import numpy as np5장: NumPy 소개

학습 내용
학습 목표
- NumPy를 사용하여
np.array(),np.arange(),np.linspace()및np.full(),np.zeros(),np.ones()등의 내장 함수가 있는 배열을 만듭니다. - 숫자 인덱싱, 슬라이싱 및 불리언(Boolean) 인덱싱을 통해 NumPy 배열의 값에 액세스할 수 있습니다.
- 배열에 대한 수학 연산을 수행합니다.
- 방송이 무엇인지, 어떻게 활용하는지 설명해보세요.
.reshape(),np.newaxis(),.ravel(),.platten()을 사용하여 축을 추가/제거/형태 변경하여 배열 형태를 변경합니다.np.sum(),np.mean(),np.log()와 같은 내장 NumPy 함수를 독립 실행형 함수 또는 numpy 배열의 메서드(사용 가능한 경우)로 사용하는 방법을 이해합니다.
1. NumPy 소개

NumPy는 “Numerical Python”의 약자이며 배열(예: 벡터 및 행렬), 선형 대수 및 기타 수치 계산 작업에 사용되는 표준 Python 라이브러리입니다. NumPy는 C로 작성되어 NumPy 배열이 Python 리스트이나 배열보다 더 빠르고 메모리 효율적입니다. 자세한 내용은 다음을 참조하세요. (링크 1, 링크 2, 링크 3).
NumPy는 conda를 사용하여 설치할 수 있습니다(아직 설치하지 않은 경우):
콘다 numpy 설치2. NumPy 배열
배열이란 무엇입니까?
배열은 모든 기본 Python 데이터 타입(예: 부동 소수점, 정수, 문자열 등)을 포함할 수 있지만 숫자 데이터에 가장 잘 작동하는 “n차원” 데이터 구조입니다. NumPy 배열(“ndarrays”)은 동질적입니다. 즉, 배열의 항목은 동일한 유형이어야 합니다. ndarray는 numpy의 방대한 내장 함수 컬렉션과도 호환됩니다!
출처: Medium.com
일반적으로 우리는 np 별칭을 사용하여 numpy를 가져옵니다(사용할 때마다 n-u-m-p-y를 입력할 필요가 없도록):
numpy 배열은 일종의 리스트과 같습니다.
my_list = [1, 2, 3, 4, 5] # noqa: F811
my_list[1, 2, 3, 4, 5]my_array = np.array([1, 2, 3, 4, 5]) # noqa: F811
my_arrayarray([1, 2, 3, 4, 5])하지만 ndarray 유형이 있습니다.
type(my_array)numpy.ndarray리스트과 달리 배열은 단일 유형(일반적으로 숫자)만 보유할 수 있습니다.
my_list = [1, "hi"] # noqa: F811
my_list[1, 'hi']my_array = np.array((1, "hi")) # noqa: F811
my_arrayarray(['1', 'hi'], dtype='<U21')위: NumPy는 정수 1을 문자열 '1'로 변환했습니다!
배열 만들기
ndarray는 일반적으로 두 가지 주요 방법을 사용하여 생성됩니다. 1. 위에서 본 것처럼 np.array()를 사용하여 기존 데이터(일반적으로 리스트 또는 튜플)에서 또는 2. np.arange(), np.linspace(), np.zeros() 등과 같은 내장 함수를 사용합니다.
my_list = [1, 2, 3] # noqa: F811
np.array(my_list)array([1, 2, 3])“다차원 리스트”(리스트에 리스트을 중첩하여)을 가질 수 있는 것처럼, 다차원 배열(이중 대괄호 [[ ]]로 표시)을 가질 수 있습니다.
list_2d = [[1, 2], [3, 4], [5, 6]] # noqa: F811
list_2d[[1, 2], [3, 4], [5, 6]]array_2d = np.array(list_2d) # noqa: F811
array_2darray([[1, 2],
[3, 4],
[5, 6]])아마도 내장된 numpy 배열 제너레이터(Generators)를 자주 사용하게 될 것입니다. 다음은 몇 가지 일반적인 함수입니다(힌트 - 이러한 함수에 대한 도움말을 보려면 독스트링(Docstrings)(Docstrings)을 확인하는 것을 잊지 마세요. Jupyter를 사용하는 경우 shift + tab 단축키를 기억하세요).
np.arange(1, 5) # from 1 inclusive to 5 exclusivearray([1, 2, 3, 4])np.arange(0, 11, 2) # step by 2 from 1 to 11array([ 0, 2, 4, 6, 8, 10])np.linspace(0, 10, 5) # 5 equally spaced points between 0 and 10array([ 0. , 2.5, 5. , 7.5, 10. ])np.ones((2, 2)) # an array of ones with size 2 x 2array([[1., 1.],
[1., 1.]])np.zeros((2, 3)) # an array of zeros with size 2 x 3array([[0., 0., 0.],
[0., 0., 0.]])np.full((3, 3), 3.14) # an array of the number 3.14 with size 3 x 3array([[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]])np.full((3, 3, 3), 3.14) # an array of the number 3.14 with size 3 x 3 x 3array([[[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]],
[[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]],
[[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]]])np.random.rand(
5, 2
) # random numbers uniformly distributed from 0 to 1 with size 5 x 2 # noqa: F405, F811, F821array([[0.99572773, 0.81999212],
[0.97339833, 0.10561435],
[0.85923126, 0.40018929],
[0.97506147, 0.78313652],
[0.99229906, 0.14525197]])numpy 배열을 호출할 수 있는 유용한 속성/메서드가 많이 있습니다:
print(dir(np.ndarray))['T', '__abs__', '__add__', '__and__', '__array__', '__array_finalize__', '__array_function__', '__array_interface__', '__array_prepare__', '__array_priority__', '__array_struct__', '__array_ufunc__', '__array_wrap__', '__bool__', '__class__', '__complex__', '__contains__', '__copy__', '__deepcopy__', '__delattr__', '__delitem__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__iand__', '__ifloordiv__', '__ilshift__', '__imatmul__', '__imod__', '__imul__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__ior__', '__ipow__', '__irshift__', '__isub__', '__iter__', '__itruediv__', '__ixor__', '__le__', '__len__', '__lshift__', '__lt__', '__matmul__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmatmul__', '__rmod__', '__rmul__', '__ror__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__setitem__', '__setstate__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__xor__', 'all', 'any', 'argmax', 'argmin', 'argpartition', 'argsort', 'astype', 'base', 'byteswap', 'choose', 'clip', 'compress', 'conj', 'conjugate', 'copy', 'ctypes', 'cumprod', 'cumsum', 'data', 'diagonal', 'dot', 'dtype', 'dump', 'dumps', 'fill', 'flags', 'flat', 'flatten', 'getfield', 'imag', 'item', 'itemset', 'itemsize', 'max', 'mean', 'min', 'nbytes', 'ndim', 'newbyteorder', 'nonzero', 'partition', 'prod', 'ptp', 'put', 'ravel', 'real', 'repeat', 'reshape', 'resize', 'round', 'searchsorted', 'setfield', 'setflags', 'shape', 'size', 'sort', 'squeeze', 'std', 'strides', 'sum', 'swapaxes', 'take', 'tobytes', 'tofile', 'tolist', 'tostring', 'trace', 'transpose', 'var', 'view']x = np.random.rand(5, 2) # noqa: F405, F811, F821
xarray([[0.0252237 , 0.3368265 ],
[0.57678161, 0.68709061],
[0.00721254, 0.61280414],
[0.65886063, 0.87372073],
[0.82815125, 0.47996047]])x.transpose()array([[0.0252237 , 0.57678161, 0.00721254, 0.65886063, 0.82815125],
[0.3368265 , 0.68709061, 0.61280414, 0.87372073, 0.47996047]])x.mean()0.5086632185578763x.astype(int)array([[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0]])배열 모양
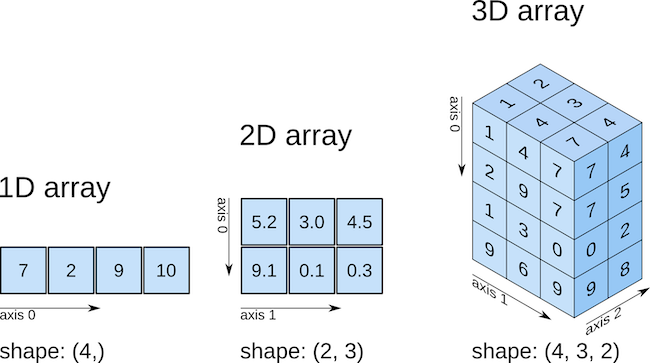
위에서 본 것처럼 배열은 원하는 차원, 모양, 크기로 구성될 수 있습니다. 실제로 배열의 특성을 파악하기 위해 알아야 할 세 가지 주요 배열 속성이 있습니다. - .ndim: 배열의 차원 수 - .shape: 각 차원의 요소 수(각 차원에서 len()을 호출하는 것과 같습니다) - .size: 배열의 총 요소 수(예: .shape의 곱)
array_1d = np.ones(3) # noqa: F811
print(f"Dimensions: {array_1d.ndim}")
print(f" Shape: {array_1d.shape}")
print(f" Size: {array_1d.size}")Dimensions: 1
Shape: (3,)
Size: 3해당 인쇄 작업을 함수로 바꾸고 다른 배열을 try해 보겠습니다.
def print_array(x): # noqa: F811
print(f"Dimensions: {x.ndim}")
print(f" Shape: {x.shape}")
print(f" Size: {x.size}")
print("")
print(x)array_2d = np.ones((3, 2)) # noqa: F811
print_array(array_2d)Dimensions: 2
Shape: (3, 2)
Size: 6
[[1. 1.]
[1. 1.]
[1. 1.]]array_4d = np.ones((1, 2, 3, 4)) # noqa: F811
print_array(array_4d)Dimensions: 4
Shape: (1, 2, 3, 4)
Size: 24
[[[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]]]3차원 이후에는 배열 인쇄가 상당히 지저분해지기 시작합니다. 위에서 볼 수 있듯이 인쇄된 출력의 대괄호([ ]) 수는 차원 수를 나타냅니다. 예를 들어 위에서 출력은 4D 배열을 나타내는 4개의 대괄호 [[[[)로 시작합니다.
1차원 배열
numpy에 대해 가장 혼란스러운 점 중 하나는 1차원 배열(벡터)이 3가지 가능한 모양을 가질 수 있다는 것입니다!
x = np.ones(5) # noqa: F811
print_array(x)Dimensions: 1
Shape: (5,)
Size: 5
[1. 1. 1. 1. 1.]y = np.ones((1, 5)) # noqa: F811
print_array(y)Dimensions: 2
Shape: (1, 5)
Size: 5
[[1. 1. 1. 1. 1.]]z = np.ones((5, 1)) # noqa: F811
print_array(z)Dimensions: 2
Shape: (5, 1)
Size: 5
[[1.]
[1.]
[1.]
[1.]
[1.]]np.array_equal()을 사용하여 두 배열의 모양과 요소가 동일한지 확인할 수 있습니다.
np.array_equal(x, x)Truenp.array_equal(x, y)Falsenp.array_equal(x, z)Falsenp.array_equal(y, z)False1차원 배열의 모양은 실제로 수학적 작업에 큰 영향을 미칠 수 있습니다!
print(f"x: {x}")
print(f"y: {y}")
print(f"z: {z}")x: [1. 1. 1. 1. 1.]
y: [[1. 1. 1. 1. 1.]]
z: [[1.]
[1.]
[1.]
[1.]
[1.]]x + y # makes sensearray([[2., 2., 2., 2., 2.]])y + z # wait, what?array([[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.]])위의 셀에서 발생한 일은 “브로드캐스팅”이며 이에 대해서는 아래에서 논의하겠습니다.
3. 어레이 작동 및 브로드캐스팅
요소별 연산
요소별 연산은 배열의 각 요소에 적용되거나 두 배열의 쌍을 이루는 요소 사이에 적용되는 연산을 나타냅니다.
x = np.ones(4) # noqa: F811
xarray([1., 1., 1., 1.])y = x + 1 # noqa: F811
yarray([2., 2., 2., 2.])x - yarray([-1., -1., -1., -1.])x == y # noqa: F811array([False, False, False, False])x * yarray([2., 2., 2., 2.])x**yarray([1., 1., 1., 1.])x / yarray([0.5, 0.5, 0.5, 0.5])np.array_equal(x, y)False방송 중
크기가 다른 ndarray는 산술 연산에 직접 사용할 수 없습니다.
a = np.ones((2, 2)) # noqa: F811
b = np.ones((3, 3)) # noqa: F811
a + b--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-54-7b429ebe865f> in <module> 1 a = np.ones((2, 2)) 2 b = np.ones((3, 3)) ----> 3 a + b ValueError: operands could not be broadcast together with shapes (2,2) (3,3)
Broadcasting은 산술 연산 중에 NumPy가 배열을 다양한 모양으로 처리하는 방법을 설명합니다. 아이디어는 작업이 요소별로 발생할 수 있도록 데이터를 랭글링하는 것입니다.
예를 살펴보겠습니다. 제가 주말에 파이를 판다고 가정해 보세요. 3가지 종류의 파이를 서로 다른 가격으로 판매하고 있는데, 지난 주말 각 파이를 다음 수량만큼 판매했습니다. 파이 종류별로 하루에 얼마를 벌었는지 알고 싶습니다.
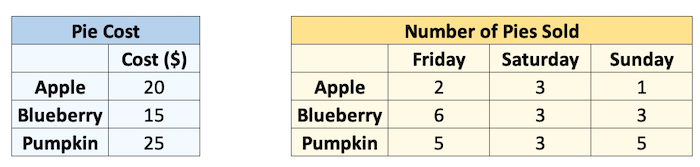
cost = np.array([20, 15, 25]) # noqa: F811
print("Pie cost:")
print(cost)
sales = np.array([[2, 3, 1], [6, 3, 3], [5, 3, 5]]) # noqa: F811
print("\nPie sales (#):")
print(sales)Pie cost:
[20 15 25]
Pie sales (#):
[[2 3 1]
[6 3 3]
[5 3 5]]이 두 배열을 어떻게 곱할 수 있나요? 루프를 사용할 수 있습니다.

total = np.zeros((3, 3)) # initialize an array of 0's # noqa: F811
for col in range(sales.shape[1]):
total[:, col] = sales[:, col] * cost
totalarray([[ 40., 60., 20.],
[ 90., 45., 45.],
[125., 75., 125.]])또는 동일한 크기로 만들고 해당 요소를 “요소별로” 곱할 수도 있습니다.

cost = np.repeat(cost, 3).reshape((3, 3)) # noqa: F811
costarray([[20, 20, 20],
[15, 15, 15],
[25, 25, 25]])cost * salesarray([[ 40, 60, 20],
[ 90, 45, 45],
[125, 75, 125]])축하해요! 방금 방송했어요! 방송은 본질적으로 Numpy가 내부적으로 np.repeat()를 수행하는 것입니다.
cost = np.array([20, 15, 25]).reshape(3, 1) # noqa: F811
print(f" cost shape: {cost.shape}")
sales = np.array([[2, 3, 1], [6, 3, 3], [5, 3, 5]]) # noqa: F811
print(f"sales shape: {sales.shape}") cost shape: (3, 1)
sales shape: (3, 3)sales * costarray([[ 40, 60, 20],
[ 90, 45, 45],
[125, 75, 125]])NumPy에서는 더 작은 배열이 더 큰 배열 전체에 “브로드캐스트”되어 호환 가능한 모양을 갖습니다.
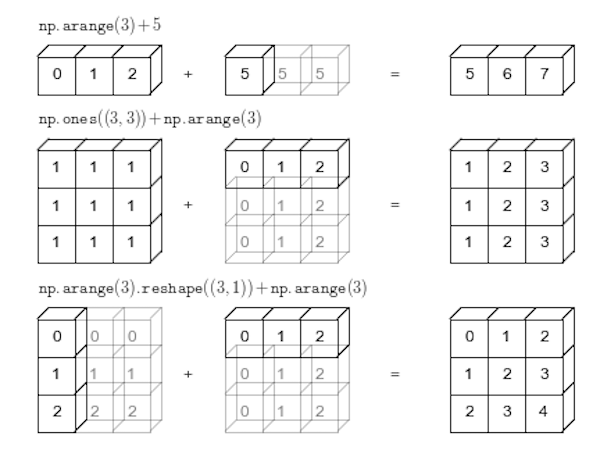
출처: Jake VanderPlas의 Python 데이터 과학 핸드북(2016)
왜 방송에 관심을 가져야 할까요? 음, 이는 루핑보다 더 깔끔하고 빠르며 산술 연산으로 인한 배열 모양에도 영향을 줍니다. 아래에서는 루프와 브로드캐스트에 걸리는 시간을 측정할 수 있습니다.
cost = np.array([20, 15, 25]).reshape(3, 1) # noqa: F811
sales = np.array([[2, 3, 1], [6, 3, 3], [5, 3, 5]]) # noqa: F811
total = np.zeros((3, 3)) # noqa: F811
time_loop = %timeit -q -o -r 3 for col in range(sales.shape[1]): total[:, col] = sales[:, col] * np.squeeze(cost) # noqa: F811
time_vec = %timeit -q -o -r 3 cost * sales # noqa: F811
print(
f"Broadcasting is {time_loop.average / time_vec.average:.2f}x faster than looping here."
)Broadcasting is 8.67x faster than looping here.물론 모든 어레이가 호환되는 것은 아닙니다! NumPy는 배열을 요소별로 비교합니다. 이는 후행 차원에서 시작하여 앞으로 진행됩니다. 다음과 같은 경우 치수가 호환됩니다. - 동등하다, 또는 - 그 중 하나는 1입니다.
아래 코드를 사용하여 배열 호환성을 테스트하십시오.
a = np.ones((3, 2)) # noqa: F811
b = np.ones((3, 2, 1)) # noqa: F811
print(f"The shape of a is: {a.shape}")
print(f"The shape of b is: {b.shape}")
print("")
try:
print(f"The shape of a + b is: {(a + b).shape}")
except Exception:
print("ERROR: arrays are NOT broadcast compatible!")The shape of a is: (3, 2)
The shape of b is: (3, 2, 1)
ERROR: arrays are NOT broadcast compatible!배열 재구성
numpy 배열을 재구성할 때 알아두었으면 하는 3가지 주요 재구성 방법이 있습니다. - .rehshape() -np.newaxis - .ravel()/.platten()
x = np.full((4, 3), 3.14) # noqa: F811
xarray([[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]])배열의 모양을 자주 변경하게 되며 .reshape() 메서드는 매우 직관적입니다.
x.reshape(6, 2)array([[3.14, 3.14],
[3.14, 3.14],
[3.14, 3.14],
[3.14, 3.14],
[3.14, 3.14],
[3.14, 3.14]])x.reshape(2, -1) # using -1 will calculate the dimension for you (if possible)array([[3.14, 3.14, 3.14, 3.14, 3.14, 3.14],
[3.14, 3.14, 3.14, 3.14, 3.14, 3.14]])a = np.ones(3) # noqa: F811
print_array(a)
b = np.ones((3, 2)) # noqa: F811
print_array(b)Dimensions: 1
Shape: (3,)
Size: 3
[1. 1. 1.]
Dimensions: 2
Shape: (3, 2)
Size: 6
[[1. 1.]
[1. 1.]
[1. 1.]]이 두 배열을 추가하려는 경우 크기가 호환되지 않기 때문에 추가할 수 없습니다.
a + b--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-69-bd58363a63fc> in <module> ----> 1 a + b ValueError: operands could not be broadcast together with shapes (3,) (3,2)
때로는 이와 같은 방송 목적으로 배열에 차원을 추가하고 싶을 수도 있습니다. np.newaxis를 사용하여 이를 수행할 수 있습니다(None은 np.newaxis의 별칭입니다). 배열을 호환 가능하게 만들기 위해 a에 차원을 추가할 수 있습니다.
print_array(a[:, np.newaxis]) # same as a[:, None]Dimensions: 2
Shape: (3, 1)
Size: 3
[[1.]
[1.]
[1.]]a[:, np.newaxis] + barray([[2., 2.],
[2., 2.],
[2., 2.]])마지막으로, 때로는 .ravel() 또는 .Flatten()을 사용하여 배열을 단일 차원으로 “평면화”하고 싶을 수도 있습니다. .Flatten()은 복사본을 반환하고 .ravel()은 보기/참조를 반환했지만 이제는 둘 다 복사본을 반환하므로 둘 중 하나를 사용해야 할 중요한 이유를 생각할 수 없습니다 🤷♂️
xarray([[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14],
[3.14, 3.14, 3.14]])print_array(x.flatten())Dimensions: 1
Shape: (12,)
Size: 12
[3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14]print_array(x.ravel())Dimensions: 1
Shape: (12,)
Size: 12
[3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14 3.14]4. 인덱싱 및 슬라이싱
인덱싱의 개념은 이제 꽤 익숙할 것입니다. 인덱싱 배열은 인덱싱 리스트과 유사하지만 차원이 더 많습니다.
숫자 인덱싱
x = np.arange(10) # noqa: F811
xarray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])x[3]3x[2:]array([2, 3, 4, 5, 6, 7, 8, 9])x[:4]array([0, 1, 2, 3])x[2:5]array([2, 3, 4])x[2:3]array([2])x[-1]9x[-2]8x[5:0:-1]array([5, 4, 3, 2, 1])2D 배열의 경우:
x = np.random.randint(10, size=(4, 6)) # noqa: F405, F811, F821
xarray([[9, 5, 0, 2, 3, 4],
[0, 8, 2, 1, 0, 7],
[0, 9, 4, 2, 9, 0],
[4, 4, 0, 8, 3, 9]])x[3, 4] # do this3x[3][4] # i do not like this as much3x[3]array([4, 4, 0, 8, 3, 9])len(x) # generally, just confusing4x.shape(4, 6)x[:, 2] # column number 2array([0, 2, 4, 0])x[2:, :3]array([[0, 9, 4],
[4, 4, 0]])x.Tarray([[9, 0, 0, 4],
[5, 8, 9, 4],
[0, 2, 4, 0],
[2, 1, 2, 8],
[3, 0, 9, 3],
[4, 7, 0, 9]])xarray([[9, 5, 0, 2, 3, 4],
[0, 8, 2, 1, 0, 7],
[0, 9, 4, 2, 9, 0],
[4, 4, 0, 8, 3, 9]])x[1, 1] = 555555
xarray([[ 9, 5, 0, 2, 3, 4],
[ 0, 555555, 2, 1, 0, 7],
[ 0, 9, 4, 2, 9, 0],
[ 4, 4, 0, 8, 3, 9]])z = np.zeros(5) # noqa: F811
zarray([0., 0., 0., 0., 0.])z[0] = 5
zarray([5., 0., 0., 0., 0.])불리언(Boolean) 인덱싱
x = np.random.rand(10) # noqa: F405, F811, F821
xarray([0.59134864, 0.18116891, 0.07089194, 0.71975976, 0.95339547,
0.71630937, 0.80956702, 0.94886201, 0.58996084, 0.03238515])x + 1array([1.59134864, 1.18116891, 1.07089194, 1.71975976, 1.95339547,
1.71630937, 1.80956702, 1.94886201, 1.58996084, 1.03238515])x_thresh = x > 0.5 # noqa: F811
x_thresharray([ True, False, False, True, True, True, True, True, True,
False])x[x_thresh] = 0.5 # set all elements > 0.5 to be equal to 0.5
xarray([0.5 , 0.18116891, 0.07089194, 0.5 , 0.5 ,
0.5 , 0.5 , 0.5 , 0.5 , 0.03238515])x = np.random.rand(10) # noqa: F405, F811, F821
xarray([0.62912775, 0.82278712, 0.26534708, 0.8847088 , 0.48882526,
0.04902107, 0.55230008, 0.6579308 , 0.24630664, 0.77826484])x[x > 0.5] = 0.5
xarray([0.5 , 0.5 , 0.26534708, 0.5 , 0.48882526,
0.04902107, 0.5 , 0.5 , 0.24630664, 0.5 ])5. 더 유용한 NumPy 함수
Numpy에는 수학 연산을 위한 많은 내장 함수가 있습니다. 실제로 라이브러리에는 수행할 수 있는 거의 모든 수치 연산이 있습니다. 여기에서 전체 라이브러리를 탐색하지는 않지만 사용 가능한 일부 함수의 예로서 변이 3m와 4m인 삼각형의 빗변을 계산하는 것을 고려해 보십시오.
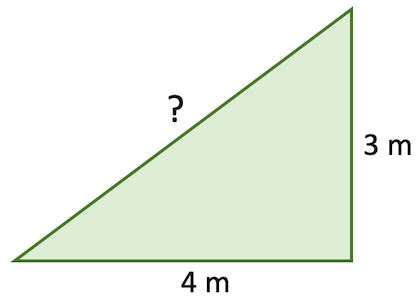
sides = np.array([3, 4]) # noqa: F811이 문제를 해결할 수 있는 방법에는 여러 가지가 있습니다. 피타고라스의 정리를 직접 사용할 수 있습니다.
\[c = \sqrt{a^2+b^2}\]
np.sqrt(np.sum([np.power(sides[0], 2), np.power(sides[1], 2)]))5.0우리는 numpy 배열을 다루고 있다는 사실을 활용하여 전체 벡터에 “벡터화된” 연산(조금 더 자세히 설명)을 한 번에 적용할 수 있습니다.
(sides**2).sum() ** 0.55.0또는 단순히 numpy 내장 함수를 사용할 수도 있습니다(존재하는 경우).
np.linalg.norm(sides) # you'll learn more about norms in 5735.0np.hypot(*sides)5.0벡터화
대체로 NumPy의 “벡터화”는 작업을 수행하기 위해 최적화된 C 코드를 사용하는 것을 의미합니다. 간단히 말해서, numpy 배열은 동질적(동일한 dtype 포함)이기 때문에 작업을 수행하기 전에 시퀀스의 요소에 대해 작업을 수행할 수 있는지 확인할 필요가 없으므로 속도가 크게 향상됩니다. 이 개념은 NumPy가 하나씩이 아니라 전체 배열에 대해 동시에 작업을 수행할 수 있는 것으로 생각할 수 있습니다(실제로는 그렇지 않습니다. 매우 효율적인 C 루프가 여전히 내부에서 실행되고 있지만 이는 관련 없는 세부 사항입니다). 여기에서 벡터화에 대한 자세한 내용을 읽을 수 있지만 알아야 할 것은 NumPy의 대부분의 작업이 벡터화되어 있으므로 “요소 수준”이 아닌 “배열 수준”에서 작업을 수행해 보세요. 예:
# DONT DO THIS
array = np.array(range(5)) # noqa: F811
for i, element in enumerate(array):
array[i] = element**2
arrayarray([ 0, 1, 4, 9, 16])# DO THIS
array = np.array(range(5)) # noqa: F811
array **= 2간단한 타이밍 실험을 해보겠습니다.
# loop method
array = np.array(range(5)) # noqa: F811
time_loop = %timeit -q -o -r 3 for i, element in enumerate(array): array[i] = element ** 2 # noqa: F811
# vectorized method
array = np.array(range(5)) # noqa: F811
time_vec = %timeit -q -o -r 3 array ** 2 # noqa: F811
print(
f"Vectorized operation is {time_loop.average / time_vec.average:.2f}x faster than looping here."
)Vectorized operation is 4.57x faster than looping here.