이 장에서는 깔끔한 데이터(tidy data) 원칙을 사용하여 파이썬에서 데이터를 구성하는 일관된 방법을 배웁니다. 깔끔한 데이터가 모든 경우에 적합한 것은 아니지만, 많은 분석과 표 형태의 데이터에서는 이것이 필요할 것입니다. 데이터를 이 형식으로 만드는 데는 초기에 노력이 필요하지만, 장기적으로는 그 노력이 보답을 해줍니다. 일단 데이터를 깔끔하게 만드는 데 성공하면, 한 표현 방식에서 다른 방식으로 데이터를 변환하는 데 드는 시간을 훨씬 줄일 수 있어, 여러분이 관심을 두는 데이터 질문에 더 많은 시간을 할애할 수 있게 됩니다.
이 장에서는 먼저 깔끔한 데이터의 정의를 배우고 간단한 장난감 데이터셋에 적용해 봅니다. 그런 다음 데이터를 깔끔하게 만드는 데 사용할 주요 도구인 ’녹이기(melting)’에 대해 깊이 알아봅니다. 녹이기를 사용하면 값은 변경하지 않으면서 데이터의 형태를 바꿀 수 있습니다. 마지막으로는 유용하게 깔끔하지 않은 데이터와 필요한 경우 이를 만드는 방법에 대한 논의로 마무리하겠습니다.
이 장이 특히 흥미롭고 기본 이론에 대해 더 자세히 알고 싶다면, Journal of Statistical Software에 게재된 Tidy Data 논문을 읽어보시길 권장합니다.
사전 준비
이 장에서는 pandas 데이터 분석 패키지를 사용합니다.
깔끔한 데이터 (Tidy Data)
데이터셋을 깔끔하게 만드는 세 가지 상호 연관된 특징이 있습니다:
각 변수는 하나의 열(column)이어야 합니다. 각 열은 하나의 변수입니다.
각 관측치는 하나의 행(row)이어야 합니다. 각 행은 하나의 관측치입니다.
각 값은 하나의 셀(cell)이어야 합니다. 각 셀은 하나의 단일 값입니다.
아래 그림은 이를 보여줍니다:
왜 데이터를 깔끔하게 유지해야 할까요? 두 가지 주요 장점이 있습니다:
데이터를 저장하는 일관된 방법 하나를 선택하는 데 따르는 일반적인 이점이 있습니다. 일관된 데이터 구조를 가지면 이를 다루는 도구들이 기저의 통일성을 가지고 있기 때문에 해당 도구들을 배우기가 더 쉽습니다. 예를 들어 데이터 시각화 패키지인 seaborn과 같은 일부 도구들은 깔끔한 데이터를 염두에 두고 설계되었습니다.
변수를 열에 배치하는 구체적인 이점은 pandas의 벡터화된 연산(더 효율적인 연산)을 활용할 수 있게 해준다는 점입니다.
깔끔한 데이터가 모든 상황과 모든 사례에 적합한 것은 아니지만, 표 형태의 데이터에 대해서는 매우 훌륭한 기본값입니다. 이를 기본값으로 사용하면 이후의 작업을 어떻게 수행할지 생각하기가 더 쉬워집니다.
깔끔한 데이터가 훌륭하다고 말씀드렸지만, 다른 데이터 분석 라이브러리와 비교했을 때 pandas의 장점 중 하나는 깔끔한 데이터에 너무 얽매이지 않고 다루기 까다로운 비정형 데이터 조작 작업도 수월하게 처리할 수 있다는 점입니다.
불러온 데이터가 깔끔하지 않게 만드는 두 가지 흔한 문제가 있습니다:
하나의 변수가 여러 열에 걸쳐 흩어져 있는 경우입니다.
하나의 관측치가 여러 행에 걸쳐 흩어져 있는 경우입니다.
전자의 경우, 여러 열로 된 ‘넓은(wide)’ 데이터를 ‘긴(long)’ 데이터로 “녹여야(melt)” 합니다.
후자의 경우, 여러 행을 열로 ‘풀어내거나(unstack)’ 피벗(pivot)해야 합니다 (즉, 긴 형태에서 넓은 형태로 가야 합니다).
아래에서 두 가지 모두 살펴보겠습니다.
pandas로 데이터를 깔끔하게 만드는 도구들
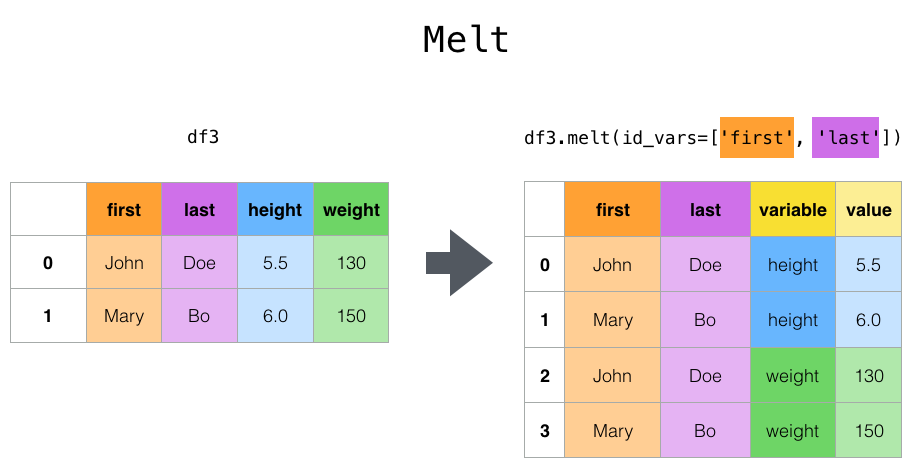
녹이기 (Melt)
melt()는 “넓은” 데이터에서 “긴” 데이터로 가는 데 도움을 주며, 꼭 기억해 두면 좋은 기능입니다.
실제로 작동하는 예제입니다:
코드 보기
import pandas as pddf = pd.DataFrame( {"first": ["John", "Mary"],"last": ["Doe", "Bo"],"job": ["Nurse", "Economist"],"height": [5.5, 6.0],"weight": [130, 150], })print("\n 녹이기 전 (Unmelted): ")print(df)print("\n 녹인 후 (Melted): ")df.melt(id_vars=["first", "last"], var_name="quantity", value_vars=["height", "weight"])
녹이기 전 (Unmelted):
first last job height weight
0 John Doe Nurse 5.5 130
1 Mary Bo Economist 6.0 150
녹인 후 (Melted):
first
last
quantity
value
0
John
Doe
height
5.5
1
Mary
Bo
height
6.0
2
John
Doe
weight
130.0
3
Mary
Bo
weight
150.0
{.callout-note} 연습 문제 `first`와 `last` 대신 `job`을 id로 사용하는 `melt()`를 수행해 보세요.
이것이 깔끔한 데이터와 어떤 관련이 있을까요? 때로는 여러 열에 걸쳐 있는 변수를 깔끔하게 정리하고 싶을 때가 있습니다. 세계보건기구(WHO)의 결핵 사례를 사용하는 이 예제를 살펴보겠습니다.
즉, 열에 걸쳐 서로 다른 변수와 시기가 있는 데이터입니다. Wide to long을 사용하면 접두어(stubnames, 여기서는 ‘A’, ‘B’), 항상 열에 걸쳐 나타나는 변수의 이름(여기서는 연도), 임의의 값(여기서는 X), 그리고 id 열에 대한 정보를 제공할 수 있습니다.
first second
bar one A 0.042293
B 0.624288
two A 0.366402
B -0.480216
baz one A -0.715803
B 1.310166
two A -0.389206
B 0.425451
foo one A -1.238631
B -1.554476
two A 0.638349
B 1.528674
qux one A -1.143951
B -0.347938
two A 0.187531
B -2.300269
dtype: float64
이것은 자동으로 다층 인덱스를 생성했지만, df.reset_index()를 사용하여 번호가 매겨진 인덱스로 되돌릴 수 있습니다.
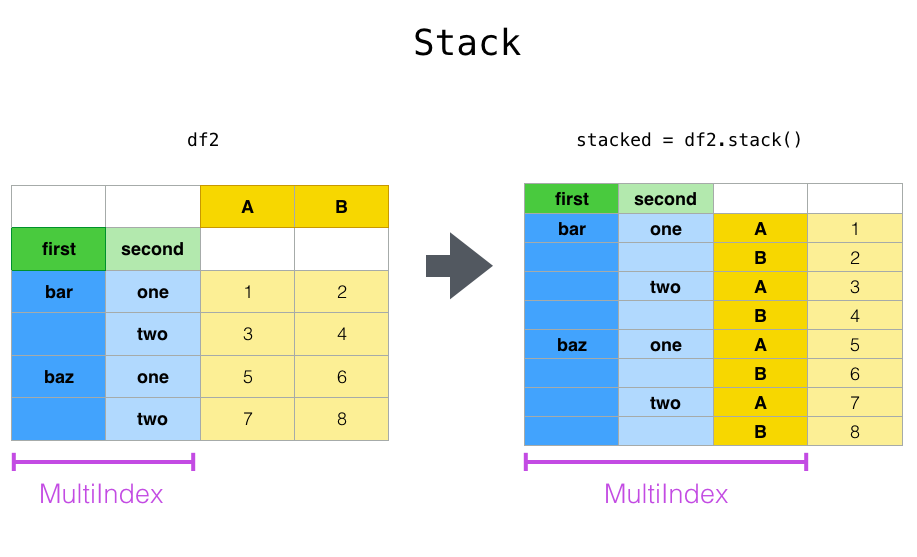
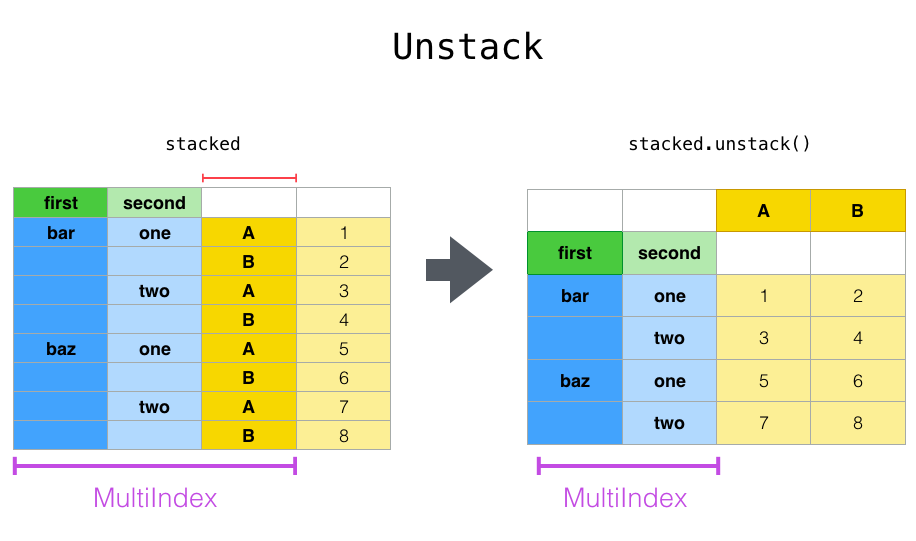
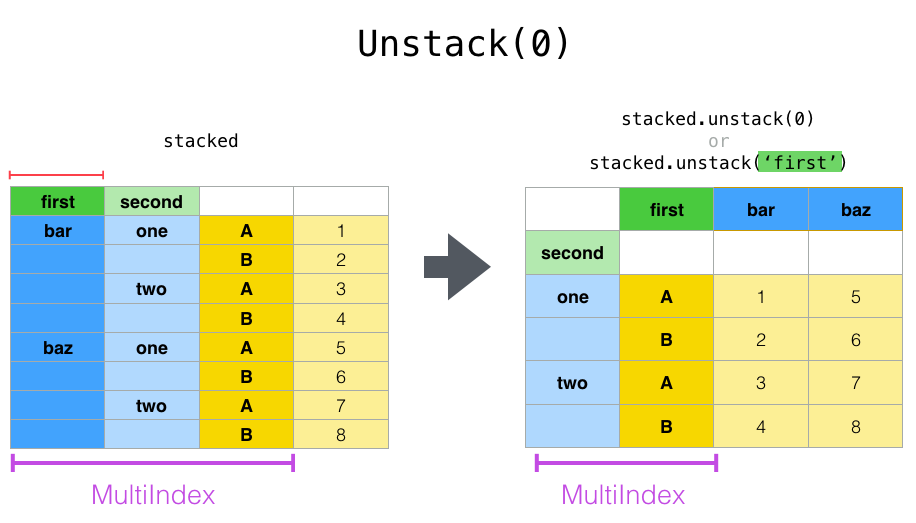
이제 풀기(unstack)를 살펴보겠습니다. 처음 시작했던 ‘A’, ‘B’ 변수를 푸는 대신, level=0을 전달하여 ‘first’ 열을 풀어보겠습니다(기본값은 가장 안쪽 인덱스를 푸는 것입니다). 이 다이어그램은 무슨 일이 일어나고 있는지 보여줍니다:
코드는 다음과 같습니다:
코드 보기
df.unstack(level=0)
first
bar
baz
foo
qux
second
one
A
0.042293
-0.715803
-1.238631
-1.143951
B
0.624288
1.310166
-1.554476
-0.347938
two
A
0.366402
-0.389206
0.638349
0.187531
B
-0.480216
0.425451
1.528674
-2.300269
{.callout-note} 연습 문제 대신 `level=1`로 풀면 어떻게 될까요? `unstack()`을 두 번 적용하면 어떻게 될까요?
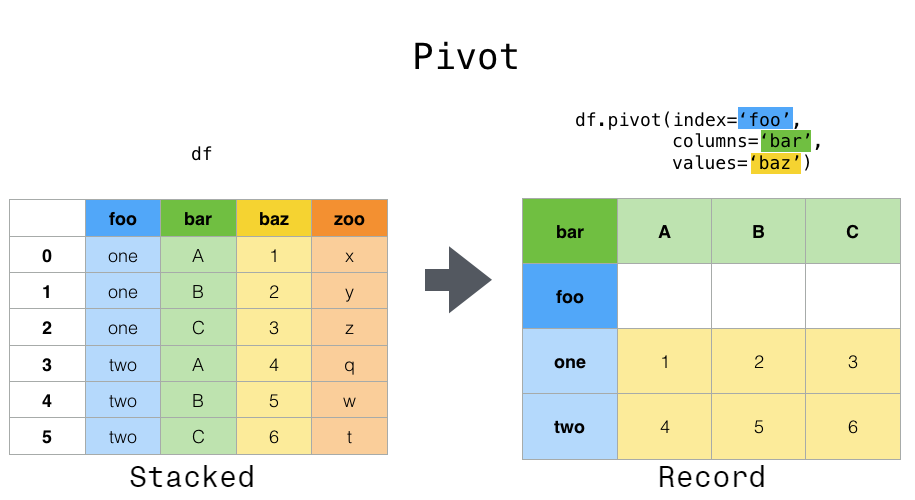
긴 형태에서 넓은 형태로 데이터 피벗하기 (Pivoting)
pivot()과 pivot_table()은 단일 관측치가 여러 행에 걸쳐 흩어져 있는 데이터를 정리하는 데 도움을 줍니다.
피벗은 시계열 데이터에서 특히 유용합니다. 시계열 데이터에서 shift()나 diff()와 같은 연산은 일반적으로 한 행의 항목이 위 행의 항목을 (시간상으로) 뒤따른다고 가정하고 적용됩니다. shift()를 수행할 때 종종 단일 변수를 시간상으로 이동시키고 싶어 하지만, 단일 관측치(이 경우 날짜)가 여러 행에 걸쳐 있다면 타이밍이 어긋나게 됩니다. 예제를 살펴보겠습니다.
위의 예제에서 카테고리가 df["category"] = np.random.choice(["type1", "type2", "type3", "type4"], 20)로 정의되어 있을 때, variable과 category 열 모두에 적용되는 pivot()을 수행해 보세요. (힌트: 여러 객체를 리스트를 통해 전달해야 함을 기억하세요.)