100일간의 머신러닝 코드
Siraj Raval이 제안한 100일간의 머신러닝 코딩
여기에서 데이터셋을 받으세요.
데이터 전처리 | 1일차
여기에서 코드를 확인하세요.

단순 선형 회귀 | 2일차
여기에서 코드를 확인하세요.

다중 선형 회귀 | 3일차
여기에서 코드를 확인하세요.

로지스틱 회귀 | 4일차

로지스틱 회귀 | 5일차
#100DaysOfMLCode를 진행하면서 오늘 로지스틱 회귀가 실제로 무엇이며 그 뒤에 숨겨진 수학은 무엇인지 더 깊이 파고들었습니다. 비용 함수가 어떻게 계산되는지, 그리고 예측 오류를 최소화하기 위해 비용 함수에 경사 하강 알고리즘을 적용하는 방법을 배웠습니다. 시간이 부족하여 이제 격일로 인포그래픽을 게시할 예정입니다. 또한 코드 문서화에 도움을 주실 분이 있고 이미 해당 분야에 경험이 있으며 github용 Markdown을 알고 계신다면 LinkedIn으로 저에게 연락해 주세요 :).
로지스틱 회귀 구현 | 6일차
여기에서 코드를 확인하세요.
K 최근접 이웃 | 7일차

로지스틱 회귀의 수학적 원리 | 8일차
#100DaysOfMLCode 로지스틱 회귀에 대한 이해를 명확히 하기 위해 인터넷에서 자료나 기사를 검색하다가 Saishruthi Swaminathan의 이 기사(https://towardsdatascience.com/logistic-regression-detailed-overview-46c4da4303bc)를 발견했습니다.
로지스틱 회귀에 대한 자세한 설명을 제공합니다. 확인해 보세요.
서포트 벡터 머신 | 9일차
SVM이 무엇이며 분류 문제를 해결하는 데 어떻게 사용되는지에 대한 직관을 얻었습니다.
SVM 및 KNN | 10일차
SVM 작동 방식에 대해 더 자세히 배우고 K-NN 알고리즘을 구현했습니다.
K-NN 구현 | 11일차
분류를 위한 K-NN 알고리즘을 구현했습니다. #100DaysOfMLCode 서포트 벡터 머신 인포그래픽이 절반 정도 완료되었습니다. 내일 업데이트하겠습니다.
서포트 벡터 머신 | 12일차
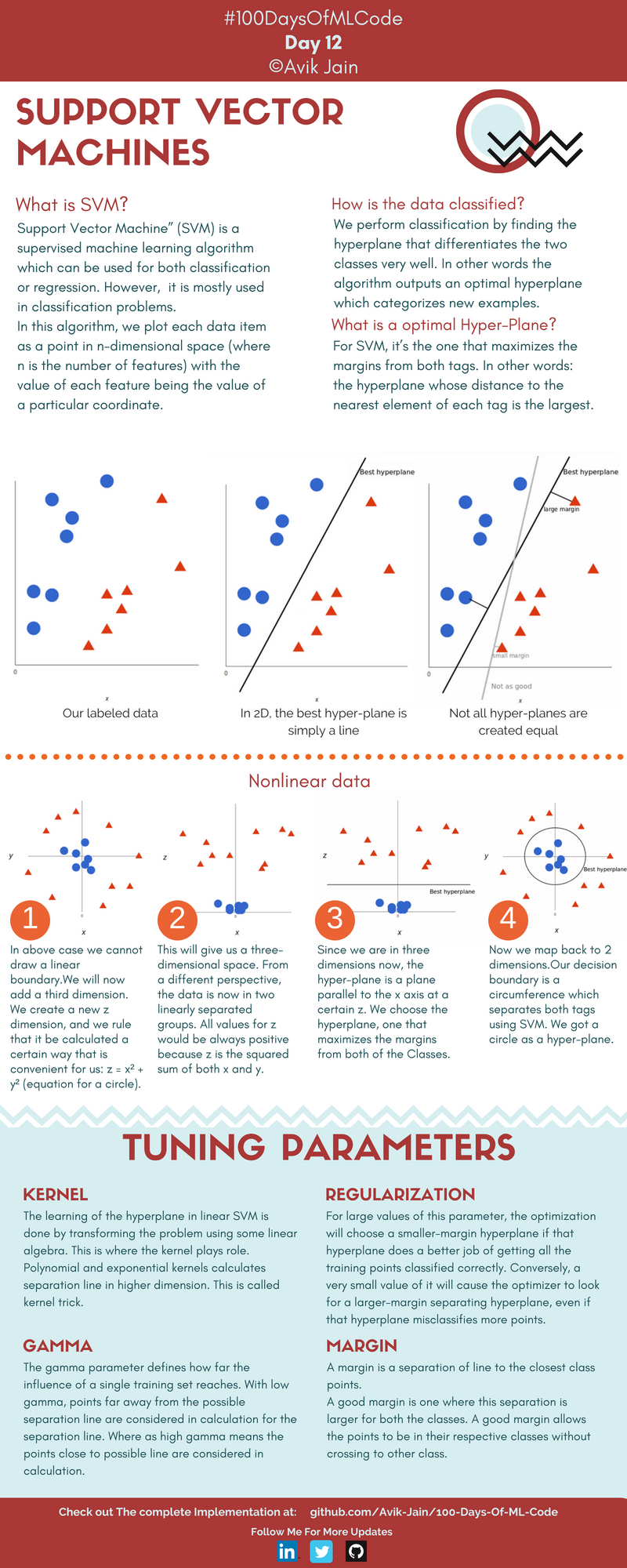
나이브 베이즈 분류기 | 13일차
#100DaysOfMLCode를 계속 진행하면서 오늘 나이브 베이즈 분류기를 살펴보았습니다. 또한 scikit-learn을 사용하여 파이썬으로 SVM을 구현하고 있습니다. 코드는 곧 업데이트하겠습니다.
SVM 구현 | 14일차
오늘 선형적으로 관련된 데이터에 SVM을 구현했습니다. Scikit-Learn 라이브러리를 사용했습니다. Scikit-Learn에는 이 작업을 수행하는 데 사용하는 SVC 분류기가 있습니다. 다음 구현에서는 커널 트릭을 사용할 예정입니다. 여기에서 코드를 확인하세요.
나이브 베이즈 분류기 및 블랙박스 머신러닝 | 15일차
다양한 유형의 나이브 베이즈 분류기에 대해 배웠습니다. 또한 Bloomberg의 강의를 듣기 시작했습니다. 재생 목록의 첫 번째 강의는 블랙박스 머신러닝이었습니다. 예측 함수, 특징 추출, 학습 알고리즘, 성능 평가, 교차 검증, 샘플 편향, 비정상성, 과적합 및 하이퍼파라미터 튜닝에 대한 전체 개요를 제공합니다.
커널 트릭을 사용한 SVM 구현 | 16일차
Scikit-Learn 라이브러리를 사용하여 데이터 포인트를 더 높은 차원으로 매핑하여 최적의 초평면을 찾는 커널 함수와 함께 SVM 알고리즘을 구현했습니다.
Coursera에서 딥러닝 전문 과정 시작 | 17일차
하루 만에 1주차와 2주차 전체를 완료했습니다. 신경망으로서의 로지스틱 회귀를 배웠습니다.
Coursera에서 딥러닝 전문 과정 | 18일차
딥러닝 전문 과정의 첫 번째 과정을 완료했습니다. 파이썬으로 신경망을 구현했습니다.
학습 문제, Yaser Abu-Mostafa 교수 | 19일차
Yaser Abu-Mostafa 교수의 Caltech 머신러닝 과정(CS 156) 18개 강의 중 첫 번째 강의를 시작했습니다. 기본적으로 다음 강의에 대한 소개였습니다. 또한 퍼셉트론 알고리즘에 대해서도 설명했습니다.
딥러닝 전문 과정 2 시작 | 20일차
심층 신경망 개선: 하이퍼파라미터 튜닝, 정규화 및 최적화 1주차를 완료했습니다.
웹 스크래핑 | 21일차
모델 구축을 위한 데이터 수집을 위해 Beautiful Soup을 사용하여 웹 스크래핑을 수행하는 방법에 대한 몇 가지 튜토리얼을 시청했습니다.
학습은 가능한가? | 22일차
Yaser Abu-Mostafa 교수의 Caltech 머신러닝 과정(CS 156) 18개 강의 중 두 번째 강의. 호프딩 부등식에 대해 배웠습니다.
결정 트리 | 23일차

통계 학습 이론 소개 | 24일차
Bloomberg ML 과정의 세 번째 강의에서는 입력 공간, 행동 공간, 결과 공간, 예측 함수, 손실 함수 및 가설 공간과 같은 핵심 개념 중 일부를 소개했습니다.
결정 트리 구현 | 25일차
여기에서 코드를 확인하세요.
선형 대수 복습으로 이동 | 26일차
유튜브에서 3Blue1Brown이라는 놀라운 채널을 발견했습니다. 선형 대수의 본질이라는 재생 목록이 있습니다. 벡터, 선형 조합, 스팬, 기저 벡터, 선형 변환 및 행렬 곱셈에 대한 전체 개요를 제공하는 4개의 비디오를 완료하며 시작했습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 27일차
재생 목록을 계속 진행하면서 3D 변환, 행렬식, 역행렬, 열 공간, 영 공간 및 비정방 행렬 주제를 다루는 다음 4개의 비디오를 완료했습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 28일차
3Blue1Brown의 재생 목록에서 선형 대수의 본질에서 3개의 비디오를 추가로 완료했습니다. 다룬 주제는 내적과 외적이었습니다.
재생 목록 링크는 여기입니다.
선형 대수 복습으로 이동 | 29일차
오늘 12-14번 비디오를 통해 전체 재생 목록을 완료했습니다. 선형 대수 개념을 복습하기에 정말 놀라운 재생 목록입니다. 다룬 주제는 기저 변경, 고유 벡터 및 고유값, 추상 벡터 공간이었습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 30일차
3blue1brown의 선형 대수의 본질 재생 목록을 완료하자 유튜브에서 같은 채널 3Blue1Brown의 비디오 시리즈에 대한 제안이 나타났습니다. 이미 이전 선형 대수 시리즈에 깊은 인상을 받았기 때문에 바로 뛰어들었습니다. 도함수, 연쇄 법칙, 곱셈 법칙 및 지수 함수의 도함수와 같은 주제에 대한 약 5개의 비디오를 완료했습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 31일차
미적분학의 본질 재생 목록에서 음함수 미분 및 극한 주제에 대한 2개의 비디오를 시청했습니다.
재생 목록 링크는 여기입니다.
미적분학의 본질 | 32일차
적분 및 고계 도함수와 같은 주제를 다루는 나머지 4개의 비디오를 시청했습니다.
재생 목록 링크는 여기입니다.
랜덤 포레스트 | 33일차
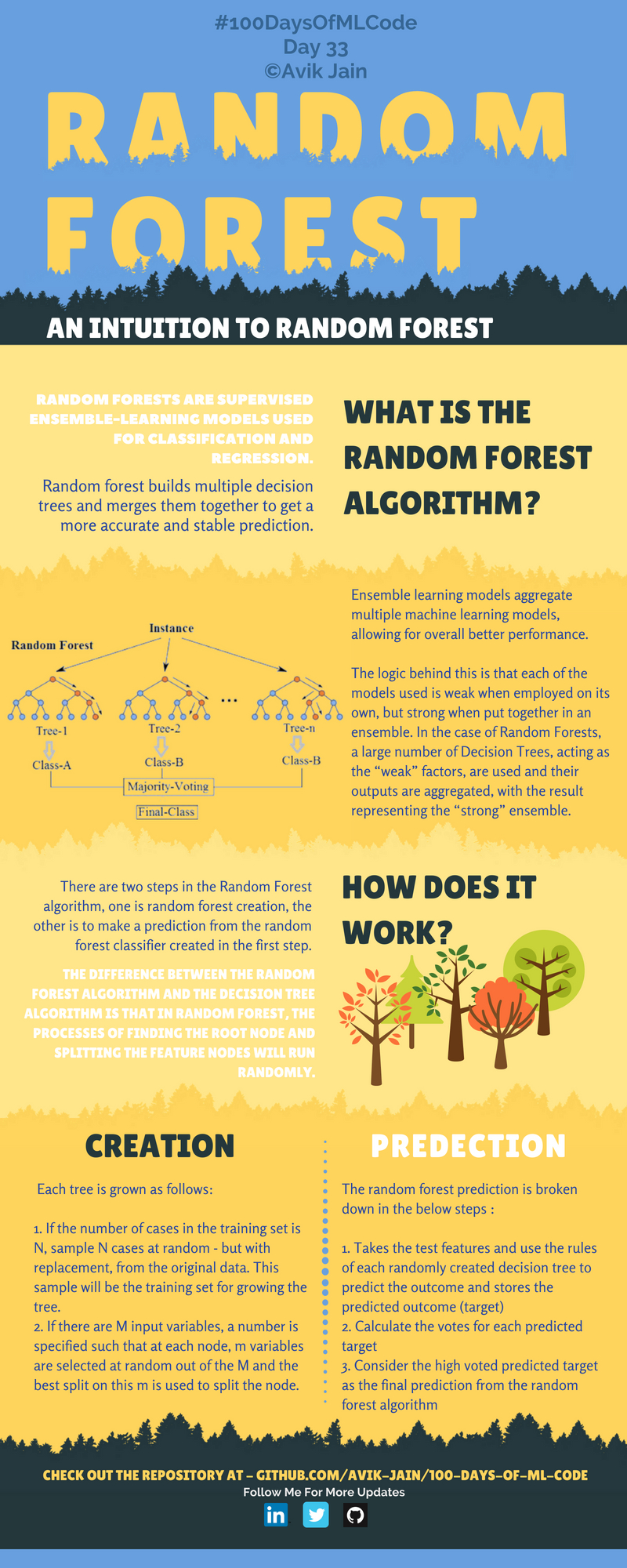
랜덤 포레스트 구현 | 34일차
여기에서 코드를 확인하세요.
하지만 신경망이란 무엇일까요? | 딥러닝, 1장 | 35일차
3Blue1Brown 유튜브 채널의 신경망에 대한 놀라운 비디오. 이 비디오는 신경망에 대한 이해를 돕고 손으로 쓴 숫자 데이터셋을 사용하여 개념을 설명합니다. 비디오 링크입니다.
경사 하강, 신경망이 학습하는 방법 | 딥러닝, 2장 | 36일차
3Blue1Brown 유튜브 채널의 신경망 2부. 이 비디오는 흥미로운 방식으로 경사 하강 개념을 설명합니다. 169 꼭 봐야 할 강력 추천 비디오입니다. 비디오 링크입니다.
역전파는 실제로 무엇을 하고 있을까요? | 딥러닝, 3장 | 37일차
3Blue1Brown 유튜브 채널의 신경망 3부. 이 비디오는 주로 편도함수와 역전파에 대해 설명합니다. 비디오 링크입니다.
역전파 미적분학 | 딥러닝, 4장 | 38일차
3Blue1Brown 유튜브 채널의 신경망 4부. 여기서 목표는 역전파가 작동하는 방식에 대한 직관을 다소 공식적인 용어로 표현하는 것이며 비디오는 주로 편도함수와 역전파에 대해 설명합니다. 비디오 링크입니다.
파이썬, 텐서플로우, 케라스를 사용한 딥러닝 튜토리얼 | 39일차
비디오 링크입니다.
자체 데이터 로드 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 기초 2부 | 40일차
비디오 링크입니다.
컨볼루션 신경망 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 기초 3부 | 41일차
비디오 링크입니다.
텐서보드를 사용한 모델 분석 - 파이썬, 텐서플로우, 케라스를 사용한 딥러닝 4부 | 42일차
비디오 링크입니다.
K 평균 군집화 | 43일차
비지도 학습으로 넘어가 군집화에 대해 공부했습니다. 제 웹사이트 avikjain.me를 확인해 보세요. 또한 K 평균 군집화를 쉽게 이해하는 데 도움이 되는 멋진 애니메이션을 찾았습니다. 링크

K 평균 군집화 구현 | 44일차
K 평균 군집화를 구현했습니다. 여기에서 코드를 확인하세요.
더 깊이 파고들기 | NUMPY | 45일차
JK VanderPlas의 새 책 “Python Data Science HandBook“을 받았습니다. 여기에서 Jupyter 노트북을 확인하세요.
2장 Numpy 소개부터 시작했습니다. 데이터 유형, Numpy 배열 및 Numpy 배열 연산과 같은 주제를 다루었습니다.
코드를 확인하세요 -
NumPy 소개
파이썬의 데이터 유형 이해
NumPy 배열의 기초
NumPy 배열 연산: 유니버설 함수
더 깊이 파고들기 | NUMPY | 46일차
2장: 집계, 비교 및 브로드캐스팅
노트북 링크:
집계: 최소, 최대 및 그 사이의 모든 것
배열 연산: 브로드캐스팅
비교, 마스크 및 부울 논리
더 깊이 파고들기 | NUMPY | 47일차
2장: 팬시 인덱싱, 배열 정렬, 구조화된 데이터
노트북 링크:
팬시 인덱싱
배열 정렬
구조화된 데이터: NumPy의 구조화된 배열
더 깊이 파고들기 | PANDAS | 48일차
3장: Pandas를 사용한 데이터 조작
Pandas 객체, 데이터 인덱싱 및 선택, 데이터 연산, 누락된 데이터 처리, 계층적 인덱싱, ConCat 및 Append와 같은 다양한 주제를 다루었습니다.
노트북 링크:
Pandas를 사용한 데이터 조작
Pandas 객체 소개
데이터 인덱싱 및 선택
Pandas의 데이터 연산
누락된 데이터 처리
계층적 인덱싱
데이터셋 결합: Concat 및 Append
더 깊이 파고들기 | PANDAS | 49일차
3장: 다음 주제 완료 - 병합 및 조인, 집계 및 그룹화, 피벗 테이블.
데이터셋 결합: 병합 및 조인
집계 및 그룹화
피벗 테이블
더 깊이 파고들기 | PANDAS | 50일차
3장: 벡터화된 문자열 연산, 시계열 작업
노트북 링크:
벡터화된 문자열 연산
시계열 작업
고성능 Pandas: eval() 및 query()
더 깊이 파고들기 | MATPLOTLIB | 51일차
4장: Matplotlib을 사용한 시각화
단순 선 플롯, 단순 산점도, 밀도 및 등고선 플롯에 대해 배웠습니다.
노트북 링크:
Matplotlib을 사용한 시각화
단순 선 플롯
단순 산점도
오류 시각화
밀도 및 등고선 플롯
더 깊이 파고들기 | MATPLOTLIB | 52일차
4장: Matplotlib을 사용한 시각화
히스토그램, 플롯 범례 사용자 지정 방법, 색상 막대 및 다중 서브플롯 만들기에 대해 배웠습니다.
노트북 링크:
히스토그램, 구간화 및 밀도
플롯 범례 사용자 지정
색상 막대 사용자 지정
다중 서브플롯
텍스트 및 주석
더 깊이 파고들기 | MATPLOTLIB | 53일차
4장: Mathplotlib의 3차원 플로팅을 다루었습니다.
노트북 링크:
Matplotlib의 3차원 플로팅
계층적 군집화 | 54일차
계층적 군집화에 대해 공부했습니다. 이 놀라운 시각화를 확인해 보세요.
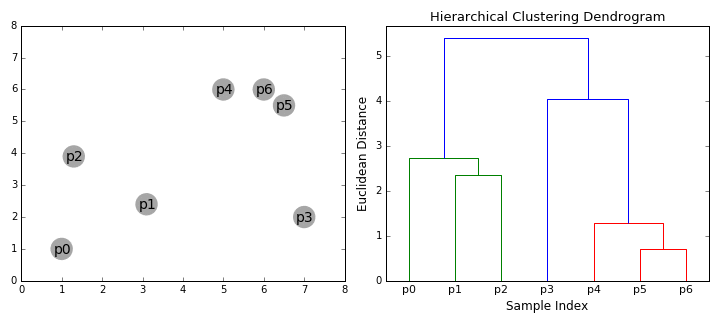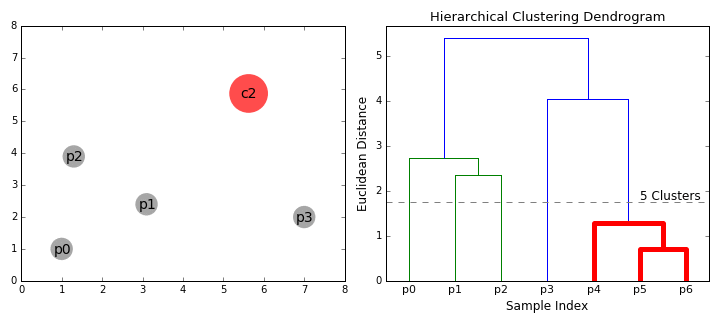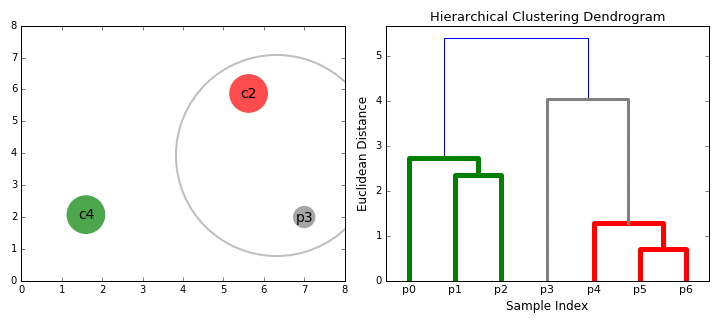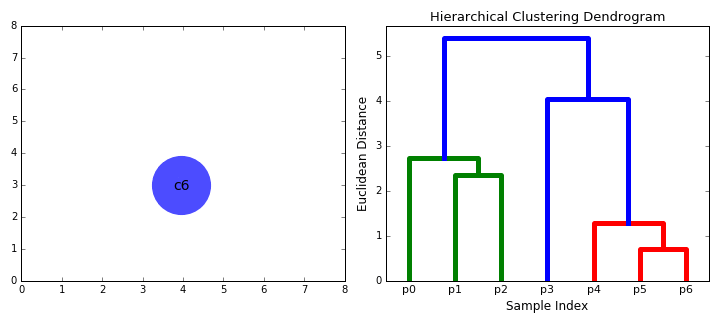{kind=link}

강화 학습 소개 | 55일차
강화 학습(RL)의 기본 개념과 용어(에이전트, 환경, 보상, 정책, 가치 함수)를 학습했습니다. 자세히 보기
마르코프 결정 과정 | 56일차
강화 학습의 핵심 프레임워크인 마르코프 결정 과정(MDP)에 대해 학습했습니다. 자세히 보기
Q-러닝 - 이론 및 알고리즘 | 57일차
모델 프리 강화 학습 알고리즘인 Q-러닝의 이론적 배경과 작동 방식에 대해 학습했습니다. 자세히 보기
Q-러닝 - 간단한 구현 | 58일차
간단한 예제(예: 그리드 월드)를 통해 Q-러닝을 구현하는 방법을 학습했습니다. 코드
심층 Q-네트워크 (DQN) | 59일차
Q-러닝과 심층 신경망을 결합한 심층 Q-네트워크(DQN)의 개념과 장점에 대해 학습했습니다. 자세히 보기
자연어 처리 소개 | 60일차
자연어 처리(NLP)의 기본 개념과 용어(코퍼스, 토큰, 임베딩)를 학습했습니다. 자세히 보기
텍스트 전처리 | 61일차
NLP의 중요한 단계인 텍스트 전처리 기법(토큰화, 어간 추출, 표제어 추출)에 대해 학습했습니다. 자세히 보기
Bag-of-Words 및 TF-IDF | 62일차
텍스트 데이터를 수치 벡터로 변환하는 대표적인 방법인 Bag-of-Words와 TF-IDF에 대해 학습하고 구현했습니다. 코드
단어 임베딩 - Word2Vec, GloVe (개념) | 63일차
단어의 의미를 밀집 벡터로 표현하는 단어 임베딩 기법인 Word2Vec과 GloVe의 개념에 대해 학습했습니다. 자세히 보기
Word2Vec 구현 | 64일차
Gensim 라이브러리를 사용하여 Word2Vec을 구현하는 방법을 학습했습니다. 코드
감성 분석 - 기본 기법 | 65일차
텍스트에 나타난 감성을 분석하는 기본 기법들에 대해 학습했습니다. 자세히 보기
간단한 감성 분석기 구축 | 66일차
학습한 내용을 바탕으로 간단한 감성 분석기를 구축했습니다. 코드
순환 신경망 (RNN) 소개 | 67일차
순서가 있는 데이터를 처리하는 데 효과적인 순환 신경망(RNN)의 기본 구조와 원리에 대해 학습했습니다. 자세히 보기
LSTM (Long Short-Term Memory) 네트워크 | 68일차
RNN의 장기 의존성 문제를 해결하기 위해 제안된 LSTM 네트워크에 대해 학습했습니다. 자세히 보기
RNN/LSTM을 이용한 텍스트 분류기 구축 | 69일차
RNN 또는 LSTM을 사용하여 텍스트 분류기를 구축하는 방법을 학습했습니다. 코드
강화 학습 및 NLP 개념 복습 | 70일차
지난 15일간 학습한 강화 학습 및 자연어 처리 관련 주요 개념들을 복습했습니다. 자세히 보기
주성분 분석 (PCA) - 이론 및 구현 | 71일차
차원 축소 기법 중 하나인 주성분 분석(PCA)의 이론을 학습하고 구현했습니다. 코드
선형 판별 분석 (LDA) | 72일차
또 다른 차원 축소 및 분류 기법인 선형 판별 분석(LDA)에 대해 학습했습니다. 코드
모델 평가 지표 | 73일차
머신러닝 모델의 성능을 평가하기 위한 다양한 지표(정밀도, 재현율, F1 점수, ROC AUC)에 대해 학습했습니다. 자세히 보기
교차 검증 기법 | 74일차
모델의 일반화 성능을 평가하기 위한 교차 검증 기법(K-폴드 교차 검증 등)에 대해 학습했습니다. 자세히 보기
하이퍼파라미터 튜닝 | 75일차
모델 성능을 최적화하기 위한 하이퍼파라미터 튜닝 방법(그리드 서치, 랜덤 서치)에 대해 학습했습니다. 자세히 보기
앙상블 방법 - 배깅, 부스팅 | 76일차
여러 모델을 결합하여 성능을 향상시키는 앙상블 기법 중 배깅(랜덤 포레스트 복습)과 부스팅(AdaBoost, Gradient Boosting)에 대해 학습했습니다. 코드
XGBoost - 소개 및 구현 | 77일차
강력한 부스팅 알고리즘인 XGBoost의 개념을 학습하고 구현했습니다. 코드
LightGBM - 소개 및 구현 | 78일차
XGBoost와 유사하지만 더 빠르고 효율적인 LightGBM에 대해 학습하고 구현했습니다. 코드
시계열 분석 소개 | 79일차
시간 순서대로 기록된 데이터인 시계열 데이터 분석의 기초 개념을 학습했습니다. 자세히 보기
시계열을 위한 ARIMA 모델 | 80일차
대표적인 시계열 예측 모델인 ARIMA 모델에 대해 학습하고 간단한 예제에 적용해 보았습니다. 코드
모델 배포 소개 | 81일차
개발한 머신러닝 모델을 실제 환경에서 사용할 수 있도록 배포하는 과정의 중요성과 기본 개념을 학습했습니다. 자세히 보기
ML 모델 배포를 위한 Flask/Django - 기초 | 82일차
웹 프레임워크인 Flask 또는 Django를 사용하여 머신러닝 모델을 배포하는 기초적인 방법을 학습했습니다. 자세히 보기
ML 모델을 위한 간단한 API 만들기 | 83일차
Flask/Django를 사용하여 학습된 머신러닝 모델을 위한 간단한 API를 만드는 실습을 진행했습니다. 코드
ML을 위한 Docker - 기초 | 84일차
컨테이너화 기술인 Docker를 머신러닝 모델 배포에 활용하는 기초적인 방법을 학습했습니다. 자세히 보기
Docker를 사용한 간단한 ML 모델 배포 | 85일차
Docker를 사용하여 간단한 머신러닝 모델을 배포하는 실습을 진행했습니다. 코드
캡스톤 프로젝트 아이디어 브레인스토밍 | 86일차
100일 챌린지를 마무리할 캡스톤 프로젝트에 대한 아이디어를 구상했습니다. 자세히 보기
캡스톤 프로젝트 선정 및 범위 정의 | 87일차
여러 아이디어 중 하나를 캡스톤 프로젝트로 선정하고, 프로젝트의 목표와 범위를 명확히 정의했습니다. 자세히 보기
프로젝트를 위한 데이터 수집 및 전처리 | 88일차
캡스톤 프로젝트에 필요한 데이터를 수집하고, 모델 학습에 적합하도록 전처리하는 작업을 수행했습니다. 자세히 보기
프로젝트를 위한 탐색적 데이터 분석 (EDA) | 89일차
수집된 데이터를 다양한 각도에서 분석하고 시각화하여 데이터의 특징과 패턴을 파악하는 EDA를 수행했습니다. 자세히 보기
프로젝트를 위한 모델 선정 및 초기 학습 | 90일차
프로젝트 목표에 맞는 머신러닝 모델을 선정하고, 전처리된 데이터를 사용하여 초기 모델 학습을 진행했습니다. 자세히 보기
프로젝트를 위한 모델 평가 및 반복 | 91일차
학습된 모델의 성능을 평가하고, 문제점을 분석하여 모델을 개선하는 반복 작업을 수행했습니다. 자세히 보기
프로젝트를 위한 미세 조정 및 최적화 | 92일차
선정된 모델의 하이퍼파라미터를 조정하고 다양한 최적화 기법을 적용하여 모델 성능을 극대화했습니다. 자세히 보기
프로젝트를 위한 간단한 UI 또는 프레젠테이션 구축 | 93일차
캡스톤 프로젝트의 결과를 효과적으로 보여줄 수 있는 간단한 사용자 인터페이스(UI) 또는 프레젠테이션 자료를 제작했습니다. 자세히 보기
캡스톤 프로젝트 문서화 | 94일차
프로젝트의 전 과정(데이터 수집, 전처리, 모델링, 평가, 결과)을 상세히 기록하여 문서화했습니다. 자세히 보기
생성적 적대 신경망 (GAN) 소개 | 95일차
새로운 데이터를 생성하는 모델인 생성적 적대 신경망(GAN)의 기본 개념과 작동 원리에 대해 학습했습니다. 자세히 보기
오토인코더 | 96일차
데이터의 특징을 효율적으로 학습하여 차원 축소나 이상치 탐지 등에 활용되는 오토인코더에 대해 학습했습니다. 자세히 보기
설명 가능한 AI (XAI) - LIME, SHAP | 97일차
머신러닝 모델의 예측 결과를 사람이 이해할 수 있도록 설명하는 XAI 기법(LIME, SHAP 등)에 대해 학습했습니다. 자세히 보기
AI 및 머신러닝 윤리 | 98일차
인공지능 기술 발전과 함께 중요성이 커지고 있는 AI 및 머신러닝 윤리 문제에 대해 고찰했습니다. 자세히 보기
ML 및 AI의 미래 동향 | 99일차
머신러닝과 인공지능 분야의 최신 연구 동향과 미래 발전 가능성에 대해 학습하고 토론했습니다. 자세히 보기
100일 여정 복습 및 다음 단계 | 100일차
지난 100일간의 머신러닝 학습 여정을 되돌아보고, 앞으로의 학습 계획 및 목표를 설정했습니다. 자세히 보기