Day 72: 선형 판별 분석 (LDA) (Linear Discriminant Analysis)
학습 목표
- 선형 판별 분석(LDA)의 기본 개념과 목적 이해
- LDA가 지도 학습 기반의 차원 축소 기법임을 인지
- LDA의 주요 아이디어: 클래스 간 분산은 최대화, 클래스 내 분산은 최소화
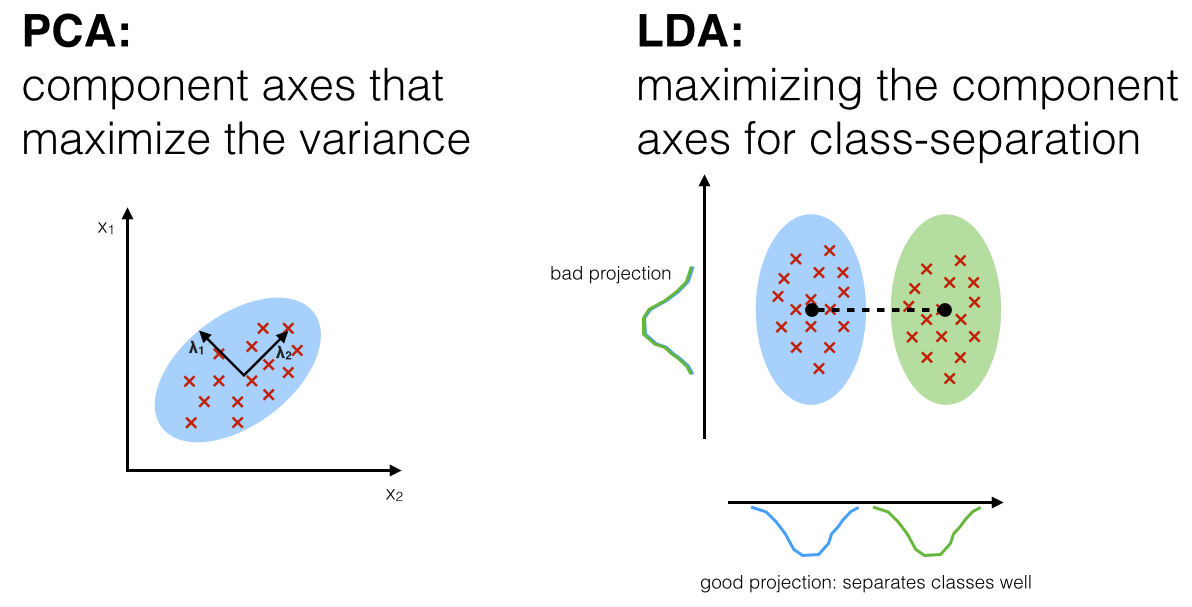
- PCA와 LDA의 차이점 비교
scikit-learn을 사용한 LDA 구현 방법 숙지
1. 선형 판별 분석 (Linear Discriminant Analysis, LDA) 소개
- 정의: 지도 학습(Supervised Learning) 기반의 차원 축소 및 분류 기법입니다.
- 주요 목적:
- 차원 축소: 데이터를 저차원 공간으로 투영하여 클래스 간의 분별력을 최대한 유지하면서 차원을 축소합니다.
- 분류: 저차원으로 축소된 공간에서 클래스를 분류하는 모델로도 사용될 수 있습니다. (LDA 분류기)
- LDA는 특히 분류 문제에서 클래스를 가장 잘 구분할 수 있는 새로운 특징 공간을 찾는 데 중점을 둡니다.
2. LDA의 핵심 아이디어
-
LDA는 데이터를 새로운 축(판별 벡터, Discriminant Vector)으로 투영(Projection)할 때, 다음 두 가지 목표를 동시에 달성하려고 합니다:
- 클래스 간 분산(Between-class scatter) 최대화: 서로 다른 클래스의 중심(평균)들이 최대한 멀리 떨어지도록 합니다.
- 클래스 내 분산(Within-class scatter) 최소화: 같은 클래스에 속하는 데이터들이 최대한 가깝게 모이도록 합니다.
-
즉, 투영된 데이터들이 클래스별로 잘 구분되도록 하는 축을 찾는 것이 목표입니다.
 (이미지 출처: Sebastian Raschka’s blog)
(위 그림에서 좋은 부분 공간(Good Subspace)은 클래스 간 분리가 잘 되도록 데이터를 투영합니다.)
(이미지 출처: Sebastian Raschka’s blog)
(위 그림에서 좋은 부분 공간(Good Subspace)은 클래스 간 분리가 잘 되도록 데이터를 투영합니다.)
3. LDA 수행 단계 (개념적)
- (선택) 데이터 스케일링: PCA와 마찬가지로 특성 스케일에 민감할 수 있으나, LDA는 분산 비율을 다루므로 PCA만큼 필수적이지는 않을 수 있습니다. 하지만 일반적으로 적용하는 것이 좋습니다.
- 클래스 내 산포 행렬 (Within-class Scatter Matrix, SW) 계산:
- 각 클래스별로 데이터들이 얼마나 흩어져 있는지를 나타냅니다.
- 각 클래스의 공분산 행렬들을 합하여 계산합니다.
- SW = Σi=1C Si, 여기서 Si는 i번째 클래스의 공분산 행렬, C는 클래스 수.
- 클래스 간 산포 행렬 (Between-class Scatter Matrix, SB) 계산:
- 각 클래스의 중심(평균)이 전체 데이터의 중심(평균)으로부터 얼마나 떨어져 있는지를 나타냅니다.
- SB = Σi=1C Ni (mi - m)(mi - m)T, 여기서 Ni는 i번째 클래스의 샘플 수, mi는 i번째 클래스의 평균 벡터, m은 전체 데이터의 평균 벡터.
- 고유값 문제 해결:
- 다음 일반화된 고유값 문제를 풀어 고유벡터(판별 벡터)와 고유값을 찾습니다:
SW-1SB v = λ v
- v: 고유벡터 (판별 벡터, LDA 축의 방향)
- λ: 고유값 (판별 벡터의 중요도, 클래스 분리 능력)
- 고유값이 큰 순서대로 고유벡터를 정렬합니다. 이 고유벡터들이 LDA의 축이 됩니다.
- 다음 일반화된 고유값 문제를 풀어 고유벡터(판별 벡터)와 고유값을 찾습니다:
SW-1SB v = λ v
- 차원 축소:
- LDA로 축소할 수 있는 최대 차원의 수는
min(클래스 수 - 1, 원래 특성 수)입니다.- 예를 들어, 클래스가 3개이고 특성이 10개라면, 최대 2개의 판별 벡터(축)를 선택할 수 있습니다.
- 선택된
k개의 판별 벡터(고유벡터)로 이루어진 변환 행렬 W를 만듭니다. - 원래 데이터를 이 변환 행렬 W를 사용하여 새로운
k차원 공간으로 투영합니다: Xlda = X W
- LDA로 축소할 수 있는 최대 차원의 수는
4. PCA vs LDA
| 특징 | PCA (주성분 분석) | LDA (선형 판별 분석) |
|---|---|---|
| 학습 유형 | 비지도 학습 (Unsupervised) | 지도 학습 (Supervised) |
| 목표 | 데이터의 분산을 최대한 보존하는 축 탐색 (정보량 최대화) | 클래스 간 분리를 최대화하는 축 탐색 (분류 성능 최적화) |
| 클래스 레이블 사용 | 사용 안 함 | 사용 함 |
| 축소 가능 차원 수 | 최대 min(샘플 수 - 1, 특성 수) | 최대 min(클래스 수 - 1, 특성 수) |
| 데이터 분포 가정 | 가우시안 분포를 암묵적으로 가정할 수 있으나 필수는 아님 | 각 클래스의 데이터가 가우시안 분포를 따르고, 공분산이 동일하다고 가정 |
| 주요 용도 | 차원 축소, 노이즈 제거, 시각화, 특징 추출 | 차원 축소 (분류 목적), 분류 |
| 데이터 스케일링 | 민감 (필수적) | 덜 민감할 수 있으나, 일반적으로 권장 |
- 언제 무엇을 사용할까?
- 단순히 데이터의 차원을 줄이고 싶거나, 데이터의 주요 변동성을 파악하고 싶을 때: PCA
- 분류 모델의 성능을 높이기 위해 클래스 분별력이 좋은 특징을 추출하고 싶을 때: LDA
- 클래스 수가 적을 경우 LDA로 축소할 수 있는 차원이 매우 제한적일 수 있습니다. 이 경우 PCA가 더 유용할 수 있습니다.
5. scikit-learn을 사용한 LDA 구현
가. 예제 데이터 (Iris 데이터셋)
- LDA는 클래스 레이블을 사용하므로, 분류용 데이터셋이 필요합니다. Iris 데이터셋은 3개의 클래스를 가집니다.
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA # LDA 임포트
from sklearn.datasets import load_iris
# Iris 데이터셋 로드
iris = load_iris()
X = iris.data
y = iris.target # 클래스 레이블
target_names = iris.target_names
print("Original data shape:", X.shape) # (150, 4) - 4개의 특성
print("Class labels shape:", y.shape) # (150,)
print("Number of classes:", len(np.unique(y))) # 3개의 클래스
나. 데이터 스케일링 (선택적이지만 권장)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
다. LDA 적용
n_components: 축소할 차원(판별 벡터)의 수. LDA의 경우min(클래스 수 - 1, 원래 특성 수)를 넘을 수 없습니다.- Iris 데이터셋의 경우 클래스가 3개이므로,
n_components는 최대 2가 됩니다.
- Iris 데이터셋의 경우 클래스가 3개이므로,
# LDA 객체 생성 및 학습
# n_components는 min(n_classes - 1, n_features) 이하로 설정
# Iris: n_classes=3, n_features=4 -> max n_components = 2
lda = LDA(n_components=2) # 2차원으로 축소
X_lda = lda.fit_transform(X_scaled, y) # LDA는 y (클래스 레이블) 정보가 필요!
print("\nLDA transformed data shape:", X_lda.shape) # (150, 2)
# 설명된 분산 비율 확인 (LDA에서는 'explained_variance_ratio_'로 제공)
# 각 판별 벡터가 클래스 분리를 얼마나 잘 설명하는지를 나타냄
print("Explained variance ratio by LDA components:", lda.explained_variance_ratio_)
print("Cumulative explained variance ratio:", np.sum(lda.explained_variance_ratio_))
라. 시각화
plt.figure(figsize=(8, 6))
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('LDA of Iris dataset (2 Components)')
plt.xlabel('LD1 (Linear Discriminant 1)')
plt.ylabel('LD2 (Linear Discriminant 2)')
plt.grid(True)
plt.show()
# PCA와 비교 (Iris 데이터셋에 PCA 적용)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled) # PCA는 y 정보 불필요
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_pca[y == i, 0], X_pca[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.title('PCA of Iris dataset (2 Components)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.grid(True)
plt.subplot(1, 2, 2)
for color, i, target_name in zip(colors, [0, 1, 2], target_names):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], color=color, alpha=.8, lw=lw,
label=target_name)
plt.title('LDA of Iris dataset (2 Components)')
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.grid(True)
plt.tight_layout()
plt.show()
- 위 시각화 결과를 보면, Iris 데이터셋의 경우 LDA가 PCA보다 클래스를 더 잘 분리하는 경향을 보일 수 있습니다. 이는 LDA가 클래스 정보를 활용하여 분별력을 높이는 방향으로 축을 찾기 때문입니다.
6. LDA의 가정 및 한계점
- 가정:
- 각 클래스의 데이터가 정규 분포(Gaussian distribution)를 따른다고 가정합니다.
- 모든 클래스가 동일한 공분산 행렬을 가진다고 가정합니다. (실제로는 이 가정이 맞지 않아도 어느 정도 잘 작동할 수 있습니다.)
- 특성들이 통계적으로 독립적이라고 가정합니다.
- 한계점:
- 위 가정이 실제 데이터와 많이 다를 경우 성능이 저하될 수 있습니다.
- 선형 변환이므로 비선형적으로 분리되는 데이터에는 적합하지 않을 수 있습니다. (커널 LDA 등으로 확장 가능)
- 축소할 수 있는 차원의 수가
클래스 수 - 1로 제한됩니다. 클래스 수가 적으면 차원 축소 효과가 미미할 수 있습니다. - 샘플 크기가 특성 수보다 훨씬 작을 때 불안정할 수 있습니다 (Small Sample Size Problem).
추가 학습 자료
- Linear Discriminant Analysis (LDA) for Dimensionality Reduction - Sebastian Raschka
- StatQuest: Linear Discriminant Analysis (LDA) clearly explained. (YouTube)
- Scikit-learn LDA Documentation
다음 학습 내용
- Day 73: 모델 평가 지표 - 정밀도, 재현율, F1-score, ROC AUC (Model Evaluation Metrics - Precision, Recall, F1-score, ROC AUC)