Day 73: 모델 평가 지표 - 정밀도, 재현율, F1-score, ROC AUC (Model Evaluation Metrics - Precision, Recall, F1-score, ROC AUC)
학습 목표
- 분류 모델의 성능을 정확하게 평가하기 위한 다양한 지표의 필요성 이해
- 오차 행렬(Confusion Matrix)의 구성 요소(TP, FP, FN, TN) 학습
- 주요 분류 평가지표 학습 및 의미 파악:
- 정확도 (Accuracy)
- 정밀도 (Precision)
- 재현율 (Recall) / 민감도 (Sensitivity)
- F1 점수 (F1-Score)
- 특이도 (Specificity)
- ROC 곡선 (Receiver Operating Characteristic Curve)과 AUC (Area Under the Curve)
1. 정확도 (Accuracy)의 한계
- 정확도: (예측이 올바른 샘플 수) / (전체 샘플 수)
- 가장 직관적인 평가지표이지만, 데이터가 불균형(Imbalanced)할 때 모델 성능을 왜곡할 수 있습니다.
- 예: 100개의 이메일 중 95개가 정상 메일, 5개가 스팸 메일인 데이터셋. 모든 메일을 정상으로 예측하는 모델도 정확도는 95%가 됩니다. 하지만 이 모델은 스팸 메일을 전혀 탐지하지 못하므로 유용하지 않습니다.
- 따라서, 특히 불균형 데이터셋에서는 정확도 외에 다른 평가지표들을 함께 고려해야 합니다.
2. 오차 행렬 (Confusion Matrix)
- 분류 모델의 예측 결과를 실제 클래스와 비교하여 시각적으로 표현한 표입니다.
- 이진 분류(Positive/Negative)의 경우 다음과 같이 구성됩니다:
| 예측: Positive (1) | 예측: Negative (0) | |
|---|---|---|
| 실제: Positive (1) | TP | FN |
| 실제: Negative (0) | FP | TN |
-
TP (True Positive, 진짜 양성): 실제 Positive인 것을 Positive로 올바르게 예측. (예: 실제 스팸 메일을 스팸으로 예측)
-
FN (False Negative, 가짜 음성): 실제 Positive인 것을 Negative로 잘못 예측. (예: 실제 스팸 메일을 정상으로 예측) - Type II Error
-
FP (False Positive, 가짜 양성): 실제 Negative인 것을 Positive로 잘못 예측. (예: 실제 정상 메일을 스팸으로 예측) - Type I Error
-
TN (True Negative, 진짜 음성): 실제 Negative인 것을 Negative로 올바르게 예측. (예: 실제 정상 메일을 정상으로 예측)
-
다중 클래스 분류의 경우, 각 클래스에 대해 오차 행렬을 확장하여 생각할 수 있습니다.
3. 주요 분류 평가지표
가. 정확도 (Accuracy)
- 정의: 전체 예측 중 올바르게 예측한 비율.
- 계산:
(TP + TN) / (TP + TN + FP + FN) - 데이터 분포가 균일할 때 유용하지만, 불균형 데이터에서는 신뢰도가 낮습니다.
나. 정밀도 (Precision)
- 정의: 모델이 Positive로 예측한 것들 중 실제로 Positive인 것의 비율.
- 계산:
TP / (TP + FP) - 의미: “모델이 Positive라고 예측했을 때, 얼마나 믿을 수 있는가?”
- FP를 낮추는 것이 중요할 때 사용됩니다. (예: 스팸 메일 필터 - 정상 메일을 스팸으로 잘못 분류(FP)하면 안 됨)
다. 재현율 (Recall) / 민감도 (Sensitivity) / 적중률 (Hit Rate)
- 정의: 실제 Positive인 것들 중 모델이 Positive로 올바르게 예측한 것의 비율.
- 계산:
TP / (TP + FN) - 의미: “실제 Positive 샘플들을 모델이 얼마나 잘 찾아내는가?”
- FN을 낮추는 것이 중요할 때 사용됩니다. (예: 암 진단 모델 - 실제 암 환자를 정상으로 잘못 진단(FN)하면 안 됨)
라. F1 점수 (F1-Score)
- 정의: 정밀도와 재현율의 조화 평균(Harmonic Mean).
- 계산:
2 * (Precision * Recall) / (Precision + Recall) - 의미: 정밀도와 재현율이 모두 중요할 때 사용. 두 지표가 한쪽으로 치우치지 않고 모두 높은 값을 가질 때 F1 점수도 높아집니다.
- 불균형 데이터셋에서 정확도보다 더 신뢰할 수 있는 성능 지표로 간주됩니다.
마. 특이도 (Specificity) / TNR (True Negative Rate)
- 정의: 실제 Negative인 것들 중 모델이 Negative로 올바르게 예측한 것의 비율.
- 계산:
TN / (TN + FP) - 의미: “실제 Negative 샘플들을 모델이 얼마나 잘 식별하는가?”
- 재현율(민감도)과 함께 사용되어 모델의 전반적인 성능을 평가합니다. (예: 질병 진단에서 건강한 사람을 건강하다고 판단하는 능력)
정밀도-재현율 트레이드오프 (Precision-Recall Trade-off)
- 일반적으로 정밀도와 재현율은 서로 반비례 관계(Trade-off)를 가집니다.
- 분류 모델의 결정 임계값(Threshold)을 조정함에 따라 한쪽이 올라가면 다른 한쪽이 내려가는 경향이 있습니다.
- 임계값을 높이면: Positive로 예측하는 기준이 엄격해져 FP가 줄고 정밀도는 높아지지만, TP도 줄어 FN이 늘고 재현율은 낮아질 수 있습니다.
- 임계값을 낮추면: Positive로 예측하는 기준이 완화되어 TP가 늘고 재현율은 높아지지만, FP도 늘어 정밀도는 낮아질 수 있습니다.
- 따라서, 문제의 특성에 따라 정밀도와 재현율 중 어떤 것을 더 중요하게 생각할지 결정하고 임계값을 조절해야 합니다. F1 점수는 이 둘의 균형을 나타냅니다.
4. ROC 곡선 (Receiver Operating Characteristic Curve)과 AUC (Area Under the Curve)
가. ROC 곡선
- 정의: 이진 분류 모델의 성능을 시각적으로 평가하는 그래프. 다양한 임계값(Threshold) 설정에 따라 분류기의 **재현율(TPR, True Positive Rate)**과 **위양성률(FPR, False Positive Rate)**의 변화를 나타냅니다.
- TPR (True Positive Rate) = Recall = Sensitivity =
TP / (TP + FN)(Y축) - FPR (False Positive Rate) =
FP / (FP + TN)= 1 - Specificity (X축)
- TPR (True Positive Rate) = Recall = Sensitivity =
- 해석:
- 곡선이 왼쪽 위 모서리(좌표 (0,1))에 가까울수록 모델 성능이 우수함을 의미합니다. (FPR은 낮고 TPR은 높은 이상적인 상태)
- 대각선(y=x)은 무작위 분류기(Random Classifier)의 성능을 나타냅니다. ROC 곡선이 이 대각선보다 위에 있어야 의미 있는 모델입니다.
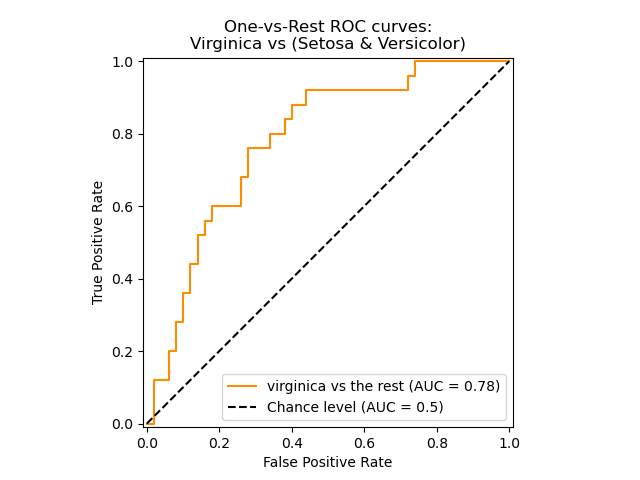 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
나. AUC (Area Under the ROC Curve)
- 정의: ROC 곡선 아래의 면적. 0과 1 사이의 값을 가집니다.
- 의미:
- AUC 값이 1에 가까울수록 모델의 성능이 우수함을 나타냅니다. (완벽한 분류기는 AUC=1)
- AUC 값이 0.5이면 무작위 분류기와 동일한 성능을 의미합니다.
- AUC는 임계값에 관계없이 모델이 얼마나 양성 클래스와 음성 클래스를 잘 구분하는지를 나타내는 전반적인 성능 지표입니다.
- 불균형 데이터셋에서도 비교적 안정적인 성능 평가를 제공합니다.
5. scikit-learn을 사용한 평가지표 계산
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification # 예제 데이터 생성용
import matplotlib.pyplot as plt
# 예제 데이터 생성 (불균형 데이터 가정 가능)
X, y = make_classification(n_samples=1000, n_features=20, weights=[0.9, 0.1], random_state=42) # 10%가 Positive 클래스
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y) # stratify=y 중요!
# 모델 학습 (예: 로지스틱 회귀)
model = LogisticRegression(solver='liblinear')
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
y_pred_proba = model.predict_proba(X_test)[:, 1] # Positive 클래스에 대한 예측 확률
# 1. 오차 행렬
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", cm)
# TN, FP
# FN, TP
# 2. 정확도
accuracy = accuracy_score(y_test, y_pred)
print(f"\nAccuracy: {accuracy:.4f}")
# 3. 정밀도
precision = precision_score(y_test, y_pred) # pos_label=1 기본값
print(f"Precision: {precision:.4f}")
# 4. 재현율
recall = recall_score(y_test, y_pred)
print(f"Recall (Sensitivity): {recall:.4f}")
# 5. F1 점수
f1 = f1_score(y_test, y_pred)
print(f"F1 Score: {f1:.4f}")
# (선택) 특이도 계산
tn, fp, fn, tp = cm.ravel() # 오차 행렬 값들을 1차원으로 풀기
specificity = tn / (tn + fp)
print(f"Specificity: {specificity:.4f}")
# 6. ROC 곡선 및 AUC
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba) # 예측 확률 사용!
auc = roc_auc_score(y_test, y_pred_proba)
print(f"\nAUC: {auc:.4f}")
# ROC 곡선 시각화
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='blue', lw=2, label=f'ROC curve (area = {auc:.2f})')
plt.plot([0, 1], [0, 1], color='gray', lw=2, linestyle='--', label='Random classifier')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate (1 - Specificity)')
plt.ylabel('True Positive Rate (Sensitivity/Recall)')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.grid(True)
plt.show()
6. 어떤 지표를 사용해야 할까?
- 문제의 종류와 중요도에 따라 다릅니다.
- 스팸 메일 필터: 정밀도가 중요 (정상 메일을 스팸으로 오판(FP)하면 안 됨).
- 암 진단: 재현율이 중요 (실제 환자를 놓치면(FN) 안 됨).
- 불균형 데이터: F1 점수, ROC AUC를 주로 사용. 정확도는 부적절.
- 모델 간 비교: ROC AUC는 임계값에 관계없이 모델의 전반적인 분류 능력을 보여주므로 유용.
- 일반적으로 여러 지표를 함께 고려하여 모델의 성능을 다각도로 평가하는 것이 좋습니다.
추가 학습 자료
- Scikit-learn: Model evaluation
- Precision and recall (Wikipedia)
- Receiver operating characteristic (Wikipedia)
- Google Developers - Classification: True vs. False and Positive vs. Negative
다음 학습 내용
- Day 74: 교차 검증 기법 (Cross-Validation techniques) - 모델의 일반화 성능을 더 신뢰성 있게 평가하는 방법.