jessica Yung은 블로그 게시물 Numpy 배열을 빠르게 만드는 이유: 메모리 및 스트라이드에서 배열과 스트라이드를 사용하는 간단하고 좋은 예를 제공합니다.