코드가 작동하면 모든 작업이 끝났다고 생각하는 것은 잘못된 것입니다. 코드에는 두 명의 “사용자”가 있습니다. 컴퓨터(컴퓨터 명령으로 변환)와 향후 코드를 읽거나 수정할 가능성이 있는 인간입니다. 이 섹션에서는 코드를 두 번째 대상인 인간에게 적합하게 만드는 방법에 대해 설명합니다.
스타일 지정은 코드를 다른 사용자(미래의 자신 포함!)와 공유할 때 특히 중요합니다. 기억하세요: “코드는 작성된 것보다 훨씬 더 자주 읽혀집니다.” PEP8은 Python 스타일 가이드입니다. PEP 8을 훑어볼 가치가 있지만 다음은 몇 가지 주요 내용입니다. - 공백 4개를 사용하여 들여쓰기 - 연산자 주변에 공백이 있어야 합니다. x = 1은 x=1이 아닙니다. - 하지만 추가 공백은 피하세요. f(1)이 아니라 f(1) - 문자열에는 작은 따옴표와 큰 따옴표 모두 괜찮지만, 독스트링(Docstrings)(Docstrings)의 경우에는 """세 개의 큰 따옴표"""를 사용하고, '''세 개의 작은 따옴표'''를 사용하지 마세요. - 변수 및 함수 이름은 underscores_between_words를 사용합니다. - 그리고 훨씬 더…
기억해야 할 것이 많지만 다행히도 린터 및 포맷터가 균일한 스타일을 고수하는 데 도움이 될 수 있습니다!
린터
Linting은 Python 소스 코드의 프로그래밍 및 문체 문제를 강조하는 것을 의미합니다. 워드 프로세싱 소프트웨어의 “맞춤법 검사”와 같다고 생각하세요. 일반적인 린터에는 pycodestyle, pylint, pyflakes, flake8 등이 포함됩니다. 이 장에서는 flake8을 사용하며, 없는 경우 다음을 사용하여 설치할 수 있습니다.
콘다 설치 -c 아나콘다 flake8
flake8을 명령줄에서 사용하여 파일을 확인할 수 있습니다:
flake8 경로/file_to_check.py
느낌표 !를 명령 앞에 추가하여 Jupyter에서 셸 명령을 실행할 수 있습니다. 이 디렉터리의 데이터 하위 디렉터리에 bad_style.py라는 예제 스크립트를 포함했습니다. 이제 여기에 flake8을 사용하겠습니다.
!flake8 data/bad_style.py
data/bad_style.py:1:6: E201 whitespace after '{'
data/bad_style.py:1:11: E231 missing whitespace after ':'
data/bad_style.py:1:14: E231 missing whitespace after ','
data/bad_style.py:1:18: E231 missing whitespace after ':'
data/bad_style.py:2:1: E128 continuation line under-indented for visual indent
data/bad_style.py:2:4: E231 missing whitespace after ':'
data/bad_style.py:4:25: E128 continuation line under-indented for visual indent
data/bad_style.py:5:5: E225 missing whitespace around operator
data/bad_style.py:7:80: E501 line too long (119 > 79 characters)
data/bad_style.py:8:2: E111 indentation is not a multiple of four
data/bad_style.py:10:2: E111 indentation is not a multiple of four
data/bad_style.py:11:2: E111 indentation is not a multiple of four
data/bad_style.py:12:2: E111 indentation is not a multiple of four
data/bad_style.py:13:10: E701 multiple statements on one line (colon)
data/bad_style.py:13:31: E261 at least two spaces before inline comment
data/bad_style.py:13:31: E262 inline comment should start with '# '
data/bad_style.py:14:1: E302 expected 2 blank lines, found 0
data/bad_style.py:14:13: E201 whitespace after '('
data/bad_style.py:14:25: E202 whitespace before ')'
data/bad_style.py:15:3: E111 indentation is not a multiple of four
data/bad_style.py:15:8: E211 whitespace before '('
data/bad_style.py:15:19: E202 whitespace before ')'
data/bad_style.py:16:11: E271 multiple spaces after keyword
data/bad_style.py:17:3: E301 expected 1 blank line, found 0
data/bad_style.py:17:3: E111 indentation is not a multiple of four
data/bad_style.py:17:16: E231 missing whitespace after ','
data/bad_style.py:18:7: E111 indentation is not a multiple of four
data/bad_style.py:20:1: E305 expected 2 blank lines after class or function definition, found 0
data/bad_style.py:28:2: W292 no newline at end of file
포맷터
포맷팅이란 줄 간격, 들여쓰기, 줄 길이 등에 대한 특정 규칙을 적용하여 코드가 표시되는 방식을 재구성하는 것을 의미합니다. 일반적인 포맷터에는 autopep8, black, yapf 등이 포함됩니다. 이 장에서는 black을 사용하며, 없는 경우 다음을 사용하여 설치할 수 있습니다.
conda install -c conda-forge 검정
black을 명령줄에서 사용하여 파일 형식을 지정할 수도 있습니다.
검은색 경로/file_to_check.py --check
--check 인수는 코드가 블랙 스타일을 준수하는지 확인하지만 해당 위치에서 형식을 다시 지정하지는 않습니다. 파일 형식을 다시 지정하려면 인수를 제거하세요.
!black data/bad_style.py --check
would reformat data/bad_style.pyOh no! 💥 💔 💥1 file would be reformatted.
주석은 코드를 이해하는 데 중요합니다. 독스트링(Docstrings)(Docstrings)은 함수가 _하는 일_을 다루지만, 여러분의 의견은 코드가 목표를 어떻게 달성하는지 문서화하는 데 도움이 될 것입니다. 주석의 길이, 간격 등에 대한 PEP 8 지침이 있습니다. - 설명: #으로 시작하고 그 뒤에 공백이 1개 있어야 하며 앞에 공백이 두 개 이상 있어야 합니다. - 블록 주석: 블록 주석의 각 줄은 #으로 시작하고 그 뒤에 단일 공백이 와야 하며 앞에 나오는 코드와 동일한 수준으로 들여쓰기되어야 합니다. - 일반적으로 주석은 불필요하게 장황하거나 명백한 내용만 기술해서는 안 됩니다. 이는 주의를 산만하게 하고 실제로 코드를 읽기 어렵게 만들 수 있기 때문입니다!
합리적인 의견의 예는 다음과 같습니다.
def random_walker(T): # noqa: F811 x =0# noqa: F811 y =0# noqa: F811for i inrange(T):# Generate a random number between 0 and 1. # noqa: F405, F811, F821# Then, go right, left, up or down if the number# is in the interval [0,0.25), [0.25,0.5),# [0.5,0.75) or [0.75,1) respectively. r = random() # noqa: F405, F811, F821if r <0.25: x +=1# Go rightelif r <0.5: x -=1# Go leftelif r <0.75: y +=1# Go upelse: y -=1# Go downprint((x, y))return x**2+ y**2
불필요하거나 형식이 잘못되어 주석의 나쁜 예는 다음과 같습니다.
def random_walker(T): # noqa: F811# intalize coords x =0# noqa: F811 y =0# noqa: F811for i inrange(T): # loop T times r = random() # noqa: F405, F811, F821if r <0.25: x +=1# go rightelif r <0.5: x -=1# go leftelif r <0.75: y +=1# go upelse: y -=1# Print the locationprint((x, y))# In Python, the ** operator means exponentiation.return x**2+ y**2
2. Python 스크립트
Jupyter는 텍스트 및 이미지와 함께 시각화를 코딩하고 생성하여 내러티브를 만들 수 있는 환상적인 데이터 과학 도구입니다. 그러나 프로젝트가 성장함에 따라 결국에는 Python 스크립트, .py 파일을 만들어야 합니다. .py 파일은 Python에서 “모듈”이라고도 하며 함수, 클래스, 변수 및/또는 실행 가능한 코드를 포함할 수 있습니다. 나는 일반적으로 Jupyter에서 프로젝트를 시작한 다음 코드를 형식화하고 구조화하고 간소화하면서 함수, 클래스, 스크립트 등을 ‘.py’ 파일로 오프로드하기 시작합니다.
IDE
Python 모듈을 작성하는 데 특별한 소프트웨어가 필요하지 않습니다. 텍스트 편집기를 사용하여 코드를 작성하고 .py 확장자로 파일을 저장할 수 있습니다. 하지만 당신의 삶을 훨씬 더 쉽게 만들어주는 소프트웨어가 존재합니다!
IDE는 “통합 개발 환경”을 의미하며 코드 개발을 위한 포괄적인 함수(예: 컴파일, 디버깅, 포맷팅, 테스트, Linting 등)을 제공하는 소프트웨어를 나타냅니다. 내 경험에 따르면 가장 인기 있는 기본 제공 Python IDE는 PyCharm 및 Spyder입니다. Python IDE 역할을 하는 확장 함수을 사용하여 사용자 정의할 수 있는 편집기도 많이 있습니다(예: VSCode, Atom, Sublime Text). 이러한 사용자 정의 가능한 편집기의 장점은 가볍고 실제로 필요한 확장만 선택할 수 있다는 것입니다(PyCharm과 같은 크고 완전한 IDE를 다운로드하는 것과는 대조적).
VSCode는 현재 제가 가장 좋아하는 편집기이며 관심이 있다면 강력히 추천하고 싶은 훌륭한 온라인 Python 튜토리얼이 있습니다! 이 장에서는 사용자 정의 .py 파일을 가져오는 작업을 일부 수행하지만 IDE에서는 어떤 작업도 수행하지 않습니다.
3. 가져오기
Python은 다른 모듈의 코드를 가져와서 액세스할 수 있습니다. 이는 이미 몇 번 본 적이 있는 import 문을 사용하여 수행됩니다. DSCI 524에서 더 많은 가져오기에 대해 논의할 것이며 Python 문서에서 이에 대한 모든 내용을 읽을 수 있지만 지금은 실제로 작동하는 모습을 보는 것이 가장 쉽습니다.
물건을 가져오는 방법
나는 현금을 저장하고, 쓰고, 얻는 데 사용할 수 있는 Wallet 클래스가 포함된 wallet.py라는 .py 파일을 작성했습니다. 계속 진행하기 전에 GitHub에서 해당 파일을 살펴보는 것이 좋습니다.
wallet.py에서 코드를 import해 보겠습니다. 다음과 같이 간단하게 .py 파일(모듈)을 가져올 수 있습니다.
import wallet
dir(wallet)을 입력하면 해당 모듈에서 사용 가능한 모든 부분을 살펴볼 수 있습니다.
Wallet(100) # now I can refer to it without the module name prefix
<wallet.Wallet at 0x15b79da50>
다음 방법을 모두 혼합할 수도 있습니다.
from wallet import Wallet as w
w(100)
<wallet.Wallet at 0x15b7acdd0>
모듈의 모든 것을 가져오는 것도 가능하지만 일반적으로 권장되지는 않습니다.
from wallet import*# noqa: F403
Wallet(100)
<wallet.Wallet at 0x15b7b2f90>
InsufficientCashError() # noqa: F405, F811, F821
wallet.InsufficientCashError()
작업 디렉터리 외부에서 함수 가져오기
wallet.py가 현재 작업 디렉토리에 있기 때문에 위에서 지갑 가져오기를 수행할 수 있습니다. 하지만 다른 위치에 있는 경우 몇 가지 추가 단계가 필요합니다. 나는 이 노트북이 있는 디렉토리의 data/ 하위 디렉토리에 hello.py라는 스크립트를 포함시켰습니다. 그 안에 있는 것은 다음과 같습니다.
행성 ="지구"def hello_world():print(f"안녕하세요 {PLANET}!")
불행히도 나는 이것을 할 수 없습니다:
from hello import hello_world
---------------------------------------------------------------------------ModuleNotFoundError Traceback (most recent call last)
<ipython-input-25-20bbd0c111a6> in <module>----> 1from hello import hello_world
ModuleNotFoundError: No module named 'hello'
내가 해야 할 일은 Python이 무언가를 가져올 때 검색하는 경로에 이 디렉토리 위치를 추가하는 것입니다. 나는 보통 sys 모듈을 사용하여 이 작업을 수행합니다.
import syssys.path.append("data/")sys.path # display the current paths Python is looking through
이제 data/가 유효한 경로인지 확인하세요. 이제 hello.py에서 가져올 수 있습니다.
from hello import PLANET
PLANET # note that I can import variable defined in a .py file!
'Earth'
hello_world()
Hello Earth!
패키지
코드가 점점 더 복잡해지고, 모듈 단위로 늘어나며, 공유하고 싶을 때 Python 패키지로 전환하고 싶을 것입니다. 패키지는 쉽게 가져올 수 있는 모듈의 논리적 컬렉션입니다. 자신만의 패키지를 만드는 데 관심이 있다면 py-pkgs 책을 살펴보세요. 지금은 다른 사람들의 인기 있는 데이터 과학 패키지를 사용할 것입니다. 특히 다음 장에서는 “Python을 사용한 과학 컴퓨팅을 위한 기본 패키지”인 numpy를 살펴보겠습니다.
설치된 패키지 가져오기
다음 몇 장에서는 아마도 데이터 과학에서 가장 인기 있는 numpy 및 pandas 패키지를 사용할 것입니다. 해당 패키지를 설치하면 Python이 이미 알고 있는 컴퓨터의 위치에 배치되므로 마음대로 간단히 가져올 수 있습니다.
Python 표준 라이브러리와 함께 제공되는 패키지가 많이 있습니다. 이러한 패키지는 conda를 사용한 설치가 필요하지 않으며 데이터 과학 여정 전반에 걸쳐 이러한 패키지를 접하게 됩니다. 아래에서 random이라는 한 가지 예를 보여 드리겠습니다. 하지만 더 고급 함수을 사용하려면 numpy, pandas 등과 같은 패키지를 설치하고 사용하세요. 특정 함수이 필요한 경우 해당 함수에 대한 패키지가 있는지 확인하세요(종종 있습니다!). 예를 들어, 내가 자주 원하는 함수 중 하나는 for 루프를 반복할 때 진행률 표시줄이 나타나는 것입니다. 이는 tqdm 패키지에서 사용할 수 있습니다.
from tqdm import tqdmfor i in tqdm(range(int(10e5))): i**2
x =1# noqa: F811y = x # noqa: F811x =2# noqa: F811y
1
그리고 다음은 어떻습니까?
x = [1] # noqa: F811y = x # noqa: F811x[0] =2y
[2]
Python에서 리스트 x는 컴퓨터 메모리에 있는 개체에 대한 참조입니다. y = x를 설정하면 이 두 변수는 이제 메모리에 있는 동일한 개체, 즉 x가 참조하는 개체를 참조합니다. x[0] = 2를 설정하면 메모리의 객체가 수정됩니다. 따라서 x와 y는 모두 수정됩니다(x[0] = 2 또는 y[0] = 2로 설정해도 다르지 않으며 둘 다 동일한 메모리를 수정합니다).
무슨 일이 일어나고 있는지 이해하는 데 도움이 될 수 있는 비유는 다음과 같습니다. - 나는 Dropbox 폴더(또는 git repo)를 당신과 공유하고 당신은 그것을 수정합니다 – 나는 당신에게 _자료의 위치_를 보냈습니다(리스트의 경우와 같습니다) - 파일이 첨부된 이메일을 보내드리면, 다운로드하시고 파일을 수정하세요. – _자료 자체_를 보내드렸습니다. (이것은 정수형과 같습니다.)
좋아요, 여기서 무슨 일이 일어날 것 같나요?
x = [1] # noqa: F811y = x # noqa: F811x = [2] # before we had x[0] = 2 # noqa: F811y
[1]
여기서는 x의 내용을 수정하는 것이 아니라 x를 설정하여 새 리스트 [2]를 참조하도록 합니다.
추가적인 이상한 점
id()를 사용하여 메모리에 있는 객체의 고유 ID를 반환할 수 있습니다.
x = np.array( # noqa: F811 [1, 2, 3, 4, 5]) # this is a numpy array which we'll learn more about next chaptery = x # noqa: F811x = x +5# noqa: F811print(f"x has the value: {x}, id: {id(x)}")print(f"y has the value: {y}, id: {id(y)}")
x has the value: [ 6 7 8 9 10], id: 5830667440
y has the value: [1 2 3 4 5], id: 5830666800
x = np.array([1, 2, 3, 4, 5]) # noqa: F811y = x # noqa: F811x +=5print(f"x has the value: {x}, id: {id(x)}")print(f"y has the value: {y}, id: {id(y)}")
x has the value: [ 6 7 8 9 10], id: 5830669856
y has the value: [ 6 7 8 9 10], id: 5830669856
따라서 x += 5는 x = x + 5와 동일하지 않은 것으로 나타났습니다. 전자는 ’x’의 내용을 수정합니다. 후자는 먼저 x + 5를 동일한 크기의 새 배열로 평가한 다음 이 새 배열에 대한 참조로 이름 x를 덮어씁니다.
하지만 좋은 소식이 있습니다. 함수를 호출하기 위해 특별한 규칙을 외울 필요가 없다는 것입니다. 복사는 int, float, bool로 이루어지며(아마 제가 잊어버린 다른 것들이 있을까요?) 나머지는 “참조에 의한” 것입니다. 이제 객체가 변경 가능하거나 불변인지에 관심을 갖는 이유를 알 수 있습니다. 참조를 전달하는 것은 위험할 수 있습니다! 일반 규칙 - x = ...를 수행하면 원본을 수정하지 않지만, x.SOMETHING = y 또는 x[SOMETHING] = y 또는 x *= y를 수행하면 아마도 수정될 것입니다.
복사 및 딥카피
다음과 같은 경우 copy 라이브러리를 사용하여 특정 복사 동작을 강제할 수 있습니다.
import copy # part of the standard library
x = [1] # noqa: F811y = x # noqa: F811x[0] =2y
[2]
x = [1] # noqa: F811y = copy.copy(x) # We "copied" x and saved that new object as y # noqa: F811x[0] =2y
[1]
좋아요, 여기서는 무슨 일이 일어날 것 같나요?
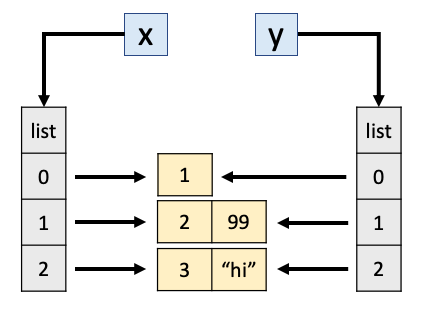
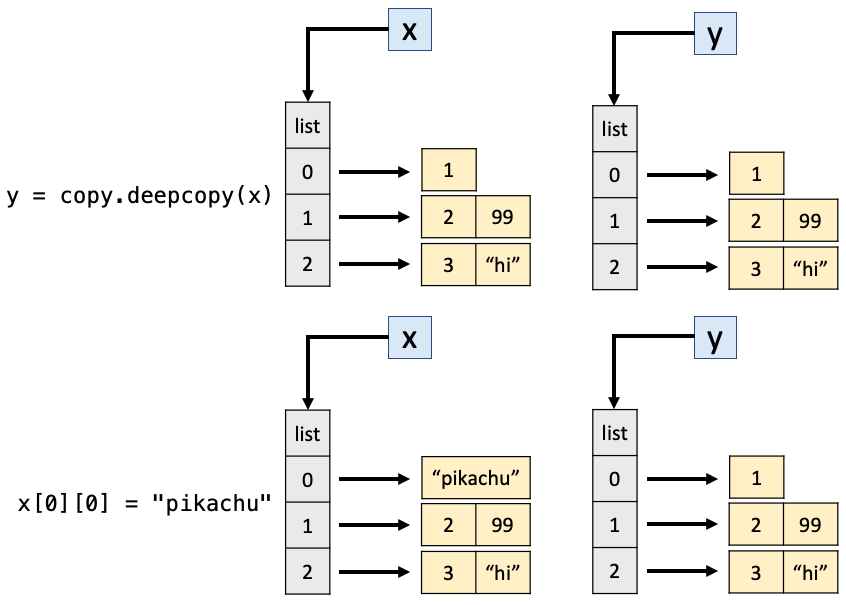
x = [[1], [2, 99], [3, "hi"]] # a list of lists # noqa: F811y = copy.copy(x) # noqa: F811print("After copy.copy():")print(x)print(y)x[0][0] ="pikachu"print("")print("After modifying x:")print(x)print(y)
그런데 잠깐만요.. 복사를 사용했습니다. 후자의 예에서 x와 y가 모두 변경된 이유는 무엇입니까? 복사는 _컨테이너_를 다르게 만듭니다. 즉, 외부 리스트만 만듭니다. 그러나 외부 리스트에는 복사되지 않은 개체에 대한 참조가 포함되어 있습니다! 이것은 y = copy.copy(x) 이후에 일어나는 일입니다:
is를 사용하여 이러한 시나리오를 구분할 수 있습니다(==와 반대). is는 두 객체가 메모리에 있는 동일한 객체를 참조하는지 알려주고 ==는 해당 내용이 동일한지 알려줍니다.
x == y # they are both lists containing the same lists # noqa: F811
True
x is y # but they are not the *same* lists of lists


{kind=link}