코드 보기
import pandas as pd데이터가 여러분에게 필요한 정확한 형태로 도착하는 경우는 매우 드뭅니다. 종종 새로운 변수나 요약치를 만들어야 하거나, 단순히 변수 이름을 바꾸거나 관측치 순서를 변경하여 데이터를 조금 더 쉽게 다루고 싶을 때가 있을 것입니다.
이 장에서는 그러한 작업들을 (그 이상의 것도!) 수행하는 방법을 배울 것입니다. pandas 패키지와 2013년에 뉴욕시를 출발한 항공편에 대한 새로운 데이터셋을 사용하여 데이터 변환을 소개합니다.
이 장의 목표는 표 형태의 데이터를 담는 특별한 종류의 객체인 데이터 프레임을 변환하는 모든 핵심 도구에 대한 개요를 제공하는 것입니다.
이후 장들에서 특정 유형의 데이터(예: 숫자, 문자열, 날짜)를 심층적으로 다루기 시작하면서 이러한 기능들을 더 자세히 다시 살펴보겠습니다.
이 장에서는 데이터 과학을 위해 가장 널리 사용되는 도구 중 하나인 pandas 패키지에 집중하겠습니다. pandas가 설치되어 있는지 확인해야 합니다. 설치하려면 다음을 실행하면 됩니다.
import pandas as pd이 명령이 실패하면 pandas가 설치되어 있지 않은 것입니다. Visual Studio Code에서 터미널(Terminal -> New Terminal)을 열고, 작업 중인 폴더로 이동(cd)한 후 pixi add pandas를 입력하세요.
또한, 사용 중인 pandas 버전을 확인하고 싶다면 다음과 같이 입력합니다.
pd.__version__'2.3.3'데이터도 필요합니다. 대부분의 경우 데이터는 파일이나 인터넷에서 불러와야 합니다. 이 데이터도 다르지 않지만, pandas의 놀라운 점 중 하나는 인터넷에 있는 파일을 포함하여 얼마나 다양한 유형의 데이터를 불러올 수 있는지입니다.
데이터 크기는 약 50MB 정도이므로 좋은 인터넷 연결 상태가 필요하며 다운로드되는 동안 약간의 인내심이 필요할 수 있습니다.
데이터를 다운로드해 보겠습니다:
url = "https://raw.githubusercontent.com/byuidatascience/data4python4ds/master/data-raw/flights/flights.csv"
flights = pd.read_csv(url)위 코드가 작동했다면, CSV 형식의 데이터를 다운로드하여 데이터 프레임에 넣은 것입니다. 모든 pandas 데이터 프레임에서 작동하는 .head() 함수를 사용하여 처음 몇 행을 살펴보겠습니다.
flights.head()| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01T10:00:00Z |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01T10:00:00Z |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01T10:00:00Z |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01T10:00:00Z |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01T11:00:00Z |
열, 각 열의 데이터 타입(dtypes), 그리고 데이터셋의 크기에 대한 더 일반적인 정보를 얻으려면 .info()를 사용하세요.
flights.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 336776 entries, 0 to 336775
Data columns (total 19 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 336776 non-null int64
1 month 336776 non-null int64
2 day 336776 non-null int64
3 dep_time 328521 non-null float64
4 sched_dep_time 336776 non-null int64
5 dep_delay 328521 non-null float64
6 arr_time 328063 non-null float64
7 sched_arr_time 336776 non-null int64
8 arr_delay 327346 non-null float64
9 carrier 336776 non-null object
10 flight 336776 non-null int64
11 tailnum 334264 non-null object
12 origin 336776 non-null object
13 dest 336776 non-null object
14 air_time 327346 non-null float64
15 distance 336776 non-null int64
16 hour 336776 non-null int64
17 minute 336776 non-null int64
18 time_hour 336776 non-null object
dtypes: float64(5), int64(9), object(5)
memory usage: 48.8+ MBDtypes 열에 나타나는 짧은 약어들을 눈치채셨을 수도 있습니다. 이들은 각 열의 값들의 타입을 알려줍니다: int64는 정수(예: 정수)의 약어이고, float64는 배정밀도 부동 소수점 숫자(실수)의 약어입니다. object는 pandas가 타입을 추론하기에 자신이 없는 경우에 사용되는 일종의 포괄적인 카테고리입니다. 여기에는 없지만, 다른 데이터 타입으로는 텍스트를 위한 string과 날짜와 시간의 조합을 위한 datetime이 있습니다.
아래 표는 여러분이 접하게 될 가장 일반적인 데이터 타입들입니다.
| 데이터 타입 이름 | 데이터 종류 |
|---|---|
| float64 | 실수 (Real numbers) |
| category | 범주 (Categories) |
| datetime64 | 날짜 시간 (Date times) |
| int64 | 정수 (Integers) |
| bool | 참 또는 거짓 (True or False) |
| string | 텍스트 (Text) |
서로 다른 열 데이터 타입은 중요한데, 이는 열에서 수행할 수 있는 연산이 그 “타입”에 크게 의존하기 때문입니다. 예를 들어 문자열에서 모든 구두점을 제거할 수 있는 반면, 정수와 실수는 서로 곱할 수 있습니다.
우리는 "time_hour" 변수를 datetime 형식으로 다루고 싶습니다. 다행히 pandas를 사용하면 해당 열에 대해 그 변환을 쉽게 수행할 수 있습니다.
flights["time_hour"]0 2013-01-01T10:00:00Z
1 2013-01-01T10:00:00Z
2 2013-01-01T10:00:00Z
3 2013-01-01T10:00:00Z
4 2013-01-01T11:00:00Z
...
336771 2013-09-30T18:00:00Z
336772 2013-10-01T02:00:00Z
336773 2013-09-30T16:00:00Z
336774 2013-09-30T15:00:00Z
336775 2013-09-30T12:00:00Z
Name: time_hour, Length: 336776, dtype: objectflights["time_hour"] = pd.to_datetime(flights["time_hour"], format="%Y-%m-%dT%H:%M:%SZ")pandas는 매우 포괄적인 패키지이며, 이 책은 그 기능을 아주 일부분만 다룰 것입니다. 하지만 몇 가지 간단한 아이디어를 중심으로 구축되어 있으며, 일단 이해하고 나면 훨씬 수월해집니다.
절대적인 기초부터 시작하겠습니다. 가장 기본적인 pandas 객체는 DataFrame입니다. DataFrame은 열에 다양한 타입의 데이터(문자, 정수, 부동 소수점 값, 범주형 데이터, 리스트 포함)를 저장할 수 있는 2차원 데이터 구조입니다. 행과 열로 구성되며(각 행-열 셀에는 값이 포함됨), 여기에 두 가지 맥락 정보가 더해집니다: 인덱스(각 행에 대한 정보를 가짐)와 열 이름(각 열에 대한 정보를 가짐)입니다.

pandas 데이터 프레임에 대해 가져야 할 아마도 가장 중요한 개념은 데이터 프레임의 왼쪽에 위치한 인덱스를 중심으로 구축되어 있다는 점입니다. 데이터 프레임에서 연산을 수행할 때마다 그것이 인덱스에 어떤 영향을 미칠지, 혹은 인덱스를 수정하고 싶은지를 생각해야 합니다.
임의로 만든 데이터 프레임으로 간단한 예를 살펴보겠습니다:
df = pd.DataFrame(
data={
"col0": [0, 0, 0, 0],
"col1": [0, 0, 0, 0],
"col2": [0, 0, 0, 0],
"col3": ["a", "b", "b", "a"],
"col4": ["alpha", "gamma", "gamma", "gamma"],
},
index=["row" + str(i) for i in range(4)],
)
df.head()| col0 | col1 | col2 | col3 | col4 | |
|---|---|---|---|---|---|
| row0 | 0 | 0 | 0 | a | alpha |
| row1 | 0 | 0 | 0 | b | gamma |
| row2 | 0 | 0 | 0 | b | gamma |
| row3 | 0 | 0 | 0 | a | gamma |
5개의 열("col0"에서 "col4")이 있고, 인덱스는 "row0"에서 "row3"까지 네 개의 항목으로 구성된 것을 볼 수 있습니다.
두 번째로 알아야 할 핵심 포인트는 pandas 데이터 프레임의 연산들을 서로 연결(chain)할 수 있다는 점입니다. 코드 한 줄당 하나의 할당을 수행할 필요 없이, 단일 명령으로 여러 할당 작업을 수행할 수 있습니다.
이것의 예를 살펴보겠습니다. 우리는 네 가지 연산을 하나로 묶을 것입니다:
query()를 사용하여 목적지 "dest" 열의 값이 "IAH"인 행들만 찾습니다. 이는 인덱스를 변경하지 않고 무관한 행들만 제거합니다. 결과적으로, 이 단계는 우리가 관심 없는 행들을 제거합니다.groupby()를 사용하여 연도, 월, 일별로 행을 그룹화합니다(컬럼 리스트를 groupby() 함수에 전달합니다). 이 단계는 인덱스를 변경합니다. 새로운 인덱스는 연도, 월, 일을 추적하는 세 개의 열을 갖게 됩니다. 결과적으로, 이 단계는 인덱스를 변경합니다.groupby() 연산 후 유지하고 싶은 열을 대괄호 리스트로 선택합니다(데이터 프레임 내의 리스트이므로 이중 대괄호를 사용합니다). 여기서는 "arr_delay"라는 하나의 열만 원합니다. 이것은 인덱스에 영향을 주지 않습니다. 결과적으로, 이 단계는 우리가 관심 없는 열들을 제거합니다.groupby() 연산을 적용할지 지정해야 합니다. 여러 행의 정보를 하나의 행으로 합칠 때, 그 정보를 어떻게 집계(aggregate)할지 말해주어야 합니다. 이 경우 mean()을 사용하겠습니다. 결과적으로, 이 단계는 앞서 생성한 그룹들에 대해 앞서 선택한 변수(들)에 통계치를 적용합니다.(flights.query("dest == 'IAH'").groupby(["year", "month", "day"])[["arr_delay"]].mean())| arr_delay | |||
|---|---|---|---|
| year | month | day | |
| 2013 | 1 | 1 | 17.850000 |
| 2 | 7.000000 | ||
| 3 | 18.315789 | ||
| 4 | -3.200000 | ||
| 5 | 20.230769 | ||
| ... | ... | ... | |
| 12 | 27 | 6.166667 | |
| 28 | 9.500000 | ||
| 29 | 23.611111 | ||
| 30 | 23.684211 | ||
| 31 | -4.933333 |
365 rows × 1 columns
여기서 새로운 인덱스를 가진 새로운 데이터 프레임을 생성한 것을 볼 수 있습니다. 이를 위해 네 가지 핵심 연산을 사용했습니다:
단일 데이터 프레임에 대해 수행하고 싶은 대부분의 작업은 이들로 커버되지만, 여러분이 필요로 하는 것에 따라 각각에 대해 다른 옵션들이 존재합니다.
이제 이 연산들에 대해 좀 더 자세히 알아보겠습니다.
이것이 어떻게 작동하는지 보여주기 위해 가짜 데이터를 만들어 보겠습니다.
import numpy as np
df = pd.DataFrame(
data=np.reshape(range(36), (6, 6)),
index=["a", "b", "c", "d", "e", "f"],
columns=["col" + str(i) for i in range(6)],
dtype=float,
)
df["col6"] = ["apple", "orange", "pineapple", "mango", "kiwi", "lemon"]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon |
특정 행에 직접 접근하려면 df.loc['rowname']을 사용하거나, 두 개의 서로 다른 행에 대해서는 df.loc[['rowname1', 'rowname2']]를 사용합니다.
예를 들어,
df.loc[["a", "b"]]| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange |
하지만 .iloc를 사용하여 데이터 프레임 내의 위치를 기반으로 특정 행에 접근할 수도 있습니다. 파이썬 인덱스는 0부터 시작하므로, 첫 번째 행을 가져오려면 .iloc[0]을 사용합니다:
df.iloc[0]col0 0.0
col1 1.0
col2 2.0
col3 3.0
col4 4.0
col5 5.0
col6 apple
Name: a, dtype: object이는 여러 행에 대해서도 작동합니다. 위치 리스트를 전달하여 첫 번째와 세 번째 행(0번과 2번 위치)을 잡아보겠습니다:
df.iloc[[0, 2]]| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
슬라이싱(slicing)을 사용하여 여러 행에 접근하는 다른 방법들도 있지만, 그 주제는 다른 기회에 남겨두겠습니다.
항공편 예제에서처럼 query()를 사용하여 조건에 따라 행을 필터링할 수도 있습니다:
df.query("col6 == 'kiwi' or col6 == 'pineapple'")| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
숫자의 경우 크다/작다 기호를 사용할 수도 있습니다:
df.query("col0 > 6")| col0 | col1 | col2 | col3 | col4 | col5 | col6 | |
|---|---|---|---|---|---|---|---|
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon |
사실 query()와 함께 작동하는 옵션은 매우 많습니다: >(크다)뿐만 아니라 >=(크거나 같다), <(작다), <=(작거나 같다), ==(같다), !=(같지 않다)를 사용할 수 있습니다. 또한 and 및 or 명령을 사용하여 여러 조건을 결합할 수 있습니다. 다음은 flights 데이터 프레임에서의 and 예제입니다:
# 1월 1일에 출발한 항공편
flights.query("month == 1 and day == 1")| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 837 | 2013 | 1 | 1 | 2356.0 | 2359 | -3.0 | 425.0 | 437 | -12.0 | B6 | 727 | N588JB | JFK | BQN | 186.0 | 1576 | 23 | 59 | 2013-01-02 04:00:00 |
| 838 | 2013 | 1 | 1 | NaN | 1630 | NaN | NaN | 1815 | NaN | EV | 4308 | N18120 | EWR | RDU | NaN | 416 | 16 | 30 | 2013-01-01 21:00:00 |
| 839 | 2013 | 1 | 1 | NaN | 1935 | NaN | NaN | 2240 | NaN | AA | 791 | N3EHAA | LGA | DFW | NaN | 1389 | 19 | 35 | 2013-01-02 00:00:00 |
| 840 | 2013 | 1 | 1 | NaN | 1500 | NaN | NaN | 1825 | NaN | AA | 1925 | N3EVAA | LGA | MIA | NaN | 1096 | 15 | 0 | 2013-01-01 20:00:00 |
| 841 | 2013 | 1 | 1 | NaN | 600 | NaN | NaN | 901 | NaN | B6 | 125 | N618JB | JFK | FLL | NaN | 1069 | 6 | 0 | 2013-01-01 11:00:00 |
842 rows × 19 columns
같음 테스트는 ==로 하며, =는 할당에 사용되므로 사용하지 않는다는 점에 유의하세요.
특정 열의 값에 따라 데이터 프레임의 행을 재정렬하고 싶을 때가 반복해서 생길 것입니다. pandas는 .sort_values() 함수를 통해 이를 매우 쉽게 만들어 줍니다. 이 함수는 데이터 프레임과 정렬할 기준이 되는 열 이름 집합을 인수로 받습니다. 둘 이상의 열 이름을 제공하면, 추가된 각 열은 앞선 열의 값들이 같을 때 순서를 결정(tie-break)하는 데 사용됩니다. 예를 들어, 다음 코드는 4개의 열에 걸쳐 있는 출발 시간을 기준으로 정렬합니다.
flights.sort_values(["year", "month", "day", "dep_time"])| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | 1545 | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | 1714 | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | 1141 | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | 725 | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | 461 | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 111291 | 2013 | 12 | 31 | NaN | 705 | NaN | NaN | 931 | NaN | UA | 1729 | NaN | EWR | DEN | NaN | 1605 | 7 | 5 | 2013-12-31 12:00:00 |
| 111292 | 2013 | 12 | 31 | NaN | 825 | NaN | NaN | 1029 | NaN | US | 1831 | NaN | JFK | CLT | NaN | 541 | 8 | 25 | 2013-12-31 13:00:00 |
| 111293 | 2013 | 12 | 31 | NaN | 1615 | NaN | NaN | 1800 | NaN | MQ | 3301 | N844MQ | LGA | RDU | NaN | 431 | 16 | 15 | 2013-12-31 21:00:00 |
| 111294 | 2013 | 12 | 31 | NaN | 600 | NaN | NaN | 735 | NaN | UA | 219 | NaN | EWR | ORD | NaN | 719 | 6 | 0 | 2013-12-31 11:00:00 |
| 111295 | 2013 | 12 | 31 | NaN | 830 | NaN | NaN | 1154 | NaN | UA | 443 | NaN | JFK | LAX | NaN | 2475 | 8 | 30 | 2013-12-31 13:00:00 |
336776 rows × 19 columns
키워드 인수 ascending=False를 사용하여 열 또는 열들을 내림차순으로 재정렬할 수 있습니다. 예를 들어, 이 코드는 가장 지연된 항공편을 보여줍니다:
flights.sort_values("dep_delay", ascending=False)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7072 | 2013 | 1 | 9 | 641.0 | 900 | 1301.0 | 1242.0 | 1530 | 1272.0 | HA | 51 | N384HA | JFK | HNL | 640.0 | 4983 | 9 | 0 | 2013-01-09 14:00:00 |
| 235778 | 2013 | 6 | 15 | 1432.0 | 1935 | 1137.0 | 1607.0 | 2120 | 1127.0 | MQ | 3535 | N504MQ | JFK | CMH | 74.0 | 483 | 19 | 35 | 2013-06-15 23:00:00 |
| 8239 | 2013 | 1 | 10 | 1121.0 | 1635 | 1126.0 | 1239.0 | 1810 | 1109.0 | MQ | 3695 | N517MQ | EWR | ORD | 111.0 | 719 | 16 | 35 | 2013-01-10 21:00:00 |
| 327043 | 2013 | 9 | 20 | 1139.0 | 1845 | 1014.0 | 1457.0 | 2210 | 1007.0 | AA | 177 | N338AA | JFK | SFO | 354.0 | 2586 | 18 | 45 | 2013-09-20 22:00:00 |
| 270376 | 2013 | 7 | 22 | 845.0 | 1600 | 1005.0 | 1044.0 | 1815 | 989.0 | MQ | 3075 | N665MQ | JFK | CVG | 96.0 | 589 | 16 | 0 | 2013-07-22 20:00:00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | NaN | 1455 | NaN | NaN | 1634 | NaN | 9E | 3393 | NaN | JFK | DCA | NaN | 213 | 14 | 55 | 2013-09-30 18:00:00 |
| 336772 | 2013 | 9 | 30 | NaN | 2200 | NaN | NaN | 2312 | NaN | 9E | 3525 | NaN | LGA | SYR | NaN | 198 | 22 | 0 | 2013-10-01 02:00:00 |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 | 2013-09-30 16:00:00 |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 | 2013-09-30 15:00:00 |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 | 2013-09-30 12:00:00 |
336776 rows × 19 columns
물론 복잡한 문제를 해결하기 위해 위의 모든 행 조작법을 결합할 수 있습니다. 예를 들어, 거의 정시에 출발했지만 도착 시 가장 많이 지연된 항공편의 상위 3개 목적지를 찾아볼 수 있습니다:
(
flights.query("dep_delay <= 10 and dep_delay >= -10")
.sort_values("arr_delay", ascending=False)
.iloc[[0, 1, 2]]
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 55985 | 2013 | 11 | 1 | 658.0 | 700 | -2.0 | 1329.0 | 1015 | 194.0 | VX | 399 | N629VA | JFK | LAX | 336.0 | 2475 | 7 | 0 | 2013-11-01 11:00:00 |
| 181270 | 2013 | 4 | 18 | 558.0 | 600 | -2.0 | 1149.0 | 850 | 179.0 | AA | 707 | N3EXAA | LGA | DFW | 234.0 | 1389 | 6 | 0 | 2013-04-18 10:00:00 |
| 256340 | 2013 | 7 | 7 | 1659.0 | 1700 | -1.0 | 2050.0 | 1823 | 147.0 | US | 2183 | N948UW | LGA | DCA | 64.0 | 214 | 17 | 0 | 2013-07-07 21:00:00 |
다음 조건에 맞는 모든 항공편을 찾으세요.
도착 지연 시간이 2시간 이상인 항공편
휴스턴으로 비행한 항공편("IAH" 또는 "HOU")
유나이티드(United), 아메리칸(American) 또는 델타(Delta) 항공사에서 운항한 항공편
여름(7월, 8월, 9월)에 출발한 항공편
2시간 이상 늦게 도착했지만, 출발은 늦지 않은 항공편
최소 한 시간 이상 지연되었지만, 비행 중에 30분 이상 시간을 단축한 항공편
flights를 정렬하여 출발 지연 시간이 가장 긴 항공편을 찾으세요.
flights를 정렬하여 가장 빠른 항공편을 찾으세요.
어떤 항공편이 가장 멀리 이동했나요?
query()와 sort_values()를 둘 다 사용할 때 순서가 중요할까요? 왜 그럴까요/그렇지 않을까요? 결과와 각 함수가 수행해야 하는 작업량을 생각해 보세요.
이 섹션에서는 데이터 프레임의 열에 적용해야 할 수 있는 다양한 연산들을 보여줍니다.
일부 **pandas** 연산은 사용된 구문에 따라 열이나 행에 모두 적용될 수 있습니다. 예를 들어, 위치별로 값에 접근하는 것은 `.iloc`를 통해 행과 열에 대해 동일한 방식으로 수행될 수 있는데, i번째 행에 접근하려면 `df.iloc[i]`를 사용하고 j번째 열에 접근하려면 `df.iloc[:, j]`를 사용합니다. 여기서 `:`는 '모든 행'을 나타냅니다.이제 새로운 정보를 사용하거나 기존 열로부터 새로운 열을 만드는 단계로 넘어가 보겠습니다. 데이터 프레임 df가 주어졌을 때, 동일한 값이 반복되는 새로운 열을 만드는 것은 대괄호와 문자열(따옴표로 묶인 텍스트)을 사용하는 것만큼 쉽습니다.
df["new_column0"] = 5
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | |
|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 5 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 5 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 5 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 5 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 5 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 |
동일한 작업을 다른 우변(right-hand side) 값으로 다시 수행하면, 해당 열에 이미 있던 내용 위에 덮어쓰게 됩니다. 새 열에 리스트를 할당하여 각 위치에 서로 다른 값을 넣는 예제를 보겠습니다.
df["new_column0"] = [0, 1, 2, 3, 4, 5]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | |
|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 |
{.callout-note} 연습 문제 우변의 값들의 길이가 데이터 프레임의 길이보다 길거나 짧은 상태에서 할당을 시도하면 어떻게 될까요?
대괄호 안에 리스트를 전달함으로써 하나 이상의 새로운 열을 실제로 생성할 수 있습니다:
df[["new_column1", "new_column2"]] = [5, 6]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | new_column1 | new_column2 | |
|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 |
기존 열에 대한 연산 결과로 새로운 열을 만들고 싶을 때가 매우 많습니다. 여기에는 몇 가지 방법이 있습니다. ‘독립형(stand-alone)’ 메서드는 방금 본 것과 유사하게 작동하지만 할당문의 우변에서도 데이터 프레임을 참조합니다:
df["new_column3"] = df["col0"] - df["new_column0"]
df| col0 | col1 | col2 | col3 | col4 | col5 | col6 | new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
다른 방법은 ‘assign()’ 문을 사용하는 것인데, 이는 앞서 보았듯이 여러 단계를 함께 연결하고 싶을 때 사용됩니다. 여기서는 ‘lambda’ 문이라는 특별한 구문을 사용하는데, 이는 (최소한 여기서는) 모든 행에 대해 연산을 수행하고 싶다는 것을 pandas에 명시하는 방법을 제공할 뿐입니다. 아래는 항공편 데이터를 사용한 예제입니다. 아래의 ’row’라는 단어는 더미(dummy)라는 점에 유의해야 합니다. 어떤 변수 이름(예: x)으로든 바꿀 수 있지만, row라고 쓰면 무슨 일이 일어나고 있는지 조금 더 명확해집니다.
(
flights.assign(
gain=lambda row: row["dep_delay"] - row["arr_delay"],
speed=lambda row: row["distance"] / row["air_time"] * 60,
)
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | ... | tailnum | origin | dest | air_time | distance | hour | minute | time_hour | gain | speed | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.0 | 515 | 2.0 | 830.0 | 819 | 11.0 | UA | ... | N14228 | EWR | IAH | 227.0 | 1400 | 5 | 15 | 2013-01-01 10:00:00 | -9.0 | 370.044053 |
| 1 | 2013 | 1 | 1 | 533.0 | 529 | 4.0 | 850.0 | 830 | 20.0 | UA | ... | N24211 | LGA | IAH | 227.0 | 1416 | 5 | 29 | 2013-01-01 10:00:00 | -16.0 | 374.273128 |
| 2 | 2013 | 1 | 1 | 542.0 | 540 | 2.0 | 923.0 | 850 | 33.0 | AA | ... | N619AA | JFK | MIA | 160.0 | 1089 | 5 | 40 | 2013-01-01 10:00:00 | -31.0 | 408.375000 |
| 3 | 2013 | 1 | 1 | 544.0 | 545 | -1.0 | 1004.0 | 1022 | -18.0 | B6 | ... | N804JB | JFK | BQN | 183.0 | 1576 | 5 | 45 | 2013-01-01 10:00:00 | 17.0 | 516.721311 |
| 4 | 2013 | 1 | 1 | 554.0 | 600 | -6.0 | 812.0 | 837 | -25.0 | DL | ... | N668DN | LGA | ATL | 116.0 | 762 | 6 | 0 | 2013-01-01 11:00:00 | 19.0 | 394.137931 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | NaN | 1455 | NaN | NaN | 1634 | NaN | 9E | ... | NaN | JFK | DCA | NaN | 213 | 14 | 55 | 2013-09-30 18:00:00 | NaN | NaN |
| 336772 | 2013 | 9 | 30 | NaN | 2200 | NaN | NaN | 2312 | NaN | 9E | ... | NaN | LGA | SYR | NaN | 198 | 22 | 0 | 2013-10-01 02:00:00 | NaN | NaN |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | ... | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 | 2013-09-30 16:00:00 | NaN | NaN |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | ... | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 | 2013-09-30 15:00:00 | NaN | NaN |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | ... | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 | 2013-09-30 12:00:00 | NaN | NaN |
336776 rows × 21 columns
람다(lambda) 함수는 이름이 없고 코드 한 줄에 포함되는 경향이 있다는 점을 제외하면 파이썬의 일반 함수와 같습니다. 람다 함수는 인수, 콜론, 표현식으로 구성됩니다. 다음은 입력을 3배로 곱하는 람다 함수 예제입니다.
lambda x: x*3행을 선택할 때와 마찬가지로, 조작할 열을 선택하는 방법도 여러 가지가 있습니다. 가장 간단한 구문은 데이터 프레임 이름 뒤에 대괄호와 (문자열 형태의) 열 이름을 사용하는 것입니다.
df["col0"]a 0.0
b 6.0
c 12.0
d 18.0
e 24.0
f 30.0
Name: col0, dtype: float64여러 열을 선택해야 하는 경우, df[...] 안에 그냥 문자열만 전달할 수는 없습니다. 대신 반복 가능한(iterable) 객체(여러 항목이 있는 객체)를 전달해야 합니다. 여러 열을 선택하는 가장 직접적인 방법은 리스트를 전달하는 것입니다. 리스트는 대괄호로 묶이므로, 데이터 프레임 내부 접근용 대괄호 하나와 리스트용 대괄호 하나, 즉 중복된 대괄호를 보게 될 것입니다.
df[["col0", "new_column0", "col2"]]| col0 | new_column0 | col2 | |
|---|---|---|---|
| a | 0.0 | 0 | 2.0 |
| b | 6.0 | 1 | 8.0 |
| c | 12.0 | 2 | 14.0 |
| d | 18.0 | 3 | 20.0 |
| e | 24.0 | 4 | 26.0 |
| f | 30.0 | 5 | 32.0 |
특정 행들에도 동시에 접근하고 싶다면, .loc 접근 함수를 사용하세요:
df.loc[["a", "b"], ["col0", "new_column0", "col2"]]| col0 | new_column0 | col2 | |
|---|---|---|---|
| a | 0.0 | 0 | 2.0 |
| b | 6.0 | 1 | 8.0 |
그리고 행의 경우와 마찬가지로, .iloc를 사용하여 위치별로 열에 접근할 수 있습니다(여기서 :는 ’모든 행’을 나타냅니다).
df.iloc[:, [0, 1]]| col0 | col1 | |
|---|---|---|
| a | 0.0 | 1.0 |
| b | 6.0 | 7.0 |
| c | 12.0 | 13.0 |
| d | 18.0 | 19.0 |
| e | 24.0 | 25.0 |
| f | 30.0 | 31.0 |
슬라이싱을 사용하는 여러 열 접근 방법들도 있지만 그 주제는 다른 기회에 남겨두겠습니다.
때로는 열이 보유한 데이터의 타입을 기준으로 열을 선택하고 싶을 때가 있습니다. 이를 위해 pandas는 .select_dtypes() 함수를 제공합니다. 이를 사용하여 항공편 데이터에서 정수가 있는 모든 열을 선택해 보겠습니다.
flights.select_dtypes("int")| year | month | day | sched_dep_time | sched_arr_time | flight | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 515 | 819 | 1545 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 529 | 830 | 1714 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 540 | 850 | 1141 | 1089 | 5 | 40 |
| 3 | 2013 | 1 | 1 | 545 | 1022 | 725 | 1576 | 5 | 45 |
| 4 | 2013 | 1 | 1 | 600 | 837 | 461 | 762 | 6 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336771 | 2013 | 9 | 30 | 1455 | 1634 | 3393 | 213 | 14 | 55 |
| 336772 | 2013 | 9 | 30 | 2200 | 2312 | 3525 | 198 | 22 | 0 |
| 336773 | 2013 | 9 | 30 | 1210 | 1330 | 3461 | 764 | 12 | 10 |
| 336774 | 2013 | 9 | 30 | 1159 | 1344 | 3572 | 419 | 11 | 59 |
| 336775 | 2013 | 9 | 30 | 840 | 1020 | 3531 | 431 | 8 | 40 |
336776 rows × 9 columns
열의 이름 패턴과 같은 기준을 바탕으로 열을 선택하고 싶을 때도 있습니다. 파이썬은 텍스트를 매우 잘 지원하기 때문에 충분히 가능하지만, pandas 함수에 내장되어 있지는 않은 편입니다. 요령은 여러분이 관심 있는 패턴으로부터 원하는 열 이름 리스트를 생성하는 것입니다.
몇 가지 예제를 살펴보겠습니다. 먼저, df 데이터 프레임에서 "new_..."로 시작하는 모든 열을 가져와 보겠습니다. 각 열이 “new”로 시작하는지 여부를 나타내는 참/거짓 리스트를 생성한 다음, 그 참/거짓 값을 .loc에 전달하면 결과가 True인 열만 반환합니다. 무슨 일이 일어나고 있는지 보여주기 위해 두 단계로 나누겠습니다:
print("열 이름 리스트:")
print(df.columns)
print("\n")
print("참/거짓 값 리스트:")
print(df.columns.str.startswith("new"))
print("\n")
print("데이터 프레임에서의 선택 결과:")
df.loc[:, df.columns.str.startswith("new")]열 이름 리스트:
Index(['col0', 'col1', 'col2', 'col3', 'col4', 'col5', 'col6', 'new_column0',
'new_column1', 'new_column2', 'new_column3'],
dtype='object')
참/거짓 값 리스트:
[False False False False False False False True True True True]
데이터 프레임에서의 선택 결과:| new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|
| a | 0 | 5 | 6 | 0.0 |
| b | 1 | 5 | 6 | 5.0 |
| c | 2 | 5 | 6 | 10.0 |
| d | 3 | 5 | 6 | 15.0 |
| e | 4 | 5 | 6 | 20.0 |
| f | 5 | 5 | 6 | 25.0 |
startswith()뿐만 아니라 endswith(), contains(), isnumeric(), islower()와 같은 다른 명령어도 있습니다.
상황에 따라 열 이름을 바꾸는 세 가지 쉬운 방법이 있습니다. 첫 번째는 ’딕셔너리’라는 객체와 함께 전용 rename() 함수를 사용하는 것입니다. 파이썬의 딕셔너리는 중괄호 안에 쉼표로 구분된 값 쌍으로 구성되며, 첫 번째 값이 두 번째 값으로 매핑됩니다. 딕셔너리의 예로는 {'old_col1': 'new_col1', 'old_col2': 'new_col2'}가 있습니다. 이를 실제로 확인해 보겠습니다(단, 결과 데이터 프레임을 ’저장’하는 것이 아니라 그냥 보여주는 것뿐입니다. 저장하려면 아래 코드의 좌변에 df =를 추가해야 합니다).
df.rename(columns={"col3": "letters", "col4": "names", "col6": "fruit"})| col0 | col1 | col2 | letters | names | col5 | fruit | new_column0 | new_column1 | new_column2 | new_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
두 번째 방법은 모든 열의 이름을 바꾸고 싶을 때입니다. 이 경우 단순히 df.columns를 원하는 새로운 열 이름 집합으로 설정하면 됩니다. 예를 들어, str.capitalize()를 사용하여 각 열의 첫 글자를 대문자로 만들고 이를 df.columns에 할당하고 싶을 수 있습니다.
df.columns = df.columns.str.capitalize()
df| Col0 | Col1 | Col2 | Col3 | Col4 | Col5 | Col6 | New_column0 | New_column1 | New_column2 | New_column3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | apple | 0 | 5 | 6 | 0.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 | orange | 1 | 5 | 6 | 5.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 | pineapple | 2 | 5 | 6 | 10.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 | mango | 3 | 5 | 6 | 15.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 | kiwi | 4 | 5 | 6 | 20.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 | lemon | 5 | 5 | 6 | 25.0 |
마지막으로, 열 이름의 특정 부분만 바꾸는 데 관심이 있을 수 있습니다. 이 경우 .str.replace()를 사용할 수 있습니다. 예시로 원래 열들 앞에 "Original"이라는 단어를 추가해 보겠습니다:
df.columns.str.replace("Col", "Original_column")Index(['Original_column0', 'Original_column1', 'Original_column2',
'Original_column3', 'Original_column4', 'Original_column5',
'Original_column6', 'New_column0', 'New_column1', 'New_column2',
'New_column3'],
dtype='object')기본적으로 새로운 열은 데이터 프레임의 오른쪽에 추가됩니다. 하지만 열이 특정 순서로 나타나기를 원하는 이유가 있을 수 있고, 혹은 데이터 프레임에 열이 많을 때(흔히 발생합니다) 새 열이 왼쪽에 있는 것이 더 편리하다고 느낄 수도 있습니다.
(모든) 열의 순서를 재배치하는 가장 간단한 방법은 원하는 순서대로 열 이름 리스트를 새로 만드는 것입니다. 하지만 유지하고 싶은 열을 하나라도 빠뜨리지 않도록 주의해야 합니다!
앞서 만든 가짜 데이터의 신선한 버전을 사용하여 예제를 살펴보겠습니다. 모든 홀수 번호 열을 먼저 내림차순으로 배치하고, 그 뒤에 짝수 번호 열을 비슷하게 배치해 보겠습니다.
df = pd.DataFrame(
data=np.reshape(range(36), (6, 6)),
index=["a", "b", "c", "d", "e", "f"],
columns=["col" + str(i) for i in range(6)],
dtype=float,
)
df| col0 | col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 |
df = df[["col5", "col3", "col1", "col4", "col2", "col0"]]
df| col5 | col3 | col1 | col4 | col2 | col0 | |
|---|---|---|---|---|---|---|
| a | 5.0 | 3.0 | 1.0 | 4.0 | 2.0 | 0.0 |
| b | 11.0 | 9.0 | 7.0 | 10.0 | 8.0 | 6.0 |
| c | 17.0 | 15.0 | 13.0 | 16.0 | 14.0 | 12.0 |
| d | 23.0 | 21.0 | 19.0 | 22.0 | 20.0 | 18.0 |
| e | 29.0 | 27.0 | 25.0 | 28.0 | 26.0 | 24.0 |
| f | 35.0 | 33.0 | 31.0 | 34.0 | 32.0 | 30.0 |
물론 열이 아주 많다면 이 작업은 매우 지루할 것입니다! 상황에 따라 이를 더 쉽게 만들어 줄 수 있는 메서드들이 있습니다. 단순히 열을 순서대로 정렬하고 싶으신가요? 이는 sorted()와 reindex() 명령어를 조합하고, 두 번째 축(즉, 열)을 의미하는 axis=1을 함께 사용하여 달성할 수 있습니다.
df.reindex(sorted(df.columns), axis=1)| col0 | col1 | col2 | col3 | col4 | col5 | |
|---|---|---|---|---|---|---|
| a | 0.0 | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 |
| b | 6.0 | 7.0 | 8.0 | 9.0 | 10.0 | 11.0 |
| c | 12.0 | 13.0 | 14.0 | 15.0 | 16.0 | 17.0 |
| d | 18.0 | 19.0 | 20.0 | 21.0 | 22.0 | 23.0 |
| e | 24.0 | 25.0 | 26.0 | 27.0 | 28.0 | 29.0 |
| f | 30.0 | 31.0 | 32.0 | 33.0 | 34.0 | 35.0 |
데이터 프레임의 값에 접근하는 이 모든 다양한 방법들 때문에 혼란스러울 수 있습니다. 다음은 데이터 프레임의 첫 번째 열을 가져오는 서로 다른 방법들입니다(첫 번째 열의 이름이 column이고 데이터 프레임 이름이 df일 때):
df.columndf["column"]df.loc[:, "column"]df.iloc[:, 0]참고로 :는 ’모든 것을 달라’는 의미입니다! 행에 접근하는 방식도 비슷합니다(여기서는 첫 번째 행의 이름이 row라고 가정합니다):
df.loc["row", :]df.iloc[0, :]그리고 첫 번째 값(즉, 첫 번째 행, 첫 번째 열의 값)에 접근하려면:
df.column[0]df["column"][0]df.iloc[0, 0]df.loc["row", "column"]위의 예제에서 대괄호는 데이터 프레임에서 어떤 부분을 가져올지에 대한 지침입니다. 이는 데이터 프레임 내 값들의 주소 체계와 비슷합니다. 하지만 대괄호는 리스트를 나타내기도 합니다. 따라서 여러 열이나 행을 동시에 선택하고 싶다면 다음과 같은 구문을 보게 될 것입니다:
df.loc[["row0", "row1"], ["column0", "column2"]]
이 코드는 ["row0", "row1"] 및 ["column0", "column2"] 리스트를 통해 두 개의 행과 두 개의 열을 골라냅니다. 값을 선택하는 일반적인 체계와 리스트가 함께 사용되기 때문에 대괄호가 두 쌍이 생깁니다.
이름으로 행과 열에 접근하는 구문을 딱 하나만 기억하고 싶다면,
df.loc[["row0", "row1", ...], ["col0", "col1", ...]]패턴을 사용하세요. 이는 단일 행이나 단일 열(또는 둘 다)에 대해서도 작동합니다. 위치로 행과 열에 접근하는 구문을 딱 하나만 기억하고 싶다면,df.iloc[[0, 1, ...], [0, 1, ...]]패턴을 사용하세요. 이 또한 단일 행이나 단일 열(또는 둘 다)에 대해서도 작동합니다.
air_time을 arr_time - dep_time과 비교해 보세요. 무엇을 볼 것으로 예상하나요? 실제로는 무엇을 보게 되나요? 이를 해결하려면 무엇을 해야 할까요?
dep_time, sched_dep_time, dep_delay를 비교해 보세요. 이 세 숫자가 어떤 관계를 가질 것으로 예상하나요?
flights에서 dep_time, dep_delay, arr_time, arr_delay를 선택할 수 있는 가능한 한 많은 방법을 생각해 보세요.
행이나 열을 선택할 때 같은 이름을 여러 번 포함하면 어떤 일이 일어나나요?
다음 코드에서 .isin() 함수는 무엇을 하나요?
flights.columns.isin(["year", "month", "day", "dep_delay", "arr_delay"])다음 코드를 실행한 결과가 여러분을 놀라게 했나요? str.contains와 같은 함수는 기본적으로 대소문자를 어떻게 처리하나요? 그 기본값을 어떻게 바꿀 수 있을까요?
flights.loc[:, flights.columns.str.contains("TIME")](힌트: 데이터 프레임에 적용되는 함수에 대해서도 도움말을 사용할 수 있습니다. 예: help(flights.columns.str.contains))
지금까지 여러분은 행과 열을 다루는 법을 배웠습니다. pandas는 그룹과 작업하는 능력이 더해질 때 훨씬 더 강력해집니다. 그룹을 만드는 것은 종종 인덱스의 변경을 의미하기도 합니다. 그리고 그룹은 데이터의 집계(aggregation)나 풀링(pooling)을 의미하는 경우가 많으므로, 요약 통계량의 적용과 밀접한 관련이 있습니다.
아래 다이어그램은 이러한 연산들이 어떻게 함께 진행될 수 있는지 보여줍니다. ‘분할(split)’ 연산은 그룹화를 통해 이루어지고, ‘적용(apply)’은 요약 통계량을 생성합니다. 마지막으로, ’결합(combine)’ 단계에서 표시된 것처럼 그룹당 하나의 항목을 가진 새로운 인덱스를 가진 데이터 프레임을 얻게 됩니다.
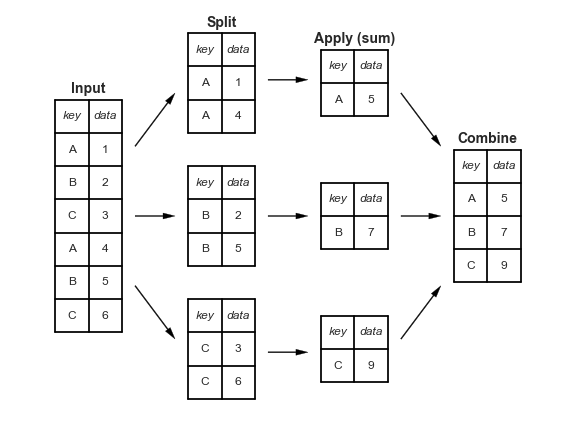
.groupby() 함수를 사용하여 그룹을 만든 다음, 열을 선택하고 집계(aggregation)를 통해 요약 통계량을 적용하는 방법을 살펴보겠습니다. 집계(.agg())를 수행하면 그룹 레벨로 정보가 축소되고 새로운 인덱스가 해당 레벨들로 구성되기 때문에 항상 새로운 인덱스가 생성된다는 점에 유의하세요.
기억해야 할 핵심 포인트는 다음과 같습니다: 그룹이 새로운 인덱스가 되기를 원할 때는 .groupby()와 함께 .agg()를 사용하세요.
(flights.groupby("month")[["dep_delay"]].mean())| dep_delay | |
|---|---|
| month | |
| 1 | 10.036665 |
| 2 | 10.816843 |
| 3 | 13.227076 |
| 4 | 13.938038 |
| 5 | 12.986859 |
| 6 | 20.846332 |
| 7 | 21.727787 |
| 8 | 12.611040 |
| 9 | 6.722476 |
| 10 | 6.243988 |
| 11 | 5.435362 |
| 12 | 16.576688 |
이 결과는 이제 월별 평균 출발 지연 시간을 나타냅니다. 인덱스가 변경된 것을 확인하세요! 원래 단순히 행 번호였던 인덱스가 이제 월(month)로 바뀌었습니다. 인덱스는 데이터 프레임의 나머지 부분에서 여러분이 가진 그룹들을 추적하기 때문에 그룹화 연산에서 중요한 역할을 합니다.
종종 여러 요약 연산을 한 번에 수행하고 싶을 수도 있습니다. 이를 위한 가장 포괄적인 구문은 .agg()를 통하는 것입니다. 위에서 했던 작업을 .agg()를 사용하여 재현할 수 있습니다:
(flights.groupby("month")[["dep_delay"]].agg("mean"))| dep_delay | |
|---|---|
| month | |
| 1 | 10.036665 |
| 2 | 10.816843 |
| 3 | 13.227076 |
| 4 | 13.938038 |
| 5 | 12.986859 |
| 6 | 20.846332 |
| 7 | 21.727787 |
| 8 | 12.611040 |
| 9 | 6.722476 |
| 10 | 6.243988 |
| 11 | 5.435362 |
| 12 | 16.576688 |
원하는 집계 방식 무엇이든 전달할 수 있습니다. 몇 가지 일반적인 옵션이 아래 표에 있습니다:
| 집계 (Aggregation) | 설명 |
|---|---|
count() |
항목 개수 |
first(), last() |
첫 번째 및 마지막 항목 |
mean(), median() |
평균 및 중앙값 |
min(), max() |
최소값 및 최대값 |
std(), var() |
표준 편차 및 분산 |
mad() |
평균 절대 편차 |
prod() |
모든 항목의 곱 |
sum() |
모든 항목의 합 |
value_counts() |
고유 값의 빈도 |
여러 열에 대해 여러 집계를 수행하고 출력 변수에 새 이름을 붙이려는 경우의 구문은 다음과 같습니다.
(
flights.groupby(["month"]).agg(
mean_delay=("dep_delay", "mean"),
count_flights=("dep_delay", "count"),
)
)| mean_delay | count_flights | |
|---|---|---|
| month | ||
| 1 | 10.036665 | 26483 |
| 2 | 10.816843 | 23690 |
| 3 | 13.227076 | 27973 |
| 4 | 13.938038 | 27662 |
| 5 | 12.986859 | 28233 |
| 6 | 20.846332 | 27234 |
| 7 | 21.727787 | 28485 |
| 8 | 12.611040 | 28841 |
| 9 | 6.722476 | 27122 |
| 10 | 6.243988 | 28653 |
| 11 | 5.435362 | 27035 |
| 12 | 16.576688 | 27110 |
평균과 빈도수만으로도 데이터 과학에서 놀라울 정도로 많은 일을 할 수 있습니다!
단일 열을 나타내는 문자열 대신 여러 열을 나타내는 리스트를 .groupby()에 전달하면 됩니다.
month_year_delay = flights.groupby(["month", "year"]).agg(
mean_delay=("dep_delay", "mean"),
count_flights=("dep_delay", "count"),
)
month_year_delay| mean_delay | count_flights | ||
|---|---|---|---|
| month | year | ||
| 1 | 2013 | 10.036665 | 26483 |
| 2 | 2013 | 10.816843 | 23690 |
| 3 | 2013 | 13.227076 | 27973 |
| 4 | 2013 | 13.938038 | 27662 |
| 5 | 2013 | 12.986859 | 28233 |
| 6 | 2013 | 20.846332 | 27234 |
| 7 | 2013 | 21.727787 | 28485 |
| 8 | 2013 | 12.611040 | 28841 |
| 9 | 2013 | 6.722476 | 27122 |
| 10 | 2013 | 6.243988 | 28653 |
| 11 | 2013 | 5.435362 | 27035 |
| 12 | 2013 | 16.576688 | 27110 |
이번에는 멀티 인덱스(둘 이상의 열을 가진 인덱스)를 갖게 된 것을 눈치채셨을 것입니다. 그것은 우리가 여러 그룹을 요청했기 때문이고, 인덱스가 각 그룹 내에서 일어나는 일을 추적하기 때문입니다. 그래서 이를 효율적으로 수행하기 위해 인덱스의 차원이 하나 이상 필요합니다.
단순히 위치를 나타내는 인덱스로 돌아가고 싶다면 reset_index()를 시도해 보세요.
month_year_delay.reset_index()| month | year | mean_delay | count_flights | |
|---|---|---|---|---|
| 0 | 1 | 2013 | 10.036665 | 26483 |
| 1 | 2 | 2013 | 10.816843 | 23690 |
| 2 | 3 | 2013 | 13.227076 | 27973 |
| 3 | 4 | 2013 | 13.938038 | 27662 |
| 4 | 5 | 2013 | 12.986859 | 28233 |
| 5 | 6 | 2013 | 20.846332 | 27234 |
| 6 | 7 | 2013 | 21.727787 | 28485 |
| 7 | 8 | 2013 | 12.611040 | 28841 |
| 8 | 9 | 2013 | 6.722476 | 27122 |
| 9 | 10 | 2013 | 6.243988 | 28653 |
| 10 | 11 | 2013 | 5.435362 | 27035 |
| 11 | 12 | 2013 | 16.576688 | 27110 |
인덱스의 한 계층만 제거하고 싶을 수도 있습니다. 이는 제거하고 싶은 인덱스의 위치를 전달함으로써 가능합니다. 예를 들어, 연도(year) 인덱스만 열로 바꾸고 싶다면 다음과 같이 사용합니다:
month_year_delay.reset_index(1)| year | mean_delay | count_flights | |
|---|---|---|---|
| month | |||
| 1 | 2013 | 10.036665 | 26483 |
| 2 | 2013 | 10.816843 | 23690 |
| 3 | 2013 | 13.227076 | 27973 |
| 4 | 2013 | 13.938038 | 27662 |
| 5 | 2013 | 12.986859 | 28233 |
| 6 | 2013 | 20.846332 | 27234 |
| 7 | 2013 | 21.727787 | 28485 |
| 8 | 2013 | 12.611040 | 28841 |
| 9 | 2013 | 6.722476 | 27122 |
| 10 | 2013 | 6.243988 | 28653 |
| 11 | 2013 | 5.435362 | 27035 |
| 12 | 2013 | 16.576688 | 27110 |
마지막으로, 선택한 인덱스 변수를 대신 열 변수로 피벗하는(다중 열 레벨 구조를 도입하는) unstack 연산을 사용하여 인덱스를 더 복잡하게 재배치할 수 있습니다. 보통은 이를 피하는 것이 좋습니다.
그룹 레벨에서 계산을 수행할 때 항상 새로운 그룹을 반영하도록 인덱스를 변경하고 싶지는 않을 수도 있습니다.
기억해야 할 핵심 포인트는 다음과 같습니다: 그룹에 대해 계산을 수행하고 싶지만 원래 인덱스로 돌아가고 싶을 때는 .groupby()와 함께 .transform()을 사용하세요.
각 항공편의 도착 지연 시간("arr_delay")을 해당 월의 최악의 도착 지연 시간의 비율로 표현하고 싶다고 가정해 보겠습니다.
flights["max_delay_month"] = flights.groupby("month")["arr_delay"].transform("max")
flights["delay_frac_of_max"] = flights["arr_delay"] / flights["max_delay_month"]
flights[
["year", "month", "day", "arr_delay", "max_delay_month", "delay_frac_of_max"]
].head()| year | month | day | arr_delay | max_delay_month | delay_frac_of_max | |
|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 11.0 | 1272.0 | 0.008648 |
| 1 | 2013 | 1 | 1 | 20.0 | 1272.0 | 0.015723 |
| 2 | 2013 | 1 | 1 | 33.0 | 1272.0 | 0.025943 |
| 3 | 2013 | 1 | 1 | -18.0 | 1272.0 | -0.014151 |
| 4 | 2013 | 1 | 1 | -25.0 | 1272.0 | -0.019654 |
"max_delay_month"의 처음 몇 개 항목이 모두 같은 것을 볼 수 있는데, 이는 해당 항목들의 월(month)이 같기 때문입니다. 하지만 지연 비율은 행마다 달라집니다.
어떤 항공사가 가장 심한 지연을 겪고 있나요? 도전 과제: 공항 문제와 항공사 문제를 분리할 수 있을까요? 왜 그럴까요/그렇지 않을까요? (힌트: flights.groupby(["carrier", "dest"]).count()를 생각해 보세요.)
각 목적지별로 가장 많이 지연된 항공편을 찾으세요.
하루 중 시간에 따라 지연이 어떻게 변하나요?