Day 78: LightGBM - 소개 및 구현 (LightGBM - Introduction and implementation)
학습 목표
- LightGBM (Light Gradient Boosting Machine)의 개념과 등장 배경 이해
- LightGBM이 XGBoost 및 기존 GBM에 비해 가지는 주요 장점 학습
- 리프 중심 트리 분할(Leaf-wise Tree Growth) 방식
- GOSS (Gradient-based One-Side Sampling)
- EFB (Exclusive Feature Bundling)
- 빠른 학습 속도와 낮은 메모리 사용량
- LightGBM의 주요 하이퍼파라미터 이해
- 파이썬 LightGBM 라이브러리를 사용한 모델 구현 방법 숙지
1. LightGBM (Light Gradient Boosting Machine) 소개
- 정의: Microsoft에서 개발한 그래디언트 부스팅 프레임워크로, XGBoost와 마찬가지로 트리 기반 학습 알고리즘입니다.
- 주요 특징: 대용량 데이터셋에서 매우 빠르고 효율적인 학습 성능을 제공하는 것을 목표로 합니다. “Light“라는 이름에서 알 수 있듯이 가볍고 빠릅니다.
- XGBoost와 함께 데이터 과학 경진대회 및 실제 산업 현장에서 널리 사용됩니다.
2. LightGBM의 주요 장점 및 핵심 기술
가. 리프 중심 트리 분할 (Leaf-wise Tree Growth)
- 기존 대부분의 트리 기반 알고리즘(예: XGBoost의
depthwise방식)은 트리를 레벨 중심(Level-wise) 또는 깊이 우선(Depth-wise) 방식으로 균형 있게 성장시킵니다. 즉, 같은 레벨의 모든 노드를 분할한 후 다음 레벨로 넘어갑니다. - LightGBM은 리프 중심(Leaf-wise) 방식을 사용합니다.
- 트리를 확장할 때, 현재까지 생성된 리프 노드 중 가장 큰 손실 감소(Max Delta Loss)가 예상되는 리프 노드를 선택하여 분할합니다.
- 이를 통해 더 깊고 비대칭적인 트리가 생성될 수 있지만, 같은 수의 분할을 수행했을 때 레벨 중심 방식보다 더 큰 손실 감소를 얻을 수 있어 학습 효율이 높습니다.
- 단, 데이터셋이 작을 경우 과적합될 가능성이 있으므로
max_depth와 같은 파라미터로 트리의 깊이를 제한하는 것이 중요합니다.
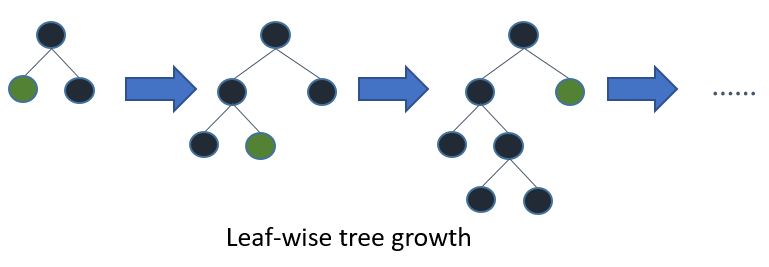 (이미지 출처: LightGBM Documentation)
(이미지 출처: LightGBM Documentation)
나. GOSS (Gradient-based One-Side Sampling)
- 아이디어: 정보 이득(Information Gain)을 계산할 때, 그래디언트가 큰(즉, 학습이 덜 된, 오류가 큰) 데이터 샘플이 더 중요한 역할을 한다는 점에 착안합니다.
- 작동 방식:
- 데이터 샘플들을 그래디언트 크기 순으로 정렬합니다.
- 그래디언트가 큰 상위 a%의 샘플들(중요한 샘플)은 모두 선택합니다.
- 그래디언트가 작은 나머지 샘플들 중에서는 무작위로 b%의 샘플들(덜 중요한 샘플)만 선택합니다.
- 정보 이득 계산 시, 선택된 작은 그래디언트 샘플들의 가중치를 (1-a)/b 만큼 증폭시켜 원래 데이터 분포를 근사합니다.
- 효과: 학습 데이터의 양을 줄이면서도 정보 손실을 최소화하여 학습 속도를 높이고, 과적합을 방지하는 데 도움을 줍니다.
다. EFB (Exclusive Feature Bundling)
- 아이디어: 고차원의 희소(Sparse) 데이터셋에서 많은 특성들은 상호 배타적(Mutually Exclusive)인 경우가 많습니다. 즉, 여러 특성 중 동시에 0이 아닌 값을 가지는 경우가 드뭅니다. (예: 원-핫 인코딩된 범주형 변수들)
- 작동 방식: 이러한 상호 배타적인 특성들을 하나의 “번들(Bundle)“로 묶어 특성의 수를 효과적으로 줄입니다.
- 특성 번들링 알고리즘을 통해 어떤 특성들을 함께 묶을지 결정합니다.
- 번들 내의 특성들은 원래 값을 유지하면서 오프셋(Offset)을 추가하여 구분합니다.
- 효과: 특성 수를 줄여 학습 속도를 향상시키고 메모리 사용량을 줄입니다. 특히 희소한 고차원 데이터에서 효과적입니다.
라. 기타 장점
- 빠른 학습 속도와 낮은 메모리 사용량: 위 기술들(리프 중심 분할, GOSS, EFB) 덕분에 특히 대용량 데이터에서 XGBoost보다 더 빠른 학습 속도와 적은 메모리 사용량을 보이는 경우가 많습니다.
- 범주형 특성 자동 처리: 명시적으로 원-핫 인코딩 등을 하지 않아도 범주형 특성을 효과적으로 처리할 수 있습니다 (
categorical_feature파라미터 사용). - GPU 학습 지원.
- 병렬 학습 지원.
3. LightGBM의 주요 하이퍼파라미터
- XGBoost와 유사한 파라미터들이 많지만, 일부 고유한 파라미터도 있습니다.
가. 핵심 파라미터 (Core Parameters)
objective[기본값=regression]: 학습 목표 함수.regression,binary(이진 분류),multiclass(다중 분류),lambdarank(랭킹) 등.boosting또는boosting_type[기본값=gbdt]: 부스팅 타입.gbdt: 전통적인 Gradient Boosting Decision Tree.dart: Dropout을 적용한 트리 부스팅 (과적합 방지에 더 효과적일 수 있으나 느림).goss: Gradient-based One-Side Sampling (GOSS 사용).rf: Random Forest (배깅 방식).
num_iterations또는n_estimators[기본값=100]: 부스팅 라운드 수 (생성할 트리의 수).learning_rate[기본값=0.1]: 학습률.num_iterations와 반비례 관계.num_leaves[기본값=31]: 하나의 트리가 가질 수 있는 최대 리프 노드의 수. 리프 중심 분할을 사용하므로max_depth보다 중요한 파라미터. 너무 크면 과적합. (일반적으로 2max_depth보다 작거나 같게 설정)max_depth[기본값=-1]: 트리의 최대 깊이. -1은 제한 없음을 의미. 리프 중심 분할에서는num_leaves로 복잡도를 주로 제어하지만, 과적합 방지를 위해 적절히 설정하는 것이 좋음.
나. 학습 제어 파라미터 (Learning Control Parameters)
min_data_in_leaf또는min_child_samples[기본값=20]: 리프 노드가 되기 위한 최소한의 레코드(데이터 샘플) 수. 과적합 방지.min_sum_hessian_in_leaf또는min_child_weight[기본값=1e-3]: 리프 노드가 되기 위한 최소 헤시안(Hessian) 합. 과적합 방지.feature_fraction또는colsample_bytree[기본값=1.0]: 각 트리를 학습할 때 무작위로 선택하는 특성의 비율. (0.0 ~ 1.0)bagging_fraction또는subsample[기본값=1.0]: 각 트리를 학습할 때 사용할 데이터의 비율 (GOSS를 사용하지 않을 경우). (0.0 ~ 1.0)bagging_freq또는subsample_freq[기본값=0]: 배깅 수행 빈도. 0이면 비활성화. k > 0 이면 k번 반복마다 배깅 수행.lambda_l1또는reg_alpha[기본값=0.0]: L1 규제 가중치.lambda_l2또는reg_lambda[기본값=0.0]: L2 규제 가중치.cat_smooth[기본값=10.0]: 범주형 특성 처리 시 스무딩 값. 과적합 방지.categorical_feature[기본값=None]: 범주형 특성의 인덱스 또는 이름 리스트. (예:categorical_feature='0,1,2'또는categorical_feature=[0,1,2])
다. IO 파라미터 (IO Parameters)
verbosity[기본값=1]: 메시지 출력 레벨. <0 (Fatal), 0 (Error), 1 (Warning), >1 (Info).max_bin[기본값=255]: 특성 값을 구간화(binning)할 때 사용할 최대 구간 수. 값이 클수록 정확도는 높아지나 학습 시간이 오래 걸리고 과적합 가능성 증가.
4. 파이썬 LightGBM 라이브러리 사용법
lightgbm라이브러리를 설치해야 합니다:pip install lightgbm
가. Scikit-Learn 래퍼 (Wrapper) 사용
- LightGBM도 Scikit-Learn과 호환되는 래퍼 클래스(
LGBMClassifier,LGBMRegressor)를 제공합니다.
import lightgbm as lgb
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 데이터 로드 (유방암 데이터셋 - 이진 분류)
cancer = load_breast_cancer()
X, y = cancer.data, cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# LGBMClassifier 모델 생성 및 학습 (Scikit-Learn 래퍼)
# 주요 하이퍼파라미터 설정 예시
lgbm_clf = lgb.LGBMClassifier(
objective='binary', # 이진 분류
metric='binary_logloss', # 평가 지표 (학습 중 출력용)
n_estimators=100, # 부스팅 라운드 수
learning_rate=0.1, # 학습률
num_leaves=31, # 리프 노드 수
max_depth=-1, # 최대 깊이 (-1은 제한 없음)
min_child_samples=20, # 리프 노드의 최소 샘플 수
subsample=0.8, # 데이터 샘플링 비율
colsample_bytree=0.8, # 특성 샘플링 비율
reg_alpha=0.0, # L1 규제
reg_lambda=0.0, # L2 규제
random_state=42,
n_jobs=-1 # 사용할 CPU 코어 수 (-1은 전체)
)
# 조기 종료(Early Stopping) 설정하여 학습
# eval_set: 검증 데이터셋
# early_stopping_rounds: 조기 종료 라운드 수
# LGBMClassifier의 fit 메소드에서는 callbacks 파라미터를 통해 조기 종료 설정
eval_set = [(X_test, y_test)]
callbacks = [lgb.early_stopping(stopping_rounds=10, verbose=1)] # verbose=1로 조기 종료 메시지 출력
lgbm_clf.fit(X_train, y_train,
eval_set=eval_set,
callbacks=callbacks)
# 예측
y_pred_lgbm = lgbm_clf.predict(X_test)
y_pred_proba_lgbm = lgbm_clf.predict_proba(X_test)[:, 1]
# 평가
accuracy_lgbm = accuracy_score(y_test, y_pred_lgbm)
print(f"\nLightGBM 정확도: {accuracy_lgbm:.4f}")
print("\nConfusion Matrix (LightGBM):\n", confusion_matrix(y_test, y_pred_lgbm))
print("\nClassification Report (LightGBM):\n", classification_report(y_test, y_pred_lgbm))
# 특성 중요도 확인
# lgb.plot_importance(lgbm_clf, max_num_features=10)
# plt.show()
나. LightGBM 고유 API 사용
- XGBoost와 유사하게 자체 데이터 구조(
Dataset)와 학습 API를 가집니다.
# 1. Dataset 생성 (LightGBM 전용 데이터 구조)
lgb_train = lgb.Dataset(data=X_train, label=y_train)
lgb_eval = lgb.Dataset(data=X_test, label=y_test, reference=lgb_train) # reference는 학습 데이터셋과 동일한 특성 사용 명시
# 2. 파라미터 설정 (딕셔너리 형태)
params_lgb = {
'objective': 'binary',
'metric': 'binary_logloss',
'boosting_type': 'gbdt',
'num_leaves': 31,
'learning_rate': 0.05,
'feature_fraction': 0.9, # colsample_bytree와 유사
'bagging_fraction': 0.8, # subsample과 유사
'bagging_freq': 5,
'verbose': -1, # 메시지 출력 안 함 (0 이상으로 설정 시 출력)
'seed': 42
}
num_boost_round_lgb = 200
# 3. 모델 학습 (lgb.train)
# callbacks 파라미터를 통해 조기 종료 설정
callbacks_native = [lgb.early_stopping(stopping_rounds=10, verbose=1)]
bst_model_lgb = lgb.train(
params=params_lgb,
train_set=lgb_train,
num_boost_round=num_boost_round_lgb,
valid_sets=[lgb_train, lgb_eval], # 학습셋과 검증셋 모두 전달 가능
callbacks=callbacks_native
)
# 4. 예측 (확률값 반환)
pred_probs_bst_lgb = bst_model_lgb.predict(X_test, num_iteration=bst_model_lgb.best_iteration)
# 확률을 이진 클래스로 변환 (임계값 0.5 기준)
preds_bst_lgb = [1 if prob > 0.5 else 0 for prob in pred_probs_bst_lgb]
# 5. 평가
accuracy_bst_lgb = accuracy_score(y_test, preds_bst_lgb)
print(f"\nLightGBM (Native API) 정확도: {accuracy_bst_lgb:.4f}")
print(f"최적 부스팅 라운드 (Native API): {bst_model_lgb.best_iteration}")
다. 교차 검증 (lgb.cv)
# lgb.cv를 사용한 교차 검증
cv_results_lgb = lgb.cv(
params=params_lgb,
train_set=lgb_train, # 전체 학습 데이터를 전달 (내부적으로 분할)
num_boost_round=num_boost_round_lgb,
nfold=5, # 5-fold cross-validation
# metrics 파라미터는 params_lgb에 이미 'metric'으로 지정됨
callbacks=callbacks_native, # 조기 종료 콜백 사용
seed=42,
# verbose_eval=50 # cv에서는 직접 지원 안 함, callbacks의 verbose 사용
)
print(f"\nLightGBM CV 결과 (마지막 라운드의 binary_logloss 평균): {cv_results_lgb['valid binary_logloss-mean'][-1]:.4f}")
# cv_results_lgb는 딕셔너리로, 각 지표의 평균과 표준편차를 라운드별로 담고 있음
# 예: cv_results_lgb['valid binary_logloss-mean']
# 최적 라운드는 조기 종료에 의해 결정되므로, 마지막 라운드의 값이 최적값 근처일 것임.
# (또는 len(cv_results_lgb['valid binary_logloss-mean']) 으로 실제 수행된 라운드 수 확인 가능)
print(f"실제 수행된 CV 라운드 수: {len(cv_results_lgb['valid binary_logloss-mean'])}")
5. LightGBM vs XGBoost
- 속도 및 메모리: 일반적으로 LightGBM이 대용량 데이터에서 더 빠르고 메모리를 적게 사용합니다.
- 정확도: 데이터셋이나 문제 특성에 따라 다르지만, 많은 경우 유사한 수준의 높은 정확도를 보입니다. 때로는 LightGBM이 약간 더 좋거나, 때로는 XGBoost가 더 좋을 수 있습니다.
- 하이퍼파라미터 튜닝: 두 라이브러리 모두 하이퍼파라미터 튜닝이 중요합니다. LightGBM은
num_leaves가 핵심적인 역할을 합니다. - 범주형 특성 처리: LightGBM이 범주형 특성을 더 직접적이고 효율적으로 처리하는 기능을 제공합니다.
- 작은 데이터셋: LightGBM의 리프 중심 분할 방식은 작은 데이터셋에서는 과적합되기 쉬우므로,
max_depth를 적절히 제한하고num_leaves를 너무 크게 설정하지 않는 것이 중요합니다.
추가 학습 자료
- LightGBM 공식 문서
- Why LightGBM is a great choice for Machine Learning tasks (Neptune.ai Blog)
- LightGBM vs XGBoost (Towards Data Science)
다음 학습 내용
- Day 79: 시계열 분석 소개 (Introduction to Time Series Analysis) - 시간 순서대로 기록된 데이터 분석의 기초.