# 업데이트된 API로 이 노트북을 실행하려면 torch 1.12+ 및 torchvision 0.13+가 필요합니다.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision 버전이 요구 사항을 충족하지 않음, nightly 버전을 설치합니다.")
!pip3 install -U torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")09 - PyTorch 모델 배포
![]()
마일스톤 프로젝트 3: PyTorch 모델 배포에 오신 것을 환영합니다!
FoodVision Mini 프로젝트를 통해 여기까지 먼 길을 달려왔습니다.
하지만 지금까지 우리의 PyTorch 모델은 우리 자신만 접근할 수 있었습니다.
이제 FoodVision Mini를 실생활에 적용하고 공개적으로 접근 가능하게 만드는 건 어떨까요?
다시 말해, 우리의 FoodVision Mini 모델을 인터넷에 사용 가능한 앱으로 배포할 것입니다!
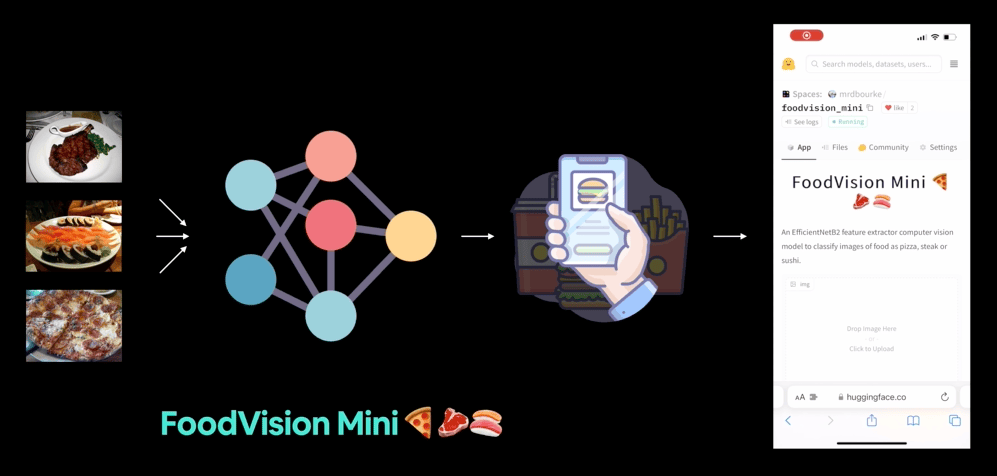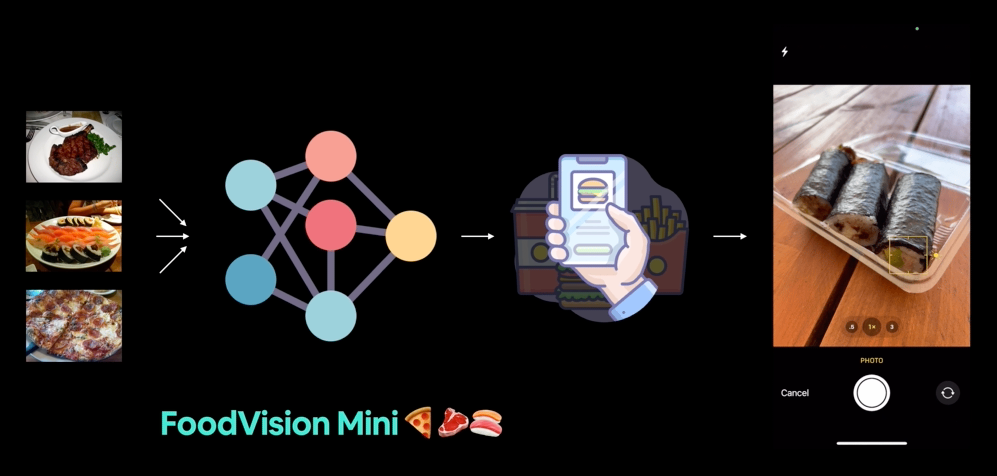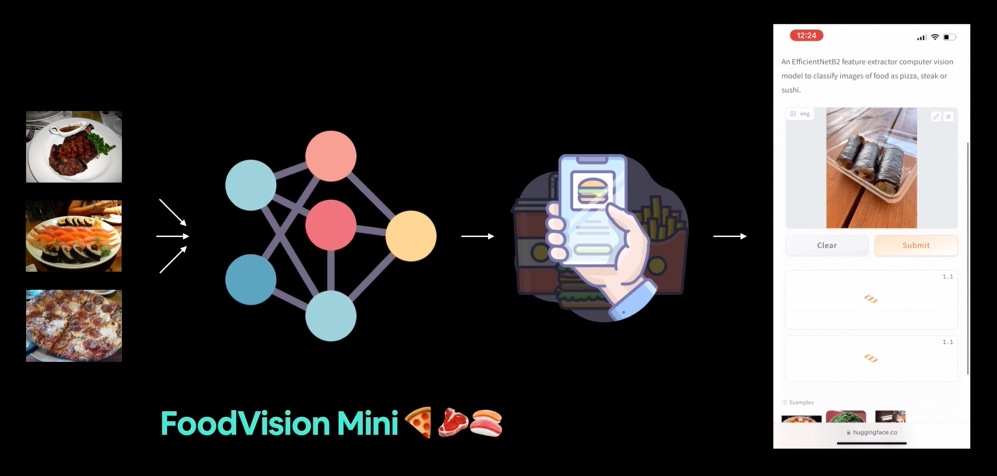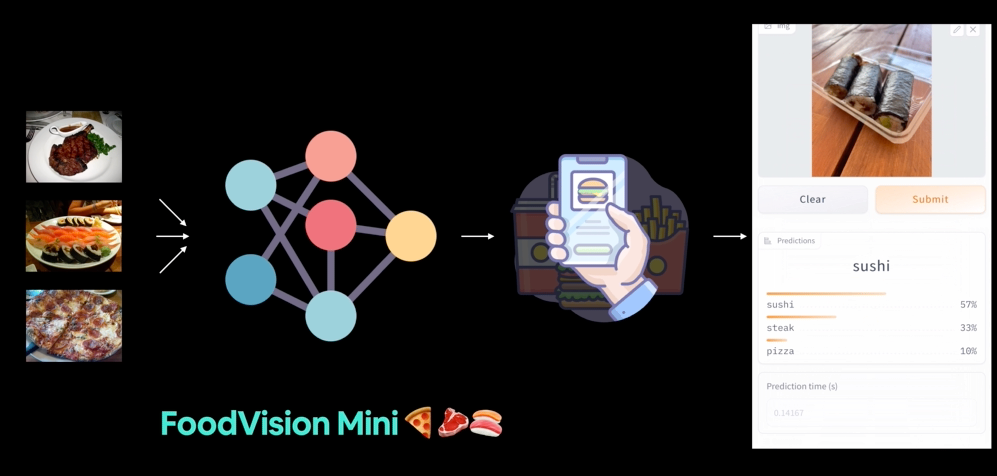
FoodVision Mini 배포 버전(우리가 만들 것)을 점심 식사 중에 사용해 보았습니다. 모델이 정답을 맞혔네요 🍣!
머신러닝 모델 배포란 무엇인가요?
머신러닝 모델 배포(Machine learning model deployment)는 머신러닝 모델을 다른 사람이나 다른 대상이 접근할 수 있도록 만드는 과정입니다.
여기서 ’다른 사람’이란 어떤 방식으로든 모델과 상호작용할 수 있는 사람을 의미합니다.
예를 들어, 스마트폰으로 음식 사진을 찍은 다음 FoodVision Mini 모델이 해당 음식을 피자, 스테이크, 초밥 중 하나로 분류하게 하는 사람입니다.
’다른 대상’은 여러분의 머신러닝 모델과 상호작용하는 또 다른 프로그램, 앱 또는 다른 모델일 수 있습니다.
예를 들어, 은행 데이터베이스는 자금을 송금하기 전에 거래가 사기인지 여부를 예측하는 머신러닝 모델에 의존할 수 있습니다.
또는 운영 체제는 특정 시간대에 누군가가 일반적으로 얼마나 많은 전력을 사용하는지 예측하는 머신러닝 모델을 기반으로 리소스 소비를 줄일 수 있습니다.
이러한 유스케이스는 서로 혼합될 수도 있습니다.
예를 들어, 테슬라 자동차의 컴퓨터 비전 시스템은 자동차의 경로 계획 프로그램(다른 대상)과 상호작용하고, 경로 계획 프로그램은 운전자(다른 사람)로부터 입력과 피드백을 받습니다.
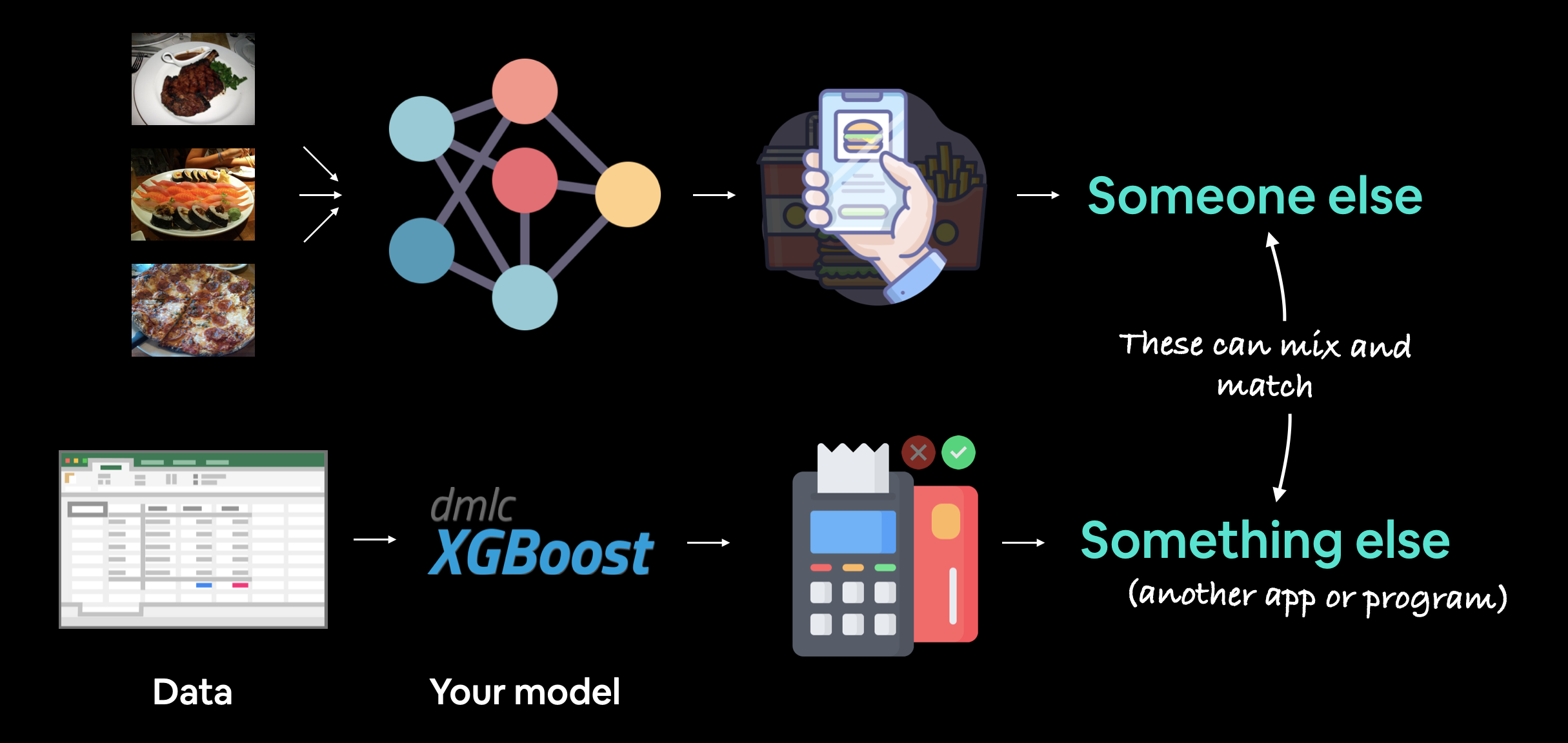
머신러닝 모델 배포에는 모델을 다른 사람이나 다른 대상이 사용할 수 있도록 만드는 작업이 포함됩니다. 예를 들어, 누군가 음식 인식 앱(FoodVision Mini 또는 Nutrify와 같은)의 일부로 모델을 사용할 수 있습니다. 또한 은행 시스템에서 거래 사기 여부를 탐지하기 위해 머신러닝 모델을 사용하는 것과 같이 다른 모델이나 프로그램이 모델을 사용할 수도 있습니다.
머신러닝 모델을 왜 배포해야 하나요?
머신러닝에서 가장 중요한 철학적 질문 중 하나는 다음과 같습니다.

모델을 배포하는 것은 모델을 훈련하는 것만큼이나 중요합니다.
잘 만들어진 테스트 세트에서 모델을 평가하거나 결과를 시각화하여 모델이 어떻게 작동할지 꽤 잘 알 수 있지만, 실제로 세상에 공개하기 전까지는 모델이 어떻게 성능을 낼지 결코 알 수 없기 때문입니다.
모델을 한 번도 사용해 본 적이 없는 사람들과 상호작용하게 하면 훈련 중에는 생각지도 못했던 예외 상황(edge cases)이 종종 드러납니다.
예를 들어, 누군가 음식이 아닌 사진을 FoodVision Mini 모델에 업로드하면 어떻게 될까요?
한 가지 해결책은 이미지를 먼저 “음식” 또는 “음식 아님”으로 분류하는 또 다른 모델을 만들고, 대상 이미지를 해당 모델에 먼저 통과시키는 것입니다(Nutrify가 하는 방식).
이미지가 “음식”인 경우 FoodVision Mini 모델로 전달되어 피자, 스테이크 또는 초밥으로 분류됩니다.
“음식 아님”인 경우 메시지가 표시됩니다.
그런데 만약 이러한 예측이 틀렸다면 어떻게 될까요?
그때는 어떤 일이 벌어질까요?
이러한 질문들이 꼬리에 꼬리를 물고 이어질 수 있다는 것을 알 수 있습니다.
따라서 이것은 모델 배포의 중요성을 강조합니다. 배포는 훈련/테스트 중에는 명확하지 않았던 모델의 오류를 파악하는 데 도움이 됩니다.
PyTorch 워크플로우는 01. PyTorch 워크플로우에서 다루었습니다. 하지만 좋은 모델이 생겼다면 배포가 다음 단계로 좋습니다. 모니터링은 모델이 가장 중요한 데이터 분할인 실제 세상의 데이터에서 어떻게 작동하는지 확인하는 작업을 포함합니다. 배포 및 모니터링에 대한 더 많은 자료는 PyTorch 추가 리소스를 참조하세요.
머신러닝 모델 배포의 다양한 유형
머신러닝 모델 배포의 다양한 유형에 대해서는 책 한 권을 쓸 수도 있을 정도입니다(많은 훌륭한 자료들이 PyTorch 추가 리소스에 나열되어 있습니다).
그리고 이 분야는 여전히 모범 사례(best practices) 측면에서 발전하고 있습니다.
하지만 저는 다음과 같은 질문으로 시작하는 것을 좋아합니다.
“내 머신러닝 모델이 사용되기에 가장 이상적인 시나리오는 무엇인가?”
그런 다음 거기서부터 거꾸로 작업해 나갑니다.
물론 미리 알지 못할 수도 있습니다. 하지만 여러분은 그런 것들을 상상할 수 있을 만큼 충분히 똑똑합니다.
FoodVision Mini의 경우, 가장 이상적인 시나리오는 다음과 같을 수 있습니다.
- 누군가 모바일 장치(앱이나 웹 브라우저를 통해)에서 사진을 찍습니다.
- 예측 결과가 빠르게 돌아옵니다.
간단하죠.
따라서 두 가지 주요 기준이 있습니다.
- 모델은 모바일 장치에서 작동해야 합니다(이는 일부 컴퓨팅 제약이 있음을 의미함).
- 모델은 예측을 빠르게 해야 합니다(느린 앱은 지루한 앱이기 때문입니다).
물론 유스케이스에 따라 요구 사항이 달라질 수 있습니다.
위의 두 가지 사항은 다음 두 가지 질문으로 나뉜다는 것을 알 수 있습니다.
- 어디로 가는가? - 즉, 어디에 저장될 것인가?
- 어떻게 작동하는가? - 즉, 예측 결과를 즉시 반환하는가? 아니면 나중에 반환하는가?
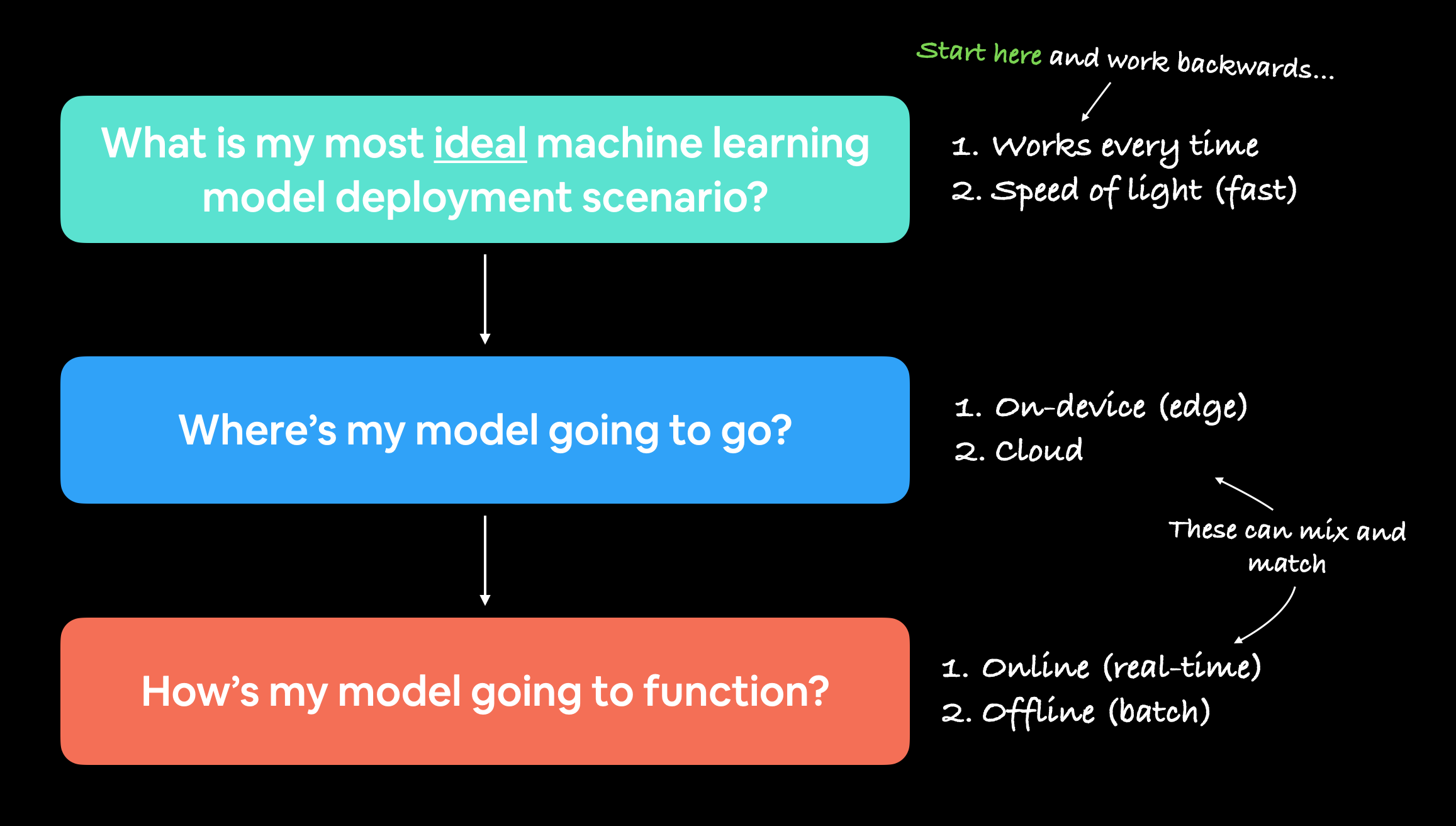
머신러닝 모델 배포를 시작할 때, 가장 이상적인 유스케이스가 무엇인지 물어본 다음 거기서부터 거꾸로 작업하여 모델이 어디로 가고 어떻게 작동할지 묻는 것이 도움이 됩니다.
어디로 가는가?
머신러닝 모델을 배포할 때, 모델은 어디에 존재할까요?
여기서 주요 논쟁은 보통 온디바이스(on-device, 에지/브라우저라고도 함) 또는 클라우드(누군가/무엇인가가 모델을 호출하는 실제 장치가 아닌 컴퓨터/서버)입니다.
둘 다 장단점이 있습니다.
| 배포 위치 | 장점 | 단점 |
|---|---|---|
| 온디바이스 (에지/브라우저) | 데이터가 장치를 떠나지 않으므로 매우 빠를 수 있음 | 제한된 컴퓨팅 파워 (큰 모델은 실행하는 데 더 오래 걸림) |
| 개인정보 보호 (데이터가 장치를 떠날 필요가 없음) | 제한된 저장 공간 (더 작은 모델 크기 필요) | |
| 인터넷 연결이 필요 없음 (때때로) | 장치별 기술이 종종 요구됨 | |
| 클라우드 | 거의 무제한의 컴퓨팅 파워 (필요할 때 확장 가능) | 비용이 걷잡을 수 없이 커질 수 있음 (적절한 확장 한도가 강제되지 않는 경우) |
| 모델 하나를 배포하고 어디서든 사용 가능 (API를 통해) | 데이터가 장치를 떠나고 예측 결과가 돌아와야 하므로 예측이 더 느려질 수 있음 (네트워크 지연) | |
| 기존 클라우드 에코시스템과 연결됨 | 데이터가 장치를 떠나야 함 (이로 인해 개인정보 보호 문제가 발생할 수 있음) |
이에 대한 더 자세한 내용은 많지만, 더 배우고 싶다면 추가 학습 자료에 리소스를 남겨두었습니다.
예를 들어 보겠습니다.
FoodVision Mini를 앱으로 배포한다면, 성능이 좋고 빨라야 합니다.
그렇다면 어떤 모델을 선호할까요?
- 예측당 1초의 추론 시간(지연 시간)과 95%의 정확도로 작동하는 온디바이스 모델.
- 예측당 10초의 추론 시간과 98%의 정확도로 작동하는 클라우드 모델(더 크고 좋은 모델이지만 계산하는 데 더 오래 걸림).
이 수치들은 제가 임의로 만든 것이지만 온디바이스와 클라우드의 잠재적인 차이를 보여줍니다.
옵션 1은 모바일 장치에 적합하여 빠르게 실행되지만 성능은 약간 떨어지는 작은 모델일 수 있습니다.
옵션 2는 더 많은 컴퓨팅과 저장 공간이 필요하지만 실행하는 데 약간 더 오래 걸리는 더 크고 성능이 좋은 모델일 수 있습니다. 데이터가 장치를 떠나고 다시 돌아와야 하기 때문에 실제 예측은 빠르더라도 네트워크 시간과 데이터 전송 시간을 고려해야 하기 때문입니다.
FoodVision Mini의 경우, 약간의 성능 하락보다 훨씬 빠른 추론 속도가 더 중요하므로 옵션 1을 선호할 가능성이 높습니다.
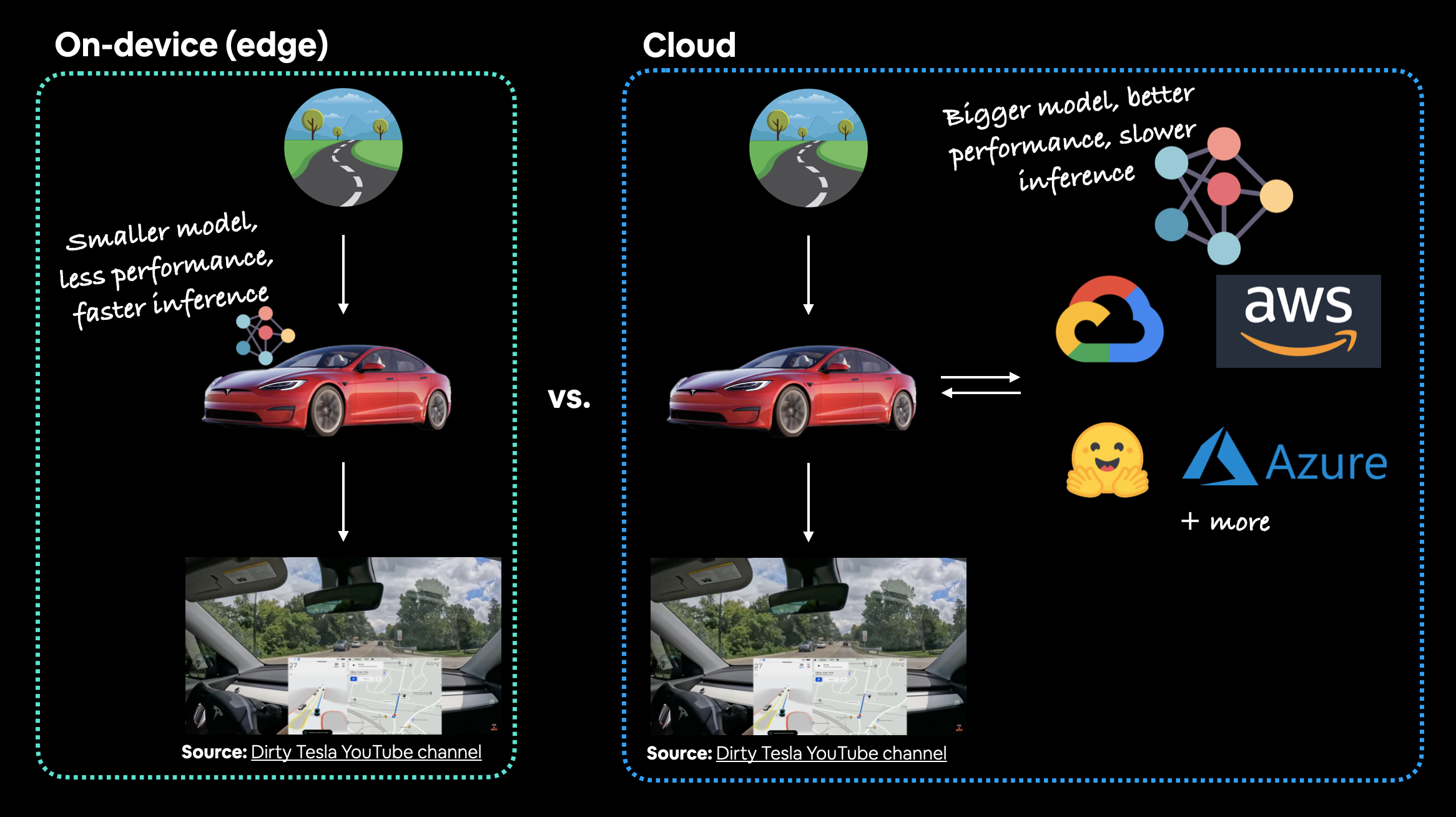
테슬라 자동차의 컴퓨터 비전 시스템의 경우, 어떤 것이 더 좋을까요? 온디바이스(모델이 자동차에 있음)에서 잘 작동하는 작은 모델일까요, 아니면 클라우드에 있는 더 성능이 좋은 큰 모델일까요? 이 경우에는 자동차에 모델이 있는 것을 훨씬 선호할 것입니다. 데이터가 자동차에서 클라우드로 갔다가 다시 자동차로 돌아오는 데 걸리는 추가 네트워크 시간은 그만한 가치가 없거나 신호가 약한 지역에서는 아예 불가능할 수도 있기 때문입니다.
참고: 에지 장치에 PyTorch 모델을 배포하는 것이 어떤 것인지 전체 예제를 보려면 라즈베리 파이에서 컴퓨터 비전 모델을 사용하여 실시간 추론(30fps+)을 달성하는 방법에 대한 PyTorch 튜토리얼을 참조하세요.
어떻게 작동하는가?
이상적인 유스케이스로 돌아가서, 머신러닝 모델을 배포할 때 모델은 어떻게 작동해야 할까요?
즉, 예측 결과가 즉시 반환되기를 원하시나요?
아니면 나중에 발생해도 괜찮나요?
이 두 가지 시나리오는 일반적으로 다음과 같이 불립니다.
- 온라인 (실시간) - 예측/추론이 즉시 발생합니다. 예를 들어, 누군가 이미지를 업로드하면 이미지가 변환되고 예측 결과가 반환되거나, 누군가 구매를 하면 모델에 의해 거래가 사기가 아님이 확인되어 구매가 진행될 수 있습니다.
- 오프라인 (배치) - 예측/추론이 주기적으로 발생합니다. 예를 들어, 모바일 장치가 충전기에 연결되어 있는 동안 사진 애플리케이션이 이미지를 여러 카테고리(해변, 식사 시간, 가족, 친구 등)로 정렬하는 작업입니다.
참고: “배치(Batch)”는 한 번에 여러 샘플에 대해 추론이 수행되는 것을 의미합니다. 하지만 약간의 혼동을 주자면, 배치 처리는 즉시/온라인(여러 이미지를 한 번에 분류) 및/또는 오프라인(여러 이미지를 한 번에 예측/훈련)으로 발생할 수 있습니다.
둘 사이의 주요 차이점은 예측이 즉시 이루어지는지 아니면 주기적으로 이루어지는지입니다.
주기적이라는 것은 몇 초마다부터 몇 시간 또는 며칠마다까지 다양한 시간 척도를 가질 수 있습니다.
그리고 두 가지를 혼합하여 사용할 수도 있습니다.
FoodVision Mini의 경우, 누군가 피자, 스테이크 또는 초밥 이미지를 업로드했을 때 예측 결과가 즉시 반환되어야 하므로 추론 파이프라인이 온라인(실시간)으로 이루어지기를 원할 것입니다(실시간보다 느리면 지루한 경험이 될 것입니다).
하지만 훈련 파이프라인의 경우, 이전 챕터들에서 해왔던 방식인 배치(오프라인) 방식으로 이루어져도 괜찮습니다.
머신러닝 모델을 배포하는 방법
머신러닝 모델을 배포하기 위한 몇 가지 옵션(온디바이스 및 클라우드)에 대해 논의했습니다.
그리고 이들 각각은 고유한 요구 사항이 있을 것입니다.
| 도구/리소스 | 배포 유형 |
|---|---|
| Google의 ML Kit | 온디바이스 (Android 및 iOS) |
Apple의 Core ML 및 coremltools Python 패키지 |
온디바이스 (모든 Apple 장치) |
| Amazon Web Service(AWS)의 Sagemaker | 클라우드 |
| Google Cloud의 Vertex AI | 클라우드 |
| Microsoft의 Azure Machine Learning | 클라우드 |
| Hugging Face Spaces | 클라우드 |
| FastAPI를 이용한 API | 클라우드/자체 호스팅 서버 |
| TorchServe를 이용한 API | 클라우드/자체 호스팅 서버 |
| ONNX (Open Neural Network Exchange) | 다목적/일반 |
| 기타 다수… |
참고: API(Application Programming Interface)는 두 개 이상의 컴퓨터 프로그램이 서로 상호작용하는 방법입니다. 예를 들어, 모델이 API로 배포되었다면 모델에 데이터를 보내고 예측 결과를 다시 받을 수 있는 프로그램을 작성할 수 있습니다.
어떤 옵션을 선택할지는 무엇을 만드는지, 누구와 협력하는지에 따라 크게 달라집니다.
하지만 옵션이 너무 많아서 매우 위협적일 수 있습니다.
따라서 작게 시작하고 단순하게 유지하는 것이 좋습니다.
그리고 그렇게 하는 가장 좋은 방법 중 하나는 머신러닝 모델을 Gradio를 사용하여 데모 앱으로 만든 다음 Hugging Face Spaces에 배포하는 것입니다.
나중에 FoodVision Mini로 바로 그 작업을 수행할 것입니다.
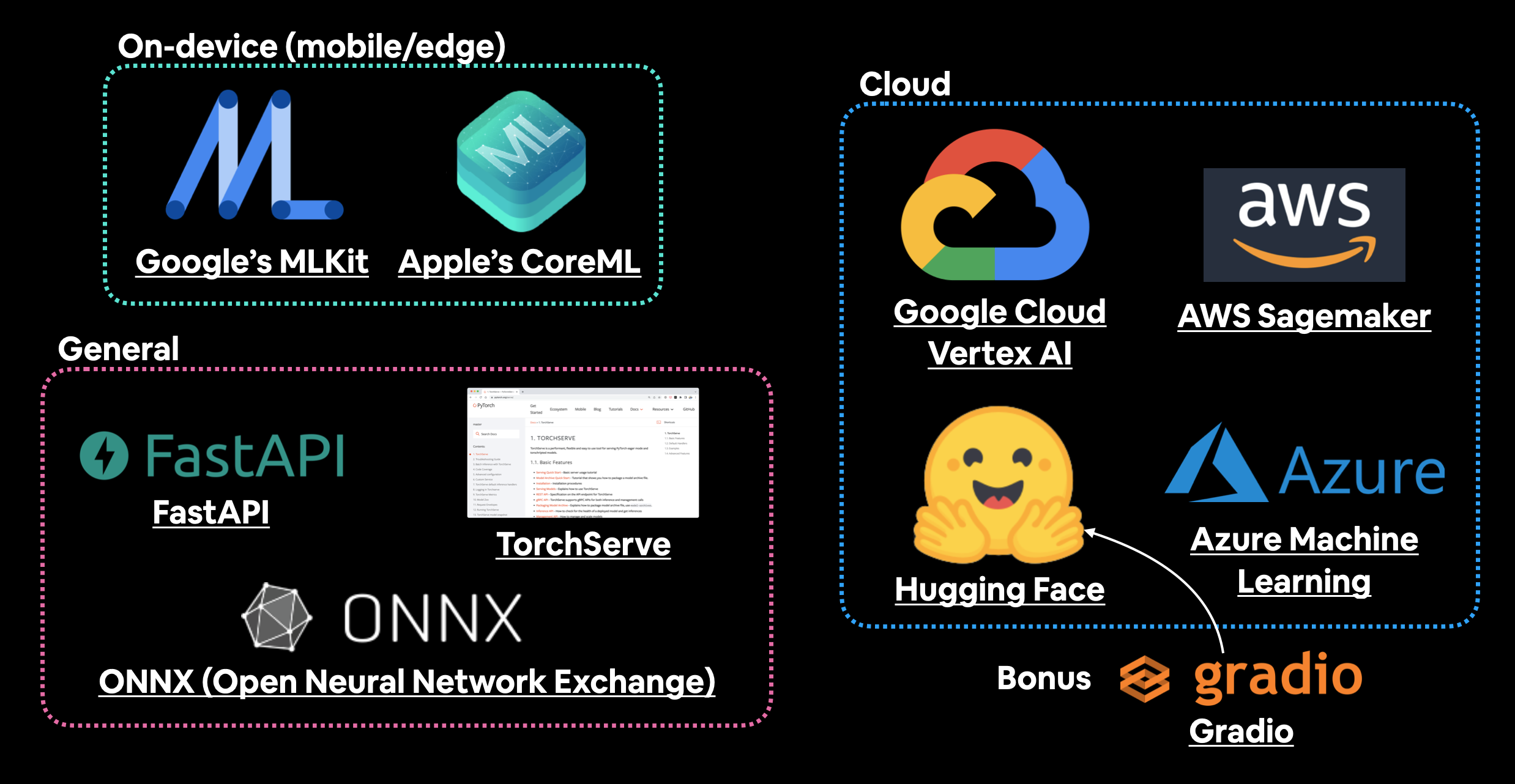
머신러닝 모델을 호스팅하고 배포하기 위한 몇 가지 장소와 도구입니다. 제가 놓친 것들도 많으니 더 추가하고 싶으시다면 GitHub Discussion에 남겨주세요.
이번 장에서 다룰 내용
머신러닝 모델 배포에 대한 이야기는 이 정도로 충분합니다.
머신러닝 엔지니어가 되어 실제로 모델을 배포해 봅시다.
우리의 목표는 다음과 같은 지표를 가진 데모 Gradio 앱을 통해 FoodVision 모델을 배포하는 것입니다. 1. 성능: 95% 이상의 정확도. 2. 속도: 30FPS 이상의 실시간 추론(각 예측의 지연 시간이 약 0.03초 미만).
먼저 지금까지 가장 성능이 좋았던 두 모델인 EffNetB2와 ViT 특성 추출기를 비교하는 실험을 진행하겠습니다.
그런 다음 목표 지표에 가장 근접한 모델을 배포할 것입니다.
마지막으로 (커다란) 깜짝 보너스로 마무리하겠습니다.
| 주제 | 내용 |
|---|---|
| 0. 설정하기 | 지난 몇 섹션 동안 작성한 유용한 코드들을 다운로드하고 다시 사용할 수 있도록 설정합니다. |
| 1. 데이터 가져오기 | 이전에 가장 성능이 좋았던 모델들을 동일한 데이터셋에서 훈련하기 위해 pizza_steak_sushi_20_percent.zip 데이터셋을 다운로드합니다. |
| 2. FoodVision Mini 모델 배포 실험 개요 | 세 번째 마일스톤 프로젝트에서도 어떤 모델(EffNetB2 또는 ViT)이 목표 지표에 가장 근접한지 확인하기 위해 여러 실험을 진행할 것입니다. |
| 3. EffNetB2 특성 추출기 만들기 | 07. PyTorch 실험 추적에서 피자, 스테이크, 초밥 데이터셋에 대해 가장 좋은 성능을 보였던 EfficientNetB2 특성 추출기를 배포 후보로 다시 만듭니다. |
| 4. ViT 특성 추출기 만들기 | 08. PyTorch 논문 복제에서 피자, 스테이크, 초밥 데이터셋에 대해 지금까지 가장 성능이 좋았던 ViT 특성 추출기를 EffNetB2와 함께 배포 후보로 다시 만듭니다. |
| 5. 훈련된 모델로 예측하고 시간 측정하기 | 지금까지 가장 성능이 좋았던 두 모델을 구축하고, 이를 사용하여 예측을 수행하며 결과를 추적합니다. |
| 6. 모델 결과, 예측 시간 및 크기 비교 | 우리의 목표에 가장 부합하는 모델이 무엇인지 비교합니다. |
| 7. Gradio 데모를 만들어 FoodVision Mini 활성화하기 | 목표 지표 측면에서 더 나은 성능을 보이는 모델 중 하나를 선택하여 실제 작동하는 앱 데모로 만듭니다! |
| 8. FoodVision Mini Gradio 데모를 배포 가능한 앱으로 변환하기 | 로컬에서 작동하는 Gradio 앱 데모를 배포할 수 있도록 준비합니다! |
| 9. Gradio 데모를 HuggingFace Spaces에 배포하기 | FoodVision Mini를 웹으로 가져와 모든 사람이 공개적으로 접근할 수 있게 만듭니다! |
| 10. FoodVision Big 만들기 | FoodVision Mini를 만들었으니, 이제 한 단계 더 나아갈 시간입니다. |
| 11. FoodVision Big 배포하기 | 앱 하나를 배포하는 것도 즐거웠지만, 두 개를 배포해 보는 건 어떨까요? |
도움을 받을 수 있는 곳
이 과정의 모든 자료는 GitHub에 있습니다.
문제가 발생하면 해당 페이지의 Discussions 페이지에서 질문할 수 있습니다.
또한 PyTorch와 관련된 모든 것에 대해 매우 도움이 되는 장소인 PyTorch 개발자 포럼과 PyTorch 문서도 있습니다.
0. 설정하기
이전에 했던 것처럼 이 섹션에 필요한 모든 모듈이 있는지 확인해 보겠습니다.
05. PyTorch 모듈화에서 만든 Python 스크립트(data_setup.py 및 engine.py 등)를 가져오겠습니다.
이를 위해 pytorch-deep-learning 저장소에서 going_modular 디렉토리를 다운로드합니다(이미 가지고 있지 않은 경우).
또한 torchinfo 패키지가 없는 경우 가져옵니다.
torchinfo는 나중에 모델의 시각적 표현을 제공하는 데 도움이 됩니다.
그리고 나중에 torchvision v0.13 패키지(2022년 7월 현재 사용 가능)를 사용할 것이므로 최신 버전이 있는지 확인하겠습니다.
참고: Google Colab을 사용 중이고 아직 GPU를 켜지 않았다면 지금
런타임 -> 런타임 유형 변경 -> 하드웨어 가속기 -> GPU를 통해 켤 시간입니다.
참고: Google Colab을 사용 중이고 위 셀이 다양한 소프트웨어 패키지를 설치하기 시작한다면, 위 셀을 실행한 후 런타임을 다시 시작해야 할 수도 있습니다. 다시 시작한 후 셀을 다시 실행하고 올바른 버전의
torch및torchvision이 있는지 확인할 수 있습니다.
이제 일반적인 임포트, 장치 독립적(device agnostic) 코드 설정을 계속하고 이번에는 GitHub에서 helper_functions.py 스크립트도 가져오겠습니다.
helper_functions.py 스크립트에는 이전 섹션에서 만든 몇 가지 함수가 포함되어 있습니다. * set_seeds(): 무작위 시드 설정(07. PyTorch 실험 추적 섹션 0에서 생성). * download_data(): 링크가 주어지면 데이터 소스 다운로드(07. PyTorch 실험 추적 섹션 1에서 생성). * plot_loss_curves(): 모델의 훈련 결과 검사(04. PyTorch 사용자 정의 데이터셋 섹션 7.8)
참고:
helper_functions.py스크립트의 많은 함수를going_modular/going_modular/utils.py로 병합하는 것이 더 좋은 아이디어일 수 있습니다. 그것이 여러분이 시도해 볼 수 있는 확장 작업일 것입니다.
# 일반적인 임포트 계속
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# torchinfo 가져오기 시도, 실패 시 설치
try:
from torchinfo import summary
except:
print("[INFO] torchinfo를 찾을 수 없음... 설치합니다.")
!pip install -q torchinfo
from torchinfo import summary
# going_modular 디렉토리 임포트 시도, 실패 시 GitHub에서 다운로드
try:
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
except:
# going_modular 스크립트 가져오기
print("[INFO] going_modular 또는 helper_functions 스크립트를 찾을 수 없음... GitHub에서 다운로드합니다.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!mv pytorch-deep-learning/helper_functions.py . # helper_functions.py 스크립트 가져오기
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves마지막으로 모델이 GPU에서 실행되도록 장치 독립적 코드를 설정하겠습니다.
device = "cuda" if torch.cuda.is_available() else "cpu"
device1. 데이터 가져오기
우리는 08. PyTorch 논문 복제의 마지막 부분에서 자체 Vision Transformer(ViT) 특성 추출기 모델을 07. PyTorch 실험 추적에서 만든 EfficientNetB2(EffNetB2) 특성 추출기 모델과 비교했습니다.
그리고 비교 과정에서 약간의 차이가 있음을 발견했습니다.
EffNetB2 모델은 Food101의 피자, 스테이크, 초밥 데이터 중 20%를 사용하여 훈련된 반면, ViT 모델은 10%를 사용하여 훈련되었습니다.
FoodVision Mini 문제에 대해 최상의 모델을 배포하는 것이 목표이므로, 우선 20% 피자, 스테이크, 초밥 데이터셋을 다운로드하고 EffNetB2 특성 추출기와 ViT 특성 추출기를 이 데이터셋으로 훈련시킨 후 두 모델을 비교해 보겠습니다.
이렇게 하면 동일한 데이터셋으로 훈련된 두 모델을 서로 동등하게 비교할 수 있습니다.
참고: 다운로드하는 데이터셋은 전체 Food101 데이터셋(각 1,000개의 이미지가 있는 101개 음식 클래스)의 샘플입니다. 구체적으로 20%는 피자, 스테이크, 초밥 클래스에서 무작위로 선택된 이미지의 20%를 의미합니다. 이 데이터셋이 어떻게 생성되었는지는
extras/04_custom_data_creation.ipynb에서, 더 자세한 내용은 04. PyTorch 사용자 정의 데이터셋 섹션 1에서 확인할 수 있습니다.
helper_functions.py에서 07. PyTorch 실험 추적 섹션 1에서 만든 download_data() 함수를 사용하여 데이터를 다운로드할 수 있습니다.
# GitHub에서 피자, 스테이크, 초밥 이미지 다운로드
data_20_percent_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi_20_percent.zip",
destination="pizza_steak_sushi_20_percent")
data_20_percent_path좋습니다!
이제 데이터셋이 생겼으므로 훈련 및 테스트 경로를 생성하겠습니다.
# 훈련 및 테스트 이미지 디렉토리 경로 설정
train_dir = data_20_percent_path / "train"
test_dir = data_20_percent_path / "test"2. FoodVision Mini 모델 배포 실험 개요
이상적인 배포 모델 FoodVision Mini는 성능이 좋고 빨라야 합니다.
우리는 모델이 가능한 한 실시간에 가깝게 작동하기를 원합니다.
여기서 실시간이란 ~30FPS(frames per second)를 의미하는데, 이는 사람의 눈이 볼 수 있는 속도 정도이기 때문입니다(이에 대해서는 논란이 있지만, 일단 ~30FPS를 벤치마크로 삼겠습니다).
그리고 세 가지 클래스(피자, 스테이크, 초밥)를 분류하기 위해 95% 이상의 정확도로 작동하는 모델을 원합니다.
물론 정확도가 높을수록 좋겠지만, 이는 속도를 희생할 수도 있습니다.
따라서 우리의 목표는 다음과 같습니다.
- 성능 (Performance) - 95% 이상의 정확도로 작동하는 모델.
- 속도 (Speed) - 약 30FPS(이미지당 추론 시간 0.03초, 지연 시간(latency)이라고도 함)로 이미지를 분류할 수 있는 모델.
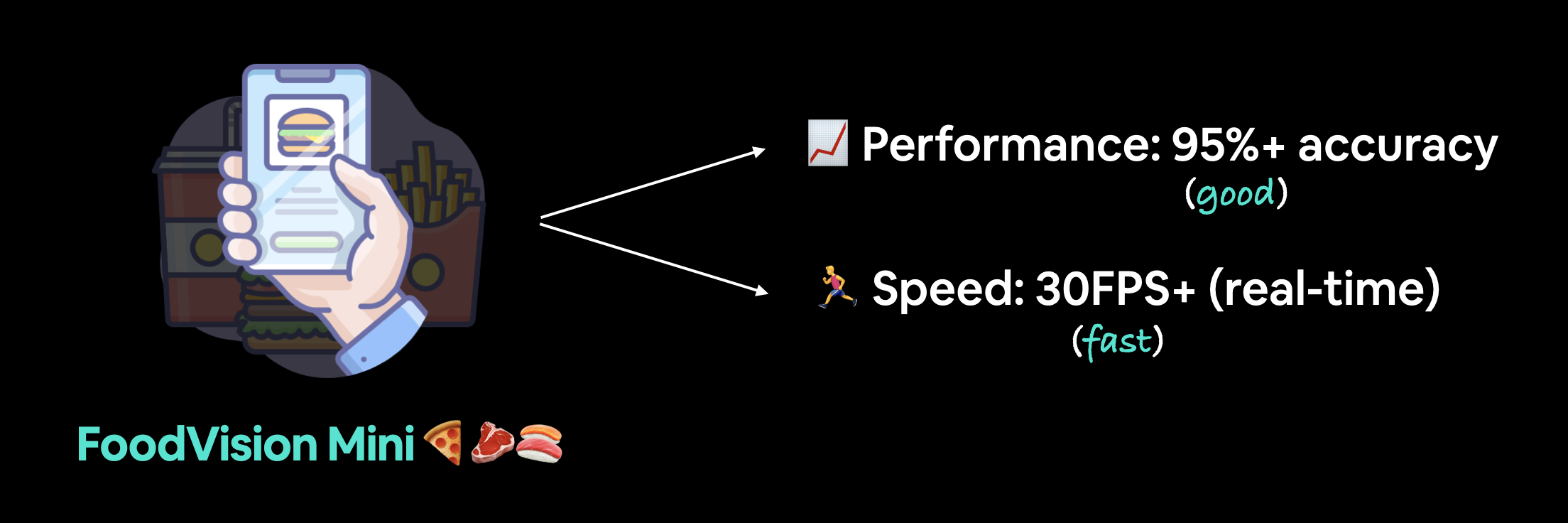
FoodVision Mini 배포 목표. 우리는 빠르게 예측하고 성능이 좋은 모델을 원합니다(느린 앱은 지루하기 때문입니다).
우리는 속도에 중점을 둘 것이며, 이는 10FPS에서 95% 이상의 정확도를 보이는 모델보다는 ~30FPS에서 90% 이상의 정확도를 보이는 모델을 더 선호한다는 의미입니다.
이러한 결과를 달성하기 위해 이전 섹션에서 가장 성능이 좋았던 모델들을 가져오겠습니다.
- EffNetB2 특성 추출기 (줄여서 EffNetB2) - 원래 07. PyTorch 실험 추적 섹션 7.5에서
classifier레이어를 조정한torchvision.models.efficientnet_b2()를 사용하여 만들었습니다. - ViT-B/16 특성 추출기 (줄여서 ViT) - 원래 08. PyTorch 논문 복제 섹션 10에서
head레이어를 조정한torchvision.models.vit_b_16()을 사용하여 만들었습니다.- 참고: ViT-B/16은 “Vision Transformer Base, 패치 크기 16”을 의미합니다.
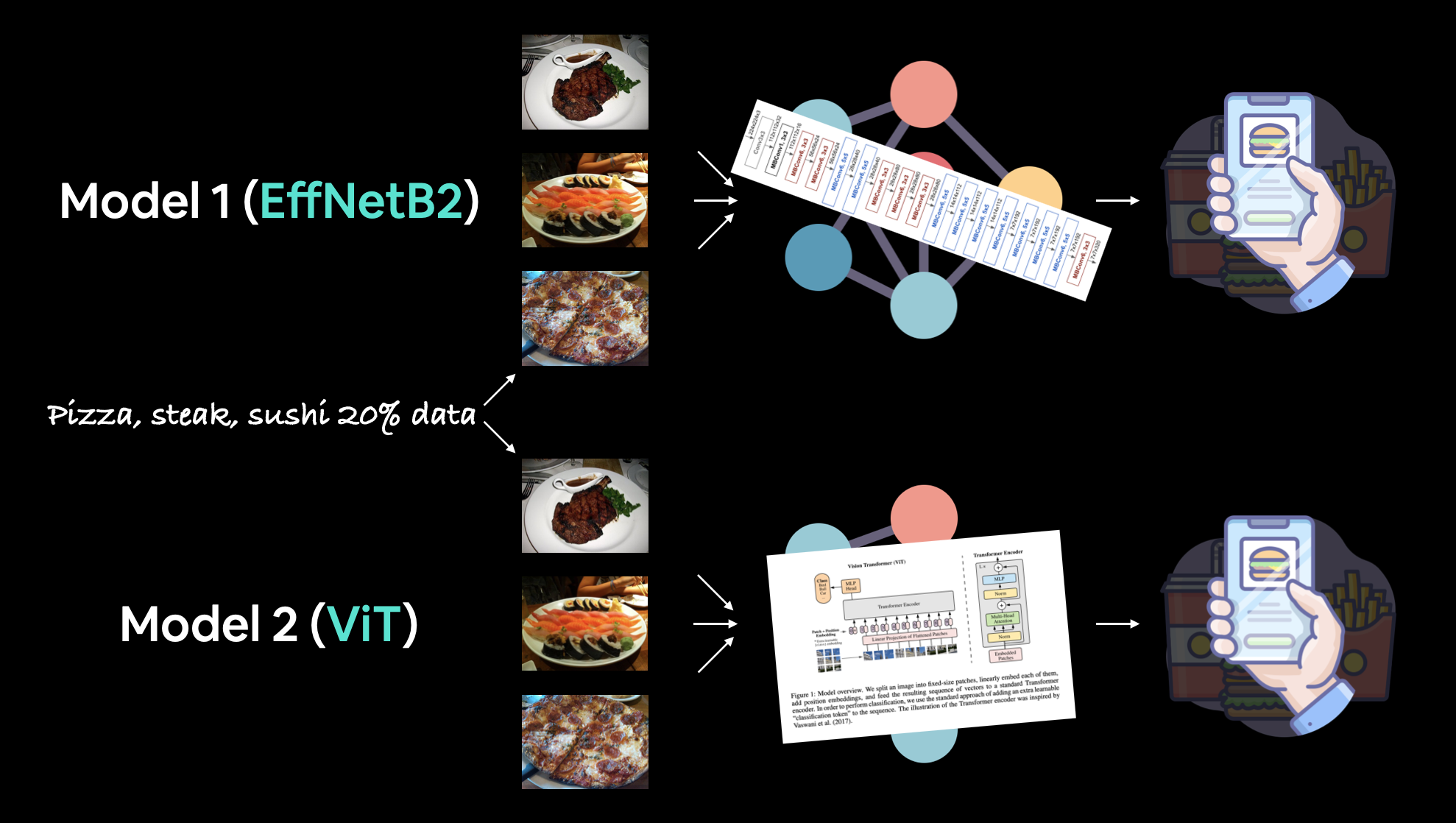
참고: “특성 추출기 모델(feature extractor model)”은 종종 여러분의 문제와 유사한 데이터셋으로 사전 훈련된 모델에서 시작합니다. 사전 훈련된 모델의 기본 레이어는 종종 고정된(사전 훈련된 패턴/가중치가 동일하게 유지됨) 상태로 두는 반면, 상단(또는 분류기/분류 헤드) 레이어 중 일부는 자신의 데이터로 훈련하여 자신의 문제에 맞게 사용자 정의합니다. 특성 추출기 모델의 개념은 06. PyTorch 전이 학습 섹션 3.4에서 다루었습니다.
3. EffNetB2 특성 추출기 만들기
우리는 07. PyTorch 실험 추적 섹션 7.5에서 EffNetB2 특성 추출기 모델을 처음 만들었습니다.
그리고 해당 섹션의 마지막 부분에서 아주 좋은 성능을 보인 것을 확인했습니다.
이제 여기에서 해당 모델을 다시 만들어 동일한 데이터로 훈련된 ViT 특성 추출기와 결과를 비교해 보겠습니다.
다음과 같이 할 수 있습니다. 1. weights=torchvision.models.EfficientNet_B2_Weights.DEFAULT를 사용하여 사전 훈련된 가중치를 설정합니다. 여기서 “DEFAULT”는 “현재 사용 가능한 최상의 가중치”를 의미합니다 (또는 weights="DEFAULT"를 사용할 수 있습니다). 2. 가중치에서 transforms() 메서드를 사용하여 사전 훈련된 모델 이미지 트랜스폼을 가져옵니다(사전 훈련된 EffNetB2가 훈련된 것과 동일한 형식으로 이미지를 변환하기 위해 필요합니다). 3. 가중치를 torchvision.models.efficientnet_b2의 인스턴스에 전달하여 사전 훈련된 모델 인스턴스를 생성합니다. 4. 모델의 기본 레이어를 고정합니다. 5. 자신의 데이터에 맞게 분류 헤드를 업데이트합니다.
# 1. 사전 훈련된 EffNetB2 가중치 설정
effnetb2_weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
# 2. EffNetB2 트랜스폼 가져오기
effnetb2_transforms = effnetb2_weights.transforms()
# 3. 사전 훈련된 모델 설정
effnetb2 = torchvision.models.efficientnet_b2(weights=effnetb2_weights) # weights="DEFAULT"를 사용할 수도 있습니다.
# 4. 모델의 기본 레이어 고정 (처음에는 모든 레이어를 고정함)
for param in effnetb2.parameters():
param.requires_grad = False이제 분류 헤드를 변경하기 위해 모델의 classifier 속성을 사용하여 먼저 검사해 보겠습니다.
# EffNetB2 분류 헤드 확인
effnetb2.classifier좋습니다! 자신의 문제에 맞게 분류 헤드를 변경하려면 out_features 변수를 우리가 가진 클래스 수와 동일하게 바꿉니다(우리의 경우 out_features=3, 피자, 스테이크, 초밥용).
참고: 출력 레이어/분류 헤드를 변경하는 이 과정은 작업 중인 문제에 따라 달라집니다. 예를 들어, 다른 출력 수나 다른 출력 종류를 원한다면 그에 따라 출력 레이어를 변경해야 합니다.
# 5. 분류 헤드 업데이트
effnetb2.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True), # 드롭아웃 레이어 유지
nn.Linear(in_features=1408, # in_features 유지
out_features=3)) # 우리 클래스 수에 맞게 out_features 변경훌륭합니다!
3.1 EffNetB2 특성 추출기를 만드는 함수 만들기
EffNetB2 특성 추출기가 준비된 것 같습니다. 하지만 여기에 몇 가지 단계가 포함되어 있으므로 나중에 다시 사용할 수 있도록 위의 코드를 함수로 만드는 건 어떨까요?
create_effnetb2_model()이라고 명명하고, 사용자 정의 가능한 클래스 수와 재현성을 위한 무작위 시드 매개변수를 받도록 하겠습니다.
이상적으로는 EffNetB2 특성 추출기와 관련 트랜스폼을 반환할 것입니다.
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""EfficientNetB2 특성 추출기 모델과 트랜스폼을 생성합니다.
인자:
num_classes (int, optional): 분류 헤드의 클래스 수.
기본값은 3.
seed (int, optional): 무작위 시드 값. 기본값은 42.
반환값:
model (torch.nn.Module): EffNetB2 특성 추출기 모델.
transforms (torchvision.transforms): EffNetB2 이미지 트랜스폼.
"""
# 1, 2, 3. 사전 훈련된 EffNetB2 가중치, 트랜스폼 및 모델 생성
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# 4. 기본 모델의 모든 레이어 고정
for param in model.parameters():
param.requires_grad = False
# 5. 재현성을 위해 무작위 시드와 함께 분류 헤드 변경
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms와우! 아주 멋진 함수네요. 한번 시도해 보겠습니다.
effnetb2, effnetb2_transforms = create_effnetb2_model(num_classes=3,
seed=42)오류가 없네요. 좋습니다. 이제 실제로 확인해 보기 위해 torchinfo.summary()로 요약을 확인해 보겠습니다.
from torchinfo import summary
# # EffNetB2 모델 요약 출력 (전체 출력을 보려면 주석 해제)
# summary(effnetb2,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])
기본 레이어는 고정되었고, 상위 레이어는 학습 가능하며 사용자 정의되었습니다!
3.2 EffNetB2를 위한 DataLoader 생성
EffNetB2 특성 추출기가 준비되었으니 이제 DataLoader를 생성할 시간입니다.
05. PyTorch 모듈화 섹션 2에서 만든 data_setup.create_dataloaders() 함수를 사용하여 이를 수행할 수 있습니다.
배치 크기를 32로 사용하고 effnetb2_transforms를 사용하여 이미지를 변환함으로써 이미지가 effnetb2 모델이 훈련된 것과 동일한 형식이 되도록 하겠습니다.
# DataLoader 설정
from going_modular.going_modular import data_setup
train_dataloader_effnetb2, test_dataloader_effnetb2, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=effnetb2_transforms,
batch_size=32)3.3 EffNetB2 특성 추출기 훈련
모델도 준비되었고 DataLoader도 준비되었으니 이제 훈련을 시작해 봅시다!
07. PyTorch 실험 추적 섹션 7.6에서와 마찬가지로 좋은 결과를 얻기 위해 10 에포크면 충분할 것입니다.
옵티마이저(학습률 1e-3인 torch.optim.Adam() 사용)와 손실 함수(다중 클래스 분류를 위한 torch.nn.CrossEntropyLoss() 사용)를 생성한 다음, 이들과 DataLoader를 05. PyTorch 모듈화 섹션 4에서 만든 engine.train() 함수에 전달하여 수행할 수 있습니다.
from going_modular.going_modular import engine
# 옵티마이저 설정
optimizer = torch.optim.Adam(params=effnetb2.parameters(),
lr=1e-3)
# 손실 함수 설정
loss_fn = torch.nn.CrossEntropyLoss()
# 재현성을 위해 시드를 설정하고 모델을 훈련시킴
set_seeds()
effnetb2_results = engine.train(model=effnetb2,
train_dataloader=train_dataloader_effnetb2,
test_dataloader=test_dataloader_effnetb2,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)3.4 EffNetB2 손실 곡선 검사
좋네요!
- PyTorch 실험 추적에서 보았듯이 EffNetB2 특성 추출기 모델은 우리 데이터에서 꽤 잘 작동합니다.
결과를 손실 곡선으로 변환하여 더 자세히 살펴보겠습니다.
참고: 손실 곡선은 모델의 성능을 시각화하는 가장 좋은 방법 중 하나입니다. 손실 곡선에 대한 자세한 내용은 04. PyTorch 사용자 정의 데이터셋 섹션 8: 이상적인 손실 곡선은 어떤 모습이어야 할까요?를 참조하세요.
from helper_functions import plot_loss_curves
plot_loss_curves(effnetb2_results)와!
손실 곡선이 아주 예쁘게 나왔네요.
우리 모델이 꽤 잘 수행되고 있으며, 아마도 훈련 시간을 조금 더 늘리고 잠재적으로 데이터 증강(data augmentation)을 추가한다면 더 좋은 결과를 얻을 수도 있을 것입니다(더 긴 훈련으로 인해 발생할 수 있는 오버피팅을 방지하기 위해).
3.5 EffNetB2 특성 추출기 저장
성능이 좋은 훈련된 모델을 얻었으므로, 나중에 임포트하여 사용할 수 있도록 파일로 저장해 보겠습니다.
모델을 저장하기 위해 05. PyTorch 모듈화 섹션 5에서 만든 utils.save_model() 함수를 사용할 수 있습니다.
target_dir을 "models"로, model_name을 "09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"로 설정하겠습니다(좀 길긴 하지만 적어도 무슨 내용인지는 알 수 있습니다).
from going_modular.going_modular import utils
# 모델 저장
utils.save_model(model=effnetb2,
target_dir="models",
model_name="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth")3.6 EffNetB2 특성 추출기 크기 확인
FoodVision Mini를 구동할 모델을 배포하기 위한 기준 중 하나가 속도(~30FPS 이상)이므로 모델의 크기를 확인해 보겠습니다.
크기를 왜 확인할까요?
항상 그런 것은 아니지만 모델의 크기는 추론 속도에 영향을 줄 수 있기 때문입니다.
즉, 모델에 파라미터가 더 많으면 일반적으로 더 많은 연산을 수행하고 각 연산에는 어느 정도의 컴퓨팅 파워가 필요합니다.
그리고 우리는 모델이 컴퓨팅 파워가 제한된 장치(예: 모바일 장치 또는 웹 브라우저)에서 작동하기를 원하므로 일반적으로 정확도 측면에서 여전히 잘 수행된다면 크기가 작을수록 좋습니다.
모델의 크기를 바이트 단위로 확인하기 위해 Python의 pathlib.Path.stat("path_to_model").st_size를 사용할 수 있으며, 이를 (1024*1024)로 나누어 (대략) 메가바이트로 변환할 수 있습니다.
from pathlib import Path
# 모델 크기를 바이트 단위로 가져온 다음 메가바이트로 변환
pretrained_effnetb2_model_size = Path("models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # 나눗셈을 통해 바이트를 메가바이트로 변환(대략)
print(f"사전 훈련된 EffNetB2 특성 추출기 모델 크기: {pretrained_effnetb2_model_size} MB")3.7 EffNetB2 특성 추출기 통계 수집
테스트 손실, 테스트 정확도, 모델 크기와 같은 EffNetB2 특성 추출기 모델에 대한 몇 가지 통계를 얻었습니다. 나중에 나올 ViT 특성 추출기와 비교할 수 있도록 이들을 모두 딕셔너리에 수집해 보겠습니다.
그리고 재미 삼아 총 파라미터 수도 계산해 보겠습니다.
effnetb2.parameters()에 있는 요소(또는 패턴/가중치)의 수를 세어 그렇게 할 수 있습니다. torch.numel()(“number of elements”의 약자) 메서드를 사용하여 각 파라미터의 요소 수에 접근할 것입니다.
# EffNetB2의 파라미터 수 계산
effnetb2_total_params = sum(torch.numel(param) for param in effnetb2.parameters())
effnetb2_total_params훌륭합니다!
이제 나중에 비교할 수 있도록 모든 것을 딕셔너리에 넣겠습니다.
# EffNetB2 통계가 포함된 딕셔너리 생성
effnetb2_stats = {"test_loss": effnetb2_results["test_loss"][-1],
"test_acc": effnetb2_results["test_acc"][-1],
"number_of_parameters": effnetb2_total_params,
"model_size (MB)": pretrained_effnetb2_model_size}
effnetb2_stats환상적이네요!
우리의 EffNetB2 모델이 95% 이상의 정확도로 수행되고 있는 것 같습니다!
기준 1번: 95% 이상의 정확도로 수행, 완료!
4. ViT 특성 추출기 만들기
이제 FoodVision Mini 모델링 실험을 계속해 볼 시간입니다.
이번에는 ViT 특성 추출기를 만들어 보겠습니다.
EffNetB2 특성 추출기와 거의 동일한 방식으로 진행하되, 이번에는 torchvision.models.efficientnet_b2() 대신 torchvision.models.vit_b_16()을 사용하겠습니다.
create_vit_model()이라는 함수를 만드는 것으로 시작하겠습니다. 이 함수는 create_effnetb2_model()과 매우 유사하지만 당연히 EffNetB2 대신 ViT 특성 추출기 모델과 트랜스폼을 반환할 것입니다.
또 다른 약간의 차이점은 torchvision.models.vit_b_16()의 출력 레이어가 classifier가 아닌 heads라는 이름이라는 점입니다.
# ViT heads 레이어 확인
vit = torchvision.models.vit_b_16()
vit.heads이 사실을 바탕으로 우리는 필요한 퍼즐 조각을 모두 갖추었습니다.
def create_vit_model(num_classes:int=3,
seed:int=42):
"""ViT-B/16 특성 추출기 모델과 트랜스폼을 생성합니다.
인자:
num_classes (int, optional): 타겟 클래스 수. 기본값은 3.
seed (int, optional): 출력 레이어의 무작위 시드 값. 기본값은 42.
반환값:
model (torch.nn.Module): ViT-B/16 특성 추출기 모델.
transforms (torchvision.transforms): ViT-B/16 이미지 트랜스폼.
"""
# 사전 훈련된 ViT_B_16 가중치, 트랜스폼 및 모델 생성
weights = torchvision.models.ViT_B_16_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.vit_b_16(weights=weights)
# 모델의 모든 레이어 고정
for param in model.parameters():
param.requires_grad = False
# 요구 사항에 맞게 분류 헤드 변경 (이 부분은 훈련 가능함)
torch.manual_seed(seed)
model.heads = nn.Sequential(nn.Linear(in_features=768, # 원본 모델과 동일하게 유지
out_features=num_classes)) # 타겟 클래스 수를 반영하도록 업데이트
return model, transformsViT 특성 추출 모델 생성 함수 준비 완료!
한번 테스트해 봅시다.
# ViT 모델 및 트랜스폼 생성
vit, vit_transforms = create_vit_model(num_classes=3,
seed=42)오류가 없네요. 보기 좋습니다!
이제 torchinfo.summary()를 사용하여 ViT 모델의 멋진 요약을 확인해 보겠습니다.
from torchinfo import summary
# # ViT 특성 추출기 모델 요약 출력 (전체 출력을 보려면 주석 해제)
# summary(vit,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])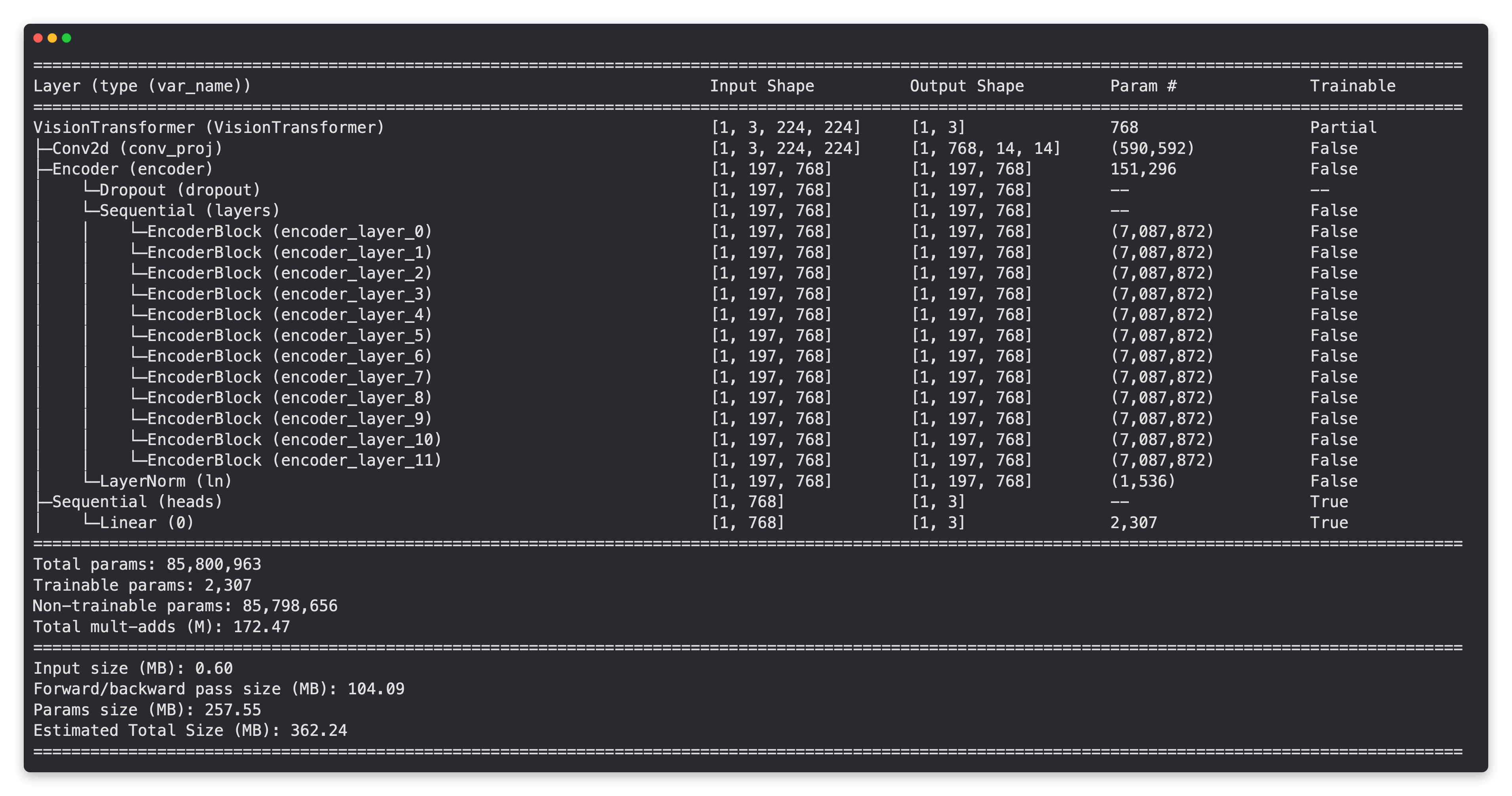
EffNetB2 특성 추출기 모델과 마찬가지로 ViT 모델의 기본 레이어는 고정되었고 출력 레이어는 우리의 요구 사항에 맞게 사용자 정의되었습니다!
하지만 큰 차이점이 보이시나요?
ViT 모델은 EffNetB2 모델보다 파라미터가 훨씬 더 많습니다. 아마도 나중에 속도와 성능 측면에서 모델을 비교할 때 이 점이 작용할 것입니다.
4.1 ViT를 위한 DataLoader 생성
ViT 모델이 준비되었으니 이제 DataLoader를 생성해 보겠습니다.
이미지를 ViT 모델이 훈련된 것과 동일한 형식으로 변환하기 위해 vit_transforms를 사용하는 것을 제외하면 EffNetB2에서 했던 방식과 동일하게 수행하겠습니다.
# ViT DataLoader 설정
from going_modular.going_modular import data_setup
train_dataloader_vit, test_dataloader_vit, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=vit_transforms,
batch_size=32)4.2 ViT 특성 추출기 훈련
지금이 무슨 시간인지 아시죠…
…바로 훈련 시간입니다.
옵티마이저로 torch.optim.Adam()과 학습률 1e-3을 사용하고 손실 함수로 torch.nn.CrossEntropyLoss()를 사용하는 engine.train() 함수를 사용하여 10 에포크 동안 ViT 특성 추출기 모델을 훈련해 보겠습니다.
훈련 전에는 set_seeds() 함수를 사용하여 결과를 최대한 재현할 수 있도록 하겠습니다.
from going_modular.going_modular import engine
# 옵티마이저 설정
optimizer = torch.optim.Adam(params=vit.parameters(),
lr=1e-3)
# 손실 함수 설정
loss_fn = torch.nn.CrossEntropyLoss()
# 재현성을 위해 시드를 설정하고 ViT 모델 훈련
set_seeds()
vit_results = engine.train(model=vit,
train_dataloader=train_dataloader_vit,
test_dataloader=test_dataloader_vit,
epochs=10,
optimizer=optimizer,
loss_fn=loss_fn,
device=device)4.3 ViT 손실 곡선 검사
좋습니다. ViT 모델 훈련이 끝났으니 이제 시각화하여 손실 곡선을 확인해 보겠습니다.
참고: 이상적인 손실 곡선이 어떤 모습이어야 하는지는 04. PyTorch 사용자 정의 데이터셋 섹션 8에서 확인할 수 있습니다.
from helper_functions import plot_loss_curves
plot_loss_curves(vit_results)와우!
손실 곡선이 아주 예쁘네요. EffNetB2 특성 추출기 모델과 마찬가지로, ViT 모델도 훈련 시간을 조금 더 늘리고 잠재적으로 데이터 증강을 추가한다면 더 좋은 결과를 얻을 수 있을 것입니다(오버피팅 방지).
4.4 ViT 특성 추출기 저장
우리의 ViT 모델이 뛰어난 성능을 보이고 있습니다!
나중에 필요할 때 임포트하여 사용할 수 있도록 파일로 저장해 보겠습니다.
05. PyTorch 모듈화 섹션 5에서 만든 utils.save_model() 함수를 사용하여 그렇게 할 수 있습니다.
# 모델 저장
from going_modular.going_modular import utils
utils.save_model(model=vit,
target_dir="models",
model_name="09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth")4.5 ViT 특성 추출기 크기 확인
여러 특성에 걸쳐 EffNetB2 모델과 ViT 모델을 비교하고 싶으므로 모델의 크기를 알아보겠습니다.
모델의 크기를 바이트 단위로 확인하기 위해 Python의 pathlib.Path.stat("path_to_model").st_size를 사용할 수 있으며, 이를 (1024*1024)로 나누어 (대략) 메가바이트로 변환할 수 있습니다.
from pathlib import Path
# 모델 크기를 바이트 단위로 가져온 다음 메가바이트로 변환
pretrained_vit_model_size = Path("models/09_pretrained_vit_feature_extractor_pizza_steak_sushi_20_percent.pth").stat().st_size // (1024*1024) # 나눗셈을 통해 바이트를 메가바이트로 변환(대략)
print(f"사전 훈련된 ViT 특성 추출기 모델 크기: {pretrained_vit_model_size} MB")흠, ViT 특성 추출기 모델 크기는 EffNetB2 모델 크기와 비교하면 어떨까요?
잠시 후에 모든 모델 특성을 비교할 때 이를 확인해 보겠습니다.
4.6 ViT 특성 추출기 통계 수집
모든 ViT 특성 추출기 모델 통계를 정리해 보겠습니다.
위의 요약 출력에서 보았지만, 총 파라미터 수도 계산해 보겠습니다.
# ViT의 파라미터 수 계산
vit_total_params = sum(torch.numel(param) for param in vit.parameters())
vit_total_params와, EffNetB2보다 꽤 많은 것 같네요!
참고: 파라미터(또는 가중치/패턴) 수가 많다는 것은 일반적으로 모델이 학습할 수 있는 용량(capacity)이 더 크다는 것을 의미하지만, 실제로 이 추가 용량을 사용하는지는 별개의 이야기입니다. 이를 고려할 때 EffNetB2 모델은 7,705,221개의 파라미터를 가지고 있는 반면 ViT 모델은 85,800,963개(11.1배 더 많음)를 가지고 있으므로, 더 많은 데이터(학습 기회)가 주어진다면 ViT 모델이 학습 용량이 더 크다고 가정할 수 있습니다. 하지만 이러한 큰 학습 용량은 종종 모델 파일 크기 증가와 더 긴 추론 시간으로 이어집니다.
이제 ViT 모델의 몇 가지 중요한 특성을 포함하는 딕셔너리를 만들어 보겠습니다.
# ViT 통계 딕셔너리 생성
vit_stats = {"test_loss": vit_results["test_loss"][-1],
"test_acc": vit_results["test_acc"][-1],
"number_of_parameters": vit_total_params,
"model_size (MB)": pretrained_vit_model_size}
vit_stats좋습니다! ViT 모델도 95% 이상의 정확도를 달성하는 것 같습니다.
5. 훈련된 모델로 예측하고 시간 측정하기
몇 가지 훈련된 모델을 얻었고 둘 다 꽤 잘 수행되고 있습니다.
이제 우리가 원하는 작업을 수행하여 모델들을 테스트해 보는 건 어떨까요?
즉, 모델들이 예측(추론 수행)을 어떻게 하는지 살펴보겠습니다.
두 모델 모두 테스트 데이터셋에서 95% 이상의 정확도를 보이고 있다는 것을 알고 있지만, 속도는 어느 정도일까요?
이상적으로 사람들이 음식 사진을 찍고 식별할 수 있도록 모바일 장치에 FoodVision Mini 모델을 배포한다면, 실시간(~초당 30프레임)으로 예측이 이루어지기를 원할 것입니다.
이것이 우리의 두 번째 기준인 ’빠른 모델’인 이유입니다.
각 모델이 추론을 수행하는 데 걸리는 시간을 알아보기 위해, 테스트 데이터셋 이미지를 하나씩 반복하며 예측을 수행하는 pred_and_store()라는 함수를 만들어 보겠습니다.
각 예측 시간을 측정하고 그 결과를 일반적인 예측 형식인 딕셔너리 리스트(리스트의 각 요소는 단일 예측이고 각 단일 예측은 딕셔너리임)로 저장하겠습니다.
참고: 모델이 배포될 때 한 번에 하나의 이미지에 대해서만 예측을 수행할 가능성이 높으므로 배치가 아닌 하나씩 예측 시간을 측정합니다. 즉, 누군가 사진을 찍으면 우리 모델은 그 단일 이미지에 대해 예측합니다.
테스트 세트의 모든 이미지에 대해 예측을 수행하고 싶으므로, 먼저 모든 테스트 이미지 경로 리스트를 가져와 반복할 수 있도록 하겠습니다.
이를 위해 Python의 pathlib.Path("target_dir").glob("*/*.jpg"))를 사용하여 확장자가 .jpg인 타겟 디렉토리의 모든 파일 경로를 찾겠습니다(모든 테스트 이미지).
from pathlib import Path
# 모든 테스트 데이터 경로 가져오기
print(f"[INFO] 디렉토리에서 '.jpg'로 끝나는 모든 파일 경로 찾는 중: {test_dir}")
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
test_data_paths[:5]5.1 테스트 데이터셋에 대해 예측을 수행하는 함수 만들기
이제 테스트 이미지 경로 리스트를 얻었으므로 pred_and_store() 함수 작업을 시작하겠습니다.
- 경로 리스트, 훈련된 PyTorch 모델, 일련의 트랜스폼(이미지 준비용), 타겟 클래스 이름 리스트 및 타겟 장치를 인자로 받는 함수를 만듭니다.
- 예측 딕셔너리를 저장할 빈 리스트를 생성합니다(함수가 각 예측에 대해 하나씩 딕셔너리 리스트를 반환하기를 원합니다).
- 타겟 입력 경로를 반복합니다(4~14단계는 루프 내부에서 발생함).
- 샘플당 예측 값을 저장하기 위해 루프의 각 반복마다 빈 딕셔너리를 생성합니다.
- 샘플 경로와 정답 클래스 이름을 가져옵니다(경로에서 클래스를 추론하여 수행할 수 있음).
- Python의
timeit.default_timer()를 사용하여 예측 타이머를 시작합니다. PIL.Image.open(path)를 사용하여 이미지를 엽니다.- 이미지를 타겟 모델과 함께 사용할 수 있도록 변환하고 배치 차원을 추가하며 이미지를 타겟 장치로 보냅니다.
- 모델을 타겟 장치로 보내고
eval()모드를 켜서 추론을 위한 모델을 준비합니다. torch.inference_mode()를 켜고 타겟 변환된 이미지를 모델에 전달하고torch.softmax()를 사용하여 예측 확률을,torch.argmax()를 사용하여 타겟 레이블을 계산합니다.- 4단계에서 생성된 예측 딕셔너리에 예측 확률과 예측 클래스를 추가합니다. 또한 나중에 검사할 때 NumPy 및 pandas와 같은 비 GPU 라이브러리와 함께 사용할 수 있도록 예측 확률이 CPU에 있는지 확인합니다.
- 6단계에서 시작된 예측 타이머를 종료하고 4단계에서 생성된 예측 딕셔너리에 시간을 추가합니다.
- 예측된 클래스가 5단계의 정답 클래스와 일치하는지 확인하고 그 결과를 4단계에서 생성된 예측 딕셔너리에 추가합니다.
- 업데이트된 예측 딕셔너리를 2단계에서 생성된 빈 예측 리스트에 추가합니다.
- 예측 딕셔너리 리스트를 반환합니다.
몇 가지 단계가 있지만, 우리가 처리할 수 없는 것은 아닙니다!
해봅시다.
import pathlib
import torch
from PIL import Image
from timeit import default_timer as timer
from tqdm.auto import tqdm
from typing import List, Dict
# 1. 샘플, 정답 레이블, 예측, 예측 확률 및 예측 시간이 포함된 딕셔너리 리스트를 반환하는 함수 생성
def pred_and_store(paths: List[pathlib.Path],
model: torch.nn.Module,
transform: torchvision.transforms,
class_names: List[str],
device: str = "cuda" if torch.cuda.is_available() else "cpu") -> List[Dict]:
# 2. 예측 딕셔너리를 저장할 빈 리스트 생성
pred_list = []
# 3. 타겟 경로를 반복
for path in tqdm(paths):
# 4. 각 샘플에 대한 예측 정보를 저장할 빈 딕셔너리 생성
pred_dict = {}
# 5. 샘플 경로와 정답 클래스 이름 가져오기
pred_dict["image_path"] = path
class_name = path.parent.stem
pred_dict["class_name"] = class_name
# 6. 예측 타이머 시작
start_time = timer()
# 7. 이미지 경로 열기
img = Image.open(path)
# 8. 이미지 변환, 배치 차원 추가 및 이미지를 타겟 장치에 배치
transformed_image = transform(img).unsqueeze(0).to(device)
# 9. 모델을 타겟 장치로 보내고 eval() 모드를 켜서 추론 준비
model.to(device)
model.eval()
# 10. 예측 확률, 예측 레이블 및 예측 클래스 가져오기
with torch.inference_mode():
pred_logit = model(transformed_image) # 타겟 샘플에 대해 추론 수행
pred_prob = torch.softmax(pred_logit, dim=1) # 로짓을 예측 확률로 변환
pred_label = torch.argmax(pred_prob, dim=1) # 예측 확률을 예측 레이블로 변환
pred_class = class_names[pred_label.cpu()] # 예측 클래스가 CPU에 있도록 하드코딩
# 11. 딕셔너리의 항목들이 CPU에 있는지 확인 (나중에 예측을 검사하는 데 필요함)
pred_dict["pred_prob"] = round(pred_prob.unsqueeze(0).max().cpu().item(), 4)
pred_dict["pred_class"] = pred_class
# 12. 타이머를 종료하고 예측당 시간 계산
end_time = timer()
pred_dict["time_for_pred"] = round(end_time-start_time, 4)
# 13. 예측이 정답 레이블과 일치하나요?
pred_dict["correct"] = class_name == pred_class
# 14. 딕셔너리를 예측 리스트에 추가
pred_list.append(pred_dict)
# 15. 예측 딕셔너리 리스트 반환
return pred_list호호!
정말 멋진 함수네요!
pred_and_store()는 예측을 수행하고 저장하는 데 아주 좋은 유틸리티 함수이므로 나중에 사용할 수 있도록 going_modular.going_modular.predictions.py에 저장할 수도 있습니다. 시도해 보고 싶은 확장 작업일 수도 있으니 아이디어를 위해 05. PyTorch 모듈화를 확인해 보세요.
5.2 EffNetB2로 예측 수행 및 시간 측정
이제 pred_and_store() 함수를 테스트해 볼 시간입니다!
먼저 EffNetB2 모델을 사용하여 테스트 데이터셋 전체에 대해 예측을 수행해 보겠으며, 두 가지 세부 사항에 주의를 기울이겠습니다.
- 장치 (Device) - 모델을 배포할 때 항상
"cuda"(GPU) 장치에 접근할 수 있는 것은 아니므로device매개변수를"cpu"를 사용하도록 하드코딩하겠습니다.- CPU에서 예측을 수행하는 것은 추론 속도를 나타내는 좋은 지표가 될 것입니다. 일반적으로 CPU 장치에서의 예측이 GPU 장치보다 느리기 때문입니다.
- 트랜스폼 (Transforms) -
transform매개변수를effnetb2_transforms로 설정하여 이미지가effnetb2모델이 훈련된 것과 동일한 방식으로 열리고 변환되도록 하겠습니다.
# EffNetB2로 테스트 데이터셋 전체에 대해 예측 수행
effnetb2_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=effnetb2,
transform=effnetb2_transforms,
class_names=class_names,
device="cpu") # CPU에서 예측 수행 좋습니다! 예측이 아주 빠르게 진행되네요!
처음 몇 개를 조사하여 어떻게 생겼는지 확인해 보겠습니다.
# 처음 2개 예측 딕셔너리 검사
effnetb2_test_pred_dicts[:2]좋아요!
pred_and_store() 함수가 잘 작동한 것 같습니다.
딕셔너리 리스트 데이터 구조 덕분에 더 자세히 검사할 수 있는 유용한 정보가 많이 생겼습니다.
이를 위해 딕셔너리 리스트를 pandas DataFrame으로 변환해 보겠습니다.
# test_pred_dicts를 DataFrame으로 변환
import pandas as pd
effnetb2_test_pred_df = pd.DataFrame(effnetb2_test_pred_dicts)
effnetb2_test_pred_df.head()아주 좋네요!
해당 예측 딕셔너리가 분석을 수행할 수 있는 정형화된 형식으로 얼마나 쉽게 변환되는지 보세요.
예를 들어 EffNetB2 모델이 얼마나 많은 예측을 틀렸는지 찾는 것과 같은 분석 말이죠…
# 정답 예측 수 확인
effnetb2_test_pred_df.correct.value_counts()총 150개 중 5개 오답이라니, 나쁘지 않네요!
평균 예측 시간은 어떨까요?
# 예측당 평균 시간 찾기
effnetb2_average_time_per_pred = round(effnetb2_test_pred_df.time_for_pred.mean(), 4)
print(f"EffNetB2 예측당 평균 시간: {effnetb2_average_time_per_pred} 초")흠, 이 평균 예측 시간이 모델의 실시간 성능 기준(~30FPS 또는 예측당 0.03초)에 얼마나 부합하나요?
참고: 예측 시간은 하드웨어 유형(예: 로컬 Intel i9 vs Google Colab CPU)에 따라 달라집니다. 하드웨어가 더 좋고 빠를수록 일반적으로 예측도 빨라집니다. 예를 들어 Intel i9 칩이 탑재된 제 로컬 딥러닝 PC에서 EffNetB2를 사용한 평균 예측 시간은 약 0.031초(실시간보다 약간 느림)입니다. 그러나 Google Colab(Colab이 어떤 CPU 하드웨어를 사용하는지는 확실하지 않지만 Intel(R) Xeon(R)인 것 같습니다)에서 EffNetB2를 사용한 평균 예측 시간은 약 0.1396초(3~4배 느림)였습니다.
EffNetB2 예측당 평균 시간을 effnetb2_stats 딕셔너리에 추가하겠습니다.
# EffNetB2 평균 예측 시간을 통계 딕셔너리에 추가
effnetb2_stats["time_per_pred_cpu"] = effnetb2_average_time_per_pred
effnetb2_stats5.3 ViT로 예측 수행 및 시간 측정
EffNetB2 모델로 예측을 수행했으니 이제 ViT 모델에 대해서도 동일하게 수행해 보겠습니다.
이를 위해 위에서 만든 pred_and_store() 함수를 사용할 수 있는데, 이번에는 vit 모델과 vit_transforms를 전달하겠습니다.
그리고 device="cpu"를 통해 예측을 CPU에 유지하겠습니다(여기서 자연스러운 확장은 CPU와 GPU에서 예측 시간을 테스트해 보는 것입니다).
# 테스트 이미지에 대해 ViT 특성 추출기 모델을 사용하여 예측 딕셔너리 리스트 생성
vit_test_pred_dicts = pred_and_store(paths=test_data_paths,
model=vit,
transform=vit_transforms,
class_names=class_names,
device="cpu")예측 완료!
이제 처음 몇 개를 확인해 보겠습니다.
# 테스트 데이터셋에 대한 처음 몇 개의 ViT 예측 확인
vit_test_pred_dicts[:2]멋지네요!
이전과 마찬가지로 ViT 모델의 예측이 딕셔너리 리스트 형식이므로, 더 자세히 검사하기 위해 pandas DataFrame으로 쉽게 변환할 수 있습니다.
# vit_test_pred_dicts를 DataFrame으로 변환
import pandas as pd
vit_test_pred_df = pd.DataFrame(vit_test_pred_dicts)
vit_test_pred_df.head()우리 ViT 모델이 얼마나 많은 예측을 맞혔나요?
# 정답 예측 수 계산
vit_test_pred_df.correct.value_counts()와!
우리 ViT 모델이 정답 예측 측면에서 EffNetB2 모델보다 약간 더 잘 수행되었으며, 전체 테스트 데이터셋에서 오답 샘플이 2개뿐이었습니다.
확장 과제로 ViT 모델의 오답 예측을 시각화하고 왜 틀렸을지 이유가 있는지 확인해 볼 수 있습니다.
ViT 모델이 예측당 걸린 시간을 계산해 보는 건 어떨까요?
# ViT 모델의 예측당 평균 시간 계산
vit_average_time_per_pred = round(vit_test_pred_df.time_for_pred.mean(), 4)
print(f"ViT 예측당 평균 시간: {vit_average_time_per_pred} 초")음, EffNetB2 모델의 예측당 평균 시간보다 약간 느려 보이지만 두 번째 기준인 속도 측면에서는 어떤가요?
일단 이 값을 vit_stats 딕셔너리에 추가하여 EffNetB2 모델의 통계와 비교해 보겠습니다.
참고: 예측당 평균 시간 값은 이를 수행하는 하드웨어에 따라 크게 달라집니다. 예를 들어 ViT 모델의 경우, Intel i9 CPU가 장착된 제 로컬 딥러닝 PC에서의 예측당 평균 시간(CPU 사용 시)은 0.0693~0.0777초였습니다. 반면 Google Colab에서 ViT 모델을 사용한 예측당 평균 시간은 0.6766~0.7113초였습니다.
# CPU에서 ViT 모델의 평균 예측 시간 추가
vit_stats["time_per_pred_cpu"] = vit_average_time_per_pred
vit_stats6. 모델 결과, 예측 시간 및 크기 비교
가장 강력한 두 후보 모델이 훈련되고 평가되었습니다.
이제 그들을 정면으로 맞붙여서 서로 다른 통계치를 비교해 보겠습니다.
이를 위해 effnetb2_stats 및 vit_stats 딕셔너리를 pandas DataFrame으로 변환하겠습니다.
모델 이름을 볼 수 있는 열을 추가하고 테스트 정확도를 소수점이 아닌 백분율로 변환하겠습니다.
# 통계 딕셔너리를 DataFrame으로 변환
df = pd.DataFrame([effnetb2_stats, vit_stats])
# 모델 이름 열 추가
df["model"] = ["EffNetB2", "ViT"]
# 정확도를 백분율로 변환
df["test_acc"] = round(df["test_acc"] * 100, 2)
df훌륭하네요!
전체적인 테스트 정확도 측면에서 우리 모델들이 꽤 근접한 것 같지만, 다른 필드들에서는 어떤가요?
이를 알아보는 한 가지 방법은 ViT 모델 통계를 EffNetB2 모델 통계로 나누어 두 모델 사이의 비율을 알아보는 것입니다.
그렇게 하기 위해 또 다른 DataFrame을 만들어 보겠습니다.
# 다양한 특성에 걸쳐 ViT와 EffNetB2 비교
pd.DataFrame(data=(df.set_index("model").loc["ViT"] / df.set_index("model").loc["EffNetB2"]), # ViT 통계를 EffNetB2 통계로 나눔
columns=["ViT to EffNetB2 ratios"]).TViT 모델이 성능 지표(낮을수록 좋은 테스트 손실과 높을수록 좋은 테스트 정확도)에서 EffNetB2 모델보다 우수하지만, 다음과 같은 희생이 따르는 것으로 보입니다. * 11배 이상의 파라미터 수 * 11배 이상의 모델 크기 * 이미지당 2.5배 이상의 예측 시간
이러한 트레이드오프(tradeoffs)를 감수할 가치가 있을까요?
아마 무제한의 컴퓨팅 파워가 있다면 그렇겠지만, FoodVision Mini 모델을 더 작은 장치(예: 모바일 폰)에 배포하려는 우리의 유스케이스에서는 성능은 약간 떨어지더라도 예측 속도가 더 빠르고 크기가 훨씬 작은 EffNetB2 모델로 시작할 가능성이 높습니다.
6.1 속도 대 성능 트레이드오프 시각화
ViT 모델이 테스트 손실 및 테스트 정확도와 같은 성능 지표 측면에서 EffNetB2 모델보다 성능이 우수함을 확인했습니다.
그러나 EffNetB2 모델은 예측을 더 빠르게 수행하며 모델 크기가 훨씬 작습니다.
참고: 성능 또는 추론 시간은 종종 “지연 시간(latency)”이라고도 합니다.
이 사실을 시각화해 보는 건 어떨까요?
matplotlib을 사용하여 다음과 같이 플롯을 생성할 수 있습니다. 1. 비교 DataFrame에서 산점도(scatter plot)를 생성하여 EffNetB2와 ViT의 time_per_pred_cpu 및 test_acc 값을 비교합니다. 2. 데이터에 맞게 제목과 레이블을 추가하고 미적 요소를 위해 폰트 크기를 조정합니다. 3. 1단계의 산점도 샘플에 적절한 레이블(모델 이름)로 주석을 추가합니다. 4. 모델 크기(model_size (MB))를 기반으로 범례(legend)를 만듭니다.
# 1. 모델 비교 DataFrame으로부터 플롯 생성
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(data=df,
x="time_per_pred_cpu",
y="test_acc",
c=["blue", "orange"], # 어떤 색상을 사용할까요?
s="model_size (MB)") # 모델 크기에 따라 점의 크기 조절
# 2. 제목, 레이블을 추가하고 미적 요소를 위해 폰트 크기 조정
ax.set_title("FoodVision Mini 추론 속도 대 성능", fontsize=18)
ax.set_xlabel("이미지당 예측 시간 (초)", fontsize=14)
ax.set_ylabel("테스트 정확도 (%)", fontsize=14)
ax.tick_params(axis='both', labelsize=12)
ax.grid(True)
# 3. 모델 이름으로 주석 추가
for index, row in df.iterrows():
ax.annotate(text=row["model"], # 참고: Matplotlib 버전에 따라 "s=..." 또는 "text=..."를 사용해야 할 수도 있습니다. https://github.com/faustomorales/keras-ocr/issues/183#issuecomment-977733270 참조
xy=(row["time_per_pred_cpu"]+0.0006, row["test_acc"]+0.03),
size=12)
# 4. 모델 크기를 기반으로 범례 생성
handles, labels = scatter.legend_elements(prop="sizes", alpha=0.5)
model_size_legend = ax.legend(handles,
labels,
loc="lower right",
title="모델 크기 (MB)",
fontsize=12)
# 그림 저장
!mkdir images/
plt.savefig("images/09-foodvision-mini-inference-speed-vs-performance.jpg")
# 그림 표시
plt.show()와!
플롯이 속도 대 성능 트레이드오프를 정말 잘 시각화해주네요. 즉, 더 크고 성능이 좋은 딥 모델(우리 ViT 모델처럼)을 사용할 때 일반적으로 추론을 수행하는 데 더 오래 걸립니다(지연 시간이 더 김).
이 규칙에는 예외가 있으며 대형 모델이 더 빠르게 작동하도록 돕는 새로운 연구 결과가 항상 발표되고 있습니다.
그리고 단순히 가장 좋은 성능을 내는 모델을 배포하고 싶은 유혹이 생길 수 있지만, 모델이 어디에서 실행될지 고려하는 것도 좋습니다.
우리의 경우, 모델의 성능 수준(테스트 손실 및 테스트 정확도) 차이가 너무 크지는 않습니다.
하지만 처음부터 속도에 중점을 두고 싶기 때문에, 더 빠르고 적은 리소스를 차지하는 EffNetB2 배포를 고수할 것입니다.
참고: 예측 시간은 하드웨어 유형(예: Intel i9 vs Google Colab CPU vs GPU)에 따라 달라지므로 모델이 최종적으로 어디에 위치할지 생각하고 테스트하는 것이 중요합니다. “모델이 어디에서 실행될 것인가?” 또는 “모델을 실행하기 위한 가장 이상적인 시나리오는 무엇인가?”와 같은 질문을 던지고 배포 과정에서 답을 얻기 위해 실험을 실행하는 것이 매우 도움이 됩니다.
7. Gradio 데모를 만들어 FoodVision Mini 활성화하기
우리는 (처음에는) EffNetB2 모델을 배포하기로 결정했습니다(이는 나중에 언제든지 변경될 수 있습니다).
그럼 어떻게 배포할 수 있을까요?
머신러닝 모델을 배포하는 방법은 여러 가지가 있으며 각 방법에는 고유한 유스케이스가 있습니다(위에서 논의한 바와 같이).
우리는 인터넷에 모델을 배포하는 가장 빠르고 확실히 가장 재미있는 방법 중 하나에 집중할 것입니다.
바로 Gradio를 사용하는 것입니다.
Gradio란 무엇일까요?
홈페이지에 아주 잘 설명되어 있습니다.
Gradio는 친숙한 웹 인터페이스를 통해 머신러닝 모델의 데모를 누구나 어디서나 사용할 수 있도록 만드는 가장 빠른 방법입니다!
모델의 데모를 왜 만드나요?
테스트 세트의 지표는 보기 좋지만, 실제로 세상에서 모델을 사용해 보기 전까지는 모델의 성능을 제대로 알 수 없기 때문입니다.
그럼 배포를 시작해 봅시다!
Gradio를 일반적인 별칭인 gr로 임포트하는 것부터 시작하고, 설치되어 있지 않다면 설치하겠습니다.
# Gradio 임포트/설치
try:
import gradio as gr
except:
!pip -q install gradio
import gradio as gr
print(f"Gradio 버전: {gr.__version__}")Gradio 준비 완료!
FoodVision Mini를 데모 애플리케이션으로 만들어 봅시다.
7.1 Gradio 개요
Gradio의 전반적인 전제는 우리가 과정 전반에 걸쳐 반복해 온 내용과 매우 유사합니다.
우리의 입력(inputs)과 출력(outputs)은 무엇인가요?
그리고 어떻게 그곳에 도달해야 할까요?
바로 우리 머신러닝 모델이 하는 일입니다.
입력 -> 머신러닝 모델 -> 출력우리의 FoodVision Mini의 경우, 입력은 음식 이미지이고, 머신러닝 모델은 EffNetB2이며, 출력은 음식 클래스(피자, 스테이크 또는 초밥)입니다.
음식 이미지 -> EffNetB2 -> 출력입력과 출력의 개념은 거의 모든 종류의 머신러닝 문제에 적용될 수 있습니다.
입력과 출력은 다음과 같은 조합일 수 있습니다. * 이미지 * 텍스트 * 비디오 * 정형 데이터 (Tabular data) * 오디오 * 숫자 * 등등
그리고 구축하는 머신러닝 모델은 입력과 출력에 따라 달라질 것입니다.
Gradio는 입력에서 출력까지의 인터페이스(gradio.Interface())를 생성하여 이 패러다임을 모방합니다.
gradio.Interface(fn, inputs, outputs)여기서 fn은 입력을 출력으로 매핑하는 Python 함수입니다.
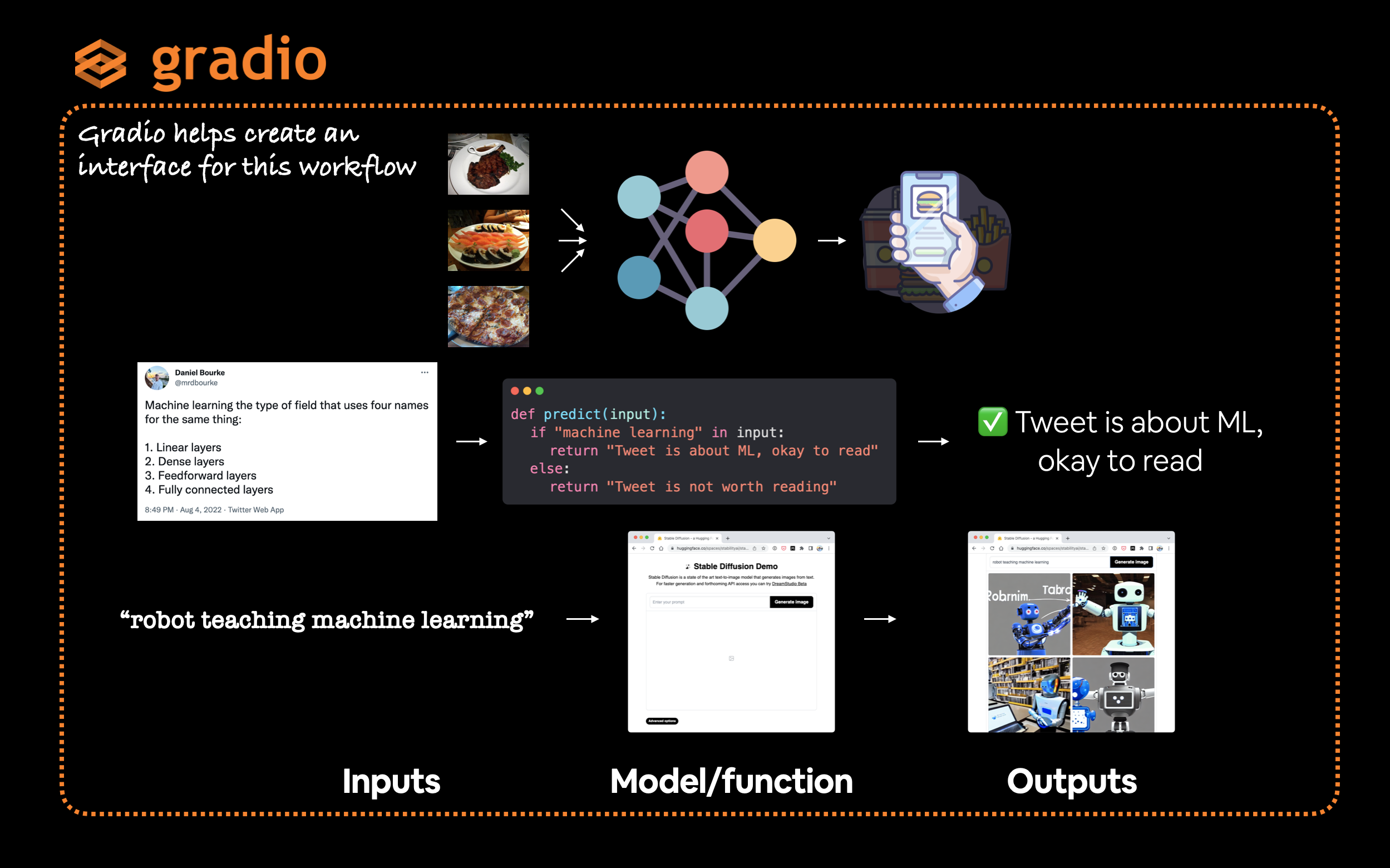
Gradio는 입력 -> 모델/함수 -> 출력 워크플로우를 쉽게 만들 수 있는 매우 유용한 Interface 클래스를 제공하며, 여기서 입력과 출력은 원하는 거의 모든 것이 될 수 있습니다. 예를 들어, 트윗(텍스트)을 입력하여 머신러닝에 관한 것인지 확인하거나 이미지를 생성하기 위해 텍스트 프롬프트를 입력할 수 있습니다.
참고: Gradio에는 이미지에서 텍스트, 숫자, 오디오, 비디오 등에 이르기까지 “구성 요소(Components)”라고 알려진 방대한 수의 가능한
입력및출력옵션이 있습니다. Gradio 구성 요소 문서에서 이들을 모두 확인할 수 있습니다.
7.2 입력과 출력을 매핑하는 함수 만들기
Gradio로 FoodVision Mini 데모를 만들려면 입력을 출력으로 매핑하는 함수가 필요합니다.
이전에 지정된 모델을 사용하여 타겟 파일 리스트에 대해 예측을 수행하고 이를 딕셔너리 리스트에 저장하는 pred_and_store() 함수를 만들었습니다.
유사한 함수를 만들되 이번에는 EffNetB2 모델을 사용하여 단일 이미지에 대해 예측을 수행하는 데 중점을 두는 건 어떨까요?
더 구체적으로, 이미지를 입력으로 받아 전처리(변환)하고, EffNetB2를 사용하여 예측을 수행한 다음 예측(간단히 pred 또는 pred label)과 예측 확률(pred prob)을 반환하는 함수를 원합니다.
그리고 하는 김에 이에 걸린 시간도 반환해 보겠습니다.
입력: 이미지 -> 변환 -> EffNetB2로 예측 -> 출력: 예측 결과, 예측 확률, 소요 시간이것이 Gradio 인터페이스의 fn 매개변수가 될 것입니다.
먼저, EffNetB2 모델이 CPU에 있는지 확인하겠습니다(CPU 전용 예측을 고수하고 있으므로, 단 GPU에 접근할 수 있다면 이를 변경할 수도 있습니다).
# EffNetB2를 CPU에 배치
effnetb2.to("cpu")
# 장치 확인
next(iter(effnetb2.parameters())).device이제 위의 워크플로우를 재현하기 위해 predict()라는 함수를 만들어 보겠습니다.
from typing import Tuple, Dict
def predict(img) -> Tuple[Dict, float]:
"""img에 대해 변환 및 예측을 수행하고 예측 결과와 소요 시간을 반환합니다.
"""
# 타이머 시작
start_time = timer()
# 타겟 이미지 변환 및 배치 차원 추가
img = effnetb2_transforms(img).unsqueeze(0)
# 모델을 평가 모드로 설정하고 추론 모드 활성화
effnetb2.eval()
with torch.inference_mode():
# 변환된 이미지를 모델에 통과시키고 예측 로짓을 예측 확률로 변환
pred_probs = torch.softmax(effnetb2(img), dim=1)
# 각 예측 클래스에 대한 예측 레이블 및 예측 확률 딕셔너리 생성 (이는 Gradio의 출력 매개변수에 필요한 형식입니다)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# 예측 시간 계산
pred_time = round(timer() - start_time, 5)
# 예측 딕셔너리와 예측 시간 반환
return pred_labels_and_probs, pred_time좋습니다!
이제 테스트 데이터셋의 임의 이미지에 대해 예측을 수행하여 함수가 작동하는지 확인해 보겠습니다.
먼저 테스트 디렉토리의 모든 이미지 경로 리스트를 가져와서 그중 하나를 무작위로 선택하겠습니다.
그런 다음 무작위로 선택된 이미지를 PIL.Image.open()으로 열겠습니다.
마지막으로 이미지를 predict() 함수에 전달하겠습니다.
import random
from PIL import Image
# 모든 테스트 이미지 파일 경로 리스트 가져오기
test_data_paths = list(Path(test_dir).glob("*/*.jpg"))
# 테스트 이미지 경로 무작위 선택
random_image_path = random.sample(test_data_paths, k=1)[0]
# 타겟 이미지 열기
image = Image.open(random_image_path)
print(f"[INFO] 경로에 있는 이미지로 예측 중: {random_image_path}\n")
# 타겟 이미지에 대해 예측을 수행하고 출력 결과 프린트
pred_dict, pred_time = predict(img=image)
print(f"예측 레이블 및 확률 딕셔너리: \n{pred_dict}")
print(f"예측 시간: {pred_time} 초")좋네요!
위의 셀을 몇 번 실행하면 EffNetB2 모델로부터 각 레이블에 대한 서로 다른 예측 확률과 예측당 소요 시간을 확인할 수 있습니다.
7.3 예시 이미지 리스트 만들기
우리의 predict() 함수를 사용하면 입력 -> 변환 -> 머신러닝 모델 -> 출력 과정을 거칠 수 있습니다.
이것이 바로 Gradio 데모에 필요한 것입니다.
하지만 데모를 만들기 전에 한 가지 더 만들 것이 있습니다. 바로 예시 리스트입니다.
Gradio의 Interface 클래스는 선택적 매개변수로 examples 리스트를 받습니다(gradio.Interface(examples=List[Any])).
그리고 examples 매개변수의 형식은 리스트의 리스트입니다.
따라서 테스트 이미지에 대한 무작위 파일 경로를 포함하는 리스트의 리스트를 만들어 보겠습니다.
세 개의 예시면 충분할 것입니다.
# Gradio 데모를 위한 예시 입력 리스트 생성
example_list = [[str(filepath)] for filepath in random.sample(test_data_paths, k=3)]
example_list완벽합니다!
우리의 Gradio 데모는 이들을 데모의 예시 입력으로 보여줄 것이며, 사람들은 자신의 데이터를 업로드하지 않고도 데모가 무엇을 하는지 시도해 보고 확인할 수 있습니다.
7.4 Gradio 인터페이스 구축
이제 모든 것을 하나로 합쳐 FoodVision Mini 데모를 세상에 선보일 시간입니다!
워크플로우를 재현하기 위해 Gradio 인터페이스를 만들어 보겠습니다.
입력: 이미지 -> 변환 -> EffNetB2로 예측 -> 출력: 예측 결과, 예측 확률, 소요 시간다음 매개변수와 함께 gradio.Interface() 클래스를 사용하여 이를 수행할 수 있습니다. * fn: 입력을 출력으로 매핑하는 Python 함수입니다. 우리의 경우에는 predict() 함수를 사용합니다. * inputs: 인터페이스에 대한 입력입니다. gradio.Image() 또는 "image"를 사용하는 이미지와 같습니다. * outputs: 입력이 fn을 통과한 후의 인터페이스 출력입니다. 모델의 예측 레이블을 위한 gradio.Label() 또는 모델의 예측 시간을 위한 숫자 gradio.Number()와 같습니다. * 참고: Gradio에는 “구성 요소(Components)”로 알려진 많은 내장 입력 및 출력 옵션이 제공됩니다. * examples: 데모를 위해 보여줄 예시 리스트입니다. * title: 데모의 문자열 제목입니다. * description: 데모의 문자열 설명입니다. * article: 데모 하단의 참조 노트입니다.
gr.Interface()의 데모 인스턴스를 생성한 후에는 gradio.Interface().launch() 또는 demo.launch() 명령을 사용하여 실행할 수 있습니다.
간단하죠!
import gradio as gr
# 제목, 설명 및 기사 문자열 생성
title = "FoodVision Mini 🍕🥩🍣"
description = "음식 이미지를 피자, 스테이크, 초밥으로 분류하는 EfficientNetB2 특성 추출기 컴퓨터 비전 모델입니다."
article = "[09. PyTorch 모델 배포](https://www.learnpytorch.io/09_pytorch_model_deployment/)에서 생성되었습니다."
# Gradio 데모 생성
demo = gr.Interface(fn=predict, # 입력을 출력으로 매핑하는 함수
inputs=gr.Image(type="pil"), # 입력은 무엇인가요?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # 출력은 무엇인가요?
gr.Number(label="Prediction time (s)")], # fn에는 두 개의 출력이 있으므로 두 개의 출력이 있습니다.
examples=example_list,
title=title,
description=description,
article=article)
# 데모 실행!
demo.launch(debug=False, # 로컬에서 오류를 출력할까요?
share=True) # 공개적으로 공유 가능한 URL을 생성할까요?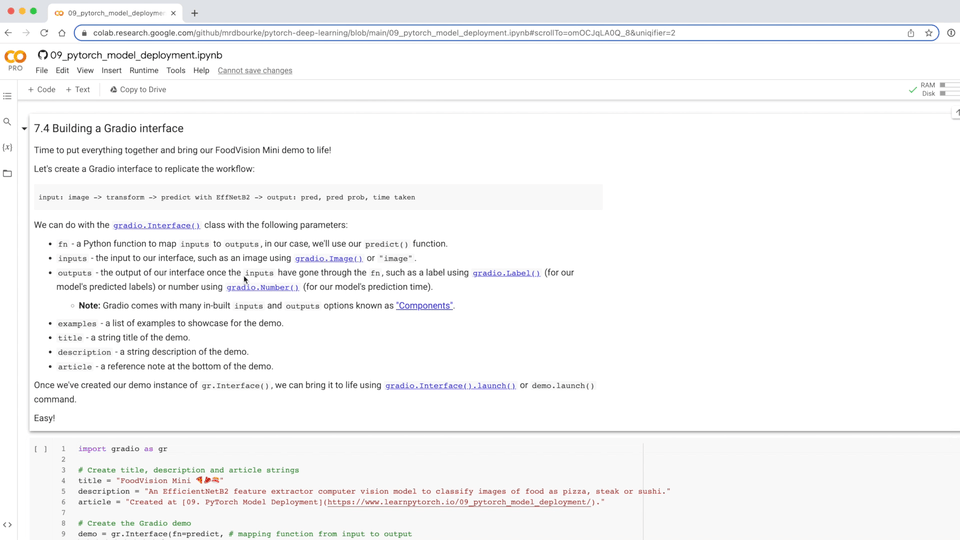
Google Colab 및 브라우저에서 실행 중인 FoodVision Mini Gradio 데모(Google Colab에서 실행할 때의 링크는 72시간 동안만 유지됩니다). Hugging Face Spaces에서 영구 라이브 데모를 볼 수 있습니다.
와아아!!! 정말 대단한 데모네요!!!
FoodVision Mini가 누구나 사용하고 시도해 볼 수 있는 인터페이스를 통해 공식적으로 세상에 나왔습니다.
launch() 메서드에서 share=True 매개변수를 설정하면, Gradio는 72시간 동안 유효한 https://123XYZ.gradio.app(이 링크는 예시일 뿐이며 만료되었을 가능성이 높습니다)와 같은 공유 가능한 링크를 제공합니다.
이 링크는 실행한 Gradio 인터페이스에 대한 프록시를 제공합니다.
더 영구적인 호스팅을 위해서는 Gradio 앱을 Hugging Face Spaces나 Python 코드가 실행되는 곳이면 어디든 업로드할 수 있습니다.
8. FoodVision Mini Gradio 데모를 배포 가능한 앱으로 변환하기
Gradio 데모를 통해 FoodVision Mini 모델이 살아 움직이는 것을 보았습니다.
하지만 이 데모를 친구들과 공유하고 싶다면 어떻게 해야 할까요?
제공된 Gradio 링크를 사용할 수 있지만, 공유 링크는 72시간 동안만 유지됩니다.
FoodVision Mini 데모를 더 영구적으로 만들기 위해 앱으로 패키징하여 Hugging Face Spaces에 업로드할 수 있습니다.
8.1 Hugging Face Spaces란 무엇인가요?
Hugging Face Spaces는 머신러닝 앱을 호스팅하고 공유할 수 있는 리소스입니다.
데모를 만드는 것은 여러분이 한 일을 보여주고 테스트하는 가장 좋은 방법 중 하나입니다.
그리고 Spaces를 사용하면 바로 그 일을 할 수 있습니다.
Hugging Face를 머신러닝계의 GitHub라고 생각하면 됩니다.
좋은 GitHub 포트폴리오가 여러분의 코딩 능력을 보여준다면, 좋은 Hugging Face 포트폴리오는 여러분의 머신러닝 능력을 보여줄 수 있습니다.
참고: Gradio 앱을 Google Cloud, AWS(Amazon Web Services) 또는 다른 클라우드 공급업체와 같은 다른 곳에 업로드하고 호스팅할 수도 있지만, 사용 편의성과 머신러닝 커뮤니티의 광범위한 채택으로 인해 Hugging Face Spaces를 사용할 것입니다.
8.2 배포된 Gradio 앱 구조
데모 Gradio 앱을 업로드하려면 데모와 관련된 모든 내용을 단일 디렉토리에 넣어야 합니다.
예를 들어, 데모는 다음과 같은 파일 구조를 가진 demos/foodvision_mini/ 경로에 위치할 수 있습니다.
demos/
└── foodvision_mini/
├── 09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth
├── app.py
├── examples/
│ ├── example_1.jpg
│ ├── example_2.jpg
│ └── example_3.jpg
├── model.py
└── requirements.txt여기서: * 09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth는 훈련된 PyTorch 모델 파일입니다. * app.py에는 Gradio 앱이 포함되어 있습니다(앱을 실행한 코드와 유사함). * 참고: app.py는 Hugging Face Spaces에서 사용하는 기본 파일 이름이며, 앱을 배포하면 Spaces는 기본적으로 실행할 app.py라는 파일을 찾습니다. 이는 설정에서 변경할 수 있습니다. * examples/에는 Gradio 앱과 함께 사용할 예시 이미지가 포함되어 있습니다. * model.py에는 모델 정의와 모델과 관련된 트랜스폼이 포함되어 있습니다. * requirements.txt에는 torch, torchvision, gradio와 같이 앱을 실행하기 위한 의존성(dependencies)이 포함되어 있습니다.
왜 이런 방식으로 할까요?
우리가 시작할 수 있는 가장 단순한 레이아웃 중 하나이기 때문입니다.
우리의 중점은 실험, 실험, 실험! 입니다.
작은 실험을 더 빨리 실행할수록 큰 실험도 더 잘 수행될 것입니다.
우리는 위의 구조를 재현하는 작업을 수행할 것이지만, Hugging Face Spaces에서 실행 중인 라이브 데모 앱과 파일 구조를 확인할 수 있습니다. * FoodVision Mini 🍕🥩🍣 라이브 Gradio 데모. * Hugging Face Spaces의 FoodVision Mini 파일 구조.
8.3 FoodVision Mini 앱 파일을 저장할 demos 폴더 생성
시작하기 위해 먼저 모든 FoodVision Mini 앱 파일을 저장할 demos/ 디렉토리를 생성하겠습니다.
Python의 pathlib.Path("path_to_dir")를 사용하여 디렉토리 경로를 설정하고 pathlib.Path("path_to_dir").mkdir()을 사용하여 생성할 수 있습니다.
import shutil
from pathlib import Path
# FoodVision mini 데모 경로 생성
foodvision_mini_demo_path = Path("demos/foodvision_mini/")
# 이미 존재하는 파일이 있으면 제거하고 새 디렉토리 생성
if foodvision_mini_demo_path.exists():
shutil.rmtree(foodvision_mini_demo_path)
# 파일이 존재하지 않으면 그래도 생성
foodvision_mini_demo_path.mkdir(parents=True,
exist_ok=True)
# 폴더에 무엇이 있는지 확인
!ls demos/foodvision_mini/8.4 FoodVision Mini 데모와 함께 사용할 예시 이미지 폴더 생성
이제 FoodVision Mini 데모 파일을 저장할 디렉토리가 생겼으니 여기에 예시를 추가해 보겠습니다.
테스트 데이터셋에서 가져온 세 개의 예시 이미지면 충분할 것입니다.
이를 위해 다음을 수행합니다. 1. demos/foodvision_mini 디렉토리 내에 examples/ 디렉토리를 생성합니다. 2. 테스트 데이터셋에서 무작위로 세 개의 이미지를 선택하고 그 파일 경로를 리스트에 수집합니다. 3. 테스트 데이터셋의 무작위 이미지 세 개를 demos/foodvision_mini/examples/ 디렉토리로 복사합니다.
import shutil
from pathlib import Path
# 1. examples 디렉토리 생성
foodvision_mini_examples_path = foodvision_mini_demo_path / "examples"
foodvision_mini_examples_path.mkdir(parents=True, exist_ok=True)
# 2. 테스트 데이터셋 이미지 경로 세 개 무작위 수집
foodvision_mini_examples = [Path('data/pizza_steak_sushi_20_percent/test/sushi/592799.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/steak/3622237.jpg'),
Path('data/pizza_steak_sushi_20_percent/test/pizza/2582289.jpg')]
# 3. 무작위 이미지 세 개를 examples 디렉토리로 복사
for example in foodvision_mini_examples:
destination = foodvision_mini_examples_path / example.name
print(f"[INFO] {example}을 {destination}으로 복사 중")
shutil.copy2(src=example, dst=destination)이제 예시가 있는지 확인하기 위해 os.listdir()을 사용하여 demos/foodvision_mini/examples/ 디렉토리의 내용을 나열한 다음, 파일 경로를 리스트의 리스트 형식으로 지정하겠습니다(Gradio의 gradio.Interface() example 매개변수와 호환되도록).
import os
# 예시 파일 경로를 리스트의 리스트로 가져오기
example_list = [["examples/" + example] for example in os.listdir(foodvision_mini_examples_path)]
example_list8.5 훈련된 EffNetB2 모델을 FoodVision Mini 데모 디렉토리로 이동
이전에 FoodVision Mini EffNetB2 특성 추출기 모델을 models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth에 저장했습니다.
저장된 모델 파일을 중복해서 만들지 않고, 모델을 demos/foodvision_mini 디렉토리로 이동하겠습니다.
Python의 shutil.move() 메서드를 사용하여 src(대상 파일의 소스 경로) 및 dst(이동할 대상 파일의 목적지 경로) 매개변수를 전달하여 그렇게 할 수 있습니다.
import shutil
# 타겟 모델의 소스 경로 생성
effnetb2_foodvision_mini_model_path = "models/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"
# 타겟 모델의 목적지 경로 생성
effnetb2_foodvision_mini_model_destination = foodvision_mini_demo_path / effnetb2_foodvision_mini_model_path.split("/")[1]
# 파일 이동 시도
try:
print(f"[INFO] {effnetb2_foodvision_mini_model_path}을 {effnetb2_foodvision_mini_model_destination}으로 이동 시도 중")
# 모델 이동
shutil.move(src=effnetb2_foodvision_mini_model_path,
dst=effnetb2_foodvision_mini_model_destination)
print(f"[INFO] 모델 이동 완료.")
# 모델이 이미 이동된 경우 이미 존재하는지 확인
except:
print(f"[INFO] {effnetb2_foodvision_mini_model_path}에서 모델을 찾을 수 없음, 이미 이동되었을까요?")
print(f"[INFO] {effnetb2_foodvision_mini_model_destination}에 모델 존재 여부: {effnetb2_foodvision_mini_model_destination.exists()}")8.6 EffNetB2 모델을 Python 스크립트로 변환 (model.py)
현재 모델의 state_dict는 demos/foodvision_mini/09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth에 저장되어 있습니다.
이를 불러오기 위해 torch.load()와 함께 model.load_state_dict()를 사용할 수 있습니다.
참고: PyTorch에서 모델(또는 모델의
state_dict)을 저장하고 불러오는 방법을 다시 보려면 01. PyTorch 워크플로우 기초 섹션 5: PyTorch 모델 저장 및 불러오기를 참조하거나 PyTorch에서state_dict란 무엇인가요?에 대한 PyTorch 레시피를 참조하세요.
하지만 이렇게 하기 전에 먼저 model을 인스턴스화할 방법이 필요합니다.
모듈식 방식으로 이를 수행하기 위해 섹션 3.1: EffNetB2 특성 추출기를 만드는 함수 만들기에서 만든 create_effnetb2_model() 함수가 포함된 model.py라는 스크립트를 만들겠습니다.
이렇게 하면 또 다른 스크립트(아래의 app.py 참조)에서 함수를 임포트한 다음 이를 사용하여 EffNetB2 model 인스턴스를 생성하고 적절한 트랜스폼을 가져올 수 있습니다.
05. PyTorch 모듈화에서와 마찬가지로, %%writefile path/to/file 매직 명령어를 사용하여 코드 셀을 파일로 변환하겠습니다.
%%writefile demos/foodvision_mini/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""EfficientNetB2 특성 추출기 모델과 트랜스폼을 생성합니다.
인자:
num_classes (int, optional): 분류 헤드의 클래스 수.
기본값은 3.
seed (int, optional): 무작위 시드 값. 기본값은 42.
반환값:
model (torch.nn.Module): EffNetB2 특성 추출기 모델.
transforms (torchvision.transforms): EffNetB2 이미지 트랜스폼.
"""
# 사전 훈련된 EffNetB2 가중치, 트랜스폼 및 모델 생성
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# 기본 모델의 모든 레이어 고정
for param in model.parameters():
param.requires_grad = False
# 재현성을 위해 무작위 시드와 함께 분류 헤드 변경
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms8.7 FoodVision Mini Gradio 앱을 Python 스크립트로 변환 (app.py)
이제 model.py 스크립트와 저장된 모델 state_dict 경로를 얻었으니 로드할 수 있습니다.
app.py를 구성할 시간입니다.
HuggingFace Space를 생성할 때 기본적으로 실행 및 호스팅할 app.py라는 파일을 찾기 때문에 이름을 app.py라고 부릅니다(설정에서 변경 가능함).
우리의 app.py 스크립트는 Gradio 데모를 만들기 위해 모든 퍼즐 조각을 하나로 모을 것이며, 네 가지 주요 부분으로 구성됩니다.
- 임포트 및 클래스 이름 설정 - 여기서는
model.py의create_effnetb2_model()함수를 포함하여 데모를 위한 다양한 의존성을 임포트하고 FoodVision Mini 앱을 위한 서로 다른 클래스 이름을 설정합니다. - 모델 및 트랜스폼 준비 - 여기서는 EffNetB2 모델 인스턴스와 이에 수반되는 트랜스폼을 생성한 다음 저장된 모델 가중치/
state_dict를 불러옵니다. 모델을 불러올 때torch.load()에서map_location=torch.device("cpu")를 설정하여 모델이 훈련된 장치에 상관없이 CPU에 로드되도록 합니다(배포할 때 GPU가 반드시 있는 것은 아니며, 모델이 GPU에서 훈련되었는데 명시적인 언급 없이 CPU에 배포하려고 하면 오류가 발생하기 때문입니다). - 예측 함수 - Gradio의
gradio.Interface()는 입력을 출력으로 매핑하는fn매개변수를 받습니다. 우리의predict()함수는 위 섹션 7.2: 입력과 출력을 매핑하는 함수 만들기에서 정의한 것과 동일하며, 이미지를 받아 로드된 트랜스폼을 사용하여 전처리를 수행한 후 로드된 모델을 사용하여 예측을 수행합니다.- 참고:
examples매개변수를 통해 예시 리스트를 즉석에서 생성해야 합니다.examples/디렉토리 내의 파일 리스트를[["examples/" + example] for example in os.listdir("examples")]와 같이 생성할 수 있습니다.
- 참고:
- Gradio 앱 - 데모의 주요 로직이 위치하는 곳으로, 입력,
predict()함수 및 출력을 하나로 모으기 위해demo라는gradio.Interface()인스턴스를 생성합니다. 그리고 스크립트 마지막에demo.launch()를 호출하여 FoodVision Mini 데모를 실행하며 마무리합니다!”
%%writefile demos/foodvision_mini/app.py
### 1. 임포트 및 클래스 이름 설정 ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# 클래스 이름 설정
class_names = ["pizza", "steak", "sushi"]
### 2. 모델 및 트랜스폼 준비 ###
# EffNetB2 모델 생성
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=3, # len(class_names)도 작동함
)
# 저장된 가중치 불러오기
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth",
map_location=torch.device("cpu"), # CPU로 불러오기
)
)
### 3. 예측 함수 ###
# 예측 함수 생성
def predict(img) -> Tuple[Dict, float]:
"""img에 대해 변환 및 예측을 수행하고 예측 결과와 소요 시간을 반환합니다.
"""
# 타이머 시작
start_time = timer()
# 타겟 이미지 변환 및 배치 차원 추가
img = effnetb2_transforms(img).unsqueeze(0)
# 모델을 평가 모드로 설정하고 추론 모드 활성화
effnetb2.eval()
with torch.inference_mode():
# 변환된 이미지를 모델에 통과시키고 예측 로짓을 예측 확률로 변환
pred_probs = torch.softmax(effnetb2(img), dim=1)
# 각 예측 클래스에 대한 예측 레이블 및 예측 확률 딕셔너리 생성 (이는 Gradio의 출력 매개변수에 필요한 형식입니다)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# 예측 시간 계산
pred_time = round(timer() - start_time, 5)
# 예측 딕셔너리와 예측 시간 반환
return pred_labels_and_probs, pred_time
### 4. Gradio 앱 ###
# 제목, 설명 및 기사 문자열 생성
title = "FoodVision Mini 🍕🥩🍣"
description = "음식 이미지를 피자, 스테이크, 초밥으로 분류하는 EfficientNetB2 특성 추출기 컴퓨터 비전 모델입니다."
article = "[09. PyTorch 모델 배포](https://www.learnpytorch.io/09_pytorch_model_deployment/)에서 생성되었습니다."
# "examples/" 디렉토리에서 예시 리스트 생성
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Gradio 데모 생성
demo = gr.Interface(fn=predict, # 입력을 출력으로 매핑하는 함수
inputs=gr.Image(type="pil"), # 입력은 무엇인가요?
outputs=[gr.Label(num_top_classes=3, label="Predictions"), # 출력은 무엇인가요?
gr.Number(label="Prediction time (s)")], # fn에는 두 개의 출력이 있으므로 두 개의 출력이 있습니다.
# "examples/" 디렉토리에서 예시 리스트 생성
examples=example_list,
title=title,
description=description,
article=article)
# 데모 실행!
demo.launch()8.8 FoodVision Mini를 위한 요구 사항 파일 생성 (requirements.txt)
FoodVision Mini 앱을 위해 마지막으로 생성해야 할 파일은 requirements.txt 파일입니다.
이것은 데모를 위해 필요한 모든 의존성이 포함된 텍스트 파일입니다.
Hugging Face Spaces에 데모 앱을 배포하면, 이 파일을 검색하여 정의한 의존성을 설치하여 앱이 실행될 수 있도록 할 것입니다.
다행히도 세 개뿐입니다!
torch==1.12.0torchvision==0.13.0gradio==3.1.4
“==1.12.0”은 설치할 버전 번호를 명시합니다.
버전 번호를 정의하는 것이 100% 필수적인 것은 아니지만, 나중에 버전 업데이트 시 앱이 계속 실행되도록 하기 위해 지금 정의하겠습니다(만약 오류를 발견하면 과정 GitHub Issues에 자유롭게 게시해 주세요).
%%writefile demos/foodvision_mini/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.4좋네요!
FoodVision Mini 데모를 배포하는 데 필요한 모든 파일을 공식적으로 얻었습니다!
9. FoodVision Mini 앱을 HuggingFace Spaces에 배포하기
FoodVision Mini 데모가 포함된 파일이 생겼는데, 이제 Hugging Face Spaces에서 어떻게 실행할까요?
Hugging Face Space(git 저장소와 유사한 Hugging Face Repository라고도 함)에 업로드하는 두 가지 주요 옵션이 있습니다. 1. Hugging Face 웹 인터페이스를 통해 업로드 (가장 쉬움). 2. 명령줄 또는 터미널을 통해 업로드. * 보너스: huggingface_hub 라이브러리를 사용하여 Hugging Face와 상호작용할 수도 있으며, 이는 위의 두 옵션에 대한 좋은 확장이 될 것입니다.
두 옵션에 대한 문서를 자유롭게 읽어보시되, 우리는 옵션 2로 진행하겠습니다.
참고: Hugging Face에서 무엇이든 호스팅하려면 무료 Hugging Face 계정에 가입해야 합니다.
9.1 FoodVision Mini 앱 파일 다운로드
demos/foodvision_mini 내부에 있는 데모 파일들을 확인해 봅시다.
타겟 파일 경로와 함께 !ls 명령어를 사용하여 확인할 수 있습니다.
ls는 “list”의 약자이며, !는 쉘 레벨에서 명령을 실행하고 싶다는 의미입니다.
!ls demos/foodvision_mini이들은 모두 우리가 생성한 파일들입니다!
Hugging Face에 파일을 업로드하기 위해, 이제 Google Colab(또는 이 노트북을 실행 중인 곳)에서 파일을 다운로드하겠습니다.
먼저 다음 명령어를 통해 파일들을 단일 zip 폴더로 압축하겠습니다.
zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"여기서: * zip은 “압축”을 의미하며 “다음 디렉토리의 파일들을 함께 압축해 주세요”라는 뜻입니다. * -r은 “recursive”의 약자로, “타겟 디렉토리의 모든 파일을 거쳐 가세요”라는 뜻입니다. * ../foodvision_mini.zip은 파일이 압축될 타겟 디렉토리입니다. * *은 “현재 디렉토리의 모든 파일”을 의미합니다. * -x는 “이 파일들은 제외해 주세요”라는 뜻입니다.
Google Colab에서 google.colab.files.download("demos/foodvision_mini.zip")을 사용하여 zip 파일을 다운로드할 수 있습니다(Google Colab 내부에서 코드를 실행하지 않을 경우를 대비해 try 및 except 블록 안에 넣고, 만약 실행되지 않는다면 수동으로 파일을 다운로드하라는 메시지를 출력하도록 하겠습니다).
한번 시도해 보죠!
# foodvision_mini 폴더로 이동한 후 특정 파일을 제외하고 압축
!cd demos/foodvision_mini && zip -r ../foodvision_mini.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# 압축된 FoodVision Mini 앱 다운로드 (Google Colab에서 실행 중인 경우)
try:
from google.colab import files
files.download("demos/foodvision_mini.zip")
except:
print("Google Colab에서 실행 중이 아님, google.colab.files.download()를 사용할 수 없으므로 수동으로 다운로드해 주세요.")와아아!!!
zip 명령어가 성공한 것 같네요.
Google Colab에서 이 노트북을 실행 중이라면 브라우저에서 파일 다운로드가 시작되는 것을 볼 수 있을 것입니다.
그렇지 않다면, 과정 GitHub의 demos/ 디렉토리에서 foodvision_mini.zip 폴더(및 기타 파일)를 확인할 수 있습니다.
9.2 로컬에서 FoodVision Mini 데모 실행
foodvision_mini.zip 파일을 다운로드했다면 다음 단계를 통해 로컬에서 테스트할 수 있습니다. 1. 파일의 압축을 풉니다. 2. 터미널 또는 명령줄 프롬프트를 엽니다. 3. foodvision_mini 디렉토리로 이동합니다 (cd foodvision_mini). 4. 환경을 생성합니다 (python3 -m venv env). 5. 환경을 활성화합니다 (source env/bin/activate). 5. 요구 사항을 설치합니다 (pip install -r requirements.txt, “-r”은 recursive의 약자). * 참고: 이 단계는 인터넷 연결 속도에 따라 5~10분 정도 걸릴 수 있습니다. 오류가 발생하면 먼저 pip를 업그레이드해야 할 수도 있습니다: pip install --upgrade pip. 6. 앱을 실행합니다 (python3 app.py).
이렇게 하면 위에서 구축한 것과 똑같은 Gradio 데모가 여러분의 기기에서 http://127.0.0.1:7860/과 같은 URL로 로컬하게 실행됩니다.
참고: 앱을 로컬에서 실행하고
flagged/디렉토리가 나타난다면, 해당 디렉토리에는 “플래그(flagged)”된 샘플들이 들어 있습니다.예를 들어, 누군가 데모를 시도했는데 모델이 잘못된 결과를 생성했다면, 해당 샘플을 “플래그”하여 나중에 검토할 수 있습니다.
Gradio의 플래깅(flagging)에 대한 자세한 내용은 플래깅 문서를 참조하세요.
9.3 Hugging Face에 업로드
FoodVision Mini 앱이 로컬에서 작동하는 것을 확인했습니다. 하지만 머신러닝 데모를 만드는 즐거움은 다른 사람들에게 보여주고 사용할 수 있게 하는 데 있습니다.
이를 위해 FoodVision Mini 데모를 Hugging Face에 업로드하겠습니다.
참고: 다음 단계 시리즈는 Git(파일 추적 시스템) 워크플로우를 사용합니다. Git의 작동 방식에 대해 더 자세히 알고 싶다면, freeCodeCamp의 초보자를 위한 Git 및 GitHub 튜토리얼을 시청하시길 권장합니다.
- Hugging Face 계정에 가입합니다.
- 프로필로 이동한 후 “New Space”를 클릭하여 새 Hugging Face Space를 시작합니다.
- 참고: Hugging Face의 Space는 “코드 저장소(code repository)” 또는 줄여서 “저장소(repo)”라고도 불립니다.
- Space에 이름을 지정합니다. 예를 들어, 제 것은
mrdbourke/foodvision_mini이며 여기에서 볼 수 있습니다: https://huggingface.co/spaces/mrdbourke/foodvision_mini - 라이선스를 선택합니다(저는 MIT를 사용했습니다).
- Space SDK(software development kit)로 Gradio를 선택합니다.
- 참고: Streamlit과 같은 다른 옵션도 사용할 수 있지만 우리 앱은 Gradio로 구축되었으므로 Gradio를 고수하겠습니다.
- Space를 공개(public)로 할지 비공개(private)로 할지 선택합니다(저는 제 Space를 다른 사람들이 사용할 수 있도록 공개를 선택했습니다).
- “Create Space”를 클릭합니다.
- 터미널 또는 명령 프롬프트에서
git clone https://huggingface.co/spaces/[사용자_이름]/[SPACE_이름]을 실행하여 저장소를 로컬로 복제합니다.- 참고: “Files and versions” 탭에서 파일을 업로드하여 추가할 수도 있습니다.
- 다운로드한
foodvision_mini폴더의 내용을 복제된 저장소 폴더로 복사하거나 이동합니다. - 대용량 파일(예: 10MB 이상의 파일 또는 우리의 경우 PyTorch 모델 파일)을 업로드하고 추적하려면 Git LFS(Git Large File Storage)를 설치해야 합니다.
- Git LFS를 설치한 후
git lfs install을 실행하여 활성화할 수 있습니다. foodvision_mini디렉토리에서git lfs track "*.file_extension"으로 10MB 이상의 파일을 추적합니다.git lfs track "09_pretrained_effnetb2_feature_extractor_pizza_steak_sushi_20_percent.pth"명령으로 EffNetB2 PyTorch 모델 파일을 추적합니다.
.gitattributes(HuggingFace에서 복제할 때 자동으로 생성됨, 이 파일은 큰 파일들이 Git LFS로 추적되도록 보장함)를 추적합니다. FoodVision Mini Hugging Face Space에서.gitattributes파일 예시를 볼 수 있습니다.git add .gitattributes실행
- 나머지
foodvision_mini앱 파일들을 추가하고 다음 명령으로 커밋합니다.git add *git commit -m "first commit"
- Hugging Face에 파일을 푸시(업로드)합니다.
git push
- 빌드가 완료될 때까지 3~5분 정도 기다리면(나중의 빌드는 더 빠름) 앱이 라이브 상태가 됩니다!
모든 것이 올바르게 작동했다면, 여기 있는 것과 같은 FoodVision Mini Gradio 데모의 라이브 실행 예제를 볼 수 있을 것입니다: https://huggingface.co/spaces/mrdbourke/foodvision_mini
또한 https://hf.space/embed/[사용자_이름]/[SPACE_이름]/+ 형식의 링크와 함께 IPython.display.IFrame을 사용하여 iframe으로 FoodVision Mini Gradio 데모를 노트북에 직접 포함시킬 수도 있습니다.
# IPython은 Python을 대화형으로 사용할 수 있도록 돕는 라이브러리입니다.
from IPython.display import IFrame
# FoodVision Mini Gradio 데모 포함
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_mini/+", width=900, height=750)10. FoodVision Big 만들기
우리는 지난 몇 섹션과 챕터에 걸쳐 FoodVision Mini를 실현하기 위해 노력해 왔습니다.
그리고 이제 라이브 데모에서 작동하는 것을 보았는데, 한 단계 더 나아가 보는 건 어떨까요?
어떻게 요?
바로 FoodVision Big입니다!
FoodVision Mini는 Food101 데이터셋(각 1000개의 이미지가 있는 101개 음식 클래스)의 피자, 스테이크, 초밥 이미지로 훈련되었으므로, 101개 클래스 전체에 대해 모델을 훈련하여 FoodVision Big을 만들어 보는 건 어떨까요!
3개 클래스에서 101개 클래스로 나아갑니다!
피자, 스테이크, 초밥에서 피자, 스테이크, 초밥, 핫도그, 애플 파이, 당근 케이크, 초콜릿 케이크, 감자튀김, 마늘 빵, 라면, 나초, 타코 등등까지!
어떻게 요?
우리는 이미 모든 단계를 갖추고 있으며, EffNetB2 모델을 약간 수정하고 다른 데이터셋을 준비하기만 하면 됩니다.
마일스톤 프로젝트 3을 마무리하기 위해, FoodVision Mini(3개 클래스)와 유사하지만 FoodVision Big(101개 클래스)을 위한 Gradio 데모를 다시 만들어 보겠습니다.

FoodVision Mini는 피자, 스테이크, 초밥의 세 가지 음식 클래스로 작동합니다. 그리고 FoodVision Big은 Food101 데이터셋의 모든 클래스인 101개 음식 클래스로 작동하도록 한 단계 더 발전시켰습니다.
10.1 FoodVision Big을 위한 모델 및 트랜스폼 생성
FoodVision Mini를 만들 때 EffNetB2 모델이 속도와 성능 사이에서 좋은 균형을 이루는 것을 보았습니다(빠른 속도로 잘 수행됨).
따라서 FoodVision Big에도 동일한 모델을 계속 사용하겠습니다.
섹션 3.1에서 만든 create_effnetb2_model() 함수를 사용하고, Food101에는 101개의 클래스가 있으므로 num_classes=101 매개변수를 전달하여 Food101용 EffNetB2 특성 추출기를 만들 수 있습니다.
# Food101의 101개 클래스에 적합한 EffNetB2 모델 생성
effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)좋습니다!
이제 모델 요약을 확인해 보겠습니다.
from torchinfo import summary
# # 101개 출력 클래스를 갖는 Food101용 EffNetB2 특성 추출기 요약 가져오기 (전체 출력을 보려면 주석 해제)
# summary(effnetb2_food101,
# input_size=(1, 3, 224, 224),
# col_names=["input_size", "output_size", "num_params", "trainable"],
# col_width=20,
# row_settings=["var_names"])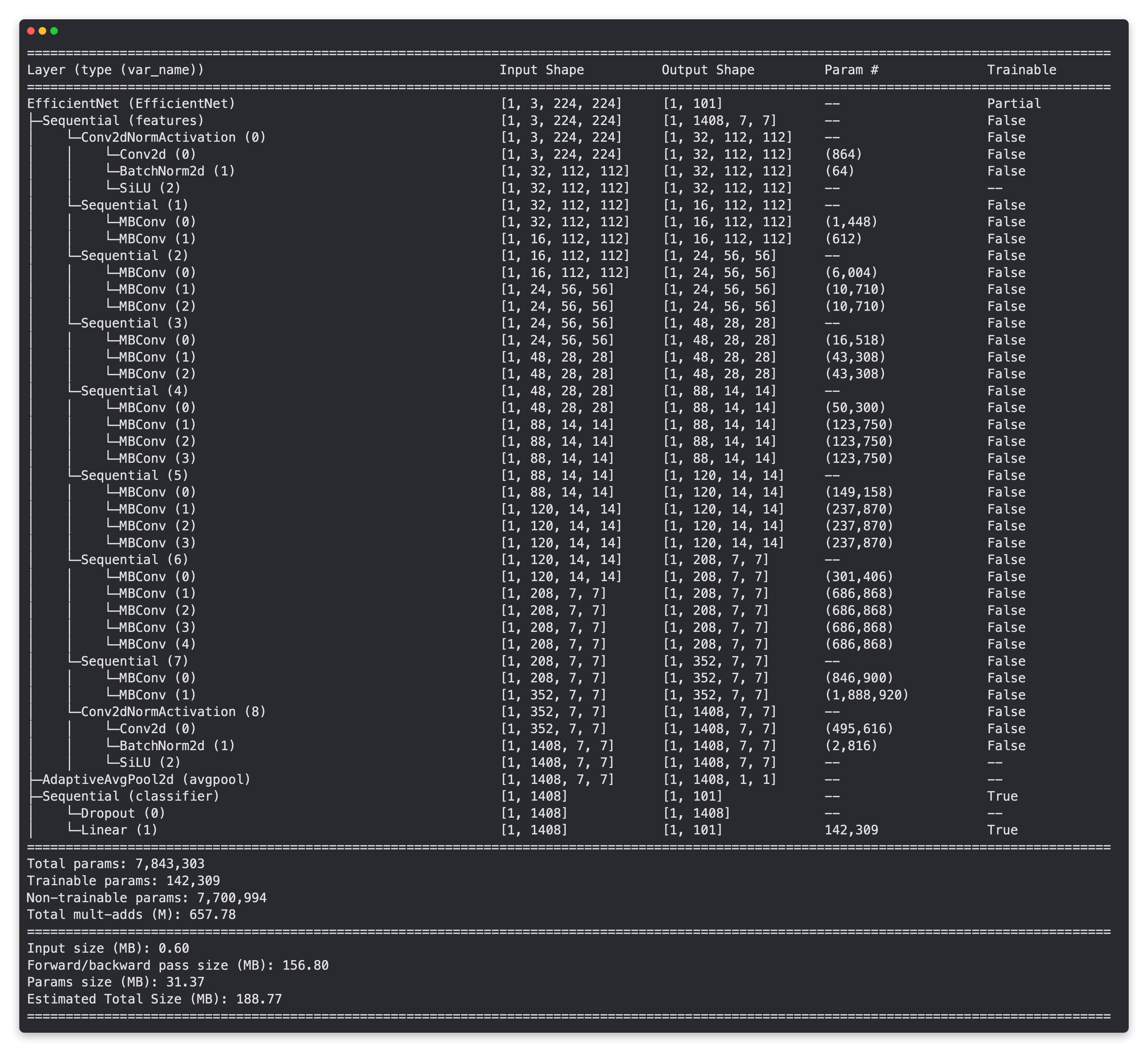
좋네요!
FoodVision Mini를 위한 EffNetB2 모델과 마찬가지로 기본 레이어는 고정되었고(ImageNet에서 사전 훈련됨), 외부 레이어(classifier 레이어)는 훈련 가능하며 Food101의 101개 클래스를 위해 [batch_size, 101]의 출력 모양을 가지고 있습니다.
이제 평소보다 상당히 많은 양의 데이터를 처리할 예정이므로, 훈련 데이터를 보강하기 위해 트랜스폼(effnetb2_transforms)에 약간의 데이터 증강(data augmentation)을 추가하는 건 어떨까요?
참고: 데이터 증강은 오버피팅을 방지하기 위해 훈련 데이터셋의 다양성을 인위적으로 증가시키기 위해 입력 훈련 샘플의 모양을 변경(예: 이미지 회전 또는 약간 기울이기)하는 기술입니다. 데이터 증강에 대한 자세한 내용은 04. PyTorch 사용자 정의 데이터셋 섹션 6에서 확인할 수 있습니다.
훈련 이미지 변환을 위해 PyTorch 팀이 컴퓨터 비전 레시피에서 사용한 것과 동일한 데이터 증강 기술인 torchvision.transforms.TrivialAugmentWide()와 effnetb2_transforms를 결합하여 torchvision.transforms 파이프라인을 구성해 보겠습니다.
# Food101 훈련 데이터 트랜스폼 생성 (훈련 이미지에 대해서만 데이터 증강 수행)
food101_train_transforms = torchvision.transforms.Compose([
torchvision.transforms.TrivialAugmentWide(),
effnetb2_transforms,
])최고네요!
이제 (훈련 데이터를 위한) food101_train_transforms와 (테스트/추론 데이터를 위한) effnetb2_transforms를 비교해 보겠습니다.
print(f"훈련 트랜스폼:\n{food101_train_transforms}\n")
print(f"테스트 트랜스폼:\n{effnetb2_transforms}")10.2 FoodVision Big을 위한 데이터 가져오기
FoodVision Mini를 위해 전체 Food101 데이터셋의 사용자 정의 데이터 분할을 만들었습니다.
전체 Food101 데이터셋을 얻으려면 torchvision.datasets.Food101()을 사용할 수 있습니다.
먼저 이미지를 저장할 data/ 디렉토리 경로를 설정하겠습니다.
그런 다음 food101_train_transforms 및 effnetb2_transforms를 사용하여 각각의 데이터셋을 변환하도록 훈련 및 테스트 데이터셋 분할을 다운로드하고 변환하겠습니다.
참고: Google Colab을 사용하는 경우 아래 셀을 실행하여 PyTorch에서 Food101 이미지를 완전히 다운로드하는 데 약 3~5분 정도 걸립니다.
다운로드되는 이미지가 100,000개가 넘기 때문입니다(101개 클래스 x 클래스당 1000개 이미지). Google Colab 런타임을 재시작하고 이 셀로 돌아오면 이미지를 다시 다운로드해야 합니다. 또는 이 노트북을 로컬에서 실행하는 경우 이미지는
torchvision.datasets.Food101()의root매개변수에 지정된 디렉토리에 캐시되어 저장됩니다.
from torchvision import datasets
# 데이터 디렉토리 설정
from pathlib import Path
data_dir = Path("data")
# 훈련 데이터 가져오기 (~750개 이미지 x 101개 음식 클래스)
train_data = datasets.Food101(root=data_dir, # 데이터를 다운로드할 경로
split="train", # 가져올 데이터셋 분할
transform=food101_train_transforms, # 훈련 데이터에 대해 데이터 증강 수행
download=True) # 다운로드할까요?
# 테스트 데이터 가져오기 (~250개 이미지 x 101개 음식 클래스)
test_data = datasets.Food101(root=data_dir,
split="test",
transform=effnetb2_transforms, # 테스트 데이터에 대해 일반 EffNetB2 트랜스폼 수행
download=True)데이터 다운로드 완료!
이제 train_data.classes를 사용하여 모든 클래스 이름 리스트를 얻을 수 있습니다.
# Food101 클래스 이름 가져오기
food101_class_names = train_data.classes
# 처음 10개 확인
food101_class_names[:10]호호! 정말 맛있어 보이는 음식들이네요(비록 “beignets”에 대해서는 들어본 적이 없지만… 업데이트: 구글 검색을 해보니 beignets도 맛있어 보입니다).
과정 GitHub의 extras/food101_class_names.txt에서 Food101 클래스 이름 전체 리스트를 확인할 수 있습니다.
10.3 더 빠른 실험을 위해 Food101 데이터셋의 서브셋 생성
이는 선택 사항입니다.
Food101 데이터셋의 또 다른 서브셋을 만들 필요는 없으며, 101,000개 이미지 전체에 대해 모델을 훈련하고 평가할 수도 있습니다.
하지만 훈련 속도를 유지하기 위해 훈련 및 테스트 데이터셋의 20% 분할을 만들겠습니다.
우리의 목표는 단 20%의 데이터만으로 원본 Food101 논문의 최고 결과를 뛰어넘을 수 있는지 확인하는 것입니다.
우리가 사용했거나 사용할 데이터셋을 요약하면 다음과 같습니다.
| 노트북 | 프로젝트 이름 | 데이터셋 | 클래스 수 | 훈련 이미지 | 테스트 이미지 |
|---|---|---|---|---|---|
| 04, 05, 06, 07, 08 | FoodVision Mini (10% 데이터) | Food101 사용자 정의 분할 | 3 (피자, 스테이크, 초밥) | 225 | 75 |
| 07, 08, 09 | FoodVision Mini (20% 데이터) | Food101 사용자 정의 분할 | 3 (피자, 스테이크, 초밥) | 450 | 150 |
| 09 (현재) | FoodVision Big (20% 데이터) | Food101 사용자 정의 분할 | 101 (모든 Food101 클래스) | 15150 | 5050 |
| 확장 | FoodVision Big | Food101 모든 데이터 | 101 | 75750 | 25250 |
경향이 보이시나요?
시간이 지남에 따라 모델 크기가 서서히 증가한 것처럼, 실험에 사용해 온 데이터셋의 크기도 증가했습니다.
참고: 20%의 데이터로 원본 Food101 논문의 결과를 진정으로 뛰어넘으려면, 훈련 데이터의 20%로 모델을 훈련시킨 다음 우리가 만든 분할이 아닌 전체 테스트 세트에서 모델을 평가해야 합니다. 이는 여러분이 시도해 볼 수 있는 확장 과제로 남겨두겠습니다. 또한 Food101 훈련 데이터셋 전체에 대해 모델을 훈련해 보시기를 권장합니다.
FoodVision Big(20% 데이터) 분할을 만들기 위해, 주어진 데이터셋을 특정 비율로 나누는 split_dataset()이라는 함수를 만들겠습니다.
lengths 매개변수를 사용하여 주어진 크기의 분할을 생성하는 torch.utils.data.random_split()을 사용할 수 있습니다.
lengths 매개변수는 원하는 분할 길이 리스트를 받으며 리스트의 총합은 데이터셋의 전체 길이와 같아야 합니다.
예를 들어 크기가 100인 데이터셋의 경우, lengths=[20, 80]을 전달하여 20%와 80%의 분할을 받을 수 있습니다.
우리는 함수가 두 개의 분할, 즉 타겟 길이(예: 훈련 데이터의 20%)를 가진 분할과 나머지 길이(예: 나머지 80%의 훈련 데이터)를 가진 분할을 반환하기를 원합니다.
마지막으로 재현성을 위해 generator 매개변수를 torch.manual_seed() 값으로 설정하겠습니다.
def split_dataset(dataset:torchvision.datasets, split_size:float=0.2, seed:int=42):
"""split_size와 seed를 기반으로 주어진 데이터셋을 두 가지 비율로 무작위 분할합니다.
인자:
dataset (torchvision.datasets): PyTorch 데이터셋, 일반적으로 torchvision.datasets에서 가져온 것.
split_size (float, optional): 데이터셋을 얼마나 분할할까요?
예: split_size=0.2는 20% 분할과 80% 분할이 있음을 의미함. 기본값은 0.2.
seed (int, optional): 무작위 생성기를 위한 시드. 기본값은 42.
반환값:
tuple: (random_split_1, random_split_2) 여기서 random_split_1은 split_size*len(dataset) 크기이고,
random_split_2는 (1-split_size)*len(dataset) 크기임.
"""
# 원본 데이터셋 길이를 기반으로 분할 길이 생성
length_1 = int(len(dataset) * split_size) # 원하는 길이
length_2 = len(dataset) - length_1 # 나머지 길이
# 정보 출력
print(f"[INFO] {len(dataset)} 길이의 데이터셋을 {length_1} ({int(split_size*100)}%), {length_2} ({int((1-split_size)*100)}%) 크기의 분할로 나누는 중")
# 주어진 무작위 시드로 분할 생성
random_split_1, random_split_2 = torch.utils.data.random_split(dataset,
lengths=[length_1, length_2],
generator=torch.manual_seed(seed)) # 재현 가능한 분할을 위해 무작위 시드 설정
return random_split_1, random_split_2데이터셋 분할 함수가 생성되었습니다!
이제 Food101의 20% 훈련 및 테스트 데이터셋 분할을 생성하여 테스트해 보겠습니다.
# Food101의 훈련용 20% 분할 생성
train_data_food101_20_percent, _ = split_dataset(dataset=train_data,
split_size=0.2)
# Food101의 테스트용 20% 분할 생성
test_data_food101_20_percent, _ = split_dataset(dataset=test_data,
split_size=0.2)
len(train_data_food101_20_percent), len(test_data_food101_20_percent)훌륭합니다!
10.4 Food101 데이터셋을 DataLoader로 변환
이제 torch.utils.data.DataLoader()를 사용하여 Food101 20% 데이터셋 분할을 DataLoader로 변환해 보겠습니다.
훈련 데이터에 대해서만 shuffle=True로 설정하고 두 데이터셋 모두 배치 크기를 32로 설정하겠습니다.
CPU 코어 수가 사용 가능하다면 num_workers를 4로, 그렇지 않다면 2로 설정하겠습니다(단, num_workers의 값은 매우 실험적이며 사용 중인 하드웨어에 따라 달라질 수 있으므로 PyTorch 포럼에 이에 대한 활발한 토론 스레드가 있습니다).
import os
import torch
BATCH_SIZE = 32
NUM_WORKERS = 2 if os.cpu_count() <= 4 else 4 # 이 값은 매우 실험적이며 사용 가능한 하드웨어에 따라 달라집니다. Google Colab은 일반적으로 2개의 CPU를 제공합니다.
# Food101 20% 훈련 DataLoader 생성
train_dataloader_food101_20_percent = torch.utils.data.DataLoader(train_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=NUM_WORKERS)
# Food101 20% 테스트 DataLoader 생성
test_dataloader_food101_20_percent = torch.utils.data.DataLoader(test_data_food101_20_percent,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=NUM_WORKERS)10.5 FoodVision Big 모델 훈련
FoodVision Big 모델과 DataLoader가 준비되었습니다!
이제 훈련할 시간입니다.
torch.optim.Adam()과 학습률 1e-3을 사용하여 옵티마이저를 만들겠습니다.
클래스가 매우 많기 때문에, torchvision의 최첨단 훈련 레시피에 따라 label_smoothing=0.1인 torch.nn.CrossEntropyLoss()를 사용하여 손실 함수를 설정하겠습니다.
레이블 스무딩(label smoothing)이란 무엇일까요?
레이블 스무딩은 모델이 특정 레이블에 부여하는 값을 줄이고 이를 다른 레이블에 분산시키는 규제(regularization) 기술입니다(규제는 오버피팅을 방지하는 과정을 설명하는 또 다른 단어입니다).
본질적으로, 모델이 단일 레이블에 대해 지나치게 확신하는 대신 레이블 스무딩은 다른 레이블에 0이 아닌 값을 부여하여 일반화에 도움을 줍니다.
예를 들어 레이블 스무딩이 없는 모델이 5개 클래스에 대해 다음과 같은 출력을 가졌다고 가정해 보겠습니다.
[0, 0, 0.99, 0.01, 0]레이블 스무딩이 있는 모델은 다음과 같은 출력을 가질 수 있습니다.
[0.01, 0.01, 0.96, 0.01, 0.01]모델은 여전히 클래스 3에 대한 예측을 확신하고 있지만, 다른 레이블에 작은 값을 부여함으로써 모델이 적어도 다른 옵션을 고려하도록 강제합니다.
마지막으로, 작업을 빠르게 진행하기 위해 05. PyTorch 모듈화 섹션 4에서 만든 engine.train() 함수를 사용하여 5 에포크 동안 모델을 훈련할 것이며, 원본 Food101 논문의 테스트 세트 정확도 결과인 56.4%를 뛰어넘는 것을 목표로 합니다.
지금까지 가장 큰 모델을 훈련해 봅시다!
참고: 아래 셀을 실행하는 데 Google Colab에서 약 15~20분 정도 걸립니다. 지금까지 사용한 데이터 중 가장 많은 양(훈련 이미지 15,150개, 테스트 이미지 5,050개)으로 가장 큰 모델을 훈련하기 때문입니다. 이것이 우리가 앞서 전체 Food101 데이터셋의 20%를 분할하기로 결정한 이유입니다(훈련에 한 시간 이상 걸리지 않도록 하기 위해).
from going_modular.going_modular import engine
# 옵티마이저 설정
optimizer = torch.optim.Adam(params=effnetb2_food101.parameters(),
lr=1e-3)
# 손실 함수 설정
loss_fn = torch.nn.CrossEntropyLoss(label_smoothing=0.1) # 클래스가 매우 많으므로 약간의 레이블 스무딩 추가
# 20%의 데이터로 원본 Food101 논문의 결과인 56.4% 이상의 테스트 데이터셋 정확도를 달성하고자 함
set_seeds()
effnetb2_food101_results = engine.train(model=effnetb2_food101,
train_dataloader=train_dataloader_food101_20_percent,
test_dataloader=test_dataloader_food101_20_percent,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=5,
device=device)우와!!!!
훈련 데이터의 20%만으로 원본 Food101 논문의 결과인 56.4% 정확도를 뛰어넘은 것 같습니다(비록 테스트 데이터의 20%에 대해서만 평가했지만, 결과를 완전히 재현하려면 테스트 데이터의 100%에 대해 평가할 수도 있습니다).
이것이 바로 전이 학습의 힘입니다!
10.6 FoodVision Big 모델의 손실 곡선 검사
우리의 FoodVision Big 손실 곡선을 시각화해 보겠습니다.
helper_functions.py의 plot_loss_curves() 함수를 사용하여 그렇게 할 수 있습니다.
from helper_functions import plot_loss_curves
# FoodVision Big의 손실 곡선 확인
plot_loss_curves(effnetb2_food101_results)좋네요!!!
우리의 규제 기술(데이터 증강 및 레이블 스무딩)이 모델의 오버피팅을 방지하는 데 도움이 된 것 같습니다(훈련 손실이 여전히 테스트 손실보다 높음). 이는 우리 모델이 학습할 수 있는 용량이 조금 더 남아 있으며 추가 훈련을 통해 더 개선될 수 있음을 나타냅니다.
10.7 FoodVision Big 저장 및 불러오기
이제 지금까지 가장 큰 모델을 훈련했으므로 나중에 다시 불러올 수 있도록 저장하겠습니다.
from going_modular.going_modular import utils
# 모델 경로 생성
effnetb2_food101_model_path = "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"
# FoodVision Big 모델 저장
utils.save_model(model=effnetb2_food101,
target_dir="models",
model_name=effnetb2_food101_model_path)모델 저장 완료!
다음으로 넘어가기 전에 모델을 다시 불러올 수 있는지 확인하겠습니다.
먼저 create_effnetb2_model(num_classes=101)(모든 Food101 클래스를 위해 101개 클래스 설정)로 모델 인스턴스를 생성하여 이를 수행합니다.
그런 다음 torch.nn.Module.load_state_dict() 및 torch.load()를 사용하여 저장된 state_dict()를 불러옵니다.
# Food101 호환 EffNetB2 인스턴스 생성
loaded_effnetb2_food101, effnetb2_transforms = create_effnetb2_model(num_classes=101)
# 저장된 모델의 state_dict() 불러오기
loaded_effnetb2_food101.load_state_dict(torch.load("models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"))10.8 FoodVision Big 모델 크기 확인
우리의 FoodVision Big 모델은 FoodVision Mini의 3개 클래스에 비해 101개 클래스를 분류할 수 있으며, 이는 33.6배 증가한 수치입니다!
이것이 모델 크기에 어떤 영향을 미칠까요?
알아봅시다.
from pathlib import Path
# 모델 크기를 바이트 단위로 가져온 다음 메가바이트로 변환
pretrained_effnetb2_food101_model_size = Path("models", effnetb2_food101_model_path).stat().st_size // (1024*1024) # 나눗셈을 통해 바이트를 메가바이트로 변환(대략)
print(f"사전 훈련된 EffNetB2 특성 추출기 Food101 모델 크기: {pretrained_effnetb2_food101_model_size} MB")흠, 클래스 수가 크게 증가했음에도 불구하고 모델 크기는 거의 동일하게 유지된 것으로 보입니다(FoodVision Big은 30MB, FoodVision Mini는 29MB).
이는 FoodVision Big을 위한 모든 추가 파라미터가 오직 마지막 레이어(분류 헤드)에만 있기 때문입니다.
모든 기본 레이어는 FoodVision Big과 FoodVision Mini 사이에 동일합니다.
위로 돌아가서 모델 요약을 비교하면 더 자세한 내용을 알 수 있습니다.
| 모델 | 출력 모양 (클래스 수) | 훈련 가능한 파라미터 | 총 파라미터 | 모델 크기 (MB) |
|---|---|---|---|---|
| FoodVision Mini (EffNetB2 특성 추출기) | 3 | 4,227 | 7,705,221 | 29 |
| FoodVision Big (EffNetB2 특성 추출기) | 101 | 142,309 | 7,843,303 | 30 |
11. FoodVision Big 모델을 배포 가능한 앱으로 변환
Food101 데이터셋의 20%로 훈련되고 저장된 EffNetB2 모델이 있습니다.
모델이 폴더에만 평생 있게 하는 대신 배포해 봅시다!
FoodVision Mini 모델을 배포한 것과 동일한 방식으로, Hugging Face Spaces에서 Gradio 데모로 FoodVision Big 모델을 배포하겠습니다.
시작하기 위해, FoodVision Big 데모 파일을 저장할 demos/foodvision_big/ 디렉토리와 데모 테스트를 위한 예시 이미지를 담을 demos/foodvision_big/examples 디렉토리를 생성하겠습니다.
완료되면 다음과 같은 파일 구조를 갖게 될 것입니다.
demos/
foodvision_big/
09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth
app.py
class_names.txt
examples/
example_1.jpg
model.py
requirements.txt여기서: * 09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth는 훈련된 PyTorch 모델 파일입니다. * app.py에는 FoodVision Big Gradio 앱이 들어 있습니다. * class_names.txt에는 FoodVision Big을 위한 모든 클래스 이름이 들어 있습니다. * examples/에는 Gradio 앱과 함께 사용할 예시 이미지가 들어 있습니다. * model.py에는 모델 정의와 모델과 관련된 모든 트랜스폼이 들어 있습니다. * requirements.txt에는 torch, torchvision, gradio와 같이 앱을 실행하기 위한 의존성이 들어 있습니다.
from pathlib import Path
# FoodVision Big 데모 경로 생성
foodvision_big_demo_path = Path("demos/foodvision_big/")
# FoodVision Big 데모 디렉토리 생성
foodvision_big_demo_path.mkdir(parents=True, exist_ok=True)
# FoodVision Big 데모 예시 디렉토리 생성
(foodvision_big_demo_path / "examples").mkdir(parents=True, exist_ok=True)11.1 예시 이미지 다운로드 및 examples 디렉토리로 이동
예시 이미지로는 믿음직한 pizza-dad 이미지(피자를 먹고 있는 제 아버지의 사진)를 사용하겠습니다.
{kind=link}
과정 GitHub에서 !wget 명령어를 통해 다운로드한 다음, !mv(“move”의 약자) 명령어를 사용하여 demos/foodvision_big/examples로 이동하겠습니다.
하는 김에 훈련된 Food101 EffNetB2 모델도 models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth에서 demos/foodvision_big으로 이동시키겠습니다.
# 예시 이미지 다운로드 및 이동
!wget https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/images/04-pizza-dad.jpeg
!mv 04-pizza-dad.jpeg demos/foodvision_big/examples/04-pizza-dad.jpg
# 훈련된 모델을 FoodVision Big 데모 폴더로 이동 (모델이 이미 이동된 경우 오류 발생)
!mv models/09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth demos/foodvision_big11.2 Food101 클래스 이름을 파일로 저장 (class_names.txt)
Food101 데이터셋에는 클래스가 매우 많기 때문에, 이를 app.py 파일에 리스트로 저장하는 대신 .txt 파일에 저장하고 필요할 때 읽어오도록 하겠습니다.
먼저 food101_class_names를 확인하여 어떻게 생겼는지 다시 한번 상기해 보겠습니다.
# 처음 10개 Food101 클래스 이름 확인
food101_class_names[:10]좋습니다. 이제 demos/foodvision_big/class_names.txt 경로를 먼저 생성한 다음 Python의 open()으로 파일을 열고 각 클래스마다 줄바꿈을 하여 기록하겠습니다.
이상적으로 클래스 이름은 다음과 같이 저장되기를 원합니다.
apple_pie
baby_back_ribs
baklava
beef_carpaccio
beef_tartare
...# Food101 클래스 이름 경로 생성
foodvision_big_class_names_path = foodvision_big_demo_path / "class_names.txt"
# Food101 클래스 이름 리스트를 파일로 기록
with open(foodvision_big_class_names_path, "w") as f:
print(f"[INFO] Food101 클래스 이름을 {foodvision_big_class_names_path}에 저장 중")
f.write("\n".join(food101_class_names)) # 각 클래스 사이에 줄바꿈 추가훌륭합니다. 이제 다시 읽어올 수 있는지 확인해 보겠습니다.
Python의 open()을 읽기 모드("r")로 사용한 다음, readlines() 메서드를 사용하여 class_names.txt 파일의 각 줄을 읽어오겠습니다.
그리고 리스트 컴프리헨션(list comprehension)과 strip()을 사용하여 각 줄의 줄바꿈 문자를 제거하고 클래스 이름을 리스트로 저장할 수 있습니다.
# Food101 클래스 이름 파일을 열고 각 줄을 리스트로 읽어오기
with open(foodvision_big_class_names_path, "r") as f:
food101_class_names_loaded = [food.strip() for food in f.readlines()]
# 다시 로드된 처음 5개 클래스 이름 확인
food101_class_names_loaded[:5]11.3 FoodVision Big 모델을 Python 스크립트로 변환 (model.py)
FoodVision Mini 데모와 마찬가지로, EffNetB2 특성 추출기 모델을 인스턴스화하고 필요한 트랜스폼을 함께 제공할 수 있는 스크립트를 만들어 보겠습니다.
%%writefile demos/foodvision_big/model.py
import torch
import torchvision
from torch import nn
def create_effnetb2_model(num_classes:int=3,
seed:int=42):
"""EfficientNetB2 특성 추출기 모델과 트랜스폼을 생성합니다.
인자:
num_classes (int, optional): 분류 헤드의 클래스 수.
기본값은 3.
seed (int, optional): 무작위 시드 값. 기본값은 42.
반환값:
model (torch.nn.Module): EffNetB2 특성 추출기 모델.
transforms (torchvision.transforms): EffNetB2 이미지 트랜스폼.
"""
# 사전 훈련된 EffNetB2 가중치, 트랜스폼 및 모델 생성
weights = torchvision.models.EfficientNet_B2_Weights.DEFAULT
transforms = weights.transforms()
model = torchvision.models.efficientnet_b2(weights=weights)
# 기본 모델의 모든 레이어 고정
for param in model.parameters():
param.requires_grad = False
# 재현성을 위해 무작위 시드와 함께 분류 헤드 변경
torch.manual_seed(seed)
model.classifier = nn.Sequential(
nn.Dropout(p=0.3, inplace=True),
nn.Linear(in_features=1408, out_features=num_classes),
)
return model, transforms11.4 FoodVision Big Gradio 앱을 Python 스크립트로 변환 (app.py)
FoodVision Big용 model.py 스크립트를 얻었으니 이제 FoodVision Big용 app.py 스크립트를 만들어 보겠습니다.
이는 다시 한번 FoodVision Mini용 app.py 스크립트와 거의 동일하지만 다음 사항들을 변경하겠습니다.
- 임포트 및 클래스 이름 설정 -
class_names변수는 피자, 스테이크, 초밥이 아닌 모든 Food101 클래스에 대한 리스트가 됩니다. 이들은demos/foodvision_big/class_names.txt를 통해 접근할 수 있습니다. - 모델 및 트랜스폼 준비 -
model은num_classes=3이 아닌num_classes=101을 갖게 됩니다. 또한 가중치를"09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"(FoodVision Big 모델 경로)에서 불러오도록 하겠습니다. - 예측 함수 - 이 부분은 FoodVision Mini의
app.py와 동일하게 유지됩니다. - Gradio 앱 - Gradio 인터페이스는 FoodVision Big의 세부 사항을 반영하기 위해 서로 다른
title,description및article매개변수를 갖게 됩니다.
또한 %%writefile 매직 명령어를 사용하여 demos/foodvision_big/app.py에 저장하도록 하겠습니다.
%%writefile demos/foodvision_big/app.py
### 1. 임포트 및 클래스 이름 설정 ###
import gradio as gr
import os
import torch
from model import create_effnetb2_model
from timeit import default_timer as timer
from typing import Tuple, Dict
# 클래스 이름 설정
with open("class_names.txt", "r") as f: # class_names.txt에서 읽어오기
class_names = [food_name.strip() for food_name in f.readlines()]
### 2. 모델 및 트랜스폼 준비 ###
# 모델 생성
effnetb2, effnetb2_transforms = create_effnetb2_model(
num_classes=101, # len(class_names)를 사용할 수도 있습니다.
)
# 저장된 가중치 불러오기
effnetb2.load_state_dict(
torch.load(
f="09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth",
map_location=torch.device("cpu"), # CPU로 불러오기
)
)
### 3. 예측 함수 ###
# 예측 함수 생성
def predict(img) -> Tuple[Dict, float]:
"""img에 대해 변환 및 예측을 수행하고 예측 결과와 소요 시간을 반환합니다.
"""
# 타이머 시작
start_time = timer()
# 타겟 이미지 변환 및 배치 차원 추가
img = effnetb2_transforms(img).unsqueeze(0)
# 모델을 평가 모드로 설정하고 추론 모드 활성화
effnetb2.eval()
with torch.inference_mode():
# 변환된 이미지를 모델에 통과시키고 예측 로짓을 예측 확률로 변환
pred_probs = torch.softmax(effnetb2(img), dim=1)
# 각 예측 클래스에 대한 예측 레이블 및 예측 확률 딕셔너리 생성 (이는 Gradio의 출력 매개변수에 필요한 형식입니다)
pred_labels_and_probs = {class_names[i]: float(pred_probs[0][i]) for i in range(len(class_names))}
# 예측 시간 계산
pred_time = round(timer() - start_time, 5)
# 예측 딕셔너리와 예측 시간 반환
return pred_labels_and_probs, pred_time
### 4. Gradio 앱 ###
# 제목, 설명 및 기사 문자열 생성
title = "FoodVision Big 🍔👁"
description = "음식 이미지를 [101가지 클래스](https://github.com/mrdbourke/pytorch-deep-learning/blob/main/extras/food101_class_names.txt)로 분류하는 EfficientNetB2 특성 추출기 컴퓨터 비전 모델입니다."
article = "[09. PyTorch 모델 배포](https://www.learnpytorch.io/09_pytorch_model_deployment/)에서 생성되었습니다."
# "examples/" 디렉토리에서 예시 리스트 생성
example_list = [["examples/" + example] for example in os.listdir("examples")]
# Gradio 인터페이스 생성
demo = gr.Interface(
fn=predict,
inputs=gr.Image(type="pil"),
outputs=[
gr.Label(num_top_classes=5, label="Predictions"),
gr.Number(label="Prediction time (s)"),
],
examples=example_list,
title=title,
description=description,
article=article,
)
# 앱 실행!
demo.launch()11.5 FoodVision Big을 위한 요구 사항 파일 생성 (requirements.txt)
이제 우리 FoodVision Big 앱에 어떤 의존성이 필요한지 Hugging Face Space에 알려주기 위해 requirements.txt 파일만 있으면 됩니다.
%%writefile demos/foodvision_big/requirements.txt
torch==1.12.0
torchvision==0.13.0
gradio==3.1.411.6 FoodVision Big 앱 파일 다운로드
Hugging Face에 FoodVision Big 앱을 배포하는 데 필요한 모든 파일을 얻었으니 이제 이들을 함께 압축하고 다운로드해 보겠습니다.
위의 FoodVision Mini 앱에서 사용했던 것과 동일한 과정을 섹션 9.1: FoodVision Mini 앱 파일 다운로드에서 사용하겠습니다.
# foodvision_big 폴더를 압축하되 특정 파일은 제외
!cd demos/foodvision_big && zip -r ../foodvision_big.zip * -x "*.pyc" "*.ipynb" "*__pycache__*" "*ipynb_checkpoints*"
# 압축된 FoodVision Big 앱 다운로드 (Google Colab에서 실행 중인 경우)
try:
from google.colab import files
files.download("demos/foodvision_big.zip")
except:
print("Google Colab에서 실행 중이 아님, google.colab.files.download()를 사용할 수 없습니다.")11.7 FoodVision Big 앱을 HuggingFace Spaces에 배포하기
B, E, A, Utiful!
전체 과정 중 가장 큰 모델을 실현할 시간입니다!
FoodVision Big Gradio 데모를 Hugging Face Spaces에 배포하여 대화형으로 테스트하고 다른 사람들이 우리의 머신러닝 노력의 마법을 경험하게 해봅시다!
참고: Hugging Face Spaces에 파일을 업로드하는 몇 가지 방법이 있습니다. 다음 단계는 파일을 추적하기 위해 Hugging Face를 git 저장소로 취급합니다. 하지만 웹 인터페이스 또는
huggingface_hub라이브러리를 통해 Hugging Face Spaces에 직접 업로드할 수도 있습니다.
다행히도 우리는 이미 FoodVision Mini를 통해 수행하는 단계를 거쳤으므로, 이제 FoodVision Big에 맞게 수정하기만 하면 됩니다.
- Hugging Face 계정에 가입합니다.
- 프로필로 이동한 후 “New Space”를 클릭하여 새 Hugging Face Space를 시작합니다.
- 참고: Hugging Face의 Space는 “코드 저장소(code repository)” 또는 줄여서 “저장소(repo)”라고도 불립니다.
- Space에 이름을 지정합니다. 예를 들어, 제 것은
mrdbourke/foodvision_big이며 여기에서 볼 수 있습니다: https://huggingface.co/spaces/mrdbourke/foodvision_big - 라이선스를 선택합니다(저는 MIT를 사용했습니다).
- Space SDK(software development kit)로 Gradio를 선택합니다.
- 참고: Streamlit과 같은 다른 옵션도 사용할 수 있지만 우리 앱은 Gradio로 구축되었으므로 Gradio를 고수하겠습니다.
- Space를 공개(public)로 할지 비공개(private)로 할지 선택합니다(저는 제 Space를 다른 사람들이 사용할 수 있도록 공개를 선택했습니다).
- “Create Space”를 클릭합니다.
- 터미널 또는 명령 프롬프트에서
git clone https://huggingface.co/spaces/[사용자_이름]/[SPACE_이름]을 실행하여 저장소를 로컬로 복제합니다.- 참고: “Files and versions” 탭에서 파일을 업로드하여 추가할 수도 있습니다.
- 다운로드한
foodvision_big폴더의 내용을 복제된 저장소 폴더로 복사하거나 이동합니다. - 대용량 파일(예: 10MB 이상의 파일 또는 우리의 경우 PyTorch 모델 파일)을 업로드하고 추적하려면 Git LFS(Git Large File Storage)를 설치해야 합니다.
- Git LFS를 설치한 후
git lfs install을 실행하여 활성화할 수 있습니다. foodvision_big디렉토리에서git lfs track "*.file_extension"으로 10MB 이상의 파일을 추적합니다.git lfs track "09_pretrained_effnetb2_feature_extractor_food101_20_percent.pth"명령으로 EffNetB2 PyTorch 모델 파일을 추적합니다.- 참고: 이미지를 업로드할 때 오류가 발생하면 이미지도
git lfs로 추적해야 할 수 있습니다. 예:git lfs track "examples/04-pizza-dad.jpg"
.gitattributes(HuggingFace에서 복제할 때 자동으로 생성됨, 이 파일은 큰 파일들이 Git LFS로 추적되도록 보장함)를 추적합니다. FoodVision Big Hugging Face Space에서.gitattributes파일 예시를 볼 수 있습니다.git add .gitattributes실행
- 나머지
foodvision_big앱 파일들을 추가하고 다음 명령으로 커밋합니다.git add *git commit -m "first commit"
- Hugging Face에 파일을 푸시(업로드)합니다.
git push
- 빌드가 완료될 때까지 3~5분 정도 기다리면(나중의 빌드는 더 빠름) 앱이 라이브 상태가 됩니다!
모든 것이 올바르게 작동했다면, 우리 FoodVision Big Gradio 데모가 분류 준비를 마쳤을 것입니다!
제 버전은 여기에서 보실 수 있습니다: https://huggingface.co/spaces/mrdbourke/foodvision_big/
또는 https://hf.space/embed/[사용자_이름]/[SPACE_이름]/+ 형식의 링크와 함께 IPython.display.IFrame을 사용하여 iframe으로 FoodVision Big Gradio 데모를 노트북에 직접 포함시킬 수도 있습니다.
# IPython은 Python을 대화형으로 사용할 수 있도록 돕는 라이브러리입니다.
from IPython.display import IFrame
# FoodVision Big Gradio 데모를 iframe으로 포함
IFrame(src="https://hf.space/embed/mrdbourke/foodvision_big/+", width=900, height=750)얼마나 멋진가요!?!
직선을 예측하기 위해 PyTorch 모델을 구축하는 것에서 시작하여… 이제 전 세계 사람들이 접근할 수 있는 컴퓨터 비전 모델을 구축하고 있습니다!
주요 요점
- 배포는 훈련만큼이나 중요합니다. 잘 작동하는 모델을 얻고 나면 첫 번째 질문은 ’이를 어떻게 배포하여 다른 사람들이 접근할 수 있게 만들 것인가?’여야 합니다. 배포를 통해 개인 훈련 및 테스트 세트가 아닌 실제 세상에서 모델을 테스트할 수 있습니다.
- 머신러닝 모델 배포를 위한 세 가지 질문:
- 모델의 가장 이상적인 유스케이스는 무엇인가(얼마나 잘 그리고 얼마나 빨리 작동하는가)?
- 모델이 어디로 갈 것인가(온디바이스 또는 클라우드)?
- 모델이 어떻게 작동할 것인가(예측이 온라인인가 오프라인인가)?
- 배포 옵션은 풍부합니다. 하지만 간단하게 시작하는 것이 가장 좋습니다. 현재 가장 좋은 방법 중 하나(이러한 것들은 항상 바뀌기 때문에 현재라고 말합니다)는 Gradio를 사용하여 데모를 만들고 Hugging Face Spaces에 호스팅하는 것입니다. 간단하게 시작하고 필요할 때 확장하세요.
- 실험을 멈추지 마세요. 머신러닝 모델 요구 사항은 시간이 지남에 따라 변할 가능성이 높으므로 단일 모델을 배포하는 것이 마지막 단계는 아닙니다. 데이터셋이 변하는 것을 발견할 수 있으므로 모델을 업데이트해야 합니다. 또는 새로운 연구 결과가 발표되어 사용할 더 나은 아키텍처가 생길 수도 있습니다.
- 따라서 하나의 모델을 배포하는 것은 훌륭한 단계이지만, 시간이 지남에 따라 업데이트하고 싶어질 것입니다.
- 머신러닝 모델 배포는 MLOps(Machine Learning Operations) 엔지니어링 실무의 일부입니다. MLOps는 DevOps(Development Operations)의 확장이며 모델 훈련과 관련된 모든 엔지니어링 부분(데이터 수집 및 저장, 데이터 전처리, 모델 배포, 모델 모니터링, 버전 관리 등)을 포함합니다. 빠르게 진화하는 분야이지만 더 많이 배울 수 있는 탄탄한 리소스들이 있으며, 그중 상당수가 PyTorch 추가 리소스에 있습니다.
연습 문제
모든 연습 문제는 위의 코드를 연습하는 데 중점을 둡니다.
각 섹션을 참조하거나 링크된 리소스를 따라 완료할 수 있어야 합니다.
리소스:
- 09 장 연습 문제 템플릿 노트북.
- 09 장 연습 문제 모범 답안 노트북 답안을 보기 전에 직접 풀어보세요.
- YouTube에서 솔루션에 대한 라이브 비디오 연습을 시청하세요 (오류 등 포함).
- GPU(
device="cuda")를 사용하여 테스트 데이터셋에서 두 특성 추출기 모델 모두에 대해 예측을 수행하고 시간을 측정합니다. 모델의 GPU 대 CPU 예측 시간을 비교해 보세요. 그 간격이 좁혀지나요? 즉, GPU에서 예측을 수행하면 ViT 특성 추출기 예측 시간이 EffNetB2 특성 추출기 예측 시간에 더 가까워지나요?- 섹션 5. 훈련된 모델로 예측하고 시간 측정하기 및 섹션 6. 모델 결과, 예측 시간 및 크기 비교에서 이 단계들을 수행하기 위한 코드를 찾을 수 있습 니다.
- ViT 특성 추출기는 EffNetB2보다 더 많은 학습 용량(더 많은 파라미터 때문)을 가지고 있는 것으로 보이는데, 전체 Food101 데이 터셋의 더 큰 20% 분할에서는 어떻게 작동하나요?
- 섹션 10. FoodVision Big 만들기에서 EffNetB2로 했던 것과 똑같이, 20% Food101 데이터셋에서 5 에포크 동안 ViT 특성 추출기를 훈련시키세요.
- 연습 문제 2의 ViT 특성 추출기를 사용하여 20% Food101 테스트 데이터셋 전체에 대해 예측을 수행하고 “가장 틀린” 예측을 찾 으세요.
- 예측 확률은 가장 높지만 예측 레이블이 틀린 것이 “가장 틀린” 예측이 됩니다.
- 왜 모델이 이러한 예측을 틀렸다고 생각하는지 한두 문장으로 적어보세요.
- 20% 버전이 아닌 Food101 테스트 데이터셋 전체에 대해 ViT 특성 추출기를 평가하면 성능이 어떤가요?
- 원본 Food101 논문의 최고 결과인 56.4% 정확도를 뛰어넘나요?
- Paperswithcode.com으로 이동하여 Food101 데이터셋에서 현재 가장 성능이 좋은 모델을 찾으세요.
- 어떤 모델 아키텍처를 사용하나요?
- 배포된 FoodVision 모델의 잠재적인 실패 지점 1~3개와 잠재적인 해결책을 적어보세요.
- 예를 들어, 누군가 음식이 아닌 사진을 FoodVision Mini 모델에 업로드하면 어떻게 될까요?
torchvision.datasets에서 임의의 데이터셋을 선택하고,torchvision.models의 모델(이미 만든 모델 중 하나인 EffNetB2 또는 ViT를 사용할 수 있음)을 사 용하여 5 에포크 동안 특성 추출기 모델을 훈련시킨 다음, Hugging Face Spaces에 Gradio 앱으로 배포하세요.- 훈련 시간이 너무 오래 걸리지 않도록 더 작은 데이터셋을 선택하거나 일부만 사용하고 싶을 수 있습니다.
- 여러분이 배포한 모델을 보고 싶습니다! Discord나 과정 GitHub Discussion 페이지에 공유해 주세요.
추가 학습 자료
- 머신러닝 모델 배포는 일반적으로 순수 머신러닝 과제라기보다는 엔지니어링 과제입니다. 자세한 내용은 PyTorch 추가 리소스 머신러닝 엔지니어링 섹션을 참조하세요.
- 그곳에서 Chip Huyen의 책 Designing Machine Learning Systems (특히 모델 배포에 관한 7장) 및 Goku Mohandas의 Made with ML MLOps 과정과 같은 리소스를 찾을 수 있습니다.
- 자신만의 프로젝트를 점점 더 많이 구축함에 따라 Git(및 잠재적으로 GitHub)을 상당히 자주 사용하게 될 것입니다. 둘 다에 대해 더 자세히 알아보려면 freeCodeCamp YouTube 채널의 초보자를 위한 Git 및 GitHub - 집중 과정 동영상을 추천합니다.
- 우리는 Gradio로 가능한 기능의 극히 일부만 살펴보았습니다. 더 자세한 내용은 전체 문서를 확인해 보시길 권장하며, 특히 다음 내용을 추천합니다.
- 모든 다양한 종류의 입력 및 출력 구성 요소.
- 더 고급 워크플로우를 위한 Gradio Blocks API.
- Hugging Face와 함께 Gradio를 사용하는 방법에 대한 Hugging Face 과정 챕터.
- 에지 장치는 모바일 폰에만 국한되지 않고 라즈베리 파이와 같은 소형 컴퓨터를 포함하며, PyTorch 팀은 라즈베리 파이에 PyTorch 모델을 배포하는 것에 대한 훌륭한 블로그 게시물 튜토리얼을 제공합니다.
- AI 및 머신러닝 기반 애플리케이션 개발에 대한 훌륭한 가이드는 Google의 People + AI 가이드북을 참조하세요. 제가 가장 좋아하는 섹션 중 하나는 올바른 기대치 설정에 관한 섹션입니다.
- 저는 Machine Learning Monthly 2021년 4월호 (머신러닝 분야의 최신 소식을 담아 매달 보내드리는 뉴스레터)에서 Apple, Microsoft 등의 가이드를 포함하여 이러한 종류의 리소스를 더 많이 다루었습니다.
- CPU에서 모델 실행 속도를 높이고 싶다면, TorchScript, ONNX (Open Neural Network Exchange), OpenVINO에 대해 알아두어야 합니다. 순수 PyTorch 모델에서 ONNX/OpenVINO 모델로 전환하면 성능이 2배 이상 향상되는 것을 보았습니다.
- 모델을 배포 및 확장 가능한 API로 변환하려면 TorchServe 라이브러리를 참조하세요.
- 브라우저에서 머신러닝 모델을 배포하는 것(에지 배포의 한 형태)이 여러 가지 이점(네트워크 전송 지연 없음)을 제공하는 이유에 대한 훌륭한 예시와 근거는 Jo Kristian Bergum의 기사 Moving ML Inference from the Cloud to the Edge를 참조하세요.