what_were_covering = {1: "데이터 (준비 및 로드)",
2: "모델 구축",
3: "데이터에 모델 맞추기 (훈련)",
4: "예측 및 모델 평가 (추론)",
5: "모델 저장 및 로드",
6: "전체 과정 합치기"
}01 - PyTorch 워크플로우
![]()
머신러닝과 딥러닝의 본질은 과거의 일부 데이터를 가져와서 패턴을 발견하기 위한 알고리즘(신경망 등)을 구축하고, 발견된 패턴을 사용하여 미래를 예측하는 것입니다.
이를 수행하는 방법은 많으며 항상 새로운 방법이 발견되고 있습니다.
하지만 작게 시작해 봅시다.
직선으로 시작하면 어떨까요?
그리고 그 직선에 맞는 모델을 PyTorch로 구축할 수 있는지 확인해 보겠습니다.
이번 장에서 다룰 내용
이 모듈에서는 표준 PyTorch 워크플로우를 다룰 것입니다(필요에 따라 자르고 변경할 수 있지만 주요 단계의 윤곽을 다룹니다).
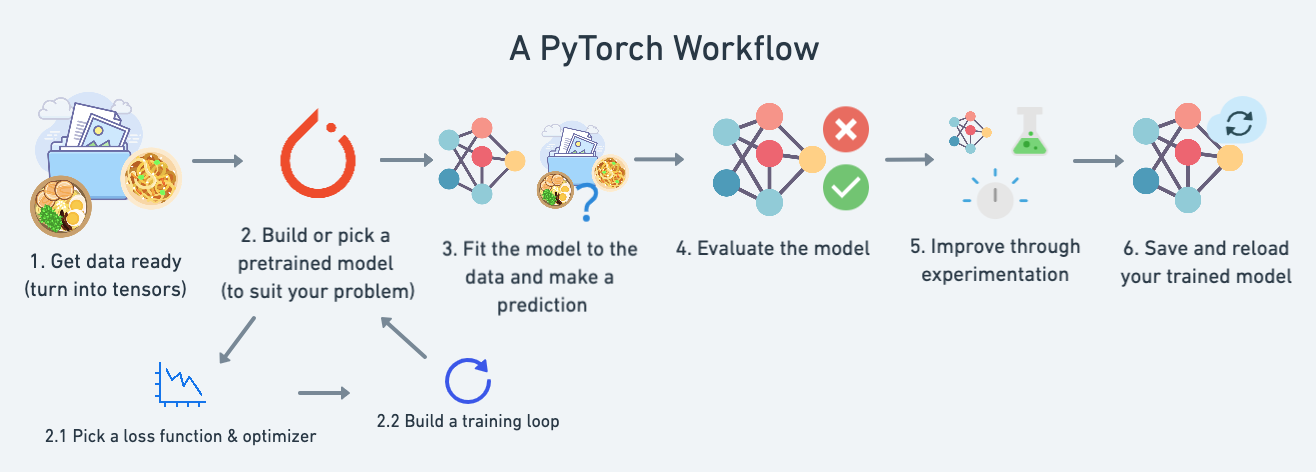
지금은 이 워크플로우를 사용하여 간단한 직선을 예측할 것이지만, 워크플로우 단계는 작업 중인 문제에 따라 반복되고 변경될 수 있습니다.
구체적으로 다음 내용을 다룹니다:
| 주제 | 내용 |
|---|---|
| 1. 데이터 준비하기 | 데이터는 거의 무엇이든 될 수 있지만, 시작하기 위해 간단한 직선을 만들 것입니다. |
| 2. 모델 구축하기 | 여기에서는 데이터의 패턴을 학습할 모델을 만들고, 손실 함수(loss function), 옵티마이저(optimizer)를 선택하고 훈련 루프(training loop)를 구축할 것입니다. |
| 3. 데이터에 모델 맞추기 (훈련) | 데이터와 모델이 준비되었으므로, 이제 모델이 (훈련) 데이터에서 패턴을 찾도록 (시도하게) 해봅시다. |
| 4. 예측 및 모델 평가 (추론) | 모델이 데이터에서 패턴을 찾았으니, 그 결과를 실제 (테스트) 데이터와 비교해 봅시다. |
| 5. 모델 저장 및 불러오기 | 모델을 다른 곳에서 사용하거나 나중에 다시 사용하고 싶을 수 있습니다. 여기에서 그 방법을 다룹니다. |
| 6. 전체 과정 합치기 | 위의 모든 내용을 하나로 합쳐 봅시다. |
도움을 받을 수 있는 곳
이 과정의 모든 자료는 GitHub에서 확인할 수 있습니다.
문제가 발생하면 해당 페이지의 Discussions 페이지에서 질문할 수 있습니다.
또한 PyTorch와 관련된 모든 것에 대해 매우 도움이 되는 장소인 PyTorch 개발자 포럼도 있습니다.
먼저 다룰 내용을 나중에 참조할 수 있도록 딕셔너리에 넣어 보겠습니다.
이제 이 모듈에 필요한 것들을 임포트해 보겠습니다.
torch, torch.nn(nn은 신경망을 뜻하며 이 패키지에는 PyTorch에서 신경망을 구축하기 위한 기본 구성 요소가 들어 있습니다) 및 matplotlib을 가져올 것입니다.
import torch
from torch import nn # nn에는 신경망을 위한 PyTorch의 모든 구성 요소가 들어 있습니다.
import matplotlib.pyplot as plt
# PyTorch 버전 확인
torch.__version__'1.11.0'1. 데이터 (준비 및 로드)
머신러닝에서 “데이터”는 상상할 수 있는 거의 모든 것이 될 수 있다는 점을 강조하고 싶습니다. 숫자 표(큰 Excel 스프레드시트와 같은 것), 모든 종류의 이미지, 비디오(YouTube에는 데이터가 많습니다!), 노래나 팟캐스트와 같은 오디오 파일, 단백질 구조, 텍스트 등입니다.
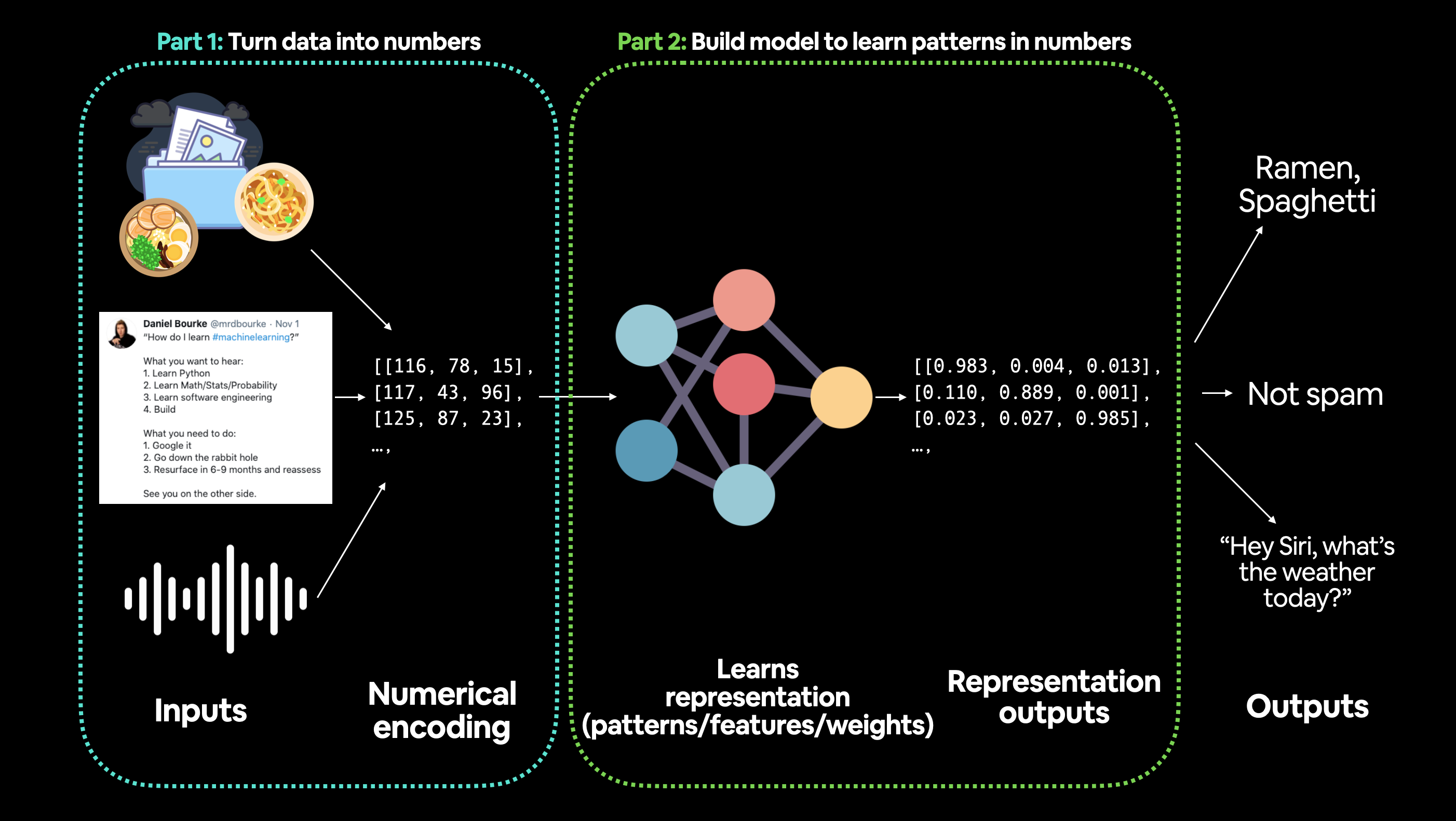
머신러닝은 두 부분으로 나뉩니다: 1. 데이터를 숫자로 변환하여 표현합니다. 2. 해당 표현을 가장 잘 학습할 수 있는 모델을 선택하거나 구축합니다.
때로는 1번과 2번이 동시에 수행될 수도 있습니다.
하지만 데이터가 없다면 어떻게 할까요?
글쎄요, 그것이 지금 우리의 상황입니다.
데이터가 없습니다.
하지만 우리는 데이터를 직접 만들 수 있습니다.
데이터를 직선으로 만들어 봅시다.
선형 회귀(linear regression)를 사용하여 알려진 파라미터(parameters)(모델이 학습할 수 있는 것들)를 가진 데이터를 생성한 다음, PyTorch를 사용하여 경사 하강법(gradient descent)을 통해 이러한 파라미터를 추정하는 모델을 구축할 수 있는지 확인해 보겠습니다.
# *알려진* 파라미터 생성
weight = 0.7
bias = 0.3
# 데이터 생성
start = 0
end = 1
step = 0.02
X = torch.arange(start, end, step).unsqueeze(dim=1)
y = weight * X + bias
X[:10], y[:10](tensor([[0.0000],
[0.0200],
[0.0400],
[0.0600],
[0.0800],
[0.1000],
[0.1200],
[0.1400],
[0.1600],
[0.1800]]),
tensor([[0.3000],
[0.3140],
[0.3280],
[0.3420],
[0.3560],
[0.3700],
[0.3840],
[0.3980],
[0.4120],
[0.4260]]))멋지네요! 이제 X (특성, features)와 y (레이블, labels) 사이의 관계를 학습할 수 있는 모델을 구축해 보겠습니다.
데이터를 훈련 세트와 테스트 세트로 분할하기
데이터가 준비되었습니다.
하지만 모델을 구축하기 전에 데이터를 분할해야 합니다.
머신러닝 프로젝트에서 가장 중요한 단계 중 하나는 훈련 세트와 테스트 세트(필요한 경우 검증 세트까지)를 만드는 것입니다.
데이터셋의 각 분할은 특정 목적을 위해 사용됩니다.
| 분할 | 목적 | 전체 데이터의 비율 | 얼마나 자주 사용되나요? |
|---|---|---|---|
| 훈련 세트(Training set) | 모델이 이 데이터로부터 학습합니다(학기 중에 공부하는 교재와 같음). | ~60-80% | 항상 |
| 검증 세트(Validation set) | 모델이 이 데이터에서 튜닝됩니다(기말고사 전에 치르는 모의고사와 같음). | ~10-20% | 자주(항상은 아님) |
| 테스트 세트(Testing set) | 모델이 학습한 내용을 테스트하기 위해 이 데이터에서 평가됩니다(학기 말에 치르는 기말고사와 같음). | ~10-20% | 항상 |
지금은 훈련 세트와 테스트 세트만 사용할 것이며, 이는 우리 모델이 학습하고 평가될 데이터셋을 갖게 됨을 의미합니다.
X 및 y 텐서를 분할하여 생성할 수 있습니다.
참고: 실제 데이터를 다룰 때 이 단계는 일반적으로 프로젝트 시작 시점에 수행됩니다(테스트 세트는 항상 다른 모든 데이터와 분리되어 보관되어야 합니다). 우리는 모델이 훈련 데이터에서 학습하도록 하고 테스트 데이터에서 평가하여 보지 못한 예제에 대해 얼마나 잘 일반화(generalizes)되는지 확인하고 싶습니다.
# 훈련/테스트 분할 생성
train_split = int(0.8 * len(X)) # 데이터의 80%를 훈련 세트로, 20%를 테스트용으로 사용
X_train, y_train = X[:train_split], y[:train_split]
X_test, y_test = X[train_split:], y[train_split:]
len(X_train), len(y_train), len(X_test), len(y_test)(40, 40, 10, 10)좋습니다. 훈련용 샘플 40개(X_train & y_train)와 테스트용 샘플 10개(X_test & y_test)를 확보했습니다.
우리가 만들 모델은 X_train과 y_train 사이의 관계를 학습하려고 노력할 것이며, 그런 다음 X_test와 y_test에서 학습한 내용을 평가할 것입니다.
하지만 지금 우리 데이터는 단지 페이지 위의 숫자에 불과합니다.
데이터를 시각화하는 함수를 만들어 보겠습니다.
def plot_predictions(train_data=X_train,
train_labels=y_train,
test_data=X_test,
test_labels=y_test,
predictions=None):
"""
훈련 데이터와 테스트 데이터를 플롯하고 예측값과 비교합니다.
"""
plt.figure(figsize=(10, 7))
# 훈련 데이터를 파란색으로 플롯
plt.scatter(train_data, train_labels, c="b", s=4, label="훈련 데이터")
# 테스트 데이터를 초록색으로 플롯
plt.scatter(test_data, test_labels, c="g", s=4, label="테스트 데이터")
if predictions is not None:
# 예측값을 빨간색으로 플롯 (예측은 테스트 데이터에서 수행됨)
plt.scatter(test_data, predictions, c="r", s=4, label="예측값")
# 범례 표시
plt.legend(prop={"size": 14});plot_predictions();
멋지네요!
이제 데이터는 페이지 위의 단순한 숫자가 아니라 직선이 되었습니다.
참고: 이제 데이터 탐험가의 좌우명인 “시각화, 시각화, 시각화!”를 소개할 좋은 시간입니다.
데이터를 다루고 숫자로 변환할 때마다 시각화할 수 있는 것이 있다면 이해하는 데 큰 도움이 된다는 점을 기억하세요.
기계는 숫자를 좋아하고 우리 인간도 숫자를 좋아하지만, 우리는 무언가를 보는 것도 좋아합니다.
2. 모델 구축
이제 데이터가 준비되었으니 파란색 점을 사용하여 초록색 점을 예측할 모델을 구축해 보겠습니다.
바로 들어가 보겠습니다.
먼저 코드를 작성한 다음 모든 것을 설명하겠습니다.
순수 PyTorch를 사용하여 표준 선형 회귀 모델을 복제해 봅시다.
# 선형 회귀 모델 클래스 생성
class LinearRegressionModel(nn.Module): # <- PyTorch의 거의 모든 것은 nn.Module입니다 (이것을 신경망 레고 블록이라고 생각하세요)
def __init__(self):
super().__init__()
self.weights = nn.Parameter(torch.randn(1, # <- 무작위 가중치로 시작 (모델이 학습함에 따라 조정됨)
requires_grad=True, # <- 경사 하강법으로 이 값을 업데이트할 수 있나요?
dtype=torch.float # <- PyTorch는 기본적으로 float32를 선호합니다
))
self.bias = nn.Parameter(torch.randn(1, # <- 무작위 편향으로 시작 (모델이 학습함에 따라 조정됨)
requires_grad=True, # <- 경사 하강법으로 이 값을 업데이트할 수 있나요?
dtype=torch.float # <- PyTorch는 기본적으로 float32를 선호합니다
))
# forward는 모델 내의 계산을 정의합니다
def forward(self, x: torch.Tensor) -> torch.Tensor: # <- "x"는 입력 데이터입니다 (예: 훈련/테스트 특성)
return self.weights * x + self.bias # <- 이것이 선형 회귀 공식입니다 (y = m*x + b)위 코드에서 꽤 많은 일이 일어나고 있는데, 하나씩 분석해 봅시다.
리소스: 신경망을 구축하기 위해 파이썬 클래스를 사용할 것입니다. 파이썬 클래스 표기법이 낯설다면 Real Python의 파이썬 3 객체 지향 프로그래밍 가이드를 몇 번 읽어보시기를 권장합니다.
PyTorch 모델 구축 필수 요소
PyTorch에는 상상할 수 있는 거의 모든 종류의 신경망을 만드는 데 사용할 수 있는 필수 모듈이 네 가지 정도 있습니다.
torch.nn, torch.optim, torch.utils.data.Dataset 및 torch.utils.data.DataLoader입니다. 지금은 처음 두 가지에 집중하고 나중에 다른 두 가지를 다룰 것입니다(그것들이 무엇을 하는지 추측할 수 있을 것입니다).
| PyTorch 모듈 | 무엇을 하나요? |
|---|---|
torch.nn |
계산 그래프(본질적으로 특정 방식으로 실행되는 일련의 계산)를 위한 모든 구성 요소를 포함합니다. |
torch.nn.Parameter |
nn.Module과 함께 사용할 수 있는 텐서를 저장합니다. requires_grad=True인 경우 경사(경사 하강법을 통해 모델 파라미터를 업데이트하는 데 사용됨)가 자동으로 계산되며, 이를 종종 “autograd”라고 합니다. |
torch.nn.Module |
모든 신경망 모듈의 기본 클래스로, 신경망의 모든 구성 요소는 이 클래스의 서브클래스입니다. PyTorch에서 신경망을 구축하는 경우 모델은 nn.Module을 상속해야 합니다. forward() 메서드 구현이 필요합니다. |
torch.optim |
다양한 최적화 알고리즘을 포함합니다(이 알고리즘은 nn.Parameter에 저장된 모델 파라미터가 경사 하강법을 개선하고 손실을 줄이기 위해 어떻게 가장 잘 변해야 하는지 알려줍니다). |
def forward() |
모든 nn.Module 서브클래스는 forward() 메서드가 필요하며, 이는 특정 nn.Module로 전달된 데이터에 대해 수행될 계산을 정의합니다(예: 위의 선형 회귀 공식). |
위 내용이 복잡하게 들린다면 이렇게 생각해 보세요. PyTorch 신경망의 거의 모든 것은 torch.nn에서 나옵니다. * nn.Module은 더 큰 구성 요소(레이어)를 포함합니다. * nn.Parameter는 가중치 및 편향과 같은 작은 파라미터를 포함합니다(이들을 함께 결합하여 nn.Module을 만듭니다). * forward()는 더 큰 블록이 nn.Module 내에서 입력(데이터가 가득 찬 텐서)에 대해 계산을 수행하는 방법을 알려줍니다. * torch.optim은 입력 데이터를 더 잘 나타내기 위해 nn.Parameter 내의 파라미터를 개선하는 최적화 방법을 포함합니다.

nn.Module을 상속하여 PyTorch 모델을 만드는 기본 구성 요소. nn.Module을 상속하는 객체의 경우 forward() 메서드가 정의되어야 합니다.
리소스: PyTorch Cheat Sheet에서 이러한 필수 모듈과 그 사용 사례를 더 많이 확인해 보세요.
PyTorch 모델의 내용 확인하기
이제 필수 요소를 살펴보았으니, 우리가 만든 클래스로 모델 인스턴스를 생성하고 .parameters()를 사용하여 해당 파라미터를 확인해 보겠습니다.
# nn.Parameter가 무작위로 초기화되므로 수동 시드 설정
torch.manual_seed(42)
# 모델의 인스턴스 생성 (이것은 nn.Parameter들을 포함하는 nn.Module의 서브클래스입니다)
model_0 = LinearRegressionModel()
# 우리가 생성한 nn.Module 서브클래스 내의 nn.Parameter들을 확인
list(model_0.parameters())[Parameter containing:
tensor([0.3367], requires_grad=True),
Parameter containing:
tensor([0.1288], requires_grad=True)].state_dict()를 사용하여 모델의 상태(모델이 포함하는 내용)를 가져올 수도 있습니다.
# 명명된 파라미터 나열
model_0.state_dict()OrderedDict([('weights', tensor([0.3367])), ('bias', tensor([0.1288]))])model_0.state_dict()에서 weights 및 bias 값이 무작위 부동 소수점 텐서로 나오는 것을 확인하셨나요?
이는 위에서 torch.randn()을 사용하여 초기화했기 때문입니다.
본질적으로 우리는 무작위 파라미터에서 시작하여 모델이 우리 데이터에 가장 잘 맞는 파라미터(직선 데이터를 만들 때 설정한 하드코딩된 weight 및 bias 값)로 업데이트되도록 하기를 원합니다.
연습: 위의 두 셀 위에서
torch.manual_seed()값을 변경해보고, 가중치와 편향 값에 어떤 일이 일어나는지 확인해 보세요.
우리 모델은 무작위 값으로 시작하기 때문에 지금은 예측 능력이 떨어집니다.
torch.inference_mode()를 사용하여 예측하기
이를 확인하기 위해 테스트 데이터 X_test를 전달하여 y_test를 얼마나 근접하게 예측하는지 볼 수 있습니다.
모델에 데이터를 전달하면 모델의 forward() 메서드를 거쳐 정의된 계산을 사용하여 결과가 생성됩니다.
예측을 해봅시다.
# 모델로 예측하기
with torch.inference_mode():
y_preds = model_0(X_test)
# 참고: 오래된 PyTorch 코드에서는 torch.no_grad()를 볼 수도 있습니다.
# with torch.no_grad():
# y_preds = model_0(X_test)음?
예측을 수행하기 위해 torch.inference_mode()를 컨텍스트 매니저(with torch.inference_mode(): 부분)로 사용한 것을 눈치채셨을 것입니다.
이름에서 알 수 있듯이, torch.inference_mode()는 추론(예측 수행)을 위해 모델을 사용할 때 사용됩니다.
torch.inference_mode()는 예측을 수행할 때 순전파(forward-passes)(forward() 메서드를 통과하는 데이터)를 더 빠르게 만들기 위해 여러 가지(훈련에는 필요하지만 추론에는 필요하지 않은 경사 추적 등)를 끕니다.
참고: 오래된 PyTorch 코드에서는 추론을 위해
torch.no_grad()가 사용되는 것을 볼 수 있습니다.torch.inference_mode()와torch.no_grad()는 비슷한 역할을 하지만,torch.inference_mode()가 더 최신 버전이며 잠재적으로 더 빠르고 권장됩니다. 자세한 내용은 PyTorch의 이 트윗을 참조하세요.
예측을 수행했습니다. 어떻게 생겼는지 확인해 봅시다.
# 예측값 확인
print(f"테스트 샘플 수: {len(X_test)}")
print(f"수행된 예측 수: {len(y_preds)}")
print(f"예측값:\n{y_preds}")Number of testing samples: 10
Number of predictions made: 10
Predicted values:
tensor([[0.3982],
[0.4049],
[0.4116],
[0.4184],
[0.4251],
[0.4318],
[0.4386],
[0.4453],
[0.4520],
[0.4588]])테스트 샘플당 하나의 예측값이 있는 것을 확인하세요.
이는 우리가 사용하는 데이터의 종류 때문입니다. 우리의 직선의 경우 하나의 X 값이 하나의 y 값에 매핑됩니다.
하지만 머신러닝 모델은 매우 유연합니다. 하나의 y 값에 100개의 X 값이 매핑될 수도 있고, 2개, 3개 또는 10개의 y 값에 매핑될 수도 있습니다. 모든 것은 작업 중인 대상에 달려 있습니다.
우리 예측값은 여전히 페이지 위의 숫자입니다. 위에서 만든 plot_predictions() 함수로 시각화해 봅시다.
plot_predictions(predictions=y_preds.cpu())
와! 빨간색 점들을 보세요. 초록색 점들과 거의 완벽하게 일치합니다. 에포크(epochs)를 늘린 것이 도움이 된 것 같네요.
6.5 모델 저장 및 로드
모델의 예측 결과가 만족스러우므로, 나중에 사용할 수 있도록 파일로 저장해 봅시다.
from pathlib import Path
# 1. 모델 디렉토리 생성
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. 모델 저장 경로 생성
MODEL_NAME = "01_pytorch_workflow_model_1.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. 모델 state dict 저장
print(f"모델 저장 경로: {MODEL_SAVE_PATH}")
torch.save(obj=model_1.state_dict(), # state_dict()만 저장하면 모델의 학습된 파라미터만 저장됩니다.
f=MODEL_SAVE_PATH) 모델 저장 경로: models/01_pytorch_workflow_model_1.pth모든 것이 잘 작동했는지 확인하기 위해 모델을 다시 로드해 봅시다.
다음 단계를 수행합니다: * LinearRegressionModelV2() 클래스의 새로운 인스턴스를 생성합니다. * torch.nn.Module.load_state_dict()를 사용하여 모델의 state dict를 로드합니다. * 코드의 장치 독립성을 보장하기 위해 모델의 새 인스턴스를 대상 장치(target device)로 보냅니다.
# LinearRegressionModelV2의 새로운 인스턴스 생성
loaded_model_1 = LinearRegressionModelV2()
# 모델 state dict 로드
loaded_model_1.load_state_dict(torch.load(MODEL_SAVE_PATH))
# 모델을 대상 장치로 보냄 (데이터가 GPU에 있으면 예측을 위해 모델도 GPU에 있어야 합니다)
loaded_model_1.to(device)
print(f"로드된 모델:\n{loaded_model_1}")
print(f"장치 위의 모델:\n{next(loaded_model_1.parameters()).device}")로드된 모델:
LinearRegressionModelV2(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
)
장치 위의 모델:
cuda:0이제 로드된 모델을 평가하여 그 예측이 저장하기 전의 예측과 일치하는지 확인할 수 있습니다.
# 로드된 모델 평가
loaded_model_1.eval()
with torch.inference_mode():
loaded_model_1_preds = loaded_model_1(X_test)
y_preds == loaded_model_1_predstensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]], device='cuda:0')모든 것이 일치합니다! 좋습니다!
먼 길을 오셨습니다. 이제 PyTorch에서 처음 두 개의 신경망 모델을 직접 구축하고 훈련했습니다!
이제 실력을 연습해 볼 시간입니다.
연습 문제
모든 연습 문제는 노트북 전체의 코드에서 영감을 얻었습니다.
주요 섹션당 하나의 연습 문제가 있습니다.
해당 섹션을 참조하여 완료할 수 있어야 합니다.
참고: 모든 연습 문제에서 코드는 장치 독립적이어야 합니다(즉, 사용 가능한 경우 CPU 또는 GPU에서 실행될 수 있어야 함).
- 선형 회귀 공식(
weight * X + bias)을 사용하여 직선 데이터셋을 만듭니다.
weight=0.3,bias=0.9로 설정하고 총 데이터 포인트는 100개 이상이어야 합니다.- 데이터를 훈련 80%, 테스트 20%로 분할합니다.
- 훈련 및 테스트 데이터를 시각적으로 플롯합니다.
nn.Module을 상속하여 PyTorch 모델을 구축합니다.
- 내부에는 무작위로 초기화된
nn.Parameter()가 있어야 하며, 하나는 가중치(weights)용, 하나는 편향(bias)용이고requires_grad=True여야 합니다. - 1번에서 데이터셋을 만드는 데 사용한 선형 회귀 함수를 계산하도록
forward()메서드를 구현합니다. - 모델을 구성한 후 인스턴스를 만들고
state_dict()를 확인합니다. - 참고: 원한다면
nn.Parameter()대신nn.Linear()를 사용할 수 있습니다.
- 각각
nn.L1Loss()및torch.optim.SGD(params, lr)를 사용하여 손실 함수와 옵티마이저를 생성합니다.
- 옵티마이저의 학습률을 0.01로 설정하고, 최적화할 파라미터는 2번에서 만든 모델의 모델 파라미터여야 합니다.
- 300 에포크 동안 적절한 훈련 단계를 수행하는 훈련 루프를 작성합니다.
- 훈련 루프는 20 에포크마다 테스트 데이터셋에서 모델을 테스트해야 합니다.
- 훈련된 모델로 테스트 데이터에 대해 예측을 수행합니다.
- 이러한 예측값을 원래 훈련 및 테스트 데이터와 함께 시각화합니다 (참고: matplotlib과 같이 CUDA를 지원하지 않는 라이브러리를 사용하여 플롯하려면 예측값이 GPU에 있지 않은지 확인해야 할 수 있습니다).
- 훈련된 모델의
state_dict()를 파일로 저장합니다.
- 2번에서 만든 모델 클래스의 새로운 인스턴스를 생성하고 방금 저장한
state_dict()를 로드합니다. - 로드된 모델로 테스트 데이터에 대해 예측을 수행하고 4번의 원래 모델 예측과 일치하는지 확인합니다.
리소스: 이 과정의 GitHub에서 연습 문제 노트북 템플릿 및 솔루션을 참조하세요.
추가 학습 자료
- 비공식 PyTorch 최적화 루프 송(The Unofficial PyTorch Optimization Loop Song)을 들어보세요 (PyTorch 훈련/테스트 루프의 단계를 기억하는 데 도움이 됨).
- PyTorch에서 가장 중요한 모듈 중 하나가 어떻게 작동하는지 더 깊이 이해하려면 Jeremy Howard의 What is
torch.nn, really?를 읽어보세요. - 접할 수 있는 다양한 PyTorch 모듈에 대해 PyTorch 문서 치트시트(cheatsheet)를 10분 정도 훑어보세요.
- PyTorch의 다양한 저장 및 로드 옵션에 익숙해지기 위해 PyTorch 웹사이트의 로딩 및 저장 문서를 10분 정도 읽어보세요.
- 우리 모델의 학습을 돕기 위해 백그라운드에서 작동해 온 두 가지 주요 알고리즘인 경사 하강법과 역전파의 내부 구조에 대한 개요를 위해 다음 자료를 1~2시간 동안 읽거나 시청하세요.
- Wikipedia의 경사 하강법 페이지
- Robert Kwiatkowski의 Gradient Descent Algorithm — a deep dive
- 3Blue1Brown의 경사 하강법, 신경망은 어떻게 학습하는가 비디오
- 3Blue1Brown의 역전파는 실제로 무엇을 하고 있는가? 비디오
- 역전파(Backpropagation) Wikipedia 페이지