from sklearn.datasets import make_circles
# 1000개의 샘플 생성
n_samples = 1000
# 원 생성
X, y = make_circles(n_samples,
noise=0.03, # 점들에 약간의 노이즈 추가
random_state=42) # 동일한 값을 얻기 위해 무작위 상태 유지02 - PyTorch 신경망 분류
![]()
분류 문제란 무엇인가요?
분류 문제는 어떤 대상이 한 가지인지 아니면 다른 것인지 예측하는 것과 관련이 있습니다.
예를 들어, 다음과 같은 작업을 원할 수 있습니다:
| 문제 유형 | 설명 | 예시 |
|---|---|---|
| 이진 분류 (Binary classification) | 타겟이 두 가지 옵션 중 하나임 (예: 예 또는 아니오) | 건강 파라미터를 기반으로 심장병 유무 예측 |
| 다중 클래스 분류 (Multi-class classification) | 타겟이 세 가지 이상의 옵션 중 하나임 | 사진이 음식, 사람, 강아지 중 무엇인지 결정 |
| 다중 레이블 분류 (Multi-label classification) | 타겟에 하나 이상의 옵션을 할당할 수 있음 | 위키피디아 기사에 할당될 카테고리 예측 (예: 수학, 과학, 철학) |

분류는 회귀(숫자 예측, 노트북 01에서 다룸)와 함께 머신러닝에서 가장 흔한 문제 유형 중 하나입니다.
이 노트북에서는 PyTorch를 사용하여 몇 가지 다른 분류 문제를 해결해 볼 것입니다.
즉, 일련의 입력을 가져와서 해당 입력이 어떤 클래스에 속하는지 예측하는 것입니다.
이번 장에서 다룰 내용
이 노트북에서는 노트북 01에서 다루었던 PyTorch 워크플로우를 반복해서 살펴볼 것입니다.
다만 직선을 예측하는 대신(회귀 문제), 분류 문제를 다룰 것입니다.
구체적으로 다음 내용을 다룹니다:
| 주제 | 내용 |
|---|---|
| 0. 분류 신경망의 구조 | 신경망은 거의 모든 모양이나 크기를 가질 수 있지만, 일반적으로 유사한 기본 설계를 따릅니다. |
| 1. 이진 분류 데이터 준비하기 | 데이터는 무엇이든 될 수 있지만, 시작하기 위해 간단한 이진 분류 데이터셋을 만들 것입니다. |
| 2. PyTorch 분류 모델 구축하기 | 데이터의 패턴을 학습할 모델을 만들고, 분류에 특화된 손실 함수, 옵티마이저 및 훈련 루프를 선택할 것입니다. |
| 3. 데이터에 모델 맞추기 (훈련) | 데이터와 모델이 준비되었으므로, 이제 모델이 (훈련) 데이터에서 패턴을 찾도록 해봅시다. |
| 4. 예측 및 모델 평가 (추론) | 모델이 데이터에서 패턴을 찾았으니, 그 결과를 실제 (테스트) 데이터와 비교해 봅시다. |
| 5. 모델 개선하기 (모델 관점에서) | 모델을 훈련하고 평가했지만 성능이 좋지 않다면, 개선을 위해 몇 가지 방법을 시도해 봅니다. |
| 6. 비선형성 (Non-linearity) | 지금까지 우리 모델은 직선만 모델링할 수 있었습니다. 곡선(비선형)은 어떻게 처리할까요? |
| 7. 비선형 함수 복제하기 | 비선형 데이터를 모델링하기 위해 비선형 함수를 사용했는데, 이들은 어떤 모습일까요? |
| 8. 전체 과정 합치기 (다중 클래스 분류) | 지금까지 이진 분류를 위해 수행한 모든 작업을 다중 클래스 분류 문제와 하나로 합쳐 봅니다. |
도움을 받을 수 있는 곳
이 과정의 모든 자료는 GitHub에 있습니다.
문제가 발생하면 해당 페이지의 Discussions 페이지에서 질문할 수 있습니다.
또한 PyTorch와 관련된 모든 것에 대해 매우 도움이 되는 장소인 PyTorch 개발자 포럼도 있습니다.
0. 분류 신경망의 구조
코드를 작성하기 전에 분류 신경망의 일반적인 구조를 살펴보겠습니다.
| 하이퍼파라미터 | 이진 분류 (Binary Classification) | 다중 클래스 분류 (Multiclass classification) |
|---|---|---|
입력 레이어 모양 (in_features) |
특성의 수와 동일 (예: 심장병 예측에서 나이, 성별, 키, 몸무게, 흡연 여부 등 5개) | 이진 분류와 동일 |
| 은닉 레이어 (Hidden layer) | 문제에 따라 다름, 최소 1개, 최대 무제한 | 이진 분류와 동일 |
| 은닉 레이어당 뉴런 수 | 문제에 따라 다름, 일반적으로 10 ~ 512개 | 이진 분류와 동일 |
출력 레이어 모양 (out_features) |
1 (두 클래스 중 하나) | 클래스당 1개 (예: 음식, 사람, 강아지 사진의 경우 3개) |
| 은닉 레이어 활성화 함수 | 주로 ReLU (rectified linear unit)를 사용하지만 다른 함수도 가능 | 이진 분류와 동일 |
| 출력 레이어 활성화 함수 | Sigmoid (PyTorch에서는 torch.sigmoid) |
Softmax (PyTorch에서는 torch.softmax) |
| 손실 함수 (Loss function) | Binary crossentropy (PyTorch에서는 torch.nn.BCELoss) |
Cross entropy (PyTorch에서는 torch.nn.CrossEntropyLoss) |
| 옵티마이저 (Optimizer) | SGD, Adam (더 많은 옵션은 torch.optim 참조) |
이진 분류와 동일 |
물론 분류 신경망 구성 요소의 이 목록은 작업 중인 문제에 따라 달라질 수 있습니다.
하지만 시작하기에는 충분합니다.
이 노트북 전체에서 이 설정을 직접 실습해 볼 것입니다.
1. 분류 데이터 생성 및 준비
먼저 데이터를 생성해 보겠습니다.
Scikit-Learn의 make_circles() 메서드를 사용하여 서로 다른 색상의 점으로 구성된 두 개의 원을 생성합니다.
좋습니다. 이제 처음 5개의 X와 y 값을 확인해 보겠습니다.
print(f"처음 5개의 X 특성:\n{X[:5]}")
print(f"\n처음 5개의 y 레이블:\n{y[:5]}")First 5 X features:
[[ 0.75424625 0.23148074]
[-0.75615888 0.15325888]
[-0.81539193 0.17328203]
[-0.39373073 0.69288277]
[ 0.44220765 -0.89672343]]
First 5 y labels:
[1 1 1 1 0]하나의 y 값당 두 개의 X 값이 있는 것 같습니다.
데이터 탐험가의 좌우명인 시각화, 시각화, 시각화를 따라 데이터를 pandas DataFrame에 넣어 보겠습니다.
# 원 데이터의 DataFrame 생성
import pandas as pd
circles = pd.DataFrame({"X1": X[:, 0],
"X2": X[:, 1],
"label": y
})
circles.head(10)| X1 | X2 | label | |
|---|---|---|---|
| 0 | 0.754246 | 0.231481 | 1 |
| 1 | -0.756159 | 0.153259 | 1 |
| 2 | -0.815392 | 0.173282 | 1 |
| 3 | -0.393731 | 0.692883 | 1 |
| 4 | 0.442208 | -0.896723 | 0 |
| 5 | -0.479646 | 0.676435 | 1 |
| 6 | -0.013648 | 0.803349 | 1 |
| 7 | 0.771513 | 0.147760 | 1 |
| 8 | -0.169322 | -0.793456 | 1 |
| 9 | -0.121486 | 1.021509 | 0 |
각 X 특성 쌍(X1 및 X2)에 대해 레이블(y) 값이 0 또는 1인 것처럼 보입니다.
옵션이 두 가지(0 또는 1)뿐이므로 이 문제가 이진 분류(binary classification)임을 알 수 있습니다.
각 클래스의 값은 몇 개입니까?
# 서로 다른 레이블 확인
circles.label.value_counts()1 500
0 500
Name: label, dtype: int64각각 500개씩 균형이 잘 잡혀 있습니다.
플롯해 봅시다.
# 플롯으로 시각화
import matplotlib.pyplot as plt
plt.scatter(x=X[:, 0],
y=X[:, 1],
c=y,
cmap=plt.cm.RdYlBu);
좋습니다. 해결해야 할 문제가 생긴 것 같네요.
점들을 빨간색(0) 또는 파란색(1)으로 분류하기 위해 PyTorch 신경망을 어떻게 구축할 수 있는지 알아봅시다.
참고: 이 데이터셋은 머신러닝에서 종종 토이 문제(toy problem)(무언가를 시도하고 테스트하는 데 사용되는 문제)로 간주됩니다.
하지만 이것은 분류의 주요 핵심을 나타냅니다. 수치로 표현된 어떤 데이터가 있고 그것을 분류할 수 있는 모델, 우리의 경우에는 빨간색 또는 파란색 점으로 분리할 수 있는 모델을 만들고자 하는 것입니다.
1.1 입력 및 출력 모양
딥러닝에서 가장 흔한 오류 중 하나는 모양(shape) 오류입니다.
텐서의 모양과 텐서 연산의 모양이 맞지 않으면 모델에 오류가 발생합니다.
이 과정 전반에 걸쳐 이러한 사례를 많이 보게 될 것입니다.
그리고 그것이 발생하지 않도록 보장하는 확실한 방법은 없습니다. 발생할 것입니다.
대신 할 수 있는 일은 작업 중인 데이터의 모양에 지속적으로 익숙해지는 것입니다.
저는 이를 입력 및 출력 모양이라고 부르는 것을 좋아합니다.
스스로에게 물어보세요:
“내 입력의 모양은 무엇이고 출력의 모양은 무엇인가?”
알아봅시다.
# 특성과 레이블의 모양 확인
X.shape, y.shape((1000, 2), (1000,))각각의 첫 번째 차원이 일치하는 것 같습니다.
1000개의 X와 1000개의 y가 있습니다.
하지만 X의 두 번째 차원은 무엇일까요?
단일 샘플(특성 및 레이블)의 값과 모양을 확인하는 것이 종종 도움이 됩니다.
그렇게 하면 모델에서 어떤 입력 및 출력 모양을 기대해야 하는지 이해하는 데 도움이 됩니다.
# 특성 및 레이블의 첫 번째 예시 확인
X_sample = X[0]
y_sample = y[0]
print(f"X 한 샘플의 값: {X_sample}, y 한 샘플의 값: {y_sample}")
print(f"X 한 샘플의 모양: {X_sample.shape}, y 한 샘플의 모양: {y_sample.shape}")Values for one sample of X: [0.75424625 0.23148074] and the same for y: 1
Shapes for one sample of X: (2,) and the same for y: ()이는 X의 두 번째 차원이 두 개의 특성(벡터)을 가짐을 의미하며, 반면 y는 단일 특성(스칼라)을 가짐을 알려줍니다.
하나의 출력에 대해 두 개의 입력이 있습니다.
1.2 데이터를 텐서로 변환하고 훈련 및 테스트 분할 생성
데이터의 입력 및 출력 모양을 조사했으므로, 이제 PyTorch와 모델링에 사용할 수 있도록 준비해 보겠습니다.
구체적으로 다음 작업이 필요합니다: 1. 데이터를 텐서로 변환합니다 (현재 데이터는 NumPy 배열이며 PyTorch는 PyTorch 텐서로 작업하는 것을 선호합니다). 2. 데이터를 훈련 세트와 테스트 세트로 분할합니다 (훈련 세트에서 모델을 훈련하여 X와 y 사이의 패턴을 학습한 다음, 테스트 데이터셋에서 학습된 패턴을 평가합니다).
# 데이터를 텐서로 변환
# 그렇지 않으면 나중에 계산할 때 문제가 발생합니다.
import torch
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# 처음 5개 샘플 확인
X[:5], y[:5](tensor([[ 0.7542, 0.2315],
[-0.7562, 0.1533],
[-0.8154, 0.1733],
[-0.3937, 0.6929],
[ 0.4422, -0.8967]]), tensor([1., 1., 1., 1., 0.]))이제 데이터가 텐서 형식이 되었으므로 훈련 세트와 테스트 세트로 분할해 보겠습니다.
그렇게 하기 위해 Scikit-Learn의 유용한 함수인 train_test_split()을 사용해 봅시다.
test_size=0.2(80% 훈련, 20% 테스트)를 사용하고, 데이터 전체에서 무작위로 분할이 발생하므로 분할을 재현할 수 있도록 random_state=42를 사용합니다.
# 데이터를 훈련 및 테스트 세트로 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2, # 20% 테스트, 80% 훈련
random_state=42) # 무작위 분할을 재현 가능하게 함
len(X_train), len(X_test), len(y_train), len(y_test)(800, 200, 800, 200)좋네요! 이제 800개의 훈련 샘플과 200개의 테스트 샘플이 생겼습니다.
2. 모델 구축하기
데이터가 준비되었으니 이제 모델을 구축할 차례입니다.
몇 가지 부분으로 나누어 보겠습니다.
- 장치에 구애받지 않는 코드 설정 (사용 가능한 경우 모델이 CPU 또는 GPU에서 실행될 수 있도록 함).
nn.Module을 상속하여 모델 구성.- 손실 함수 및 옵티마이저 정의.
- 훈련 루프 생성 (다음 섹션에 나옵니다).
좋은 소식은 노트북 01에서 위의 모든 단계를 이미 거쳤다는 것입니다.
다만 이제는 분류 데이터셋에 맞게 조정할 것입니다.
PyTorch와 torch.nn을 임포트하고 장치에 구애받지 않는 코드를 설정하는 것부터 시작해 봅시다.
# 표준 PyTorch 임포트
import torch
from torch import nn
# 장치에 구애받지 않는 코드 만들기
device = "cuda" if torch.cuda.is_available() else "cpu"
device'cuda'좋습니다. 이제 device가 설정되었으므로 생성하는 모든 데이터나 모델에 이를 사용할 수 있으며, PyTorch는 사용 가능한 경우 CPU(기본값) 또는 GPU에서 이를 처리합니다.
모델을 만들어 볼까요?
우리는 X 데이터를 입력으로 처리하고 y 데이터 모양의 무언가를 출력으로 생성할 수 있는 모델을 원합니다.
즉, X(특성)가 주어지면 모델이 y(레이블)를 예측하기를 원합니다.
특성과 레이블이 있는 이 설정을 지도 학습(supervised learning)이라고 합니다. 데이터가 특정 입력이 주어졌을 때 출력이 무엇이어야 하는지 모델에 알려주기 때문입니다.
이러한 모델을 만들려면 X와 y의 입력 및 출력 모양을 처리해야 합니다.
입력 및 출력 모양이 중요하다고 했던 것을 기억하시나요? 여기서 그 이유를 알게 될 것입니다.
다음과 같은 모델 클래스를 만들어 보겠습니다: 1. nn.Module을 상속합니다 (거의 모든 PyTorch 모델은 nn.Module의 서브클래스입니다). 2. X와 y의 입력 및 출력 모양을 처리할 수 있는 2개의 nn.Linear 레이어를 생성자에 생성합니다. 3. 모델의 순전파 계산을 포함하는 forward() 메서드를 정의합니다. 4. 모델 클래스를 인스턴스화하고 대상 device로 보냅니다.
# 1. nn.Module을 상속하는 모델 클래스 구성
class CircleModelV0(nn.Module):
def __init__(self):
super().__init__()
# 2. X와 y의 입력 및 출력 모양을 처리할 수 있는 2개의 nn.Linear 레이어 생성
self.layer_1 = nn.Linear(in_features=2, out_features=5) # 2개의 특성(X)을 받아 5개의 특성을 생성
self.layer_2 = nn.Linear(in_features=5, out_features=1) # 5개의 특성을 받아 1개의 특성(y)을 생성
# 3. 순전파 계산을 포함하는 forward 메서드 정의
def forward(self, x):
# layer_2의 출력을 반환하며, 이는 y와 동일한 모양의 단일 특성입니다.
return self.layer_2(self.layer_1(x)) # 계산은 layer_1을 먼저 거친 후 layer_1의 출력이 layer_2를 거칩니다.
# 4. 모델의 인스턴스를 생성하고 대상 장치로 보냄
model_0 = CircleModelV0().to(device)
model_0CircleModelV0(
(layer_1): Linear(in_features=2, out_features=5, bias=True)
(layer_2): Linear(in_features=5, out_features=1, bias=True)
)여기서 무슨 일이 일어나고 있나요?
우리는 이전에 이러한 단계 중 몇 가지를 보았습니다.
유일한 주요 변화는 self.layer_1과 self.layer_2 사이에서 일어나는 일입니다.
self.layer_1은 2개의 입력 특성 in_features=2를 가져와서 5개의 출력 특성 out_features=5를 생성합니다.
이를 5개의 은닉 유닛(hidden units) 또는 뉴런을 갖는 것이라고 합니다.
이 레이어는 입력 데이터를 2개의 특성에서 5개의 특성으로 바꿉니다.
왜 이렇게 할까요?
이를 통해 모델은 단지 2개의 숫자가 아닌 5개의 숫자로부터 패턴을 학습할 수 있으며, 이는 잠재적으로 더 나은 출력으로 이어질 수 있습니다.
잠재적이라고 말한 이유는 때때로 작동하지 않기 때문입니다.
신경망 레이어에서 사용할 수 있는 은닉 유닛의 수는 하이퍼파라미터(직접 설정할 수 있는 값)이며, 정해진 값은 없습니다.
일반적으로 많을수록 좋지만 너무 많은 것도 좋지 않을 수 있습니다. 선택하는 양은 모델 유형과 작업 중인 데이터셋에 따라 달라집니다.
우리 데이터셋은 작고 간단하므로 작게 유지하겠습니다.
은닉 유닛의 유일한 규칙은 다음 레이어(우리의 경우 self.layer_2)가 이전 레이어의 out_features와 동일한 in_features를 가져야 한다는 것입니다.
그렇기 때문에 self.layer_2는 in_features=5를 가지며, self.layer_1에서 out_features=5를 가져와 선형 계산을 수행하여 out_features=1(y와 동일한 모양)로 변환합니다.
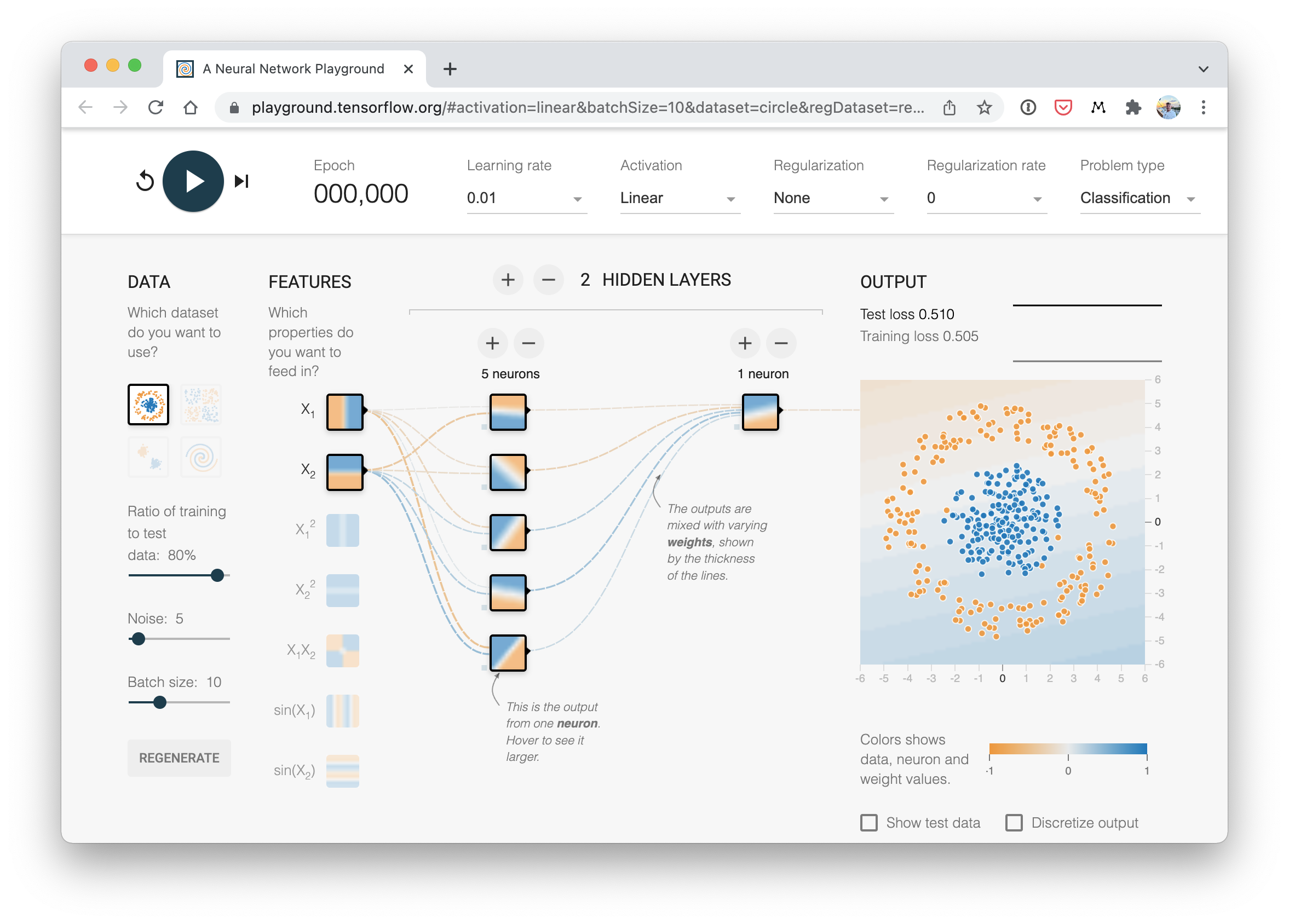 방금 구축한 것과 유사한 분류 신경망이 어떻게 생겼는지에 대한 시각적 예시입니다. TensorFlow Playground 웹사이트에서 직접 만들어 보세요.
방금 구축한 것과 유사한 분류 신경망이 어떻게 생겼는지에 대한 시각적 예시입니다. TensorFlow Playground 웹사이트에서 직접 만들어 보세요.
nn.Sequential을 사용하여 위와 동일하게 수행할 수도 있습니다.
nn.Sequential은 입력 데이터를 나타나는 순서대로 레이어를 통해 순전파 계산을 수행합니다.
# nn.Sequential로 CircleModelV0 복제
model_0 = nn.Sequential(
nn.Linear(in_features=2, out_features=5),
nn.Linear(in_features=5, out_features=1)
).to(device)
model_0Sequential(
(0): Linear(in_features=2, out_features=5, bias=True)
(1): Linear(in_features=5, out_features=1, bias=True)
)와, nn.Module을 상속하는 것보다 훨씬 간단해 보이는데, 왜 항상 nn.Sequential을 사용하지 않을까요?
nn.Sequential은 간단한 계산에는 환상적이지만, 이름에서 알 수 있듯이 항상 순차적으로 실행됩니다.
따라서 단순히 순차적인 계산이 아닌 다른 일이 일어나길 원한다면 고유한 커스텀 nn.Module 서브클래스를 정의하고 싶을 것입니다.
이제 모델이 생겼으니 데이터를 통과시키면 어떻게 되는지 봅시다.
# 모델로 예측하기
untrained_preds = model_0(X_test.to(device))
print(f"예측값의 길이: {len(untrained_preds)}, 모양: {untrained_preds.shape}")
print(f"테스트 샘플의 길이: {len(y_test)}, 모양: {y_test.shape}")
print(f"\n처음 10개의 예측값:\n{untrained_preds[:10]}")
print(f"\n처음 10개의 테스트 레이블:\n{y_test[:10]}")Length of predictions: 200, Shape: torch.Size([200, 1])
Length of test samples: 200, Shape: torch.Size([200])
First 10 predictions:
tensor([[0.7311],
[0.7607],
[0.4336],
[0.8163],
[0.0846],
[0.1053],
[0.4653],
[0.3110],
[0.4488],
[0.7589]], device='cuda:0', grad_fn=<SliceBackward0>)
First 10 test labels:
tensor([1., 0., 1., 0., 1., 1., 0., 0., 1., 0.])음, 예측값의 수는 테스트 레이블의 수와 동일한 것 같지만, 예측값이 테스트 레이블과 동일한 형태나 모양이 아닌 것 같습니다.
이를 해결하기 위해 몇 가지 단계를 수행할 수 있으며, 나중에 살펴볼 것입니다.
2.1 손실 함수 및 옵티마이저 설정
우리는 이전에 노트북 01에서 손실(기준 또는 비용 함수라고도 함)과 옵티마이저를 설정했습니다.
하지만 문제 유형에 따라 서로 다른 손실 함수가 필요합니다.
예를 들어, 회귀 문제(숫자 예측)의 경우 평균 절대 오차(MAE) 손실을 사용할 수 있습니다.
그리고 우리와 같은 이진 분류 문제의 경우, 종종 binary cross entropy를 손실 함수로 사용합니다.
그러나 동일한 옵티마이저 함수는 종종 다른 문제 영역에서도 사용될 수 있습니다.
예를 들어, 확률적 경사 하강법 옵티마이저(SGD, torch.optim.SGD())는 다양한 문제에 사용될 수 있으며 Adam 옵티마이저(torch.optim.Adam())도 마찬가지입니다.
| 손실 함수/옵티마이저 | 문제 유형 | PyTorch 코드 |
|---|---|---|
| 확률적 경사 하강법 (SGD) 옵티마이저 | 분류, 회귀 등 다수 | torch.optim.SGD() |
| Adam 옵티마이저 | 분류, 회귀 등 다수 | torch.optim.Adam() |
| Binary cross entropy 손실 | 이진 분류 | torch.nn.BCELossWithLogits 또는 torch.nn.BCELoss |
| Cross entropy 손실 | 다중 클래스 분류 | torch.nn.CrossEntropyLoss |
| 평균 절대 오차 (MAE) 또는 L1 손실 | 회귀 | torch.nn.L1Loss |
| 평균 제곱 오차 (MSE) 또는 L2 손실 | 회귀 | torch.nn.MSELoss |
다양한 손실 함수 및 옵티마이저 표입니다. 더 많이 있지만 이것들이 자주 보게 될 일반적인 것들입니다.
이진 분류 문제를 다루고 있으므로 binary cross entropy 손실 함수를 사용해 봅시다.
참고: 손실 함수는 모델의 예측이 얼마나 틀렸는지를 측정하는 것이며, 손실이 높을수록 모델의 성능이 좋지 않음을 상기하세요.
또한 PyTorch 문서는 종종 손실 함수를 “loss criterion” 또는 “criterion”이라고 부르기도 하는데, 이들은 모두 같은 것을 설명하는 다른 방식일 뿐입니다.
PyTorch에는 두 가지 binary cross entropy 구현이 있습니다: 1. torch.nn.BCELoss() - 타겟(레이블)과 입력(특성) 사이의 binary cross entropy를 측정하는 손실 함수를 생성합니다. 2. torch.nn.BCEWithLogitsLoss() - 위와 동일하지만 시그모이드 레이어(nn.Sigmoid)가 내장되어 있습니다 (이것이 무엇을 의미하는지 곧 알게 될 것입니다).
어떤 것을 사용해야 할까요?
torch.nn.BCEWithLogitsLoss() 문서는 nn.Sigmoid 레이어 뒤에 torch.nn.BCELoss()를 사용하는 것보다 수치적으로 더 안정적이라고 명시하고 있습니다.
따라서 일반적으로 구현 2가 더 나은 옵션입니다. 그러나 고급 사용의 경우 nn.Sigmoid와 torch.nn.BCELoss()의 조합을 분리하고 싶을 수도 있지만 이는 이 노트북의 범위를 벗어납니다.
이를 바탕으로 손실 함수와 옵티마이저를 생성해 보겠습니다.
옵티마이저의 경우 학습률 0.1로 모델 파라미터를 최적화하기 위해 torch.optim.SGD()를 사용합니다.
참고: PyTorch 포럼에서
nn.BCELoss와nn.BCEWithLogitsLoss사용에 대한 논의가 있습니다. 처음에는 혼란스러울 수 있지만 많은 일들이 그렇듯 연습하면 더 쉬워집니다.
# 손실 함수 생성
# loss_fn = nn.BCELoss() # BCELoss = 시그모이드 내장 안 됨
loss_fn = nn.BCEWithLogitsLoss() # BCEWithLogitsLoss = 시그모이드 내장 됨
# 옵티마이저 생성
optimizer = torch.optim.SGD(params=model_0.parameters(),
lr=0.1)이제 평가 지표(evaluation metric)도 만들어 보겠습니다.
평가 지표는 모델이 어떻게 진행되고 있는지에 대한 또 다른 관점을 제공하는 데 사용될 수 있습니다.
손실 함수가 모델이 얼마나 틀렸는지를 측정한다면, 평가 지표는 모델이 얼마나 맞았는지를 측정하는 것이라고 생각합니다.
물론 이 두 가지가 같은 일을 하고 있다고 주장할 수 있지만, 평가 지표는 다른 관점을 제공합니다.
결국 모델을 평가할 때는 여러 관점에서 사물을 보는 것이 좋습니다.
분류 문제에 사용할 수 있는 여러 평가 지표가 있지만, 정확도(accuracy)부터 시작해 봅시다.
정확도는 총 예측 수 대비 정답 예측 수의 비율로 측정할 수 있습니다.
예를 들어, 100번의 예측 중 99번을 맞게 예측한 모델은 99%의 정확도를 가집니다.
이를 수행하는 함수를 작성해 봅시다.
# 정확도 계산 (분류 지표)
def accuracy_fn(y_true, y_pred):
correct = torch.eq(y_true, y_pred).sum().item() # torch.eq()는 두 텐서가 같은 위치를 계산함
acc = (correct / len(y_pred)) * 100
return acc좋습니다! 이제 모델을 훈련하면서 이 함수를 사용하여 손실과 함께 성능을 측정할 수 있습니다.
3. 모델 훈련하기
자, 이제 손실 함수와 옵티마이저가 준비되었으니 모델을 훈련해 봅시다.
PyTorch 훈련 루프의 단계를 기억하시나요?
기억이 안 난다면 여기 리마인더가 있습니다.
훈련 단계:
PyTorch 훈련 루프 단계
-
순전파 (Forward pass) - 모델이 모든 훈련 데이터를 한 번 훑으며
forward()함수 계산을 수행합니다 (model(x_train)). -
손실 계산 (Calculate the loss) - 모델의 출력(예측)을 정답 레이블과 비교하여 얼마나 틀렸는지 평가합니다 (
loss = loss_fn(y_pred, y_train)). -
옵티마이저 제로 그래디언트 (Zero gradients) - 옵티마이저의 그래디언트를 0으로 설정하여(기본적으로 누적됨) 특정 훈련 단계에 대해 다시 계산할 수 있도록 합니다 (
optimizer.zero_grad()). -
손실에 대한 역전파 수행 (Perform backpropagation on the loss) - 업데이트할 모든 모델 파라미터(
requires_grad=True인 각 파라미터)에 대해 손실의 그래디언트를 계산합니다. 이를 역전파라고 하며, 그래서 “backwards”입니다 (loss.backward()). -
옵티마이저 단계 수행 (경사 하강법) (Step the optimizer) - 손실 그래디언트와 관련하여
requires_grad=True인 파라미터를 업데이트하여 개선합니다 (optimizer.step()).
3.1 원시 모델 출력에서 예측 레이블로 가기 (로짓 -> 예측 확률 -> 예측 레이블)
훈련 루프 단계를 수행하기 전에, 순전파 동안 모델에서 무엇이 나오는지 확인해 봅시다 (순전파는 forward() 메서드에 의해 정의됩니다).
이를 위해 모델에 일부 데이터를 전달해 보겠습니다.
# 테스트 데이터에 대한 순전파의 처음 5개 출력 확인
y_logits = model_0(X_test.to(device))[:5]
y_logitstensor([[0.7311],
[0.7607],
[0.4336],
[0.8163],
[0.0846]], device='cuda:0', grad_fn=<SliceBackward0>)우리 모델은 아직 훈련되지 않았기 때문에 이 출력들은 기본적으로 무작위입니다.
하지만 이것들은 무엇일까요?
이것들은 우리 forward() 메서드의 출력입니다.
내부적으로 다음 방정식을 호출하는 두 개의 nn.Linear() 레이어를 구현합니다:
\[ \mathbf{y} = x \cdot \mathbf{Weights}^T + \mathbf{bias} \]
이 방정식의 원시 출력(수정되지 않은)(\(\mathbf{y}\))과 결과적으로 우리 모델의 원시 출력은 종종 로짓(logits)이라고 불립니다.
모델이 입력 데이터(방정식의 \(x\) 또는 코드의 X_test)를 받아 위에서 출력하는 것이 바로 로짓입니다.
그러나 이러한 숫자는 해석하기 어렵습니다.
우리는 정답 레이블과 비교할 수 있는 숫자를 원합니다.
모델의 원시 출력(로짓)을 이러한 형태로 바꾸기 위해 시그모이드 활성화 함수(sigmoid activation function)를 사용할 수 있습니다.
한번 시도해 봅시다.
# 모델 로짓에 시그모이드 사용
y_pred_probs = torch.sigmoid(y_logits)
y_pred_probstensor([[0.6751],
[0.6815],
[0.6067],
[0.6935],
[0.5211]], device='cuda:0', grad_fn=<SigmoidBackward0>)이제 출력에 어떤 일관성이 생긴 것 같습니다 (여전히 무작위이긴 하지만요).
이제 이들은 예측 확률(prediction probabilities)(저는 주로 y_pred_probs라고 부릅니다) 형태가 되었습니다. 즉, 이 값들은 이제 모델이 해당 데이터 포인트가 특정 클래스에 속한다고 생각하는 정도를 나타냅니다.
우리의 경우 이진 분류를 다루고 있으므로 이상적인 출력은 0 또는 1입니다.
따라서 이러한 값은 결정 경계로 볼 수 있습니다.
0에 가까울수록 모델은 샘플이 클래스 0에 속한다고 생각하고, 1에 가까울수록 모델은 샘플이 클래스 1에 속한다고 생각합니다.
더 구체적으로: * y_pred_probs >= 0.5 이면, y=1 (클래스 1) * y_pred_probs < 0.5 이면, y=0 (클래스 0)
예측 확률을 예측 레이블로 바꾸기 위해 시그모이드 활성화 함수의 출력을 반올림할 수 있습니다.
# 예측 레이블 찾기 (예측 확률 반올림)
y_preds = torch.round(y_pred_probs)
# 전체 과정
y_pred_labels = torch.round(torch.sigmoid(model_0(X_test.to(device))[:5]))
# 동일한지 확인
print(torch.eq(y_preds.squeeze(), y_pred_labels.squeeze()))
# 추가 차원 제거
y_preds.squeeze()tensor([True, True, True, True, True], device='cuda:0')tensor([1., 1., 1., 1., 1.], device='cuda:0', grad_fn=<SqueezeBackward0>)멋지네요! 이제 모델의 예측값이 정답 레이블(y_test)과 동일한 형태가 된 것 같습니다.
y_test[:5]tensor([1., 0., 1., 0., 1.])이는 모델의 예측값을 테스트 레이블과 비교하여 얼마나 잘 진행되고 있는지 확인할 수 있음을 의미합니다.
요약하자면, 시그모이드 활성화 함수를 사용하여 모델의 원시 출력(로짓)을 예측 확률로 변환했습니다.
그런 다음 예측 확률을 반올림하여 예측 레이블로 변환했습니다.
참고: 시그모이드 활성화 함수의 사용은 종종 이진 분류 로짓에만 해당됩니다. 다중 클래스 분류의 경우 소프트맥스 활성화 함수(softmax activation function)의 사용을 살펴볼 것입니다(나중에 나옵니다).
그리고 모델의 원시 출력을
nn.BCEWithLogitsLoss에 전달할 때는 시그모이드 활성화 함수를 사용할 필요가 없습니다(로짓 손실의 “로짓”은 모델의 원시 로짓 출력에서 작동하기 때문입니다). 이는 시그모이드 함수가 내장되어 있기 때문입니다.
3.2 훈련 및 테스트 루프 구축하기
원시 모델 출력을 가져와 예측 레이블로 변환하는 방법을 논의했으므로 이제 훈련 루프를 구축해 보겠습니다.
100 에포크 동안 훈련하고 10 에포크마다 모델의 진행 상황을 출력하는 것부터 시작해 봅시다.
torch.manual_seed(42)
# 에포크 수 설정
epochs = 100
# 데이터를 대상 장치로 이동
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# 훈련 및 평가 루프 구축
for epoch in range(epochs):
### 훈련
model_0.train()
# 1. 순전파 (모델은 원시 로짓을 출력함)
y_logits = model_0(X_train).squeeze() # 추가 '1' 차원을 제거하기 위해 스퀴즈, 모델과 데이터가 동일한 장치에 있지 않으면 작동하지 않음
y_pred = torch.round(torch.sigmoid(y_logits)) # 로짓 -> 예측 확률 -> 예측 레이블로 변환
# 2. 손실/정확도 계산
# loss = loss_fn(torch.sigmoid(y_logits), # nn.BCELoss를 사용하는 경우 torch.sigmoid()가 필요함
# y_train)
loss = loss_fn(y_logits, # nn.BCEWithLogitsLoss를 사용하면 원시 로짓에서 작동함
y_train)
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. 옵티마이저 제로 그래디언트
optimizer.zero_grad()
# 4. 손실 역전파
loss.backward()
# 5. 옵티마이저 단계 수행
optimizer.step()
### 테스트
model_0.eval()
with torch.inference_mode():
# 1. 순전파
test_logits = model_0(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits))
# 2. 손실/정확도 계산
test_loss = loss_fn(test_logits,
y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# 10 에포크마다 진행 상황 출력
if epoch % 10 == 0:
print(f"에포크: {epoch} | 손실: {loss:.5f}, 정확도: {acc:.2f}% | 테스트 손실: {test_loss:.5f}, 테스트 정확도: {test_acc:.2f}%")Epoch: 0 | Loss: 0.72095, Accuracy: 50.00% | Test loss: 0.72767, Test acc: 50.50%
Epoch: 10 | Loss: 0.70546, Accuracy: 53.87% | Test loss: 0.71203, Test acc: 52.50%
Epoch: 20 | Loss: 0.70011, Accuracy: 52.25% | Test loss: 0.70601, Test acc: 49.50%
Epoch: 30 | Loss: 0.69792, Accuracy: 51.50% | Test loss: 0.70315, Test acc: 49.50%
Epoch: 40 | Loss: 0.69682, Accuracy: 51.12% | Test loss: 0.70148, Test acc: 48.50%
Epoch: 50 | Loss: 0.69613, Accuracy: 50.75% | Test loss: 0.70034, Test acc: 49.50%
Epoch: 60 | Loss: 0.69565, Accuracy: 51.00% | Test loss: 0.69948, Test acc: 49.50%
Epoch: 70 | Loss: 0.69527, Accuracy: 50.75% | Test loss: 0.69880, Test acc: 50.00%
Epoch: 80 | Loss: 0.69497, Accuracy: 50.62% | Test loss: 0.69825, Test acc: 49.50%
Epoch: 90 | Loss: 0.69472, Accuracy: 50.62% | Test loss: 0.69779, Test acc: 49.50%음, 우리 모델의 성능에 대해 무엇을 알 수 있나요?
훈련 및 테스트 단계를 잘 거친 것 같지만 결과가 너무 많이 움직이지 않은 것 같습니다.
정확도는 각 데이터 분할에서 50%를 간신히 넘습니다.
그리고 균형 잡힌 이진 분류 문제를 다루고 있기 때문에, 이는 우리 모델이 무작위 추측만큼 성능을 내고 있음을 의미합니다 (클래스 0과 클래스 1의 샘플이 500개씩 있을 때 매번 클래스 1을 예측하는 모델은 50%의 정확도를 달성합니다).
4. 예측 수행 및 모델 평가
지표로 보아 우리 모델은 무작위 추측을 하고 있는 것 같습니다.
이를 어떻게 더 조사할 수 있을까요?
좋은 생각이 있습니다.
데이터 탐험가의 좌우명!
“시각화, 시각화, 시각화!”
모델의 예측값, 예측하려는 데이터 및 클래스 0인지 1인지에 대해 생성하는 결정 경계를 플롯해 보겠습니다.
그렇게 하기 위해 Learn PyTorch for Deep Learning 저장소에서 helper_functions.py 스크립트를 다운로드하여 임포트하는 코드를 작성할 것입니다.
여기에는 모델이 특정 클래스를 예측하는 서로 다른 점을 시각적으로 플롯하기 위해 NumPy 메시그리드(meshgrid)를 생성하는 plot_decision_boundary()라는 유용한 함수가 포함되어 있습니다.
또한 나중에 사용하기 위해 노트북 01에서 작성한 plot_predictions()도 임포트할 것입니다.
import requests
from pathlib import Path
# Learn PyTorch 저장소에서 헬퍼 함수 다운로드 (이미 다운로드되지 않은 경우)
if Path("helper_functions.py").is_file():
print("helper_functions.py가 이미 존재합니다. 다운로드를 건너뜁니다.")
else:
print("helper_functions.py를 다운로드합니다.")
request = requests.get("https://raw.githubusercontent.com/mrdbourke/pytorch-deep-learning/main/helper_functions.py")
with open("helper_functions.py", "wb") as f:
f.write(request.content)
from helper_functions import plot_predictions, plot_decision_boundaryDownloading helper_functions.py# 훈련 및 테스트 세트에 대한 결정 경계 플롯
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("훈련")
plot_decision_boundary(model_0, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("테스트")
plot_decision_boundary(model_0, X_test, y_test)
와, 모델의 성능 문제의 원인을 찾은 것 같습니다.
현재 직선을 사용하여 빨간색과 파란색 점을 분리하려고 시도하고 있습니다…
그것이 50% 정확도의 이유입니다. 데이터가 원형이기 때문에 직선을 긋는 것은 기껏해야 중간을 가로지르는 정도일 뿐입니다.
머신러닝 용어로 우리 모델은 과소적합(underfitting) 상태입니다. 즉, 데이터에서 예측 패턴을 학습하지 못하고 있습니다.
이를 어떻게 개선할 수 있을까요?
5. 모델 개선하기 (모델 관점에서)
모델의 과소적합 문제를 해결해 봅시다.
데이터가 아닌 모델에 구체적으로 초점을 맞추면 몇 가지 방법이 있을 수 있습니다.
| 모델 개선 기술* | 설명 |
|---|---|
| 레이어 추가하기 | 각 레이어는 모델의 학습 능력을 잠재적으로 증가시키며, 각 레이어는 데이터의 어떤 새로운 패턴을 학습할 수 있습니다. 레이어를 더 많이 추가하는 것을 신경망을 더 깊게 만든다고 합니다. |
| 은닉 유닛 추가하기 | 위와 유사하게 레이어당 은닉 유닛을 더 많이 추가하면 모델의 학습 능력이 잠재적으로 증가합니다. 은닉 유닛을 더 많이 추가하는 것을 신경망을 더 넓게 만든다고 합니다. |
| 더 오래 훈련하기 (에포크 늘리기) | 모델이 데이터를 더 많이 볼 수 있는 기회가 있다면 더 많은 것을 학습할 수 있습니다. |
| 활성화 함수 변경하기 | 일부 데이터는 우리가 본 것처럼 직선만으로는 적합할 수 없습니다. 비선형 활성화 함수를 사용하는 것이 도움이 될 수 있습니다 (힌트!). |
| 학습률 변경하기 | 모델 자체보다는 관련이 있지만, 옵티마이저의 학습률은 모델이 매 단계마다 파라미터를 얼마나 변경해야 할지를 결정합니다. 너무 크면 과잉 수정이 발생하고 너무 작으면 충분히 학습하지 못합니다. |
| 손실 함수 변경하기 | 역시 모델에 따라 다르지만 중요합니다. 문제마다 다른 손실 함수가 필요합니다. 예를 들어 binary cross entropy 손실 함수는 다중 클래스 분류 문제에서 작동하지 않습니다. |
| 전이 학습 (Transfer learning) 사용하기 | 여러분의 것과 유사한 문제 영역에서 이미 훈련된 모델을 가져와 자신의 문제에 맞게 조정합니다. 전이 학습은 노트북 06에서 다룹니다. |
참고: *이 모든 것을 수동으로 조정할 수 있기 때문에 이를 하이퍼파라미터라고 부릅니다.
그리고 이것이 머신러닝이 절반은 예술이고 절반은 과학인 이유이기도 합니다. 프로젝트에 가장 적합한 값의 조합이 무엇인지 알 수 있는 실질적인 방법은 없으며, 데이터 과학자의 좌우명인 “실험, 실험, 실험”을 따르는 것이 가장 좋습니다.
모델에 레이어를 하나 더 추가하고, 더 오래 훈련하고(epochs=100 대신 epochs=1000), 은닉 유닛의 수를 5에서 10으로 늘리면 어떻게 되는지 봅시다.
몇 가지 하이퍼파라미터를 변경하여 위와 동일한 단계를 따를 것입니다.
class CircleModelV1(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear(in_features=2, out_features=10)
self.layer_2 = nn.Linear(in_features=10, out_features=10) # 추가 레이어
self.layer_3 = nn.Linear(in_features=10, out_features=1)
def forward(self, x): # 참고: 항상 forward 스펠링이 올바른지 확인하세요!
# 이와 같이 모델을 만드는 것은 아래와 동일하지만, 아래 방식이
# 일반적으로 가능한 경우 속도 향상의 이점이 있습니다.
# z = self.layer_1(x)
# z = self.layer_2(z)
# z = self.layer_3(z)
# return z
return self.layer_3(self.layer_2(self.layer_1(x)))
model_1 = CircleModelV1().to(device)
model_1CircleModelV1(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=10, bias=True)
(layer_3): Linear(in_features=10, out_features=1, bias=True)
)이제 모델이 생겼으므로 이전과 동일한 설정을 사용하여 손실 함수와 옵티마이저 인스턴스를 다시 생성합니다.
# loss_fn = nn.BCELoss() # 입력에 시그모이드가 필요함
loss_fn = nn.BCEWithLogitsLoss() # 입력에 시그모이드가 필요하지 않음
optimizer = torch.optim.SGD(model_1.parameters(), lr=0.1)좋습니다. 모델, 옵티마이저 및 손실 함수가 준비되었으니 훈련 루프를 만들어 보겠습니다.
이번에는 더 오래(epochs=1000 vs epochs=100) 훈련해보고 모델이 개선되는지 확인해 봅시다.
torch.manual_seed(42)
epochs = 1000 # 더 오래 훈련
# 데이터를 대상 장치로 이동
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
for epoch in range(epochs):
### 훈련
# 1. 순전파
y_logits = model_1(X_train).squeeze()
y_pred = torch.round(torch.sigmoid(y_logits)) # 로짓 -> 예측 확률 -> 예측 레이블
# 2. 손실/정확도 계산
loss = loss_fn(y_logits, y_train)
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. 옵티마이저 제로 그래디언트
optimizer.zero_grad()
# 4. 손실 역전파
loss.backward()
# 5. 옵티마이저 단계 수행
optimizer.step()
### 테스트
model_1.eval()
with torch.inference_mode():
# 1. 순전파
test_logits = model_1(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits))
# 2. 손실/정확도 계산
test_loss = loss_fn(test_logits,
y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# 100 에포크마다 진행 상황 출력
if epoch % 100 == 0:
print(f"에포크: {epoch} | 손실: {loss:.5f}, 정확도: {acc:.2f}% | 테스트 손실: {test_loss:.5f}, 테스트 정확도: {test_acc:.2f}%")Epoch: 0 | Loss: 0.69396, Accuracy: 50.88% | Test loss: 0.69261, Test acc: 51.00%
Epoch: 100 | Loss: 0.69305, Accuracy: 50.38% | Test loss: 0.69379, Test acc: 48.00%
Epoch: 200 | Loss: 0.69299, Accuracy: 51.12% | Test loss: 0.69437, Test acc: 46.00%
Epoch: 300 | Loss: 0.69298, Accuracy: 51.62% | Test loss: 0.69458, Test acc: 45.00%
Epoch: 400 | Loss: 0.69298, Accuracy: 51.12% | Test loss: 0.69465, Test acc: 46.00%
Epoch: 500 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69467, Test acc: 46.00%
Epoch: 600 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00%
Epoch: 700 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00%
Epoch: 800 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00%
Epoch: 900 | Loss: 0.69298, Accuracy: 51.00% | Test loss: 0.69468, Test acc: 46.00%네? 모델을 더 오래 훈련하고 레이어를 하나 더 추가했지만, 여전히 무작위 추측보다 나은 패턴을 학습하지 못한 것 같습니다.
시각화해 봅시다.
# 훈련 및 테스트 세트에 대한 결정 경계 플롯
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("훈련")
plot_decision_boundary(model_1, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("테스트")
plot_decision_boundary(model_1, X_test, y_test)
음.
우리 모델은 여전히 빨간색과 파란색 점 사이에 직선을 긋고 있습니다.
우리 모델이 직선을 그리고 있다면, 선형 데이터를 모델링할 수 있을까요? 노트북 01에서 했던 것처럼 말이죠.
5.1 모델이 직선을 모델링할 수 있는지 확인하기 위한 데이터 준비
선형 데이터를 생성하여 우리 모델이 이를 모델링할 수 있는지, 아니면 단순히 아무것도 배울 수 없는 모델을 사용하고 있는지 확인해 봅시다.
# 일부 데이터 생성 (노트북 01과 동일)
weight = 0.7
bias = 0.3
start = 0
end = 1
step = 0.01
# 데이터 생성
X_regression = torch.arange(start, end, step).unsqueeze(dim=1)
y_regression = weight * X_regression + bias # 선형 회귀 공식
# 데이터 확인
print(len(X_regression))
X_regression[:5], y_regression[:5]100(tensor([[0.0000],
[0.0100],
[0.0200],
[0.0300],
[0.0400]]), tensor([[0.3000],
[0.3070],
[0.3140],
[0.3210],
[0.3280]]))멋지네요. 이제 데이터를 훈련 세트와 테스트 세트로 분할해 보겠습니다.
# 훈련 및 테스트 분할 생성
train_split = int(0.8 * len(X_regression)) # 데이터의 80%를 훈련 세트로 사용
X_train_regression, y_train_regression = X_regression[:train_split], y_regression[:train_split]
X_test_regression, y_test_regression = X_regression[train_split:], y_regression[train_split:]
# 각 분할의 길이 확인
print(len(X_train_regression),
len(y_train_regression),
len(X_test_regression),
len(y_test_regression))80 80 20 20좋습니다. 데이터가 어떻게 생겼는지 확인해 봅시다.
이를 위해 노트북 01에서 만든 plot_predictions() 함수를 사용할 것입니다.
이 함수는 위에서 다운로드한 Learn PyTorch for Deep Learning 저장소의 helper_functions.py 스크립트에 포함되어 있습니다.
plot_predictions(train_data=X_train_regression,
train_labels=y_train_regression,
test_data=X_test_regression,
test_labels=y_test_regression
);
5.2 직선에 적합하도록 model_1 조정하기
이제 데이터가 생겼으니, 우리 회귀 데이터에 적합한 손실 함수를 사용하여 model_1을 다시 만들어 보겠습니다.
# model_1과 동일한 구조 (단, nn.Sequential 사용)
model_2 = nn.Sequential(
nn.Linear(in_features=1, out_features=10),
nn.Linear(in_features=10, out_features=10),
nn.Linear(in_features=10, out_features=1)
).to(device)
model_2Sequential(
(0): Linear(in_features=1, out_features=10, bias=True)
(1): Linear(in_features=10, out_features=10, bias=True)
(2): Linear(in_features=10, out_features=1, bias=True)
)손실 함수를 nn.L1Loss() (평균 절대 오차와 동일)로, 옵티마이저를 torch.optim.SGD()로 설정하겠습니다.
# 손실 및 옵티마이저
loss_fn = nn.L1Loss()
optimizer = torch.optim.SGD(model_2.parameters(), lr=0.1)이제 epochs=1000 (model_1과 동일) 동안 일반적인 훈련 루프 단계를 사용하여 모델을 훈련해 보겠습니다.
참고: 우리는 유사한 훈련 루프 코드를 반복해서 작성해 왔습니다. 하지만 연습을 계속하기 위해 의도적으로 그렇게 만들었습니다. 그러나 이를 함수화할 수 있는 방법이 있을까요? 그렇게 하면 미래에 상당한 코딩 시간을 절약할 수 있을 것입니다. 잠재적으로 훈련을 위한 함수와 테스트를 위한 함수가 있을 수 있습니다.
# 모델 훈련
torch.manual_seed(42)
# 에포크 수 설정
epochs = 1000
# 데이터를 대상 장치로 이동
X_train_regression, y_train_regression = X_train_regression.to(device), y_train_regression.to(device)
X_test_regression, y_test_regression = X_test_regression.to(device), y_test_regression.to(device)
for epoch in range(epochs):
### 훈련
# 1. 순전파
y_pred = model_2(X_train_regression)
# 2. 손실 계산 (분류가 아닌 회귀 문제이므로 정확도는 없음)
loss = loss_fn(y_pred, y_train_regression)
# 3. 옵티마이저 제로 그래디언트
optimizer.zero_grad()
# 4. 손실 역전파
loss.backward()
# 5. 옵티마이저 단계 수행
optimizer.step()
### 테스트
model_2.eval()
with torch.inference_mode():
# 1. 순전파
test_pred = model_2(X_test_regression)
# 2. 손실 계산
test_loss = loss_fn(test_pred, y_test_regression)
# 진행 상황 출력
if epoch % 100 == 0:
print(f"에포크: {epoch} | 훈련 손실: {loss:.5f}, 테스트 손실: {test_loss:.5f}")Epoch: 0 | Train loss: 0.75986, Test loss: 0.54143
Epoch: 100 | Train loss: 0.09309, Test loss: 0.02901
Epoch: 200 | Train loss: 0.07376, Test loss: 0.02850
Epoch: 300 | Train loss: 0.06745, Test loss: 0.00615
Epoch: 400 | Train loss: 0.06107, Test loss: 0.02004
Epoch: 500 | Train loss: 0.05698, Test loss: 0.01061
Epoch: 600 | Train loss: 0.04857, Test loss: 0.01326
Epoch: 700 | Train loss: 0.06109, Test loss: 0.02127
Epoch: 800 | Train loss: 0.05599, Test loss: 0.01426
Epoch: 900 | Train loss: 0.05571, Test loss: 0.00603좋습니다. 분류 데이터에 대한 model_1과는 달리 model_2의 손실은 실제로 감소하고 있는 것 같습니다.
정말 그런지 확인하기 위해 예측값을 플롯해 봅시다.
그리고 모델과 데이터가 대상 device를 사용하고 있고 이 장치가 GPU일 수 있지만, 플로팅 함수는 matplotlib을 사용하고 matplotlib은 GPU의 데이터를 처리할 수 없음을 기억하세요.
이를 처리하기 위해 plot_predictions()에 데이터를 전달할 때 .cpu()를 사용하여 모든 데이터를 CPU로 보낼 것입니다.
# 평가 모드 켜기
model_2.eval()
# 예측 수행 (추론)
with torch.inference_mode():
y_preds = model_2(X_test_regression)
# CPU의 데이터로 데이터 및 예측값 플롯 (matplotlib은 GPU의 데이터를 처리할 수 없음)
# (아래 중 하나에서 .cpu()를 제거하고 어떤 일이 일어나는지 확인해 보세요)
plot_predictions(train_data=X_train_regression.cpu(),
train_labels=y_train_regression.cpu(),
test_data=X_test_regression.cpu(),
test_labels=y_test_regression.cpu(),
predictions=y_preds.cpu());
좋습니다. 우리 모델이 직선에 대해 무작위 추측보다 훨씬 더 잘 수행할 수 있는 것 같습니다.
이것은 좋은 징후입니다.
이는 우리 모델이 최소한 학습할 수 있는 어느 정도의 능력이 있음을 의미합니다.
참고: 딥러닝 모델을 구축할 때 유용한 문제 해결 단계는 모델을 확장하기 전에 모델이 작동하는지 확인하기 위해 가능한 한 작게 시작하는 것입니다.
이는 간단한 신경망(레이어와 은닉 뉴런이 많지 않음)과 작은 데이터셋(우리가 만든 것과 같은)으로 시작한 다음, 데이터 양이나 모델 크기/설계를 늘려 과적합을 줄이기 전에 해당 작은 예제에서 과적합(모델의 성능이 너무 좋게 만듦)을 시도하는 것을 의미할 수 있습니다.
그렇다면 무엇이 문제일까요?
알아봅시다.
6. 누락된 조각: 비선형성 (Non-linearity)
선형 레이어 덕분에 우리 모델이 직선(선형)을 그릴 수 있다는 것을 보았습니다.
하지만 우리 모델에 직선이 아닌(비선형) 선을 그릴 수 있는 능력을 부여하면 어떨까요?
어떻게 할까요?
알아봅시다.
6.1 비선형 데이터 재생성 (빨간색 및 파란색 원)
먼저 새롭게 시작하기 위해 데이터를 다시 생성해 보겠습니다. 이전과 동일한 설정을 사용합니다.
# 데이터 생성 및 플롯
import matplotlib.pyplot as plt
from sklearn.datasets import make_circles
n_samples = 1000
X, y = make_circles(n_samples=1000,
noise=0.03,
random_state=42,
)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdBu);
좋습니다! 이제 데이터의 80%를 훈련에, 20%를 테스트에 사용하여 훈련 및 테스트 세트로 분할해 보겠습니다.
# 텐서로 변환하고 훈련 및 테스트 세트로 분할
import torch
from sklearn.model_selection import train_test_split
# 데이터를 텐서로 변환
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# 훈련 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.2,
random_state=42
)
X_train[:5], y_train[:5](tensor([[ 0.6579, -0.4651],
[ 0.6319, -0.7347],
[-1.0086, -0.1240],
[-0.9666, -0.2256],
[-0.1666, 0.7994]]), tensor([1., 0., 0., 0., 1.]))6.2 비선형성을 사용한 모델 구축하기
이제 재미있는 부분이 나옵니다.
제한 없는 직선(선형)과 직선이 아닌(비선형) 선으로 어떤 패턴을 그릴 수 있다고 생각하시나요?
꽤 창의적이 될 수 있을 것입니다.
지금까지 우리 신경망은 선형(직선) 함수만 사용해 왔습니다.
하지만 우리가 작업해 온 데이터는 비선형(원)입니다.
모델에 비선형 활성화 함수를 사용할 수 있는 기능을 도입하면 어떤 일이 일어날까요?
한번 봅시다.
PyTorch에는 유사하지만 다른 작업을 수행하는 기성 비선형 활성화 함수가 많이 있습니다.
가장 일반적이고 성능이 좋은 것 중 하나는 ReLU (rectified linear-unit, torch.nn.ReLU())입니다.
말로 설명하기보다 순전파의 은닉 레이어 사이에 이를 넣고 어떤 일이 일어나는지 봅시다.
# 비선형 활성화 함수가 있는 모델 구축
from torch import nn
class CircleModelV2(nn.Module):
def __init__(self):
super().__init__()
self.layer_1 = nn.Linear(in_features=2, out_features=10)
self.layer_2 = nn.Linear(in_features=10, out_features=10)
self.layer_3 = nn.Linear(in_features=10, out_features=1)
self.relu = nn.ReLU() # <- ReLU 활성화 함수 추가
# 모델에 시그모이드를 넣을 수도 있음
# 이는 예측값에 이를 사용할 필요가 없음을 의미함
# self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 레이어 사이에 ReLU 활성화 함수 배치
return self.layer_3(self.relu(self.layer_2(self.relu(self.layer_1(x)))))
model_3 = CircleModelV2().to(device)
print(model_3)CircleModelV2(
(layer_1): Linear(in_features=2, out_features=10, bias=True)
(layer_2): Linear(in_features=10, out_features=10, bias=True)
(layer_3): Linear(in_features=10, out_features=1, bias=True)
(relu): ReLU()
)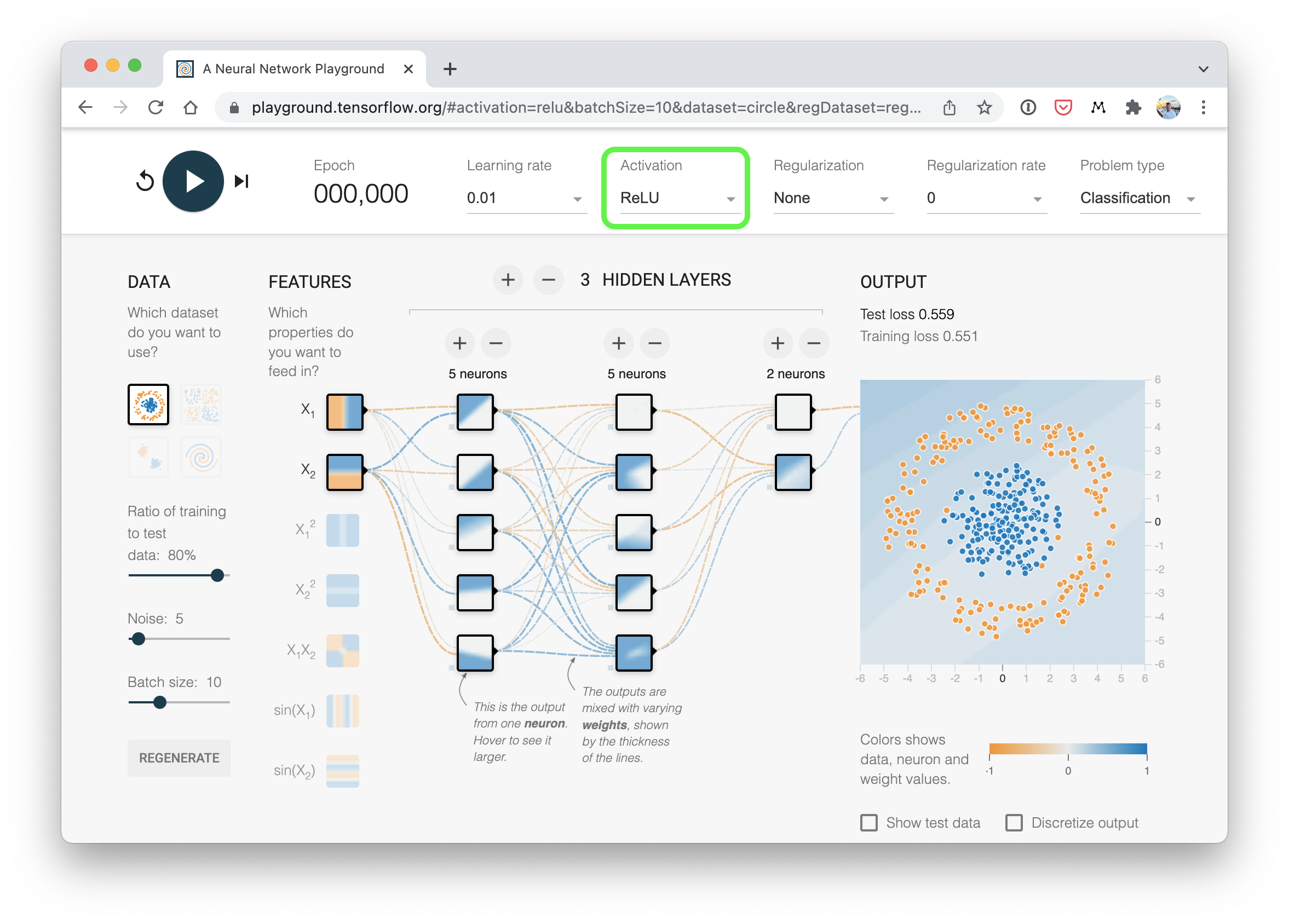 방금 구축한 것과 유사한(ReLU 활성화를 사용하는) 분류 신경망이 어떻게 생겼는지에 대한 시각적 예시입니다. TensorFlow Playground 웹사이트에서 직접 만들어 보세요.
방금 구축한 것과 유사한(ReLU 활성화를 사용하는) 분류 신경망이 어떻게 생겼는지에 대한 시각적 예시입니다. TensorFlow Playground 웹사이트에서 직접 만들어 보세요.
질문: 신경망을 구축할 때 비선형 활성화 함수를 어디에 두어야 하나요?
경험 법칙은 은닉 레이어 사이와 출력 레이어 바로 뒤에 두는 것이지만, 정해진 옵션은 없습니다. 신경망과 딥러닝에 대해 더 배우다 보면 사물을 결합하는 다양한 방법을 발견하게 될 것입니다. 그동안은 실험, 실험, 실험을 하는 것이 가장 좋습니다.
이제 모델이 준비되었으므로 이진 분류 손실 함수와 옵티마이저를 만들어 보겠습니다.
# 손실 및 옵티마이저 설정
loss_fn = nn.BCEWithLogitsLoss()
optimizer = torch.optim.SGD(model_3.parameters(), lr=0.1)멋지네요!
6.3 비선형성을 사용한 모델 훈련하기
익숙한 방식대로 모델, 손실 함수, 옵티마이저가 준비되었으니 훈련 및 테스트 루프를 만들어 보겠습니다.
# 모델 적합
torch.manual_seed(42)
epochs = 1000
# 모든 데이터를 대상 장치로 이동
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
for epoch in range(epochs):
# 1. 순전파
y_logits = model_3(X_train).squeeze()
y_pred = torch.round(torch.sigmoid(y_logits)) # 로짓 -> 예측 확률 -> 예측 레이블
# 2. 손실 및 정확도 계산
loss = loss_fn(y_logits, y_train) # BCEWithLogitsLoss는 로짓을 사용하여 손실을 계산함
acc = accuracy_fn(y_true=y_train,
y_pred=y_pred)
# 3. 옵티마이저 제로 그래디언트
optimizer.zero_grad()
# 4. 손실 역전파
loss.backward()
# 5. 옵티마이저 단계 수행
optimizer.step()
### 테스트
model_3.eval()
with torch.inference_mode():
# 1. 순전파
test_logits = model_3(X_test).squeeze()
test_pred = torch.round(torch.sigmoid(test_logits)) # 로짓 -> 예측 확률 -> 예측 레이블
# 2. 손실 및 정확도 계산
test_loss = loss_fn(test_logits, y_test)
test_acc = accuracy_fn(y_true=y_test,
y_pred=test_pred)
# 100 에포크마다 진행 상황 출력
if epoch % 100 == 0:
print(f"에포크: {epoch} | 손실: {loss:.5f}, 정확도: {acc:.2f}% | 테스트 손실: {test_loss:.5f}, 테스트 정확도: {test_acc:.2f}%")Epoch: 0 | Loss: 0.69295, Accuracy: 50.00% | Test Loss: 0.69319, Test Accuracy: 50.00%
Epoch: 100 | Loss: 0.69115, Accuracy: 52.88% | Test Loss: 0.69102, Test Accuracy: 52.50%
Epoch: 200 | Loss: 0.68977, Accuracy: 53.37% | Test Loss: 0.68940, Test Accuracy: 55.00%
Epoch: 300 | Loss: 0.68795, Accuracy: 53.00% | Test Loss: 0.68723, Test Accuracy: 56.00%
Epoch: 400 | Loss: 0.68517, Accuracy: 52.75% | Test Loss: 0.68411, Test Accuracy: 56.50%
Epoch: 500 | Loss: 0.68102, Accuracy: 52.75% | Test Loss: 0.67941, Test Accuracy: 56.50%
Epoch: 600 | Loss: 0.67515, Accuracy: 54.50% | Test Loss: 0.67285, Test Accuracy: 56.00%
Epoch: 700 | Loss: 0.66659, Accuracy: 58.38% | Test Loss: 0.66322, Test Accuracy: 59.00%
Epoch: 800 | Loss: 0.65160, Accuracy: 64.00% | Test Loss: 0.64757, Test Accuracy: 67.50%
Epoch: 900 | Loss: 0.62362, Accuracy: 74.00% | Test Loss: 0.62145, Test Accuracy: 79.00%허허! 훨씬 좋아 보이네요!
6.4 비선형 활성화 함수로 훈련된 모델 평가하기
우리 원 데이터가 비선형인 것 기억하시나요? 자, 이제 비선형 활성화 함수로 훈련된 모델의 예측이 어떻게 보이는지 봅시다.
# 예측 수행
model_3.eval()
with torch.inference_mode():
y_preds = torch.round(torch.sigmoid(model_3(X_test))).squeeze()
y_preds[:10], y[:10] # 예측값이 실제 레이블과 동일한 형식인지 확인(tensor([1., 0., 1., 0., 0., 1., 0., 0., 1., 0.], device='cuda:0'),
tensor([1., 1., 1., 1., 0., 1., 1., 1., 1., 0.]))# 훈련 및 테스트 세트에 대한 결정 경계 플롯
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("훈련")
plot_decision_boundary(model_1, X_train, y_train) # model_1 = 비선형성 없음
plt.subplot(1, 2, 2)
plt.title("테스트")
plot_decision_boundary(model_3, X_test, y_test) # model_3 = 비선형성 있음
멋지네요! 완벽하지는 않지만 이전보다는 훨씬 낫습니다.
모델의 테스트 정확도를 개선하기 위해 몇 가지 트릭을 시도해 볼 수 있을까요? (힌트: 모델 개선을 위한 팁은 섹션 5로 돌아가 확인하세요)
7. 비선형 활성화 함수 복제하기
모델에 비선형 활성화 함수를 추가하는 것이 비선형 데이터를 모델링하는 데 어떻게 도움이 되는지 보았습니다.
참고: 실생활에서 접하게 될 많은 데이터는 비선형(또는 선형과 비선형의 조합)입니다. 지금 우리는 2D 플롯의 점들을 다루고 있습니다. 하지만 분류하고 싶은 식물 이미지가 있다고 상상해 보세요. 매우 다양한 식물 모양이 있습니다. 또는 요약하고 싶은 위키피디아의 텍스트가 있다면, 단어들이 결합되는 수많은 방식(선형 및 비선형 패턴)이 있습니다.
그런데 비선형 활성화는 어떤 모습일까요?
일부를 복제하고 그들이 하는 일을 알아볼까요?
소량의 데이터를 생성하는 것부터 시작하겠습니다.
# 토이 텐서 생성 (우리 모델에 들어가는 데이터와 유사함)
A = torch.arange(-10, 10, 1, dtype=torch.float32)
Atensor([-10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0., 1.,
2., 3., 4., 5., 6., 7., 8., 9.])좋습니다. 이제 플롯해 봅시다.
# 토이 텐서 시각화
plt.plot(A);
직선이네요, 좋습니다.
이제 ReLU 활성화 함수가 여기에 어떻게 영향을 미치는지 봅시다.
그리고 PyTorch의 ReLU(torch.nn.ReLU)를 사용하는 대신 직접 만들어 보겠습니다.
ReLU 함수는 모든 음수를 0으로 바꾸고 양수 값은 그대로 둡니다.
# 직접 ReLU 함수 만들기
def relu(x):
return torch.maximum(torch.tensor(0), x) # 입력은 반드시 텐서여야 함
# 토이 텐서를 ReLU 함수에 통과시키기
relu(A)tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 2., 3., 4., 5., 6., 7.,
8., 9.])우리 ReLU 함수가 잘 작동한 것 같네요. 모든 음수 값이 0이 되었습니다.
플롯해 봅시다.
# ReLU가 적용된 토이 텐서 플롯
plt.plot(relu(A));
좋습니다! ReLU Wikipedia 페이지에 있는 ReLU 함수의 모양과 똑같아 보이네요.
우리가 사용해 온 시그모이드 함수(sigmoid function)는 어떨까요?
시그모이드 함수 공식은 다음과 같습니다:
\[ out_i = \frac{1}{1+e^{-input_i}} \]
또는 \(x\)를 입력으로 사용하면:
\[ S(x) = \frac{1}{1+e^{-x_i}} \]
여기서 \(S\)는 시그모이드를 나타내고, \(e\)는 지수(exponential) (torch.exp())를 나타내며, \(i\)는 텐서의 특정 요소를 나타냅니다.
PyTorch로 시그모이드 함수를 복제하는 함수를 구축해 보겠습니다.
# 커스텀 시그모이드 함수 만들기
def sigmoid(x):
return 1 / (1 + torch.exp(-x))
# 토이 텐서로 커스텀 시그모이드 테스트
sigmoid(A)tensor([4.5398e-05, 1.2339e-04, 3.3535e-04, 9.1105e-04, 2.4726e-03, 6.6929e-03,
1.7986e-02, 4.7426e-02, 1.1920e-01, 2.6894e-01, 5.0000e-01, 7.3106e-01,
8.8080e-01, 9.5257e-01, 9.8201e-01, 9.9331e-01, 9.9753e-01, 9.9909e-01,
9.9966e-01, 9.9988e-01])와, 이 값들은 이전에 보았던 예측 확률과 매우 유사해 보이네요. 시각화하면 어떻게 보이는지 봅시다.
# 시그모이드가 적용된 토이 텐서 플롯
plt.plot(sigmoid(A));
좋아 보이네요! 직선에서 곡선으로 바뀌었습니다.
PyTorch에는 우리가 시도하지 않은 훨씬 더 많은 비선형 활성화 함수가 존재합니다.
하지만 이 두 가지가 가장 일반적인 두 가지입니다.
그리고 핵심은 여전합니다. 무제한의 직선(선형)과 직선이 아닌(비선형) 선을 사용하여 어떤 패턴을 그릴 수 있을까요?
거의 무엇이든 가능하겠죠?
그것이 바로 선형 함수와 비선형 함수를 결합할 때 우리 모델이 수행하는 작업입니다.
모델에 무엇을 해야 할지 지시하는 대신, 데이터에서 패턴을 가장 잘 발견하는 방법을 알아낼 수 있는 도구를 제공합니다.
그리고 그 도구가 바로 선형 및 비선형 함수입니다.
8. 다중 클래스 PyTorch 모델을 구축하여 전체 과정 합치기
꽤 많은 내용을 다루었습니다.
이제 다중 클래스 분류 문제를 사용하여 이 모든 것을 하나로 합쳐 보겠습니다.
상기해 보면, 이진 분류 문제는 대상을 두 가지 옵션 중 하나(예: 사진이 고양이 사진인지 개 사진인지)로 분류하는 반면, 다중 클래스 분류 문제는 대상을 세 가지 이상의 옵션 목록 중 하나(예: 사진이 고양이, 개, 닭 중 무엇인지)로 분류합니다.
 이진 분류 vs 다중 클래스 분류의 예시. 이진 분류는 두 개의 클래스(하나 또는 다른 것)를 다루는 반면, 다중 클래스 분류는 두 개 이상의 클래스를 다룰 수 있습니다. 예를 들어, 인기 있는 ImageNet-1k 데이터셋은 컴퓨터 비전 벤치마크로 사용되며 1000개의 클래스를 가집니다.
이진 분류 vs 다중 클래스 분류의 예시. 이진 분류는 두 개의 클래스(하나 또는 다른 것)를 다루는 반면, 다중 클래스 분류는 두 개 이상의 클래스를 다룰 수 있습니다. 예를 들어, 인기 있는 ImageNet-1k 데이터셋은 컴퓨터 비전 벤치마크로 사용되며 1000개의 클래스를 가집니다.
8.1 다중 클래스 분류 데이터 생성
다중 클래스 분류 문제를 시작하기 위해 다중 클래스 데이터를 만들어 보겠습니다.
이를 위해 Scikit-Learn의 make_blobs() 메서드를 활용할 수 있습니다.
이 메서드는 우리가 원하는 수만큼의 클래스(centers 매개변수 사용)를 생성합니다.
구체적으로 다음 작업을 수행해 봅시다:
make_blobs()로 다중 클래스 데이터를 생성합니다.- 데이터를 텐서로 변환합니다 (
make_blobs()의 기본값은 NumPy 배열을 사용하는 것입니다). train_test_split()을 사용하여 데이터를 훈련 및 테스트 세트로 분할합니다.- 데이터를 시각화합니다.
# 의존성 임포트
import torch
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
# 데이터 생성을 위한 하이퍼파라미터 설정
NUM_CLASSES = 4
NUM_FEATURES = 2
RANDOM_SEED = 42
# 1. 다중 클래스 데이터 생성
X_blob, y_blob = make_blobs(n_samples=1000,
n_features=NUM_FEATURES, # X 특성
centers=NUM_CLASSES, # y 레이블
cluster_std=1.5, # 클러스터에 약간의 변화를 줌 (기본값인 1.0으로 변경해 보세요)
random_state=RANDOM_SEED
)
# 2. 데이터를 텐서로 변환
X_blob = torch.from_numpy(X_blob).type(torch.float)
y_blob = torch.from_numpy(y_blob).type(torch.LongTensor)
print(X_blob[:5], y_blob[:5])
# 3. 훈련 및 테스트 세트로 분할
X_blob_train, X_blob_test, y_blob_train, y_blob_test = train_test_split(X_blob,
y_blob,
test_size=0.2,
random_state=RANDOM_SEED
)
# 4. 데이터 플롯
plt.figure(figsize=(10, 7))
plt.scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob, cmap=plt.cm.RdYlBu);tensor([[-8.4134, 6.9352],
[-5.7665, -6.4312],
[-6.0421, -6.7661],
[ 3.9508, 0.6984],
[ 4.2505, -0.2815]]) tensor([3, 2, 2, 1, 1])
좋네요! 준비된 다중 클래스 데이터가 생긴 것 같습니다.
색상 블롭(blobs)을 분리할 모델을 구축해 봅시다.
질문: 이 데이터셋에 비선형성이 필요한가요? 아니면 일련의 직선을 그어 분리할 수 있을까요?
8.2 PyTorch에서 다중 클래스 분류 모델 구축하기
지금까지 PyTorch에서 몇 가지 모델을 만들었습니다.
여러분은 또한 신경망이 얼마나 유연한지 감을 잡기 시작했을 수도 있습니다.
model_3과 유사하지만 다중 클래스 데이터를 처리할 수 있는 모델을 만들어 보면 어떨까요?
그렇게 하기 위해 세 가지 하이퍼파라미터를 받는 nn.Module의 서브클래스를 만들어 봅시다: * input_features - 모델에 들어오는 X 특성의 수. * output_features - 우리가 원하는 이상적인 출력 특성의 수 (이는 NUM_CLASSES 또는 다중 클래스 분류 문제의 클래스 수와 동일합니다). * hidden_units - 각 은닉 레이어에서 사용하려는 은닉 뉴런의 수.
전체 과정을 합치는 중이므로 장치에 구애받지 않는 코드를 설정하겠습니다 (같은 노트북에서 다시 할 필요는 없지만 리마인더 용도입니다).
그런 다음 위의 하이퍼파라미터를 사용하여 모델 클래스를 생성하겠습니다.
# 장치에 구애받지 않는 코드 생성
device = "cuda" if torch.cuda.is_available() else "cpu"
device'cuda'from torch import nn
# 모델 구축
class BlobModel(nn.Module):
def __init__(self, input_features, output_features, hidden_units=8):
"""다중 클래스 분류 모델에 필요한 모든 하이퍼파라미터를 초기화합니다.
Args:
input_features (int): 모델에 입력되는 특성의 수.
out_features (int): 모델의 출력 특성 수
(클래스가 몇 개인지).
hidden_units (int): 레이어 사이의 은닉 유닛 수, 기본값 8.
"""
super().__init__()
self.linear_layer_stack = nn.Sequential(
nn.Linear(in_features=input_features, out_features=hidden_units),
# nn.ReLU(), # <- 우리 데이터셋에 비선형 레이어가 필요한가요? (주석을 해제하고 결과가 바뀌는지 확인해 보세요)
nn.Linear(in_features=hidden_units, out_features=hidden_units),
# nn.ReLU(), # <- 우리 데이터셋에 비선형 레이어가 필요한가요? (주석을 해제하고 결과가 바뀌는지 확인해 보세요)
nn.Linear(in_features=hidden_units, out_features=output_features), # 클래스가 몇 개인가요?
)
def forward(self, x):
return self.linear_layer_stack(x)
# BlobModel의 인스턴스를 생성하고 대상 장치로 보냄
model_4 = BlobModel(input_features=NUM_FEATURES,
output_features=NUM_CLASSES,
hidden_units=8).to(device)
model_4BlobModel(
(linear_layer_stack): Sequential(
(0): Linear(in_features=2, out_features=8, bias=True)
(1): Linear(in_features=8, out_features=8, bias=True)
(2): Linear(in_features=8, out_features=4, bias=True)
)
)멋지네요! 다중 클래스 모델이 준비되었으므로 이에 대한 손실 함수와 옵티마이저를 만들어 보겠습니다.
8.3 다중 클래스 PyTorch 모델을 위한 손실 함수 및 옵티마이저 생성
다중 클래스 분류 문제를 다루고 있으므로 nn.CrossEntropyLoss() 메서드를 손실 함수로 사용하겠습니다.
그리고 model_4 파라미터를 최적화하기 위해 학습률 0.1의 SGD를 계속 사용하겠습니다.
# 손실 및 옵티마이저 생성
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model_4.parameters(),
lr=0.1) # 연습: 여기서 학습률을 변경하고 모델 성능에 어떤 일이 일어나는지 확인해 보세요8.4 다중 클래스 PyTorch 모델에 대한 예측 확률 얻기
자, 손실 함수와 옵티마이저가 준비되었으며 모델을 훈련할 준비가 되었지만, 그 전에 모델이 작동하는지 확인하기 위해 한 번의 순전파를 수행해 보겠습니다.
# 데이터에 대해 한 번의 순전파를 수행 (작동하려면 대상 장치로 이동시켜야 함)
model_4(X_blob_train.to(device))[:5]tensor([[-1.2711, -0.6494, -1.4740, -0.7044],
[ 0.2210, -1.5439, 0.0420, 1.1531],
[ 2.8698, 0.9143, 3.3169, 1.4027],
[ 1.9576, 0.3125, 2.2244, 1.1324],
[ 0.5458, -1.2381, 0.4441, 1.1804]], device='cuda:0',
grad_fn=<SliceBackward0>)여기서 무엇이 나오고 있나요?
각 샘플의 특성당 하나의 값이 나오는 것 같습니다.
모양을 확인하여 확인해 봅시다.
# 단일 예측 샘플에 몇 개의 요소가 있나요?
model_4(X_blob_train.to(device))[0].shape, NUM_CLASSES(torch.Size([4]), 4)멋지네요. 모델이 우리가 가진 각 클래스에 대해 하나의 값을 예측하고 있습니다.
모델의 원시 출력을 무엇이라고 부르는지 기억하시나요?
힌트: “로짓”입니다.
맞습니다, 로짓입니다.
현재 모델은 로짓을 출력하고 있지만, 샘플에 정확히 어떤 레이블을 부여하고 있는지 알아내고 싶다면 어떻게 해야 할까요?
즉, 이진 분류 문제에서 했던 것처럼 로짓 -> 예측 확률 -> 예측 레이블로 어떻게 갈 수 있을까요?
여기서 소프트맥스 활성화 함수(softmax activation function)가 등장합니다.
소프트맥스 함수는 다른 모든 가능한 클래스와 비교하여 각 예측 클래스가 실제 예측 클래스일 확률을 계산합니다.
이해가 안 된다면 코드로 확인해 봅시다.
# 모델로 예측 로짓 생성
y_logits = model_4(X_test.to(device))
# 로짓에 대해 차원 1을 따라 소프트맥스 계산을 수행하여 예측 확률을 얻음
y_pred_probs = torch.softmax(y_logits, dim=1)
print(y_logits[:5])
print(y_pred_probs[:5])tensor([[ 0.2341, -0.3357, 0.2307, 0.2534],
[ 0.1198, -0.3702, 0.0998, 0.1887],
[ 0.3790, -0.2037, 0.4095, 0.2689],
[ 0.1936, -0.3733, 0.1807, 0.2496],
[ 0.1338, -0.1378, 0.1487, 0.0247]], device='cuda:0',
grad_fn=<SliceBackward0>)
tensor([[0.2792, 0.1579, 0.2782, 0.2846],
[0.2729, 0.1672, 0.2675, 0.2924],
[0.2869, 0.1602, 0.2958, 0.2570],
[0.2769, 0.1571, 0.2733, 0.2928],
[0.2722, 0.2075, 0.2763, 0.2441]], device='cuda:0',
grad_fn=<SliceBackward0>)음, 여기서 무슨 일이 일어났나요?
소프트맥스 함수의 출력이 여전히 뒤섞인 숫자처럼 보일 수 있지만 (실제로 그렇습니다. 우리 모델이 훈련되지 않았고 무작위 패턴을 사용하여 예측하고 있기 때문입니다), 각 샘플마다 매우 구체적인 차이점이 있습니다.
로짓을 소프트맥스 함수에 통과시킨 후, 각 개별 샘플의 합은 이제 1(또는 매우 근접한 값)이 됩니다.
확인해 봅시다.
# 소프트맥스 활성화 함수의 첫 번째 샘플 출력 합계
torch.sum(y_pred_probs[0])tensor(1., device='cuda:0', grad_fn=<SumBackward0>)이러한 예측 확률은 본질적으로 모델이 대상 X 샘플(입력)이 각 클래스에 매핑된다고 생각하는 정도를 말해줍니다.
y_pred_probs에는 각 클래스당 하나의 값이 있으므로, 가장 높은 값의 인덱스가 모델이 특정 데이터 샘플이 가장 많이 속한다고 생각하는 클래스입니다.
torch.argmax()를 사용하여 어떤 인덱스가 가장 높은 값을 갖는지 확인할 수 있습니다.
# 인덱스 0 샘플에서 모델이 가장 가능성이 높다고 생각하는 클래스는 무엇인가요?
print(y_pred_probs[0])
print(torch.argmax(y_pred_probs[0]))tensor([0.2792, 0.1579, 0.2782, 0.2846], device='cuda:0',
grad_fn=<SelectBackward0>)
tensor(3, device='cuda:0')torch.argmax()의 출력이 3을 반환하는 것을 볼 수 있으므로 인덱스 0 샘플의 특성(X)에 대해 모델은 가장 가능성이 높은 클래스 값(y)이 3이라고 예측하고 있습니다.
물론 지금은 단지 무작위 추측일 뿐이므로 맞을 확률은 25%입니다(클래스가 4개이므로). 하지만 모델을 훈련하면 그 확률을 높일 수 있습니다.
참고: 위 내용을 요약하면 모델의 원시 출력을 로짓(logits)이라고 합니다.
다중 클래스 분류 문제에서 로짓을 예측 확률로 바꾸려면 소프트맥스 활성화 함수(
torch.softmax)를 사용합니다.가장 높은 예측 확률을 가진 값의 인덱스가 모델이 해당 샘플의 입력 특성이 주어졌을 때 가장 가능성이 높다고 생각하는 클래스 번호입니다 (이것은 예측이지만 정답임을 의미하지는 않습니다).
8.5 다중 클래스 PyTorch 모델을 위한 훈련 및 테스트 루프 생성
자, 이제 모든 준비 단계가 끝났으므로 모델을 개선하고 평가하기 위한 훈련 및 테스트 루프를 작성해 보겠습니다.
우리는 이전에 이러한 단계 중 많은 부분을 수행했으므로 대부분 연습이 될 것입니다.
유일한 차이점은 모델 출력(로짓)을 예측 확률(소프트맥스 활성화 함수 사용)로 변환한 다음 예측 레이블(소프트맥스 활성화 함수의 출력에서 argmax를 취함)로 변환하도록 단계를 조정한다는 것입니다.
epochs=100 동안 모델을 훈련하고 10 에포크마다 평가해 보겠습니다.
# 모델 적합
torch.manual_seed(42)
# 에포크 수 설정
epochs = 100
# 데이터를 대상 장치로 이동
X_blob_train, y_blob_train = X_blob_train.to(device), y_blob_train.to(device)
X_blob_test, y_blob_test = X_blob_test.to(device), y_blob_test.to(device)
for epoch in range(epochs):
### 훈련
model_4.train()
# 1. 순전파
y_logits = model_4(X_blob_train) # 모델은 원시 로짓을 출력함
y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # 로짓 -> 예측 확률 -> 예측 레이블로 이동
# print(y_logits)
# 2. 손실 및 정확도 계산
loss = loss_fn(y_logits, y_blob_train)
acc = accuracy_fn(y_true=y_blob_train,
y_pred=y_pred)
# 3. 옵티마이저 제로 그래디언트
optimizer.zero_grad()
# 4. 손실 역전파
loss.backward()
# 5. 옵티마이저 단계 수행
optimizer.step()
### 테스트
model_4.eval()
with torch.inference_mode():
# 1. 순전파
test_logits = model_4(X_blob_test)
test_pred = torch.softmax(test_logits, dim=1).argmax(dim=1)
# 2. 테스트 손실 및 정확도 계산
test_loss = loss_fn(test_logits, y_blob_test)
test_acc = accuracy_fn(y_true=y_blob_test,
y_pred=test_pred)
# 10 에포크마다 진행 상황 출력
if epoch % 10 == 0:
print(f"에포크: {epoch} | 손실: {loss:.5f}, 정확도: {acc:.2f}% | 테스트 손실: {test_loss:.5f}, 테스트 정확도: {test_acc:.2f}%")Epoch: 0 | Loss: 1.04324, Acc: 65.50% | Test Loss: 0.57861, Test Acc: 95.50%
Epoch: 10 | Loss: 0.14398, Acc: 99.12% | Test Loss: 0.13037, Test Acc: 99.00%
Epoch: 20 | Loss: 0.08062, Acc: 99.12% | Test Loss: 0.07216, Test Acc: 99.50%
Epoch: 30 | Loss: 0.05924, Acc: 99.12% | Test Loss: 0.05133, Test Acc: 99.50%
Epoch: 40 | Loss: 0.04892, Acc: 99.00% | Test Loss: 0.04098, Test Acc: 99.50%
Epoch: 50 | Loss: 0.04295, Acc: 99.00% | Test Loss: 0.03486, Test Acc: 99.50%
Epoch: 60 | Loss: 0.03910, Acc: 99.00% | Test Loss: 0.03083, Test Acc: 99.50%
Epoch: 70 | Loss: 0.03643, Acc: 99.00% | Test Loss: 0.02799, Test Acc: 99.50%
Epoch: 80 | Loss: 0.03448, Acc: 99.00% | Test Loss: 0.02587, Test Acc: 99.50%
Epoch: 90 | Loss: 0.03300, Acc: 99.12% | Test Loss: 0.02423, Test Acc: 99.50%8.6 다중 클래스 모델을 사용하여 예측 수행 및 평가
훈련된 모델이 꽤 잘 작동하는 것 같습니다.
하지만 이를 확실히 하기 위해 몇 가지 예측을 수행하고 시각화해 보겠습니다.
# 예측 수행
model_4.eval()
with torch.inference_mode():
y_logits = model_4(X_blob_test)
# 처음 10개 예측값 확인
y_logits[:10]tensor([[ 4.3377, 10.3539, -14.8948, -9.7642],
[ 5.0142, -12.0371, 3.3860, 10.6699],
[ -5.5885, -13.3448, 20.9894, 12.7711],
[ 1.8400, 7.5599, -8.6016, -6.9942],
[ 8.0726, 3.2906, -14.5998, -3.6186],
[ 5.5844, -14.9521, 5.0168, 13.2890],
[ -5.9739, -10.1913, 18.8655, 9.9179],
[ 7.0755, -0.7601, -9.5531, 0.1736],
[ -5.5918, -18.5990, 25.5309, 17.5799],
[ 7.3142, 0.7197, -11.2017, -1.2011]], device='cuda:0')좋습니다. 모델의 예측값이 여전히 로짓 형태인 것 같습니다.
하지만 이를 평가하려면 정수 형태인 우리 레이블(y_blob_test)과 동일한 형태여야 합니다.
모델의 예측 로짓을 예측 확률(torch.softmax() 사용)로 변환한 다음 예측 레이블(각 샘플의 argmax()를 취함)로 변환해 봅시다.
참고:
torch.softmax()함수를 건너뛰고 로짓에서 직접torch.argmax()를 호출하여예측 로짓 -> 예측 레이블로 바로 갈 수 있습니다.예를 들어,
y_preds = torch.argmax(y_logits, dim=1)은 계산 단계 하나를 절약하지만 (torch.softmax()없음), 사용할 수 있는 예측 확률은 생성되지 않습니다.
# 예측 로짓을 예측 확률로 변환
y_pred_probs = torch.softmax(y_logits, dim=1)
# 예측 확률을 예측 레이블로 변환
y_preds = y_pred_probs.argmax(dim=1)
# 처음 10개 모델 예측값과 테스트 레이블 비교
print(f"예측값: {y_preds[:10]}\n레이블: {y_blob_test[:10]}")
print(f"테스트 정확도: {accuracy_fn(y_true=y_blob_test, y_pred=y_preds)}%")Predictions: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0')
Labels: tensor([1, 3, 2, 1, 0, 3, 2, 0, 2, 0], device='cuda:0')
Test accuracy: 99.5%멋지네요! 이제 모델 예측값이 테스트 레이블과 동일한 형태입니다.
plot_decision_boundary()로 시각화해 봅시다. 우리 데이터가 GPU에 있으므로 matplotlib에서 사용하려면 CPU로 옮겨야 한다는 점을 기억하세요 (plot_decision_boundary()가 자동으로 이 작업을 수행해 줍니다).
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("훈련")
plot_decision_boundary(model_4, X_blob_train, y_blob_train)
plt.subplot(1, 2, 2)
plt.title("테스트")
plot_decision_boundary(model_4, X_blob_test, y_blob_test)
9. 더 많은 분류 평가 지표
지금까지 분류 모델을 평가하는 몇 가지 방법(정확도, 손실 및 예측 시각화)만 다루었습니다.
이것들은 접하게 될 가장 일반적인 방법 중 일부이며 좋은 시작점입니다.
그러나 다음과 같은 더 많은 지표를 사용하여 분류 모델을 평가하고 싶을 수 있습니다:
| 지표 이름/평가 방법 | 정의 | 코드 |
|---|---|---|
| 정확도 (Accuracy) | 100번의 예측 중 모델이 몇 개를 맞혔나요? 예: 95% 정확도는 100번 중 95번을 맞혔음을 의미합니다. | torchmetrics.Accuracy() 또는 sklearn.metrics.accuracy_score() |
| 정밀도 (Precision) | 전체 샘플 중 참 양성(true positive)의 비율. 높은 정밀도는 거짓 양성(실제로는 0인데 모델이 1로 예측)이 적음을 의미합니다. | torchmetrics.Precision() 또는 sklearn.metrics.precision_score() |
| 재현율 (Recall) | 참 양성과 거짓 음성(실제로는 1인데 모델이 0으로 예측)의 합 중 참 양성의 비율. 높은 재현율은 거짓 음성이 적음을 의미합니다. | torchmetrics.Recall() 또는 sklearn.metrics.recall_score() |
| F1-스코어 (F1-score) | 정밀도와 재현율을 하나의 지표로 결합합니다. 1이 최고, 0이 최악입니다. | torchmetrics.F1Score() 또는 sklearn.metrics.f1_score() |
| 혼동 행렬 (Confusion matrix) | 예측값과 실제값을 표 형식으로 비교합니다. 100% 정확하면 행렬의 모든 값이 왼쪽 위에서 오른쪽 아래 대각선에 위치합니다. | torchmetrics.ConfusionMatrix 또는 sklearn.metrics.plot_confusion_matrix() |
| 분류 보고서 (Classification report) | 정밀도, 재현율, f1-스코어와 같은 주요 분류 지표들의 모음입니다. | sklearn.metrics.classification_report() |
Scikit-Learn(인기 있고 세계적인 수준의 머신러닝 라이브러리)에는 위 지표들의 많은 구현이 있으며, PyTorch와 유사한 버전을 찾고 있다면 TorchMetrics, 특히 TorchMetrics 분류 섹션을 확인해 보세요.
torchmetrics.Accuracy 지표를 사용해 봅시다.
!pip -q install torchmetrics
from torchmetrics import Accuracy
# 지표 설정 및 대상 장치에 있는지 확인
torchmetrics_accuracy = Accuracy().to(device)
# 정확도 계산
torchmetrics_accuracy(y_preds, y_blob_test) |████████████████████████████████| 409 kB 5.2 MB/s eta 0:00:01tensor(0.9950, device='cuda:0')연습 문제
모든 연습 문제는 위의 섹션들에 있는 코드를 연습하는 데 중점을 둡니다.
각 섹션을 참조하거나 링크된 리소스를 따라 완료할 수 있어야 합니다.
모든 연습 문제는 장치에 구애받지 않는 코드(device-agonistic code)를 사용하여 완료해야 합니다.
리소스: * 02 연습 문제 노트북 템플릿 * 02 예시 솔루션 노트북 (솔루션을 보기 전에 먼저 연습 문제를 시도해 보세요)
- Scikit-Learn의
make_moons()함수를 사용하여 이진 분류 데이터셋을 만듭니다.
- 일관성을 위해 데이터셋은 1000개의 샘플을 가져야 하며
random_state=42여야 합니다. - 데이터를 PyTorch 텐서로 변환합니다.
train_test_split을 사용하여 데이터를 훈련 80%, 테스트 20%로 분할합니다.
- 비선형 활성화 함수를 포함하고 1번에서 만든 데이터에 적합할 수 있는
nn.Module상속 모델을 구축합니다.
- 원하는 PyTorch 레이어(선형 및 비선형)의 조합을 자유롭게 사용하세요.
- 모델 훈련 시 사용할 이진 분류 호환 손실 함수와 옵티마이저를 설정합니다.
- 2번에서 만든 모델을 1번에서 만든 데이터에 적합시키기 위한 훈련 및 테스트 루프를 생성합니다.
- 모델 정확도를 측정하기 위해 자신만의 정확도 함수를 만들거나 TorchMetrics의 정확도 함수를 사용할 수 있습니다.
- 정확도가 96% 이상이 될 때까지 충분히 오래 모델을 훈련합니다.
- 훈련 루프는 매 10 에포크마다 모델의 훈련 및 테스트 세트 손실과 정확도 진행 상황을 출력해야 합니다.
- 훈련된 모델로 예측을 수행하고 이 노트북에서 만든
plot_decision_boundary()함수를 사용하여 플롯합니다. - 순수 PyTorch로 Tanh(쌍곡 탄젠트) 활성화 함수를 복제합니다.
- 공식은 ML cheatsheet 웹사이트를 참조하세요.
- CS231n의 나선형(spirals) 데이터 생성 함수를 사용하여 다중 클래스 데이터셋을 생성합니다 (아래 코드 참조).
- 데이터에 적합할 수 있는 모델을 구축합니다 (선형 및 비선형 레이어의 조합이 필요할 수 있습니다).
- 다중 클래스 데이터를 처리할 수 있는 손실 함수와 옵티마이저를 구축합니다 (선택적 확장: SGD 대신 Adam 옵티마이저를 사용해 보세요. 작동시키려면 학습률의 다양한 값을 실험해야 할 수도 있습니다).
- 다중 클래스 데이터에 대한 훈련 및 테스트 루프를 만들고 모델을 훈련하여 테스트 정확도 95% 이상을 달성합니다 (여기서는 원하는 어떤 정확도 측정 함수든 사용할 수 있습니다).
- 모델 예측에서 나선형 데이터셋의 결정 경계를 플롯합니다.
plot_decision_boundary()함수가 이 데이터셋에서도 작동해야 합니다.
# CS231n의 나선형 데이터셋 생성을 위한 코드
import numpy as np
N = 100 # 클래스당 점의 수
D = 2 # 차원
K = 3 # 클래스 수
X = np.zeros((N*K,D)) # 데이터 행렬 (각 행 = 단일 샘플)
y = np.zeros(N*K, dtype='uint8') # 클래스 레이블
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # 반지름
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # 세타
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# 데이터 시각화
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show()추가 학습 자료
- 머신 분류가 유용할 것 같은 3가지 문제를 적어보세요 (무엇이든 가능하며 창의력을 발휘해 보세요. 예를 들어 구매 금액과 구매 위치 특성을 기반으로 신용카드 거래를 사기 또는 사기가 아닌 것으로 분류하기).
- 경사 기반 옵티마이저(SGD 또는 Adam)에서 “모멘텀(momentum)”의 개념을 조사해 보세요. 무엇을 의미하나요?
- 다양한 활성화 함수에 대한 Wikipedia 페이지를 10분 동안 읽어보고, 이 중 몇 개가 PyTorch의 활성화 함수와 일치하는지 확인해 보세요.
- 정확도가 부적절한 지표가 될 수 있는 경우를 조사해 보세요 (힌트: 아이디어를 위해 Will Koehrsen의 [“Beyond Accuracy”] (https://willkoehrsen.github.io/statistics/learning/beyond-accuracy-precision-and-recall/)를 읽어보세요).
- 시청: 우리 신경망 내부에서 어떤 일이 일어나고 있고 학습을 위해 무엇을 하고 있는지에 대한 아이디어를 얻으려면 MIT의 Introduction to Deep Learning 비디오를 시청하세요.