코드 보기
import pandas as pd
from lets_plot import *
LetsPlot.setup_html()이전 장들에서 단순히 산점도, 막대 그래프, 박스 플롯을 만드는 법 이상의 것을 배웠습니다. 여러분은 lets-plot으로 어떤 유형의 그래프든 만드는 데 사용할 수 있는 토대를 닦았습니다.
이 장에서는 그래픽의 계층적 문법(layered grammar of graphics)에 대해 배우면서 그 토대를 확장할 것입니다. 에스테틱 매핑, 기하 객체(geoms), 그리고 패싯(facets)에 대해 더 깊이 파고드는 것으로 시작하겠습니다. 그다음, 그래프를 생성할 때 lets-plot이 배후에서 수행하는 통계적 변환(statistical transformations)에 대해 배울 것입니다. 이러한 변환은 막대 그래프의 높이나 박스 플롯의 중앙값과 같이 플롯할 새로운 값들을 계산하는 데 사용됩니다. 또한 그래프에서 geom이 표시되는 방식을 수정하는 위치 조정(position adjustments)에 대해서도 배울 것입니다. 마지막으로 좌표계(coordinate systems)를 간략하게 소개하겠습니다.
이러한 각 레이어에 대한 모든 함수와 옵션을 다 다루지는 않겠지만, lets-plot에서 제공하는 가장 중요하고 흔히 사용되는 기능들을 안내해 드리겠습니다.
이 장에서는 letsplot 패키지와 pandas를 설치해야 합니다.
파이썬 세션에서, 사용할 라이브러리들을 불러옵니다:
import pandas as pd
from lets_plot import *
LetsPlot.setup_html()“그림의 가장 큰 가치는 우리가 전혀 예상하지 못했던 것을 알아차리게 할 때이다.” — 존 터키 (John Tukey)
이 섹션에서는 mpg 데이터셋을 사용할 것이므로, 먼저 다운로드하겠습니다.
mpg = pd.read_csv(
"https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2/mpg.csv", index_col=0
)
mpg = mpg.astype(
{
"manufacturer": "category",
"model": "category",
"displ": "double",
"year": "int64",
"cyl": "int64",
"trans": "category",
"drv": "category",
"cty": "double",
"hwy": "double",
"fl": "category",
"class": "category",
}
)
mpg.head()| manufacturer | model | displ | year | cyl | trans | drv | cty | hwy | fl | class | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| rownames | |||||||||||
| 1 | audi | a4 | 1.8 | 1999 | 4 | auto(l5) | f | 18.0 | 29.0 | p | compact |
| 2 | audi | a4 | 1.8 | 1999 | 4 | manual(m5) | f | 21.0 | 29.0 | p | compact |
| 3 | audi | a4 | 2.0 | 2008 | 4 | manual(m6) | f | 20.0 | 31.0 | p | compact |
| 4 | audi | a4 | 2.0 | 2008 | 4 | auto(av) | f | 21.0 | 30.0 | p | compact |
| 5 | audi | a4 | 2.8 | 1999 | 6 | auto(l5) | f | 16.0 | 26.0 | p | compact |
mpg에 포함된 변수들 중 일부는 다음과 같습니다:
displ: 자동차의 엔진 크기 (리터 단위). 수치형 변수.
hwy: 자동차의 고속도로 연비 (갤런당 마일, mpg). 연비가 낮은 차는 같은 거리를 주행할 때 연비가 높은 차보다 더 많은 연료를 소비합니다. 수치형 변수.
class: 자동차의 유형. 범주형 변수.
먼저 다양한 자동차의 class에 따른 displ과 hwy 사이의 관계를 시각화해 보겠습니다. 수치형 변수들은 x 및 y 에스테틱에 매핑하고, 범주형 변수는 color나 shape와 같은 에스테틱에 매핑하여 산점도로 나타낼 수 있습니다.
(ggplot(mpg, aes(x="displ", y="hwy", color="class")) + geom_point())(ggplot(mpg, aes(x="displ", y="hwy", shape="class")) + geom_point())이와 비슷하게 class를 size나 alpha 에스테틱에 매핑할 수도 있는데, 이들은 각각 점의 크기와 투명도를 조절합니다.
(ggplot(mpg, aes(x="displ", y="hwy", size="class")) + geom_point())(ggplot(mpg, aes(x="displ", y="hwy", alpha="class")) + geom_point())할 수는 있지만, 순서가 없는 이산형(범주형) 변수인 class를 순서가 있는 에스테틱 변수인 size나 alpha에 매핑하는 것은 좋지 않은 생각입니다. 실제로는 존재하지 않는 순위 정보를 암시하기 때문입니다.
일단 에스테틱을 매핑하면 lets-plot이 나머지를 처리합니다. 에스테틱에 사용할 적절한 스케일을 선택하고, 레벨과 값 사이의 매핑을 설명하는 범례(legend)를 구성합니다. x 및 y 에스테틱의 경우 lets-plot은 범례를 만들지 않지만, 눈금과 레이블이 있는 축 선(axis line)을 만듭니다. 축 선은 범례와 동일한 정보를 제공합니다. 즉, 위치와 값 사이의 매핑을 설명합니다.
변수 매핑에 의존하여 모양을 결정하는 대신, 에스테틱의 시각적 속성을 (aes() 외부의) geom 함수의 인수로 직접 수동 설정할 수도 있습니다. 예를 들어, 플롯의 모든 점을 파란색으로 만들 수 있습니다:
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point(color="blue"))여기서 색상은 변수에 대한 정보를 전달하지 않으며, 단지 플롯의 모양만 바꿉니다. 해당 에스테틱에 맞는 값을 선택해야 합니다:
color = "blue"size = 1shape = 1위의 플롯을 바꾸어 보되, 색상을 지정하는 대신 shape 에스테틱을 지정해 보세요. shape를 1, 2, 3으로 설정했을 때 각각 어떤 결과가 나오나요?
지금까지 포인트 geom을 사용하는 산점도에서 매핑하거나 설정할 수 있는 에스테틱들에 대해 논의했습니다.
플롯에 사용할 수 있는 구체적인 에스테틱은 데이터를 표현하기 위해 사용하는 geom에 따라 달라집니다. 다음 섹션에서는 geom에 대해 더 깊이 알아봅니다.
점이 분홍색으로 채워진 삼각형인 hwy 대 displ 산점도를 만드세요.
다음 코드가 왜 파란색 점이 있는 플롯을 결과로 내지 않을까요?
(
ggplot(mpg) +
geom_point(aes(x = "displ", y = "hwy", color = "blue"))
)stroke 에스테틱은 무엇을 하나요? 어떤 모양들과 함께 작동하나요? (힌트: 전역 에스테틱에서 stroke를 사용하고 geom_point()에서 shape를 사용해 보세요)
위의 마지막 플롯을 바꾸어 보되, 색상을 지정하는 대신 shape 에스테틱을 지정해 보세요. shape를 1, 2, 3으로 설정했을 때 각각 어떤 결과가 나오나요?
이 두 플롯은 어떻게 비슷할까요?
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point(size=4))(ggplot(mpg, aes(x="displ", y="hwy")) + geom_smooth(method="loess", size=2))두 플롯 모두 동일한 x 변수와 동일한 y 변수를 포함하며, 둘 다 동일한 데이터를 설명합니다. 하지만 플롯이 동일하지는 않습니다. 각 플롯은 데이터를 표현하기 위해 서로 다른 기하 객체(geom)를 사용합니다. 왼쪽 플롯은 포인트 geom을 사용하고, 오른쪽 플롯은 데이터에 적합된 부드러운 선인 smooth geom을 사용합니다.
플롯의 geom을 변경하려면 ggplot()에 추가하는 geom 함수를 바꾸면 됩니다.
lets-plot의 모든 geom 함수는 mapping 인수를 받는데, 이는 geom 레이어에서 지역적으로 정의하거나 ggplot() 레이어에서 전역적으로 정의할 수 있습니다. 하지만 모든 에스테틱이 모든 geom과 작동하는 것은 아닙니다. 점의 모양(shape)은 설정할 수 있지만, 선의 “모양”은 설정할 수 없습니다. 시도해 보더라도 lets-plot은 해당 에스테틱 매핑을 자동으로 무시할 것입니다. 반면, 선의 유형(linetype)은 설정할 수 있습니다. geom_smooth()는 linetype에 매핑된 변수의 각 고유 값에 대해 서로 다른 linetype으로 별도의 선을 그립니다.
직접 확인해 보겠습니다:
(ggplot(mpg, aes(x="displ", y="hwy", line="drv")) + geom_smooth(method="loess"))(ggplot(mpg, aes(x="displ", y="hwy", linetype="drv")) + geom_smooth(method="loess"))여기서 geom_smooth()는 자동차의 구동 방식인 drv 값에 따라 자동차들을 세 개의 선으로 분리합니다. 한 선은 4 값을 가진 모든 포인트들을 설명하고, 다른 선은 f 값을 가진 포인트들을, 마지막 선은 r 값을 가진 포인트들을 설명합니다. 여기서 4는 4륜 구동, f는 전륜 구동, r은 후륜 구동을 의미합니다.
이것이 너무 혼란스럽다면, 원본 데이터 위에 선을 겹쳐 놓고 모든 것을 drv에 따라 색칠하여 더 명확하게 만들 수 있습니다.
(
ggplot(mpg, aes(x="displ", y="hwy", color="drv"))
+ geom_point()
+ geom_smooth(aes(linetype="drv"), method="loess")
)이 플롯에는 동일한 그래프 안에 두 개의 geom이 포함되어 있음에 유의하세요.
geom_smooth()와 같은 많은 geom들은 여러 행의 데이터를 표시하기 위해 단일 기하 객체를 사용합니다. 이러한 geom들의 경우, 여러 객체를 그리기 위해 group 에스테틱을 범주형 변수로 설정할 수 있습니다. lets-plot은 그룹화 변수의 각 고유 값에 대해 별도의 객체를 그릴 것입니다. 실제로 lets-plot은 에스테틱을 이산형 변수에 매핑할 때마다 자동으로 데이터를 그룹화하므로 이 기능에 의존하는 것이 편리합니다. group 에스테틱 자체는 범례나 구별되는 특징을 geom에 추가하지 않기 때문입니다.
geom 함수에 매핑을 배치하면 lets-plot은 이를 해당 레이어의 지역 매핑으로 처리합니다. 이 매핑들을 사용하여 해당 레이어에 대해서만 전역 매핑을 확장하거나 덮어쓰게 됩니다. 이를 통해 서로 다른 레이어에 서로 다른 에스테틱을 표시할 수 있습니다.
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point(aes(color="class")) + geom_smooth())동일한 아이디어를 사용하여 각 레이어에 서로 다른 데이터를 지정할 수 있습니다. 여기서는 빨간색 점과 빈 원을 사용하여 2인승(2-seater) 차량을 강조합니다. geom_point()의 지역 데이터 인수는 해당 레이어에 대해서만 ggplot()의 전역 데이터 인수를 덮어씁니다.
(
ggplot(mpg, aes(x="displ", y="hwy"))
+ geom_point()
+ geom_point(data=mpg.loc[mpg["class"] == "2seater", :], color="red", size=2)
+ geom_point(
data=mpg.loc[mpg["class"] == "2seater", :], shape=1, size=3, color="red"
)
)Geom은 lets-plot의 핵심적인 빌딩 블록입니다. Geom을 바꿈으로써 플롯의 모습을 완전히 변형시킬 수 있으며, 서로 다른 geom은 데이터의 서로 다른 특징을 드러낼 수 있습니다.
lets-plot은 40개 이상의 geom을 제공하지만 이것이 만들 수 있는 모든 가능한 플롯을 커버하지는 않습니다. lets-plot 문서의 해당 부분에서 개요를 찾을 수 있습니다.
포함되지 않은 geom이 필요한 경우 크게 세 가지 옵션이 있습니다: 1. lets-plot을 확장하고 여러분이 필요한 기능을 수행하는 패키지들을 찾아봅니다. 2. lets-plot 깃허브 페이지에 이슈를 제기하여 새로운 기능으로 요청합니다. 다만 유지관리자들에게 우선순위가 아닐 수 있으며, 다른 사람들에게 얼마나 유용할지나 구현이 얼마나 쉬울지에 따라 추가된다는 보장은 없음을 염두에 두어야 합니다. 3. 처음부터 직접 차트를 구축할 수 있도록 미세한 제어를 제공하는 명령형 플로팅 패키지로 눈을 돌립니다. matplotlib이 이를 위해 정말 훌륭합니다.
선 그래프(line chart)를 그리려면 어떤 geom을 사용해야 할까요? 박스 플롯은요? 히스토그램은요? 영역 차트(area chart)는요?
다음 이전 예제를 실행할 때:
(
ggplot(mpg, aes(x = "displ", y = "hwy", alpha = "class")) +
geom_point()
)show_legend=False 키워드 인수를 추가하면 생성된 차트에 어떤 효과가 있을까요?
geom_smooth()의 se 인수는 무엇을 하나요?
다음 그래프를 생성하는 데 필요한 파이썬 코드를 재현해 보세요.
데이터 시각화 (Data Visualisation) 에서 범주형 변수를 기반으로 데이터를 부분 집합별로 나누어 서브플롯으로 표시하는 facet_wrap()을 사용한 패시팅(faceting)에 대해 배웠습니다.
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point() + facet_wrap("cyl"))두 변수의 조합으로 플롯을 패싯하려면 facet_wrap()에서 facet_grid()로 바꾸세요.
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point() + facet_grid("drv", "cyl"))기본적으로 각 패싯은 x축과 y축에 대해 동일한 스케일과 범위를 공유합니다. 이는 패싯 간에 데이터를 비교하고 싶을 때 유용하며 권장되는 기본값이지만, 각 패싯 내에서의 관계를 더 잘 시각화하고 싶을 때는 제약이 될 수 있습니다. 패시팅 함수에서 scales 인수를 "free"로 설정하면 행과 열 모두에서 서로 다른 축 스케일을 허용하고, "free_x"는 행 간에 서로 다른 스케일을, "free_y"는 열 간에 서로 다른 스케일을 허용합니다.
(
ggplot(mpg, aes(x="displ", y="hwy"))
+ geom_point()
+ facet_grid("drv", "cyl", scales="free_y")
)(ggplot(mpg) + geom_point(aes(x="displ", y="hwy")) + facet_wrap("class", nrow=2))연속형 변수로 패싯을 하면 어떻게 되나요?
facet_grid("drv", "cyl")을 사용한 플롯에서 빈 셀은 무엇을 의미하나요? 다음 코드를 실행해 보세요. 결과 플롯과 이들이 어떻게 관련되어 있나요?
(
ggplot(mpg) +
geom_point(aes(x = "drv", y = "cyl"))
)다음 코드는 어떤 플롯을 만드나요? 두 번째 변수를 생략하면 무엇을 하나요?
(
ggplot(mpg) +
geom_point(aes(x = "displ", y = "hwy")) +
facet_grid("drv")
)
(
ggplot(mpg) +
geom_point(aes(x = displ, y = "hwy")) +
facet_grid("cyl")
)이 섹션의 첫 번째 패싯 플롯을 살펴보세요:
(
ggplot(mpg) +
geom_point(aes(x = "displ", y = "hwy")) +
facet_wrap("class", nrow = 2)
)color 에스테틱 대신 패시팅을 사용했을 때의 장점은 무엇인가요? 단점은 무엇인가요? 더 큰 데이터셋을 가졌을 때 그 균형이 어떻게 바뀔까요?
help(facet_wrap)을 읽거나 Visual Studio Code에서 facet_wrap() 위에 마우스를 올려보세요. nrow는 무엇을 하나요? ncol은 무엇을 하나요? 개별 패널의 레이아웃을 제어하는 다른 옵션은 무엇인가요? facet_grid()에는 왜 nrow와 ncol 인수가 없나요?
facet_grid() 대신 facet_wrap()을 사용하여 다음 플롯을 재현해 보세요. 패싯 레이블의 위치가 어떻게 바뀌나요?
(
ggplot(mpg) +
geom_point(aes(x = "displ", y = "hwy")) +
facet_grid("drv")
)geom_bar()나 geom_col()로 그려진 기본적인 막대 그래프를 생각해 보세요. 다음 차트는 diamonds 데이터셋에 있는 다이아몬드의 총 개수를 cut별로 그룹화하여 표시합니다. diamonds 데이터셋에는 각 다이아몬드의 price, carat, color, clarity, cut 정보를 포함하여 약 54,000개의 다이아몬드 정보가 담겨 있습니다. 잠시 후에 불러오겠습니다. 차트는 저품질의 컷보다 고품질의 컷을 가진 다이아몬드가 더 많음을 보여줍니다.
diamonds = pd.read_csv(
"https://vincentarelbundock.github.io/Rdatasets/csv/ggplot2/diamonds.csv",
index_col=0,
)
diamonds_cut_order = ["Fair", "Good", "Very Good", "Premium", "Ideal"]
diamonds["cut"] = diamonds["cut"].astype(
pd.CategoricalDtype(categories=diamonds_cut_order, ordered=True)
)
diamonds.head()| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| rownames | ||||||||||
| 1 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 2 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 3 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 4 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 5 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
(ggplot(diamonds, aes(x="cut")) + geom_bar())x축에서 차트는 diamonds의 변수인 cut을 표시합니다. y축에서는 빈도수(count)를 표시하는데, 빈도수는 diamonds에 있는 변수가 아닙니다! 빈도수는 어디에서 왔을까요? 산점도와 같은 많은 그래프는 데이터셋의 가공되지 않은(raw) 값을 플롯합니다. 막대 그래프와 같은 다른 그래프들은 플롯할 새로운 값들을 계산합니다:
막대 그래프, 히스토그램, 빈도 다각형은 데이터를 빈으로 나누고 각 빈에 속하는 포인트의 수인 빈 빈도수를 플롯합니다.
부드럽게 만드는 도구(smoothers)는 데이터에 모델을 맞춘 다음 모델로부터 예측된 값을 플롯합니다.
박스 플롯은 분포의 다섯 수치 요약을 계산한 다음 그 요약을 특별한 형식의 박스로 표시합니다.
그래프를 위해 새로운 값을 계산하는 데 사용되는 알고리즘을 stat(statistical transformation의 약자)이라고 합니다. 아래 그림은 이 프로세스가 geom_bar()와 함께 어떻게 작동하는지 보여줍니다.
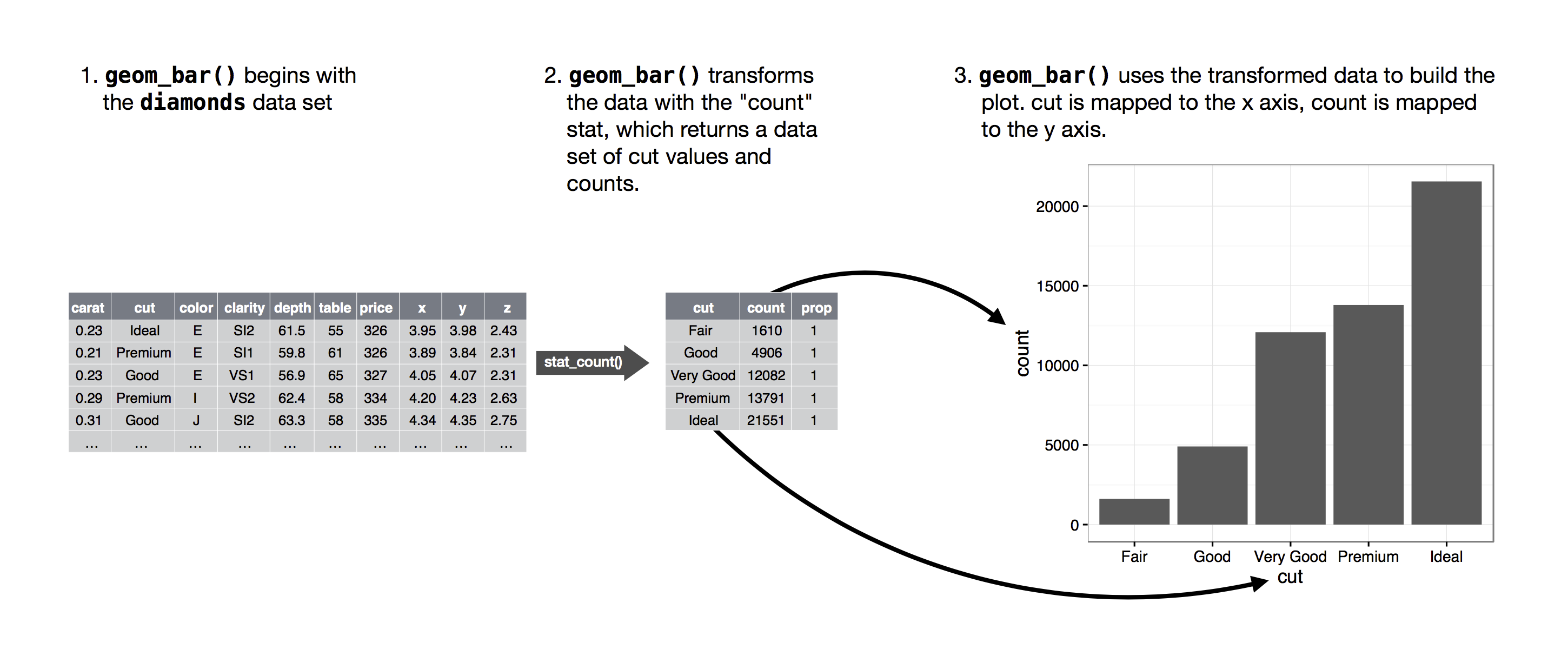
geom이 사용하는 stat이 무엇인지 알아보려면 stat 인수의 기본값을 검사하면 됩니다. 예를 들어, help(geom_bar)를 보거나 코드에 적힌 함수 위에 마우스를 올리면 stat의 기본값이 “count”임을 알 수 있는데, 이는 geom_bar()가 발생 횟수를 사용함을 의미합니다.
모든 geom은 기본 stat을 가지며, 모든 stat은 기본 geom을 가집니다. 이는 대개 기저의 통계적 변환에 대해 걱정하지 않고도 geom을 사용할 수 있음을 의미합니다. 하지만 stat을 명시적으로 사용해야 할 몇 가지 이유가 있습니다. 예를 들어, 기본 stat을 재정의하고 싶을 때입니다. 아래 코드에서는 geom_bar()의 stat을 기본값인 count에서 identity로 변경합니다. 이를 통해 막대의 높이를 y 변수의 가공되지 않은 값에 매핑할 수 있습니다.
(
ggplot(
diamonds.value_counts("cut").reset_index(name="counts"),
aes(x="cut", y="counts"),
)
+ geom_bar(stat="identity")
)막대 그래프와 관련된 마법 같은 기능이 하나 더 있습니다. color 에스테틱을 사용하거나, 더 유용하게는 fill 에스테틱을 사용하여 막대 그래프에 색상을 입힐 수 있습니다:
(ggplot(mpg, aes(x="drv", color="drv")) + geom_bar())(ggplot(mpg, aes(x="drv", fill="drv")) + geom_bar())fill 에스테틱을 class와 같은 다른 변수에 매핑하면 어떻게 되는지 주목하세요: 막대들이 자동으로 누적(stacked)됩니다. 각 색칠된 사각형은 drv와 class의 조합을 나타냅니다.
(ggplot(mpg, aes(x="drv", fill="class")) + geom_bar())누적 작업은 position 인수에 의해 지정된 위치 조정(position adjustment)을 사용하여 자동으로 수행됩니다. 누적 막대 그래프를 원하지 않는다면 "identity", "dodge" 또는 "fill" 세 가지 옵션 중 하나를 사용할 수 있습니다.
position = "identity"는 각 객체를 그래프의 맥락에서 정확히 그 지점에 배치합니다. 이는 막대의 경우 서로 겹치게 되므로 그리 유용하지 않습니다. 겹침을 확인하려면 대개 alpha를 작은 값으로 설정하여 막대를 약간 투명하게 만들어야 합니다.(ggplot(mpg, aes(x="drv", fill="class")) + geom_bar(alpha=0.5, position="identity"))identity 위치 조정은 포인트와 같은 2D geom에 더 유용하며, 거기서는 이것이 기본값입니다.
position = "fill"은 누적과 비슷하게 작동하지만, 누적된 각 막대 세트의 높이를 동일하게 만듭니다. 이를 통해 그룹 간의 비율을 더 쉽게 비교할 수 있습니다.(ggplot(mpg, aes(x="drv", fill="class")) + geom_bar(position="fill"))position = "dodge"는 겹치는 객체들을 서로 옆에 배치합니다. 이를 통해 개별 값들을 더 쉽게 비교할 수 있습니다.(ggplot(mpg, aes(x="drv", fill="class")) + geom_bar(position="dodge"))막대 그래프에는 유용하지 않지만 산점도에는 매우 유용할 수 있는 또 다른 유형의 조정이 있습니다. 우리의 첫 번째 산점도를 떠올려 보세요. 데이터셋에 234개의 관측치가 있음에도 불구하고 플롯에는 일부 점만 표시된다는 사실을 눈치채셨나요?
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point())hwy와 displ의 기저 값이 반올림되어 있어 점들이 그리드 위에 나타나고 많은 점이 서로 겹칩니다. 이 문제를 오버플로팅(overplotting)이라고 합니다. 이러한 배치는 데이터의 분포를 확인하기 어렵게 만듭니다. 데이터 포인트들이 그래프 전체에 고르게 퍼져 있나요, 아니면 109개의 값을 포함하는 하나의 특별한 hwy와 displ 조합이 있나요?
위치 조정을 “jitter”로 설정하여 이러한 그리드 현상을 피할 수 있습니다. position = "jitter"는 각 점에 소량의 무작위 노이즈를 추가합니다. 어떤 두 점도 동일한 양의 무작위 노이즈를 받을 가능성이 낮으므로 점들이 흩어지게 됩니다.
(ggplot(mpg, aes(x="displ", y="hwy")) + geom_point(position="jitter"))무작위성을 추가하는 것이 그래프를 개선하는 이상한 방법처럼 보일 수 있지만, 작은 규모에서 그래프의 정확도는 떨어뜨리더라도 큰 규모에서는 그래프를 더 많이 드러나게 해줍니다.
이것은 매우 유용한 작업이므로 letsplot에는 geom_point(position = "jitter")에 대한 지름길인 geom_jitter()가 포함되어 있습니다.
물론 오버플로팅을 다루는 더 정교한 방법은 binsreg 패키지에서 제공하는 빈스캐터(binscatter) 플롯을 통하는 것입니다.
위치 조정에 대해 더 알고 싶다면 문서를 살펴보세요.
(ggplot(mpg, aes(x="cty", y="hwy")) + geom_point())두 플롯 사이에 차이점이 있나요? 있다면 무엇인가요? 왜 그럴까요?
(
ggplot(mpg, aes(x = "displ", y = "hwy")) +
geom_point()
)
(
ggplot(mpg, aes(x = "displ", y = "hwy")) +
geom_point(position = "identity")
)geom_jitter()의 어떤 파라미터들이 지터링(jittering) 양을 제어하나요?
geom_boxplot()의 기본 위치 조정 방식은 무엇인가요? 이를 보여주는 mpg 데이터셋 시각화를 만들어 보세요.
지금까지 배운 그래프 템플릿에 위치 조정, stat, 좌표계, 그리고 패시팅을 추가하여 확장할 수 있습니다:
ggplot(data = <데이터>) +
<GEOM_함수>(
mapping = aes(<매핑들>),
stat = <STAT>,
position = <위치>
) +
<패싯_함수>새로운 템플릿은 템플릿에 나타나는 대괄호로 묶인 단어들인 6개의 파라미터를 받습니다. 실제로 그래프를 만들 때 7개의 파라미터를 모두 제공해야 하는 경우는 드문데, lets-plot이 데이터, 매핑, geom 함수를 제외한 모든 것에 유용한 기본값을 제공하기 때문입니다.
템플릿의 6개 파라미터는 플롯을 구축하기 위한 공식 시스템인 그래픽 문법(grammar of graphics)을 구성합니다. 그래픽 문법은 모든 플롯을 데이터셋, geom, 매핑 집합, stat, 위치 조정, 좌표계, 패시팅 체계, 그리고 테마의 조합으로 고유하게 설명할 수 있다는 통찰에 기반합니다.
이것이 어떻게 작동하는지 보려면 처음부터 기본 플롯을 어떻게 구축할 수 있을지 고려해 보십시오: 데이터셋에서 시작하여 (stat을 사용하여) 표시하고 싶은 정보로 변환할 수 있습니다. 다음으로 변환된 데이터의 각 관측치를 나타낼 기하 객체를 선택할 수 있습니다. 그런 다음 데이터의 변수들을 나타내기 위해 geom의 에스테틱 속성들을 사용할 수 있습니다. 각 변수의 값을 에스테틱의 레벨에 매핑할 것입니다. 이 단계들은 아래 그림에 설명되어 있습니다.
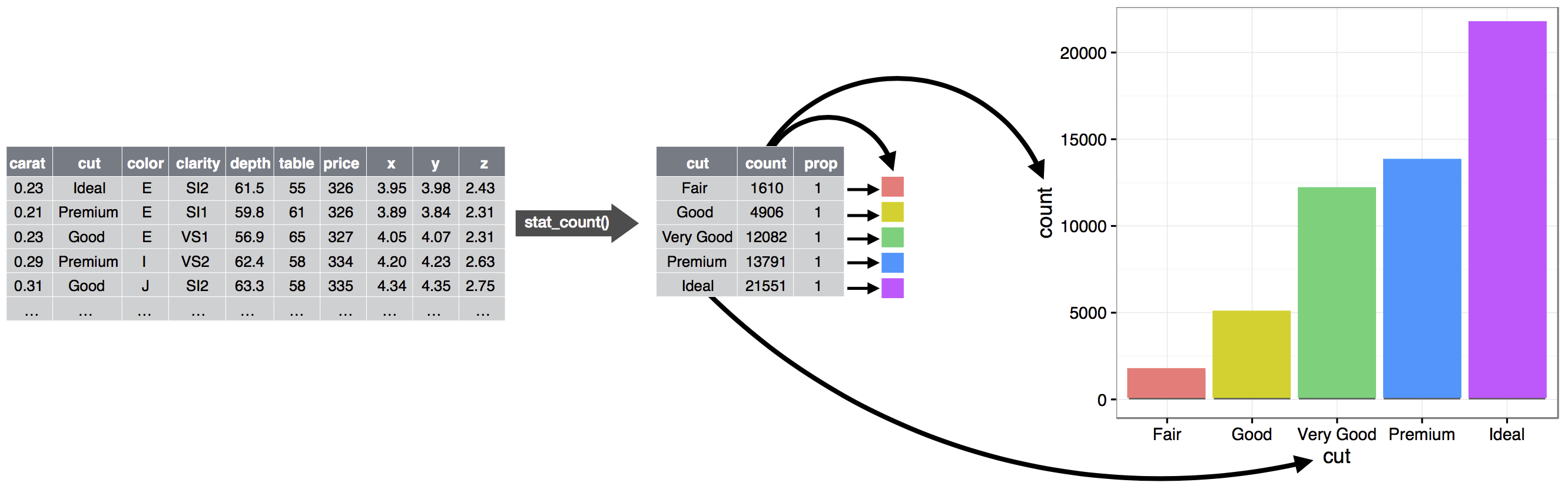
이 시점에서 완전한 그래프를 갖게 되지만, 좌표계 내에서 geom의 위치를 추가로 조정하거나(위치 조정) 그래프를 서브플롯으로 나눌 수 있습니다(패시팅). 또한 각 추가 레이어가 데이터셋, geom, 매핑 집합, stat, 위치 조정을 사용하는 하나 이상의 추가 레이어를 더해 플롯을 확장할 수도 있습니다.
이 방법을 사용하여 여러분이 상상할 수 있는 많은 플롯을 만들 수 있습니다.
이 장에서는 에스테틱과 기하 객체로 시작하여 간단한 플롯을 구축하고, 부분 집합으로 플롯을 나누기 위한 패싯, geom이 계산되는 방식을 이해하기 위한 통계치, geom이 겹칠 때 세부 위치를 제어하기 위한 위치 조정, 그리고 x와 y의 의미를 근본적으로 바꿀 수 있게 해주는 좌표계에 이르기까지 그래픽의 계층적 문법에 대해 배웠습니다.
lets-plot에 관한 가장 유용한 추가 리소스는 공식 문서입니다.