# 업데이트된 API로 이 노트북을 실행하려면 torch 1.12+ 및 torchvision 0.13+가 필요합니다.
try:
import torch
import torchvision
assert int(torch.__version__.split(".")[1]) >= 12, "torch version should be 1.12+"
assert int(torchvision.__version__.split(".")[1]) >= 13, "torchvision version should be 0.13+"
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")
except:
print(f"[INFO] torch/torchvision 버전이 요구 사항을 충족하지 않음, nightly 버전을 설치합니다.")
!pip3 install -U --pre torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/nightly/cu113
import torch
import torchvision
print(f"torch version: {torch.__version__}")
print(f"torchvision version: {torchvision.__version__}")08 - PyTorch 논문 복제
![]()
TK 서론
ViT 논문 재현하기: “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” - https://arxiv.org/abs/2010.11929 - 본 노트북 전체에서 이를 “ViT 논문”으로 지칭합니다.
TK ViT란 무엇인가?
TK - Transformer라는 이름은 원래 도입된 논문인 Attention is all you need의 아키텍처 이름에서 유래되었습니다. 특정 패턴으로 어텐션 레이어를 사용하는 경우 일반적으로 트랜스포머 변형으로 간주됩니다. 원래 트랜스포머 아키텍처는 텍스트 데이터에 초점을 맞췄기 때문에 ViT 논문의 목표는 이를 비전 분야로 가져오는 것이었습니다.
TK - 원본 트랜스포머는 텍스트 시퀀스(1D)에서 작동하도록 만들어졌으며, Vision Transformer는 이미지를 “패치(patch)” 시퀀스로 변환합니다.
TK - 원본 ViT는 “바닐라 비전 트랜스포머(vanilla vision transformer)”라고도 불립니다.
TK - 논문 복제(Paper Replicating)란 무엇인가요?
머신러닝이 빠르게 발전하고 있다는 사실은 비밀이 아닙니다.
이러한 발전의 상당수는 머신러닝 연구 논문에 발표됩니다.
그리고 논문 복제의 목표는 이러한 발전을 코드로 재현하여 자신의 문제에 기술을 사용할 수 있도록 하는 것입니다.
예를 들어, 다양한 벤치마크에서 이전의 어떤 아키텍처보다 성능이 뛰어난 새로운 모델 아키텍처가 출시되었다고 가정해 봅시다. 해당 아키텍처를 여러분의 문제에 직접 시도해 보는 것이 좋지 않을까요?
- TK 이미지: 논문 복제 = 연구 논문 (언어 + 도표 + 수학) -> 코드 (언어, 도표, 수학을 사용 가능한 코드로 전환) / (연구 논문을 사용 가능한 코드로 번역)
TK - 머신러닝 연구 논문이란 무엇인가요?
머신러닝 연구 논문은 특정 분야에 대한 연구 그룹의 연구 결과를 상세히 기술한 과학 논문입니다.
머신러닝 연구 논문의 내용은 논문마다 다를 수 있지만 일반적으로 다음과 같은 구조를 따릅니다.
| 섹션 | 내용 |
|---|---|
| 초록 (Abstract) | 논문의 주요 결과/기여에 대한 개요/요약입니다. |
| 서론 (Introduction) | 논문의 주요 문제와 이를 해결하기 위해 사용된 이전 방법은 무엇인가요? |
| 방법 (Method) | 연구자들은 연구를 어떻게 수행했나요? 예를 들어, 어떤 모델이 사용되었는지, 데이터 소스, 훈련 설정 등입니다. |
| 결과 (Results) | 논문의 성과는 무엇인가요? 새로운 유형의 모델이나 훈련 설정이 사용된 경우, 연구 결과가 이전 작업과 어떻게 비교되었나요(여기에서 실험 추적이 유용합니다)? |
| 결론 (Conclusion) | 제안된 방법의 한계는 무엇인가요? 연구 커뮤니티를 위한 다음 단계는 무엇인가요? |
| 참고 문헌 (References) | 연구자들이 자신의 작업을 구축하기 위해 살펴본 리소스/다른 논문은 무엇인가요? |
| 부록 (Appendix) | 위의 섹션에 포함되지 않은 추가 리소스/결과가 있나요? |
TK - 머신러닝 연구 논문을 복제하는 이유는 무엇인가요?
머신러닝 연구 논문은 종종 세계 최고의 머신러닝 팀이 수행한 수개월 간의 작업과 실험을 몇 페이지의 텍스트로 압축하여 발표한 결과물입니다.
그리고 이러한 실험이 작업 중인 문제와 관련된 영역에서 더 나은 결과로 이어진다면, 이를 시도해 보는 것이 좋습니다.
또한 다른 사람의 작업을 재현하는 것은 기술을 연습할 수 있는 환상적인 방법입니다.

George Hotz는 자율 주행 자동차 회사인 comma.ai의 설립자이며 Twitch에서 머신러닝 코딩을 라이브 스트리밍하고 해당 동영상은 YouTube에 전체로 게시됩니다. 그의 라이브 스트림 중 하나에서 이 인용문을 가져왔습니다. “٭”는 머신러닝 엔지니어링에는 종종 데이터를 전처리하고 다른 사람이 사용할 수 있도록 모델을 제공하는 추가 단계(배포)가 포함된다는 점을 참고하기 위한 것입니다.
연구 논문 복제를 처음 시작할 때는 압도당할 가능성이 높습니다.
그것은 정상입니다.
연구 팀은 이러한 성과물을 만들기 위해 수주, 수개월, 때로는 수년을 소비하므로 연구 성과물을 재현하는 것은 고사하고 읽는 데도 어느 정도 시간이 걸리는 것은 당연합니다.
연구 복제는 매우 어려운 문제이기 때문에 HuggingFace, PyTorch Image Models (timm 라이브러리) 및 fast.ai와 같은 놀라운 머신러닝 라이브러리와 도구가 머신러닝 연구를 더 쉽게 접근할 수 있도록 탄생했습니다.
TK - 머신러닝 연구 논문에 대한 코드 예제는 어디에서 찾을 수 있나요?
머신러닝 연구와 관련하여 가장 먼저 눈에 띄는 것 중 하나는 연구 자료가 매우 많다는 것입니다.
따라서 최신 상태를 유지하려고 노력하는 것은 쳇바퀴를 돌리는 것과 같다는 점을 주의하세요.
관심을 따라가며 눈에 띄는 몇 가지를 선택하세요.
이와 관련하여 머신러닝 연구 논문을 찾고 읽을 수 있는 장소는 다음과 같습니다. * arXiv - “archive”라고 발음하는 arXiv는 물리학에서 컴퓨터 과학(머신러닝 포함)에 이르기까지 모든 분야의 기술 기사를 읽을 수 있는 무료 개방형 리소스입니다. * Papers with Code - 트렌드, 활발하고 위대한 머신러닝 논문을 엄선한 컬렉션으로, 대부분 코드 리소스가 포함되어 있습니다. 또한 일반적인 머신러닝 데이터셋, 벤치마크 및 현재 최첨단(state-of-the-art) 모델의 컬렉션도 포함되어 있습니다. * AK Twitter - AK Twitter 계정은 거의 매일 라이브 데모와 함께 머신러닝 연구 하이라이트를 게시합니다. 게시물의 9/10은 이해하지 못하지만 가끔씩 살펴보는 것이 재미있습니다. * lucidrains의 vit-pytorch GitHub 저장소 - 연구 논문을 찾는 곳이라기보다는 대규모 코드 복제 논문의 예시입니다. vit-pytorch 저장소는 PyTorch 코드로 재현된 다양한 연구 논문의 Vision Transformer 모델 아키텍처 컬렉션입니다(본 노트북의 많은 영감을 이 저장소에서 얻었습니다).
TK 이미지: 위 내용 전시
TK - 이 모듈에서 다룰 내용
할 일
- ViT -> FoodVision Mini
- 레이어(Layers) = 데이터를 조작하기 위한 함수의 컬렉션 -> 아키텍처(Architectures) = 레이어의 컬렉션 (블록) -> 모든 레이어(및 블록)에는 입력과 출력이 있음
- 연구 논문 복제는 레이어 -> 블록 -> 모델의 입력과 출력을 파악하는 것부터 시작됩니다.
TK - 도움을 받을 수 있는 곳
이 과정의 모든 자료는 GitHub에 있습니다.
문제가 발생하면 해당 페이지의 Discussions 페이지에서 질문할 수 있습니다.
또한 PyTorch와 관련된 모든 것에 대해 매우 도움이 되는 장소인 PyTorch 개발자 포럼과 PyTorch 문서도 있습니다.
TK 0. 설정하기
이전에 했던 것처럼 이 섹션에 필요한 모든 모듈이 있는지 확인해 보겠습니다.
05. PyTorch 모듈화에서 만든 Python 스크립트(data_setup.py 및 engine.py 등)를 활용하겠습니다.
이를 위해 pytorch-deep-learning 저장소에서 going_modular 디렉토리를 다운로드합니다(이미 가지고 있지 않은 경우).
또한 torchinfo 패키지가 없는 경우 가져옵니다.
torchinfo는 나중에 모델의 시각적 요약을 제공하는 데 도움이 됩니다.
그리고 나중에 torchvision 패키지의 최신 버전(2022년 6월 현재 v0.13)을 사용할 것이므로 최신 버전이 있는지 확인하겠습니다.
참고: Google Colab을 사용하는 경우 위 셀을 실행한 후 런타임을 다시 시작해야 할 수도 있습니다. 다시 시작한 후 셀을 다시 실행하고 올바른 버전의
torch및torchvision이 있는지 확인할 수 있습니다.
이제 일반적인 임포트, 장치 독립적(device agnostic) 코드 설정을 계속하고 이번에는 GitHub에서 helper_functions.py 스크립트도 가져오겠습니다.
helper_functions.py 스크립트에는 이전 섹션에서 만든 몇 가지 함수가 포함되어 있습니다. * set_seeds(): 무작위 시드 설정(07. PyTorch 실험 추적 섹션 0에서 생성). * download_data(): 링크가 주어지면 데이터 소스 다운로드(07. PyTorch 실험 추적 섹션 1에서 생성). * plot_loss_curves(): 모델의 훈련 결과 검사(04. PyTorch 사용자 정의 데이터셋 섹션 7.8에서 생성).
참고:
helper_functions.py스크립트의 많은 함수를going_modular/going_modular/utils.py로 병합하는 것이 더 좋은 아이디어일 수 있습니다. 그것이 여러분이 시도해 볼 수 있는 확장 작업일 것입니다.
# 일반적인 임포트 계속
import matplotlib.pyplot as plt
import torch
import torchvision
from torch import nn
from torchvision import transforms
# torchinfo 가져오기 시도, 실패 시 설치
try:
from torchinfo import summary
except:
print("[INFO] torchinfo를 찾을 수 없음... 설치합니다.")
!pip install -q torchinfo
from torchinfo import summary
# going_modular 디렉토리 임포트 시도, 실패 시 GitHub에서 다운로드
try:
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves
except:
# going_modular 스크립트 가져오기
print("[INFO] going_modular 또는 helper_functions 스크립트를 찾을 수 없음... GitHub에서 다운로드합니다.")
!git clone https://github.com/mrdbourke/pytorch-deep-learning
!mv pytorch-deep-learning/going_modular .
!mv pytorch-deep-learning/helper_functions.py . # helper_functions.py 스크립트 가져오기
!rm -rf pytorch-deep-learning
from going_modular.going_modular import data_setup, engine
from helper_functions import download_data, set_seeds, plot_loss_curves참고: Google Colab을 사용 중이고 아직 GPU를 켜지 않았다면 지금
런타임 -> 런타임 유형 변경 -> 하드웨어 가속기 -> GPU를 통해 켤 시간입니다.
device = "cuda" if torch.cuda.is_available() else "cpu"
deviceTK 1. 데이터 가져오기
FoodVision Mini를 계속 진행하고 있으므로 사용해 온 피자, 스테이크, 초밥 이미지 데이터셋을 다운로드해 보겠습니다.
이를 위해 07. PyTorch 실험 추적 섹션 1에서 만든 helper_functions.py의 download_data() 함수를 사용할 수 있습니다.
pizza_steak_sushi.zip 데이터의 raw GitHub 링크를 source로, destination을 pizza_steak_sushi로 설정합니다.
# GitHub에서 피자, 스테이크, 초밥 이미지 다운로드
image_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
image_path좋습니다! 데이터가 다운로드되었습니다. 훈련 및 테스트 디렉토리를 설정하겠습니다.
# 훈련 및 테스트 이미지 디렉토리 경로 설정
train_dir = image_path / "train"
test_dir = image_path / "test"TK 2. Dataset 및 DataLoader 만들기
데이터가 있으므로 이제 DataLoader로 변환해 보겠습니다.
이를 위해 data_setup.py의 create_dataloaders() 함수를 사용할 수 있습니다.
먼저 이미지를 준비하기 위한 트랜스폼(transform)을 만들겠습니다.
여기서 ViT 논문에 대한 첫 번째 참조 중 하나가 나타납니다.
표 3에서 훈련 해상도는 224(높이=224, 너비=224)로 언급되어 있습니다.
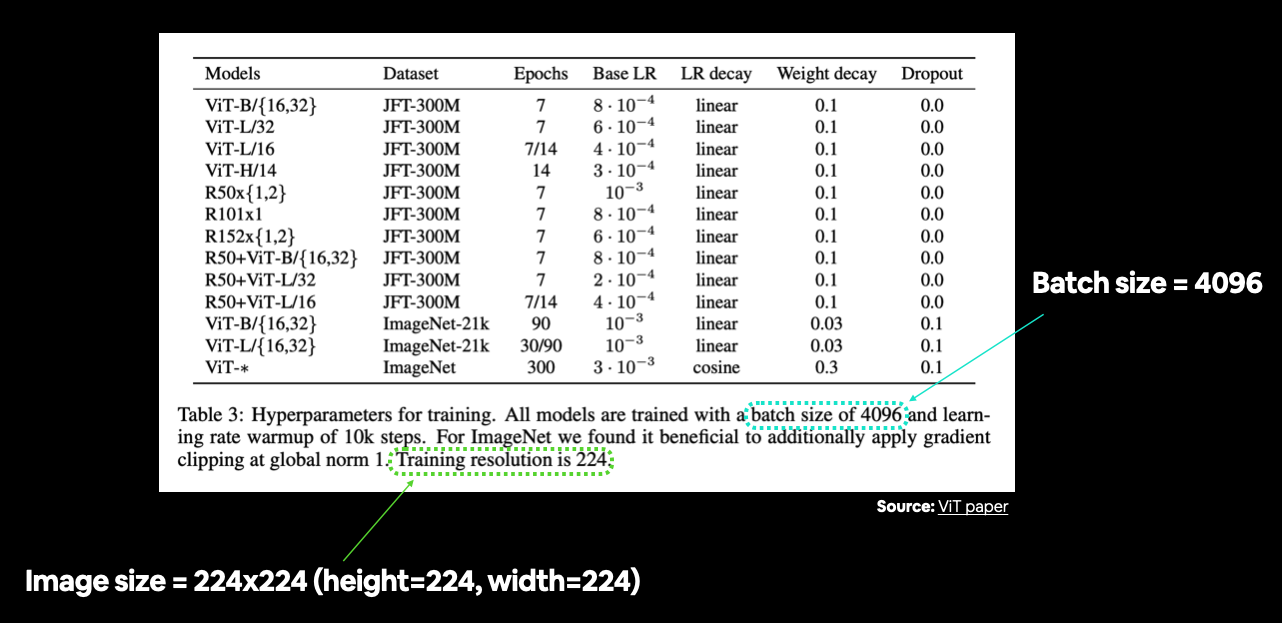
테이블에서 나열된 다양한 하이퍼파라미터 설정을 종종 찾을 수 있습니다. 이 경우 우리는 여전히 데이터를 준비하고 있으므로 주로 이미지 크기 및 배치 크기와 같은 사항에 관심이 있습니다. 출처: ViT 논문의 표 3.
따라서 트랜스폼이 이미지 크기를 적절하게 조정하도록 합니다.
그리고 처음부터 모델을 훈련할 것이므로(처음에는 전이 학습 없음), 06. PyTorch 전이 학습 섹션 2.1에서 했던 것처럼 normalize 트랜스폼을 제공하지 않겠습니다.
2.1 이미지 트랜스폼 준비
# 이미지 크기 생성 (ViT 논문의 표 3에서 가져옴)
IMG_SIZE = 224
# 트랜스폼 파이프라인 수동 생성
manual_transforms = transforms.Compose([
"transforms.Resize((IMG_SIZE, IMG_SIZE)),\n",
"transforms.ToTensor(),\n",
])"2.2 이미지를 DataLoader로 변환
트랜스폼이 생성되었습니다!
이제 DataLoader를 만들어 보겠습니다.
ViT 논문에서는 배치 크기 4096을 사용한다고 명시되어 있는데, 이는 우리가 사용해 온 배치 크기(32)의 128배입니다.
우리는 배치 크기 32를 유지할 것입니다.
왜 그럴까요?
일부 하드웨어(Google Colab의 무료 티어 포함)는 배치 크기 4096을 처리하지 못할 수도 있기 때문입니다.
배치 크기가 4096이라는 것은 한 번에 4096개의 이미지가 GPU 메모리에 들어갈 수 있어야 함을 의미합니다.
이는 Google의 연구 팀처럼 하드웨어를 갖춘 경우에 작동하지만, 단일 GPU(예: Google Colab 사용)에서 실행하는 경우 먼저 더 작은 배치 크기로 작동하는지 확인하는 것이 좋습니다.
더 높은 배치 크기 값을 시도해 보고 어떤 일이 일어나는지 확인하는 것이 이 프로젝트의 확장이 될 수 있습니다.
참고: 계산 속도를 높이기 위해
create_dataloaders()함수에서pin_memory=True매개변수를 사용하고 있습니다.pin_memory=True는 이전에 본 예제를 “고정(pinning)”하여 CPU와 GPU 메모리 간의 불필요한 메모리 복사를 방지합니다. 이에 대한 더 자세한 내용은 PyTorchtorch.utils.data.DataLoader문서 또는 Horace He의 Making Deep Learning Go Brrrr from First Principles를 참조하세요. 비록 이 기능의 이점은 더 큰 데이터셋 크기에서 나타날 가능성이 높지만(우리의 FoodVision Mini 데이터셋은 매우 작음) 말이죠.
# 배치 크기 설정
BATCH_SIZE = 32 # ViT 논문보다 낮지만 작게 시작하기 때문입니다.
# 데이터 로더 생성
train_dataloader, test_dataloader, class_names = data_setup.create_dataloaders(
train_dir=train_dir,
test_dir=test_dir,
transform=manual_transforms, # 수동으로 생성한 트랜스폼 사용
batch_size=BATCH_SIZE
)
train_dataloader, test_dataloader, class_namesTK 2.3 단일 이미지 시각화
이제 데이터를 로드했으므로 시각화, 시각화, 시각화! 해보겠습니다.
ViT 논문에서 중요한 단계는 이미지를 패치(patch)로 준비하는 것입니다.
이게 무엇을 의미하는지는 곧 살펴보겠지만, 지금은 단일 이미지와 그 레이블을 보겠습니다.
이를 위해 데이터 배치에서 단일 이미지와 레이블을 가져와 모양을 확인해 보겠습니다.
# 이미지 배치 가져오기
image_batch, label_batch = next(iter(train_dataloader))
# 배치에서 단일 이미지 가져오기
image, label = image_batch[0], label_batch[0]
# 배치 모양 확인
image.shape, label좋습니다!
이제 matplotlib을 사용하여 이미지와 레이블을 그려보겠습니다.
# matplotlib을 사용하여 이미지 그리기
plt.imshow(image.permute(1, 2, 0)) # matplotlib에 맞게 이미지 차원 재배열 [색상_채널, 높이, 너비] -> [높이, 너비, 색상_채널]
plt.title(class_names[label])
plt.axis(False);좋네요!
이미지가 올바르게 임포트된 것 같습니다. 논문 재현을 계속해 보겠습니다.
TK 3. ViT 논문 재현: 개요
더 많은 코드를 작성하기 전에 우리가 무엇을 하고 있는지 논의해 보겠습니다.
자체 문제인 FoodVision Mini를 위해 ViT 논문을 재현하고자 합니다.
따라서 입력은 피자, 스테이크, 초밥 이미지입니다.
그리고 이상적인 모델 출력은 피자, 스테이크, 초밥의 예측 레이블입니다.
이전 섹션에서 해왔던 것과 다르지 않습니다.
문제는 입력에서 원하는 출력으로 어떻게 이동하느냐입니다.
3.1 입력 및 출력, 레이어 및 블록
ViT는 딥러닝 신경망 아키텍처입니다.
모든 신경망 아키텍처는 일반적으로 레이어(layers)로 구성됩니다.
그리고 레이어의 컬렉션을 종종 블록(block)이라고 합니다.
그리고 많은 블록을 쌓는 것이 전체 아키텍처를 제공하는 것입니다.
레이어는 입력(예: 이미지 텐서)을 가져와서 어떤 종류의 기능을 수행한(예: 레이어의 forward() 메서드에 있는 내용) 다음 출력을 반환합니다.
따라서 단일 레이어가 입력을 받고 출력을 제공한다면, 레이어의 컬렉션 또는 블록도 입력을 받고 출력을 제공합니다.
이를 구체화해 보겠습니다. * 레이어 - 입력을 받고 함수를 수행하며 출력을 반환합니다. * 블록 - 레이어의 컬렉션으로, 입력을 받고 일련의 함수를 수행하며 출력을 반환합니다. * 아키텍처 (또는 모델) - 블록의 컬렉션으로, 입력을 받고 일련의 함수를 수행하며 출력을 반환합니다.
이 이념은 우리가 ViT 논문을 재현하기 위해 사용할 내용입니다.
레이어별로, 블록별로, 함수별로 퍼즐 조각을 레고처럼 맞춰서 원하는 전체 아키텍처를 얻을 것입니다.
이렇게 하는 이유는 전체 연구 논문을 한꺼번에 보는 것이 위협적일 수 있기 때문입니다.
따라서 더 나은 이해를 위해 단일 레이어의 입력과 출력부터 시작하여 전체 모델의 입력과 출력까지 단계적으로 구축해 나갈 것입니다.
TK 이미지: 레고처럼 네트워크 쌓기 (함수 + 레이어 + 블록 = 모델).
3.2 구체적으로 살펴보기: ViT는 무엇으로 구성되어 있나요?
논문 곳곳에는 ViT 모델에 대한 많은 세부 정보가 흩어져 있습니다.
그것들을 모두 찾는 것은 마치 하나의 큰 보물 찾기와 같습니다!
연구 논문은 종종 수개월 간의 작업을 몇 페이지로 압축한 것이므로 재현하는 데 연습이 필요한 것은 당연하다는 점을 기억하세요.
하지만 아키텍처 설계를 위해 살펴볼 주요 세 가지 리소스는 다음과 같습니다. 1. 그림 1 - 그래픽적인 의미에서 모델의 개요를 보여주며, 이 그림만으로도 아키텍처를 거의 재현할 수 있습니다. 2. 섹션 3.1의 네 가지 방정식 - 이 방정식은 그림 1의 색칠된 블록에 좀 더 수학적인 토대를 제공합니다. 3. 표 1 - 이 표는 다양한 ViT 모델 변형에 대한 다양한 하이퍼파라미터 설정(예: 레이어 수 및 은닉 유닛 수)을 보여줍니다. 우리는 가장 작은 버전인 ViT-Base에 집중할 것입니다.
TK 3.2.1 그림 1 살펴보기
ViT 논문의 그림 1을 살펴보는 것부터 시작하겠습니다.
주로 주의를 기울여야 할 사항은 다음과 같습니다. 1. 레이어 (Layers) - 입력을 받고 연산이나 함수를 수행하며 출력을 생성합니다. 2. 블록 (Blocks) - 레이어의 컬렉션이며, 역시 입력을 받고 출력을 생성합니다.
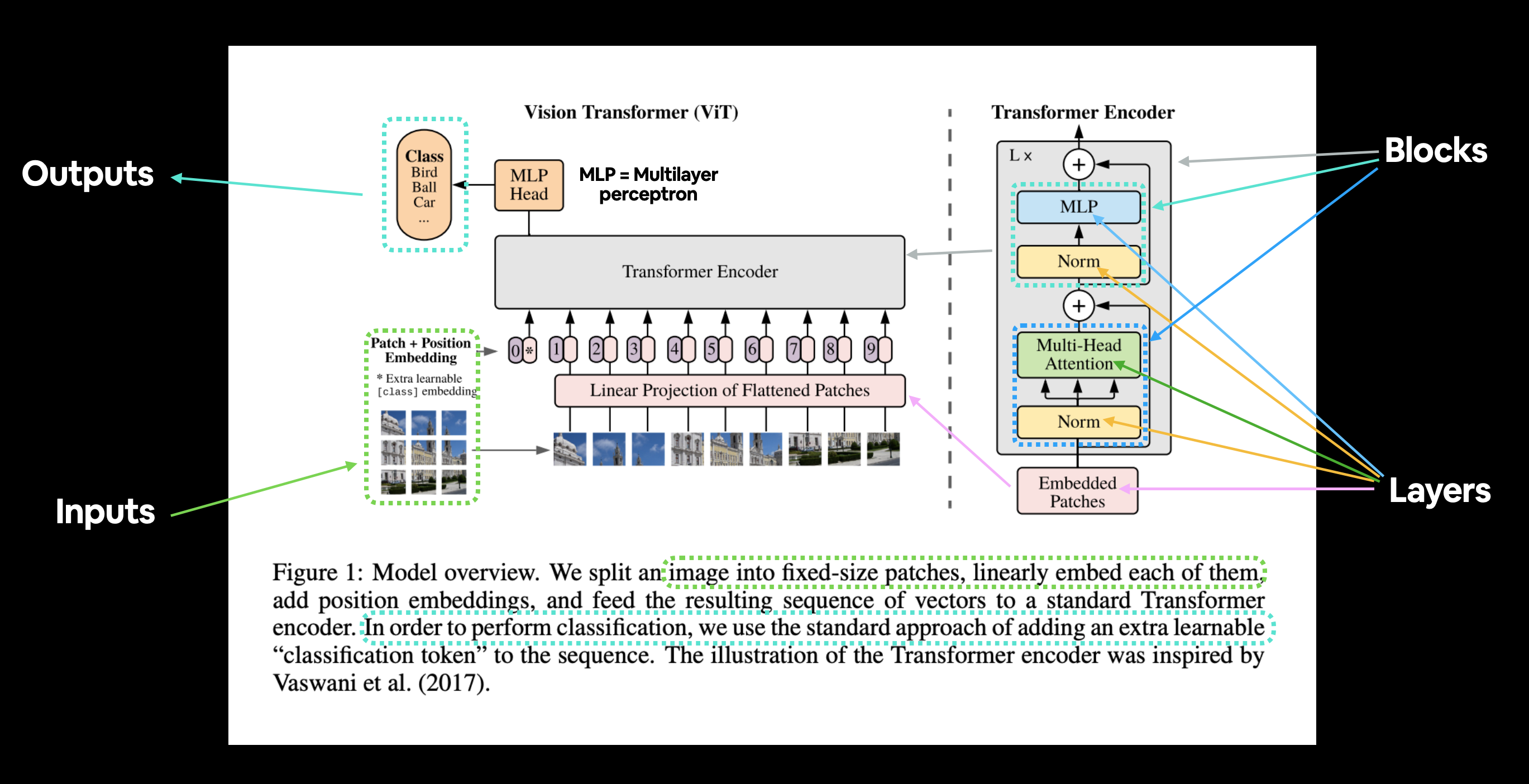
아키텍처를 구성하는 다양한 입력, 출력, 레이어 및 블록을 보여주는 ViT 논문의 그림 1. 우리의 목표는 PyTorch 코드를 사용하여 이들 각각을 재현하는 것입니다.
ViT 아키텍처는 여러 단계로 구성됩니다. * 패치 + 위치 임베딩 (Patch + Position Embedding, 입력) - 입력 이미지를 이미지 패치 시퀀스로 변환하고 패치가 나오는 순서인 위치 번호를 추가합니다. * 평탄화된 패치의 선형 투영 (Linear projection of flattened patches, 임베딩된 패치) - 이미지 패치는 임베딩으로 변환되는데, 이미지 값만 사용하는 대신 임베딩을 사용하는 이점은 임베딩이 훈련을 통해 개선될 수 있는 이미지의 학습 가능한 표현(일반적으로 벡터 형태)이라는 점입니다. * 노름 (Norm) - “레이어 정규화(Layer Normalization)” 또는 “LayerNorm”의 약자로, 신경망을 규제(오버피팅 감소)하기 위한 기술입니다. PyTorch 레이어 torch.nn.LayerNorm()을 통해 LayerNorm을 사용할 수 있습니다. * 멀티헤드 어텐션 (Multi-Head Attention) - 이것은 멀티헤드 셀프 어텐션 레이어(Multi-Headed Self-Attention layer) 또는 줄여서 “MSA”입니다. PyTorch 레이어 torch.nn.MultiheadAttention()을 통해 MSA 레이어를 만들 수 있습니다. * MLP (또는 [다층 퍼셉트론(Multilayer perceptron)]) - MLP는 종종 피드포워드 레이어의 모든 컬렉션(또는 PyTorch의 경우 forward() 메서드가 있는 레이어 컬렉션)을 의미할 수 있습니다. ViT 논문에서 저자는 MLP를 “MLP 블록”이라고 지칭하며, 여기에는 두 개의 torch.nn.Linear() 레이어와 그 사이에 torch.nn.GELU() 비선형 활성화 함수가 포함되어 있으며(섹션 3.1), 각 레이어 뒤에 torch.nn.Dropout() 레이어가 있습니다(부록 B.1). * 트랜스포머 인코더 (Transformer Encoder) - 트랜스포머 인코더는 위에 나열된 레이어들의 컬렉션입니다. 트랜스포머 인코더 내부에는 두 개의 스킵 연결(“+” 기호)이 있는데, 이는 레이어의 입력이 즉각적인 레이어뿐만 아니라 후속 레이어에도 직접 공급됨을 의미합니다. 전체 ViT 아키텍처는 서로 쌓인 다수의 트랜스포머 인코더로 구성됩니다. * MLP 헤드 (MLP Head) - 아키텍처의 출력 레이어로, 입력의 학습된 특성을 클래스 출력으로 변환합니다. 이미지 분류 작업을 수행하고 있으므로 이를 “분류 헤드(classifier head)”라고 부를 수도 있습니다. MLP 헤드의 구조는 MLP 블록과 유사합니다.
ViT 아키텍처의 많은 부분이 기존 PyTorch 레이어로 생성될 수 있음을 알 수 있습니다.
이는 PyTorch가 연구자와 머신러닝 실무자 모두를 위해 재사용 가능한 신경망 레이어를 만들도록 설계되었기 때문입니다.
질문: 왜 모든 것을 처음부터 코딩하지 않나요?
논문의 모든 수학 방정식을 사용자 정의 PyTorch 레이어로 재현하여 확실히 그렇게 할 수도 있고, 그것은 분명 교육적인 연습이 될 것이지만, 기존 PyTorch 레이어를 사용하는 것이 일반적으로 선호됩니다. 기존 레이어는 종종 올바르고 빠르게 실행되는지 확인하기 위해 광범위하게 테스트되고 성능이 점검되었기 때문입니다.
참고: 우리는 이러한 레이어를 만들기 위한 PyTorch 코드를 작성하는 데 집중할 것이며, 각 레이어가 무엇을 하는지에 대한 배경 지식은 ViT 논문을 전체적으로 읽거나 각 레이어에 대해 링크된 리소스를 읽는 것을 권장합니다.
그림 1을 가져와서 이미지를 피자, 스테이크 또는 초밥으로 분류하는 FoodVision Mini 문제에 맞게 조정해 보겠습니다.
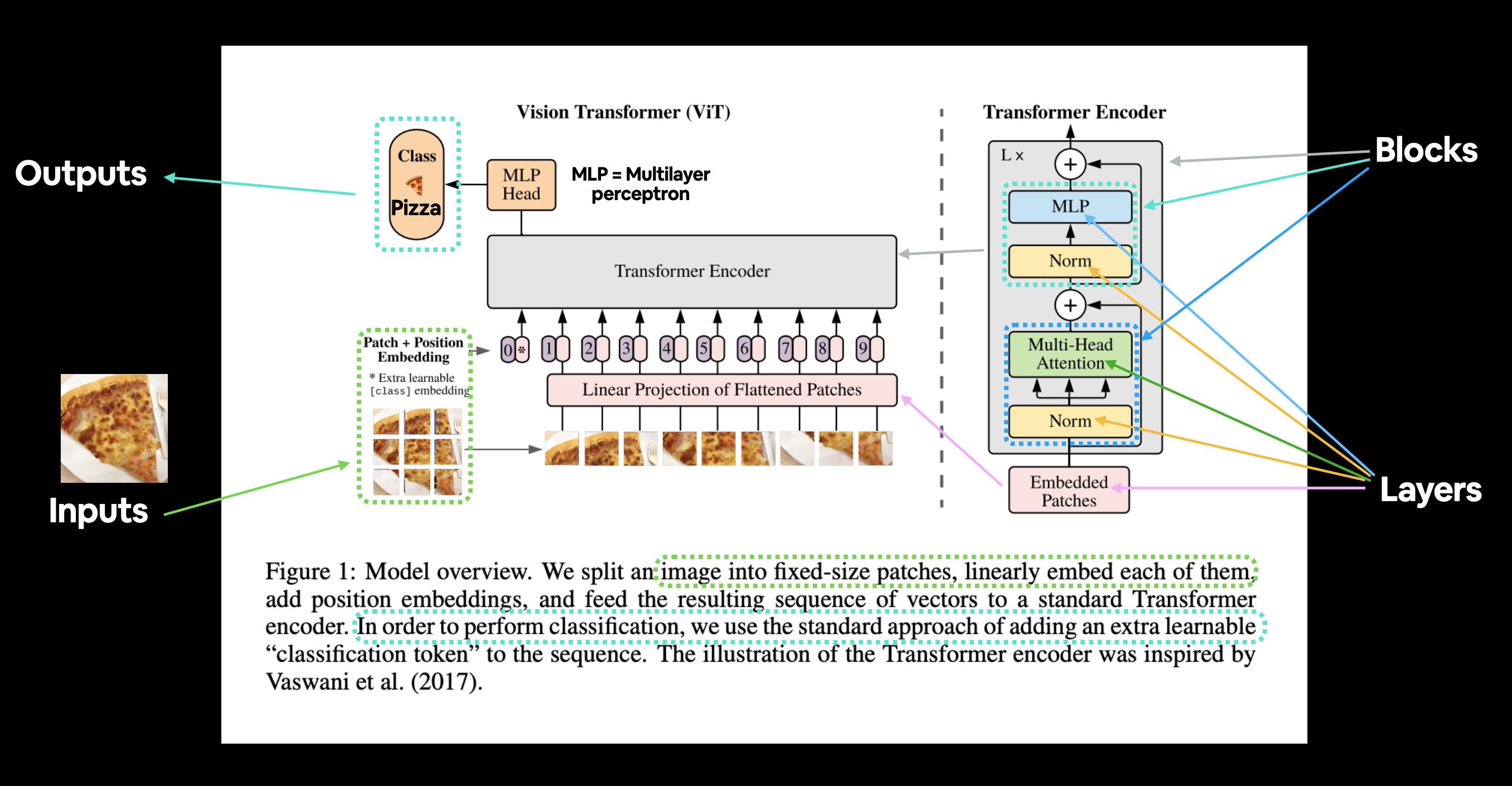
FoodVision Mini를 위해 조정된 ViT 논문의 그림 1. 음식 이미지(피자)가 들어가고 이미지는 패치로 변환된 다음 임베딩으로 투영됩니다. 임베딩은 다양한 레이어와 블록을 통과하고 (바라건대) 클래스 “피자”가 반환됩니다.
TK - 3.2.2 네 가지 방정식 살펴보기
다음으로 살펴볼 ViT 논문의 주요 부분은 섹션 3.1의 네 가지 방정식입니다.
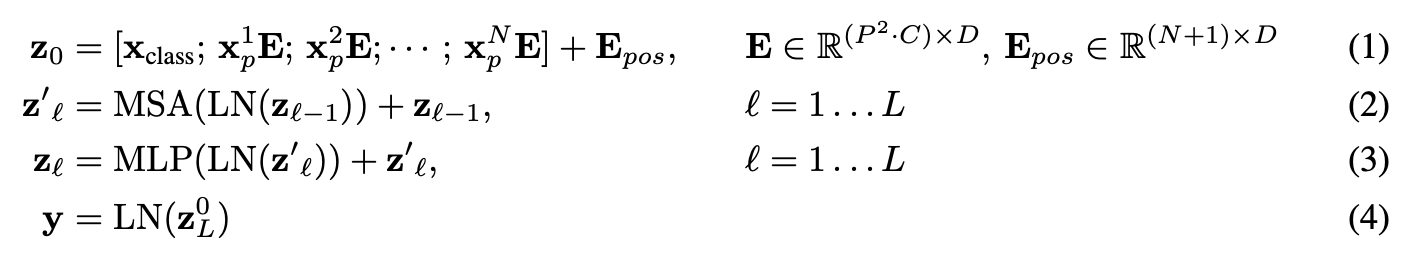
이 네 가지 방정식은 ViT 아키텍처의 네 가지 주요 부분 뒤에 있는 수학을 나타냅니다.
섹션 3.1에서 각각에 대해 설명합니다(간결함을 위해 일부 텍스트는 생략되었으며 굵은 글씨는 강조를 위한 것입니다).
| 방정식 번호 | ViT 논문 섹션 3.1의 설명 |
|---|---|
| 1 | …트랜스포머는 모든 레이어에서 일정한 잠재 벡터 크기 \(D\)를 사용하므로, 패치를 평탄화하고 훈련 가능한 선형 투영을 사용하여 \(D\) 차원으로 매핑합니다(식 1). 이 투영의 출력을 패치 임베딩이라고 합니다. |
| 2 | 트랜스포머 인코더(Vaswani et al., 2017)는 교대로 나타나는 멀티헤드 셀프 어텐션(MSA, 부록 A 참조) 및 MLP 블록 레이어로 구성됩니다(식 2, 3). 모든 블록 이전에 레이어 노름(LN)이 적용되고, 모든 블록 이후에 잔차 연결(residual connections)이 적용됩니다(Wang et al., 2019; Baevski & Auli, 2019). |
| 3 | 위와 동일합니다. |
| 4 | BERT의 [ class ] 토큰과 유사하게, 임베딩된 패치 시퀀스 앞에 학습 가능한 임베딩을 추가하며 \(\left(\mathbf{z}_{0}^{0}=\mathbf{x}_{\text {class }}\right)\), 트랜스포머 인코더 출력에서의 상태 \(\left(\mathbf{z}_{L}^{0}\right)\)는 이미지 표현 \(\mathbf{y}\) 역할을 합니다(식 4)… |
이러한 설명을 그림 1의 ViT 아키텍처에 매핑해 보겠습니다.
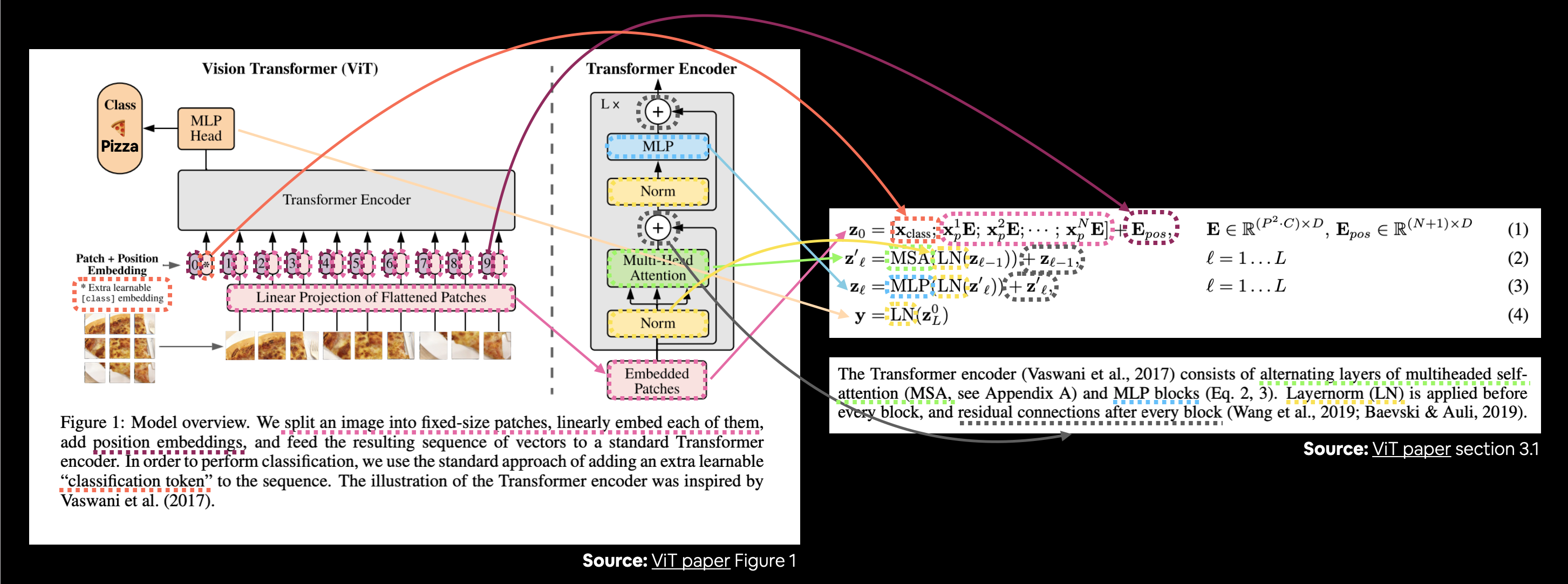
그림 1의 ViT 아키텍처를 레이어/블록 뒤의 수학을 설명하는 섹션 3.1의 네 가지 방정식에 연결합니다. “모든 블록 뒤의 잔차 연결”과 같은 일부 세부 사항은 그림 1과 텍스트에는 언급되어 있지만 방정식에는 언급되어 있지 않습니다.
위 이미지에는 많은 일이 일어나고 있지만 색칠된 선과 화살표를 따라가면 ViT 아키텍처의 주요 개념이 드러납니다.
각 방정식을 더 자세히 분석해 보는 건 어떨까요(이것들을 코드로 재현하는 것이 우리의 목표가 될 것입니다)?
모든 방정식(방정식 4 제외)에서 “\(\mathbf{z}\)”는 특정 레이어의 원시 출력입니다.
- \(\mathbf{z}_{0}\)은 “z zero”입니다 (이는 초기 패치 임베딩 레이어의 출력입니다).
- \(\mathbf{z}_{\ell}^{\prime}\)는 “특정 레이어 prime의 z”입니다 (또는 z의 중간 값).
- \(\mathbf{z}_{\ell}\)은 “특정 레이어의 z”입니다.
그리고 \(\mathbf{y}\)는 아키텍처의 전체 출력입니다.
방정식 1
\[ \begin{aligned} \mathbf{z}_{0} &=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{\text {pos }}, & & \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{\text {pos }} \in \mathbb{R}^{(N+1) \times D} \end{aligned} \]
이 방정식은 입력 이미지의 클래스 토큰, 패치 임베딩 및 위치 임베딩(\(\mathbf{E}\)는 임베딩을 의미함)을 다룹니다.
벡터 형식에서 임베딩은 다음과 같이 보일 수 있습니다.
TK - 벡터 형식을 업데이트하여 실제 사례를 반영하세요.
x_input = [class_token, image_patch_1, image_patch_2, image_patch_3...] + [class_token_position, image_patch_1_position, image_patch_2_position, image_patch_3_position...]여기서 벡터의 각 요소는 학습 가능합니다(requires_grad=True).
방정식 2
\[ \begin{aligned} \mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right)+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \end{aligned} \]
이는 레이어 1부터 \(L\)(총 레이어 수)까지 모든 레이어에 대해 LayerNorm(LN) 레이어를 래핑하는 MSA(Multi-Head Attention) 레이어가 있음을 나타냅니다.
끝부분의 덧셈은 입력을 출력에 더하고 스킵/잔차 연결(skip/residual connection)을 형성하는 것과 같습니다.
이 레이어를 “MSA 블록”이라고 부르겠습니다.
의사코드(pseudocode)로는 다음과 같을 수 있습니다.
x_output_MSA_block = MSA_layer(LN_layer(x_input)) + x_input끝부분의 스킵 연결(레이어의 출력을 레이어의 입력에 더함)에 주의하세요.
방정식 3
\[ \begin{aligned} \mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+\mathbf{z}_{\ell}^{\prime}, & & \ell=1 \ldots L \\ \end{aligned} \]
이는 레이어 1부터 \(L\)(총 레이어 수)까지 모든 레이어에 대해 LayerNorm(LN) 레이어를 래핑하는 다층 퍼셉트론(MLP) 레이어도 있음을 나타냅니다.
끝부분의 덧셈은 잔차 연결의 존재를 보여줍니다.
이 레이어를 “MLP 블록”이라고 부르겠습니다.
의사코드로는 다음과 같을 수 있습니다.
x_output_MLP_block = MLP_layer(LN_layer(x_output_MSA_block)) + x_output_MSA_block끝부분의 스킵 연결(레이어의 출력을 레이어의 입력에 더함)에 주의하세요.
방정식 4
\[ \begin{aligned} \mathbf{y} &=\operatorname{LN}\left(\mathbf{z}_{L}^{0}\right) & & \end{aligned} \]
이는 마지막 레이어 \(L\)에 대해 출력 \(y\)가 LayerNorm(LN) 레이어에 래핑된 \(z\)의 0번 인덱스 토큰임을 의미합니다.
우리의 경우 x_output_MLP_block의 0번 인덱스입니다.
y = LN_layer(Linear_layer(x_output_MLP_block[0]))물론 위에는 약간의 단순화가 있지만 각 섹션에 대한 PyTorch 코드를 작성하기 시작할 때 이를 처리할 것입니다.
참고: 위 섹션은 많은 정보를 다룹니다. 하지만 이해가 되지 않는 부분이 있다면 항상 더 자세히 조사할 수 있다는 점을 잊지 마세요. “잔차 연결이란 무엇인가?”와 같은 질문을 던지면서 말이죠.
TK - 3.2.3 표 1 살펴보기
ViT 아키텍처 퍼즐의 마지막 조각(현재로서는)은 표 1입니다.
| 모델 | 레이어 (Layers) | 은닉 크기 (Hidden size) \(D\) | MLP 크기 | 헤드 (Heads) | 파라미터 (Params) |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | \(86M\) |
| ViT-Large | 24 | 1024 | 4096 | 16 | \(307M\) |
| ViT-Huge | 32 | 1280 | 5120 | 16 | \(632M\) |
<i>표 1: Vision Transformer 모델 변형의 세부 정보. 출처: <a href="https://arxiv.org/abs/2010.11929">ViT 논문</a>.</i>이 표는 각 ViT 아키텍처의 다양한 하이퍼파라미터를 보여줍니다.
숫자가 ViT-Base에서 ViT-Huge로 갈수록 점진적으로 증가하는 것을 볼 수 있습니다.
우리는 ViT-Base를 재현하는 데 집중할 것이지만(작게 시작하여 필요할 때 확장), 더 큰 변형으로 쉽게 확장될 수 있는 코드를 작성할 것입니다.
하이퍼파라미터를 분석해 보면 다음과 같습니다. * 레이어 (Layers) - 트랜스포머 인코더 블록이 몇 개 있나요? (이들 각각에는 MSA 블록과 MLP 블록이 포함됩니다) * 은닉 크기 (Hidden size) \(D\) - 이는 아키텍처 전체의 임베딩 차원으로, 이미지가 패치되고 임베딩될 때 이미지가 변환되는 벡터의 크기가 됩니다. 일반적으로 임베딩 차원이 클수록 더 많은 정보를 캡처할 수 있고 결과가 더 좋아집니다. 그러나 큰 임베딩은 더 많은 계산 비용을 수반합니다. * MLP 크기 - MLP 레이어의 은닉 유닛 수는 얼마인가요? * 헤드 (Heads) - Multi-Head Attention 레이어에는 헤드가 몇 개 있나요? * 파라미터 (Params) - 모델의 총 파라미터 수는 얼마인가요? 일반적으로 파라미터가 많을수록 성능이 좋아지지만 계산 비용이 더 많이 듭니다. ViT-Base조차 이전에 사용했던 다른 어떤 모델보다 파라미터가 훨씬 많다는 것을 알 수 있습니다.
이러한 값을 ViT 아키텍처의 하이퍼파라미터 설정으로 사용하겠습니다.
TK - 3.3 논문 재현을 위한 나의 워크플로우
논문 재현 작업을 시작할 때 나는 다음과 같은 단계를 거칩니다.
- 전체 논문을 처음부터 끝까지 한 번 읽습니다 (주요 개념을 파악하기 위해).
- 각 섹션을 다시 살펴보며 서로 어떻게 연결되는지 확인하고 이를 코드로 변환하는 방법을 생각하기 시작합니다 (위에서 했던 것처럼).
- 꽤 좋은 개요를 얻을 때까지 2단계를 반복합니다.
- mathpix.com (매우 유용한 도구)을 사용하여 논문의 모든 섹션을 노트북에 넣을 마크다운/LaTeX로 변환합니다.
- 가능한 한 가장 단순한 버전의 모델을 재현합니다.
- 막히면 다른 예시를 찾아봅니다.
TK - mathpix의 gif
우리는 이미 위의 처음 몇 단계를 거쳤으며(아직 전체 논문을 읽지 않았다면 한 번 읽어보시길 권장합니다), 다음으로 집중할 것은 5단계인 가능한 한 가장 단순한 버전의 모델을 재현하는 것입니다.
이것이 우리가 ViT-Base부터 시작하는 이유입니다.
가장 작은 버전의 아키텍처를 재현하고 작동시킨 다음 원한다면 확장할 수 있습니다.
참고: 이전에 연구 논문을 읽어본 적이 없다면 위의 많은 단계가 위협적일 수 있습니다. 하지만 다른 것과 마찬가지로 논문을 읽고 재현하는 기술도 연습을 통해 향상될 것입니다. 연구 논문은 종종 여러 사람의 수개월 간의 작업을 몇 페이지로 압축한 결과물이라는 점을 잊지 마세요. 따라서 혼자서 이를 재현하려고 노력하는 것은 결코 작은 성과가 아닙니다.
TK 4. 방정식 1: 데이터를 패치로 분할하고 클래스, 위치 및 패치 임베딩 생성
내 머신러닝 엔지니어 친구 중 한 명이 “모든 것은 임베딩에 달려 있다”고 말하곤 했던 것이 기억납니다.
임베딩은 학습 가능한 표현이므로 데이터를 좋고 학습 가능한 방식으로 표현할 수 있다면 학습 알고리즘이 해당 데이터에서 좋은 성능을 낼 가능성이 높다는 뜻입니다.
따라서 이를 바탕으로 ViT 아키텍처를 위한 클래스, 위치 및 패치 임베딩을 만들어 보겠습니다.
패치 임베딩부터 시작하겠습니다.
이는 입력 이미지를 패치 시퀀스로 변환한 다음 해당 패치를 임베딩하는 것을 의미합니다.
임베딩은 어떤 형태의 학습 가능한 표현이며 종종 벡터라는 점을 기억하세요. 학습 가능하다는 용어는 입력 이미지의 표현이 시간이 지남에 따라 개선되고 학습될 수 있음을 의미하기 때문에 중요합니다.
ViT 논문의 섹션 3.1 첫 번째 단락을 따르는 것으로 시작해 보겠습니다(굵은 글씨는 강조를 위한 것입니다).
표준 트랜스포머는 토큰 임베딩의 1D 시퀀스를 입력으로 받습니다. 2D 이미지를 처리하기 위해 이미지 \(\mathbf{x} \in \mathbb{R}^{H \times W \times C}\)를 평탄화된 2D 패치 시퀀스 \(\mathbf{x}_{p} \in \mathbb{R}^{N \times\left(P^{2} \cdot C\right)}\)로 재구성합니다. 여기서 \((H, W)\)는 원본 이미지의 해상도이고, \(C\)는 채널 수이며, \((P, P)\)는 각 이미지 패치의 해상도이고, \(N=H W / P^{2}\)는 결과 패치 수이며 트랜스포머의 유효 입력 시퀀스 길이 역할도 합니다. 트랜스포머는 모든 레이어에서 일정한 잠재 벡터 크기 \(D\)를 사용하므로, 패치를 평탄화하고 학습 가능한 선형 투영(식 1)을 사용하여 \(D\) 차원으로 매핑합니다. 이 투영의 출력을 패치 임베딩이라고 합니다.
그리고 이미지 모양을 다루고 있으므로 ViT 논문 표 3의 한 줄을 명심합시다.
훈련 해상도는 224입니다.
위의 텍스트를 분석해 보겠습니다.
- \(D\)는 패치 임베딩의 크기이며, \(D\)에 대한 다양한 값은 표 1에서 찾을 수 있습니다.
- 이미지는 크기가 \({H \times W \times C}\)인 2D로 시작합니다.
- 이미지는 크기가 \({N \times\left(P^{2} \cdot C\right)}\)인 평탄화된 2D 패치 시퀀스로 변환됩니다.
- \((H, W)\)는 원본 이미지의 해상도입니다.
- \(C\)는 채널 수입니다.
- \((P, P)\)는 각 이미지 패치의 해상도(패치 크기)입니다.
- \(N=H W / P^{2}\)는 결과 패치 수이며, 트랜스포머의 유효 입력 시퀀스 길이 역할도 합니다.
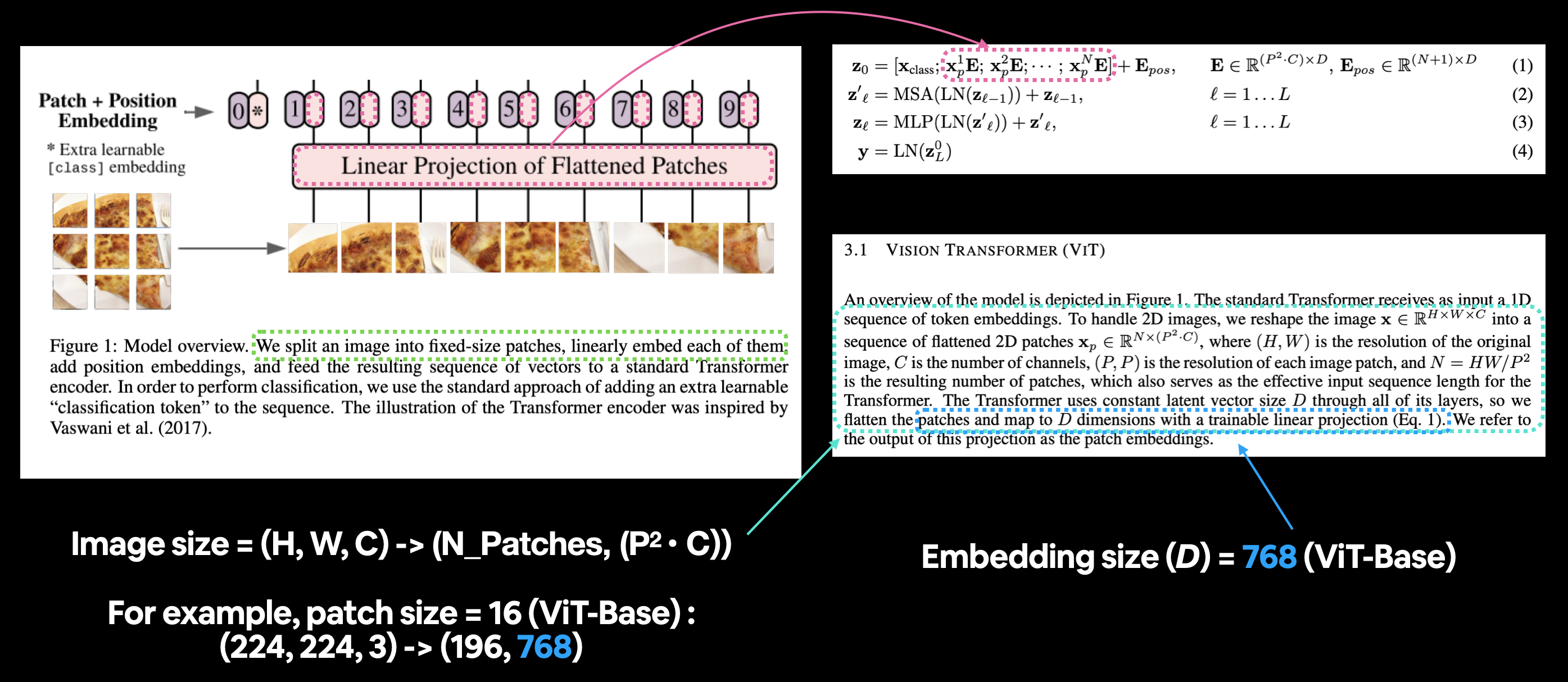
그림 1의 ViT 아키텍처 패치 및 위치 임베딩 부분을 방정식 1에 매핑합니다. 섹션 3.1의 도입 단락에서는 패치 임베딩 레이어의 다양한 입력 및 출력 모양을 설명합니다.
TK - 4.1 패치 임베딩 입력 및 출력 모양 수동 계산
이러한 입력 및 출력 모양 값을 수동으로 계산하는 것부터 시작해 보는 건 어떨까요?
그렇게 하기 위해 위의 각 용어(\(H\), \(W\) 등)를 모방하는 몇 가지 변수를 만들어 보겠습니다.
패치 크기(\(P\))는 ViT-Base가 사용하는 가장 성능이 좋은 버전인 16을 사용하겠습니다(자세한 내용은 ViT 논문의 표 5에서 “ViT-B/16” 열 참조).
# 예시 값 생성
height = 224 # H ("훈련 해상도는 224입니다.")
width = 224 # W
color_channels = 3 # C
patch_size = 16 # P
# N (패치 수) 계산
number_of_patches = int((height * width) / patch_size**2)
print(f"이미지 높이(H={height}), 너비(W={width}) 및 패치 크기(P={patch_size})인 경우 패치 수(N): {number_of_patches}")패치 수를 구했습니다. 이미지 출력 크기도 만들어 보는 건 어떨까요?
더 나아가 패치 임베딩 레이어의 입력 및 출력 모양을 재현해 보겠습니다.
다시 기억해 봅시다.
- 입력: 이미지는 크기가 \({H \times W \times C}\)인 2D로 시작합니다.
- 출력: 이미지는 크기가 \({N \times\left(P^{2} \cdot C\right)}\)인 평탄화된 2D 패치 시퀀스로 변환됩니다.
# 입력 모양
input_shape = (height, width, color_channels)
# 출력 모양
output_shape = (number_of_patches, patch_size**2 * color_channels)
print(f"입력 모양 (2D 이미지): {input_shape}")
print(f"출력 모양 (평탄화된 2D 패치): {output_shape}")입력 및 출력 모양 획득!
TK - 4.2 단일 이미지를 패치로 변환
이제 패치 임베딩 레이어에 대한 이상적인 입력 및 출력 모양을 알았습니다.
여기서 우리가 하고 있는 작업은 전체 아키텍처를 더 작은 조각으로 나누어 개별 레이어의 입력과 출력에 집중하는 것입니다.
그렇다면 패치 임베딩 레이어는 어떻게 만들까요?
곧 다루겠지만, 먼저 이미지를 패치로 변환하는 것이 어떤 모습인지 시각화, 시각화, 시각화! 해보겠습니다.
단일 이미지부터 시작하겠습니다.
# 단일 이미지 보기
plt.imshow(image.permute(1, 2, 0)) # matplotlib에 맞게 조정
plt.title(class_names[label])
plt.axis(False);ViT 논문의 그림 1과 일치하도록 이 이미지를 자체 패치로 변환하고 싶습니다.
먼저 패치된 픽셀의 상단 행만 시각화해 보는 건 어떨까요?
다른 이미지 차원을 인덱싱하여 이를 수행할 수 있습니다.
# matplotlib과 호환되도록 이미지 모양 변경 [색상_채널, 높이, 너비] -> [높이, 너비, 색상_채널]
image_permuted = image.permute(1, 2, 0)
# 패치된 픽셀의 상단 행을 그리기 위한 인덱스
patch_size = 16
plt.figure(figsize=(patch_size, patch_size))
plt.imshow(image_permuted[:patch_size, :, :]);이제 상단 행을 얻었으므로 패치로 바꾸어 보겠습니다.
상단 행에 있을 패치 수를 반복하여 이를 수행할 수 있습니다.
# 하이퍼파라미터 설정 및 IMG_SIZE와 patch_size가 호환되는지 확인
img_size = 224
patch_size = 16
num_patches = img_size/patch_size
assert img_size % patch_size == 0, "이미지 크기는 패치 크기로 나누어 떨어져야 합니다."
print(f"행당 패치 수: {num_patches}")
# 일련의 서브플롯 생성
fig, axs = plt.subplots(nrows=1,
ncols=img_size // patch_size, # 각 패치 당 하나의 열
figsize=(num_patches, num_patches),
sharex=True,
sharey=True)
# 상단 행의 패치 수를 반복
for i, patch in enumerate(range(0, img_size, patch_size)):
axs[i].imshow(image_permuted[:patch_size, patch:patch+patch_size, :]); # 높이 인덱스는 일정하게 유지, 너비 인덱스 변경
axs[i].set_xlabel(i+1) # 레이블 설정
axs[i].set_xticks([])
axs[i].set_yticks([])패치들이 아주 좋아 보이네요!
이미지 전체에 대해 수행해 보면 어떨까요?
이번에는 높이와 너비에 대한 인덱스를 반복하고 각 패치를 자체 서브플롯으로 그릴 것입니다.
# 하이퍼파라미터 설정 및 IMG_SIZE와 patch_size가 호환되는지 확인
img_size = 224
patch_size = 16
num_patches = img_size/patch_size
assert img_size % patch_size == 0, "이미지 크기는 패치 크기로 나누어 떨어져야 합니다."
print(f"행당 패치 수: {num_patches}\n열당 패치 수: {num_patches}\n총 패치 수: {num_patches*num_patches}")
# 일련의 서브플롯 생성
fig, axs = plt.subplots(nrows=img_size // patch_size, # float가 아닌 int가 필요함
ncols=img_size // patch_size,
figsize=(num_patches, num_patches),
sharex=True,
sharey=True)
# 이미지의 높이와 너비를 반복
for i, patch_height in enumerate(range(0, img_size, patch_size)): # 높이 반복
for j, patch_width in enumerate(range(0, img_size, patch_size)): # 너비 반복
# 치환된 이미지 패치 그리기 (image_permuted -> (높이, 너비, 색상 채널))
axs[i, j].imshow(image_permuted[patch_height:patch_height+patch_size, # 높이 반복
patch_width:patch_width+patch_size, # 너비 반복
:]) # 모든 색상 채널 가져오기
# 레이블 정보 설정, 명확성을 위해 틱(ticks) 제거 및 레이블을 바깥쪽으로 설정
axs[i, j].set_ylabel(i+1,
rotation="horizontal",
horizontalalignment="right",
verticalalignment="center")
axs[i, j].set_xlabel(j+1)
axs[i, j].set_xticks([])
axs[i, j].set_yticks([])
axs[i, j].label_outer()
# 슈퍼 타이틀 설정
fig.suptitle(f"{class_names[label]} -> 패치화됨", fontsize=16)
plt.show()이미지가 패치화되었습니다!
와, 정말 멋지네요.
이제 이러한 각 패치를 어떻게 임베딩으로 변환하고 시퀀스로 바꿀까요?
힌트: PyTorch 레이어를 사용할 수 있습니다. 어떤 것인지 맞힐 수 있나요?
TK - 4.3 torch.nn.Conv2d()로 이미지 패치 생성하기
이제 PyTorch로 패치 임베딩 레이어를 재현하는 쪽으로 넘어가 볼 시간입니다.
단일 이미지를 시각화하기 위해 단일 이미지의 다른 높이 및 너비 차원을 반복하고 개별 패치를 그리는 코드를 작성했습니다.
이 연산은 03. PyTorch 컴퓨터 비전 섹션 7.1: nn.Conv2d() 단계별 살펴보기에서 보았던 컨볼루션 연산과 매우 유사합니다.
사실, ViT 논문의 저자들은 섹션 3.1에서 패치 임베딩이 컨볼루션 신경망(CNN)으로 달성 가능하다는 점을 언급합니다.
하이브리드 아키텍처. 원시 이미지 패치의 대안으로, CNN의 특성 맵(feature map)으로부터 입력 시퀀스를 형성할 수 있습니다(LeCun et al., 1989). 이 하이브리드 모델에서, 패치 임베딩 투영 \(\mathbf{E}\)(식 1)는 CNN 특성 맵에서 추출된 패치에 적용됩니다. 특수한 경우로, 패치는 \(1 \times 1\)의 공간 크기를 가질 수 있는데, 이는 특성 맵의 공간 차원을 단순하게 평탄화하고 트랜스포머 차원으로 투영함으로써 입력 시퀀스를 얻음을 의미합니다. 분류 입력 임베딩 및 위치 임베딩은 위에서 설명한 대로 추가됩니다.
여기서 언급하는 “특성 맵(feature map)”은 주어진 이미지를 통과하는 컨볼루션 레이어에 의해 생성된 가중치/활성화를 의미합니다.

torch.nn.Conv2d() 레이어의 kernel_size 및 stride 매개변수를 patch_size와 동일하게 설정함으로써, 이미지를 패치로 분할하고 각 패치의 학습 가능한 임베딩(ViT 논문에서는 “선형 투영”이라고 지칭함)을 생성하는 레이어를 효과적으로 얻을 수 있습니다.
패치 임베딩 레이어에 대한 우리의 이상적인 입력 및 출력 모양을 기억하시나요?
- 입력: 이미지는 크기가 \({H \times W \times C}\)인 2D로 시작합니다.
- 출력: 이미지는 크기가 \({N \times\left(P^{2} \cdot C\right)}\)인 평탄화된 2D 패치 시퀀스로 변환됩니다.
또는 이미지 크기가 224이고 패치 크기가 16인 경우:
- 입력 (2D 이미지): (224, 224, 3)
- 출력 (평탄화된 2D 패치): (196, 768)
우리는 다음과 같은 방법으로 이것들을 재현할 수 있습니다. * torch.nn.Conv2d(): 이미지를 CNN 특성 맵 패치로 변환합니다. * torch.nn.Flatten(): 특성 맵의 공간 차원을 평탄화합니다.
torch.nn.Conv2d() 레이어부터 시작하겠습니다.
kernel_size 및 stride를 patch_size와 동일하게 설정하여 패치 생성을 재현할 수 있습니다.
이는 각 컨볼루션 커널이 (patch_size x patch_size) 크기이거나 patch_size=16인 경우 (16 x 16)(한 개의 전체 패치와 동일함)임을 의미합니다.
그리고 컨볼루션 커널의 각 단계 또는 stride는 16픽셀 길이가 됩니다(다음 패치로 넘어가는 것과 동일함).
이미지의 색상 채널 수에 대해 in_channels=3을 설정하고, ViT-Base에 대한 표 1의 \(D\) 값과 동일한 out_channels=768을 설정합니다(이는 임베딩 차원으로, 각 이미지는 크기가 768인 벡터로 임베딩됩니다).
from torch import nn
# 패치 크기 설정
patch_size=16
# ViT 논문의 하이퍼파라미터를 사용하여 Conv2d 레이어 생성
conv2d = nn.Conv2d(in_channels=3, # 색상 채널 수
out_channels=768, # 표 1에서 가져옴: 은닉 크기 D, 이것이 임베딩 크기가 됩니다.
kernel_size=patch_size, # (patch_size, patch_size)를 사용할 수도 있습니다.
stride=patch_size,
padding=0)이제 컨볼루션 레이어가 생겼으므로 단일 이미지를 통과시킬 때 어떤 일이 일어나는지 확인해 보겠습니다.
# 단일 이미지 보기
plt.imshow(image.permute(1, 2, 0)) # matplotlib에 맞게 조정
plt.title(class_names[label])
plt.axis(False);# 이미지를 컨볼루션 레이어에 통과시킴
image_out_of_conv = conv2d(image.unsqueeze(0)) # 단일 배치 차원 추가 (높이, 너비, 색상_채널) -> (배치, 높이, 너비, 색상_채널)
print(image_out_of_conv.shape)이미지를 컨볼루션 레이어에 통과시키면 일련의 768개(이는 임베딩 크기 또는 \(D\)입니다) 특성/활성화 맵으로 변환됩니다.
따라서 출력 모양은 다음과 같이 읽을 수 있습니다.
torch.Size([1, 768, 14, 14]) -> [배치_크기, 임베딩_차원, 특성_맵_높이, 특성_맵_너비]임의의 특성 맵 5개를 시각화하여 어떻게 생겼는지 확인해 보겠습니다.
# 임의의 5개 컨볼루션 특성 맵 플롯
import random
random_indexes = random.sample(range(0, 758), k=5) # 0과 임베딩 크기 사이에서 5개의 숫자 선택
print(f"인덱스에서 무작위 컨볼루션 특성 맵 표시: {random_indexes}")
# 플롯 생성
fig, axs = plt.subplots(nrows=1, ncols=5, figsize=(12, 12))
# 무작위 이미지 특성 맵 플롯
for i, idx in enumerate(random_indexes):
image_conv_feature_map = image_out_of_conv[:, idx, :, :] # 컨볼루션 레이어의 출력 텐서에서 인덱싱
axs[i].imshow(image_conv_feature_map.squeeze().detach().numpy())
axs[i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[]);특성 맵이 모두 원본 이미지를 어느 정도 나타내고 있음을 알 수 있습니다. 몇 가지를 시각화하면 서로 다른 주요 윤곽선과 몇 가지 주요 특성을 볼 수 있습니다.
주목해야 할 중요한 점은 이러한 특성이 신경망이 학습함에 따라 시간이 지나면 변할 수 있다는 것입니다.
이러한 점 때문에 이러한 특성 맵은 우리 이미지의 학습 가능한 임베딩(learnable embedding)으로 간주될 수 있습니다.
수치 형식으로 하나 확인해 보겠습니다.
# 텐서 형식으로 단일 특성 맵 가져오기
single_feature_map = image_out_of_conv[:, 0, :, :]
single_feature_map, single_feature_map.requires_gradsingle_feature_map의 grad_fn 출력과 required_grad=True 속성은 PyTorch가 이 특성 맵의 그래디언트를 추적하고 있으며 훈련 중에 경사 하강법에 의해 업데이트될 것임을 의미합니다.
TK - 4.4 torch.nn.Flatten()을 사용하여 패치 임베딩 평탄화하기
이미지를 패치 임베딩으로 변환했지만 여전히 2D 형식입니다.
어떻게 하면 ViT 모델의 패치 임베딩 레이어의 원하는 출력 모양으로 만들 수 있을까요?
- 원하는 출력 (평탄화된 2D 패치): (196, 768) -> \({N \times\left(P^{2} \cdot C\right)}\)
현재 모양을 확인해 보겠습니다.
# 현재 텐서 모양
print(f"현재 텐서 모양: {image_out_of_conv.shape} -> [배치, 임베딩_차원, 특성_맵_높이, 특성_맵_너비]")768 부분( \((P^{2} \cdot C)\) )은 얻었지만 여전히 패치 수(\(N\))가 필요합니다.
ViT 논문의 섹션 3.1을 다시 읽어보면 다음과 같이 적혀 있습니다(굵은 글씨는 강조를 위한 것입니다).
특수한 경우로, 패치는 \(1 \times 1\)의 공간 크기를 가질 수 있는데, 이는 특성 맵의 공간 차원을 단순하게 평탄화하고 트랜스포머 차원으로 투영함으로써 입력 시퀀스를 얻음을 의미합니다.
특성 맵의 공간 차원을 평탄화한다고요?
PyTorch에 평탄화할 수 있는 레이어가 있나요?
torch.nn.Flatten()은 어떨까요?
하지만 전체 텐서를 평탄화하고 싶지는 않고 “특성 맵의 공간 차원”만 평탄화하고 싶습니다.
우리의 경우에는 image_out_of_conv의 feature_map_height 및 feature_map_width 차원입니다.
따라서 해당 차원만 평탄화하도록 torch.nn.Flatten() 레이어를 만들고, start_dim 및 end_dim 매개변수를 사용하여 이를 설정해 보는 건 어떨까요?
# Flatten 레이어 생성
flatten = nn.Flatten(start_dim=2, # feature_map_height(차원 2) 평탄화
end_dim=3) # feature_map_width(차원 3) 평탄화좋습니다! 이제 모든 것을 하나로 합쳐 봅시다!
우리는 다음 단계를 수행할 것입니다. 1. 단일 이미지를 가져옵니다. 2. 이미지를 컨볼루션 레이어(conv2d)에 통과시켜 2D 특성 맵(패치 임베딩)으로 변환합니다. 3. 2D 특성 맵을 단일 시퀀스로 평탄화합니다.
# 1. 단일 이미지 보기
plt.imshow(image.permute(1, 2, 0)) # matplotlib에 맞게 조정
plt.title(class_names[label])
plt.axis(False);
print(f"원본 이미지 모양: {image.shape}")
# 2. 이미지를 특성 맵으로 변환
image_out_of_conv = conv2d(image.unsqueeze(0)) # 모양 오류를 방지하기 위해 배치 차원 추가
print(f"이미지 특성 맵 모양: {image_out_of_conv.shape}")
# 3. 특성 맵 평탄화
image_out_of_conv_flattened = flatten(image_out_of_conv)
print(f"평탄화된 이미지 특성 맵 모양: {image_out_of_conv_flattened.shape}")좋아요! image_out_of_conv_flattened 모양이 우리가 원하는 출력 모양과 매우 유사해 보입니다.
- 원하는 출력 (평탄화된 2D 패치): (196, 768) -> \({N \times\left(P^{2} \cdot C\right)}\)
- 현재 모양: (1, 768, 196)
유일한 차이점은 현재 모양에 배치 크기가 있고 차원 순서가 원하는 출력과 다르다는 것입니다.
이 문제를 어떻게 해결할 수 있을까요?
차원을 재배열해 보는 건 어떨까요?
matplotlib으로 이미지를 그리기 위해 이미지 텐서를 재배열할 때와 마찬가지로 torch.Tensor.permute()를 사용하여 그렇게 할 수 있습니다.
시도해 봅시다.
# 올바른 모양의 평탄화된 이미지 패치 임베딩 가져오기
image_out_of_conv_flattened_reshaped = image_out_of_conv_flattened.permute(0, 2, 1) # [배치_크기, P^2•C, N] -> [배치_크기, N, P^2•C]
print(f"패치 임베딩 시퀀스 모양: {image_out_of_conv_flattened_reshaped.shape} -> [배치_크기, 패치_수, 임베딩_크기]")좋아요!!!
이제 몇 개의 PyTorch 레이어를 사용하여 ViT 아키텍처의 패치 임베딩 레이어에 대해 원하는 입력 및 출력 모양을 일치시켰습니다.
평탄화된 특성 맵 중 하나를 시각화해 보는 건 어떨까요?
# 단일 평탄화된 특성 맵 가져오기
single_flattened_feature_map = image_out_of_conv_flattened_reshaped[:, :, 0]
# 평탄화된 특성 맵 시각적으로 플롯
plt.figure(figsize=(22, 22))
plt.imshow(single_flattened_feature_map.detach().numpy())
plt.title(f"평탄화된 특성 맵 모양: {single_flattened_feature_map.shape}")
plt.axis(False);흠, 평탄화된 특성 맵은 시각적으로는 별 의미가 없어 보이지만, 우리가 걱정할 부분은 아닙니다. 이것이 패치 임베딩 레이어의 출력이자 나머지 ViT 아키텍처의 입력이 될 것입니다.
TK 이미지 - 단일 이미지 -> conv2d -> 평탄화 -> 위 출력 얻기 (워크플로우와 변환 과정을 보여주며, 이는 우리가 사용해 온 gif일 수 있지만 평탄화 섹션과 작동하도록 확장됨)
참고: 원본 트랜스포머 아키텍처는 텍스트와 함께 작동하도록 설계되었습니다. Vision Transformer 아키텍처(ViT)는 원본 트랜스포머를 이미지에 사용하는 것을 목표로 했습니다. 이것이 ViT 아키텍처의 입력이 이러한 방식으로 처리되는 이유입니다. 우리는 본질적으로 2D 이미지를 가져와서 1D 텍스트 시퀀스처럼 보이도록 형식을 지정하고 있습니다.
평탄화된 특성 맵을 텐서 형식으로 보는 건 어떨까요?
# 평탄화된 특성 맵을 텐서로 보기
single_flattened_feature_map, single_flattened_feature_map.requires_grad, single_flattened_feature_map.shape좋습니다!
우리는 단일 2D 이미지를 단일 1D 학습 가능한 임베딩 벡터(또는 ViT 논문의 그림 1에 있는 “Linear Projection of Flattned Patches”)로 변환했습니다.
TK - 4.5 ViT 패치 임베딩 레이어를 PyTorch 모듈로 변환하기
패치 임베딩을 만들기 위해 수행한 모든 작업을 단일 PyTorch 레이어에 넣을 시간입니다.
nn.Module을 서브클래싱하고 위의 모든 단계를 수행하는 작은 PyTorch “모델”을 만들어 이를 수행할 수 있습니다.
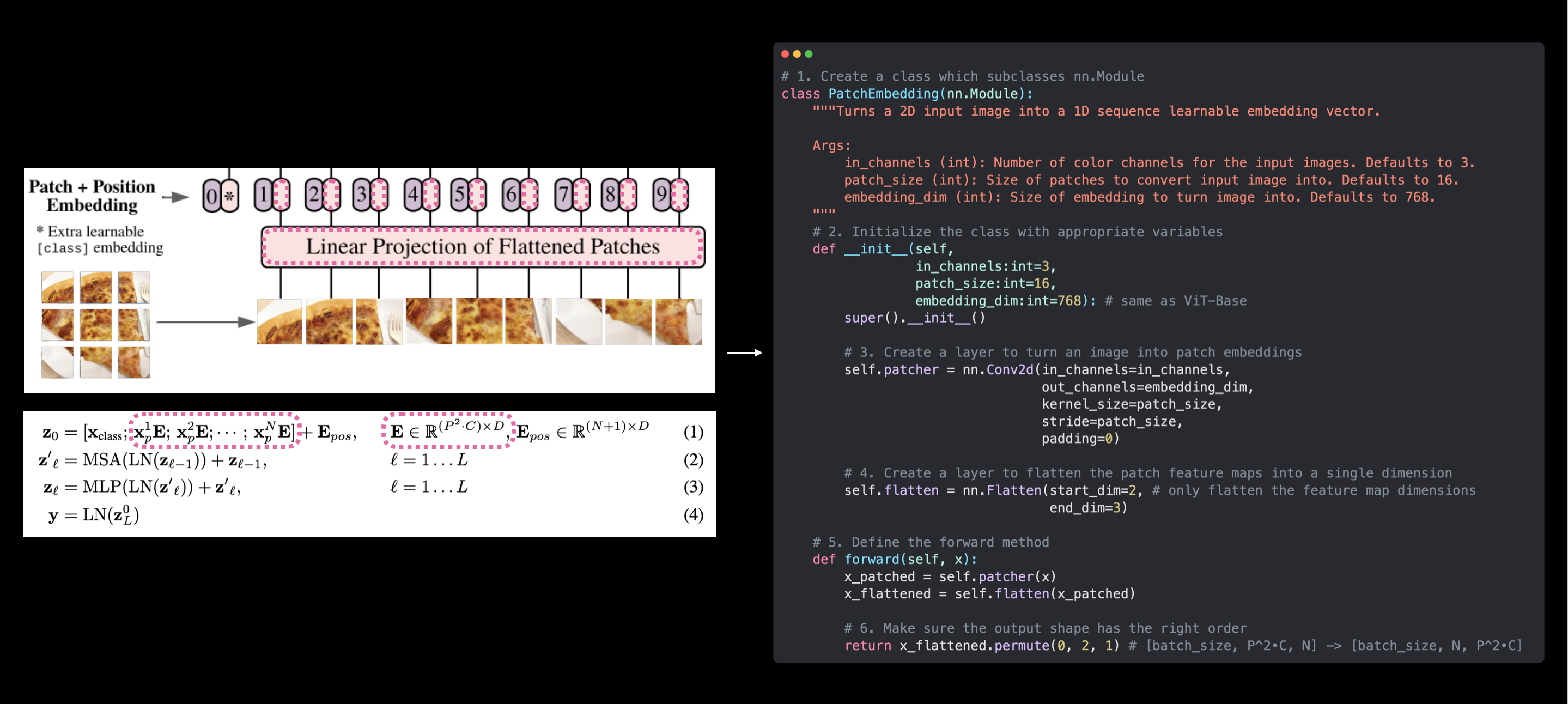
구체적으로 다음을 수행합니다. 1. PatchEmbedding이라는 클래스를 만듭니다. 이 클래스는 nn.Module을 상속합니다(따라서 PyTorch 레이어로 사용될 수 있습니다). 2. 매개변수 in_channels=3, patch_size=16(ViT-Base용) 및 embedding_dim=768(표 1의 ViT-Base용 \(D\))을 사용하여 클래스를 초기화합니다. 3. nn.Conv2d()를 사용하여 이미지를 패치로 변환하는 레이어를 만듭니다(위의 4.3에서와 동일). 4. 패치 특성 맵을 단일 차원으로 평탄화하는 레이어를 만듭니다(위의 4.4에서와 동일). 5. 입력을 받아 3단계와 4단계에서 생성된 레이어를 통과시키는 forward() 메서드를 정의합니다. 6. 출력 모양이 ViT 아키텍처의 필수 출력 모양(\({N \times\left(P^{2} \cdot C\right)}\))을 반영하는지 확인합니다.
해봅시다!
# 1. nn.Module을 상속받는 클래스 생성
class PatchEmbedding(nn.Module):
"""2D 입력 이미지를 1D 시퀀스 학습 가능 임베딩 벡터로 변환합니다.
인자:
in_channels (int): 입력 이미지의 색상 채널 수. 기본값은 3.
patch_size (int): 입력 이미지를 나눌 패치 크기. 기본값은 16.
embedding_dim (int): 이미지를 변환할 임베딩 크기. 기본값은 768.
"""
# 2. 적절한 변수를 사용하여 클래스 초기화
def __init__(self,
in_channels:int=3,
patch_size:int=16,
embedding_dim:int=768):
super().__init__()
# 3. 이미지를 패치로 변환하는 레이어 생성
self.patcher = nn.Conv2d(in_channels=in_channels,
out_channels=embedding_dim,
kernel_size=patch_size,
stride=patch_size,
padding=0)
# 4. 패치 특성 맵을 단일 차원으로 평탄화하는 레이어 생성
self.flatten = nn.Flatten(start_dim=2, # 특성 맵 차원만 단일 벡터로 평탄화
end_dim=3)
# 5. forward 메서드 정의
def forward(self, x):
# 입력이 올바른 모양인지 확인하기 위해 assertion 생성
image_resolution = x.shape[-1]
assert image_resolution % patch_size == 0, f"입력 이미지 크기는 패치 크기로 나누어 떨어져야 함, 이미지 모양: {image_resolution}, 패치 크기: {patch_size}"
# 순전파 수행
x_patched = self.patcher(x)
x_flattened = self.flatten(x_patched)
# 6. 출력 모양이 올바른 순서가 되도록 보장
return x_flattened.permute(0, 2, 1) # 임베딩이 마지막 차원이 되도록 조정 [배치_크기, P^2•C, N] -> [배치_크기, N, P^2•C]PatchEmbedding 레이어가 생성되었습니다!
단일 이미지에서 시도해 봅시다.
set_seeds()
# 패치 임베딩 레이어 인스턴스 생성
patchify = PatchEmbedding(in_channels=3,
patch_size=16,
embedding_dim=768)
# 단일 이미지 통과
print(f"입력 이미지 모양: {image.unsqueeze(0).shape}")
patch_embedded_image = patchify(image.unsqueeze(0)) # 0번 인덱스에 추가 배치 차원 추가, 그렇지 않으면 오류 발생
print(f"출력 패치 임베딩 모양: {patch_embedded_image.shape}")좋습니다!
출력 모양은 패치 임베딩 레이어에서 보고 싶은 이상적인 입력 및 출력 모양과 일치합니다.
- 입력: 이미지는 크기가 \({H \times W \times C}\)인 2D로 시작합니다.
- 출력: 이미지는 크기가 \({N \times\left(P^{2} \cdot C\right)}\)인 평탄화된 2D 패치 시퀀스로 변환됩니다.
여기서: * \((H, W)\)는 원본 이미지의 해상도입니다. * \(C\)는 채널 수입니다. * \((P, P)\)는 각 이미지 패치의 해상도(패치 크기)입니다. * \(N=H W / P^{2}\)는 결과 패치 수이며, 트랜스포머의 유효 입력 시퀀스 길이 역할도 합니다.
이제 방정식 1에 대한 패치 임베딩을 재현했지만 클래스 토큰/위치 임베딩은 아직 재현하지 않았습니다.
이것들은 나중에 다룰 것입니다.
우리의 PatchEmbedding 클래스(오른쪽)는 ViT 논문(왼쪽)의 그림 1 및 식 1로부터 ViT 아키텍처의 패치 임베딩을 재현합니다. 그러나 학습 가능한 클래스 임베딩 및 위치 임베딩은 아직 생성되지 않았습니다. 이것들은 곧 나올 것입니다.
이제 PatchEmbedding 레이어의 요약을 확인해 보겠습니다.
# 무작위 입력 크기 생성
random_input_image = (1, 3, 224, 224)
random_input_image_error = (1, 3, 250, 250) # 이미지 크기가 patch_size와 호환되지 않으므로 오류가 발생함
# PatchEmbedding의 입력 및 출력 요약 가져오기
summary(PatchEmbedding(),
input_size=random_input_image, # 이를 "random_input_image_error"로 바꾸어 보세요
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"])TK 4.6 클래스 토큰 임베딩 생성
이미지 패치 임베딩을 만들었으니, 이제 클래스 토큰 임베딩 작업을 시작할 시간입니다.
또는 방정식 1의 \(\mathbf{x}_\text {class }\)입니다.
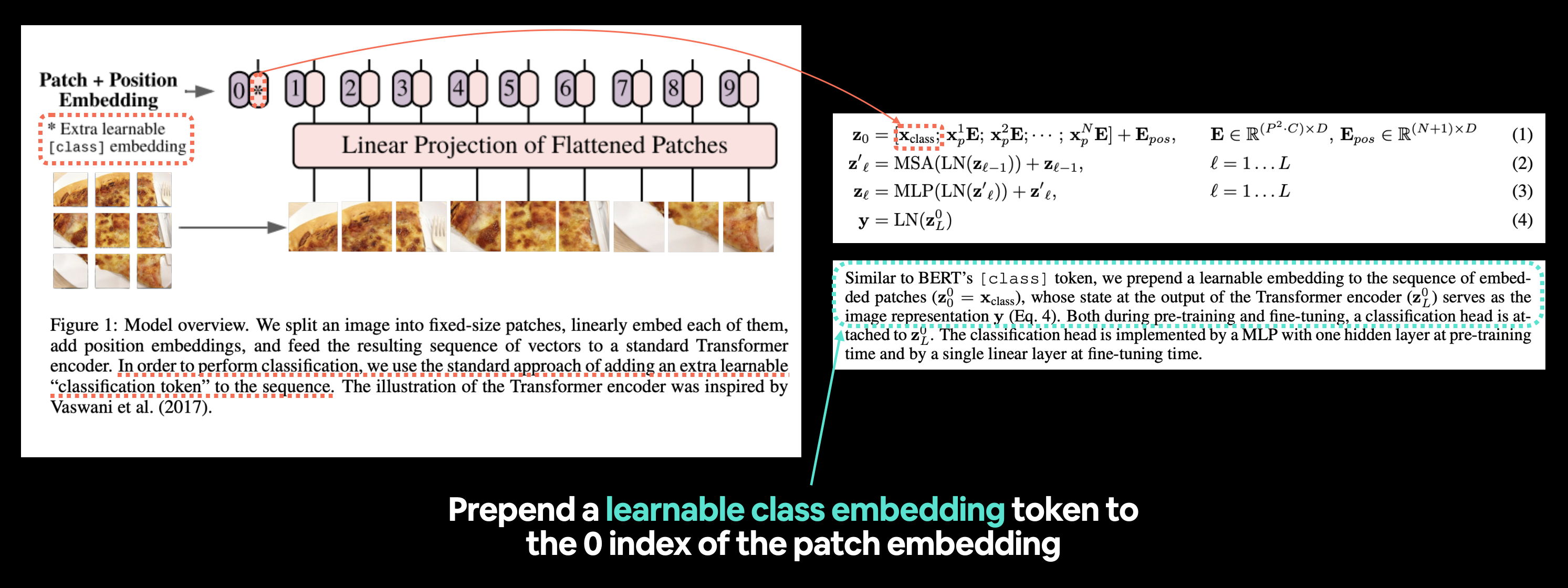
왼쪽: 재현할 “분류 토큰” 또는 [class] 임베딩 토큰이 강조된 ViT 논문의 그림 1. 오른쪽: 학습 가능한 클래스 임베딩 토큰과 관련된 ViT 논문의 식 1 및 섹션 3.1.
ViT 논문의 섹션 3.1 두 번째 단락을 읽어보면 다음과 같은 설명을 볼 수 있습니다.
BERT의
[ class ]토큰과 유사하게, 임베딩된 패치 시퀀스 \(\left(\mathbf{z}_{0}^{0}=\mathbf{x}_{\text {class }}\right)\) 앞에 학습 가능한 임베딩을 추가하며, 트랜스포머 인코더의 출력에서의 상태 \(\left(\mathbf{z}_{L}^{0}\right)\)는 이미지 표현 \(\mathbf{y}\) 역할을 합니다(식 4).
참고: BERT(Bidirectional Encoder Representations from Transformers)는 트랜스포머 아키텍처를 사용하여 자연어 처리(NLP) 작업에서 뛰어난 결과를 달성한 최초의 머신러닝 연구 논문 중 하나이며, 시퀀스 시작 부분에
[ class ]토큰을 두는 아이디어가 시작된 곳으로, 클래스는 시퀀스가 속한 “분류” 클래스에 대한 설명입니다.
따라서 “임베딩된 패치 시퀀스 앞에 학습 가능한 임베딩을 추가”해야 합니다.
임베딩된 패치 텐서 시퀀스(4.5에서 생성됨)와 그 모양을 보는 것으로 시작해 보겠습니다.
# 패치 임베딩 및 패치 임베딩 모양 보기
print(patch_embedded_image)
print(f"패치 임베딩 모양: {patch_embedded_image.shape} -> [배치_크기, 패치_수, 임베딩_차원]")“임베딩된 패치 시퀀스 앞에 학습 가능한 임베딩을 추가”하려면 embedding_dimension(\(D\)) 모양의 학습 가능한 임베딩을 만든 다음 이를 number_of_patches 차원에 추가해야 합니다.
또는 의사코드로는 다음과 같습니다.
patch_embedding = [image_patch_1, image_patch_2, image_patch_3...]
class_token = learnable_embedding
patch_embedding_with_class_token = torch.cat((class_token, patch_embedding), dim=1)연결(torch.cat())이 dim=1(number_of_patches 차원)에서 발생하는 것을 확인하세요.
클래스 토큰에 대한 학습 가능한 임베딩을 만들어 보겠습니다.
이를 위해 배치 크기와 임베딩 차원 모양을 얻은 다음 [batch_size, 1, embedding_dimension] 모양의 torch.ones() 텐서를 만듭니다.
그리고 requires_grad=True와 함께 nn.Parameter()에 전달하여 텐서를 학습 가능하게 만듭니다.
# 배치 크기 및 임베딩 차원 가져오기
batch_size = patch_embedded_image.shape[0]
embedding_dimension = patch_embedded_image.shape[-1]
# 임베딩 차원(D)과 동일한 크기를 공유하는 학습 가능한 매개변수로 클래스 토큰 임베딩 생성
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension), # [배치_크기, 패치_수, 임베딩_차원]
requires_grad=True) # 임베딩을 학습 가능하도록 설정
# class_token의 처음 10개 예제 표시
print(class_token[:, :, :10])
# class_token 모양 출력
print(f"클래스 토큰 모양: {class_token.shape} -> [배치_크기, 토큰_수, 임베딩_차원]")참고: 여기서는 시연 목적으로 클래스 토큰 임베딩을
torch.ones()로만 생성하고 있습니다. 실제로는torch.randn()을 사용하여 클래스 토큰 임베딩을 생성할 가능성이 높습니다(무작위 숫자로 시작).
패치 임베딩 시퀀스 시작 부분에 하나의 클래스 토큰 값만 추가하고 싶으므로 class_token의 number_of_patches 차원이 1인 것을 확인할 수 있습니다.
이제 클래스 토큰 임베딩을 얻었으므로 이를 이미지 패치 시퀀스인 patch_embedded_image 앞에 추가해 보겠습니다.
torch.cat()을 사용하고 dim=1로 설정하여 그렇게 할 수 있습니다(따라서 class_token의 number_of_patches 차원이 patch_embedded_image의 number_of_patches 차원 앞에 추가됨).
# 패치 임베딩 앞에 클래스 토큰 임베딩 추가
patch_embedded_image_with_class_embedding = torch.cat((class_token, patch_embedded_image),
dim=1) # 첫 번째 차원에서 연결
# 클래스 토큰 임베딩이 앞에 추가된 패치 임베딩 시퀀스 출력
print(patch_embedded_image_with_class_embedding)
print(f"클래스 토큰이 추가된 패치 임베딩 시퀀스 모양: {patch_embedded_image_with_class_embedding.shape} -> [배치_크기, 패치_수, 임베딩_차원]")좋아요! 학습 가능한 클래스 토큰이 앞에 추가되었습니다!

학습 가능한 클래스 토큰을 만들기 위해 수행한 작업을 검토해 보면, 단일 이미지에서 PatchEmbedding()으로 생성된 이미지 패치 임베딩 시퀀스로 시작하여 각 임베딩 차원에 대해 하나의 값을 갖는 학습 가능한 클래스 토큰을 만든 다음 원본 패치 임베딩 시퀀스 앞에 추가했습니다. 참고: 학습 가능한 클래스 토큰을 만들기 위해 torch.ones()를 사용하는 것은 주로 시연용이며, 실제로는 torch.randn()을 사용하여 생성할 가능성이 높습니다.
TK 4.7 위치 임베딩 생성
클래스 토큰 임베딩과 패치 임베딩이 생겼는데, 이제 위치 임베딩은 어떻게 만들 수 있을까요?
또는 방정식 1의 \(\mathbf{E}_{\text {pos }}\)입니다. 여기서 \(E\)는 “임베딩(embedding)”을 의미합니다.
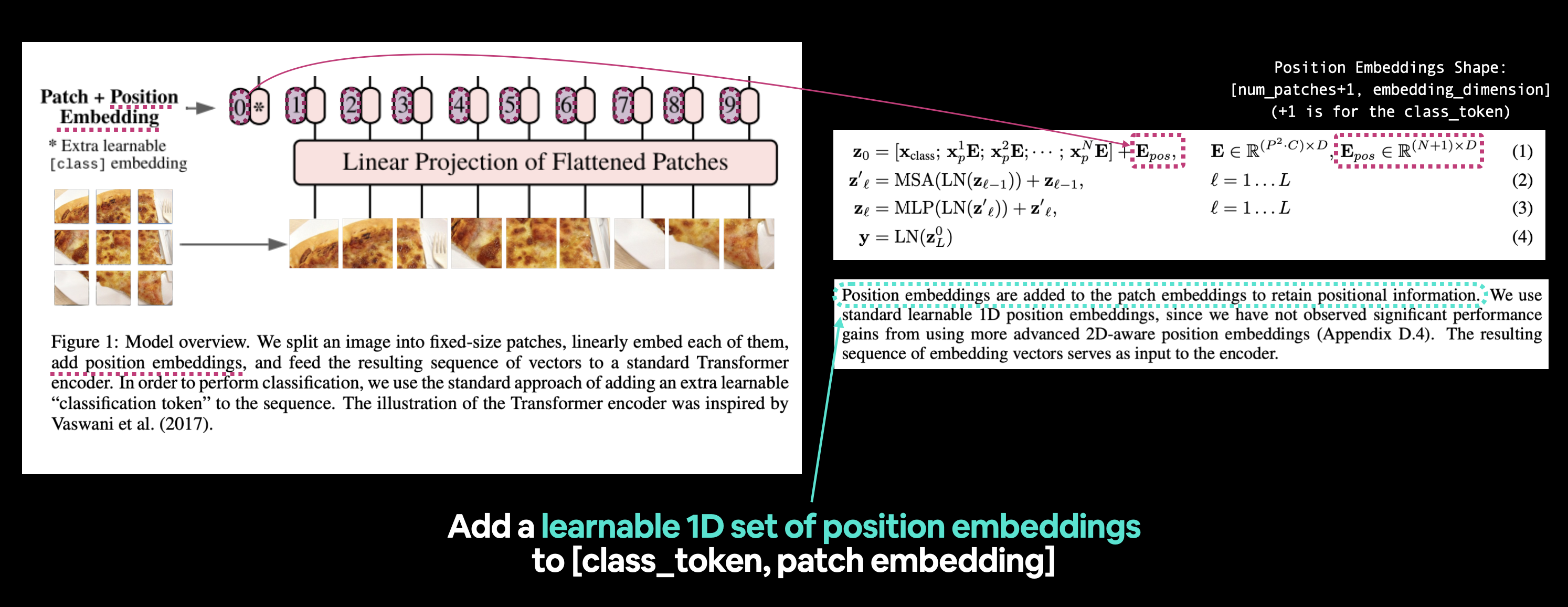
왼쪽: 재현할 위치 임베딩이 강조된 ViT 논문의 그림 1. 오른쪽: 위치 임베딩과 관련된 ViT 논문의 식 1 및 섹션 3.1.
ViT 논문의 섹션 3.1을 읽어 더 자세히 알아보겠습니다(굵은 글씨는 강조를 위한 것입니다).
위치 정보를 유지하기 위해 패치 임베딩에 위치 임베딩이 추가됩니다. 더 발전된 2D 인식 위치 임베딩(부록 D.4)을 사용하더라도 상당한 성능 향상을 관찰하지 못했기 때문에 표준 학습 가능 1D 위치 임베딩을 사용합니다. 결과적인 임베딩 벡터 시퀀스는 인코더의 입력으로 사용됩니다.
위치 임베딩 생성을 시작하기 위해 현재 임베딩을 살펴보겠습니다.
# 클래스 임베딩이 앞에 추가된 패치 임베딩 시퀀스 보기
patch_embedded_image_with_class_embedding, patch_embedded_image_with_class_embedding.shape방정식 1은 위치 임베딩이 \((N + 1) \times D\) 모양이어야 한다고 명시하고 있습니다. 여기서: * \(N=H W / P^{2}\)는 결과 패치 수이며 트랜스포머의 유효 입력 시퀀스 길이 역할도 합니다. * \(D\)는 패치 임베딩의 크기이며, \(D\)에 대한 다양한 값은 표 1에서 찾을 수 있습니다.
다행히 우리는 이미 이 두 값을 모두 가지고 있습니다.
따라서 torch.ones()로 학습 가능한 1D 임베딩을 만들어 \(\mathbf{E}_{\text {pos }}\)를 만들어 보겠습니다.
# N (패치 수) 계산
number_of_patches = int((height * width) / patch_size**2)
# 임베딩 차원 가져오기
embedding_dimension = patch_embedded_image_with_class_embedding.shape[2]
# 학습 가능한 1D 위치 임베딩 생성
position_embedding = nn.Parameter(torch.ones(1,
number_of_patches+1,
embedding_dimension),
requires_grad=True) # 학습 가능하도록 설정
# 처음 10개 시퀀스와 10개 위치 임베딩 값을 표시하고 위치 임베딩의 모양 확인
print(position_embedding[:, :10, :10])
print(f"위치 임베딩 모양: {position_embedding.shape} -> [배치_크기, 패치_수, 임베딩_차원]")참고: 시연 목적으로 위치 임베딩을
torch.ones()로만 생성하고 있으며, 실제로는torch.randn()을 사용하여 위치 임베딩을 생성할 가능성이 높습니다(무작위 숫자로 시작하여 경사 하강법을 통해 개선).
위치 임베딩이 생성되었습니다!
이를 클래스 토큰이 추가된 패치 임베딩 시퀀스에 추가해 보겠습니다.
# 패치 및 클래스 토큰 임베딩에 위치 임베딩 추가
patch_and_position_embedding = patch_embedded_image_with_class_embedding + position_embedding
print(patch_and_position_embedding)
print(f"패치 임베딩, 클래스 토큰 추가 및 위치 임베딩이 더해진 모양: {patch_and_position_embedding.shape} -> [배치_크기, 패치_수, 임베딩_차원]")임베딩 텐서의 각 요소 값이 1씩 증가하는 것을 볼 수 있습니다(이는 위치 임베딩이 torch.ones()로 생성되었기 때문입니다).
참고: 원한다면 클래스 토큰 임베딩과 위치 임베딩을 모두 자체 레이어에 넣을 수도 있습니다. 하지만 나중에 전체 ViT 아키텍처의
forward()메서드에 어떻게 통합될 수 있는지 살펴보겠습니다.

패치 임베딩 시퀀스와 클래스 토큰에 위치 임베딩을 추가하는 데 사용한 워크플로우입니다. 참고: torch.ones()는 그림 설명을 위해 임베딩을 생성하는 데만 사용되었으며, 실제로는 torch.randn()을 사용하여 무작위 숫자로 시작할 가능성이 높습니다.
TK 4.8 전체 과정 합치기: 이미지에서 임베딩까지
입력 이미지를 임베딩으로 변환하고 ViT 논문의 섹션 3.1에서 방정식 1을 재현하는 데 많은 진척이 있었습니다.
\[ \begin{aligned} \mathbf{z}_{0} &=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{\text {pos }}, & & \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{\text {pos }} \in \mathbb{R}^{(N+1) \times D} \end{aligned} \]
이제 모든 것을 단일 코드 셀에 넣고 입력 이미지(\(x\))에서 출력 임베딩 \({z}_0\)까지 진행해 보겠습니다.
다음과 같이 할 수 있습니다. 1. 패치 크기를 설정합니다(논문 전체와 ViT-Base에서 널리 사용되므로 16을 사용하겠습니다). 2. 단일 이미지를 가져와 모양을 출력하고 높이와 너비를 저장합니다. 3. 단일 이미지에 배치 차원을 추가하여 PatchEmbedding 레이어와 호환되도록 합니다. 4. patch_size=16 및 embedding_dim=768(ViT-Base용 표 1에서 가져옴)을 사용하여 PatchEmbedding 레이어를 만듭니다. 5. 4단계의 PatchEmbedding 레이어에 단일 이미지를 통과시켜 패치 임베딩 시퀀스를 생성합니다. 6. 섹션 4.6과 같이 클래스 토큰 임베딩을 만듭니다. 7. 클래스 토큰 임베딩을 5단계에서 생성된 패치 임베딩 앞에 추가합니다. 8. 섹션 4.7과 같이 위치 임베딩을 만듭니다. 9. 7단계에서 생성된 클래스 토큰 및 패치 임베딩에 위치 임베딩을 추가합니다.
또한 set_seeds()를 사용하여 무작위 시드를 설정하고 진행 과정에서 각 텐서의 모양을 출력하겠습니다.
set_seeds()
# 1. 패치 크기 설정
patch_size = 16
# 2. 원본 이미지 텐서 모양 출력 및 이미지 크기 가져오기
print(f"이미지 텐서 모양: {image.shape}")
height, width = image.shape[1], image.shape[2]
# 3. 이미지 텐서 가져오기 및 배치 차원 추가
x = image.unsqueeze(0)
print(f"배치 차원이 추가된 입력 이미지 모양: {x.shape}")
# 4. 패치 임베딩 레이어 생성
patch_embedding_layer = PatchEmbedding(in_channels=3,
patch_size=patch_size,
embedding_dim=768)
# 5. 패치 임베딩 레이어에 이미지 통과
patch_embedding = patch_embedding_layer(x)
print(f"패치 임베딩 모양: {patch_embedding.shape}")
# 6. 클래스 토큰 임베딩 생성
batch_size = patch_embedding.shape[0]
embedding_dimension = patch_embedding.shape[-1]
class_token = nn.Parameter(torch.ones(batch_size, 1, embedding_dimension),
requires_grad=True) # 학습 가능하도록 설정
print(f"클래스 토큰 임베딩 모양: {class_token.shape}")
# 7. 패치 임베딩 앞에 클래스 토큰 임베딩 추가
patch_embedding_class_token = torch.cat((class_token, patch_embedding), dim=1)
print(f"클래스 토큰이 포함된 패치 임베딩 모양: {patch_embedding_class_token.shape}")
# 8. 위치 임베딩 생성
number_of_patches = int((height * width) / patch_size**2)
position_embedding = nn.Parameter(torch.ones(1, number_of_patches+1, embedding_dimension),
requires_grad=True) # 학습 가능하도록 설정
# 9. 클래스 토큰이 포함된 패치 임베딩에 위치 임베딩 추가
patch_and_position_embedding = patch_embedding_class_token + position_embedding
print(f"패치 및 위치 임베딩 모양: {patch_and_position_embedding.shape}")좋아요!
단일 이미지에서 단일 코드 셀의 패치 및 위치 임베딩까지 완료했습니다.
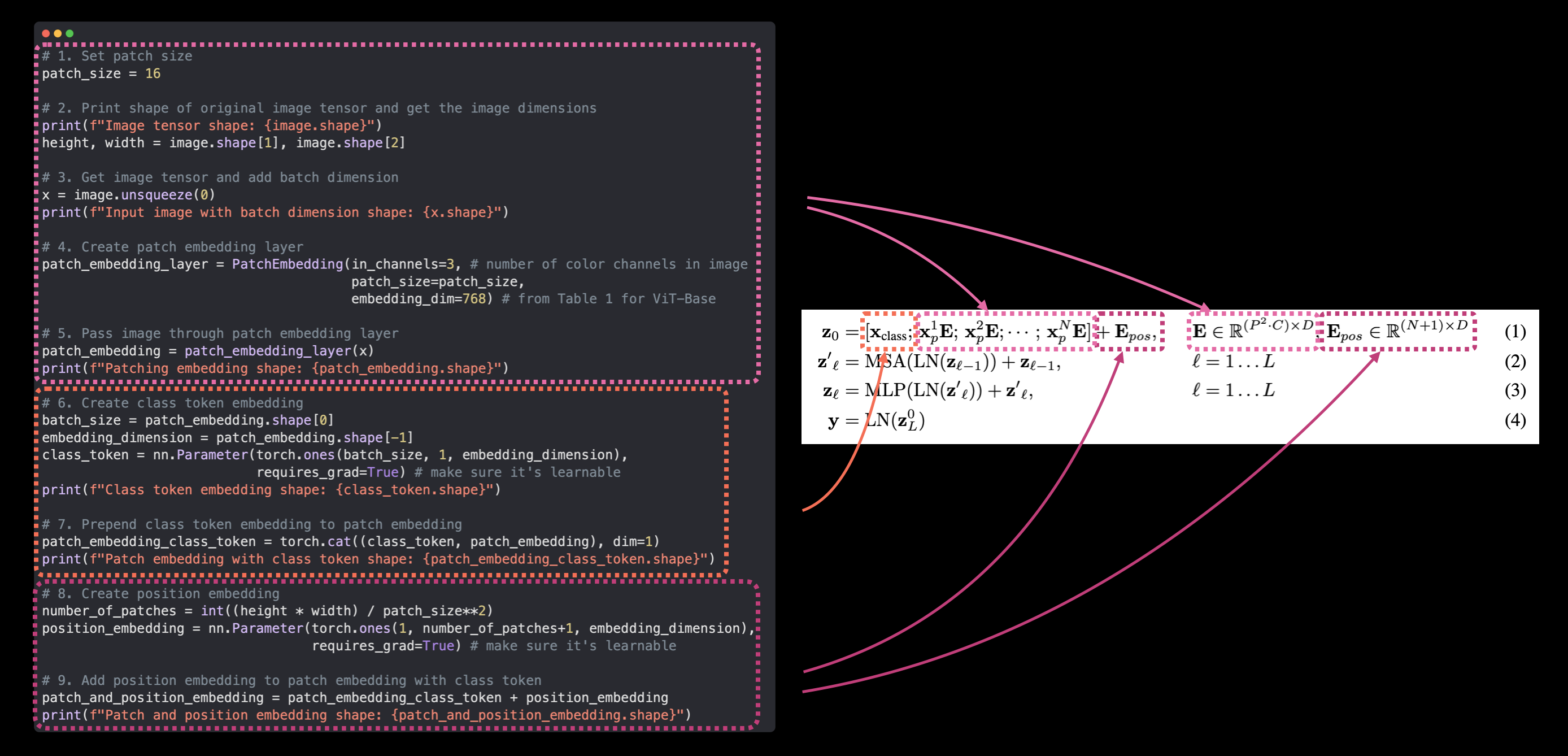
ViT 논문의 식 1을 PyTorch 코드에 매핑합니다. 이것이 논문 재현의 본질이며, 연구 논문을 실행 가능한 코드로 바꾸는 것입니다.
이제 이미지를 인코딩하여 ViT 논문의 그림 1에 있는 트랜스포머 인코더로 전달할 방법이 생겼습니다.

전체 ViT 워크플로우 애니메이션: 패치 임베딩에서 트랜스포머 인코더, MLP 헤드까지.
코드 관점에서 패치 임베딩을 만드는 것은 아마도 ViT 논문을 재현하는 데 있어 가장 큰 섹션일 것입니다.
Multi-Head Attention 및 Norm 레이어와 같은 ViT 논문의 다른 많은 부분은 기존 PyTorch 레이어를 사용하여 만들 수 있습니다.
계속 가보죠!
TK. 5. 방정식 2: 멀티헤드 어텐션 (MSA)
입력 데이터를 패치화하고 임베딩했으니, 이제 ViT 아키텍처의 다음 부분으로 넘어가 보겠습니다.
시작하기 위해 트랜스포머 인코더 섹션을 두 부분으로 나누겠습니다(작게 시작하여 필요할 때 확장).
첫 번째는 방정식 2이고 두 번째는 방정식 3입니다.
방정식 2는 다음과 같습니다.
\[ \begin{aligned} \mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right)+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \end{aligned} \]
이는 잔차 연결(레이어의 입력이 출력에 더해짐)과 함께 LayerNorm(LN) 레이어에 래핑된 MSA(Multi-Head Attention) 레이어를 나타냅니다.
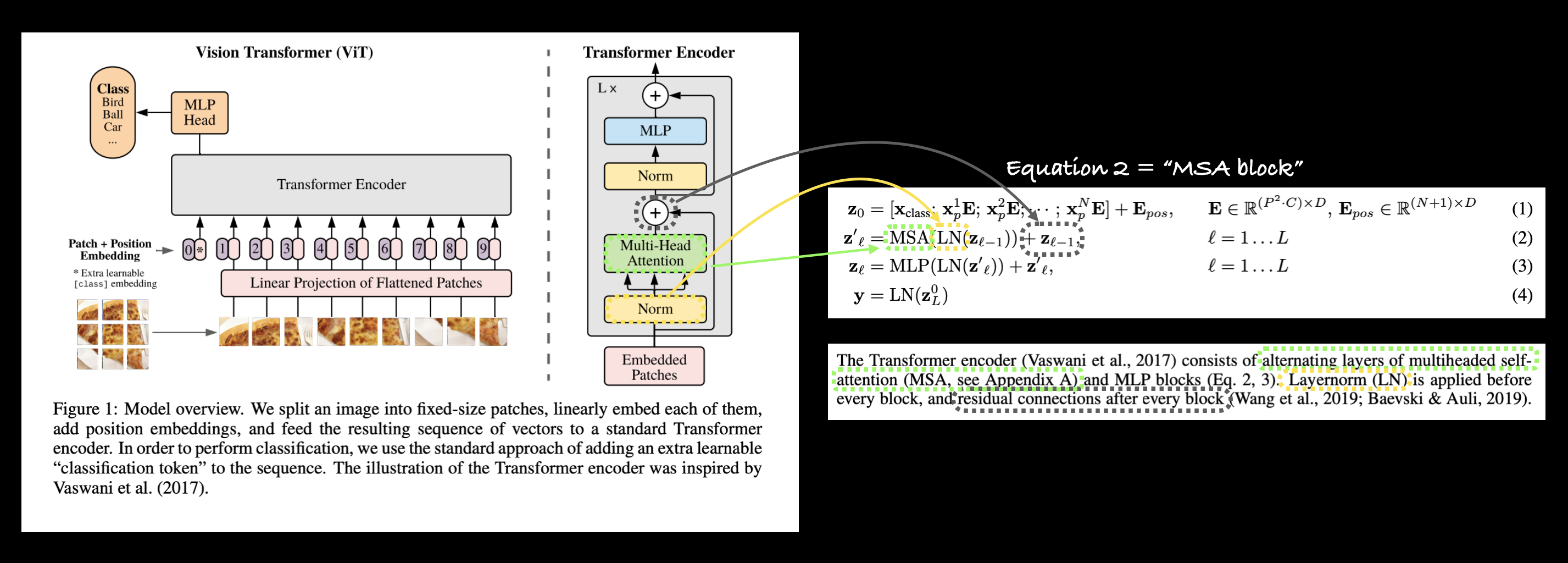
왼쪽: 트랜스포머 인코더 블록 내에서 Multi-Head Attention 및 Norm 레이어와 잔차 연결(+)이 강조된 ViT 논문의 그림 1. 오른쪽: Multi-Head Self Attention(MSA) 레이어, Norm 레이어 및 잔차 연결을 ViT 논문의 식 2의 각 부분에 매핑.
연구 논문에서 볼 수 있는 많은 레이어는 이미 PyTorch와 같은 현대적인 딥러닝 프레임워크에 구현되어 있습니다.
이를 감안할 때, 이러한 레이어와 잔차 연결을 PyTorch 코드로 재현하기 위해 다음을 사용할 수 있습니다. * 멀티헤드 셀프 어텐션 (MSA) - torch.nn.MultiheadAttention(). * 노름 (LN 또는 LayerNorm) - torch.nn.LayerNorm(). * 잔차 연결 (Residual connection) - 입력과 출력을 더합니다 (나중에 전체 트랜스포머 인코더 블록을 만들 때 살펴보겠습니다).
5.1 LayerNorm (LN) 레이어
레이어 정규화(Layer Normalization)(torch.nn.LayerNorm() 또는 Norm 또는 LayerNorm 또는 LN)는 마지막 차원에 대해 입력을 정규화합니다.
normalized_shape를 정규화하려는 차원 크기와 동일하게 설정할 수 있습니다(우리의 경우에는 ViT-Base용 \(D\) 또는 768이 됩니다).
torch.nn.LayerNorm()의 공식 정의는 PyTorch 문서에서 찾을 수 있습니다.
이게 무슨 역할을 할까요?
레이어 정규화는 훈련 시간과 모델 일반화(보이지 않는 데이터에 적응하는 능력)를 개선하는 데 도움이 됩니다.
나는 어떤 종류의 정규화이든 “데이터를 유사한 형식으로 만드는 것” 또는 “데이터 샘플을 유사한 분포로 만드는 것”으로 생각하기를 좋아합니다.
높이와 길이가 모두 다른 계단을 (위아래로) 걸어간다고 상상해 보세요.
각 단계마다 조정이 필요하겠죠?
그리고 각 단계에서 배우는 내용이 계단이 모두 다르기 때문에 다음 단계에 반드시 도움이 되는 것은 아닙니다.
정규화(레이어 정규화 포함)는 계단이 데이터 샘플이라는 점을 제외하면 모든 계단을 동일한 높이와 길이로 만드는 것과 같습니다.
따라서 높이와 길이가 비슷한 계단을 높이와 너비가 불규칙한 계단보다 훨씬 쉽게 오르내릴 수 있는 것처럼, 신경망은 분포가 다양한 데이터 샘플보다 분포가 비슷한 데이터 샘플(평균과 표준편차가 비슷함)에서 더 쉽게 최적화할 수 있습니다.
5.2 멀티헤드 셀프 어텐션 (MSA) 레이어
셀프 어텐션(self-attention)과 멀티헤드 어텐션(셀프 어텐션이 여러 번 적용됨)의 강력함은 Attention is all you need 연구 논문에서 소개된 원본 트랜스포머 아키텍처의 형태로 드러났습니다.
트랜스포머 아키텍처 및 어텐션 매커니즘에 대해 자세히 알아볼 수 있는 온라인 리소스는 Jay Alammar의 훌륭한 Illustrated Transformer 게시물 및 Illustrated Attention 게시물 등이 있습니다.
하지만 우리는 자체적으로 만들기보다는 기존 PyTorch MSA 구현을 코딩하는 데 더 집중할 것입니다.
그러나 ViT 논문의 MSA 구현에 대한 공식 정의는 부록 A에 정의되어 있습니다.
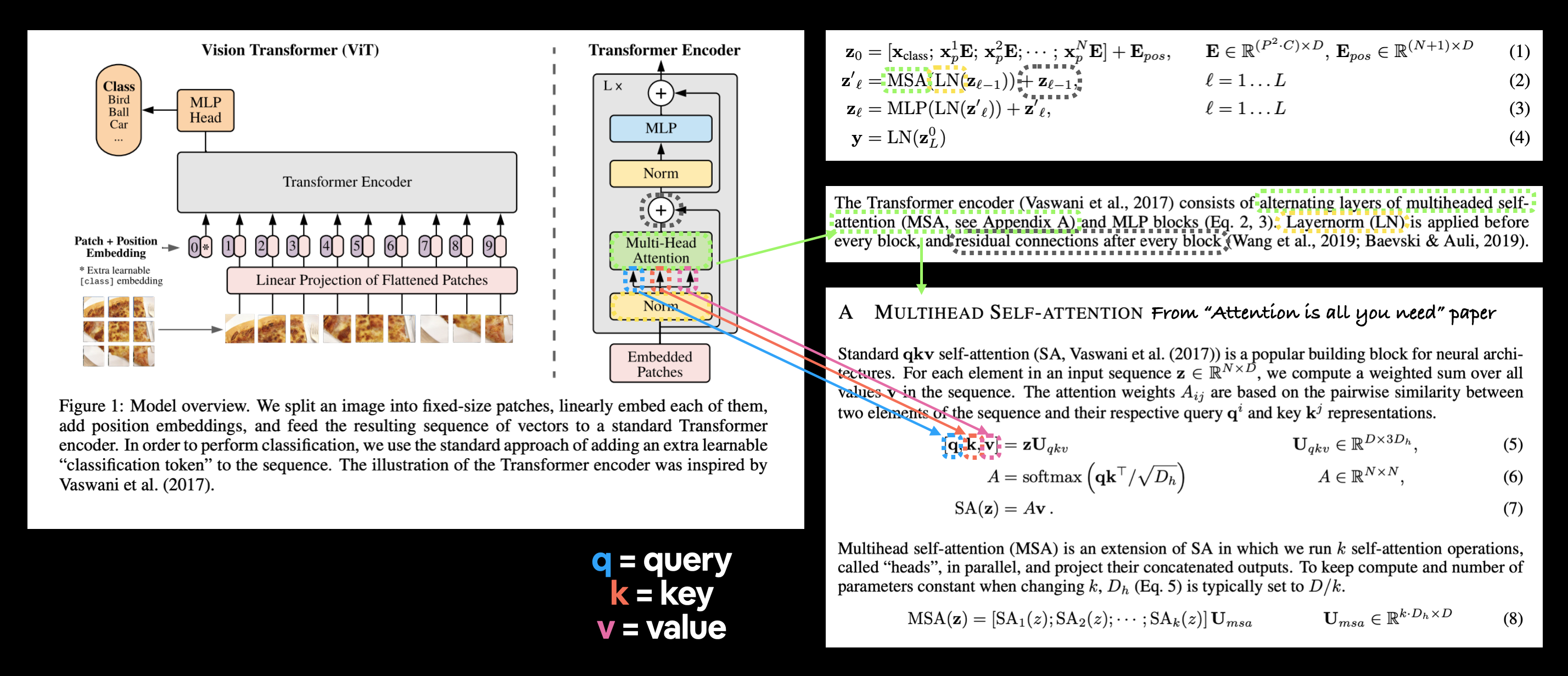
왼쪽: ViT 논문의 그림 1에서 가져온 Vision Transformer 아키텍처 개요. 오른쪽: 그림 1의 각 부분을 반영하도록 강조된 ViT 논문의 식 2, 섹션 3.1 및 부록 A의 정의.
위 이미지는 MSA 레이어에 대한 삼중 입력을 강조합니다.
이는 셀프 어텐션 메커니즘의 기본인 쿼리(query), 키(key), 값(value) 입력 또는 줄여서 qkv로 알려져 있습니다.
우리의 경우 삼중 입력은 Norm 레이어 출력의 세 가지 버전이 됩니다.
또는 섹션 4.8에서 생성된 레이어 정규화된 이미지 패치 및 위치 임베딩의 세 가지 버전입니다.
다음 매개변수와 함께 torch.nn.MultiheadAttention()을 사용하여 PyTorch에서 MSA 레이어를 구현할 수 있습니다. * embed_dim: 표 1의 임베딩 차원(은닉 크기 \(D\)). * num_heads: 사용할 어텐션 헤드 수(“멀티헤드”라는 용어가 여기서 유래됨), 이 값도 표 1(헤드)에 있습니다. * dropout: 어텐션 레이어에 드롭아웃을 적용할지 여부(부록 B.1에 따르면 qkv-투영 후에는 드롭아웃이 사용되지 않음).
5.3 식 2를 PyTorch 레이어로 재현하기
방정식 2의 LayerNorm(LN) 및 Multi-Head Attention(MSA) 레이어에 대해 논의한 모든 내용을 실제로 적용해 보겠습니다.
이를 위해 다음을 수행합니다.
torch.nn.Module을 상속받는MultiheadSelfAttentionBlock()이라는 클래스를 만듭니다.- ViT-Base 모델에 대한 ViT 논문의 표 1 하이퍼파라미터로 클래스를 초기화합니다.
- 임베딩 차원(표 1의 \(D\))과 동일한
normalized_shape매개변수를 사용하여torch.nn.LayerNorm()으로 레이어 정규화(LN) 레이어를 만듭니다. - 적절한
embed_dim,num_heads,dropout및batch_first매개변수를 사용하여 멀티헤드 어텐션(MSA) 레이어를 만듭니다. - LN 레이어와 MSA 레이어를 통해 입력을 전달하는 클래스의
forward()메서드를 만듭니다.
# 1. nn.Module을 상속받는 클래스 생성
class MultiheadSelfAttentionBlock(nn.Module):
"""멀티헤드 셀프 어텐션 블록(줄여서 "MSA 블록")을 만듭니다.
"""
# 2. 표 1의 하이퍼파라미터를 사용하여 클래스 초기화
def __init__(self,
embedding_dim:int=768, # ViT-Base용 표 1에서 가져옴
num_heads:int=12, # ViT-Base용 표 1에서 가져옴
attn_dropout:int=0): # 논문에서는 MSABlocks에서 드롭아웃을 사용하지 않는 것 같음
super().__init__()
# 3. 노름 레이어(LN) 생성
self.layer_norm = nn.LayerNorm(normalized_shape=embedding_dim)
# 4. 멀티헤드 어텐션(MSA) 레이어 생성
self.multihead_attn = nn.MultiheadAttention(embed_dim=embedding_dim,
num_heads=num_heads,
dropout=attn_dropout,
batch_first=True) # 배치 차원이 먼저 오나요?
# 5. 레이어를 통해 데이터를 전달하는 forward() 메서드 생성
def forward(self, x):
x = self.layer_norm(x)
attn_output, _ = self.multihead_attn(query=x, # 쿼리 임베딩
key=x, # 키 임베딩
value=x, # 값 임베딩
need_weights=False) # 가중치가 필요한가요, 아니면 레이어 출력만 필요한가요?
return attn_output참고: 그림 1과 달리, 우리의
MultiheadSelfAttentionBlock()은 스킵 또는 잔차 연결(식 2의 “\(+\mathbf{z}_{\ell-1}\)”)을 포함하지 않는데, 나중에 전체 트랜스포머 인코더를 만들 때 이를 포함시킬 것입니다.
MSABlock이 생성되었습니다!
MultiheadSelfAttentionBlock의 인스턴스를 만들고 섹션 4.8에서 생성한 patch_and_position_embedding 변수를 통과시켜 시도해 보겠습니다.
# MSABlock 인스턴스 생성
multihead_self_attention_block = MultiheadSelfAttentionBlock(embedding_dim=768, # 표 1에서 가져옴
num_heads=12) # 표 1에서 가져옴
# 패치 및 위치 이미지 임베딩을 MSABlock에 통과시킴
patched_image_through_msa_block = multihead_self_attention_block(patch_and_position_embedding)
print(f"MSA 블록의 입력 모양: {patch_and_position_embedding.shape}")
print(f"MSA 블록의 출력 모양: {patched_image_through_msa_block.shape}")데이터가 MSA 블록을 통과할 때 입력 및 출력 모양이 동일하게 유지되는 것을 확인하세요.
이는 데이터가 통과하면서 변경되지 않는다는 것을 의미하지는 않습니다.
입력 및 출력 텐서를 출력하여 어떻게 변하는지 확인할 수 있습니다(단, 이 변화는 1 * 197 * 768 값에 걸쳐 발생합니다).
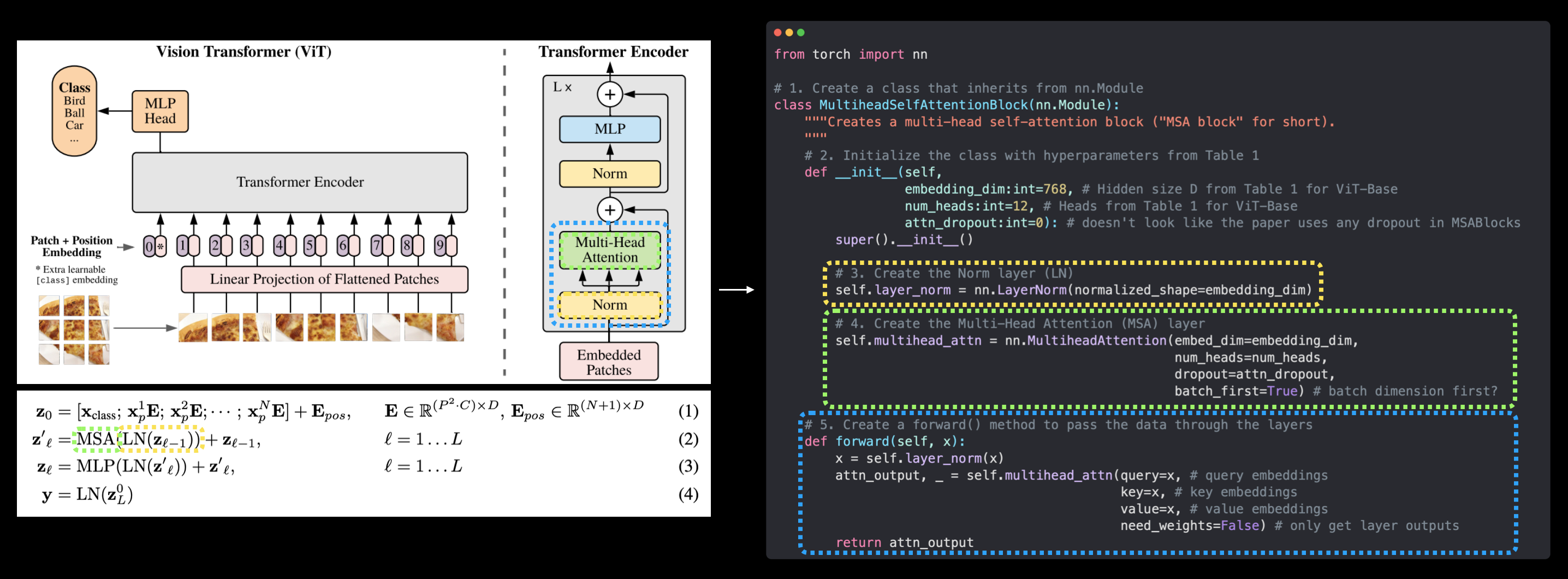
왼쪽: 그림 1에서 Multi-Head Attention 및 LayerNorm 레이어가 강조된 Vision Transformer 아키텍처. 이러한 레이어는 논문 섹션 3.1의 식 2를 구성합니다. 오른쪽: PyTorch 레이어를 사용하여 식 2(끝 부분의 스킵 연결 제외)를 재현합니다.
이제 공식적으로 방정식 2를 재현했습니다(끝부분의 잔차 연결은 제외되었지만 섹션 7에서 다룰 것입니다)!
다음으로 가봅시다!
TK 6. 식 3: 다층 퍼셉트론 (MLP)
여기까지: * 식 2를 재현한 것처럼 식 3을 재현합니다.
- TK는 “피드포워드(feedforward)”라고도 불립니다.
드롭아웃이 사용되는 경우, qkv-투영을 제외한 모든 밀집 레이어 뒤와 위치-패치 임베딩을 추가한 직후에 적용됩니다.
MLP에는 GELU 비선형성이 있는 두 개의 레이어가 포함됩니다.
\[ \begin{aligned} \mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+\mathbf{z}_{\ell}^{\prime}, & & \ell=1 \ldots L \end{aligned} \]
- TK - PyTorch의 GELU – https://pytorch.org/docs/stable/generated/torch.nn.GELU.html
# "피드포워드(FeedForward)"라고도 부를 수 있습니다.
class MLPBlock(nn.Module):
"""Vision Transformer 아키텍처의 MLPBlock을 만듭니다."""
def __init__(self,
embedding_dim, # 임베딩 차원 (표 1의 은닉 크기 D)
mlp_size, # 표 1의 MLP 크기
dropout=0): # "드롭아웃...은 모든 밀집 레이어에 적용됩니다... (부록 B.1)"
super().__init__()
self.layer_norm = nn.LayerNorm(normalized_shape=embedding_dim)
self.mlp = nn.Sequential(
nn.Linear(in_features=embedding_dim,
out_features=mlp_size),
nn.GELU(), # "MLP에는 GELU 비선형성을 갖는 두 개의 레이어가 포함됩니다(섹션 3.1)."
nn.Dropout(p=dropout),
nn.Linear(in_features=mlp_size, # 위 레이어의 out_features와 동일한 in_features를 가져야 함
out_features=embedding_dim), # 다시 embedding_dim으로 가져옴
nn.Dropout(p=dropout)
)
def forward(self, x):
x = self.layer_norm(x)
x = self.mlp(x)
return xmlp_block = MLPBlock(embedding_dim=768, # 표 1
mlp_size=3072) # 표 1
patched_image_through_mlp_block = mlp_block(patched_image_through_msa_block)
patched_image_through_mlp_block.shapeTK 7. 트랜스포머 인코더 생성
- Tk - “인코더(encoder)”란 무엇인가요?
- Tk - “트랜스포머 블록” 또는 “트랜스포머 인코더”? - 논문과 일치시키세요
사전 구축된 트랜스포머 블록/레이어는 여기를 참조하세요: https://pytorch.org/docs/stable/nn.html#transformer-layers
class TransformerEncoderBlock(nn.Module):
"""트랜스포머 인코더 블록을 만듭니다."""
def __init__(self,
embedding_dim=768, # 표 1에서 가져옴
num_heads=12, # 표 1에서 가져옴
mlp_size=3072, # 표 1에서 가져옴
mlp_dropout=0.1,
attn_dropout=0):
super().__init__()
# MSA 블록 생성 (식 2용)
self.msa_block = MultiheadSelfAttentionBlock(embedding_dim=embedding_dim,
num_heads=num_heads,
attn_dropout=attn_dropout)
# MLP 블록 생성 (식 3용)
self.mlp_block = MLPBlock(embedding_dim=embedding_dim,
mlp_size=mlp_size,
dropout=mlp_dropout)
def forward(self, x):
x = self.msa_block(x) + x # 스킵 연결 생성
x = self.mlp_block(x) + x # 스킵 연결 생성
return xTK 8. 전체 과정 합치기: ViT 생성
TK - 이를 TransformerEncoderLayer로 재현하세요 - https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/
트랜스포머 블록과 패치된 임베딩을 결합하여 ViT 아키텍처를 만듭니다.
class ViT(nn.Module):
"""Vision Transformer 아키텍처를 만듭니다."""
def __init__(self,
img_size=224, # ViT 논문의 표 3에서 가져옴
in_channels=3,
patch_size=16,
num_transformer_layers=12, # ViT 논문의 표 1에서 가져옴
embedding_dim=768,
mlp_size=3072,
num_heads=12,
attn_dropout=0,
mlp_dropout=0.1,
embedding_dropout=0.1,
num_classes=1000): # ImageNet용 기본값
super().__init__() # super().__init__()을 잊지 마세요!
# 이미지 크기 가져오기
self.img_height, self.img_width = img_size, img_size
# 패치 수 계산 (높이 * 너비 / 패치^2)
self.num_patches = (self.img_height * self.img_width) // patch_size**2
# 클래스 임베딩 생성 (시퀀스 임베딩 앞에 와야 함)
self.class_embedding = nn.Parameter(data=torch.randn(1, 1, embedding_dim),
requires_grad=True)
# 위치 임베딩 생성
self.position_embedding = nn.Parameter(data=torch.randn(1, self.num_patches+1, embedding_dim),
requires_grad=True)
# 임베딩 드롭아웃 생성
self.embedding_dropout = nn.Dropout(p=embedding_dropout)
# 패치 임베딩 레이어 생성
self.patch_embedding = PatchEmbedding(in_channels=in_channels,
patch_size=patch_size,
embedding_dim=embedding_dim)
# 트랜스포머 인코더 블록 생성
self.transformer_enedoder = nn.Sequential(*[TransformerEncoderBlock(embedding_dim=embedding_dim,
num_heads=num_heads,
mlp_size=mlp_size,
mlp_dropout=mlp_dropout) for _ in range(num_transformer_layers)])
# 분류 헤드 생성 (식 4)
self.classifier = nn.Sequential(
nn.LayerNorm(normalized_shape=embedding_dim),
nn.Linear(in_features=embedding_dim,
out_features=num_classes)
)
def forward(self, x):
# 배치 크기 가져오기
batch_size = x.shape[0]
# 클래스 토큰 임베딩 생성
class_token = self.class_embedding.expand(batch_size, -1, -1)
# 패치 임베딩 생성
x = self.patch_embedding(x)
# 클래스 임베딩과 패치 임베딩 연결 (식 1)
x = torch.cat((class_token, x), dim=1)
# 모든 배치에 대해 패치 임베딩에 위치 임베딩 추가 (식 1)
x = self.position_embedding + x
# 임베딩 드롭아웃 실행
x = self.embedding_dropout(x)
# 트랜스포머 인코더 레이어를 통해 패치, 위치 및 클래스 임베딩 전달 (식 2 및 3)
x = self.transformer_enedoder(x)
# 분류기를 통해 0번 인덱스 로짓 입력 (식 4)
x = self.classifier(x[:, 0]) # 배치의 각 샘플에 대해 0번 인덱스에서 실행
return x
batch_size = 32
class_tokens = nn.Parameter(data=torch.randn(1, 1, 768))
class_tokens.expand(batch_size, -1, -1).shapeset_seeds()
device = "cuda" if torch.cuda.is_available() else "cpu"
rand_image = torch.randn(1, 3, 224, 224)
# vit = ViT(num_classes=len(class_names))
vit = ViT(num_classes=3)
vit(rand_image)TK 9. 모델 검사
참고: 너무 크게 설정하면 하드웨어가 감당하지 못할 수도 있습니다… (예: 배치 크기가 너무 큼…)
TK - 파라미터 수는 다음 사이트와 동일해야 함: https://pytorch.org/vision/main/models/generated/torchvision.models.vit_b_16.html#torchvision.models.vit_b_16 (num_params=86,567,656)
from torchinfo import summary
# TK - 요약을 정리하여 출력 시 보기 좋게 만듭니다.
# torchinfo를 사용하여 요약 출력 (실제 출력을 보려면 주석 해제)
summary(model=vit,
input_size=(128, 3, 224, 224), # "input_shape"이 아닌 "input_size"인지 확인
# col_names=["input_size"], # 더 작은 출력을 원할 시 주석 해제
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)- TK - 다음 사이트와 동일한 파라미터 수: https://pytorch.org/vision/main/models/generated/torchvision.models.vit_b_16.html#torchvision.models.vit_b_16 -> 86567656
batch_size = 32
cls_embedding = nn.Parameter(torch.randn(1, 1, 768))
# 여기 참조: https://pytorch.org/docs/stable/generated/torch.Tensor.expand.html
cls_embedding.shape, cls_embedding.expand(batch_size, -1, -1).shapeTK 10. 모델 훈련
from going_modular.going_modular import engine
optimizer = torch.optim.Adam(params=vit.parameters(),
lr=1e-3,
betas=(0.9, 0.999), # 기본값
weight_decay=0.1) # ViT 논문 섹션 4.1에서 가져옴
loss_fn = torch.nn.CrossEntropyLoss()
set_seeds()
results = engine.train(model=vit,
train_dataloader=train_dataloader,
test_dataloader=test_dataloader,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=10,
device=device)TK 11. 모델 평가
TK - 손실 곡선 플롯
from helper_functions import plot_loss_curves
plot_loss_curves(results)TK - 손실 곡선이 왜 그런 식으로 나타날까요? (모델이 너무 크고 데이터가 충분하지 않음)
TK 12. 동일한 데이터셋에서 torchvision.models의 사전 훈련된 ViT 가져오기
- 여기에서 비슷한 모델 가져오기 - https://pytorch.org/vision/main/models/generated/torchvision.models.vit_b_16.html#torchvision.models.vit_b_16
# 다음은 torch v0.12+ 및 torchvision v0.13+가 필요합니다.
import torch
import torchvision
print(torch.__version__)
print(torchvision.__version__)device = "cuda" if torch.cuda.is_available() else "cpu"
device# 시드 설정
def set_seeds(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)# torchvision >= 0.13 필요
pretrained_vit_weights = torchvision.models.ViT_B_16_Weights.DEFAULT
pretrained_vit = torchvision.models.vit_b_16(weights=pretrained_vit_weights).to(device)
# 기본 파라미터 고정
for parameter in pretrained_vit.parameters():
parameter.requires_grad = False
# 분류 헤드 변경
set_seeds()
pretrained_vit.heads = nn.Linear(in_features=768, out_features=len(class_names)).to(device)# torchinfo를 사용하여 요약 출력 (실제 출력을 보려면 주석 해제)
summary(model=pretrained_vit,
input_size=(128, 3, 224, 224), # "input_shape"이 아닌 "input_size"인지 확인
# col_names=["input_size"], # 더 작은 출력을 원할 시 주석 해제
col_names=["input_size", "output_size", "num_params", "trainable"],
col_width=20,
row_settings=["var_names"]
)# TK - 위 출력은 우리가 직접 만든 모델과 동일한 수의 파라미터를 가지고 있습니다.# GitHub에서 피자, 스테이크, 초밥 이미지 다운로드
image_path = download_data(source="https://github.com/mrdbourke/pytorch-deep-learning/raw/main/data/pizza_steak_sushi.zip",
destination="pizza_steak_sushi")
image_pathtrain_dir = image_path / "train"
test_dir = image_path / "test"
train_dir, test_dir# 사전 훈련된 ViT를 위한 데이터셋 생성
pretrained_vit_transforms = pretrained_vit_weights.transforms()
print(pretrained_vit_transforms)
train_dataloader_pretrained, test_dataloader_pretrained, class_names = data_setup.create_dataloaders(train_dir=train_dir,
test_dir=test_dir,
transform=pretrained_vit_transforms,
batch_size=1024) # 여기에서 가져옴: https://arxiv.org/abs/2205.01580 (다른 개선 사항도 있음...)# 피자, 스테이크, 초밥에 대해 사전 훈련된 특성 추출기 ViT를 10 에포크 동안 훈련
# TK - 전체 모델을 훈련하는 것이 아니라 특성 추출을 사용하므로 여기에서 batch_size를 늘릴 수 있을 것입니다.
from going_modular.going_modular import engine
optimizer = torch.optim.Adam(params=pretrained_vit.parameters(),
lr=1e-3)
loss_fn = torch.nn.CrossEntropyLoss()
set_seeds()
pretrained_vit_results = engine.train(model=pretrained_vit,
train_dataloader=train_dataloader_pretrained,
test_dataloader=test_dataloader_pretrained,
optimizer=optimizer,
loss_fn=loss_fn,
epochs=10,
device=device)# 손실 곡선 플롯
from helper_functions import plot_loss_curves
plot_loss_curves(pretrained_vit_results) # 모델 저장
from going_modular.going_modular import utils
utils.save_model(model=pretrained_vit,
target_dir="models",
model_name="08_pretrained_vit_feature_extractor_pizza_steak_sushi.pth")from pathlib import Path
# 모델 크기를 바이트 단위로 가져온 다음 메가바이트로 변환
pretrained_vit_model_size = Path("models/08_pretrained_vit_feature_extractor_pizza_steak_sushi.pth").stat().st_size // (1024*1024)
print(f"사전 훈련된 ViT 특성 추출기 모델 크기: {pretrained_vit_model_size} MB")TK - 이 재현에서 빠진 부분들
TK 논문과 이 재현의 차이점 기록 * 이 중 상당수는 표 3에 있습니다. * 훈련 데이터 (바닥부터 훈련한 ImageNet vs FoodVision Mini 데이터) * LR 웜업(warmup) * LR 감쇠(decay) * 가중치 감쇠(Weight decay) * 에포크 수
TK - 연습 문제
TK - 추가 학습 자료
- layernorm
- 트랜스포머 모델의 개요를 보려면 illustrated transformer를 참조하세요: https://jalammar.github.io/illustrated-transformer/ + https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
- Attention is all you need 논문 - Yannic 비디오
- Vision transformer - yannic 비디오