Day 74: 교차 검증 기법 (Cross-Validation techniques)
학습 목표
- 모델 일반화 성능 평가의 중요성 이해
- 기존의 단일 학습/테스트 데이터 분할 방식의 한계점 인식
- 교차 검증(Cross-Validation)의 개념과 필요성 학습
- 주요 교차 검증 기법 학습:
- K-폴드 교차 검증 (K-Fold Cross-Validation)
- 계층별 K-폴드 교차 검증 (Stratified K-Fold Cross-Validation)
- LOOCV (Leave-One-Out Cross-Validation)
scikit-learn을 사용한 교차 검증 구현 방법 숙지
1. 모델 일반화 성능 평가의 중요성
- 머신러닝 모델의 최종 목표는 학습 데이터에만 잘 맞는 모델이 아니라, 새로운, 보지 못한 데이터(Unseen Data)에 대해서도 좋은 성능을 내는 것입니다. 이를 일반화(Generalization) 성능이라고 합니다.
- 모델이 학습 데이터에 과도하게 최적화되어 일반화 성능이 떨어지는 현상을 **과적합(Overfitting)**이라고 합니다.
- 따라서, 모델의 일반화 성능을 신뢰성 있게 평가하는 것은 매우 중요합니다.
2. 단일 학습/테스트 데이터 분할 방식의 한계점
- 가장 기본적인 모델 평가 방법은 전체 데이터를 학습 데이터(Training Data)와 테스트 데이터(Test Data)로 한 번 분할하고, 학습 데이터로 모델을 학습시킨 후 테스트 데이터로 성능을 평가하는 것입니다 (
train_test_split). - 한계점:
- 데이터 분할에 따른 성능 변동성: 데이터를 어떻게 분할하느냐에 따라 테스트 성능이 우연히 좋게 나오거나 나쁘게 나올 수 있습니다. 즉, 평가 결과가 불안정하고 신뢰하기 어려울 수 있습니다.
- 데이터의 효율적 사용 부족: 특히 데이터 양이 적을 경우, 테스트 데이터로 분리된 만큼 학습에 사용할 데이터가 줄어들어 모델 성능에 영향을 줄 수 있습니다.
- 과적합 평가의 한계: 테스트 데이터에 대한 성능이 좋더라도, 그것이 특정 데이터 분할에 대한 우연한 결과일 수 있으며, 모델이 실제로 일반화 성능이 좋은지 확신하기 어렵습니다.
3. 교차 검증 (Cross-Validation)
- 정의: 모델의 일반화 성능을 보다 신뢰성 있게 평가하기 위해, 데이터를 여러 번에 걸쳐 다양한 방식으로 학습 세트와 검증 세트(Validation Set)로 나누어 모델을 학습하고 평가하는 기법입니다.
- 목적:
- 모델 성능 평가의 안정성 및 신뢰성 향상.
- 제한된 데이터를 최대한 효율적으로 활용.
- 모델의 과적합 여부 판단 및 일반화 능력 측정.
- 하이퍼파라미터 튜닝 시 최적의 파라미터 조합을 찾는 데 활용.
4. 주요 교차 검증 기법
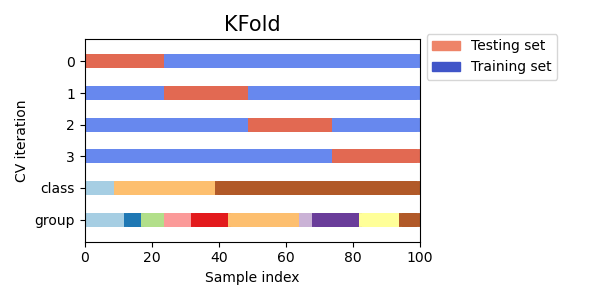
가. K-폴드 교차 검증 (K-Fold Cross-Validation)
- 가장 널리 사용되는 교차 검증 방법입니다.
- 수행 단계:
- 전체 데이터를 동일한 크기의 K개의 부분집합(폴드, Fold)으로 나눕니다.
- 첫 번째 폴드를 검증 세트(Validation Set)로 사용하고, 나머지 K-1개 폴드를 학습 세트(Training Set)로 사용하여 모델을 학습하고 평가합니다.
- 두 번째 폴드를 검증 세트로 사용하고, 나머지 K-1개 폴드를 학습 세트로 사용하여 모델을 학습하고 평가합니다.
- 이 과정을 K번 반복하여 각 폴드가 한 번씩 검증 세트가 되도록 합니다.
- K번의 평가 결과를 평균 내어 최종적인 모델 성능 지표로 사용합니다.
 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
- K 값 선택:
- 일반적으로 K=5 또는 K=10이 많이 사용됩니다.
- K가 너무 작으면 (예: K=2) 검증 세트가 너무 커서 학습 데이터가 부족해지고, 평가 결과의 분산이 커질 수 있습니다.
- K가 너무 크면 (예: K=데이터 샘플 수, 아래 LOOCV 참조) 학습 및 평가 시간이 오래 걸리고, 각 폴드의 평가 결과 간 상관관계가 높아질 수 있습니다.
- 장점:
- 모든 데이터가 최소 한 번은 검증에, 여러 번 학습에 사용되므로 데이터를 효율적으로 활용합니다.
- 단일 분할 방식보다 안정적이고 신뢰할 수 있는 성능 추정치를 제공합니다.
- 단점:
- 학습/평가 과정을 K번 반복하므로 시간이 더 오래 걸립니다.
나. 계층별 K-폴드 교차 검증 (Stratified K-Fold Cross-Validation)
- K-폴드 교차 검증의 변형으로, 특히 분류 문제에서 데이터가 불균형(Imbalanced)할 때 유용합니다.
- 핵심 아이디어: 각 폴드를 생성할 때, 원래 데이터셋의 클래스 비율을 각 폴드에서도 동일하게 유지하도록 샘플을 추출합니다.
- 이를 통해 각 폴드가 전체 데이터셋의 클래스 분포를 잘 대표하도록 하여, 보다 안정적이고 편향되지 않은 성능 평가를 가능하게 합니다.
- 분류 문제에서는 일반적인 K-폴드보다 계층별 K-폴드를 사용하는 것이 권장됩니다.
 (이미지 출처: Scikit-learn documentation)
(이미지 출처: Scikit-learn documentation)
다. LOOCV (Leave-One-Out Cross-Validation)
- K-폴드 교차 검증에서 K 값을 전체 데이터 샘플 수(N)와 동일하게 설정한 특수한 경우입니다.
- 수행 단계:
- N개의 샘플 중 단 하나의 샘플만을 검증 세트로 사용하고, 나머지 N-1개 샘플을 학습 세트로 사용합니다.
- 이 과정을 N번 반복하여 각 샘플이 한 번씩 검증 세트가 되도록 합니다.
- N번의 평가 결과를 평균하여 최종 성능을 추정합니다.
- 장점:
- 거의 모든 데이터를 학습에 사용하므로 모델 성능을 최대한 활용할 수 있습니다.
- 데이터 분할 방식에 따른 무작위성이 없어 결과가 항상 동일하게 나옵니다.
- 단점:
- N번의 학습과 평가를 수행해야 하므로 계산 비용이 매우 큽니다. (데이터가 클 경우 현실적으로 사용하기 어려움)
- 각 학습 세트가 매우 유사하여 평가 결과의 분산이 클 수 있습니다.
5. scikit-learn을 사용한 교차 검증 구현
가. K-폴드 교차 검증 예시
from sklearn.model_selection import KFold, cross_val_score
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
import numpy as np
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 모델 정의
model = LogisticRegression(solver='liblinear', max_iter=200) # max_iter는 수렴 경고 방지용
# K-Fold 교차 검증 설정
k = 5
kfold = KFold(n_splits=k, shuffle=True, random_state=42) # shuffle=True로 데이터 섞기 권장
# cross_val_score를 사용하여 교차 검증 수행
# cv 파라미터에 KFold 객체 또는 정수(폴드 수)를 전달할 수 있음
# scoring 파라미터로 평가 지표 지정 (예: 'accuracy', 'f1', 'roc_auc')
scores = cross_val_score(model, X, y, cv=kfold, scoring='accuracy')
print(f"K-Fold ({k} folds) 교차 검증 정확도 점수: {scores}")
print(f"평균 정확도: {scores.mean():.4f}")
print(f"정확도 표준편차: {scores.std():.4f}")
# 직접 KFold 객체를 사용하여 반복문으로 구현할 수도 있음
# accuracies = []
# for train_index, val_index in kfold.split(X):
# X_train_fold, X_val_fold = X[train_index], X[val_index]
# y_train_fold, y_val_fold = y[train_index], y[val_index]
# model.fit(X_train_fold, y_train_fold)
# accuracy = model.score(X_val_fold, y_val_fold)
# accuracies.append(accuracy)
# print(f"수동 K-Fold 정확도 점수: {np.array(accuracies)}")
# print(f"수동 K-Fold 평균 정확도: {np.mean(accuracies):.4f}")
나. 계층별 K-폴드 교차 검증 예시
from sklearn.model_selection import StratifiedKFold
# Stratified K-Fold 교차 검증 설정 (분류 문제에 권장)
# 계층화는 y (클래스 레이블)를 기준으로 수행
skfold = StratifiedKFold(n_splits=k, shuffle=True, random_state=42)
stratified_scores = cross_val_score(model, X, y, cv=skfold, scoring='accuracy')
print(f"\nStratified K-Fold ({k} folds) 교차 검증 정확도 점수: {stratified_scores}")
print(f"평균 정확도 (Stratified): {stratified_scores.mean():.4f}")
print(f"정확도 표준편차 (Stratified): {stratified_scores.std():.4f}")
다. LOOCV 예시
from sklearn.model_selection import LeaveOneOut
# LOOCV 설정
loo = LeaveOneOut()
# 데이터가 작을 때만 실행 권장 (시간이 매우 오래 걸림)
# n_samples = X.shape[0]
# if n_samples <= 30: # 예시로 작은 데이터에만 실행
# loo_scores = cross_val_score(model, X, y, cv=loo, scoring='accuracy')
# print(f"\nLOOCV 교차 검증 정확도 점수 (처음 10개): {loo_scores[:10]}") # 너무 많으므로 일부만 출력
# print(f"평균 정확도 (LOOCV): {loo_scores.mean():.4f}")
# else:
# print(f"\nLOOCV는 샘플 수({n_samples})가 많아 실행하지 않습니다.")
# Iris 데이터 (150개 샘플)에 LOOCV를 cross_val_score로 실행하면 150번 학습/평가.
# 여기서는 직접적인 실행보다 개념 이해에 중점.
# cross_val_score(model, X, y, cv=X.shape[0]) 와 유사하게 동작.
참고: cross_val_score는 내부적으로 모델을 복제하여 각 폴드마다 독립적으로 학습시킵니다.
6. 교차 검증 활용 시 주의사항
- 데이터 전처리: 교차 검증 시 데이터 전처리(스케일링, 특징 선택 등)는 각 폴드별로 학습 데이터에 대해서만
fit하고, 검증 데이터에는transform만 적용해야 합니다. 전체 데이터에 대해fit을 수행하고 교차 검증을 하면 검증 데이터의 정보가 학습에 누수(Data Leakage)되어 성능이 과대평가될 수 있습니다.scikit-learn의Pipeline을 사용하면 이러한 과정을 더 쉽게 관리할 수 있습니다.
- 시간적 순서가 있는 데이터: 시계열 데이터와 같이 시간적 순서가 중요한 경우에는 일반적인 K-폴드 방식이 적합하지 않을 수 있습니다. 과거 데이터로 미래를 예측해야 하므로, 검증 세트는 항상 학습 세트보다 시간적으로 뒤에 와야 합니다. (
TimeSeriesSplit사용)
추가 학습 자료
- Scikit-learn: Cross-validation: evaluating estimator performance
- A Gentle Introduction to k-fold Cross-Validation (Machine Learning Mastery)
- StatQuest: Cross Validation (YouTube)
다음 학습 내용
- Day 75: 하이퍼파라미터 튜닝 - 그리드 서치, 랜덤 서치 (Hyperparameter Tuning - Grid Search, Random Search) - 교차 검증을 활용하여 모델의 최적 하이퍼파라미터를 찾는 방법.