코드 보기
import pandas as pd
url = "https://raw.githubusercontent.com/byuidatascience/data4python4ds/master/data-raw/flights/flights.csv"
flights = pd.read_csv(url)이 장에서는 수치 벡터를 생성하고 조작하는 유용한 도구들을 배웁니다. 먼저 .count()에 대해 좀 더 자세히 알아본 후, 다양한 수치 변환(numeric transformations)에 대해 살펴보겠습니다. 그런 다음 수치형 열에 자주 사용되지만 다른 유형의 열에도 적용할 수 있는 보다 일반적인 변환에 대해 배웁니다. 마지막으로 몇 가지 유용한 요약 수치들에 대해 알아보겠습니다.
이 장에서는 주로 pandas의 함수들을 사용합니다. 아마 이미 설치되어 있겠지만, 터미널에서 pixi add pandas를 사용하여 설치할 수 있습니다. nycflights13의 실제 예제와 가짜 데이터로 만든 장난감 예제를 함께 사용하겠습니다.
먼저 NYC 항공편 데이터를 불러옵니다.
import pandas as pd
url = "https://raw.githubusercontent.com/byuidatascience/data4python4ds/master/data-raw/flights/flights.csv"
flights = pd.read_csv(url)단순한 빈도 계산과 약간의 기본 산술만으로도 얼마나 많은 데이터 과학을 할 수 있는지 놀랍습니다. 그래서 pandas는 .count()와 .value_counts()를 통해 빈도 계산을 최대한 쉽게 만들려고 노력합니다. 전자는 NA가 아닌 모든 항목의 개수를 단순히 제공합니다:
flights["dest"].count()np.int64(336776)후자는 타입별로 분류된 빈도를 제공합니다:
flights["dest"].value_counts()dest
ORD 17283
ATL 17215
LAX 16174
BOS 15508
MCO 14082
...
MTJ 15
SBN 10
ANC 8
LEX 1
LGA 1
Name: count, Length: 105, dtype: int64이는 가장 흔한 카테고리 순으로 자동 정렬됩니다. group_by(), agg()를 사용하고 count 함수를 직접 사용하여 동일한 계산을 “수동으로” 수행할 수도 있습니다. 이는 다른 요약치들을 동시에 계산할 수 있게 해주므로 유용합니다:
(
flights.groupby(["dest"])
.agg(
mean_delay=("dep_delay", "mean"),
count_flights=("dest", "count"),
)
.sort_values(by="count_flights", ascending=False)
)| mean_delay | count_flights | |
|---|---|---|
| dest | ||
| ORD | 13.570484 | 17283 |
| ATL | 12.509824 | 17215 |
| LAX | 9.401344 | 16174 |
| BOS | 8.730613 | 15508 |
| MCO | 11.275998 | 14082 |
| ... | ... | ... |
| HDN | 12.285714 | 15 |
| SBN | 21.100000 | 10 |
| ANC | 12.875000 | 8 |
| LGA | NaN | 1 |
| LEX | -9.000000 | 1 |
105 rows × 2 columns
가중 빈도는 단순히 합계(sum)라는 점에 유의하세요. 예를 들어 각 비행기가 비행한 마일 수를 “셀” 수 있습니다:
(flights.groupby("tailnum").agg(miles=("distance", "sum")))| miles | |
|---|---|
| tailnum | |
| D942DN | 3418 |
| N0EGMQ | 250866 |
| N10156 | 115966 |
| N102UW | 25722 |
| N103US | 24619 |
| ... | ... |
| N997DL | 54669 |
| N998AT | 15432 |
| N998DL | 66052 |
| N999DN | 54623 |
| N9EAMQ | 167317 |
4043 rows × 1 columns
sum()과 isnull()을 결합하여 누락된 값의 개수를 셀 수 있습니다. 항공편 데이터셋에서 이는 취소된 항공편을 나타냅니다. 단순히 “sum”과 같은 문자열 이름으로 .isnull() 뒤에 .sum()을 적용하는 방법이 없으므로(그냥 sum()을 실행하는 것과는 다르게), 아래에서는 람다 함수를 사용해야 합니다:
(flights.groupby("dest").agg(n_cancelled=("dep_time", lambda x: x.isnull().sum())))| n_cancelled | |
|---|---|
| dest | |
| ABQ | 0 |
| ACK | 0 |
| ALB | 20 |
| ANC | 0 |
| ATL | 317 |
| ... | ... |
| TPA | 59 |
| TUL | 16 |
| TVC | 5 |
| TYS | 52 |
| XNA | 25 |
105 rows × 1 columns
변환 함수의 출력은 입력과 길이가 같습니다. 대다수의 변환 함수는 파이썬에 내장되어 있거나 수치 패키지인 numpy와 함께 제공됩니다. 가능한 모든 수치 변환을 나열하는 것은 비현실적이므로 이 섹션에서는 가장 유용한 것들을 보여드리겠습니다.
기본적인 수치 산술은 +(더하기), -(빼기), *(곱하기), /(나누기), **(거듭제곱), %(나머지), 그리고 @(텐서 곱)으로 수행됩니다. 대부분의 함수는 이미 익숙하실 것이기에 큰 설명이 필요 없으며(필요할 때 찾아보시면 됩니다).
길이가 같은 두 개의 수치형 열이 있고 이들을 더하거나 빼면 무슨 일이 일어날지 명확합니다. 하지만 연산에 관련된 변수의 길이가 열의 길이와 같지 않을 때 어떤 일이 일어나는지 이야기해야 합니다. 이는 flights.assign(air_time = air_time / 60)과 같은 연산에서 중요합니다. 왜냐하면 /의 왼쪽에는 336,776개의 숫자가 있지만 오른쪽에는 하나만 있기 때문입니다. 이 경우 pandas는 air_time의 모든 값을 60으로 나누고 싶어 한다는 것을 이해합니다. 이를 때로는 ’브로드캐스팅(broadcasting)’이라고 합니다. 아래는 무슨 일이 일어나는지 설명하려는 다이어그램입니다:
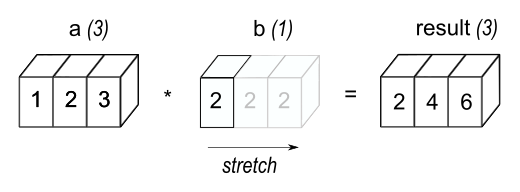
numpy 문서에서 브로드캐스팅에 대해 훨씬 더 많은 내용을 찾을 수 있습니다. pandas는 numpy 위에 구축되었으며 그 기능의 일부를 상속받습니다.
두 열에 대해 연산을 수행할 때, pandas는 그 모양(shapes)을 요소별로 비교합니다. 두 열은 모양이 같거나, 그중 하나가 스칼라(scalar)일 때 호환 가능합니다. 이러한 조건이 충족되지 않으면 에러가 발생합니다.
산술 함수들은 여러분이 기대하는 대로 작동합니다.
flights["distance"].max()np.int64(4983)때로는 행 또는 열을 가로지르는 최대값이나 최소값을 찾고 싶을 때가 있습니다. pandas에서 흔히 그렇듯이, 해당 함수에 axis=0(인덱스) 또는 axis=1(열)을 전달하여 함수를 적용할 행이나 열을 지정할 수 있습니다. 축 지정은 혼동될 수 있습니다: 여러분이 집계/축소하고 싶은 차원이 무엇인지 묻는 것이며, 그 결과 다른 차원이 남게 된다는 점을 기억하세요. 따라서 각 행의 최소값을 찾으려면 열을 집계/축소해야 하므로 axis=1을 전달해야 합니다.
df = pd.DataFrame({"x": [1, 5, 7], "y": [3, 2, pd.NA]})
df| x | y | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 5 | 2 |
| 2 | 7 | <NA> |
이제 행별 최소값을 찾아보겠습니다:
df.min(axis=1)0 1
1 2
2 7
dtype: object모듈러 산술은 정수에 대해 수행하는 수학 유형의 전문 용어로, 즉 정수 몫과 나머지를 산출하는 나눗셈입니다. 파이썬에서 //는 정수 나눗셈을 수행하고 %는 나머지를 계산합니다:
print([x for x in range(1, 11)])
print("3으로 나누었을 때의")
print("나머지:")
print([x % 3 for x in range(1, 11)])
print("몫:")
print([x // 3 for x in range(1, 11)])[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
3으로 나누었을 때의
나머지:
[1, 2, 0, 1, 2, 0, 1, 2, 0, 1]
몫:
[0, 0, 1, 1, 1, 2, 2, 2, 3, 3]모듈러 산술은 항공편 데이터셋에서 유용합니다. sched_dep_time 변수를 hour와 minute으로 분해하는 데 사용할 수 있기 때문입니다:
flights.assign(
hour=lambda x: x["sched_dep_time"] // 100,
minute=lambda x: x["sched_dep_time"] % 100,
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01T10:00:00Z |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01T10:00:00Z |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01T10:00:00Z |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01T10:00:00Z |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01T11:00:00Z |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | NaN | 1455 | NaN | NaN | 1634 | NaN | 9E | 3393 | NaN | JFK | DCA | NaN | 213 | 14 | 55 | 2013-09-30T18:00:00Z |
| 336772 | 2013 | 9 | 30 | NaN | 2200 | NaN | NaN | 2312 | NaN | 9E | 3525 | NaN | LGA | SYR | NaN | 198 | 22 | 0 | 2013-10-01T02:00:00Z |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 | 2013-09-30T16:00:00Z |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 | 2013-09-30T15:00:00Z |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 | 2013-09-30T12:00:00Z |
336776 rows × 19 columns
로그는 여러 자릿수에 걸쳐 있는 데이터를 다루는 데 매우 유용한 변환입니다. 또한 지수적 성장을 선형적 성장으로 변환해 줍니다. 예를 들어 복리를 생각해 보십시오. year + 1 시점의 금액은 year 시점의 금액에 이자율을 곱한 것입니다. 이는 money = starting * interest ** year와 같은 공식을 제공합니다:
import numpy as np
starting = 100
interest = 1.05
money = pd.DataFrame(
{"year": 2000 + np.arange(1, 51), "money": starting * interest ** np.arange(1, 51)}
)
money.head()| year | money | |
|---|---|---|
| 0 | 2001 | 105.000000 |
| 1 | 2002 | 110.250000 |
| 2 | 2003 | 115.762500 |
| 3 | 2004 | 121.550625 |
| 4 | 2005 | 127.628156 |
이 데이터를 그래프로 그리면 지수 곡선이 나옵니다:
money.plot(x="year", y="money");
y축을 로그 변환하면 직선이 나옵니다:
money.plot(x="year", y="money", logy=True);
이것이 직선인 이유는 log(money) = log(starting) + n * log(interest)가 직선의 패턴인 y = m * x + b와 일치하기 때문입니다. 이는 유용한 패턴입니다: 만약 y축을 로그 변환한 후 (대략적으로) 직선이 보인다면, 기저에 지수적 성장이 있음을 알 수 있습니다.
데이터를 로그 변환할 때 numpy가 제공하는 많은 로그 중 하나를 선택할 수 있지만, 흔히 사용하게 될 세 가지가 있습니다: import numpy as np로 가져왔다고 가정할 때, np.log() (자연로그, 밑이 e), np.log2() (밑이 2), 그리고 np.log10() (밑이 10)입니다.
log()의 역함수는 np.exp()입니다. np.log2()나 np.log10()의 역함수를 계산하려면 2** 또는 10**를 사용해야 합니다.
특정 소수점 자리수까지 반올림하려면 .round(n)을 사용하세요. 여기서 n은 반올림하고자 하는 소수점 자리수입니다.
money.head().round(2)| year | money | |
|---|---|---|
| 0 | 2001 | 105.00 |
| 1 | 2002 | 110.25 |
| 2 | 2003 | 115.76 |
| 3 | 2004 | 121.55 |
| 4 | 2005 | 127.63 |
이는 개별 열에 적용하거나 딕셔너리를 통해 열마다 다르게 적용할 수도 있습니다:
money.head().round({"year": 0, "money": 1})| year | money | |
|---|---|---|
| 0 | 2001 | 105.0 |
| 1 | 2002 | 110.2 |
| 2 | 2003 | 115.8 |
| 3 | 2004 | 121.6 |
| 4 | 2005 | 127.6 |
.round(n)은 가장 가까운 10**(-n)으로 반올림하므로 n = 2는 가장 가까운 0.01로 반올림합니다. 이 정의는 .round(-2)가 가장 가까운 백 단위로 반올림함을 의미하므로 유용합니다:
money.tail().round({"year": 0, "money": -2})| year | money | |
|---|---|---|
| 45 | 2046 | 900.0 |
| 46 | 2047 | 1000.0 |
| 47 | 2048 | 1000.0 |
| 48 | 2049 | 1100.0 |
| 49 | 2050 | 1100.0 |
때로는 소수점 자리가 아니라 유효숫자(significant figures)에 따라 반올림하고 싶을 때가 있습니다. 이를 수행하는 아주 쉬운 방법은 없지만 커스텀 함수를 정의할 수 있습니다. 다음은 유효숫자 2자리로 반올림하는 예제입니다(다른 유효숫자 자리수로 반올림하려면 아래의 2를 변경하세요):
money["money"].head().apply(lambda x: float(f"{float(f'{x:.2g}'):g}"))0 100.0
1 110.0
2 120.0
3 120.0
4 130.0
Name: money, dtype: float64데이터 프레임 외부의 숫자 배열이나 리스트가 있다면 numpy 함수를 사용할 수 있습니다.
np.round([1.5, 2.5, 1.4])array([2., 2., 1.])numpy에는 올림(.ceil())과 내림(.floor()) 메서드도 있습니다
real_nums = 100 * np.random.random(size=10)
real_numsarray([56.2591834 , 32.87967537, 58.67690659, 53.63017185, 29.89582109,
62.07903108, 76.03831387, 17.27078719, 33.51220173, 17.38415767])np.ceil(real_nums)array([57., 33., 59., 54., 30., 63., 77., 18., 34., 18.])np.floor(real_nums)array([56., 32., 58., 53., 29., 62., 76., 17., 33., 17.])numpy 함수를 다음과 같이 pandas 데이터 프레임 열에 항상 적용할 수 있다는 점을 기억하세요:
money["money"].head().apply(np.ceil)0 105.0
1 111.0
2 116.0
3 122.0
4 128.0
Name: money, dtype: float64pandas에는 .cumsum() (누적합), .cummax() (누적 최대), .cummin() (누적 최소), 그리고 .cumprod() (누적곱)을 포함한 여러 누적 함수들이 있습니다.
money["money"].tail().cumsum()45 943.425818
46 1934.022928
47 2974.149892
48 4066.283205
49 5213.023184
Name: money, dtype: float64항상 그렇듯이, 이는 axis=1을 전달하여 행을 가로질러 적용될 수도 있습니다.
다음 섹션들에서는 수치 벡터에 자주 사용되지만 다른 모든 열 타입에도 적용할 수 있는 일반적인 변환들을 설명합니다.
pandas의 순위 함수는 .rank()입니다. 앞서 만든 데이터를 다시 보고 순위를 매겨 보겠습니다:
df| x | y | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 5 | 2 |
| 2 | 7 | <NA> |
df.rank()| x | y | |
|---|---|---|
| 0 | 1.0 | 2.0 |
| 1 | 2.0 | 1.0 |
| 2 | 3.0 | NaN |
항목들이 이미 정렬되어 있었으므로 당연히 아무런 변화가 없습니다! pct=True 키워드 인수를 전달하여 백분위수 순위(pct rank)를 매길 수도 있습니다.
df.rank(pct=True)| x | y | |
|---|---|---|
| 0 | 0.333333 | 1.0 |
| 1 | 0.666667 | 0.5 |
| 2 | 1.000000 | NaN |
오프셋을 사용하면 원래 위치를 기준으로 열을 위아래로 ‘굴릴’ 수 있습니다. 즉, 인덱스를 기준으로 위치를 오프셋 시키는 것입니다. 이를 수행하는 함수는 shift()이며, 각각 양수 또는 음수 값을 사용하는지에 따라 리드(leads) 또는 래그(lags)를 생성합니다. 리드는 인덱스에 대해 플롯했을 때 데이터의 패턴을 왼쪽으로 이동시키는 반면, 래그는 패턴을 오른쪽으로 이동시킨다는 점을 기억하세요. 리드와 래그는 시계열 데이터(아직 보지 못했습니다)에 특히 유용합니다.
앞서 본 money 데이터 프레임을 사용하여 오프셋 예제를 살펴보겠습니다:
money["money_lag_5"] = money["money"].shift(5)
money["money_lead_10"] = money["money"].shift(-10)
money.set_index("year").plot();
순위 함수를 사용하여 가장 지연된 항공편 10개를 찾으세요.
어떤 비행기("tailnum")가 정시 운항 기록이 가장 나쁜가요?
지연을 최대한 피하고 싶다면 하루 중 몇 시에 비행기를 타야 할까요?
각 목적지별로 총 지연 시간을 계산하세요. 각 항공편에 대해 목적지별 총 지연 시간에서 차지하는 비율을 계산하세요.
지연은 대개 시간적으로 상관관계가 있습니다: 초기 지연을 유발한 문제가 해결된 후에도, 앞선 항공편이 출발할 수 있도록 뒷 항공편들이 지연됩니다. .shift()를 사용하여 한 시간의 평균 항공편 지연이 이전 시간의 평균 지연과 어떤 관련이 있는지 탐색해 보세요.
각 목적지를 살펴보세요. 수상할 정도로 빠른 항공편을 찾을 수 있나요? (즉, 잠재적인 데이터 입력 오류를 나타내는 항공편). 목적지까지의 최단 비행시간 대비 해당 항공편의 비행시간을 계산해 보세요. 공중에서 가장 많이 지연된 항공편은 무엇인가요?
최소 두 개 이상의 항공사가 운항하는 모든 목적지를 찾으세요. 해당 목적지들을 사용하여 동일 목적지에 대한 운항 실적을 바탕으로 항공사들의 상대적 순위를 매겨 보세요.
우리는 .mean(), .count(), 그리고 .value_counts()가 분석에 얼마나 유용한지 보았습니다. 하지만 pandas에는 훨씬 더 많은 내장 요약 통계 함수가 있습니다. 여기에는 .median() (항공편 데이터의 시간당 출발 지연을 볼 때 평균과 중앙값을 비교해 보는 것도 흥미로울 것입니다), .mode(), .min(), 그리고 .max()가 포함됩니다.
유용한 요약 통계량 클래스로 .quantile 함수가 제공하는 것들이 있는데, 이는 .quantile(0.5)일 때 median과 같습니다. x%의 분위수(quantile)는 전체 값의 x%가 그 아래에 있는 값입니다. (이 정의에 따르면 .quantile(1)은 .max()와 같아집니다.) 25번째 백분위수 예제를 보겠습니다.
money["money"].quantile(0.25)np.float64(190.92197566022773)때로는 하나의 백분위수뿐만 아니라 여러 개를 원할 수도 있습니다. pandas는 분위수 리스트를 전달할 수 있게 함으로써 이를 매우 쉽게 만들어 줍니다:
money["money"].quantile([0, 0.25, 0.5, 0.75])0.00 105.000000
0.25 190.921976
0.50 347.101381
0.75 630.945970
Name: money, dtype: float64때로는 데이터의 대다수가 어디에 위치하는지가 아니라 얼마나 퍼져 있는지에 관심이 있을 때가 있습니다. 자주 사용되는 두 가지 요약치는 표준 편차(.std())와 사분위간 범위(IQR)입니다. 사분위간 범위는 관련 분위수들로부터 계산할 수 있는데, 즉 75% 분위수에서 25% 분위수를 뺀 값이며 데이터의 중간 50%를 포함하는 범위를 나타냅니다.
이를 사용하여 항공편 데이터에서 작은 이상함을 발견할 수 있습니다. 공항은 항상 같은 위치에 있으므로 출발지와 목적지 사이 거리의 산포는 0일 것이라고 예상할 수 있습니다. 하지만 아래 코드를 실행하면 EGE라는 한 공항이 마치 이동한 것처럼 보입니다.
(
flights.groupby(["origin", "dest"])
.agg(
distance_sd=("distance", lambda x: x.quantile(0.75) - x.quantile(0.25)),
count=("distance", "count"),
)
.query("distance_sd > 0")
)| distance_sd | count | ||
|---|---|---|---|
| origin | dest | ||
| EWR | EGE | 1.0 | 110 |
| JFK | EGE | 1.0 | 103 |
위에서 설명한 모든 요약 통계량은 분포를 단 하나의 숫자로 줄이는 방법이라는 점을 기억할 가치가 있습니다. 이는 근본적으로 정보를 축소하는 것이며, 만약 잘못된 요약치를 선택한다면 그룹 간의 중요한 차이를 쉽게 놓칠 수 있습니다. 그래서 집계 통계량을 사용하는 것뿐만 아니라 값들의 분포를 시각화하는 것이 항상 좋은 생각입니다.
아래 그래프는 출발 지연 시간의 전체 분포를 보여줍니다. 분포가 너무 한쪽으로 치우쳐 있어서(skewed) 데이터의 대다수를 보려면 줌(zoom)을 해야 합니다. 이는 평균(mean)이 좋은 요약치가 아닐 가능성이 높으며 대신 중앙값(median)을 선호할 수 있음을 시사합니다.
flights["dep_delay"].plot.hist(bins=50, title=" 분포: 지연 시간");/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 48516 (\N{HANGUL SYLLABLE BUN}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 54252 (\N{HANGUL SYLLABLE PO}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 51648 (\N{HANGUL SYLLABLE JI}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 50672 (\N{HANGUL SYLLABLE YEON}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 49884 (\N{HANGUL SYLLABLE SI}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 44036 (\N{HANGUL SYLLABLE GAN}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 48516 (\N{HANGUL SYLLABLE BUN}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 54252 (\N{HANGUL SYLLABLE PO}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 51648 (\N{HANGUL SYLLABLE JI}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 50672 (\N{HANGUL SYLLABLE YEON}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 49884 (\N{HANGUL SYLLABLE SI}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 44036 (\N{HANGUL SYLLABLE GAN}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
flights.query("dep_delay <= 120")["dep_delay"].plot.hist(
bins=50, title=" 분포: 지연 시간"
);/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 48516 (\N{HANGUL SYLLABLE BUN}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 54252 (\N{HANGUL SYLLABLE PO}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 51648 (\N{HANGUL SYLLABLE JI}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 50672 (\N{HANGUL SYLLABLE YEON}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 49884 (\N{HANGUL SYLLABLE SI}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/events.py:82: UserWarning: Glyph 44036 (\N{HANGUL SYLLABLE GAN}) missing from font(s) STIXGeneral.
func(*args, **kwargs)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 48516 (\N{HANGUL SYLLABLE BUN}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 54252 (\N{HANGUL SYLLABLE PO}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 51648 (\N{HANGUL SYLLABLE JI}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 50672 (\N{HANGUL SYLLABLE YEON}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 49884 (\N{HANGUL SYLLABLE SI}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
/home/runner/work/python4DS/python4DS/.pixi/envs/default/lib/python3.10/site-packages/IPython/core/pylabtools.py:170: UserWarning: Glyph 44036 (\N{HANGUL SYLLABLE GAN}) missing from font(s) STIXGeneral.
fig.canvas.print_figure(bytes_io, **kw)
"dep_delay"에 대한 두 개의 히스토그램입니다. 전자의 경우, 0 근처에 매우 큰 스파이크가 있고 막대 높이가 급격히 감소하며 플롯의 대부분에서 막대들이 너무 짧아 보이지 않는다는 점 외에는 어떤 패턴도 보기가 매우 어렵습니다. 2시간 이상의 지연을 제외한 후자의 경우, 스파이크가 0보다 약간 아래에서 발생함(즉, 대부분의 항공편이 몇 분 일찍 출발함)을 알 수 있지만, 그 이후에도 여전히 매우 가파른 감소를 보입니다.
작업 중인 데이터에 특별히 맞춤화된 나만의 커스텀 요약치를 탐색하는 것을 두려워하지 마세요. 이 경우, 일찍 출발한 항공편과 늦게 출발한 항공편을 별도로 요약하거나, 값이 워낙 심하게 치우쳐 있으므로 로그 변환을 시도해 볼 수도 있습니다. 마지막으로, 요약치를 생성할 때 각 그룹의 관측치 수를 포함하는 것이 항상 좋은 생각이라는 점을 잊지 마세요.
항공편 그룹의 전형적인 지연 특성을 평가하는 최소 5가지 이상의 서로 다른 방법을 브레인스토밍해 보세요. 다음 시나리오들을 고려해 보세요:
도착 지연과 출발 지연 중 어느 것이 더 중요하다고 생각하시나요?
어떤 목적지가 비행 속도에서 가장 큰 변동을 보이나요?
EGE의 모험을 더 탐색하기 위해 그래프를 만들어 보세요. 공항이 위치를 옮겼다는 증거를 찾을 수 있나요?